
Mid-Term Electricity Market Clearing Price Forecasting with Sparse Data: A Case in Newly-Reformed Yunnan Electricity Market


Abstract
:1. Introduction
- The input variables of the model would affect the forecasting result directly. Thus, the selection of appropriate influence factors of electricity MCP is extremely important, but also tough, as it varies from different electricity markets.
- The mid-term electricity MCP is obviously volatile in nature and out of a monotonous trend. The forecasting accuracy is unsatisfactory when the value of the next forecasting point is away from the fitting model constructed only with known data.
- The least square method (LSM) used in the traditional GM(0, N) model to identify parameters is effective on condition of the existence of the inverse of matrix , but this does not work when is a singular matrix in some cases.
- Based on depth analysis of the newly-reformed electricity market, the influence factors of electricity MCP are studied, and input variables are carefully selected according to three aspects: supply factors, demand factors and supplemented factors.
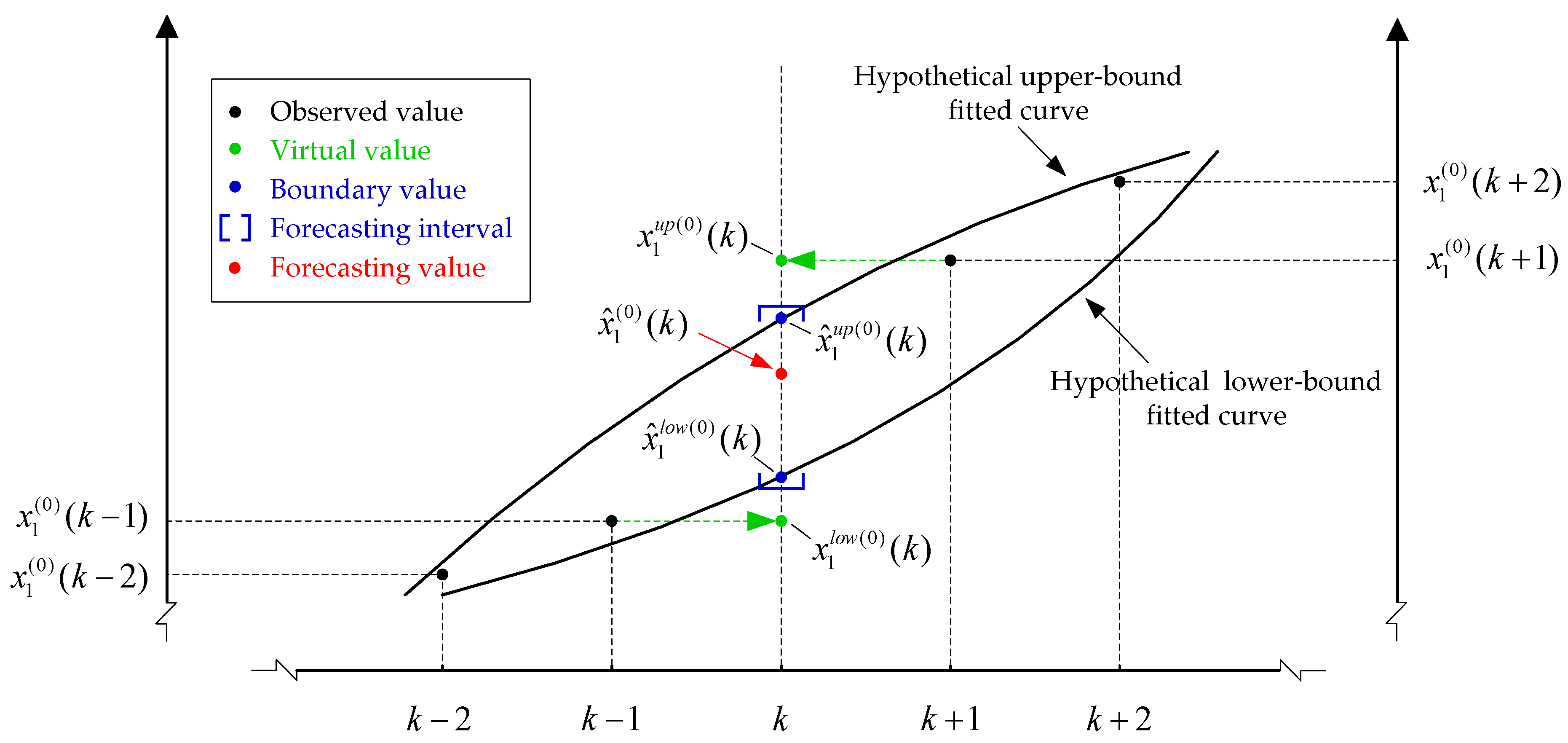
- In the proposed interval GM(0, N) model, two improved GM(0, N) models are included, respectively estimating the upper and lower bounds of the forecasting value. Firstly, to reduce randomness and increase smoothness, all input sequences (not containing values of the next forecasting point) including the MCP sequence and factor sequences are ranked in accordance with the ascending order of the MCP sequence. Then, one of the factor sequences is selected as the benchmark ranking sequence according to its ranking order and correlation with the MCP sequence. The position of the forecasting point in the ranked MCP sequence thus can be determined by sorting the benchmark ranking sequence, which contains the factor value of the forecasting point. Finally, two neighboring (upper and lower) points of the forecasting point in the ranked MCP sequence are regarded as two virtual values to construct two new MCP sequences, which are respectively used as characteristic sequences for two improved GM(0, N) models, obtaining the forecasting interval. In the two improved GM(0, N) models, the input sequences used for building the model include not only known data, but also the virtual MCP and predicted influence factors of the forecasting point.
- Based on the forecasting interval, a novel whitenization method considering correlations between electricity MCP and influence factors is established to determine the definite forecasting value.
- The parameters of the GM(0, N) model are identified by an improved particle swarm optimization (PSO) instead of LSM.
- The performance of the proposed model has been validated by applying it to the newly-reformed Yunnan electricity market. Further comparisons between the proposed model and other models, including the multiple linear regression (MLR) model, the traditional GM(0, N) model and the artificial neural network (ANN) model, are carefully discussed and also evaluated by using the modified Diebold–Mariano (MDM) test. The results indicate that the proposed model is an effective means of mid-term electricity MCP forecasting with sparse data.
