1. Introduction
Currently, smart meters are being deployed in millions of houses, offering bidirectional communication between the consumers and the utility companies; which has given rise to a pervasive computing environment generating extensive volumes of data with high velocity and veracity attributes. Such data have a time-series notion typically consisting of energy usage measurements of component appliances over a time interval [
1]. The advent of big data technologies, capable of ingesting this large volume of time series streams and facilitating data-driven decision making through transforming data into actionable insights, can revolutionize utility providers’ capabilities for learning customer energy usage patterns, forecasting demand, preventing outages, and optimizing energy usage.
Utility companies are constantly working towards determining the best ways to reduce cost and improve profitability by introducing programs, such as demand-side management and demand response, that best fit the consumers’ energy consumption profiles. Although there has been a marginal success in achieving the goals of such programs, sustainable results are yet to be accomplished [
2]. This is because it is a challenging to understand consumers’ habits individually and tailor strategies that take into account the benefits vs. discomfort from modifying behavior according to suggested energy-saving plans. Furthermore, the relationship between human behavior and the parameters affecting energy consumption patterns are non-static [
2]. Consumer behavior is dependent on weather and seasons and has a variable influence on energy consumption decisions. Thereby, actively engaging consumers in personalized energy management by facilitating well-timed feedback on energy consumption and related cost is key to steering suitable energy saving schemes or programs [
3]. Therefore, designing models that are capable of analyzing energy time series from smart meters that is capable of intelligently infer and forecast the energy usage is very critical.
The purpose of this paper is to present models for analyzing, forecasting and visualizing energy time series data to uncover various temporal energy consumption patterns, which directly reflect consumers’ behavior and expected comfort. Furthermore, the proposed study analyzes consumers’ temporal energy consumption patterns at the appliance level to predict the short and long-term energy usage patterns. These patterns define the appliance usage in terms of association with time (appliance-time associations) such as hour of the day, period of the day, weekday, week, month and season of the year as well as appliance-appliance associations in a household, which are key factors to analyze the impact of consumers’ behavior on energy consumption and predict appliance usage patterns while assisting success of the smart grid energy saving programs in different ways. With such information, not only utilities can recommend energy saving plans for consumers, but also can plan to balance the supply and demand of energy ahead of time. For example, daily energy predictions can be used to optimize scheduling and allocation; weekly prediction can be used to plan energy purchasing policies and maintenance routines while monthly and yearly predictions can be used to balance the grid’s production and strategic planning. Such endeavor is very challenging since it is not trivial to mine complex interdependencies between different appliance usages where multiple concurrent data streams are occurring. Also, it is difficult to derive accurate relationships between interval-based events where multiple appliance usages persist for some duration.
The aforementioned challenges are addressed in the open literature through big data techniques related to behavioral and predictive analytics using energy time series. For examples, extensive arguments in support of exploiting behavioral energy consumption information to encourage and obtain greater energy efficiency are made in [
2,
3]. The impact of behavioral changes for energy savings was also examined by [
4,
5] and end-user participation towards effective and improved energy savings were emphasized. Prediction of consumers’ energy consumption behavior is also studied in several papers. For examples, the work presented in [
6] uses the Bayesian network to predict occupant behavior as a service request using a single appliance but does not provide a model to be applied to real-world scenarios. Authors in [
7,
8], propose a time-series multi-label classifier for a decision tree taking appliance correlation into consideration, to predict appliance usage, but consider only the last 24 h window for future predictions along with appliance sequential relationships. The study in [
9] inspects the rule-mining-based approach to identify the association between energy consumption and the time of appliance usage to assist energy conservation, demand-response and anomaly detection, but lacks formal rule mining mechanism and fails to consider appliance association of a greater degree. The work in [
1] proposes a new algorithm to consider the incremental generation of data and mining appliance associations incrementally. Similarly, in [
10], appliance association and sequential rule mining are studied to generate and define energy demand patterns. The authors in [
11] suggest a clustering approach to identify the distribution of consumers’ temporal consumption patterns, however, the study does not consider appliance level usage details, which are a direct reflection of consumers’ comfort and does not provide a correlation between generated rules and energy consumption characterization.
The study in [
12] uses clustering as a means to group customers according to load consumption patterns to improvise on load forecasting at the system level. Similar to [
12], the authors in [
13] use k-means clustering to discover consumers’ segmentation and use socio-economic inputs with Support Vector Machine (SVM) to predict load profiles towards demand side management planning. Context-aware association mining through frequent pattern recognition is studied in [
14] where the aim is to discover consumption and operation patterns and effectively regulate power consumption to save energy. The work in [
15] proposes a methodology to disclose usage pattern using hierarchical and c-means clustering, multidimensional scaling, grade data analysis and sequential association rule mining; while considering appliances’ ON and OFF event. However, the study does not consider the duration of appliance usage or the expected variations in the sequence of appliance usage, which is directly related to energy consumption behavior characterization. The study in [
16] employs hierarchical clustering, association analysis, decision tree and SVM to support short-term load forecasting, but does not consider variable behavioral traits of the occupants.
The work presented by [
17,
18] mine sequential patterns to understand appliance usage patterns to save energy. An incremental sequential mining technique to discover correlation patterns among appliances is presented in [
1]. The authors propose a new algorithm which offers memory reduction with improved performance. Authors in [
19] utilize k-means clustering to analyze electricity consumption patterns in buildings. The approach provided in [
20] uses an auto-regression model to compute energy consumption profile for residential consumers to facilitate energy saving recommendations but without the consideration of occupants’ behavioral attributes. The methodology proposed by [
21] uses a two-step clustering process to examine load shapes and propose segmentation schemes with appropriate selection strategies for energy programs and related pricing. The work in [
22] proposes graphical model-based algorithm to predict human behavior and appliance inter-dependency patterns and use it to predict multiple appliance usages using a Bayesian model. The study in [
23] considers structural properties and environmental properties along with occupants’ behavior such as thermostat settings or buying energy efficient appliances to analyze the energy consumption for houses/buildings. The study is not aimed towards energy consumption predictions and does not consider appliance level energy consumption and occupants’ energy consumption patterns, which are influenced by occupants’ behavior. The proposed system in [
24] uses an interactive system to minimize the energy cost of operating an appliance when switched on waits for an order from the system. It is a fixed input system and does not learn continuously. Also, the study is tailored towards electrical setup rather data-driven decision making. The work in [
25] uses only light and blind control to simulate behavior patterns. In this way, it takes only partial patterns of daily usage of energy to test a stochastic model of prediction. However, in reality, occupants’ behavior is more complex to be captured by only two parameters. The works in [
26,
27] are surveys of existing studies, does not discuss on occupants’ behavior or appliance level analysis, all the models discussed are at the premise, building, or even national level. Similarly, [
28] use Support Vector Regression (SVR) and [
29] use weighted Support Vector Regression (SVR) with nu-SVR and epsilon-SVR while using differential evolution (DE) algorithm for selecting parameters to forecast electricity consumption at daily and 30 min at a building level. Study [
30] use ANN (Artificial Neural Network) to predict energy consumption for a residential building. Works in [
31,
32] employ deep learning approach for energy consumption predictions at a building level.
