1. Introduction
Conventional development of the distribution networks has been driven by a worst-case fit-and-forget principle to tackle most of medium-voltage (MV) and low-voltage (LV) congestion challenges due to the long lifetime of their assets and planning horizon [
1,
2,
3,
4]. This led to limited distributed energy resources (DER) capacity allowed to be connected and costly network reinforcements, although peak loads generally occur only for a few hours in a year [
1]. It is definitely recommendable to stop operating the distribution networks as static black boxes [
5,
6].
Despite promising examples of voltage and reactive power regulation that have been implemented in Germany and Italy according to national standards VDE 4105 and CEI 0-2 respectively [
7], congestion management is normally approached dynamically only in transmission networks [
8], for example by rescheduling and readjusting set points in generation units [
9,
10]. Nonetheless, the threats posed by the intermittent and dynamic nature of distributed generators, electric vehicles (EVs), or energy storage systems, to cite some of the most relevant DER technologies [
11,
12], require new means to help distribution system operators (DSOs) in their key function of congestion management in those complex scenarios [
10]. This is the case of control algorithms proposed for operations such as curtailment of MV wind generators [
13] or EV smart charging [
14]. Therefore, flexibility in distribution networks is an active research question, including DER units and end users in market models that exploit their capabilities to relieve congestion [
15] and improve security of supply [
16].
However, in the case of LV networks, other means that can be considered as an alternative to those commonly widespread, such as asset oversizing or reinforcement, are scarce [
17]. In addition to this, congestion limits are not clearly defined for LV distribution network assets, such as MV/LV power transformers or LV feeders, apart from conventional criteria initially designed for static network planning [
18,
19] or the maximum admissible power determined by their nominal characteristics.
Determining what we have defined here as optimal congestion threshold may help DSOs in their dynamic operation of the LV networks. These thresholds provide them with technical references for the value of current measured individually in a certain distribution network element. Thereby, DSOs may enable preventive actions, by means of their own controllable network assets or with the help of other participating agents such as demand aggregators, before congestion definitively takes place and potential risk of failure may severely increase. Consequently, those thresholds must be optimized, as detailed in
Section 3, considering not only the highest values of current experienced in the distribution network elements and their admissible congestion limits, but also the time duration and repetition of those congested or close to congestion situations over time.
Congestion management is addressed by classical methods by means of market mechanisms, as in the case of demand side management models [
20], or by means of network planning-based methodologies, as in hosting capacity models [
21], to cite some relevant examples, but limitations may arise at the time of their implementation on LV networks. Indeed, these models may be adapted to this new paradigm, with the help of present innovative solutions such as LV network-monitoring technologies and MV/LV state estimation algorithms [
22]. Particularly, hosting capacity approaches are strongly conditioned by the nominal admissible limits on the network element of study [
21] or the number and characteristics of scenarios considered [
23], while demand side management requires the development of models oriented to facilitate end users’ decision-making [
24] and read locational market signals in order to boost participation in LV networks [
20].
The methodology proposed here is especially designed for LV networks and seeks a compromise between the subjective human-based criteria and the precise but limited, as explained before, classical models. A data analysis is proposed here to address this challenge by means of clustering a significant group of distribution network elements. The aim is to provide insight into underlying patterns of data, to accelerate knowledge discovery, elements’ classification, and subsequent computational efforts [
25,
26]. In addition to this, an optimization problem is formulated in order to help make decisions for preventing and managing congestion in heterogeneous massive sets of distribution network elements [
27]. This provides DSOs with enriched objective criteria for the proactive preventive operation and maintenance of their assets, unlike the mentioned precedents based on their subjective, conservative, and generalized experience. In particular, particle swarm optimization (PSO) is proposed here thanks to its applicability to solve multi-objective optimization problems, and to its capability to avoid finding solutions biased by predetermined human initial decisions [
