Eco-Efficient Resource Management in HPC Clusters through Computer Intelligence Techniques




Abstract
:1. Introduction
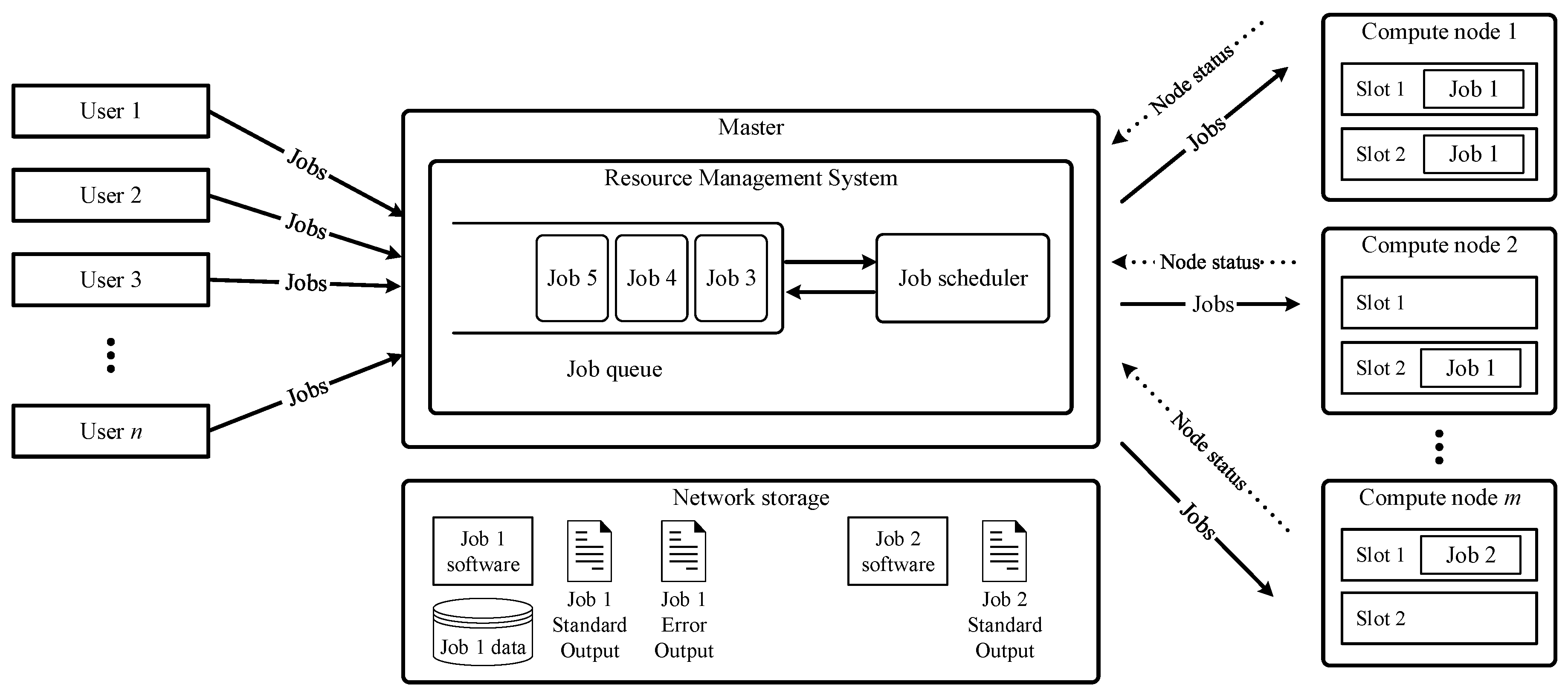
2. System Overview
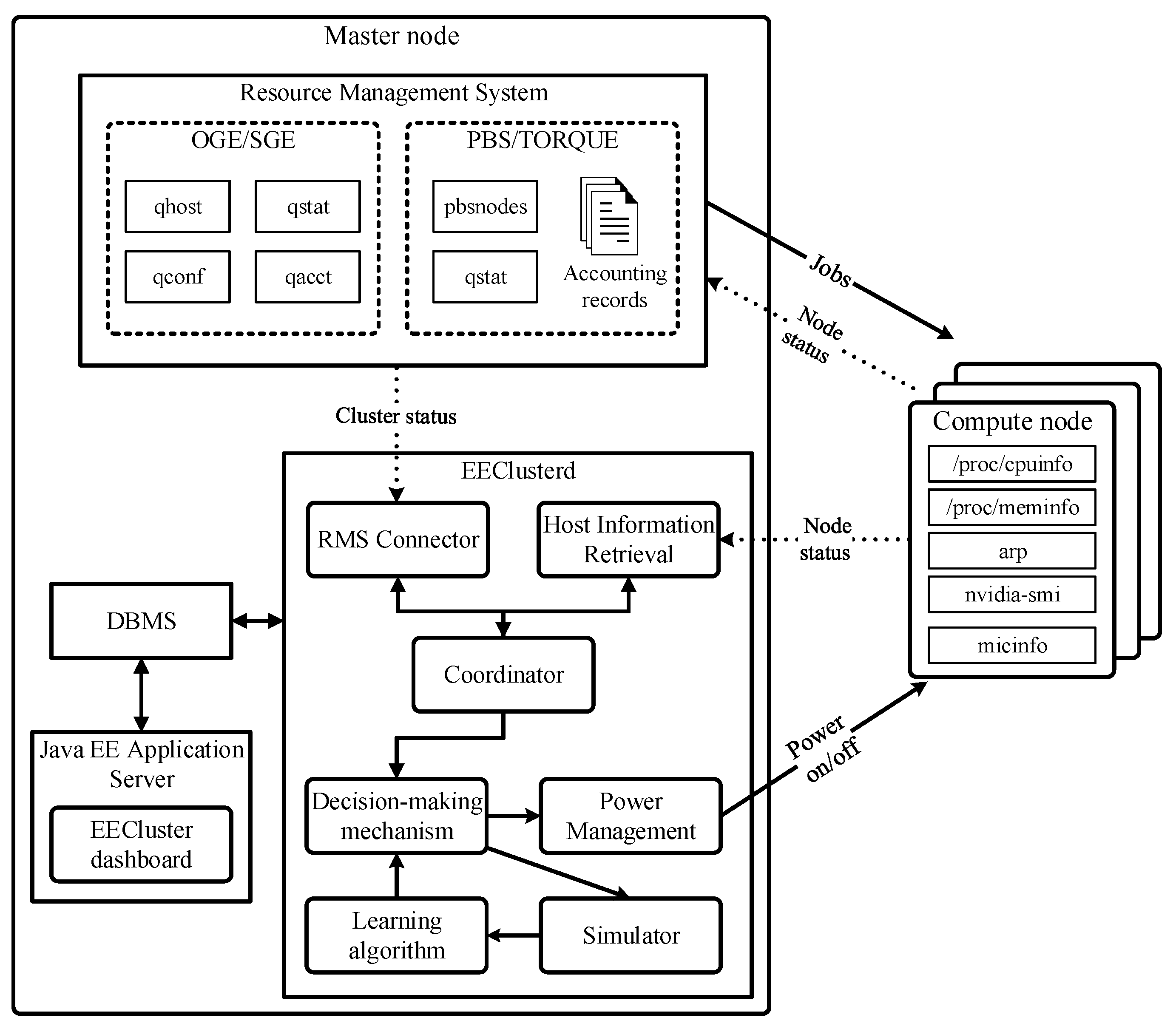
3. Architecture
- Synchronise EECluster’s internal records with the system current status and workload.
- Run the first stage of the decision-making mechanism to determine the optimal number of slots that should be on at the current time
- Run the second stage of the decision-making mechanism to select the target compute nodes to be powered on or off.
- Issue power-on/off commands to the selected nodes through the power management module.
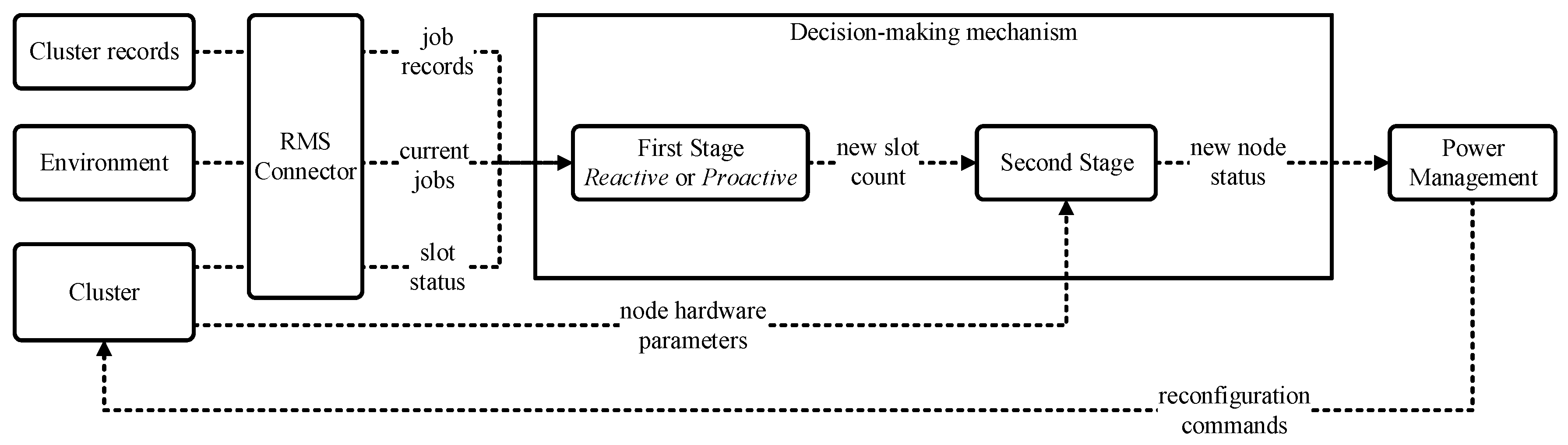
4. Optimising Slot Allocation
4.1. Reactive Strategy
- ifthen power on slots
- if or then power on 1 slot
