1. Introduction
The alloy 304 austenitic stainless steel has good corrosion resistance, as well as robust mechanical properties at high temperatures and aggressive environments [
1,
2,
3]. Due to its superior properties, 304 stainless steel has been used in a variety of fields, including marine service, power plant, the nuclear sector, oil industries, etc. [
1,
2,
3,
4]. Correspondingly, the deformation characteristics and mechanical properties of 304 stainless and other austenitic stainless steel under various environments have represented one of the major research topics in the field. The deformation characteristics of austenitic stainless steel are complex, and the characteristics significantly depend on the temperature and strain rates.
To date, many studies have examined the deformation of austenitic stainless steel and modeled the flow stress [
5,
6,
7,
8,
9,
10]. Haj et al. [
5] conducted hot compression experiments for AISI 321 austenitic stainless steel under temperatures ranging from 950 °C–1000 °C and strain rates ranging from 0.01/s–1/s. The experimental study found that the flow stress variation is significantly influenced by the deformation temperatures and strain rates. The flow stress of the AISI 321 austenitic stainless steel was modeled by a constitutive equation based on the Zener-Hollomon theory. Kotkunde et al. [
6] carried out tensile experiments for austenitic stainless steel 316 at temperatures ranging from 150 °C–600 °C and strain rates ranging from 0.0001/s–0.01/s. In the study, the flow stress behavior of stainless steel 316 was modeled by the modified Fields-Backofen equation and the KHL (Khan-Huang-Liang) equation. The research showed that the KHL model is superior to the other model. Babu et al. [
7] performed hot deformation tests for super austenitic stainless steel at temperatures ranging from 1173K–1423K and strain rates ranging from 0.001/s–10/s. In this study, the flow stress model of the stainless steel was developed based on the Zener-Hollomon parameters and regression methods. Pu et al. [
8] studied the high temperature deformation of super austenitic stainless steel S32654 by conducting hot compression tests at temperatures ranging from 950 °C to 1250 °C and strain rates ranging from 0.001/s to 10/s. In this study, the flow stress of the stainless steel was modeled by Arrhenius-type constitutive equations. Cadoni et al. [
9] carried out high-speed deformation tests for AISI304 stainless steel under strain rates ranging from 0.001/s–1000/s. In this research, the flow stress was modeled by a modified type of Johnson-Cook equation. Zhang et al. [
10] performed the constitutive modeling for nitrogen-containing austenitic stainless steel 316LN by performing hot compression tests at temperatures ranging from 900 °C–1250 °C and strain rates ranging from 0.001/s–10/s. In that study, the flow stress of stainless steel 316LN was predicted using the Arrhenius-type equation.
Although modeling the flow stress by using the traditional constitutive equation has generally been successful, the approach has some drawbacks in predicting the accuracy. For example, the Arrhenius-type equation, which is known as one of the most popular and efficient equations for hot deformation study, has some drawbacks, such as the fact that, sometimes, the equation has limited accuracy and the fact that one needs to recalculate the new parameters in the equation when optimizing the equation with new data [
11].
Due to the drawbacks of the traditional approach, many researchers have begun to conduct research on predicting the flow stress using a neural network approach [
11,
12,
13,
14,
15,
16]. Yan et al. [
12] conducted hot compression tests for the Al−6.2Zn−0.70Mg−0.30Mn−0.17Zr alloy at temperatures ranging from 623K–773K and strain rates ranging from 0.01/s–20/s. The research used Arrhenius-type constitutive equations and an artificial neural network approach to predict the flow stress, and the results showed that the artificial neural network model predicted the flow stress more accurately and efficiently than the Arrhenius equations. Bobbili et al. [
13] performed high-speed compression tests for high-strength armor steel at temperatures ranging from 500 °C–650 °C and strain rates ranging from 1000/s–5500/s. In that study, an artificial neural network model and the Johnson-Cook constitutive model were used to predict the flow stress, and the results showed that the artificial neural network model outperforms the Johnson-Cook model. Guo et al. [
14] modeled the flow stress of the TC21 alloy during hot compression at strain rates and temperatures, respectively, ranging from 0.01/s–50/s and from 900 °C–1000 °C. The research showed that the developed model predicted the flow stress of the alloy with good accuracy. Quan et al. [
15] also carried out hot compression tests for the AZ80 alloy at temperatures ranging from 523K–673K and strain rates ranging from 0.01/s–10/s. The flow stress was modeled using the Arrhenius-type equation and the BP-ANN (back propagation artificial neural network) model, and it was found that the BP-ANN predicted the flow stress with better accuracy than the Arrhenius-type equation. Han et al. [
11] also performed a comparison between the Arrhenius-type model and the artificial neural network model in their ability to model the flow stress of as-cast 904L austenitic stainless steel, and they found that the neural network model is superior to the Arrhenius-type model. Zhu et al. [
16] also used the ANN (artificial neural network) model to model the flow stress of as-cast titanium alloy during compression at 1000 °C–1150 °C and 0.01/s–10/s, and they compared the accuracy using the regression method. The research found that the ANN model outperforms the regression method.
