Bayesian Optimized Echo State Network Applied to Short-Term Load Forecasting

 , and
, and 
Abstract
:1. Introduction
2. Background
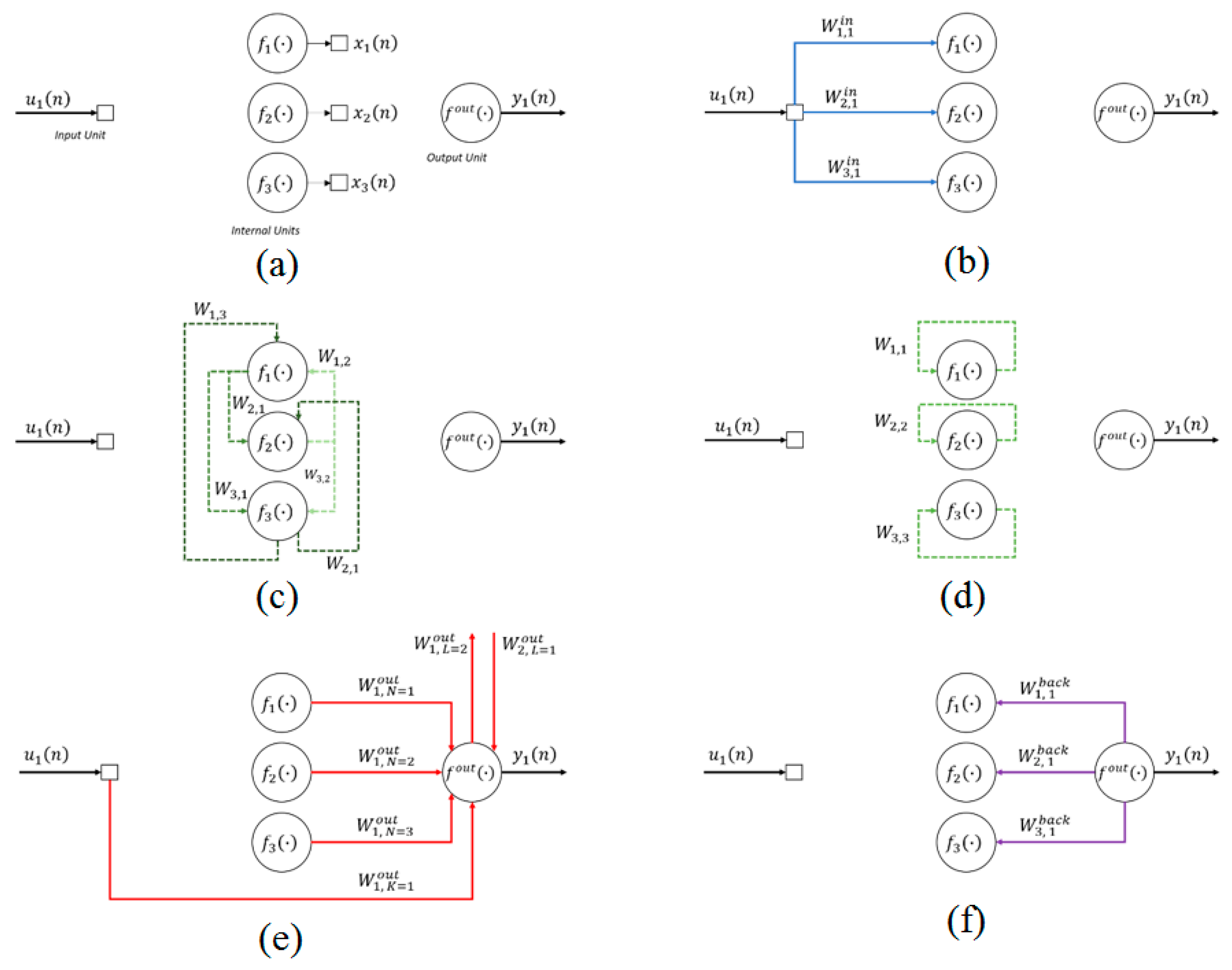
2.1. Echo State Networks
2.2. Bayesian Optimization Algorithm
3. Proposed BOA Optimized ESN for Load Forecasting
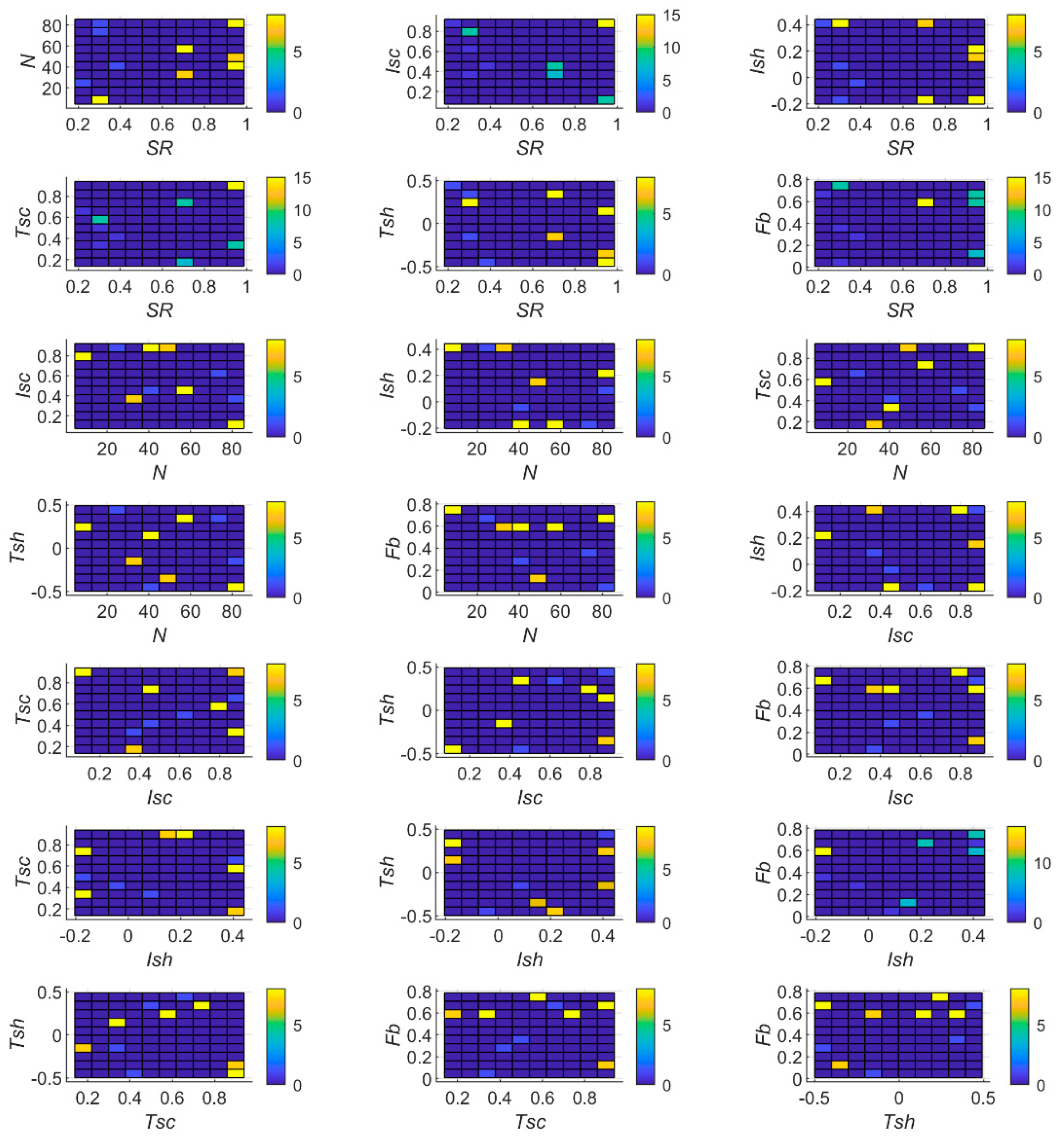
3.1. ESN Hyperparameters
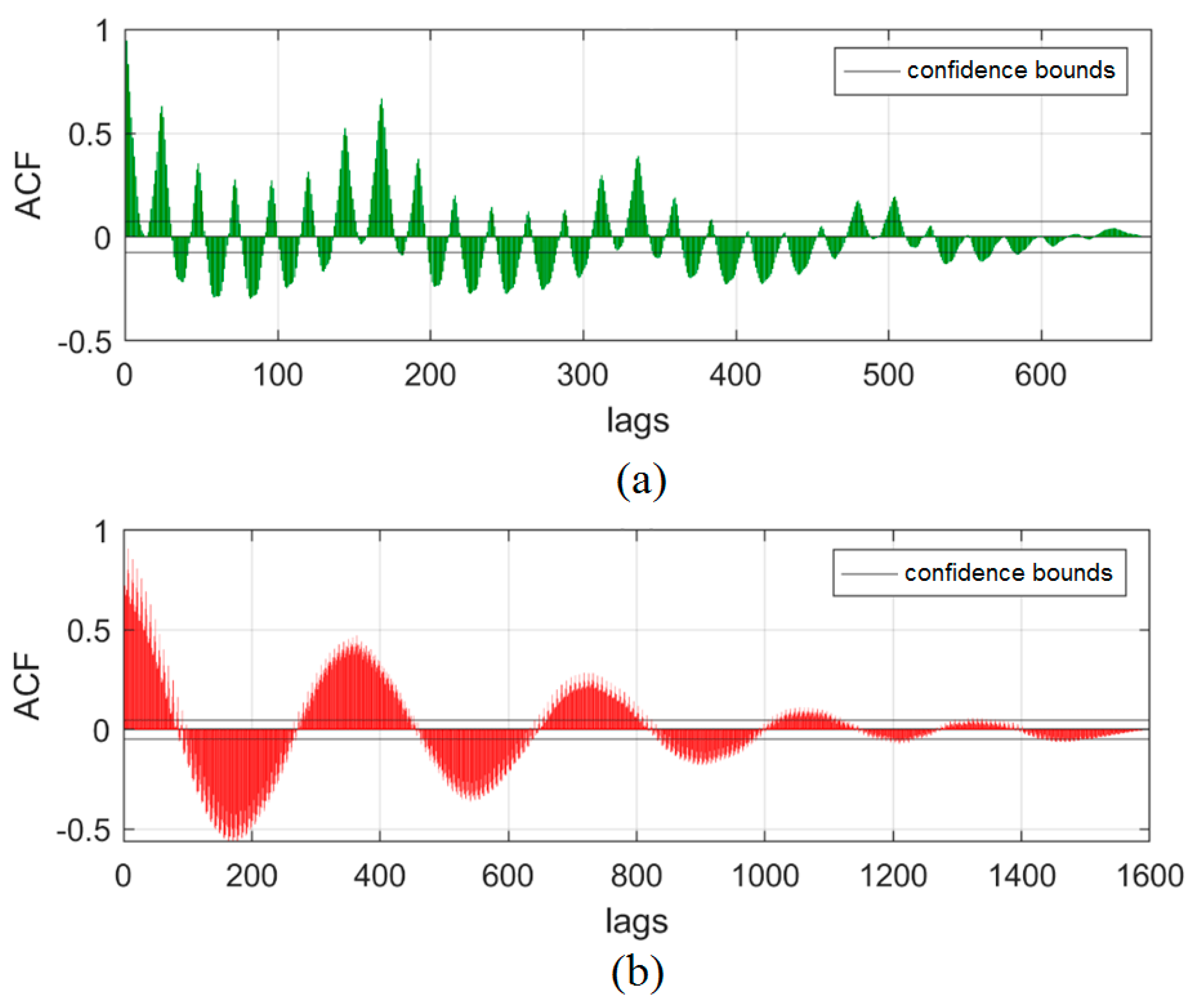
3.2. Datasets
3.3. Performance Evaluation of the Forecasting
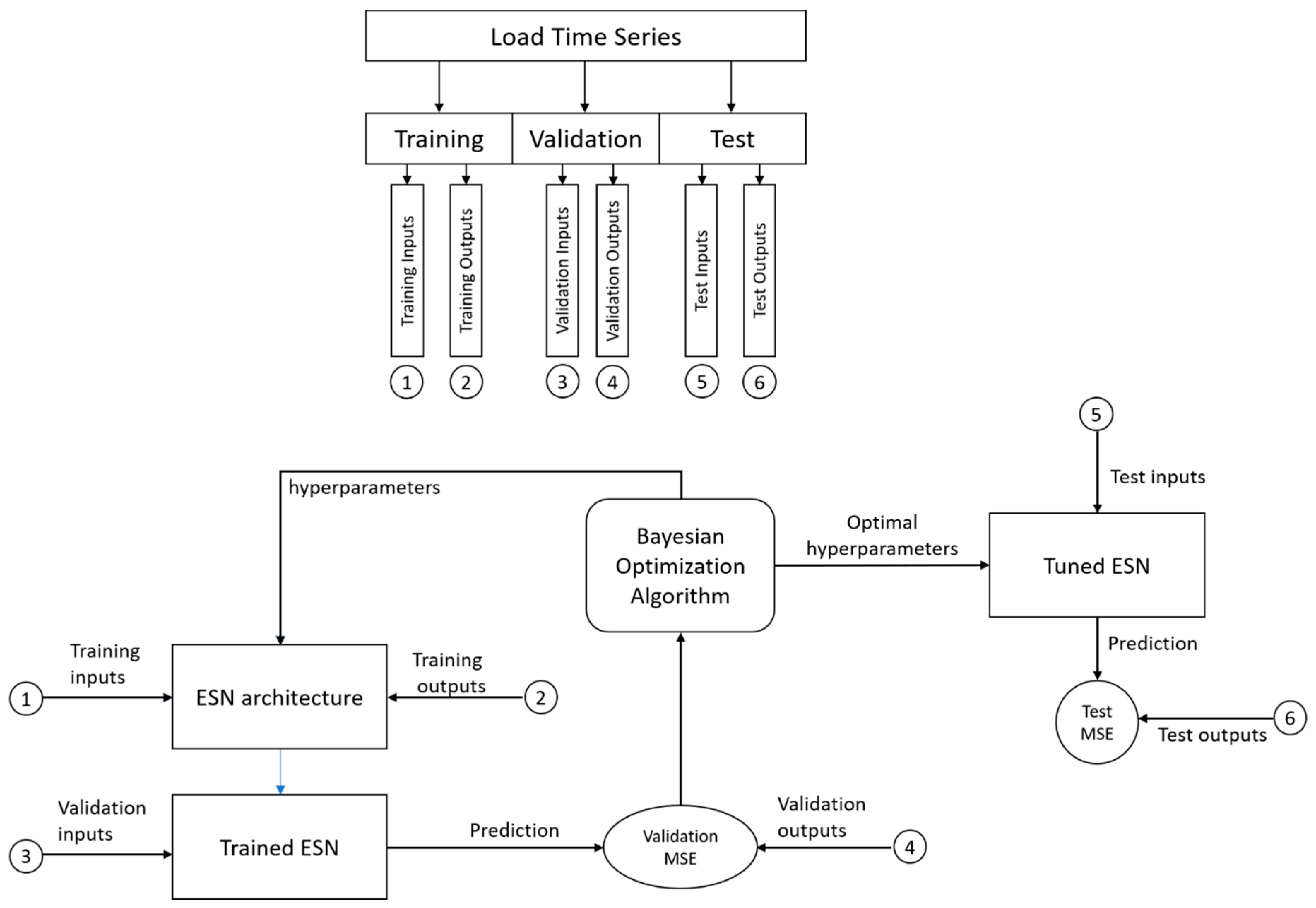
3.4. General View of the Proposed Forecasting Approach
4. Results and Discussion
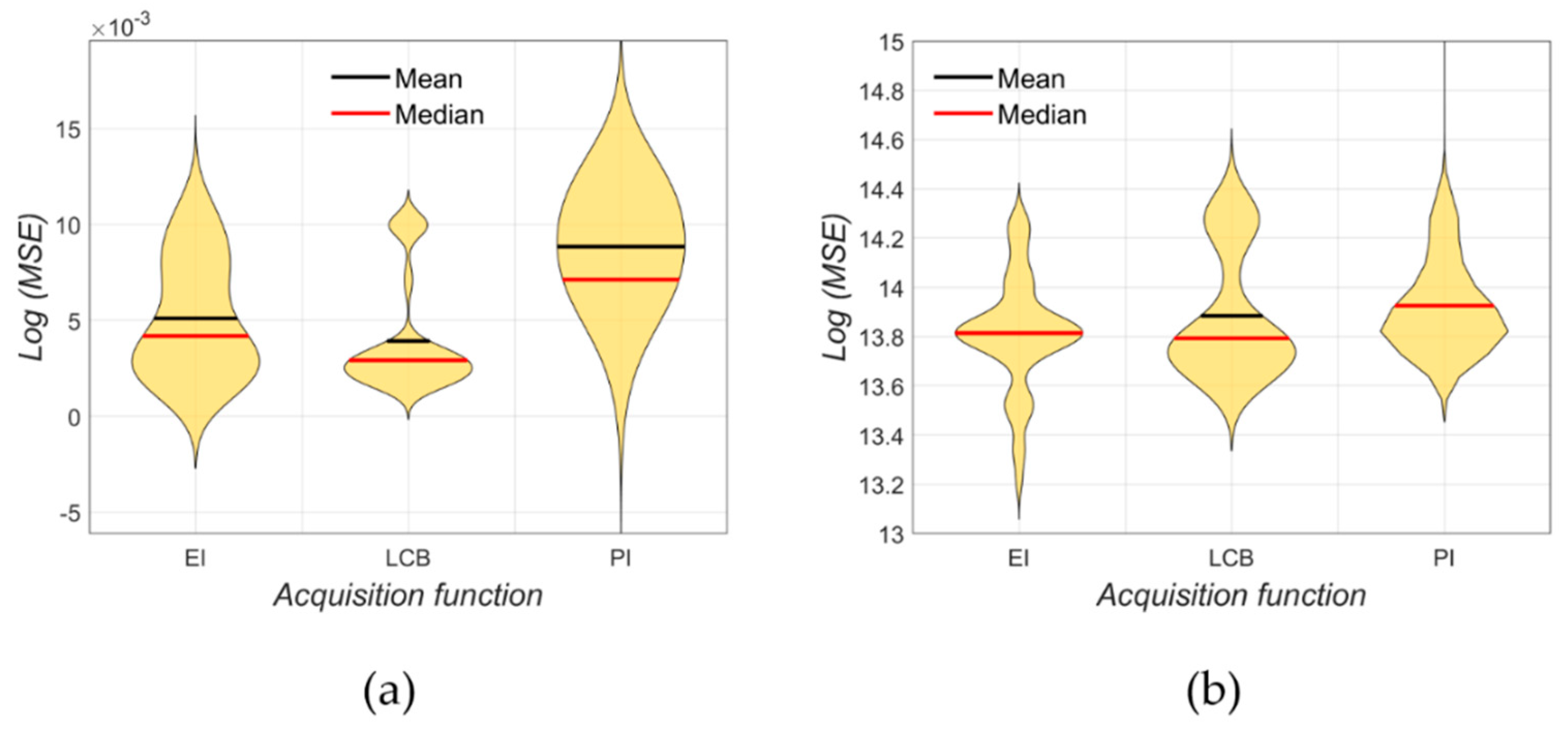
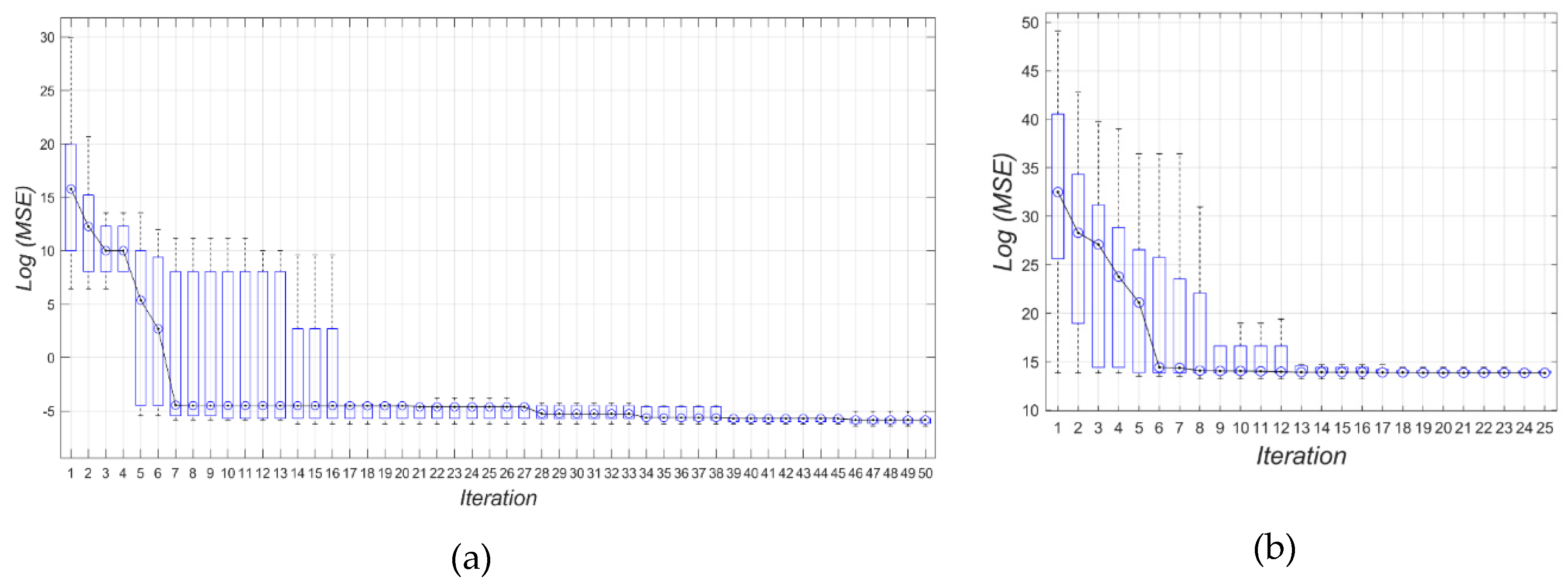
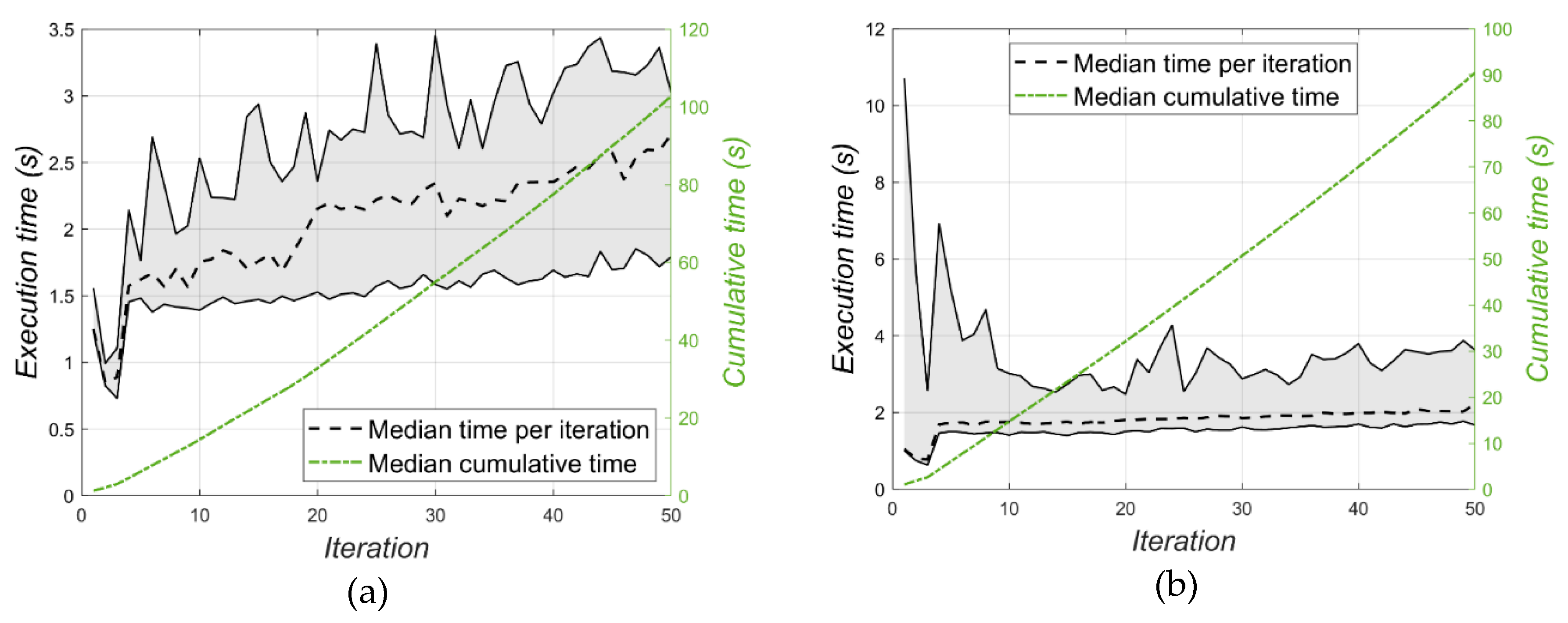
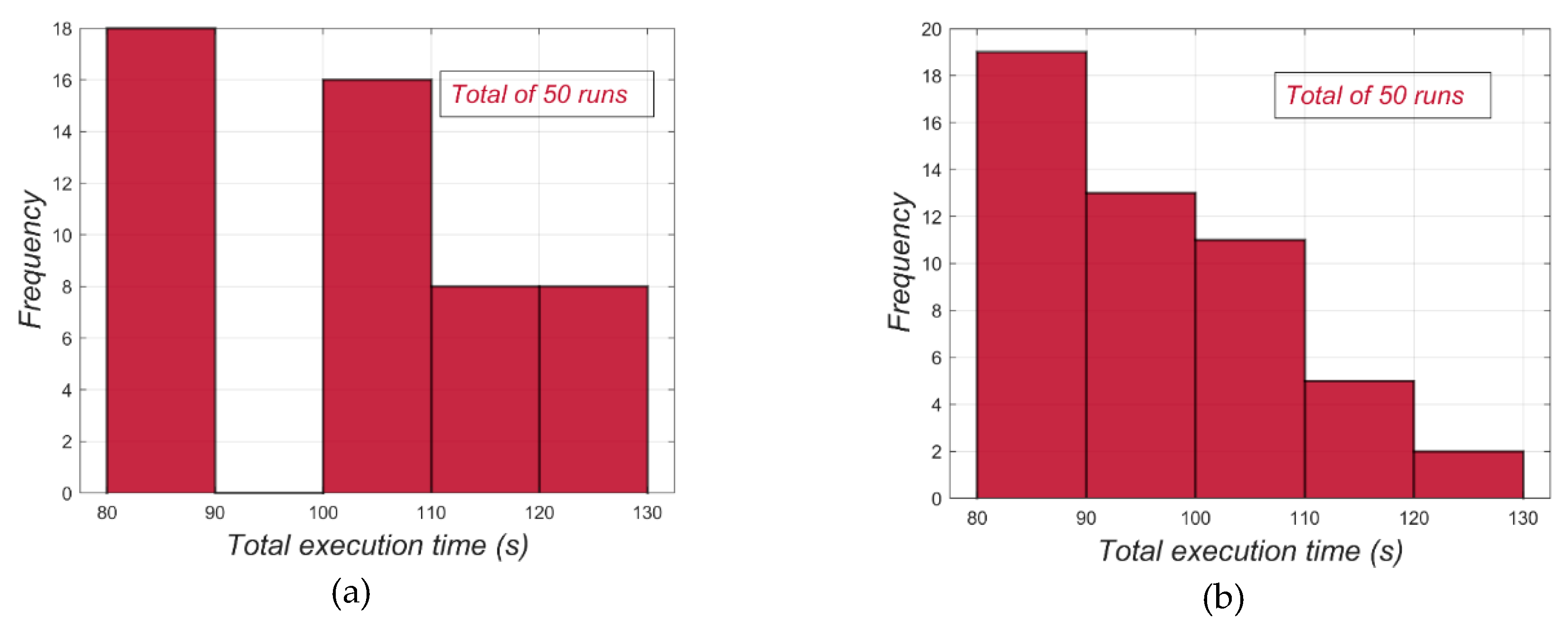
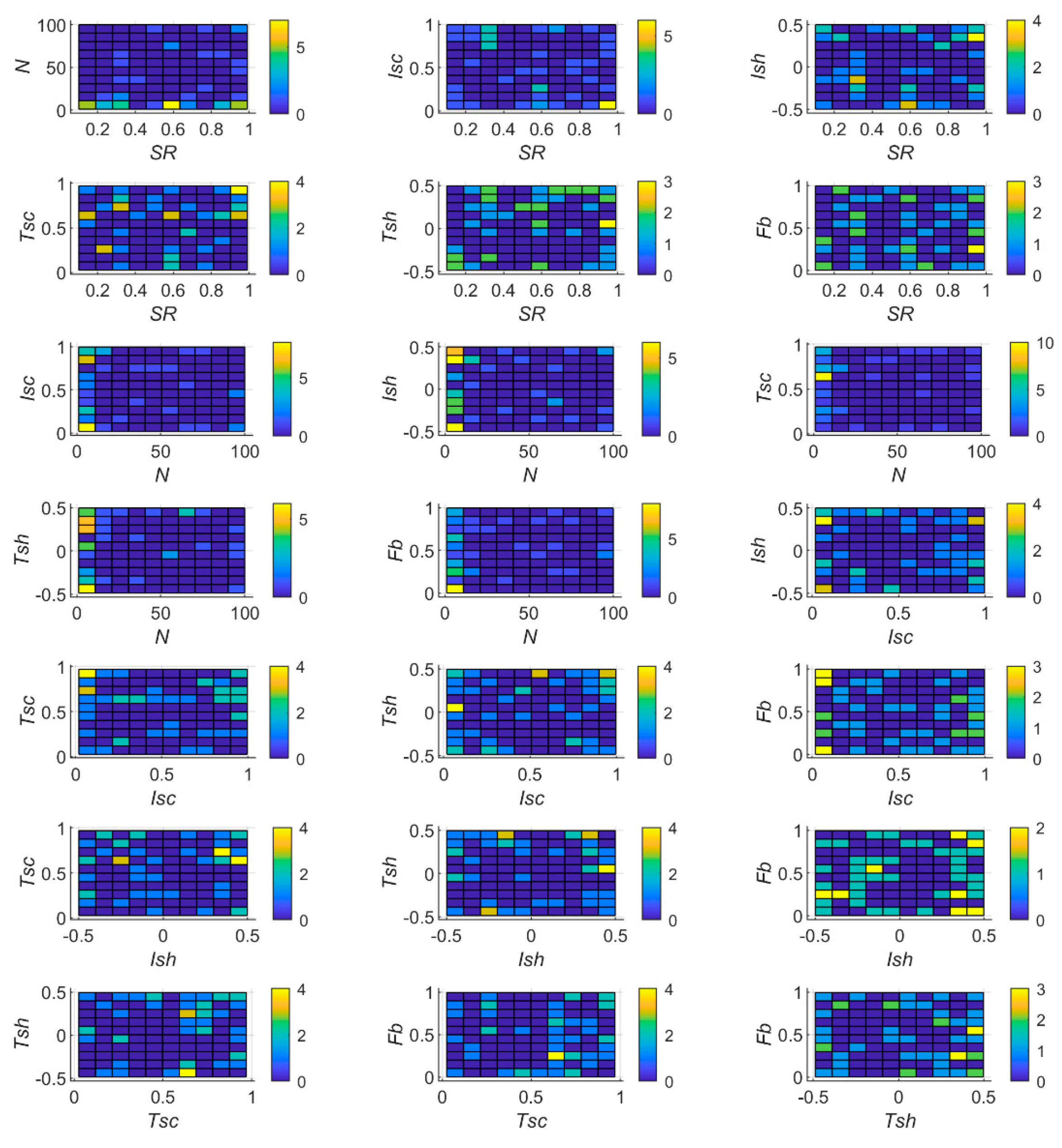
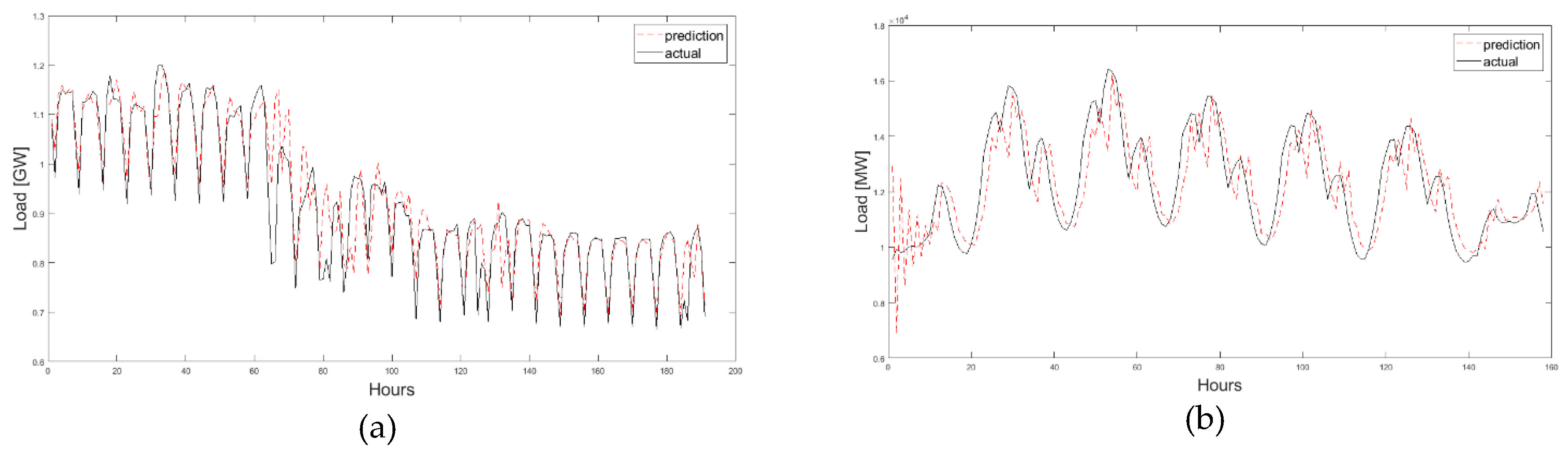
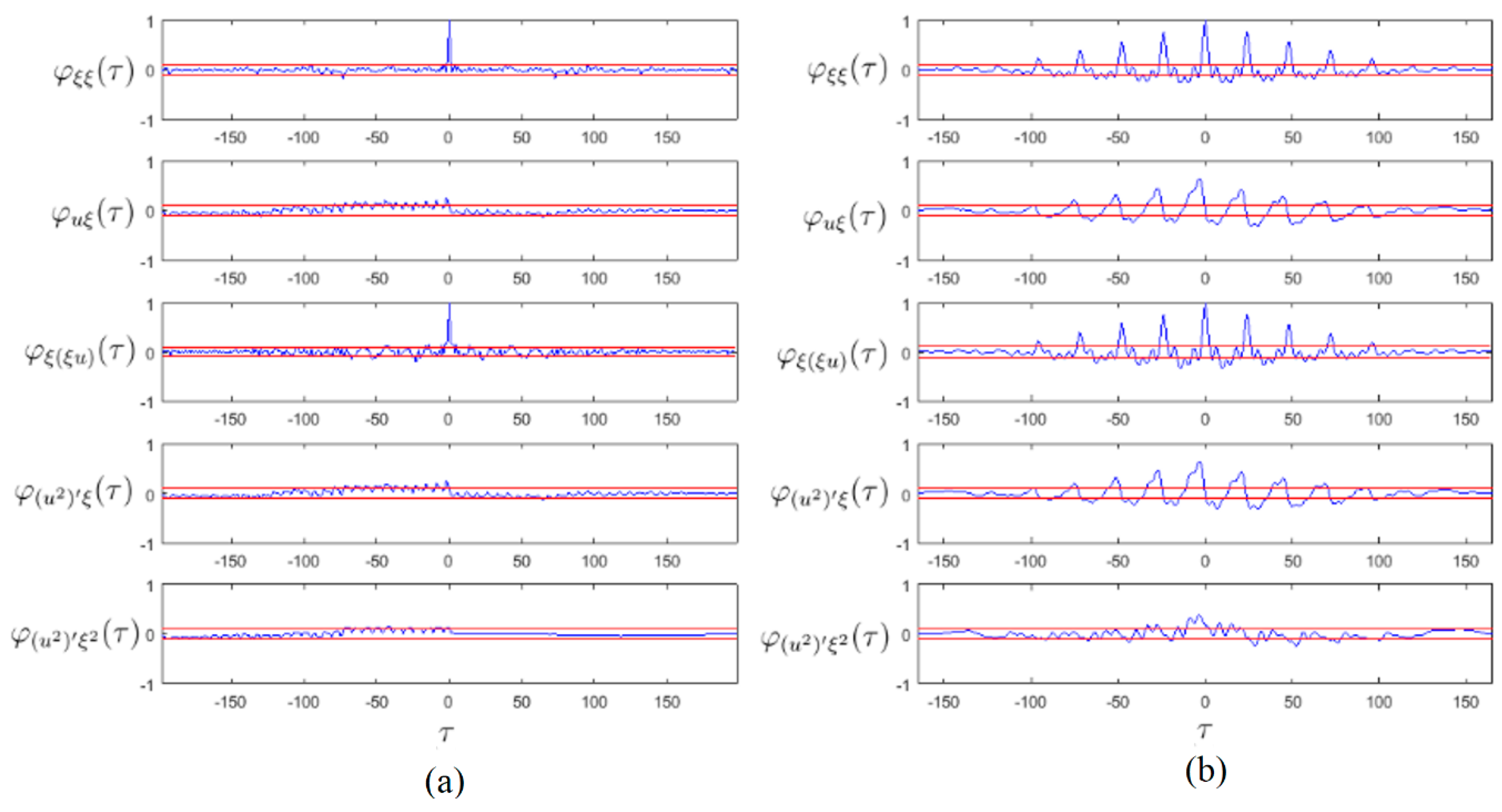
4.1. Results
4.2. Discussion
5. Conclusions and Future Research Direction
Author Contributions
Funding
Conflicts of Interest
References
- Amarasinghe, K.; Marino, D.L.; Manic, M. Deep neural networks for energy load forecasting. In Proceedings of the 26th IEEE International Symposium on Industrial Electronics (ISIE), Edinburgh, Scotland, 19–21 June 2017; pp. 1483–1488. [Google Scholar] [CrossRef]
- Qiu, X.; Ren, Y.; Nagaratnam, P.; Amaratunga, G.A.J. Empirical mode decomposition based ensemble deep learning for load demand time series forecasting. Appl. Soft Comput. J. 2017, 54, 246–255. [Google Scholar] [CrossRef]
- Bedi, J.; Toshniwal, D. Deep learning framework to forecast electricity demand. Appl. Energy 2019, 238, 1312–1326. [Google Scholar] [CrossRef]
- Xiuyun, G.; Ying, W.; Yang, G.; Chengzhi, S.; Wen, X.; Yimiao, Y. Short-term load forecasting model of gru network based on deep learning framework. In Proceedings of the 2nd IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 20–22 October 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Yudantaka, K.; Kim, J.S.; Song, H. Dual deep learning networks based load forecasting with partial real-time information and its application to system marginal price prediction. Energies 2019, 13, 148. [Google Scholar] [CrossRef] [Green Version]
