Modular Predictor for Day-Ahead Load Forecasting and Feature Selection for Different Hours


Abstract
:1. Introduction
2. Feature Selection
2.1. Filter Method of Feature Selection
2.1.1. Mutual Information
2.1.2. Conditional Mutual Information
2.1.3. RreliefF
2.2. Embedded Method for Feature Selection
2.2.1. Classification and Regression Tree
2.2.2. Random Forest
3. The Short-Term Load Forecasting (STLF) Predictor
3.1. Support Vector Regression
3.2. Back-Propagation Neural Network
3.3. Gaussian Process Regression (GPR)
4. Data Analysis
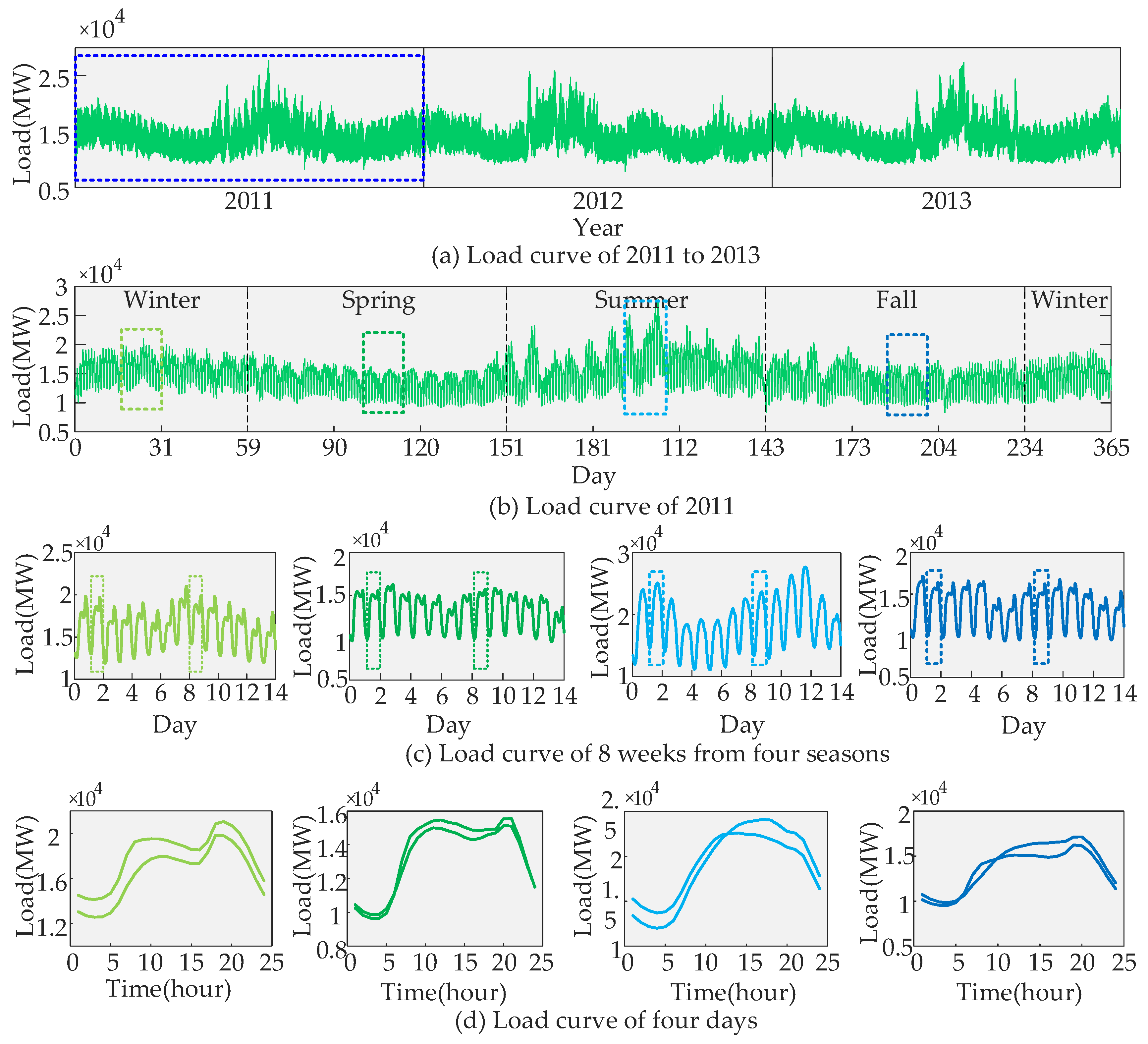
4.1. Load Analysis
4.2. Candidate Feature Set
5. Experimental Setup
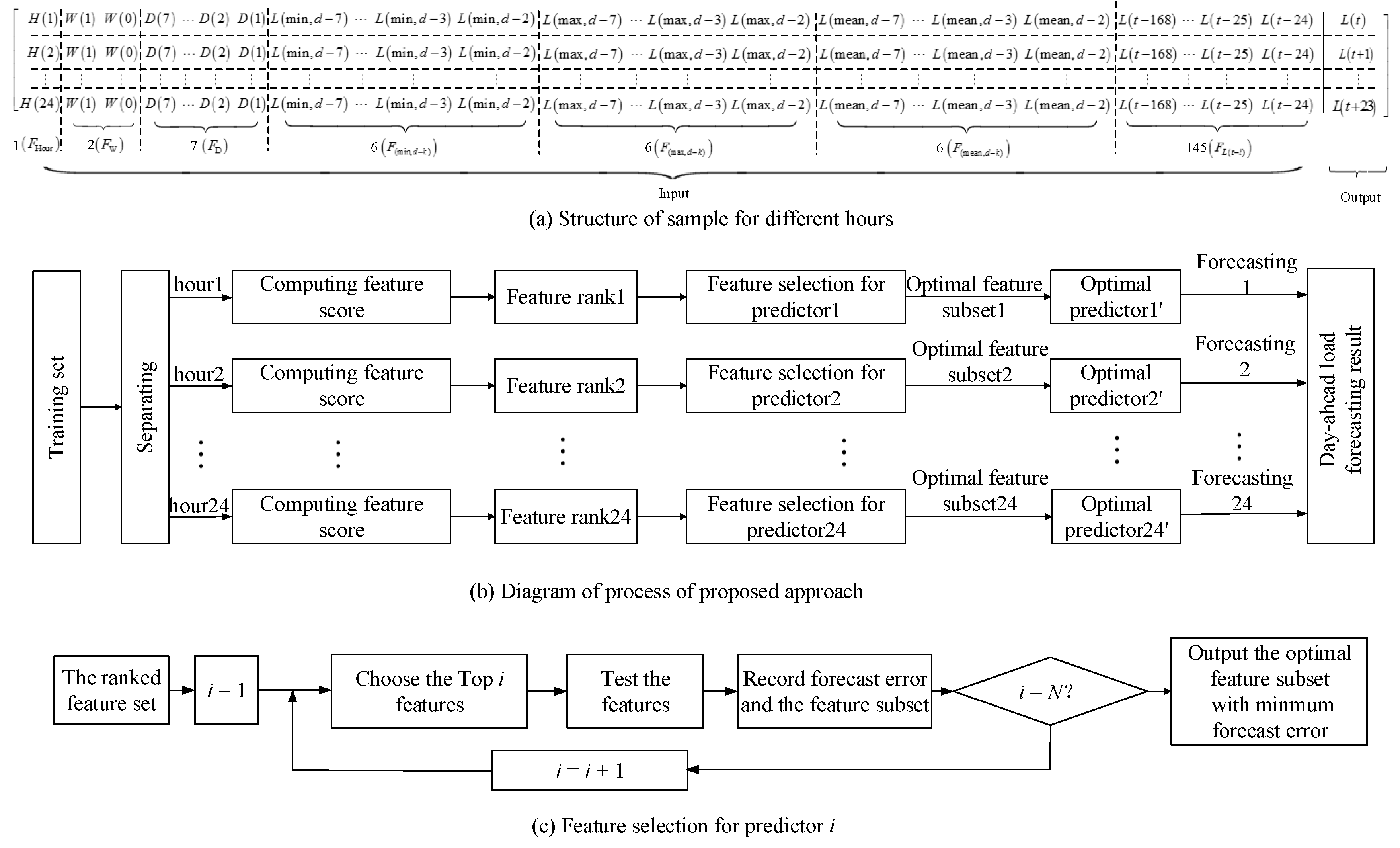
5.1. Proposed STLF Process with Feature Selection
5.2. Dataset Split
5.3. Evaluation Criterion
6. Results
6.1. Load Forecasting for New England
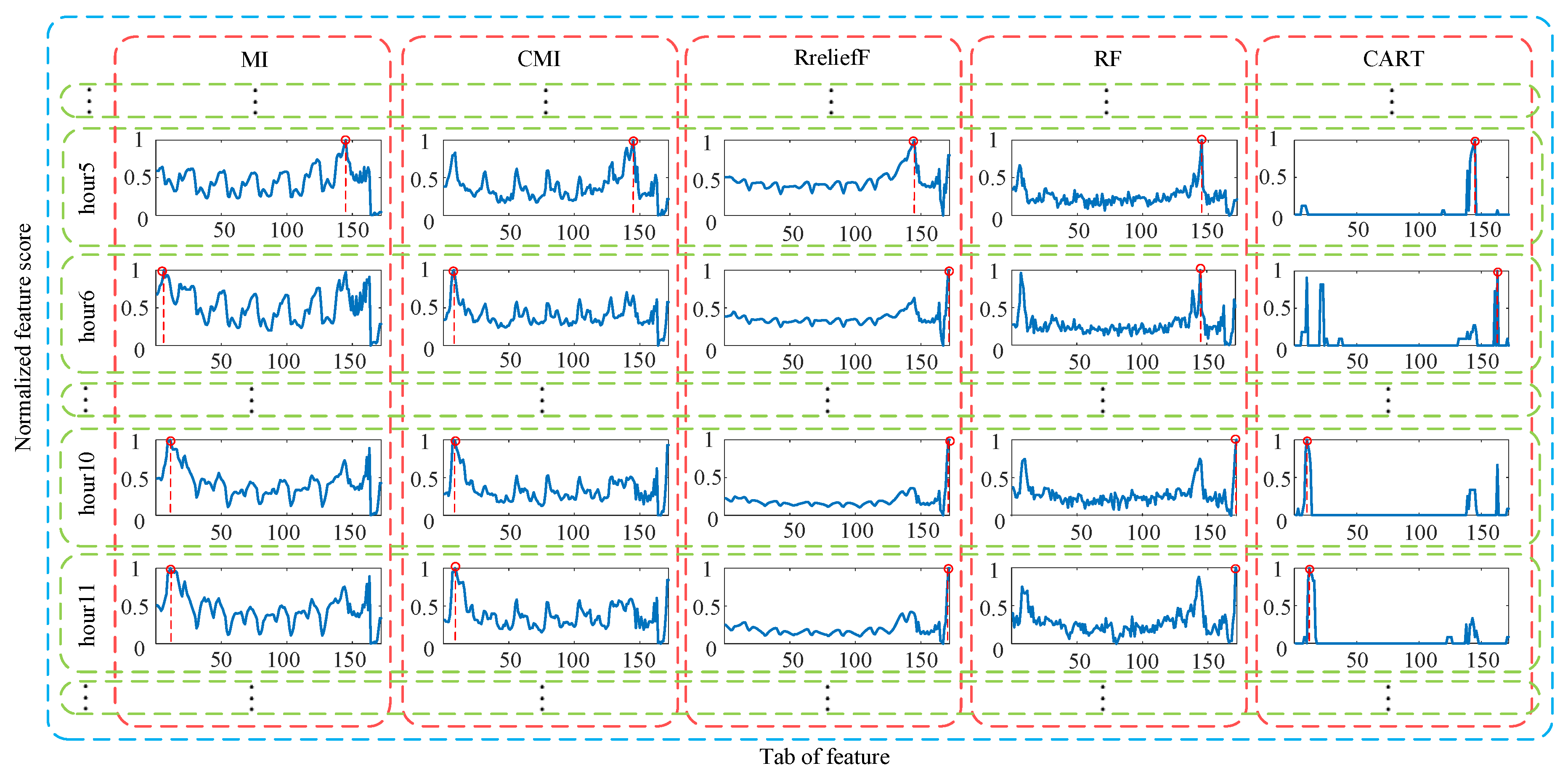
6.1.1. Feature Selection for Different-Hour Loads
Feature Score for Feature Analysis
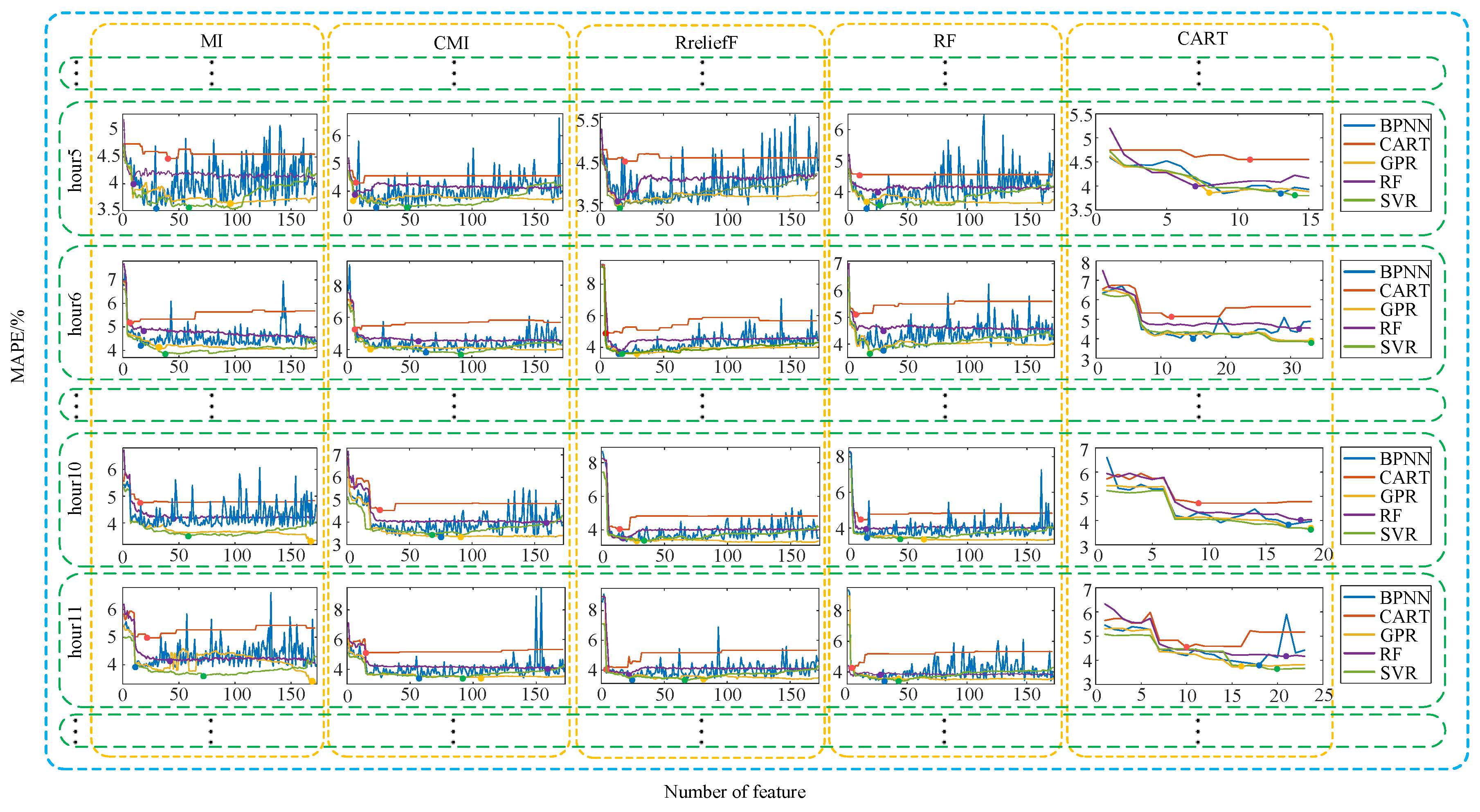
Optimal Feature Subset Selection Process
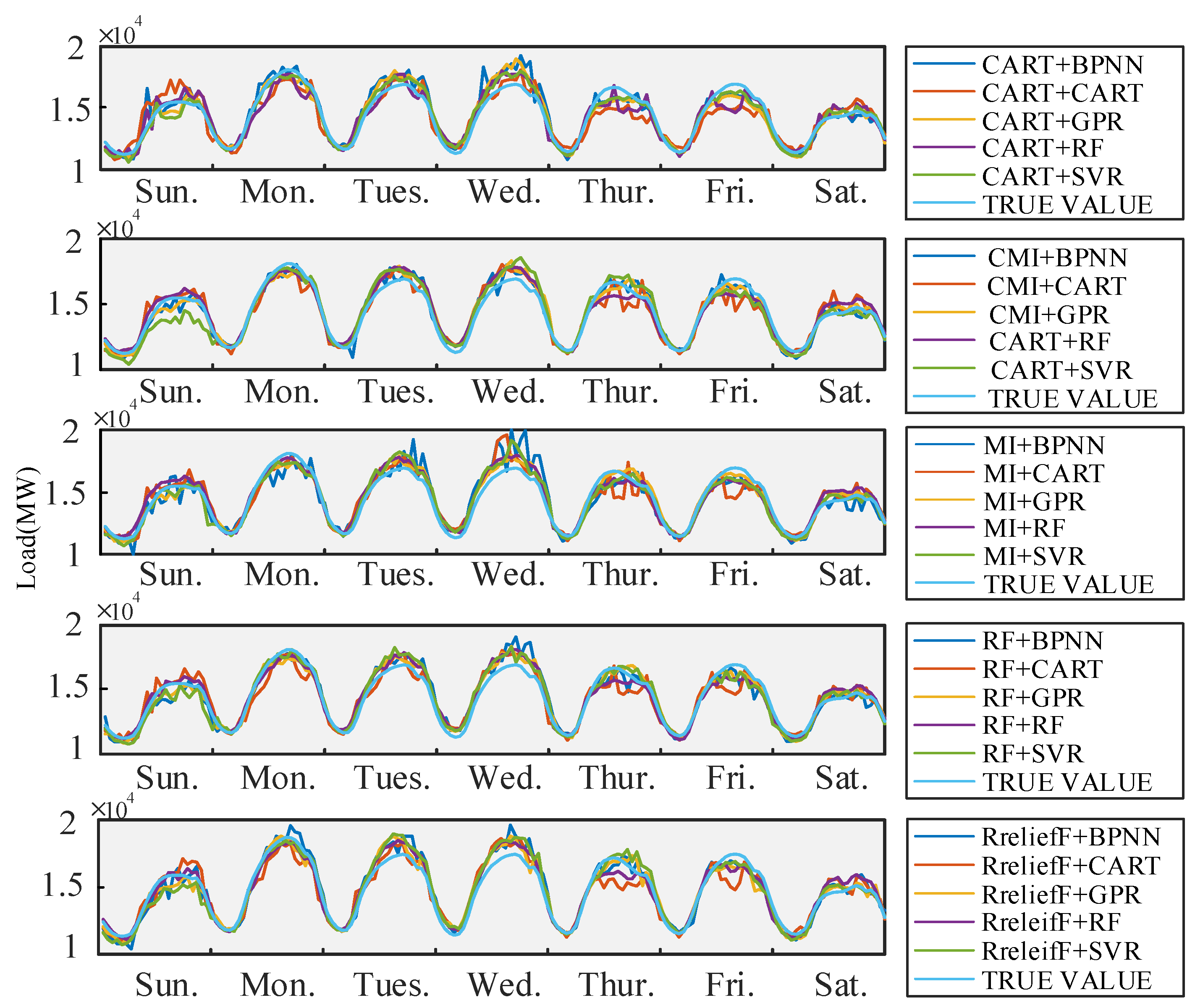
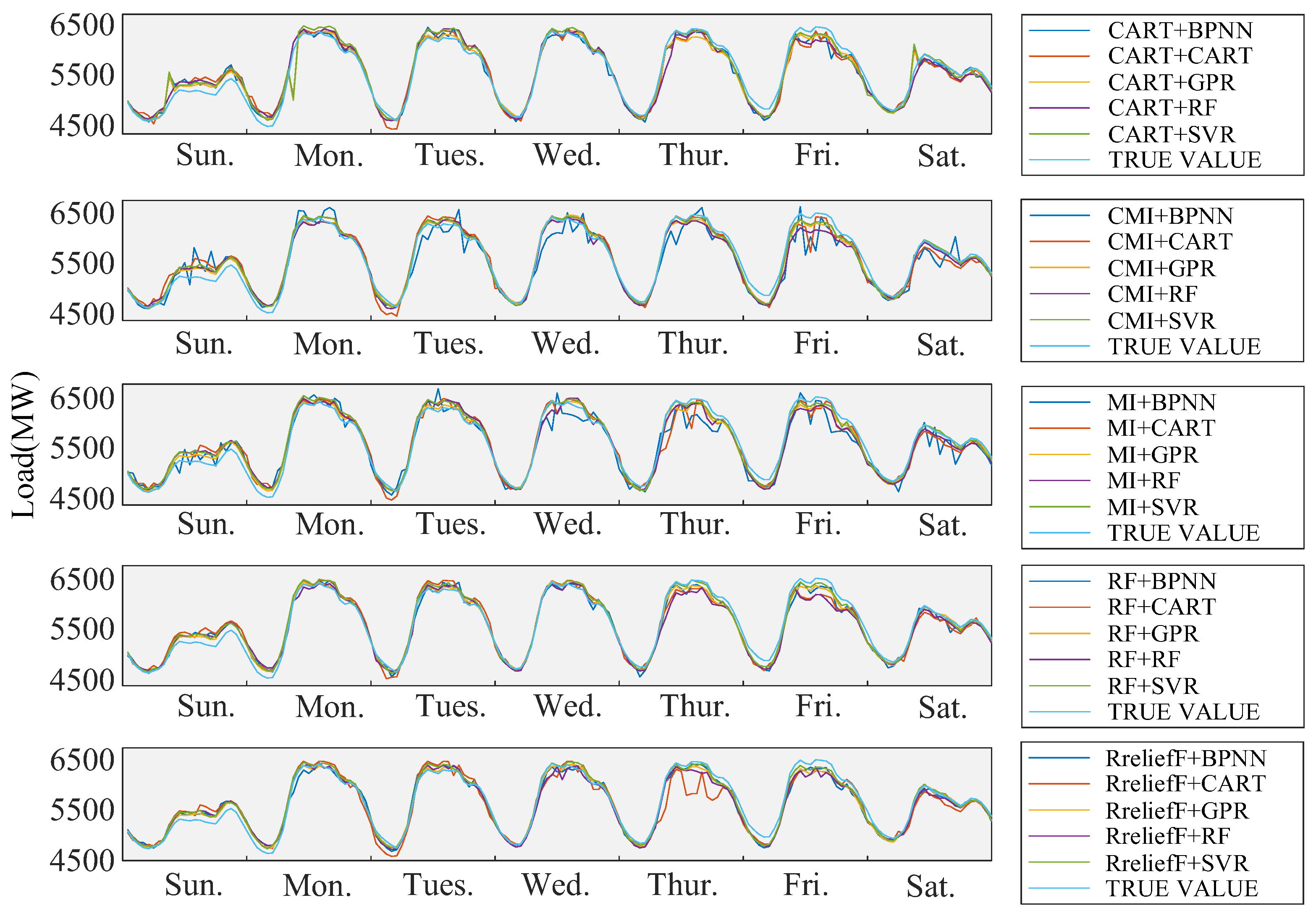
6.1.2. Forecasting Result of Method Combinations with Optimal Feature Subsets for New England Load Data
6.2. Load Forecasting for Singapore
6.2.1. Feature Selection for Hour Loads
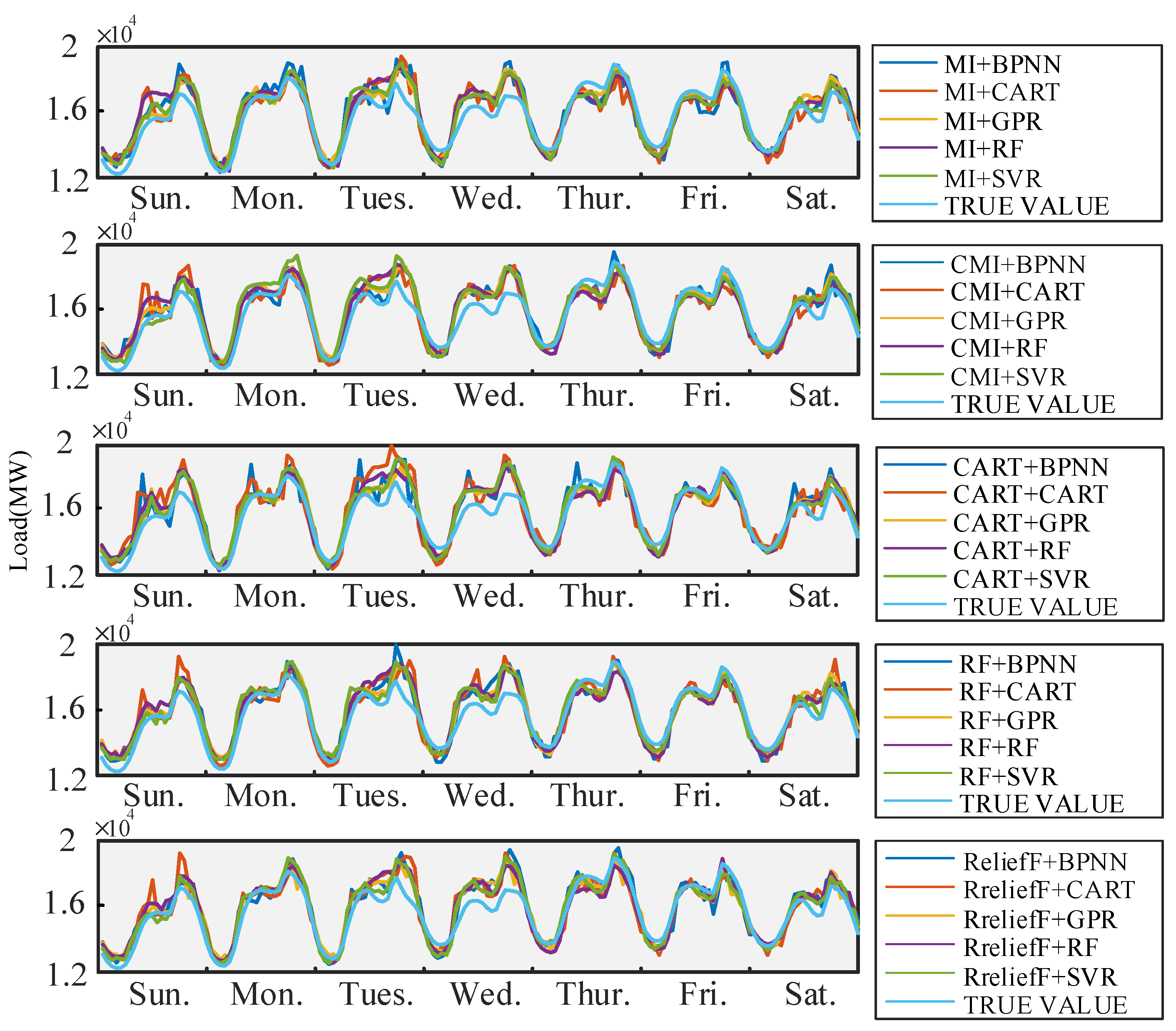
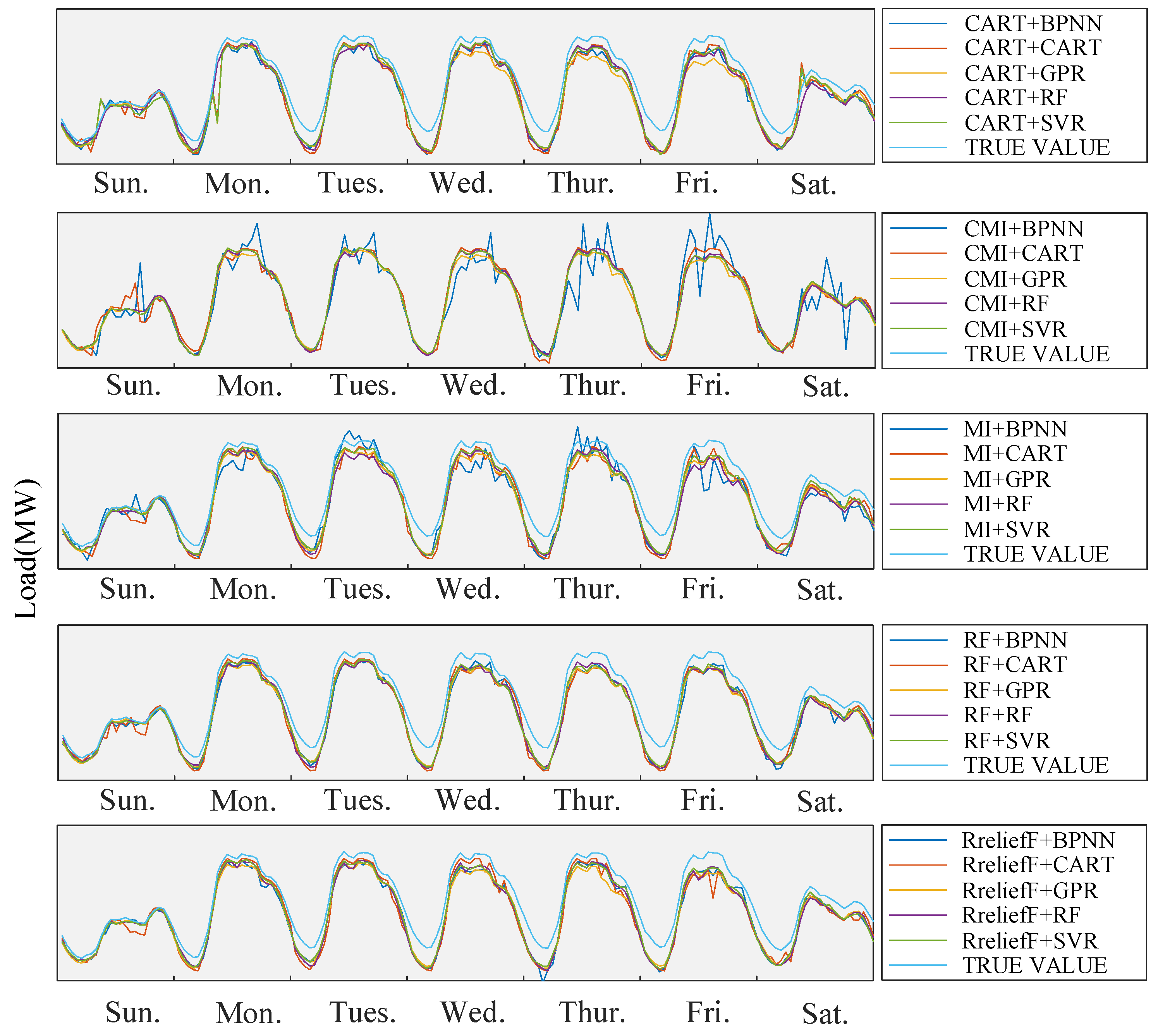
6.2.2. Forecasting Results of Method Combinations with Optimal Feature Subsets for Singapore Load Data
6.3. Comparison and Discussion
6.3.1. Comparison of Forecasting Methods without Feature Selection for New England and Singapore
6.3.2. Comparison of Forecasting Approaches with Feature Selection for New England and Singapore
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Point | 1:00 | 2:00 | 3:00 | 4:00 | 5:00 | 6:00 | 7:00 | 8:00 | 9:00 | 10:00 | 11:00 | 12:00 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Error | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | |
| MI | CART | 3.741 | 7 | 3.769 | 2 | 4.071 | 12 | 4.083 | 84 | 4.472 | 40 | 5.140 | 6 | 4.949 | 164 | 4.748 | 164 | 4.627 | 164 | 4.765 | 15 | 4.978 | 21 | 5.529 | 130 |
| RF | 3.294 | 34 | 3.419 | 22 | 3.632 | 9 | 3.783 | 30 | 4.008 | 9 | 4.828 | 18 | 5.456 | 61 | 5.314 | 59 | 4.526 | 64 | 4.171 | 45 | 4.147 | 42 | 4.414 | 67 | |
| SVR | 3.064 | 10 | 3.167 | 28 | 3.189 | 27 | 3.314 | 23 | 3.553 | 59 | 3.852 | 38 | 4.353 | 57 | 4.327 | 47 | 3.682 | 61 | 3.510 | 58 | 3.598 | 72 | 3.789 | 23 | |
| ANN | 3.226 | 8 | 3.329 | 7 | 3.422 | 26 | 3.897 | 27 | 3.521 | 30 | 4.215 | 16 | 4.889 | 40 | 4.345 | 29 | 3.891 | 23 | 3.848 | 31 | 3.911 | 11 | 4.342 | 32 | |
| GPR | 3.087 | 119 | 3.226 | 115 | 3.359 | 9 | 3.381 | 99 | 3.629 | 96 | 4.087 | 36 | 4.476 | 54 | 4.432 | 102 | 3.805 | 65 | 3.645 | 49 | 3.781 | 36 | 3.852 | 31 | |
| CMI | CART | 3.729 | 2 | 3.769 | 2 | 4.058 | 7 | 4.192 | 16 | 4.296 | 8 | 5.242 | 6 | 4.926 | 99 | 4.523 | 27 | 5.076 | 15 | 4.523 | 27 | 5.076 | 15 | 5.413 | 106 |
| RF | 3.447 | 20 | 3.447 | 23 | 3.590 | 12 | 3.717 | 13 | 3.848 | 6 | 4.505 | 57 | 4.750 | 40 | 4.531 | 130 | 4.136 | 49 | 3.949 | 159 | 4.009 | 159 | 4.281 | 124 | |
| SVR | 3.043 | 13 | 3.126 | 12 | 3.238 | 12 | 3.341 | 4 | 3.375 | 48 | 3.722 | 91 | 4.008 | 60 | 3.972 | 73 | 3.469 | 88 | 3.351 | 68 | 3.448 | 93 | 3.667 | 88 | |
| ANN | 3.062 | 47 | 3.123 | 42 | 3.134 | 28 | 3.329 | 53 | 3.365 | 23 | 3.821 | 64 | 4.178 | 83 | 4.167 | 35 | 3.590 | 78 | 3.341 | 75 | 3.418 | 57 | 3.576 | 63 | |
| GPR | 3.052 | 134 | 3.189 | 23 | 3.288 | 18 | 3.366 | 16 | 3.593 | 21 | 4.017 | 18 | 4.128 | 150 | 3.911 | 158 | 3.517 | 168 | 3.352 | 91 | 3.455 | 106 | 3.612 | 88 | |
| CART | CART | 3.729 | 3 | 4.050 | 6 | 4.071 | 4 | 4.134 | 5 | 4.558 | 6 | 5.596 | 13 | 4.958 | 9 | 4.751 | 4 | 4.634 | 7 | 4.725 | 10 | 4.524 | 19 | 5.512 | 10 |
| RF | 3.422 | 11 | 3.511 | 5 | 3.589 | 6 | 3.615 | 12 | 3.963 | 7 | 4.511 | 32 | 4.512 | 20 | 4.367 | 11 | 4.062 | 22 | 3.989 | 18 | 4.151 | 21 | 4.546 | 11 | |
| SVR | 3.068 | 11 | 3.167 | 11 | 3.548 | 11 | 3.433 | 12 | 3.798 | 14 | 3.846 | 33 | 3.804 | 20 | 3.870 | 18 | 3.524 | 22 | 3.629 | 19 | 3.633 | 20 | 4.260 | 18 | |
| ANN | 3.270 | 9 | 3.301 | 11 | 3.670 | 5 | 3.483 | 12 | 3.836 | 13 | 4.012 | 15 | 3.974 | 19 | 4.081 | 16 | 3.921 | 17 | 3.775 | 17 | 3.806 | 18 | 4.397 | 11 | |
| GPR | 3.245 | 8 | 3.280 | 11 | 3.526 | 11 | 3.458 | 8 | 3.858 | 8 | 3.911 | 33 | 3.753 | 20 | 3.872 | 18 | 3.707 | 22 | 3.659 | 19 | 3.732 | 16 | 4.360 | 11 | |