- if or then power off 1 slot
| = number of slots currently running | |
| = number of slots currently starting | |
| = number of slots that are at least required to run any of the jobs currently queued | |
| = average waiting time of the jobs in the queue | |
| = maximum average waiting time for the jobs in the queue | |
| = minimum average waiting time for the jobs in the queue | |
| = maximum number of queued jobs | |
| = minimum number of queued jobs |
- if is then off
- if is then off
- if⋯then⋯
- if is then off
4.2. Proactive Strategy
5. Optimising Cluster Eco-Efficiency
- if is and is and is then value
- if is and is and is then value
- if is and is and is then value
- if is and is and is then value
- if⋯then⋯
- if is and is and is then value
- if is and is and is then value
- if is and is and is then value
- if is and is and is then value
- if⋯then⋯
- if is and is and is then value
- if is and is and is then value
| Algorithm 1 Node reallocation algorithm. |
| input:, , , , 1: if and then 2: if then 3: ▹ Power on slots 4: for each do 5: Compute and 6: 7: while do 8: Power on 9: 10: else if then 11: ▹ Power off slots 12: for each do 13: Compute and 14: 15: while and do 16: Power off 17: 18: else 19: Do nothing 20:else 21: Do nothing |
6. Learning Algorithm
7. Experimental Results
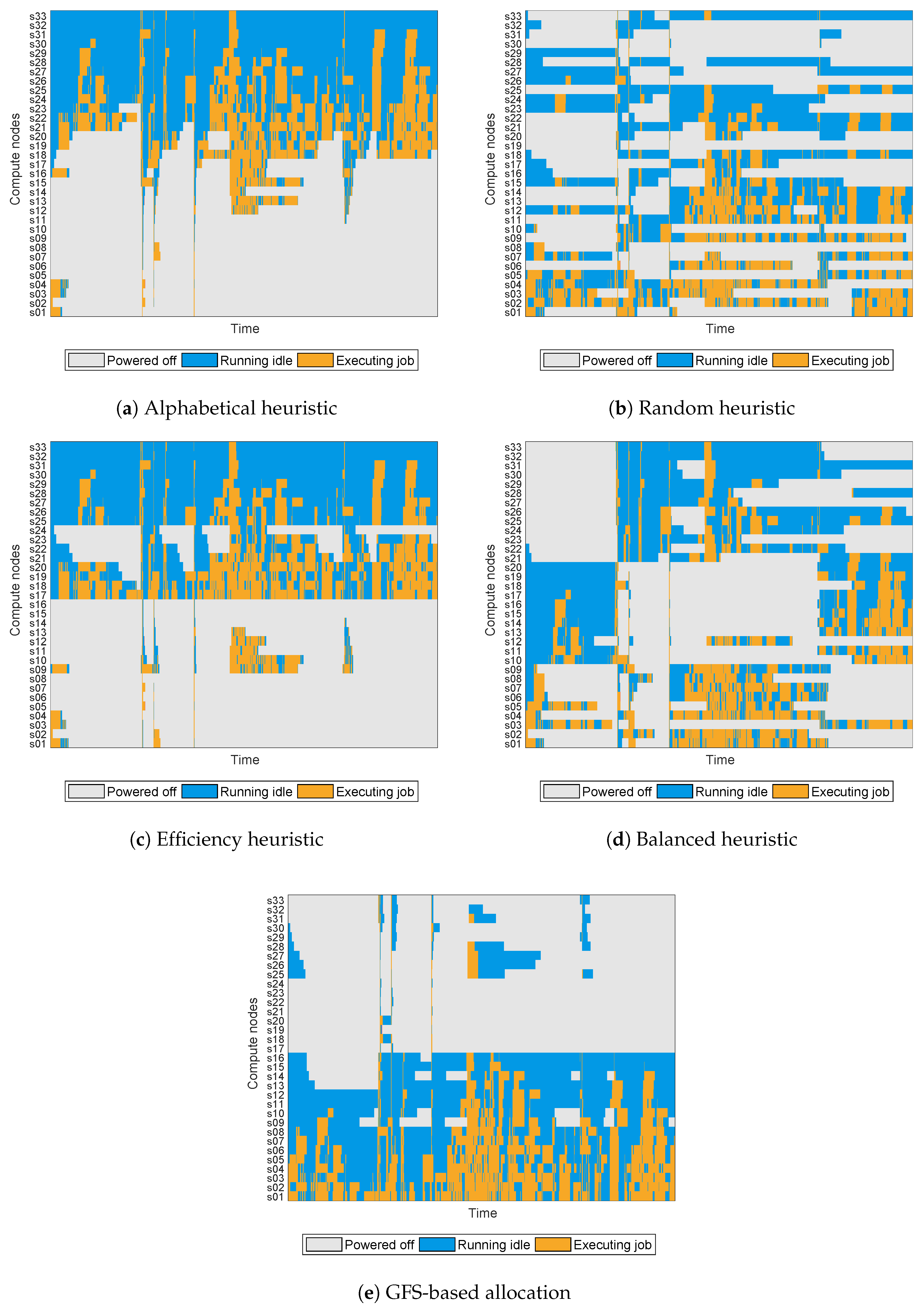
- An alphabetical node-ordering heuristic (labelled “Alphabetical heuristic”) consisting in selecting the nodes to switch on or off according to an alphabetical sort of the name of the node, powering off the nodes starting from the beginning of the list and powering on nodes starting from the end.