- Shi, T.; Mei, F.; Lu, J.; Pan, Y.; Zhou, C.; Wu, J.; Zheng, J. Phase space reconstruction algorithm and deep learning-based very short-term bus load forecasting. Energies 2019, 12, 4349. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, G.T.; Gritti, M.C.; Ayala, H.V.; Mariani, V.C.; Coelho, L.S. Short-term load forecasting using wavenet ensemble approaches. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 727–734. [Google Scholar] [CrossRef]
- Li, S.; Wang, P.; Goel, L. A Novel wavelet-based ensemble method for short-term load forecasting with hybrid neural networks and feature selection. IEEE Trans. Power Syst. 2016, 31, 1788–1798. [Google Scholar] [CrossRef]
- Chen, L.; Chiang, H.; Dong, N.; Liu, R. Group-based chaos genetic algorithm and non-linear ensemble of neural networks for short-term load forecasting. IET Gener. Transm. Distrib. 2016, 10, 1440–1447. [Google Scholar] [CrossRef]
- Nowotarski, J.; Liu, B.; Weron, R.; Hong, T. Improving short term load forecast accuracy via combining sister forecasts. Energy 2016, 98, 40–49. [Google Scholar] [CrossRef]
- Hassan, S.; Khosravi, A.; Jaafar, J. Examining performance of aggregation algorithms for neural network-based electricity demand forecasting. Int. J. Electr. Power Energy Syst. 2015, 64, 1098–1105. [Google Scholar] [CrossRef]
- Khwaja, A.S.; Naeem, M.; Anpalagan, A.; Venetsanopoulos, A.; Venkatesh, B. Improved short-term load forecasting using bagged neural networks. Electr. Power Syst. Res. 2015, 125, 109–115. [Google Scholar] [CrossRef]
- Khuntia, S.R.; Rueda, J.L.; van der Meijden, M.A.M.M. Neural network-based load forecasting and error implication for short-term horizon. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 4970–4975. [Google Scholar] [CrossRef]
- Dudek, G. Neural networks for pattern-based short-term load forecasting: A comparative study. Neurocomputing 2016, 205, 64–74. [Google Scholar] [CrossRef]
- Rana, M.; Koprinska, I. Forecasting electricity load with advanced wavelet neural networks. Neurocomputing 2016, 182, 118–132. [Google Scholar] [CrossRef]
- Zjavka, L. Short-term power demand forecasting using the differential polynomial neural network. Int. J. Comput. Intell. Syst. 2014, 8, 297–306. [Google Scholar] [CrossRef] [Green Version]
- Li, L.-L.; Sun, J.; Wang, C.-H.; Zhou, Y.-T.; Lin, K.-P. Enhanced Gaussian process mixture model for short-term electric load forecasting. Inf. Sci. 2019, 477, 386–398. [Google Scholar] [CrossRef]