| RF | CART | 3.741 | 7 | 3.769 | 2 | 4.059 | 9 | 4.128 | 44 | 4.552 | 9 | 5.084 | 7 | 4.807 | 52 | 4.656 | 5 | 4.337 | 6 | 4.464 | 10 | 4.147 | 3 | 4.155 | 6 |
| RF | 3.533 | 51 | 3.679 | 27 | 3.790 | 28 | 3.777 | 11 | 3.991 | 25 | 4.522 | 30 | 4.624 | 12 | 4.416 | 9 | 3.973 | 26 | 3.922 | 15 | 3.801 | 28 | 4.227 | 7 | |
| SVR | 3.140 | 41 | 3.512 | 14 | 3.312 | 42 | 3.469 | 11 | 3.5518 | 26 | 3.6554 | 19 | 3.9069 | 27 | 3.8594 | 46 | 3.3732 | 31 | 3.3966 | 44 | 3.376 | 43 | 3.7329 | 51 | |
| ANN | 3.069 | 18 | 3.255 | 20 | 3.097 | 21 | 3.469 | 17 | 3.486 | 16 | 3.816 | 27 | 4.262 | 11 | 4.278 | 13 | 3.682 | 11 | 3.542 | 19 | 3.424 | 31 | 3.923 | 14 | |
| GPR | 3.099 | 81 | 3.239 | 80 | 3.338 | 64 | 3.447 | 150 | 3.632 | 16 | 3.679 | 19 | 4.208 | 15 | 3.964 | 56 | 3.522 | 86 | 3.359 | 63 | 3.484 | 43 | 3.787 | 37 | |
| RreliefF | CART | 3.741 | 10 | 3.769 | 2 | 4.059 | 8 | 4.156 | 42 | 4.475 | 20 | 4.917 | 4 | 4.729 | 38 | 4.646 | 15 | 4.443 | 7 | 4.030 | 15 | 4.417 | 4 | 4.448 | 20 |
| RF | 3.310 | 26 | 3.390 | 20 | 3.466 | 17 | 3.560 | 19 | 3.528 | 14 | 3.764 | 14 | 4.534 | 30 | 4.294 | 23 | 3.643 | 10 | 3.514 | 17 | 3.680 | 22 | 4.006 | 18 | |
| SVR | 3.043 | 18 | 3.107 | 19 | 3.233 | 19 | 3.351 | 30 | 3.434 | 16 | 3.928 | 14 | 3.716 | 34 | 3.648 | 21 | 3.320 | 34 | 3.205 | 34 | 3.407 | 66 | 3.594 | 53 | |
| ANN | 3.269 | 9 | 3.306 | 14 | 3.338 | 13 | 3.368 | 17 | 3.445 | 16 | 3.555 | 15 | 4.193 | 35 | 3.760 | 23 | 3.399 | 19 | 3.329 | 20 | 3.427 | 25 | 3.820 | 24 | |
| GPR | 3.019 | 134 | 3.156 | 152 | 3.329 | 32 | 3.346 | 117 | 3.460 | 16 | 3.578 | 29 | 3.811 | 34 | 3.715 | 24 | 3.414 | 22 | 3.333 | 28 | 3.358 | 81 | 3.807 | 29 | |
| Time Point | 13:00 | 14:00 | 15:00 | 16:00 | 17:00 | 18:00 | 19:00 | 20:00 | 21:00 | 22:00 | 23:00 | 24:00 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Error | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPEE | FD | MAPEE | FD | MAPEE | FD | MAPE | FD | MAPEE | FD | |
| MI | CART | 4.654 | 164 | 5.143 | 164 | 5.764 | 164 | 5.406 | 164 | 6.170 | 41 | 6.313 | 6 | 6.066 | 12 | 5.388 | 9 | 5.166 | 14 | 5.105 | 12 | 5.198 | 6 | 5.086 | 8 |
| RF | 4.663 | 41 | 4.926 | 33 | 5.190 | 38 | 5.351 | 46 | 5.547 | 31 | 5.358 | 98 | 5.117 | 136 | 4.506 | 23 | 4.376 | 28 | 4.779 | 9 | 4.794 | 41 | 4.847 | 72 | |
| SVR | 3.927 | 23 | 4.263 | 35 | 4.456 | 49 | 4.518 | 82 | 4.645 | 68 | 4.516 | 69 | 4.418 | 69 | 4.165 | 21 | 3.867 | 24 | 3.901 | 73 | 3.860 | 154 | 4.039 | 115 | |
| ANN | 4.042 | 19 | 4.362 | 14 | 4.626 | 35 | 4.799 | 29 | 4.746 | 37 | 5.262 | 46 | 4.849 | 33 | 4.371 | 15 | 3.919 | 27 | 4.599 | 42 | 4.261 | 27 | 4.203 | 35 | |
| GPR | 3.974 | 24 | 4.177 | 36 | 4.524 | 29 | 4.689 | 28 | 4.616 | 32 | 4.823 | 21 | 4.770 | 32 | 4.272 | 24 | 4.010 | 26 | 4.157 | 24 | 4.291 | 22 | 4.446 | 18 | |
| CMI | CART | 5.459 | 14 | 5.045 | 53 | 5.519 | 24 | 5.406 | 91 | 5.985 | 18 | 6.382 | 5 | 5.973 | 5 | 5.299 | 19 | 5.134 | 20 | 5.178 | 19 | 5.164 | 8 | 4.994 | 14 |
| RF | 4.445 | 146 | 4.608 | 151 | 4.843 | 150 | 5.064 | 162 | 5.326 | 164 | 5.352 | 157 | 5.136 | 126 | 4.496 | 136 | 4.394 | 126 | 4.176 | 145 | 4.731 | 153 | 4.804 | 133 | |
| SVR | 3.923 | 107 | 4.102 | 97 | 4.339 | 99 | 4.539 | 86 | 4.501 | 105 | 4.540 | 70 | 4.398 | 87 | 3.944 | 113 | 3.717 | 90 | 3.763 | 94 | 3.895 | 93 | 3.972 | 111 | |
| ANN | 3.846 | 64 | 3.827 | 53 | 4.304 | 54 | 4.452 | 49 | 4.698 | 86 | 4.500 | 72 | 4.416 | 94 | 4.273 | 156 | 3.780 | 32 | 3.943 | 76 | 3.971 | 78 | 3.902 | 117 | |
| GPR | 3.916 | 105 | 4.080 | 40 | 4.474 | 53 | 4.686 | 94 | 4.469 | 172 | 4.455 | 168 | 4.709 | 76 | 4.508 | 16 | 4.116 | 39 | 4.075 | 49 | 4.304 | 103 | 4.432 | 118 | |
| CART | CART | 4.655 | 11 | 5.141 | 8 | 5.768 | 12 | 5.412 | 9 | 6.320 | 11 | 6.955 | 8 | 6.393 | 9 | 5.978 | 13 | 5.324 | 11 | 5.742 | 9 | 5.214 | 6 | 5.182 | 7 |
| RF | 4.587 | 19 | 4.846 | 15 | 5.113 | 28 | 5.409 | 22 | 5.390 | 25 | 5.720 | 22 | 5.444 | 17 | 4.634 | 15 | 4.665 | 24 | 5.001 | 29 | 4.700 | 7 | 4.806 | 7 | |
| SVR | 4.105 | 15 | 4.371 | 21 | 4.393 | 28 | 4.882 | 22 | 4.804 | 24 | 5.515 | 22 | 4.804 | 26 | 4.236 | 30 | 4.099 | 24 | 4.256 | 21 | 4.228 | 18 | 4.168 | 20 | |
| ANN | 4.205 | 15 | 4.713 | 18 | 4.666 | 18 | 4.931 | 20 | 5.248 | 16 | 5.205 | 22 | 4.986 | 26 | 4.302 | 26 | 4.248 | 24 | 4.441 | 18 | 4.152 | 17 | 3.988 | 22 | |
| GPR | 4.174 | 13 | 4.507 | 21 | 4.573 | 28 | 5.109 | 22 | 5.054 | 23 | 5.124 | 21 | 4.864 | 28 | 4.424 | 32 | 4.304 | 21 | 4.545 | 18 | 4.405 | 17 | 4.321 | 21 | |
| RF | CART | 4.448 | 12 | 5.022 | 23 | 5.476 | 6 | 5.350 | 7 | 5.678 | 5 | 6.129 | 5 | 6.040 | 22 | 5.273 | 11 | 4.820 | 26 | 5.175 | 98 | 4.980 | 5 | 5.080 | 45 |
