1. Introduction
Wind power has been identified as one of the most important and efficient renewable energy and has been extensively utilized throughout the world [
1,
2,
3]. With the rapid development of wind power, the proportion of wind power in the whole power system is becoming larger. However, wind power is a rolling source of electrical energy due to the variability of wind speed, temperature and other factors. The uncertainty of wind power undoubtedly affects the power system stability and increases the operation cost of power systems [
2]. Therefore, accurate forecasting approaches with respect to wind power generation have positive implications on power system planning for unit commitment and dispatch, and electricity trading in certain electricity markets.
There is abundant literature on wind power forecasting, most of which has been published in recent years. In contrast to the wealth of studies on wind speed prediction, there has been less research looking at wind power generation forecasting. The approaches of these studies can be classified into three categories: time series models [
4,
5,
6,
7,
8], artificial intelligent algorithm models [
9,
10,
11,
12,
13,
14,
15,
16,
17] and time-series artificial intelligent algorithm models [
18]. Most of these approaches utilize time series analysis models, including vector autoregressive (VAR) models [
4,
5], autoregressive moving average (AMRA) models, and autoregressive integrated moving average (ARIMA) models. Erdem [
6] decomposed wind speed into lateral and longitudinal components with each component being represented by an ARMA model, then the predictive value results were obtained by accumulation. Liu [
7] proposed an autoregressive moving average-generalized autoregressive conditional heteroscedasticity algorithm for modeling the mean and volatility of wind speed, with the model effectiveness being evaluated by multiple methods. The results suggested the proposed method effectively captured the characteristics of wind speed. Kavasseri [
8] examined the use of ARIMA model to forecast wind speed. The simulation results indicated the forecasting accuracy of the proposed method outperformed the persistence models. Nevertheless, the wide implementation of time series models on wind power prediction can be problematic due to the poor nonlinear fitting capacity.
On the contrary, the adaptive and self-organized learning features of intelligent algorithms apparently facilitate the estimation of nonlinear time series. For instance, artificial neural network (ANN) [
9,
10] and least squares support vector machine (LSSVM) [
11,
12,
13,
14] are perceived to be highly effective methods in the field of wind power forecasting. Guo [
11] successfully developed a hybrid seasonal auto-regression integrated moving average and LSSVM model to forecast the mean monthly wind speed. De Giorgi [
12] developed a comparative study for the prediction of the power production of a wind farm using historical data and numerical weather predictions. The findings demonstrated that the hybrid approach based on wavelet decomposition with LSSVM significantly outperformed the hybrid artificial neural network (ANN)-based methods. Yuan [
13] established a LSSVM model in the light of gravitational search algorithm (GSA) for short-term output power prediction of a wind farm. Compared with the back propagation (BP) neural network and support vector machine (SVM) model, the simulation results indicated that the GSA-LSSVM model had higher accuracy for short-term output power prediction. Wang [
14] decomposed the non-stationary time series into several intrinsic mode functions (IMFs) and the corresponding, residue, then each sub-series was forecasted using diverse LSSVM models.
With the burgeoning use of artificial intelligence technology, many researchers have devoted increasing effort and time to delving into least squares support machine approaches. Since the performance of the prediction model depends on the regularization parameter and the kernel parameter of the LSSVM models, considerable research has established LSSVM models based on different intelligent algorithms for wind power prediction to attain satisfactory results [
15,
16,
17]. Hu [
15] introduced a modified quantum particle swarm optimization (QPSO) algorithm to select the optimal parameters of LSSVM, and the results suggested that the generalization capability and learning performance of LSSVM model were apparently enhanced. Sun [
16] established a LSSVM model optimized by particle swarm optimization (PSO). The simulation results recognized that the proposed method can distinctly increase the predicting accuracy. Wang [
17] constructed a LSSVM model where the parameters were tuned by a PSO method based on simulated annealing (PSOSA). A case study from four wind farms in Gansu Province, Northwest China was applied to corroborate the effectiveness of the hybrid model. Cai [
18] utilized a time series model to select the input variables and multi-layer back propagation neural network and generalized regression neural network are applied it to conduct forecasting.
