
Efficient Modeling of Distributed Energy Resources’ Impact on Electric Grid Technical Losses: A Dynamic Regression Approach

 ,
,  ,
,
Abstract
:1. Introduction
2. Literature Review
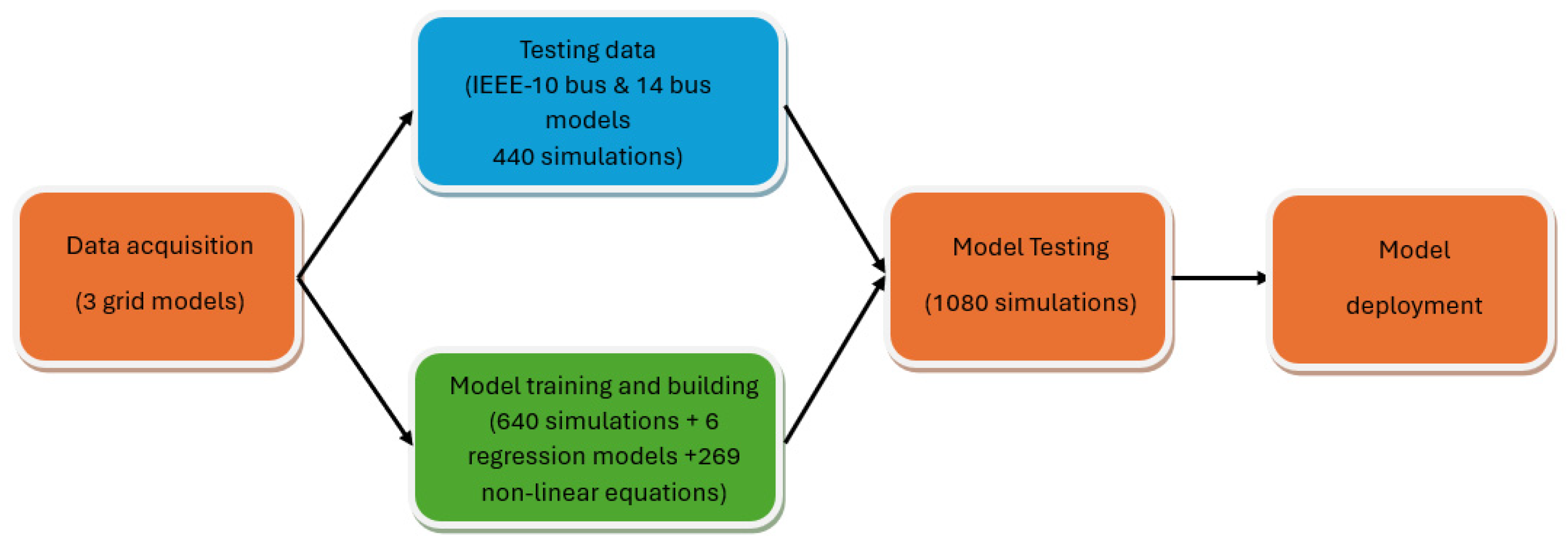
3. Methodology
- –
- Simulate the baseline model without any DER integration, and calculate the total losses of the reference grid model (IEEE-33 bus)
- –
- Integrate a certain percentage of DER at a particular bus i, simulate the whole model, and calculate the total grid losses. The total loss output value is then logged.
- –
- Increase the DER penetration by a step of 5%, and repeat the simulation and calculation process. Then, this step is repeated until 100% of DER integration at bus i is achieved.
- –
- This process is repeated until all busses in our reference model are simulated with DER penetration levels ranging from 0% to 100% with a step of 5%.
- –
- Mean Squared Error (MSE): MSE calculates the average squared difference between predicted and actual values. It penalizes significant errors more heavily than more minor errors.where is the observed value, is the predicted value, and is the number of observations.
- –
- Root Mean Squared Error (RMSE): RMSE is the square root of the MSE and represents the average magnitude of the errors in the same units as the dependent variable.
- –
- Mean Absolute Error (MAE): MAE calculates the average absolute difference between the predicted and actual values, providing a measure of the average magnitude of the errors.
- –
- The coefficient of determination measures the proportion of the variance in the dependent variable explained by the model’s independent variables. It ranges from 0 to 1, where a higher value indicates a better fit of the model to the data.where is the mean of the observed values.
- –
- Mean Percentage Error (MPE): MPE measures the average percentage difference between the predicted and actual values, providing insights into the average directional accuracy of the predictions.
- –
- Mean Absolute Percentage Error (MAPE): MAPE calculates the average percentage difference between the predicted and actual values, providing a measure of the overall accuracy of the predictions relative to the observed values.
4. Model Building
- Symmetry: The error distribution is approximately symmetric around zero, indicating that the model is equally likely to overpredict and underpredict the target variable. A symmetric error distribution suggests that the model is unbiased and does not systematically overestimate or underestimate the outcomes.
- Normality: The error distribution closely follows a normal (Gaussian) distribution. Normality implies that most prediction errors are minor, with fewer extreme errors. A normal error distribution simplifies interpretation and analysis and is often assumed by many statistical techniques.
- Constant Variance (Homoscedasticity): The variance of the errors remains relatively constant across different levels of the predictor variables. Homoscedasticity indicates that the model’s predictive performance is consistent across the entire range of the data, and the spread of errors does not systematically change with the magnitude of the predicted values.
- Zero Mean: The mean of the error distribution is close to zero, indicating that, on average, the model predictions are accurate. A non-zero mean suggests systematic bias in the model predictions, which should be investigated and corrected.
- No Outliers: The error distribution does not contain extreme outliers or anomalies. Outliers may indicate data points with unusual characteristics or errors in the data collection process. Identifying and addressing outliers is important for improving the overall reliability and performance of the model.
- Low Dispersion: The dispersion of the error distribution is relatively low, indicating that most prediction errors are concentrated around the mean. Low dispersion suggests that the model provides consistent and precise predictions with little error variability.
