
An Intelligent Task Scheduling Mechanism for Autonomous Vehicles via Deep Learning




Abstract
:
1. Introduction
1.1. Conventional Scheduling Algorithms on Real-Time Embedded IoT Systems
Research Gap on Existing Models
1.2. Challenges on Conventional Task Scheduling Policy for Self-Driving Cars
- Task miss ratio is the significant constraint to be minimized in the autonomous vehicles to minimize the accident rates, which is not considered in any previous scheduling methods.
- Hardware resources in autonomous vehicles to be efficiently utilized to maintain the lifetime of the devices, such as sensors, actuators, and processing units.
- Time complexity (overall execution time) is another essential metric for optimizing autonomous vehicles due to the battery-based device.
- A trade-off between task miss ratio and overall execution time in task scheduling is an NP-hard problem.
1.3. Significant Contributions
1.4. Outline
2. Related Works
3. Groundworks
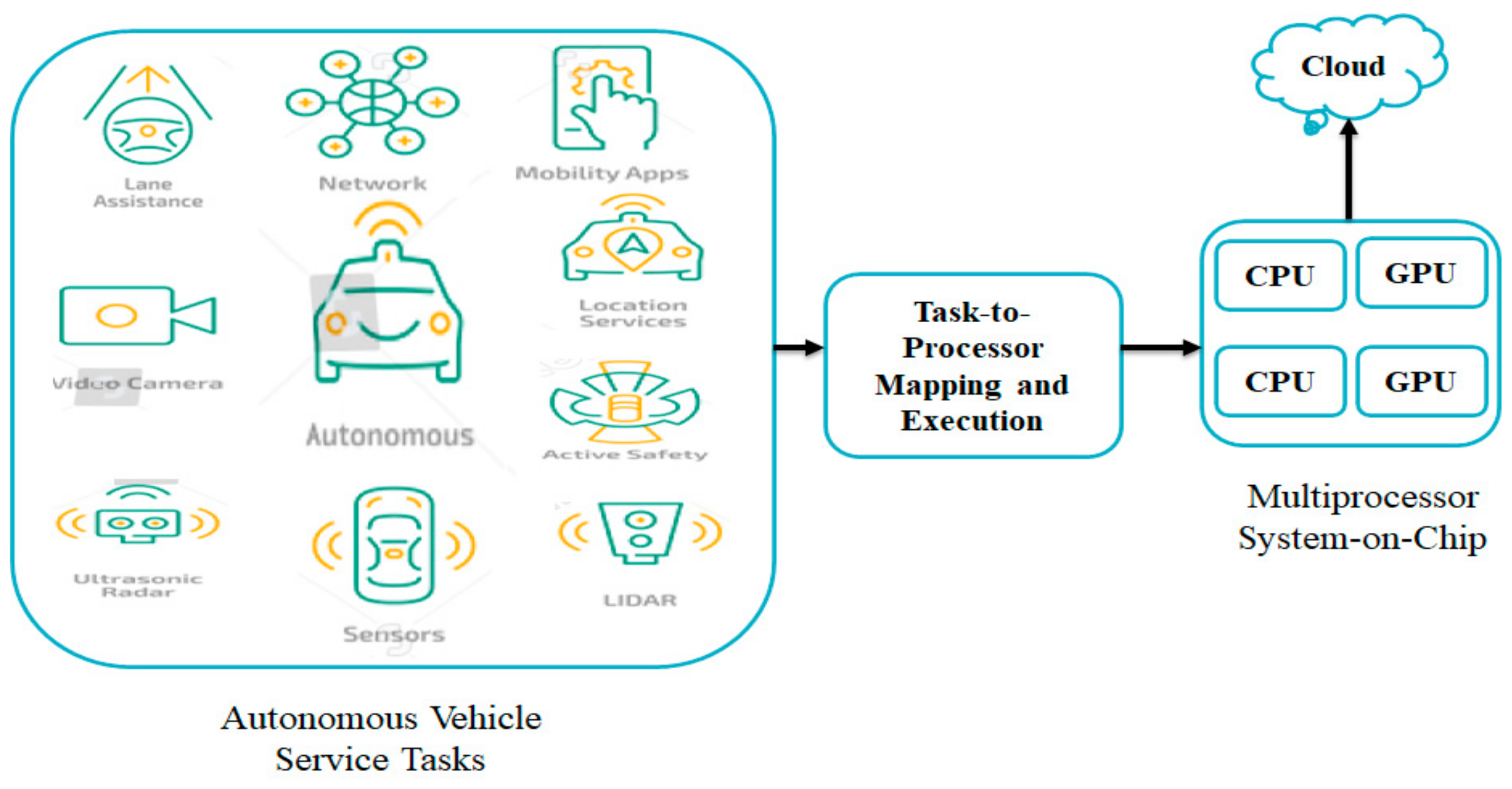
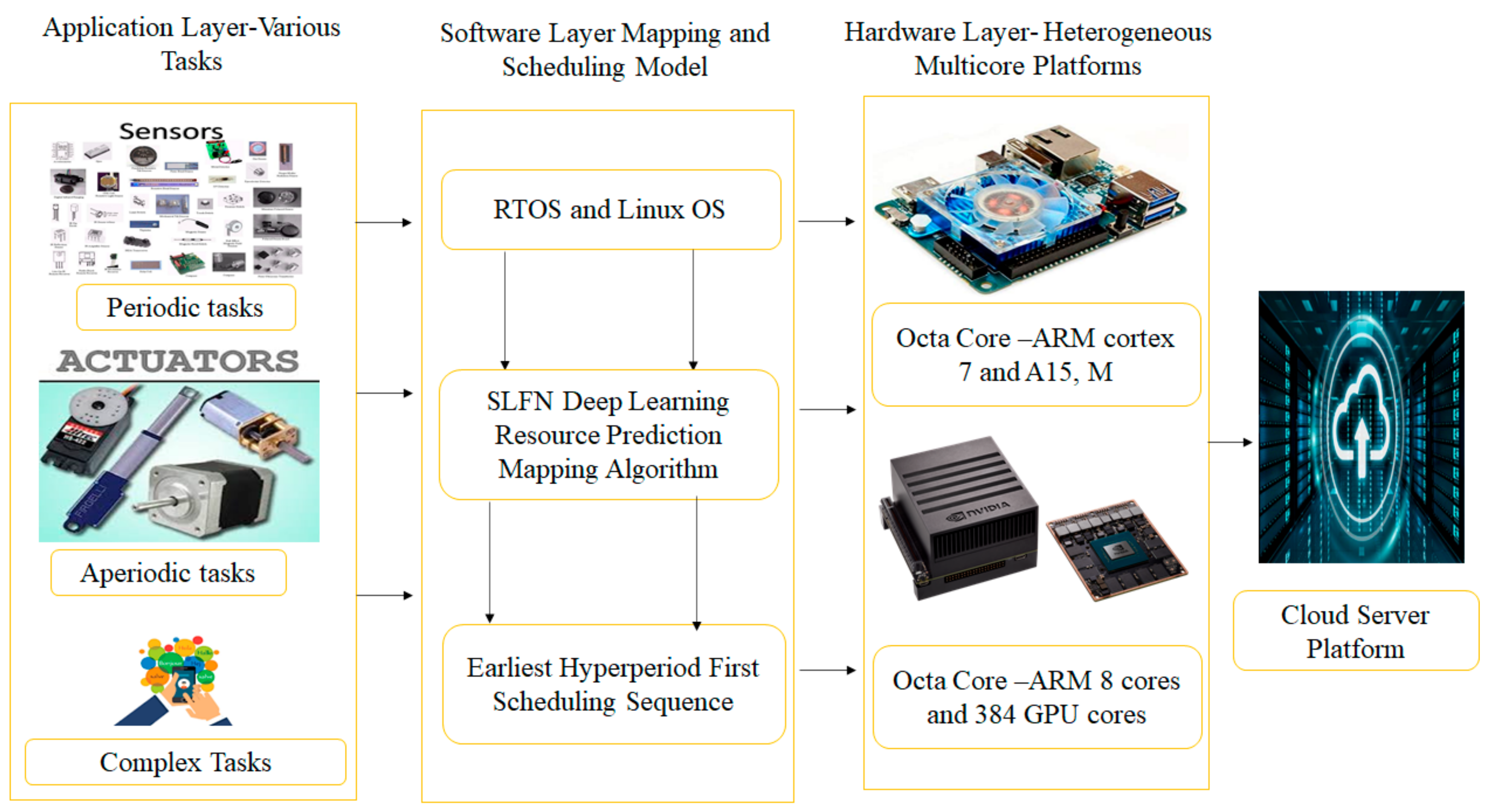
3.1. Autonomous Vehicle Service Module
3.1.1. Application Layer Structure
3.1.2. Constraints Involved in the Application Layer
3.2. Hardware Layer Multicore Processor System-on-Chip
4. Intelligent Task Management for IoT Based AV
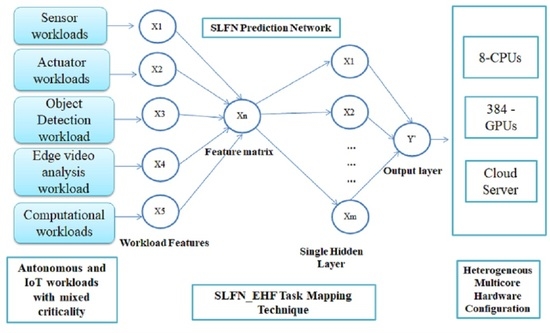
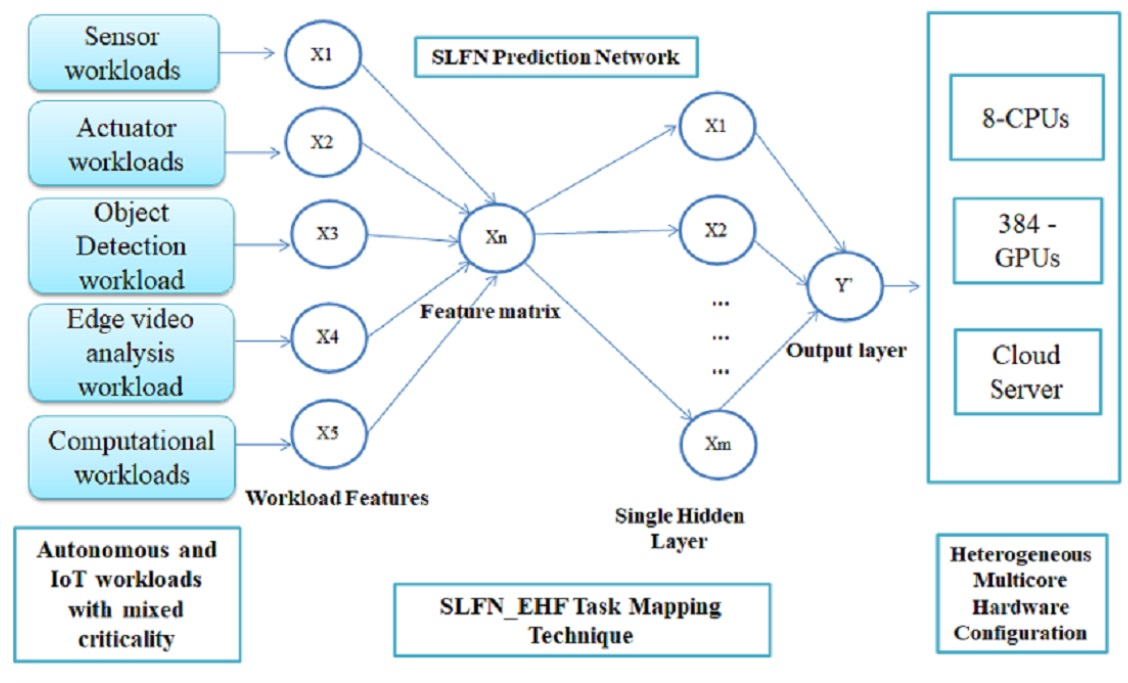
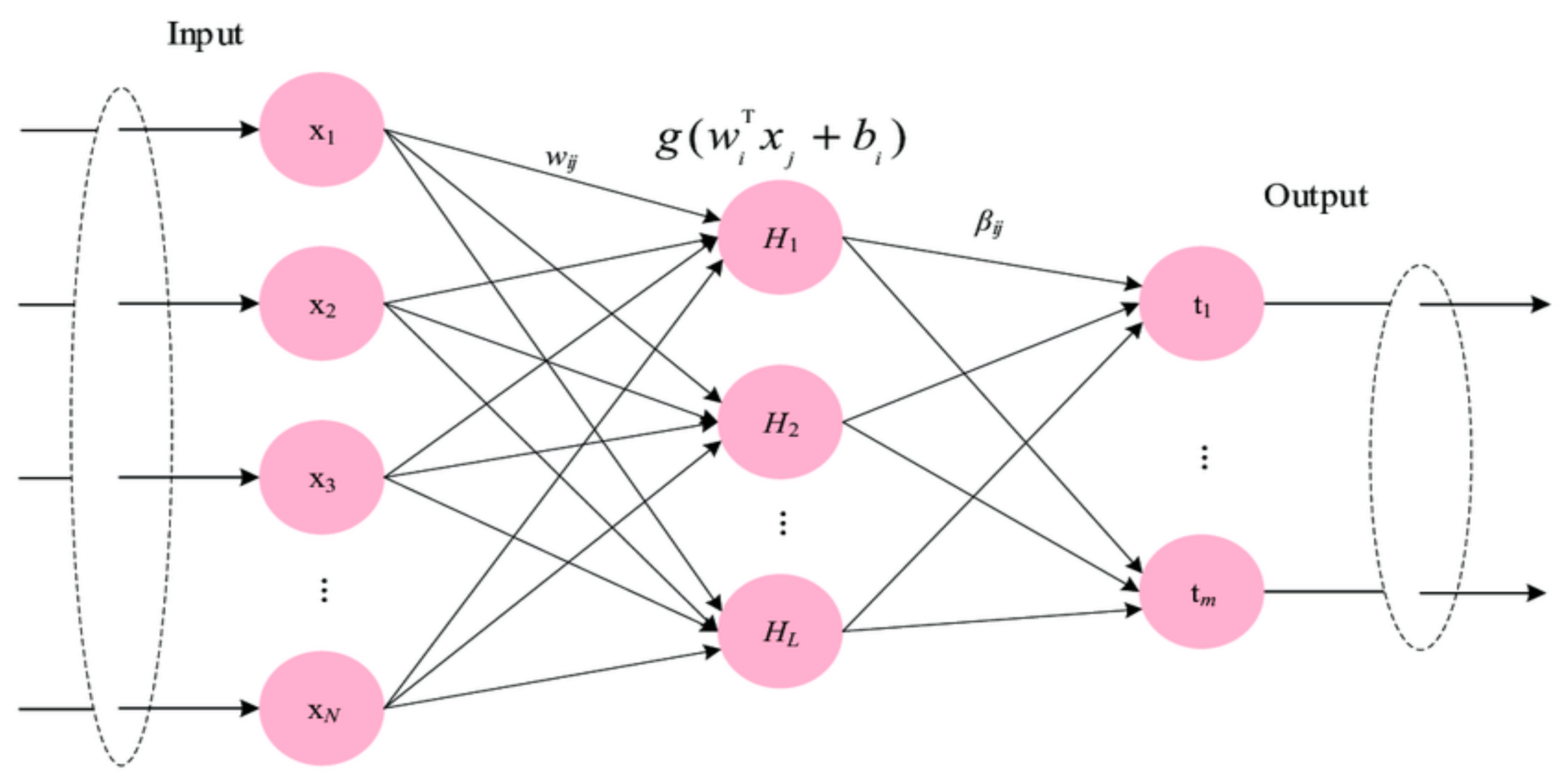
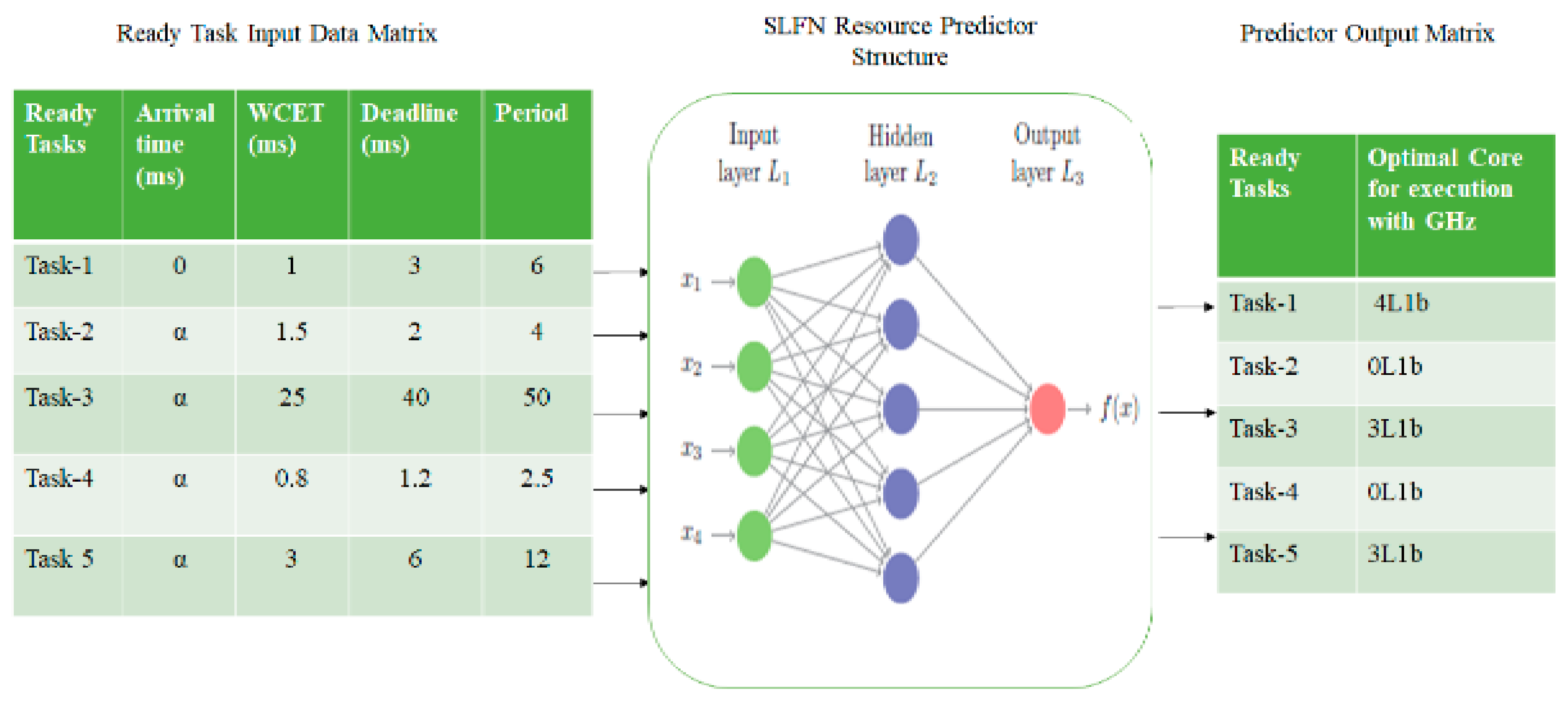
4.1. Resource Prediction Model
Feature Extraction
4.2. Modeling of SLFN Predictor
| Algorithm 1: SLFN Resource Predictor |
| Input: Trained dataset with a random number of weights and bias values Output: Predicted Score in terms of optimal core and frequency parameter 1: The network is initialized with input neurons ‘X’. 2: A set of concealed neurons are generated as a single layer. 3: Sigmoid and relu functions are defined as activation functions. 4: Synapse parameters are generated through the gaussian random method. 5: After each iteration concealed matrix are updated 6: The output matrix values are calculated. 7: Final prediction scores are observed for the entire system. |
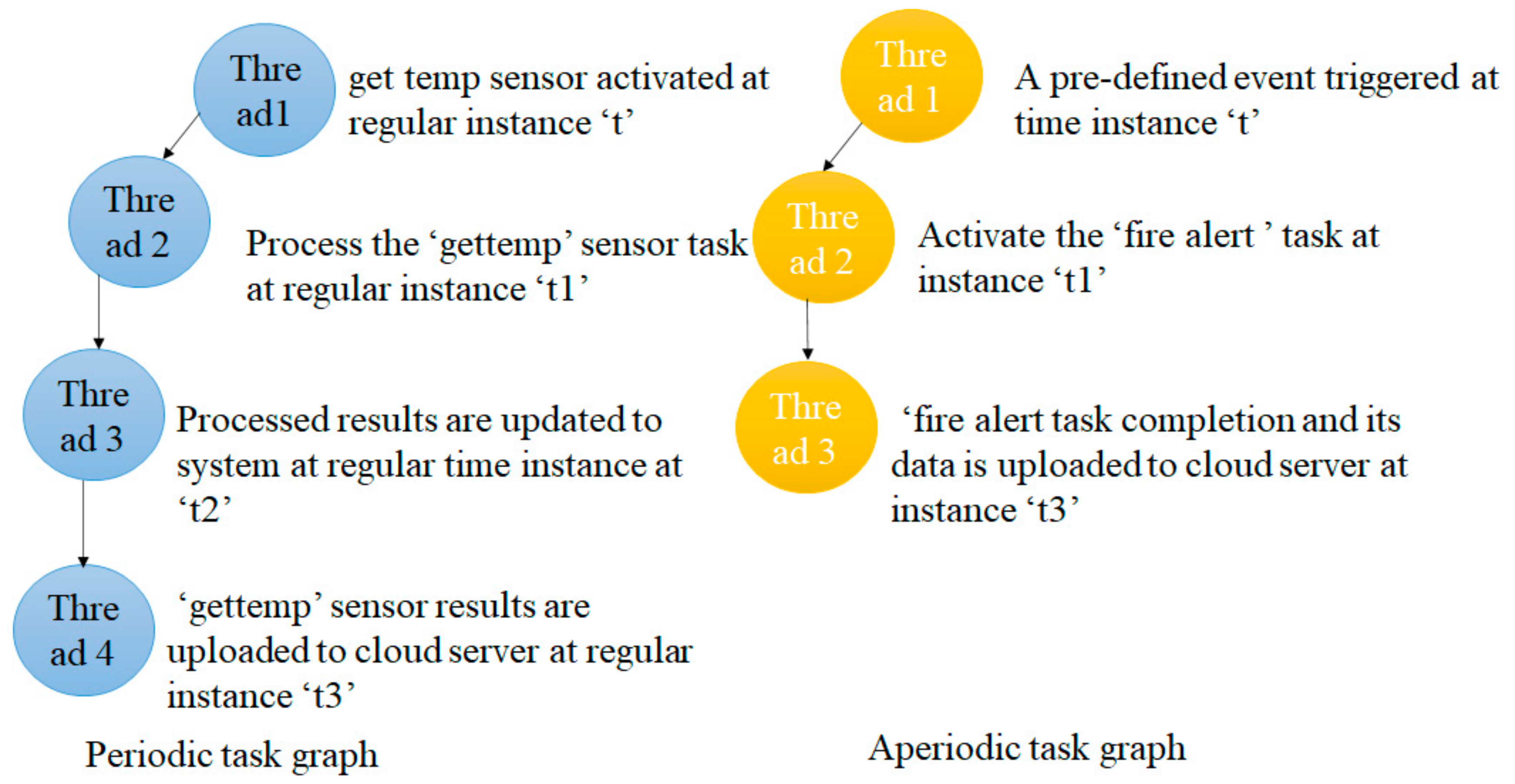
4.3. Task Scheduler Method
Earliest Hyperperiod First Scheduling Sequence
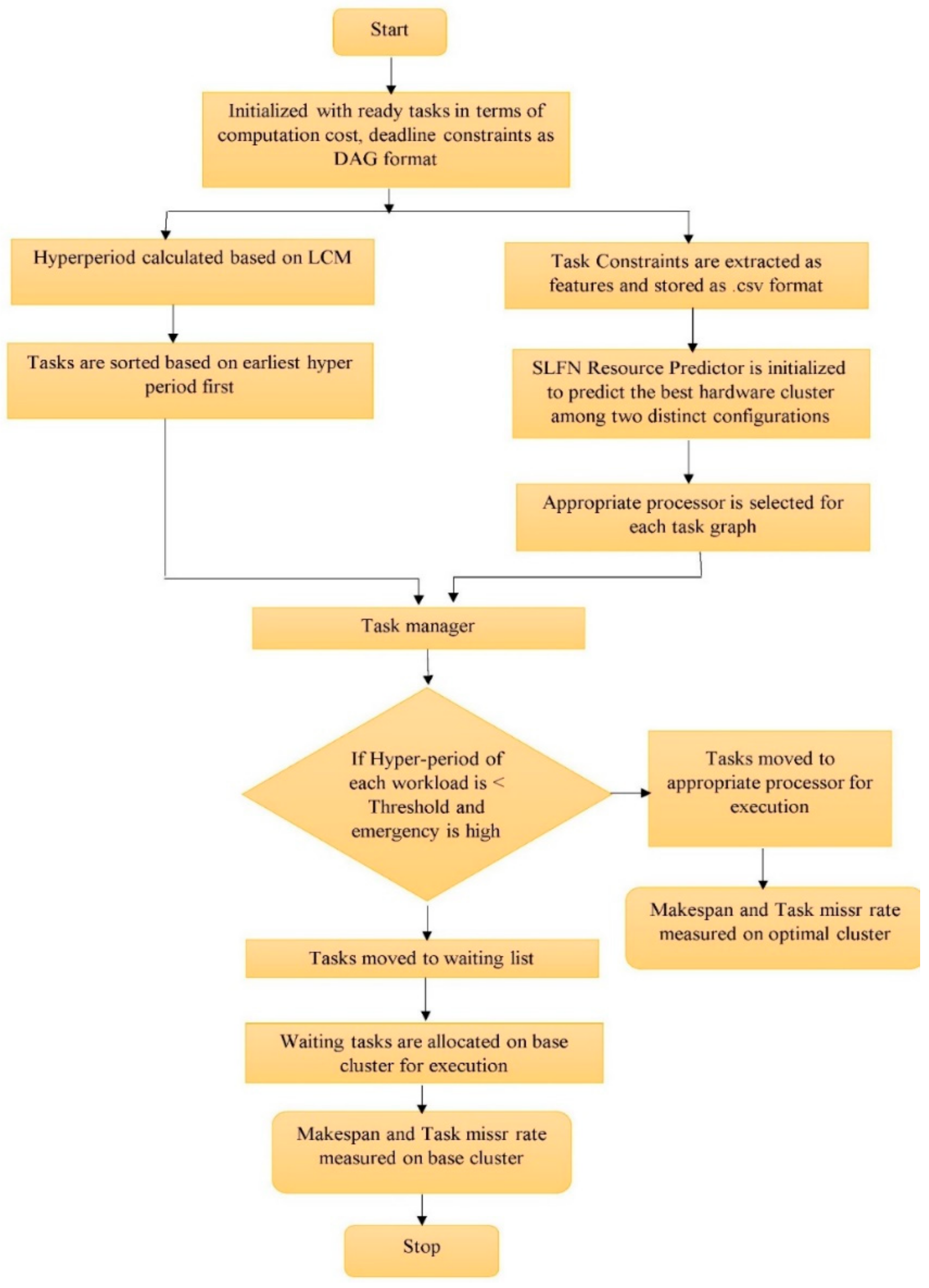
5. Proposed SLFN_EHF Scheduling Algorithm
| Algorithm 2 Task Scheduling Mechanism |
| Input: Periodic, Aperiodic, and Complex tasks With respective arrival time, Average case Execution time, deadline, period, priority list. Outcome: Prediction Accuracy, Task Miss rate, Execution time metrics |
