Research on Key Parameters Operation Range of Central Air Conditioning Based on Binary K-Means and Apriori Algorithm

Abstract
:1. Introduction
2. CACS
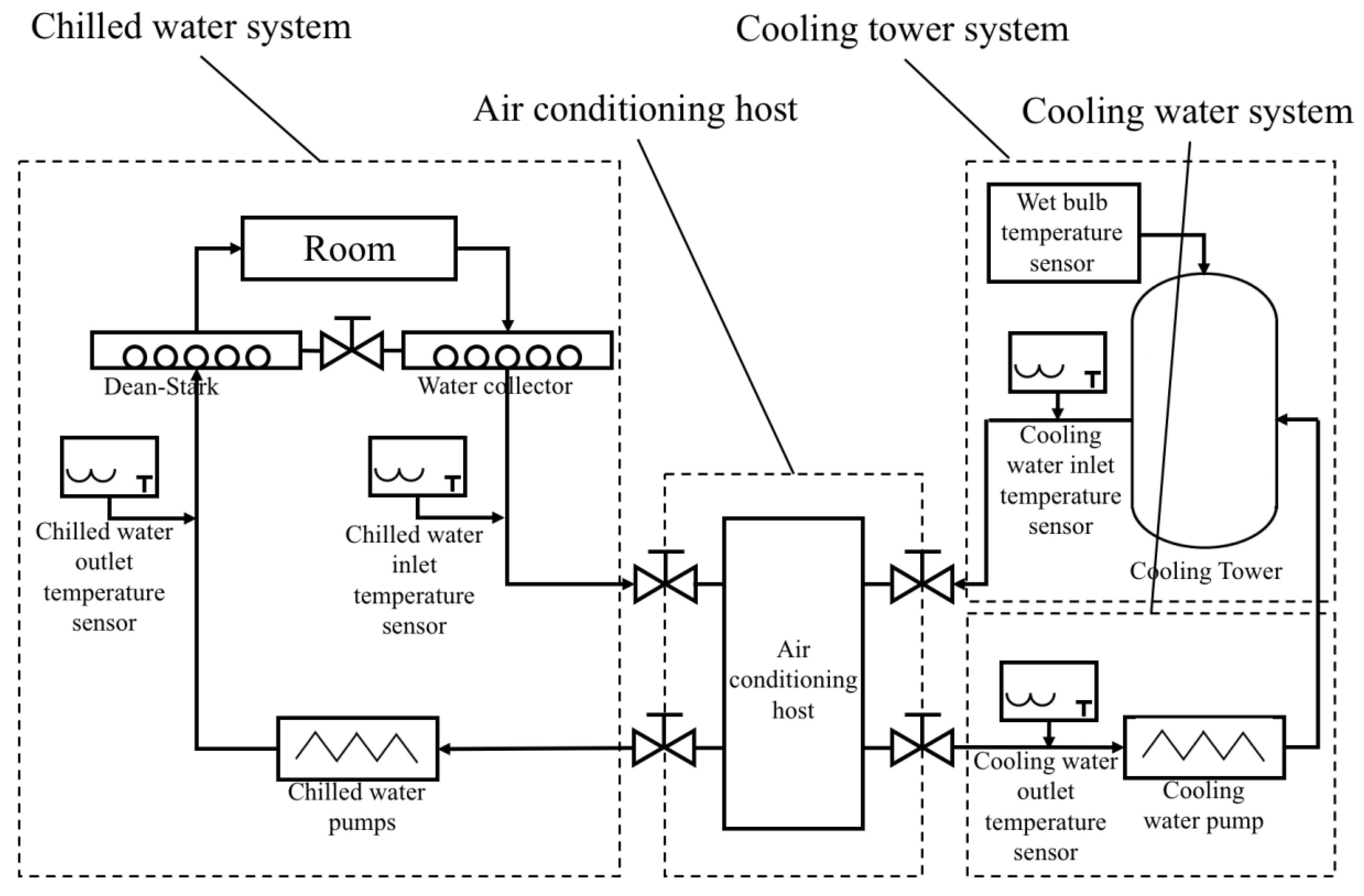
2.1. Architecture of CACS
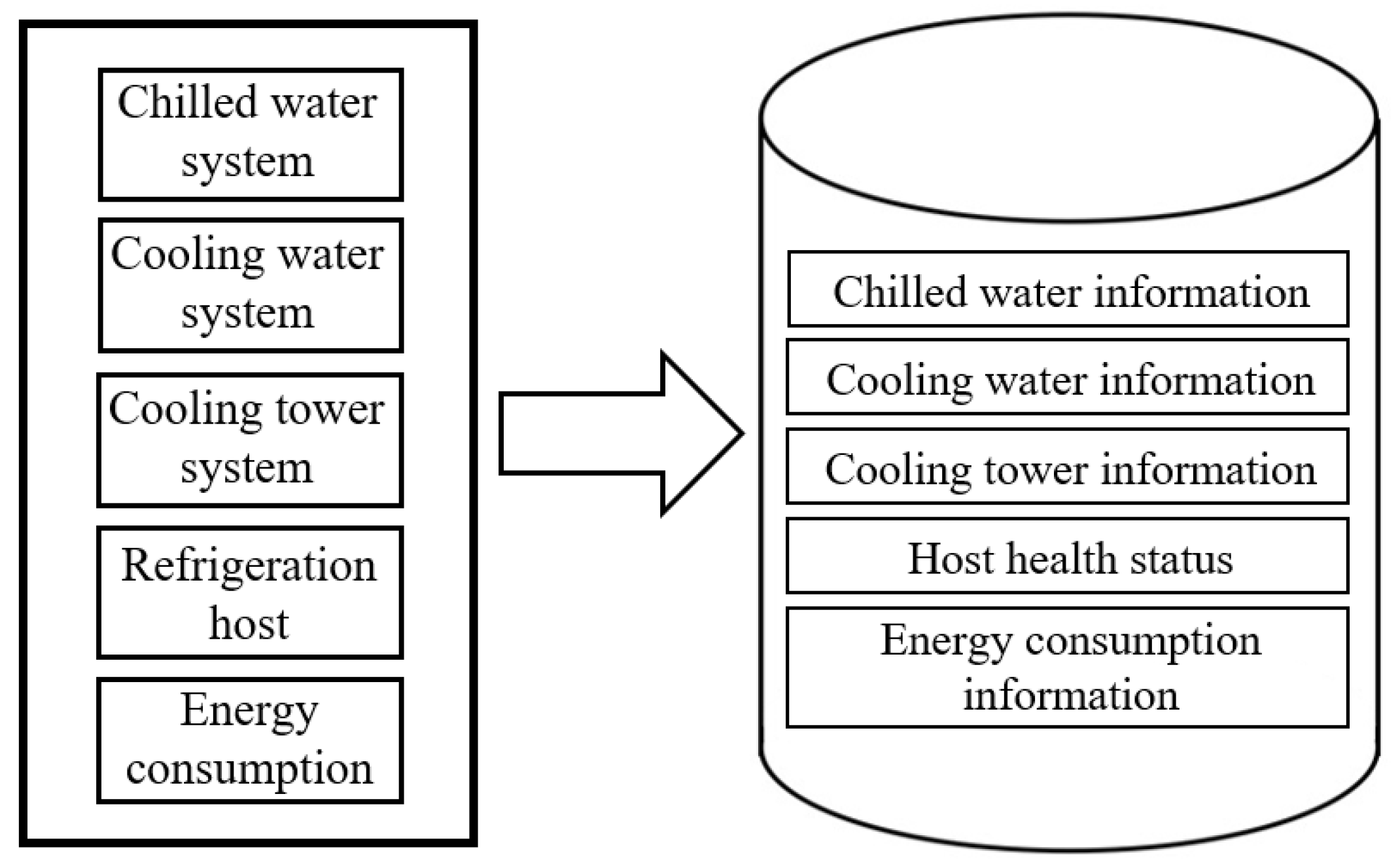
2.2. Operation Data
- (1)
- Chilled water system: The data include parameters of chilled inlet water temperature, chilled outlet water temperature, chilled water pump frequency, chilled water pump flux, chilled water pump power and cooling capacity.
- (2)
- Cooling water system: The data include parameters of cooling inlet water temperature, outlet water temperature, cooling water pump frequency, cooling water pump flow and cooling water pump power.
- (3)
- Cooling tower system: The data include parameters of inverter frequency, cooling tower outlet water temperature, cooling tower inlet water temperature, outdoor wet bulb temperature, outdoor AT, outdoor relative humidity and cooling tower power.
- (4)
- Refrigeration host system: The data include parameters of host operating conditions, fault alarm conditions, power, the given capacity of compressor and the current capacity of compressor.
- (5)
- Energy consumption: The data include parameters of host energy consumption, energy consumption of chilled water pump, energy consumption of cooling water pump, energy consumption of cooling tower, total energy consumption of the system, and system COP value.
