1. Introduction
With the continuous development of smart grids, short term load forecasting (STLF) results have become the important basis for dynamic pricing in the power market. Electricity prices formulated based on results of STLF lead electricity consumption during the off-peak period, reduce differences between peak and valley loads and ensure the economic operation of the power system. Compared to the traditional power grid, the influence of STLF on the economic performance of the smart grid is more direct [
1,
2]. References [
3,
4] showed that a 1% increase of the prediction error would lead to an extra ten million pounds of cost in the UK.
Feature sets are the foundation of constructing STLF models. The historical load time series contain certain load trend and cycle information, it is must be included in feature sets. In addition to historical loads, other exogenous variables such as temperature and day types which affect the accuracy of STLF also should be considered. Particularly, there is a high correlation between temperature and load data, so adding the temperature variables can effectively improve the accuracy of STLF. However, the temperature data used to construct the feature sets is obtained from numerical weather prediction (NWP), where prediction errors exist, so the influence of NWP errors on load forecasting precision should be considered when establishing any forecast model [
5,
6].
Generally, the existing STLF methods can be divided into time series methods [
7,
8,
9,
10,
11] and artificial intelligence methods [
12,
13,
14,
15,
16,
17,
18,
19,
20]. The time series methods are used to establish the load forecasting model with historical load data, which mainly include exponential smoothing [
7] and autoregressive integrated moving average (ARIMA) models [
8,
9,
10,
11]. The ARIMA models have the advantages of modeling simplicity, high computation speed and they are not affected by NWP errors [
11]. Therefore, they are suitable for forecasting stable working day loads, but the relationship between load demand and exogenous variables is nonlinear, thus, it is difficult for ARIMA models to precisely forecast load in the scenarios in which the temperature and other exogenous variables change suddenly. Meanwhile, obtaining continuous weekends load series with uniform characteristics is difficult due to the long time interval between different weekends, so the time series method is less effective for the load forecasting during weekends.
Artificial intelligence methods mainly include the artificial neural network (ANN) [
12,
13,
14,
15] and support vector regression (SVR) [
16,
17,
18,
19,
20]. ANN has excellent self-adaptive and nonlinear modeling ability. Therefore, ANN is widely used with high prediction accuracy in STLF. However, ANN needs a large number of training samples and easily falls into local optimal solutions [
21,
22,
23,
24]. Different from the traditional neural network using the empirical risk minimization principle, SVR is based on the principle of structural risk minimization. It has many advantages, such as obtaining global optimal solutions, avoiding the “curse of dimensionality”, good generalization ability, and handling small samples [
25,
26,
27,
28]. In summary, SVR has better performance than ANN for STLF [
17,
18,
25]. However, from the aspect of feature sets, the high accuracy of STLF prediction models based on SVR is largely dependent on the exogenous variables. When there are large errors in the temperature data of the feature sets, the forecasting accuracy of SVR is obviously decreased [
4,
21].
The selection of parameters and construction of feature sets play a pivotal role in the prediction precision of SVR [
18,
29,
30]. Therefore, many parameter optimization algorithms are used to determine reasonable parameters of the SVR model, such as the genetic algorithm (GA) and particle swarm optimization (PSO). Nevertheless, GA suffers from the weakness of being time consuming and lacking memory function knowledge. PSO falls into local optima easily and its performance is affected by the particle parameters [
31,
32,
33,
34]. The artificial bee colony (ABC) algorithm is a novel swarm intelligence optimization algorithm [
31,
32,
33,
34,
35,
36,
37]. The algorithm simulates the foraging behavior of bee colonies. Different types of bees play distinct roles in the foraging process. By collecting and sharing the food source, the bees find the best food source. The ABC algorithm resolves the conflict between expanding new solution space and searching exactly in the old solution space through cooperation between different types of bees. Therefore, compared with GA and PSO, the ABC algorithm overcomes the problem of local optimization, and has better performance [
31,
32,
33].
To enhance the responsiveness of the time series models to exogenous variables and reduce the influence of the NWP error on the load forecasting results, a hybrid STLF model based on improved seasonal ARIMA (SARIMA) and SVR is proposed in this paper. Firstly, forecasting results of the methods in scenarios of different day types and NWP errors are analyzed. Secondly, various load forecasting models are constructed for different day types based on the characters of loads and predictors. The ABC-SVR model is constructed for forecasting load on weekends. SARIMA modified by ABC-SVR (AS-SARIMA) is constructed for forecasting load on working days. Finally, the International Organization for Standardization (ISO) New England data are used for comparative experiments to demonstrate the superiority of the proposed method in STLF.
3. The Proposed Short Term Load Forecasting Method
To construct the appropriate features as the input of the prediction model, the characteristics of the load data and the influence of the exogenous variables on load are analyzed in
Section 3.1. The prediction accuracy of SARIMA and SVR under the circumstance of actual temperature and noisy temperature are compared in
Section 3.2. To increase the prediction accuracy of SVR and SARIMA, the improved methods based on the two models are proposed in
Section 3.3 and
Section 3.4, respectively. By comparing the performance of the improved models in the scenarios of different day types and NWP errors in
Section 3.5, a new hybrid STLF model based on combing the advantages of the models is proposed in
Section 3.6.
