
Structure Optimization of Ensemble Learning Methods and Seasonal Decomposition Approaches to Energy Price Forecasting in Latin America: A Case Study about Mexico

 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
- The reduction of the signal variation is achieved by using the seasonal decomposition using moving averages. This technique can be used for denoising (noise reduction) in chaotic time series.
- A comparison of the adaptive boosting (AdaBoost), bootstrap aggregation (Bagging), Gradient Boosting, Histogram-Based Gradient Boosting, and Random Forest ensemble learning models are evaluated.
- An optimized ensemble learning method is presented, combining multiple ensembles and determining the best model structure using a voter selected through Optuna.
2. Related Works
3. Proposed Method
3.1. Regression
3.1.1. AdaBoost
3.1.2. Bagging
3.1.3. Gradient Boosting
3.1.4. Histogram-Based Gradient Boosting
3.1.5. Random Forest
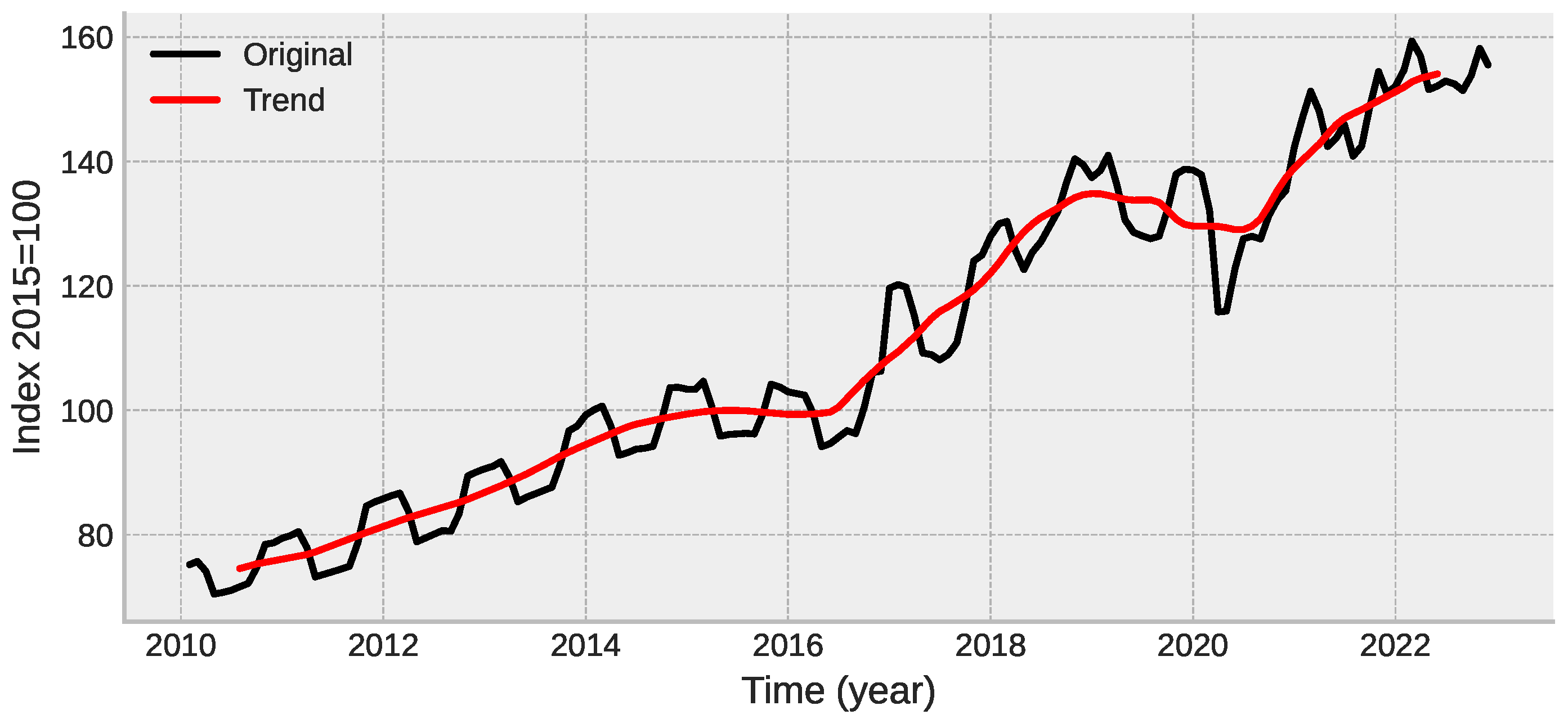
3.2. Seasonal Decomposition Using Moving Averages
3.3. Dataset
3.4. Quantile Regression
4. Results and Discussion
4.1. Preparing the Data
4.2. Single Model Prediction
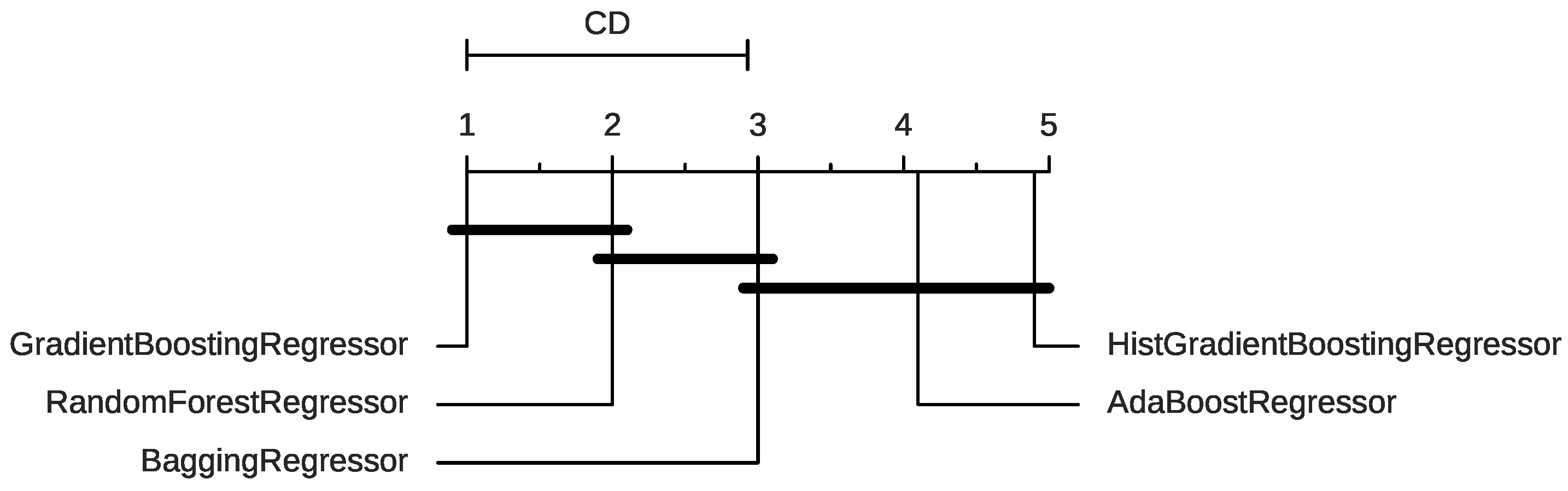
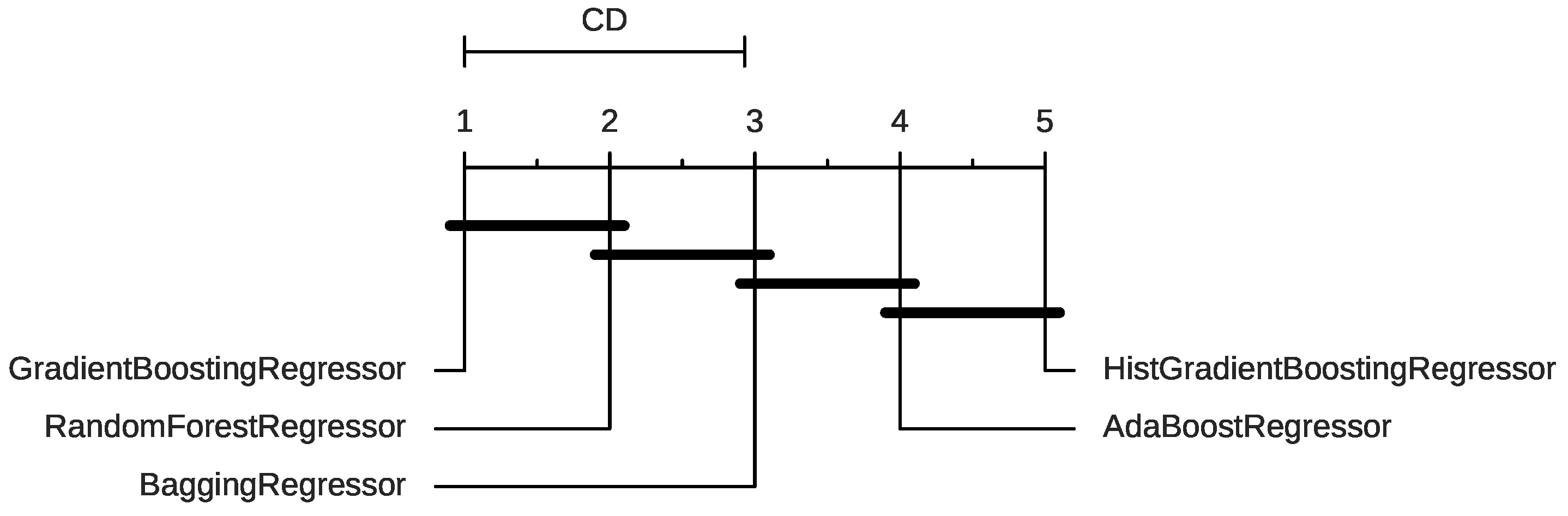
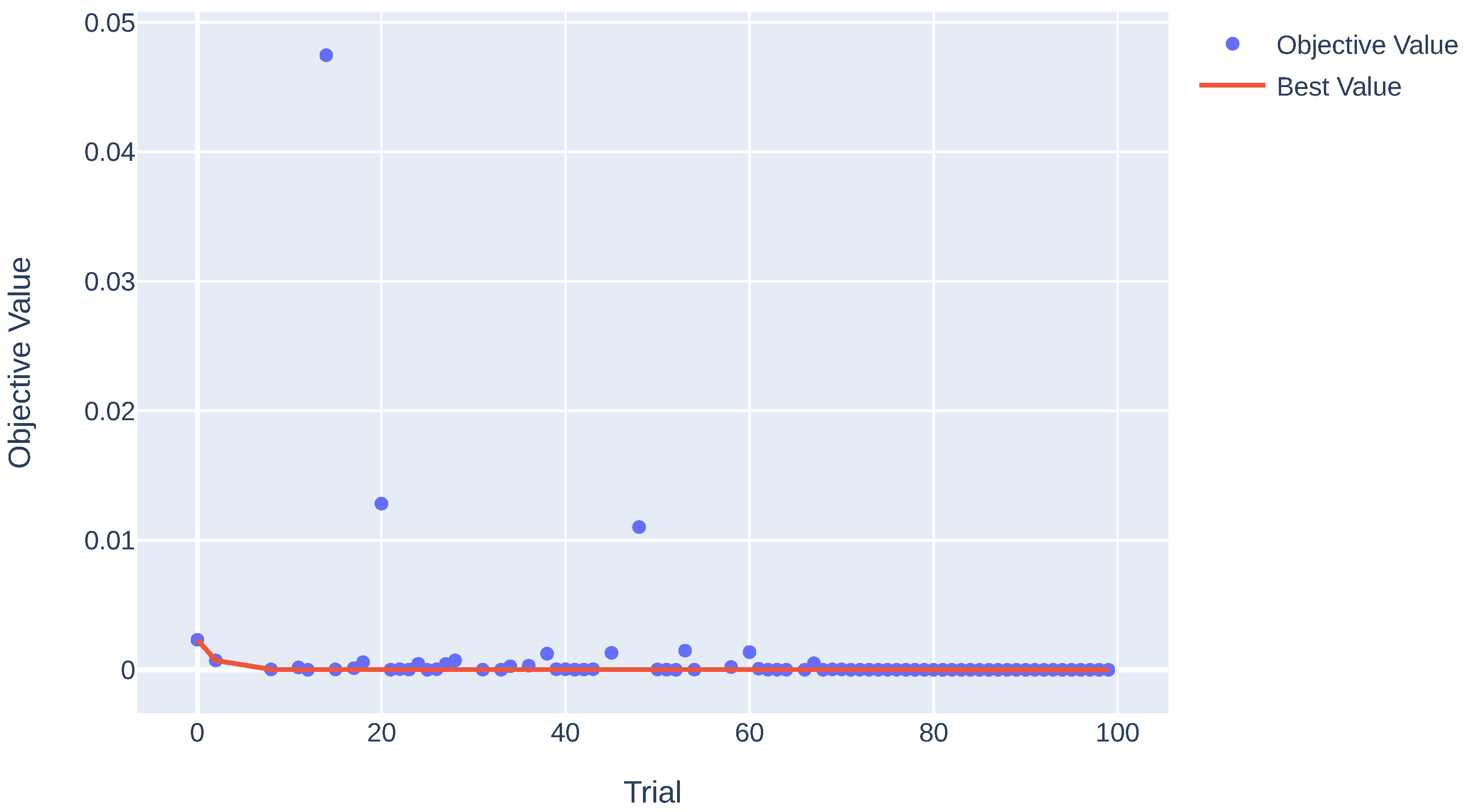
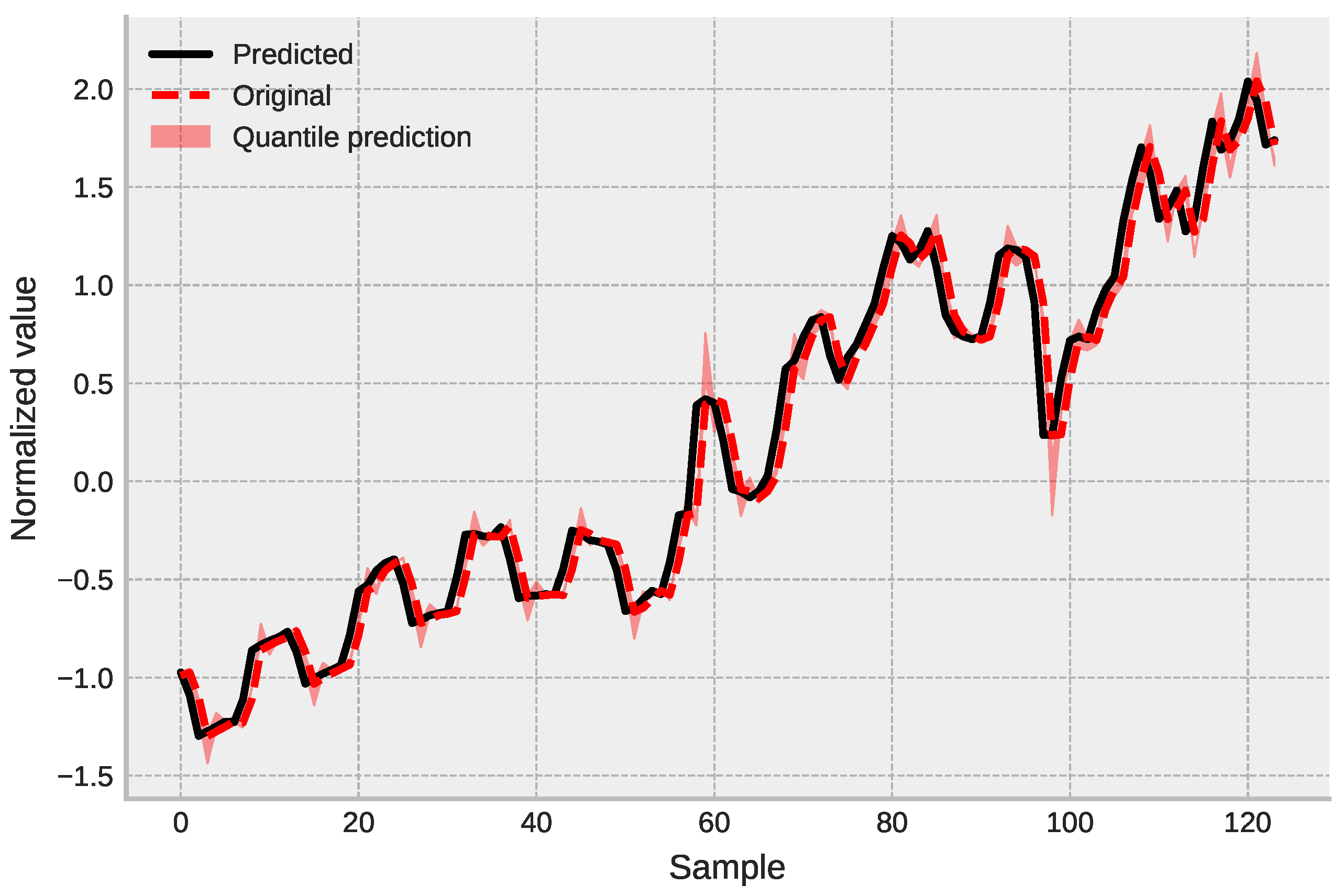
4.3. Ensemble Model
| Algorithm 1: Time Series Prediction using Ensemble Regression |
 |
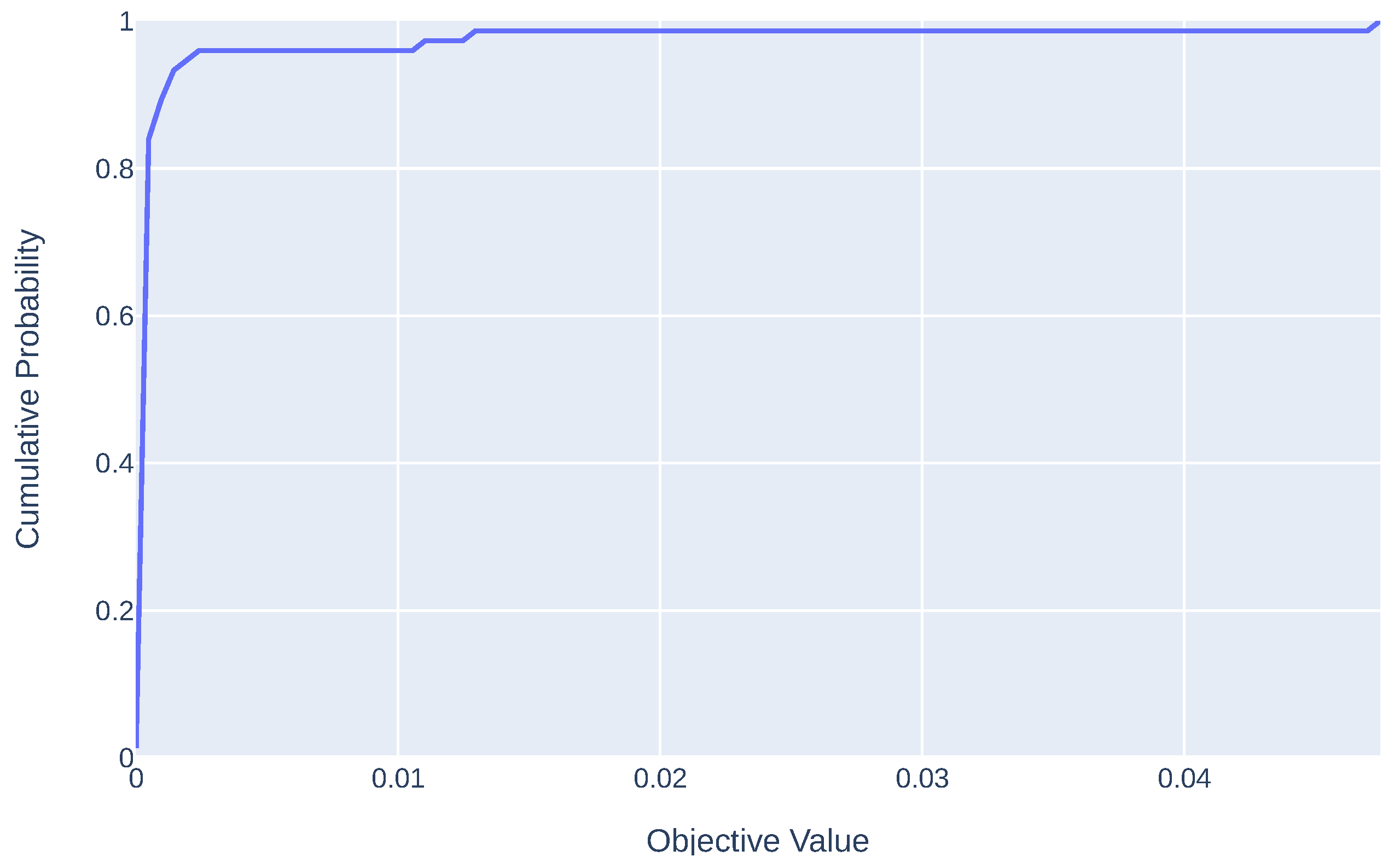
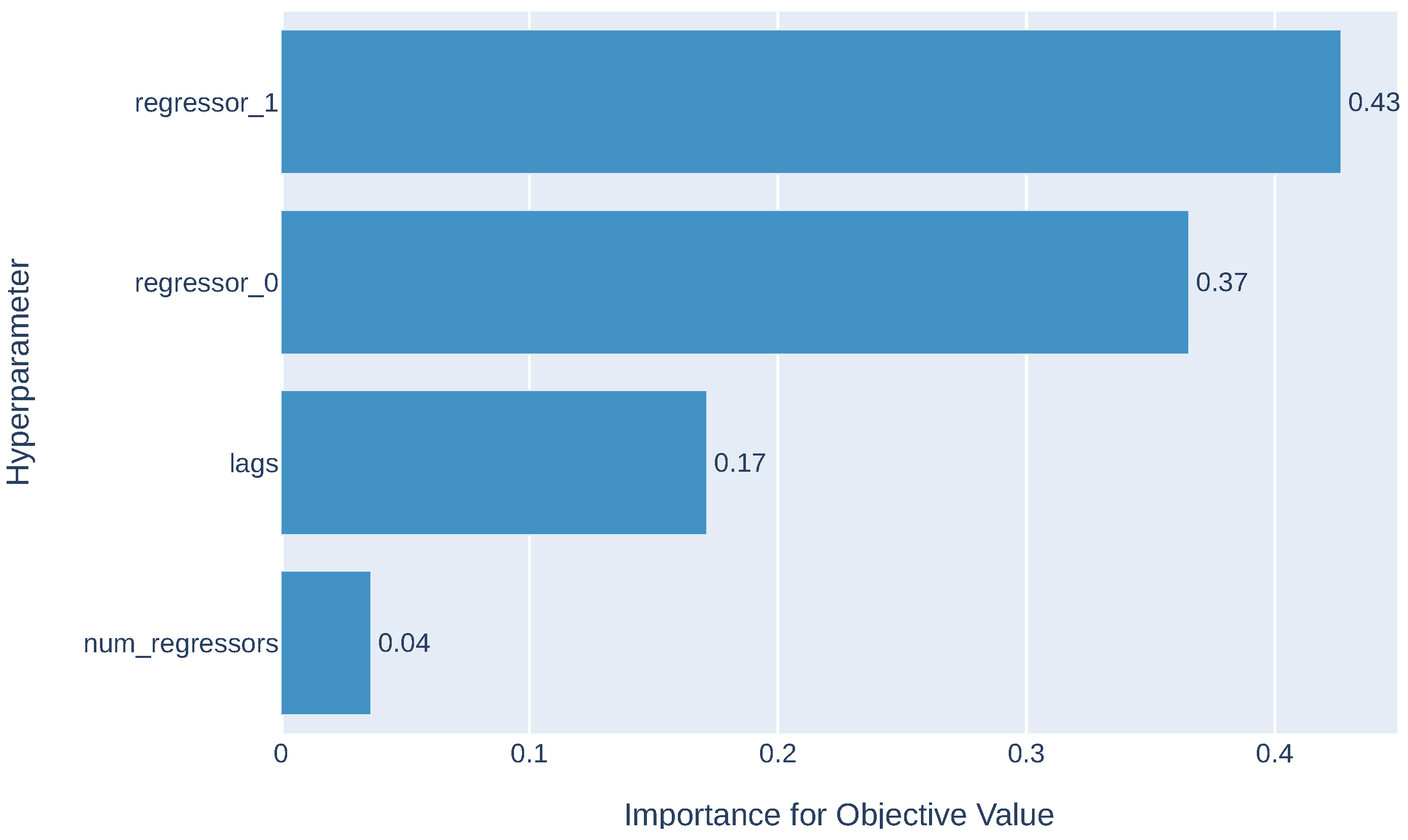
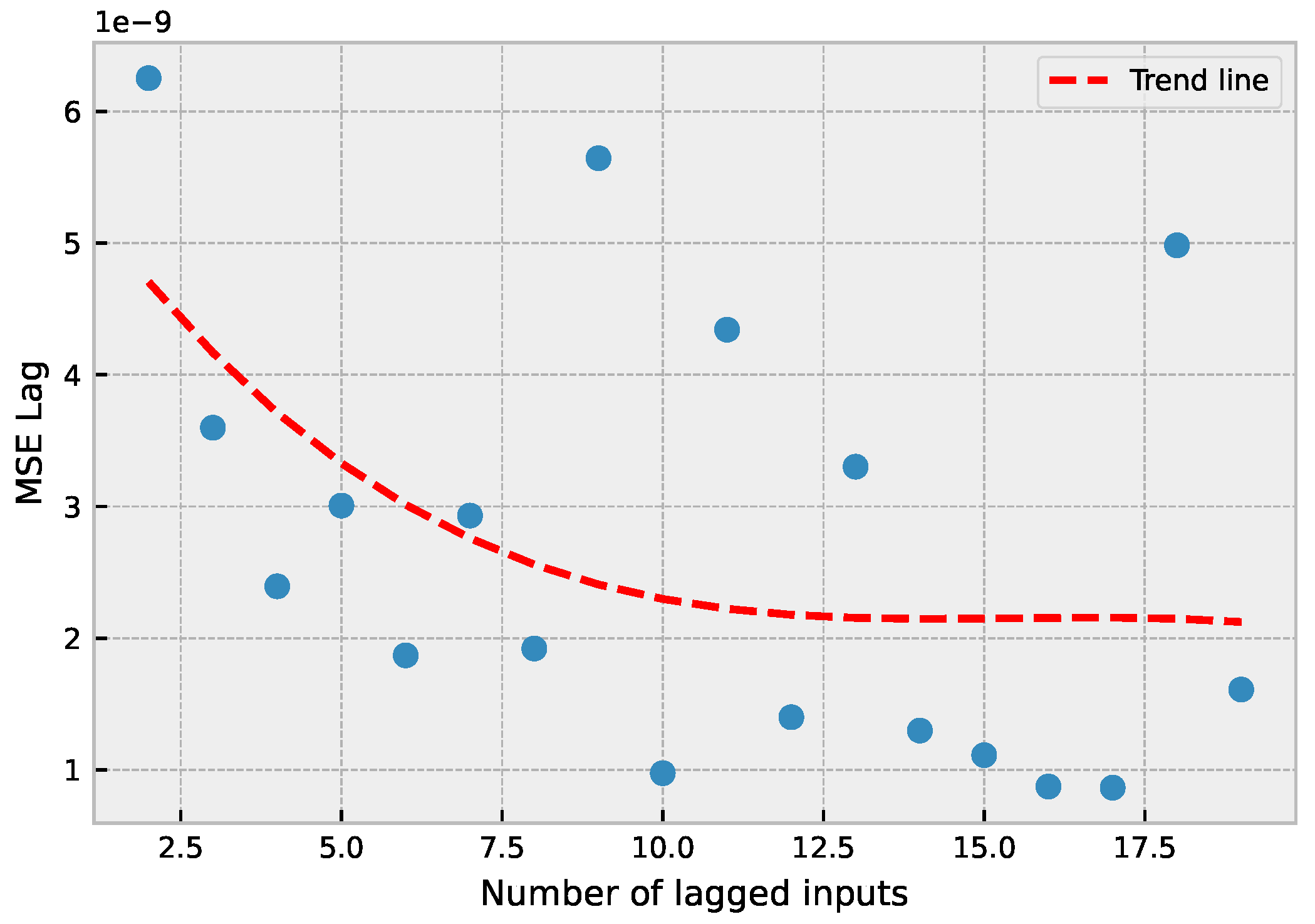
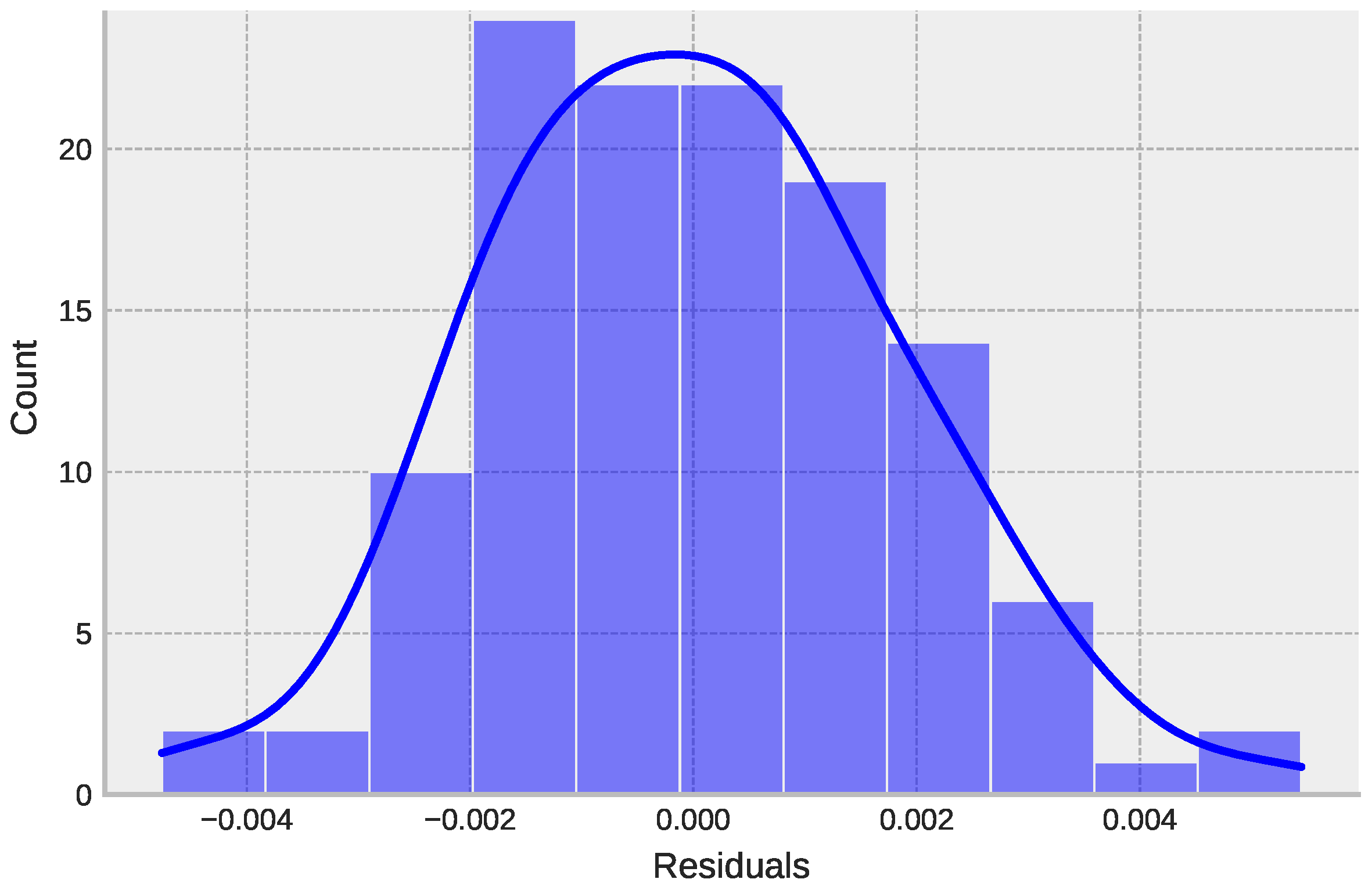
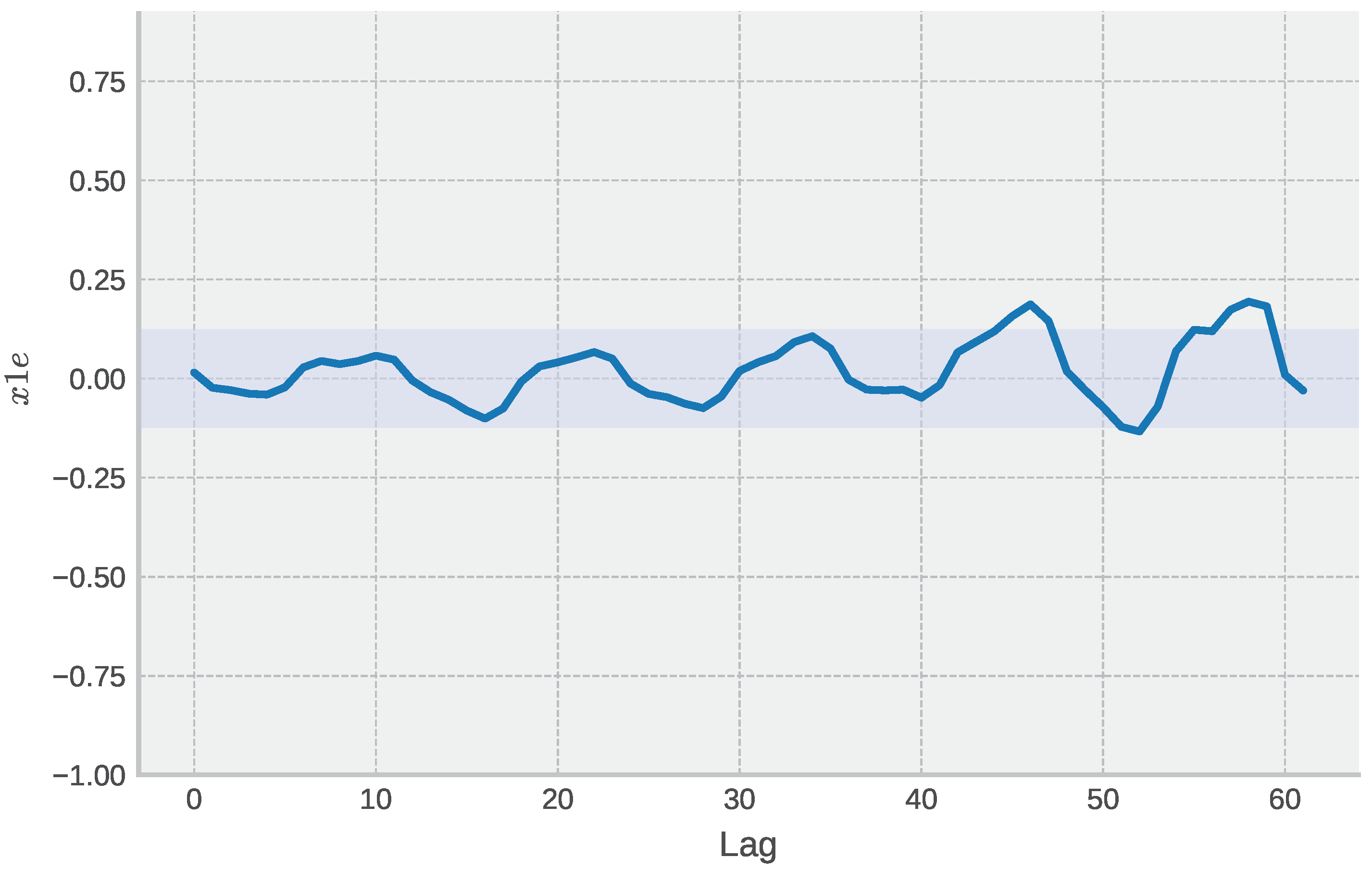
4.4. Additional Analysis
