Big Data for Energy Management and Energy-Efficient Buildings


Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Scalable Big Data Management
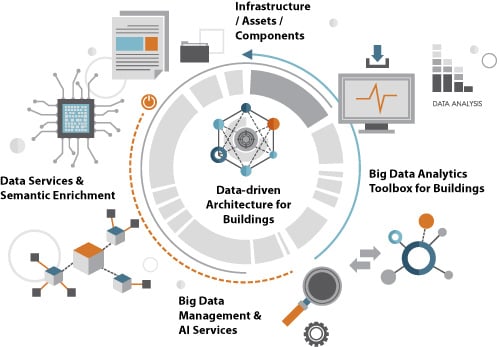
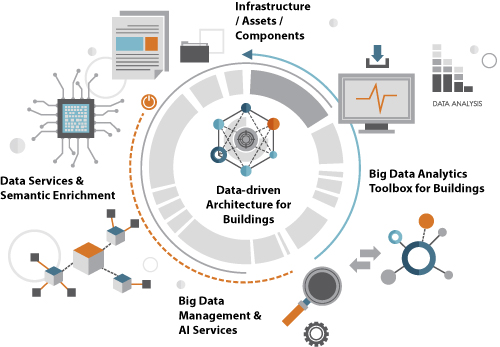
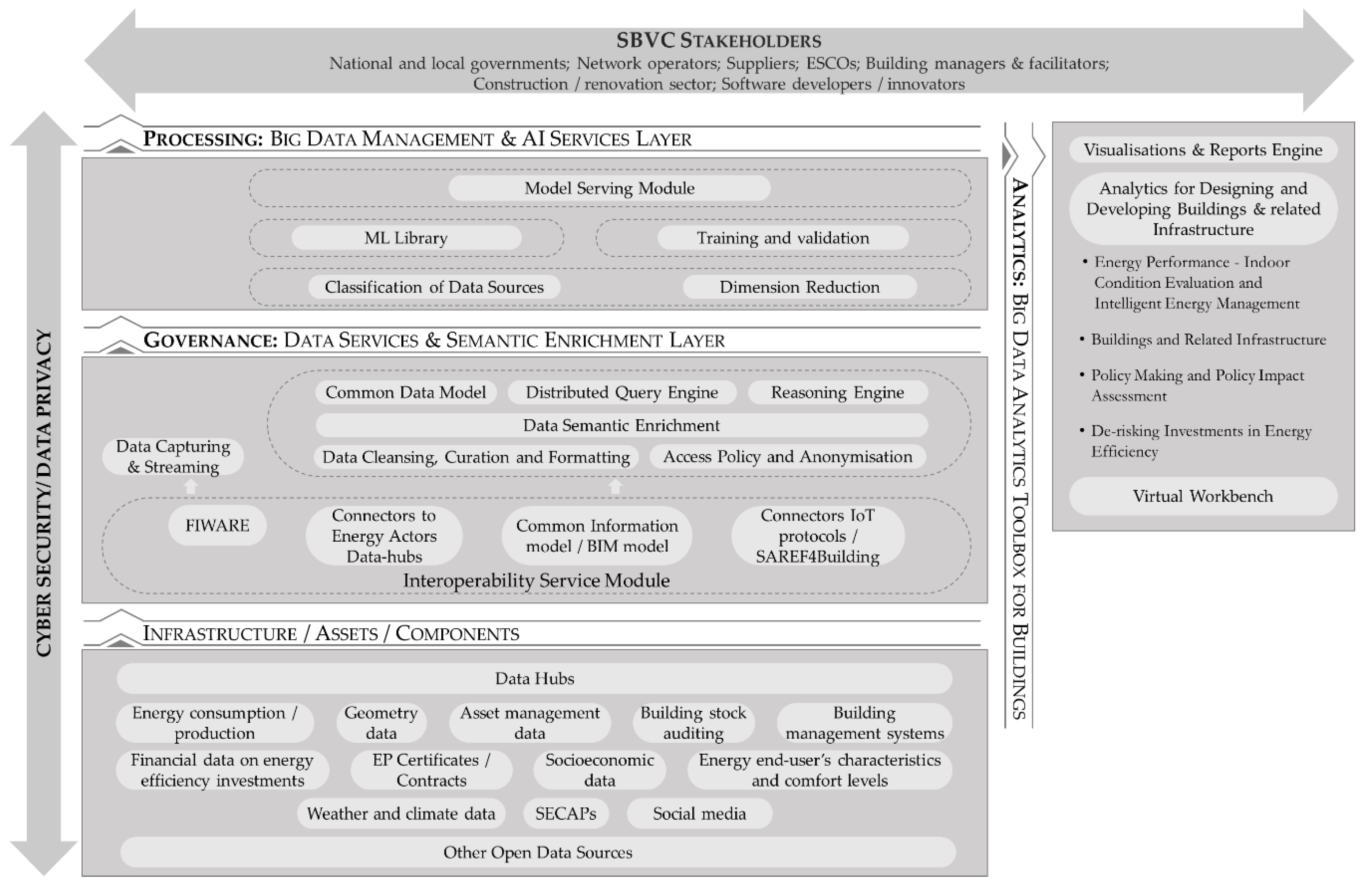
3. High-Level Architecture for Building Data
- The Governance Layer, encompassing modules related to data collection, semantic annotation and distributed storage.