| RF | 4.445 | 7 | 4.617 | 55 | 4.845 | 109 | 5.045 | 52 | 5.226 | 73 | 5.296 | 70 | 5.101 | 85 | 4.484 | 68 | 4.450 | 76 | 4.780 | 75 | 4.711 | 64 | 4.810 | 50 | |
| SVR | 3.971 | 100 | 3.983 | 35 | 4.122 | 82 | 4.635 | 94 | 4.556 | 32 | 4.589 | 40 | 4.725 | 101 | 4.089 | 37 | 7.848 | 25 | 3.847 | 97 | 3.936 | 90 | 3.996 | 141 | |
| ANN | 4.101 | 17 | 4.638 | 16 | 4.585 | 32 | 4.882 | 13 | 5.205 | 17 | 5.275 | 11 | 5.227 | 11 | 4.413 | 17 | 3.890 | 21 | 4.411 | 10 | 4.328 | 23 | 4.336 | 19 | |
| GPR | 4.069 | 48 | 4.091 | 74 | 4.515 | 42 | 4.662 | 41 | 4.912 | 32 | 4.577 | 159 | 4.886 | 56 | 4.491 | 43 | 4.026 | 70 | 4.182 | 81 | 4.367 | 79 | 4.497 | 18 | |
| RreliefF | CART | 4.574 | 20 | 4.949 | 21 | 5.529 | 29 | 5.405 | 108 | 5.817 | 22 | 6.238 | 23 | 5.860 | 17 | 5.321 | 24 | 4.796 | 37 | 4.721 | 23 | 5.005 | 9 | 4.986 | 20 |
| RF | 4.365 | 17 | 4.716 | 20 | 4.908 | 74 | 5.065 | 136 | 5.293 | 15 | 5.166 | 16 | 5.029 | 81 | 4.403 | 109 | 4.368 | 140 | 4.613 | 14 | 4.612 | 20 | 4.619 | 16 | |
| SVR | 3.693 | 65 | 3.876 | 66 | 4.104 | 52 | 4.426 | 49 | 4.496 | 67 | 4.528 | 41 | 4.558 | 68 | 3.983 | 52 | 3.809 | 44 | 3.803 | 109 | 4.008 | 43 | 4.056 | 38 | |
| ANN | 4.089 | 19 | 4.246 | 26 | 4.644 | 20 | 4.902 | 39 | 5.000 | 25 | 5.216 | 16 | 5.161 | 31 | 4.633 | 30 | 4.379 | 23 | 4.218 | 14 | 4.566 | 24 | 4.291 | 21 | |
| GPR | 3.980 | 40 | 4.161 | 34 | 4.411 | 33 | 4.632 | 36 | 4.748 | 45 | 4.472 | 160 | 4.391 | 170 | 4.301 | 45 | 3.976 | 43 | 4.284 | 34 | 4.001 | 172 | 4.324 | 16 | |
| Time Point | 1:00 | 2:00 | 3:00 | 4:00 | 5:00 | 6:00 | 7:00 | 8:00 | 9:00 | 10:00 | 11:00 | 12:00 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Error | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | |
| MI | CART | 1.595 | 59 | 1.479 | 57 | 1.402 | 4 | 1.482 | 10 | 1.535 | 6 | 1.624 | 108 | 2.041 | 29 | 2.727 | 62 | 2.515 | 48 | 2.526 | 43 | 2.615 | 59 | 2.451 | 58 |
| RF | 1.349 | 72 | 1.138 | 64 | 1.112 | 61 | 1.137 | 66 | 1.201 | 79 | 1.453 | 75 | 1.836 | 57 | 2.229 | 55 | 2.389 | 55 | 2.359 | 52 | 2.379 | 59 | 2.332 | 58 | |
| SVR | 1.225 | 74 | 1.057 | 61 | 1.056 | 58 | 1.025 | 57 | 1.114 | 59 | 1.377 | 90 | 1.401 | 57 | 1.565 | 43 | 1.749 | 44 | 1.723 | 55 | 1.796 | 58 | 1.738 | 57 | |
| ANN | 1.349 | 47 | 1.179 | 56 | 1.133 | 10 | 1.276 | 59 | 1.262 | 76 | 1.453 | 33 | 1.558 | 30 | 1.926 | 48 | 2.323 | 58 | 2.319 | 53 | 2.321 | 48 | 2.424 | 21 | |
| GPR | 1.170 | 75 | 0.955 | 109 | 0.904 | 92 | 0.963 | 86 | 1.025 | 110 | 1.281 | 101 | 1.452 | 94 | 1.859 | 110 | 2.021 | 113 | 2.039 | 41 | 1.952 | 98 | 1.876 | 99 | |
| CMI | CART | 1.528 | 11 | 1.470 | 4 | 1.386 | 4 | 1.396 | 9 | 1.475 | 4 | 1.632 | 62 | 1.998 | 72 | 2.752 | 108 | 2.709 | 135 | 2.534 | 124 | 2.531 | 114 | 2.485 | 125 |
| RF | 1.266 | 31 | 1.093 | 15 | 1.305 | 33 | 1.052 | 30 | 1.133 | 50 | 1.416 | 44 | 1.847 | 23 | 2.191 | 49 | 2.333 | 42 | 2.345 | 38 | 2.353 | 43 | 2.237 | 43 | |
| SVR | 1.209 | 43 | 1.027 | 28 | 0.950 | 33 | 1.082 | 35 | 1.123 | 55 | 1.316 | 65 | 1.387 | 39 | 1.508 | 34 | 1.651 | 52 | 1.732 | 33 | 1.692 | 44 | 1.631 | 44 | |
| ANN | 1.239 | 17 | 1.062 | 21 | 1.034 | 28 | 1.072 | 31 | 1.149 | 29 | 1.312 | 27 | 1.542 | 23 | 1.979 | 31 | 2.202 | 23 | 2.107 | 28 | 2.037 | 24 | 2.129 | 47 | |
| GPR | 1.148 | 122 | 0.930 | 138 | 0.882 | 163 | 0.900 | 167 | 1.037 | 73 | 1.090 | 122 | 1.470 | 27 | 1.879 | 36 | 2.054 | 43 | 2.012 | 48 | 1.925 | 135 | 1.892 | 50 | |
| CART | CART | 1.559 | 14 | 1.528 | 14 | 1.403 | 3 | 1.482 | 12 | 1.608 | 2 | 1.675 | 143 | 2.323 | 50 | 2.718 | 7 | 2.950 | 18 | 2.875 | 19 | 2.593 | 102 | 2.478 | 102 |
| RF | 1.303 | 26 | 1.113 | 12 | 1.100 | 21 | 1.105 | 32 | 1.214 | 25 | 1.431 | 38 | 1.917 | 44 | 2.289 | 19 | 2.417 | 45 | 2.458 | 45 | 2.544 | 56 | 2.477 | 19 | |
| SVR | 1.103 | 56 | 0.995 | 36 | 1.031 | 17 | 1.001 | 73 | 1.038 | 22 | 1.138 | 32 | 1.575 | 83 | 1.653 | 25 | 1.803 | 73 | 1.863 | 46 | 1.916 | 53 | 1.845 | 53 | |
| ANN | 1.210 | 16 | 1.061 | 21 | 1.043 | 15 | 1.037 | 24 | 1.122 | 32 | 1.252 | 31 | 1.876 | 22 | 1.981 | 27 | 2.082 | 23 | 2.158 | 19 | 2.254 | 28 | 2.274 | 13 | |
| GPR | 1.169 | 60 | 1.015 | 74 | 0.902 | 120 | 0.918 | 115 | 1.066 | 25 | 1.216 | 33 | 1.415 | 173 | 1.813 | 172 | 1.959 | 172 | 1.903 | 172 | 1.893 | 172 | 1.851 | 173 | |
| RF | CART | 1.594 | 72 | 1.583 | 19 | 1.425 | 2 | 1.525 | 11 | 1.577 | 9 | 1.672 | 14 | 2.147 | 8 | 2.456 | 4 | 2.754 | 10 | 2.710 | 21 | 2.615 | 42 | 2.488 | 29 |
| RF | 1.371 | 5 | 1.089 | 24 | 1.081 | 22 | 1.105 | 31 | 1.190 | 35 | 1.381 | 21 | 1.608 | 10 | 2.042 | 9 | 2.336 | 10 | 2.239 | 18 | 2.334 | 41 | 2.238 | 19 | |
