1. Introduction
Microgrid (MG) is a small-scale electric power system, which can be operated both in islanded and grid-connected modes. The operation of the MG is generally carried out by an energy management system (EMS) [
1,
2]. In recent years, the development of centralized EMSs has been extensively studied and used for the operation of MGs [
3,
4,
5]. However, these centralized EMSs are facing many problems such as computational burden and complexity in communication networks especially, when the numbers of control devices increase. Therefore, this may lead to scalability issues for future expansion [
6]. In addition, there are several entities in the MG system that have different owners and different operation objectives [
7]. Therefore, it is difficult to provide a common operation objective for the operation of the entire system. Recently, decentralized EMSs are becoming popular due to their ability to overcome the limitations of centralized EMSs [
8,
9,
10]. In decentralized EMSs, each entity in the system is monitored and controlled by a local controller, which only communicates with its neighboring controllers via a communication network. Due to the lack of detailed information about the other entities in the system, the solution may not be globally optimal [
11].
Therefore, the use of centralized or decentralized EMSs is not efficient for the operation of a distributed system with different entities having diverse operation objectives. A potential solution could be developing an EMS with a combination of both of these approaches to take advantage of each framework. In this approach, a group of entities having the same operation objectives are operated under a centralized controller, while the other entities having different operation objectives are operated by using other local controllers. Centralized controllers gather all system information and determine the optimal schedule for each component by using mathematical programming. On the other hand, the reinforcement learning (RL) approach has been introduced for the distributed operation of independent entities having local operation objectives in case the independent entities do not have complete information of the environment [
12,
13,
14,
15,
16,
17]. In RL, agents learn to achieve a given task by interacting with their environment. Since the agents do not require any model of the environment, they only need to know the existing states and possible actions in each state. This method drives the learning process based on penalties or rewards assessed on a sequence of actions taken in response to the environment dynamics [
17,
18]. In contrast to the conventional distributed methods, learning-based methods can be easily adapted with a real-time problem after the off-line training process. In RL, Q-learning is a popular method and is widely used for the optimal operation of microgrids [
19,
20,
21,
22,
23]. A fitted Q-iteration-based algorithm has been proposed in [
19] for a BESS. A data-driven method is utilized in [
19] and it uses a state-action value function to optimize a scheduling plan for the BESS in grid-connected mode. An RL-based energy management algorithm has been proposed by [
20] to reduce the operation cost of a smart energy building under unknown future information. The authors in [
21] have proposed a multiagent RL-based distributed optimization of a solar MG by optimizing the schedule of an energy storage system. A two steps-ahead RL algorithm has been developed in [
22] to plan battery scheduling. By using this method, the utilization rate of the battery is increased during high electricity demand while the utilization rate of the wind turbine for local demand is also increased to reduce the consumer dependence on the utility grid. The authors in [
23] have presented an improved RL method to minimize the operation cost of an MG in the grid-connected mode.
However, most of the existing Q-learning-based operation methods have been developed for optimal operation of an agent in the grid-connected mode only for a particular objective, i.e., maximization of profit (competitive model). However, in the case of islanded mode, they may have adverse effects and reduce the reliability of the entire system, such as the increased load shedding amount. Therefore, an energy management strategy, which is applicable for both grid-connected and islanded modes with different objectives need to be developed. In addition, most of the existing literature on Q-learning-based methods have been developed for optimal operation of a single MG and only focused on the operation of the local components of an MG. Adjacent MGs can be interconnected to form a multi-microgrid system to improve network reliability by sharing power among MGs and other community entities [
11]. However, the power transfers between other community entities and among MGs of the network have not been considered in the existing Q-learning-based operation methods [
19,
20,
21,
22,
23]. Therefore, the existing methods are not suitable to apply for multi-microgrid systems.
In order to overcome the problems mentioned above, a Q-learning-based energy management strategy is developed in this paper for managing the operation of a distributed system. The system is comprised of an MG and a community BESS (CBESS). A microgrid EMS (MG-EMS) is used for managing the operation of the MG while a Q-learning-based operation strategy is proposed for the optimal operation of the CBESS. In contrast to the existing literature [
19,
20,
21,
22,
23], where only grid-connected mode operation is considered, both grid-connected and islanded mode operations are considered in this study. The objective in grid-connected mode is to maximize the profit of the CBESS via optimal charging/discharging decisions by trading power with the utility grid and other MGs of the network. However, in islanded mode, the objective is to minimize the load shedding amount in the network by cooperating with the MGs of the network. Due to the consideration of power trading among community resources and MGs of the network, the proposed method can be easily extended for multi-microgrid systems. However, the existing methods in the literature [
19,
20,
21,
22,
23] focus on simplified single MGs, cannot be applied for networked MGs. To analyze the effectiveness of the proposed Q-learning-based optimization method, the operation results of the proposed method are compared with the conventional centralized EMS results. Simulation results have proved that the proposed method can get similar results with the centralized EMS results, despite being a decentralized approach. Finally, an adjusted epsilon method is applied in the epsilon-greedy policy to reduce the learning time and improve the operation results.