Although the neural network approach of modeling the flow stress of hot deformation was quite successful, the neural network model still has some drawbacks in modeling the efficiency and computational cost. Specifically, the neural network model has to optimize the model by adjusting the process parameters, including the number of hidden layers, neurons in each layer, epochs, etc. Therefore, there is still a need to adopt a model with good modeling efficiency and prediction accuracy.
In the present study, a random forest algorithm [
17] is adopted to model the flow stress of the hot deformation process. To this end, hot deformation testing for 304 stainless steel at various temperatures and strain rates was presented. The measured flow stress variation was modeled using traditional Arrhenius-type equations and a random forest algorithm. The presented model was also compared with other models in terms of the accuracy and other aspects of modeling.
2. Materials and Methods
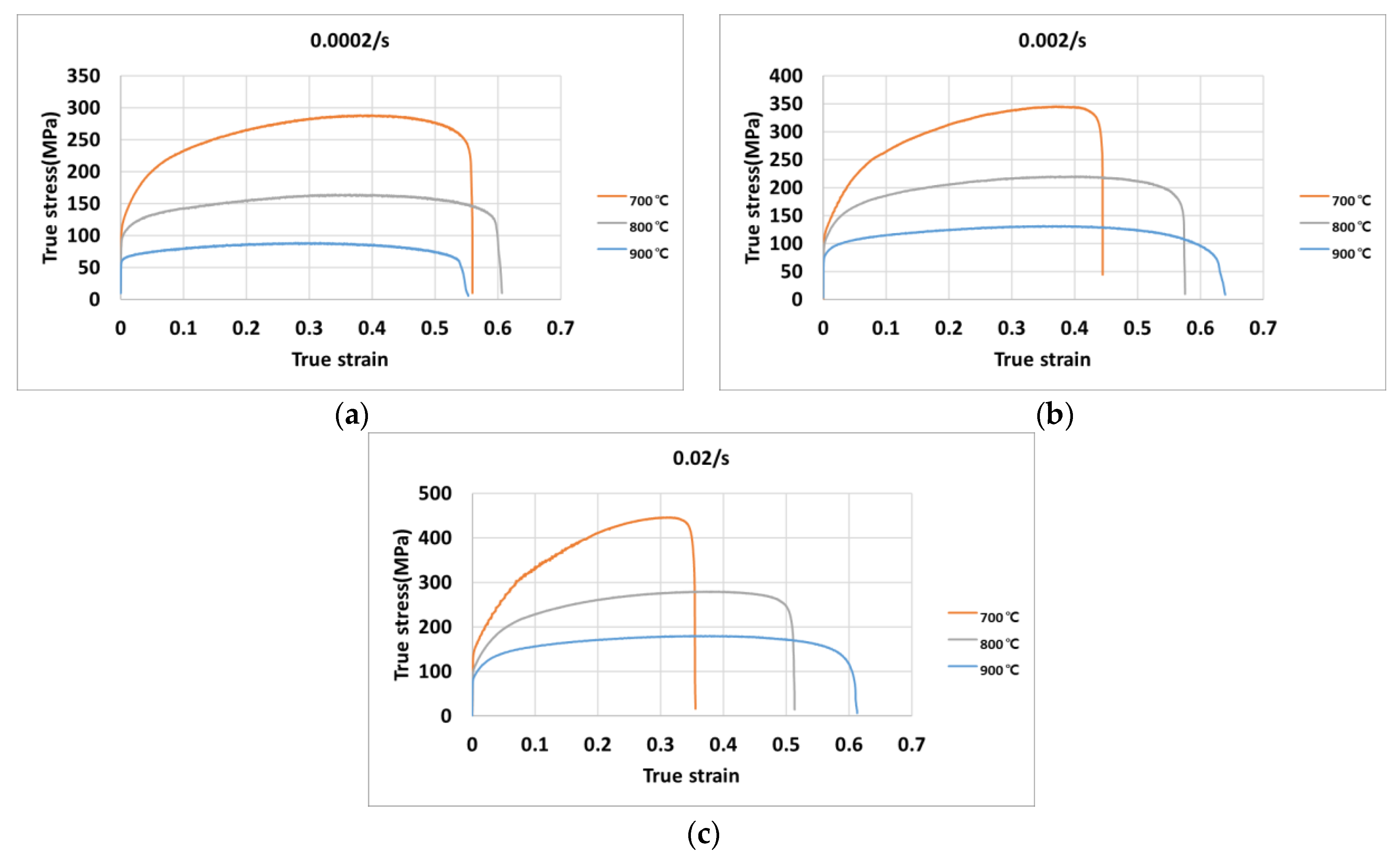
For the high-temperature tensile test, specimens of 304 stainless steel were prepared. Wire-EDM (Electrical discharge machining) machining was used to machine the planar specimens. The dimensions of each specimen were about 203.7 mm in length, 9.5 mm in width, and 2 mm in thickness. The test specimens are heated in a furnace to high temperatures. Tensile tests were conducted in a testing machine of model MTS-810.