| SVR | 1.186 | 58 | 0.993 | 13 | 0.904 | 30 | 0.972 | 38 | 1.035 | 27 | 1.080 | 39 | 1.370 | 20 | 1.483 | 27 | 1.617 | 30 | 1.588 | 29 | 1.682 | 30 | 1.649 | 23 | |
| ANN | 1.242 | 17 | 1.016 | 18 | 0.926 | 28 | 1.014 | 44 | 1.033 | 24 | 1.149 | 23 | 1.461 | 11 | 1.689 | 14 | 1.945 | 25 | 1.930 | 31 | 1.953 | 9 | 1.952 | 15 | |
| GPR | 1.163 | 38 | 0.949 | 76 | 0.897 | 76 | 0.897 | 60 | 0.946 | 105 | 1.115 | 39 | 1.427 | 27 | 1.835 | 30 | 1.982 | 31 | 1.966 | 26 | 1.952 | 35 | 1.882 | 31 | |
| RreliefF | CART | 1.530 | 7 | 1.506 | 9 | 1.283 | 10 | 1.395 | 8 | 1.513 | 9 | 1.574 | 13 | 1.754 | 24 | 2.579 | 38 | 2.579 | 38 | 2.464 | 40 | 2.412 | 43 | 2.295 | 42 |
| RF | 1.300 | 10 | 1.083 | 18 | 1.042 | 38 | 1.070 | 31 | 1.178 | 12 | 1.173 | 14 | 1.448 | 18 | 2.109 | 19 | 2.248 | 57 | 2.216 | 59 | 2.204 | 64 | 2.191 | 9 | |
| SVR | 1.197 | 21 | 1.019 | 13 | 1.003 | 14 | 1.047 | 14 | 1.098 | 59 | 1.080 | 26 | 1.343 | 38 | 1.464 | 24 | 1.620 | 42 | 1.671 | 43 | 1.679 | 42 | 1.678 | 34 | |
| ANN | 1.242 | 17 | 1.016 | 18 | 0.926 | 28 | 1.014 | 44 | 1.033 | 24 | 1.149 | 23 | 1.645 | 11 | 1.689 | 14 | 1.945 | 25 | 1.930 | 31 | 1.953 | 9 | 1.952 | 15 | |
| GPR | 1.159 | 95 | 0.950 | 94 | 0.910 | 95 | 0.925 | 96 | 0.989 | 88 | 1.128 | 16 | 1.442 | 22 | 1.780 | 18 | 1.886 | 34 | 1.901 | 37 | 1.876 | 41 | 1.778 | 42 | |
| Time Point | 13:00 | 14:00 | 15:00 | 16:00 | 17:00 | 18:00 | 19:00 | 20:00 | 21:00 | 22:00 | 23:00 | 24:00 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Error | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | |
| MI | CART | 2.501 | 75 | 2.522 | 37 | 2.700 | 43 | 2.637 | 45 | 2.619 | 58 | 2.398 | 51 | 2.113 | 87 | 1.884 | 49 | 1.790 | 64 | 1.588 | 90 | 1.614 | 66 | 1.820 | 13 |
| RF | 2.353 | 49 | 2.376 | 42 | 2.387 | 48 | 2.486 | 44 | 2.534 | 57 | 2.258 | 62 | 2.049 | 49 | 1.793 | 43 | 1.632 | 64 | 1.526 | 59 | 1.485 | 45 | 1.529 | 55 | |
| SVR | 1.795 | 49 | 1.850 | 42 | 1.878 | 43 | 1.898 | 43 | 2.010 | 54 | 1.883 | 54 | 1.629 | 111 | 1.469 | 39 | 1.317 | 94 | 1.372 | 40 | 1.337 | 41 | 1.301 | 75 | |
| ANN | 2.280 | 25 | 2.362 | 36 | 2.466 | 23 | 2.334 | 32 | 2.259 | 44 | 2.324 | 29 | 1.936 | 45 | 1.797 | 52 | 1.682 | 65 | 1.482 | 41 | 1.450 | 38 | 1.390 | 33 | |
| GPR | 1.912 | 95 | 2.036 | 40 | 2.032 | 43 | 2.098 | 43 | 2.095 | 102 | 1.821 | 170 | 1.752 | 101 | 1.554 | 44 | 1.357 | 94 | 1.304 | 91 | 1.283 | 102 | 1.253 | 119 | |
| CMI | CART | 2.368 | 111 | 2.749 | 126 | 2.517 | 127 | 2.665 | 113 | 2.481 | 125 | 2.423 | 110 | 1.983 | 115 | 1.884 | 139 | 1.779 | 66 | 1.587 | 121 | 1.580 | 7 | 1.667 | 5 |
| RF | 2.263 | 37 | 2.307 | 36 | 2.309 | 36 | 2.349 | 28 | 2.342 | 35 | 2.160 | 31 | 1.933 | 40 | 1.672 | 41 | 1.593 | 30 | 1.466 | 29 | 1.456 | 8 | 1.451 | 53 | |
| SVR | 1.702 | 49 | 1.768 | 34 | 1.792 | 45 | 1.914 | 42 | 1.937 | 41 | 1.806 | 33 | 1.646 | 32 | 1.442 | 27 | 1.359 | 33 | 1.301 | 41 | 1.324 | 54 | 1.352 | 37 | |
| ANN | 2.232 | 27 | 2.125 | 30 | 2.163 | 43 | 2.300 | 36 | 2.381 | 23 | 2.218 | 39 | 1.761 | 31 | 1.851 | 21 | 1.488 | 15 | 1.405 | 34 | 1.358 | 22 | 1.377 | 25 | |
| GPR | 1.913 | 48 | 1.978 | 45 | 1.994 | 44 | 2.055 | 40 | 2.054 | 102 | 1.884 | 128 | 1.667 | 171 | 1.448 | 172 | 1.296 | 172 | 1.244 | 171 | 1.239 | 125 | 1.282 | 92 | |
| CART | CART | 2.486 | 103 | 2.557 | 4 | 2.630 | 4 | 2.734 | 4 | 2.626 | 151 | 2.398 | 104 | 2.132 | 15 | 1.940 | 20 | 1.911 | 86 | 1.591 | 58 | 1.638 | 156 | 1.734 | 7 |
| RF | 2.414 | 22 | 2.463 | 18 | 2.493 | 46 | 2.622 | 7 | 2.653 | 8 | 2.352 | 17 | 1.909 | 20 | 1.903 | 27 | 1.760 | 24 | 1.448 | 25 | 1.499 | 23 | 1.503 | 45 | |
| SVR | 1.871 | 52 | 1.935 | 54 | 1.885 | 54 | 2.115 | 40 | 2.188 | 39 | 1.843 | 54 | 1.601 | 87 | 1.606 | 87 | 1.511 | 69 | 1.322 | 29 | 1.284 | 47 | 1.227 | 85 | |
| ANN | 2.218 | 19 | 2.213 | 18 | 2.202 | 19 | 2.387 | 19 | 2.404 | 31 | 2.179 | 19 | 1.832 | 32 | 1.773 | 19 | 1.754 | 12 | 1.438 | 33 | 1.453 | 22 | 1.351 | 17 | |
| GPR | 1.871 | 172 | 1.950 | 173 | 1.948 | 168 | 1.981 | 171 | 2.011 | 169 | 1.824 | 168 | 1.663 | 172 | 1.442 | 168 | 1.285 | 169 | 1.235 | 168 | 1.205 | 166 | 1.203 | 169 | |
| RF | CART | 2.501 | 67 | 2.759 | 27 | 2.673 | 7 | 2.651 | 34 | 2.617 | 38 | 2.416 | 35 | 1.999 | 13 | 1.794 | 27 | 1.750 | 17 | 1.583 | 52 | 1.638 | 41 | 1.692 | 2 |
| RF | 2.272 | 36 | 2.323 | 33 | 2.328 | 35 | 2.364 | 34 | 2.396 | 39 | 2.098 | 26 | 1.881 | 25 | 1.628 | 19 | 1.527 | 10 | 1.427 | 16 | 1.410 | 15 | 1.478 | 24 | |