5. Final Remarks and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hernández-Fontes, J.V.; Martínez, M.L.; Wojtarowski, A.; González-Mendoza, J.L.; Landgrave, R.; Silva, R. Is ocean energy an alternative in developing regions? A case study in Michoacan, Mexico. J. Clean. Prod. 2020, 266, 121984. [Google Scholar] [CrossRef]
- De La Peña, L.; Guo, R.; Cao, X.; Ni, X.; Zhang, W. Accelerating the energy transition to achieve carbon neutrality. Resour. Conserv. Recycl. 2022, 177, 105957. [Google Scholar] [CrossRef]
- Moshiri, S.; Santillan, M.A.M. The welfare effects of energy price changes due to energy market reform in Mexico. Energy Policy 2018, 113, 663–672. [Google Scholar] [CrossRef]
- Alvarez, J.; Valencia, F. Made in Mexico: Energy reform and manufacturing growth. Energy Econ. 2016, 55, 253–265. [Google Scholar] [CrossRef]
- Wang, Q.; Su, M.; Li, R.; Ponce, P. The effects of energy prices, urbanization and economic growth on energy consumption per capita in 186 countries. J. Clean. Prod. 2019, 225, 1017–1032. [Google Scholar] [CrossRef]
- Qin, L.; Li, W.; Li, S. Effective passenger flow forecasting using STL and ESN based on two improvement strategies. Neurocomputing 2019, 356, 244–256. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Ribeiro, M.H.D.M.; Nied, A.; Mariani, V.C.; Coelho, L.S.; Leithardt, V.R.Q.; Silva, L.A.; Seman, L.O. Hybrid wavelet stacking ensemble model for insulators contamination forecasting. IEEE Access 2021, 9, 66387–66397. [Google Scholar] [CrossRef]
- Ribeiro, M.H.D.M.; Stefenon, S.F.; de Lima, J.D.; Nied, A.; Mariani, V.C.; Coelho, L.d.S. Electricity price forecasting based on self-adaptive decomposition and heterogeneous ensemble learning. Energies 2020, 13, 5190. [Google Scholar] [CrossRef]