28].
Authors in Reference [
9] surveyed some applications of PSO on power systems, emphasizing its capabilities in facing issues such as uncertainty in load demand incorporating distributed generation, EV charging management, or economical dispatch to determine generation operating conditions while network constraints are met. Other relevant applications are those oriented to optimal power flow calculation and congestion management [
10]. PSO-based algorithms can also deal with non-smooth functions, especially those related to frequency regulation and voltage constraints [
10]. Further approaches are outlined in Reference [
9], such as balancing loads between feeders or deciding on the optimal configuration, size, and topology of the distribution system.
PSO bears similarities to other advanced optimization algorithms, such as evolutionary computation techniques, where genetic and ant colony algorithms stand out for their popularity. Nevertheless, those techniques are more complex and present some serious restrictions to be applied in our methodology. Genetic algorithms may be faster than PSO and restrict the reproduction of weak solutions, but their crossover and mutation operations result as incompatible with our optimization problem [
29], since it is formed by load duration curves, with individuals defined by non-independent characteristics [
30]. Ant colony algorithms, despite of being based on swarm behavior [
31] as in the case of PSO, assure convergence in problems where source and destination are predefined and specific [
32], unlike in the congestion threshold determination problem proposed here. The objective of this article is threefold: (1) To determine optimal technical thresholds to prevent congestion in distribution network assets, such as MV/LV power transformers and LV feeders; (2) to contribute with an optimization methodology not based on subjective previous experience and replicable in any kind of network, by employing clustering and multi objective particle swarm optimization (MOPSO); and (3) to apply the methodology to a real dataset obtained from Smartcity Malaga Living Lab, an area with more than 15,000 real end users, where 750 sensors installed in 56 MV/LV secondary substations are measuring current, voltage, power, and energy every 5 min [
33].
This article is organized as follows.
Section 2 addresses the congestion management problem in LV distribution networks, presenting the limitations of the DSOs to tackle saturation problems. In
Section 3, the methodology for optimal congestion threshold determination is presented, detailing the data analytics-based and optimization algorithm developed, as well as its objectives, formulation, constraints, and pseudocode. The results of this methodology are discussed in
Section 4 thanks to its application on power transformers and LV feeders from a real case of study from Smartcity Malaga Living Lab. Finally,
Section 5 presents the conclusions and the fundamental ideas discussed in the article.
2. Congestion in LV Distribution Networks
Distribution networks have their end users spread, distributed in any form, independently if regarding a LV feeder and its phases, or among different feeders connected to the same power transformer in a secondary substation [
4,
34,
35]. Moreover, each end user, whether consumer, prosumer, or generator, has its own arbitrary pattern, even more diverse with the proliferation of DER technologies.
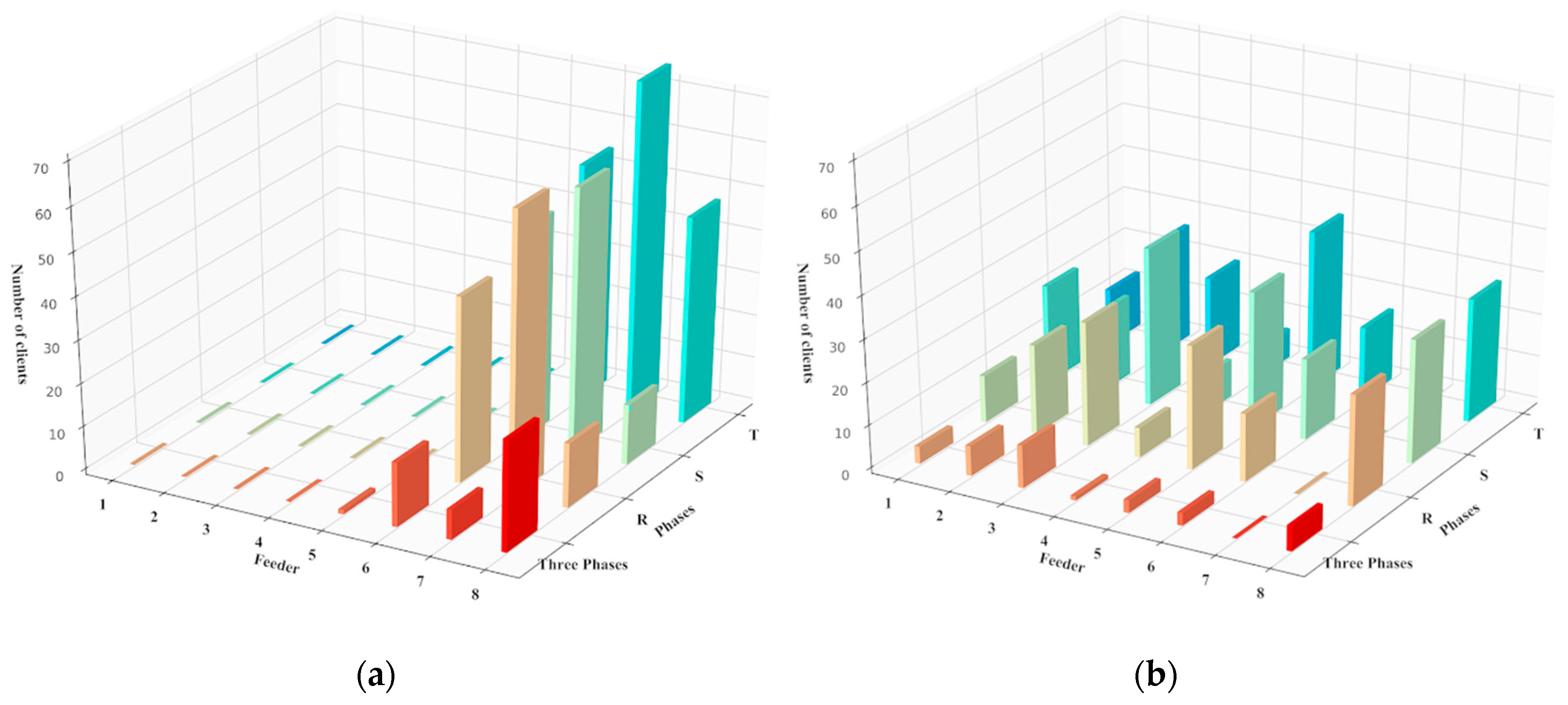
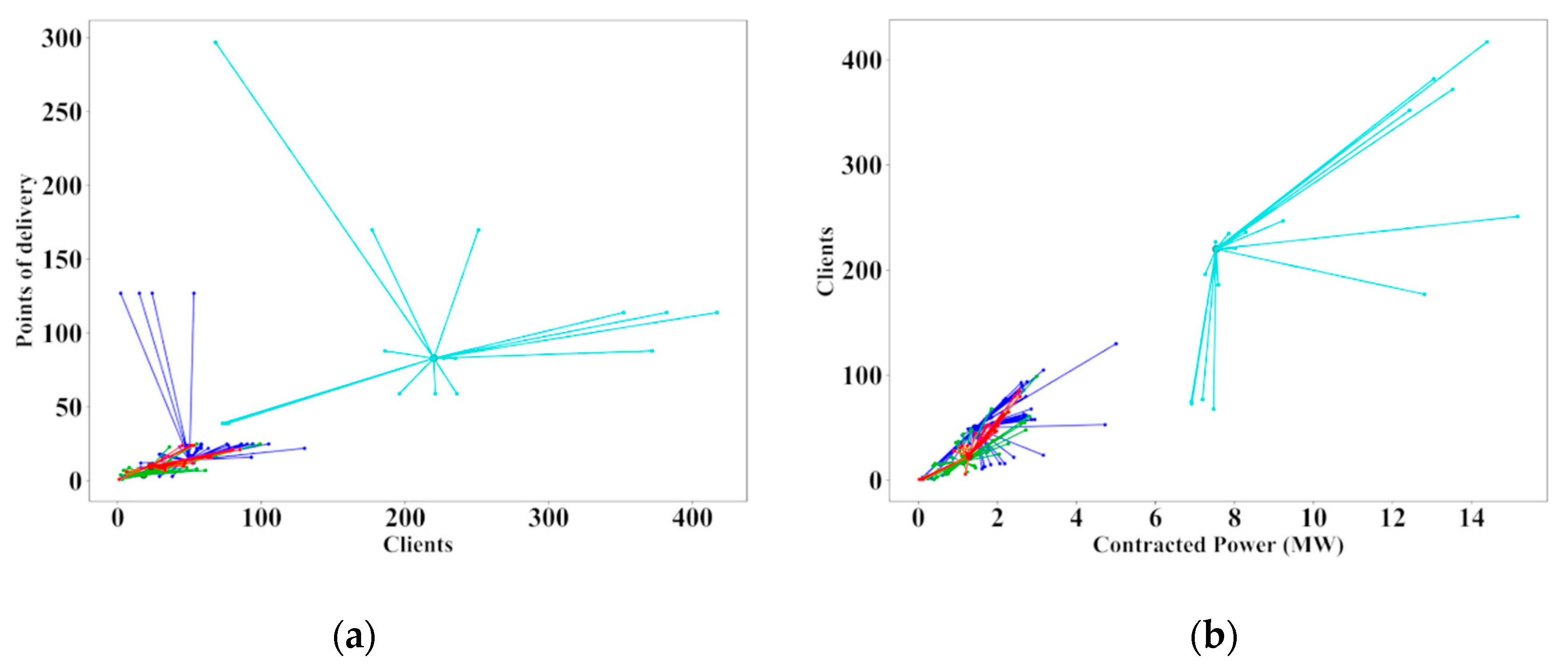
A clear example of this highly heterogeneous distribution of clients of the LV networks can be seen in
Figure 1 for two MV/LV (medium voltage/low voltage) secondary substations of Smartcity Malaga Living Lab [
36], despite being located in the same geographical area, having the same number of LV feeders and nominal rating in their power transformers, and also the same number of predominantly residential single-phase end users, which is slightly above 500 in each case.
This heterogeneity influences severe congestion and voltage in the network. In order to compensate for the voltage drop and to avoid subsequent undervoltage at the end of the feeder, the voltage at the LV side of a MV/LV power transformer has been traditionally set over 1 p.u. [
1] with a conventional off-line fixed setting [
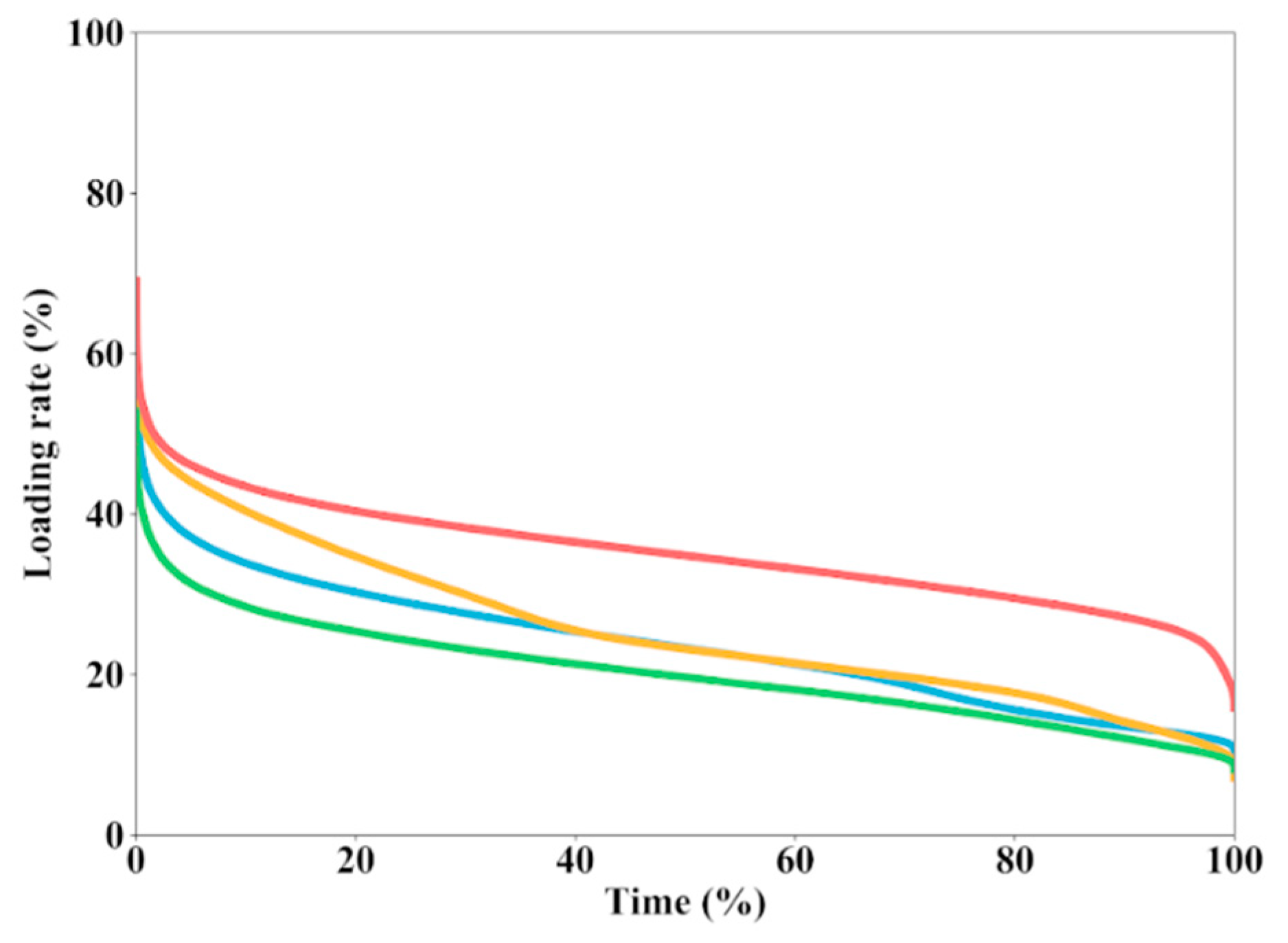
37]. Meanwhile, conventional options to tackle congestion go predominantly through network oversizing and extension, as in the case of rating upgrade of power transformer or construction of new secondary substations to overcome critical situations that take place in short periods of time [
38,
39], as can be seen in the load duration curves of a set of Smartcity Malaga power transformers displayed in
Figure 2.
