1. Introduction
In recent years, electrical power systems have progressively evolved from centralized bulk systems to decentralized systems in a distributed generation (DG) scenario characterized by smaller generating units connected directly to distribution networks near the consumer [
1]. Several economic and environmental reasons, driven by government financial incentives [
2], have considerably pushed the widespread adoption of DG in the energy marketplace, especially that from renewable resources (e.g., solar power and wind energy).
However, technical barriers often impede the entrance of DG into the current distribution infrastructure with a significant penetration level due to the intermittent nature of the renewable energy resources that often do not match the energy load demands [
3]. Indeed, the transition to an energy economy primarily founded on renewable resources depends on overcoming the difficulties associated with the variability and reliability of these non-dispatchable resources [
4]. These issues give rise to substantial critical issues with respect to the usual working habits of the transmission (TSO) and distribution (DSO) system operators, utility companies, as well as power producers: voltage and frequency regulation, islanding detection, harmonic distortion, distribution issues, as well as demand side management of prosumers. Certainly, energy storage systems (EES) could become a valuable response providing specific support services for renewable energy production in order to reduce short-term output fluctuations and, consequently, improve power quality [
5].
In this framework, it is of paramount importance to forecast accurately the power output of plants over the next hours or days in order to integrate in an optimal way the DG from non-programmable renewable resources into power systems on a large scale [
6]. The ability to forecast the amount of power fed by renewable energy plants into substations is a necessary requirement for the TSO in order to optimize short- and middle-term decisions, such as corrections to out-of-region trade and unit commitments [
7]. Besides, accurate short-term and intra-hour forecasting are required for regulatory, dispatching and load-following issues [
8], while power system operators are more sensitive to intra-day forecasts [
9], especially when handling multiple load zones, since they avoid possible penalties that are incurred due to deviations between forecasted and produced energy. Moreover, power system operators are mostly interested in developing methods to be used in the framework of the daily session of the electricity market where the producers must present energy bid offers for the 24 h of the following day [
10].
Forecasting can be broadly divided into four major categories [
11], namely long-, medium-, short- and very short-term forecast, on the basis of the time horizon’s scale, which ranges from several years in the long-term forecasting to hours in the medium-term forecasting, till arriving at minutes in the very short-term forecasting. When adopted for photovoltaic (PV) power plants, forecasting techniques can be applied directly to the produced power (direct methods) or indirectly to the solar irradiation, which is the main factor related to the output power that is calculated in a second successive step (indirect methods) [
12]. Both cases share similar techniques that can be broadly divided [
11] into persistence methods, physical techniques, statistical techniques and hybrid models. Usually, physical methods try to obtain an accurate forecast using a white box approach, that is to say physical parametric equations. On the other hand, statistical or probabilistic methods try to predict the relevant quantities extracting dominant relations from past data that can be used to predict the future behavior. In addition, both methods can be properly mixed, originating the so-called “gray box” approaches [
13].
In the prediction of time series, past observations are used to develop a method able to describe underlying relationships among data. Therefore, a mathematical model is adopted to extrapolate future values, especially for those contexts where missing and incomplete data can limit the ability to gain knowledge about the underlying, unknown process. Complexity and dynamics of real-world problems require advanced methods and tools able to use past samples of the sequence in order to make an accurate prediction [
14]. Additionally, the problem of forecasting future values of a time series is often mandatory for the cost-effective management of available resources. These are well-known hard problems [
6], given the non-stationarity and, often, the non-linearity of time series, which result in a complex dynamics that is hard to model adequately by using standard predictive models.
For many years, regressive statistical approaches [
15] have been considered for prediction; among them, moving average (MA), auto regressive (AR), auto regressive moving average (ARMA), auto regressive integrated moving average (ARIMA) and autoregressive integrated moving average with exogenous variables (ARIMAX) are typical examples of these approaches. Unfortunately, standard structural models provide a poor representation of actual data and therefore result in poor accuracy when used for forecasting. Consequently, many worldwide research activities intend to improve the accuracy of prediction models. In this regard, computational intelligence is considered as one of the most fruitful approaches for prediction [
16]. Several forecasting methods, with different mathematical backgrounds, such as fuzzy predictors, artificial neural networks (ANN), evolutionary and genetic algorithms and support vector machines, have been considered [
17]. Nevertheless, dealing with noisy and missing training examples and the lack of robustness against outliers are still open problems.
In this paper, our attention is mainly concentrated on short-term forecasting with a time horizon of one day. Nevertheless, the proposed techniques can be applied to shorter or longer time horizons, yet always remaining in a short-term forecast. A huge amount of literature is available on short-term forecasting models applied to PV plants, even if most of them deal with irradiation forecasting models: while not claiming to be exhaustive, the proposed techniques include mainly statistical models [
18], stochastic predictors [
19], fuzzy systems [
20], ANN [
21], ANN in conjunction with statistical feature parameters [
22] and artificial intelligence (AI)-based techniques [
23]. Some papers present also the comparison between the predictions obtained through different models based on two or more forecasting techniques [
24]. Despite the large amount of literature on forecasting techniques, only a few papers describe forecasting models to be used for directly predicting the daily energy production of the PV plant. These few papers use general techniques appropriately applied to the day-ahead horizon. Starting from the input of past power measurements and meteorological forecasts of solar irradiance, the power output is estimated by means of ANN [
25] or soft computing [
26], while in [
27], the ANN is applied only on past energy production values. Additionally, the ANN can be used in conjunction with numerical weather prediction (NWP) models [
28], which can be based on satellite and land-based sky imaging [
29]. NWP models have been also used to build an outperforming multi-model ensemble (MME) for day-ahead prediction of PV power generation [
30]. More complex schemes are proposed in [
31], where an ANN is used to improve the performance of baseline prediction models, i.e., a physical deterministic model based on cloud tracking techniques, an ARMA model and a k-nearest neighbor (kNN) model, and in [
32], where a Kalman filter is used in conjunction with a state-space model (SSM).
The use of three inference systems for data regression based on neural and fuzzy neural networks is proposed here. The main distinguishing idea of our work is that we properly tailor new learning approaches to analyze data associated with renewable power sources starting from available techniques based on computational intelligence that have proven to produce very accurate predictions in several fields of application, like for example, risk management, biomedical engineering and financial forecasting [
33], but also to analyze accurately the data associated with renewable power sources [
34]. Actually, the stochastic and often chaotic behavior of time series in the prediction of output power of PV plants calls for ad hoc procedures to forecast power time series, which are here developed working only on the past measurements of electric quantities, as initially tested in our previous work [
35].
We introduce a prediction problem as a two-fold process. First, the observed time series is embedded in order to select, among the available samples, the ones to be used to predict the next one. Then, such samples are used to feed three different function approximation models and techniques based on neural and fuzzy neural networks, which are suited to predict data sequences that often show a chaotic behavior: radial basis function (RBF) [
36]; the adaptive neuro-fuzzy inference system (ANFIS) [
37]; the higher-order neuro-fuzzy inference system (HONFIS) [
38]. As explained in the body of the paper, a predictor can be based on such function approximation models, whose parameters are estimated by data-driven learning procedures.
The rest of the paper is organized as follows. In
Section 2, we introduce the function approximation models that are used for time series prediction. The application is ascertained by several benchmark results and extensive computer simulations reported in
Section 3 and discussed in
Section 4 proving the validity of the proposed learning procedure and showing a favorable comparison with other well-known prediction techniques. Finally, our conclusions are drawn in
Section 5.
2. Materials and Methods
There is a huge amount of literature pertaining to time series prediction techniques that rely on neural and fuzzy neural networks [
39], which are actually of high importance in this field since they can be used to solve data regression problems [
40]. A sequence
can be predicted by considering a function approximation
,
. For instance, by using linear models each input vector
is made of
N subsequent samples of
, and the output
is the sample to be predicted:
Then, we obtain:
where
is the prediction of the true value
at the time distance
m. Considering the statistical properties of
, as the autocorrelation function, it is possible to determine the parameters
,
, of the function
.
Generally speaking, input vectors
are obtained through the so-called “embedding technique”, which makes use of previous samples of
to build the vectors themselves. There are two parameters to be set in this regard, the embedding dimension
D and the time lag
T, resulting in the following embedding structure:
These two parameters are estimated in two different ways, by using the false nearest neighbors (FNN) algorithm for the embedding dimension and the average mutual information (AMI) criterion for the time lag [
41]. In the following part of the paper,
D and
T will be chosen by such algorithms via the VRA software [
42].