2. Method and Theory
2.1. Principle of the Traditional GM(0, N) Model
2.2. Limitation and Requirement for Implementation
2.2.1. Limitation of Least Square Method (LSM) in the Traditional GM(0, N) Model
2.2.2. Requirements for Input Variables
2.3. Performance Evaluation
2.3.1. Checking Method of Grey Prediction Models
2.3.2. Performance Evaluation of Forecasting Models
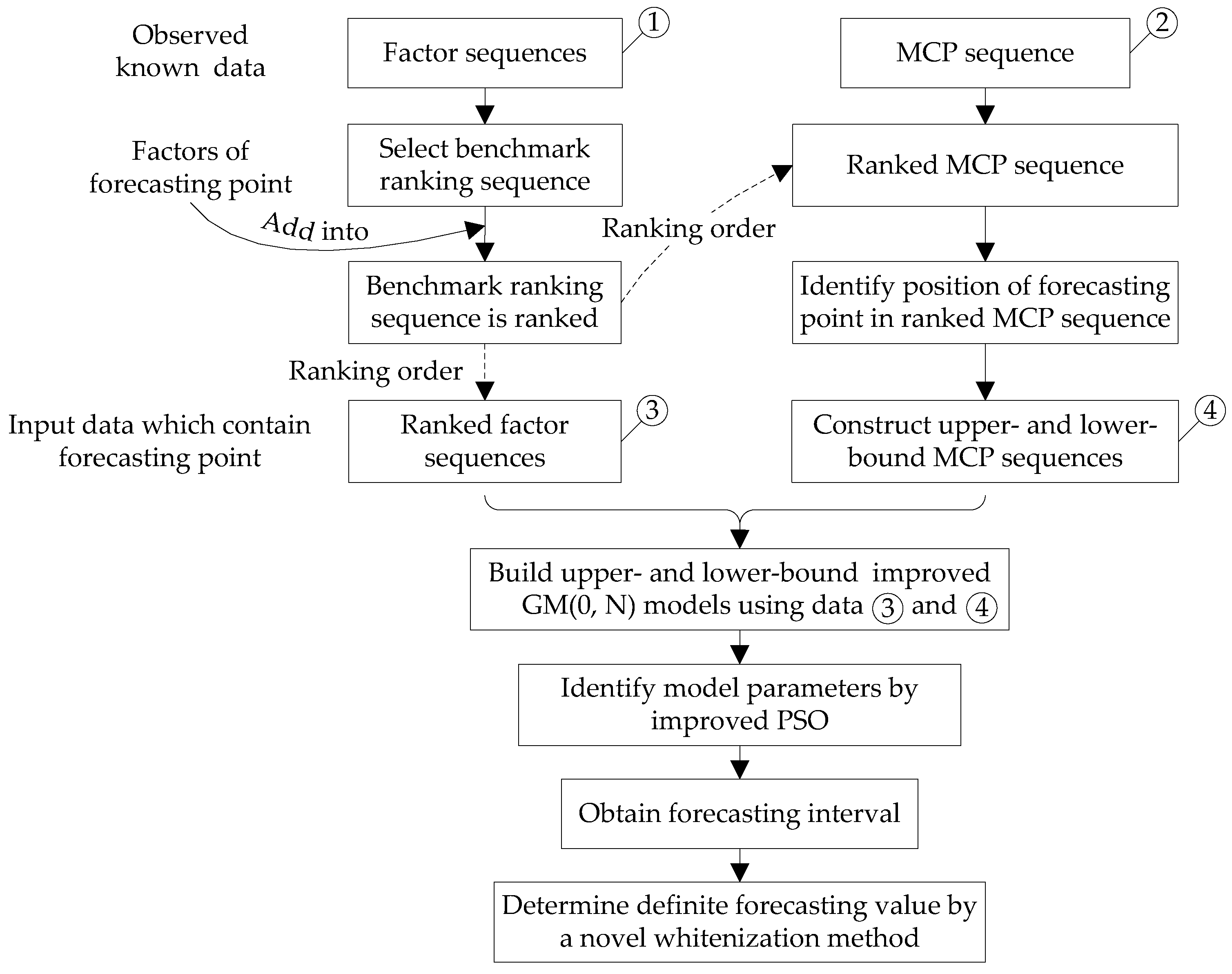
3. Novel Interval GM(0, N) Model
3.1. Selection of the Benchmark Ranking Sequence
- (1)
- The lengths of and are equal.
- (2)
- A new sequence is obtained by ranking in ascending order of value. Corresponding with the same index of the subscript, is formed. For any , there is (or ).
3.2. Calculation for Forecasting Interval
3.3. Definite Forecasting Value Determination
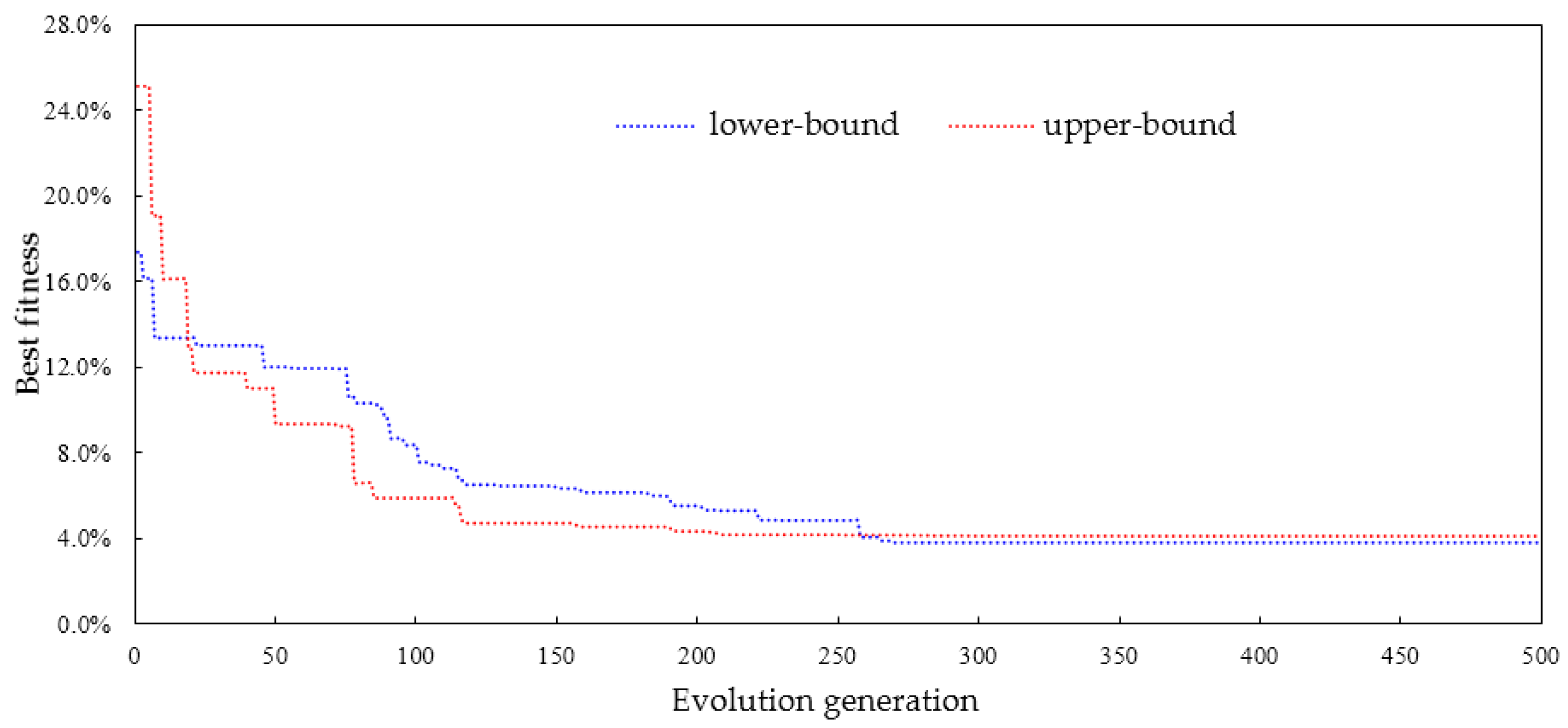
3.4. Parameters Identification by Improved Particle Swarm Optimization (PSO)
3.5. Summary of Calculation Process