Figure 1a shows the machined specimens, and
Figure 1b shows the geometry of the test specimens in detail. In this research, the high-temperature tests were conducted at temperatures of 700 °C, 800 °C, and 900 °C and strain rates of 0.0002/s, 0.002/s, and 0.02/s.
2.1. Modeling by Arrhenius-Type Constitutive Equation
In this research, the Arrhenius-type equation with the Zener-Hollomon theory is used to model the flow stress of the high-temperature deformation of 304 stainless steel. When the function
F(
σ) is in the form shown below:
where
,
,
, and
denotes material constants, and the strain rate
is described as
where
is the material constant. The Zener-Hollomon parameter
can be written as follows.
where
(K) is the temperature,
denotes the strain rate of the deformation,
is the activation energy, and
denotes the gas constant.
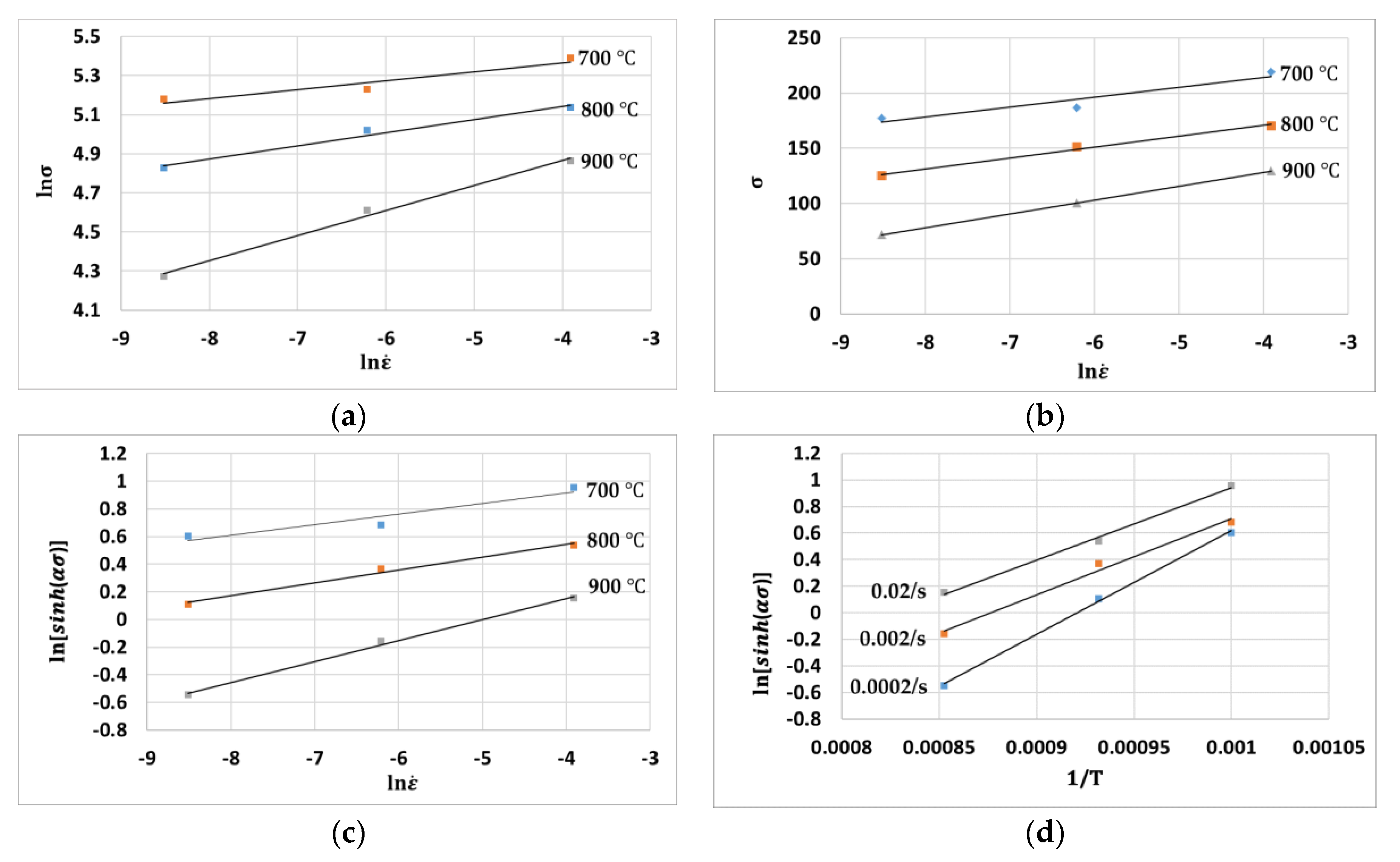
Equation (4) is obtained after substituting the first Equation (1) into Equation (2) and taking the logarithms of both sides, as noted in Equation (4).
