1. Introduction
With the massive consumption of fossil fuel and the increasing pressure of environmental protection, wind energy, one of the most major sustainable and clean energy sources, has been attracting an increasing attention in the last decades due to its remarkable features, such as broad distribution and abundant reserves [
1]. Therefore, wind energy is a promising substitute in many parts of the world. As the Global Wind Energy Council (GWEC) have reported, over 54 GW of clean and sustainable wind power has been installed across the global market in 2016, which now contains over 90 countries, including nine with over 10,000 MW installed, and 29 which have now exceeded the 1000 MW mark. Cumulative capacity increased by 12.6% to reach a total of 486.8 GW [
1]. However, affected by various factors (e.g., terrain, air pressure, temperature), wind energy is seriously intermittent, random, highly non-linear, and non-stationary, which is not conducive to the large-scale grid-connected operation of wind farms, and can bring a series of fatal problems for the safe and stable operation of power systems. Fortunately, accurate and reliable wind speed forecasting can effectively mitigate the negative impacts of wind energy on the power grid. Thus, many efforts have been done in wind speed forecasting to achieve higher wind energy utilization rates, safe and stable operation of power grids, and thereby gain more economic profits.
At present, various forecasting models have been developed and applied in many fields [
2,
3,
4,
5,
6]. Weron [
3] provided a thorough review of the strengths, weaknesses, and future for the state-of-the-art forecasting methods. Models used in wind speed/power forecasting can be divided into four main types, including physical models, statistical models, machine learning (ML) models, and hybrid models. The physical models are established according to hydrodynamic and thermodynamic equations. They usually require various meteorological and geographic information, such as wind speed, wind direction, temperature, humidity, barometric pressure, air density, elevation, among others. Therefore, the input dimension of the physical models is extremely high and their implementation process are very complex due to the large dimension of inputs. These two features limit the generalization of the physical models in practical engineering applications.
Unlike physical models, statistical models are constructed using relative less historical data through the analysis of the relevance between each point in the observed wind speed series. Most commonly used statistical models are auto regressive (AR) model [
7], autoregressive moving average (ARMA) model [
8], auto regressive integrated moving average (ARIMA) model [
9], and their variants. These models have simple structures, whereas they are often inefficient when handle time series with high-nonlinear and non-stationary characteristics which are two essential features of wind speed series. Therefore, machine learning (ML) models are exploited in this field due to their remarkable abilities of nonlinear learning and generalization abilities. Cincotti et al. [
6] has demonstrated that the ARMA-Generalized AutoRegressive Conditional Heteroscedasticity (GARCH) model is inferior to computational intelligence methods. Artificial neural networks (ANNs), the most popular ML models, have been widely exploited over the last decades. Traditional ANNs mainly include multi-layer perceptron (MLP) [
6,
10], back-propagation neural networks (BPNNs) [
11,
12,
13], generalized regression neural networks (GRNNs) [
13], radial basis function neural networks (RBFNNs) [
13], and Elman neural networks (ENNs) [
14,
15]. Recently, the extreme learning machine (ELM), a new single hidden layer feed-forward network (SLFN), has been developed [
16]. Compared with conventional ANNs, the most prominent characteristics of ELM are its simple structure, fast learning rate, and strong generalization ability [
16]. Unfortunately, the standard ELM is easy to over-fit and sensitive to outliers, because it only takes the empirical risk minimization principle into account during its implementation process [
17,
18,
19]. Many researchers have applied their efforts to improving the performance of ELM [
17,
18]. The most effective way is introducing regularization methods into the basic ELM model to build the regularized ELM (RELM) model. Compared with the basic ELM, the RELM can provide more accurate and stable results, which has been proved by [
5,
17,
18].
With the rapid development of data mining and computational intelligence techniques, a number of hybrid models with signal decomposition approaches and/or optimization algorithms have been proposed/developed. The signal decomposition approaches are able to decompose the raw data into a group of subseries which are smoother and easier to predict. Signal decomposition methods, such as wavelet decomposition (WD) [
20,
21], empirical mode decomposition (EMD) [
22,
23,
24], ensemble empirical mode decomposition (EEMD), and variational mode decomposition (VMD) [
25,
26] are widely used in recent years. Generally, the WD method depends heavily on the determination of the mother wavelet functions, while, EMD has many drawbacks, including lack of an accurate mathematical expression, interpolation method selection, and trapping into mode mixing problems. Although EEMD is capable of solving the mode mixing issues of EMD, it still lacks a mathematical theory, which may reduce its robustness. In contrast, the VMD method can adaptively decompose the raw signal into several modes with specific sparsity properties and is also capable to overcoming the problem of mode mixing [
27].