| SVR | 1.670 | 28 | 1.751 | 23 | 1.857 | 22 | 1.853 | 39 | 1.944 | 36 | 1.789 | 16 | 1.577 | 57 | 1.394 | 22 | 1.299 | 56 | 1.240 | 15 | 1.195 | 12 | 1.244 | 38 | |
| ANN | 1.972 | 11 | 2.256 | 10 | 2.224 | 8 | 2.245 | 10 | 2.326 | 13 | 1.949 | 21 | 1.822 | 33 | 1.551 | 7 | 1.419 | 12 | 1.323 | 17 | 1.244 | 19 | 1.396 | 32 | |
| GPR | 1.876 | 44 | 1.981 | 30 | 2.125 | 34 | 2.023 | 54 | 2.108 | 42 | 1.893 | 91 | 1.767 | 35 | 1.502 | 32 | 1.377 | 13 | 1.269 | 16 | 1.244 | 18 | 1.265 | 47 | |
| RreliefF | CART | 2.323 | 41 | 2.532 | 41 | 2.662 | 42 | 2.533 | 24 | 2.366 | 58 | 2.220 | 42 | 1.949 | 66 | 1.766 | 7 | 1.674 | 15 | 1.605 | 21 | 1.624 | 12 | 1.642 | 10 |
| RF | 2.201 | 84 | 2.298 | 9 | 2.243 | 17 | 2.262 | 14 | 2.271 | 35 | 1.998 | 14 | 1.713 | 18 | 1.468 | 21 | 1.366 | 17 | 1.308 | 15 | 1.337 | 17 | 1.400 | 24 | |
| SVR | 1.714 | 41 | 1.768 | 20 | 1.799 | 37 | 1.801 | 15 | 1.815 | 14 | 1.646 | 23 | 1.564 | 20 | 1.409 | 11 | 1.258 | 16 | 1.265 | 24 | 1.252 | 24 | 1.299 | 21 | |
| ANN | 1.972 | 11 | 2.256 | 10 | 2.224 | 8 | 2.244 | 10 | 2.326 | 13 | 1.949 | 21 | 1.822 | 33 | 1.551 | 7 | 1.419 | 12 | 1.322 | 12 | 1.244 | 19 | 1.396 | 32 | |
| GPR | 1.856 | 29 | 1.882 | 41 | 1.861 | 31 | 1.937 | 41 | 1.936 | 30 | 1.789 | 33 | 1.645 | 95 | 1.450 | 35 | 1.316 | 56 | 1.296 | 41 | 1.279 | 72 | 1.208 | 170 | |
References
- He, Y.; Xu, Q.; Wan, J.; Yang, S. Short-term power load probability density forecasting based on quantile regression neural network and triangle kernel function. Energy 2016, 114, 498–512. [Google Scholar] [CrossRef]
- Nikmehr, N.; Najafi-Ravadanegh, S. Optimal operation of distributed generations in micro-grids under uncertainties in load and renewable power generation using heuristic algorithm. IET Renew. Power Gener. 2015, 9, 982–990. [Google Scholar] [CrossRef]
- Duan, Z.Y.; Gutierrez, B.; Wang, L. Forecasting Plug-In Electric Vehicle Sales and the Diurnal Recharging Load Curve. IEEE Trans. Smart Grid 2014, 5, 527–535. [Google Scholar] [CrossRef]
- Ferlito, S.; Adinolfi, G.; Graditi, G. Comparative analysis of data-driven methods online and offline trained to the forecasting of grid-connected photovoltaic plant production. Appl. Energy 2017, 205, 116–129. [Google Scholar] [CrossRef]
- Ferruzzi, G.; Cervone, G.; Delle Monache, L.; Graditi, G.; Jacobone, F. Optimal bidding in a Day-Ahead energy market for Micro Grid under uncertainty in renewable energy production. Energy 2016, 106, 194–202. [Google Scholar] [CrossRef]
- Feng, Y.H.; Ryan, S.M. Day-ahead hourly electricity load modeling by functional regression. Appl. Energy 2016, 170, 455–465. [Google Scholar] [CrossRef] [Green Version]
- Bindiu, R.; Chindris, M.; Pop, G.V. Day-Ahead Load Forecasting Using Exponential Smoothing. Sci. Bull. Petru Maior Univ. Tîrgu Mureș 2009, 6, 89–93. [Google Scholar]
- Al-Hamadi, H.M.; Soliman, S.A. Fuzzy short-term electric load forecasting using Kalman filter. IEE Proc.-Gener. Transm. Distrib. 2012, 153, 217–227. [Google Scholar] [CrossRef]
- Lee, C.M.; Ko, C.N. Short-term load forecasting using lifting scheme and ARIMA models. Expert Syst. Appl. 2011, 38, 5902–5911. [Google Scholar] [CrossRef]
- Luy, M.; Ates, V.; Barisci, N.; Polat, H.; Cam, E. Short-Term Fuzzy Load Forecasting Model Using Genetic–Fuzzy and Ant Colony–Fuzzy Knowledge Base Optimization. Appl. Sci. 2018, 8, 864. [Google Scholar] [CrossRef]
- Xiao, L.Y.; Shao, W.; Liang, L.L.; Wang, C. A combined model based on multiple seasonal patterns and modified firefly algorithm for electrical load forecasting. Appl. Energy 2016, 167, 135–153. [Google Scholar] [CrossRef]
- Khotanzad, A.; Zhou, E.; Elragal, H. A neuro-fuzzy approach to short-term load forecasting in a price-sensitive environment. IEEE Trans. Power Syst. 2002, 17, 1273–1282. [Google Scholar] [CrossRef]
- Felice, M.D.; Yao, X. Short-Term Load Forecasting with Neural Network Ensembles: A Comparative Study Application Notes. IEEE Comput. Intell. Mag. 2012, 6, 47–56. [Google Scholar] [CrossRef]
- Ahmad, A.; Javaid, N.; Alrajeh, N.; Khan, Z.A.; Qasim, U.; Khan, A. A Modified Feature Selection and Artificial Neural Network-Based Day-Ahead Load Forecasting Model for a Smart Grid. Appl. Sci. 2015, 5, 1756–1772. [Google Scholar] [CrossRef] [Green Version]
- Che, J.X.; Wang, J.Z.; Tang, Y.J. Optimal training subset in a support vector regression electric load forecasting model. Appl. Soft Comput. 2012, 12, 1523–1531. [Google Scholar] [CrossRef]
- Dudek, G. Short-Term Load Forecasting Using Random Forests. Intell. Syst. 2015, 323, 821–828. [Google Scholar]