3.1. Feature Set Construction
The prediction accuracy of the SVR is highly dependent on the selection of its input variables. Therefore, it is necessary to construct a reasonable feature set as input of SVR. Considering the load data characteristics and the impact of exogenous variables such as temperature, day of week and time index on the load, the feature set is determined by the following analysis steps. The experiments of the paper are carried out on the basis of the hourly load data of ISO New England [
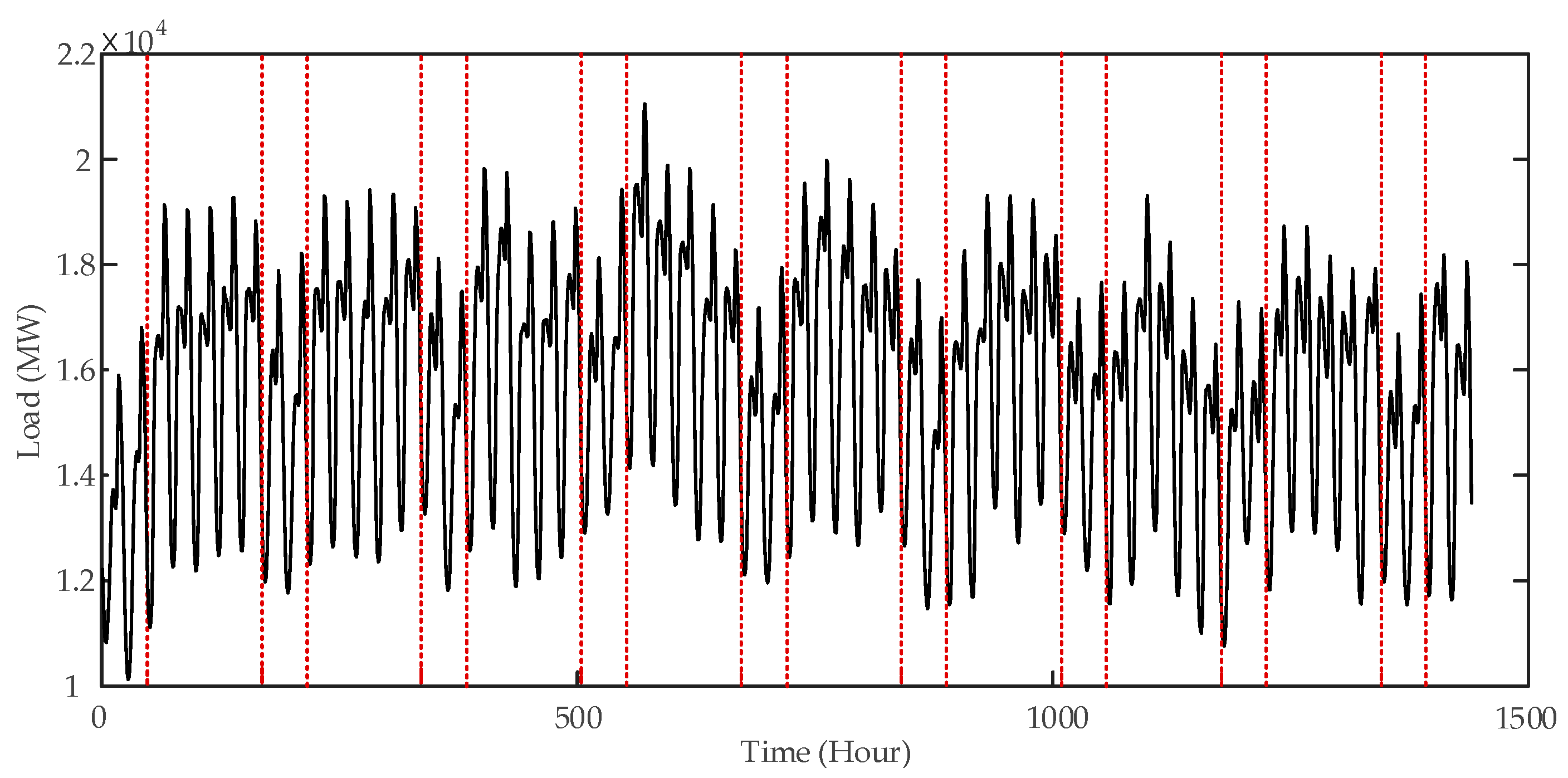
5]. The load curve from 1 January to 1 March 2011 is shown in
Figure 3. The loads during working days and weekends are separated by red dashed lines [
39].
- (1)
Historical load.
Figure 3 shows that the historical load data has the following characteristics: firstly, the load time series takes 24 h as a cycle. Secondly, the neighboring curve is similar and the load values on the different curve are close to each other at the same time. Finally, there is obvious difference between the load values during the weekends and working days. The load demands during weekends are less than working days.
L(
t,
d) is defined as the load value at the time
of forecasted day. When doing day-ahead load forecasting, the load value at every hour of forecasted day is unknown. The results of the selection of historical load features are described as follows: load at time
t and
t − 1 of the previous day,
L(
t,
d − 1) and
L(
t − 1,
d − 1), load at
t of the seven days before forecasted day
L(
t,
d − 7), maximum and average load of the previous day,
Lmax(
d − 1) and
Lmean(
d − 1), load at 24 of the previous day
L(24,
d − 1) [
40].
- (2)
Day of week. Numbers from 1 to 7 represent Monday to Sunday, respectively.
- (3)
Day type. Numbers 1 and 0 represent working days and weekends, respectively (the midweek holidays are identified as number 1).