On the other hand, optimization algorithms have become popular in constructing hybrid models by tuning the parameters of ML models to further enhance forecasting accuracy. For example, Ren et al. [
11] applied the particle swarm optimization (PSO) algorithm to optimize the parameters of BPNN so as to improve prediction accuracy of wind speed. Similarly, Gao et al. [
28] used the firefly algorithm (FA) instead of PSO to adjust the weights and thresholds of the BPNN, and then developed a new hybrid model. There are more examples of hybrid models based on optimization algorithms in the wind speed/power forecasting, such as BPNN optimized by genetic algorithm (GA) [
12], ELM optimized by crisscross optimization algorithm [
29], MLP optimized by GA [
10], MLP optimized by mind evolutionary algorithm (MEA) [
10], SVM optimized by GA [
21], least squares support vector machine (LSSVM) optimized by gravitational search algorithm (GSA) [
30], and adaptive neuro-fuzzy inference system (ANFIS) optimized by an evolution PSO [
31]. Though there are many examples of successful applications for these optimization algorithms, the problems of premature convergence and deficiencies in balancing global search and local mining still exist in these algorithms. Therefore, it is worthwhile to find new efficient algorithms to solve wind speed forecasting problems. Recently, the backtracking search algorithm (BSA), a novel stochastic search algorithm, has been proposed by [
32]. Compared with the other stochastic population-based algorithms, BSA needs to set only one control parameter and is easy to implement. Due to its simple structure and easy operation, BSA has been applied to settle various complex nonlinear optimization problems [
33,
34,
35], and therefore we attempt to use it for solving wind speed forecasting problem in our work.