- Lloyd, R.J. GEFCom2012 hierarchical load forecasting: Gradient boosting machines and Gaussian processes. Int. J. Forecast. 2014, 30, 369–374. [Google Scholar] [CrossRef] [Green Version]
- Che, J.X.; Wang, J.Z. Short-term load forecasting using a kernel-based support vector regression combination model. Appl. Energy 2014, 132, 602–609. [Google Scholar] [CrossRef]
- Božić, M.; Stojanović, M.; Stajić, Z.; Stajić, N. Mutual Information-Based Inputs Selection for Electric Load Time Series Forecasting. Entropy 2013, 15, 926–942. [Google Scholar] [CrossRef] [Green Version]
- Rong, G.; Liu, X. Support vector machine with PSO algorithm in short-term load forecasting. In Proceedings of the 2008 Chinese Control and Decision Conference, Yantai, China, 2–4 July 2008; pp. 1140–1142. [Google Scholar]
- Ma, L.H.; Zhou, S.; Lin, M. Support Vector Machine Optimized with Genetic Algorithm for Short-Term Load Forecasting. In Proceedings of the International Symposium on Knowledge Acquisition and Modeling IEEE, Wuhan, China, 21–22 December 2008; pp. 654–657. [Google Scholar]
- Zhang, Y.J.; Peng, X.Y.; Peng, Y.; Pang, J.Y.; Liu, D.T. Weighted bagging gaussion process regression to predict remaining useful life of electro-mechanical actuator. In Proceedings of the Prognostics and System Health Management Conference, Chengdu, China, 19–21 October 2016; pp. 1–6. [Google Scholar]
- Lahouar, A.; Slama, J.B.H. Day-ahead load forecast using random forest and expert input selection. Energy Convers. Manag. 2015, 103, 1040–1051. [Google Scholar] [CrossRef]
- Ghofrani, M.; West, K.; Ghayekhloo, M. Hybrid time series-bayesian neural network short-term load forecasting with a new input selection method. In Proceedings of the 2015 IEEE Power & Energy Society General Meeting, Denver, CO, USA, 26–30 July 2015; pp. 1–5. [Google Scholar]
- Chandrashekar, G.; Sahin, F. A Survey on Feature Selection Methods; Pergamon Press, Inc.: New York, NY, USA, 2014. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1996, 97, 273–324. [Google Scholar] [CrossRef]
- Hu, Z.Y.; Bao, Y.K.; Chiong, R.; Xiong, T. Mid-term interval load forecasting using multi-output support vector regression with a memetic algorithm for feature selection. Energy 2015, 84, 419–431. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1990; pp. 2104–2116. [Google Scholar]
- Hyojoo, S.; Kim, C. Forecasting Short-term Electricity Demand in Residential Sector Based on Support Vector Regression and Fuzzy-rough Feature Selection with Particle Swarm Optimization. Procedia Eng. 2015, 118, 1162–1168. [Google Scholar]
- Isabelle, G.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Koprinska, I.; Rana, M.; Agelidis, V.G. Correlation and instance based feature selection for electricity load forecasting. Knowl.-Based Syst. 2015, 82, 29–40. [Google Scholar] [CrossRef]
- Hu, Z.Y.; Bao, Y.K.; Xiong, T.; Chiong, R. Hybrid filter–wrapper feature selection for short-term load forecasting. Eng. Appl. Artif. Intell. 2015, 40, 17–27. [Google Scholar] [CrossRef]
- Abedinia, O.; Amjady, N.; Zareipour, H. A New Feature Selection Technique for Load and Price Forecast of Electrical Power Systems. IEEE Trans. Power Syst. 2016, 32, 62–74. [Google Scholar] [CrossRef]
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Li, S.; Goel, L.; Wang, P. An ensemble approach for short-term load forecasting by extreme learning machine. Appl. Energy 2016, 170, 22–29. [Google Scholar] [CrossRef]
- Kononenko, I. Theoretical and Empirical Analysis of ReliefF and RReliefF. Mach. Learn. J. 2003, 53, 23–69. [Google Scholar] [Green Version]
- Breiman, L.I.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees (CART). Biometrics 1984, 40, 17–23. [Google Scholar]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- He, Y.Y.; Liu, R.; Li, H.Y.; Wang, S.; Lu, X.F. Short-term power load probability density forecasting method using kernel-based support vector quantile regression and Copula theory. Appl. Energy 2107, 185, 254–266. [Google Scholar] [CrossRef]
- Yu, F.; Xu, X.Z. A short-term load forecasting model of natural gas based on optimized genetic algorithm and improved BP neural network. Appl. Energy 2014, 134, 102–113. [Google Scholar] [CrossRef]
- Seeger, M. Gaussian processes for machine learning. J. Neural Syst. 2011, 14, 69–106. [Google Scholar] [CrossRef] [PubMed]
- ISO New England Load Data. Available online: https://www.iso-ne.com/isoexpress/web/reports/pricing/-/tree/zone-info (accessed on 11 November 2014).
- Singapore Load Data. Available online: https://www.emcsg.com/PriceInformation#download (accessed on 19 December 2016).