From the curves in the above equation, the material constant is obtained by calculating the slope of the curve. In the development of the Arrhenius equation described in this research, the necessary calculations to obtain n’ are done at strains ranging from 0.03–0.3, with an interval of 0.03.
After substituting the second part of Equation (1) into Equation (2) and taking the logarithms of the obtained equation, one can obtain the relationship shown in Equation (5). The material constant
is obtained by calculating the slopes of the
curves.
The material constant
, which is defined as shown in Equation (6), is calculated using
and
.
and
are also calculated at the strains of 0.03–0.3, with an interval of 0.03.
After substituting the third equation of (1) into (2) to take logarithms of the obtained equation, we obtain the equation shown in (7). The material constant
is obtained after calculating the slopes of the
curves. As with the other materials constants described above,
is also obtained for the same strain values as above.
The material constant is similarly calculated from the slope of the curve.
Finally, the material constant
is obtained by using the
y-axis intercept of the
plot from Equation (8), which is derived from Equations (1) and (7).
Similar to the other material constant,
and
are also obtained at various strain values ranging from 0.03–0.3 with an interval of 0.03.
Figure 2 shows the plots of (a) ln
, (b)
(c)
, and (d)
for the strain of 0.03.
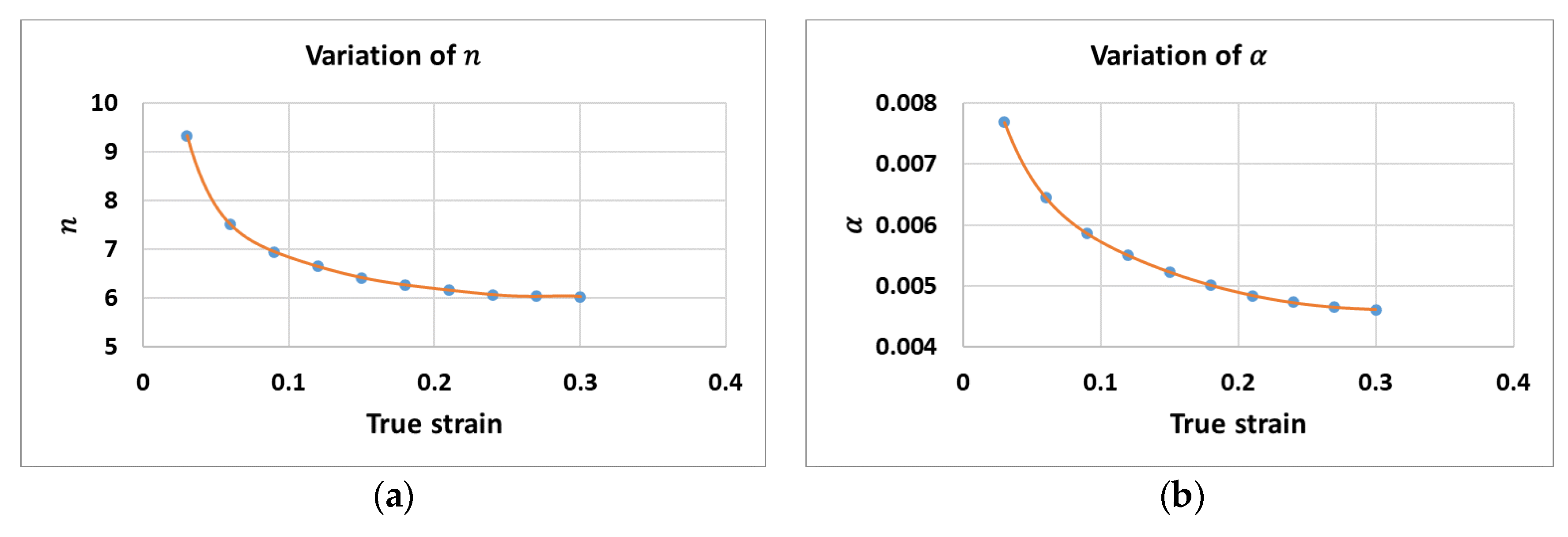
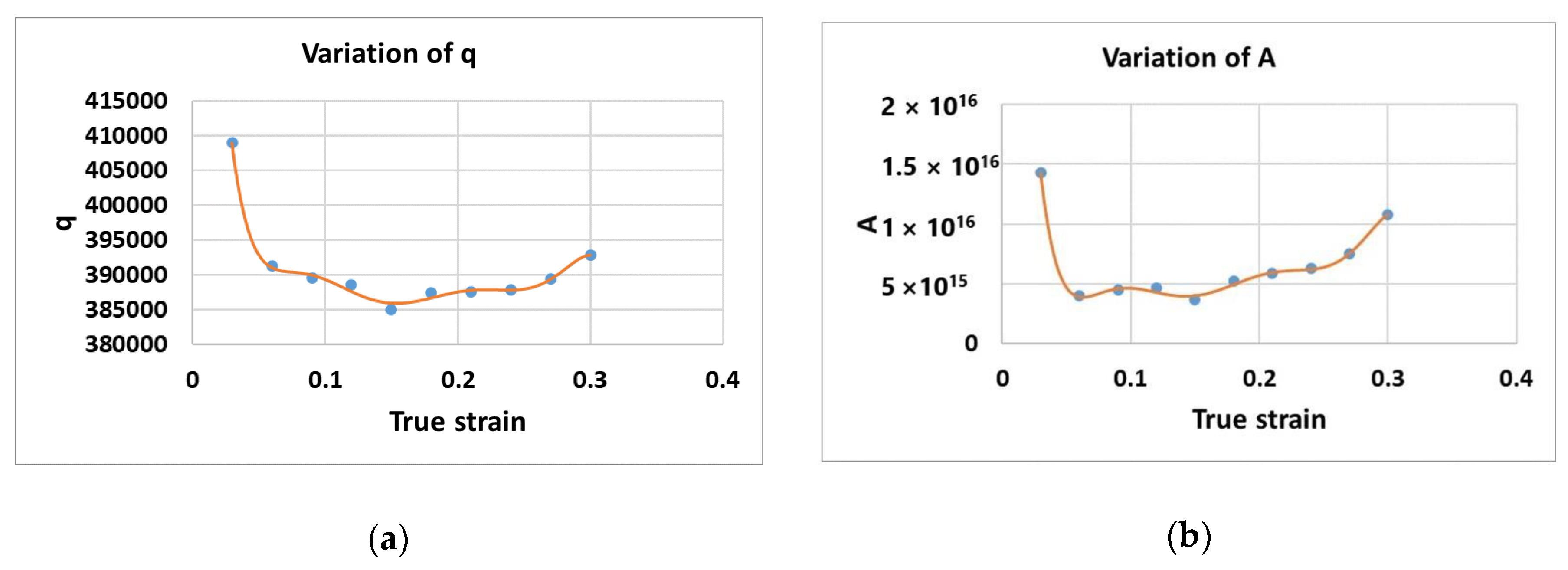
Since the material constants
,
,
,
, and
are the functions of the strain, the constants
,
,
, and
can be described as the 7th-order polynomial function, as in Equations (9)–(12). A regression analysis was conducted to determine the coefficients of the polynomials.
Table 1 presents the list of the calculated coefficients of
,
,
, and
.
Table 2 presents the RMSE (root mean square error) of the material constants calculated by the polynomial functions.
Figure 3 shows the variations of (a)
and (b)
. Meanwhile,
Figure 4a and
Figure 4b present the variations of
and
, respectively.