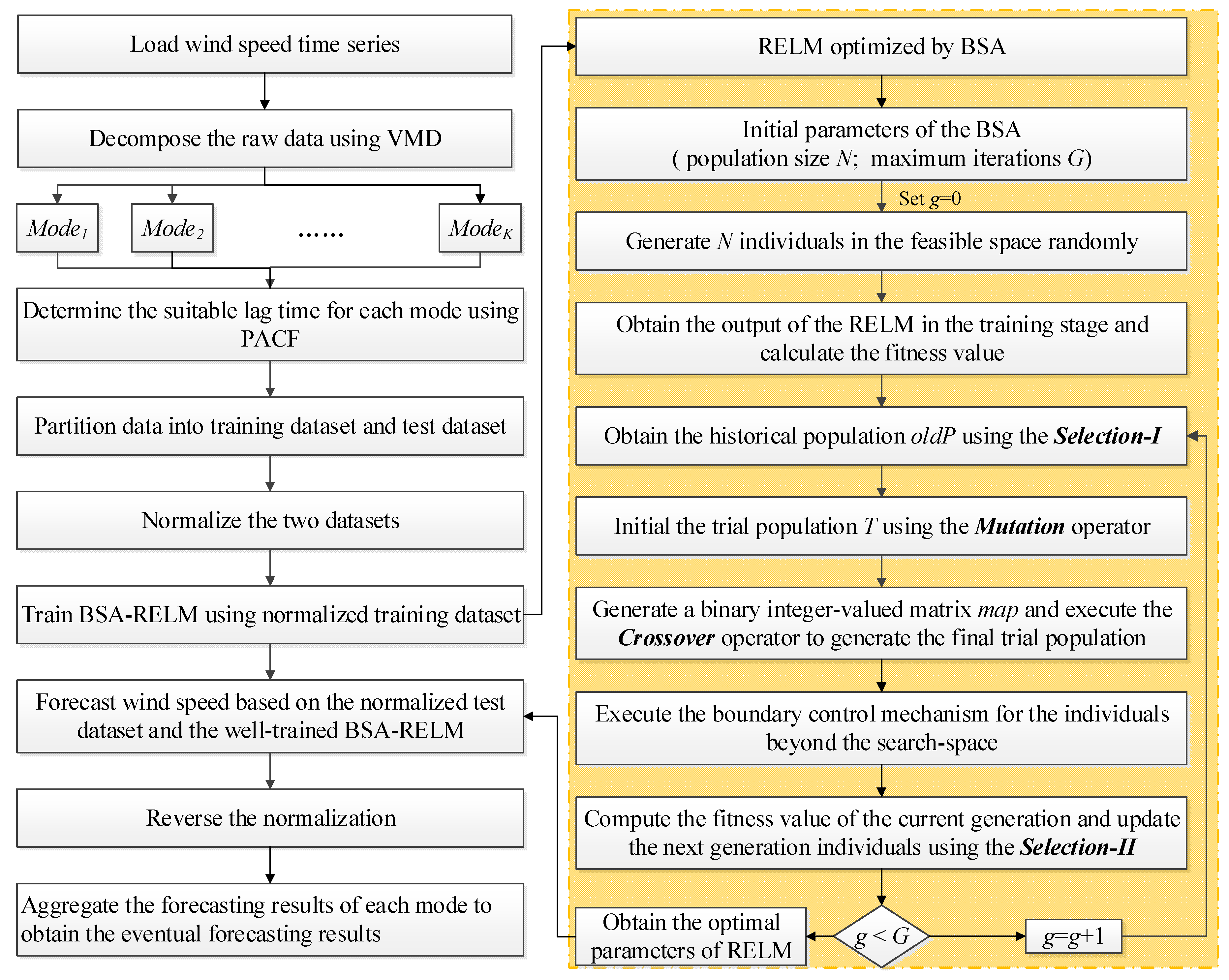
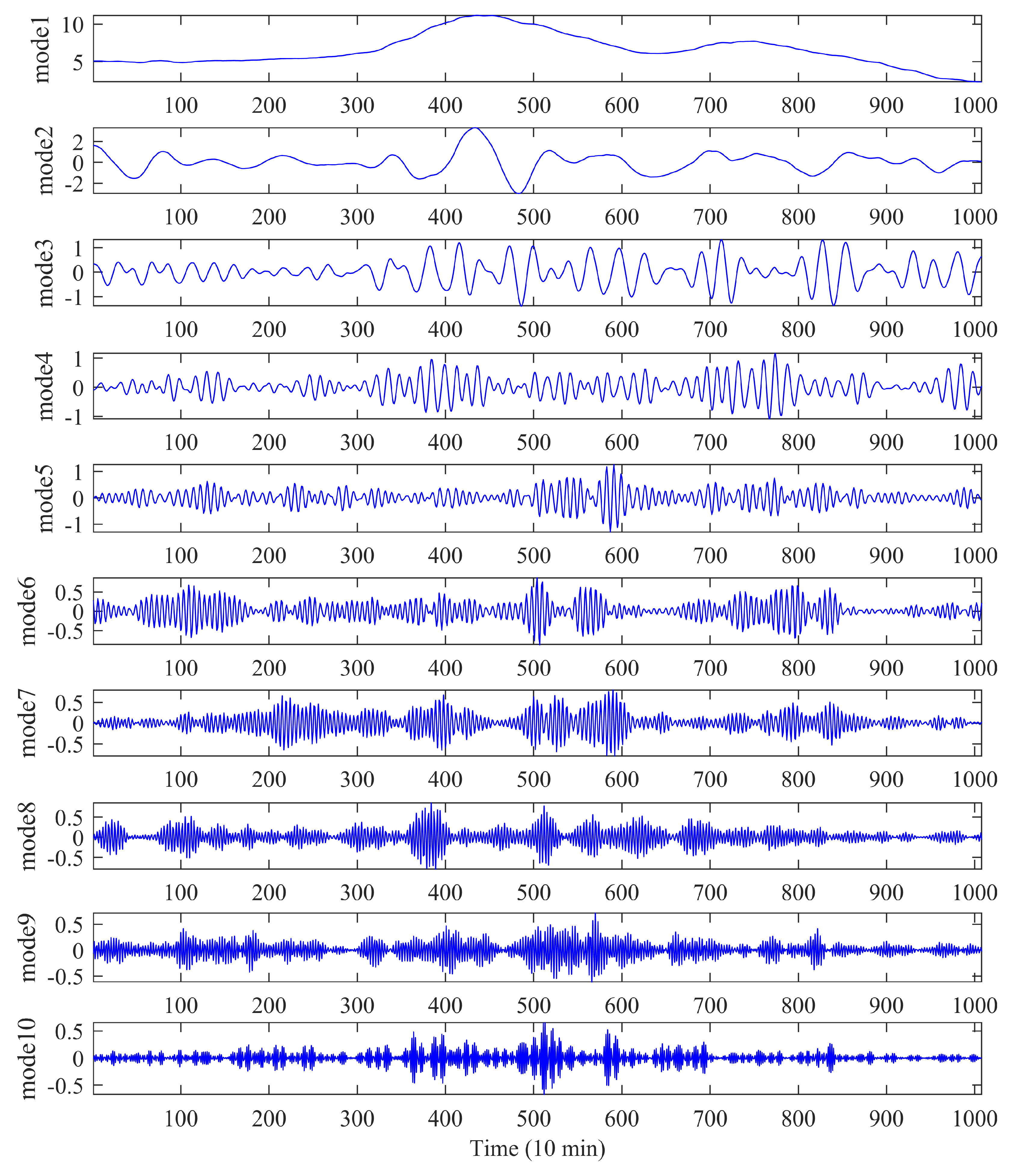
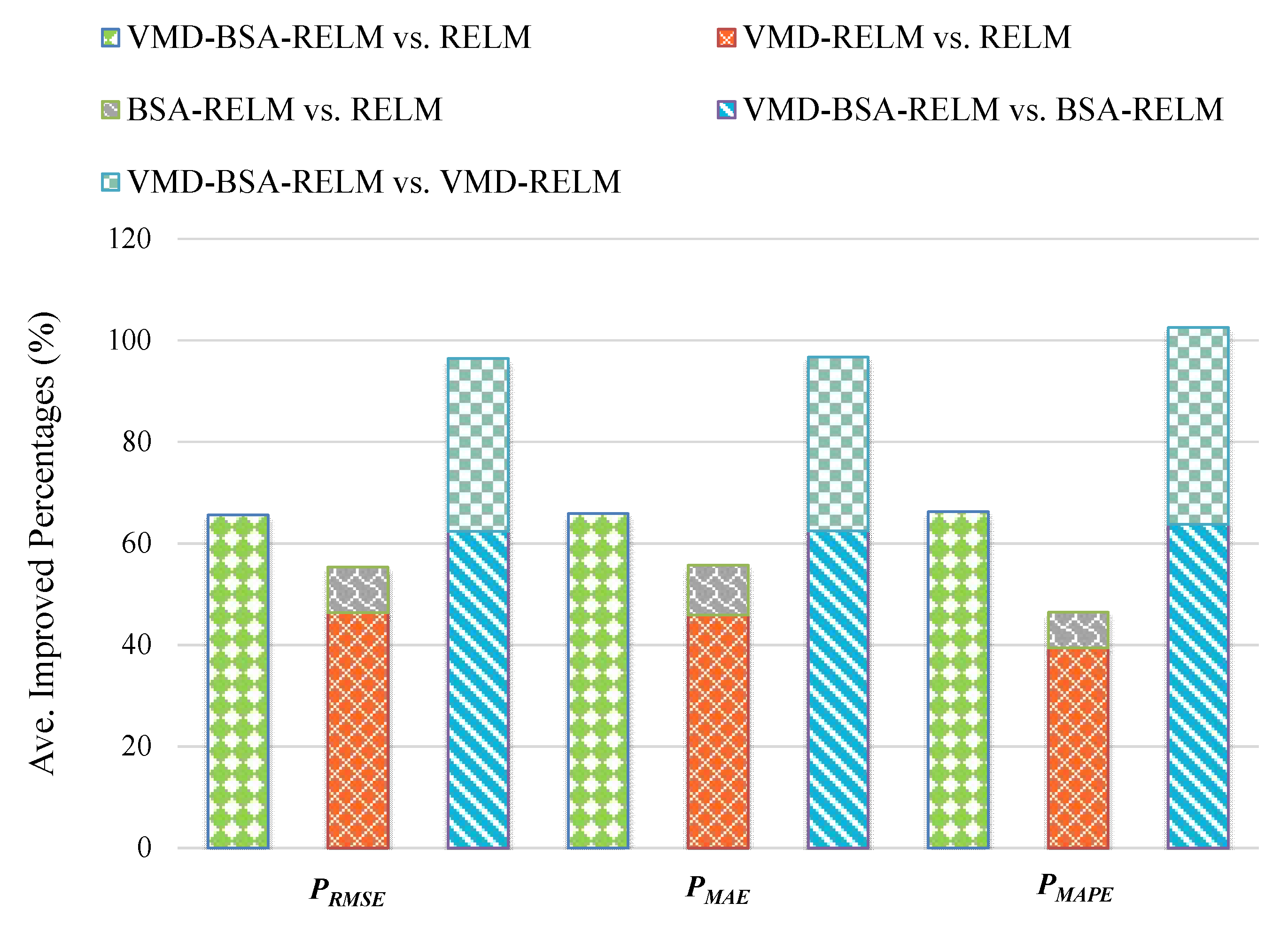
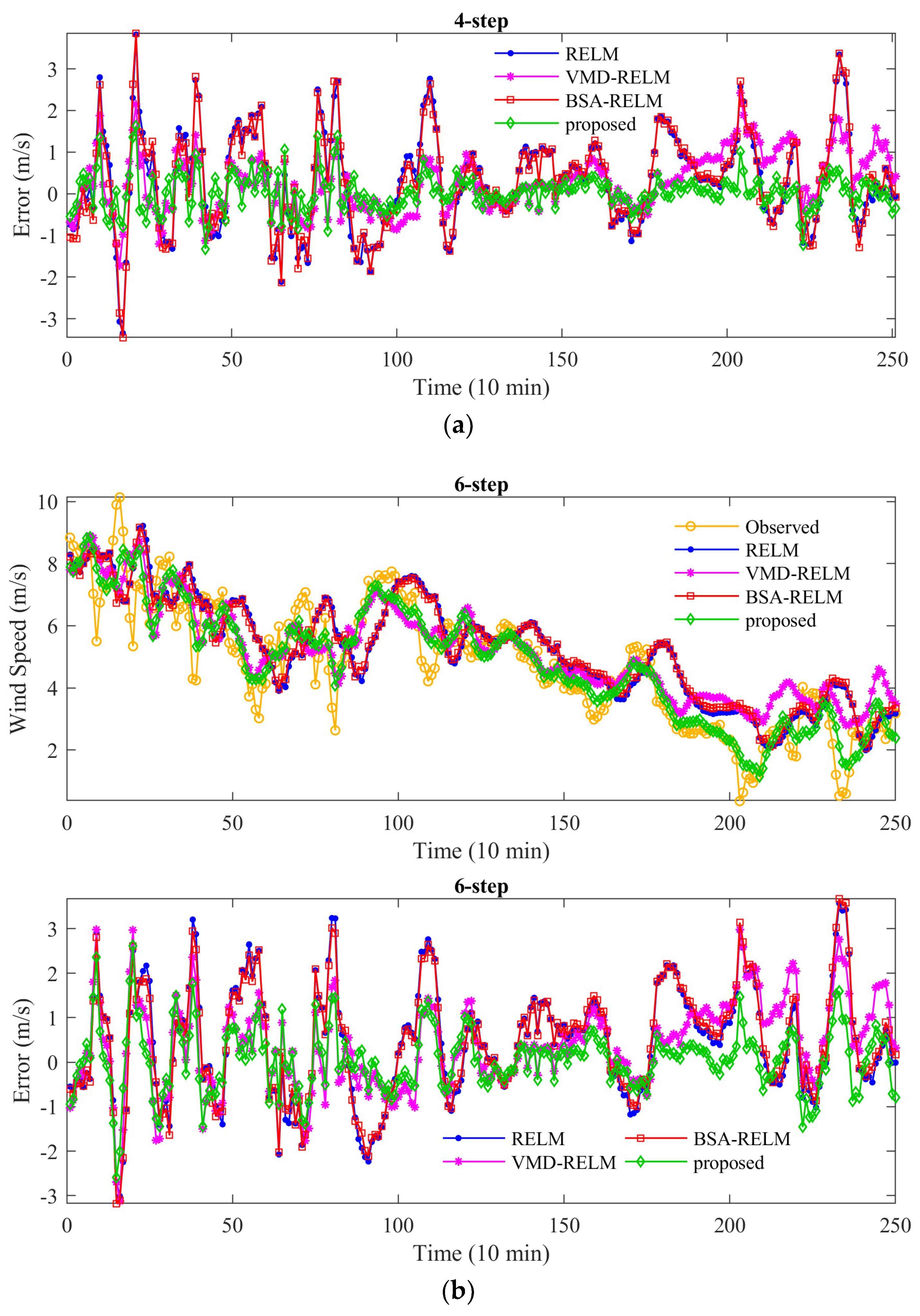
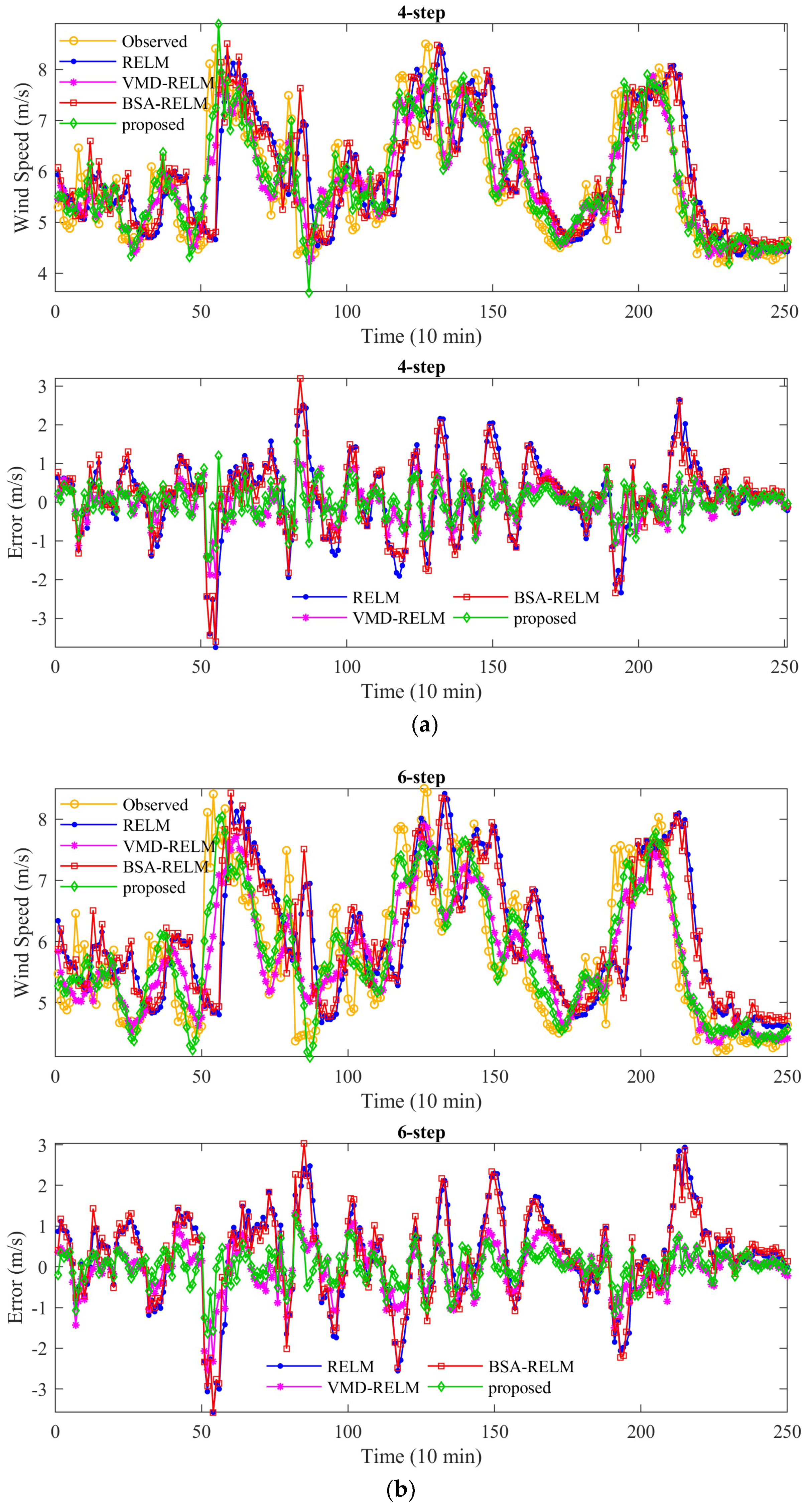
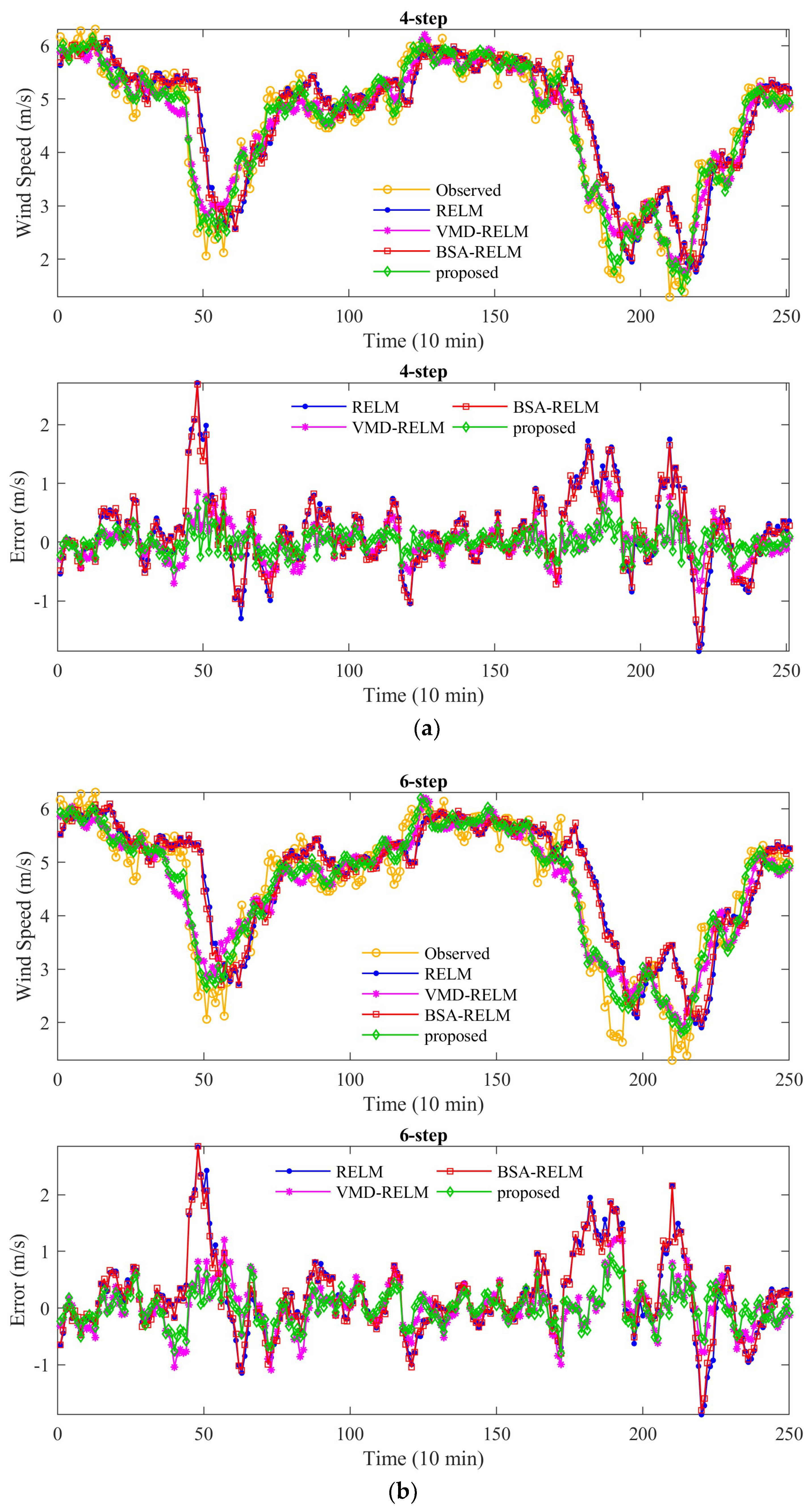
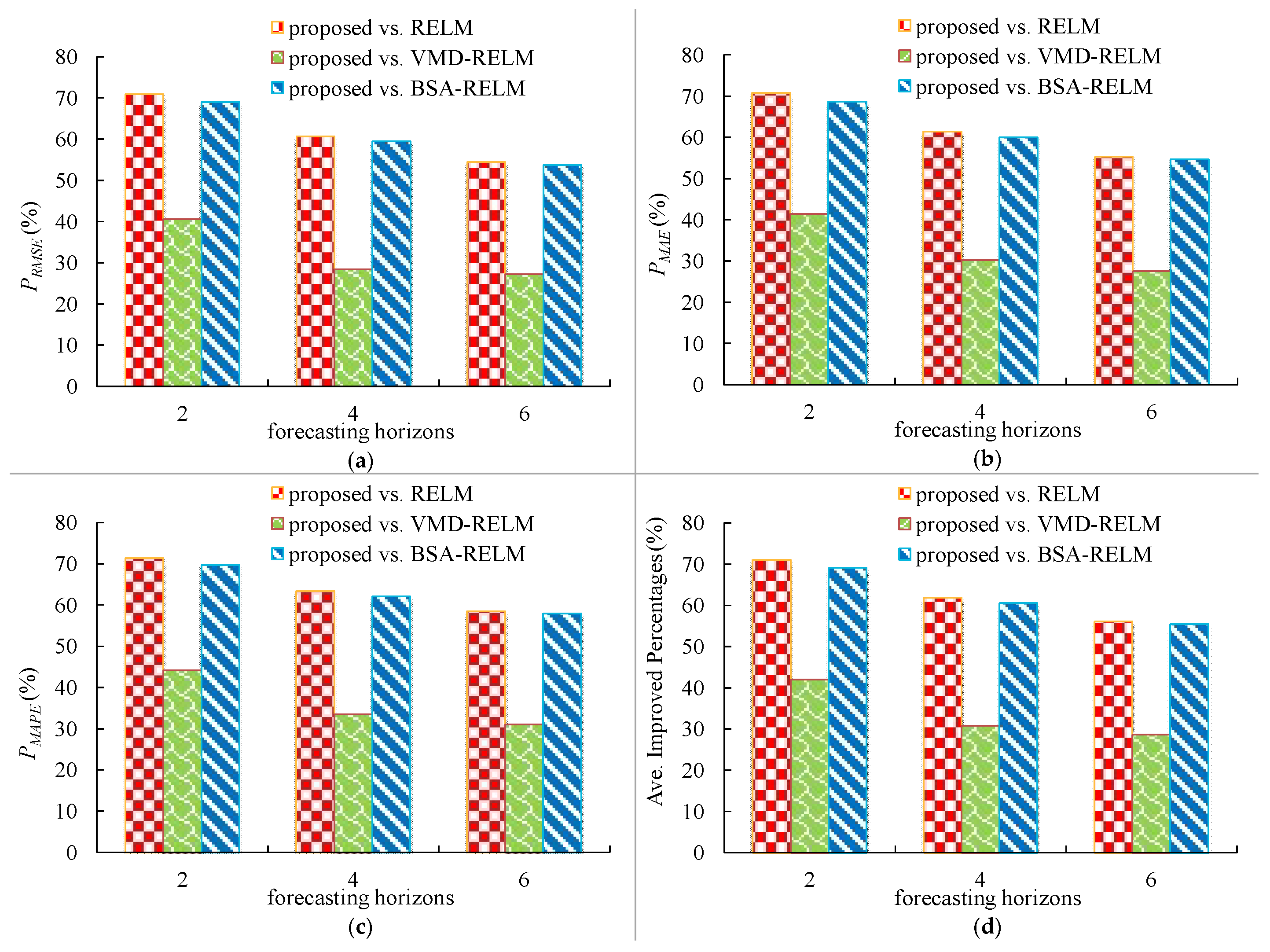
In this study, a novel decomposition-optimization model is proposed through combining RELM, VMD, and BSA to achieve more accurate and reliable ultra-short-term wind speed forecasting. Firstly, VMD is applied to decompose the original wind speed series into a group of relatively stable subseries to reduce the distractions of the randomness