
A Machine Learning Method for Predicting Corrosion Weight Gain of Uranium and Uranium Alloys

Abstract
:1. Introduction
2. Methods
2.1. Corrosion Data and Data Preprocessing
2.2. Feature Selection
2.3. Modeling Process
3. Results and Discussion
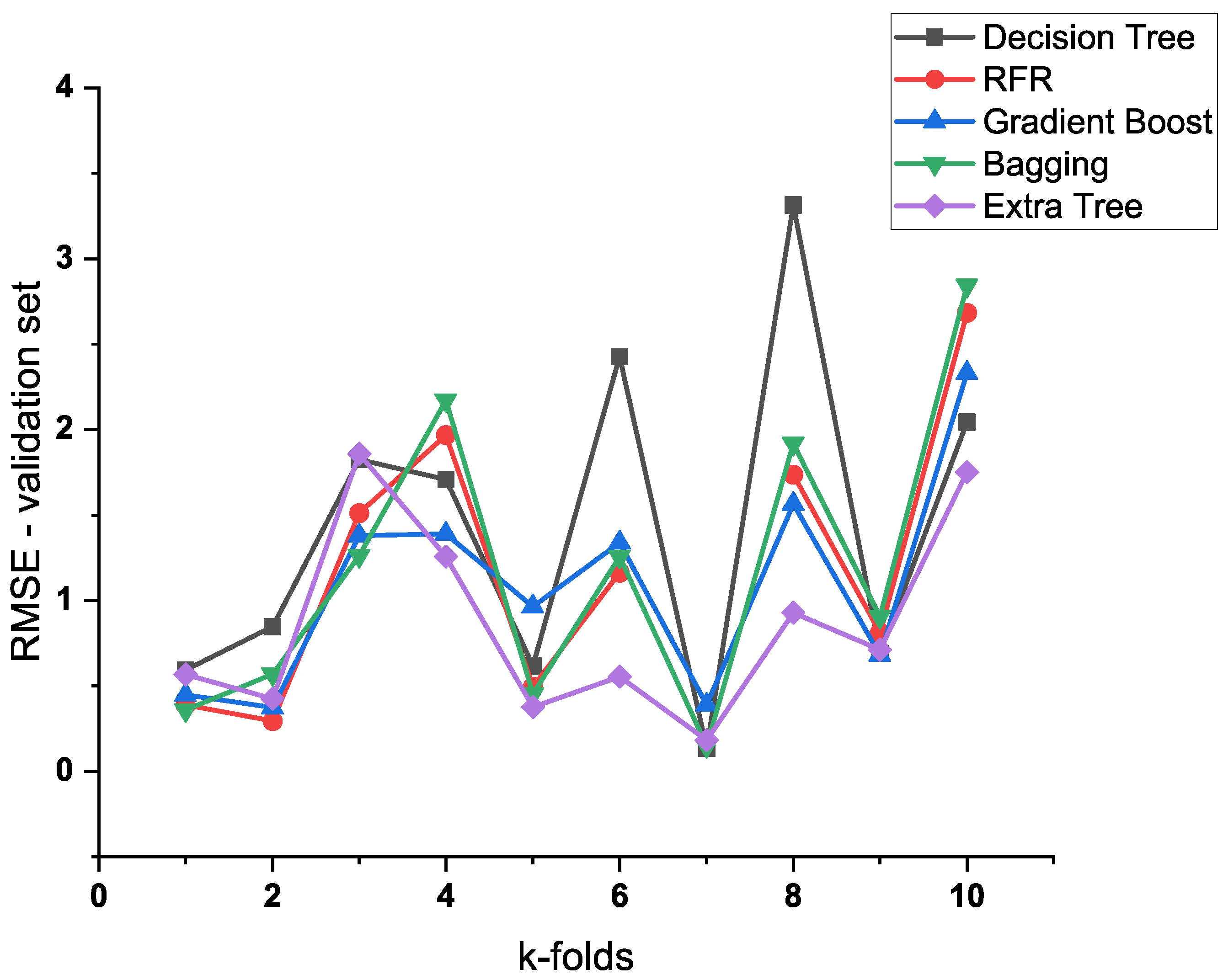
3.1. Comparison of Different Algorithms
3.2. Results of Feature Selection
3.3. Evaluation Results
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pei, Z.; Zhang, D.; Zhi, Y.; Yang, T.; Jin, L.; Fu, D.; Cheng, X.; Terryn, H.A.; Mol, J.M.C.; Li, X. Towards understanding and prediction of atmospheric corrosion of an Fe/Cu corrosion sensor via machine learning. Corros. Sci. 2020, 170, 108697. [Google Scholar] [CrossRef]
- Kelly, D.; Lillard, J.A. Surface characterization of oxidative corrosion of uranium-niobium alloys. In Proceedings of the American Vacuum Society 2000 Meeting, Boston, MA, USA, 2–6 October 2000. [Google Scholar]
- Zubelewicz, A.; Aleksander, F.L. A constitutive model for a uranium-niobium alloy. J. Appl. Phys. 2006, 100, 013523. [Google Scholar] [CrossRef]
- Yang, J.; Wang, X.L.; Zhou, P.; Lang, D.M.; Xiao, H. Oxidation of U-2.5%Nb Alloy in Air. J. Nucl. Radiochem. 2009, 31, 129–133. [Google Scholar]
- Wang, S.P.; Li, H.B.; Li, G.; Tang, T.; Gu, Y.J.; Hu, Y.; Chen, X.L.; Wang, Y.; Lv, J.B.; Luo, W.H. The oxidative kinetics of uranium at different stages. Corros. Sci. 2022, 206, 110487. [Google Scholar] [CrossRef]
- Coelho, L.B.; Zhang, D.W.; Ingelgem, Y.V. Reviewing machine learning of corrosion prediction in a data-oriented perspective. NPJ Mater. Degrad. 2022, 6, 8. [Google Scholar] [CrossRef]
- Li, H.; Ding, Q.; Gu, Y. The initial oxidation behavior of uranium and uranium-titanium alloys in standing storage. Corros. Sci. 2020, 176, 108879. [Google Scholar] [CrossRef]
- Tom, G.; Andreas, M.; Daniel, H.; Mikhail, Z.; Kainer, K.U. Enhanced predictive corrosion modeling with implicit corrosion products. Mater. Corros. 2020, 70, 2247–2255. [Google Scholar]
- Wang, H.W.; Yu, C.; Wang, S.X.; Gao, J. Electrochemical Corrosion Behavior and Prediction of Corrosion Rate for Low Alloy Steel after Tempering Treatment. Int. J. Electrochem. Sci. 2015, 10, 1169–1185. [Google Scholar]