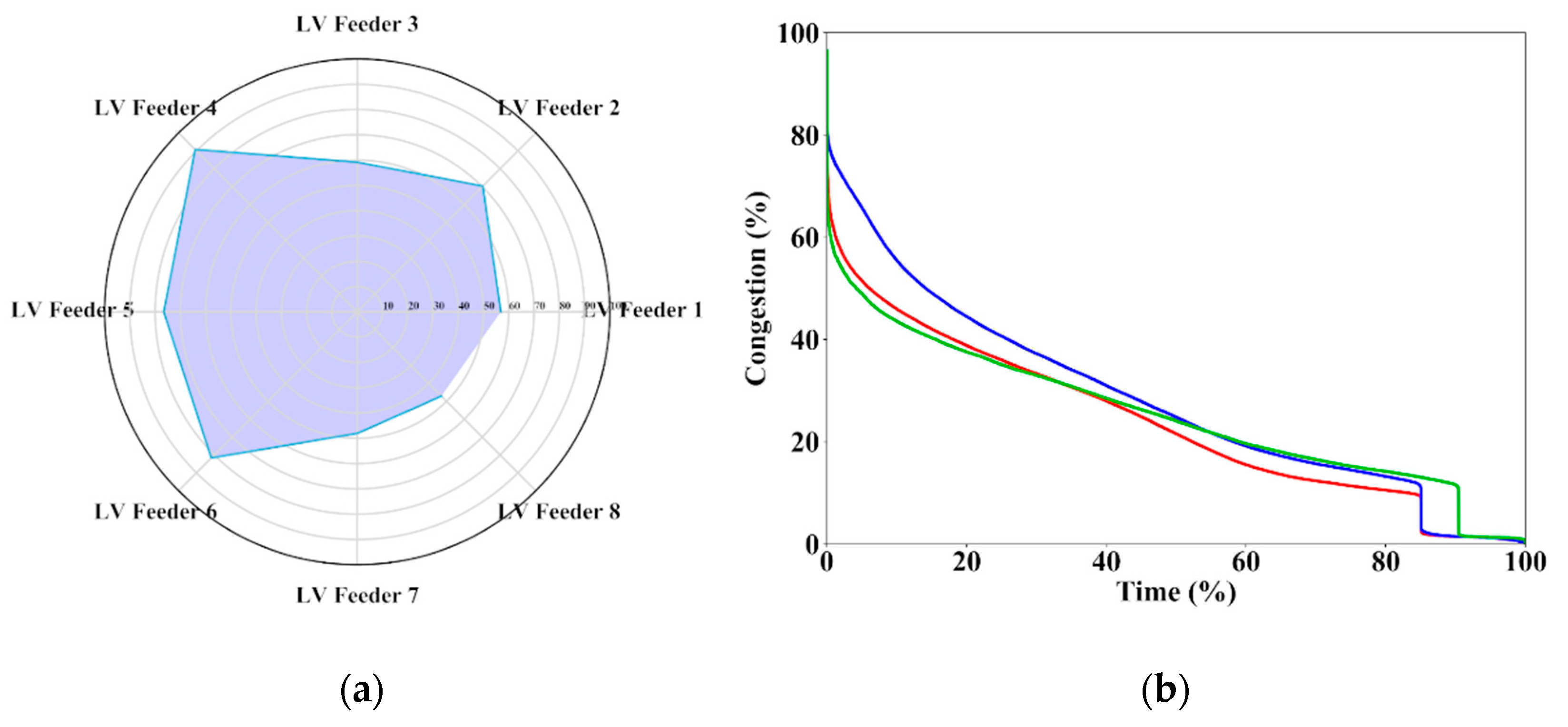
Furthermore, congestion variations experienced in adjacent LV feeders and their phases, as displayed in
Figure 3, evidence a totally decoupled unbalanced performance, leading to highly diverse characteristic values. Therefore, this means having situations close to congestion along a LV feeder, or particular phase, at the same moment the neighbor ones may not.
Unlike voltage, network congestion limits are not clearly defined by international grid codes, such as in EN50160 [
40], which states that voltage on MV and LV distribution network nodes must remain within ±10% for 95% of the week, and between +10% and −15% for all time. Apart from the maximum limit determined by the nominal admissible power of each asset of the network, other values commonly used to set maximum congestion thresholds are 95% by the transmission system operator in Spain for their cables [
18], or 75% by the regulator of the electric sector in Peru for both cables and power transformers [
19], to cite some examples. However, these values are based on their local experience.
Power transformers are critical expensive assets in distribution networks, hence special attention must be given to their operation and maintenance [
41,
42]. Nonetheless, detailed information is scarce at the LV network level, such as the particular phase where a single-end user or DER unit is connected [
43], despite successful smart grid pilot projects such as Smartcity Malaga [
44], INTEGRIS [
5], IDE4L [
45], or MONICA [
46] have dedicated special efforts in distribution network digitalization and state estimation. Therefore, technical solutions are available today to address congestion in singular elements such as LV feeder phases, avoiding bottlenecks that may arise even earlier in the case of significant DER penetration or demand growth [
47,
48], since technical constraint violations may occur at an earlier stage [
49].
Therefore, DSOs may operate the distribution networks by means of a permanent dynamic supervision of the congestion level, taking into account the optimal congestion threshold assigned by this methodology to any particular network element. As pointed out in
Section 1, those thresholds provide DSOs with technical references that prevent them before congestion definitively takes place in a particular distribution network element and, consequently, potential risk of failure increases. This lets them leave behind corrective processes and act before an incident occurs, therefore optimizing budget allocation and the quality of service provided to end users [
50] by means of preventive actions, such as adjusting on-load tap changing (OLTC) MV/LV power transformers [
51] or interacting with DER units so that they adjust their operating regime to the existing network conditions [
7].
3. Proposed Approach for LV Congestion Determination
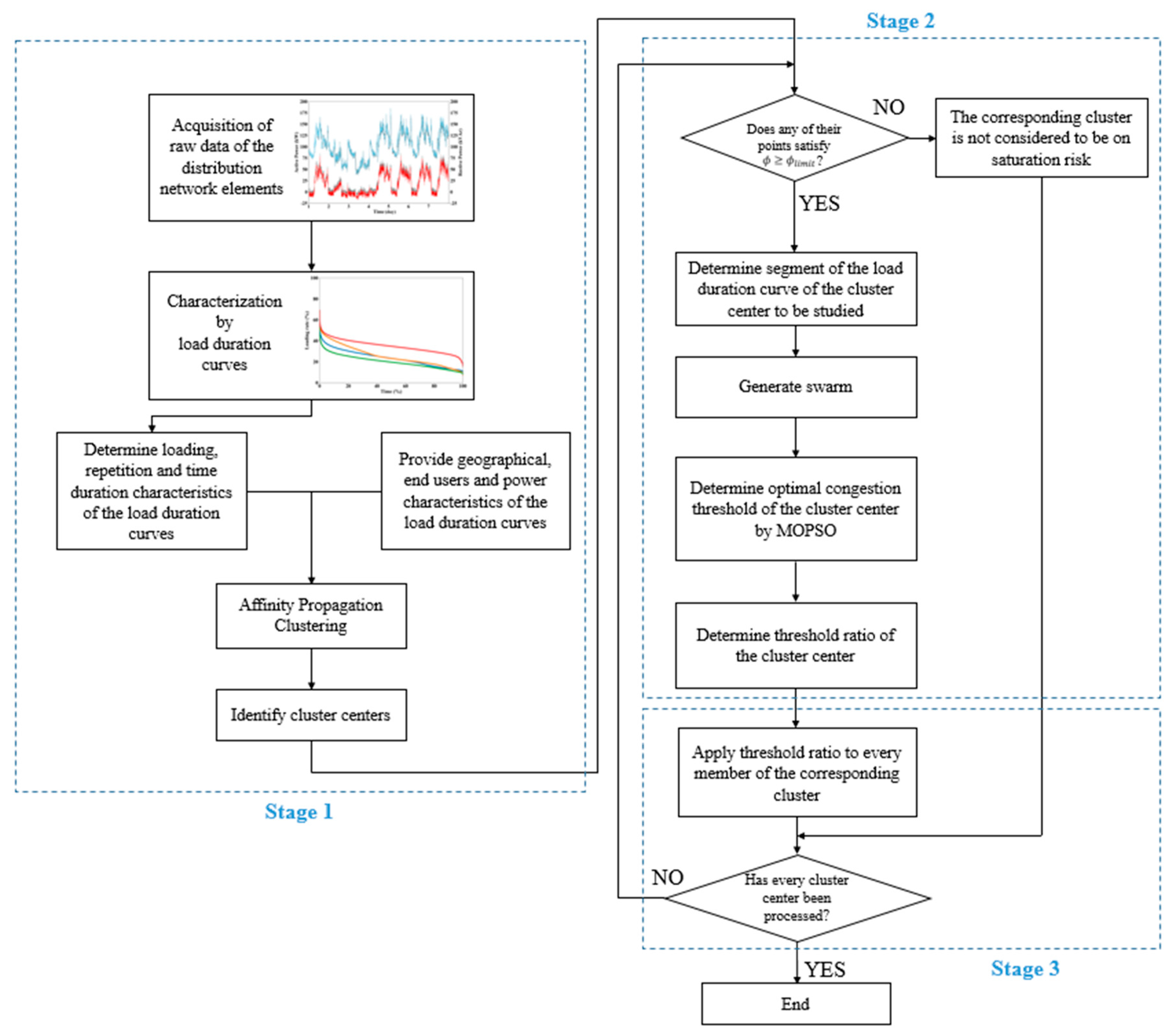
The proposed methodology consists of three stages, as displayed in
Figure 4. Firstly, data acquisition allows for the creation of the search space, which is formed in this problem by load duration curves of distribution network elements. They may represent a numerous diverse dataset for modern DSOs, hence, data analysis techniques must be applied. On the one hand, this allows for the classification of assets by grouping them regarding their similarities. On the other hand, the most representative elements can be identified, so deeper studies can be performed on them, and later be extrapolated to the rest of similar assets for the sake of the efficiency of the analysis.
Data analytics is approached here by means of an affinity propagation clustering technique [
25]. Apart from initially considering any of those distribution network elements as potential cluster centers, this technique is characterized by not requiring any previous specification about the number of clusters to be formed, in addition to exchanging messages iteratively between elements until a high-quality set of exemplars and clusters emerges, doing so in less than one hundredth the time and at a lower error rate than other exemplar-based methods [
25,
52]. Consequently, only a basic identification and characterization of those assets to be clustered is needed to initiate the analytics.
The second stage focuses on determining the optimal congestion thresholds. For this, a particle swarm optimization (PSO) problem is formulated, which is a stochastic-based artificial intelligence search technique inspired on natural life [
28]. A population of particles, called
swarm, formed by points,
flows through the search space taking into consideration the historical best position for each particle itself and the rest as a whole, naturally orienting the search towards an optimal or near-optimal solution [
9,
17].
Multi-objective PSO (MOPSO) is proposed here due to its capacity for simultaneous resolution of multiple conflicting objectives in congestion threshold determination [
17]. In addition to this, MOPSO presents a low computational cost to provide a set of solutions, that, unlike classical multi-objective methods, are diverse and spread enough [
17]. This allows for finding the best, non-trivial trade off among more than one objective, since no single solution may simultaneously optimize the whole search objective [
53].
The affinity propagation clustering previously executed allows for the application of MOPSO only on the most representative element of each cluster. Then, the third stage addresses the extrapolation of the result obtained in the optimization process to the rest of assets.
