Surrogate Model with a Deep Neural Network to Evaluate Gas–Liquid Flow in a Horizontal Pipe



Abstract
:1. Introduction
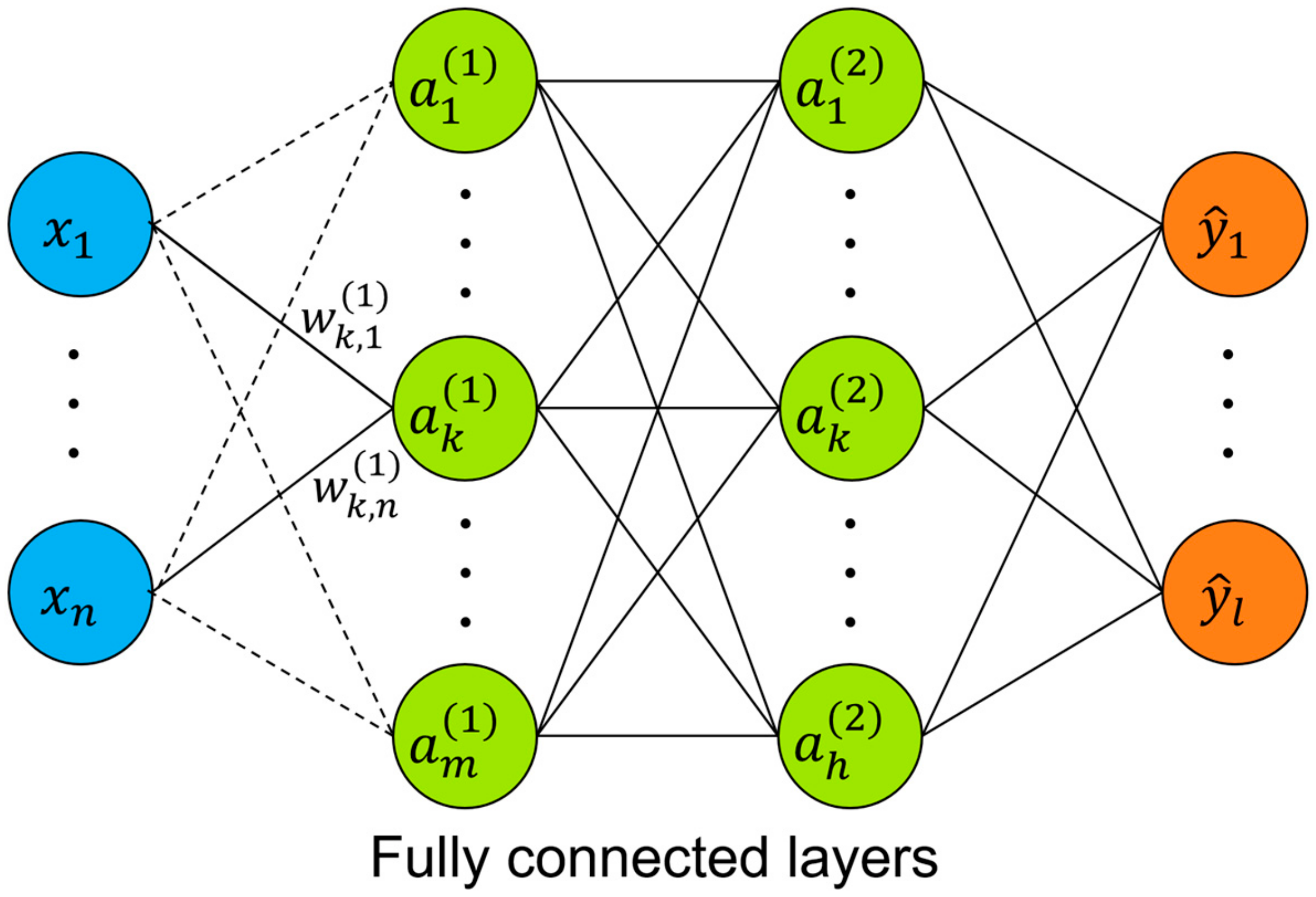
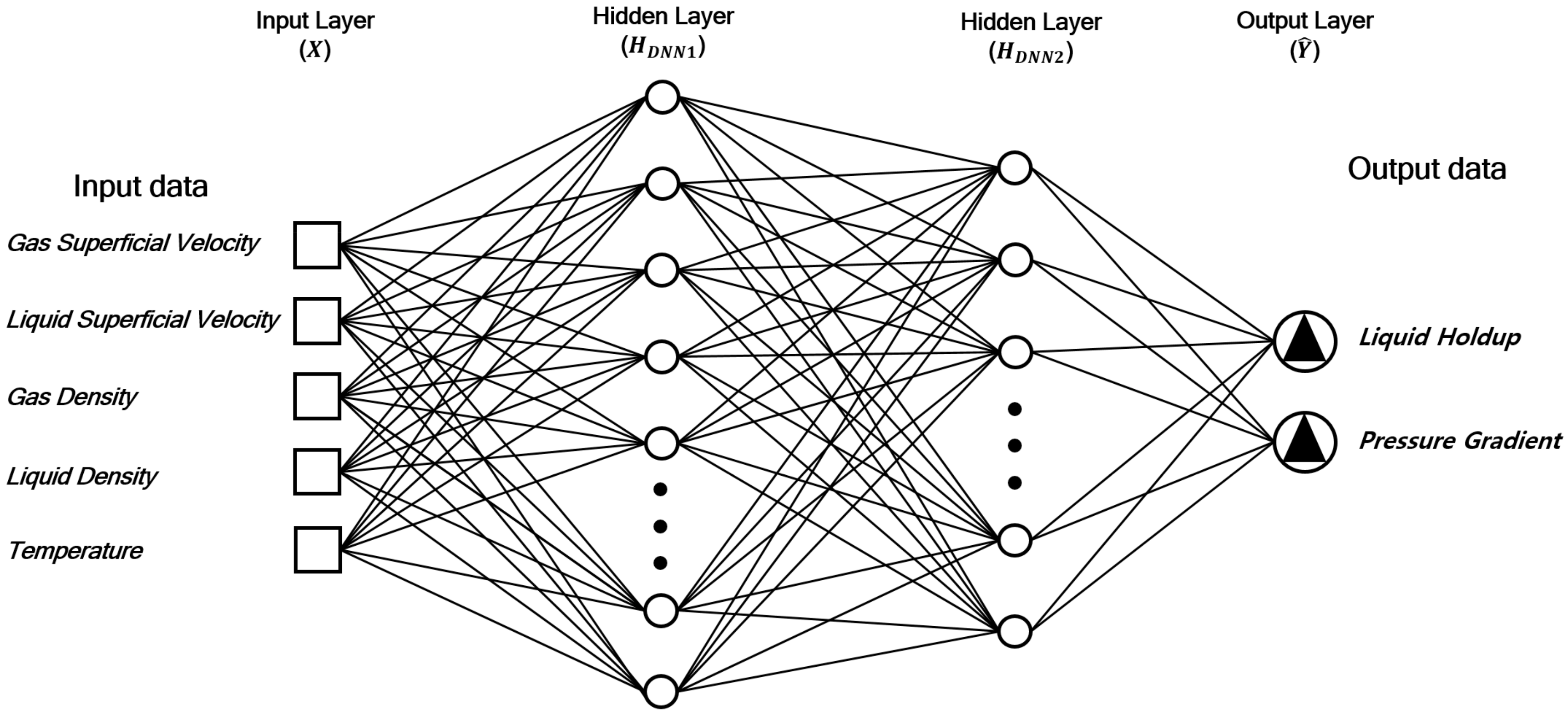
2. Methodology
3. Results and Discussion
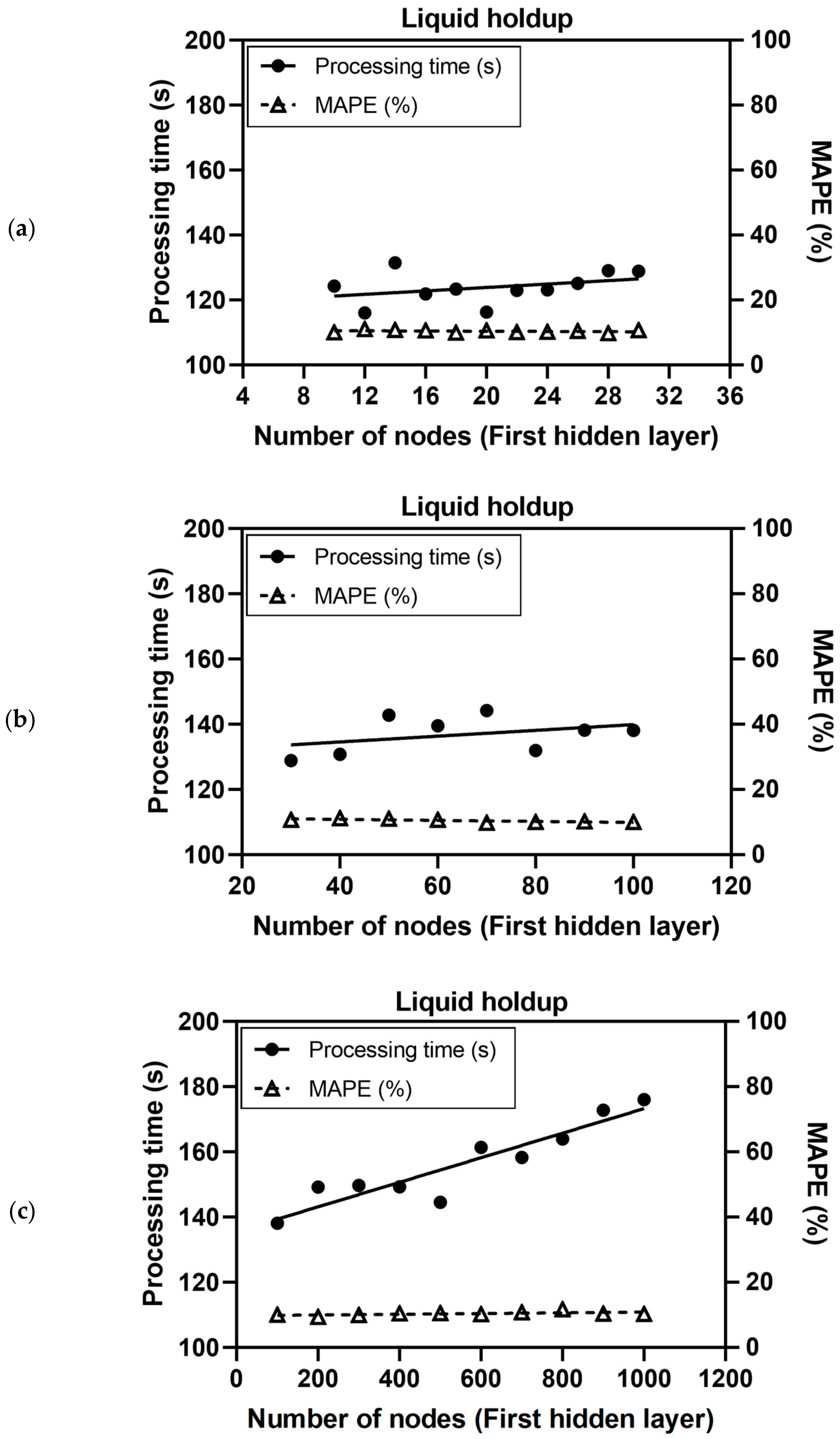
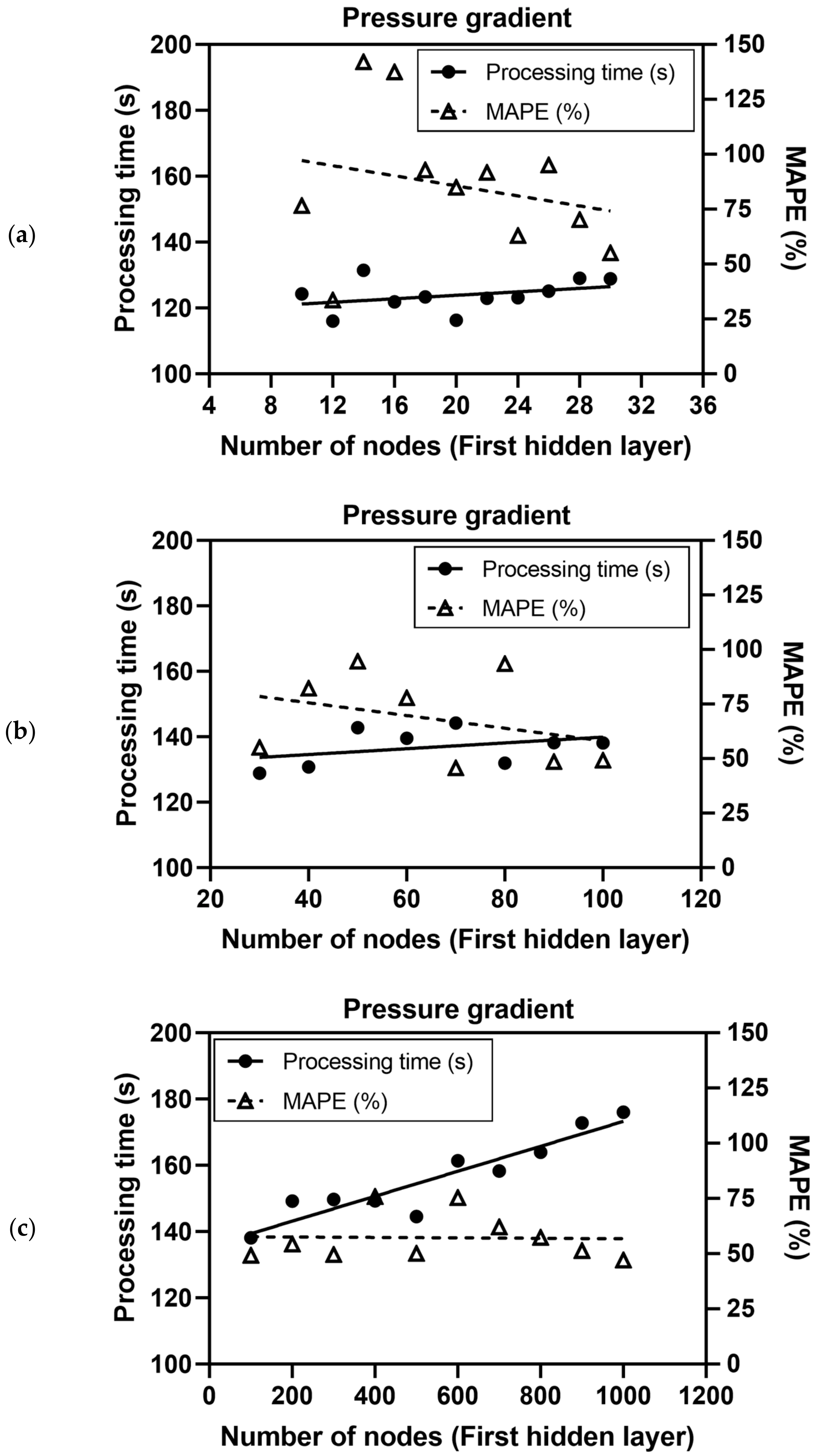
3.1. Design of the Deep Neural Network: The Number of Hidden Neurons
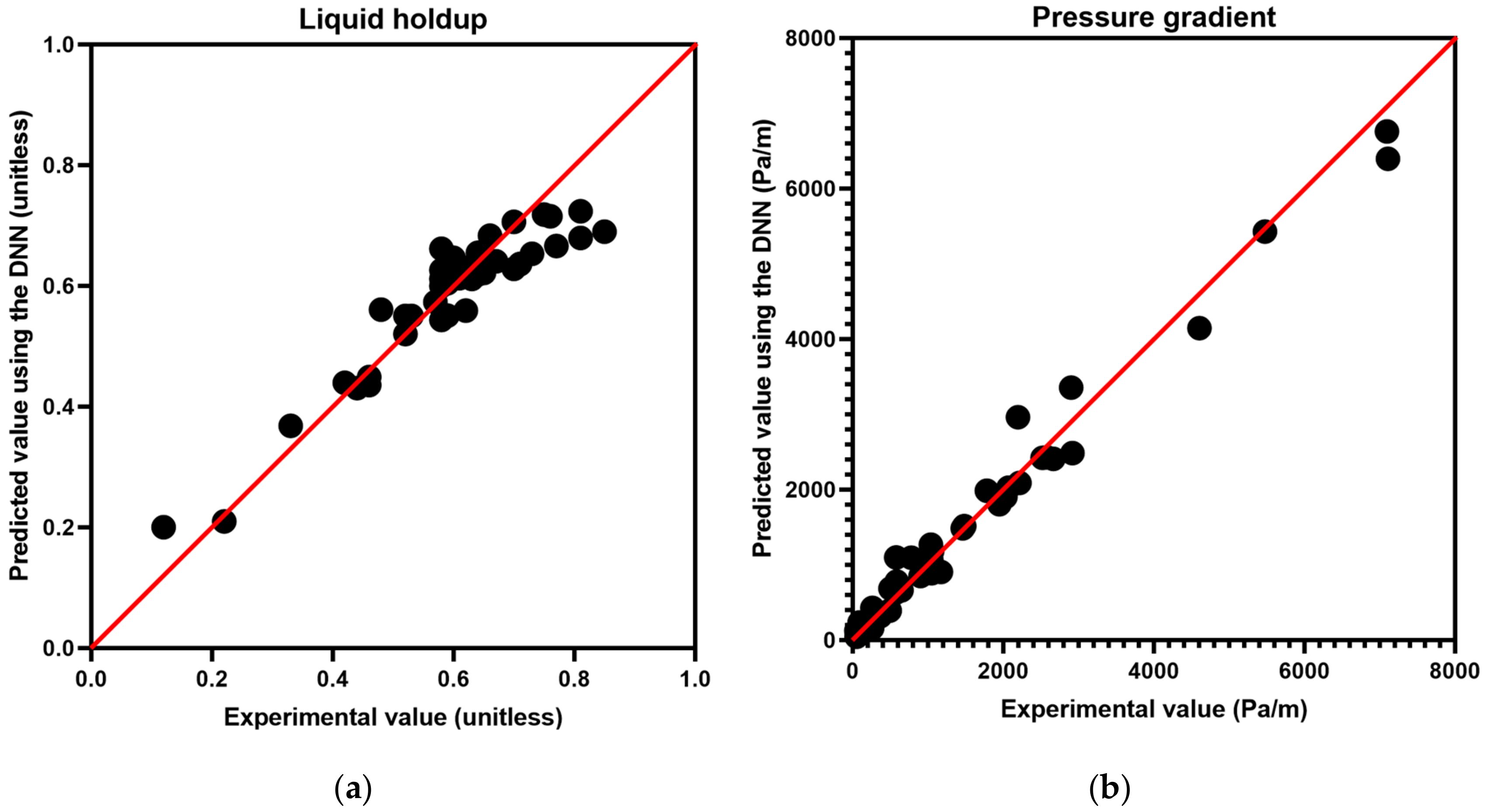
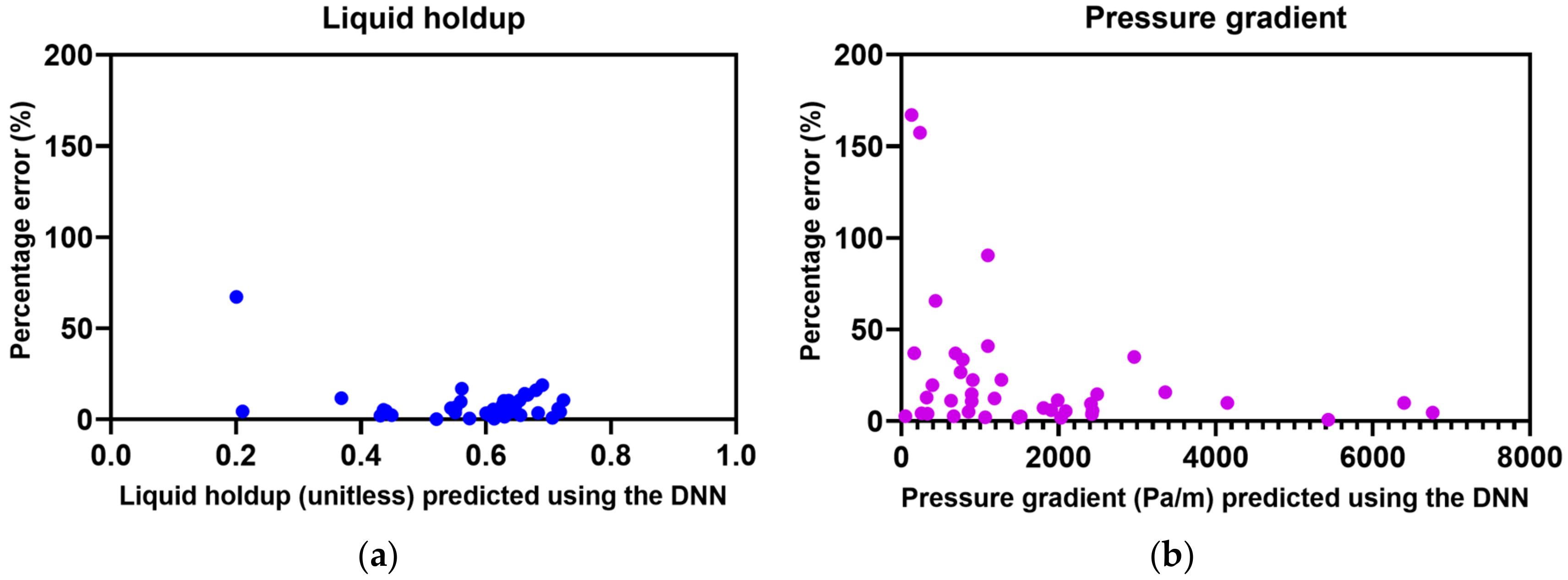
3.2. Prediction Accuracy of the Liquid Holdups and Pressure Gradients
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Choi, J.; Pereyra, E.; Sarica, C.; Lee, H.; Jang, I.; Kang, J. Development of a fast transient simulator for gas–liquid flow in pipes. J. Petro. Sci. Eng. 2013, 102, 27–35. [Google Scholar] [CrossRef]
- López, J.; Pineda, H.; Bello, D.; Ratkovich, N. Study of liquid–gas two–phase flow in horizontal pipes using high speed filming and computational fluid dynamics. Exp. Therm. Fluid. Sci. 2016, 76, 126–134. [Google Scholar] [CrossRef]