- Muzaffar, S.; Afshari, A. Short-term load forecasts using LSTM networks. Energy Procedia 2019, 158, 2922–2927. [Google Scholar] [CrossRef]
- Wang, S.; Wang, X.; Wang, S.; Wang, D. Bi-directional long short-term memory method based on attention mechanism and rolling update for short-term load forecasting. Int. J. Electr. Power Energy Syst. 2019, 109, 470–479. [Google Scholar] [CrossRef]
- Wang, X.; Fang, F.; Zhang, X.; Liu, Y.; Wei, L.; Shi, Y. LSTM-based Short-term Load Forecasting for Building Electricity Consumption. In Proceedings of the IEEE 28th International Symposium on Industrial Electronics (ISIE), Vancouver, BC, Canada, 24–29 July 2019; pp. 1418–1423. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Multi-sequence LSTM-RNN deep learning and metaheuristics for electric load forecasting. Energies 2020, 13, 391. [Google Scholar] [CrossRef] [Green Version]
- Dedinec, A.; Filiposka, S.; Dedinec, A.; Kocarev, L. Deep belief network based electricity load forecasting: An analysis of Macedonian case. Energy 2016, 115, 1688–1700. [Google Scholar] [CrossRef]
- Ouyang, T.; He, Y.; Li, H.; Sun, Z.; Baek, S. Modeling and forecasting short-term power load with copula model and deep belief network. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 3, 127–136. [Google Scholar] [CrossRef] [Green Version]
- Dudek, G. Heterogeneous ensembles for short-term electricity demand forecasting. In Proceedings of the 17th International Scientific Conference on Electric Power Engineering (EPE), Prague, Czech Republic, 16–18 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Barak, S.; Sadegh, S.S. Forecasting energy consumption using ensemble ARIMA–ANFIS hybrid algorithm. Int. J. Electr. Power Energy Syst. 2016, 82, 92–104. [Google Scholar] [CrossRef] [Green Version]
- Burger, E.M.; Moura, S.J. Gated ensemble learning method for demand-side electricity load forecasting. Energy Build. 2015, 109, 23–34. [Google Scholar] [CrossRef]
- Shen, W.; Babushkin, V.; Aung, Z.; Woon, W.L. An ensemble model for day-ahead electricity demand time series forecasting. In Proceedings of the 4th International Conference on Future Energy Systems (e-Energy ’13); ACM Press: New York, NY, USA, 2013; pp. 51–62. [Google Scholar] [CrossRef]