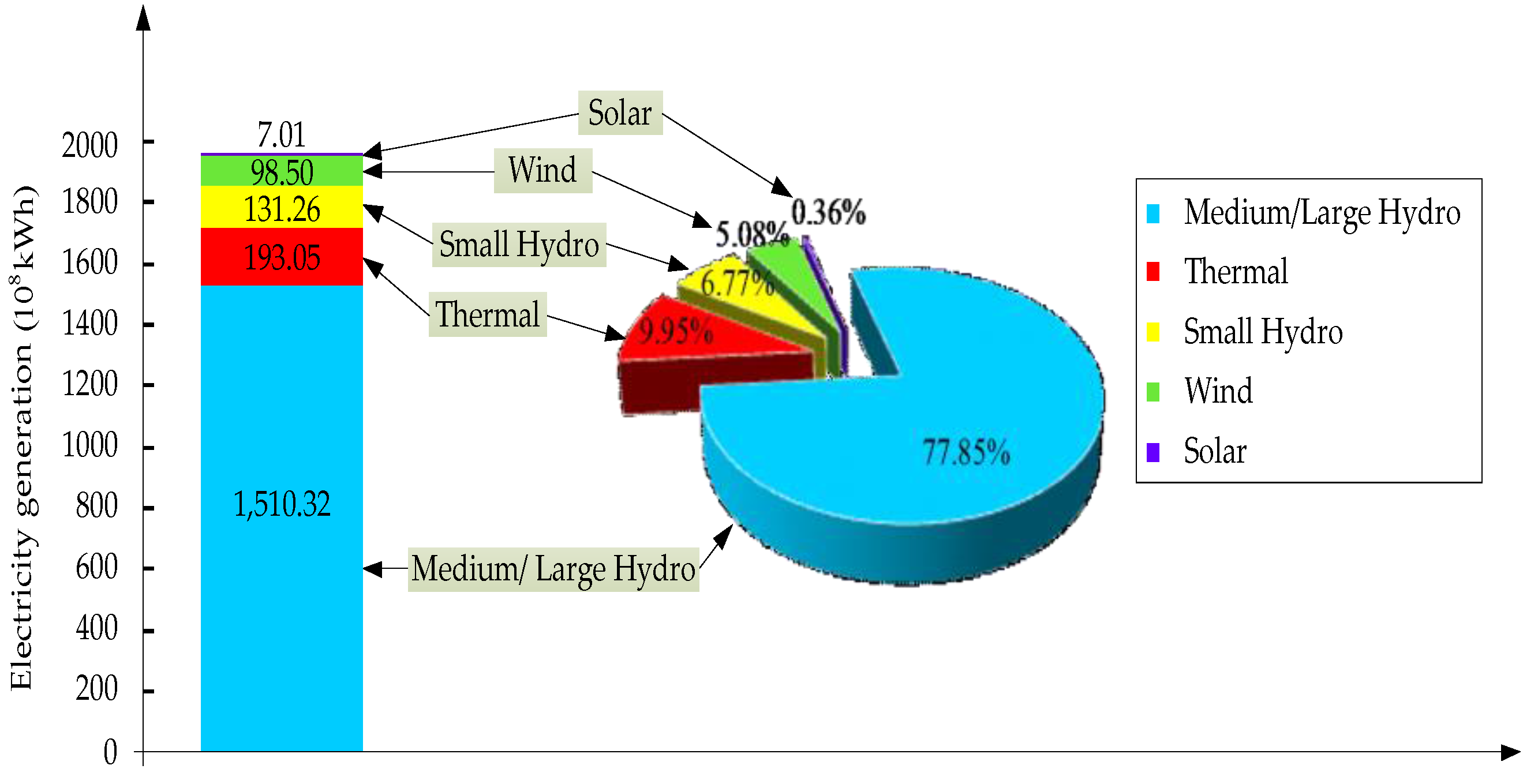
4. Study Area and Influence Factors
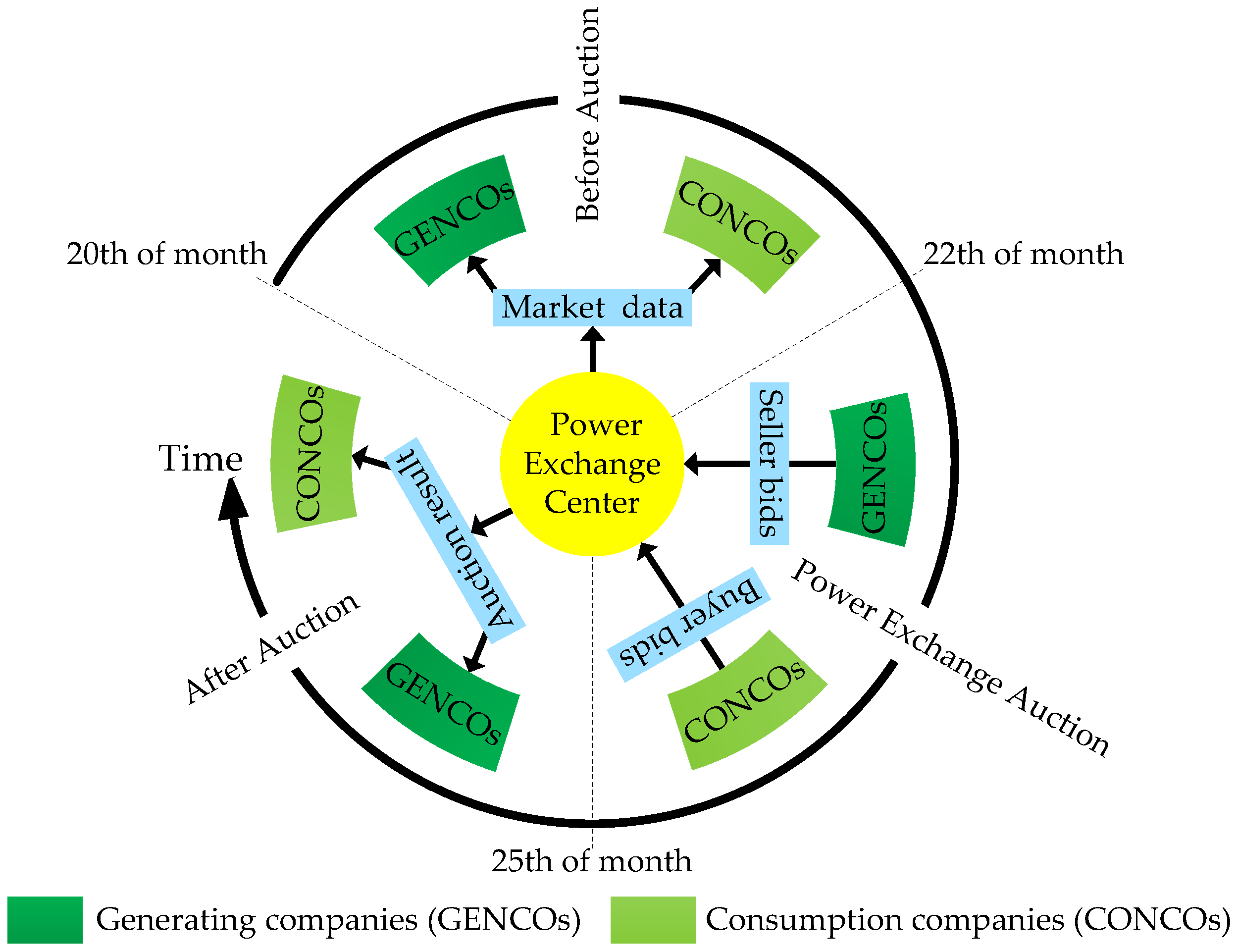
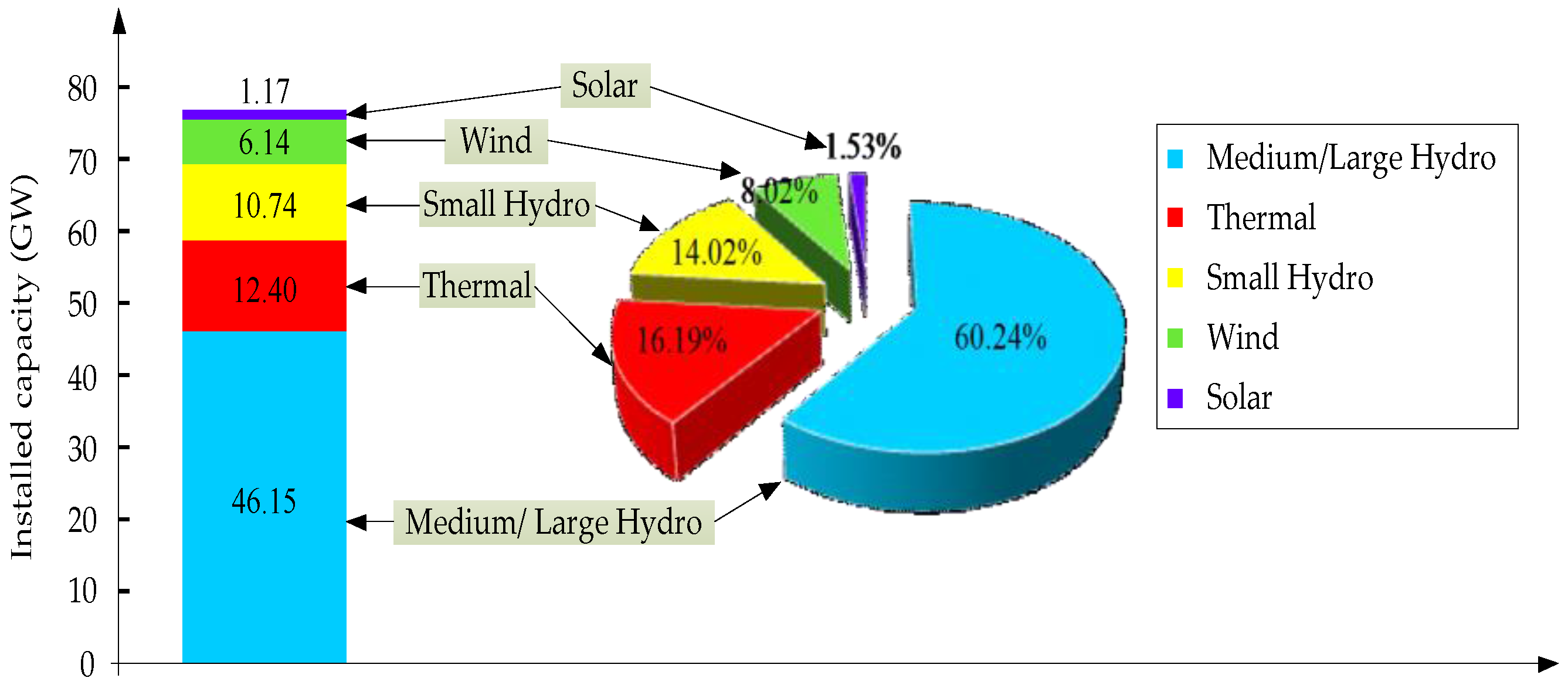
4.1. Newly-Reformed Yunnan Electricity Market
4.2. Identification of Input Variables
4.2.1. Supply Factors
4.2.2. Demand Factors
4.2.3. Supplemented Factors
4.3. Data Collection and Normalization
5. Case Study
5.1. An Example for Forecasting
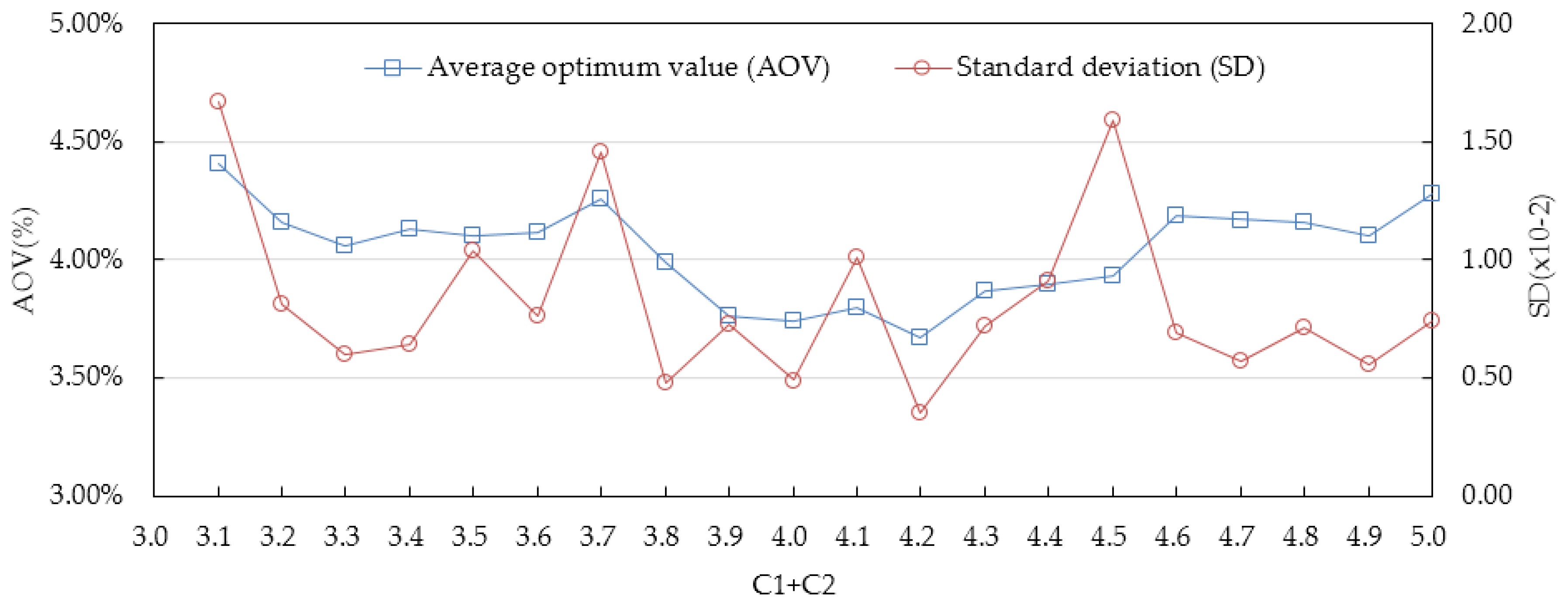
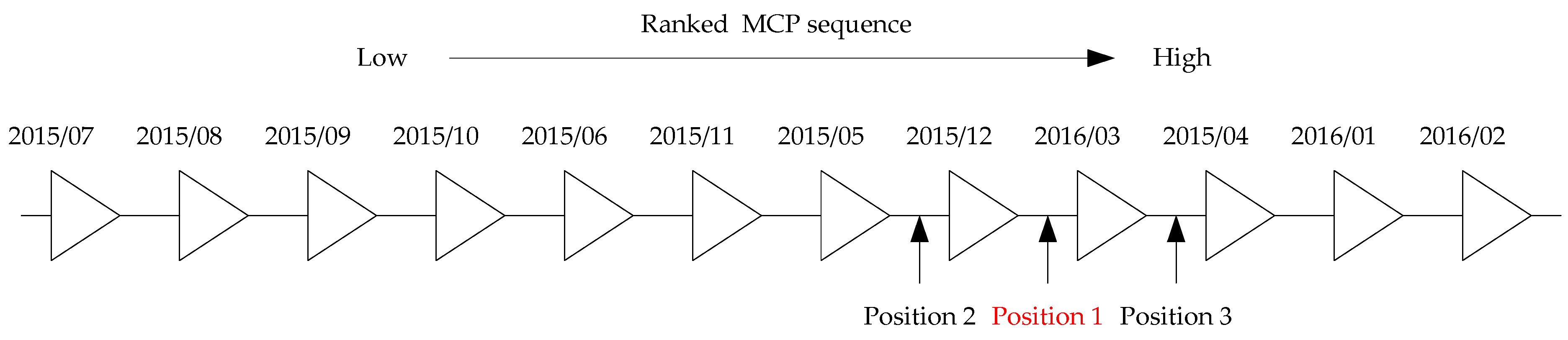
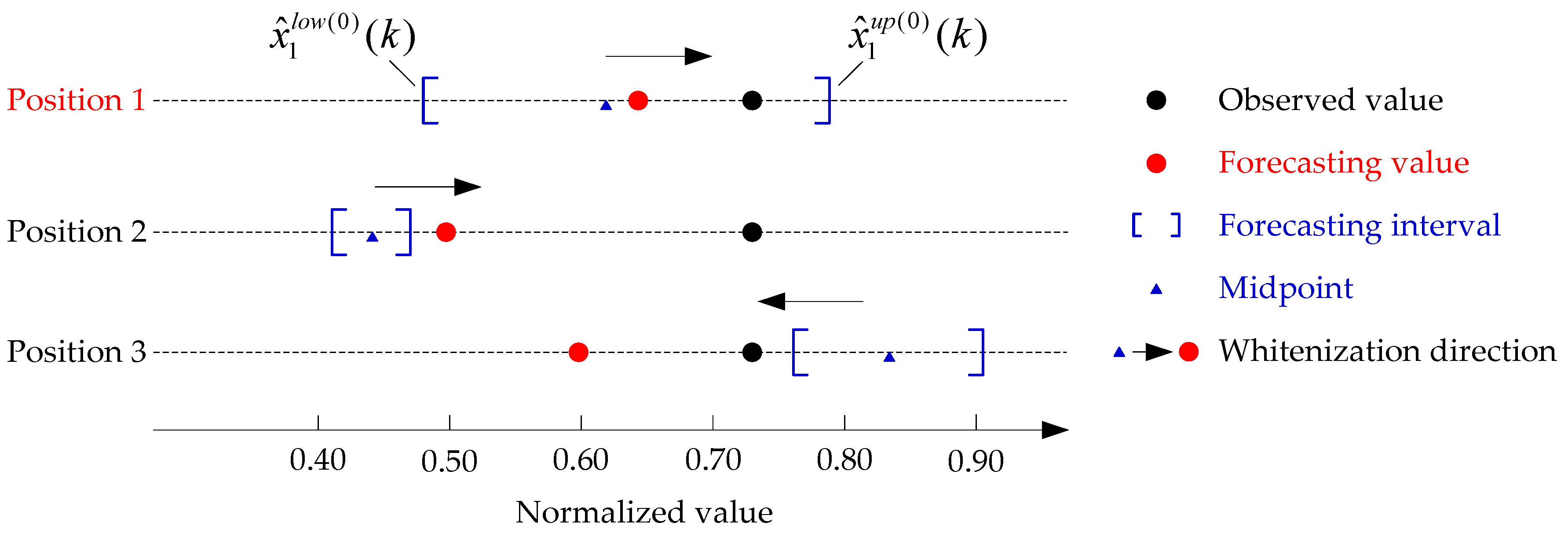
5.2. Sensitivity Analysis of Position
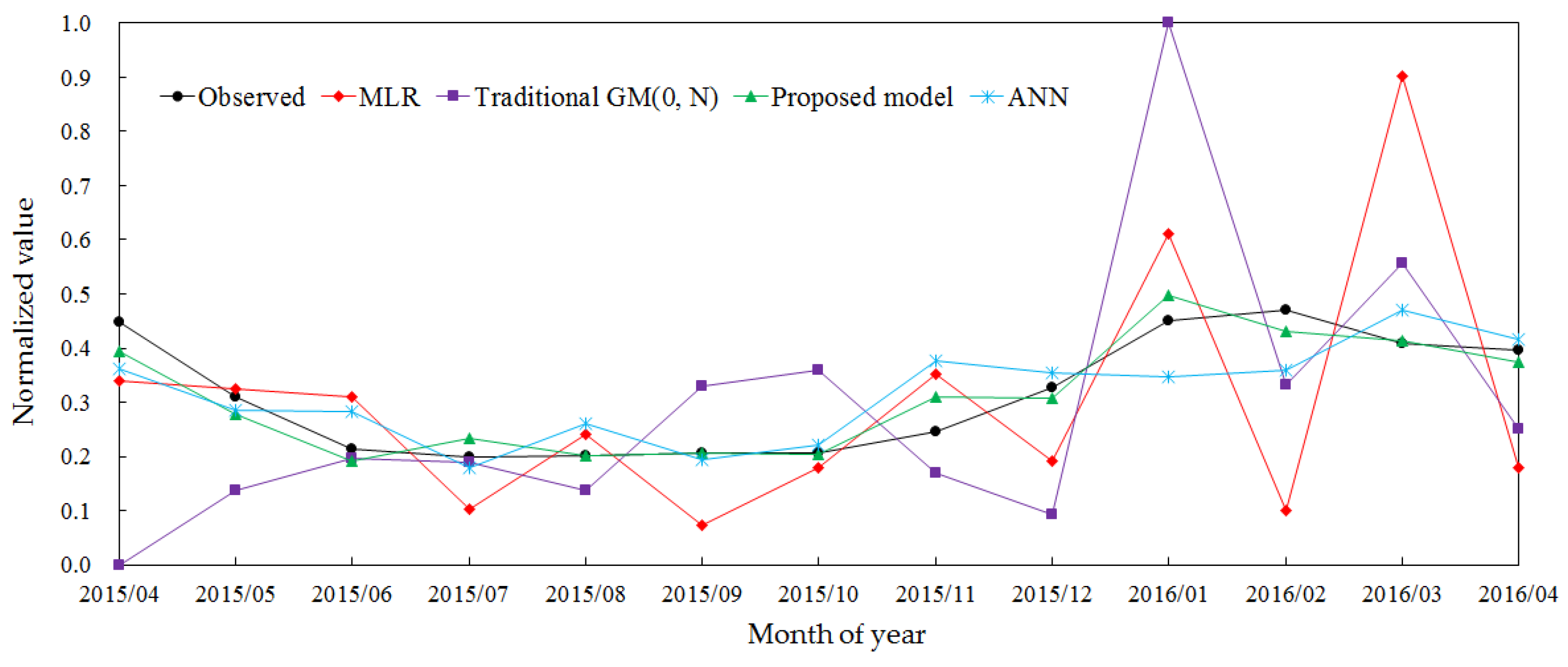
5.3. Comparison with Other Models
5.4. Forecasting Evaluation Based on the Modified Diebold–Mariano (MDM) Test
- According to the MDM test based on the MAE loss function, the null hypothesis is rejected at the 1% level of significance. In other words, the observed differences are pretty significant, and the forecasting performance of Model 4 is better than Model 1.