- Sheela, K.G.; Deepa, S.N. Review on Methods to Fix Number of Hidden Neurons in Neural Networks. Math. Prob. Eng. 2013, 6, 389–405. [Google Scholar] [CrossRef]









| Feature Type | Feature Name | Feature Number |
|---|---|---|
| Endogenous predictor | , i = 24, 25, …, 168 | 145 |
| , , , k = 2, 3, 4, 5, 6, 7 | 18 | |
| Exogenous predictor | , W = 1, 2, 3, 4, 5, 6, 7 | 7 |
| 2 | ||
| 1 |
| Data Set | Detail Information of Experimental Data (New England) | Detail Information of Experimental Data (Singapore) | |||
|---|---|---|---|---|---|
| 2011 | 2012 | 2013 | 2014 | 2015 | |
| Training set | Jan., Feb., Mar., Apr., May, Jun., Jul., Aug., Sept., Oct., Nov., Dec. | Jan., Feb., Apr., Jun., Jul., Aug., Oct., Dec. | - | Jan., Feb., Mar., Apr., May, Jun., Jul., Aug., Sept., Oct., Nov., Dec. | Jan., Apr., Aug., Dec. |
| Validation set | - | Mar., May, Sept., Nov. | - | - | Feb., May, Jul., Oct. |
| Test set | - | - | Jan., Feb., Mar., Apr., May, Jun., Jul., Aug., Sept., Oct., Nov., Dec. | - | Mar., Jun., Sept., Nov. |
| MI | CMI | RreliefF | RF | CART | |
|---|---|---|---|---|---|
| Hour 5 | FL(t−24), FL(t−25), FL(t−26), FL(t−27), FL(t−28), FL(t−29), FL(min, d−2), FL(t−30), FL(mean, d−2), FL(t−44) | FL(t−24), FL(t−25), FL(t−29), FL(t−28), FL(t−160), FL(t−26), FL(t−161), FL(t−162), FL(t−27), FL(max, d−2) | FL(t−24), FL(t−25), FL(t−26), FL(t−27), FL(t−28), , , FL(t−28), FL(max, d−2), FL(t−31) | FL(t−24), FL(t−25), FL(t−163), FL(t−162), FL(t−26), FL(t−164), FL(t−30), FL(t−29), FL(t−160), FL(t−27) | FL(t−24), FL(t−25), FL(t−26), FL(t−27), FL(t−28), FL(t−30), FL(t−163), FL(t−160), FL(t−161), FL(t−162) |
| Hour 6 | FL(t−160), FL(t−162), FL(t−161), FL(t−24), FL(t−164), FL(mean, d−7), FL(t−163), FL(t−159), FL(t−28), FL(t−29) | FL(t−161), FL(t−162), FL(t−160), FL(t−163), FL(t−159), FL(t−29), FL(t−145), FL(t−158), FL(t−141), FL(t−65) | , , , FL(t−24), FL(t−25), FL(t−26), , FL(t−28), FL(t−27), FL(t−29) | FL(t−24), FL(t−162), FL(t−161), FL(t−160), FL(t−30), FL(t−29), FL(t−25), , FL(t−163), FL(mean, d−7) | FL(mean, d−7), FL(t−159), FL(t−147), FL(t−146), FL(t−148), FL(max, d−7), FL(t−24), FL(t−25), FL(t−30), FL(t−26) |
| Hour 10 | FL(t−158), FL(t−159), FL(t−157), FL(mean, d−7), FL(t−160), FL(t−156), FL(t−24), FL(t−154), FL(t−147), FL(t−153) | FL(t−161), FL(t−160), FL(t−162), , , FL(t−159), FL(t−158), FL(t−157), FL(t−154), FL(t−155), FL(t−159) | , , , , FL(t−26), FL(t−25), FL(t−27), FL(t−24), FL(t−28), | , , FL(t−159), FL(t−25), FL(t−160), FL(t−24), FL(t−161), FL(t−26), FL(t−28), FL(t−27) | FL(t−159), FL(t−158), FL(t−160), FL(t−157), FL(mean, d−7), FL(t−156), FL(t−25), FL(t−27), FL(t−28), FL(t−26) |
| Hour 11 | FL(t−159), FL(t−157), FL(t−158), FL(t−156), FL(mean, d−7), FL(t−153), FL(t−155), FL(t−152), FL(t−160), FL(t−154) | FL(t−160), FL(t−162), FL(t−161), FL(t−159), FL(t−158), , , FL(t−154), FL(t−156), FL(t−155) | , , , FL(t−26), FL(t−27), FL(t−25), FL(t−33), FL(t−24), FL(t−34), FL(t−28) | , , FL(t−26), FL(t−27), FL(t−25), FL(t−161), FL(t−157), FL(t−160), FL(t−24), FL(t−158) | FL(t−157), FL(t−156), FL(t−155), FL(t−153), FL(t−154), FL(t−158), FL(t−26), FL(t−25), FL(t−27), FL(t−28) |
| Time | MAPE | FD | Time | MAPE | FD |
|---|---|---|---|---|---|
| 1 | 3.294 | 34 | 13 | 4.663 | 41 |
| 2 | 3.419 | 22 | 14 | 4.926 | 33 |
| 3 | 3.632 | 9 | 15 | 5.190 | 38 |
| 4 | 3.783 | 30 | 15 | 5.351 | 46 |
| 5 | 4.008 | 9 | 17 | 5.547 | 31 |
| 6 | 4.828 | 18 | 18 | 5.358 | 98 |
| 7 | 5.456 | 61 | 19 | 5.117 | 136 |
| 8 | 5.314 | 59 | 20 | 4.506 | 23 |
| 9 | 4.526 | 64 | 21 | 4.376 | 28 |
| 10 | 4.171 | 45 | 22 | 4.779 | 9 |
| 11 | 4.147 | 42 | 23 | 4.794 | 41 |
| 12 | 4.414 | 67 | 24 | 4.847 | 72 |
| Method | CART | RF | SVR | ANN | GPR | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | |
| MI | 3.741 | 7 | 3.294 | 34 | 3.064 | 10 | 3.226 | 8 | 3.087 | 119 |
| CMI | 3.729 | 2 | 3.447 | 20 | 3.043 | 13 | 3.062 | 47 | 3.052 | 134 |
| CART | 3.729 | 3 | 3.422 | 11 | 3.068 | 11 | 3.270 | 9 | 3.245 | 8 |
| RF | 3.741 | 7 | 3.533 | 51 | 3.140 | 41 | 3.069 | 18 | 3.099 | 81 |
| RreliefF | 3.741 | 10 | 3.310 | 26 | 3.043 | 18 | 3.269 | 9 | 3.019 | 134 |
| Method | CART | RF | GPR | BPNN | SVR | |
|---|---|---|---|---|---|---|
| MI | MAPE | 5.027 | 4.376 | 4.223 | 5.705 | 4.286 |
| MAE | 849.194 | 732.926 | 709.848 | 962.649 | 720.361 | |
| RMSE | 1191.968 | 871.897 | 988.378 | 1323.916 | 921.862 | |
| CMI | MAPE | 4.672 | 4.423 | 4.299 | 4.457 | 4.880 |
| MAE | 784.550 | 719.337 | 699.910 | 566.609 | 809.988 | |
| RMSE | 1016.001 | 931.743 | 942.492 | 715.524 | 1027.936 | |
| CART | MAPE | 6.179 | 4.936 | 4.449 | 4.910 | 3.634 |
| MAE | 1034.009 | 833.712 | 752.653 | 823.088 | 599.284 | |
| RMSE | 1282.515 | 1077.501 | 961.304 | 1142.275 | 753.655 | |
| RF | MAPE | 4.936 | 4.231 | 4.381 | 4.291 | 4.262 |
| MAE | 833.712 | 711.268 | 815.776 | 711.438 | 705.789 | |
| RMSE | 1077.501 | 855.686 | 915.139 | 969.156 | 916.701 | |
| RreliefF | MAPE | 4.577 | 3.710 | 4.239 | 4.270 | 4.204 |
| MAE | 786.561 | 629.120 | 717.094 | 710.419 | 700.174 | |
| RMSE | 1072.662 | 781.775 | 1045.609 | 922.320 | 910.103 | |
| Method | CART | RF | GPR | BPNN | SVR | |
|---|---|---|---|---|---|---|
| MI | MAPE | 5.420 | 5.783 | 4.862 | 5.823 | 4.977 |
| MAE | 809.153 | 855.560 | 706.073 | 868.632 | 734.877 | |
| RMSE | 1052.017 | 1038.861 | 875.357 | 1059.056 | 897.331 | |
| CMI | MAPE | 5.479 | 5.515 | 4.862 | 5.072 | 5.262 |
| MAE | 814.890 | 821.482 | 710.464 | 733.701 | 788.030 | |
| RMSE | 1029.141 | 983.674 | 867.158 | 941.800 | 956.224 | |
| CART | MAPE | 6.876 | 5.154 | 4.754 | 5.206 | 4.770 |
| MAE | 1027.157 | 763.678 | 704.088 | 776.566 | 705.472 | |
| RMSE | 1307.768 | 1031.547 | 892.356 | 1055.224 | 911.921 | |
| RF | MAPE | 5.154 | 5.421 | 4.817 | 5.190 | 4.540 |
| MAE | 763.678 | 795.999 | 697.702 | 757.221 | 666.295 | |
| RMSE | 1031.547 | 955.704 | 858.767 | 961.667 | 849.553 | |
| RreliefF | MAPE | 4.985 | 4.830 | 5.026 | 4.689 | 4.207 |
| MAE | 741.379 | 713.534 | 749.809 | 702.243 | 628.159 | |
| RMSE | 1019.697 | 893.103 | 1034.086 | 931.176 | 810.417 | |
| Feature Selection Method | Forecaster | Evaluated Criterion | ||
|---|---|---|---|---|
| MAPE (%) | RMSE (MW) | MAE (MW) | ||
| MI | CART | 6.021 | 1360.445 | 934.560 |
| RF | 5.536 | 1260.281 | 864.385 | |
| SVR | 4.872 | 1196.775 | 773.447 | |
| BPNN | 5.491 | 1320.809 | 865.842 | |
| GPR | 4.785 | 1141.372 | 755.325 | |
| CMI | CART | 6.088 | 1371.643 | 945.217 |
| RF | 5.364 | 1235.216 | 841.376 | |
| SVR | 4.870 | 1225.231 | 776.654 | |
| BPNN | 5.054 | 1179.931 | 793.064 | |
| GPR | 4.758 | 1135.260 | 750.937 | |
| CART | CART | 6.495 | 1493.344 | 1013.322 |
| RF | 5.364 | 1228.542 | 837.765 | |
| SVR | 4.794 | 1158.022 | 758.601 | |
| BPNN | 5.414 | 1270.671 | 847.104 | |
| GPR | 5.018 | 1176.996 | 790.088 | |
| RF | CART | 5.883 | 1322.730 | 911.334 |
| RF | 5.385 | 1236.724 | 843.334 | |
| SVR | 5.534 | 1260.281 | 834.385 | |
| BPNN | 5.287 | 1248.014 | 827.752 | |
| GPR | 4.839 | 1244.614 | 761.119 | |
| RreliefF | CART | 5.804 | 1898.190 | 1305.192 |
| RF | 5.202 | 1220.145 | 816.788 | |
| SVR | 4.746 | 1229.229 | 759.143 | |
| BPNN | 5.175 | 1244.537 | 812.642 | |
| GPR | 5.543 | 1410.293 | 883.576 | |
| Time | MAPE | FD | Time | MAPE | FD |
|---|---|---|---|---|---|
| 1 | 1.349 | 72 | 13 | 2.353 | 49 |
| 2 | 1.138 | 64 | 14 | 2.376 | 42 |
| 3 | 1.112 | 61 | 15 | 2.387 | 48 |
| 4 | 1.137 | 66 | 15 | 2.486 | 44 |
| 5 | 1.201 | 79 | 17 | 2.534 | 57 |
| 6 | 1.453 | 75 | 18 | 2.258 | 62 |
| 7 | 1.836 | 57 | 19 | 2.049 | 49 |
| 8 | 2.229 | 55 | 20 | 1.793 | 43 |