2. System Model
2.1. Test System Configuration
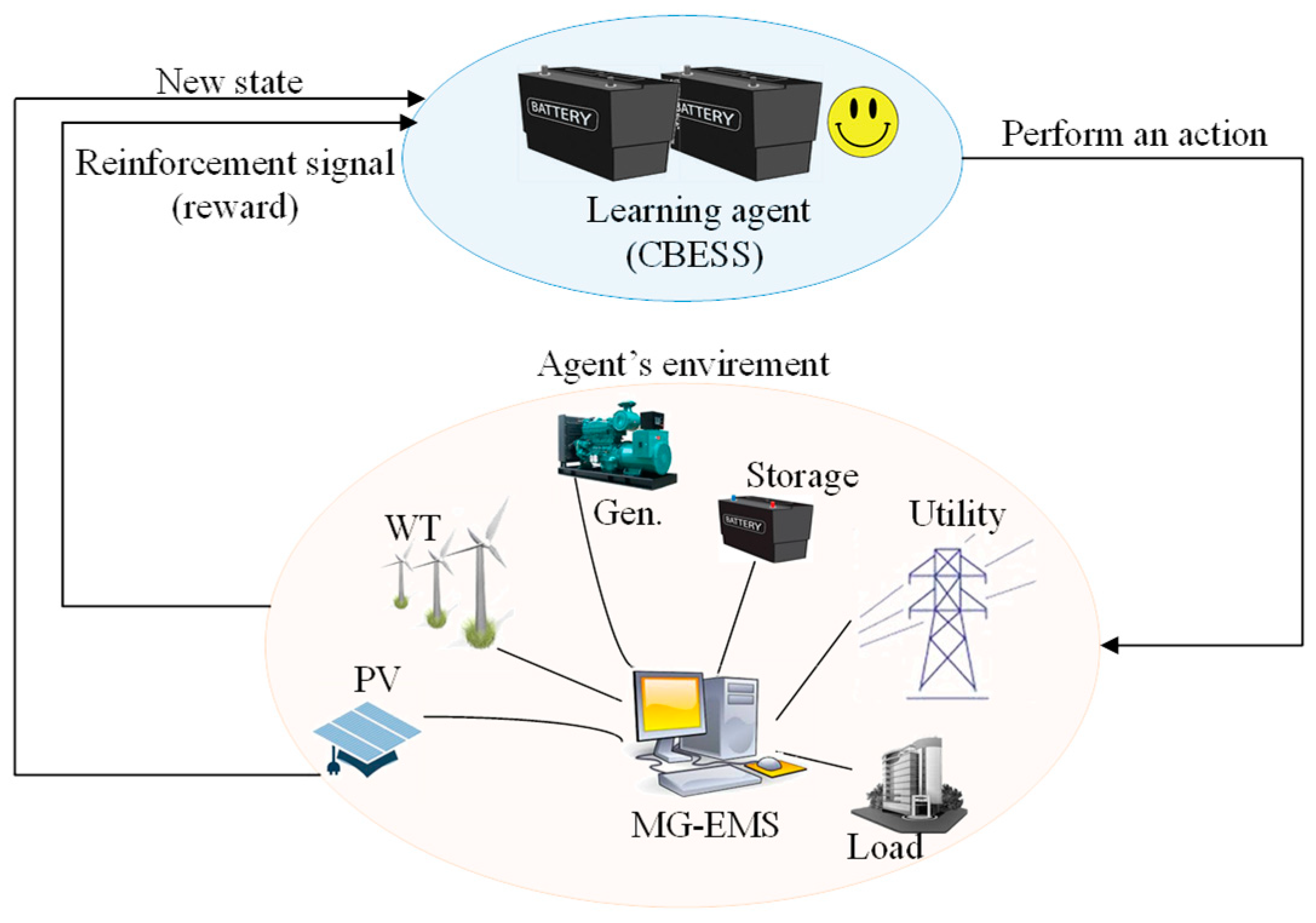
Figure 1 describes a test system configuration, which is comprised of an MG and a CBESS. In this study, MG is a group of entities having the same operation objectives, such as CDG, RDGs, BESS, and loads, which are operated under a centralized controller (i.e., MG-EMS), while the CBESS having different operation objectives is operated by using its local controller. A Q-learning-based operation strategy is proposed for CBESS.
In the grid-connected mode, power can be traded among MG, CBESS, and the utility grid for minimizing the total operation cost. In islanded mode, the MG system is not connected to the utility grid, CBESS and MG can trade power to minimize load shedding in the network. The MG considered in this study consists of a controllable distributed generator (CDG), a renewable distributed generator (RDG) system, a BESS as the energy storage device, and residential loads. MG is operated by an MG-EMS for minimizing its operation cost. In grid-connected mode, MG-EMS communicates with the utility grid to get the buying/selling price and decides the amount of buying/selling power to be traded with the utility grid and CBESS. In islanded mode, MG cannot trade with the utility grid. Thus MG cooperatively operates with CBESS to minimize the load shedding amount. The detailed algorithms for both operation modes are explained in the following section.
2.2. Q-Learning-Based Operation Strategy for CBESS
Q-learning is a model-free reinforcement learning where an agent explores the environment and finds the optimal way to maximize the cumulative reward [
19,
20,
21,
22,
23]. In Q-learning, the agent does not need to have any model of the environment. It only needs to know the existing states and possible actions in each state. Each state-action pair is assigned an estimated value, called a Q value, which is the brain of the agent. A Q-table represents all the knowledge of an agent about the environment. When the agent comes to a state and takes an action, it receives a reward. The reward is used to update the Q value of the agent. The overall Q-learning principle diagram for CBESS is summarized in
Figure 2.