- The Processing Layer, including ML and DL models.
- The Analytics Layer, providing a set of analytics tools.
3.1. Infrastructure/Asset/Components
3.2. Data Services and Semantic Enrichment
- At the bottom, an interoperability service module is in charge of facilitating data sharing from different sources and/or platforms belonging to different actors in the energy and non-energy ecosystem, such as smart meters, sensors, IoT devices, building management systems (BMSs), systems (TBMs), building automation and control systems (BACs), energy performance contracts, energy performance certificates, legacy systems. It is based on open standards, open APIs (e.g., NGSI-LD CIM APIs [54]) and open data models (e.g., FIWARE Smart Energy Reference Architecture [55], Building Information Modeling (BIM) [56], Smart Appliances REFerence (SAREF) [57]). Interfaces to other third-party energy and non-energy datasets/data platforms willing to federate/integrate with the proposed framework are provided, with a view to allowing the incremental population of the platform’s data hub.
- Data Cleansing Curation and Formatting Module is an umbrella term for tasks that span from simple data pre-processing, such as restructuring, predefined value substitutions and reformatting of fields (e.g., dates) to more advanced processes, such as outliers’ detection and elimination from a dataset, data inconsistencies handling and noise reduction. To better organize the data collected and facilitate their future use, special ML pre-processing algorithms are developed for automatically cleansing and formatting it. This includes algorithms for normalizing their values, handling possible outliers, filling missing observations and dealing with different timestamp formats. The abovementioned algorithms take into consideration the particular characteristics of the data examined, such as their frequency, trend, seasonality, cycle, randomness and empirical distribution, enhancing that way the quality and the content of the constructed dataset, decreasing simultaneously the time required for training the algorithms of the toolbox and boosting their expected performance.
- Access Policy and Anonymization Module: The proposed framework incorporates enforcement policies mechanisms for data access policy brokerage, hence allowing to address and programmatically encapsulate (via DLT/smart contracts) specialized and context-based data hubs access policies brokerage. In order to be able to handle datasets containing sensitive information, this module also performs anonymization on the data ingestion process to protect this information, by either complete data removal-suppression, generalization or pseudonymity.
- Data Capturing and Streaming Module aimed to manage dynamically the frequency rate of the data streaming for the subsequent in-memory processing of the high latency near real time data. Such component could be tightly connected to the performance of some analytics.
- Data Semantic Enrichment Module is responsible for the semantic annotation and enrichment of data to facilitate their processing at upper analytics layers. Semantic enrichment uses well-established vocabularies and schemas related to the domains of energy, buildings, weather and climate, sensors network (e.g., SAREF4Building [58], BRICK schema [59], HAYSTACK [60], IFC [61], BACnet [62], LonMark [63]). The Common Data Model serves data interoperability by ensuring that all data processed by the system adhere to the same standards of semantics based on a common set of terms, concepts and relations across different data sources.
- On top of the data integration and semantic enrichment components, the platform enables easy access and querying of data to be exposed in upper analytics layer:
- Reasoning Engine—A Graph Database technology (i.e., AllegroGraph) can be used as a triplestore in order to persist the dataset semantics and any Resource Description Framework (RDF) information produced by the Semantic Enrichment Module. On top of that, a Semantic Reasoning Engine, such as PoolParty Semantic Classifier, Jena or BaseVisor is going to enable the application of semantic queries on the triplestore to retrieve the semantic information and improve the performance of reasoning operations to extract new insights. This component exposes intelligent querying and search capabilities as API to the Virtual Workbench or directly feeds UI and recommender engines supporting the analytics for designing and developing buildings and related infrastructure.
- Distributed Query Engine: The data retrieval from the distributed data warehouse is performed by utilizing a high-performance distributed query execution engine, like Presto, Tez or Apache Druid while also utilizing column-oriented approaches like MonetDB for handling the analytics workload. Such engines provide the ability to perform complex queries on a distributed Data Lake in very efficient and high-scalable way. The distributed query execution over a pure memory-based architecture allows the fast generation of the result-sets required from the analytical processes.
3.3. Big Data Management and AI Services
- Classification of data sources: In order for the AI-based analytics to be meaningful, accurate and easy to construct, their input variables have to be highly correlated and refer to the same time, place and application. For instance, when constructing a model for predicting the hourly energy produced by a Photovoltaic (PV) system, the weather forecasts exploited, such as radiation and temperature forecasts, must all be easy to track and refer to the same geographic location and time. Given the size and the diversity of the data present, retrieving the most relevant variables becomes a challenging problem, especially for cases of semi-structured or completely unstructured data. To deal with this problem, special ML algorithms are exploited to effectively classify the data available in terms of domain, type, location, time and frequency. These algorithms consider Natural Language Processing and Sentiment Analysis techniques to effectively process the description and the labels provided for each variable and classify them in representative classes based on their content (domain, type and location). The timestamp being available is also be processed to extract additional valuable information (frequency and time) and introduce further filters (sub-classes) that can improve the categorization of the available data and facilitate modelling.