The proposed model in this paper differs from existing works in two main aspects. Firstly, the model utilizes big data mining techniques to analyze behavioral energy consumption patterns resulted from uncovering appliance-to-appliance and appliance-to-time associations which are derived from energy time series of a household. This is rather important as it gives insight not only about when and how large energy appliances (e.g., washing machines, dryers, etc.) are being used, but also gives insight about how small appliances and devices (e.g., lights, TVs, etc.) that result in significant energy consumption due to excessive use that is directly linked to behavioral attributes of occupants. Such energy usage behavior is often neglected when analyzing cost reduction programs or scheduling mechanisms in previous work. Secondly, we utilize the Bayesian network for energy consumption prediction. In a real-world application, it is required to predict all the possible appliances expected to operate together. The proposed mechanism uses a probabilistic model to forecast multiple appliance usages on the short and long-term basis. The results can be used in forecasting energy consumption and demand, learning energy consumption behavioral patterns, daily activity prediction, and other smart grid energy efficiency programs.
For the evaluation of the proposed model, we used three datasets of energy time series: the UK Domestic Appliance Level Electricity dataset (UK-Dale) [
33]-time series data of power consumption collected from 2012 to 2015 with time resolution of six seconds for five houses with 109 appliances from Southern England, and the AMPds2 [
34] dataset-time series data of power consumption collected from a residential house in Canada from 2012 to 2014 at a time resolution of one minute, and a synthetic dataset. A more detailed explanation on datasets is presented in
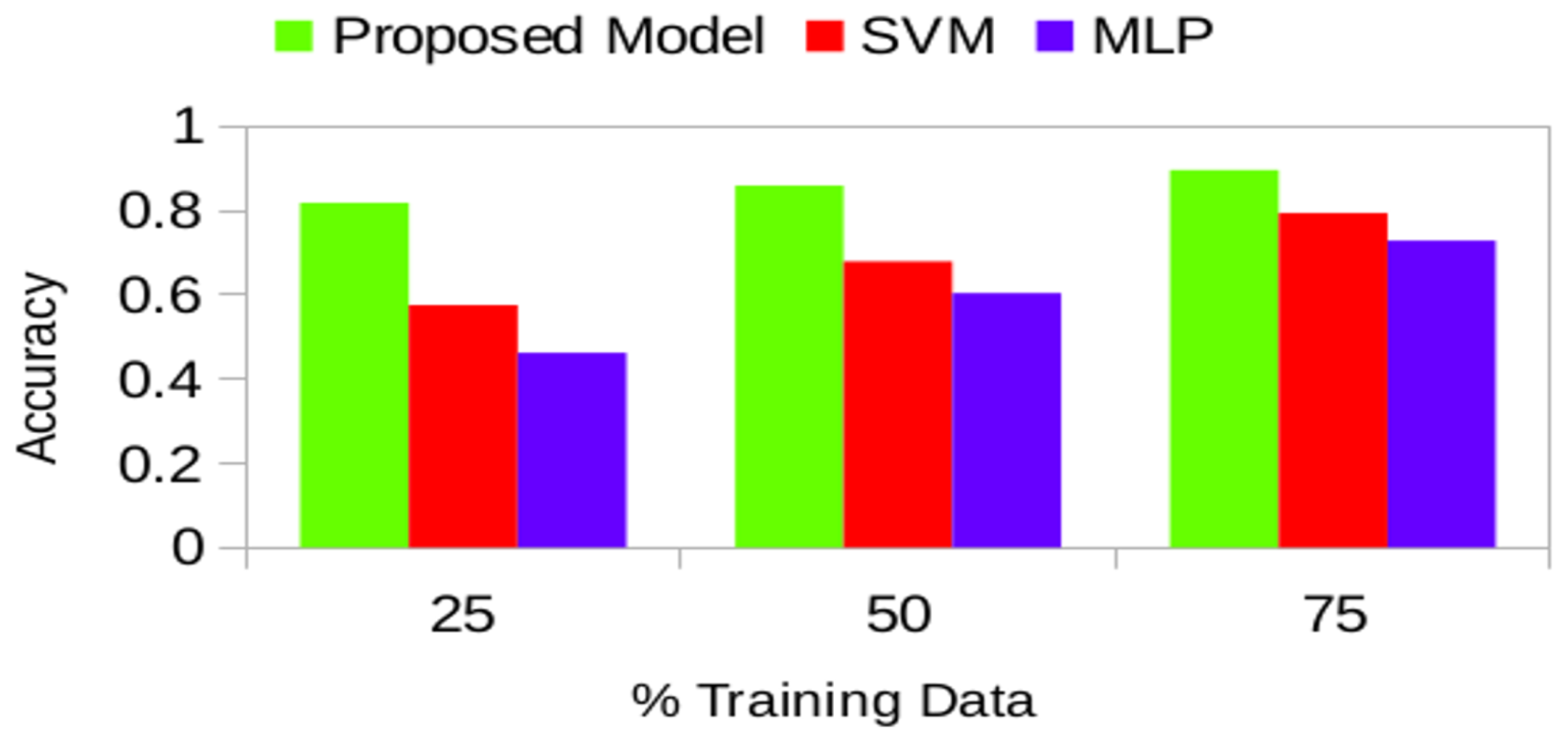
Section 3.2 with a sample of raw data. After extensive experiments, the accuracy of identifying usage patterns using our proposed model outperformed Support Vector Machine (SVM) and Multi-Layer Perceptron (MLP) at each stage. Our model obtains accuracies of 81.82%, 85.90%, 89.58% for multiple appliance usage predictions on 25%, 50% and 75% of the training data size respectively. Moreover, it produces energy consumption forecast accuracies of 81.89%, 75.88%, 79.23%, 74.74%, and 72.81% for short-term (hourly), and long-term (day, week, month, season) respectively.
This work is different from our previously published work [
35,
36] which focuses on energy consumption analysis of appliances and their impact during peak and non-peak hours. Also, this work is different from [
37] which focuses on determining activity recognition for healthcare applications. This paper introduces the specific analysis of behavioral treats, detail clustering algorithms and forecasting models that have not been discussed in our previous work.
The paper is organized as follows: The next
Section 2 discusses the proposed model followed by evaluation and results analysis in
Section 3. Finally, we conclude the paper and discuss future directions in
Section 4.