- Zhang, R.; Xu, Y.; Dong, Z.Y.; Kong, W.; Wong, K.P. A composite k-nearest neighbor model for day-ahead load forecasting with limited temperature forecasts. In Proceedings of the IEEE Power and Energy Society General Meeting (PESGM), Boston, MA, USA, 17–21 July 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Bianchi, F.M.; De Santis, E.; Rizzi, A.; Sadeghian, A. Short-term electric load forecasting using echo state networks and PCA decomposition. IEEE Access 2015, 3, 1931–1943. [Google Scholar] [CrossRef]
- Wang, Z.; Zeng, Y.R.; Wang, S.; Wang, L. Optimizing echo state network with backtracking search optimization algorithm for time series forecasting. Eng. Appl. Artif. Intell. 2019, 81, 117–132. [Google Scholar] [CrossRef]
- Ma, Q.; Shen, L.; Cottrell, G.W. DeePr-ESN: A deep projection-encoding echo-state network. Inf. Sci. (Ny). 2020, 511, 152–171. [Google Scholar] [CrossRef]
- McDermott, P.L.; Wikle, C.K. Deep echo state networks with uncertainty quantification for spatio-temporal forecasting. Environmetrics 2019, 30, e2553. [Google Scholar] [CrossRef] [Green Version]
- Hu, H.; Wang, L.; Peng, L.; Zeng, Y.R. Effective energy consumption forecasting using enhanced bagged echo state network. Energy 2020, 193. [Google Scholar] [CrossRef]
- Li, Z.; Liu, X.; Chen, L. Load interval forecasting methods based on an ensemble of Extreme Learning Machines. In Proceedings of the IEEE Power & Energy Society General Meeting, Denver, CO, USA, 26–30 July 2015; IEEE: Denver, CO, USA, 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Xu, Y.; Dong, Z.Y.; Meng, K.; Wong, K.P.; Zhang, R. Short-term load forecasting of Australian National Electricity Market by an ensemble model of extreme learning machine. IET Gener. Transm. Distrib. 2013, 7, 391–397. [Google Scholar] [CrossRef]
- Papadopoulos, S.; Karakatsanis, I. Short-term electricity load forecasting using time series and ensemble learning methods. In Proceedings of the IEEE Power and Energy Conference at Illinois (PECI), Champaign, IL, USA, 20–21 Feburary 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Nadtoka, I.I.; Balasim, M.A.-Z. Mathematical modelling and short-term forecasting of electricity consumption of the power system, with due account of air temperature and natural illumination, based on support vector machine and particle swarm. Procedia Eng. 2015, 129, 657–663. [Google Scholar] [CrossRef] [Green Version]