| 1: Ready tasks = [ ] 2: Arrival time = [ ] 3: The average Case Execution time of each task is calculated by ET = WCEC/period. 4: Task parameters are modeled as neurons (i.e., features), which enter the core prediction model. 5: Single Hidden Layer Feedforward Neural Network core prediction network 6: X1…Xn = [] 7: Randomly generated bias and weights for SLFN at runtime. 8: Activation function = relu, optimizer = adam, 9: Trained with workload characteristics which executed using Nvidia SoC 10: Ready tasks are feedforwarded to the SLFN resource predictor in order to predict the optimal hardware processor. 11: Predicted optimal core in the final layer using the softmax function 12: Tasks are allocated in the optimal core (i.e., queue), given the SLFN network. 13: The pre-assumed condition is Aperiodic tasks alone executed immediately on current processors to avoid devastation. 14: Periodic and complex tasks on each core are scheduled and executed based on the hyper period method. 15: Hyperperiod (Hp) = {LCM) 1 < 0 < n} 16: Tasks are sorted in non-decreasing order of Hp. 17: If condition has been checked 18: The task set is schedulable and executed on a predicted processor 19: else 20: The task set is moved to the waiting queue, and the same is executed on the base cluster 21: end 22: Task miss deadline = miss/Total tasks on each queue 23: Execution time is calculated based on CPU processing time for the entire process. 24: Every iteration results are updated to the cloud server automatically at a regular 2: time interval. 25: End |
5.1. Simulation Environment
5.2. Implementation Setup’s
5.3. Realtime Benchmark Programs
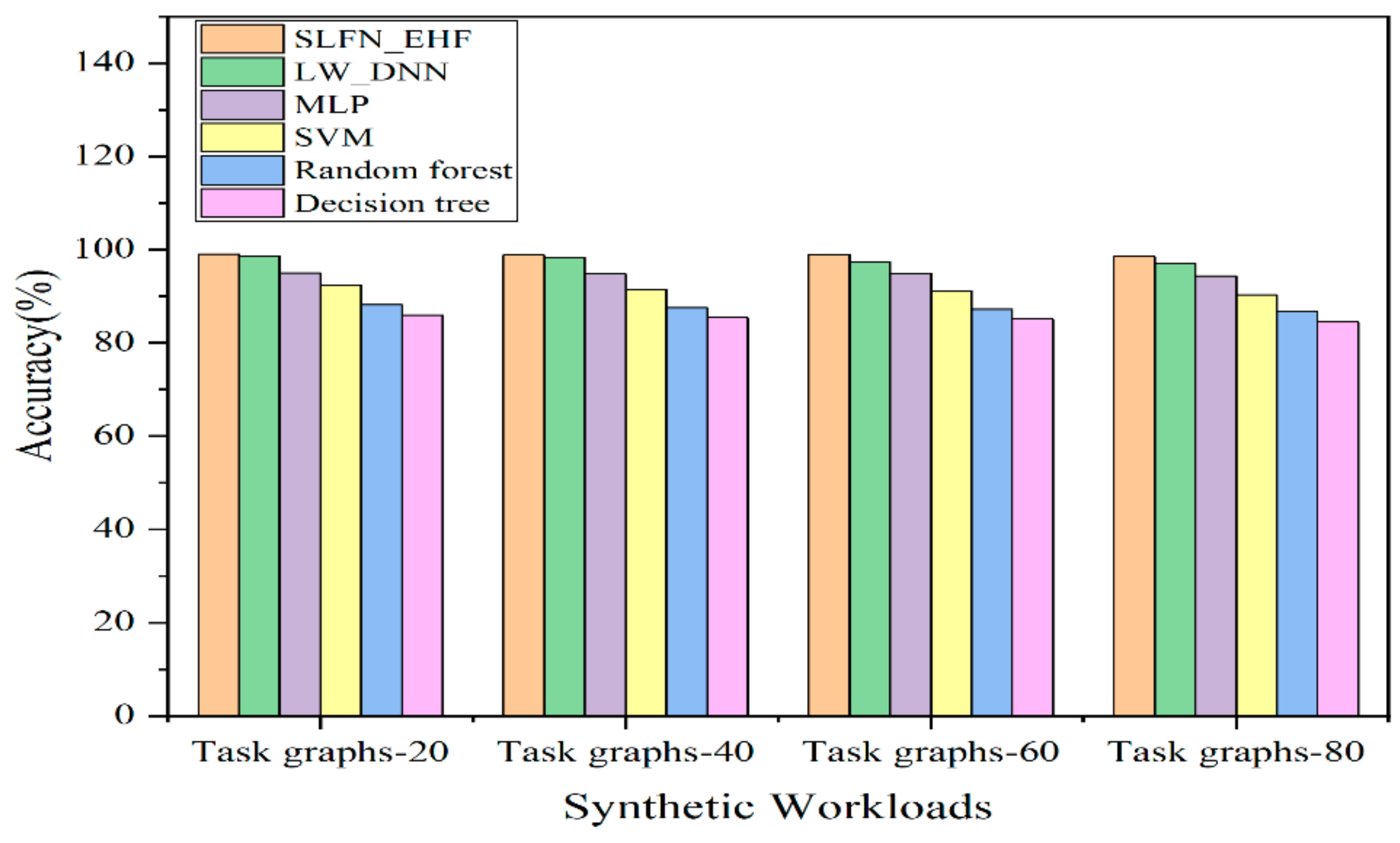
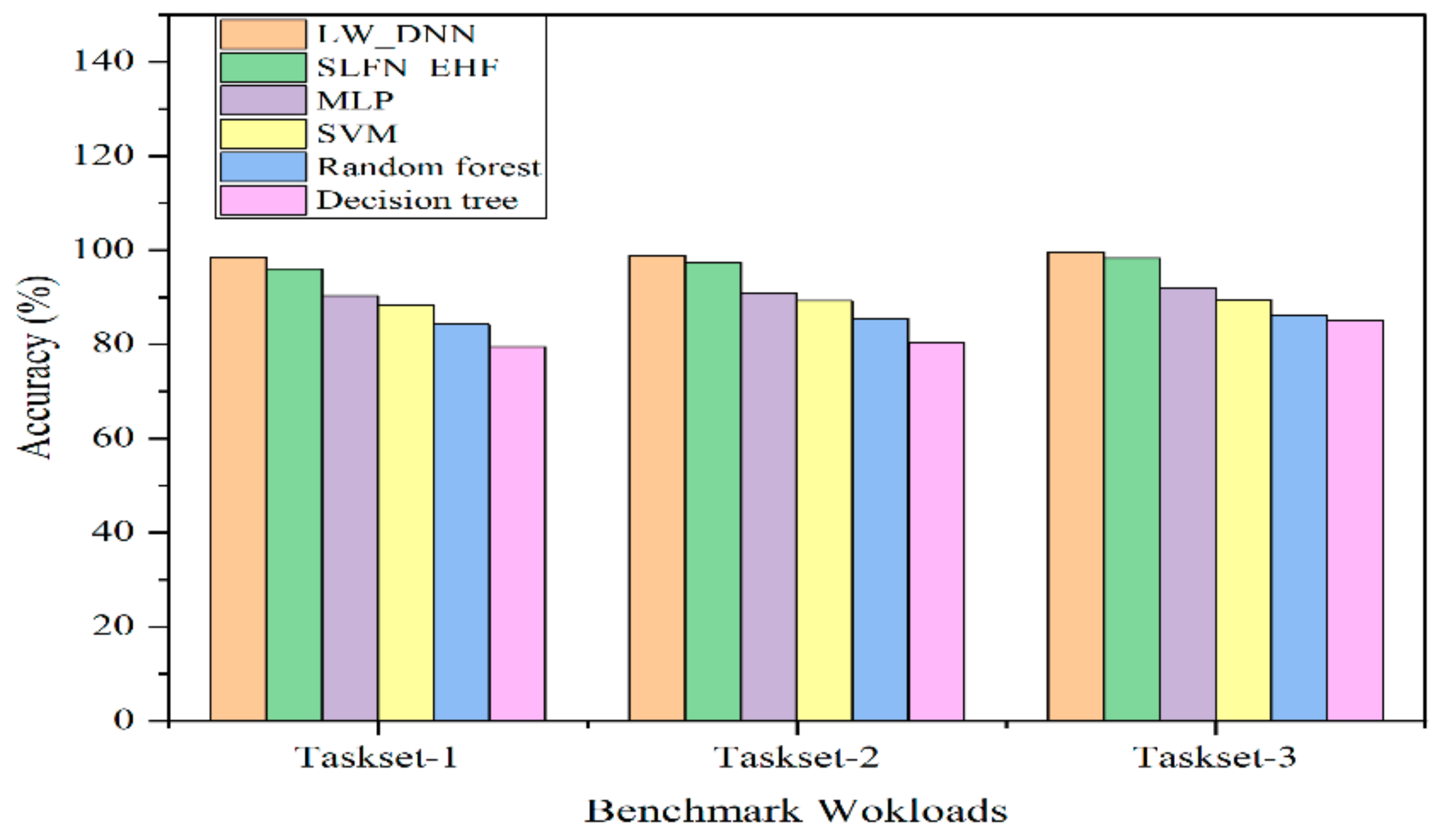
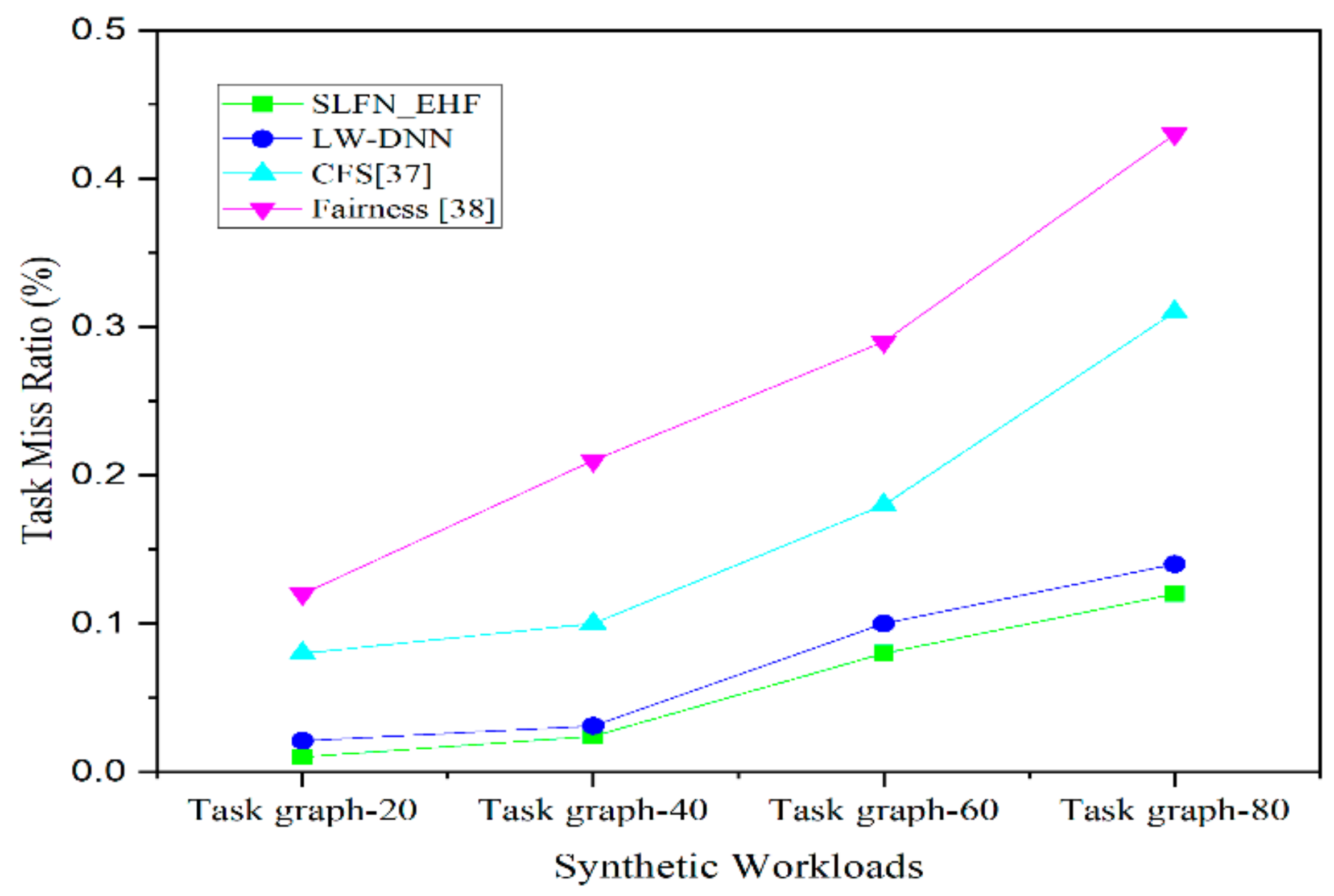
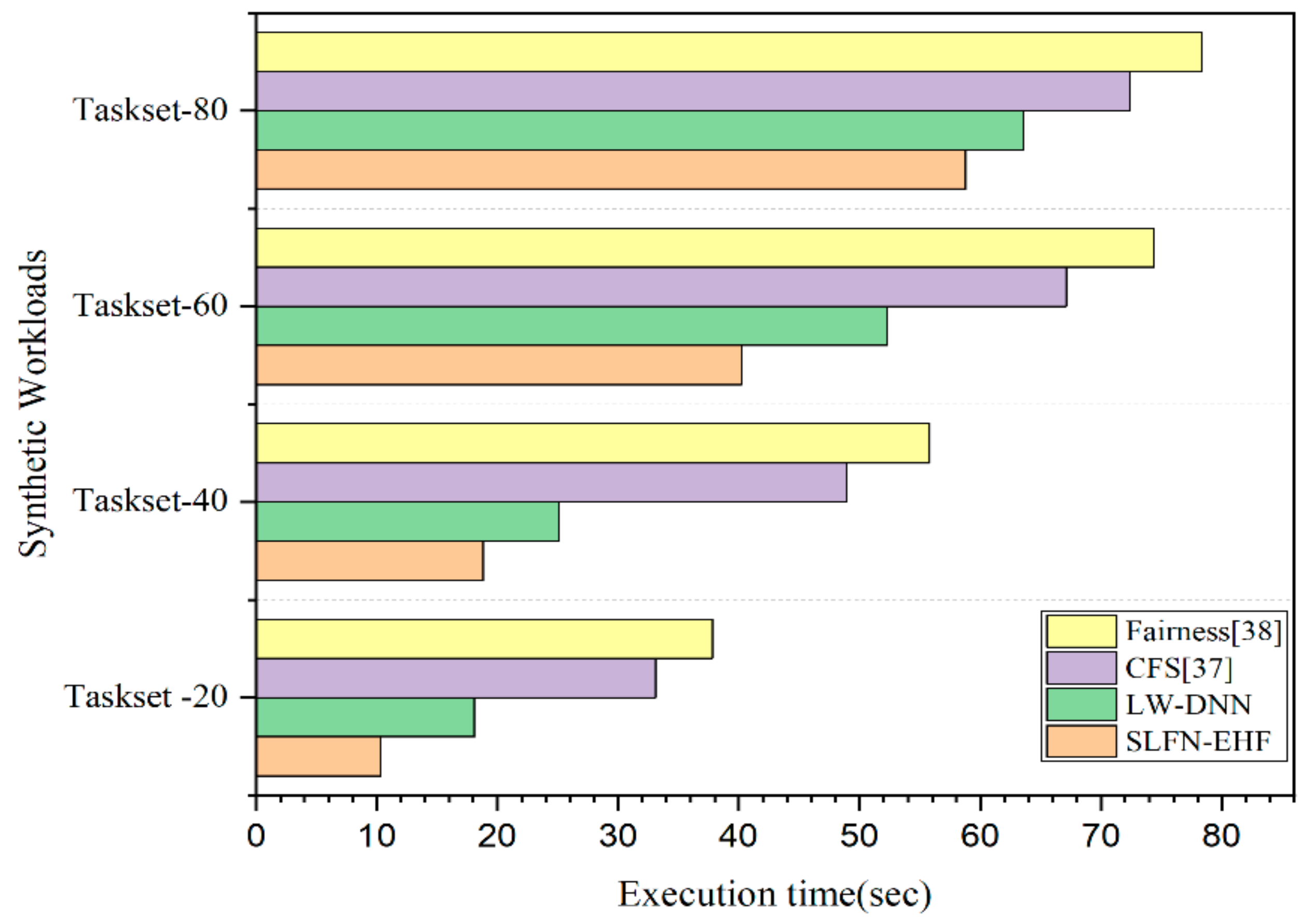
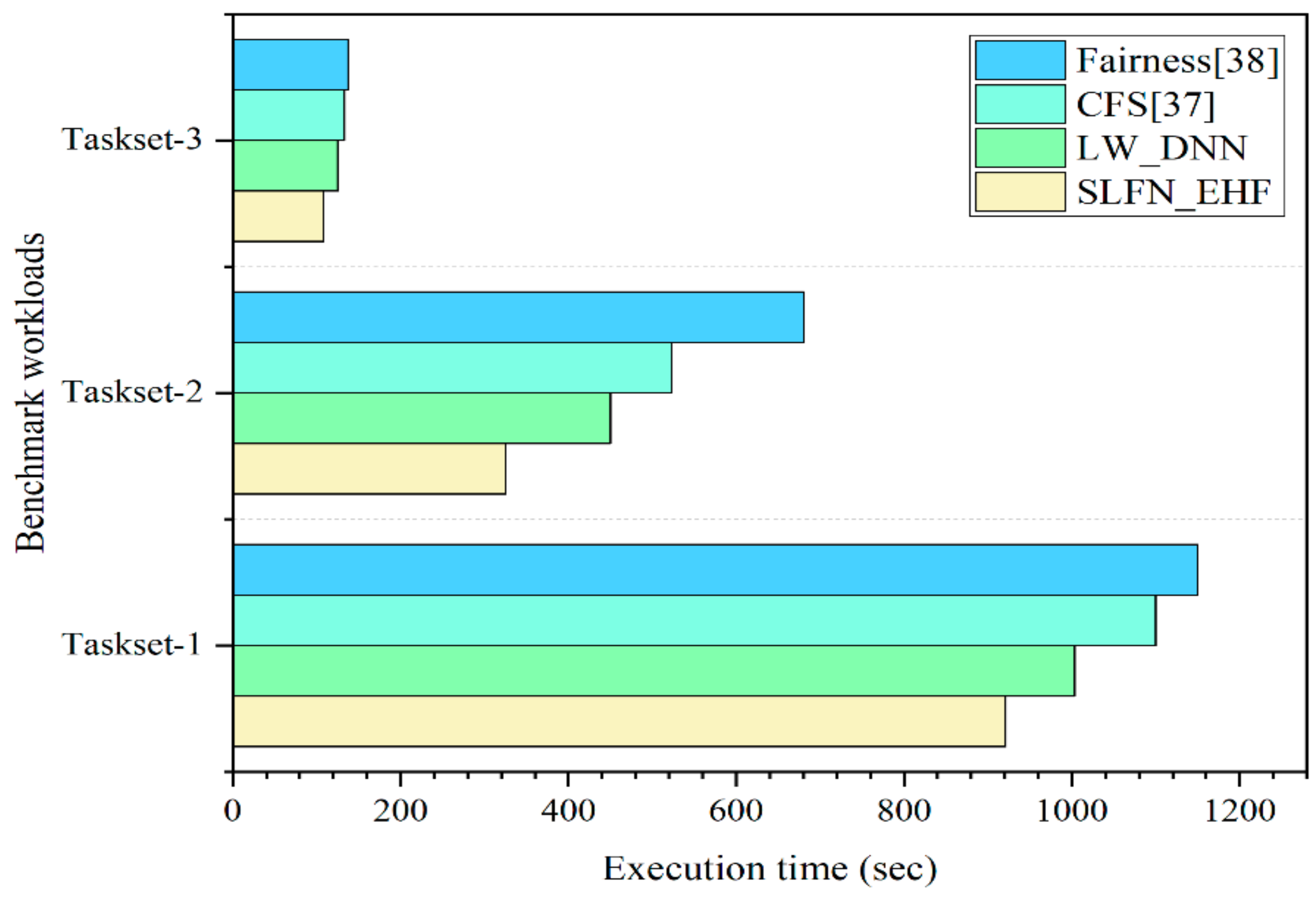
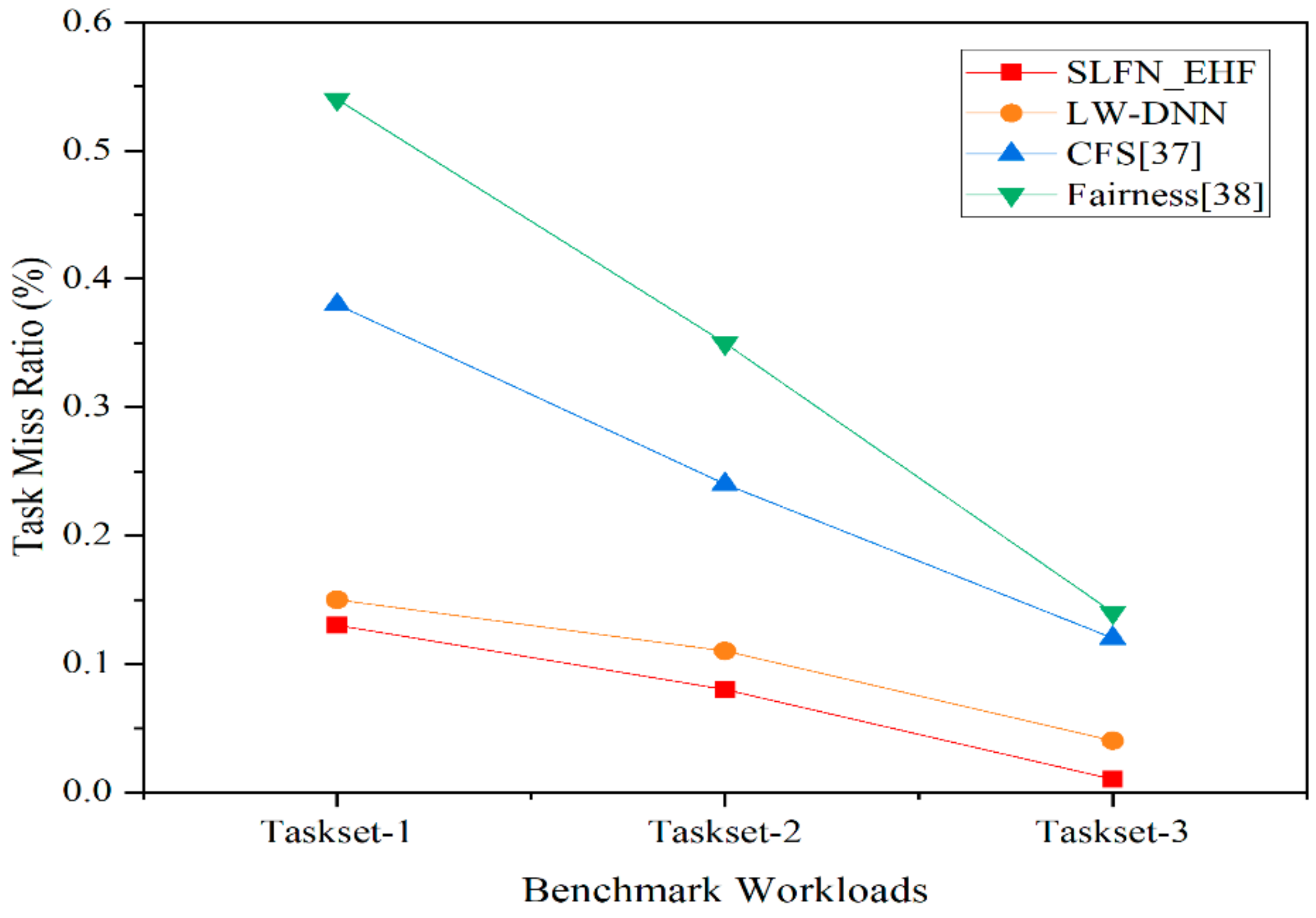
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Amalraj, J.J.; Banumathi, S.; John, J.J. IOT Sensors and Applications: A Survey. Int. J. Sci. Technol. Res. 2019, 8, 998–1003. [Google Scholar]
- Shafique, K.; Khawaja, B.A.; Sabir, F.; Qazi, S.; Mustaqim, M. Internet of Things (IoT) for Next-Generation Smart Systems: A Review of Current Challenges, Future Trends and Prospects for Emerging 5G-IoT Scenarios. IEEE Access 2020, 8, 23022–23040. [Google Scholar] [CrossRef]
- Barabás, I.; Todoruţ, A.; Cordoş, N.; Molea, A. Current challenges in autonomous driving. IOP Conf. Ser. Mater. Sci. Eng. 2017, 252, 012096. [Google Scholar] [CrossRef]