The final form of the equation describing the flow stress with the Zener-Hollomon parameter is obtained using Equations (1) and (2) after calculating all the material constants. The equation of stress is as shown below in Equation (13).
2.2. Modeling by Random Forest Algorithm
In a random forest algorithm, an ensemble method of learning is performed by a forest structure of multiple decision trees. To understand the random forest algorithm in detail, it is worth mentioning the decision tree first. The decision tree algorithm splits the original dataset at each classifying point, called a node, with certain classifying attributes. Starting from the initial point called the root node (top node), the datasets repeat being split into smaller classes through continuous actions by different attributes at child nodes (sub-nodes). The decision tree algorithm is originally a splitting algorithm. However, the algorithm can be utilized as a regression algorithm when the target classes are numeric. To this end, this decision algorithm has been effectively adopted in many classifying and regression works. To obtain even greater effectiveness, a random forest algorithm is developed by utilizing multiple tree structures. Each decision tree becomes a predictor, and predictions from trees are used to choose the most popular prediction.
In this research, the python/scikit learn package was used to adopt a random forest algorithm in a regression problem. In the developed random forests model, the input attributes were the strain rate, temperature, and strain; the output attribute was stress. From each stress–strain curve, the strain range from 0.03–0.3 was chosen as the area of research, and 10 data points from each curve were chosen at strains ranging from 0.03–0.3, with a 0.03 interval. Therefore, 90 data points in total were chosen as the test set. In addition, 40 data points were randomly chosen from each curve (at the range of 0.03–0.3) to be the learning set, and hence, 360 data points in total were used as the learning set. Bootstrapping was used in this calculation to avoid overfitting in the regression.
Table 3 lists the process parameters of the random forest algorithm used in this research.