- Kumaran, J.; Ravi, G. Long-term sector-wise electrical energy forecasting using artificial neural network and biogeography-based optimization. Electr. Power Components Syst. 2015, 43, 1225–1235. [Google Scholar] [CrossRef]
- Kavousi-Fard, A. A new fuzzy-based feature selection and hybrid TLA–ANN modelling for short-term load forecasting. J. Exp. Theor. Artif. Intell. 2013, 25, 543–557. [Google Scholar] [CrossRef]
- Singh, P.; Dwivedi, P. A novel hybrid model based on neural network and multi-objective optimization for effective load forecast. Energy 2019, 182, 606–622. [Google Scholar] [CrossRef]
- Bento, P.M.R.; Pombo, J.A.N.; Calado, M.R.A.; Mariano, S.J.P.S. Optimization of neural network with wavelet transform and improved data selection using bat algorithm for short-term load forecasting. Neurocomputing 2019, 358, 53–71. [Google Scholar] [CrossRef]
- Singh, P.; Dwivedi, P. Integration of new evolutionary approach with artificial neural network for solving short term load forecast problem. Appl. Energy 2018, 217, 537–549. [Google Scholar] [CrossRef]
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Hernandez, L.; Baladron, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.J.; Lloret, J.; Massana, J. A survey on electric power demand forecasting: Future trends in smart grids, microgrids and smart buildings. Commun. Surv. Tutorials IEEE 2014, 16, 1460–1495. [Google Scholar] [CrossRef]
- Tüfekci, P. Prediction of full load electrical power output of a base load operated combined cycle power plant using machine learning methods. Int. J. Electr. Power Energy Syst. 2014, 60, 126–140. [Google Scholar] [CrossRef]
- Matijaš, M.; Suykens, J.A.K.; Krajcar, S. Load forecasting using a multivariate meta-learning system. Expert Syst. Appl. 2013, 40, 4427–4437. [Google Scholar] [CrossRef] [Green Version]
- DING, Y. Data Science for Wind Energy; CRC Press: Boca Raton, FL, USA, 2019; ISBN 9781138590526. [Google Scholar]
- Liu, Y.; Zhao, J.; Wang, W. A Gaussian process echo state networks model for time series forecasting. In Proceedings of the Joint IFSA World Congress and NAFIPS Annual Meeting (IFSA/NAFIPS), Edmonton, AB, Canada, 24–28 June 2013; IEEE: Edmonton, AB, Canada, 2013; pp. 643–648. [Google Scholar] [CrossRef]