- Lehna, M.; Scheller, F.; Herwartz, H. Forecasting day-ahead electricity prices: A comparison of time series and neural network models taking external regressors into account. Energy Econ. 2022, 106, 105742. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Yow, K.C.; Nied, A.; Meyer, L.H. Classification of distribution power grid structures using inception v3 deep neural network. Electr. Eng. 2022, 104, 4557–4569. [Google Scholar] [CrossRef]
- Xie, H.; Zhang, L.; Lim, C.P. Evolving CNN-LSTM models for time series prediction using enhanced grey wolf optimizer. IEEE Access 2020, 8, 161519–161541. [Google Scholar] [CrossRef]
- Shao, Z.; Zheng, Q.; Liu, C.; Gao, S.; Wang, G.; Chu, Y. A feature extraction- and ranking-based framework for electricity spot price forecasting using a hybrid deep neural network. Electr. Power Syst. Res. 2021, 200, 107453. [Google Scholar] [CrossRef]
- Baule, R.; Naumann, M. Volatility and dispersion of hourly electricity contracts on the German continuous intraday market. Energies 2021, 14, 7531. [Google Scholar] [CrossRef]
- Zhang, T.; Tang, Z.; Wu, J.; Du, X.; Chen, K. Short term electricity price forecasting using a new hybrid model based on two-layer decomposition technique and ensemble learning. Electr. Power Syst. Res. 2022, 205, 107762. [Google Scholar] [CrossRef]
- Yang, H.; Schell, K.R. GHTnet: Tri-Branch deep learning network for real-time electricity price forecasting. Energy 2022, 238, 122052. [Google Scholar] [CrossRef]
- Wang, K.; Yu, M.; Niu, D.; Liang, Y.; Peng, S.; Xu, X. Short-term electricity price forecasting based on similarity day screening, two-layer decomposition technique and Bi-LSTM neural network. Appl. Soft Comput. 2023, 136, 110018. [Google Scholar] [CrossRef]