- Dimension reduction: Identifying the most appropriate variables for solving a regression, classification or clustering problem is a complicated task, especially when lots and diverse data are present. To cope with this issue, dimension reduction ML algorithms are used to enable the identification and creation of principal variables, either through feature selection or feature extraction approaches. Such algorithms have been proven particularly effective when constructing deep learning models that effectively extract information from large unstructured datasets and provide solutions in a completely unsupervised way. For instance, Convolution Neural Networks can be exploited to minimize the pre-processing required for training other ML algorithms, filter and clear the raw information provided and boost the final performance of the algorithms.
- Training and validation: In order to make sure that the developed algorithms will be accurate and robust and mitigate the uncertainty present in the whole modelling process, the adoption of proper training and validation procedures becomes a prerequisite. Depending on the problem examined and the algorithms tested, different procedures and measures for assessing the performance of the available alternatives might be required. In this respect, the proposed framework involves a variety of training and evaluation procedures, as well as advanced criteria for selecting the most appropriate one per case. Simple holdout tests, cross-validation and random sampling are just some examples of the validation procedures that are considered, while Classification Accuracy, Logarithmic Loss, Confusion Matrix, F1 Score and Mean Absolute/Squared Error some of the indicative performance measures that will accompany them. Note that the type of the problem being solved (supervised or unsupervised learning / classification, regression or clustering), the size of the sample data and the objectives of the algorithm (accuracy vs. efficiency) is also taken into consideration for performing an incremental analysis and determining the selections made. Moreover, different hyper parameters are examined for each one of the considered algorithms and the most successive ones are adopted per case to maximize their potential and ensure that they are properly optimized for the particular training dataset.
- Library of ML algorithms: The Processing Layer provides a variety of advanced ML algorithms that are supported by diverse and multiple data to support, in a smart way, complex decisions related to energy management and energy-efficient services. The aim of these services is to enhance energy systems’ reliability and robustness, mitigate the effect of critical events and power unavailability, improve the profit-loss function of the power generation units, perform proactive analytics to track buildings’ performance and decrease the risk of malfunctions and deterioration, interact and exchange data between different power generation units to provide smart energy solutions at local level, provide accurate power & capacity forecasting and planning, exploit smart meter data to enhance energy conservation and promote efficiency, improve energy storage options and finally, provide powerful descriptive analytics and evaluations. Each algorithm has different data import requirements, pre-defined based on the type of decision support problem being supported. However, these requirements are as abstract and generalized as possible, in order to enable their direct utilization from the majority of the users and parties interested in their exploitation.
- Model Serving Module: It includes the set of the developed and trained models and constitutes the building block of the upper layer. These models are fed with both batch and streaming data coming from the Query Engine and the Data Streaming Module respectively. The models will be evaluated and refined over several iterations until will be finally used (served).
3.4. Big Data Analytics Toolbox for Buildings
- A Visualizations and Reports Engine, responsible for the visual representation of the stored data and the results produced from the analytical components. It offers a variety of visual representations including charts and map visualizations, based on specific Key Performance Indicators (KPIs).
- A range of innovative Analytics Building Services, such as: (1) Analytics for energy performance—indoor condition evaluation and intelligent energy management; (2) Analytics for building systems and infrastructure; (3) Analytics for policy making and policy impact assessment on building level; (4) Analytics for building efficiency investments.
- A ‘virtual workbench’, to incorporate a variety of assets, including data, third party services, ML models, computing resources, storage resources as tradable assets. It provides a set of tools targeting Small-Medium Enterprises (SMEs), developers, researchers and potential innovators, who design and develop new applications for the buildings sector. The tools at this level constitute a set of APIs exposing the ML/DL models and data to be tailored on specific circumstances and context provided by the users.