- Martínez-Díaz, M.; Soriguera, F. Autonomous vehicles: Theoretical and practical challenges. Transp. Res. Procedia 2018, 33, 275–282. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Mohammadi, A.; Akl, S.G. Scheduling Algorithms for Real-Time Systems; Technical Report; School of Computing Queens University: Kingston, ON, Canada, 2005. [Google Scholar]
- Wolf, W. The future of multiprocessor systems-on-chips. In Proceedings of the 41st Design Automation Conference, San Diego, CA, USA, 7–11 July 2004; pp. 681–685. [Google Scholar] [CrossRef]
- Singh, A.K.; Dey, S.; McDonald-Maier, K.; Basireddy, K.R.; Merrett, G.V.; Al-Hashimi, B.M. Dynamic Energy and Thermal Management of Multi-core Mobile Platforms: A Survey. IEEE Des. Test 2020, 37, 25–33. [Google Scholar] [CrossRef]
- Bechtel, M.G.; McEllhiney, E.; Kim, M.; Yun, H. DeepPicar: A Low-Cost Deep Neural Network-Based Autonomous Car. In Proceedings of the 24th International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA), Hakodate, Japan, 28–31 August 2018; pp. 11–21. [Google Scholar] [CrossRef] [Green Version]
- Cheng, L. Mixed-Criticality Scheduling of an Autonomous Driving Car. Master’s Thesis, Institute for Integrated Systems, Technische Universitat Munchen, Munchen, Germany, 2016. [Google Scholar]
- Wang, X.; Huang, K.; Knoll, A. Performance Optimisation of Parallelized ADAS Applications in FPGA-GPU Heterogeneous Systems: A Case Study with Lane Detection. IEEE Trans. Intell. Veh. 2019, 4, 519–531. [Google Scholar] [CrossRef]
- Adegbija, T.; Rogacs, A.; Patel, C.; Gordon-Ross, A. Microprocessor Optimizations for the Internet of Things: A Survey. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2017, 37, 7–20. [Google Scholar] [CrossRef] [Green Version]
- Chetto, H.; Chetto, M. Some Results of the Earliest Deadline Scheduling Algorithm. IEEE Trans. Softw. Eng. 1989, 15, 1261–1269. [Google Scholar] [CrossRef]
- Dai, H.; Zeng, X.; Yu, Z.; Wang, T. A Scheduling Algorithm for Autonomous Driving Tasks on Mobile Edge Computing Servers. J. Syst. Arch. 2019, 94, 14–23. [Google Scholar] [CrossRef]
- El Ghor, H.; Aggoune, E.-H.M. Energy efficient scheduler of aperiodic jobs for real-time embedded systems. Int. J. Autom. Comput. 2016, 17, 733–743. [Google Scholar] [CrossRef]
- Wu, X.; Tian, S.; Zhang, L. The Internet of Things Enabled Shop Floor Scheduling and Process Control Method Based on Petri Nets. IEEE Access 2019, 7. [Google Scholar] [CrossRef]