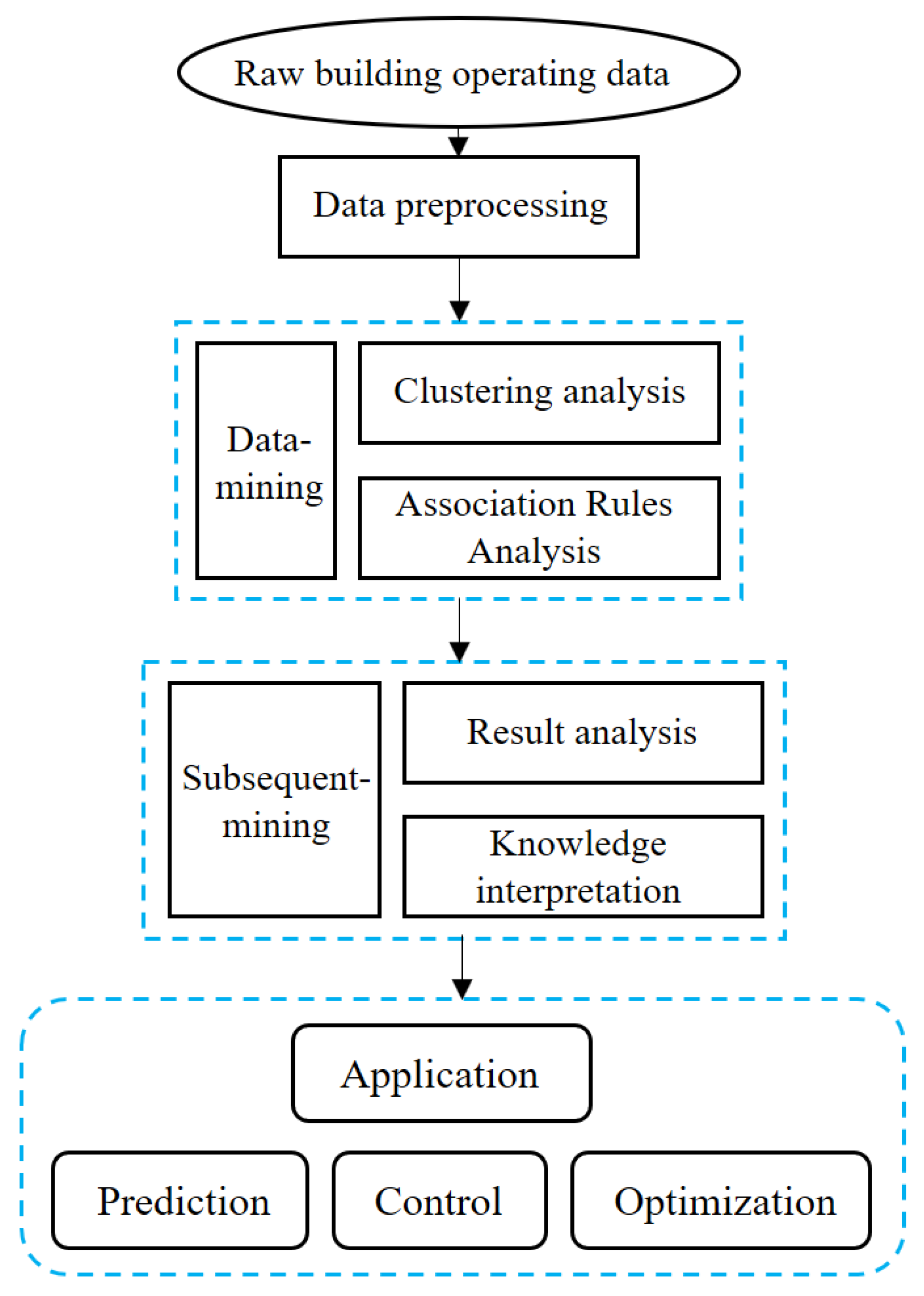
2.3. Data Analysis Process
3. Methods
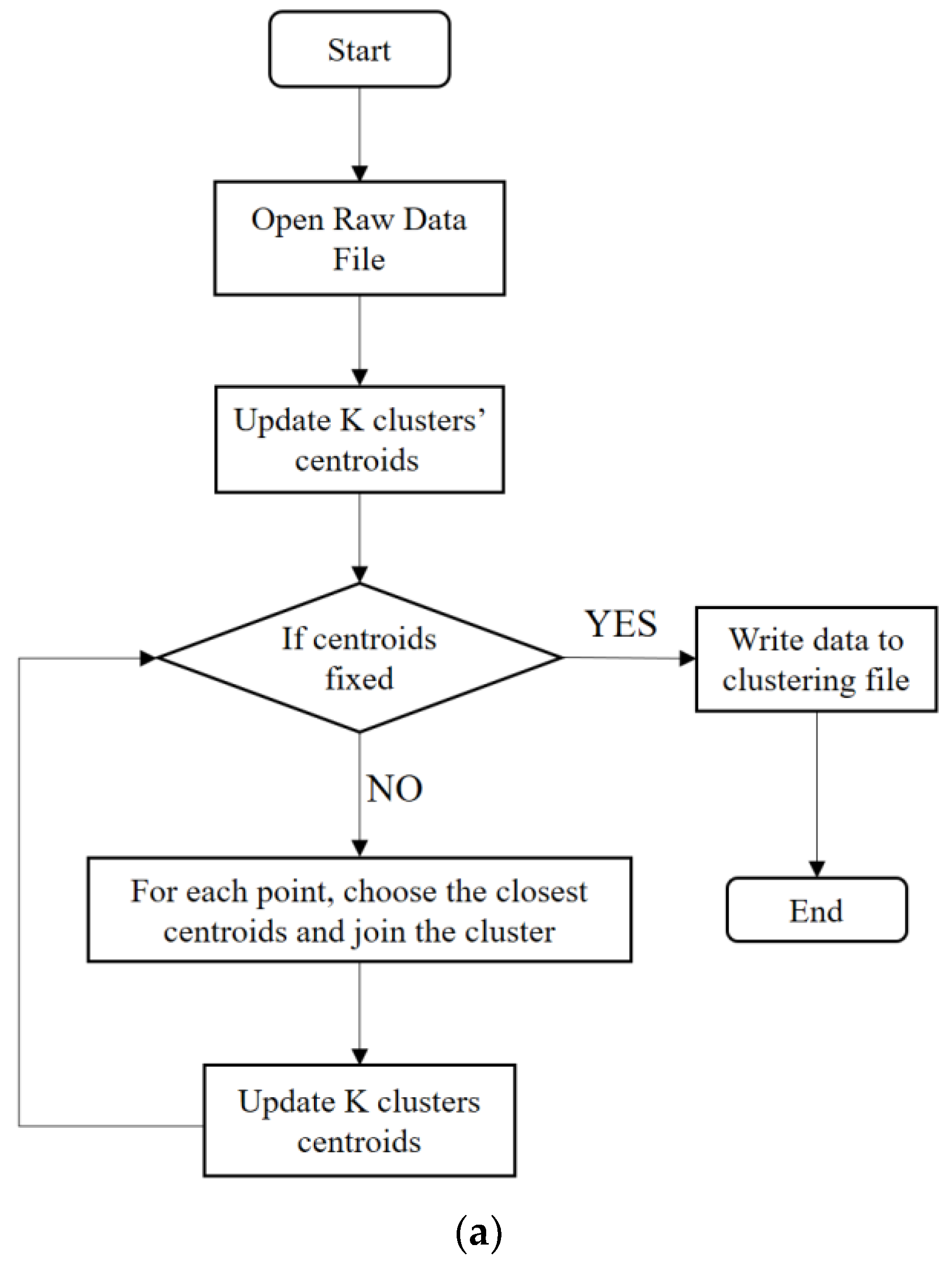
