Properties of Vector Embeddings in Social Networks

Abstract
:1. Introduction
2. Definitions and Preliminaries
3. Related Work
3.1. Graph Embedding Techniques
- DeepWalk [12]: This approach learns d-dimensional feature representations by simulating uniform random walks over the graph. It preserves higher-order proximities by maximizing the probability of observing the last c nodes and the next c nodes in the random walk centered at . More formally, DeepWalk maximizes:where is the embedding vector of the node and c is the context size. We denote the mapping function for this method , where d is the embedding size. Therefore, the DeepWalk embedding of the node v is denoted by .
- node2vec [10]: Inspired by DeepWalk, node2vec preserves higher-order proximities by maximizing the probability of occurrence of subsequent nodes in fixed length random walks. The crucial difference from DeepWalk is that node2vec employs biased-random walks that provide a trade-off between BFS and DFS graph searches, and hence produces higher-quality and more informative embeddings than DeepWalk. More specifically, there are two key hyper-parameters and that control the random walk. Parameter p controls the likelihood of immediately revisiting a node in the walk. Parameter q controls the traverse behavior to approximate BFS or DFS. For , node2vec is identical to DeepWalk. We denote the node2vec embedding by node2vec: , where d is the embedding size. Therefore, the node2vec embedding of the node v is shown by node2vec.
- loc [15]: This approach limits random walks to the neighborhood around egos to make artificial paragraphs. ParagraphVector [16] is properly applied to learn local embeddings for egos by optimizing the likelihood objective using stochastic gradient descent with negative sampling [27]. Formally, given an artificial paragraph for ego , the goal is to update representations in order to maximize the average log probability:where is the embedding vector of the ego , l is the length of the artificial paragraph, and c is the context size. Therefore, there is a mapping function , where d is the embedding size. We denote the loc embedding of the ego u by .
- LINE [14]: It learns two embedding vectors for each node by preserving the first-order and second-order proximity of the network in two phases. In the first phase, it learns dimensions by BFS-style simulations over immediate neighbors of nodes. In the second phase, it learns the next dimensions by sampling nodes strictly at a 2-hop distance from the source nodes. Then, the embedding vectors are concatenated as the final representation for a node. Indeed, LINE defines two joint probability distributions for each pair of nodes, one using adjacency matrix and the other using the embedding. It minimizes the Kullback–Leibler (KL) divergence [28] of these two distributions. The first phase distributions and the objective function are as follows:Probability distributions and objective function are similarly defined for the second phase. This technique adopts the asynchronous stochastic gradient algorithm (ASGD) [29] for optimization. In each step, the ASGD algorithm samples a mini-batch of nodes and then updates the model parameters. We denote this embedding as a function that maps nodes to the vector space, where d is the embedding size. Therefore, the LINE embedding of the node v is denoted by .
3.2. Techniques for Inspecting Embeddings
- Visualization: To gain insight into binary relationships between objects, the relations are often coded into a graph, which is then visualized. The visualization is usually split in the layout and the drawing phase. The layout is a mapping of graph elements to points in . The drawing assigns graphical shapes to the graph elements and draws them using the positions computed in the layout [30]. The effectiveness of DeepWalk is illustrated by visualizing the Zachary’s Karate Club network [12]. The authors of LINE visualized the DataBase systems and Logic Programming (DBLP) co-authorship network, and showed that LINE is able to cluster together authors in the same field. Structural Deep Network Embedding (SDNE) [31] was applied on a 20-Newsgroup document similarity network to obtain clusters of documents based on topics.
- Network Compression: The idea in network compression is to reconstruct the graph with a smaller number of edges [23]. Graph embedding can also be interpreted as a compression of the graph. Wang et al. [31] and Ou et al. [32] tested this hypothesis explicitly by reconstructing the original graph from the embedding and evaluating the reconstruction error. They show that a low-dimensional representation for each node suffices to reconstruct the graph with high precision.