3.5. Cyber Security and Data Privacy
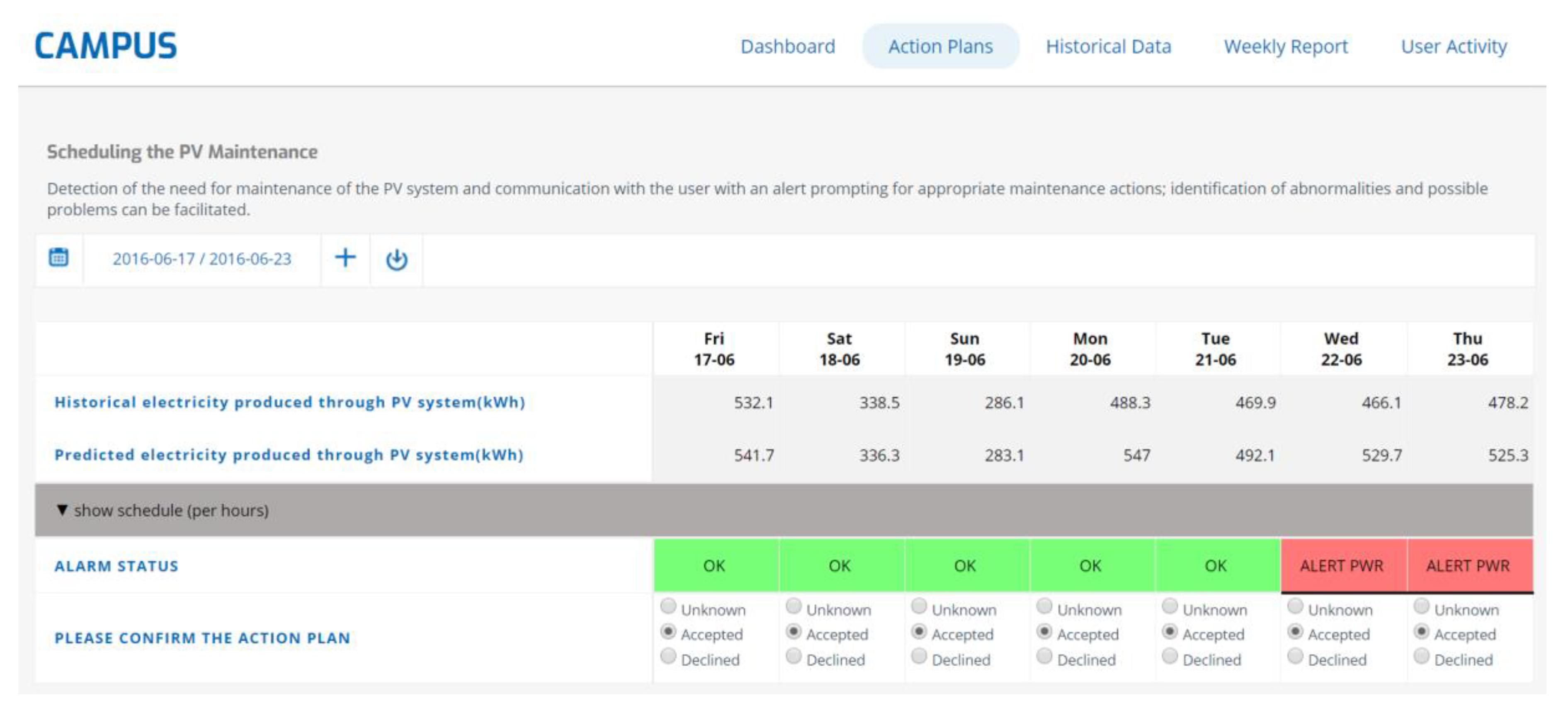
4. Case Study: Scheduling the PV Maintenance
4.1. Methodological Approach
4.2. Pilot Appraisal
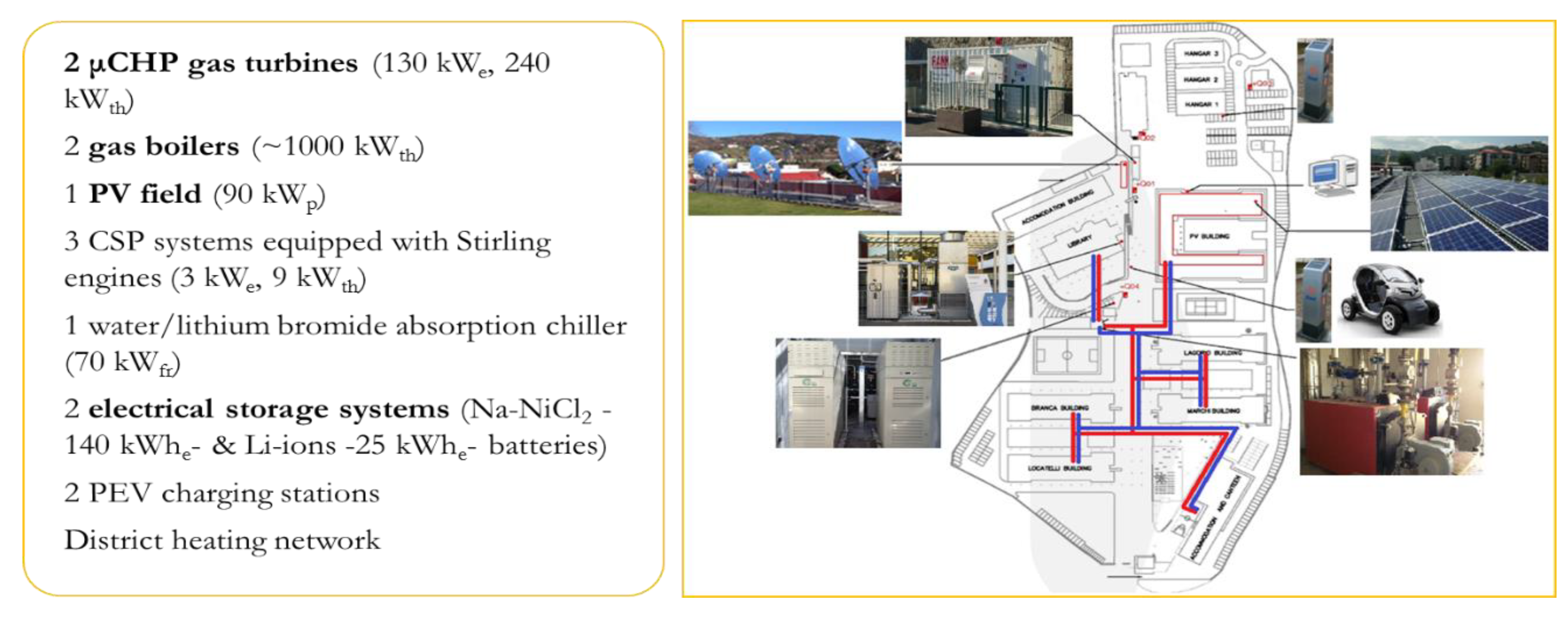
4.2.1. Infrastructure/Asset/Components
4.2.2. Data Governance and Processing
4.2.3. Data Analytics
4.2.4. Results
5. Enabling Data-Driven Applications and Services for Buildings
5.1. Data-Driven Management of Self-Production Systems in Energy Communities
5.2. SECAPs Impact Assessment, Implementation and Monitoring
- Data related to the planned actions’ characteristics and specific category: building, street lighting or transport action, as well as the type of the action (e.g., building insulation, etc.) and more specific characteristics, such as the envisaged energy savings, envelope design, construction techniques and materials, size, building type, appliances used, lighting technology etc.