The performances of a predictor that relies on a linear approximation model, as the one in Equation (
1), are very poor when it is applied to data sequences in real environments. They often have noisy and chaotic components that force one to wisely choose the embedding parameters, as well as the function approximation model by using appropriate procedures [
43]. In this context, the underlying, unknown system is observed through
, and its state-space evolution is obtained by the trajectories of embedded vectors.
Overall, the estimated sample
predicted at a distance
m will be:
where
is the regression model to be determined. Thus, the function
will approximate the link from the reconstructed state
to the corresponding output
[
41]. It is important to note that
must be non-linear since the considered system has a complex behavior. In the following, we will consider the usual case of a “one-step-ahead” prediction, that is
.
By driving the function approximation model with embedding data, neural networks and fuzzy logic are very suited to solving a prediction problem dealing with real-world sequences. In this paper, three models of this kind are proposed for the study of the considered photovoltaic time series. They are introduced in the following, considering as a baseline for benchmarking in the successive tests: the linear predictor reported in Equation (
1), whose parameters are estimated through a common least-squares estimator (LSE) [
44]; the well-known ARIMA model, which handles non-stationarity and seasonality and whose parameters are determined by a maximum likelihood approach [
45]. Both of these models will be estimated by using lagged samples at the input, as determined by the embedding procedure, similarly to the adopted neural networks.
2.1. RBF
An RBF neural network is used to build up a function approximation model having the following structure:
where
is the input vector,
is a radial basis function centered in
and weighted by an appropriate coefficient
. The choice of
and
must be considered for the approximation capability of the network. Commonly-used types of radial basis functions include:
Several methods can be used to minimize the error between desired output and model output and, hence, to identify the parameters
and
[
46].
2.2. ANFIS
An ANFIS neural network implements a fuzzy inference system to approximate the function
,
. It is composed of
M rules of the Sugeno first-order type, where the
k-th rule,
, is:
where
is the input to the network and
is the output of the rule. The antecedent part of the rule depends on the Membership Functions (MFs)
of the fuzzy input variables
,
; the consequent part is determined by the coefficients
,
, of the crisp output
. By using standard options for composing the input MFs and combining the rule outputs [
40], the output of the ANFIS network is represented by:
where
is the estimation of
y and
is the composed MF of the
k-th rule.
The ANFIS learning of network coefficients is based on a classical back-propagation technique associated with a least-squares estimation [
47].
2.3. HONFIS
The HONFIS model adopted for data regression is a Takagi–Sugeno (TS) fuzzy inference system that is a generalization of ANFIS where the consequent part in Equation (
9) is a polynomial of order greater than one combining the input values
,
. It is made of
M different fuzzy rules, and the coefficients are obtained through the use of a clustering procedure in the joint input-output space [
48].
Let
be a set of
M clusters (each associated with a rule output), and let every pattern of the training set be assigned randomly to one of these clusters. Then, the clustering procedure is fundamentally an alternating optimization technique that aims at identifying the
M cluster prototypes [
44]. At the end of the iterations, a label
q,
, is associated with each pattern, representing the rule it has been assigned to during the last iteration. In this way, a classification model able to assign a fuzzy label
to any pattern
of the input space is obtained:
where the
k-th element of
represents the fuzzy membership of the pattern to the
k-th class, that is the firing strength
in Equation (
10).
In the following, we will adopt a
K-nearest neighbor (
K-NN) strategy for classification of the fuzzy label during the prediction tests. This is done by using the input value
only, and hence, the fuzzy label of
will be:
where
are the
K patterns of the training set that score the smallest Euclidean distance from
, with their fuzzy labels determined during the training phase.
The output
is calculated through Equation (
10) by means of the firing strengths contained in the fuzzy label
and the output consequents whose parameters have been previously determined by clustering in the joint input-output space. For instance, in the case of a 3rd order polynomial as adopted in the following, the
k-th rule’s consequent,
, is:
Regarding the generalization capability, the optimal number of rules is automatically determined on the basis of learning theory [
49]. The best model is chosen by evaluating a cost function based on network complexity and approximation error [
50]. As a measure of the network performance on the training set, the mean squared error (MSE) is adopted:
where
is the number of samples in the training set to be predicted and
is the output generated by HONFIS in correspondence with the
t-th input pattern
. The optimal network is selected by minimizing the following cost function that depends on the maximum allowed number of the HONFIS rules:
where
and
are the extreme values of the performance
E that are encountered during the analysis of the different models, while
is a non-critical weight,
, set to 0.5 by default.
3. Results
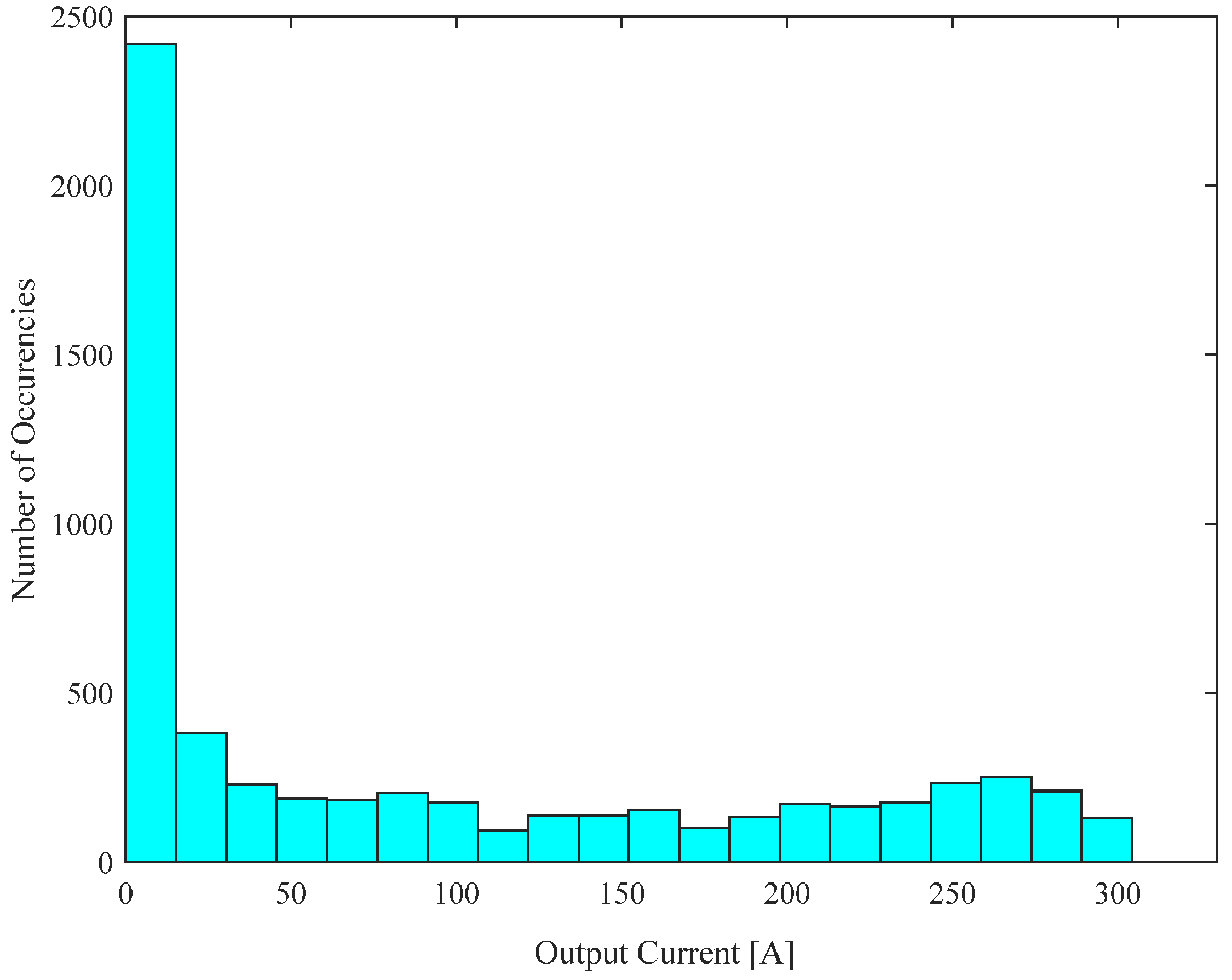
The prediction performances of the considered models were investigated by means of several simulation tests carried out using data from the De Nittis Power Plant in the Apulia Region, Italy (latitude
, longitude
). Data were relative to a single photovoltaic plant, organized with eight cabins with two inverters each. The output current was used as the variable to be predicted. The value was sampled at the source with a 5-min sample interval, and it was collected from 6:00 a.m. to 10:55 p.m., resulting in 204 samples per day. The used data stream comes from a single inverter of a single cabin, and it is relative to the year 2012. In order to provide a statistical characterization of the handled time series, whose samples are measured in Amperes, we have computed the first four statistical moments of the whole 2012 dataset, whose histogram is also reported in
Figure 1: mean 85.1291; variance
; skewness 0.8151; kurtosis 2.1082. Successively, the whole time series has been normalized linearly between zero and one in order to cope with the numerical requirements of learning algorithms, especially for neural network models.