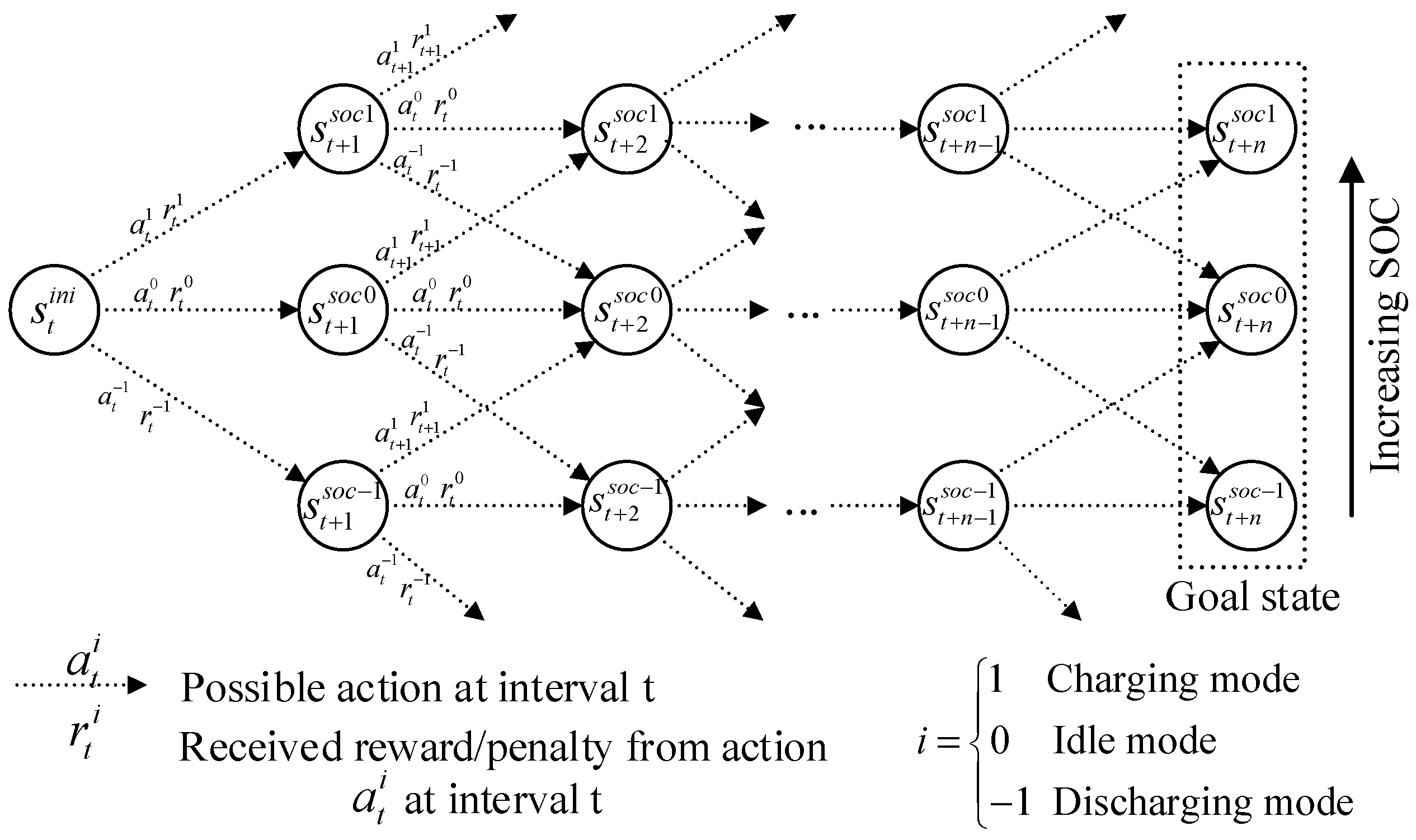
Figure 3 shows the states and possible actions of CBESS. In this study, each state is a vector
s with three features: time interval, SOC of CBESS, and market price signal at the current interval. The CBESS agent starts from an initial state with an initial value of SoC and initial interval
t. The CBESS is operated for a 24-hour scheduling horizon and each time interval is set to be one hour. Therefore, the initial interval
t is usually taken as the first interval (
t = 1). CBESS chooses a random action and receives a reward according to the action. CBESS will perform several actions until reaching the goal state. CBESS can be either in charging, discharging, or idle mode in each state. Thus, SoC of CBESS can also be increased, decreased, or kept the same with the previous state depending on the choosing action and charging/discharging amount. This amount could be any values in the operation bounds of CBESS. There are some special cases, as following.
If the CBESS is fully charged, it cannot charge more. In case the CBESS decides to charge, it is facing a high penalty to avoid this action in the future and the suitable actions are discharging or idle mode. In contrast, if the CBESS is fully discharged, the CBESS cannot discharge more. It is facing a high penalty for a discharge decision and the suitable actions are charging or idle mode. The objective of CBESS is to maximize its profit by optimal charging/discharging decisions. This can be obtained by maximizing the cumulative reward following the Q-table. The reward function for CBESS is determined by Algorithm 1 based on the chosen action. In grid-connected mode, the charging/discharging price signals are taken from the market price signals. However, in islanded mode, MG-EMS decides the charging/discharging price signals to increase the utilization of CBESS for minimizing load shedding amount. For instance, during off-peak load intervals, the charging price is low, CBESS buys surplus power for charging mode. During the peak load intervals, in order to avoid load shedding in the MG system, the discharging price is high. Thus CBESS discharges power to fulfill the shortage power.