However, it can be concluded from the previous research that the PSO algorithm seems to suffer from the local optimum problem during the regularization parameter selection process. In order to overcome the weakness of existing algorithms, a novel global algorithm, namely, the bat algorithm (BA) originally was proposed by Yang in 2010, based on the echolocation behavior of bats [
19]. With a good combination of the paramount advantages of PSO and genetic algorithm (GA), the superiority of the BA results from its simplification, powerful searching ability and fast convergence. Recently, a burgeoning number of studies focusing on the BA for parameter optimization have appeared [
20,
21,
22]. Hafezi [
20] explored a hybrid solution based on a BA to predict stock prices over a long term period. The model was examined through forecasting eight years of deutscher aktienindex (DAX) stock prices and conceived as an appropriate tool for predicting stock prices. Senthilkumar [
21] selected the best set of features from the initial sets using a BA, perceived as a the recent optimization algorithm for reducing the time consumption in detecting record duplication. Yang [
22] exploited an efficient multi-objective optimization method in accordance with the BA to suppress critical harmonics and determine power factors for passive power filters (PPFs). Considering the excellent capacity of the BA during the process of parameter optimization, it is the purpose of the current study to select the two pertinent parameters of the LSSVM model and obtain the global optimal strategy using the BA method.
From the previous literature, it can be seen that the original series tend to be regarded as the independent variables pertaining to wind power forecasting. However, it might be difficult to attain satisfactory results due to the stochastic nature and complexity of wind power generation. In order to explore a successful forecasting model, the necessity of analyzing the features of the raw time series should be increasingly highlighted. Therefore, the decomposition of wind power generation series appears to be an indispensable part in improving the forecasting accuracy. Empirical mode decomposition (EMD), perceived as an efficient decomposition method, is employed to decompose the wind power series into diverse IMFs for prediction [
23,
24]. Bao [
23] presented a short term wind power output prediction model and the prediction of short-term wind power was implemented by differential EMD and relevance vector machine (RVM). In [
24] a hybrid prediction model of wind farm power using EMD, chaotic theory and grey theory was constructed. The ultimate results indicated that the proposed method had good prediction accuracy. From the presented literature, it is possible to see that sometimes EMD cannot correctly decompose the raw data sequences. The IMFs extracted by EMD have lost their physical meaning and weaken the regularity. To address the mode mixing issue of the EMD technology, an improved method called ensemble empirical mode decomposition (EEMD) was introduced by Wu and Huang in 2009 [
25]. Wang [
26] selected EEMD as a data-cleaning method aiming to remove the high frequency noise embedded in the wind speed series. In this study, the EEMD is applied to decompose the original wind power generation series into several empirical modes, and the simulation results are encompassed in comparison with EMD.
Furthermore, a wealth of variables have great influence on the forecasting accuracy and efficiency, and the literature on the input selection gives this scant regard. These studies tend to select inputs using personal experience alone. However, in this research reported here, principal component analysis (PCA) was conducted to select inputs. PCA, a multivariate data analysis technology, can transform a set of correlated variables into new uncorrelated variables, namely principal components, containing most of the comprehensive variability of the original dataset. Lam [
27] conducted PCA to extract a 2-component model from five raw variables for modelling the electricity use in office buildings. The literature on the importance of input dimensionality reduction and the appropriate selection of modelling variables has been widely reported. Ndiaye [
28] applied PCA to select nine variables from all available variables to predict the electricity consumption in residential dwellings. Hong [
29] proposed a hybrid PCA neural network model to forecast the day-ahead electricity price.