3.1. Data Analytics based on Affinity Propagation Clustering
The affinity propagation algorithm [
25] applied here is set with a dumping factor of 0.9 in order to avoid high numerical oscillations and favor the convergence of the clustering process, and is trained with a dataset formed by the characteristics listed on
Table 1.
Standardization in the clustering process is important, since the values of those characteristics are often measured in different units, meaning that some of them could be dominating other ones, hence influencing the course of the cluster analysis [
54]. To overcome this, the characteristic values considered in this methodology are re-scaled by using min-max standardization.
In addition to the nominal admissible power or the maximum congestion value for each asset, such as power transformers or LV feeder, the time duration of those congested situations experienced has to be carefully considered, as in the case of Spain, where the annual maximum demand is denoted by the congestion level reached around the 100 most critical hours [
55], about 0.01% of the year. Furthermore, here it is proposed to consider the number of different days where the maximum congestion levels took place in order to take into consideration the degree of repetition of those risky situations.
Other key aspects, such as the number and type of end users connected to every distribution network element, its length (which is zero in the case of power transformers, but includes any segment downstream associated in the case of LV feeder phases), or the total power contracted, are also considered. Hence, the clustering process provides a data analysis based not only on graphical features of each load duration curve, but also based on physical parameters of the corresponding asset.
3.2. Multi-Objective Particle Swarm Optimization
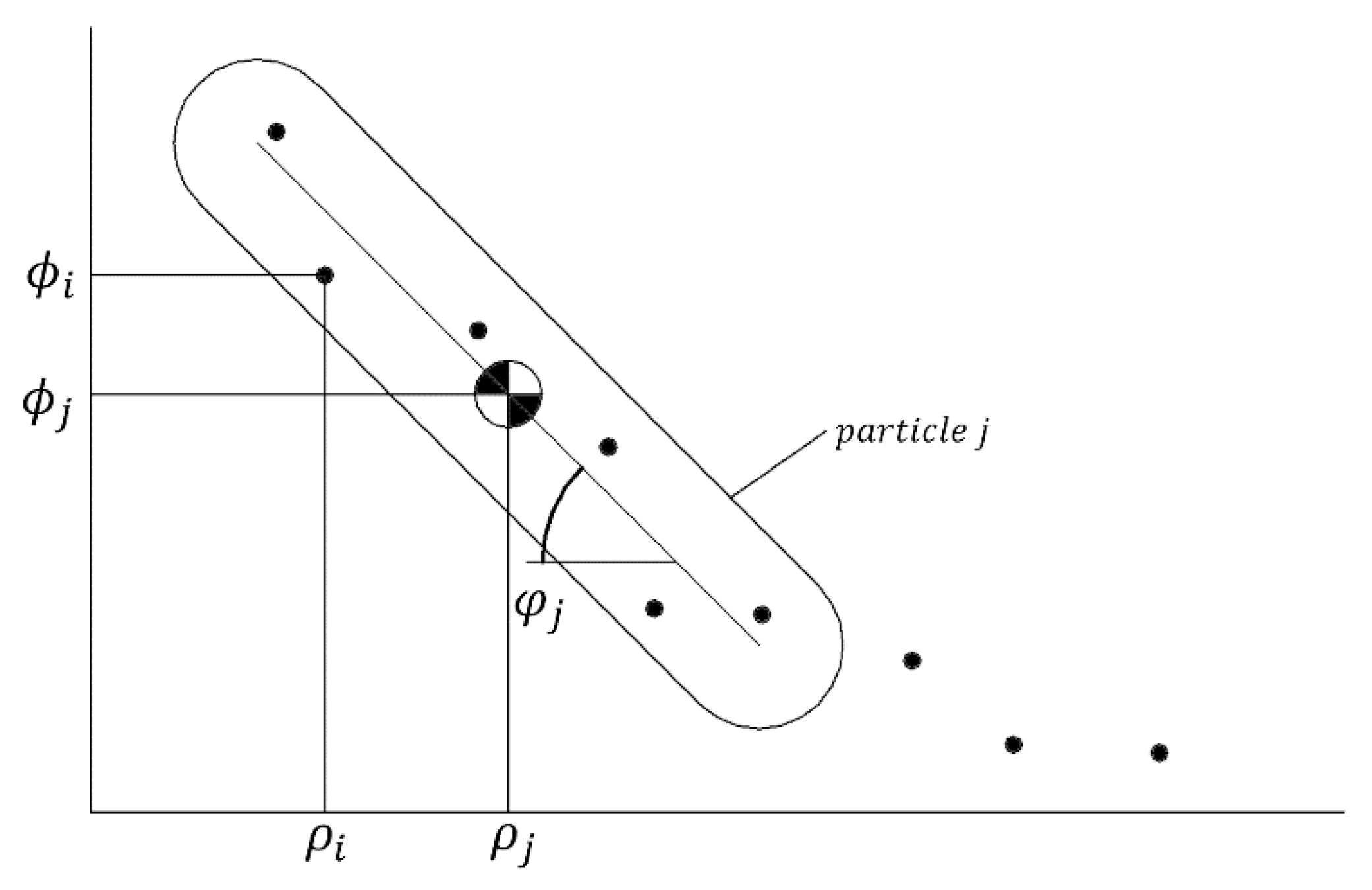
The determination of the optimal congestion threshold is a constrained optimization problem where a specific multi-objective function is minimized. The aim is to find the optimal characteristic value of congestion in the load duration curve of a distribution network element considered, valid for the longest time scenarios of operation and being the closest to the maximum demand level experienced on it.
The multi-objective function is formed by three subfunctions. The first objective subfunction aims to minimize the standard deviation of the congestion characteristic values of the load duration curve, leading to select groups of points that are more concentrated around a certain congestion level. This diminishes the influence of abrupt changes in congestion characteristic values, exceptionally unconnected with neighboring values, and typically corresponding to the highest demand scenarios.
The second objective subfunction tackles the percentage of time scenario characteristic values of the load duration curve. Having the maximum standard deviation here aims to find a solution far from unrepresentative short time variations. This subfunction is characterized by the inverse of the standard deviation in order to fit it in the minimization of the multi-objective problem.
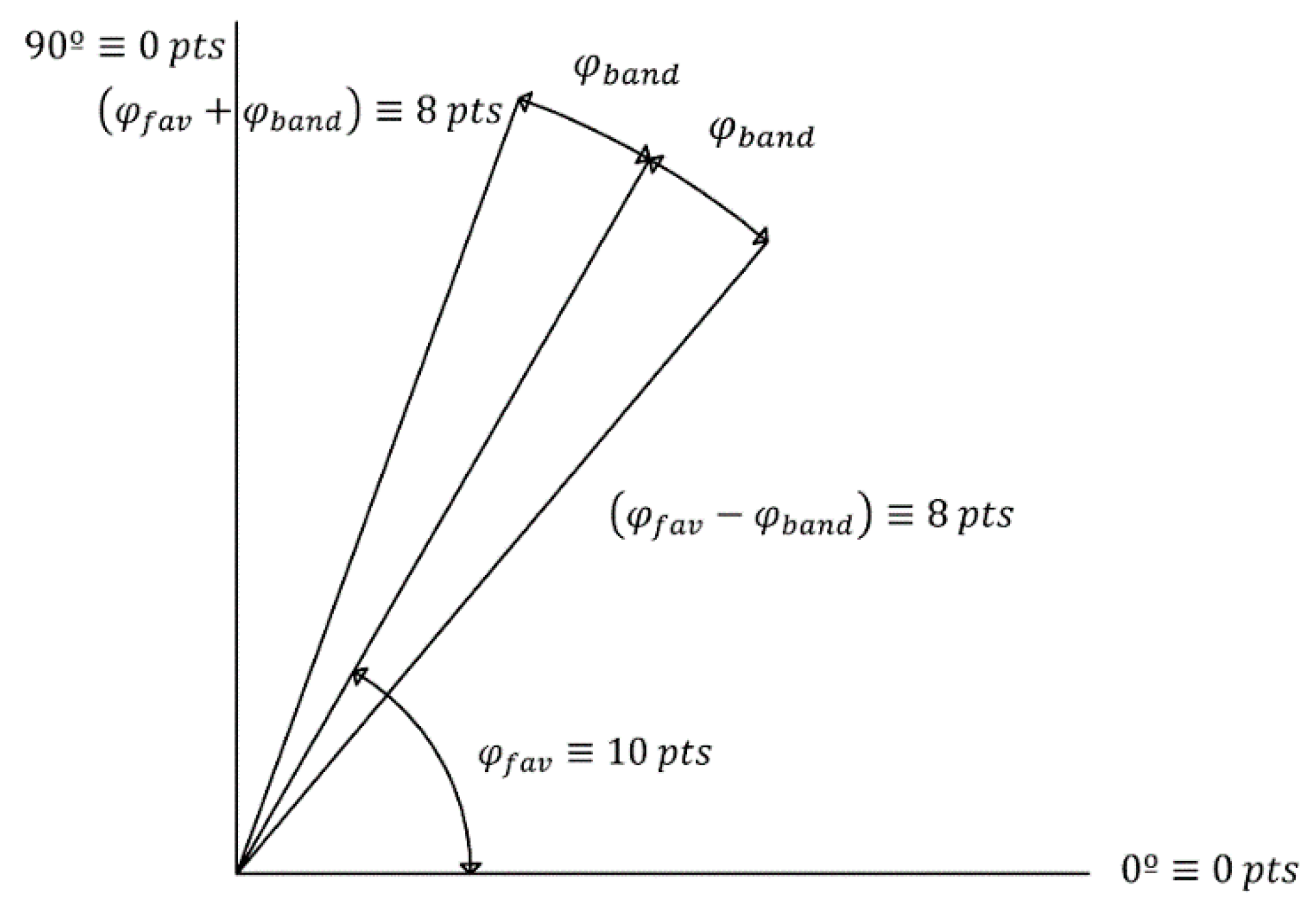
Finally, the third objective subfunction
addresses the inclination angle
by scoring linearly between 0 and 10 points of the linear regression of any group of points forming a particle of the load duration curve. An inclination angle of 45° presents the best compromise between congestion measurements and time scenarios, namely, between its vertical and horizontal projections. However, with the aim of not losing the influence of the highest demand experienced, a favorable inclination angle, called
, must be set above 45°, helping the optimization problem converge towards more stabilized congestion characteristic values but without being too close to 90° and then falling into unrepresentative, extremely brief, and highest-congestion scenarios. A band of the most favorable angles,
, is also set in order to help define diverse punctuation areas, as shown in
Figure 5. This objective subfunction is characterized by the inverse, as expressed in Equation (7), in order to fit it in the minimization of the multi-objective problem, as in the case of objective subfunction 2.