| Algorithm 1: Reward Function for CBESS |
- 1:
Input: a state s and action a - 2:
ifa = “charge” do - 3:
if SoC = SoCmax do - 4:
r = a high penalty - 5:
else - 6:
r = −Pchar.price - 7:
end if - 8:
else ifa = “idle” do - 9:
r = 0 - 10:
elsea = “discharge” do - 11:
if SoC = SoCmax do - 12:
r = a high penalty - 13:
else - 14:
r = Pdis.price - 15:
end if - 16:
end if
|
The learning strategy for CBESS is summarized in Algorithm 2. Firstly, the discount factor (
γ) and learning rate (
α) are taken as input data for the algorithm. The value of the discounted factor contributes to determining the value of the future reward. This value varies from 0 to 1, in case the value is near 0, the immediate reward is given preference and in case the value is near 1, the importance of future rewards is increased. The learning rate affects the speed of convergence of Q values. The value of the learning rate also varies from 0 to 1. However, it should be a small value to ensure the convergence of the model. Therefore, the value of the discount factor and learning rate are 0.99 and 0.1, respectively. The CBESS agent explores the environment for a large number of episodes. In each episode, the CBESS agent starts from an initial state (interval
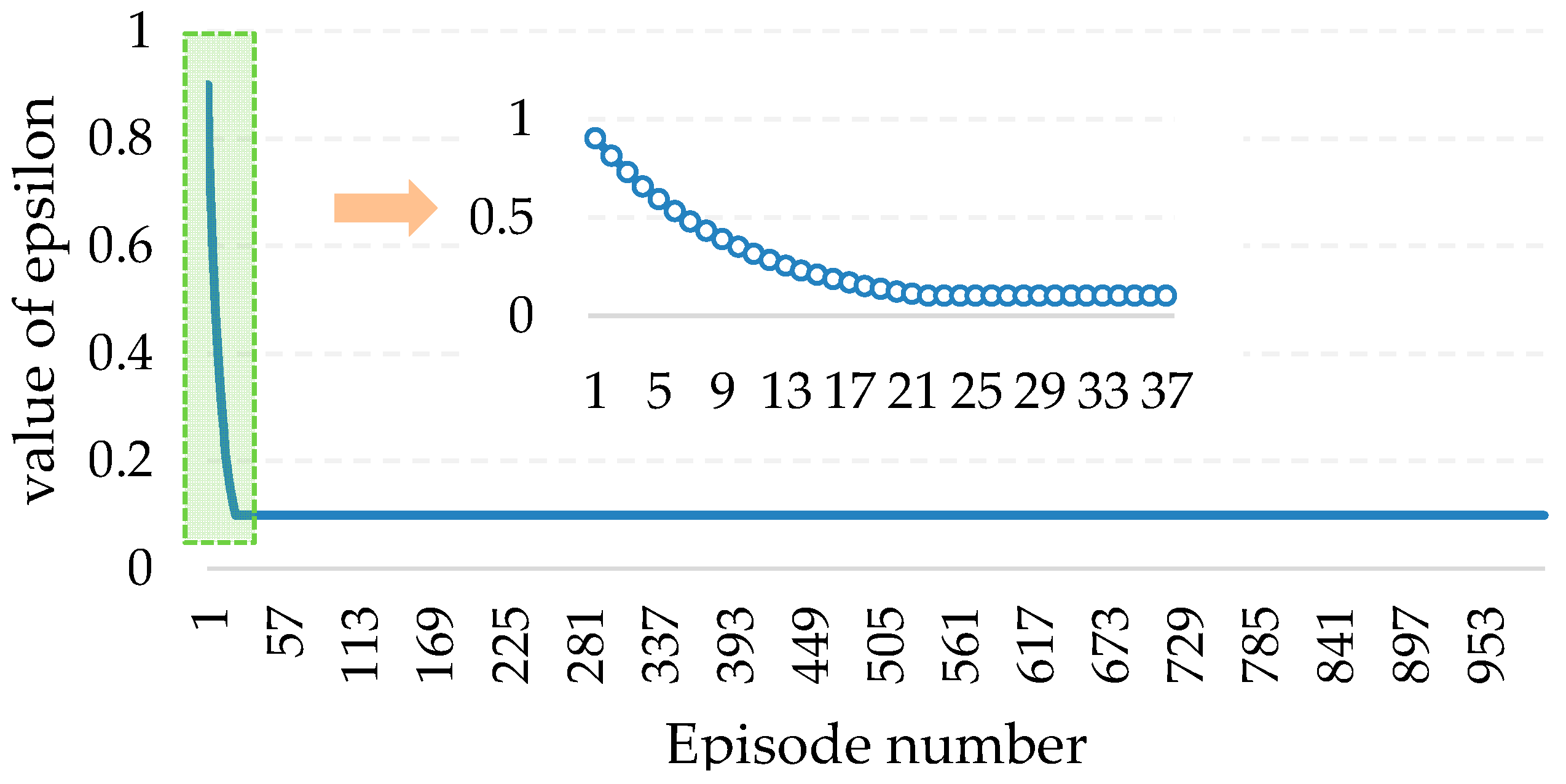
t = 1 with an initial value of SoC), the agent performs several actions until reaching the goal state and updates its knowledge (Q-table). The choosing action is based on the epsilon-greedy policy, which is a way of selecting random actions with uniform distribution from a set of possible actions [
24,
25].
| Algorithm 2: Q-Learning-Based Operation Strategy for CBESS |
- 1:
Input data: setting - 2:
Initialize a Q-table arbitrarily · - 3:
forepisode < episodemaxdo - 4:
while s is not terminal do - 5:
Initialize a starting state s (i.e., interval = 1, SoC = SoCini, and market price (interval = 1)) - 6:
Select a possible action a from s using ε-greedy policy - 7:
Take action a and observe reward r, and come to state s’ (Algorithm 1) - 8:
if s’ is not in Q-table do - 9:
Initialize Q(s’, ai) = 0 - 10:
end if - 11:
Update the Q-table: - 12:
Update state s to the next state s’ with new SoC - 13:
if interval = 24 do - 14:
s is terminal - 15:
end if - 16:
end while - 17:
end for
|
Using this policy, the agent selects a random action with
ε probability and an action with a probability of (1 −
ε) that gives a maximum reward in a given state. After performing an action, the Q value is updated by using Equation (1).