- Ma, X.; Gao, H.; Xu, H.; Bian, M. An IoT-based task scheduling optimization scheme considering the deadline and costaware scientific workflow for cloud computing. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 249. [Google Scholar] [CrossRef] [Green Version]
- Bini, E.; Buttazzo, G.C. Schedulability analysis of periodic fixed priority systems. IEEE Trans. Comput. 2004, 53, 1462–1473. [Google Scholar] [CrossRef]
- Cha, H.-J.; Jeong, W.-H.; Kim, J.-C. Control-Scheduling Codesign Exploiting Trade-Off between Task Periods and Deadlines. Mob. Inf. Syst. 2016, 2016, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Chen, C.-Y.; Hasan, M.; Mohan, S. Securing Real-Time Internet-of-Things. Sensors 2018, 18, 4356. [Google Scholar] [CrossRef] [Green Version]
- Nasri, M.; Fohler, G. An Efficient Method for Assigning Harmonic Periods to Hard Real-Time Tasks with Period Ranges. In Proceedings of the 27th Euromicro Conference on Real-Time Systems, Lund, Sweden, 7–10 July 2015; pp. 149–159. [Google Scholar]
- Liu, S.; Tang, J.; Zhang, Z.; Gaudiot, J.-L. Computer Architectures for Autonomous Driving. Computer 2017, 50, 18–25. [Google Scholar] [CrossRef]
- Sarangi, S.R.; Goel, S.; Singh, B. Energy efficient scheduling in IoT networks. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; pp. 733–740. [Google Scholar]
- Ahmad, S.; Malik, S.; Ullah, I.; Fayaz, M.; Park, D.-H.; Kim, K.; Kim, D. An Adaptive Approach Based on Resource-Awareness Towards Power-Efficient Real-Time Periodic Task Modeling on Embedded IoT Devices. Processes 2018, 6, 90. [Google Scholar] [CrossRef] [Green Version]
- Malik, S.; Ahmad, S.; Ullah, I.; Park, D.H.; Kim, D. An Adaptive Emergency First Intelligent Scheduling Algorithm for Efficient Task Management and Scheduling in Hybrid of Hard Real-Time and Soft Real-Time Embedded IoT Systems. Sustainability 2019, 11, 2192. [Google Scholar] [CrossRef] [Green Version]
- Samie, F.; Bauer, L.; Henkel, J. Iot Technologies for Embedded Computing: A Survey. In Proceedings of the International Conference on Hardware/Software Codesign and System Synthesis, Pittsburgh, PA, USA, 2–7 October 2016; pp. 1–10. [Google Scholar]
- Tang, J.; Yu, B.; Liu, S.; Zhang, Z.; Fang, W.; Zhang, Y. π-SoC: Heterogeneous SoC Architecture for Visual Inertial SLAM Applications. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 8302–8307. [Google Scholar]
- Xu, J. A method for adjusting the periods of periodic processes to reduce the least common multiple of the period lengths in real-time embedded systems. In Proceedings of the 2010 IEEE/ASME International Conference on Mechatronics and Embedded Systems and Applications (MESA), Qingdao, China, 15–17 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 288–294. [Google Scholar]