All of the computational models were trained using time series subsampled at an interval of 1 h, thus resulting in 17 samples per day. Four different kinds of training conditions were considered: 1-, 3-, 7- and 30-day, associated with training sets composed of 17, 51, 119 and 510 samples, respectively. Every computational model estimated by using one of these training sets was applied to test the day following the latest one in the training set, that is on a test set of 17 samples. The successive experiments would consider for testing one day for each month of 2012, and we have chosen the 15th of each month for the sake of uniformity (the last 15 samples of 2011 are also used for the 30-day training of 15 January). For the same reason, after the preliminary analysis we carried out for determining the embedding parameters, as the latter did not show a considerable sensitivity to seasonality and to the length of the training set, which was relatively small with respect to the usual length of time series processed by the AMI and FNN methods, we had adopted as the optimal choice the values and for every training set and the related experiment. We remark that all of the test sets had different irradiation and meteorological conditions, and thus, they could be considered as a good ensemble for representing the typical behaviors that might be encountered.
All of the experiments had been performed using MATLAB
® 2016b, running on a
-GHz Intel Core i7 platform equipped with 16 GB of memory. As previously mentioned, in addition to the three proposed neural and fuzzy neural models, the linear (LSE) and ARIMA predictors were adopted for benchmarking. LSE did not have parameters to be set in advance, while for ARIMA, RBF and ANFIS, we had adopted the default options provided by the software platform for training and model regularization (ARIMA, RBF and ANFIS models were trained by using the supported