- Classification: Often in social networks, a fraction of nodes are labeled which indicate interests, beliefs, or demographics, but the rest are missing labels. Missing labels can be inferred using the labeled nodes through links in the network. The task of predicting these missing labels is also known as node classification. Recent work [10,12,14,31] has evaluated the predictive power of embedding on various information networks including language, social, biology and collaboration graphs. The authors in [15] predict the social circles for a new node added into the network.
- Clustering: Graph clustering in social networks aim to detect social communities. In [33], the authors evaluated the effectiveness of embedding representations of DeepWalk and LINE on network clustering. Both approaches showed nearly the same performance.
- Link Prediction: Social networks are constructed from the observed interactions between entities, which may be incomplete or inaccurate. The challenge often lies in predicting missing interactions. Link prediction refers to the task of predicting either missing interactions or links that may appear in the future in an evolving network. Link prediction is used to predict probable friendships, which can be used for recommendation and lead to a more satisfactory user experience. Liao et al. [34] used link prediction to evaluate node2vec and LINE. Node2vec outperforms LINE in terms of area under the Receiver Operating Characteristic (ROC) curve.
4. Approach
4.1. Problem Statement
4.2. Explaining Embedding Relatedness
4.3. Predicting Graph Properties
- Input layer: The input is given by one of the different embeddings for a single node, namely , , or .
- Hidden layer: The hidden layer consists of a single dense layer with ReLU activation units [45] .
- Output layer: The output layer has a sigmoid unit [46]. We choose the sigmoid unit since normalized centrality values are in the range of .
- Optimizer: Stochastic gradient descent (SGD) [47], which is a popular technique for large-scale optimization problems in machine learning.
5. Experiments
5.1. Dataset
- With a probability , this new node connects to m existing nodes uniformly at random.
- With a probability , this new node connects to m existing nodes with a probability proportional to the degree of node which it will be connected to.
5.2. Parameter Settings
- loc: Here, we apply Paragraph Vector [16] to learn embeddings for limited sequence of nodes, the same as paragraphs in text. In the Paragraph Vector Distributed Memory (PV-DM) model, optimal context size is 8 and the learned vector representations have 400 dimensions for both words and paragraphs [16].
- node2vec: This algorithm operates the same as DeepWalk, but the hyper-parameter p and q control the walking procedure. With the random walk is biased towards nodes close to the start node. Such walks obtain a local view of the underlying graph with respect to the start node in the walk and approximate BFS behavior in the sense that samples are comprised of nodes within a small locality. The parameter p controls the likelihood of immediately revisiting a node in the walk. If p is low , it would lead the walk to backtrack a step and this would keep the walk "local" close to the starting node. The optimal values of p and q depend a lot on the dataset [10]. In our experiment, we consider two settings: node2vec(1) keeps the walk local with , while node2vec(2) walks more exploratively with .
- LINE: LINE with first-order proximity, in which linked nodes will have closer representations, and LINE with second-order proximity, in which nodes with similar neighbors will have similar representations. In both settings, we consider the embedding size , batch-size= 1000, learning-rate .
5.3. Quantitative Results
5.3.1. Inspecting Embedding Properties
- Overall, we can explain the ranking either by combining betweenness or eigenvector or degree centralities of the node’s neighborhood. Closeness is not important in order to retain the ranking. The accuracy of SVM in all experiments is around , which shows that there are some explaining network properties missing.
- LINE and DeepWalk, which are able to explore the entire graph, can learn betweenness and eigenvector centrality of nodes. Betweenness is a global centrality metric that is based on shortest-path enumeration. Therefore, it is needed to walk over the whole graph to estimate betweenness centrality of nodes. Eigenvector centrality measures the influence of a node by exploiting the idea that connections to high-scoring nodes are more influential. This means that a node is important if it is connected to important neighbors. Therefore, computing eigenvector centrality also requires exploring globally the entire graph. This is done in practice by both LINE and DeepWalk, hence they learn eigenvector and betweenness centrality of nodes around .