- (4)
Time index. The period of load time series is 24 h. Therefore,
and
[
5] are defined as time variables to capture cycles.
and
can be calculated by Equations (15) and (16):
- (5)
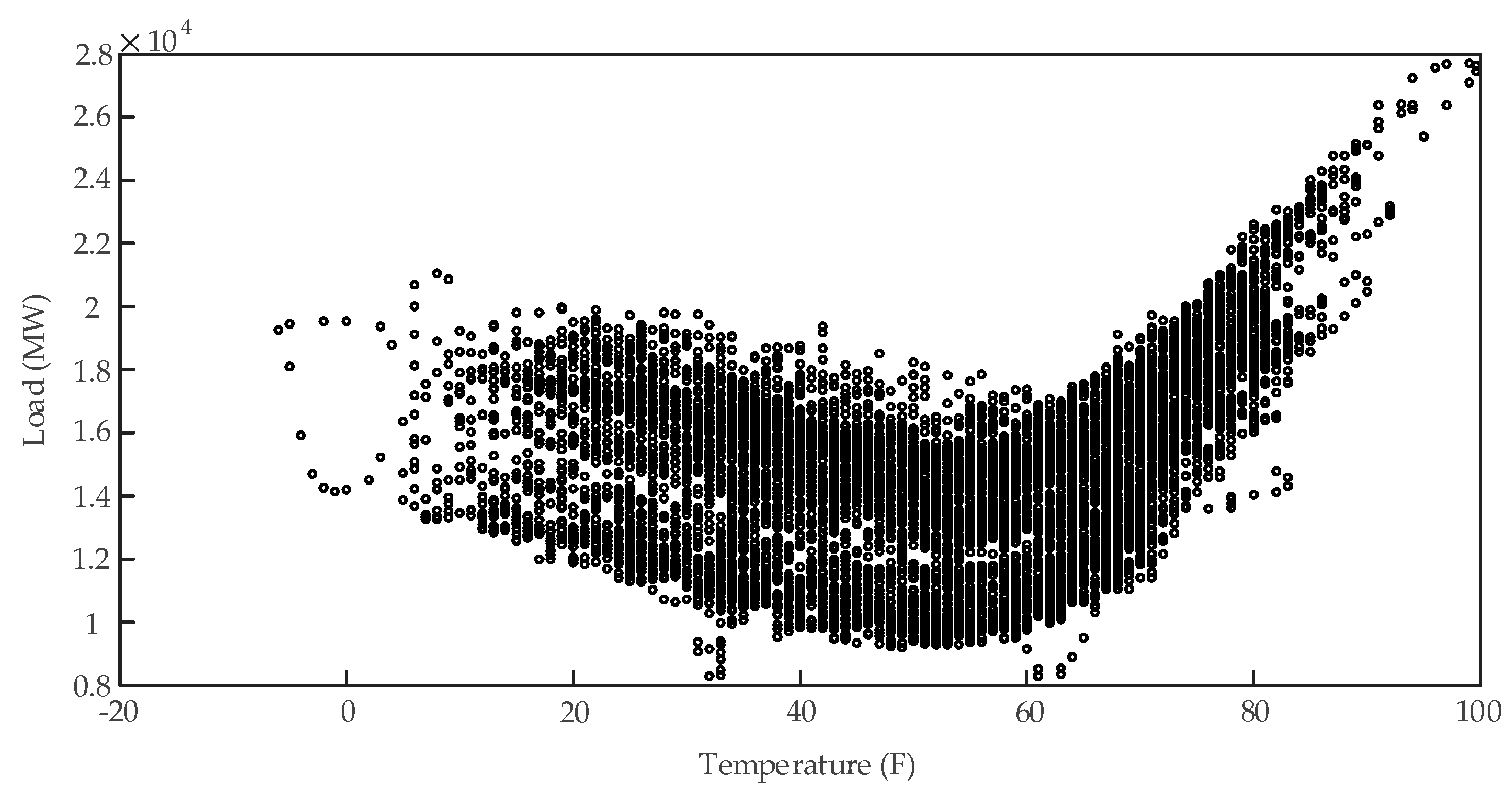
Temperature. The relationship between load and temperature in 2011 is shown in
Figure 4.
Figure 4 shows that load values are greatly influenced by temperature. The load values increase when the temperature is lower than 40 F or higher than 60 F. The temperature variables are selected as follows: the temperature at time
of the forecasted day
and the previous day
T(
t,
d − 1), the maximum and minimum temperature of the previous day,
Tmax(
d − 1) and
Tmin(
d − 1). Besides, the response time of load demand to temperature changes is larger than that of the sampling period. Therefore the average temperature of the past 3 h (
Tav(3)), 6 h (
Tav(6)), and 24 h (
Tav(24)) are selected as temperature variables [
40].
Table 1 lists the composition of the feature set.
3.2. Comparison of Load Forecasting Accuracy between SARIMA and SVR
In order to analyze the influence of NWP error on the load forecasting accuracy, noisy temperature data is simulated by adding Gaussian noise to the actual temperature data. The mean value of the Gaussian noise is zero and the standard deviation is 0.6 °C [
5,
6]. SVR [
41] and SARIMA are used to forecast the load obtained from ISO New England [
5] from 6 to 12 February 2012. The mean absolute percentage error (
MAPE) is adopted as criterion of error evaluation. The
MAPE can be expressed as:
where
is the actual load value, and
is the forecasting value,
is the number of samples. The results of prediction are listed in
Table 2 (AT denotes the actual temperature and NT denotes a noisy temperature).