5. Testing and Results Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. IEEE-33 Bus Grid Model Data


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Impedance Reference | Connection | x (Ohm) | r (Ohm) | Impedance z (Ohm) |
|---|---|---|---|---|
| Z1 | Bus 0_1 | 0.0922 | 0.477 | 0.485829023 |
| Z2 | Bus 1_2 | 0.493 | 0.2511 | 0.553263238 |
| Z3 | Bus 2_3 | 0.366 | 0.1864 | 0.410732224 |
| Z4 | Bus 3_4 | 0.3811 | 0.1941 | 0.427682148 |
| Z5 | Bus 4_5 | 0.819 | 0.707 | 1.081947318 |
| Z6 | Bus 5_6 | 0.1872 | 0.6188 | 0.646496156 |
| Z7 | Bus 6_7 | 1.7114 | 1.2351 | 2.110535944 |
| Z8 | Bus 7_8 | 1.03 | 0.74 | 1.268266534 |
| Z9 | Bus 8_9 | 1.044 | 0.74 | 1.279662455 |
| Z10 | Bus 9_10 | 0.1966 | 0.065 | 0.207066559 |
| Z11 | Bus 10_11 | 0.3744 | 0.1238 | 0.394337165 |
| Z12 | Bus 11_12 | 1.468 | 1.155 | 1.867899623 |
| Z13 | Bus 12_13 | 0.5416 | 0.7129 | 0.895297141 |
| Z14 | Bus 13_14 | 0.591 | 0.526 | 0.791174443 |
| Z15 | Bus 14_15 | 0.7463 | 0.545 | 0.924115085 |
| Z16 | Bus 15_16 | 1.289 | 1.721 | 2.150200456 |
| Z17 | Bus 16_17 | 0.732 | 0.574 | 0.930215029 |
| Z18 | Bus 1_18 | 0.164 | 0.1565 | 0.226689766 |
| Z19 | Bus 18_19 | 1.5042 | 1.3554 | 2.02477821 |
| Z20 | Bus 19_20 | 0.4095 | 0.4784 | 0.629727568 |
| Z21 | Bus 20_21 | 0.7089 | 0.9373 | 1.175189559 |
| Z22 | Bus 2_22 | 0.4512 | 0.3083 | 0.546470795 |
| Z23 | Bus 22_23 | 0.898 | 0.7091 | 1.144214495 |
| Z24 | Bus 23_24 | 0.896 | 0.7011 | 1.137698207 |
| Z25 | Bus 5_25 | 0.203 | 0.1034 | 0.227816944 |
| Z26 | Bus 25_26 | 0.2842 | 0.1449 | 0.319007288 |
| Z27 | Bus 26_27 | 1.059 | 0.9337 | 1.411834512 |
| Z28 | Bus 27_28 | 0.8042 | 0.7006 | 1.066573017 |
| Z29 | Bus 28_29 | 0.5075 | 0.2585 | 0.56954236 |
| Z30 | Bus 29_30 | 0.9744 | 0.936 | 1.351129661 |
| Z31 | Bus 30_31 | 0.3105 | 0.3619 | 0.47684574 |
| Z32 | Bus 31_32 | 0.341 | 0.5302 | 0.63039118 |
| Bus Number | Load (KW) | Load (KVA) | Total Impedance Z (Ohm) |
|---|---|---|---|
| 1 | 100 | 117 | 0.4858 |
| 2 | 90 | 98.5 | 1.0391 |
| 3 | 120 | 144 | 1.4498 |
| 4 | 60 | 67.1 | 1.8775 |
| 5 | 60 | 63.2 | 2.9595 |
| 6 | 200 | 224 | 3.6060 |
| 7 | 200 | 224 | 5.7165 |
| 8 | 60 | 63.2 | 6.9848 |
| 9 | 60 | 63.2 | 8.2644 |
| 10 | 45 | 54.1 | 8.4715 |
| 11 | 60 | 69.5 | 8.8658 |
| 12 | 60 | 69.5 | 10.7337 |
| 13 | 120 | 144 | 11.6290 |
| 14 | 60 | 60.8 | 12.4202 |
| 15 | 60 | 63.2 | 13.3443 |
| 16 | 60 | 63.2 | 15.4945 |
| 17 | 90 | 98.5 | 16.4247 |
| 18 | 90 | 98.5 | 0.7125 |
| 19 | 90 | 98.5 | 2.7373 |
| 20 | 90 | 98.5 | 3.3670 |
| 21 | 90 | 98.5 | 4.5422 |
| 22 | 90 | 103 | 1.5856 |
| 23 | 420 | 465 | 2.7298 |
| 24 | 420 | 465 | 3.8675 |
| 25 | 60 | 65 | 3.1873 |
| 26 | 60 | 65 | 3.5063 |
| 27 | 60 | 63.2 | 4.9181 |
| 28 | 120 | 139 | 5.9847 |
| 29 | 200 | 632 | 6.5542 |
| 30 | 150 | 166 | 7.9054 |
| 31 | 210 | 233 | 8.3822 |
| 32 | 60 | 72.1 | 9.0126 |
Appendix B. Non Linear Fitting Equations
| Ref. | Equation | Ref. | Equation |
| 1 | Y = A*(X1^B)*X2^C | 136 | Y = (A+X2)/(B+C*X1^2)+D*X1 |
| 2 | Y = X1/(A+B*X2) | 137 | Y = A*X1^(B*X2^C)+D*X1 |
| 3 | Y = X2/(A+B*X1) | 138 | Y = A*X2^(B*X1^C)+D*X1 |
| 4 | Y = A*X1^(B*X2) | 139 | Y = A*X1+B*X2+C*X1^4 |
| 5 | Y = A*X2^(B*X1) | 140 | Y = A*X1+B*X1^3+C*X2+D*X2^3 |
| 6 | Y = A*X1^(B/X2) | 141 | Y = A*(X1^B)*LOG(X2+C)+D*X2 |
| 7 | Y = A*X2^(B/X1) | 142 | Y = A*(X2^B)*LOG(X1+C)+D*X2 |
| 8 | Y = A*X1+B*X2^2 | 143 | Y = A/X1+B*EXP(C/X2)+D*X2 |
| 9 | Y = A*X2+B*X1^2 | 144 | Y = A/X2+B*EXP(C/X1)+D*X2 |
| 10 | Y = X1/(A+B*X2^2) | 145 | Y = A/X1+B*EXP(C*X2)+D*X2 |
| 11 | Y = X2/(A+B*X1^2) | 146 | Y = A/X2+B*EXP(C*X1)+D*X2 |
| 12 | Y = A*(B^X1)*X2^C | 147 | Y = A*X1^(B+C*X2)+D*X2 |
| 13 | Y = A*(B^X2)*X1^C | 148 | Y = A*X2^(B+C*X1)+D*X2 |
| 14 | Y = A*(X1*X2)^B | 149 | Y = A*X1^(B+C/X2)+D*X2 |
| 15 | Y = A*(X1/X2)^B | 150 | Y = A*X2^(B+C/X1)+D*X2 |
| 16 | Y = A*(X1/X2)^B+C | 151 | Y = A*X1^(B+C*LOG(X2))+D*X2 |
| 17 | Y = A*(B^(1/X1))*X2^C | 152 | Y = A*X2^(B+C*LOG(X1))+D*X2 |
| 18 | Y = A*(B^(1/X2))*X1^C | 153 | Y = A*X2^(B+C/LOG(X1))+D*X2 |
| 19 | Y = A+B/X1+C/X2^2 | 154 | Y = A*X1^(B+C/LOG(X2))+D*X2 |
| 20 | Y = A+B/X2+C/X1^2 | 155 | Y = A*EXP(B*X1+C*X2^2)+D*X2 |
| 21 | Y = A+B*X1+C/X2 | 156 | Y = A*EXP(B*X2+C*X1^2)+D*X2 |
| 22 | Y = A+B*X2+C/X1 | 157 | Y = A*EXP(B/X1+C*X2)+D*X2 |
| 23 | Y = A*((X1/B)^C)*EXP(X2/B) | 158 | Y = A*EXP(B/X2+C*X1)+D*X2 |
| 24 | Y = A*((X2/B)^C)*EXP(X1/B) | 159 | Y = (A+X1)/(B+C*X2)+D*X2 |