and fluctuations of the original series on the prediction accuracy. Then, RELM optimized by BSA is establish to forecast each subseries. Meanwhile, partial autocorrelation function (PACF) is utilized to determine the optimal input vector. Finally, eventual results can be obtained by the aggregation method. To demonstrate the effectiveness of the proposed model, it has been thoroughly tested on several real wind speed datasets from the Sotavento Galicia (SG) wind farm in Spain. Experimental results demonstrate that by using decomposition and optimization techniques together, the forecasting performance of the proposed VMD-BSA-RELM model is significantly better than that of the basic RELM model. Moreover, the decomposition method VMD plays a more important role in the final improvement of the VMD-BSA-RELM model than the optimization method BSA. This clearly shows how important it is to smooth time series to achieve a desired prediction performance.
The main contributions of this study are listed as follows: (a) we first investigate the ability of the combination of VMD, RELM, and BSA to forecast multi-step short-term wind speed; (b) the proposed model can take full advantages of the signal decomposition approach, machine learning, and optimization algorithm; (c) the positive effects of the decomposition and optimization approaches on the final improvement are quantitatively analyzed.
The rest of the paper is organized as follows: the methods involved in the proposed model including VMD, RELM, and BSA are briefly introduced in
Section 2; the framework of the proposed decomposition-optimization model is presented in
Section 3; experiments and comprehensive analyses to validate the proposed model are presented in
Section 4 and
Section 5; and
Section 6 concludes the paper.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}