- Wei, J.; Zhang, Y.; Wang, J.; Cao, X.; Khan, M.A. Multi-period planning of multi-energy microgrid with multi-type uncertainties using chance constrained information gap decision method. Appl. Energy 2020, 260, 114188. [Google Scholar] [CrossRef]
- Jiang, P.; Nie, Y.; Wang, J.; Huang, X. Multivariable short-term electricity price forecasting using artificial intelligence and multi-input multi-output scheme. Energy Econ. 2023, 117, 106471. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Seman, L.O.; Mariani, V.C.; Coelho, L.d.S. Aggregating prophet and seasonal trend decomposition for time series forecasting of Italian electricity spot prices. Energies 2023, 16, 1371. [Google Scholar] [CrossRef]
- Klaar, A.C.R.; Stefenon, S.F.; Seman, L.O.; Mariani, V.C.; Coelho, L.S. Optimized EWT-Seq2Seq-LSTM with attention mechanism to insulators fault prediction. Sensors 2023, 23, 3202. [Google Scholar] [CrossRef]
- Branco, N.W.; Cavalca, M.S.M.; Stefenon, S.F.; Leithardt, V.R.Q. Wavelet LSTM for fault forecasting in electrical power grids. Sensors 2022, 22, 8323. [Google Scholar] [CrossRef] [PubMed]
- Sopelsa Neto, N.F.; Stefenon, S.F.; Meyer, L.H.; Ovejero, R.G.; Leithardt, V.R.Q. Fault prediction based on leakage current in contaminated insulators using enhanced time series forecasting models. Sensors 2022, 22, 6121. [Google Scholar] [CrossRef] [PubMed]
- Stefenon, S.F.; Kasburg, C.; Freire, R.Z.; Silva Ferreira, F.C.; Bertol, D.W.; Nied, A. Photovoltaic power forecasting using wavelet neuro-fuzzy for active solar trackers. J. Intell. Fuzzy Syst. 2021, 40, 1083–1096. [Google Scholar] [CrossRef]
- Beltrán, S.; Castro, A.; Irizar, I.; Naveran, G.; Yeregui, I. Framework for collaborative intelligence in forecasting day-ahead electricity price. Appl. Energy 2022, 306, 118049. [Google Scholar] [CrossRef]