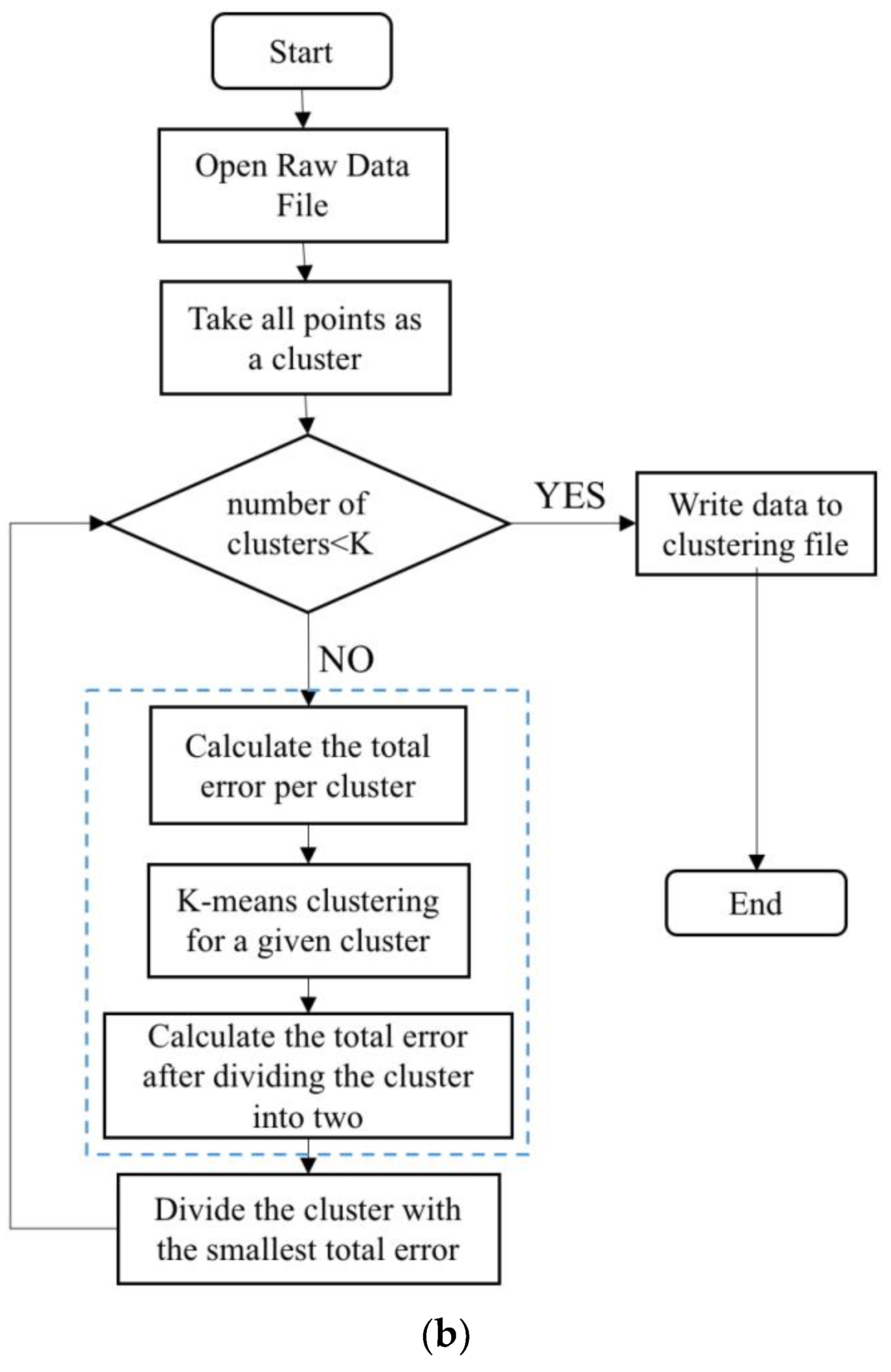
3.1. Binary K-Means Clustering Algorithm