2. Proposed Model
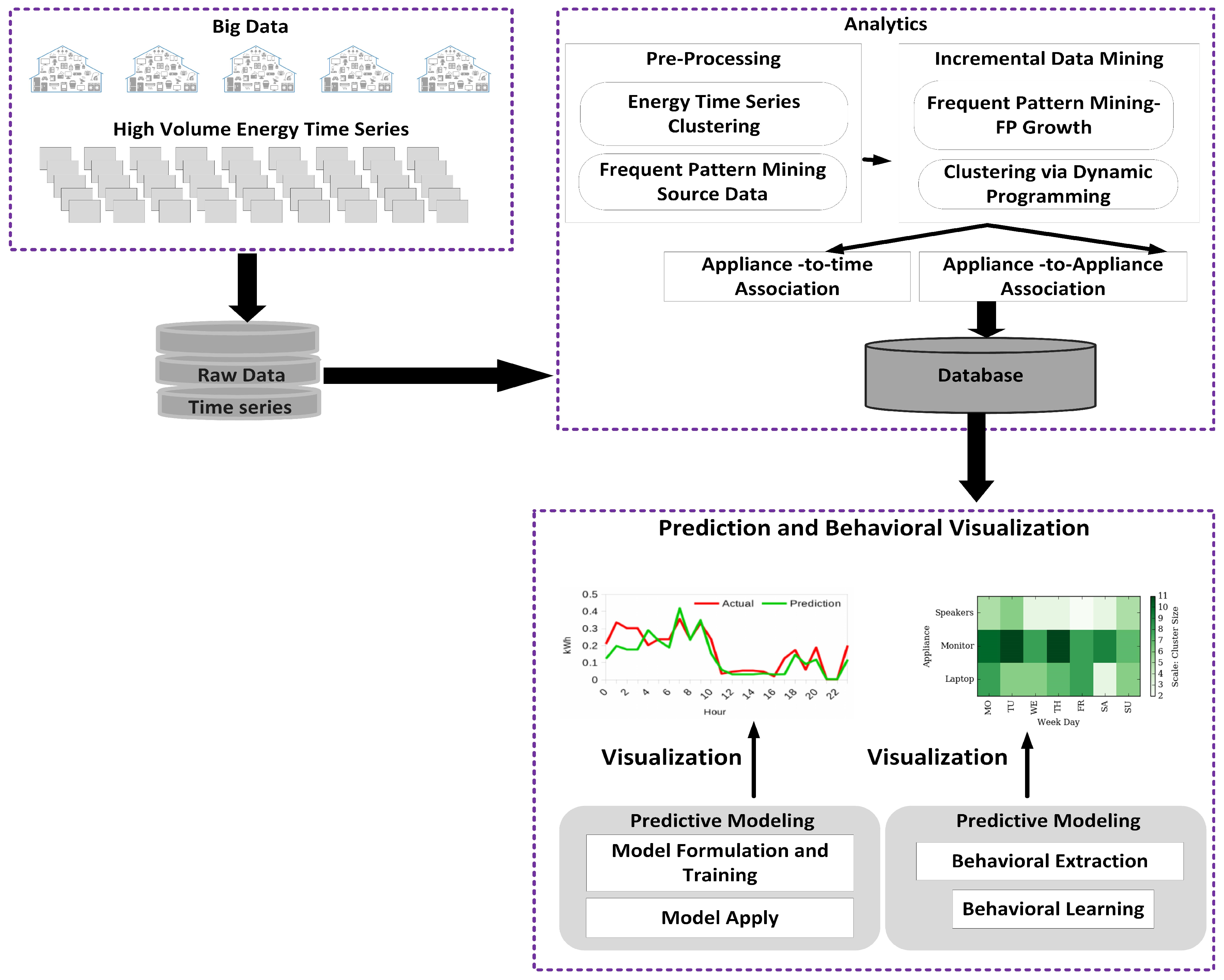
Figure 1 illustrates the proposed model with its distinct phases: pre-processing/data preparation, incremental frequent pattern mining and clustering analysis, association rules extraction, prediction and visualization. In this section, we discuss these phases and provide details about their respective mechanisms along with related theoretical background.
In the first phase, raw data, which contain millions of records of energy time series of consumption data, are prepared and processed for further analysis. In the following phase, incremental frequent pattern mining and clustering is performed. Frequent patterns are repeated itemsets or patterns that often appear in a dataset. Considering energy time series data, an itemset could comprise, for example, of a kettle and laptop and when this itemset is repeatedly encountered it is considered a frequent pattern. The aim is to uncover association and correlation between appliances in conjunction with understanding the time of appliance usage with respect to hours and time (Morning, Afternoon, Evening, Night) of day, weekdays, weeks, months and seasons. This latent information in energy time series data facilitates the discovery of appliance-time associations through clustering analysis of appliances over time. Clustering analysis is the process of constructing classes, where members of a cluster display similarity with one another and dissimilarity with members of other clusters. While learning these associations, it is important to identify what we refer to as Appliance of Interest (AoI), that is, major contributors to energy consumption, and develop capabilities to predict multiple appliance usages in time.
The mining of frequent patterns and cluster analysis are typically recognized as an off-line and expensive process on large size databases. However, in real-world applications, data generation is a continuous process, where new records are generated and existing ones may become obsolete as the time progresses, thereby, refuting existing frequent patterns and clusters and/or forming new associations and groups. This is the case of time series of energy consumption data, which is continuously generated at high resolution. Therefore, a progressive and incremental update approach is vital, where ongoing data updates are taken into account and existing frequent patterns and clusters are accordingly maintained with updated information. For example, an appliance such as a room-heater generally will be used during winter, and we can expect reduced usage frequency during other seasons. As an effect, a significant gain in use during winter but the decline in other seasons will be recorded. As a result, room-heater should appear higher on the list of frequent patterns and association rules during winter, but much lower during summer or spring. Similarly, appliance usage frequency would affect size or strength of clusters; i.e., association with time. This objective of capturing the variations can be achieved through progressive incremental data mining while eliminating the need to re-mine the entire database at regular intervals. For a large database, frequent pattern mining can be accomplished through pattern growth approach [
38,
39], whereas cluster analysis can be achieved through k-means clustering analysis [
40]. In the proposed model, we expand these two techniques and present an online progressive incremental mining strategy where available data is recursively mined in quanta/slices of 24 h. This way, our data mining strategy can be viewed as an incremental process being administered every day. During each consecutive mining operation, existing frequent patterns and clusters are updated with new information, whereas new discovered patterns and clusters are appended to the persistent database in an incremental and progressive manner. With this technique, we mine only a fraction of the entire database at every iteration thus minimize memory overhead and accomplishing improved efficiency for real-world online applications where data generation is an ongoing process, and extraction of meaningful, relevant information to support continuous decision making at various levels is of paramount importance.
Frequent patterns and clusters can be stored and maintained in-memory using hash table data-structure or stored in off the memory Database Management System. The latter approach reduces memory requirement at the cost of a marginal increase in processing time, whereas the former approach reduces processing time but requires more memory. Considering the smart meter environment, quicker processing time is of importance; however, the persistence of information discovered through days, months or years is more vital to achieving useful and usable results for the future. Therefore, we prefer permanent storage using Database Management System over in-memory volatile storage.
