
Learning Latent Representation of Freeway Traffic Situations from Occupancy Grid Pictures Using Variational Autoencoder





Abstract
:1. Introduction
2. Problem Statement
3. Contributions of the Paper
4. Solution
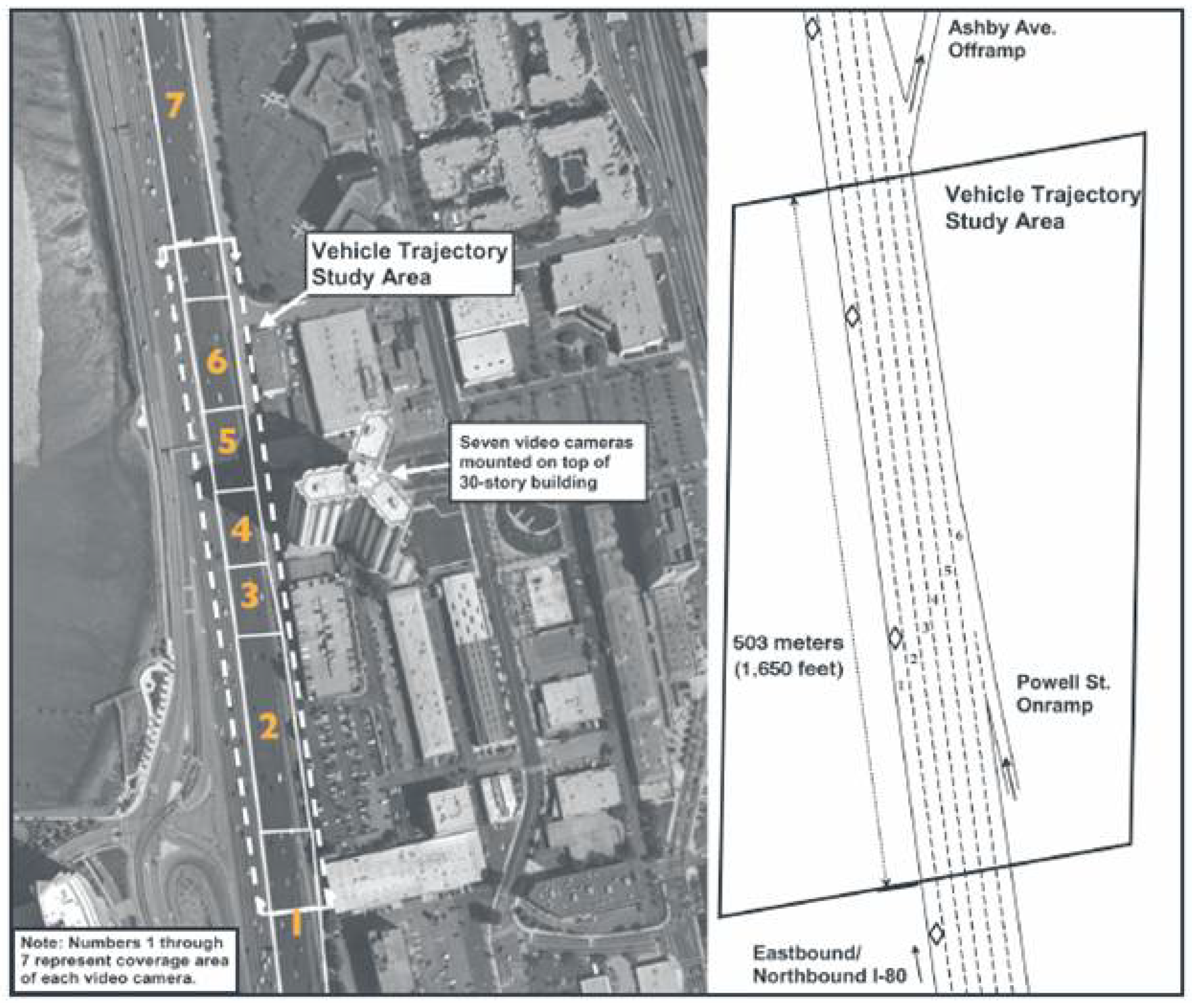
4.1. Training Dataset
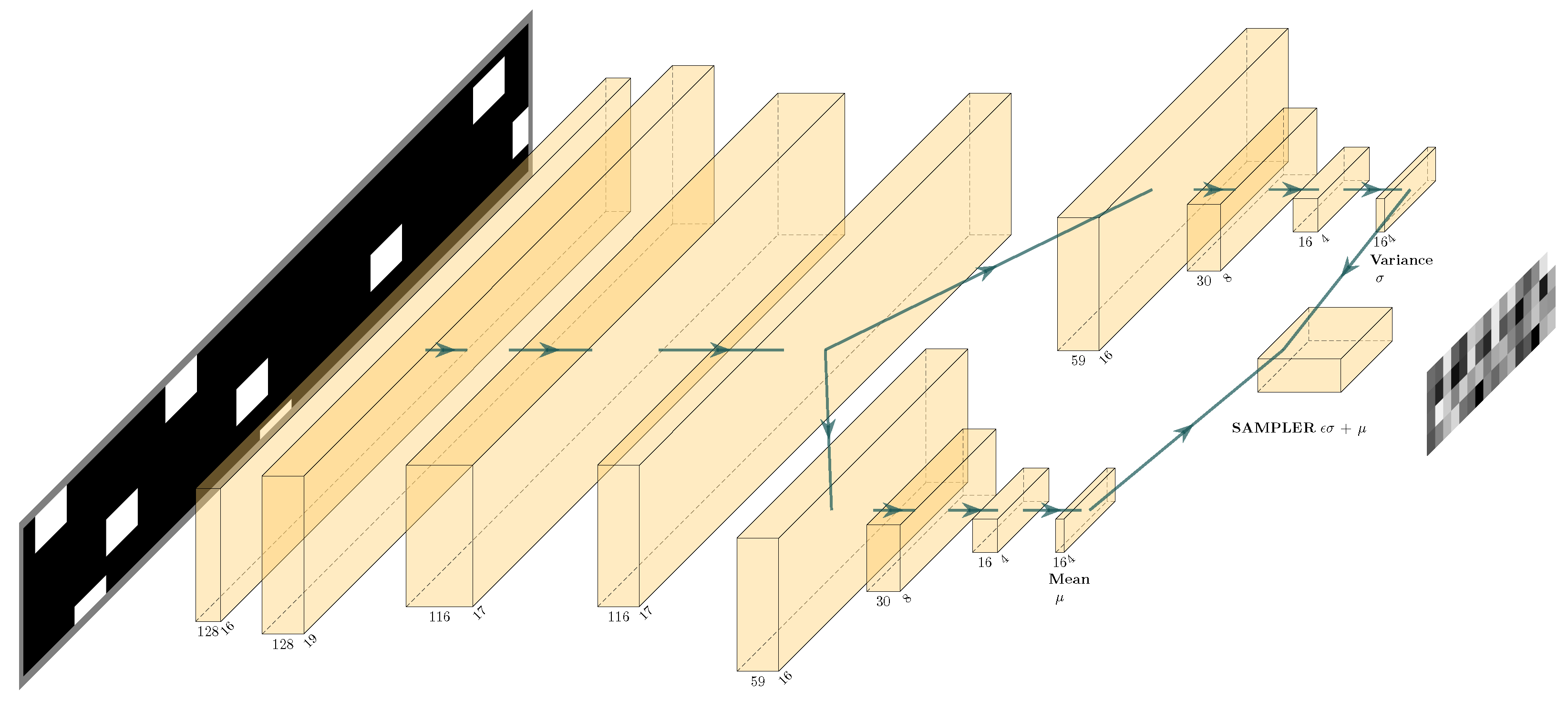
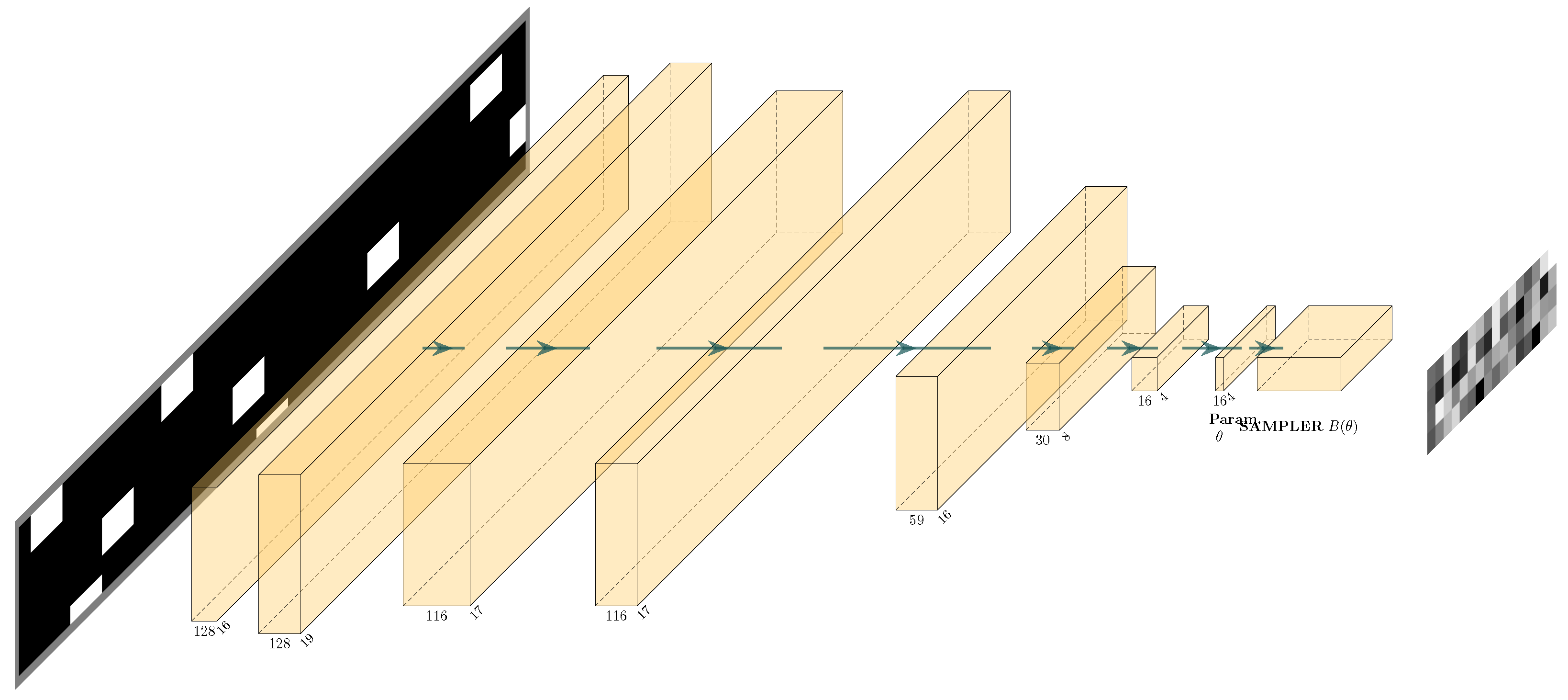
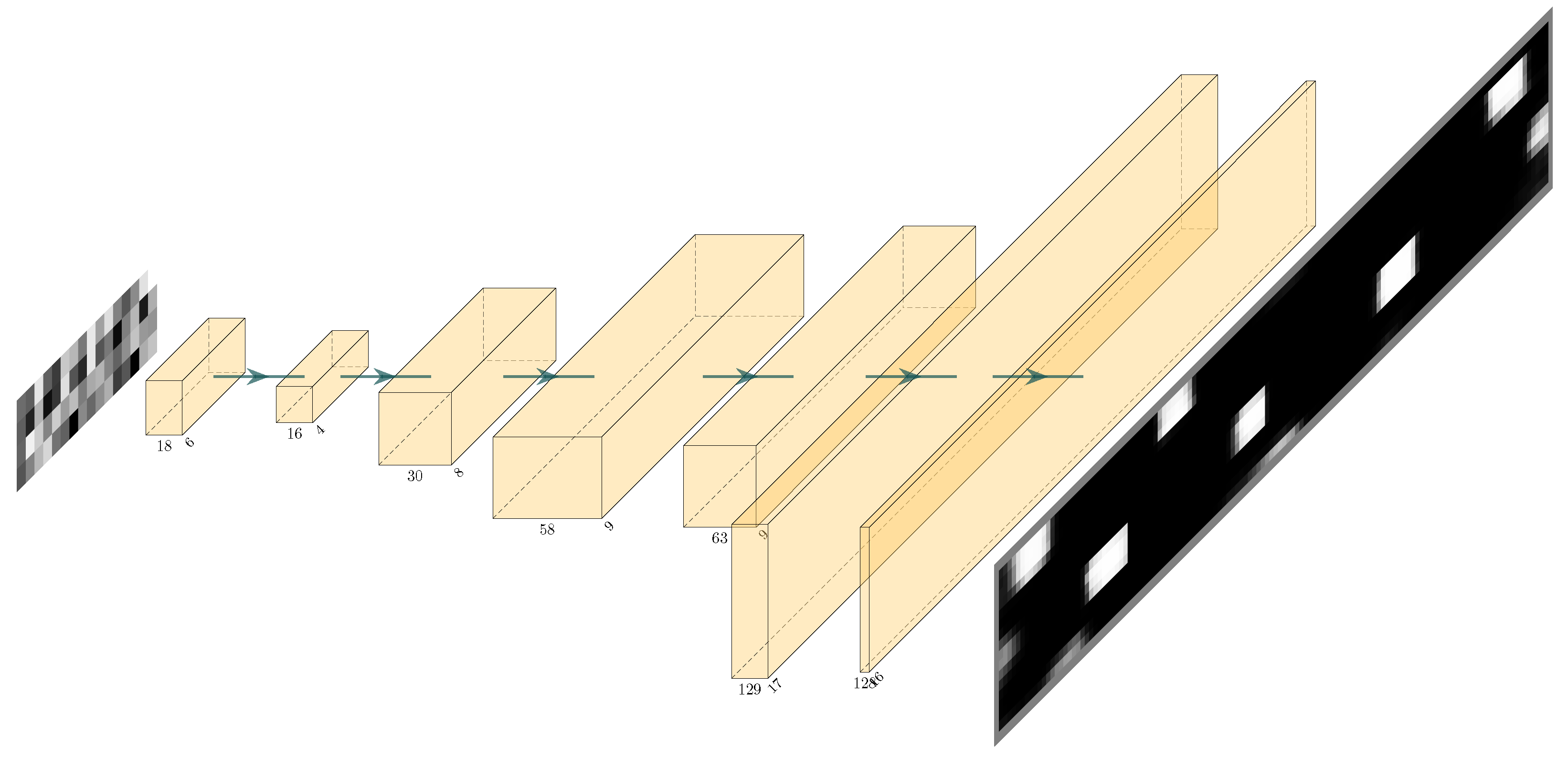
4.2. Methodology
4.3. Training Details
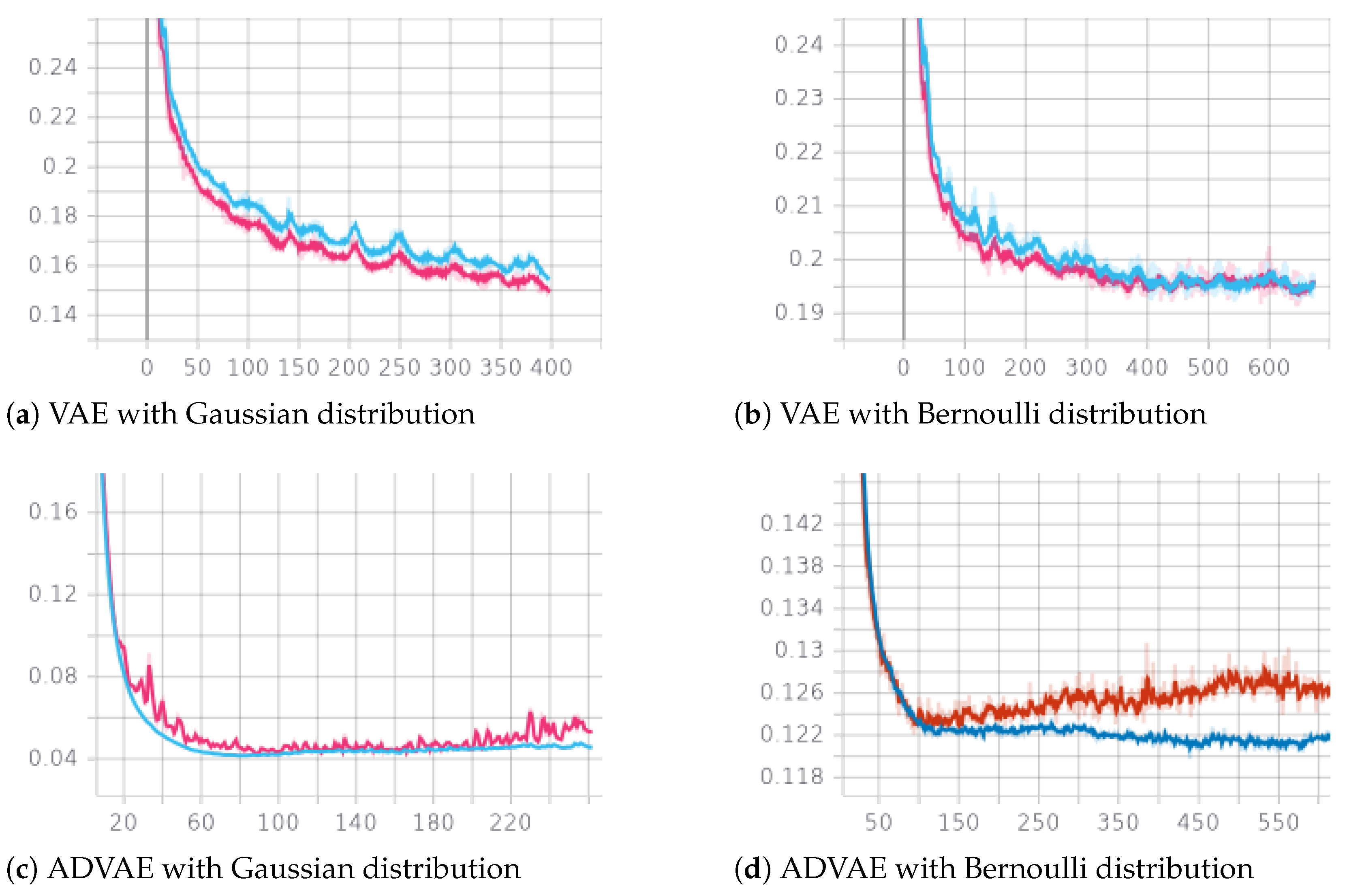
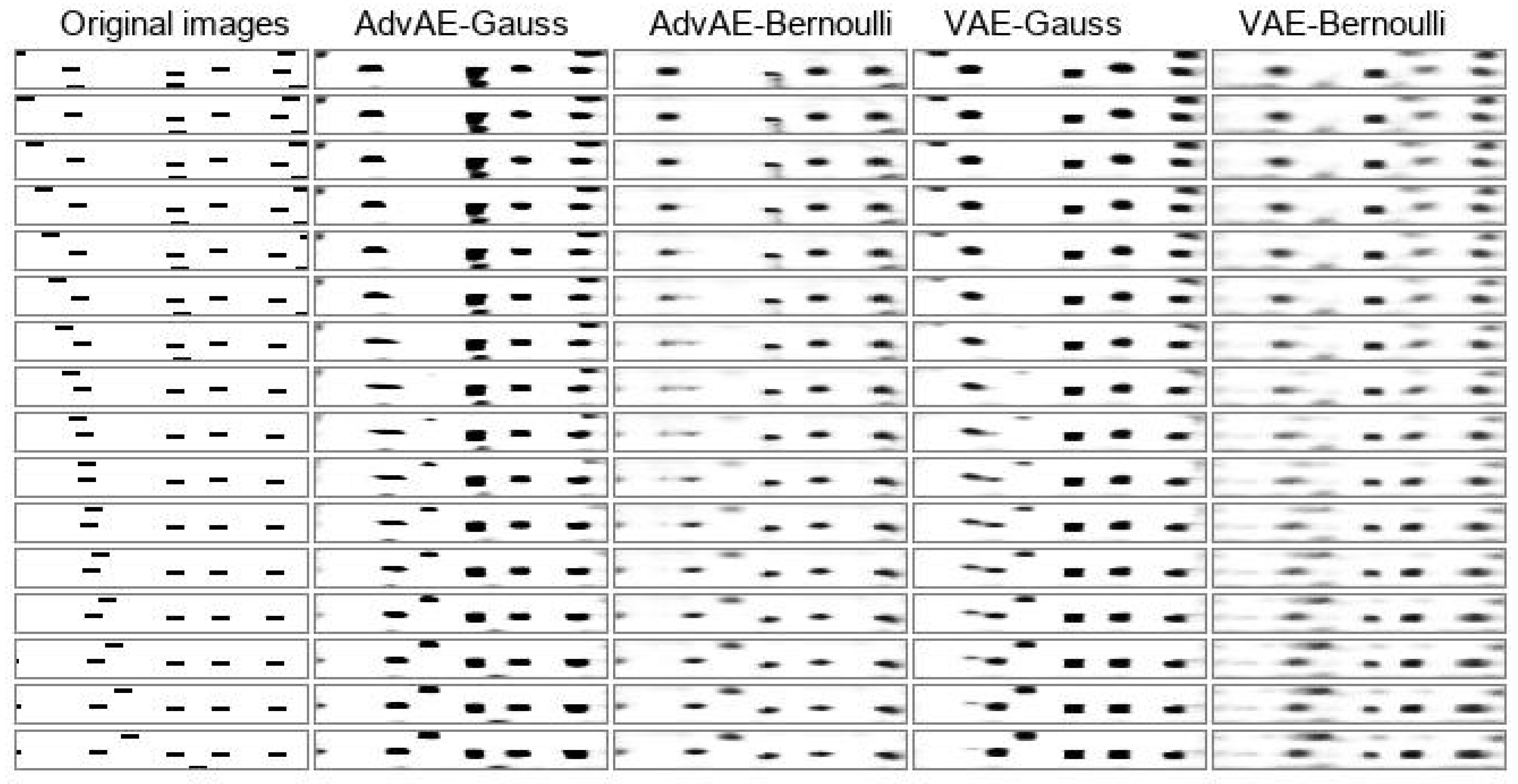
5. Results
5.1. Reconstruction Capability
5.2. Latent Space
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Networks |
| VAE | Variational Autoencoder |
| CVAE | Convolutional Variational Autoencoder |
| ADVAE | Adversarial Autoencoder |
| LSTM | Long-Short Term Memory |
| ego | self vehicle |
| KLD | Kullback–Leibler Divergence |