In this paper, the principal purpose of the experiment was to investigate a more accurate forecasting method for wind power generation. A hybrid model based on EEMD-principal component analysis (PCA)-least squares support vector machine (LSSVM)-bat algorithm (BA) was employed to forecast wind power generation. In addition, different models were developed using all available variables (least squares support machine-bat algorithm (LSSVM-BA), ensemble empirical mode decomposition-least squares support machine-bat algorithm (EEMD-LSSVM-BA)), and using only the variables deemed as significant by the PCA procedure (PCA-LSSCM-BA, ensemble empirical mode decomposition-principal component analysis-least squares support machine (EEMD-PCA-LSSVM), EEMD-PCA-LSSVM-BA). Therefore, a secondary aim of the present study was to determine whether an accuracy loss occurs when reducing the number of modelling variables using PCA. In comparison with the EMD method, the EEMD method can effectively mine the features of the original series through decomposing the series according to the difference of frequencies. First, the EEMD method was adopted to decompose the original wind power generation series to enhance the prediction performance. Then, PCA was utilized to reduce the number of modelling inputs by identifying the significant variables maintaining most of the information present in the data set. Finally, LSSVM models were developed to predict the sub-series. Noticeably, in this work the two parameters of LSSVM were fine-tuned by the BA to ensure the generalization and the learning ability of LSSVM. The wind power generation forecasting values can be obtained according to the accumulation of the prediction values of all sub-series. To demonstrate the effectiveness of the proposed method, a case study from China was examined and the grey relational analysis was applied to evaluate the rationality of the forecasting series stemmed from the hybrid model from the perspective of geometric shape.
The advantages of the proposed hybrid model, which result in the better forecasting performance, can be summed up in the following several aspects: in the beginning, many single methods are applied to implement wind prediction using the original series directly, but the forecasting accuracy is not very satisfactory due to the influence of random noise in the raw series. In this study, EEMD is employed to preprocess the original wind power generation series to reduce the effect of random noise. Then, the determination of inputs in the proposed model is more novel. From previous papers, the selection of inputs is usually based on personal experience. However, wind power generation may be affected by many factors such as temperature, wind speed and installed capacity. Thus, the innovation of this paper is the application of PCA to select the proper inputs. Moreover, since artificial neutral networks suffer from several disadvantages such as the occurrence of local minima, over fitting and slow convergence rate, LSSVM utilized in this study can improve the training speed for solving the problem. Unlike other LSSVM parameters optimization methods, which only utilize personal experience or traditional intelligent algorithms such as particle swarm optimization, the BA applied in this paper can avoid falling into local optimization and guarantee the generalization and the learning ability of LSSVM. Finally, grey relational analysis is utilized to demonstrate the superiority of the presented model considering the geometric shape of forecasting series and statistics. In brief, the novelty of the proposed model is described as follows: (a) a data preprocessing approach is explored to achieve the treatment of the original wind power generation series; (b) a PCA procedure is conducted to reduce the number of inputs without lowering the forecasting accuracy; (c) a LSSVM model with the relevant parameters optimized by BA is built to predict wind power generation; (d) grey relational analysis is adopted to cast light on the forecasting capacity of the proposed model.
The rest of this paper is organized as follows:
Section 2 describes the modelling approaches of the proposed technique in detail. In
Section 3 a hybrid model is constructed which is designed to predict wind power generation. Then, in
Section 4 the proposed model is examined by a case study and an in depth comparison with other existing methods. Finally,
Section 5 provides some conclusions of the whole research.