- Diao, Y.P.; Yan, L.C.; Gao, K.W. Improvement of the machine learning-based corrosion rate prediction model through the optimization of input features. Mater. Des. 2021, 198, 109326. [Google Scholar] [CrossRef]
- Liu, Y.; Guo, B.; Zou, X.; Li, Y.; Shi, S. Machine learning assisted materials design and discovery for rechargeable batteries. Energy Storage Mater. 2020, 31, 434–450. [Google Scholar] [CrossRef]
- Chen, A.; Zhang, X.; Zhou, Z. Machine learning: Accelerating materials development for energy storage and conversion. InfoMat 2020, 2, 553–576. [Google Scholar] [CrossRef]
- Deringer, V.L. Modelling and understanding battery materials with machine-learning-driven atomistic simulations. J. Phys. Energy. 2020, 2, 041003. [Google Scholar] [CrossRef]
- Yuan, J.H.; Wang, Q.; Li, Z.; Dong, C.; Zhang, P.C.; Ding, X.L. Domain-knowledge-oriented data pre-processing and machine learning of corrosion-resistant γ-U alloys with a small database. Comput. Mater. Sci. 2021, 194, 110472. [Google Scholar] [CrossRef]
- Mythreyi, O.V.; Srinivaas, M.R.; Kumar, T.A.; Jayaganthan, R. Machine-Learning-Based Prediction of Corrosion Behavior in Additively Manufactured Inconel 718. Data 2021, 6, 80. [Google Scholar] [CrossRef]
- Bennett, M.J.; Myatt, B.L.; Silvester, D.R.V.; Antill, J.E. The oxidation behaviour of uranium in air at 50–300 °C. J. Nucl. Mater. 1975, 57, 221–236. [Google Scholar] [CrossRef]
- Yang, J.; Wang, X.L.; Luo, L.Z.; Zhou, P. Investigation of oxidation of a U-2.5 wt% Nb alloy in air at low temperatures: Kinetic study and oxide characterization. Surf. Interface Anal. 2008, 40, 299–302. [Google Scholar]
- Guyon, I.; Gunn, S.R.; Nikravesh, M.; Zadeh, L.A. Feature Extraction Foundations and Applications; Springer: Berlin, Germany, 2006. [Google Scholar]
- Alfian, G.; Syafrudin, M.; Fahrurrozi, I.; Fitriyani, N.L.; Atmaji, F.T.D.; Widodo, T.; Bahiyah, N.; Benes, F.; Rhee, J. Predicting Breast Cancer from Risk Factors Using SVM and Extra-Trees-Based FeatureSelection Method. Computers 2022, 11, 136. [Google Scholar] [CrossRef]