4. Discussion
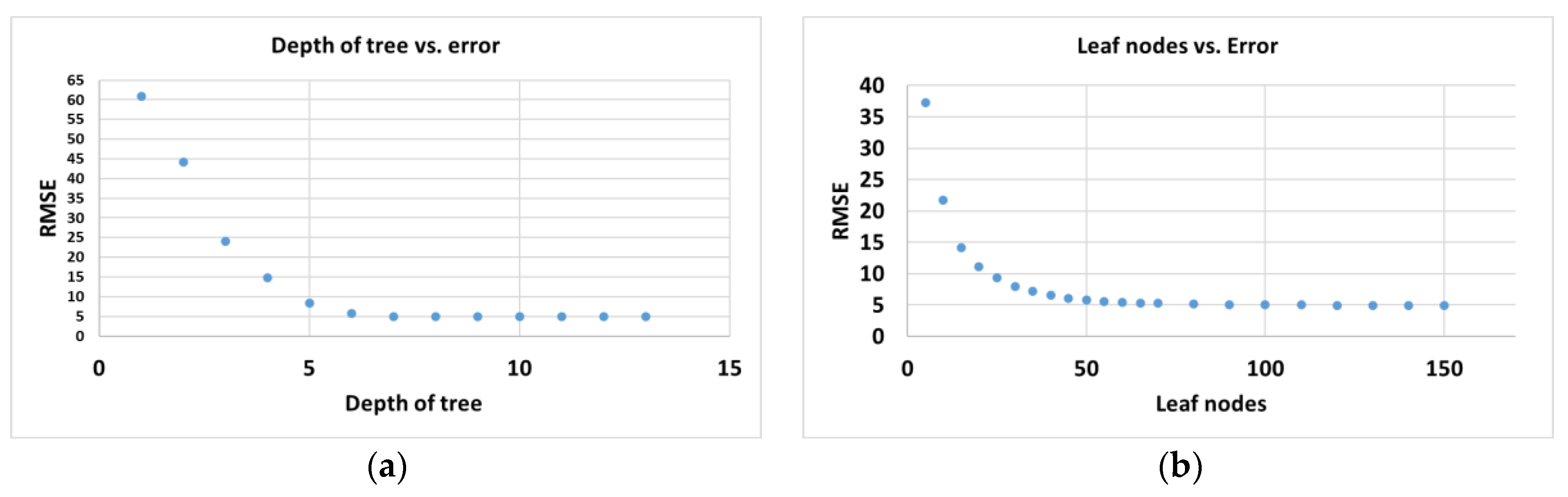
An analysis of the influence of the maximum depth and leaf nodes of the tree structure of the random forest algorithm on the accuracy of the model was performed.
Figure 8 shows the (a) RMSE versus the maximum depth of the tree and (b) RMSE versus the maximum leaf nodes.
In this research, developing the prediction model by the random forest approach could be done efficiently, and the developed model was computationally inexpensive. The advantages of the random forest algorithm could be noticeable when one considers other computationally expensive algorithms (e.g., neural networks.).