- Wang, D.; Gryshova, I.; Kyzym, M.; Salashenko, T.; Khaustova, V.; Shcherbata, M. Electricity price instability over time: Time series analysis and forecasting. Sustainability 2022, 14, 9081. [Google Scholar] [CrossRef]
- Cruz May, E.; Bassam, A.; Ricalde, L.J.; Escalante Soberanis, M.; Oubram, O.; May Tzuc, O.; Alanis, A.Y.; Livas-García, A. Global sensitivity analysis for a real-time electricity market forecast by a machine learning approach: A case study of Mexico. Int. J. Electr. Power Energy Syst. 2022, 135, 107505. [Google Scholar] [CrossRef]
- Rodriguez-Aguilar, R.; Marmolejo-Saucedo, J.A.; Retana-Blanco, B. Prices of Mexican wholesale electricity market: An application of alpha-stable regression. Sustainability 2019, 11, 3185. [Google Scholar] [CrossRef] [Green Version]
- Rehman Javed, A.; Jalil, Z.; Atif Moqurrab, S.; Abbas, S.; Liu, X. Ensemble adaboost classifier for accurate and fast detection of botnet attacks in connected vehicles. Trans. Emerg. Telecommun. Technol. 2022, 33, e4088. [Google Scholar] [CrossRef]
- Khairy, R.S.; Hussein, A.; ALRikabi, H. The detection of counterfeit banknotes using ensemble learning techniques of AdaBoost and voting. Int. J. Intell. Eng. Syst. 2021, 14, 326–339. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Bruns, R.; Sartori, A.; Meyer, L.H.; Ovejero, R.G.; Leithardt, V.R.Q. Analysis of the ultrasonic signal in polymeric contaminated insulators through ensemble learning methods. IEEE Access 2022, 10, 33980–33991. [Google Scholar] [CrossRef]
- Nsaif, Y.M.; Hossain Lipu, M.S.; Hussain, A.; Ayob, A.; Yusof, Y.; Zainuri, M.A.A.M. A new voltage based fault detection technique for distribution network connected to photovoltaic sources using variational mode decomposition integrated ensemble bagged trees approach. Energies 2022, 15, 7762. [Google Scholar] [CrossRef]