- Ottens, M.; Hoefsloot, H.C.J.; Hamersma, P.J. Correlations predicting liquid hold–up and pressure gradient in steady–state (nearly) horizontal co–current gas–liquid pipe flow. Chem. Eng. Res. Des. 2001, 79, 581–592. [Google Scholar] [CrossRef]
- Meng, W.; Chen, X.T.; Kouba, G.E.; Sarica, C.; Brill, J.P. Experimental study of low–liquid–loading gas–liquid flow in near–horizontal pipes. SPE Prod. Facil. 2001, 16, 240–249. [Google Scholar] [CrossRef]
- Vielma, J.C.; Shoham, O.; Mohan, R.S.; Gomez, L.E. Prediction of frictional pressure gradient in horizontal oil/water dispersion flow. SPE J. 2011, 16, 148–154. [Google Scholar] [CrossRef]
- Choi, J.; Pereyra, E.; Sarica, C.; Park, C.; Kang, J. An efficient drift–flux closure relationship to estimate liquid holdups of gas–liquid two–phase flow in pipes. Energies 2012, 5, 5294–5306. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Al–Sarkhi, A.; Pereyra, E.; Sarica, C.; Park, C.; Kang, J.; Choi, J. Hydrodynamics model for gas–liquid stratified flow in horizontal pipes using minimum dissipated energy concept. J. Petro. Sci. Eng. 2013, 108, 336–341. [Google Scholar] [CrossRef]
- Xu, D.; Li, X.; Li, Y.; Teng, S. A two–phase flow model to predict liquid holdup and pressure gradient of horizontal well. In Proceedings of the SPE/IATMI Asia Pacific Oil & Gas Conference and Exhibition, Bali, Indonesia, 20–22 October 2015. SPE-176229. [Google Scholar] [CrossRef]
- Luo, C.; Zhang, L.; Liu, Y.; Zhao, Y.; Xie, C.; Wang, L.; Wu, P. An improved model to predict liquid holdup in vertical gas wells. J. Petro. Sci. Eng. 2020, 184, 106491. [Google Scholar] [CrossRef]
- Osman, E.A. Artificial neural networks models for identifying flow regimes and predicting liquid holdup in horizontal multiphase flow. In Proceedings of the SPE Middle East Oil Show, Manama, Bahrain, 17–20 March 2001. SPE-68219. [Google Scholar] [CrossRef]