- According to the MDM test based on the MSE loss function, the null hypothesis is rejected at the 10% level of significance. That is to say, the observed differences are also significant, and the forecasting performance of Model 4 is better than Model 1.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- The Communist Party of China (CPC) Central Committee and State Council of PRC. Opinions on Further Deepening the Reforms of electricity power system. Available online: http://www.cec.org.cn/huanbao/xingyexinxi/fazhangaige/2015-03-25/135625.html (accessed on 25 March 2015).
- Ma, C.; He, L. From state monopoly to renewable portfolio: Restructuring China’s electric utility. Energy Policy 2008, 36, 1697–1711. [Google Scholar] [CrossRef]
- Yan, X.; Chowdhury, N.A. Mid-term electricity market clearing price forecasting: A hybrid LSSVM and ARMAX approach. Int. J. Electr. Power Energy Syst. 2013, 53, 20–26. [Google Scholar] [CrossRef]
- Weron, R. Electricity price forecasting: A review of the state-of-the-art with a look into the future. Int. J. Forecast. 2014, 30, 1030–1081. [Google Scholar] [CrossRef]
- Aggarwal, S.K.; Saini, L.M.; Kumar, A. Electricity price forecasting in deregulated markets: A review and evaluation. Int. J. Electr. Power Energy Syst. 2009, 31, 13–22. [Google Scholar] [CrossRef]
- Rubin, O.D.; Babcock, B.A. The impact of expansion of wind power capacity and pricing methods on the efficiency of deregulated electricity markets. Energy 2013, 59, 676–688. [Google Scholar] [CrossRef]
- Sapio, S.; Wylomanska, A. The impact of forward trading on the spot power price volatility with Cournot competition. In Proceedings of the 5th international conference on the European electricity market, Lisboa, Portugal, 28–30 May 2008; pp. 105–110.