- Velasco Rueda, C. EsnPredictor: Ferramenta de Previsão de Séries Temporais Baseada em Echo State Networks Otimizada por Algoritmos Genéticos e Particle Swarm Optimization; Pontifícia Universidade Católica do Rio de Janeiro: Rio de Janeiro, Brazil, 2014; (In Portuguese). [Google Scholar] [CrossRef]
- Liu, C.; Zhang, H.; Yao, X.; Zhang, K. Echo state networks with double-reservoir for time-series prediction. In Proceedings of the 7th International Conference on Intelligent Control and Information Processing (ICICIP), Siem Reap, Cambodia, 1–4 December 2016; pp. 196–202. [Google Scholar] [CrossRef]
- López, E.; Valle, C.; Allende, H.; Gil, E.; Madsen, H. Wind power forecasting based on echo state networks and long short-term memory. Energies 2018, 11, 526. [Google Scholar] [CrossRef] [Green Version]
- Gouveia, H.T.V.; De Aquino, R.R.B.; Ferreira, A.A. Enhancing short-term wind power forecasting through multiresolution analysis and echo state networks. Energies 2018, 11, 824. [Google Scholar] [CrossRef] [Green Version]
- López, M.; Sans, C.; Valero, S.; Senabre, C. Empirical comparison of neural network and auto-regressive models in short-term load forecasting. Energies 2018, 11, 2080. [Google Scholar] [CrossRef] [Green Version]
- Luy, M.; Ates, V.; Barisci, N.; Polat, H.; Cam, E. Short-term fuzzy load forecasting model using genetic–fuzzy and ant colony–fuzzy knowledge base optimization. Appl. Sci. 2018, 8, 864. [Google Scholar] [CrossRef] [Green Version]
- Siqueira, H.; Boccato, L.; Attux, R.; Lyra, C. Unorganized machines for seasonal streamflow series forecasting. Int. J. Neural Syst. 2014, 24, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Li, B.J.; Yu, X.G.; Cheng, C.T. Echo state network with Bayesian regularization for forecasting short-term power production of small hydropower plants. Energies 2015, 8, 12228–12241. [Google Scholar] [CrossRef] [Green Version]
- Han, M.; Mu, D. Multi-reservoir echo state network with sparse Bayesian learning. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2010; pp. 450–456. [Google Scholar]
- Shutin, D.; Zechner, C.; Kulkarni, S.R.; Poor, H.V. Regularized variational bayesian learning of echo state networks with delay&sum readout. Neural Comput. 2012, 24, 967–995. [Google Scholar] [PubMed]