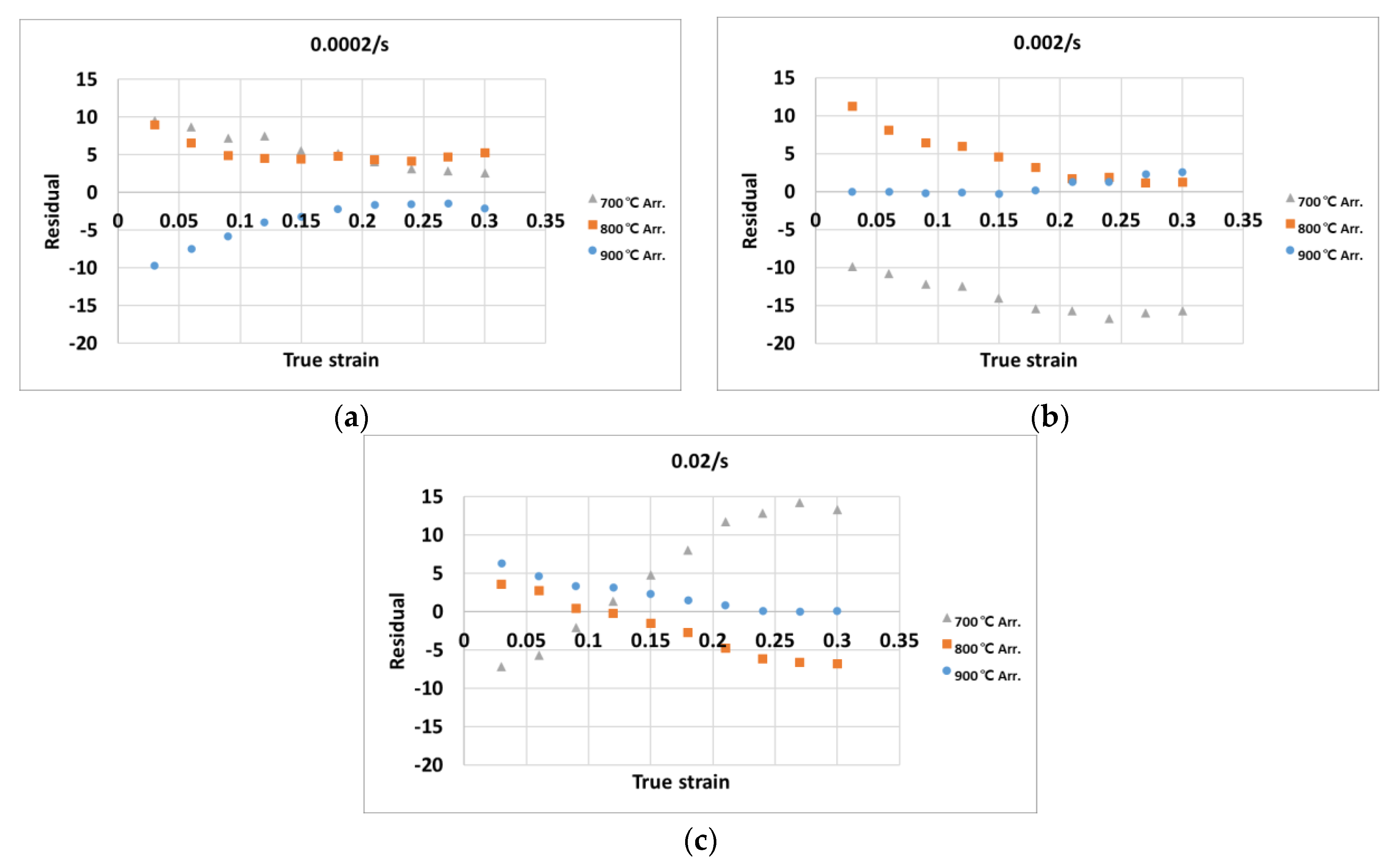
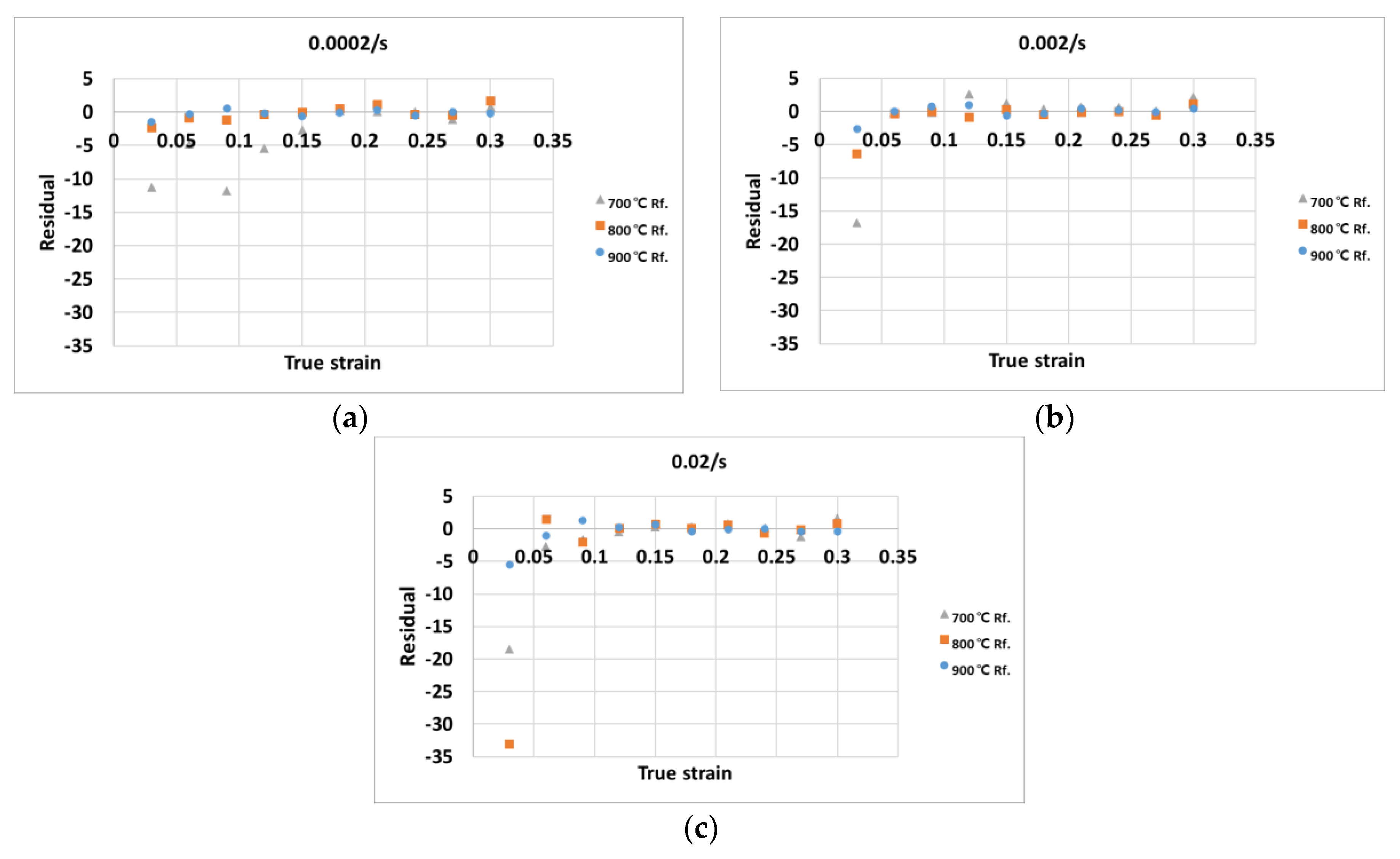
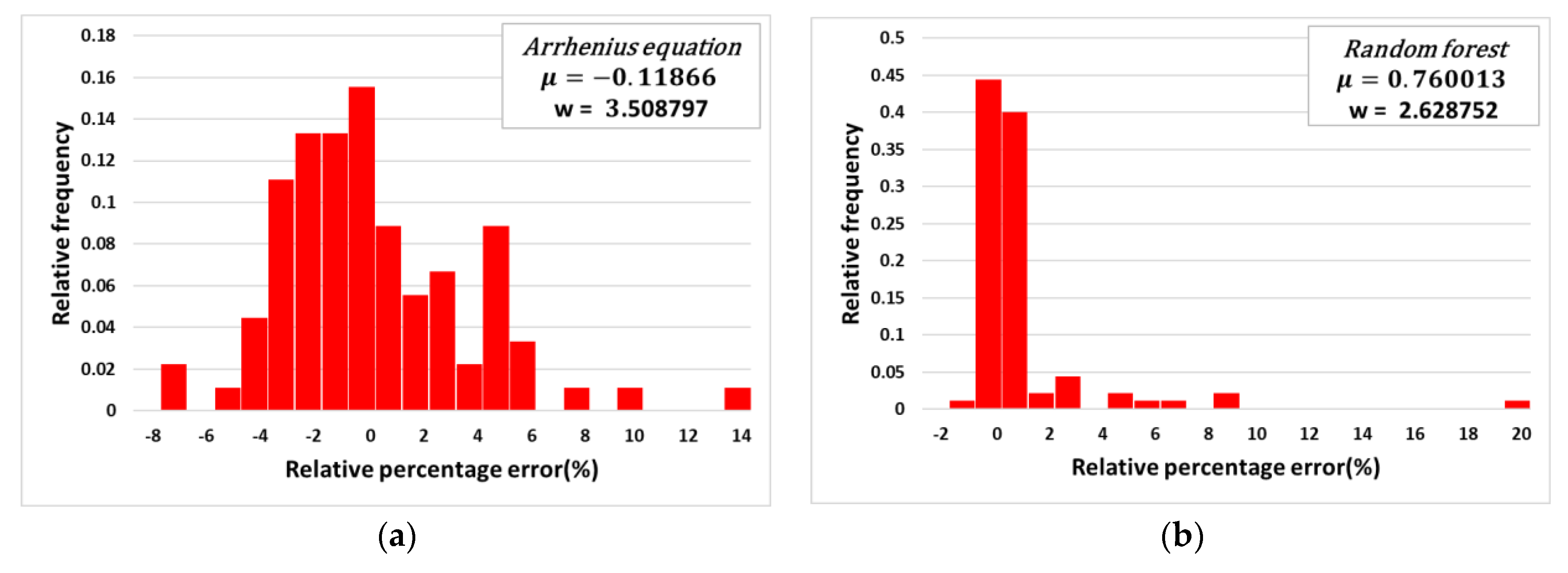
The analysis of the relative percentage error was conducted for the flow stress values calculated by the Arrhenius constitutive equation and the random forest algorithm.
Figure 9 shows the relative percentage errors versus the relative frequency for the (a) Arrhenius constitutive approach and (b) random forest approach. For each approach, the mean value of the relative percentage error, indicated as μ, was about −0.12 and 0.76, respectively. The standard deviation for the relative percentage error, indicated as w, was about 3.51 and 2.63, respectively. In other words, the absolute mean value of the relative percentage error for the random forest approach was larger than the error obtained by the Arrhenius constitutive equation. However, the standard deviation of the relative percentage error for the Arrhenius constitutive equation was larger than that for the random forest approach. This indicates that the errors of the Arrhenius-type equation exist in a more dispersed manner, while the random forest approach performs more reliably than the Arrhenius-type equation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}