- Shippen, M.E.; Scott, S.L. A neural network model for prediction of liquid holdup in two–phase horizontal flow. SPE Prod. Facil. 2004, 19, 67–76. [Google Scholar] [CrossRef]
- Al-Naser, M.; Elshafei, M.; Al-Sarkhi, A. Artificial neural network application for multiphase flow patterns detection: A new approach. J. Petro. Sci. Eng. 2016, 145, 548–564. [Google Scholar] [CrossRef]
- Mask, G.; Wu, X.; Ling, K. An improved model for gas–liquid flow pattern prediction based on machine learning. J. Petro. Sci. Eng. 2019, 183, 106370. [Google Scholar] [CrossRef]
- Kanin, E.A.; Osiptsov, A.A.; Vainshtein, A.L.; Burnaev, E.V. A predictive model for steady–state multiphase pipe flow: Machine learning on lab data. J. Petro. Sci. Eng. 2019, 180, 727–746. [Google Scholar] [CrossRef] [Green Version]
- Mohammadi, S.; Papa, M.; Pereyra, E.; Sarica, C. Genetic algorithm to select a set of closure relationships in multiphase flow models. J. Petro. Sci. Eng. 2019, 181, 106224. [Google Scholar] [CrossRef]
- Reed, R.; Marks, R.J. Neural Smithing: Supervised Learning in Feedforward Artificial Neural Networks; MIT Press: London, UK, 1999; ISBN 9780262282215. [Google Scholar]
- Hinton, G.; Osindero, S.; Teh, Y. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Mishra, S.; Datta–Gupta, A. Applied Statistical Modeling and Data Analytics: A Practical Guide for the Petroleum Geosciences; Elsevier: Amsterdam, The Netherlands, 2018; ISBN 9780128032794. [Google Scholar] [CrossRef]
- Beggs, D.H.; Brill, J.P. A study of two–phase flow in inclined pipes. J. Petrol. Technol. 1973, 25, 607–617. [Google Scholar] [CrossRef]
- Shoham, O. Mechanistic Modeling of Gas–liquid Two–phase Flow in Pipes; Society of Petroleum Engineers: Richardson, TX, USA, 2006; ISBN 9781555631079. [Google Scholar]
- Al-Safran, E.M.; Brill, J.P. Applied Multiphase Flow in Pipes and Flow Assurance: Oil and Gas Production; Society of Petroleum Engineers: Richardson, TX, USA, 2017; ISBN 978613994924. [Google Scholar]