- Ruibal, C.M.; Mazumdar, M. Forecasting the mean and the variance of electricity prices in deregulated markets. IEEE Trans. Power Syst. 2008, 23, 25–32. [Google Scholar] [CrossRef]
- Wood, A.J.; Wollenberg, B.F. Power Generation, Operation and Control; Wiley: New York, NY, USA, 1996. [Google Scholar]
- Batlle, C.; Barquin, J. A strategic production costing model for electricity market price analysis. IEEE Trans. Power Syst. 2005, 20, 67–74. [Google Scholar] [CrossRef]
- Kian, A.; Keyhani, A. Stochastic price modeling of electricity in deregulated energy markets. In Proceedings of the 34th Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 6 January 2001; pp. 1–7.
- Robinson, T.A. Electricity pool prices: A case study in nonlinear time-series modelling. Appl. Econ. 2000, 32, 527–532. [Google Scholar] [CrossRef]
- Carpio, J.; Juan, J.; López, D. Multivariate exponential smoothing and dynamic factor model applied to hourly electricity price analysis. Technometrics 2014, 56, 494–503. [Google Scholar] [CrossRef]
- Nogales, F.J.; Contreras, J.; Conejo, A.J.; Espinola, R. Forecasting next-day electricity prices by time series models. IEEE Trans. Power Syst. 2002, 17, 342–348. [Google Scholar] [CrossRef]
- Obradovic, Z.; Tomsovic, K. Time series methods for forecasting electricity market pricing. In Proceedings of the IEEE Power Engineering Society Summer Meeting, Edmonton, AB, Canada, 18–22 July 1999; pp. 1264–1265.
- Cuaresma, J.C.; Hlouskova, J.; Kossmeier, S.; Obersteiner, M. Forecasting electricity spot-prices using linear univariate time-series models. Appl. Energy 2004, 77, 87–106. [Google Scholar] [CrossRef]
- Conejo, A.J.; Plazas, M.A.; Espinola, R.; Molina, A.B. Day-ahead electricity price forecasting using the Wavelet Transform and ARIMA Models. IEEE Trans. Power Syst. 2005, 20, 1035–1042. [Google Scholar] [CrossRef]
- Kim, C.; Yu, I.K.; Song, Y.H. Prediction of system marginal price of electricity using wavelet transform analysis. Energy Convers. Manag. 2002, 43, 1839–1851. [Google Scholar] [CrossRef]
- Zhang, J.; Tan, Z. Day-ahead electricity price forecasting using WT, CLSSVM and EGARCH model. Int. J. Electr. Power Energy Syst. 2013, 45, 362–368. [Google Scholar] [CrossRef]
- Contreras, J.; Espinola, R.; Nogales, F.J.; Conejo, A.J. ARIMA models to predict next-day electricity prices. IEEE Trans. Power Syst. 2003, 18, 1014–1020. [Google Scholar] [CrossRef]
- Jakaša, T.; Andročec, I.; Sprčić, P. Electricity price forecasting - ARIMA model approach. In Proceedings of the 8th International Conference on the European Energy Market (EEM), Zagreb, Croatia, 25–27 May 2011; pp. 222–225.
- Xie, M.; Sandels, C.; Zhu, K. A seasonal ARIMA model with exogenous variables for elspot electricity prices in Sweden. In Proceedings of the 10th International Conference on the European Energy Market (EEM), Stockholm, Sweden, 27–31 May 2013; pp. 1–4.
- Szkuta, B.R.; Sanabria, L.A.; Dillon, T.S. Electricity price short-term forecasting using artificial neural networks. IEEE. Trans. Power Syst. 1999, 14, 851–857. [Google Scholar] [CrossRef]
- Keles, D.; Scelle, J.; Paraschiv, F.; Fichtner, W. Extended forecast methods for day-ahead electricity spot prices applying artificial neural networks. Appl. Energy 2016, 162, 218–230. [Google Scholar] [CrossRef]
- Shrivastava, N.A.; Khosravi, A.; Panigrahi, B.K. Prediction interval estimation of electricity prices using PSO-Tuned Support Vector Machines. IEEE Trans. Ind. Inf. 2015, 11, 322–331. [Google Scholar] [CrossRef]
- Papadimitriou, T.; Gogas, P.; Stathakis, E. Forecasting energy markets using support vector machines. Energy Econ. 2014, 44, 135–142. [Google Scholar] [CrossRef]
- Zhao, J.H.; Dong, Z.; Li, X.; Wong, K. A framework for electricity price spike analysis with advanced data mining methods. IEEE Trans. Power Syst. 2007, 22, 376–385. [Google Scholar] [CrossRef]
- Huang, D.; Zareipour, H.; Rosehartet, W.D.; Amjady, N. Data mining for electricity price classification and the application to demand-side management. IEEE Trans. Smart Grid 2012, 3, 808–817. [Google Scholar] [CrossRef]
- Tan, Z.F.; Zhang, J.L.; Wang, J.H.; Xu, J. Day-ahead electricity price forecasting using wavelet transform combined with ARIMA and GARCH models. Appl. Energy 2010, 87, 3606–3610. [Google Scholar] [CrossRef]
- Gonzalez, V.; Contreras, J.; Bunn, D. Forecasting power prices using a hybrid Fundamental-Econometric model. IEEE Trans. Power Syst. 2012, 27, 363–372. [Google Scholar] [CrossRef]
- Cerjan, M.; Matijaš, M.; Delimar, M. Dynamic hybrid model for short-term electricity price forecasting. Energies 2014, 7, 3304–3318. [Google Scholar] [CrossRef]
- Torghaban, S.S.; Zareipour, H.; Tuan, L.A. Medium-term electricity market price forecasting: a data-driven approach. In Proceedings of the 2010 North American Power Symposium (NAPS 2010), Arlington, TX, USA, 26–28 September 2010; pp. 1–7.
- Torghaban, S.S.; Motamedi, A.; Zareipour, H.; Tuan, L.A. Medium-term electricity price forecasting. In Proceedings of the 2012 North American Power Symposium (NAPS 2012), Champaign, IL, USA, 9–11 September 2012; pp. 1–8.
- Bello, A.; Reneses, J.; Munoz, A. Medium-term probabilistic forecasting of extremely low prices in electricity markets: Application to the Spanish case. Energies 2016, 9, 193. [Google Scholar] [CrossRef]
- Yan, X.; Chowdhury, N.A. Mid-term electricity market clearing price forecasting: A multiple SVM approach. Int. J. Electr. Power Energy Syst. 2014, 58, 206–214. [Google Scholar] [CrossRef]
- Liu, S.; Forrest, J.; Yang, Y. A brief introduction to grey systems theory. Grey Systems: Theory Appl. 2012, 2, 89–104. [Google Scholar] [CrossRef]
- Deng, J.L. The control problem of grey systems. Syst. Control Lett. 1982, 1, 288–294. [Google Scholar]
- Qiu, B.J.; Zhang, J.H.; Qi, Y.T.; Liu, Y. Grey-theory-based optimization model of emergency logistics considering time uncertainty. PLoS ONE 2015, 10, e0139132. [Google Scholar] [CrossRef] [PubMed]
- Wei, J.C.; Zhou, L.; Wang, F.; Wu, D.S. Work safety evaluation in Mainland China using grey theory. Appl. Math. Model. 2015, 39, 924–933. [Google Scholar] [CrossRef]
- Zhou, H.; Wu, X.H.; Wang, W.; Chen, L.P. Forecast of next day clearing price in deregulated electricity market. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; pp. 4397–4401.