- node2vec with and walks locally around the starting node. loc also walks over a limited area of the network. Therefore, they are not able to capture the structure of the entire network to learn betweenness or eigenvector centrality. The only property that is locally available is degree of nodes, hence is it learnt by node2vec(1) and loc.
- node2vec with and is more inclined to visit nodes that are further away from the starting node. Such behavior is reflective of DFS, which encourages outward exploration. Since node2vec(2) walks through the graph deeply, it could learn the eigenvector centrality.
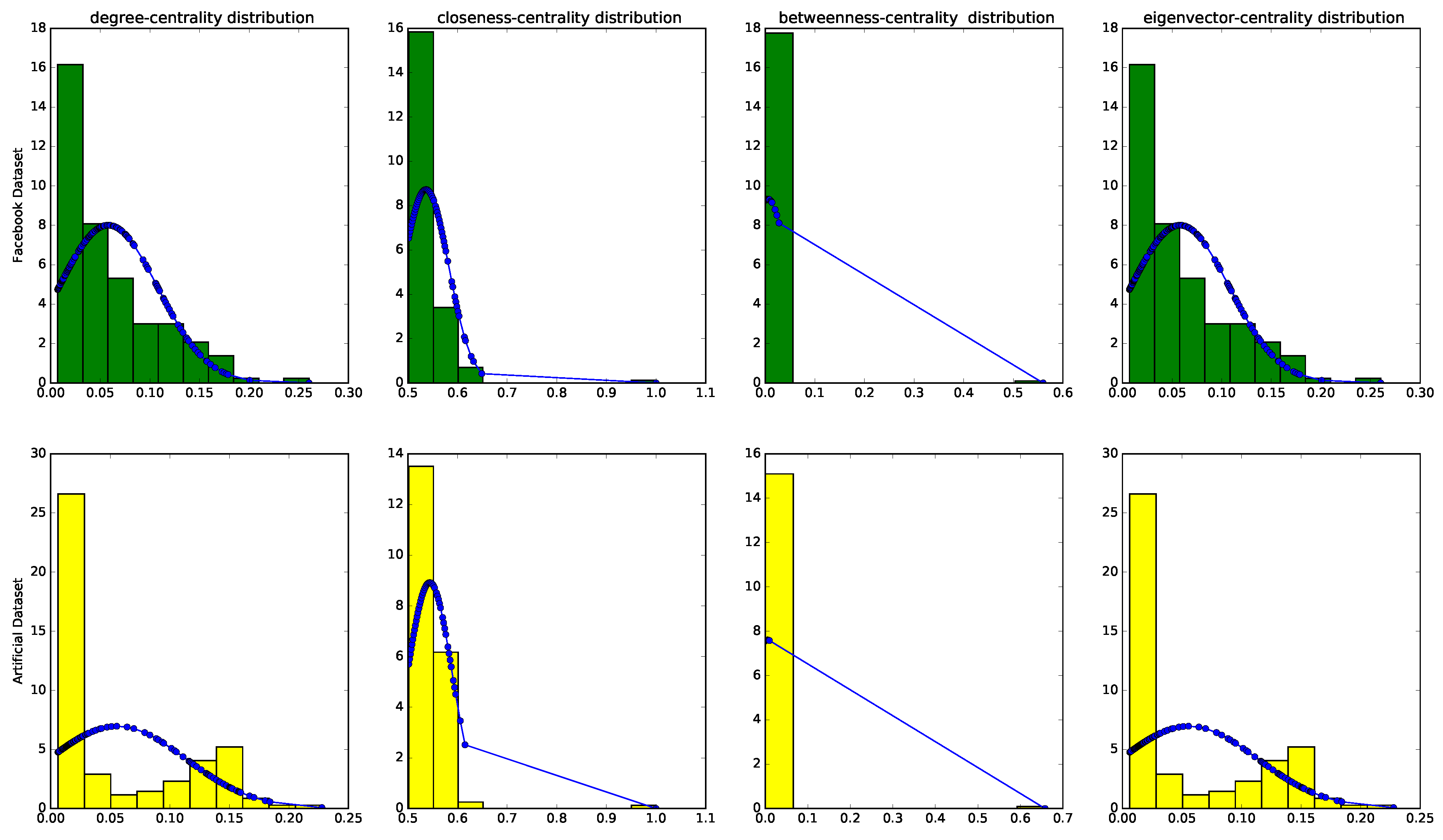
5.3.2. Approximating Centrality Values
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kossinets, G.; Watts, D.J. Empirical analysis of an evolving social network. Science 2006, 311, 88–90. [Google Scholar] [CrossRef] [PubMed]
- Romero, D.M.; Kleinberg, J.M. The directed closure process in hybrid social-information networks, with an analysis of link formation on Twitter. In Proceedings of the Fourth International Conference on Weblogs and Social Media, ICWSM 2010, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Szabo, G.; Huberman, B.A. Predicting the popularity of online content. Commun. ACM 2010, 53, 80–88. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th international conference on World wide web, ACM, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Helic, D.; Strohmaier, M.; Granitzer, M.; Scherer, R. Models of human navigation in information networks based on decentralized search. In Proceedings of the 24th ACM Conference on Hypertext and Social Media, Paris, France, 2–4 May 2013; pp. 89–98. [Google Scholar]
- Helic, D.; Körner, C.; Granitzer, M.; Strohmaier, M.; Trattner, C. Navigational efficiency of broad vs. narrow folksonomies. In Proceedings of the 23rd ACM conference on Hypertext and social media, Milwaukee, WI, USA, 25–28 June 2012; pp. 63–72. [Google Scholar]
- He, X.; Gao, M.; Kan, M.Y.; Wang, D. Birank: Towards ranking on bipartite graphs. IEEE Trans. Knowl. Data Eng. 2017, 29, 57–71. [Google Scholar] [CrossRef]
- Wang, X.; Nie, L.; Song, X.; Zhang, D.; Chua, T.S. Unifying virtual and physical worlds: Learning toward local and global consistency. ACM Trans. Inf. Syst. 2017, 36, 4. [Google Scholar] [CrossRef]
- Asur, S.; Huberman, B.A. Predicting the Future with Social Media. In Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Toronto, ON, Canada, 31 August–3 September 2010; Volume 1, pp. 492–499. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 24–27 August 2016; pp. 855–864. [Google Scholar]