- Gokcal, B. Effects of High Viscosity on Two-Phase Oil-Gas Flow Behaviour in Horizontal Pipes. Master’s Thesis, University of Tulsa, Tulsa, OK, USA, 2005. [Google Scholar]
- Gokcal, B. An Experimental and Theoretical Investigation of Slug Flow for High Oil Viscosity in Horizontal Pipes. Ph.D. Thesis, University of Tulsa, Tulsa, OK, USA, 2008. [Google Scholar]
- Leung, H.; Haykin, S. The complex backpropagation algorithm. IEEE T. Signal Process. 1991, 39, 2101–2104. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2017, arXiv:1609.04747. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human–level performance on imageNet classification. arXiv 2017, arXiv:1502.01852v1. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Data | Parameters 1 | Number of Data Points |
|---|---|---|
| Gokcal [23] | Air and oil (Citgo sentry 220 oil) ID = 0.0508 m, T = 20.8–38.1 °C ρL = 833.6–884.5 kg/m3, ρG =1.25–4.5 kg/m3 vSL = 0.01–1.76 m/s, vSG = 0.09–20.3 m/s Annular (33) 2, annular/slug (4), stratified wavy (3), slug (120), elongated bubble (19), dispersed bubble/slug (4) | 183 |
| Gokcal [24] | Air and oil (Citgo sentry 220 oil) ID = 0.0508 m, T = 20.8–38.1 °C ρL = 833.6–884.5 kg/m3, ρG = 1.12–2.08 kg/m3 vSL = 0.05–0.8 m/s, vSG = 0.1–2.17 m/s Slug (167) | 167 |
| Training Operation | Prediction (Test Set) | ||
|---|---|---|---|
| Training | Validation | ||
| Number of Data Points | 279 | 31 | 40 |
| Flow pattern | Annular (31), annular/slug (3), stratified wavy (3), elongated bubble (14), dispersed bubble/slug (4), slug (257) | Annular (4), annular/slug (1), elongated bubble (5), slug (30) | |
| Number of Nodes 1 (First Hidden Layer) | Processing Time (s) | RMSE | MAPE (%) |
|---|---|---|---|
| 10–30 | 116.02–131.49 | 0.0648–0.0742 () 681.04–838.40 () | 9.778–11.015 () 33.564–142.051 () |
| 30–100 | 128.87–144.19 | 0.0648–0.0721 () 618.04–773.73 () | 9.791–11.170 () 45.690–94.514 () |
| 100–1000 | 138.16–176.02 | 0.0632–0.0735 () 615.87–903.84 () | 9.376–11.687 () 47.104–75.831 () |
| Parameter | RMSE | MAPE (%) | R2 |
|---|---|---|---|
| Liquid holdup | 0.0056 | 8.07868 | 0.8855 |
| Pressure gradient | 261.6052 | 23.7609 | 0.9802 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seong, Y.; Park, C.; Choi, J.; Jang, I. Surrogate Model with a Deep Neural Network to Evaluate Gas–Liquid Flow in a Horizontal Pipe. Energies 2020, 13, 968. https://doi.org/10.3390/en13040968
Seong Y, Park C, Choi J, Jang I. Surrogate Model with a Deep Neural Network to Evaluate Gas–Liquid Flow in a Horizontal Pipe. Energies. 2020; 13(4):968. https://doi.org/10.3390/en13040968
Chicago/Turabian StyleSeong, Yongho, Changhyup Park, Jinho Choi, and Ilsik Jang. 2020. "Surrogate Model with a Deep Neural Network to Evaluate Gas–Liquid Flow in a Horizontal Pipe" Energies 13, no. 4: 968. https://doi.org/10.3390/en13040968
APA StyleSeong, Y., Park, C., Choi, J., & Jang, I. (2020). Surrogate Model with a Deep Neural Network to Evaluate Gas–Liquid Flow in a Horizontal Pipe. Energies, 13(4), 968. https://doi.org/10.3390/en13040968