Table 2 indicates that the whole prediction accuracy of SVR is higher than that of SARIMA in working days and weekends. However, the
MAPE of the SVR increases significantly when the Gaussian noise is added to the actual temperature. Without considering the impact of variables such as day types and temperature on the load, the SARIMA model is established based on the load data, so the performance of SARIMA in STLF is not good. The forecasting accuracy of SARIMA is not affected by NWP error at the same time.
From the above analysis, we can further improve the prediction efficiency of SVR by optimizing the parameters, and modify the results of SARIMA by forecasting residuals. When predicting the residuals from SARIMA, the exogenous variables such as day types and temperature will be considered.
3.3. ABC Algorithm for Parameters Selection of SVR
From the analysis in the
Section 2.2, it can be known that the forecast accuracy of SVR is largely dependent on the selection of parameters including
, σ and ε. To improve the performance of SVR in STLF, the ABC algorithm is used to determine the SVR parameters in this paper. The specific steps of constructing the ABC-SVR model are as follows:
- (1)
Initialize the parameters of ABC algorithm such as population of bees, maximum cycle number (
MCN), abandonment cycle number (
limit). The
ith solution
of the algorithm is a vector with three elements including
C, σ and ε:
where
FN is the number of solution,
C, σ and ε are within the range [2
−8, 2
8].
- (2)
A worker bee finds a new solution in the neighborhood of the present solution, and calculates the fitness values of the two solutions. The fitness value is calculated by Equation (19):
where
is the mean square error (MSE) of the SVR model, in which the elements of
are chosen as SVR parameters. MSE is defined as:
where
is the actual load value, and
is the forecasting value,