| BCE | Binary Cross-Entropy |
References
- Geng, X.; Liang, H.; Yu, B.; Zhao, P.; He, L.; Huang, R. A scenario-adaptive driving behavior prediction approach to urban autonomous driving. Appl. Sci. 2017, 7, 426. [Google Scholar] [CrossRef]
- Ploeg, J.; de Haan, R. Cooperative Automated Driving: From Platooning to Maneuvering. In Proceedings of the 5th International Conference on Vehicle Technology and Intelligent Transport Systems-Volume 1: VEHITS, INSTICC, Heraklion, Greece, 3–5 May 2019; SciTePress: Setubal, Portugal, 2019; pp. 5–10. [Google Scholar] [CrossRef]
- Llamazares, A.; Molinos, E.J.; Ocaña, M. Detection and Tracking of Moving Obstacles (DATMO): A Review. Robotica 2020, 38, 761–774. [Google Scholar] [CrossRef]
- Rákos, O.; Aradi, S.; Bécsi, T. Lane Change Prediction Using Gaussian Classification, Support Vector Classification and Neural Network Classifiers. Period. Polytech. Transp. Eng. 2020, 48, 327–333. [Google Scholar] [CrossRef]
- Trautman, P.; Krause, A. Unfreezing the robot: Navigation in dense, interacting crowds. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 797–803. [Google Scholar]
- Dagli, I.; Brost, M.; Breuel, G. Action recognition and prediction for driver assistance systems using dynamic belief networks. In Proceedings of the NODe 2002 Agent-Related Conference on Agent Technologies, Infrastructures, Tools, and Applications for E-Services, Erfurt, Germany, 7–10 October 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 179–194. [Google Scholar]
- Lefèvre, S.; Vasquez, D.; Laugier, C. A survey on motion prediction and risk assessment for intelligent vehicles. ROBOMECH J. 2014, 1, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Rákos, O.; Aradi, S.; Bécsi, T.; Szalay, Z. Compression