- Shaw, B.; Jebara, T. Structure Preserving Embedding. In Proceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, Montreal, QC, Canada, 14–18 June 2009; pp. 937–944. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Fatemeh Salehi Rizi, M.G.; Ziegler, K. Global and Local Feature Learning for Ego-Network Analysis. In Proceedings of the 14th International Workshop on Technologies for Information Retrieval (TIR), Lyon, France, 28–31 August 2017. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Mcauley, J.; Leskovec, J. Discovering social circles in ego networks. ACM Trans. Knowl. Discov. Data 2014, 8, 4. [Google Scholar] [CrossRef]
- Ding, C.H.; He, X.; Zha, H.; Gu, M.; Simon, H.D. A min-max cut algorithm for graph partitioning and data clustering. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 107–114. [Google Scholar]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Assoc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef]
- Ziegler, K.; Caelen, O.; Garchery, M.; Granitzer, M.; He-Guelton, L.; Jurgovsky, J.; Portier, P.E.; Zwicklbauer, S. Injecting Semantic Background Knowledge into Neural Networks using Graph Embeddings. In Proceedings of the 2017 IEEE 26th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Poznan, Poland, 21–23 June 2017. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Visualizing deep convolutional neural networks using natural pre-images. Int. J. Comput. Vis. 2016, 120, 233–255. [Google Scholar] [CrossRef]
- Feder, T.; Motwani, R. Clique partitions, graph compression and speeding-up algorithms. In Proceedings of the Twenty-Third Annual ACM Symposium on Theory of Computing, New Orleans, LA, USA, 5–8 May 1991; pp. 123–133. [Google Scholar]
- Newman, M.E. A measure of betweenness centrality based on random walks. Soc. Netw. 2005, 27, 39–54. [Google Scholar] [CrossRef]
- Rojas, R. Neural Networks: A Systematic Introduction; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Goyal, P.; Ferrara, E. Graph Embedding Techniques, Applications, and Performance: A Survey. arXiv, 2017; arXiv:1705.02801. [Google Scholar]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv, 2014; arXiv:1402.3722. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Recht, B.; Re, C.; Wright, S.; Niu, F. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; pp. 693–701. [Google Scholar]
- Janicke, S.; Heine, C.; Hellmuth, M.; Stadler, P.F.; Scheuermann, G. Visualization of graph products. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1082–1089. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar]