- A randomised node-ordering heuristic (labelled “Random heuristic”) consisting in randomly selecting the nodes to switch on or off.
- An efficiency-based node-ordering heuristic (labelled “Efficiency heuristic”) consisting in sorting the nodes to switch on or off according to a precomputed priority based on their power efficiency, as given by Equation (6), so that the least efficient nodes are powered off and the most efficient nodes are powered on.
- A balanced node-ordering heuristic (labelled “Balanced heuristic”) consisting in sorting the nodes according to the amount of time that each node has been active, so that the nodes that have been active for a longer period of time are powered off, and the nodes that have been inactive for longer are powered on.
- The GFS-based algorithm proposed in Section 5 (labelled “GFS-based allocation”) with three linguistic terms in the first partition () and two in the second one ().
8. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| HPC | High Performance Computing |
| HPCCs | High Performance Computing Clusters |
| RMS | Resource Management System |
| OGE | Oracle Grid Engine/Open Grid Engine |
| SGE | Sun Grid Engine/Son of Grid Engine |
| PBS | Portable Batch System |
| TORQUE | Terascale Open-source Resource and QUEue Manager |
| QoS | Quality of Service |
| AFR | Annualised Failure Rate |
| SFR | Simulation Failure Rates |
| MTTF | Mean Time To Failure |
| DBMS | Database Management System |
| HGFS | Hybrid Genetic Fuzzy System |
| TSK | Tagaki–Sugeno–Kang |
| NSGA-II | Non-dominated Sorting Genetic Algorithm-II |
| MOEAs | MultiObjective Evolutionary Algorithms |
References
- Yeo, C.S.; Buyya, R.; Pourreza, H.; Eskicioglu, R.; Graham, P.; Sommers, F. Cluster Computing: High-Performance, High-Availability, and High-Throughput Processing on a Network of Computers. In Handbook of Nature-Inspired and Innovative Computing; Zomaya, A., Ed.; Springer: Boston, MA, USA, 2006; pp. 521–551. [Google Scholar] [CrossRef]
- Avgerinou, M.; Bertoldi, P.; Castellazzi, L. Trends in Data Centre Energy Consumption under the European Code of Conduct for Data Centre Energy Efficiency. Energies 2017, 10, 1470. [Google Scholar] [CrossRef]
- Ni, J.; Bai, X. A review of air conditioning energy performance in data centers. Renew. Sustain. Energy Rev. 2017, 67, 625–640. [Google Scholar] [CrossRef]
- Shehabi, A.; Smith, S.; Sartor, D.; Brown, R.; Herrlin, M.; Koomey, J.; Masanet, E.R.; Horner, N.; Azevedo, I.L.; Lintner, W. United States Data Center Energy Usage Report | Energy Technologies Area; Technical report; Environmental and Energy Impact Division, Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2016.
- Ebbers, M.; Archibald, M.; da Fonseca, C.F.F.; Griffel, M.; Para, V.; Searcy, M. Smarter Data Centers: Achieving Greater Efficiency; Technical report; IBM Redpaper: Research Triangle Park, NC, USA, 2011. [Google Scholar]
- The Economist Intelligence Unit. IT and the Environment a New Item on the CIO’s Agenda? Technical report; The Economist: London, UK, 2007. [Google Scholar]
- Whitehead, B.; Andrews, D.; Shah, A. The life cycle assessment of a UK data centre. Int. J. Life Cycle Assess. 2015, 20, 332–349. [Google Scholar] [CrossRef]
- Gartner. Gartner Estimates ICT Industry Accounts for 2 Percent of Global CO2 Emissions; Gartner: Stamford, CT, USA, 2007. [Google Scholar]
- EU Science Hub. Code of Conduct for Energy Efficiency in Data Centres. Available online: https://ec.europa.eu/jrc/en/energy-efficiency/code-conduct/datacentres (accessed on 31 May 2019).
- Google. Efficiency: How We Do It. Available online: https://www.google.com/about/datacenters/efficiency/internal/ (accessed on 31 May 2019).
- Amazon Web Services. AWS & Sustainability. Available online: https://aws.amazon.com/about-aws/sustainability/ (accessed on 31 May 2019).
- Facebook. Open Sourcing PUE/WUE Dashboards. Available online: https://code.fb.com/data-center-engineering/open-sourcing-pue-wue-dashboards/ (accessed on 31 May 2019).