- Data about the envisaged costs, discount rates used, as well as any calculated financial indicators, such as net present value (NPV), internal rate of return (IRR), etc.
- Data regarding the reduction of the carbon footprint and cross comparison with similar actions from other plans at the national and European level.
5.3. Next Generation Energy Performance Assessment and Certification
5.4. Improving the Financeability of Energy Efficiency Investments
5.5. Data-Driven Policy Making and Policy Impact Assessment for Energy-Efficient Buildings
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- United Nations. World’s Population Increasingly Urban with More Than Half Living in Urban Areas. 2014. Available online: https://www.un.org/en/development/desa/news/population/world-urbanization-prospects-2014.html (accessed on 18 January 2020).
- Word Green Building Council. COP24: Time to Address the Building and Construction Sector’s Total Emissions Impact. 2018. Available online: https://www.worldgbc.org/news-media/cop24-time-address-building-and-construction-sector%E2%80%99s-total-emissions-impact (accessed on 28 January 2020).
- Doukas, H.; Nikas, A. Decision support models in climate policy. Eur. J. Oper. Res. 2020, 280, 1–24. [Google Scholar] [CrossRef]
- Petidis, I.; Aryblia, M.; Daras, T.; Tsoutsos, T. Energy saving and thermal comfort interventions based on occupants’ needs: A students’ residence building case. Energy Build. 2018, 174, 347–364. [Google Scholar] [CrossRef]
- European Commission. Energy Use in Buildings. Available online: https://ec.europa.eu/energy/en/eu-buildings-factsheets-topics-tree/energy-use-buildings (accessed on 12 January 2020).
- United Nations Climate Change. What Is the Paris Agreement? Available online: https://unfccc.int/process-and-meetings/the-paris-agreement/what-is-the-paris-agreement (accessed on 18 December 2019).
- European Commission. Energy Performance of Buildings Directive. Available online: https://ec.europa.eu/energy/en/topics/energy-efficiency/energy-performance-of-buildings/energy-performance-buildings-directive (accessed on 28 January 2020).
- European Commission. Directive 2012/27/EU of the European Parliament and of the Council of 25 October 2012 on Energy Efficiency, Amending Directives 2009/125/EC and 2010/30/EU and Repealing Directives 2004/8/EC and 2006/32/EC; European Commission: Brussels, Belgium, 2012. [Google Scholar]
- European Commission. Directive (EU) 2018/2002 of the European Parliament and of the Council of 11 December 2018 Amending Directive 2012/27/EU on Energy Efficiency; European Commission: Brussels, Belgium, 2018. [Google Scholar]
- European Commission. Directive 2009/125/EC of the European Parliament and of the Council of 21 October 2009 Establishing a Framework for the Setting of Ecodesign Requirements for Energy-Related Products (Recast); European Commission: Brussels, Belgium, 2009. [Google Scholar]
- European Commission. Regulation (EU) 2017/1369 of the European Parliament and of the Council of 4 July 2017 Setting a Framework for Energy Labelling and Repealing Directive 2010/30/EU; European Commission: Brussels, Belgium, 2017. [Google Scholar]
- Ecodesign. Available online: https://ec.europa.eu/growth/industry/sustainability/ecodesign_en (accessed on 28 January 2020).