In the third phase, the model extracts critical information of the appliance-appliance association rules from the appliance-appliance frequent patterns, incrementally and progressively. Frequent patterns discovered and clusters formed can determine the probabilistic association of appliance with other appliances and time while identifying AoIs. In the last phase, we use the Bayesian network based prediction approach, while taking in results from the previous phase, to predict the multiple appliance usages and energy consumption for both short-term and long-term forecasting. This phase includes the visualization of behavioral analytics and forecasting results.
The details of the mechanisms used in each phase are described in the following subsections.
2.1. Data Preparation
Energy time-series raw data is a high time-resolution data; it is transformed into a 1-min resolution energy consumption or load data. Afterwards, it is translated into a 30-min time-resolution source data for next stage of data mining process. Therefore, reducing data points to a
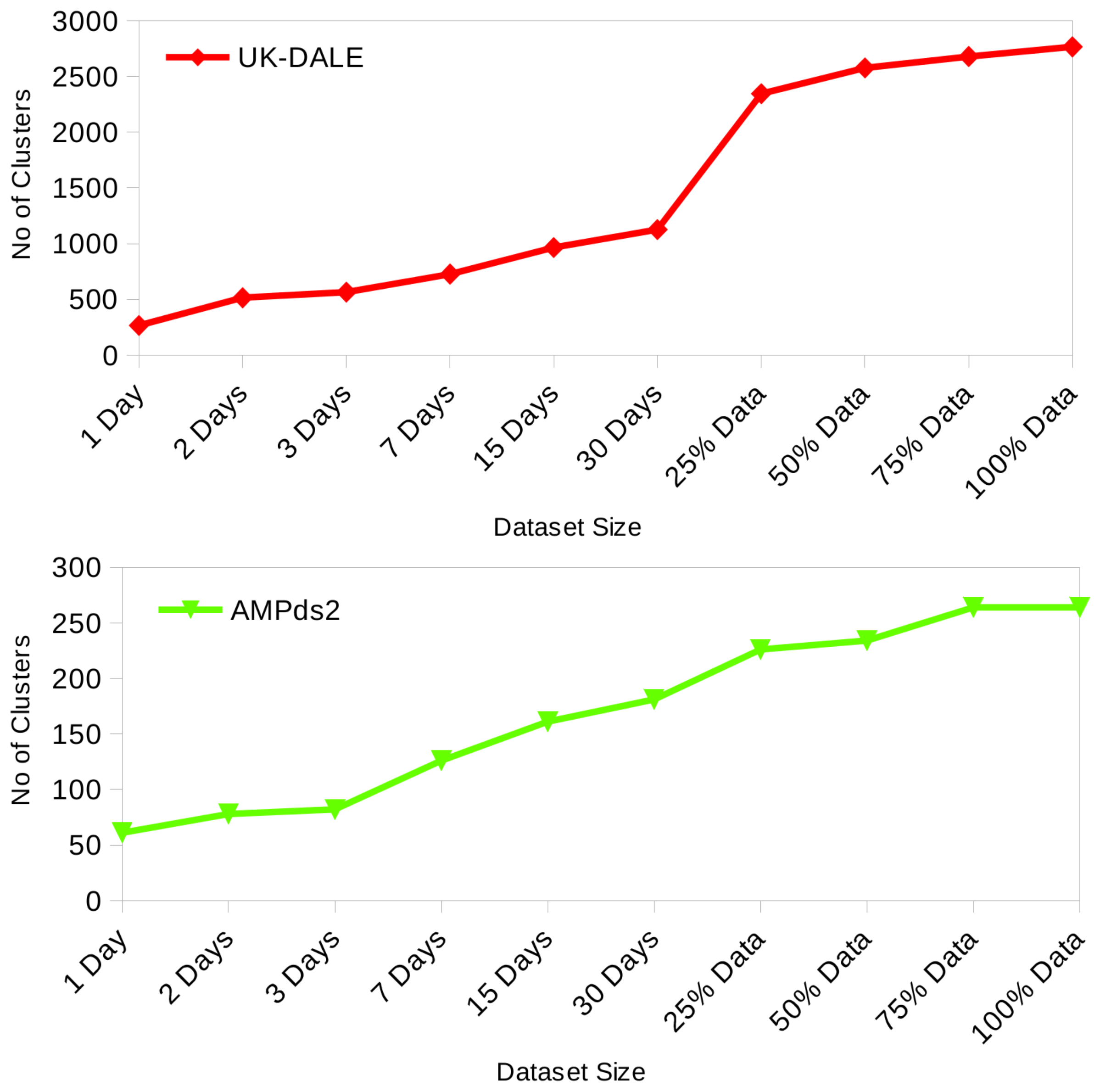
readings per day per appliance, while recording usage duration, average load, and energy consumption for each active appliance. All the appliances registered active during this 30-min time interval are included in the source data for frequent pattern mining and cluster analysis. We analyzed and found time-resolution of 30-min as most suitable because it does not only capture appliance-time and appliance-appliance associations adequately but also keeps the number of patterns eligible for analysis sufficiently low and makes it appropriate for a real-world application. Three datasets (two real and one synthetic) were utilized for this research. The first real dataset has over 400 million raw energy consumption records from five houses having a time resolution of 6 s. It was reduced to just over 20 million during pre-processing phase without loss of accuracy or precision. Similarly, the second real dataset AMPds2 [
34] was reduced to 4 million records from over 21 million raw records, which initially had 1-min time-resolution. Additionally, we constructed a synthetic dataset for preliminary evaluation of our model, having over 1.2 million records. In
Table 1,
Table 2 and
Table 3, presents an example of source data comprising of four appliances for one house that is ready to mine for extraction of frequent patterns and clusters.
2.2. Frequent Pattern Mining and Association Rules Generation
Appliance-appliance and appliance-time associations represent critical consumer energy consumption behavioral characteristics and can identify peak load/energy consumption hours. These associations also explain respective behavioral traits and the expected comfort of the occupants. Therefore, with the gigantic volume of data continuously being gathered from smart meters, it is not only of avid interest to utilities and energy producers, but also to consumers to mine such frequent patterns and clusters for decision-making processes such as energy cost reduction, demand response optimization, and energy saving plans.
Frequent pattern mining which is conducted over the input data and presented in
Table 1, can discover a recurring pattern; i.e., a pattern comprising of itemsets which exist repeatedly. In our case, these itemsets are individual appliances operating in specific houses/premises. Hence, the appliances appearing frequently together form frequent patterns are deemed to be associated. Therefore, the discovery of these frequent patterns aids us to identify appliance-appliance associations. The following subsection presents an introductory background on frequent pattern mining that is built on [
41].
Let
be an itemset consisting
k items (appliances), which can be designated as
k-itemset (
). Let
, denote a transaction database where every transaction
is such that
and
.