functions in the econometrics toolbox, neural network toolbox and fuzzy logic toolbox of MATLAB, respectively). Regarding HONFIS, a preliminary analysis had been performed in order to evaluate the best model order for the rule consequents. In the following, the results of the third-order model are reported, as it was able to obtain the best performance in almost all of the considered cases. The input space classification was obtained by a three-NN classifier (i.e.,
). The optimal number of rules was determined by Equation (
15), using
and varying
M from 1–50% of
.
The prediction performances were measured by two metrics commonly adopted for energy time series, which were independent of the said procedure for data normalization:
Normalized Mean Square Error (NMSE):
where
is the average value of samples
in the test set;
Mean Absolute Range Error (MARE):
where
and
are the maximum and minimum value of samples
in the test set, respectively.
The numerical results for each tested day are reported in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
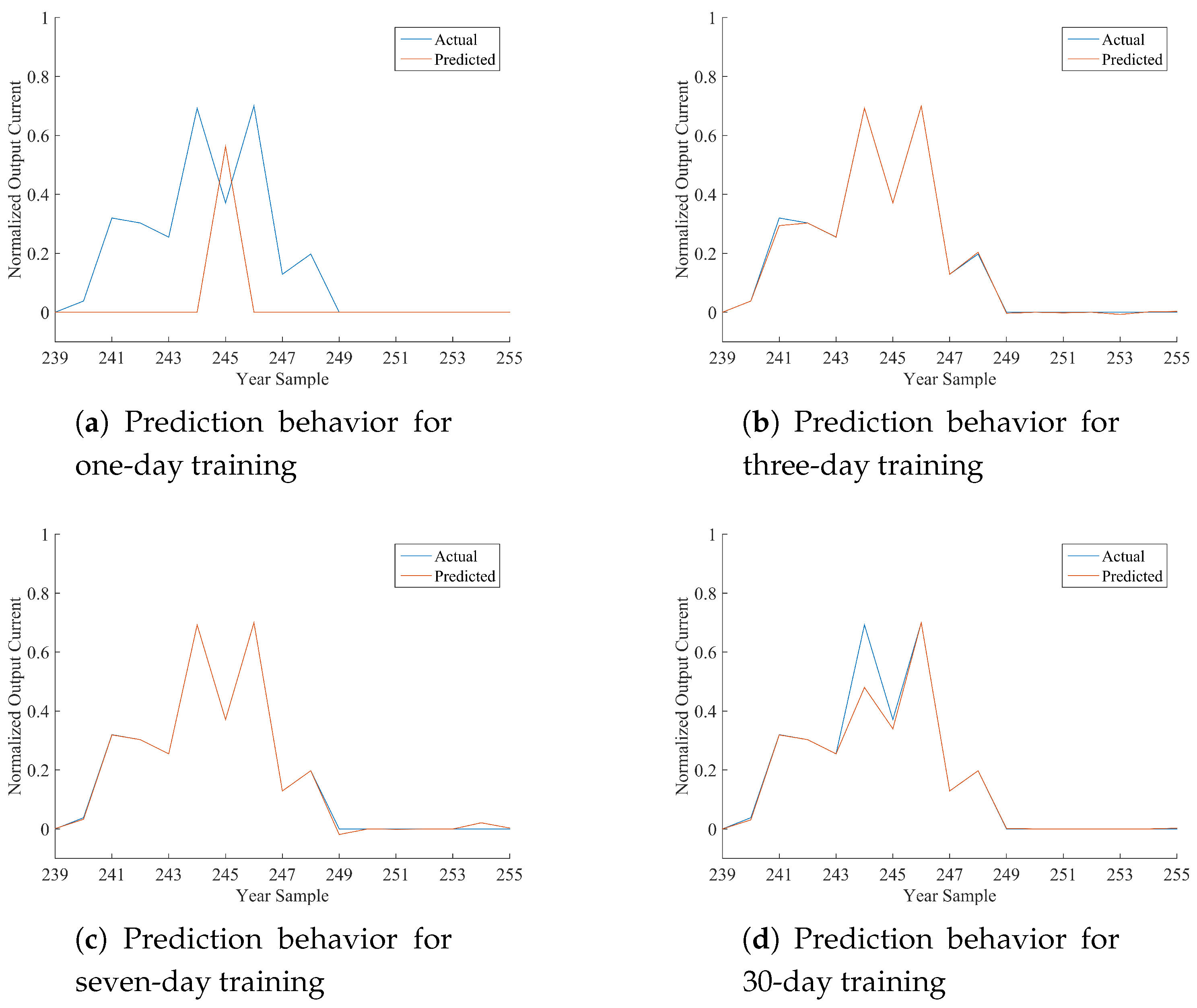
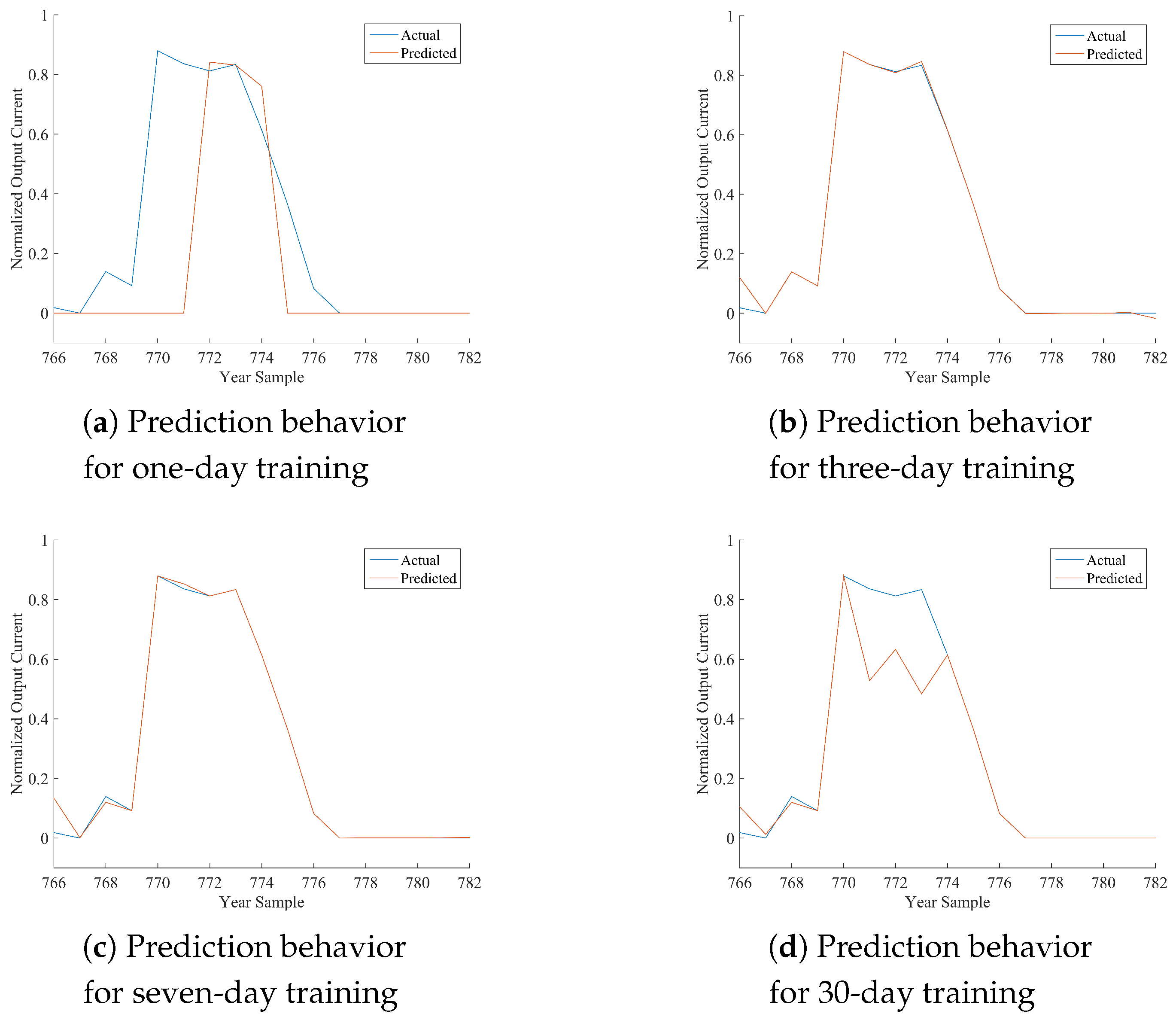
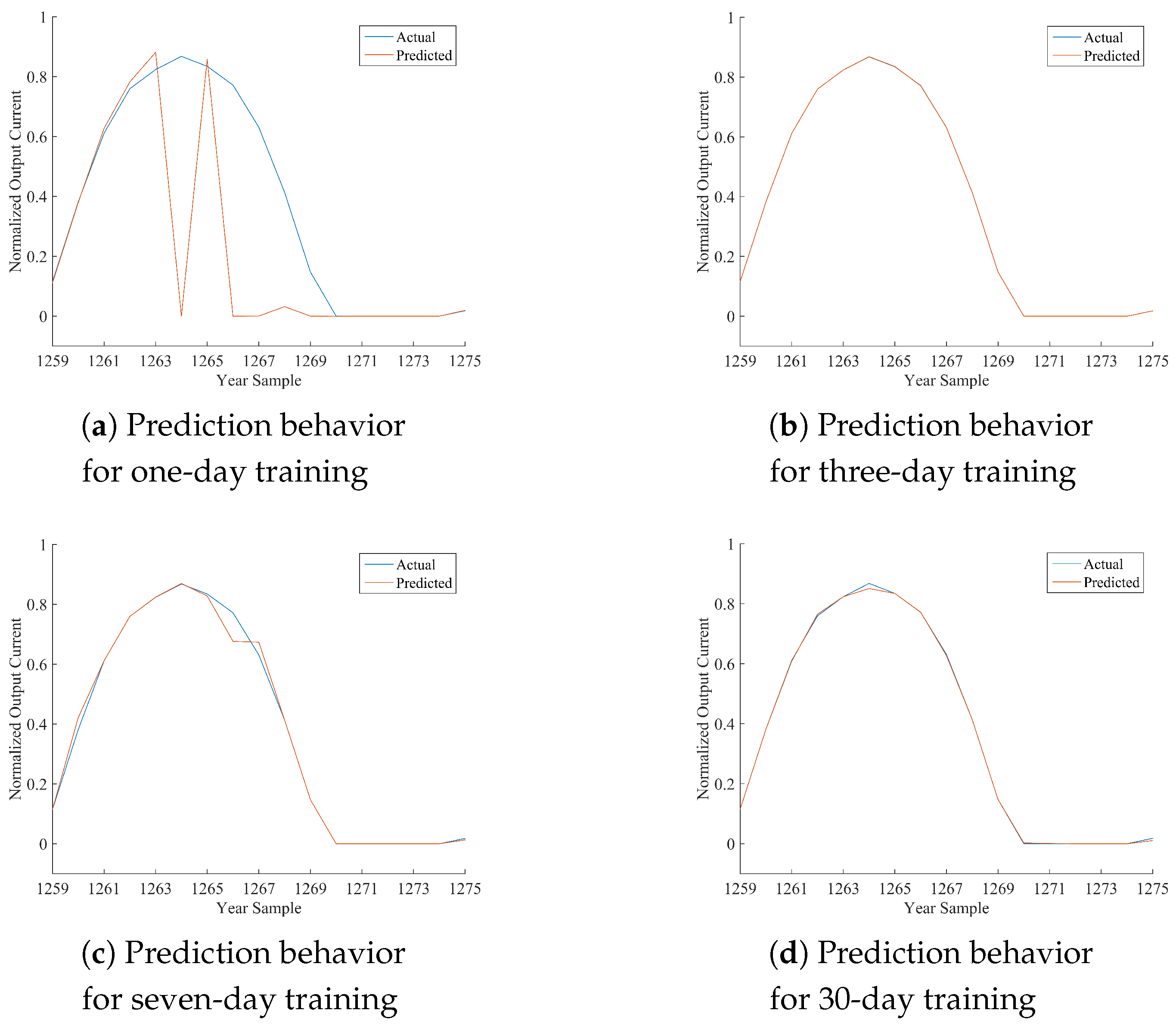
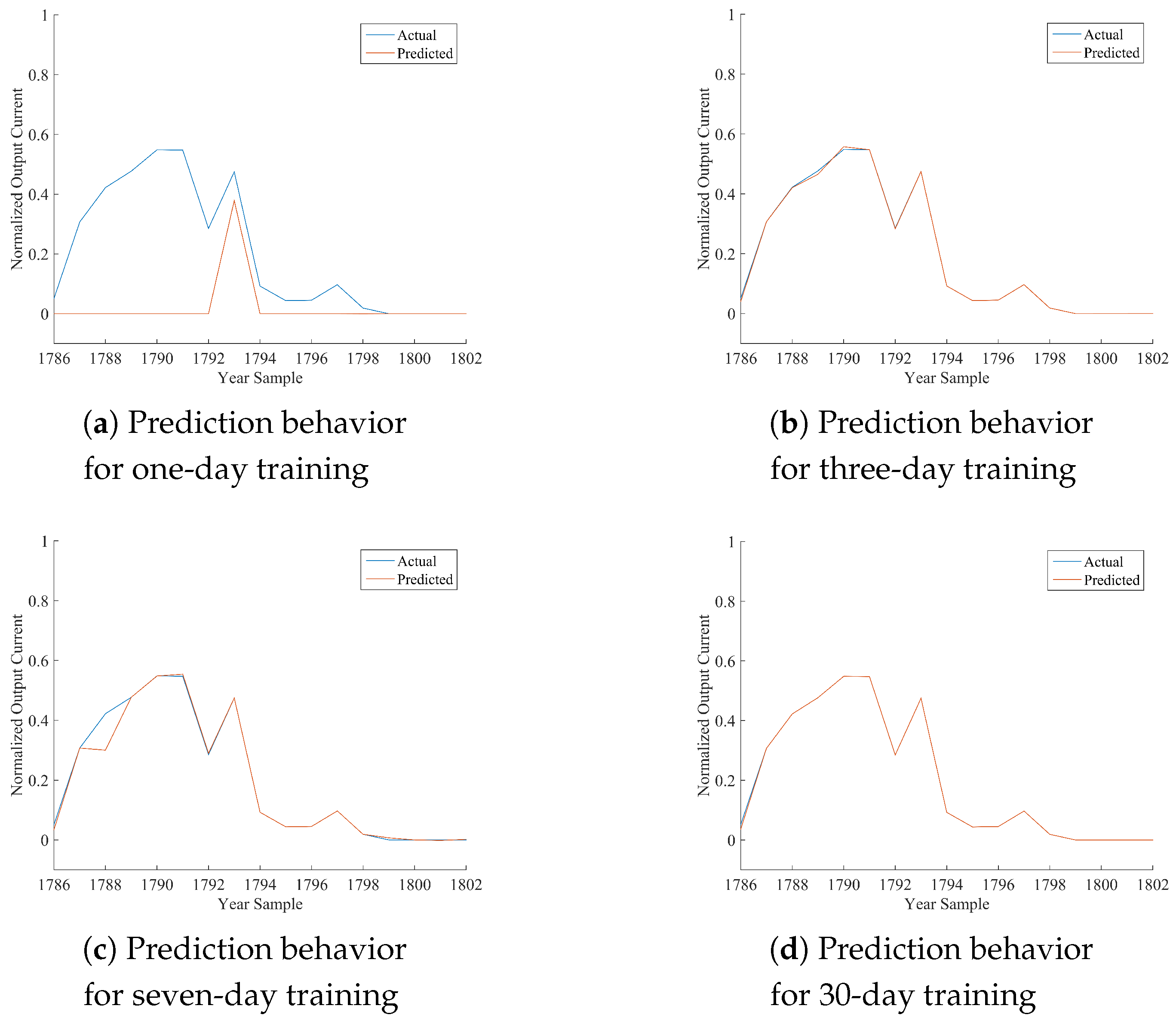
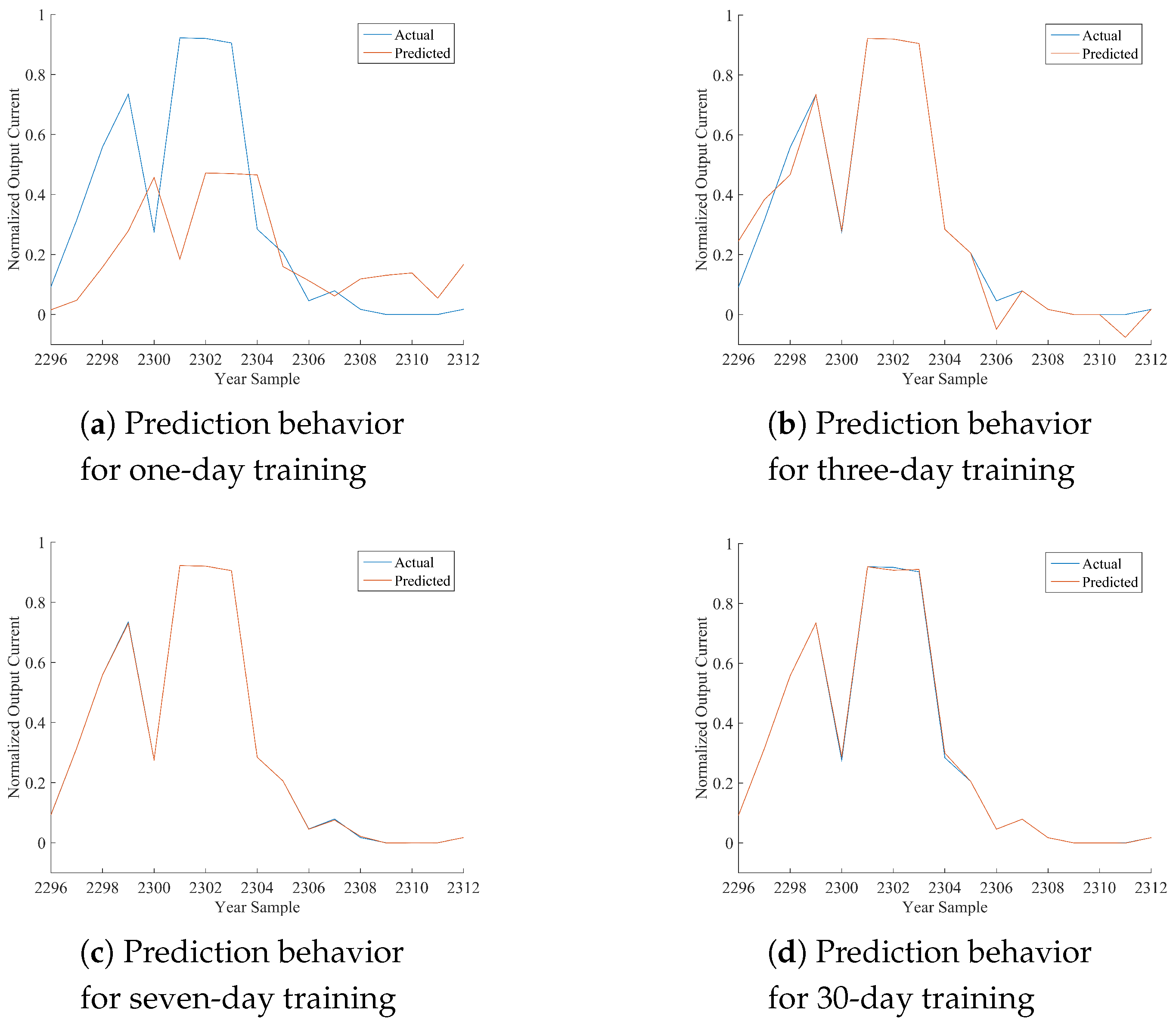
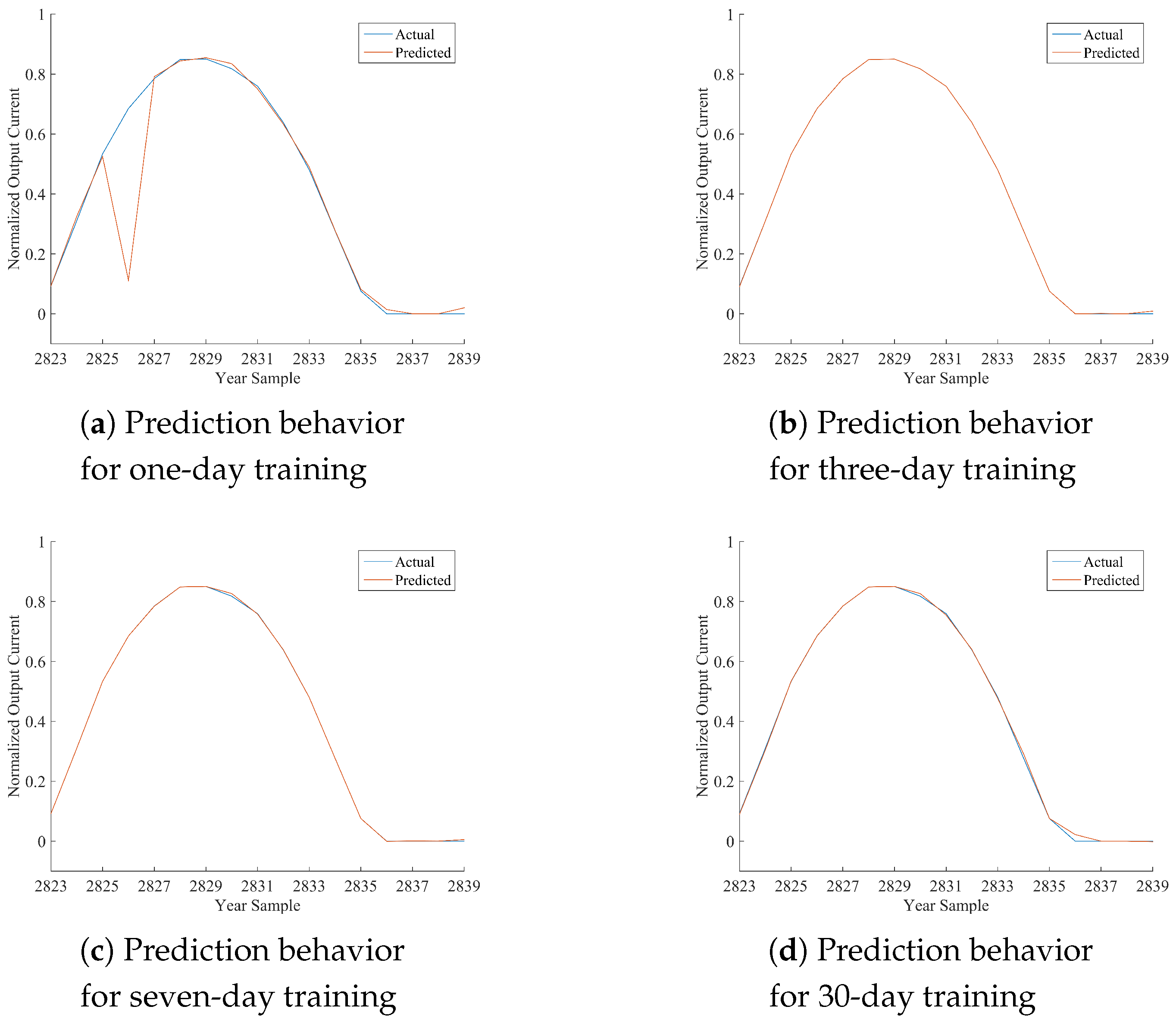
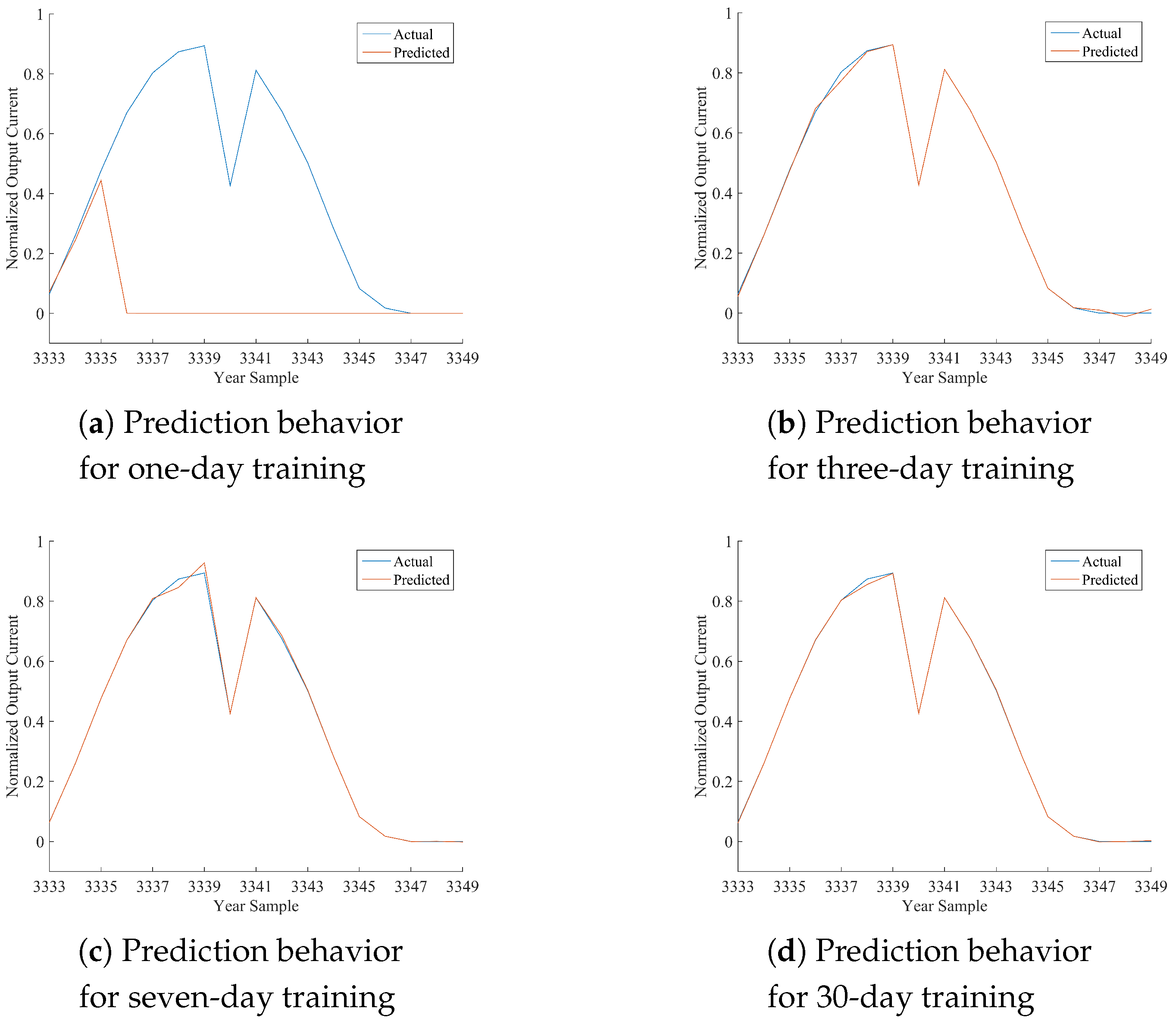
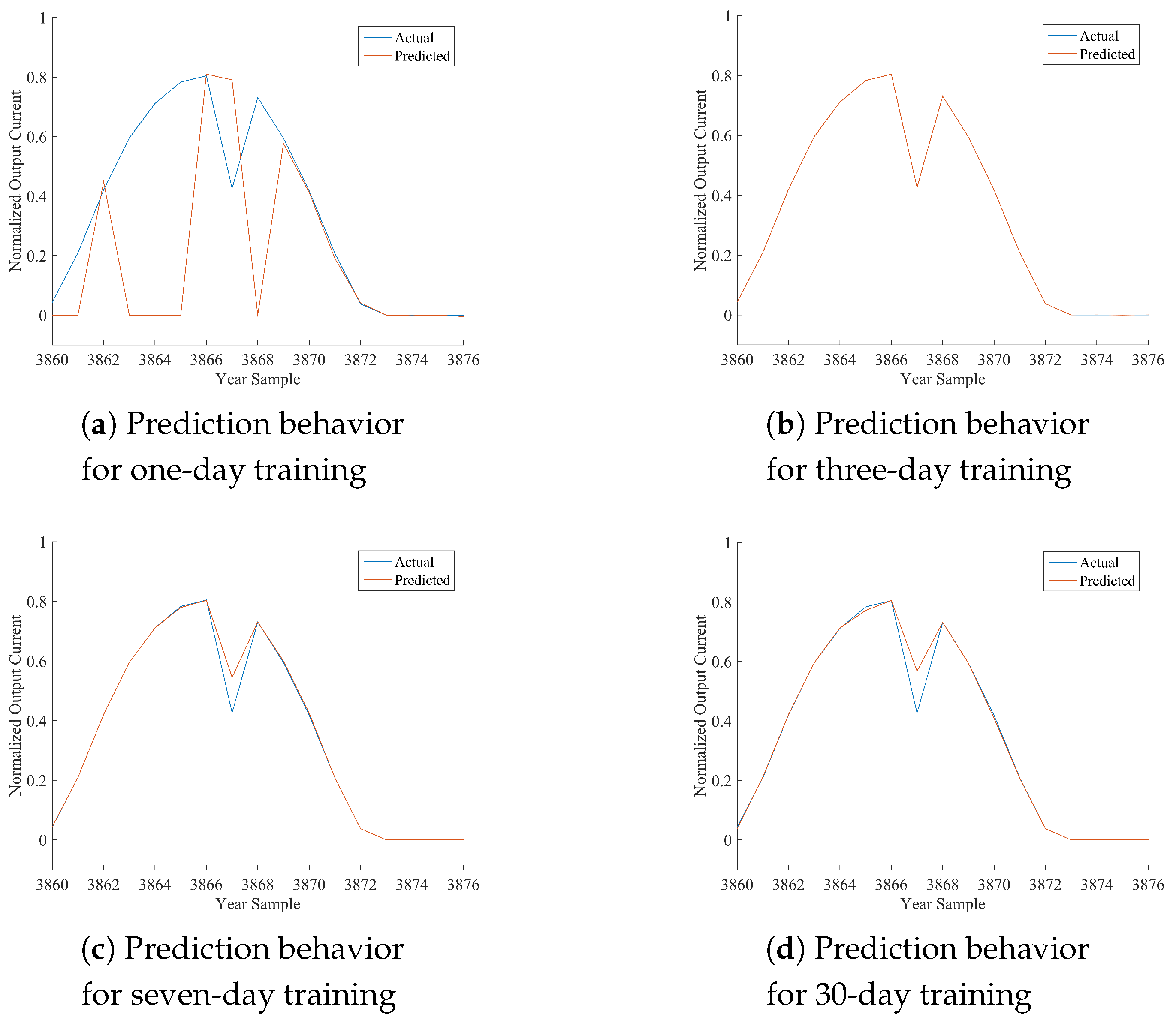
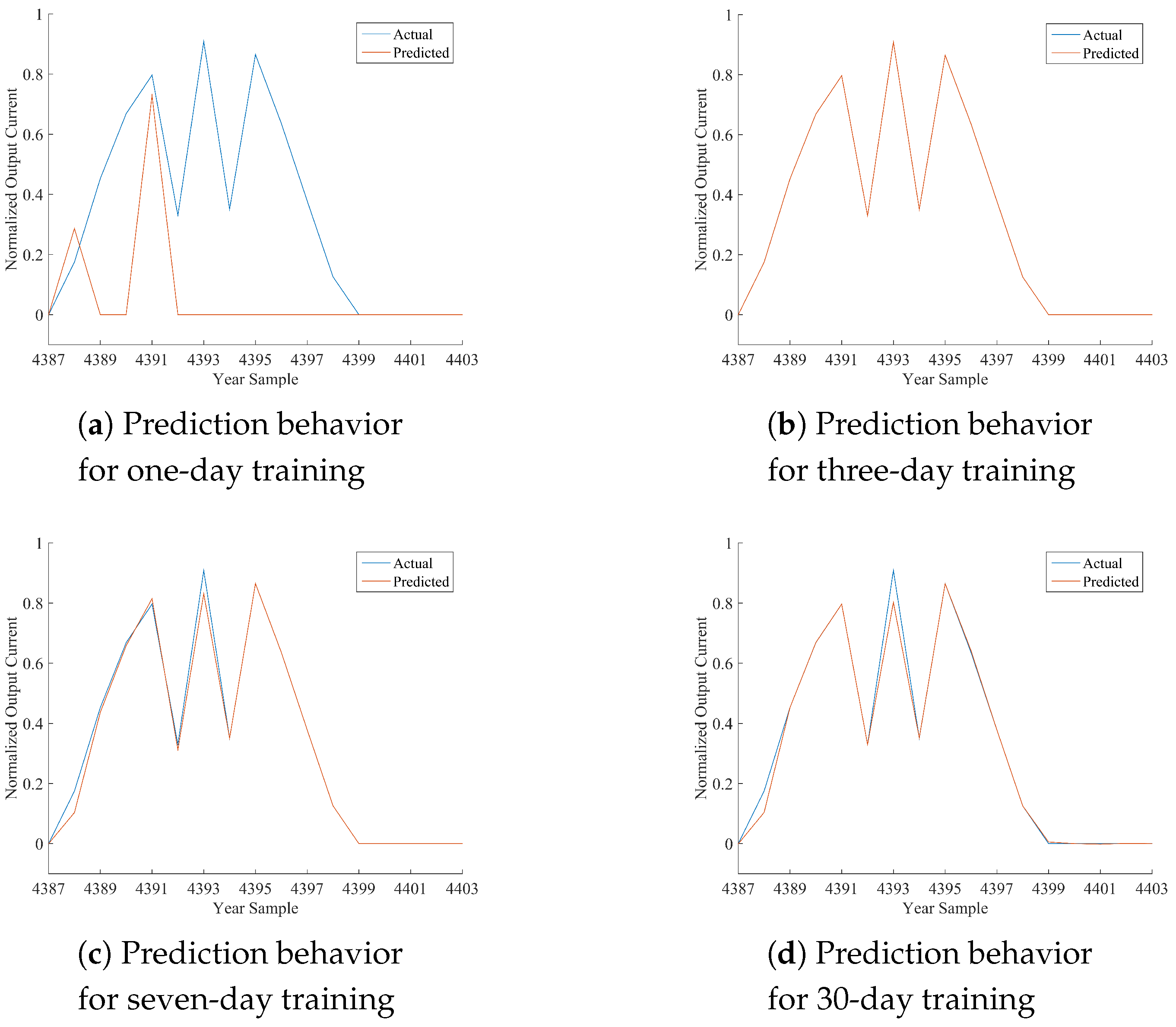
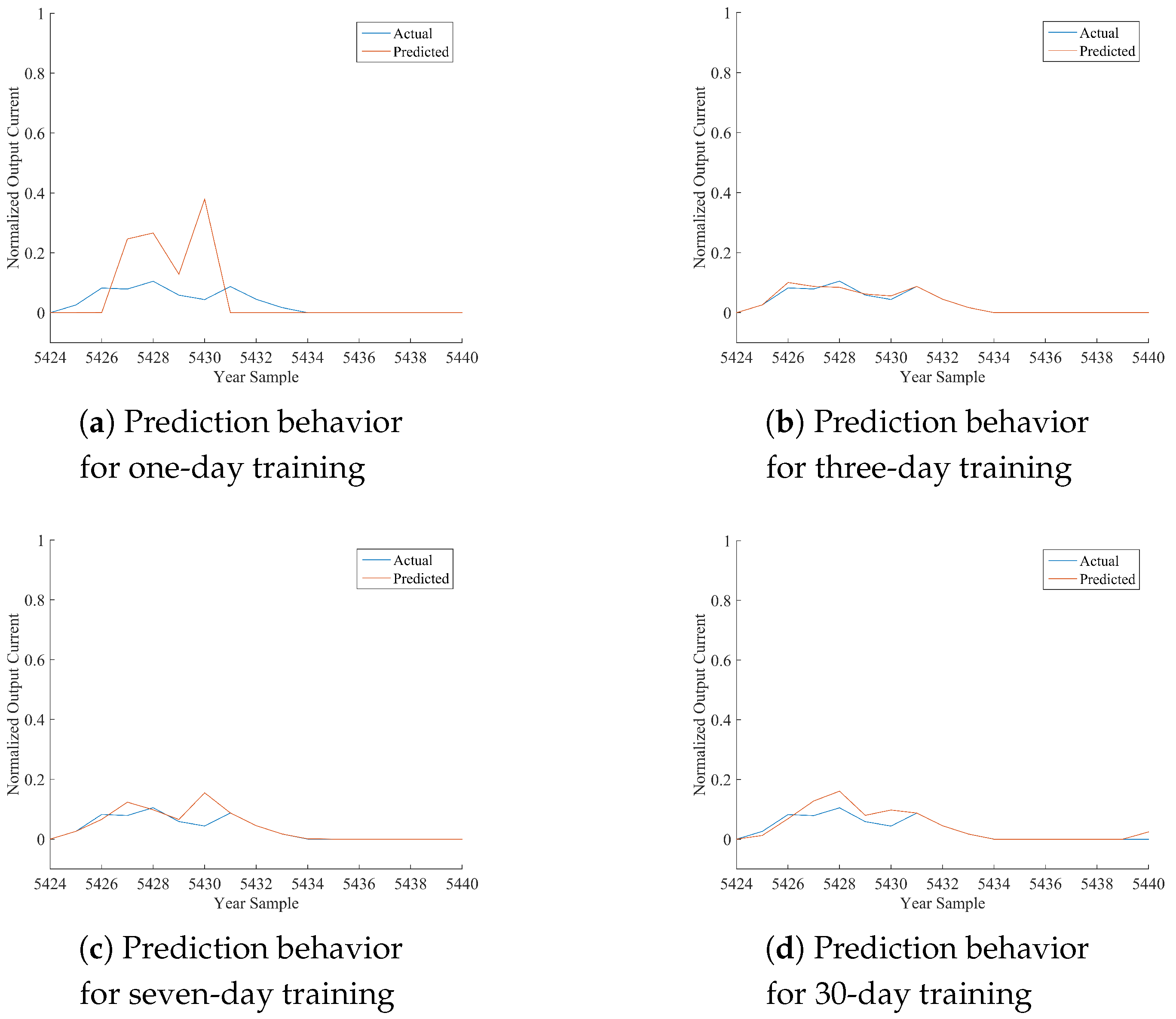
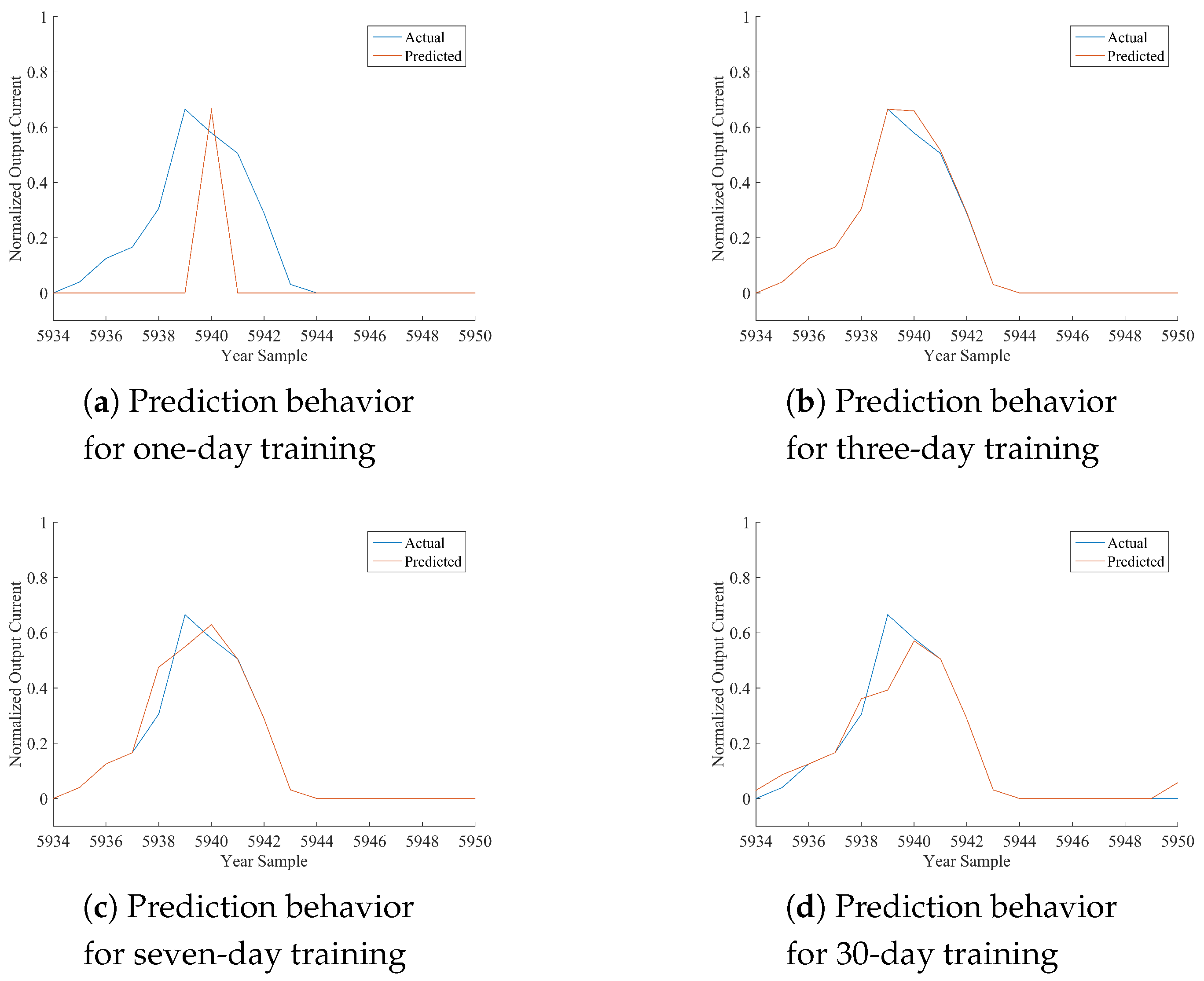
Table 12, where the performance of the best model is marked in bold font. As per the following discussion, being HONFIS the model that assures the best performance in most of the situations, the graphical illustration of the actual time series (blue line) and the one predicted by HONFIS (red line), over the four training conditions, is reported in
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13, respectively. In the