| 9 | 2.389 | 55 | 21 | 1.632 | 64 |
| 10 | 2.359 | 52 | 22 | 1.526 | 59 |
| 11 | 2.379 | 59 | 23 | 1.485 | 45 |
| 12 | 2.332 | 58 | 24 | 1.529 | 55 |
| Method | CART | RF | SVR | ANN | GPR | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | MAPE | FD | |
| MI | 1.595 | 59 | 1.349 | 72 | 1.225 | 74 | 1.349 | 47 | 1.170 | 75 |
| CMI | 1.528 | 11 | 1.266 | 31 | 1.209 | 43 | 1.239 | 17 | 1.148 | 122 |
| CART | 1.559 | 14 | 1.303 | 26 | 1.103 | 56 | 1.210 | 16 | 1.169 | 60 |
| RF | 1.594 | 72 | 1.371 | 5 | 1.186 | 58 | 1.242 | 17 | 1.163 | 38 |
| RreliefF | 1.530 | 7 | 1.300 | 10 | 1.197 | 21 | 1.242 | 17 | 1.159 | 95 |
| Method | CART | RF | GPR | BPNN | SVR | |
|---|---|---|---|---|---|---|
| MI | MAPE | 2.321 | 2.145 | 1.439 | 2.719 | 1.662 |
| MAE | 128.596 | 119.058 | 79.453 | 153.693 | 91.493 | |
| RMSE | 162.801 | 137.462 | 99.346 | 202.410 | 110.360 | |
| CMI | MAPE | 2.117 | 1.867 | 1.419 | 3.165 | 1.482 |
| MAE | 115.395 | 103.810 | 78.407 | 180.786 | 81.177 | |
| RMSE | 150.781 | 134.390 | 99.425 | 322.873 | 102.596 | |
| CART | MAPE | 2.420 | 2.136 | 1.645 | 1.963 | 1.911 |
| MAE | 132.823 | 118.571 | 91.358 | 108.851 | 106.369 | |
| RMSE | 175.615 | 143.584 | 139.408 | 160.930 | 152.349 | |
| RF | MAPE | 2.213 | 2.000 | 1.435 | 1.702 | 1.404 |
| MAE | 123.568 | 112.369 | 77.803 | 94.085 | 77.236 | |
| RMSE | 148.988 | 146.759 | 97.686 | 117.295 | 95.627 | |
| RreliefF | MAPE | 2.720 | 1.862 | 1.428 | 1.917 | 1.402 |
| MAE | 154.605 | 103.586 | 79.134 | 105.902 | 74.400 | |
| RMSE | 201.458 | 128.291 | 101.035 | 127.631 | 93.092 | |
| Method | CART | RF | GPR | BPNN | SVR | |
|---|---|---|---|---|---|---|
| MI | MAPE | 3.895 | 3.854 | 3.806 | 4.273 | 3.637 |
| MAE | 217.339 | 217.647 | 215.942 | 243.454 | 204.362 | |
| RMSE | 250.640 | 240.934 | 236.196 | 283.816 | 232.913 | |
| CMI | MAPE | 3.573 | 3.518 | 3.899 | 5.023 | 3.585 |
| MAE | 200.803 | 197.387 | 221.095 | 288.472 | 200.942 | |
| RMSE | 229.837 | 217.891 | 239.055 | 390.638 | 229.780 | |
| CART | MAPE | 3.868 | 3.587 | 4.115 | 3.897 | 3.599 |
| MAE | 215.523 | 200.915 | 234.630 | 219.650 | 201.124 | |
| RMSE | 260.178 | 225.501 | 272.193 | 254.684 | 235.158 | |
| RF | MAPE | 3.799 | 3.711 | 3.851 | 3.871 | 3.599 |
| MAE | 212.788 | 209.019 | 218.327 | 218.218 | 201.083 | |
| RMSE | 245.087 | 231.296 | 236.664 | 241.936 | 230.831 | |
| RreliefF | MAPE | 3.981 | 3.895 | 4.104 | 3.935 | 3.567 |
| MAE | 222.013 | 219.243 | 233.919 | 221.717 | 200.711 | |
| RMSE | 262.683 | 242.705 | 254.076 | 247.552 | 224.017 | |
| Feature Selection Method | Forecaster | Evaluated Criterion | ||
|---|---|---|---|---|
| MAPE (%) | RMSE (MW) | MAE (MW) | ||
| MI | CART | 2.019 | 172.293 | 112.003 |
| RF | 1.668 | 157.946 | 92.817 | |
| SVR | 1.474 | 154.191 | 80.67 | |
| BPNN | 2.551 | 218.916 | 145.116 | |
| GPR | 1.492 | 147.726 | 82.693 | |
| CMI | CART | 2.174 | 189.964 | 121.050 |
| RF | 1.623 | 156.450 | 90.309 | |
| SVR | 1.440 | 151.230 | 78.764 | |
| ANN | 3.072 | 332.424 | 177.185 | |
| GPR | 1.538 | 148.127 | 85.497 | |
| CART | CART | 2.219 | 201.990 | 123.030 |
| RF | 1.733 | 164.604 | 96.589 | |
| SVR | 1.748 | 188.225 | 96.562 | |
| BPNN | 1.954 | 192.515 | 109.282 | |
| GPR | 1.774 | 183.266 | 99.119 | |
| RF | CART | 2.012 | 172.188 | 111.418 |
| RF | 1.641 | 160.659 | 91.235 | |
| SVR | 1.387 | 148.926 | 75.885 | |
| BPNN | 1.663 | 158.088 | 92.355 | |
| GPR | 1.461 | 145.833 | 81.011 | |
| RreliefF | CART | 2.075 | 177.441 | 116.199 |
| RF | 1.608 | 155.962 | 89.551 | |
| SVR | 1.373 | 147.585 | 75.118 | |
| BPNN | 1.669 | 157.988 | 92.890 | |
| GPR | 1.446 | 144.170 | 80.283 | |
| Method | Forecaster | Test for New England | Test for Singapore | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAPE (%) | MAE (MW) | RMSE (MW) | Time (s) | MAPE (%) | MAE (MW) | RMSE (MW) | Time (s) | ||
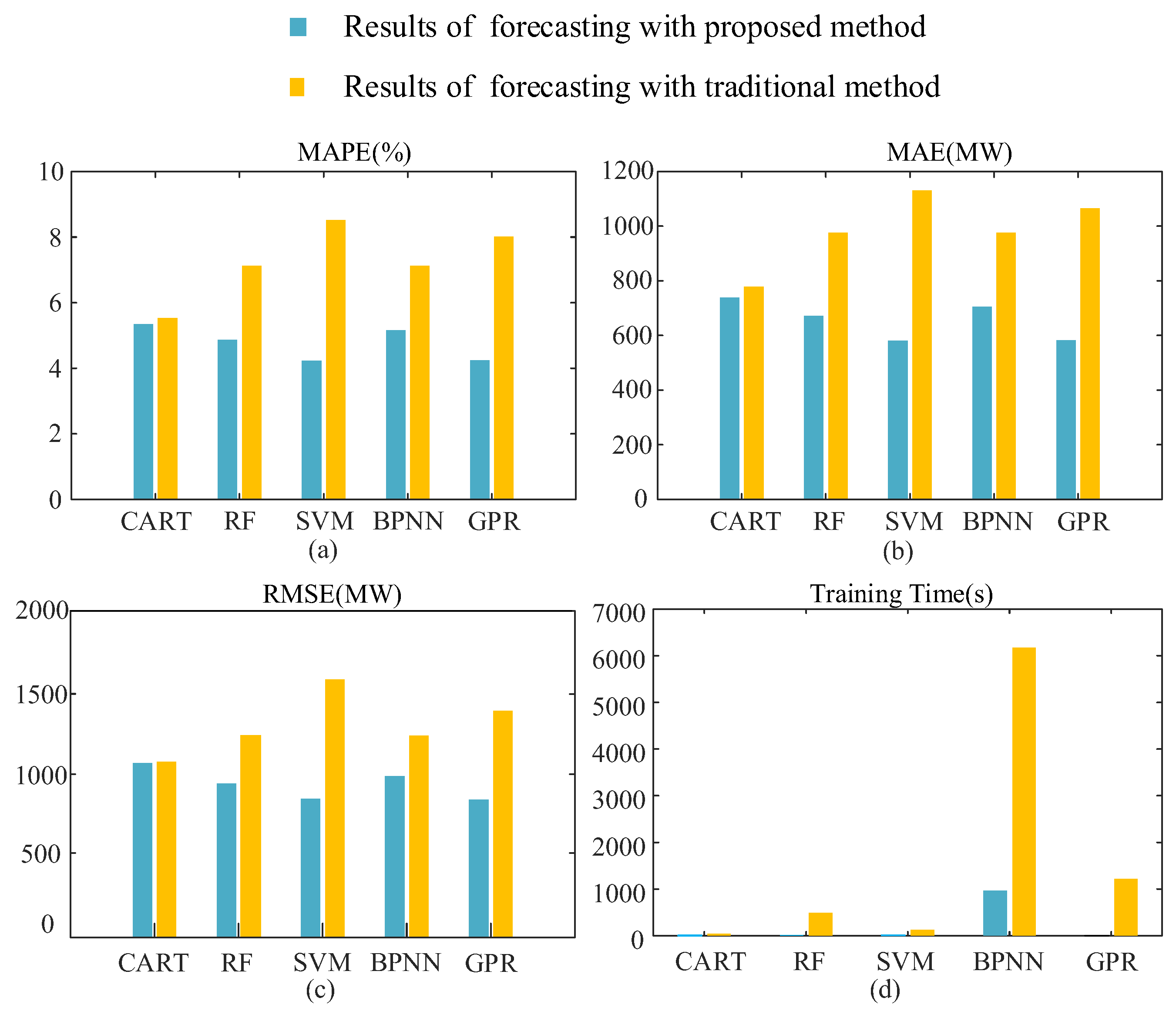
| The proposed method | CART | 5.348 | 738.641 | 1067.723 | 0.106 | 2.166 | 116.742 | 209.413 | 0.275 |
| RF | 4.867 | 671.261 | 941.661 | 10.445 | 1.930 | 105.306 | 199.974 | 10.776 | |
| SVR | 4.228 | 580.80 | 849.806 | 0.431 | 1.914 | 103.356 | 196.145 | 0.405 | |
| BPNN | 5.167 | 705.324 | 986.974 | 962.457 | 3.133 | 174.104 | 285.083 | 844.257 | |
| GPR | 4.242 | 581.889 | 844.0766 | 2.102 | 1.523 | 82.573 | 170.478 | 1.569 | |
| The traditional method | CART | 5.530 | 778.083 | 1076.316 | 7.976 | 3.597 | 196.391 | 273.112 | 2.601 |
| RF | 7.120 | 975.272 | 1235.783 | 486.263 | 2.088 | 114.732 | 209.064 | 402.743 | |
| SVR | 8.522 | 1130.870 | 1556.371 | 123.394 | 5.067 | 267.048 | 361.547 | 91.623 | |
| BPNN | 7.120 | 975.272 | 1235.783 | 6170.835 | 4.864 | 267.416 | 408.305 | 4686.007 | |
| GPR | 8.017 | 1065.700 | 1387.252 | 1219.056 | 5.072 | 287.277 | 405.181 | 1054.359 | |
| Feature Selection Method | Forecaster | Test for New England | Test for Singapore | ||||
|---|---|---|---|---|---|---|---|
| MAPE (%) | MAE (MW) | RMSE (MW) | MAPE (%) | MAE (MW) | RMSE (MW) | ||
| MI | CART | 8.452 | 1269.711 | 1701.808 | 3.247 | 178.082 | 239.891 |
| RF | 5.911 | 920.201 | 1339.227 | 1.855 | 103.612 | 168.744 | |
| SVR | 7.587 | 1116.529 | 1521.691 | 4.246 | 222.376 | 314.547 | |
| BPNN | 5.854 | 909.553 | 1390.574 | 2.103 | 115.674 | 176.764 | |
| GPR | 5.680 | 881.310 | 1296.119 | 2.161 | 118.833 | 180.018 | |
| CMI | CART | 8.420 | 1267.213 | 1705.926 | 3.320 | 182.186 | 241.884 |
| RF | 5.645 | 878.479 | 1281.361 | 1.838 | 102.269 | 164.790 | |
| SVR | 7.669 | 1134.308 | 1560.853 | 4.206 | 219.965 | 313.680 | |
| BPNN | 7.697 | 1173.160 | 1929.675 | 2.053 | 113.328 | 173.493 | |
| GPR | 6.562 | 1029.708 | 1558.377 | 2.104 | 115.482 | 175.308 | |
| CART | CART | 8.420 | 1267.213 | 1705.926 | 3.212 | 175.834 | 238.396 |
| RF | 5.970 | 921.976 | 1318.980 | 1.940 | 108.871 | 175.704 | |
| SVR | 7.635 | 1127.940 | 1506.504 | 4.170 | 217.423 | 312.793 | |
| BPNN | 6.044 | 922.497 | 1404.137 | 5.026 | 278.908 | 462.199 | |
| GPR | 5.904 | 920.084 | 1372.375 | 2.860 | 161.948 | 250.843 | |
| RF | CART | 8.056 | 1212.114 | 1653.079 | 3.262 | 179.431 | 242.135 |
| RF | 5.483 | 858.934 | 1306.136 | 1.833 | 102.516 | 167.013 | |
| SVR | 7.316 | 1081.404 | 1482.864 | 4.147 | 216.703 | 310.201 | |
| BPNN | 5.348 | 831.493 | 1196.481 | 1.790 | 99.181 | 160.264 | |
| GPR | 5.774 | 902.872 | 1321.057 | 1.951 | 108.686 | 169.148 | |
| RreliefF | CART | 8.056 | 1212.114 | 1653.079 | 3.188 | 174.799 | 237.592 |
| RF | 5.506 | 866.377 | 1333.577 | 2.003 | 111.688 | 176.002 | |
| SVR | 7.350 | 1081.259 | 1464.366 | 4.319 | 226.854 | 319.170 | |
| BPNN | 5.789 | 894.686 | 1320.901 | 1.958 | 107.762 | 168.592 | |
| GPR | 6.015 | 967.163 | 1682.298 | 2.130 | 117.884 | 188.138 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, L.; Xue, L.; Hu, Z.; Huang, N. Modular Predictor for Day-Ahead Load Forecasting and Feature Selection for Different Hours. Energies 2018, 11, 1899. https://doi.org/10.3390/en11071899
Lin L, Xue L, Hu Z, Huang N. Modular Predictor for Day-Ahead Load Forecasting and Feature Selection for Different Hours. Energies. 2018; 11(7):1899. https://doi.org/10.3390/en11071899
Chicago/Turabian StyleLin, Lin, Lin Xue, Zhiqiang Hu, and Nantian Huang. 2018. "Modular Predictor for Day-Ahead Load Forecasting and Feature Selection for Different Hours" Energies 11, no. 7: 1899. https://doi.org/10.3390/en11071899
APA StyleLin, L., Xue, L., Hu, Z., & Huang, N. (2018). Modular Predictor for Day-Ahead Load Forecasting and Feature Selection for Different Hours. Energies, 11(7), 1899. https://doi.org/10.3390/en11071899