Therefore, the formulation of this multi-objective is stated as follows:
The problem constraint
refers to all those congestion characteristic values above a particular value, which is considered to represent a realistic, considerable, potential risk of saturation of the distribution network elements. It is recommended to consider a wider range of congestion states than in traditional criteria, as mentioned in
Section 2 for 95% [
18] and 75% [
19], in order to cover a broader set of representative scenarios and then to avoid extremely singular transient states.
By checking compliance with this restriction, MOPSO is not applied in the case of those clusters whose elements are not satisfying the problem constraints for none of the points of their load duration curves, since they are not considered to be above a minimum level of potential risk.
In our methodology, and according to MOPSO algorithm, the
swarm is formed by
particles, each of them composed by
points, as displayed in
Figure 6, that move along the search space, that is to say, in a certain load duration curve. Consequently, each particle
is characterized by the congestion
and the corresponding percentage of time scenarios
of its center, and its position
in a moment of time
along the load duration curve depends on its previous position
and its velocity
[
27]:
This velocity
is composed by terms related to the inertia
and the velocity of the particle in the previous state
to represent its tendency to continue in the same direction, and the attraction towards the best position
ever found by the particle and by any of the particles of the swarm
[
27]:
Authors in Reference [
27] pointed that the sum of constants
and
should be 4.0, meaning
to give the same weight to the individual and group experience.
and
are random values between 0 and 1 [
27], and the inertia of the particle
is given by:
where
and
are also constant values set at 1 and 0 respectively, in order to reach an initial high value near to 0.9 as pointed in Reference [
27], hence moving fast towards the global optimum.
Therefore, in each iteration, every
and
corresponding to the center of each particle, in addition to
,
and the inclination angle of the linear regression
of their
points, will be evaluated in the following subfunctions of the multi-objective function, leading to a solution:
where:
is the mean congestion value in the particle
;
is the mean percentage time scenario value in the particle
.
Pareto dominance must be checked every time the position of a swarm is updated, storing those non-dominated solutions among the obtained for the
particles after their evaluation on the mentioned subfunctions of the multi-objective function, in order to approximate the Pareto front [
9].
In relation to this, the first stopping criterion is determined for the algorithm developed here: The global optimum results from the best particle of the swarm after a certain number of consecutive iterations without any progress in the Pareto front. In addition to this, the second stopping criterion consists of a maximum number of iterations.
As pointed out in
Section 1, other advanced optimization algorithms, such as genetic and ant colony algorithms, apart from being more complex than this PSO-based approach, present serious restrictions to be applied in our methodology due to the impossibility to cross and mutate points defined by non-independent congestion and time characteristics [
29,
30], and to the absence of a clear, predefined optimal solution area [
32].
3.3. Applications in LV Networks
This methodology can be applied on wide groups of distribution network elements by means of the ratio between the optimal congestion threshold
determined by the MOPSO algorithm and the maximum congestion value measured
for each cluster center
. Therefore, this so-called
can be employed individually on any of the members
belonging to that cluster
in order to determine its particular optimal congestion threshold
, where:
Moreover, the use of the threshold ratio reflects the existing differences among the congestion experienced in each element, instead of simply imposing the optimal of the cluster center. Thus, the application of the methodology follows the flowchart described in
Figure 7.
4. Results and Discussion
This methodology has been applied on real data obtained from Smartcity Malaga Living Lab. In particular, data from five MV/LV secondary substations are considered here, including a total of six power transformers and their 18 corresponding LV side phases. In addition to this, as displayed in
Table 2, their corresponding 45 LV feeder lines, with three phases in each case, are also here considered, therefore taking into account their highly dispersed and heterogeneous distribution of clients, as shown in
Figure 1. Consequently, this methodology has been implemented on load duration curves from 153 distribution network elements, a group of elements linked to around 5000 out of the 15,000 real end users of the Living Lab.
4.1. Data Analytics for Data Pre-Processing
Every distribution network element has been characterized by 5-min data acquisition during a whole year period, meaning more than 109,000 current measurements in each case. Thus, this group formed by a total of 153 elements involves handling around 16,000,000 data. Consequently, the size of this dataset provides a wide, varied dataset to reflect the reality of the operation and maintenance of the distribution networks, not only because of the number of assets considered, but also because of the time interval, including summertime, wintertime, working days, and holidays.
According to the methodology detailed in
Section 3, the first stage is data analytics. Applying affinity propagation to cluster those 153 elements results in the composition of four different clusters, as shown in
Figure 8,
Figure 9 and
Figure 10, and the identification of their corresponding cluster centers listed in
Table 3.
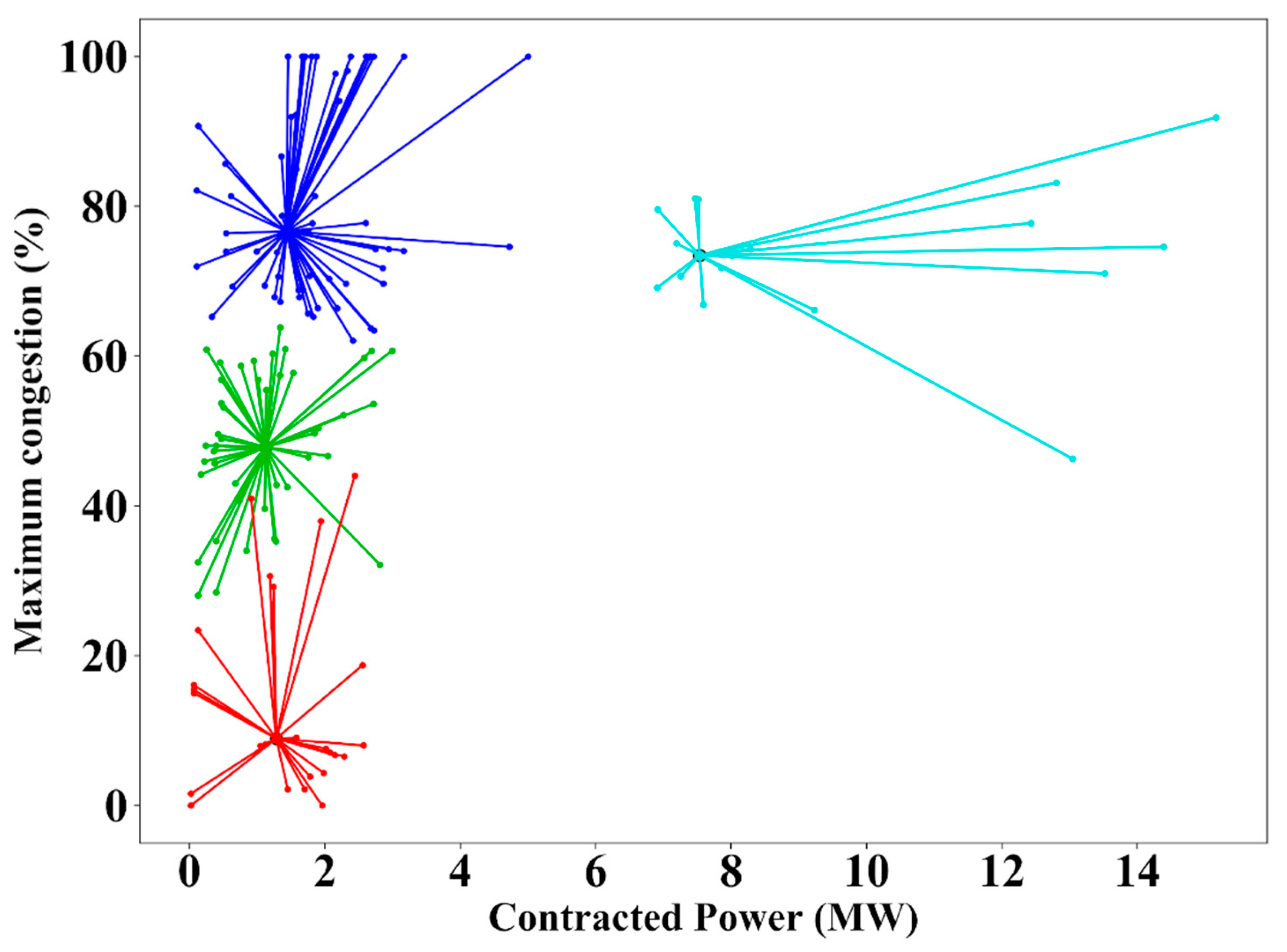
The lowest values obtained at the maximum congestion characteristic can be found in the members of cluster 4. Although all the power transformers of the group belong to cluster 3, which has the least number of members, clusters 1, 2, and 4 are highly heterogeneous since they have LV feeder phases belonging to every secondary substation of the group. In addition to this, three out of the four cluster centers belong to the same secondary substation, which evidences the diversity among elements that can be found even in the same asset of the distribution network.
Regarding maximum congestion, 16 distribution network elements have measured values over 95% of their maximum admissible power [
18], and 14 out of them reached their nominal maximum congestion of 100%. Regarding the conventional congestion threshold of 75% [
19], 40 elements experienced congestion over that limit, and only 10 out of them remain over it at 1% of time scenarios. At the same time, 29 elements present a maximum congestion value measured below 35%, representing almost the fifth part of the group, and 17 out of them remained below 10%.