- Brüning, J.; Forbrig, P. TTMS: A Task Tree Based Workflow Management System. In Proceedings of the International Conference, BPMDS 2011, and 16th International Conference, EMMSAD 2011, London, UK, 20–21 June 2011; Volume 81, pp. 186–200. [Google Scholar]
- Gomatheeshwari, B.; Selvakumar, J. Appropriate allocation of workloads on performance asymmetric multicore architectures via deep learning algorithms. Microprocess. Microsyst. 2020, 73, 102996. [Google Scholar] [CrossRef]
- Akusok, A. Extreme Learning Machines: Novel Extensions and Application to Big Data. Ph.D. Thesis, University of Iowa, Iowa City, IA, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Topcuoglu, H.; Hariri, S.; Wu, M.-Y. Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans. Parallel Distrib. Syst. 2002, 13, 260–274. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.; Liu, S.; Liu, K.; Yu, B.; Shi, W. LoPECS: A Low-Power Edge Computing System for Real-Time Autonomous Driving Services. IEEE Access 2020, 8, 30467–30479. [Google Scholar] [CrossRef]
- Limaye, A.; Adegbija, T. HERMIT: A Benchmark Suite for the Internet of Medical Things. IEEE Internet Things J. 2018, 5, 4212–4222. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, S.; Wu, X.; Shi, W. CAVBench: A Benchmark Suite for Connected and Autonomous Vehicles. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), San Jose, CA, USA, 14–17 December 2018; pp. 30–42. [Google Scholar]
- Saez, J.C.; Pousa, A.; Castro, F.; Chaver, D.; Prieto-Matias, M. Towards completely fair scheduling on asymmetric single-ISA multicore processors. J. Parallel Distrib. Comput. 2017, 102, 115–131. [Google Scholar] [CrossRef]
- Van Craeynest, K.; Akram, S.; Heirman, W.; Jaleel, A.; Eeckhout, L. Fairnessaware Scheduling on single-is heterogeneous multicores. In Proceedings of the 22nd International Conference on Parallel Architectures and Compilation Techniques, Boston, MA, USA, 20–23 October 1996; pp. 177–187. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Existing Models | Inference | System Structure | Application Model | Resource Utilization | Execution Time Optimization | Task Miss Ratio Optimization |
|---|---|---|---|---|---|---|
| [21] | Formation of RT–IoT with the embedded system is deliberated with its current challenges in hardware/software, task scheduling, and security issues. | Multicore platforms, IoT networks are studied. | IoT tasks with mixed-criticalities | - | - | - |