3. Wind Power Generation Forecasting Model
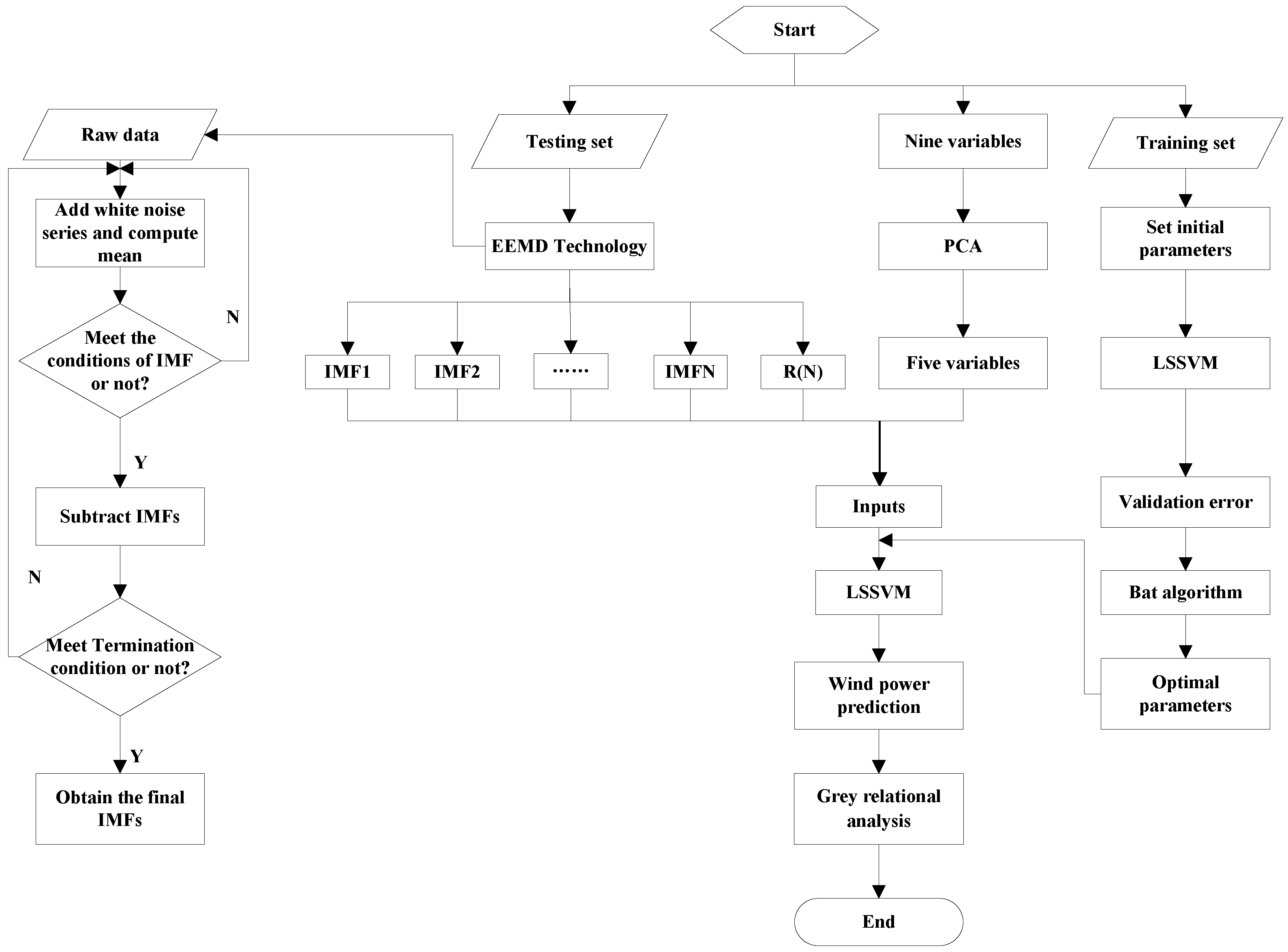
In this section, the proposed model (EEMD-PCA-LSSVM-BA) is constructed in detail. The flowchart of the presented model is given in
Figure 1. In addition, the diverse LSSVM models are developed by using all variables from the data set, and using only the variables previously deemed significant by PCA procedure. The forecasting accuracy of both methods is compared to determine whether the PCA procedure is successful in selecting significant inputs. The following four parts constitute the hybrid model.