of Vehicle Trajectories with a Variational Autoencoder. Appl. Sci. 2020, 10, 6739. [Google Scholar] [CrossRef]
- Kim, B.; Kang, C.M.; Kim, J.; Lee, S.H.; Chung, C.C.; Choi, J.W. Probabilistic vehicle trajectory prediction over occupancy grid map via recurrent neural network. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 399–404. [Google Scholar] [CrossRef] [Green Version]
- Deo, N.; Trivedi, M.M. Multi-Modal Trajectory Prediction of Surrounding Vehicles with Maneuver based LSTMs. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; pp. 1179–1184. [Google Scholar]
- Feng, X.; Cen, Z.; Hu, J.; Zhang, Y. Vehicle Trajectory Prediction Using Intention-based Conditional Variational Autoencoder. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3514–3519. [Google Scholar] [CrossRef]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social LSTM: Human Trajectory Prediction in Crowded Spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Deo, N.; Trivedi, M.M. Convolutional Social Pooling for Vehicle Trajectory Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hoermann, S.; Bach, M.; Dietmayer, K. Dynamic Occupancy Grid Prediction for Urban Autonomous Driving: A Deep Learning Approach with Fully Automatic Labeling. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2056–2063. [Google Scholar] [CrossRef] [Green Version]
- Cui, H.; Radosavljevic, V.; Chou, F.; Lin, T.; Nguyen, T.; Huang, T.; Schneider, J.; Djuric, N. Multimodal Trajectory Predictions for Autonomous Driving using Deep Convolutional Networks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2090–2096. [Google Scholar]