| [22] | Fixed-priority and Rate monotonic scheduling algorithms designed with optimized period bounds | Hardware is not focused on this work. | IoT tasks with mixed-criticalities (control applications are modeled as periodic task sets) | Resource utilization is improved with harmonic period selections. | - | - |
| [23] | Autonomous driving workloads are experimentally tested on various HMPSoC platforms. | HMPSoCs are utilized for evaluation. | Autonomous vehicle workloads are considered. | Resources are utilized up to 100% | Execution time is improved based on the appropriate selection of processors. | - |
| [24] | Energy consumption is targeted in this work. DVFS based heuristics are developed for the RT-IoT system | HMPSoC | RT–IoT workloads are considered for evaluation. | - | 25–30% of execution time is minimized based on the DVFS adjustment | Task miss rates are reduced with a penalty |
| [25] | A resource-based task scheduler is designed to optimize the hyper-period metric. | Raspberry pi-3 HMPSoC used for evaluation | Sensor tasks are modeled as Periodic task sets with a mixed-period range. | - | 20% improved | - |
| [26] | Fair emergency first scheduling algorithms is designed with ANN resource predictor. | Intel PC has been used for evaluation. | Sensor and actuator tasks are modeled with mixed-criticalities. | - | 30% improved | 35% task miss ratio is improved |
| [27] | Various machine learning algorithms are discussed | MPSoC platform used for analysis | Embedded workloads are used | - | - | - |
| [28] | Dragonfly’s low-cost autonomous vehicle is designed and executed with an inter-core scheduling algorithm. | HMPSoC | Autonomous vehicle workloads are utilized. | - | 10–27% minimized the overall execution time | - |
| [29] | Task periods are minimized using the DVFS technique. | MPSoC | Embedded workloads are considered. | - | 10% minimized | - |
| Proposed Framework | Two heuristics are modeled, such as EHF, SLFN-EHF with intelligent resource predictors to solve hardware/software challenges of autonomous vehicles. The proposed modules are evaluated on two HMPSoC testbeds. | HMPSoC | The autonomous vehicle, IoT workloads as a Tree structure | Resources are clustered and utilized fully | 35% compared with traditional methods CFS and fairness algorithms | 65% improvement is achieved |
| Data Type | Workload Features |
|---|---|
| performance | Instruction per count (IPC) |
| Time | Deadline, period |
| Emergency value | Token ID |
| Runtime utilization | No of active CPUs and GPUs |