- Wen, C.; Zhang, Y.; Wang, C.; Xue, D.; Bai, Y.; Antonov, S.; Dai, L.; Lookman, T.; Su, Y. Machine learning assisted design of high entropy alloys with desired property. Acta Mater. 2019, 170, 109–117. [Google Scholar] [CrossRef] [Green Version]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B 1974, 36, 111–133. [Google Scholar] [CrossRef]
- Wang, Y.; Tian, Y.; Kirk, T.; Laris, O.; Ross, J.H.; Noebe, R.D.; Keylin, V.; Arroyave, R. Accelerated design of Fe-based soft magnetic materials using machine learning and stochastic optimization. Acta Mater. 2020, 194, 144–155. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Unit | Data Range | |
|---|---|---|---|
| Material | Type | Data | 1–3 |
| Impurity | % | 0.0005–0.002 | |
| Phase_number | Number | 1,2 | |
| Phase_type | \ | 1–3 | |
| Environmental | Medium | \ | 1–2 |
| Temperature | K | 323–573 | |
| Pressure | ×105 Pa | 1.01325 | |
| Reaction time | Time | h | 0–200,463 |
| Corrosion weight gain | Weight_gain | mg/cm2 | 0–25 |
| Methods | RMSE | R2 |
|---|---|---|
| Without feature selection | 0.634 | 0.931 |
| With feature selection | 0.516 | 0.968 |
| Hyperparameter | Value |
|---|---|
| criterion | “squared_error” |
| splitter | “random” |
| max_depth | None |
| min_samples_split | 2 |
| min_samples_leaf | 1 |
| min_weight_fraction_leaf | 0.0 |
| Max_features | 1.0 |
| Max_leaf_nodes | None |
| min_impurity_decrease | 0.0 |
| random_state | None |
| ccp_alpha | 0.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Zhang, W.; Zhang, W.; Ai, Y. A Machine Learning Method for Predicting Corrosion Weight Gain of Uranium and Uranium Alloys. Materials 2023, 16, 631. https://doi.org/10.3390/ma16020631
Wang X, Zhang W, Zhang W, Ai Y. A Machine Learning Method for Predicting Corrosion Weight Gain of Uranium and Uranium Alloys. Materials. 2023; 16(2):631. https://doi.org/10.3390/ma16020631
Chicago/Turabian StyleWang, Xiaoyuan, Wanying Zhang, Weidong Zhang, and Yibo Ai. 2023. "A Machine Learning Method for Predicting Corrosion Weight Gain of Uranium and Uranium Alloys" Materials 16, no. 2: 631. https://doi.org/10.3390/ma16020631
APA StyleWang, X., Zhang, W., Zhang, W., & Ai, Y. (2023). A Machine Learning Method for Predicting Corrosion Weight Gain of Uranium and Uranium Alloys. Materials, 16(2), 631. https://doi.org/10.3390/ma16020631