- Lei, M.; Feng, Z. A proposed grey model for short-term electricity price forecasting in competitive power markets. Int. J. Electr. Power Energy Syst. 2012, 43, 531–538. [Google Scholar] [CrossRef]
- Ou, S.L. Forecasting agricultural output with an improved grey forecasting model based on the genetic algorithm. Comput. Electron. Agr. 2012, 85, 33–39. [Google Scholar] [CrossRef]
- Wang, C.H.; Hsu, L.C. Using genetic algorithms grey theory to forecast high technology industrial output. Appl. Math. Comput. 2008, 95, 256–263. [Google Scholar] [CrossRef]
- Harvey, D.; Leybourne, S.; Newbold, P. Testing the equality of prediction mean squared errors. Int. J. Forecast. 1997, 13, 281–291. [Google Scholar] [CrossRef]
- Diebold, F.X.; Mariano, R.S. Comparing predictive accuracy. J. Bus. Econ. Stat. 1995, 13, 253–263. [Google Scholar]
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the 6th micro-machine and human, science, Nagoya, Japan, 4–6 October 1995; pp. 39–43.
- Shi, Y.; Eberhart, R. Empirical study of particle swarm optimization. In Proceedings of the IEEE International Congress, Evolutionary Computation, Washington, DC, USA, 6–9 July 1999; pp. 101–106.
- Chatterjee, A.; Siarry, P. Nonlinear inertia weight variation for dynamic adaptation in particle swarm optimization. Comput. Oper. Res. 2006, 33, 859–871. [Google Scholar] [CrossRef]
- Ratnaweera, A.; Halgamuge, S.K.; Watson, H.C. Self-organizing hierarchical particle swarm optimizer with time-varying acceleration coefficients. IEEE Trans. Evol. Comput. 2004, 8, 240–255. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, J.Z.; Zhou, C. An improved self-adaptive PSO technique for short-term hydrothermal scheduling. Expert Syst. Appl. 2012, 39, 2288–2295. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the IEEE World Congress on Computational Intelligence, Anchorage, AK, USA, 4–9 May 1998; pp. 69–73.
- National Development and Reform Commission. Notice to Accelerate Reform of Transmission and Distribution Price. Available online: http://jgs.ndrc.gov.cn/zcfg/201504/t20150416_688233.html (accessed on 13 April 2014).
- Gao, F.; Guan, X.; Cao, X.; Papalexopoulos, A. Forecasting power market clearing price and quantity using a neural network method. In Proceedings of the Power Engineering Society Summer Meeting, Seattle, WA, USA, 16–20 July 2000; pp. 2183–2188.
- Jiang, Y.; Liu, C.; Huang, C. Improved particle swarm algorithm for hydrological parameter optimization. Appl. Math. Comput. 2010, 217, 3207–3215. [Google Scholar] [CrossRef]
- Montalvo, I.; Izquierdo, J.; Pérez, R. A diversity-enriched variant of discrete PSO applied to the design of water distribution networks. Eng. Optimiz. 2008, 40, 655–668. [Google Scholar] [CrossRef]
- Gong, Y.J.; Zhang, J.; Chung, H.S. An efficient resource allocation scheme using particle swarm optimization. IEEE Trans. Evol. Comput. 2012, 16, 801–816. [Google Scholar] [CrossRef]
- Clerc, M.; Kennedy, J. The particle swarm-explosion, stability, and convergence in a multidimensional complex space. IEEE Trans. Evol. Comput. 2002, 6, 58–73. [Google Scholar] [CrossRef]
- Trelea, I.C. The particle swarm optimization algorithm: convergence analysis and parameter selection. Inf. Process. Lett. 2003, 85, 317–325. [Google Scholar] [CrossRef]
- Zhang, J.; Cheng, C.T. Day-ahead electricity price forecasting using artificial intelligence. In Proceedings the of IEEE Electric Power and Energy Conference, Vancouver, BC, Canada, 6–7 October 2008; pp. 1–5.
- Cheng, C.T.; Niu, W.J.; Feng, Z.K.; Shen, J.J.; Chau, K.W. Daily reservoir runoff forecasting method using artificial neural network based on quantum-behaved particle swarm optimization. Water 2015, 7, 4232–4246. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Fitting Precision Grade | |||
|---|---|---|---|---|
| Good | Qualified | Just | Unqualified | |
| <0.35 | 0.35–0.50 | 0.50–0.65 | ≥0.65 | |
| >0.95 | 0.80–0.95 | 0.70–0.80 | ≤0.70 | |
| Index | Types | Input Variables | Symbols |
|---|---|---|---|
| 1 | Supply factors | Energy production of medium/large hydro power | |
| 2 | Energy production of thermal power | ||
| 3 | Energy production of small hydro power | ||
| 4 | Energy production of wind power | ||
| 5 | Energy production of solar power | ||
| 6 | Demand factors | Export electricity demand | |
| 7 | Provincial electricity demand | ||
| 8 | Supplemented factors | Number of GENCOs | |
| 9 | Number of CONCOs |
| Month | MCP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| April 2015 | 0.9174 | 0.2015 | 0.8689 | 0.0374 | 0.3354 | 0.0945 | 0.2972 | 0.7269 | 0.3462 | 0.0044 |
| May 2015 | 0.4128 | 0.3630 | 0.8592 | 0.0290 | 0.2925 | 0.0199 | 0.5315 | 0.7343 | 0.2308 | 0.0000 |
| June 2015 | 0.0494 | 0.5985 | 0.3532 | 0.3125 | 0.1701 | 0.0000 | 0.6965 | 0.8876 | 0.3846 | 0.1027 |
| July 2015 | 0.0000 | 1.0000 | 0.3647 | 0.8816 | 0.0000 | 0.0995 | 0.9156 | 0.8774 | 0.6154 | 0.1754 |
| August 2015 | 0.0105 | 0.9298 | 0.2992 | 1.0000 | 0.0241 | 0.0995 | 1.0000 | 0.9368 | 0.5000 | 0.1789 |
| September 2015 | 0.0296 | 0.7841 | 0.0000 | 0.8854 | 0.0377 | 0.0945 | 0.9657 | 1.0000 | 0.2308 | 0.2170 |
| October 2015 | 0.0303 | 0.7627 | 0.7197 | 0.5264 | 0.2543 | 0.1592 | 0.8949 | 0.9885 | 0.2692 | 0.2365 |
| November 2015 | 0.1692 | 0.3667 | 0.7306 | 0.3354 | 0.3747 | 0.2985 | 0.3693 | 0.5218 | 0.2692 | 0.2294 |
| December 2015 | 0.4726 | 0.3381 | 1.0000 | 0.2895 | 0.4741 | 0.3483 | 0.3101 | 0.5220 | 0.0000 | 0.1798 |
| January 2016 | 0.9259 | 0.1890 | 0.6754 | 0.1360 | 0.6410 | 0.5323 | 0.2268 | 0.8476 | 1.0000 | 0.8335 |