Part one: Data preprocessing. The EEMD approach is adopted to decompose the original wind power generation series into different IMFs. The aim of this technology is to diminish the non-stationary character of the series for the high-precision prediction.
Part two: Input selection. Using the PCA to reduce the number of modelling inputs without lowering the prediction accuracy, the procedure can efficiently mine the significant variables containing most of the overall variability present in the data sets.
Part three: Training and validation of model. In this study, wind power generation forecasting approach is in the light of LSSVM-BA model, the basic steps can be described as follows:
The main parameters of BA are initial population size n, maximum iteration number N, original loudness A, pulse rate r, location vector x, speed vector v, respectively.
Initialize the bat populations position, each bat location strategy is a component of
, which can be defined as follows:
where the dimension of the bat population:
d = 2.
Calculate the fitness value of population, find the current optimal solution and update the pulse frequency, velocity and position of bats as follows:
where β denotes uniformly random numbers, β ∈ [0,1];
fi is the search pulse frequency of the bat
i,
fi ∈ [
fmin,
fmax];
and
are the velocities of the bat
i at time
t and
t – 1, respectively; further,
and
represent the location of the bat
i at time
t and
t – 1, respectively;
x* is the present optimal solution for all bats.
Produce a uniformly random number rand, if rand >
ri, disturb the optimal strategy randomly and acquire a new strategy; if rand <
Ai and
f(
x) >
f(
x*), then the new strategy can be accepted, the
ri and
Ai of the bat are updated as follows:
where α and γ are constants.