- Marinakis, V.; Doukas, H. An advanced IoT-based system for intelligent energy management in buildings. Sensors 2018, 18, 610. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhattarai, B.P.; Paudyal, S.; Luo, Y.; Mohanpurkar, M.; Cheung, K.; Tonkoski, R.; Manic, M. Big data analytics in smart grids: State-of-the-art, challenges, opportunities, and future directions. IET Smart Grid 2019, 2, 141–154. [Google Scholar] [CrossRef]
- Pancholi, S. Solving Big Data Challenges, Us Electric Utility Industry. In Proceedings of the IEEE PES General Meeting Presentation, National Harbor, MD, USA, 27–31 July 2014. [Google Scholar]
- Wen, L.; Zhou, K.; Yang, S.; Li, L. Compression of smart meter big data: A survey. Renew. Sustain. Energy Rev. 2018, 91, 59–69. [Google Scholar] [CrossRef]
- Marinakis, V.; Doukas, H.; Tsapelas, J.; Mouzakitis, S.; Sicilia, Á.; Madrazo, L.; Sgouridis, S. From big data to smart energy services: An application for intelligent energy management. Future Gener. Comput. Syst. 2018. [Google Scholar] [CrossRef]
- Ferreira, J.; Agostinho, C.; Lopes, R.; Chatzikokolakis, K.; Zissis, D.; Vidal, M.E.; Mouzakitis, S. Maritime Data Technology Landscape and Value Chain Exploiting Oceans of Data for Maritime Applications. In Proceedings of the 2017 International Conference on Engineering, Technology and Innovation (ICE/ITMC), Funchal, Portugal, 27–29 June 2017. [Google Scholar]
- Wang, Y.; Chen, Q.; Kang, C.; Xia, Q. Clustering of electricity consumption behavior dynamics toward big data applications. IEEE Trans. Smart Grid 2016, 7, 2437–2447. [Google Scholar] [CrossRef]
- Sheng, G.; Hou, H.; Jiang, X.; Chen, Y. A novel association rule mining method of big data for power transformers state parameters based on probabilistic graph model. IEEE Trans. Smart Grid 2018, 9, 695–702. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A review of data-driven approaches for prediction and classification of building energy consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- Amasyali, K.; El-Gohary, N.M. A review of data-driven building energy consumption prediction studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Yu, Z.; Haghighat, F.; Fung, B.C.M. Advances and challenges in building engineering and data mining applications for energy-efficient communities. Sustain. Cities Soc. 2016, 25, 33–38. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, T.; Chen, H.; Huang, R.; Yabin, G.; Wang, J.; Shair, J.; Muhammad, H.; Akram, A.; Agha, S.; Mohsan, H.; et al. Supervised based machine learning models for short, medium and long-term energy prediction in distinct building environment. Energy 2018, 158, 17–32. [Google Scholar] [CrossRef]
- Deb, C.; Siew Eang, L.; Yang, J.; Santamouris, M. Forecasting diurnal cooling energy load for institutional buildings using Artificial Neural Networks. Energy Build. 2016, 121, 284–297. [Google Scholar] [CrossRef]
- Sadeghi, A.; Sinaki, R.Y.; Young, W.A.; Weckman, G.R. An intelligent model to predict energy performances of residential buildings based on deep neural networks. Energies 2020, 13, 571. [Google Scholar] [CrossRef] [Green Version]
- Dong, B.; Cao, C.; Eang Lee, S. Applying support vector machines to predict building energy consumption in tropical region. Energy Build. 2005, 37, 545–553. [Google Scholar] [CrossRef]
- Chen, Y.B.; Tan, H. Short-term prediction of electric demand in building sector via hybrid support vector regression. Appl. Energy 2017, 204, 1363–1374. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Wang, S. Development of prediction models for next-day building energy consumption and peak power demand using data mining techniques. Appl. Energy 2014, 127, 1–10. [Google Scholar] [CrossRef]
- Wang, Z.Y.; Wang, Y.; Srinivasan, R.S. A novel ensemble learning approach to support building energy use prediction. Energy Build. 2018, 159, 109–122. [Google Scholar] [CrossRef]
- Zeng, A.; Liu, S.; Yu, Y. Comparative study of data driven methods in building electricity use prediction. Energy Build. 2019, 194, 289–300. [Google Scholar] [CrossRef]
- Zhou, K.; Fu, C.; Yang, S. Big data driven smart energy management: From big data to big insights. Renew. Sustain. Energy Rev. 2016, 56, 215–225. [Google Scholar] [CrossRef]
- Livani, H. Supervised Learning-Based Fault Location in Power Grids. In Big Data Application in Power Systems; Arghandeh, R., Zhou, Y., Eds.; Elsevier: Amsterdam, The Netherlands, 2018; pp. 303–319. [Google Scholar]
- Andrew, C.; Kilcher, L.; Lundquist, J.K.; Fleming, P. Using machine learning to predict wind turbine power output. Environ. Res. Lett. 2013, 8, 024009. [Google Scholar] [CrossRef]
- Heinermann, J.; Kramer, O. Machine learning ensembles for wind power prediction. Renew. Energy 2016, 89, 671–679. [Google Scholar] [CrossRef]