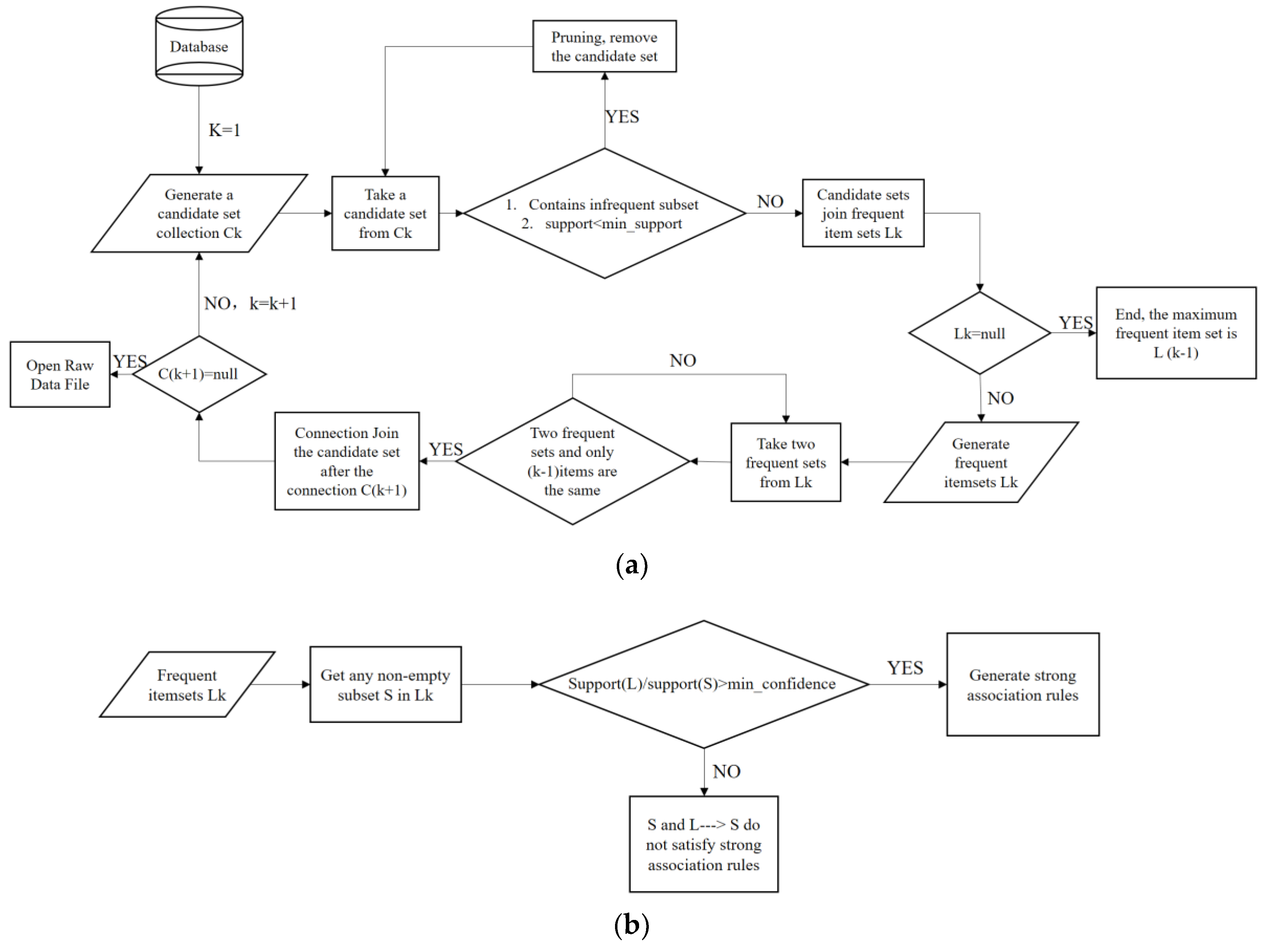
3.2. Apriori Association Algorithm
3.3. Protocol
4. Results
- Type 1:
- Expected Rules.