- Pinheiro, E.; Bianchini, R.; Carrera, E.V.; Heath, T. Load Balancing and Unbalancing for Power and Performance in Cluster-Based Systems; Workshop on Compilers and Operating Systems for Low Power: Barcelona, Spain, 2001; Volume 180, pp. 182–195. [Google Scholar]
- Elnozahy, E.N.; Kistler, M.; Rajamony, R. Energy-efficient Server Clusters. In Proceedings of the 2nd International Conference on Power-Aware Computer Systems, Cambridge, MA, USA, 2 February 2002; Springer: Berlin/Heidelberg, Germany, 2003; pp. 179–197. [Google Scholar]
- Das, R.; Kephart, J.O.; Lefurgy, C.; Tesauro, G.; Levine, D.W.; Chan, H. Autonomic Multi-agent Management of Power and Performance in Data Centers. In Proceedings of the 7th International Joint Conference on Autonomous Agents and Multiagent Systems: Industrial Track, Estoril, Portugal, 12–16 May 2008; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2008; pp. 107–114. [Google Scholar]
- Berral, J.L.; Goiri, Í.; Nou, R.; Julià, F.; Guitart, J.; Gavaldà, R.; Torres, J. Towards energy-aware scheduling in data centers using machine learning. In Proceedings of the 1st International Conference on Energy-Efficient Computing and Networking—E-Energy ’10, Passau, Germany, 13–15 April 2010; ACM Press: New York, NY, USA, 2010; p. 215. [Google Scholar] [CrossRef]
- Lang, W.; Patel, J.M.; Naughton, J.F. On energy management, load balancing and replication. ACM SIGMOD Rec. 2010, 38, 35. [Google Scholar] [CrossRef]
- Cocaña-Fernández, A.; Rodríguez-Soares, J.; Sánchez, L.; Ranilla, J. Improving the energy efficiency of virtual data centers in an IT service provider through proactive fuzzy rules-based multicriteria decision making. J. Supercomput. 2019, 75, 1078–1093. [Google Scholar] [CrossRef]
- Dolz, M.F.; Fernández, J.C.; Iserte, S.; Mayo, R.; Quintana-Ortí, E.S.; Cotallo, M.E.; Díaz, G. EnergySaving Cluster experience in CETA-CIEMAT. In Proceedings of the 5th Iberian GRID Infrastructure conference, Santander, Spain, 8 June 2011. [Google Scholar]
- Alvarruiz, F.; de Alfonso, C.; Caballer, M.; Hernández, V. An Energy Manager for High Performance Computer Clusters. In Proceedings of the 2012 IEEE 10th International Symposium on Parallel and Distributed Processing with Applications, Leganes, Spain, 10–13 July 2012; pp. 231–238. [Google Scholar] [CrossRef]
- Kiertscher, S.; Zinke, J.; Gasterstadt, S.; Schnor, B. Cherub: Power Consumption Aware Cluster Resource Management. In Proceedings of the 2010 IEEE/ACM International Conference on Green Computing and Communications International Conference on Cyber, Physical and Social Computing, Hangzhou, China, 18–20 December 2010; pp. 325–331. [Google Scholar] [CrossRef]
- Cocaña-Fernández, A.; Sánchez, L.; Ranilla, J. A software tool to efficiently manage the energy consumption of HPC clusters. In Proceedings of the 2015 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Istanbul, Turkey, 2–5 August 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Hsu, C.H.; Kremer, U. The design, implementation, and evaluation of a compiler algorithm for CPU energy reduction. ACM SIGPLAN Not. 2003, 38, 38. [Google Scholar] [CrossRef]
- Hsu, C.H.; Feng, W.c. A Power-Aware Run-Time System for High-Performance Computing. In Proceedings of the ACM/IEEE SC 2005 Conference (SC’05), Seattle, WA, USA, 12–18 November 2005; p. 1. [Google Scholar] [CrossRef]
- Freeh, V.W.; Lowenthal, D.K.; Pan, F.; Kappiah, N.; Springer, R.; Rountree, B.L.; Femal, M.E. Analyzing the Energy-Time Trade-Off in High-Performance Computing Applications. IEEE Trans. Parallel Distrib. Syst. 2007, 18, 835–848. [Google Scholar] [CrossRef]
- Lim, M.; Freeh, V.; Lowenthal, D. Adaptive, Transparent Frequency and Voltage Scaling of Communication Phases in MPI Programs. In Proceedings of the ACM/IEEE SC 2006 Conference (SC’06), Tampa, FL, USA, 11–17 November 2006; p. 14. [Google Scholar] [CrossRef]