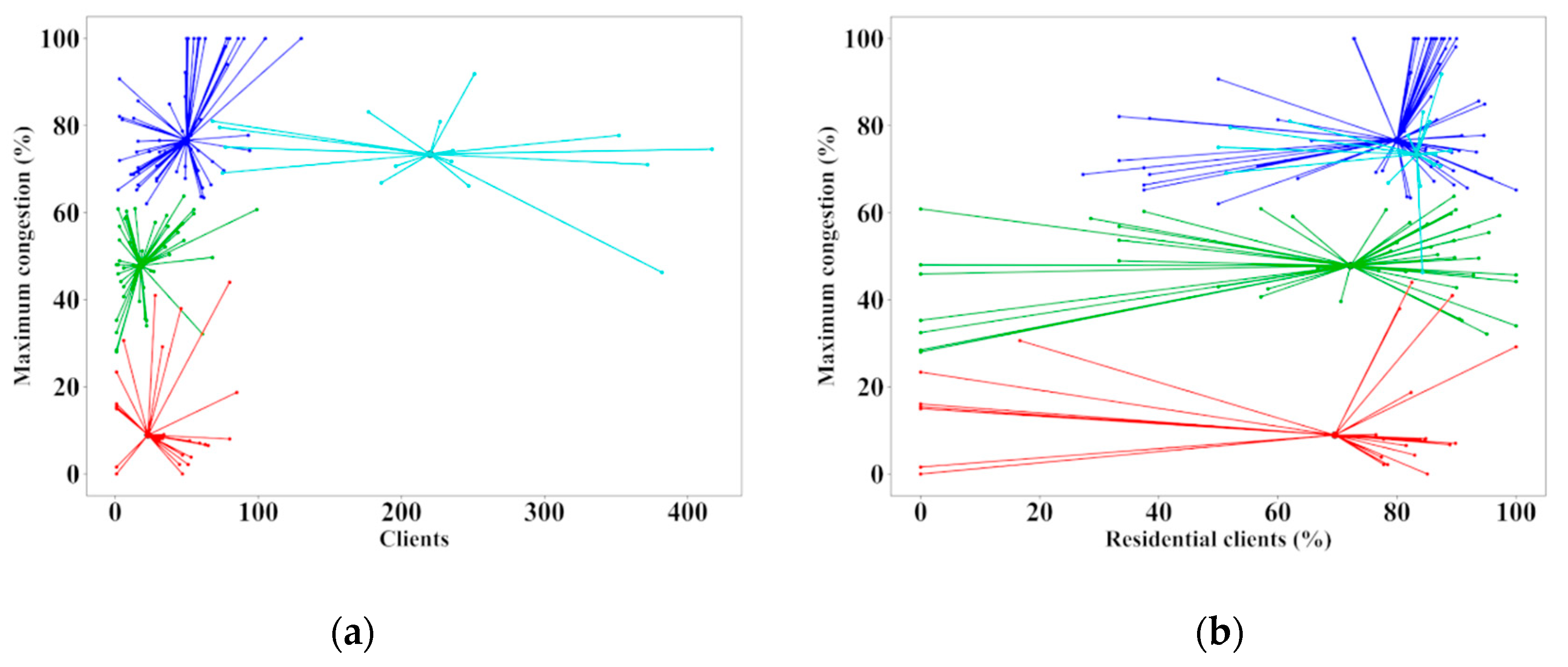
The highest number of clients in a secondary substation, by grouping those connected to the three LV sides of its power transformer, is around 1300 clients, and the lowest is 225, while the average per LV feeder phase is 37 clients, ranging from 1 to 130. Despite the area being predominantly residential, representing 50% or more of the clients in 100 LV feeder phases, only 15 LV feeder phases present 100% industrial clients.
Geographically, more than 600 points of delivery are included in the group of elements, ranging from 1 to 25 per LV feeder phase and with an average of 14 per each of them. The average length per LV feeder phase is 200 m. The clustering executed here makes it possible to identify differences that are not easily discernible a priori, as can be seen in
Figure 10, where most of the elements from clusters 1, 2, and 4 are coincident for the represented characteristics.
4.2. Optimization
The second stage of the methodology is optimization. To evaluate the different cluster centers obtained, a particular is set in order to focus the analysis only on potentially risky congestion states, according to the reality observed in the real electrical network of study of Smartcity Malaga Living Lab. In addition to this, adapts the methodology to the search space without rejecting any predetermined proportion or number of assets.
Once
restrictions have been checked, it is observed that the cluster center 4, in red in
Figure 8,
Figure 9 and
Figure 10, does not satisfy it for any of its points. Therefore, this cluster is out of the following optimization process because of not being in a situation of risk minimally considerable. At the same time, applying
to the cluster centers 1, 2, and 3 allow for the focus of the optimization problem in a limited set of points of their load duration curves, listed in
Table 4, corresponding to the most saturated scenarios.
MOPSO is then applied on cluster centers 1, 2, and 3, where a favorable inclination angle
, a tolerance band
, a maximum number of iterations without any progress in Pareto front
, and a maximum number of iterations
have been set. The initialization of the population is carried out by means of a random stochastic process that distributes them arbitrarily along the search space. The optimization algorithm that has been executed for the series of particles and their corresponding points is shown in
Table 5.
The results obtained from the MOPSO algorithm developed are displayed in
Table 6 showing a good robustness of the method, with a low standard deviation despite being a stochastic-based method. Therefore, the methodology can be considered to be slightly dependent on the size of the population.
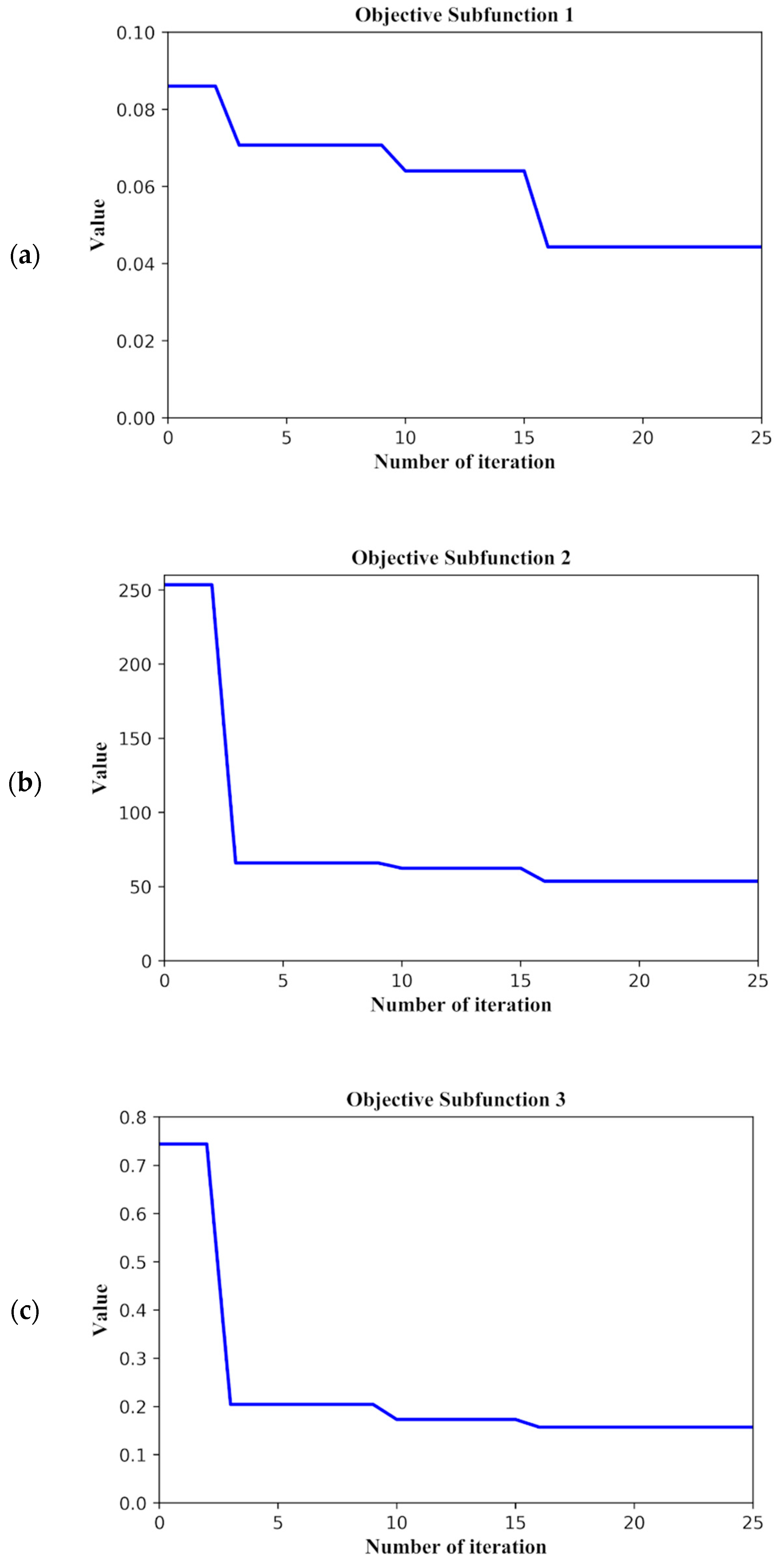
A representation of the evolution in the values obtained in the three objective subfunctions is displayed in
Figure 11. Particularly, those are the values obtained by the best particle in each iteration of the algorithm in the Case 1, which is formed by a swarm of 15 particles with 3 points each, applied to cluster center 1. It must be noted that the role of the best particle can be played by different particles of the swarm along the different iterations, according to Pareto compliance.