x-axis is reported the cumulative index of samples of the considered day, starting from Index 1 for the first sample of 1 January 2012 (which is a leap year) and considering 17 samples per day. The output current reported in the
y-axis is a dimensionless value between zero and one, as the whole dataset has been normalized before the model processing. Some negative values may occur because of possible numerical issues of a trained model when its performance is inadequate.
It is important to remark that the number of samples that should be predicted in a test set is strictly related to the computational cost of the learning procedure, as well as to the desired horizon of predictability, for which it is necessary to follow a given strategy for the energy management and to broadcast the relevant information to the involved operators. For instance, as the learning times of the previous models were in the order of some minutes and the considered time series are subsampled at 1 h, any model could be re-trained on a hourly basis for a new sample to be predicted (i.e., using a test set with one sample only), thus incorporating the new information given by the the latest available sample that was measured.
However, in order to ensure a wide range of action, it is worth forecasting more than one sample at a time, as previously done considering an entire day. Although longer test sets might not be so useful and accurate, we consider in the following also weekly test sets, so as to report the prediction results for more days in a year and to evaluate the sensitivity of the proposed approach not only to different training, but also to different test conditions. The numerical results for each tested week are reported in
Table 13,
Table 14,
Table 15,
Table 16,
Table 17,
Table 18,
Table 19,
Table 20,
Table 21,
Table 22,
Table 23 and