- Ou, M.; Cui, P.; Pei, J.; Zhang, Z.; Zhu, W. Asymmetric Transitivity Preserving Graph Embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1105–1114. [Google Scholar]
- Li, J.; Dani, H.; Hu, X.; Tang, J.; Chang, Y.; Liu, H. Attributed Network Embedding for Learning in a Dynamic Environment. arXiv, 2017; arXiv:1706.01860. [Google Scholar]
- Liao, L.; He, X.; Zhang, H.; Chua, T.S. Attributed Social Network Embedding. arXiv, 2017; arXiv:1705.04969. [Google Scholar]
- Okamoto, K.; Chen, W.; Li, X.Y. Ranking of closeness centrality for large-scale social networks. Lect. Notes Comput. Sci. 2008, 5059, 186–195. [Google Scholar]
- Zafarani, R.; Abbasi, M.A.; Liu, H. Social Media Mining: An Introduction; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Borgatti, S.P. Centrality and network flow. Soc. Netw. 2005, 27, 55–71. [Google Scholar] [CrossRef]
- Ferrara, E.; Fiumara, G. Topological features of online social networks. arXiv, 2012; arXiv:1202.0331. [Google Scholar]
- Sun, B.; Mitra, P.; Giles, C.L. Learning to rank graphs for online similar graph search. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 1871–1874. [Google Scholar]
- Agarwal, S. Learning to rank on graphs. Mach. Learn. 2010, 81, 333–357. [Google Scholar] [CrossRef]
- Yazdani, M.; Collobert, R.; Popescu-Belis, A. Learning to rank on network data. In Proceedings of the Eleventh Workshop on Mining and Learning with Graphs, Chicago, IL, USA, 11 August 2013. [Google Scholar]
- Herbrich, R.; Graepel, T.; Obermayer, K. Large margin rank boundaries for ordinal regression. In Advances in Large Margin Classifiers; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, Pennsylvania, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Han, J.; Moraga, C. The influence of the sigmoid function parameters on the speed of backpropagation learning. In From Natural to Artificial Neural Computation; Springer: Berlin/Heidelberg, Germany, 1995; pp. 195–201. [Google Scholar]
- Li, M.; Zhang, T.; Chen, Y.; Smola, A.J. Efficient mini-batch training for stochastic optimization. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 661–670. [Google Scholar]
- Albert, R.; Barabási, A.L. Statistical mechanics of complex networks. Rev. Mod. Phys. 2002, 74, 47. [Google Scholar] [CrossRef]
- Thomas, A. Community Detection for NetworkX’s Documentation. Available online: https://bitbucket.org/taynaud/python-louvain(accessed on 25 September 2017).