| 25 | Y = A+B*X1+C*X2^2 | 160 | Y = (A+X2)/(B+C*X1)+D*X2 |
| 26 | Y = A+B*X2+C*X1^2 | 161 | Y = (A+X1)/(B+C*X2^2)+D*X2 |
| 27 | Y = A*(X1^B)*X2^C+D | 162 | Y = (A+X2)/(B+C*X1^2)+D*X2 |
| 28 | Y = X1/(A+B*X2)+C | 163 | Y = A*X1^(B*X2^C)+D*X2 |
| 29 | Y = X2/(A+B*X1)+C | 164 | Y = A*X2^(B*X1^C)+D*X2 |
| 30 | Y = A*X1^(B*X2)+C | 165 | Y = A*X1+B*X2+C*X2^4 |
| 31 | Y = A*X2^(B*X1)+C | 166 | Y = A*X1+B/X1^3+C*X2+D/X2^3 |
| 32 | Y = A*X1^(B/X2)+C | 167 | Y = A*(X1^B)*LOG(X2+C)+D/X2 |
| 33 | Y = A*X2^(B/X1)+C | 168 | Y = A*(X2^B)*LOG(X1+C)+D/X2 |
| 34 | Y = A*(B^(1/X1))*X2^C+D | 169 | Y = A/X1+B*EXP(C/X2)+D/X2 |
| 35 | Y = A*(B^(1/X2))*X1^C+D | 170 | Y = A/X2+B*EXP(C/X1)+D/X2^2 |
| 36 | Y = X1/(A+B*X2^2)+C | 171 | Y = A/X1+B*EXP(C*X2)+D/X2 |
| 37 | Y = X2/(A+B*X1^2)+C | 172 | Y = A/X2+B*EXP(C*X1)+D/X2^2 |
| 38 | Y = A*(B^X1)*X2^C+D | 173 | Y = A*X1^(B+C*X2)+D/X2 |
| 39 | Y = A*(B^X2)*X1^C+D | 174 | Y = A*X2^(B+C*X1)+D/X2 |
| 40 | Y = A*((X1/B)^C)*EXP(X2/B)+D | 175 | Y = A*X1^(B+C/X2)+D/X2 |
| 41 | Y = A*((X2/B)^C)*EXP(X1/B)+D | 176 | Y = A*X2^(B+C/X1)+D/X2 |
| 42 | Y = 1/(A+B*X1+C/X2) | 177 | Y = A*X1^(B+C*LOG(X2))+D/X2 |
| 43 | Y = 1/(A+B*X2+C/X1) | 178 | Y = A*X2^(B+C*LOG(X1))+D/X2 |
| 44 | Y = A+B*X1+C/X2^2 | 179 | Y = A*X2^(B+C/LOG(X1))+D/X2 |
| 45 | Y = A+B*X2+C/X1^2 | 180 | Y = A*X1^(B+C/LOG(X2))+D/X2 |
| 46 | Y = A*X1^(B+C*X2) | 181 | Y = A*EXP(B*X1+C*X2^2)+D/X2 |
| 47 | Y = A*X2^(B+C*X1) | 182 | Y = A*EXP(B*X2+C*X1^2)+D/X2 |
| 48 | Y = A*X1^(B+C/X2) | 183 | Y = A*EXP(B/X1+C*X2)+D/X2 |
| 49 | Y = A*X2^(B+C/X1) | 184 | Y = A*EXP(B/X2+C*X1)+D/X2 |
| 50 | Y = A*X1^(B+C*LnX2) | 185 | Y = (A+X1)/(B+C*X2)+D/X2 |
| 51 | Y = A*X2^(B+C*LnX1) | 186 | Y = (A+X2)/(B+C*X1)+D/X2 |
| 52 | Y = A*X2^(B+C/LnX1) | 187 | Y = (A+X1)/(B+C*X2^2)+D/X2 |
| 53 | Y = A*X1^(B+C/LnX2) | 188 | Y = (A+X2)/(B+C*X1^2)+D/X2 |
| 54 | Y = A*EXP(B*X1+C*X2^2) | 189 | Y = A*X1^(B*X2^C)+D/X2 |
| 55 | Y = A*EXP(B*X2+C*X1^2) | 190 | Y = A*X2^(B*X1^C)+D/X2 |
| 56 | Y = A*EXP(B/X1+C*X2) | 191 | Y = A*X1+B*X2+C/X2^4 |
| 57 | Y = A*EXP(B/X2+C*X1) | 192 | Y = A*X1+B/X1^2+C*X2+D/X2^2 |
| 58 | Y = (A+X1)/(B+C*X2) | 193 | Y = A*(X1^B)*LOG(X2+C)+D/X1 |
| 59 | Y = (A+X2)/(B+C*X1) | 194 | Y = A*(X2^B)*LOG(X1+C)+D/X1 |
| 60 | Y = (A+X1)/(B+C*X2^2) | 195 | Y = A/X1+B*EXP(C/X2)+D/X1^2 |
| 61 | Y = (A+X2)/(B+C*X1^2) | 196 | Y = A/X2+B*EXP(C/X1)+D/X1 |
| 62 | Y = A*EXP(B*X1)+C*EXP(D*X2) | 197 | Y = A/X1+B*EXP(C*X2)+D/X1^2 |
| 63 | Y = A*(EXP(B*X1)-EXP(C*X2)) | 198 | Y = A/X2+B*EXP(C*X1)+D/X1 |
| 64 | Y = A*X1^B+C*X2^D | 199 | Y = A*X1^(B+C*X2)+D/X1 |
| 65 | Y = A*X1^B+C*EXP(D*X2) | 200 | Y = A*X2^(B+C*X1)+D/X1 |
| 66 | Y = A*X2^B+C*EXP(D*X1) | 201 | Y = A*X1^(B+C/X2)+D/X1 |
| 67 | Y = A*(X1^B)*(C-X2)^D | 202 | Y = A*X2^(B+C/X1)+D/X1 |
| 68 | Y = A*(X2^B)*(C-X1)^D | 203 | Y = A*X1^(B+C*LOG(X2))+D/X1 |
| 69 | Y = (A+B*X1^C)/(D+X2^C) | 204 | Y = A*X2^(B+C*LOG(X1))+D/X1 |
| 70 | Y = (A+B*X2^C)/(D+X1^C) | 205 | Y = A*X2^(B+C/LOG(X1))+D/X1 |
| 71 | Y = (A+B*X1)/(1+C*X2+D*X2^2) | 206 | Y = A*X1^(B+C/LOG(X2))+D/X1 |
| 72 | Y = (A+B*X2)/(1+C*X1+D*X1^2) | 207 | Y = A*EXP(B*X1+C*X2^2)+D/X1 |
| 73 | Y = A*X1^(B*X2^C) | 208 | Y = A*EXP(B*X2+C*X1^2)+D/X1 |
| 74 | Y = A*X2^(B*X1^C) | 209 | Y = A*EXP(B/X1+C*X2)+D/X1 |
| 75 | Y = X1/(A+B*X2+C*SQ | 210 | Y = A*EXP(B/X2+C*X1)+D/X1 |
| 76 | Y = X2/(A+B*X1+C*SQ | 211 | Y = (A+X1)/(B+C*X2)+D/X1 |
| 77 | Y = A*X1^B+C*EXP(D/X2) | 212 | Y = (A+X2)/(B+C*X1)+D/X1 |
| 78 | Y = A*X2^B+C*EXP(D/X1) | 213 | Y = (A+X1)/(B+C*X2^2)+D/X1 |
| 79 | Y = A*X2^2+B*X2+C*X1+D | 214 | Y = (A+X2)/(B+C*X1^2)+D/X1 |
| 80 | Y = A*X1^2+B*X1+C*X2+D | 215 | Y = A*X1^(B*X2^C)+D/X1 |
| 81 | Y = A*X1^3+B*X1^2+C*X1+D*X2 | 216 | Y = A*X2^(B*X1^C)+D/X1 |
| 82 | Y = A*X2^3+B*X2^2+C*X2+D*X1 | 217 | Y = A*X1+B*X2+C/X1^4 |
| 83 | Y = EXP(A+B/X1+C*LOG(X2)) | 218 | Y = A*X1+B/X1^3+C*X2+D*Ln(X2)^3 |
| 84 | Y = EXP(A+B/X2+C*LOG(X1)) | 219 | Y = A*(X1^B)*LOG(X2+C)+D*Ln(X2) |
| 85 | Y = EXP(A+B/X1+C*LOG(X2))+D | 220 | Y = A*(X2^B)*LOG(X1+C)+D*Ln(X2) |
| 86 | Y = EXP(A+B/X2+C*LOG(X1))+D | 221 | Y = A/X1+B*EXP(C/X2)+D*Ln(X2) |
| 87 | Y = A*(X1^B)*LOG(X2+C) | 222 | Y = A/X2+B*EXP(C/X1)+D*Ln(X2)^2 |
| 88 | Y = A*(X2^B)*LOG(X1+C) | 223 | Y = A/X1+B*EXP(C*X2)+D*Ln(X2) |
| 89 | Y = A*(X1^B)*LOG(X2+C)+D | 224 | Y = A/X2+B*EXP(C*X1)+D*Ln(X2)^2 |
| 90 | Y = A*(X2^B)*LOG(X1+C)+D | 225 | Y = A*X1^(B+C*X2)+D*Ln(X2) |
| 91 | Y = A/X1+B*EXP(C/X2)+D | 226 | Y = A*X2^(B+C*X1)+D*Ln(X2) |