Table 24. In such a case, we have considered seven-day or 30-day training sets only, that is longer than the test set or of the same length. As the starting day in the test set is still the 15th of each month, the training results are the same as the ones reported in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12, respectively.
4. Discussion
Considering the experimental results reported in this paper, it can be noted that all of the proposed approaches are suitable for the prediction of the considered time series, depending on the chosen training set. The numerical results in terms of either NMSE or MARE basically agree, and they are coherent with the graphical behaviors, reported in the figures, between actual and predicted time series. Note that a perfect match is obtained when the NMSE is smaller than about .
In the days with the most stable meteorological conditions (i.e., 15 March or 15 June), the prediction results for daily test sets are better than the others. Furthermore, there are differences among the results associated with diverse training procedures. The tests with one-day training sets have a high variability for all of the algorithms because the prediction is highly affected by the difference in irradiation between the day of the training and the day of the test. In fact, when the meteorological condition varies greatly from the training day to the sequent test day, the algorithms are trained on a set that is almost not correlated with the test set. It can also be noted that when the irradiation is very similar (no clouds, good weather), the performance is very good also for the one-day training set.
A similar discussion can be made, with smaller variability, for the three-day training sets. It has to be noted that we have inserted the one-day and three-day training sets mainly to show the sensitivity of the models to different training conditions. The results for seven-day training sets are much more