- Stephens, M.A. EDF statistics for goodness of fit and some comparisons. J. Am. Stat. Assoc. 1974, 69, 730–737. [Google Scholar] [CrossRef]


{kind=link}
| Google+ | ||||
|---|---|---|---|---|
| nodes | 4,039 | 81,306 | 107,614 | |
| edges | 88,234 | 1,768,149 | 13,673,453 | |
| egos | 10 | 973 | 132 |
| Facebook’s Ego | Nodes | Barabási–Albert’s Ego | nodes | Centrality | KS Statistic | p-Value |
|---|---|---|---|---|---|---|
| 686 | 1826 | 25 | 1871 | degree | 0.12865 | 0.12432 |
| closeness | 0.10099 | 0.35831 | ||||
| betweenness | 0.10684 | 0.29330 | ||||
| eigenvector | 0.07805 | 0.68533 | ||||
| 686 | 1826 | 28 | 1682 | degree | 0.12865 | 0.10042 |
| closeness | 0.14099 | 0.15841 | ||||
| betweenness | 0.05684 | 0.59340 | ||||
| eigenvector | 0.10805 | 0.39473 | ||||
| 414 | 1848 | 25 | 1871 | degree | 0.11865 | 0.13402 |
| closeness | 0.08899 | 0.35851 | ||||
| betweenness | 0.10684 | 0.23456 | ||||
| eigenvector | 0.08805 | 0.69573 | ||||
| 414 | 1848 | 28 | 1682 | degree | 0.13865 | 0.22532 |
| closeness | 0.11543 | 0.35551 | ||||
| betweenness | 0.10334 | 0.25510 | ||||
| eigenvector | 0.06805 | 0.55573 |
| Dataset | Weight | DeepWalk | LINE | Loc | Node2vec(1) | Node2vec(2) |
|---|---|---|---|---|---|---|
| Google+ | ||||||
| Artificial | ||||||
| Centrality | Average Value | Std | Input of the Model | RMSE | NRMSE | CV (RMSE) |
|---|---|---|---|---|---|---|
| degree | 0.012581 | 0.01516 | deepwalk | 0.01848 | 0.09898 | 1.46908 |
| loc | 0.01681 | 0.09000 | 1.33579 | |||
| node2vec(1) | 0.02074 | 0.11108 | 1.64857 | |||
| node2vec(2) | 0.02226 | 0.11919 | 1.76898 | |||
| LINE | 0.03132 | 0.16772 | 2.48925 | |||
| closeness | 0.25302 | 0.02319 | deepwalk | 0.04755 | 0.22282 | 0.18795 |
| loc | 0.03647 | 0.17088 | 0.14413 | |||
| node2vec(1) | 0.05906 | 0.27674 | 0.23342 | |||
| node2vec(2) | 0.06260 | 0.29331 | 0.24740 | |||
| LINE | 0.04695 | 0.21998 | 0.18555 | |||
| betweenness | 0.00105 | 0.01180 | deepwalk | 0.01630 | 0.06905 | 15.44306 |
| loc | 0.02024 | 0.08573 | 19.17428 | |||
| node2vec(1) | 0.01568 | 0.06639 | 14.84949 | |||
| node2vec(2) | 0.01554 | 0.06583 | 14.72446 | |||
| LINE | 0.01761 | 0.07458 | 16.68014 | |||
| eigenvector | 0.01036 | 0.02355 | deepwalk | 0.02412 | 0.25284 | 2.32737 |
| loc | 0.02724 | 0.28549 | 2.62788 | |||
| node2vec(1) | 0.02664 | 0.27918 | 2.56986 | |||
| node2vec(2) | 0.02731 | 0.28625 | 2.63491 | |||
| LINE | 0.02534 | 0.26561 | 2.44495 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salehi Rizi, F.; Granitzer, M. Properties of Vector Embeddings in Social Networks. Algorithms 2017, 10, 109. https://doi.org/10.3390/a10040109
Salehi Rizi F, Granitzer M. Properties of Vector Embeddings in Social Networks. Algorithms. 2017; 10(4):109. https://doi.org/10.3390/a10040109
Chicago/Turabian StyleSalehi Rizi, Fatemeh, and Michael Granitzer. 2017. "Properties of Vector Embeddings in Social Networks" Algorithms 10, no. 4: 109. https://doi.org/10.3390/a10040109
APA StyleSalehi Rizi, F., & Granitzer, M. (2017). Properties of Vector Embeddings in Social Networks. Algorithms, 10(4), 109. https://doi.org/10.3390/a10040109