| 92 | Y = A/X2+B*EXP(C/X1)+D | 227 | Y = A*X1^(B+C/X2)+D*Ln(X2) |
| 93 | Y = A/X1+B*EXP(C*X2)+D | 228 | Y = A*X2^(B+C/X1)+D*Ln(X2) |
| 94 | Y = A/X2+B*EXP(C*X1)+D | 229 | Y = A*X1^(B+C*LOG(X2))+D*Ln(X2) |
| 95 | Y = A*X1^(B+C*X2)+D | 230 | Y = A*X2^(B+C*LOG(X1))+D*Ln(X2) |
| 96 | Y = A*X2^(B+C*X1)+D | 231 | Y = A*X2^(B+C/LOG(X1))+D*Ln(X2) |
| 97 | Y = A*X1^(B+C/X2)+D | 232 | Y = A*X1^(B+C/LOG(X2))+D*Ln(X2) |
| 98 | Y = A*X2^(B+C/X1)+D | 233 | Y = A*EXP(B*X1+C*X2^2)+D*Ln(X2) |
| 99 | Y = A*X1^(B+C*LOG(X2))+D | 234 | Y = A*EXP(B*X2+C*X1^2)+D*Ln(X2) |
| 100 | Y = A*X2^(B+C*LOG(X1))+D | 235 | Y = A*EXP(B/X1+C*X2)+D*Ln(X2) |
| 101 | Y = A*X2^(B+C/LOG(X1))+D | 236 | Y = A*EXP(B/X2+C*X1)+D*Ln(X2) |
| 102 | Y = A*X1^(B+C/LOG(X2))+D | 237 | Y = (A+X1)/(B+C*X2)+D*Ln(X2) |
| 103 | Y = A*EXP(B*X1+C*X2^2)+D | 238 | Y = (A+X2)/(B+C*X1)+D*Ln(X2) |
| 104 | Y = A*EXP(B*X2+C*X1^2)+D | 239 | Y = (A+X1)/(B+C*X2^2)+D*Ln(X2) |
| 105 | Y = A*EXP(B/X1+C*X2)+D | 240 | Y = (A+X2)/(B+C*X1^2)+D*Ln(X2) |
| 106 | Y = A*EXP(B/X2+C*X1)+D | 241 | Y = A*X1^(B*X2^C)+D*Ln(X2) |
| 107 | Y = (A+X1)/(B+C*X2)+D | 242 | Y = A*X2^(B*X1^C)+D*Ln(X2) |
| 108 | Y = (A+X2)/(B+C*X1)+D | 243 | Y = A*X1+B*X2+C*Ln(X2)^4 |
| 109 | Y = (A+X1)/(B+C*X2^2)+D | 244 | Y = A*X1+B/X1^2+C*X2+D*Ln(X2)^2 |
| 110 | Y = (A+X2)/(B+C*X1^2)+D | 245 | Y = A*(X1^B)*LOG(X2+C)+D*Ln(X1) |
| 111 | Y = A*X1^(B*X2^C)+D | 246 | Y = A*(X2^B)*LOG(X1+C)+D*Ln(X1) |
| 112 | Y = A*X2^(B*X1^C)+D | 247 | Y = A/X1+B*EXP(C/X2)+D*Ln(X1)^2 |
| 113 | Y = A*X1+B*X2+C | 248 | Y = A/X2+B*EXP(C/X1)+D*Ln(X1) |
| 114 | Y = A*X1+B*X1^2+C*X2+D*X2^2 | 249 | Y = A/X1+B*EXP(C*X2)+D*Ln(X1)^2 |
| 115 | Y = A*(X1^B)*LOG(X2+C)+D*X1 | 250 | Y = A/X2+B*EXP(C*X1)+D*Ln(X1) |
| 116 | Y = A*(X2^B)*LOG(X1+C)+D*X1 | 251 | Y = A*X1^(B+C*X2)+D*Ln(X1) |
| 117 | Y = A/X1+B*EXP(C/X2)+D*X1 | 252 | Y = A*X2^(B+C*X1)+D*Ln(X1) |
| 118 | Y = A/X2+B*EXP(C/X1)+D*X1 | 253 | Y = A*X1^(B+C/X2)+D*Ln(X1) |
| 119 | Y = A/X1+B*EXP(C*X2)+D*X1 | 254 | Y = A*X2^(B+C/X1)+D*Ln(X1) |
| 120 | Y = A/X2+B*EXP(C*X1)+D*X1 | 255 | Y = A*X1^(B+C*LOG(X2))+D*Ln(X1) |
| 121 | Y = A*X1^(B+C*X2)+D*X1 | 256 | Y = A*X2^(B+C*LOG(X1))+D*Ln(X1) |
| 122 | Y = A*X2^(B+C*X1)+D*X1 | 257 | Y = A*X2^(B+C/LOG(X1))+D*Ln(X1) |
| 123 | Y = A*X1^(B+C/X2)+D*X1 | 258 | Y = A*X1^(B+C/LOG(X2))+D*Ln(X1) |
| 124 | Y = A*X2^(B+C/X1)+D*X1 | 259 | Y = A*EXP(B*X1+C*X2^2)+D*Ln(X1) |
| 125 | Y = A*X1^(B+C*LOG(X2))+D*X1 | 260 | Y = A*EXP(B*X2+C*X1^2)+D*Ln(X1) |
| 126 | Y = A*X2^(B+C*LOG(X1))+D*X1 | 261 | Y = A*EXP(B/X1+C*X2)+D*Ln(X1) |
| 127 | Y = A*X2^(B+C/LOG(X1))+D*X1 | 262 | Y = A*EXP(B/X2+C*X1)+D*Ln(X1) |
| 128 | Y = A*X1^(B+C/LOG(X2))+D*X1 | 263 | Y = (A+X1)/(B+C*X2)+D*Ln(X1) |
| 129 | Y = A*EXP(B*X1+C*X2^2)+D*X1 | 264 | Y = (A+X2)/(B+C*X1)+D*Ln(X1) |
| 130 | Y = A*EXP(B*X2+C*X1^2)+D*X1 | 265 | Y = (A+X1)/(B+C*X2^2)+D*Ln(X1) |
| 131 | Y = A*EXP(B/X1+C*X2)+D*X1 | 266 | Y = (A+X2)/(B+C*X1^2)+D*Ln(X1) |
| 132 | Y = A*EXP(B/X2+C*X1)+D*X1 | 267 | Y = A*X1^(B*X2^C)+D*Ln(X1) |
| 133 | Y = (A+X1)/(B+C*X2)+D*X1 | 268 | Y = A*X2^(B*X1^C)+D*Ln(X1) |
| 134 | Y = (A+X2)/(B+C*X1)+D*X1 | 269 | Y = A*X1+B*X2+C*Ln(X1)^4 |
| 135 | Y = (A+X1)/(B+C*X2^2)+D*X1 |
Appendix C. The 14-Bus Grid Model Data

| Bus | Impedance Reference | R (Ohm) | X (Ohm) | Z (Ohm) |
|---|---|---|---|---|
| Bus 1_2 | Z1 | 0.1233 | 0.4127 | 0.430725179 |
| Bus 2_3 | Z2 | 0.018 | 0.0609 | 0.063504409 |
| Bus 3_4 | Z3 | 0.8463 | 1.1 | 1.38788461 |
| Bus 4_5 | Z4 | 0.6984 | 0.6084 | 0.926235996 |
| Bus 5_6 | Z5 | 1.531 | 1.622 | 2.230436056 |
| Bus 6_7 | Z6 | 0.9 | 0.78 | 1.190965994 |
| Bus 7_8 | Z7 | 2.2 | 1.05 | 2.437724349 |
| Bus 8_9 | Z8 | 4.52 | 2.1 | 4.984014446 |
| Bus 9_10 | Z9 | 5.5 | 3 | 6.264982043 |
| Bus 4_11 | Z10 | 0.54 | 0.92 | 1.066770828 |
| Bus 11_12 | Z11 | 1.29 | 1.06 | 1.66964068 |
| Bus 9_13 | Z12 | 0.93 | 0.8 | 1.226743657 |
| Bus 13_14 | Z13 | 2.1 | 1 | 2.32594067 |
| Bus Reference | Load (KVA) | Load (KW) | Total Impedance Z (Ohm) |
|---|---|---|---|
| 2 | 1077 | 1000 | 0.430725179 |
| 3 | 901 | 850 | 0.494229588 |
| 4 | 1456 | 1400 | 1.882114198 |
| 5 | 1562 | 1200 | 2.808350194 |
| 6 | 1643 | 1530 | 5.03878625 |
| 7 | 788 | 780 | 6.229752245 |
| 8 | 1052 | 1050 | 8.667476593 |
| 9 | 712 | 700 | 13.65149104 |
| 10 | 1434 | 1420 | 19.91647308 |
| 11 | 636 | 550 | 2.948885027 |
| 12 | 1063 | 1020 | 4.618525706 |
| 13 | 873 | 800 | 14.8782347 |
| 14 | 761 | 635 | 17.20417537 |
| R2 | a | b | c | |