stable for all of the algorithms and the days. The results for 30-day training sets are stable as well, but the sequences are much longer; thus, if the days are variable in terms of meteorological conditions, the model has a worse performance because the training process is more difficult. Training sets longer than 30 days were also considered in some preliminary tests, and the results confirm such a trend for which the performance decreases progressively as much as the length of the training set increases.
Overall, a one-day training is based on a very small number of samples in the training set, which is interesting for the computational cost of the learning procedure but it is an issue when many model parameters must be estimated, which is the well-known curse of dimensionality for neural networks. In fact, the third-order polynomial adopted for HONFIS makes it the most complex model among the ones considered in this paper, and its performances improve with respect to the other models as much as the number of samples increases in the training set, although a larger training set may not be the optimal choice.
Although of relative usefulness, the numerical results for weekly test sets are similar to the previous ones. In the case of seven-day training sets, all of the neural models suffer from the curse of dimensionality, as the information given by a training set of the same length of the test set is too small to ensure a robust estimation of the model parameters. In such cases, the LSE predictor yields better performances than the others models albeit too shallow in absolute terms. In the case of 30-day training sets, HONFIS is able to obtain the best results for weekly test sets, with a numerical score in terms of both NMSE and MARE that is stable enough with respect to shorter test sets of one day only.