is the number of samples.
- (3)
The onlooker bee selects a solution by calculating the probability of the solution by Equation (14), and updates the information of the present solution.
- (4)
When the number of cycles satisfies the abandonment criteria (), a new solution will be generated by Equation (12).
- (5)
Repeat Steps 2–4, until the number of cycles is equal to MCN.
- (6)
The elements of best solution are determined as parameters of SVR.
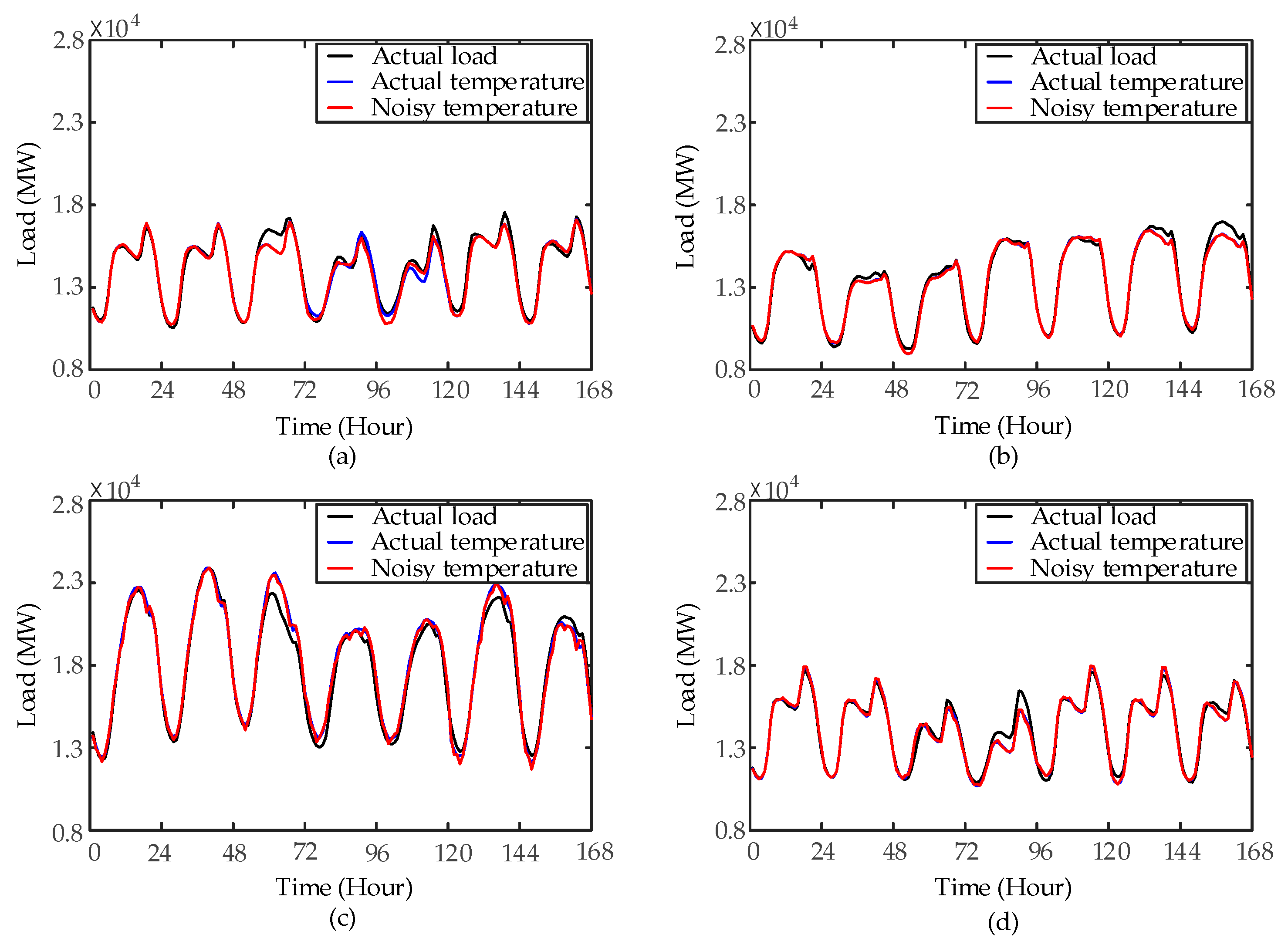
According to the above steps, the ABC-SVR model is constructed. Then, SVR and ABC-SVR are used to forecast the load from 20 to 26 February in the scenario of actual temperature and noisy temperature. The load data is obtained from ISO New England [
5] and the noisy temperature is simulated by adding Gaussian noise of zero mean and standard deviation of 0.6 °C to actual temperature. The forecast results are shown in
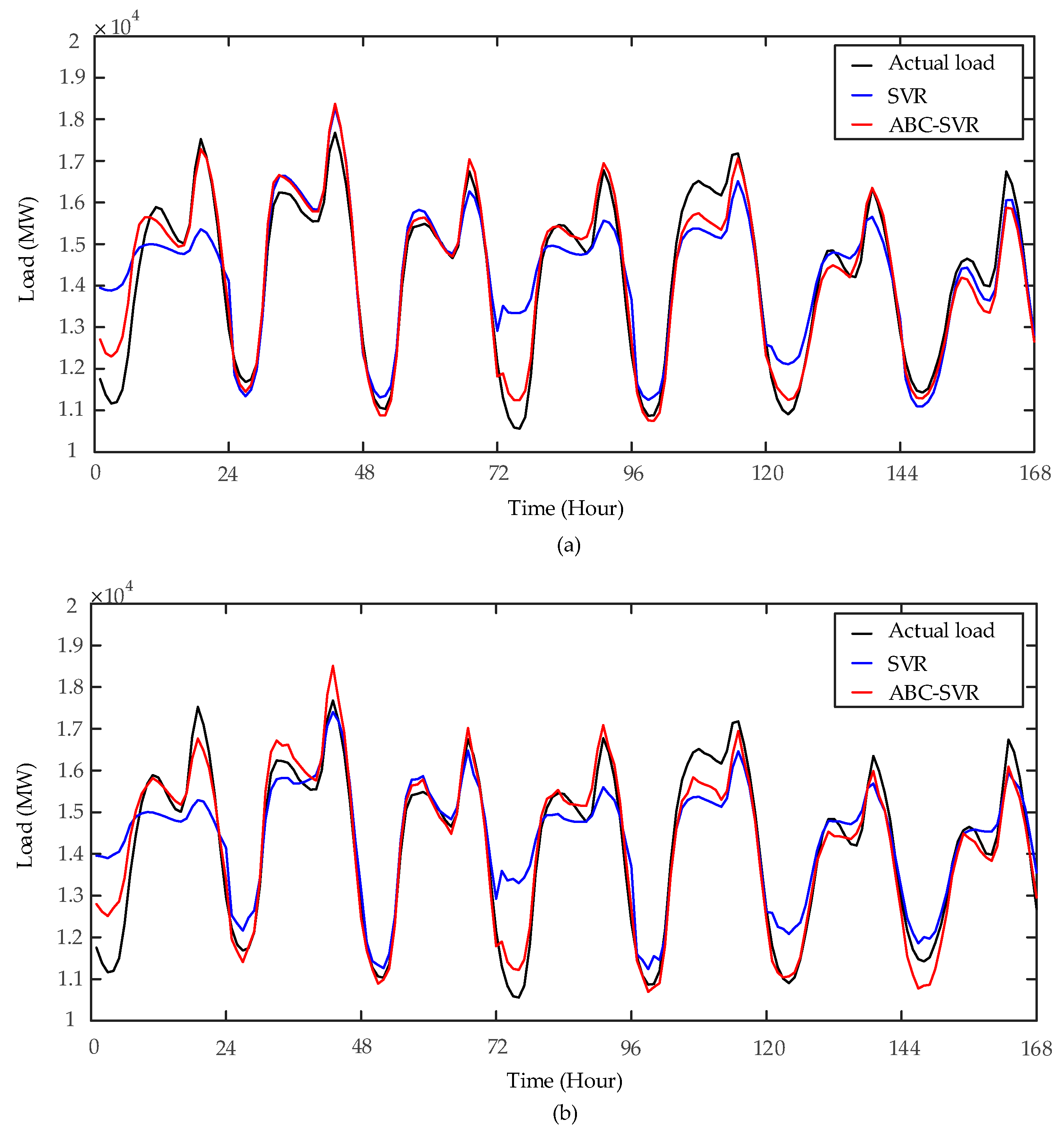
Figure 5.
Figure 5a shows that, the accuracy of SVR is obviously improved by using ABC algorithm to optimize the SVR parameters in the actual temperature scenario. The average
MAPE of SVR and ABC-SVR are 4.59% and 2.43%, respectively.
Figure 5b shows that the prediction accuracy of ABC-SVR is still higher than that of SVR when the noisy temperature data is used as the temperature variables of models. The average
MAPE of SVR and ABC-SVR are 4.67% and 2.51%, respectively. Compared with the results achieved in scenario of actual temperature, the forecast accuracy of SVR and ABC-SVR are all decreased. The average
MAPE of ABC-SVR increases from 2.52% to 2.59% during working days and increases from 2.20% to 2.31% during weekends. The increase of the forecast error in ABC-SVR is less than that in SVR. Therefore, ABC-SVR can effectively improve the prediction accuracy of SVR, but its forecast accuracy is still affected by the NWP error.