- Nawaz, A.; Huang, Z.; Wang, S.; Akbar, A.; AlSalman, H.; Gumaei, A. GPS Trajectory Completion Using End-to-End Bidirectional Convolutional Recurrent Encoder-Decoder Architecture with Attention Mechanism. Sensors 2020, 20, 5143. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Zhang, W.; Yao, Z.; Li, M.; Liang, Z.; Cao, Z.; Zhang, H.; Huang, Q. Design of a Hybrid Indoor Location System Based on Multi-Sensor Fusion for Robot Navigation. Sensors 2018, 18, 3581. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gonzalez-Arjona, D.; Sanchez, A.; López-Colino, F.; De Castro, A.; Garrido, J. Simplified Occupancy Grid Indoor Mapping Optimized for Low-Cost Robots. ISPRS Int. J. Geo-Inf. 2013, 2, 959–977. [Google Scholar] [CrossRef] [Green Version]
- Schreiber, M.; Hoermann, S.; Dietmayer, K. Long-Term Occupancy Grid Prediction Using Recurrent Neural Networks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9299–9305. [Google Scholar] [CrossRef] [Green Version]
- Park, S.H.; Kim, B.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-Sequence Prediction of Vehicle Trajectory via LSTM Encoder-Decoder Architecture. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; pp. 1672–1678. [Google Scholar] [CrossRef] [Green Version]
- Lu, C.; van de Molengraft, M.J.G.; Dubbelman, G. Monocular Semantic Occupancy Grid Mapping With Convolutional Variational Encoder–Decoder Networks. IEEE Robot. Autom. Lett. 2019, 4, 445–452. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Colyar, J.; Halkias, J. Us Highway 80 Dataset; Federal Highway Administration (FHWA): Washington, DC, USA, 2006.
- Colyar, J.; Halkias, J. US Highway 101 Dataset; Technical Report, FHWA-HRT-07-030; Federal Highway Administration (FHWA): Washington, DC, USA, 2007.