- Type 2:
- Unexpected Rules.
5. Discussion
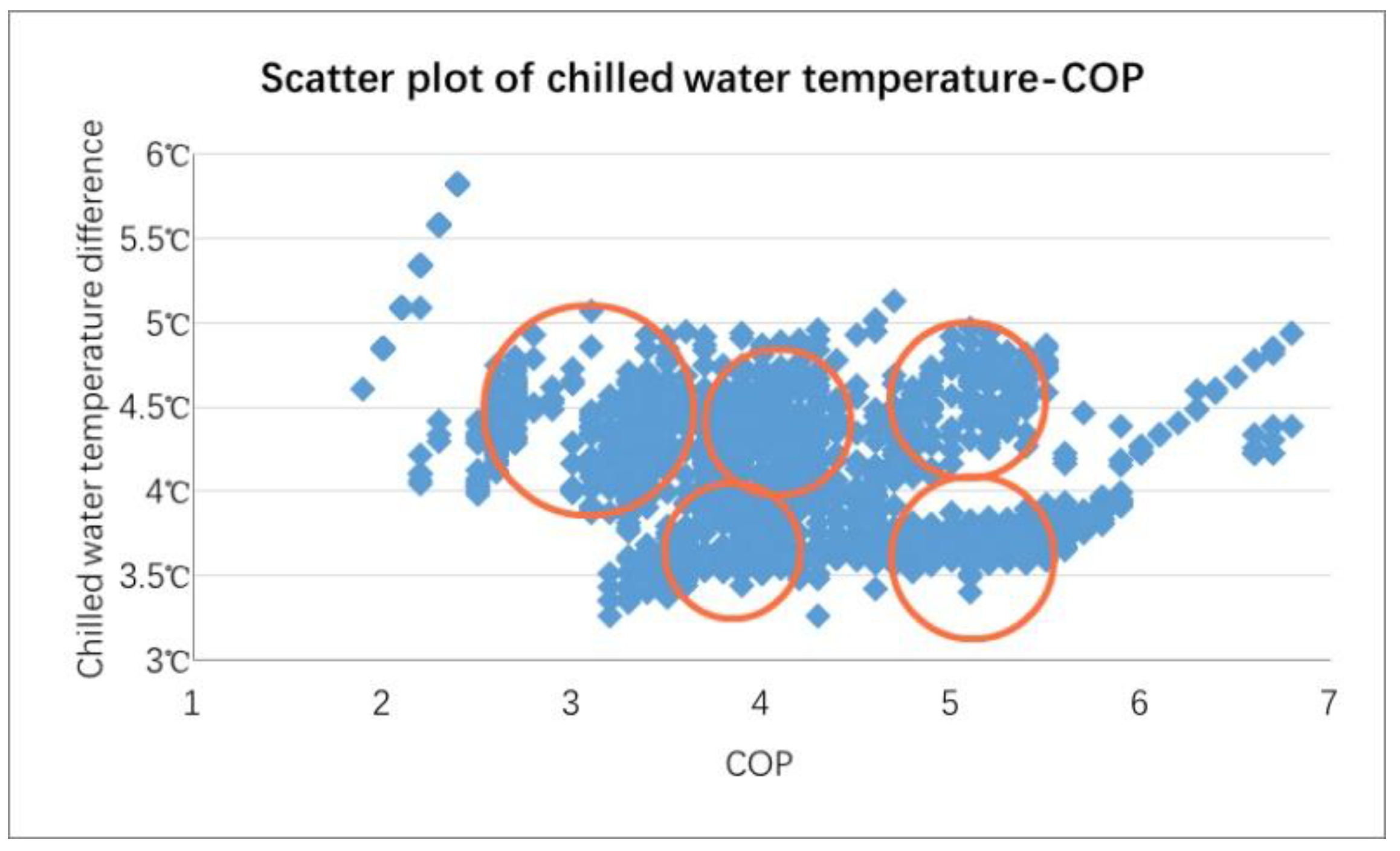
5.1. Discussion of Dichotomous K-Means Clustering
5.2. Discussion of Apriori Association Analysis Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kontogiorgos, P.; Chrysanthopoulos, N.; Papavassilopoulos, G. A Mixed-Integer Programming Model for Assessing Energy-Saving Investments in Domestic Buildings under Uncertainty. Energies 2018, 11, 989. [Google Scholar] [CrossRef]
- Fu, X.; Cheng, F. Data mining in building automation system for improving building operational performance. Energy Build. 2014, 75, 109–118. [Google Scholar]
- Wu, X.; Zhu, X.; Wu, G.Q.; Ding, W. Data mining with big data. IEEE Trans. Knowl. Data Eng. 2013, 26, 97–107. [Google Scholar]
- Fan, C.; Xiao, F.; Wang, S. Development of prediction models for next-day building energy consumption and peak power demand using data mining techniques. Appl. Energy 2014, 127, 1–10. [Google Scholar] [CrossRef]
- Wei, X.; Kusiak, A.; Li, M.; Tang, F.; Zeng, Y. Multi-objective optimization of the HVAC (heating, ventilation, and air conditioning) system performance. Energy 2015, 83, 294–306. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Yan, C. A framework for knowledge discovery in massive building automation data and its application in building diagnostics. Autom. Constr. 2015, 50, 81–90. [Google Scholar] [CrossRef]
- Zhao, H.X.; Magoulès, F. A review on the prediction of building energy consumption. Renew. Sustain. Energy Rev. 2012, 16, 3586–3592. [Google Scholar] [CrossRef]
- Yu, Z.; Haghighat, F.; Fung, B.C.M.; Zhou, L. A novel methodology for knowledge discovery through mining associations between building operational data. Energy Build. 2012, 47, 430–440. [Google Scholar] [CrossRef]
- Hou, Z.; Lian, Z.; Ye, Y.; Yuan, X. Data mining based sensor fault diagnosis and validation for building air conditioning system. Energy Convers. Manag. 2006, 47, 2479–2490. [Google Scholar] [CrossRef]
- Zhao, Z.; Yu, N.; Yu, T.; Zhang, H. Data Analysis and Modeling of Chilled Water Loops in Air Conditioning Systems. Math. Probl. Eng. 2017, 2017, 1–16. [Google Scholar] [CrossRef]
- Wang, Z.; Han, N.; Wang, Y. Studies on Neural Network Modeling for Air Conditioning System by Using Data Mining with Association Analysis. In Proceedings of the International Conference on Internet Computing and Information Services, Hong Kong, China, 17–18 September 2011; pp. 423–427. [Google Scholar]
- Chen, H.; Sun, S.; Liu, J.; Li, G. Application of data mining technology to refrigeration and air conditioning industry. Heat. Vent. Air Cond. 2016, 46, 20–26. [Google Scholar]