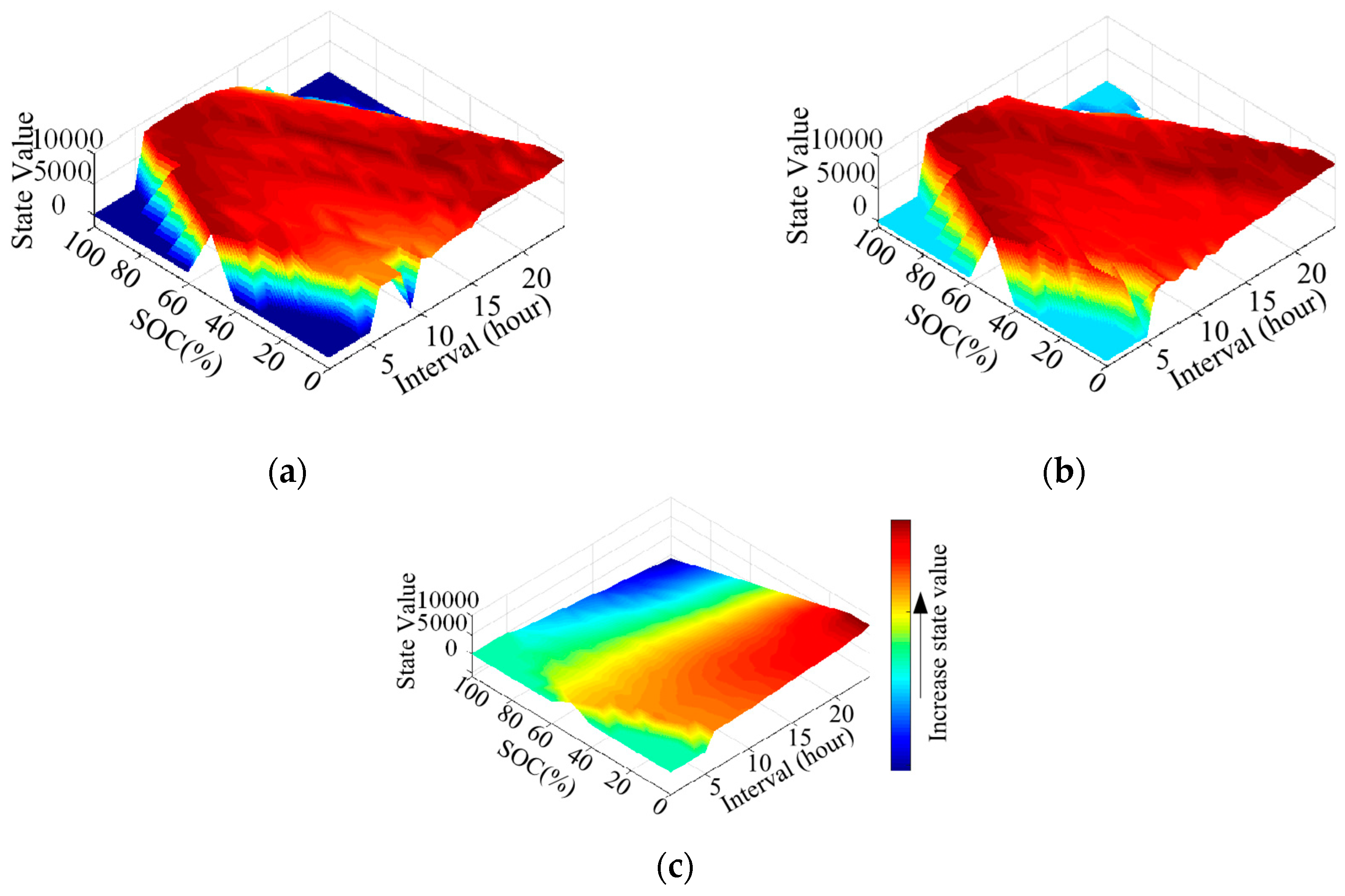
The current state is moved to a next state with updated SoC. The process for each episode is terminated when the goal state is reached. The CBESS can find optimal actions after exploring the environment with a large number of episodes.