|---|---|---|---|---|
| Bus 2 | 0.999773182 | 2.35 × 10−5 | −0.06599 | 1116.619 |
| Bus 3 | 0.999812644 | 1.91 × 10−5 | −0.06524 | 1116.616 |
| Bus 4 | 0.999998579 | 0.000353 | −0.6958 | 1116.585 |
| Bus 5 | 0.999999199 | 0.000479 | −0.93365 | 1116.58 |
| Bus 6 | 0.999999694 | 0.001858 | −2.07243 | 1116.599 |
| Bus 7 | 0.999953147 | 0.000752 | −1.27143 | 1116.459 |
| Bus 8 | 0.999999724 | 0.002145 | −2.37369 | 1116.556 |
| Bus 9 | 0.999991109 | 0.001346 | −2.27562 | 1117.953 |
| Bus 10 | 0.999993147 | 0.012075 | −5.53086 | 1115.824 |
| Bus 11 | 0.998644071 | 7.86 × 10−5 | −0.29256 | 1116.588 |
| Bus 12 | 0.998644071 | 0.001013 | −0.67768 | 1117.429 |
| Bus 13 | 0.999999455 | 0.002947 | −2.77489 | 1116.533 |
| Bus 14 | 0.999999423 | 0.002144 | −2.25015 | 1116.548 |
Appendix D. IEEE-10 Bus Grid Model Data

| Bus | Impedance Reference | X (Ohm) | R (Ohm) | Z (Ohm) |
|---|---|---|---|---|
| Bus 1_2 | Z1 | 0.1233 | 0.4127 | 0.430725 |
| Bus 2_3 | Z2 | 0.014 | 0.6057 | 0.605862 |
| Bus 3_4 | Z3 | 0.7463 | 1.205 | 1.417388 |
| Bus 4_5 | Z4 | 0.6984 | 0.6084 | 0.926236 |
| Bus 5_6 | Z5 | 1.9831 | 1.7276 | 2.630074 |
| Bus 6_7 | Z6 | 0.9053 | 0.7886 | 1.200607 |
| Bus 7_8 | Z7 | 2.0552 | 1.164 | 2.361936 |
| Bus 8_9 | Z8 | 4.7943 | 2.716 | 5.51017 |
| Bus 9_10 | Z9 | 5.3434 | 3.0264 | 6.14093 |
| Bus Reference | Load (KW) | Load (KVA) | Total Impedance Z (Ohm) |
|---|---|---|---|
| 2 | 1840 | 1897 | 0.4307 |
| 3 | 980 | 1037 | 0.6059 |
| 4 | 1790 | 1845 | 1.4174 |
| 5 | 1598 | 2437 | 0.9262 |
| 6 | 1610 | 1718 | 2.6301 |
| 7 | 750 | 788 | 1.2006 |
| 8 | 1150 | 1152 | 2.3619 |
| 9 | 980 | 989 | 5.5102 |
| 10 | 1640 | 1652 | 6.1409 |
References
- Navidi, T.; El Gamal, A.; Rajagopal, R. Coordinating distributed energy resources for reliability can significantly reduce future distribution grid upgrades and peak load. Joule 2023, 7, 1769–1792. [Google Scholar] [CrossRef]
- Hu, C.; Zhang, X.; Wu, Q. Collaborative Active and Reactive Power Control of DERs for Voltage Regulation and Frequency Support by Distributed Event-Triggered Heavy Ball Method. IEEE Trans. Smart Grid 2023, 14, 3804–3815. [Google Scholar] [CrossRef]
- Eid, C.; Codani, P.; Perez, Y.; Reneses, J.; Hakvoort, R. Managing electric flexibility from Distributed Energy Resources: A review of incentives for market design. Renew. Sustain. Energy Rev. 2016, 64, 237–247. [Google Scholar] [CrossRef]
- Patnam, B.S.K.; Pindoriya, N.M. Demand response in consumer-centric electricity market: Mathematical models and optimization problems. Electr. Power Syst. Res. 2021, 193, 106923. [Google Scholar] [CrossRef]
- Kempton, W.; Tomić, J. Vehicle-to-grid power implementation: From stabilizing the grid to supporting large-scale renewable energy. J. Power Sources 2005, 144, 280–294. [Google Scholar] [CrossRef]
- Padullaparti, H.; Pratt, A.; Mendoza, I.; Tiwari, S.; Baggu, M.; Bilby, C.; Ngo, Y. Peak Load Management in Distribution Systems Using Legacy Utility Equipment and Distributed Energy Resources. In Proceedings of the 2021 IEEE Green Technologies Conference (GreenTech), Denver, CO, USA, 7–9 April 2021; pp. 435–441. [Google Scholar] [CrossRef]
- Agüero, J.R. Improving the efficiency of power distribution systems through technical and nontechnical losses reduction. In Proceedings of the PES T&D 2012, Orlando, FL, USA, 7–10 May 2012; pp. 1–8. [Google Scholar] [CrossRef]
- Recalde, D.; Trpovski, A.; Troitzsch, S.; Zhang, K.; Hanif, S.; Hamacher, T. A Review of Operation Methods and Simulation Requirements for Future Smart Distribution Grids. In Proceedings of the 2018 IEEE Innovative Smart Grid Technologies—Asia (ISGT Asia), Singapore, 22–25 May 2018; pp. 475–480. [Google Scholar] [CrossRef]
- Sokolova, E.S.; Martynyuk, M.V.; Dmitriev, D.V.; Tyurin, A.I. Optimization of the Parameters of the Distribution Network Computer Model to Reduce Losses. In Proceedings of the 2018 International Multi-Conference on Industrial Engineering and Modern Technologies (FarEastCon), Vladivostok, Russia, 3–4 October 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Chen, Z.; Amani, A.M.; Yu, X.; Jalili, M. Control and Optimisation of Power Grids Using Smart Meter Data: A Review. Sensors 2023, 23, 2118. [Google Scholar] [CrossRef] [PubMed]
- Farag, H.E.; El-Saadany, E.F.; El Shatshat, R.; Zidan, A. A generalized power flow analysis for distribution systems with high penetration of distributed generation. Electr. Power Syst. Res. 2011, 81, 1499–1506. [Google Scholar] [CrossRef]