| Load | No of assigned processes count on each core |
| Threshold limit | CPUs and GPUs capacity (pre-defined) |
| memory | L1-D cache, L1-I cache, L2-cache access and cache miss ratio |
| Instructions (%) | Arithmetic integer/float/add/mul |
| branch | Branch misprediction data’s |
| TLB | dTLB misses, iTLB misses |
| power | average power consumption in watts for a time slice |
| Time | The overall execution time of the workload |
| Total tasks | Total no.of tasks on each queue |
| Queue id | Each task queue id |
| Network Type | Single-Layer Neural Network |
|---|---|
| Activation variable | Sigmoid and Relu functions |
| No of the hidden nodes | 20 |
| Input parameters | N (Ready Task parameters form Allocation Queue) |
| Output parameters | 1 (Optimal Hardware cluster) |
| Hardware Configurations | Multicore Processor Config.1 | Multicore Processor Config.2 |
|---|---|---|
| No. of. cores (CPUs and GPUs) | 8 (‘ARM Cortex-A15, A7’) Mali-T628MP6 | 384-core Volta GPU with 48 Tensor Cores, 6-Core ARM v8.2 64-bit CPU, 8-MB L2 + 4 MB L3 |
| Operating freq. max | 2.0 GHz and | 1100 MHz and 1.4 GHz |
| Operating voltage. max | 5 V | 5 V |
| Power | 10–20 W | 10–15 W |
| Memory | 8 GB | 16 GB |
| Cache used | L1-64 KB & L2-2 MB | 16 GB 256-bit LPDDR4x| 137 GB/s |
| Execution order | Out-of-order | In-order |
| Synthetic Task Graphs | Task Graphs | Task Nodes | Task Edges | Deadline (s) | Period (s) |
|---|---|---|---|---|---|
| Synthetic Tasks-20 | Graphs {0–20} | {1–20} | {1–20} | {0.0001–30} | {0.0001–30} |
| Synthetic Tasks-40 | Graphs {0–40} | {1–40} | {1–39} | {0.0001–60} | {0.0001–60} |
| Synthetic Tasks-60 | Graphs {0–60} | {1–60} | {1–59} | {0.0001–90} | {0.0001–90} |
| Synthetic Tasks-80 | Graphs {0–80} | {1–80} | {1–79} | {0.0001–50} | {0.0001–50} |
| Real-Time Benchmark Programs | Task Graphs | Task Nodes | Task Edges | Deadline (s) | Period (s) |
|---|---|---|---|---|---|
| Object_tracking-graph | Graph-0 | 165 | 164 | 280 | 400 |
| Video_Analysis-graph | Graph-0 | 120 | 119 | 165 | 250 |
| Path_planning-graph | Graph-0 | 145 | 144 | 233 | 300 |
| Navigation-graph | Graph-0 | 100 | 99 | 120 | 500 |
| AES-graph | Graph-0 | 4 | 4 | 0.01 | 0.01 |
| Graph-1 | 6 | 6 | 0.01 | 0.02 | |
| Graph-2 | 6 | 6 | 0.01 | 0.02 | |
| Graph-3 | 3 | 2 | 0.001 | 0.001 | |
| Graph-4 | 3 | 2 | 0.001 | 0.001 | |
| Graph-5 | 2 | 1 | 0.0004 | 0.0003 | |
| Graph-6 | 2 | 1 | 0.0001 | 0.0005 | |
| Graph-7 | 2 | 1 | 0.0004 | 0.0005 | |
| Graph-8 | 2 | 1 | 0.0004 | 0.0005 | |
| Imhist-graph | Graph-0 | 8 | 8 | 0.002 | 0.002 |
| Graph-1 | 5 | 4 | 0.004 | 0.004 | |