2.3. Operation Strategy for Microgrid and CBESS
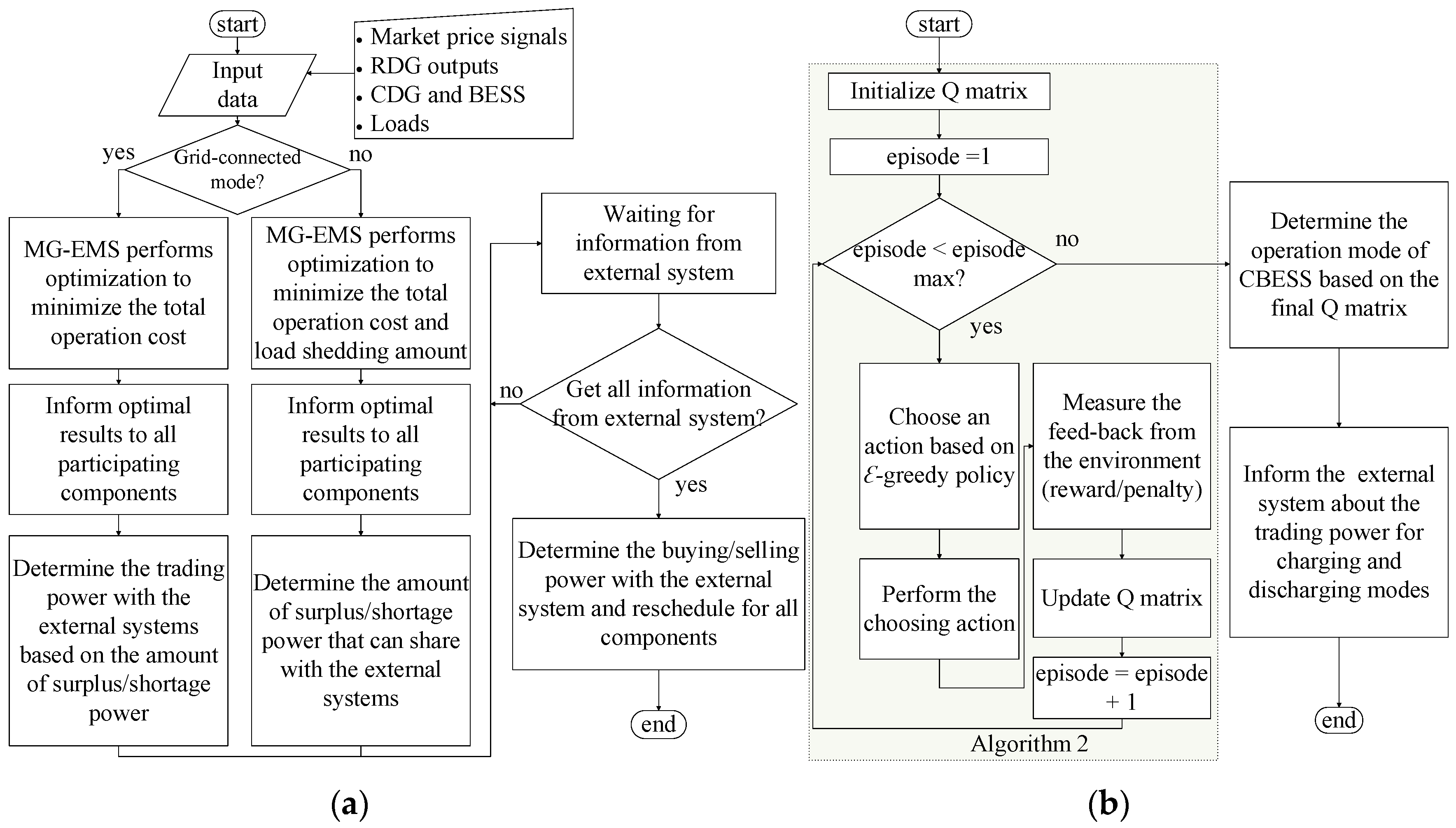
Figure 4 shows the detailed operation strategy for MG and CBESS. In the grid-connected mode, MG-EMS receives the market price signals from the utility grid. MG-EMS also gathers all information of the MG system and performs optimization to minimize the total operation cost. The amount of surplus/shortage power is determined based on the optimal results. Then the MG-EMS waits for information from the other external systems. The CBESS also learns from the environment and updates its knowledge according to Algorithm 2. The amount of charging/discharging power is determined at the end of the process. All information for trading amount with the external system is informed by CBESS. After gathering the information from the CBESS and the utility grid, MG-EMS decides the amount of buying/selling power from/to the utility grid and CBESS and informs the optimal results to its components. In islanded mode, there is no connection to the utility grid. Load shedding could be implemented to maintain the power balance. In order to reduce the amount of load shedding, CBESS could be in cooperative operation mode with the MG. After performing optimization by MG-EMS, the information of surplus/shortage power is determined in each interval of time. Similarly, CBESS learns with a large number of episodes for optimizing its operation based on the feedback from MG-EMS. The final operation of CBESS is informed to MG-EMS with the charging/discharging amount. Finally, MG-EMS reschedules the operation of all the components based on the charging/discharging amount from CBESS. Load shedding is implemented for maintaining the power balance in the whole system in case of having a shortage of power.
2.4. Mathematical Model
In this section, a mixed integer linear program (MILP)-based formulation is presented for day-ahead scheduling (i.e.,
T = 24 h) for all components in MG system for both grid-connected and islanded modes. In grid-connected mode, the objective function (2) is to minimize the total operation cost associated with the fuel cost, start-up/shut-down cost of CDGs, and cost/benefit of purchasing/selling power from/to the utility grid, as shown in Equation (2).
The constraints associated with CDGs include Equations (3)–(8). Constraint (3) enforces the upper and lower operation bounds of CDGs. Equation (4) gives the on/off status of CDGs. The start-up and shut-down modes are determined by using constraints (5) and (6) based on the on/off status of CDGs. The bounds for ramp up/ramp down rates of CDGs are enforced by Equations (7) and (8), respectively.
The power balance between the power sources and power demand is given by Equation (9). The buying/selling power is the amount of power trading with the external systems, which is divided into trading with the utility grid or CBESS, as given in Equations (10) and (11), respectively.
The constraints related to BESS include Equations (12)–(16). Constraint (12) and (13) are the maximum charging/discharging power of the BESS. The value of SoC is updated by Equation (14) after charging/discharging power at each interval of time. Equation (15) shows the value of SoC is set by initial SoC at the first interval of time (
t = 1). The operation bounds of BESS are enforced by (16).