3.4. Modifying Results of SARIMA by Forecasting Residuals Using ABC-SVR
To improve the forecast accuracy of SARIMA, it is necessary to enhance the response ability of the model responses to exogenous variables. The AS-SARIMA models are constructed by using ABC-SVR to modify the results of the SARIMA. The steps of building the AS-SARIMA models are described as follows.
- (1)
Establish reasonable SARIMA models for STLF, then obtain the historical residuals and load values of forecasted day from SARIMA.
- (2)
Build the ABC-SVR models to forecast the residuals achieved from Step 1, then obtain the residuals of the forecasted day. The same variables including day of week, day type, time index and temperature variables as described in
Section 3.1 are selected as the inputs of the model. Particularly, the historical load variables are replaced by historical residuals variables when construct the feature set of ABC-SVR.
- (3)
By adding the output values of ABC-SVR to the output values of SARIMA, the final load forecasting values are obtained.
SARIMA and AS-SARIMA models are used to forecast the load from 20 to 26 February 2012 in the scenarios of actual temperature and noisy temperature. The Gaussian noise of zero mean and standard deviation of 0.6 °C is added to the measured temperature to simulated noisy temperature. The above data are achieved from ISO New England [
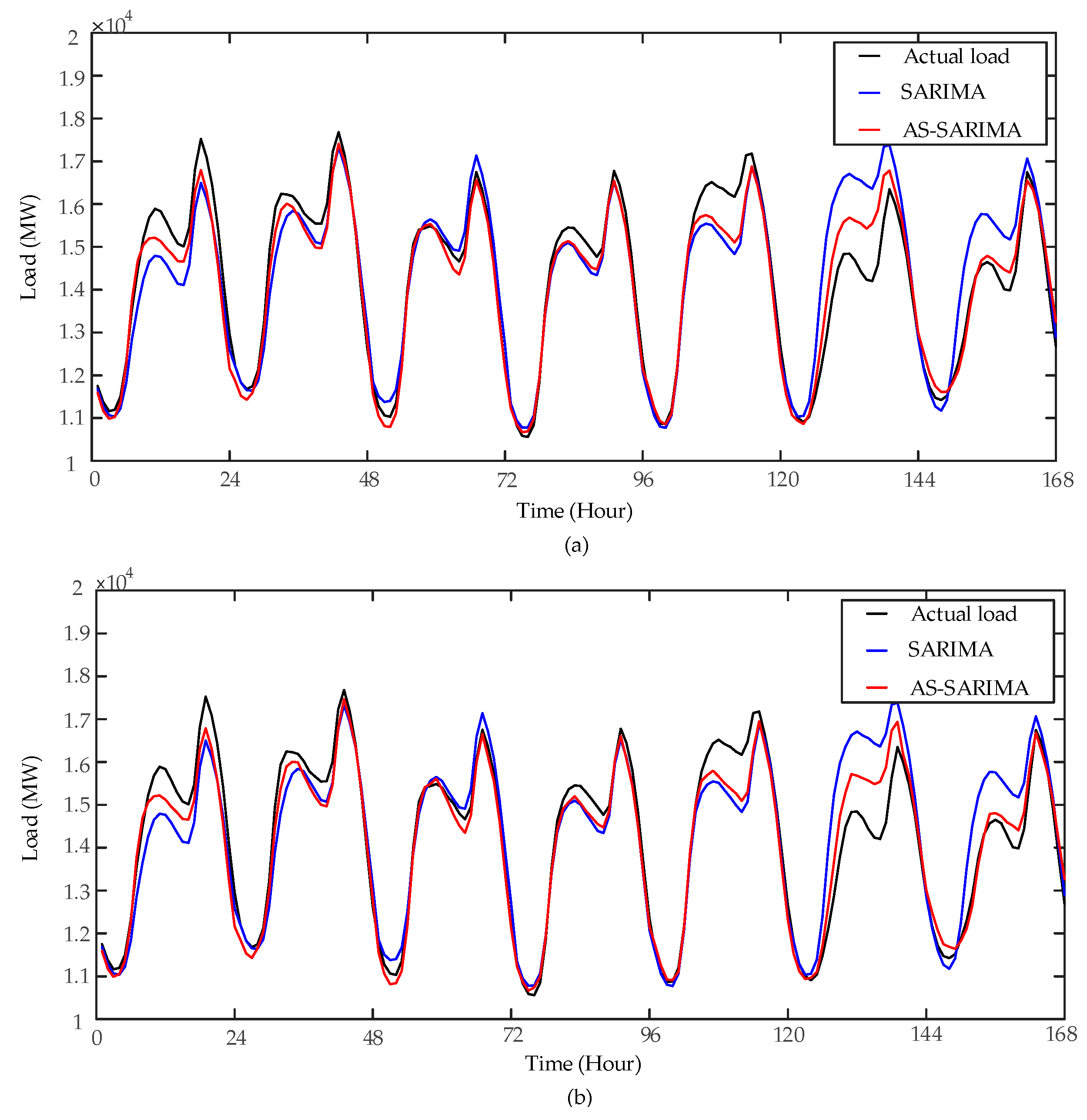
5]. The load forecast results are shown in
Figure 6.