| Activity-graph | Graph-0 | 6 | 6 | 0.05 | 0.05 |
| Graph-1 | 4 | 3 | 0.004 | 0.004 | |
| Graph-2 | 7 | 5 | 0.06 | 0.08 | |
| Iradon-graph | Graph-0 | 4 | 3 | 0.001 | 0.002 |
| Graph-1 | 4 | 4 | 0.004 | 0.003 | |
| Graph-2 | 3 | 3 | 0.003 | 0.003 | |
| Squ_web-graph | Graph-0 | 8 | 8 | 0.002 | 0.002 |
| Graph-1 | 5 | 4 | 0.004 | 0.004 | |
| HRV-graph | Graph-0 | 6 | 6 | 0.05 | 0.05 |
| Graph-1 | 4 | 3 | 0.004 | 0.004 | |
| LZW-graph | Graph-0 | 8 | 10 | 0.08 | 0.08 |
| Apet-graph | Graph-0 | 15 | 14 | 0.2 | 0.5 |
| Graph-1 | 10 | 9 | 0.4 | 0.4 | |
| Graph-2 | 8 | 7 | 0.8 | 0.8 | |
| gettemp-graph | Graph-0 | 6 | 6 | 0.05 | 0.05 |
| 4 | 3 | 0.004 | 0.004 | ||
| 7 | 5 | 0.06 | 0.08 | ||
| gethumidity-graph | Graph-0 | 3 | 2 | 0.01 | 0.03 |
| getmotion-graph | Graph-0 | 3 | 3 | 0.01 | 0.03 |
| Getpressure-graph | Graph-0 | 3 | 3 | 0.01 | 0.03 |
| LED-graph | Graph-0 | 8 | 7 | 0.5 | 0.8 |
| Task Models | Normalized Execution Time (s) | Task Miss Rate (%) | ||
|---|---|---|---|---|
| Hardware Clusters | Base Cluster | Optimal Cluster | Base Cluster | Optimal Cluster |
| IoT based AV Workloads {1–150 nodes} | 1800 | 1400 | 0.21 | 0.026 |
| IoMT workloads {1–50 nodes} | 1000 | 855 | 0.18 | 0.22 |
| Synthetic task workloads {1–80 nodes} | 200 | 120 | - | 0.01 |
| Task Models | Normalized Execution Time (s) | Task Miss Rate (%) | ||
|---|---|---|---|---|
| Hardware Clusters | Base Cluster | Optimal Cluster | Base Cluster | Optimal Cluster |
| IoT based AV Workloads {1–150 nodes} | 1000 | 855 | 0.33 | 0.31 |
| IoMT workloads {1–50 nodes} | 500 | 399 | 0.22 | 0.25 |
| Synthetictask workloads {1–80 nodes} | 110 | 89 | - | 0.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balasekaran, G.; Jayakumar, S.; Pérez de Prado, R. An Intelligent Task Scheduling Mechanism for Autonomous Vehicles via Deep Learning. Energies 2021, 14, 1788. https://doi.org/10.3390/en14061788
Balasekaran G, Jayakumar S, Pérez de Prado R. An Intelligent Task Scheduling Mechanism for Autonomous Vehicles via Deep Learning. Energies. 2021; 14(6):1788. https://doi.org/10.3390/en14061788
Chicago/Turabian StyleBalasekaran, Gomatheeshwari, Selvakumar Jayakumar, and Rocío Pérez de Prado. 2021. "An Intelligent Task Scheduling Mechanism for Autonomous Vehicles via Deep Learning" Energies 14, no. 6: 1788. https://doi.org/10.3390/en14061788
APA StyleBalasekaran, G., Jayakumar, S., & Pérez de Prado, R. (2021). An Intelligent Task Scheduling Mechanism for Autonomous Vehicles via Deep Learning. Energies, 14(6), 1788. https://doi.org/10.3390/en14061788