- Zechner, C.; Shutin, D. Bayesian learning of echo state networks with tunable filters and delay& sum readouts. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA , 14–19 March 2010 ; IEEE: Dallas, TX, USA, 2010; pp. 1998–2001. [Google Scholar] [CrossRef]
- Cerina, L.; Franco, G.; Santambrogio, M.D. Lightweight autonomous bayesian optimization of Echo-State Networks. In Proceedings of the ESANN 2019 Proceedings, 27th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2019; pp. 637–642. [Google Scholar]
- Jaeger, H. The “Echo State” Approach to Analysing and Training Recurrent Neural Networks-with an Erratum Note 1; GMD Technical Report 148; German National Research Center for Information Technology: Bonn, Germany, 2010. [Google Scholar]
- Aalto University—Applications of Machine Learning Group Home Page. Available online: https://research.cs.aalto.fi/aml/datasets.shtml (accessed on 6 May 2020).
- Operador Nacional do Sistema elétrico—ONS Home Page. Available online: http://www.ons.org.br/Paginas/resultados-da-operacao/historico-da-operacao/curva_carga_horaria.aspx (accessed on 6 May 2020).
- Billings, S.A. Nonlinear System Identification; John Wiley & Sons, Ltd.: Chichester, UK, 2013; ISBN 9781119943594. [Google Scholar]
- Yaslan, Y.; Bican, B. Empirical mode decomposition based denoising method with support vector regression for time series prediction: A case study for electricity load forecasting. Measurement 2017, 103, 52–61. [Google Scholar] [CrossRef]
- Coelho, L.S.; Mariani, V.C.; Guerra, F.A.; da Luz, M.V.F.; Leite, J.V. Multiobjective optimization of transformer design using a chaotic evolutionary approach. IEEE Trans. Magn. 2014, 50, 669–672. [Google Scholar] [CrossRef]
- Coelho, L.S.; Ayala, C.H.; Mariani, V.C. A self-adaptive chaotic differential evolution algorithm using gamma distribution for unconstrained global optimization. Appl. Math. Comput. 2014, 23415, 452–459. [Google Scholar] [CrossRef]
- Santos, G.S.; Luvizotto, L.G.J.; Mariani, V.C.; Coelho, L.S. Least squares support vector machines with tuning based on chaotic differential evolution approach applied to the identification of a thermal process. Expert Syst. Appl. 2012, 39, 4805–4812. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Lower Bound | Upper Bound |
|---|---|---|
| Spectral radius (SR) | 0.10 | 0.99 |
| Internal units (N) | 1 | 100 |
| Input scaling (Isc) | 0.01 | 1 |