Table 1 represents sample of transaction database. Support count of the itemset can be defined as the frequency of its appearance; i.e., count of transactions that contain the itemset. Let,
X (
) and
Y (
) be set two itemsets or patterns.
X and
Y are considered frequent itemsets/patterns if their respective
and
are greater than or equal to
.
is a pre-determined minimum support count threshold.
can be viewed as the probability of the itemset or pattern in the transaction database
. It is also referred to as the relative support. Whereas, the frequency of occurrence is known as the absolute support. Hence, if the relative support of an itemset fulfills a pre-defined minimum support threshold
, then the absolute support of
X (or
Y) satisfies the corresponding minimum support count threshold.
In the second stage of the (
FP) mining process extracted frequent items, or frequent patterns are processed to develop association rules. Association rules, having configuration
, are developed through employing
–
framework, where
[Equation (
1)] is the percentage of transactions having
in the database
that can be viewed as the probability
. Additionally, the
, as shown in equation [Equation (
2)], can be described as the percentage of transactions, in transaction database
, consisting of
X that also contain
Y; i.e., the conditional probability
[
41]. Equations (
1) and (
2) defines the notion of
and
respectively:
–
frame-work is a common workhorse for the algorithms to extract frequent patterns and generate association rules. They eliminate uninteresting rules through comparing
with
and
with
. However,
–
frame-work do not examine correlation of the rule’s
and
. This makes this approach ineffective for eliminating uninteresting (association) rules. Therefore, it is vital to determine the correlation among the rules’ components to learn the negative or positive effect of their presence or absence and eliminate the rules that are deemed uninteresting.
is one of the most generally employed correlation measures, but it has a negative impact of null-transactions. Null-transactions, are transactions where the possible constituents of association rules (itemsets) are not part of these transactions; i.e.,
null-transaction and
null-transaction. In a large transaction database, null-transactions can outweigh the
count for these itemsets. Thus, in a situation where minimum support threshold is low or extended patterns are of importance, the technique of using
as criterion fails to yield results as described by [
41]. The study proposes to use Kulczynski measure (
) in conjunction with the Imbalance Ratio (
) that are interestingness measures of null-invariant nature to supplement
–
frame-work in order to improve the efficiency of extracting rules that are interesting [
41].
A correlation rule can be defined as:
Kulczynski Measure (Kulc) [
41]: Kulczynski measure of
X and
Y, is an average of their
. Considering the definition of
this can be interpreted as the average of conditional probabilities for
X and
Y.
or Kulczynski measure is null-invariant, and it is described as:
where,
indicates that X and Y are negatively correlated; i.e., the occurrence of one indicates the absence of other
, signifies that X and Y have positively correlation; i.e., occurrence one indicates presence of other
signifies that X and Y are unrelated or independent having no correlation among them
Imbalance Ratio (IR) [
41]:
is used to asses the imbalance between
and
for a rule. It can be defined as:
where
represent perfectly balanced and
represent a very skewed context respectively. IR is null-invariant, and it is not affected by database size.
2.2.1. Extracting Frequent Pattern
In the work [
38,
39], the authors present
FP-growth a pattern growth approach that utilizes divide-and-conquer depth-first technique. It starts by generating a frequent pattern tree or FP-tree, which is a compact form representation of the database transactions. An
FP-tree stores the association information that is extracted from transactions with the support count for each component item. Next,
for each frequent pattern item is derived from FP-Tree to mine or generate frequent patterns where the item that is under consideration is present. By employing this approach, only a divided portion that is relevant to the item and its corresponding growing patterns are examined that addresses both the deficiencies of the Apriori [
42] technique. Moreover, we do not use minimum support
threshold at the data mining phase to eliminate candidate patterns; rather we let the discovery of all the feasible frequent patterns. This change in approach ensures avoiding missing of any candidate pattern that may become a frequent pattern if the time slice is increased or mining activity is taken up for the complete database as a single process. All the frequent patterns extracted or discovered are stored in a persistent Database Management System, which ensures the continued availability of all the historical results to the consecutive mining operations. This is inline as discussed earlier. Additionally, new frequent patterns are compared with the frequent patterns in the database, and the
for the patterns are updated if found to exists else the new pattern is added and stored in the persistent database. At the completion of each data mining activity, the
is updated for all the frequent patterns in the database to make sure
is computed all the time correctly. Algorithm 1 presents the incremental progressive frequent pattern mining technique, and corresponding results are shown in
Table 4. Further, if we consider the definition of
for an itemset in a database, which is the probability of the existence of the itemset in the transaction database, the marginal distribution for appliance-to-appliance association can be calculated at a global level. It is shown in
Table 4. The computed marginal distribution establishes the probability of appliance being concurrently active.
| Algorithm 1 Frequent Pattern mining: Incremental. |
Require: Transactional database (), Frequent patterns discovered storage database ()
Ensure: Incremental mining of frequent patterns, permanently stored in frequent patterns discovered storage database ()
- 1:
for all Transaction data slice in quanta of 24 h in database do {Process time-series data in 24 h time slices} - 2:
Compute database size for the data quantum/slice - 3:
Extract Frequent patterns in data slice through extended FP-growth technique - 4:
for all Frequent Pattern in do - 5:
Look a frequent pattern in - 6:
if Found Frequent Pattern then - 7:
Update new information for frequent pattern in database - 8:
else - 9:
Add/append newly discovered Frequent Pattern to database - 10:
end if - 11:
end for - 12:
For all Frequent Patterns discovered and stored in Database increase size of database i.e., by value of - 13:
end for
|
2.2.2. Generating Association/Correlation Rules
Generation of appliance association rules is an uncomplicated process of extracting these rules from the frequent patterns for itemsets captured from transactions in a transaction database
. We extract the association rules by extending the Apriori [
42] technique. We propose to use the correlation measure
to eliminate uninteresting association/correlation rules while use measure imbalance ratio
to explain it.