- Ibrahim, K.A.; Au, M.T.; Gan, C.K.; Tang, J.H. System wide MV distribution network technical losses estimation based on reference feeder and energy flow model. Int. J. Electr. Power Energy Syst. 2017, 93, 440–450. [Google Scholar] [CrossRef]
- Kapoor, S.; Blackhall, L.; Sturnaberg, B.; Shaw, M. Distribution System State Estimation With Losses. In Proceedings of the 2021 IEEE PES Innovative Smart Grid Technologies Europe (ISGT Europe), Espoo, Finland, 18–21 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Nainar, K.; Iov, F. Three-Phase State Estimation for Distribution-Grid Analytics. Clean Technol. 2021, 3, 395–408. [Google Scholar] [CrossRef]
- Majdoub, M.; Boukherouaa, J.; Cheddadi, B.; Belfqih, A.; Sabri, O.; Haidi, T. A Review on Distribution System State Estimation Techniques. In Proceedings of the 2018 6th International Renewable and Sustainable Energy Conference (IRSEC), Rabat, Morocco, 5–8 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Kebir, N.; Maaroufi, M. Technical losses computation for short-term predictive management enhancement of grid-connected distributed generations. Renew. Sustain. Energy Rev. 2017, 76, 1011–1021. [Google Scholar] [CrossRef]
- Ashish, V.; Shivya, S. Solar PV Performance Parameter and Recommendation for Optimization of Performance in Large Scale Grid Connected Solar PV Plant—Case Study. J. Energy Power Source 2015, 2, 40–53. [Google Scholar]
- Bezerra, U.H.; Soares, T.M.; Vieira, J.P.A.; Tostes, M.E.L.; Manito, A.R.R.; Paye, J.C.H. Equivalent operational impedance: A new approach to calculate technical and nontechnical losses in electric distribution systems. In Proceedings of the 2018 Simposio Brasileiro de Sistemas Eletricos (SBSE), Niteroi, Brazil, 12–16 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Oureilidis, K.O.; Demoulias, C.S. A decentralized impedance-based adaptive droop method for power loss reduction in a converter-dominated islanded microgrid, Sustainable Energy. Grids Netw. 2016, 5, 39–49. [Google Scholar] [CrossRef]
- Monteiro, R.V.A.; Guimarães, G.C.; Silva, F.B.; da Silva Teixeira, R.F.; Carvalho, B.C.; Finazzi, A.D.P.; de Vasconcellos, A.B. A medium-term analysis of the reduction in technical losses on distribution systems with variable demand using artificial neural networks: An Electrical Energy Storage approach. Energy 2018, 164, 1216–1228. [Google Scholar] [CrossRef]
- Toma, R.N.; Hasan, M.N.; Nahid, A.-A.; Li, B. Electricity Theft Detection to Reduce Nontechnical Loss using Support Vector Machine in Smart Grid. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, 3–5 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Yao, M.; Zhu, Y.; Li, J.; Wei, H.; He, P. Research on Predicting Line Loss Rate in Low Voltage Distribution Network Based on Gradient Boosting Decision Tree. Energies 2019, 12, 2522. [Google Scholar] [CrossRef]
- Queiroz, L.M.O.; Lyra, C. Adaptive Hybrid Genetic Algorithm for Technical Loss Reduction in Distribution Networks Under Variable Demands. IEEE Trans. Power Syst. 2009, 24, 445–453. [Google Scholar] [CrossRef]
- Tuzikova, V.; Tlusty, J.; Muller, Z. A Novel Power Losses Reduction Method Based on a Particle Swarm Optimization Algorithm Using STATCOM. Energies 2018, 11, 2851. [Google Scholar] [CrossRef]
- Ahuja, A.; Pahwa, A. Using ant colony optimization for loss minimization in distribution networks. In Proceedings of the 37th Annual North American Power Symposium, 2015, Ames, IA, USA, 25 October 2005; pp. 470–474. [Google Scholar] [CrossRef]
- Nagi, J.; Yap, K.S.; Tiong, S.K.; Ahmed, S.K.; Mohammad, A.M. Detection of abnormalities and electricity theft using genetic Support Vector Machines. In Proceedings of the TENCON 2008—2008 IEEE Region 10 Conference, Hyderabad, India, 19–21 November 2008; pp. 1–6. [Google Scholar] [CrossRef]
- Public Utility Regulatory Policies Act of 1978, 16 USC §2601. Available online: https://www.ferc.gov/media/public-utility-regulatory-policies-act-1978 (accessed on 25 February 2024).
- Alam, M.S.; Al-Ismail, F.S.; Salem, A.; Abido, M.A. High-Level Penetration of Renewable Energy Sources Into Grid Utility: Challenges and Solutions. IEEE Access 2020, 8, 190277–190299. [Google Scholar] [CrossRef]