Figure 6a shows that, the forecast accuracy of AS-SARIMA is significantly higher than that of SARIMA in the scenario of actual temperature. The
MAPE of SARIMA and AS-SARIMA are 4.03% and 2.34%, respectively.
Figure 6b shows that by considering the temperature variables, the
MAPE of AS-SARIMA increases from 2.34% to 2.36%, but the overall prediction accuracy of AS-SARIMA is still higher than that of SARIMA. Therefore, although the prediction accuracy of the AS-SARIMA is affected by the NWP error, it is still superior to the forecast accuracy of the SARIMA.
3.5. Comparison of Forecast Accuracy of ABC-SVR and AS-SARIMA and Construction of the Proposed Method
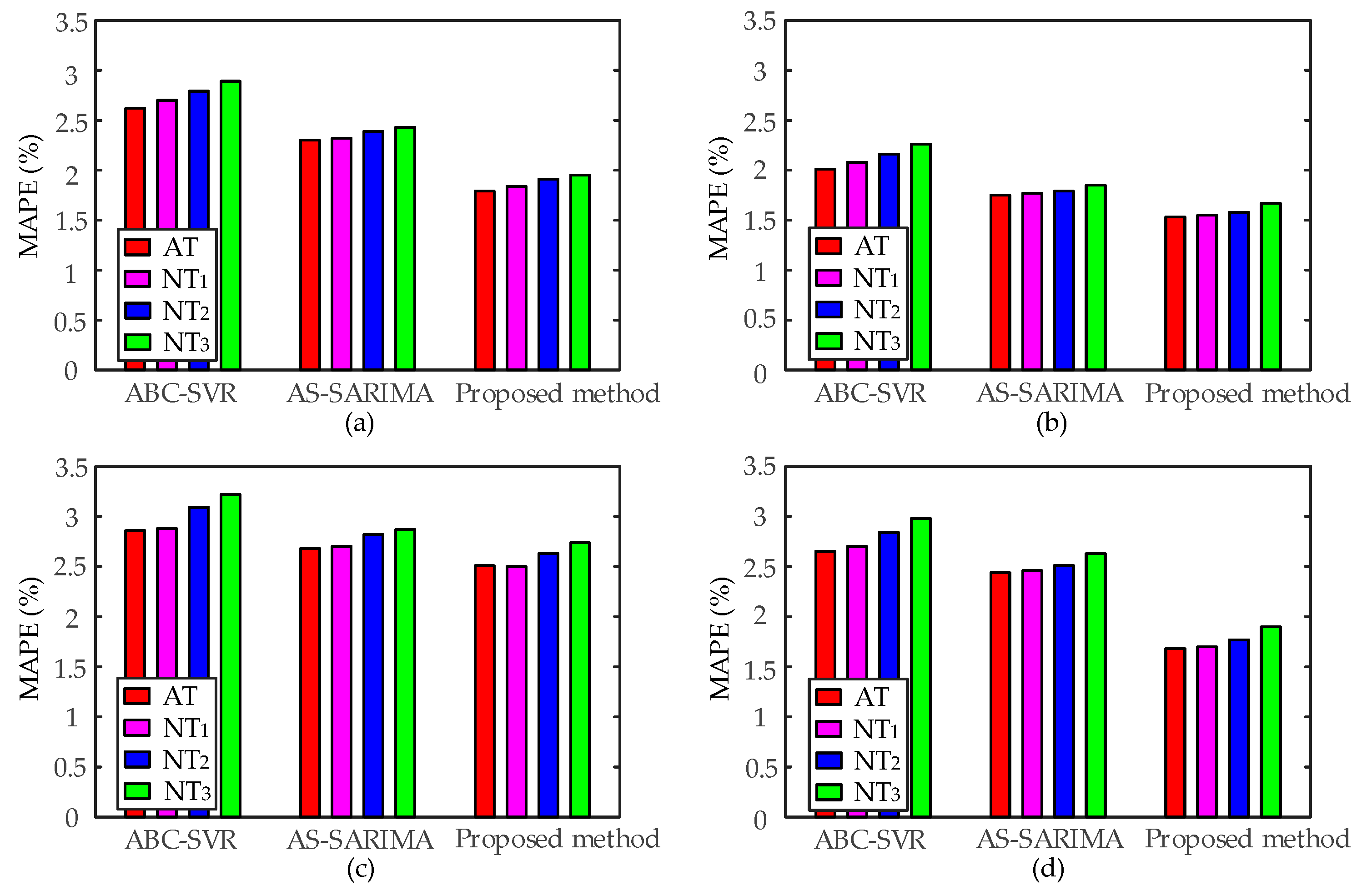
In order to compare the prediction accuracy of optimal approaches and analyze the forecasting performance affected by NWP errors of the two models, ABC-SVR and AS-SARIMA are used to forecast the load from 20 to 26 February in the scenarios of actual temperature and noisy temperature. The Gaussian noise of zero mean and standard deviation of 0.6 °C is added to actual temperature. The forecast curves of ABC-SVR and AS-SARIMA are shown in
Figure 7, and the
MAPE of the two models are listed in
Table 3 (where AT denotes actual temperature, NT denotes noisy temperature). In
Table 3, shadowed areas are results of forecasting load in working days and weekends correspondingly generated by AS-SARIMA and ABC-SVR.