- Cheng, Y.; Zeng, Y. Automatic Energy Status Controlling with Dynamic Voltage Scaling in Power-Aware High Performance Computing Cluster. In Proceedings of the 2011 12th International Conference on Parallel and Distributed Computing, Applications and Technologies, Gwangju, Korea, 20–22 October 2011; pp. 412–416. [Google Scholar] [CrossRef]
- Ge, R.; Feng, X.; Feng, W.c.; Cameron, K.W. CPU MISER: A Performance-Directed, Run-Time System for Power-Aware Clusters. In Proceedings of the 2007 International Conference on Parallel Processing (ICPP 2007), Xi’an, China, 10–14 September 2007; p. 18. [Google Scholar] [CrossRef]
- Huang, S.; Feng, W. Energy-Efficient Cluster Computing via Accurate Workload Characterization. In Proceedings of the 2009 9th IEEE/ACM International Symposium on Cluster Computing and the Grid, Shanghai, China, 18–21 May 2009; pp. 68–75. [Google Scholar] [CrossRef]
- Chetsa, G.L.T.; Lefrvre, L.; Pierson, J.M.; Stolf, P.; Da Costa, G. A Runtime Framework for Energy Efficient HPC Systems without a Priori Knowledge of Applications. In Proceedings of the 2012 IEEE 18th International Conference on Parallel and Distributed Systems, Singapore, 17–19 December 2012; pp. 660–667. [Google Scholar] [CrossRef]
- Alonso, P.; Badia, R.M.; Labarta, J.; Barreda, M.; Dolz, M.F.; Mayo, R.; Quintana-Orti, E.S.; Reyes, R. Tools for Power-Energy Modelling and Analysis of Parallel Scientific Applications. In Proceedings of the 2012 41st International Conference on Parallel Processing, Pittsburgh, PA, USA, 10–13 September 2012; pp. 420–429. [Google Scholar] [CrossRef]
- Schubert, S.; Kostic, D.; Zwaenepoel, W.; Shin, K.G. Profiling Software for Energy Consumption. In Proceedings of the 2012 IEEE International Conference on Green Computing and Communications, Besancon, France, 20–23 November 2012; pp. 515–522. [Google Scholar] [CrossRef]
- Freeh, V.W.; Lowenthal, D.K. Using multiple energy gears in MPI programs on a power-scalable cluster. In Proceedings of the Tenth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming—PPoPP ’05, Chicago, IL, USA, 15–17 June 2005; ACM Press: New York, NY, USA, 2005; p. 164. [Google Scholar] [CrossRef]
- Li, D.; Nikolopoulos, D.S.; Cameron, K.; de Supinski, B.R.; Schulz, M. Power-aware MPI task aggregation prediction for high-end computing systems. In Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS), Atlanta, GA, USA, 19–23 April 2010; pp. 1–12. [Google Scholar] [CrossRef]
- Xian, C.; Lu, Y.H.; Li, Z. A programming environment with runtime energy characterization for energy-aware applications. In Proceedings of the 2007 International Symposium on Low Power Electronics and Design—ISLPED ’07, Portland, OR, USA, 27–29 August 2007; ACM Press: New York, NY, USA, 2007; pp. 141–146. [Google Scholar] [CrossRef]
- Bash, C.; Forman, G. Cool Job Allocation: Measuring the Power Savings of Placing Jobs at Cooling-efficient Locations in the Data Center. In Proceedings of the 2007 USENIX Annual Technical Conference on Proceedings of the USENIX Annual Technical Conference, Santa Clara, CA, USA, 17–22 June 2007; USENIX Association: Berkeley, CA, USA, 2007; pp. 291–296. [Google Scholar]
- Tang, Q.; Gupta, S.K.S.; Varsamopoulos, G. Energy-Efficient Thermal-Aware Task Scheduling for Homogeneous High-Performance Computing Data Centers: A Cyber-Physical Approach. IEEE Trans. Parallel Distrib. Syst. 2008, 19, 1458–1472. [Google Scholar] [CrossRef]
- Zong, Z.; Ruan, X.; Manzanares, A.; Bellam, K.; Qin, X. Improving Energy-Efficiency of Computational Grids via Scheduling. In Handbook of Research on P2P and Grid Systems for Service-Oriented Computing; Antonopoulos, N., Exarchakos, G., Li, M., Liotta, A., Eds.; IGI Global: Hershey, PA, USA, 2010; Chapter 22. [Google Scholar] [CrossRef]
- Zong, Z.; Nijim, M.; Manzanares, A.; Qin, X. Energy efficient scheduling for parallel applications on mobile clusters. Clust. Comput. 2007, 11, 91–113. [Google Scholar] [CrossRef]
- Guenter, B.; Jain, N.; Williams, C. Managing cost, performance, and reliability tradeoffs for energy-aware server provisioning. In Proceedings of the 2011 Proceedings IEEE INFOCOM, Shanghai, China, 10–15 April 2011; pp. 1332–1340. [Google Scholar] [CrossRef]