- Cole, W.J.; Greer, D.; Denholm, P.; Frazier, A.W.; Machen, S.; Mai, T.; Vincent, N.; Baldwin, S.F. Quantifying the challenge of reaching a 100% renewable energy power system for the United States. Joule 2021, 5, 1732–1748. [Google Scholar] [CrossRef]
- Conejo, A.J.; Arroyo, J.M.; Alguacil, N.; Guijarro, A.L. Transmission loss allocation: A comparison of different practical algorithms. IEEE Trans. Power Syst. 2002, 17, 571–576. [Google Scholar] [CrossRef]
- Happ, H.H. Cost of wheeling methodologies. IEEE Trans. Power Syst. 1994, 9, 147–156. [Google Scholar] [CrossRef]
- Costa, P.M.; Matos, M.A. Loss allocation in distribution networks with embedded generation. IEEE Trans. Power Syst. 2004, 19, 384–389. [Google Scholar] [CrossRef]
- Galiana, F.D.; Conejo, A.J.; Kockar, I. Incremental transmission loss allocation under pool dispatch. IEEE Trans. Power Syst. 2002, 17, 26–33. [Google Scholar] [CrossRef]
- Carpaneto, E.; Chicco, G.; Sumaili Akilimali, J. Loss partitioning and loss allocation in three-phase radial distribution systems with distributed generation. IEEE Trans. Power Syst. 2008, 23, 1039–1049. [Google Scholar] [CrossRef]
- Atanasovski, M.; Taleski, R. Energy Summation Method for Loss Allocation in Radial Distribution Networks With DG. IEEE Trans. Power Syst. 2012, 27, 1433–1440. [Google Scholar] [CrossRef]
- Conejo, A.J.; Galiana, F.D.; Kockar, I. Z-bus loss allocation. IEEE Trans. Power Syst. 2001, 16, 105–110. [Google Scholar] [CrossRef]
- Parastar, A.; Pirayesh, A.; Mozafari, B.; Khaki, B.; Sirjani, R.; Mehrtash, A. A new method for power loss allocation by modified Y-Bus matrix. In Proceedings of the 2008 IEEE International Conference on Sustainable Energy Technologies, Singapore, 24–27 November 2008; pp. 1184–1188. [Google Scholar] [CrossRef]
- Carpaneto, E.; Chicco, G.; Akilimali, J.S. Branch current decomposition method for loss allocation in radial distribution systems with distributed generation. IEEE Trans. Power Syst. 2006, 21, 1170–1179. [Google Scholar] [CrossRef]
- Fang, W.L.; Ngan, H.W. Succinct method for allocation of network losses. Gener. Transm. Distrib. IEEE Proc. 2002, 149, 171–174. [Google Scholar] [CrossRef]
- Strbac, G.; Kirschen, D.; Ahmed, S. Allocating transmission system usage on the basis of traceable contributions of generators and loads to flows. IEEE Trans. Power Syst. 1998, 13, 527–534. [Google Scholar] [CrossRef]
- Lim, V.S.C.; McDonald, J.D.F.; Saha, T.K. Development of a new loss allocation method for a hybrid electricity market using graph theory. Electr. Power Syst. Res. 2009, 79, 301–310. [Google Scholar] [CrossRef]
- Rao, M.S.S.; Soman, S.A.; Chitkara, P.; Gajbhiye, R.K.; Hemachandra, N.; Menezes, B.L. Min-max fair power flow tracing for transmission system usage cost allocation: A large system perspective. IEEE Trans. Power Syst. 2010, 25, 1457–1468. [Google Scholar] [CrossRef]
- Savier, J.S.; Das, D. An exact method for loss allocation in radial distribution systems. Int. J. Electr. Power Energy Syst. 2012, 36, 100–106. [Google Scholar] [CrossRef]
- Jagtap, K.M.; Khatod, D.K. Loss allocation in radial distribution networks with various distributed generation and load models. Int. J. Electr. Power Energy Syst. 2016, 75, 173–186. [Google Scholar] [CrossRef]
- Kalambe, S.; Agnihotri, G. Loss minimization techniques used in distribution network: Bibliographical survey. Renew. Sustain. Energy Rev. 2014, 29, 184–200. [Google Scholar] [CrossRef]
- Exposito, A.G.; Santos, J.M.R.; Garcia, T.G.; Velasco, E.A.R. Fair allocation of transmission power losses. IEEE Trans. Power Syst. 2000, 15, 184–188. [Google Scholar] [CrossRef]
- Ehsan, A.; Yang, Q. Optimal integration and planning of renewable distributed generation in the power distribution networks: A review of analytical techniques. Appl. Energy 2018, 210, 44–59. [Google Scholar] [CrossRef]
- Aryani, N.K.; Abdillah, M.; Negara, I.M.Y.; Soeprijanto, A. Optimal placement and sizing of Distributed Generation using Quantum Genetic Algorithm for reducing losses and improving voltage profile. In Proceedings of the TENCON 2011—2011 IEEE Region 10 Conference, Bali, Indonesia, 21–24 November 2011; pp. 108–112. [Google Scholar] [CrossRef]
- Avchat, H.S.; Mhetre, S. Optimal Placement of Distributed Generation in Distribution Network Using particle Swarm Optimization. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 5–7 June 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Bhumkittipich, K.; Phuangpornpitak, W. Optimal Placement and Sizing of Distributed Generation for Power Loss Reduction Using Particle Swarm Optimization. Energy Procedia 2013, 34, 307–317. [Google Scholar] [CrossRef]