The current optimal solution can be obtained depending on the rank of all fitness values of the bat population. Repeat the steps of Equation (19) to Equation (21) till the maximum iterations are completed and output the global optimal solution. Therefore, a wind power generation prediction model can be generated.
In addition, the LSSVM approach is employed to model the training set, and the mean square errors of the true values and forecasting values are adopted as the fitness functions of the BA. Then, the group of parameters of LSSVM is optimized by BA for the minimum fitness value. Finally, the LSSVM model with optimal parameters can be applied to predict the wind power generation.
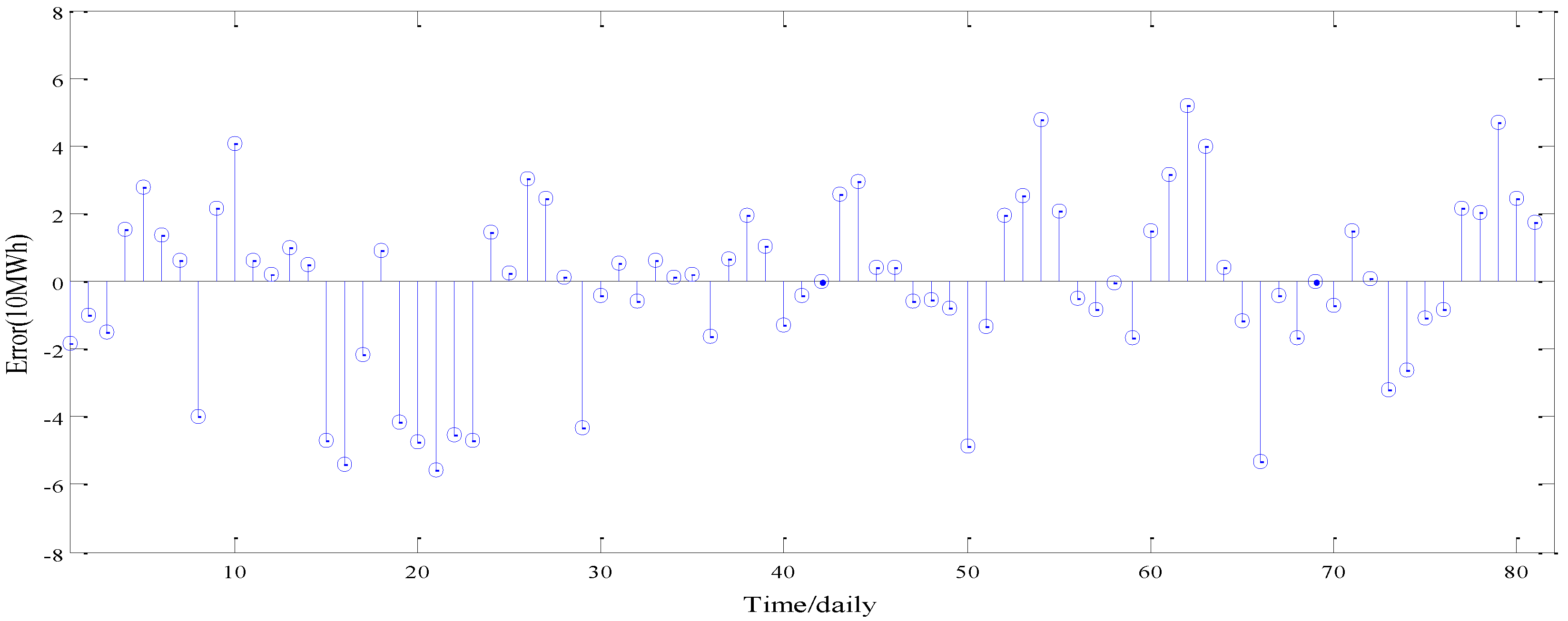
Part four: Wind power generation forecasting. In this part, the LSSVM approach with the parameters optimized by the BA is employed to predict each series decomposed by EEMD. Then, the forecasting series of wind power generation can be obtained by accumulating the prediction values of each subsequence. After obtaining the prediction values through the presented hybrid model, grey relational analysis was developed to determine the forecasting performance of the hybrid model.
5. Conclusions
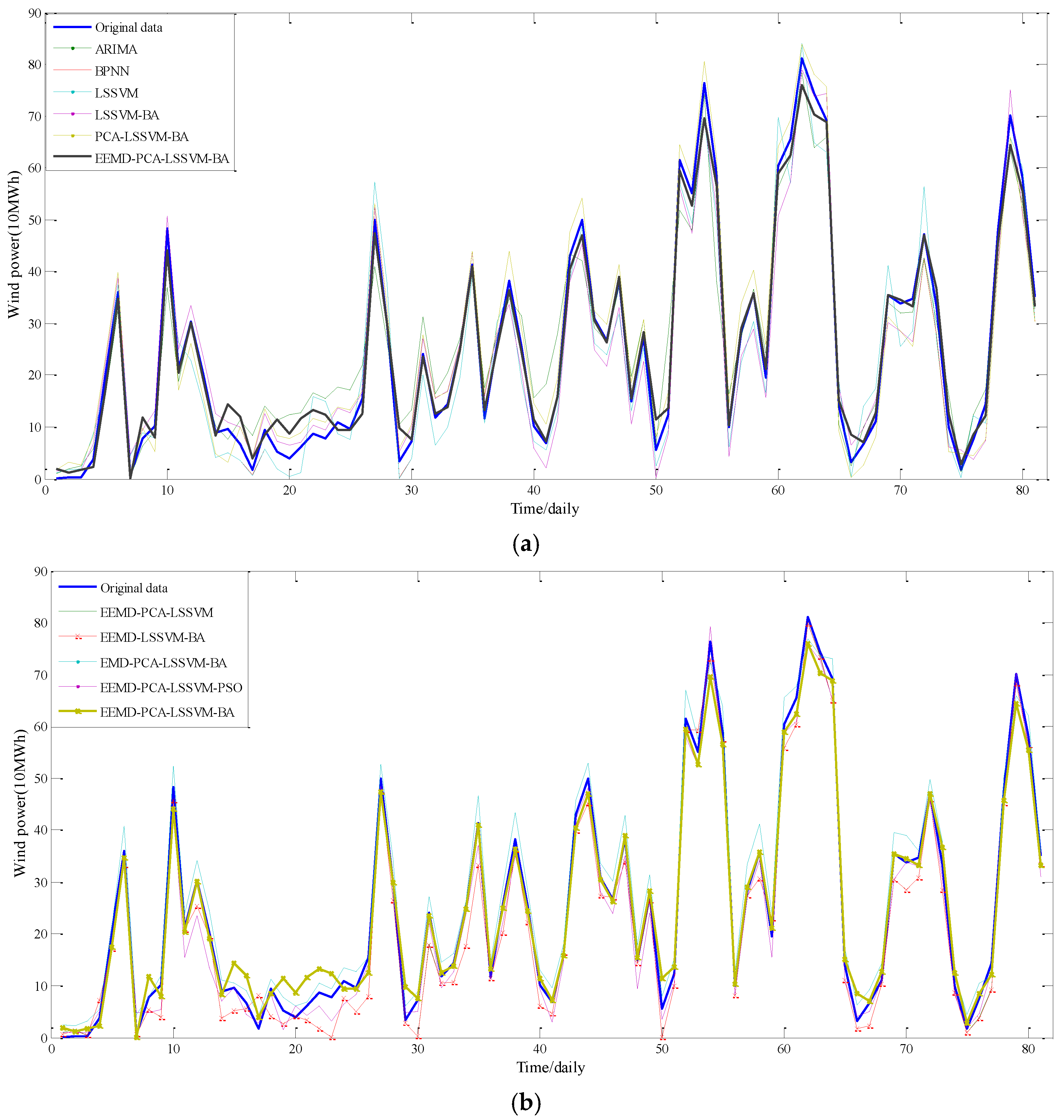
In order to enhance the forecasting accuracy wind power generation efficiently, a hybrid model is framed in this study. First, an EEMD technology was employed to decompose the original wind power generation series. Then, principal component (PCA) was applied to select the significant modelling inputs: five significant variables were selected from nine available inputs. Next, the relevant parameters of the proposed model were optimized by a BA. Finally, the presented method with favorable learning ability and generalization was developed to predict wind power generation. The simulation results and grey relational analysis indicate that the proposed hybrid model performs better than ARIMA, BPNN, LSSVM, LSSVM-BA, PCA-LSSVM-BA, EEMD-PCA-LSSVM, EEMD-LSSVM-BA, EMD-PCA-LSSVM-BA and EEMD-PCA-LSSVM-PSO models.