- Deng, W.; Liu, F.; Jin, H.; Liao, X.; Liu, H.; Chen, L. Lifetime or energy: Consolidating servers with reliability control in virtualized cloud datacenters. In Proceedings of the 4th IEEE International Conference on Cloud Computing Technology and Science Proceedings, Taipei, Taiwan, 3–6 December 2012; pp. 18–25. [Google Scholar] [CrossRef]
- Srinivasan, J.; Adve, S.V.; Bose, P.; Rivers, J.A. Lifetime reliability: Toward an architectural solution. IEEE Micro 2005, 25, 70–80. [Google Scholar] [CrossRef]
- Chen, Y.; Das, A.; Qin, W.; Sivasubramaniam, A.; Wang, Q.; Gautam, N. Managing Server Energy and Operational Costs in Hosting Centers. In Proceedings of the 2005 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, Banff, AB, Canada, 6–10 June 2005; ACM: New York, NY, USA, 2005; pp. 303–314. [Google Scholar] [CrossRef]
- Xie, T.; Sun, Y. Sacrificing Reliability for Energy Saving: Is it worthwhile for disk arrays? In Proceedings of the 2008 IEEE International Symposium on Parallel and Distributed Processing, Miami, FL, USA, 14–18 April 2008; pp. 1–12. [Google Scholar] [CrossRef]
- Cocaña-Fernández, A.; Ranilla, J.; Sánchez, L. Energy-efficient allocation of computing node slots in HPC clusters through parameter learning and hybrid genetic fuzzy system modeling. J. Supercomput. 2014, 71, 1163–1174. [Google Scholar] [CrossRef]
- Cocaña-Fernández, A.; Sánchez, L.; Ranilla, J. Leveraging a predictive model of the workload for intelligent slot allocation schemes in energy-efficient HPC clusters. Eng. Appl. Artif. Intell. 2016, 48, 95–105. [Google Scholar] [CrossRef]
- National Science Foundation. Advisory Committee for Cyberinfrastructure Task Force on Grand Challenges; Technical report; National Science Foundation: Arlington, VA, USA, 2011.
- Hendrik, A.; Bidwell, V.R. Measuring Eco-Efficiency: A Guide to Reporting Company Performance; World Business Council for Sustainable Development: Geneva, Switzerland, 2000. [Google Scholar]
- Cocaña-Fernández, A.; Sánchez, L.; Ranilla, J. Improving the Eco-Efficiency of High Performance Computing Clusters Using EECluster. Energies 2016, 9, 197. [Google Scholar] [CrossRef]
- Cacheiro, J. Analysis of Batch Systems; Technical report; CESGA: Santiago de Compostela, Spain, 2014. [Google Scholar]
- Ishibuchi, H.; Nakashima, T.; Nii, M. Classification and Modeling with Linguistic Information Granules: Advanced Approaches to Linguistic Data Mining (Advanced Information Processing); Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Cordón, O.; Herrera, F.; Hoffmann, F. Genetic Fuzzy Systems: Evolutionary Tuning and Learning of Fuzzy Knowledge Bases; World Scientific: London, UK, 2001. [Google Scholar]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. Syst. Man Cybern. 1985, SMC-15, 116–132. [Google Scholar] [CrossRef]
- Standard Performance Evaluation Corporation. SPEC CPU® 2017. Available online: https://www.spec.org/cpu2017/ (accessed on 31 May 2019).
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Jordan, M.; Rumelhart, D.E. Forward models: Supervised learning with a distal teacher. Cognit. Sci. 1992, 16, 307–354. [Google Scholar] [CrossRef]
- MOEA Framework, a Java Library for Multiobjective Evolutionary Algorithms. Available online: http://moeaframework.org/ (accessed on 31 May 2019).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Day of Week | Hour Range | Week of Year | Value |
|---|---|---|---|---|
| 1 | All | All | All | s |
| 2 | Monday–Friday | 8:00–20:00 | All | s |
| Satday–Sunday | 8:00–20:00 | All | s | |
| Monday–Sunday | 20:00–8:00 | All | s | |
| 3 | Monday–Friday | 8:00–20:00 | s | |
| s | ||||
| s | ||||
| s | ||||
| s | ||||
| Monday–Sunday | 20:00–8:00 | All | s | |
| Monday–Friday | 8:00–20:00 | All | s | |
| 4 | Monday–Friday | 8:00–20:00 | s | |
| s | ||||
| s | ||||
| s | ||||
| s | ||||
| Monday–Sunday | 20:00–8:00 | All | s | |
| Monday–Friday | 8:00–20:00 | All | s |