- Miller, C.; Nagy, Z.; Schlueter, A. A review of unsupervised statistical learning and visual analytics techniques applied to performance analysis of non-residential buildings. Renew. Sustain. Energy Rev. 2018, 81, 1365–1377. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Li, Z.; Wang, J. Unsupervised data analytics in mining big building operational data for energy efficiency enhancement: A review. Energy Build. 2018, 159, 296–308. [Google Scholar] [CrossRef]
- Lapalu, J.; Bouchard, K.; Bouzouane, A.; Bouchard, B.; Giroux, S. Unsupervised mining of activities for smart home prediction. Procedia Comput. Sci. 2013, 19, 503–510. [Google Scholar] [CrossRef] [Green Version]
- Fiorini, L.; Cavallo, F.; Dario, P.; Eavis, A.; Caleb-Solly, P. Unsupervised machine learning for developing personalised behaviour models using activity data. Sensors 2017, 17, 1034. [Google Scholar] [CrossRef] [Green Version]
- Naganathan, H.; Chong, W.K.; Chen, X. Semi-supervised Energy Modeling (SSEM) for building clusters using machine learning techniques. Procedia Eng. 2015, 118, 1189–1194. [Google Scholar] [CrossRef] [Green Version]
- Aicha, N.; Englebienne, G.; Krse, B. Modeling Visit Behaviour in Smart Homes Using Unsupervised Learning. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, ser. UbiComp ‘14 Adjunct, New York, NY, USA, 13–17 September 2014; pp. 1193–1200. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding Deep Learning Requires Rethinking Generalization. arXiv 2017, arXiv:1611.03530. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. arXiv 2017, arXiv:1610.05820. [Google Scholar]
- Bassily, R.; Smith, A.D.; Thakurta, A. Differentially private empirical risk minimization: Efficient algorithms and tight error bounds. arXiv 2014, arXiv:1405.7085. [Google Scholar]
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning differentially private language models without losing accuracy. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- Papernot, N.; Song, S.; Mironov, I.; Raghunathan, A.; Talwar, K.; Erlingsson, Ú. Scalable private learning with PATE. arXiv 2018, arXiv:1802.08908. [Google Scholar]
- Doukas, H.; Patlitzianas, K.D.; Iatropoulos, K.; Psarras, J. Intelligent building energy management system using rule sets. Build. Environ. 2007, 42, 3562–3569. [Google Scholar] [CrossRef]
- LEAP, the Long-Range Energy Alternatives Planning System. Available online: http://www.energycommunity.org/default.asp?action=47 (accessed on 28 January 2020).
- AleaSoft. Available online: http://www.aleasoft.com/ (accessed on 28 January 2020).
- Modelica Association. Available online: http://www.modelica.org (accessed on 28 January 2020).
- Spiliotis, E.; Assimakopoulos, V.; Makridakis, S. Generalizing the Theta method for automatic forecasting. Eur. J. Oper. Res. 2020, 284, 550–558. [Google Scholar] [CrossRef]
- Mocanu, E.; Nguyen, P.H.; Kling, W.L.; Gibescu, M. Unsupervised energy prediction in a Smart Grid context using reinforcement cross-building transfer learning. Energy Build. 2016, 116, 646–655. [Google Scholar] [CrossRef] [Green Version]
- Spiliotis, E.; Petropoulos, F.; Kourentzes, N.; Assimakopoulos, V. Cross-temporal aggregation: Improving the forecast accuracy of hierarchical electricity consumption. Appl. Energy 2020, 261, 114339. [Google Scholar] [CrossRef]
- Bees, D.; Frost, L.; Bauer, M.; Fisher, M.; Li, W. NGSI-LD API: For Context Information Management. ETSI White Paper No. 31. 2019. Available online: https://www.etsi.org/images/files/ETSIWhitePapers/etsi_wp31_NGSI_API.pdf (accessed on 28 January 2020).
- FIWARE Smart Energy. Available online: https://www.fiware.org/community/smart-energy/ (accessed on 28 January 2020).
- Lee, S.-K.; Kim, K.-R.; Yu, J.-H. BIM and ontology-based approach for building cost estimation. Autom. Constr. 2014, 41, 96–105. [Google Scholar] [CrossRef]
- Smart Appliances REFerence (SAREF) Ontology. Available online: https://sites.google.com/site/smartappliancesproject/ontologies/reference-ontology (accessed on 12 January 2020).
- Villalon, P.M.; Castro, G.R. SAREF Extension for Building Device. 2017. Available online: http://ontoology.linkeddata.es/publish/saref4bldg/index-en.html (accessed on 12 January 2020).
- Brick. Available online: https://brickschema.org/ (accessed on 12 January 2020).
- Project Haystack. Available online: https://project-haystack.org/ (accessed on 12 January 2020).
- BuildingSMART International. IFC Specifications Database. Available online: https://technical.buildingsmart.org/standards/ifc/ifc-schema-specifications/ (accessed on 12 January 2020).
- BACnet—A Data Communication Protocol for Building Automation and Control Networks. Available online: http://www.bacnet.org/ (accessed on 12 January 2020).
- LonMark International. Available online: http://www.lonmark.org/ (accessed on 12 January 2020).