The superiority of the proposed hybrid model over other models may be accounted for by following aspects: (a) the forecasting performance of wind power generation series can be greatly augmented by using an EEMD method; (b) the simplified model using a reduced number of inputs selected by PCA procedure is more accurate than the models using all the inputs. This could suggest that variables not considered significant not only do not bring valuable information to the input set, but also add noise and unnecessary variability affecting the forecasting accuracy of models; (c) the parameters of the LSSVM models play an essential role in wind power generation prediction. Therefore, in this paper the BA is employed to optimize the parameters of the LSSVM model; (d) the hybrid model can comprehensively capture the characteristics of the raw wind power generation series, whilst the single models can only tap into the limited features of the original series. In this sense, it might be rational to see that the proposed hybrid model performs better than the other single or hybrid models regarding the criteria of MAE, RMSE and MAPE. In addition, the larger grey relational values also confirm that the proposed model outperforms the other models from the perspective of the geometric shape of forecasting series and statistics. Thus, the current method is a credible and promising algorithm for wind power generation prediction.
Regarding some limitations of this study, further research is necessary. Due to the unavailability of a reliable numerical weather prediction system, the meteorological data such as pressure, relative humidity and air density cannot be obtained. Therefore, this study only selected nine variables as alternative variables of the modelling inputs. The other relevant variables that affect wind power generation need to be investigated in further research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}