2.3. Cluster Analysis: Incremental k-Means Clustering to Uncover Appliance-Time Associations
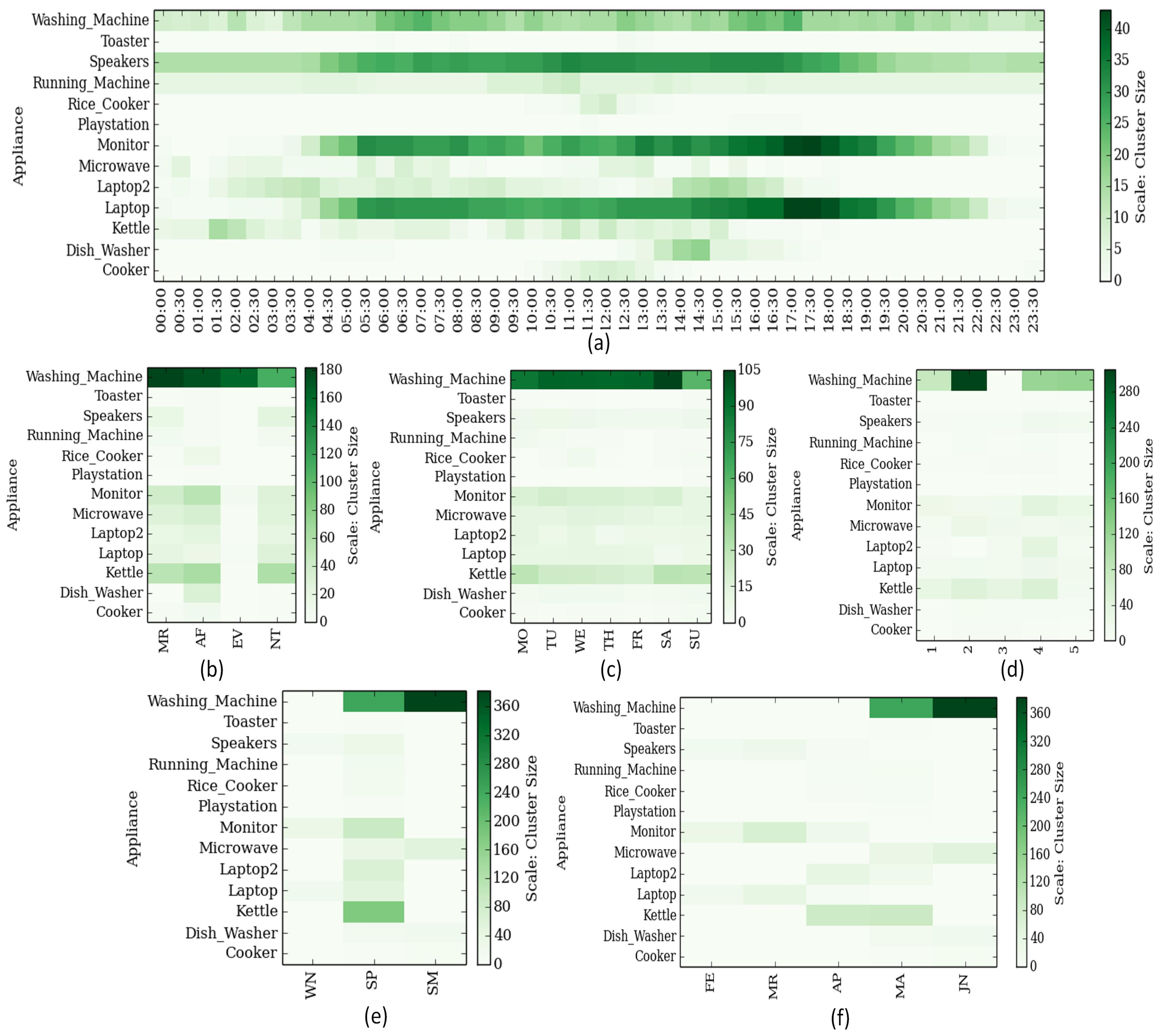
In addition to uncovering inter-appliance association, understanding the appliance-time association can aid critical analysis of consumer energy consumption behavior. Appliance-time associations can be defined in terms of hour of day (00:00–23:59), time of day (Morning/Afternoon/Evening/Night), weekday, week of month, week of year, month and/or season (Winter/Summer/Spring/Fall). Finding appliance-to-time associations can be seen as assembling of adequately adjoining time-stamps, for an active appliance that is recorded as operational, to construct a class or cluster for the given appliance. The clusters formed defines the appliance-to-time associations, while the size of clusters, determined by the count of members in the clusters, defines the relative strength of the clusters. Therefore, the finding of appliance-to-time associations can be interpreted as clustering of appliances into groups of time-intervals; where every cluster belongs to one appliance with time-stamps (data points) of activity as members of the cluster.
Cluster analysis is a process of constructing batches of data points according to the information retrieved from the data, but without external intervention; i.e., unsupervised classification. This extracted information outlines the relationship among the data points and acts as the base for classification to ensure data points within a cluster are closer to one another but distant from members of other clusters [
43,
44]. “Closer” and “Distant” are measures of association, defining how closely members of a cluster are related to one another. Hence, clustering analysis conducted over the input data, presented in
Table 2 and
Table 3, can generate clusters or classes defining natural associations of appliances with time while respective support or strength defines the degree of association. These appliance-to-time associations are capable of not only determining peak load or energy consumption hours but can reveal the energy consumption behavioral characteristics of occupants or consumers as well.
We extend one of the most widely used prototype-based partitional clustering technique to extract appliance-time associations. The prototype of a cluster is defined by its centroid, which is the mean of all the member data points. In this approach, clusters are formed from non-overlapping distinct groups; i.e., each member data point belongs to one and only one group or cluster [
43]. Moreover, we mine data incrementally in a progressive manner, which we explain next.
2.3.1. k-Means Cluster Analysis
We introduce preliminary background on k-means clustering based on [
43,
44]. For a dataset,
, that has
n data points in the Euclidean space, partitional clustering allocates the data points from dataset
into
k number of clusters,
, having centroids
such that
,
and
for (
). An objective function that is based on Euclidean distance, Equation (7), is employed to measure the cohesion between data points that demonstrate the quality of the cluster. The objective function is defined as the sum of the squared error (SSE), define in Equation (
6), and k-means clustering algorithm strives to minimize the SSE.
The k-means starts by selecting k data points from , where , and form k clusters having centroids or cluster centers as the selected data points. Next, for each of the remaining data points d in , data point is assigned to a cluster having least Euclidean distance from its centroid () i.e., . After a new data point is assigned the revised cluster centroids are determined by computing the cluster centers for the clusters, and k-means algorithm repetitively refines the cluster composition to reduce intra-cluster dissimilarities by reassigning the data points until clusters are balanced; i.e., no reassignment is possible, while evaluating the cluster quality by computing the sum of the squared error (SSE) covering all the data points in the cluster from its centroid.
2.3.2. Optimal k: Determining k using
We exploit
that is calculated based on the Euclidean distance, to ascertain the optimal number of clusters; i.e.,
k, while assessing the quality of clustering by analyzing intra-cluster cohesion and inter-cluster separation of data points among clusters.
measures the degree of similarities and dissimilarities to indicates “How well clusters are formed?”.
can be computed as defined in Equations (
8)–(
12) [
45],
Compute
as average distance of
to all other data points in cluster
Compute Average distance of
to all other data points in clusters
, having
; Determine
=
across all the clusters except
.
Compute
for
Compute
for cluster
Compute
for clustering, having
k clusters
can range from −1 to 1; where a negative value indicates misfit as the average distance of data point
to data points in the cluster
(
) is greater than the average distance
to data points in a cluster other than
(
) , and a positive number indicates better-fit clusters. Overall the quality of the cluster can be assessed by computing average
by computing the average of
(
) for all the member data points for the cluster, as shown in Equation (
11). Similarly, an average
(
) can be calculated for complete clustering by obtaining the average of
for all the member data points across all the clusters, as in Equation (
12) [
45].