| Level 1 | Level 2 | Level 3 | Components of Level 3 |
|---|---|---|---|
| Losses | Technical Losses | Fixed Losses | Hysteresis losses Eddy current losses |
| Variable Losses | Ohmic losses | ||
| Nontechnical Losses | Network Equipment issues | Theft and fraud Measurement errors | |
| Network information issues | Missing or unregistered connection points Incorrect location or energization status of connection points Incorrect information on measurement equipment | ||
| Energy data processing issues | Estimation of unmetered consumptions Estimation of consumptions between meter readings and calculations Estimation of technical losses Estimation of detected issues Other energy data processing issues |
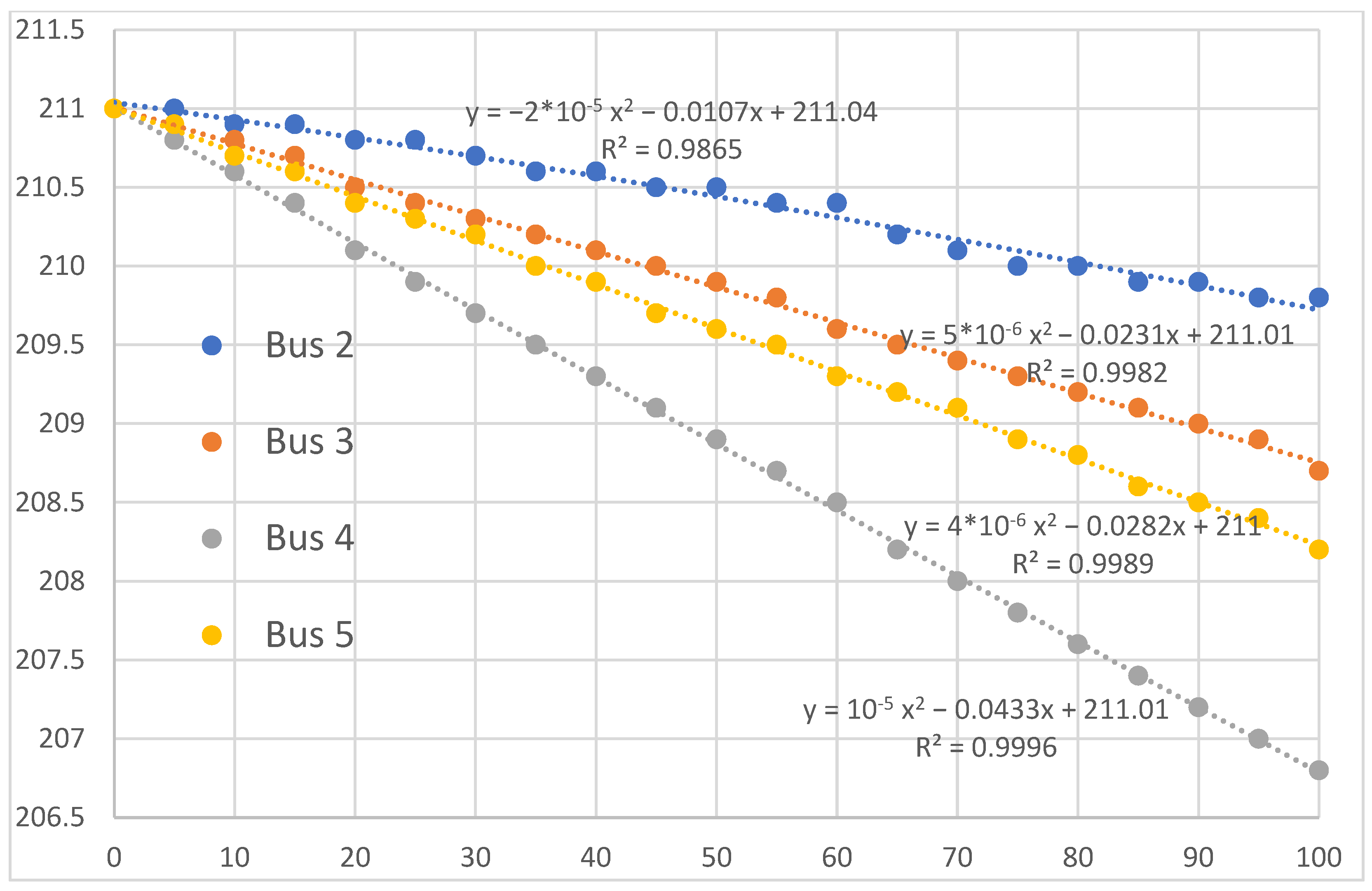
| Bus | a | b | c | Z (Ohm) | L (kW) | Bus | a | b | c | Z (Ohm) | L (kW) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 0.000004 | 0.0107 | 211 | 0.4858 | 100 | 18 | 0.00008 | 0.1342 | 211 | 16.4247 | 90 |
| 3 | 0.000005 | 0.0231 | 211 | 1.0391 | 90 | 19 | 0.000009 | 0.0053 | 211 | 0.7125 | 90 |
| 4 | 0.00001 | 0.0433 | 211 | 1.4498 | 120 | 20 | 0.00001 | 0.0092 | 211 | 2.7373 | 90 |
| 5 | 0.000004 | 0.0282 | 211 | 1.8775 | 60 | 21 | 0.00001 | 0.0098 | 211 | 3.3670 | 90 |
| 6 | 0.000002 | 0.0424 | 211 | 2.9595 | 60 | 22 | 0.00001 | 0.0107 | 211 | 4.5422 | 90 |
| 7 | 0.00007 | 0.1513 | 211 | 3.6060 | 200 | 23 | 0.000008 | 0.0279 | 211 | 1.5856 | 90 |
| 8 | 0.0001 | 0.1948 | 211 | 5.7165 | 200 | 24 | 0.0002 | 0.1668 | 211 | 2.7298 | 420 |
| 9 | 0.000008 | 0.0639 | 211 | 6.9848 | 60 | 25 | 0.0003 | 0.1864 | 211 | 3.8675 | 420 |
| 10 | 0.00002 | 0.0707 | 211 | 8.2644 | 60 | 26 | 0.00003 | 0.0477 | 211 | 3.1873 | 60 |
| 11 | 0.000008 | 0.0548 | 211 | 8.4715 | 45 | 27 | 0.00004 | 0.0483 | 211 | 3.5063 | 60 |
| 12 | 0.00002 | 0.0727 | 211 | 8.8658 | 60 | 28 | 0.000008 | 0.0539 | 211 | 4.9181 | 60 |
| 13 | 0.00002 | 0.0793 | 211 | 10.7337 | 60 | 29 | 0.00005 | 0.1189 | 211 | 5.9847 | 120 |
| 14 | 0.00009 | 0.1631 | 211 | 11.6290 | 120 | 30 | 0.0002 | 0.2118 | 211 | 6.5542 | 200 |
| 15 | 0.00003 | 0.0835 | 211 | 12.4202 | 60 | 31 | 0.0001 | 0.1678 | 211 | 7.9054 | 150 |
| 16 | 0.00003 | 0.0855 | 211 | 13.3443 | 60 | 32 | 0.0002 | 0.2369 | 211 | 8.3822 | 210 |
| 17 | 0.00003 | 0.0863 | 211 | 15.4945 | 60 | 33 | 0.00003 | 0.0678 | 211 | 9.0126 | 60 |
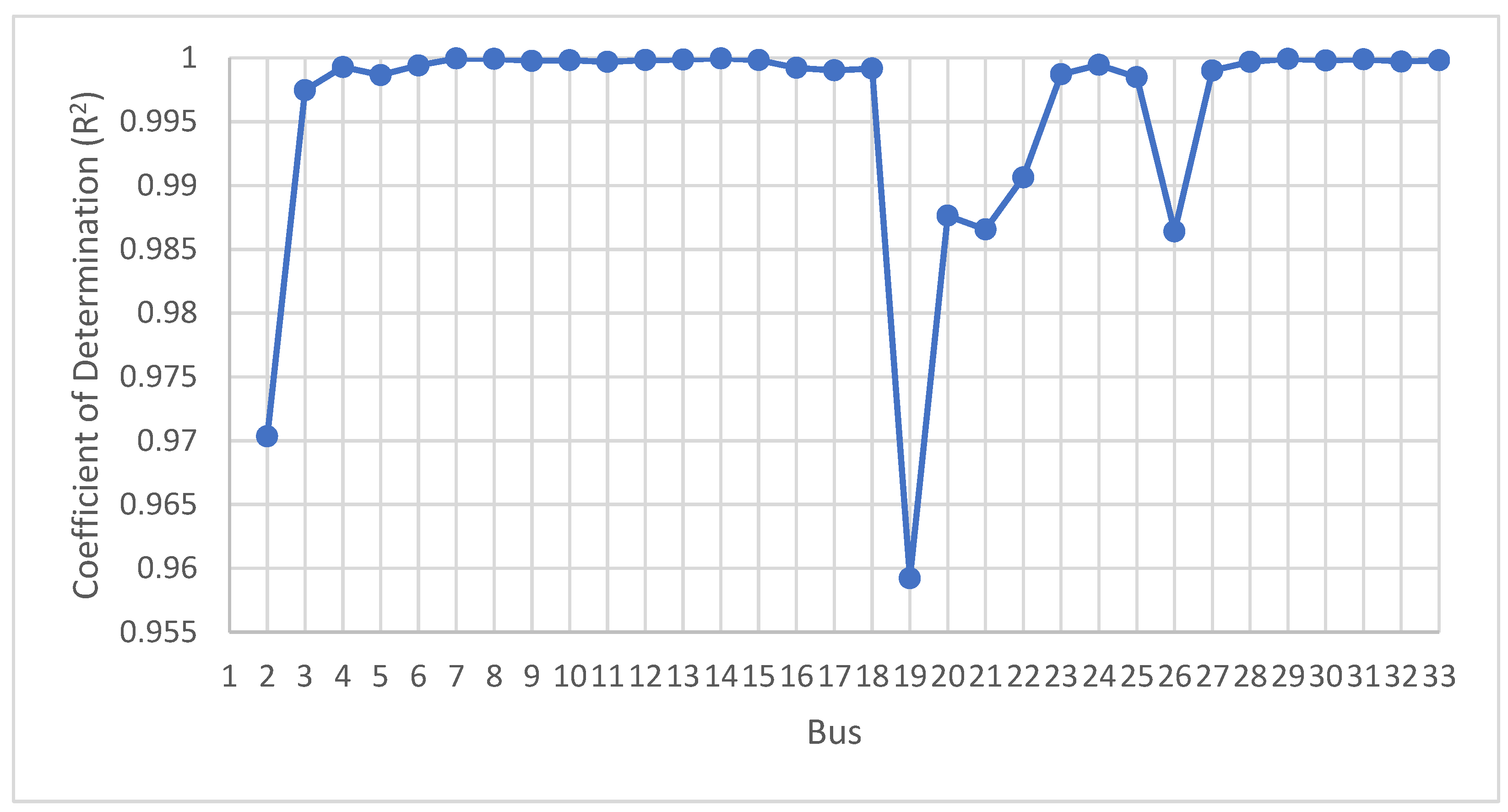
| IEEE-33 Bus Model | MSE | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|
| Value | 3.28 | 1.81 | 1.12 | 0.55 | 0.89 |
| Recommendation | <10 | ~1 |
| R2 Value | Correlation Intensity |
|---|---|
| 0.00 | (N) null |
| (0.00–0.09) | (L) low |
| (0.09–0.36) | (M) moderate |
| (0.36–0.81) | (H) high |
| (0.81–0.98) | (VH) very high |
| 1.00 | (P) perfect |
| IEEE-10 Bus Model | MSE | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|
| Value | 618.24 | 24.86 | 13.33 | 2.32 | 0.95 |
| Recommendation | <10 | ~1 |
| 14-Bus Grid Model | MSE | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|
| Value | 970.55 | 31.15 | 21.89 | 2.24 | 0.95 |
| Recommendation | <10 | ~1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aoun, A.; Adda, M.; Ilinca, A.; Ghandour, M.; Ibrahim, H.; Salloum, S. Efficient Modeling of Distributed Energy Resources’ Impact on Electric Grid Technical Losses: A Dynamic Regression Approach. Energies 2024, 17, 2053. https://doi.org/10.3390/en17092053
Aoun A, Adda M, Ilinca A, Ghandour M, Ibrahim H, Salloum S. Efficient Modeling of Distributed Energy Resources’ Impact on Electric Grid Technical Losses: A Dynamic Regression Approach. Energies. 2024; 17(9):2053. https://doi.org/10.3390/en17092053
Chicago/Turabian StyleAoun, Alain, Mehdi Adda, Adrian Ilinca, Mazen Ghandour, Hussein Ibrahim, and Saba Salloum. 2024. "Efficient Modeling of Distributed Energy Resources’ Impact on Electric Grid Technical Losses: A Dynamic Regression Approach" Energies 17, no. 9: 2053. https://doi.org/10.3390/en17092053
APA StyleAoun, A., Adda, M., Ilinca, A., Ghandour, M., Ibrahim, H., & Salloum, S. (2024). Efficient Modeling of Distributed Energy Resources’ Impact on Electric Grid Technical Losses: A Dynamic Regression Approach. Energies, 17(9), 2053. https://doi.org/10.3390/en17092053