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I. Adversarial Autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Nice, France, 2019; pp. 8024–8035. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Channels Input Output | Kernel | Stride | Padding | |
|---|---|---|---|---|---|
| First segment | |||||
| Conv2D | 1 | 3 | (2, 5) | 1 | 2 |
| Leaky ReLU (0.2) | |||||
| Conv2D | 3 | 4 | (3, 8) | 1 | 1 |
| Batch Norm2D (5) | |||||
| Leaky ReLU (0.2) | |||||
| Conv2D | 5 | 8 | (3, 8) | 1 | 0 |
| Batch Norm2D (8) | |||||
| Leaky ReLU (0.2) | |||||
| Conv2D | 8 | 5 | 1 | 1 | 0 |
| Batch Norm2D (5) | |||||
| Leaky ReLU (0.2) | |||||
| Second segment | |||||
| Conv2D | 5 | 5 | (4, 4) | (1, 2) | (1, 2) |
| Batch Norm2D (5) | |||||
| Leaky ReLU (0.2) | |||||
| Conv2D | 5 | 4 | (4, 4) | (2, 2) | (1, 2) |
| Leaky ReLU (0.2) | |||||
| Conv2D | 4 | 3 | (4, 4) | (2, 2) | (1, 2) |
| Leaky ReLU (0.2) | |||||
| Conv2D | 3 | 1 | 1 | 1 | 0 |
| Sigmoid (With Bernoulli) | |||||
| Layers | Channels Input Output | Kernel | Stride | Padding | |
|---|---|---|---|---|---|
| ConvTranspose2D | 1 | 4 | (3, 3) | 1 | 0 |
| Batch Norm2D (4) | |||||
| Leaky ReLU (0.2) | |||||
| ConvTranspose2D | 4 | 4 | (3, 3) | (1, 1) | 2 |
| Batch Norm2D (4) | |||||
| Leaky ReLU (0.2) | |||||
| ConvTranspose2D | 4 | 8 | (4, 4) | (1, 1) | 2 |
| Batch Norm2D (8) | |||||
| Leaky ReLU (0.2) | |||||
| ConvTranspose2D | 8 | 12 | (4, 4) | (2, 2) | (1, 2) |
| Batch Norm2D (8) | |||||
| Leaky ReLU (0.2) | |||||
| ConvTranspose2D | 12 | 8 | (3, 8) | (1, 1) | (1, 1) |
| Batch Norm2D (8) | |||||
| Leaky ReLU (0.2) | |||||
| ConvTranspose2D | 8 | 4 | (3, 8) | (2, 2) | (1, 2) out. pad. = (0, 1) |
| Batch Norm2D (4) | |||||
| Leaky ReLU (0.2) | |||||
| ConvTranspose2D | 4 | 1 | (2, 4) | 1 | (1, 2) |
| Sigmoid | |||||
| Reconstruciton Loss Train Valid | Gauss | Bernoulli |
|---|---|---|
| ADVAE | 0.0406 0.0415 | 0.120 0.121 |
| VAE | 0.931 0.897 | 0.168 0.165 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rákos, O.; Bécsi, T.; Aradi, S.; Gáspár, P. Learning Latent Representation of Freeway Traffic Situations from Occupancy Grid Pictures Using Variational Autoencoder. Energies 2021, 14, 5232. https://doi.org/10.3390/en14175232
Rákos O, Bécsi T, Aradi S, Gáspár P. Learning Latent Representation of Freeway Traffic Situations from Occupancy Grid Pictures Using Variational Autoencoder. Energies. 2021; 14(17):5232. https://doi.org/10.3390/en14175232
Chicago/Turabian StyleRákos, Olivér, Tamás Bécsi, Szilárd Aradi, and Péter Gáspár. 2021. "Learning Latent Representation of Freeway Traffic Situations from Occupancy Grid Pictures Using Variational Autoencoder" Energies 14, no. 17: 5232. https://doi.org/10.3390/en14175232
APA StyleRákos, O., Bécsi, T., Aradi, S., & Gáspár, P. (2021). Learning Latent Representation of Freeway Traffic Situations from Occupancy Grid Pictures Using Variational Autoencoder. Energies, 14(17), 5232. https://doi.org/10.3390/en14175232