- Wang, J.; Zhou, P.; Huang, G.; Wang, W. A Data Mining Approach to Discover Critical Events for Event-Driven Optimization in Building Air Conditioning Systems. Energy Procedia 2017, 143, 251–257. [Google Scholar] [CrossRef]
- Malyavina, E.; Kryuchkova, O. Analysis of annual power consumption by central air conditioning systems using the climatic data stochastic statistics model. In Proceedings of the Environmental Engineering. Proceedings of the International Conference on Environmental Engineering, Vilnius, Lithuania, 19–20 May 2011; p. 776. [Google Scholar]
- Tang, W.J.; Yang, H.T. Data Mining and Neural Networks Based Self-Adaptive Protection Strategies for Distribution Systems with DGs and FCLs. Energies 2018, 11, 426. [Google Scholar] [CrossRef]
- Li, X.; Song, K.; Wei, G.; Lu, R.; Zhu, C. A Novel Grouping Method for Lithium Iron Phosphate Batteries Based on a Fractional Joint Kalman Filter and a New Modified K-Means Clustering Algorithm. Energies 2015, 2015, 7703–7728. [Google Scholar] [CrossRef]
- Huang, Z. Extensions to the k-Means Algorithm for Clustering Large Data Sets with Categorical Values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Celebi, M.E.; Kingravi, H.A.; Vela, P.A. A Comparative Study of Efficient Initialization Methods for the K-Means Clustering Algorithm. Expert Syst. Appl. 2012, 40, 200–210. [Google Scholar] [CrossRef]
- Kavšek, B.; Lavrač, N.; Jovanoski, V. APRIORI-SD: Adapting Association Rule Learning to Subgroup Discovery. Appl. Artif. Intell. 2006, 20, 543–583. [Google Scholar] [CrossRef]
- Minaeibidgoli, B.; Barmaki, R.; Nasiri, M. Mining numerical association rules via multi-objective genetic algorithms. Inf. Sci. 2013, 233, 15–24. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Preprocessing | Problems | Solutions |
|---|---|---|
| Data cleaning | Data quality problem, e.g., data missing, inconsistent values, outliers | Missing value: moving average, imputation, and inference-based Outlier: graphical, model-based, hybrid methods |
| Data normalization | Different data scale, Units and difference Data sources | Data value scaling: Max-min, Z-score, and decimal scaling normalization Data sampling scaling |
| Data transform | Different data type | Equal-frequency binning, equal-interval binning, and entropy-based discretization |
| Data Source | Data Type | Data Amount |
|---|---|---|
| A five-star hotel at Jiangyin, Jiangsu Province | HVAC equipment operating parameters, environmental parameters and energy consumption records | 1.2 G/0.5 year |