Finally, to determine optimal , where n is the unique set of data points in database/dataset, the process of analyzing the quality of clusters formed is repeated while computing () and k is chosen having maximum .
2.3.3. Optimal One-Dimensional k-Means Cluster Analysis: Dynamic Programming
With reference to the clustering input database, presented in
Table 2 and
Table 3, we have a cluster analysis requirement for a single dimension data. We make use of dynamic programming algorithm for optimal one-dimensional k-means clustering proposed by [
46], which ensures optimality and efficient runtime. We further extend the algorithm to achieve incremental data mining to discover appliance-time associations.
Here we provide the relevant background based on [
46]. A one-dimension k-means cluster analysis can be viewed as grouping
n data points
into
k clusters, while minimizing sum of the squared error (SSE), shown in Equation (
6). A sub-problem for the original dynamic programming problem can be defined as finding the minimum SSE of clustering
data points into m clusters. The respective minimum SSE are stored in a Distance Matrix (
) of size
, where
records the minimum SSE for the stated sub-problem, and
provides the minimum SSE for the original problem. For a data point
in the m clusters, where
is the first data element of cluster
m, the optimal solution (SSE) to the sub-problem is
; therefore,
must be the optimal SSE for the first
data points in the
clusters. This provides optimal substructure defined by Equation (
13).
where
is the computed SSE for
from their centroid/cluster center, and
, for
or
.
is computed iteratively from
as shown in Equation (
14) .
where,
is the mean of the first
data elements.
A backtrack matrix
is maintained, of size
, to record the starting index of the first data element of respective cluster. Backtrack matrix is used to extract cluster members by determining the starting and ending indices for the corresponding cluster and retrieving the data points from the original dataset. Equation (
16) captures this notion.
2.3.4. Incremental Mining: Cluster Analysis
We achieve incremental progressive clustering by merging clusters and/or adding new clusters extracted during each successive mining operation into a persistent database in the Database Management System. Discovered clusters database records all the relevant cluster parameters and information that includes centroid, (width), SSE, and data points along with their distance from the centroid. This enables the easy addition of new data points or clusters while computing cluster parameters with respect to the newly added data points and updating the information in the database accordingly. Considering, the translation of the raw time series data into a source data having 30 min time-resolution during the data preparation phase, this time-resolution unit is sufficient to capture vital information regarding consumer energy consumption decision patterns. The cluster analysis for hour of day done on this source data will result in clusters created with a separation between clusters’ centroids as multiples of such time-resolution, which is 30 min in the current case. This time-resolution is identified as . Whereas, a cluster analysis on the other bases such as time of day, weekday, week of month, week of year, month and seasons have natural segmentation. With this operation, we achieve more exclusive homogeneity and separation among clusters.
Upon completion of mining on the incremental quantum of data, newly discovered clusters are matched against the existing clusters in the database to determine the closest cluster(s) to merge with, having centroid within the distance of
from the new cluster. If there exists no cluster in the database, which is closer to the new cluster satisfying the permissible centroid distance constraint, the new cluster is added/stored into the discovered clusters database with all the accompanying parameters and information. However, in the case of success, data points from the new cluster will be added to the searched cluster(s) while evaluating the quality of the final cluster by computing the
. The data points from the new cluster are picked according to increasing order of distance from the centroid. The most stable cluster configuration, having the maximum
, are saved to the database. Algorithm 2 outlines the incremental cluster analysis using one-dimensional k-means clustering via dynamic programming and results are presented in
Table 5. During the analysis of the clustering results, it can be noted that for a cluster centroid, the marginal distribution for the appliances at a global level can be computed as shown in
Table 6. The computed marginal distribution decides the probability of appliances being operational or active during the period identified by the centroid.
| Algorithm 2 Incremental k-means Clustering. |
Require: Transactional database , permissible centroid distance between clusters = 30
Ensure: Incremental k-means clustering, clusters and associated configuration (, SSE, and data points along with distance from centroid) stored in clusters discovered database - 1:
for all 24 h quantum transaction data in do {Process time-series data in 24 h time slices} - 2:
Find optimal k for data quantum by evaluating for clustering - 3:
Construct k clusters in using one-dimensional k-means clustering through dynamic programming, while recording , SSE, and data points along with their distance from cluster center or centroid - 4:
for all Cluster c in do - 5:
Seek the closest cluster in , having cluster center or centroid within the distance of - 6:
if Found Cluster(s) then - 7:
Combine/merge the clusters and c while assessing quality of cluster by determining the and store it in database - 8:
else - 9:
Add new cluster c with associated information in the database - 10:
end if - 11:
end for - 12:
end for
|
2.4. Bayesian Network for Multiple Appliance Usage Prediction and Household Energy Forecast
We utilize a Bayesian Network (BN) that is a probabilistic graphical model using directed acyclic graph (DAG) to predict the multiple appliances usage at some point in the future. Bayesian networks are directed acyclic graphs, where nodes symbolize random variables and edges represent probabilistic dependencies among them. Each node or variable in BN is autonomous; i.e., it does not depend on its nondescendants. It is accompanied by local conditional probability distribution in the form of a node probability table that aids the determination of the joint conditional probability distribution for the complete model [
47,
48]. Therefore, the local probability distributions furnish quantitative probabilities that can be multiplied according to qualitative independencies described by the structure of Bayesian Network to obtains the joint probability distributions for the model. The Bayesian network has advantages such as the ability to effectively make use of historical facts and observations, learn relationships, mitigate missing data while preventing overfitting of data [
49]. A Bayesian network can be illustrated by the probabilistic distribution defined by Equation (
17) [
50,
51].