The example displayed in
Figure 11 shows how values obtained for objective subfunctions 1, 2, and 3 are decreasing progressively, but not continuously, towards the minimum, leading to identifying a particle with the corresponding optimal congestion characteristic value of 68.00% displayed in
Table 6. The global optimum finally results after 25 iterations, meaning that the stopping criterion of 10 consecutive iterations without any progress in the Pareto front has been applied; hence, the other stopping criterion of a maximum number of iterations of 100 has not been reached.
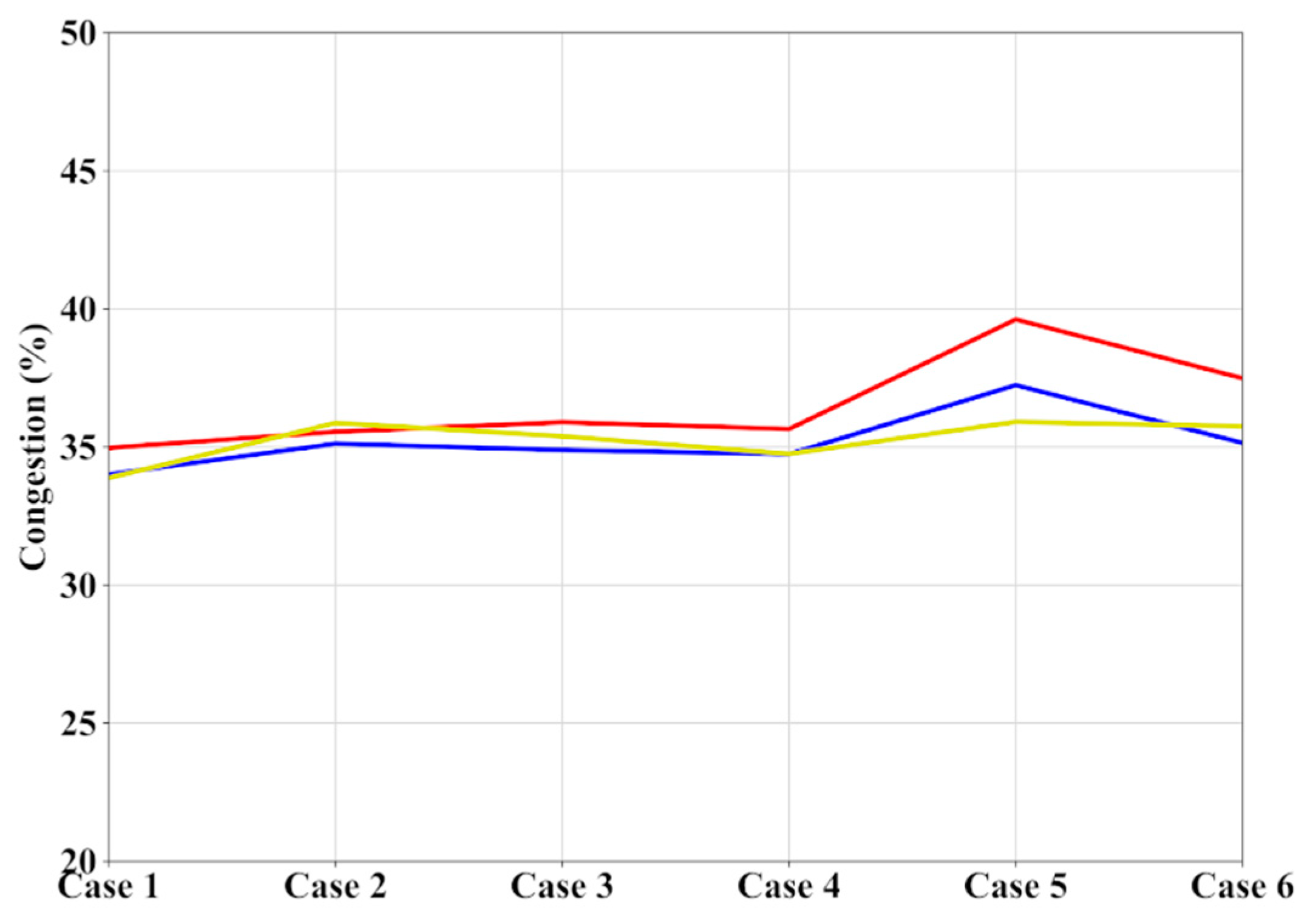
Apart from considering a favorable inclination angle of 75° ± 5°, the MOPSO algorithm has also been executed for 70° ± 5° and 65° ± 5°. As shown in the results displayed in
Figure 11 for cluster center 2, the algorithm presents a good stability in the results obtained and therefore a low dependence on this parameter, as evidenced in
Figure 12, despite the varied characteristics of the swarms employed. In addition to this, it evidences that higher values of favorable inclination angles result in higher optimal values due to the greater influence of the maximum congestion values measured in the element.
4.3. Application on the Distribution Network of the Case Study
The third and last stage of the methodology is its application in LV networks. To do so, once the congestion thresholds have been determined for each cluster center, the mean threshold ratio is calculated for each cluster center of the case study, as shown in
Table 7.
Therefore, by applying the corresponding mean threshold ratio, an individual, particular optimal congestion threshold is set for 135 out of the 153 distribution network elements of Smartcity Malaga Living Lab belonging to clusters 1, 2, and 3. To cite some relevant figures, 22 distribution network elements have been set with optimal thresholds over the conventional 75% [
19] of their maximum admissible power, 63 elements over 60%, and 78 over 50%.
The numerical results here obtained, as displayed in
Figure 13, provide the network operators with an objective, individual determination of the optimal congestion threshold in order to establish supervision and control strategies such as those mentioned in
Section 1 and
Section 2. In addition to this, as shown in
Table 8 in the case of the cluster centers, this methodology provides the time scenarios corresponding to those optimal congestion thresholds.
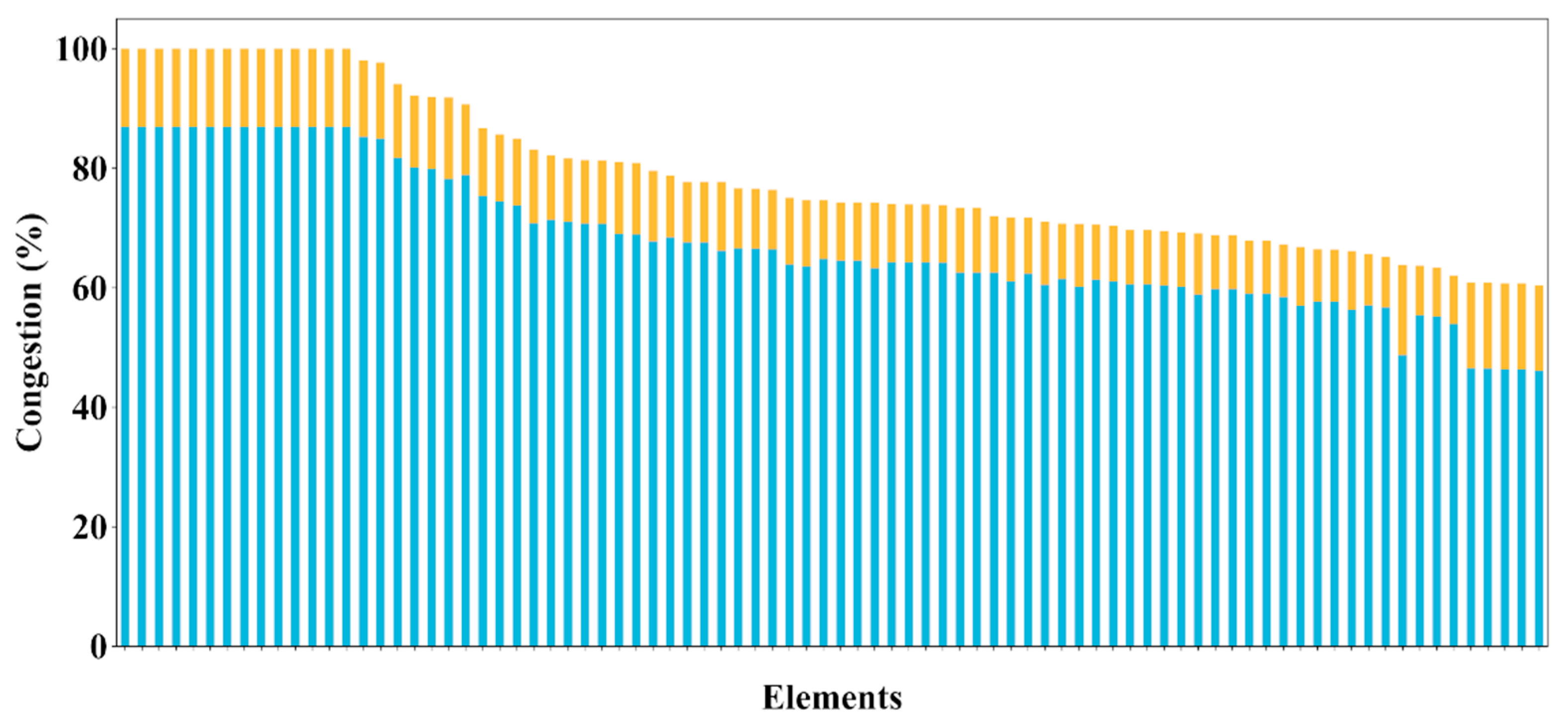
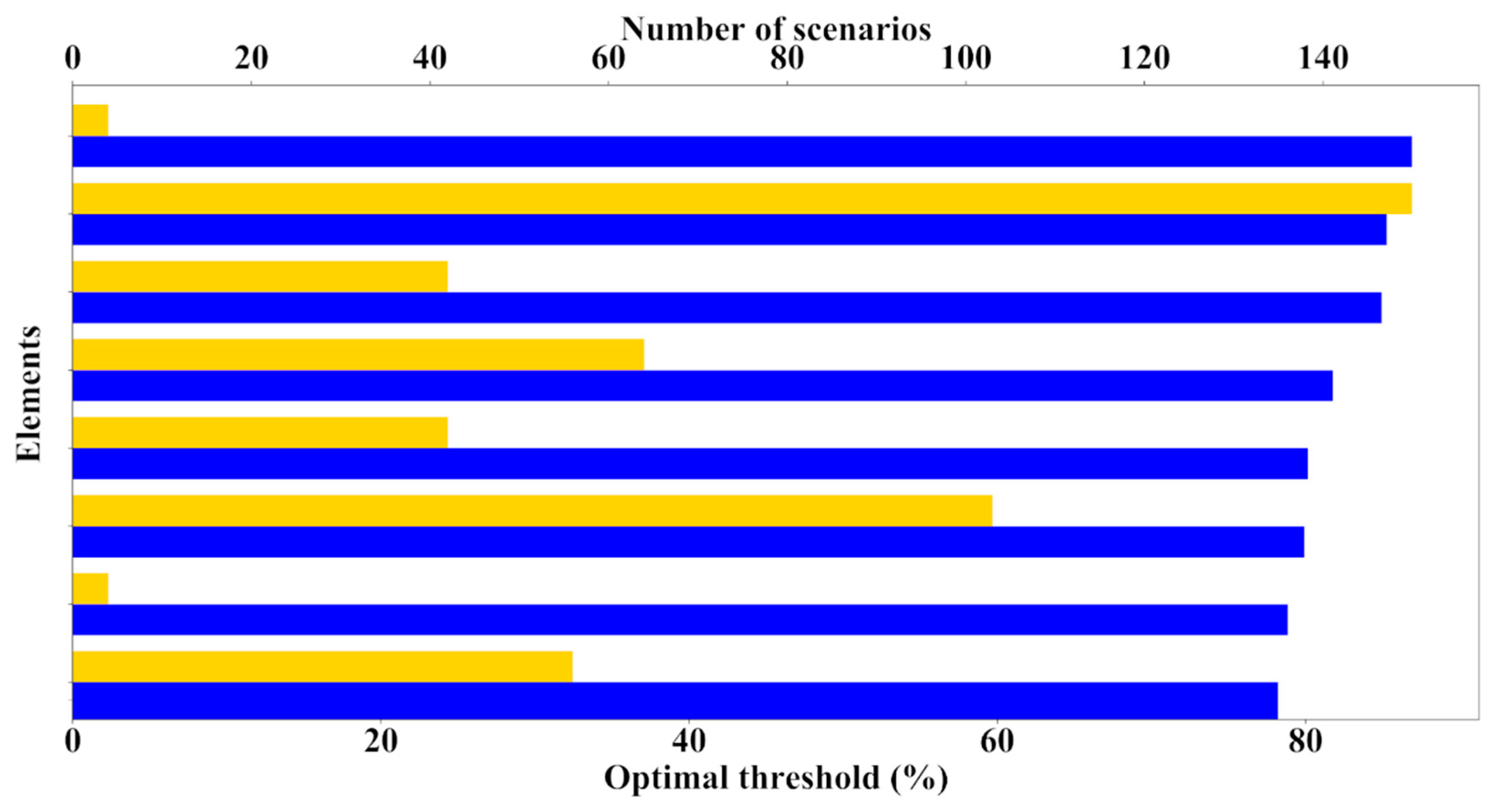
For instance, in the case of cluster center 1, the optimal congestion threshold determined at 66.63% potentially means intervening in 0.025% of the year of time considered in this dataset. Even more, 27 different scenarios experienced congestion above that threshold, each one of a 5-min duration, taking place over 13 different days. In this way, the distribution network elements of the group can be ranked according to their optimal congestion threshold but also considering the number of congested time scenarios, as displayed in
Figure 14, given the useful additional information provided.
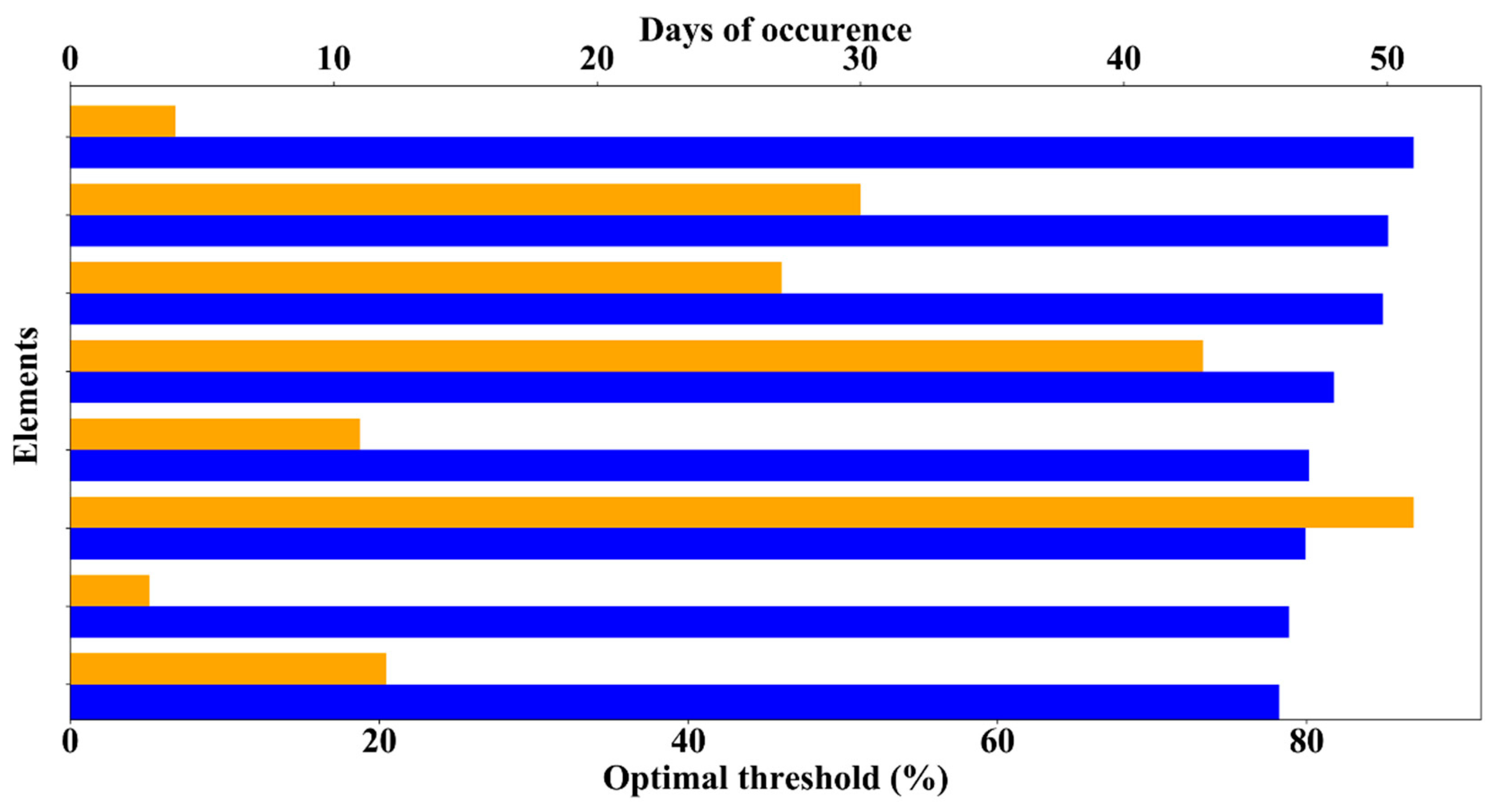
Moreover, the previous set of distribution network elements can also be ranked according to their optimal congestion threshold but considering now the number of different days presenting congestion, as displayed in