The performance of the prediction is highly affected by the intrinsic seasonality of the time series considered. Anyway, HONFIS achieves the best results for almost all of the training sets with respect to the other proposed neural models, and all of them outperform both the LSE benchmark and the ARIMA approach, which is not a feasible solution in this case mainly for the intrinsic chaotic properties of the sequence. This reinforces the fact that the prediction of photovoltaic production is a promising field for the application of neural and fuzzy neural approaches along with the use of a suitable embedding procedure.
5. Conclusions
In this paper, we presented new embedding approaches based on neural and fuzzy neural networks that have been properly tailored to be efficiently applied to PV time series prediction. The models were applied to the time series of sampled output current of a test PV plant, predicting a single day of operation. The models were trained using different training sets, namely 1-day, 3-day, 7-day or 30-day.
The obtained results demonstrate that in normal operation conditions, all of the solutions are suitable for the proposed goal, except for the shorter training sets, which result in less reliable performances. In particular, the approaches were shown to be very accurate when considering a seven-day training set to forecast the successive day, mostly because in a single-week window, the solar irradiation is more stable.
The results are very promising and suggest several opportunities for future work. We could make use of detrending techniques, such as mean-reverting approaches, in order to remove seasonal differences and spike outliers, as well as to improve the training accuracy. Additionally, it could be useful to test distributed learning approaches [
51], by which the results could be improved sharing the data from different cabins of the same plant or from different nearby plants.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}