Figure 7 and
Table 3 show that, when forecasting the load during weekends in the scenario of actual temperature, the average
MAPE generated by ABC-SVR and AS-SARIMA are 2.20% and 2.92%, respectively. With considering the NWP errors, the average of the two models are 2.31% and 3.00%. Therefore, the ABC-SVR has higher prediction accuracy than AS-SARIMA for weekend load forecasting. When forecasting the load during working days, the average
MAPE of ABC-SVR and AS-SARIMA are 2.52% and 2.11% in the actual temperature scenario. After considering the NWP errors, the average
MAPE of the two models are 2.59% and 2.10%. Therefore, the forecasting performance of AS-SARIMA is better than that of ABC-SVR during working days.
3.6. The Establishment of the Proposed Method
According to the above analysis, it is concluded that the ABC-SVR model is suitable for forecasting load in weekends and the AS-SARIMA model is suitable for forecasting the load in the working days, so a novel hybrid forecast method can be constructed by using ABC-SVR and AS-SARIMA to forecast the weekends and working days load values, respectively. The efficiency of the proposed method in the scenarios of actual temperature and noisy temperature with the Gaussian noise of standard deviations of 0.6 °C has been preliminarily proved through the above comparative experiments.
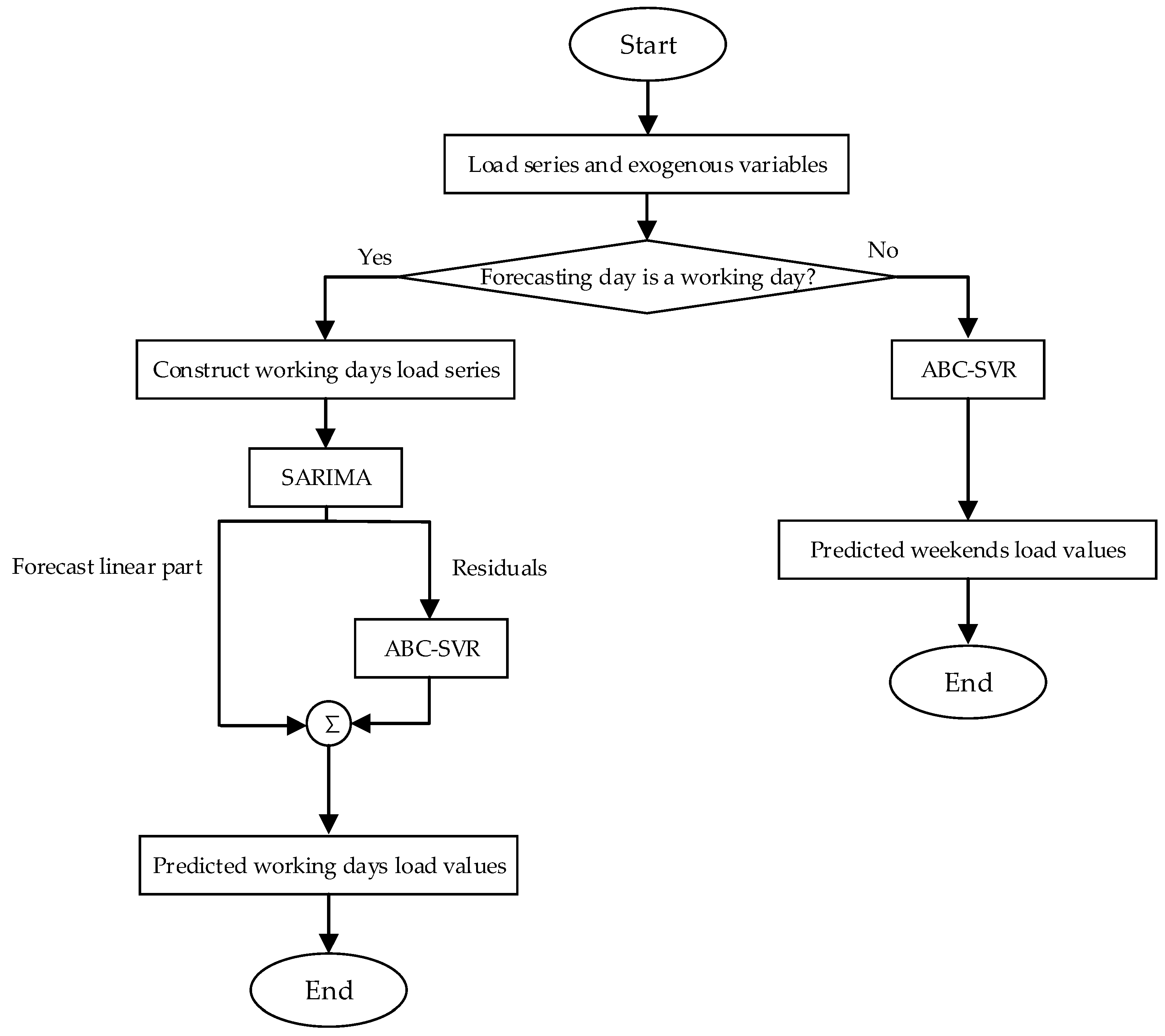
When forecasting the load in working days, the load data of first 20 working days (without weekends) are used to construct historical working days load series. By build the SARIMA models, the residuals of the first 20 working days are achieved. Then, the ABC-SVR model is established to forecast the residuals from SARIMA. Finally, the predicted load in working days is obtained by using ABC-SVR to modify the results from SARIMA. When ABC-SVR models are constructed to forecast the load during weekends, data of the first 20 days (including working days and weekends) are used as training samples. The flowchart of the proposed method is shown in
Figure 8.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}