| Cluster | Chilled Water Temp Difference (°C) | Chilled Water Pump Frequency (Hz) | Cooling Water Temp Difference (°C) | Cooling Pump Frequency (Hz) | Wet Bulb Temp (°C) | Cooling Tower Frequency (Hz) | COP | Temp (°C) | Relative Humidity (%) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 4.5630 | 41.4704 | 3.3000 | 41.9926 | 26.3796 | 12.0607 | 4.3656 | 35.2333 | 49.9852 |
| 2 | 3.2200 | 40.6697 | 3.2981 | 30.2116 | 24.5077 | 17.2828 | 4.5782 | 26.8329 | 83.8129 |
| 3 | 4.2466 | 43.4582 | 3.5555 | 45.0129 | 26.4996 | 44.3682 | 3.9104 | 30.1626 | 75.6207 |
| 4 | 3.1248 | 39.9822 | 3.3039 | 30.3435 | 24.3119 | 49.3978 | 4.5326 | 26.4971 | 84.1991 |
| 5 | 4.8915 | 46.0203 | 4.3944 | 46.1344 | 27.2867 | 40.0540 | 3.7865 | 33.6890 | 61.1712 |
| 6 | 5.2388 | 44.1753 | 4.3262 | 45.5552 | 27.3579 | 41.7690 | 4.0713 | 37.5562 | 45.0564 |
| Left-Hand-Side | Right-Hand-Side | Support | Confidence | Lift |
|---|---|---|---|---|
| CWTD = [−, 3.6 °C] | COP > 4.42 | 0.1089 | 0.6399 | 2.5596 |
| CWTD = [3.6 °C, 5.3 °C] | COP > 4.42 | 0.1029 | 0.3018 | 0.6036 |
| CWTD = [, 3.6 °C], COWTD = [3.1 °C, 4.8 °C] | COP > 4.42 | 0.0582 | 0.3404 | 1.3616 |
| COWTD = [−, 3.6 °C] | COP > 4.42 | 0.0571 | 0.6353 | 2.5412 |
| COWTD = [3.1 °C, 4.8 °C] | COP < 3.72 | 0.18 | 0.3493 | 0.6986 |
| COWTD = [4.8 °C, + ] | COP < 3.72 | 0.0643 | 0.2659 | 1.0636 |
| Left-Hand-Side | Right-Hand-Side | Support | Confidence | Lift |
|---|---|---|---|---|
| AT = [29, 34.9 °C] | COP < 3.72 | 0.18 | 0.3644 | 0.7288 |
| AT = [34.9 °C, +] | COP < 3.72 | 0.0632 | 0.5493 | 2.1972 |
| AT = [−, 29 °C], Relative humidity = [80.7%, +] | COP > 4.42 | 0.0985 | 0.5526 | 2.2104 |
| CWTD = [−, 3.6 °C], Relative humidity = [80.7%, +] | COP > 4.42 | 0.0839 | 0.5841 | 2.3364 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, L.; Qian, F.; Li, W. Research on Key Parameters Operation Range of Central Air Conditioning Based on Binary K-Means and Apriori Algorithm. Energies 2019, 12, 102. https://doi.org/10.3390/en12010102
Yan L, Qian F, Li W. Research on Key Parameters Operation Range of Central Air Conditioning Based on Binary K-Means and Apriori Algorithm. Energies. 2019; 12(1):102. https://doi.org/10.3390/en12010102
Chicago/Turabian StyleYan, Liangwen, Fengfeng Qian, and Wei Li. 2019. "Research on Key Parameters Operation Range of Central Air Conditioning Based on Binary K-Means and Apriori Algorithm" Energies 12, no. 1: 102. https://doi.org/10.3390/en12010102
APA StyleYan, L., Qian, F., & Li, W. (2019). Research on Key Parameters Operation Range of Central Air Conditioning Based on Binary K-Means and Apriori Algorithm. Energies, 12(1), 102. https://doi.org/10.3390/en12010102