- Galicia, A.; Talavera-Llames, R.; Troncoso, A.; Koprinska, I.; Martínez-Álvarez, F. Multi-step forecasting for big data time series based on ensemble learning. Knowl.-Based Syst. 2019, 163, 830–841. [Google Scholar] [CrossRef]
- Guo, R.; Fu, D.; Sollazzo, G. An ensemble learning model for asphalt pavement performance prediction based on gradient boosting decision tree. Int. J. Pavement Eng. 2022, 23, 3633–3646. [Google Scholar] [CrossRef]
- Saha, S.; Saha, M.; Mukherjee, K.; Arabameri, A.; Ngo, P.T.T.; Paul, G.C. Predicting the deforestation probability using the binary logistic regression, random forest, ensemble rotational forest, REPTree: A case study at the Gumani River Basin, India. Sci. Total Environ. 2020, 730, 139197. [Google Scholar] [CrossRef] [PubMed]
- Anjum, M.; Khan, K.; Ahmad, W.; Ahmad, A.; Amin, M.N.; Nafees, A. Application of ensemble machine learning methods to estimate the compressive strength of fiber-reinforced nano-silica modified concrete. Polymers 2022, 14, 3906. [Google Scholar] [CrossRef] [PubMed]
- Sharafati, A.; Asadollah, S.B.H.S.; Al-Ansari, N. Application of bagging ensemble model for predicting compressive strength of hollow concrete masonry prism. Ain Shams Eng. J. 2021, 12, 3521–3530. [Google Scholar] [CrossRef]
- Yang, S.; Wu, J.; Du, Y.; He, Y.; Chen, X. Ensemble learning for short-term traffic prediction based on gradient boosting machine. J. Sens. 2017, 2017, 7074143. [Google Scholar] [CrossRef] [Green Version]
- Lin, S.; Zheng, H.; Han, B.; Li, Y.; Han, C.; Li, W. Comparative performance of eight ensemble learning approaches for the development of models of slope stability prediction. Acta Geotech. 2022, 17, 1477–1502. [Google Scholar] [CrossRef]