- Behera, M.K.; Majumder, I.; Nayak, N. Solar photovoltaic power forecasting using optimized modified extreme learning machine technique. Eng. Sci. Technol. Int. J. 2018, 21, 428–438. [Google Scholar] [CrossRef]
- Trigo-González, M.; Batlles, F.J.; Alonso-Montesinos, J.; Ferrada, P.; del Sagrado, J.; Martínez-Durbán, M.; Cortés, M.; Portillo, C.; Marzo, A. Hourly PV production estimation by means of an exportable multiple linear regression model. Renew. Energy 2019, 135, 303–312. [Google Scholar] [CrossRef]
- Spiliotis, E.; Kouloumos, A.; Assimakopoulos, V.; Makridakis, S. Are forecasting competitions data representative of the reality? Int. J. Forecast. 2020, 36, 37–53. [Google Scholar] [CrossRef]
- Bracco, S.; Delfino, F.; Ferro, G.; Pagnini, L.; Robba, M.; Rossi, M. Energy planning of sustainable districts: Towards the exploitation of small size intermittent renewables in urban areas. Appl. Energy 2018, 228, 2288–2297. [Google Scholar] [CrossRef]
- Bracco, S.; Brignone, M.; Delfino, F.; Procopio, R. An Energy Management System for the Savona Campus Smart Polygeneration Microgrid. IEEE Syst. J. 2017, 11, 1799–1809. [Google Scholar] [CrossRef]
- Sicilia, Á.; Costa, G.; Doukas, H.; Spiliotis, E.; Anastasopoulos, G.; Capozzoli, A.; Corrado, V.; Gorrino, A.; Tellado, B. Analysis Tools to Process Data and Inference Rules; Deliverable No: 3.2; OPTIMising the Energy USe in Cities with Smart Decision Support System; OPTIMUS, 2016. [Google Scholar]
- Sifakis, N.; Savvakis, N.; Daras, T.; Tsoutsos, T. Analysis of the energy consumption behavior of European RES cooperative members. Energies 2019, 12, 970. [Google Scholar] [CrossRef] [Green Version]
- Chalkiadakis, G.; Akasiadis, C.; Savvakis, N.; Tsoutsos, T.; Hoppe, T.; Coenen, F. Providing a scientific arm to renewable energy cooperatives. Green Energy Technol. 2018, 717–731. [Google Scholar] [CrossRef]
- Tsoutsos, T.; Drandaki, M.; Frantzeskaki, N.; Iosifidis, E.; Kiosses, I. Sustainable energy planning by using multi-criteria analysis application in the island of Crete. Energy Policy 2009, 37, 1587–1600. [Google Scholar] [CrossRef]
- Doukas, H.; Papadopoulou, A.; Savvakis, N.; Tsoutsos, T.; Psarras, J. Assessing energy sustainability of rural communities using Principal Component Analysis. Renew. Sustain. Energy Rev. 2012, 16, 1949–1957. [Google Scholar] [CrossRef]
- Marinakis, V.; Doukas, H.; Xidonas, P.; Zopounidis, C. Multicriteria decision support in local energy planning: An evaluation of alternative scenarios for the Sustainable Energy Action Plan. Omega 2017, 69, 1–16. [Google Scholar] [CrossRef]
- The Carbonn® Center. Supporting Cities, Towns and Regions Tackling Climate Change to Create Transparency, Accountability and Credibility. Available online: http://carbonn.org/ (accessed on 12 January 2020).
- Li, Y.; Kubicki, S.; Guerriero, A.; Rezgui, Y. Review of building energy performance certification schemes towards future improvement. Renew. Sustain. Energy Rev. 2019, 113, 109244. [Google Scholar] [CrossRef]
- Miguel-Herrero, F.J.; Serna-González, V.I.; Hernández-Moral, G. Supporting tool for multi-scale energy planning through procedures of data enrichment. Int. J. Sustain. Energy Plan. Manag. 2019, 24, 125–134. [Google Scholar]
- Doukas, H. On the appraisal of “Triple-A” energy efficiency investments. Energy Sources Part B Econ. Plan. Policy 2018, 13, 320–327. [Google Scholar] [CrossRef]
- Stamtsis, G.; Doukas, H. Cooperation or localization in european capacity markets? A coalitional game over graph approach. Energies 2018, 11, 1473. [Google Scholar] [CrossRef] [Green Version]
- European Commission. The European Green Deal. COM(2019) 640 FInal; European Commission: Brussels, Belgium, 2019. [Google Scholar]
- Housing Europe. European Commission’s Green Deal Clearly Recognises Role of Social, Cooperative and Public Housing Providers in Making the “Renovation Wave” Happen While Acknowledging Obstacles and Financial Needs. 2019. Available online: http://www.housingeurope.eu/resource-1343/european-commission-s-green-deal-clearly-recognises-role-of-social-cooperative-and-public-housing-providers-in-making-the-renovation-wave-happen-while-acknowledging-obstacles-and-financial-needs (accessed on 12 January 2020).
- European Commission. Building and Renovating: The European Green Deal. 2019. Available online: https://ec.europa.eu/commission/presscorner/api/files/attachment/859198/Building_and_Renovating_en.pdf.pdf (accessed on 12 January 2020).



© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marinakis, V. Big Data for Energy Management and Energy-Efficient Buildings. Energies 2020, 13, 1555. https://doi.org/10.3390/en13071555
Marinakis V. Big Data for Energy Management and Energy-Efficient Buildings. Energies. 2020; 13(7):1555. https://doi.org/10.3390/en13071555
Chicago/Turabian StyleMarinakis, Vangelis. 2020. "Big Data for Energy Management and Energy-Efficient Buildings" Energies 13, no. 7: 1555. https://doi.org/10.3390/en13071555
APA StyleMarinakis, V. (2020). Big Data for Energy Management and Energy-Efficient Buildings. Energies, 13(7), 1555. https://doi.org/10.3390/en13071555