| Input shift (Ish) | −0.5 | 0.5 |
| Teacher scaling (Tsc) | 0.01 | 1 |
| Teacher shift (Tsh) | −0.5 | 0.5 |
| Feedback scaling (Fb) | 0 | 1 |
| Descriptive Statistics | Brazilian Dataset | Polish Dataset |
|---|---|---|
| Number of samples | 672 | 1601 |
| Sample interval | 1 h | 1 h |
| Mean | 11,880 MW | 0.96601 GW |
| Standard deviation | 1953.50 MW | 0.16394 GW |
| Minimum | 6949.90 MW | 0,6181 GW |
| First quartile | 10,413 MW | 0.83669 GW |
| Median | 11,773 MW | 0.95184 GW |
| Third quartile | 13,384 MW | 1.1156 GW |
| Maximum | 16,429 MW | 1.349 GW |
| Statistical Measure | EI-BO-ESN | LCB-BO-ESN | PI-BO-ESN | Single SVR | Denoised SVR | EMD SVR |
|---|---|---|---|---|---|---|
| Mean | 0.0051 | 0.0039 1 | 0.0088 | – | – | – |
| Median | 0.0042 | 0.0029 1 | 0.0071 | – | – | – |
| Std | 0.0030 | 0.0029 | 0.0026 1 | – | – | – |
| Min | 0.0019 | 0.0017 1 | 0.0020 | 0.0048 | 0.0047 | 0.0027 |
| Max | 0.0110 | 0.0100 1 | 0.0115 | – | – | – |
| Statistical Measure | EI-BO-ESN | LCB-BO-ESN | PI-BO-ESN |
|---|---|---|---|
| Mean | 1.02 × 1 | 1.11 × | 8.78 × |
| Median | 9.99 × | 9.77 × 1 | 1.12 × |
| Standard deviation | 2.31 × 1 | 2.99 × | 1.68 × |
| Minimum | 5.51 × 1 | 8.46 × | 9.30 × |
| Maximum | 1.57 × 1 | 1.68 × | 4.81 × |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trierweiler Ribeiro, G.; Guilherme Sauer, J.; Fraccanabbia, N.; Cocco Mariani, V.; dos Santos Coelho, L. Bayesian Optimized Echo State Network Applied to Short-Term Load Forecasting. Energies 2020, 13, 2390. https://doi.org/10.3390/en13092390
Trierweiler Ribeiro G, Guilherme Sauer J, Fraccanabbia N, Cocco Mariani V, dos Santos Coelho L. Bayesian Optimized Echo State Network Applied to Short-Term Load Forecasting. Energies. 2020; 13(9):2390. https://doi.org/10.3390/en13092390
Chicago/Turabian StyleTrierweiler Ribeiro, Gabriel, João Guilherme Sauer, Naylene Fraccanabbia, Viviana Cocco Mariani, and Leandro dos Santos Coelho. 2020. "Bayesian Optimized Echo State Network Applied to Short-Term Load Forecasting" Energies 13, no. 9: 2390. https://doi.org/10.3390/en13092390
APA StyleTrierweiler Ribeiro, G., Guilherme Sauer, J., Fraccanabbia, N., Cocco Mariani, V., & dos Santos Coelho, L. (2020). Bayesian Optimized Echo State Network Applied to Short-Term Load Forecasting. Energies, 13(9), 2390. https://doi.org/10.3390/en13092390