In grid-connected mode, CBESS also optimizes its operation to maximize its profit. The CBESS is decided to charge power from the utility grid during off-peak price intervals or from the MG. It is in discharging mode during peak price intervals. The constraints for CBESS in grid-connected mode are shown in Equations (17)–(23). The total CBESS charging/discharging amount are the sum of charging/discharging power from/to both the utility grid and MG, as shown in Equations (17) and (18). The charging and discharging bounds are given by Equations (19) and (20). In this paper, the maximum charging/discharging power is 10% of the capacity of CBESS at each interval of time [
22]. The value of SoC of CBESS is updated by using Equations (21) and (22). Finally, the operation bounds of CBESS is enforced by Equation (23).
In islanded mode, the system is disconnected from the utility grid. MG system can only trade its surplus/shortage power with CBESS. In peak intervals, MG and CBESS could not fulfill the power demand in the system. Therefore, the load shedding should be performed to keep the power balance in the system. In order to reduce the load shedding amount, MG-EMS performs optimization for minimizing both the total operation cost and the load shedding amount. The cost objective function is changed to (24) with the generation cost and the penalty for load shedding. The power balance of the power source and power demand is given by Equation (25) for the islanded mode. Additionally, the objective function (24) is also constrained by Equations (3)–(8) and Equations (12)–(16).
In the islanded mode, the objective of CBESS is to reduce the amount of shortage power in MG system by optimal charging/discharging mode decisions. The CBESS is decided to charge surplus power from the MG system and discharge during intervals having shortage power. Constraints (26) and (27) show the bounds for charging/ discharging amount at an interval of time. These constraints also ensure that the charging mode is possible when the MG has surplus power, while the discharging mode is possible when the MG has shortage power. Additionally, the CBESS are also constrained by Equations (21)–(23) for updating the value of SoC and operation bounds of CBESS.