2.4.1. Probabilistic Prediction Model
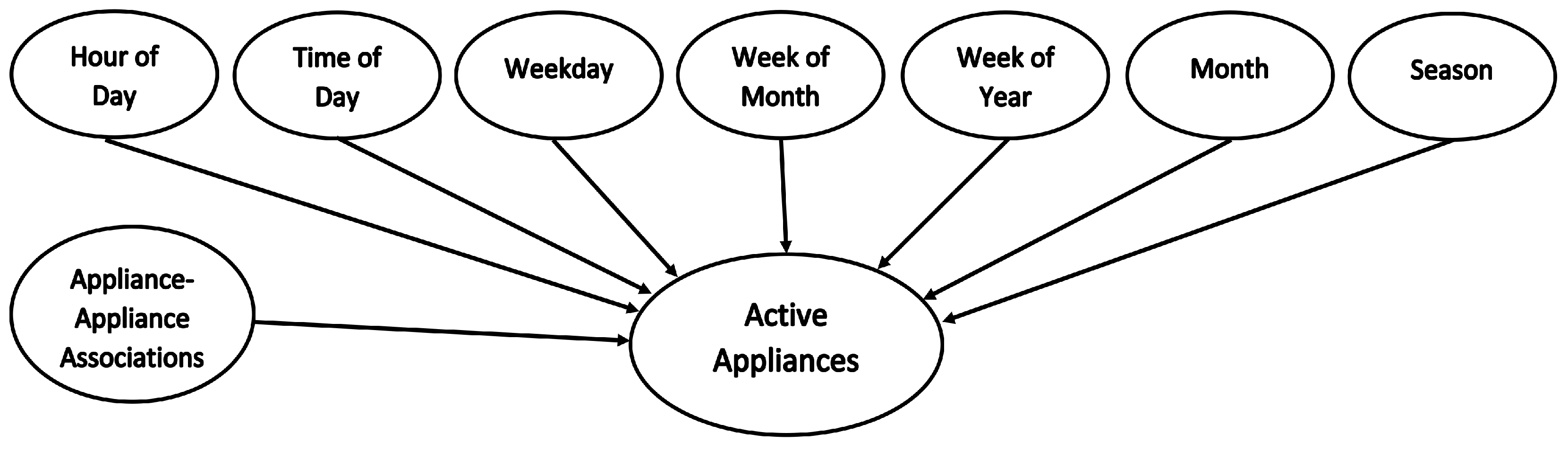
We construct our model based on Bayesian network, having eight nodes representing probabilities for appliances-to-time associations in terms of hour of day (00:00–23:59), time of day (Morning/Afternoon/Evening/Night), weekday, week of month, week of year, month and/or season (Winter/Summer/Spring/Fall), and appliance-appliance associations. The resulting Bayesian network has a very simple topology, with known structure and full observability, comprising only one level of input evidence nodes, accompanied by respective unconditional probabilities, converging to one output node. The Equation (
18) and
Figure 2 present the posterior probability or marginal distribution and network structure for the proposed prediction model.
We use the output of the earlier two phases; i.e., cluster analysis and frequent pattern mining to train the model, which effectively incrementally learns the prior information through progressive mining.
Table 7 represents a sample of the training data with marginal distribution for the various appliances, and the probability of appliances to be active during the period, for the node variable/parameter vector. The probabilities are computed from the clusters, formed and contentiously updated during the mining operation. The respective cluster strength or size determines the relative probability for the individual appliance. Additionally, appliance-appliance association, the outcome of the frequent pattern mining, computes the probabilities for the appliances to operate or be active concurrently. Therefore, the model uses top-down reasoning to deduce and predict active appliances consuming energy, operating concurrently, using historical evidence from the results of cluster analysis (appliance-to-time associations) and frequent pattern mining (appliance-to-appliance associations).
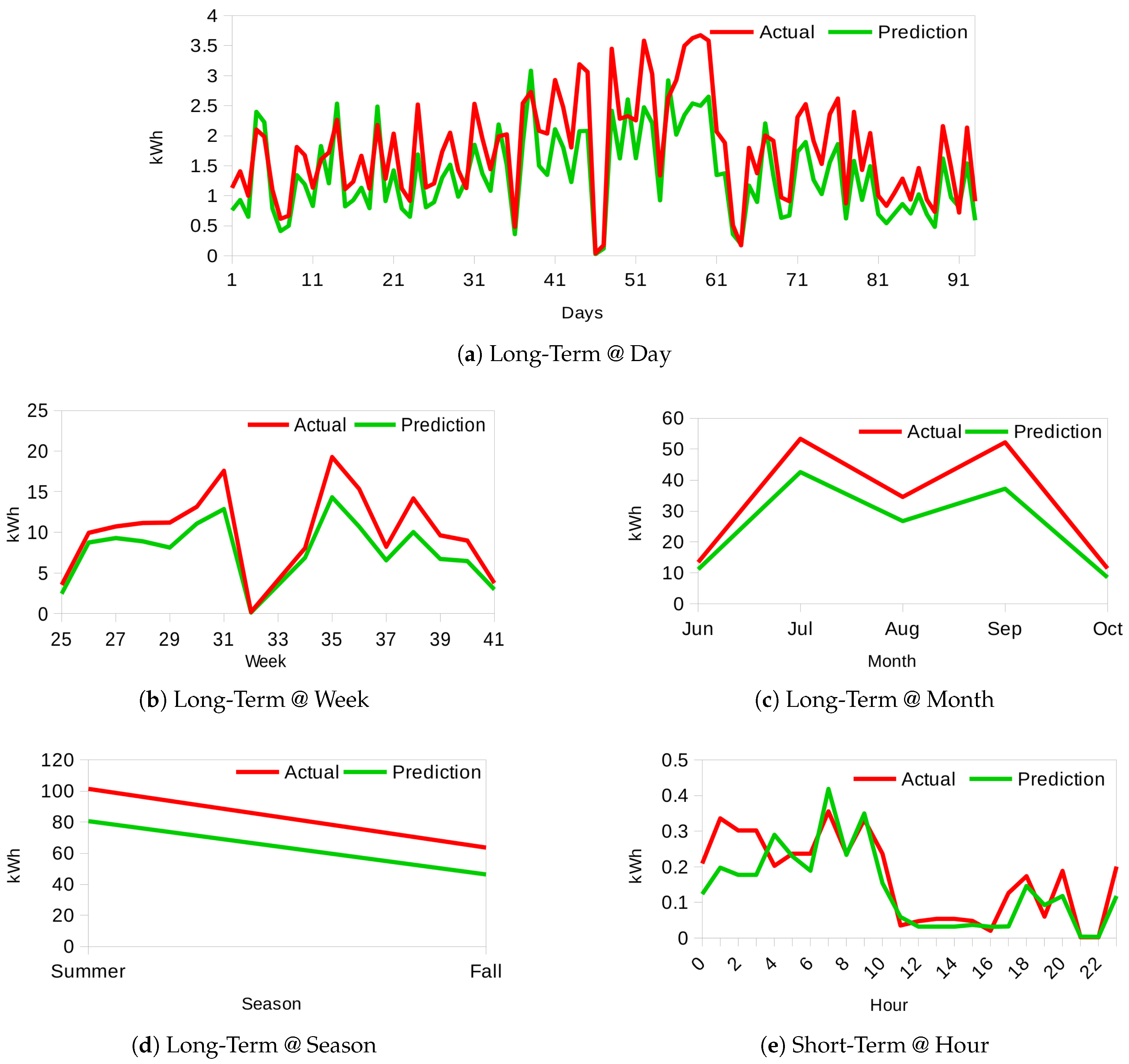
Furthermore, the multiple appliance usage prediction results build the foundation for household energy consumption forecast, where, average appliance load and average appliance usage duration are extracted from the historical raw time-series data at the respective time resolution that is an hour, weekday, week, month or season level. In this way, we are capable of predicting energy consumption for a defined time in the future for short-term: from the next hour up to 24 h and long-term: days, weeks, months, or seasons. Next, we evaluate our proposed model and provide results of the analysis.
Table 8 shows an example of extracted raw data for data mining for one appliance.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}