Figure 15; hence, a totally different ranking can be composed, since there is not a direct relation between them.
Consequently, this methodology allows DSOs to tackle potential congestion states in their assets by prioritizing the operation of those distribution network elements which are closer to saturation according to both the optimal threshold determined and the expected congested situations.
5. Conclusions
This methodology provides a tool that supports DSOs in making decisions to manage congestion in any of the elements of the distribution network, such as MV/LV power transformers or LV feeders and their corresponding phases. It allows them to operate and maintain their assets in a preventive way beyond the classic planning criteria traditionally used, hence bringing an alternative to oversizing and reinforcements, and not based on previous, subjective precedents. Moreover, the methodology has been validated with real data obtained from Smartcity Malaga Living Lab, under real operating conditions.
Due to the means available today for the digitalization of the network, the large volumes of data to be handled far outweigh human experience, as in the case study presented here, based on a dataset formed by more than 16,000,000 data for a single year from a network related to around 5000 real end users. The pre-processing performed by means of affinity propagation clustering results in a more efficient computational analysis. Thus, the 153 distribution network elements considered here were divided into four clusters, with three of them meeting the restrictions of the optimization problem. In the case of the fourth cluster, formed by 18% of the distribution network elements, their congestion levels were not considered to be over a minimum level of risk.
The optimization process carried out provides enriched criteria with respect to traditional methods, such as considering a fixed threshold of 75%, which implies only 26% of the elements were considered to be over a minimum risky saturation level, and even less in the case of 95% fixed threshold. Meanwhile, our MOPSO algorithm not only takes into account congestion, but also time scenarios, in order to determine an optimal congestion threshold to 82% of the elements of the group of study, characterizing them individually and under an objective basis. Furthermore, 41% of the elements of the case study were provided with optimal congestion thresholds over 60% of their nominal admissible power, evidencing that using this methodology gives an expanded view of congestion situations that are not negligible under preventive operation and maintenance standards.
The methodology can be applied to online processing. Nonetheless, an adaptation of the methodology may be necessary. The computational time required, and the granularity and size of the dataset considered, must be carefully assessed, having in mind that, as in the case of the clustering process considered here, data analytics techniques may help in handling those massive datasets. In addition to this, the availability of online data is a major issue, since proper data acquisition, processing, and provision to the methodology must be designed, for example by means of big data techniques [
56], since, as the network conditions change, the optimization solution and clusters might change as well.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}