- Speiser, J.L.; Miller, M.E.; Tooze, J.; Ip, E. A comparison of random forest variable selection methods for classification prediction modeling. Expert Syst. Appl. 2019, 134, 93–101. [Google Scholar] [CrossRef]
- Chen, D.; Zhang, J.; Jiang, S. Forecasting the short-term metro ridership with seasonal and trend decomposition using LOESS and LSTM neural networks. IEEE Access 2020, 8, 91181–91187. [Google Scholar] [CrossRef]
- Li, Y.; Bao, T.; Gong, J.; Shu, X.; Zhang, K. The prediction of dam displacement time series using STL, extra-trees, and stacked LSTM neural network. IEEE Access 2020, 8, 94440–94452. [Google Scholar] [CrossRef]
- Safaei Pirooz, A.A.; Flay, R.G.; Minola, L.; Azorin-Molina, C.; Chen, D. Effects of sensor response and moving average filter duration on maximum wind gust measurements. J. Wind. Eng. Ind. Aerodyn. 2020, 206, 104354. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Ensemble Type | Base Learner | Sampling | Feature Selection | Gradient Boosting |
|---|---|---|---|---|---|
| AdaBoost [35] | Boosting | DT | Weighted | All | Yes |
| Bagging [36] | Bagging | DT | Bootstrapped | Subset | No |
| Gradient Boosting [37] | Boosting | DT | Sequential | Subset | Yes |
| HistGradient B. [38] | Boosting | DT | Sequential | Subset | Yes |
| Random Forest [39] | Bagging | DT | Bootstrapped | Subset | No |
| Regressor | MSE without SDMA | MSE with SDMA |
|---|---|---|
| AdaBoostRegressor | 0.002578 | 0.001204 |
| BaggingRegressor | 0.000904 | 0.000433 |
| GradientBoostingRegressor | 0.000001 | 0.000001 |
| HistGradientBoostingRegressor | 0.004272 | 0.004059 |
| RandomForestRegressor | 0.000256 | 0.000239 |
| Regressor | MSE with SDMA |
|---|---|
| AdaBoostRegressor | 0.001204 |