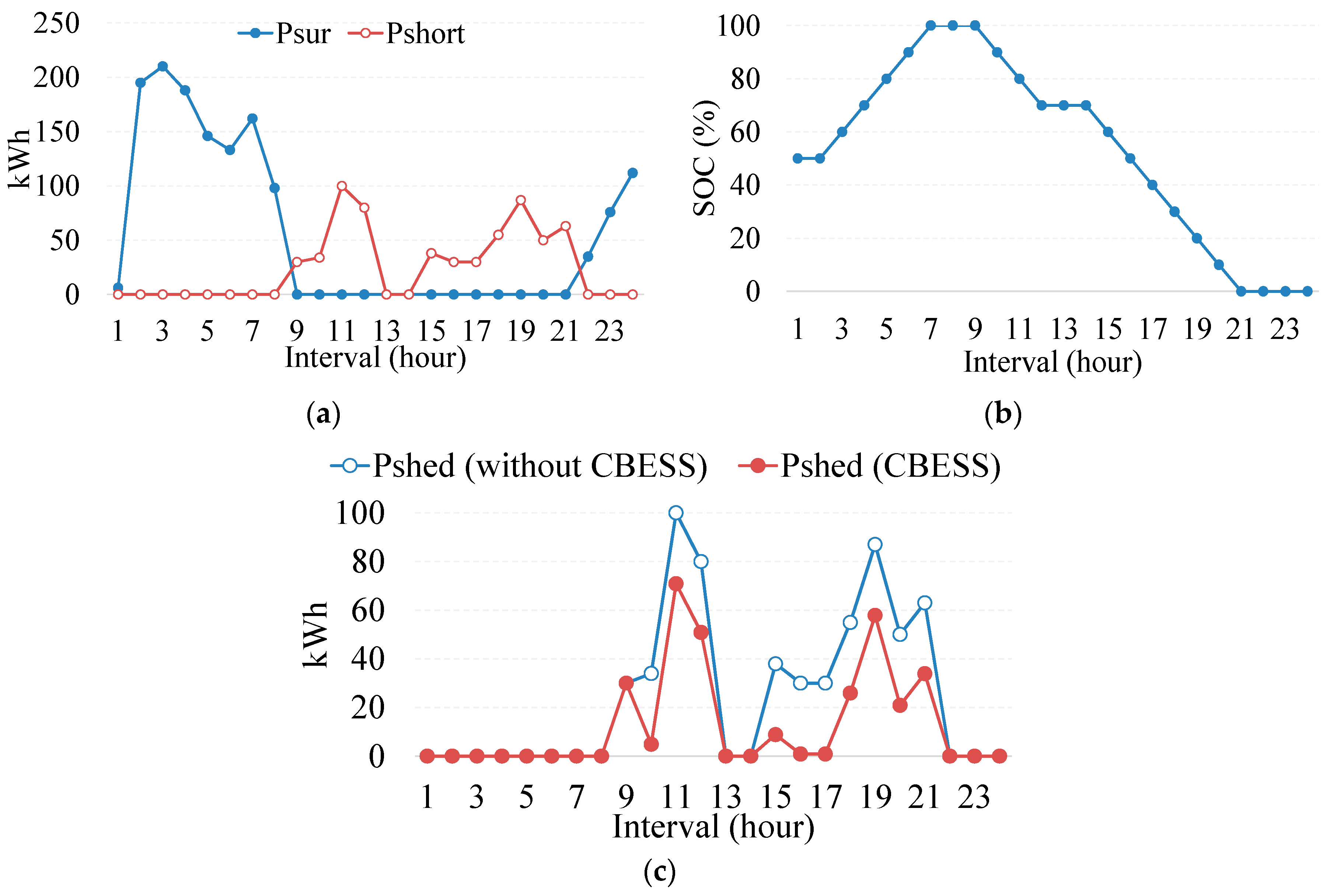
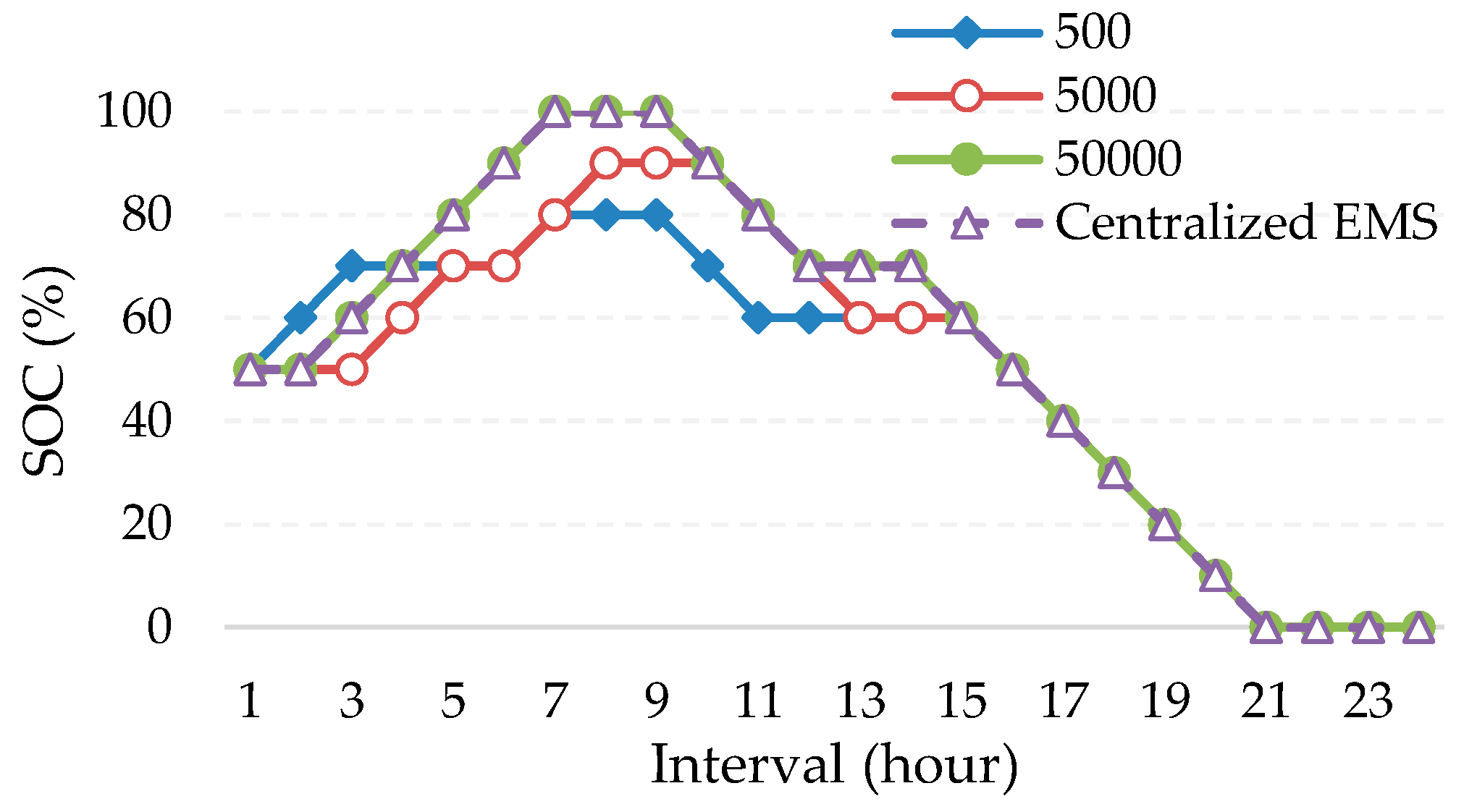
In this paper, a Q-learning-based operation strategy for CBESS is proposed for the optimal operation of CBESS. To show the effectiveness of the Q-learning-based operation, the results of Q-learning-based operation methods are compared with the results of the centralized operation method. The detailed numerical results are presented in the following section.
4. Future Extension of the Proposed Strategy
In this study, an operation strategy for CBESS is proposed for maximizing profit in the grid-connected mode and reducing load shedding in islanded mode. The operation of CBESS is determined based on the information of the forecasted market price signals and surplus/shortage power of the MG. However, it is difficult to determine this information exactly. Thus the operation strategy of CBESS considering the uncertainties of market price signals and surplus/shortage power should be considered. These uncertainties result in a large state space, i.e., continuous state space.
As discussed in the previous section, in Q-learning, a Q-table is used to represent the knowledge of the agent about the environment. The Q-value for each state and action pair reflects the future reward associated with taking such an action in this state. However, Q-learning-based operation methods are only suitable for problems with small state space. They are not suitable for a continuous state space or for an environment with uncertainties. With any new state, the agent has to learn again to update the Q-table for optimizing the decisions. This could take a long time for the learning process in a real-time problem. Therefore, a model which maps the state information provided as input to Q-values of the possible set of actions should be developed, i.e., the Q-function approximator [
28,
29,
30]. To solve this problem, Q-learning is combined with a deep neural network, which is called deep Q-learning method to enhance the performance of Q-learning for large scale problems. The operation strategy of CBESS using deep Q-learning will be discussed in a future extension of this study considering a continuous state space.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}