| Parameter/Node | Value | Unit | |||
|---|---|---|---|---|---|
| s01–s08 | s09–s16 | s17–s24 | s25–s33 | ||
| 0.15 | €/kWh | ||||
| 0.37 | kg /kWh | ||||
| Power at idle | 200 | 190 | 180 | 175 | Watts |
| Power at high load | 500 | 475 | 425 | 400 | Watts |
| 90 | 75 | 15 | 5 | % | |
| 3800 | 4200 | 5000 | 5500 | € | |
| 9536 | kg | ||||
| 109,500 | 146,000 | 219,000 | 292,000 | h | |
| 22 | °C | ||||
| 24 | °C | ||||
| 50 | °C | ||||
| 65 | °C | ||||
| 50 | °C | ||||
| 150 | € | ||||
| 238.41 | kg | ||||
| 4 | HDDs | ||||
| 146,000 | h | ||||
| f | 350 | times/month | |||
| Node-Selection Algorithm | Scenario 1 Test Set | |||
|---|---|---|---|---|
| Direct Cost | Indirect Cost | Total Cost | Carbon Footpr. | |
| (EUR) | (EUR) | (EUR) | (Mt ) | |
| Alphabetical heuristic | 6080.89 | 4086.56 | 10,167.45 | 22.70 |
| Random heuristic | 6349.58 | 3105.76 | 9455.34 | 21.72 |
| Efficiency heuristic | 6080.89 | 4065.68 | 10,146.57 | 22.67 |
| Balanced heuristic | 6305.56 | 3244.51 | 9550.07 | 21.83 |
| GFS-based allocation | 6471.63 | 2506.75 | 8978.39 | 20.92 |
| Node-Selection Algorithm | Scenario 2 Test Set | |||
|---|---|---|---|---|
| Direct Cost | Indirect Cost | Total Cost | Carbon Footpr. | |
| (EUR) | (EUR) | (EUR) | (Mt ) | |
| Alphabetical heuristic | 2680.29 | 2068.65 | 4748.94 | 10.31 |
| Random heuristic | 2929.01 | 1254.27 | 4183.28 | 9.64 |
| Efficiency heuristic | 2679.92 | 2062.77 | 4742.70 | 10.29 |
| Balanced heuristic | 2926.20 | 1251.53 | 4177.73 | 9.62 |
| GFS-based allocation | 3135.42 | 528.28 | 3663.70 | 8.94 |
| Node-Selection Algorithm | Scenario 3 Test Set | |||
|---|---|---|---|---|
| Direct Cost | Indirect Cost | Total Cost | Carbon Footpr. | |
| (EUR) | (EUR) | (EUR) | (Mt ) | |
| Alphabetical heuristic | 4685.53 | 2528.33 | 7213.86 | 16.28 |
| Random heuristic | 4835.08 | 1968.35 | 6803.43 | 15.71 |
| Efficiency heuristic | 4678.91 | 2530.06 | 7208.97 | 16.27 |
| Balanced heuristic | 4825.33 | 2017.22 | 6842.55 | 15.76 |
| GFS-based allocation | 4932.14 | 1555.20 | 6487.34 | 15.24 |
| Node-Selection Algorithm | Scenario 4 Test Set | |||
|---|---|---|---|---|
| Direct Cost | Indirect Cost | Total Cost | Carbon Footpr. | |
| (EUR) | (EUR) | (EUR) | (Mt ) | |
| Alphabetical heuristic | 4494.20 | 2442.23 | 6936.43 | 15.64 |
| Random heuristic | 4649.38 | 1837.98 | 6487.36 | 15.00 |
| Efficiency heuristic | 4493.77 | 2442.15 | 6935.92 | 15.64 |
| Balanced heuristic | 4647.97 | 1890.62 | 6538.60 | 15.09 |
| GFS-based allocation | 4710.18 | 1515.60 | 6225.78 | 14.60 |
| Node-Selection Algorithm | CMS Cluster Test Set | |||
|---|---|---|---|---|
| Direct Cost | Indirect Cost | Total Cost | Carbon Footpr. | |
| (EUR) | (EUR) | (EUR) | (Mt ) | |
| Alphabetical heuristic | 2760.07 | 1927.10 | 4687.17 | 10.29 |
| Random heuristic | 2975.89 | 1129.52 | 4105.41 | 9.54 |
| Efficiency heuristic | 2759.22 | 1920.07 | 4679.29 | 10.28 |
| Balanced heuristic | 2952.79 | 1242.47 | 4195.26 | 9.65 |
| GFS-based allocation | 3084.11 | 615.89 | 3700.00 | 8.94 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cocaña-Fernández, A.; San José Guiote, E.; Sánchez, L.; Ranilla, J. Eco-Efficient Resource Management in HPC Clusters through Computer Intelligence Techniques. Energies 2019, 12, 2129. https://doi.org/10.3390/en12112129
Cocaña-Fernández A, San José Guiote E, Sánchez L, Ranilla J. Eco-Efficient Resource Management in HPC Clusters through Computer Intelligence Techniques. Energies. 2019; 12(11):2129. https://doi.org/10.3390/en12112129
Chicago/Turabian StyleCocaña-Fernández, Alberto, Emilio San José Guiote, Luciano Sánchez, and José Ranilla. 2019. "Eco-Efficient Resource Management in HPC Clusters through Computer Intelligence Techniques" Energies 12, no. 11: 2129. https://doi.org/10.3390/en12112129
APA StyleCocaña-Fernández, A., San José Guiote, E., Sánchez, L., & Ranilla, J. (2019). Eco-Efficient Resource Management in HPC Clusters through Computer Intelligence Techniques. Energies, 12(11), 2129. https://doi.org/10.3390/en12112129