| BaggingRegressor | 0.000433 |
| GradientBoostingRegressor | 0.000001 |
| HistGradientBoostingRegressor | 0.004059 |
| RandomForestRegressor | 0.000239 |
| Proposed Method | 3.375 |
| Feature | Feature Importance |
|---|---|
| Lag 1 | 0.095993 |
| Lag 2 | 0.001148 |
| Lag 3 | 0.000135 |
| Lag 4 | 0.000135 |
| Lag 5 | 0.000409 |
| Lag 6 | 0.000307 |
| Lag 7 | 0.000116 |
| Lag 8 | 0.000601 |
| Lag 9 | 0.031291 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Klaar, A.C.R.; Stefenon, S.F.; Seman, L.O.; Mariani, V.C.; Coelho, L.d.S. Structure Optimization of Ensemble Learning Methods and Seasonal Decomposition Approaches to Energy Price Forecasting in Latin America: A Case Study about Mexico. Energies 2023, 16, 3184. https://doi.org/10.3390/en16073184
Klaar ACR, Stefenon SF, Seman LO, Mariani VC, Coelho LdS. Structure Optimization of Ensemble Learning Methods and Seasonal Decomposition Approaches to Energy Price Forecasting in Latin America: A Case Study about Mexico. Energies. 2023; 16(7):3184. https://doi.org/10.3390/en16073184
Chicago/Turabian StyleKlaar, Anne Carolina Rodrigues, Stefano Frizzo Stefenon, Laio Oriel Seman, Viviana Cocco Mariani, and Leandro dos Santos Coelho. 2023. "Structure Optimization of Ensemble Learning Methods and Seasonal Decomposition Approaches to Energy Price Forecasting in Latin America: A Case Study about Mexico" Energies 16, no. 7: 3184. https://doi.org/10.3390/en16073184
APA StyleKlaar, A. C. R., Stefenon, S. F., Seman, L. O., Mariani, V. C., & Coelho, L. d. S. (2023). Structure Optimization of Ensemble Learning Methods and Seasonal Decomposition Approaches to Energy Price Forecasting in Latin America: A Case Study about Mexico. Energies, 16(7), 3184. https://doi.org/10.3390/en16073184