| February 2016 | 1.0000 | 0.0000 | 0.4339 | 0.0000 | 0.8095 | 0.6169 | 0.0000 | 0.0000 | 0.9231 | 0.6740 |
| March 2016 | 0.7791 | 0.2034 | 0.5140 | 0.0053 | 1.0000 | 1.0000 | 0.2783 | 0.4350 | 0.9231 | 0.7741 |
| April 2016 | 0.7330 | 0.2547 | 0.5546 | 0.0031 | 0.6599 | 0.7761 | 0.2992 | 0.7086 | 1.0000 | 1.0000 |
| Month | MCP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| … | - | - | - | … | - | - | - | … | ||
| May 2015 | 0.4128 | 0.3630 | 0.8592 | 0.0290 | 0.2925 | 0.0199 | 0.5315 | 0.7343 | 0.2308 | 0.0000 |
| December 2015 | 0.4726 | 0.3381 | 1.0000 | 0.2895 | 0.4741 | 0.3483 | 0.3101 | 0.5220 | 0.0000 | 0.1798 |
| April 2016 | 0.2547 | 0.5546 | 0.0031 | 0.6599 | 0.7761 | 0.2992 | 0.7086 | 1.0000 | 1.0000 | |
| March 2016 | 0.7791 | 0.2034 | 0.5140 | 0.0053 | 1.0000 | 1.0000 | 0.2783 | 0.4350 | 0.9231 | 0.7741 |
| April 2015 | 0.9174 | 0.2015 | 0.8689 | 0.0374 | 0.3354 | 0.0945 | 0.2972 | 0.7269 | 0.3462 | 0.0044 |
| … | - | - | - | … | - | - | - | … | ||
| Different Values and Ranges of and | |||||
|---|---|---|---|---|---|
| Statistical Index | = 3.1 | = 3.2 | = 3.3 | = 3.4 | = 3.5 |
| = 2.6~0.5 | = 2.7~0.5 | = 2.8~0.5 | = 2.9~0.5 | = 3.0~0.5 | |
| = 0.5~2.6 | = 0.5~2.7 | = 0.5~2.8 | = 0.5~2.9 | = 0.5~3.0 | |
| AOV (%) | 4.41 | 4.16 | 4.06 | 4.13 | 4.10 |
| SD (×10−2) | 1.67 | 0.81 | 0.60 | 0.64 | 1.04 |
| Statistical Index | = 3.6 | = 3.7 | = 3.8 | = 3.9 | = 4.0 |
| = 3.1~0.5 | = 3.2~0.5 | = 3.3~0.5 | = 3.4~0.5 | = 3.5~0.5 | |
| = 0.5~3.1 | = 0.5~3.2 | = 0.5~3.3 | = 0.5~3.4 | = 0.5~3.5 | |
| AOV (%) | 4.12 | 4.26 | 3.99 | 3.76 | 3.74 |
| SD (×10−2) | 0.76 | 1.46 | 0.48 | 0.73 | 0.49 |
| Statistical Index | = 4.1 | = 4.2 | = 4.3 | = 4.4 | = 4.5 |
| = 3.6~0.5 | = 3.7~0.5 | = 3.8~0.5 | = 3.9~0.5 | = 4.0~0.5 | |
| = 0.5~3.6 | = 0.5~3.7 | = 0.5~3.8 | = 0.5~3.9 | = 0.5~4.0 | |
| AOV (%) | 3.80 | 3.67 | 3.87 | 3.90 | 3.93 |
| SD (×10−2) | 1.01 | 0.35 | 0.72 | 0.91 | 1.59 |
| Statistical Index | = 4.6 | = 4.7 | = 4.8 | = 4.9 | = 5.0 |
| = 4.1~0.5 | = 4.2~0.5 | = 4.3~0.5 | = 4.4~0.5 | = 4.5~0.5 | |
| = 0.5~4.1 | = 0.5~4.2 | = 0.5~4.3 | = 0.5~4.4 | = 0.5~4.5 | |
| AOV (%) | 4.19 | 4.17 | 4.16 | 4.10 | 4.28 |
| SD (×10−2) | 0.69 | 0.57 | 0.71 | 0.56 | 0.74 |
| Position | Observed Value | Virtual Values | Forecasting Interval | Forecasting Value | MAPE (%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Nor. | Inv. | Lower | Upper | Lower | Upper | α | Nor. | Inv. | ||
| Position 1 | 0.7330 | 0.2893 | 0.4726 | 0.7791 | 0.4787 | 0.7910 | 0.4700 | 0.6442 | 0.2803 | 3.10 |
| Position 2 | 0.4128 | 0.4726 | 0.4186 | 0.4702 | −0.5047 | 0.4962 | 0.2653 | 8.28 | ||
| Position 3 | 0.7791 | 0.9174 | 0.7735 | 0.9098 | 2.3012 | 0.5961 | 0.2755 | 4.79 | ||
| Average | 0.7330 | 0.2893 | 0.5548 | 0.7230 | 0.5569 | 0.7237 | 0.7555 | 0.5789 | 0.2737 | 5.39 |
| Month | Observed Value | Forecasting Value | Absolute Percentage Error (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Model 1 | Model 2 | Model 3 | Model 4 | Model 1 | Model 2 | Model 3 | Model 4 | ||
| April 2015 | 0.4471 | 0.3394 | 0.0000 | 0.3627 | 0.3929 | 13.08 | 54.32 | 10.25 | 6.58 |
| May 2015 | 0.3107 | 0.3253 | 0.1370 | 0.2841 | 0.2778 | 2.14 | 25.30 | 3.87 | 4.79 |
| June 2015 | 0.2124 | 0.3101 | 0.1957 | 0.2815 | 0.1920 | 16.62 | 2.83 | 11.75 | 3.46 |
| July 2015 | 0.1990 | 0.1023 | 0.1901 | 0.1794 | 0.2334 | 16.81 | 1.55 | 3.42 | 5.98 |
| August 2015 | 0.2018 | 0.2403 | 0.1369 | 0.2595 | 0.2005 | 6.65 | 11.24 | 9.98 | 0.23 |
| September 2015 | 0.2070 | 0.0733 | 0.3286 | 0.1949 | 0.2056 | 22.94 | 20.85 | 2.09 | 0.25 |
| October 2015 | 0.2072 | 0.1795 | 0.3583 | 0.2202 | 0.2033 | 4.75 | 25.90 | 2.23 | 0.68 |
| November 2015 | 0.2448 | 0.3530 | 0.1696 | 0.3759 | 0.3111 | 17.43 | 12.11 | 21.12 | 10.68 |
| December 2015 | 0.3268 | 0.1926 | 0.0917 | 0.3543 | 0.3069 | 19.10 | 33.45 | 3.91 | 2.83 |
| January 2016 | 0.4494 | 0.6114 | 1.0000 | 0.3468 | 0.4981 | 19.62 | 66.71 | 12.43 | 5.89 |
| February 2016 | 0.4695 | 0.0991 | 0.3321 | 0.3601 | 0.4307 | 43.80 | 16.24 | 12.93 | 4.59 |
| March 2016 | 0.4097 | 0.9014 | 0.5564 | 0.4701 | 0.4125 | 62.58 | 18.66 | 7.68 | 0.35 |
| April 2016 | 0.3972 | 0.1793 | 0.2502 | 0.4157 | 0.3732 | 28.18 | 19.01 | 2.39 | 3.10 |
| MAPE | - | - | - | - | - | 22.06 | 23.70 | 8.00 | 3.80 |
| Indicators | MDM Test Results between Different Models | ||
|---|---|---|---|
| Models 1 and 4 | Models 2 and 4 | Models 3 and 4 | |
| MDM-MAE | 3.2614 *** | 3.5409 *** | 3.4856 *** |
| MDM-MSE | 2.0354 * | 2.0850 * | 2.8789 ** |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, C.; Luo, B.; Miao, S.; Wu, X. Mid-Term Electricity Market Clearing Price Forecasting with Sparse Data: A Case in Newly-Reformed Yunnan Electricity Market. Energies 2016, 9, 804. https://doi.org/10.3390/en9100804
Cheng C, Luo B, Miao S, Wu X. Mid-Term Electricity Market Clearing Price Forecasting with Sparse Data: A Case in Newly-Reformed Yunnan Electricity Market. Energies. 2016; 9(10):804. https://doi.org/10.3390/en9100804
Chicago/Turabian StyleCheng, Chuntian, Bin Luo, Shumin Miao, and Xinyu Wu. 2016. "Mid-Term Electricity Market Clearing Price Forecasting with Sparse Data: A Case in Newly-Reformed Yunnan Electricity Market" Energies 9, no. 10: 804. https://doi.org/10.3390/en9100804
APA StyleCheng, C., Luo, B., Miao, S., & Wu, X. (2016). Mid-Term Electricity Market Clearing Price Forecasting with Sparse Data: A Case in Newly-Reformed Yunnan Electricity Market. Energies, 9(10), 804. https://doi.org/10.3390/en9100804