Game Theory-Inspired Evolutionary Algorithm for Global Optimization


Abstract
:1. Introduction
- A novel game evolutionary algorithm (GameEA) is introduced which is a framework to simulate human game behavior. GameEA includes imitation and belief learning strategies and a payoff expectation mechanism. Learning strategies are used to improve competitiveness of the players, while the payoff expectation formulation is employed to estimate and master the information of the players.
- We compared GameEA with the standard genetic algorithm (StGA) [24], island-model genetic algorithms (IMGA) [25], finding multimodal solutions using restricted tournament selection (RTS) [26], dual-population genetic algorithm (DPGA) [27], and GameEA outperforms the compared four algorithms in terms of stability and accuracy.
2. Related Works
3. Proposed Algorithm: GameEA
3.1. Fundamentals of GameEA
- Stable payoffs are achieved by a player after winning against an opponent and another challenger.
- If a player accepts a game, then he/she can learn something from the opponent whether he/she losses or wins, which indirectly influences future competition.
- If a player gives up in a competition, then he/she can improve by self-training.
3.2. Framework of Proposed Algorithm
| Algorithm 1. GameEA. |
| Begin |
| 1. t: = 1; // iteration number |
| 2. Initialize players set I, Iia:= 0, and Iip:= 0 (|It| = N, 0 < I < N); // Initialize players population for iteration |
| 3. Evaluate f(I); // for each Ii of I, evaluate Iiobj; |
| 4. while t > Tmax do |
| 5. Select 2 different competitors Ii and Ij from I; |
| 6. Refresh the payoff of Ii and Ij: Iiv:= Iia + Iip, Ijv:= Ija + Ijp; // the following steps are responsible to reproduce a new player Ii |
| 7. if Iiv == 0 && random() < P1 then Perform imitation operator : Ii = imitation(Ii, Ij); |
| 8. else |
| 9. Calculate the expectation payoffs E(Ii) of Ii using Equation (3); |
| 10. if E(Ii) > 0 then Perform imitation operator: Ii = imitation(Ii, Ij); |
| 11. else if random() < P2 then Perform belief learning operator: Ii = beliefLearning(Ii); |
| 12. t: = t + 1; |
| 14. end while |
| end |
3.3. Initialization Players Population
3.4. Imitation Operator
- (1)
- Ip.gen[r2] = 0.5(1 − τ) Ii.gen[r2] + (1 + τ) Ij.gen[r1].
- (2)
- If the value of Ip.gen[r2] is out of range, then a random value must be assigned to Ip.gen[r2].
- (3)
- Ii strategically copies a segment of genes from Ij via Ip.gen[r1] = 0.5(1 − τ) Ii.gen[r1] + (1 + τ) Ij.gen[r1].
- (4)
- If the value of Ip.gen[r1] is out of the decision space, then a random value must be assigned to Ip.gen[r1].
| Algorithm 2. Imitation (Ii, Ij). |
| Begin |
| 1. if Iiobj < Ijobj then Iia:= Iia + 1; |
| 2. else Ijp = Ijp + 1; |
| 3. Initialize temporary variable Ip = Ii and B:= 0; |
| 4. if (random() × (Ha + 1)/(2Hs + 1)) < P3 then |
| 5. Modify genes of Ip by speculatively learning from Ij; |
| 6. B = 1 and Ha = Ha + 1; |
| 7. else change genes of Ii by strategically copying a segment of genes from Ij; |
| 8. update the objectives value Ipobj; |
| 9. if Ipobj < Iiobj then Ii = Ip ; |
| 10. if B == 1 then Hs = Hs + 1; |
| 11. return Ii; |
| end |
3.5. Belief Learning Operator
| Algorithm 3. Belieflearning(Ii). // for real-valued presentation. |
| Begin |
| 1. r1:= rand(0, n − 1), β:= random() |
| 2. Δ:= difference of maximum and minimum value of r1th dimension |
| 3. if β < 0.5 then τ = (2β)1/21 − 1 |
| 4. else τ =1 − (2 − 2β)1/21 |
| 5. Ii.gen[r1] = Ii.gen[r1] + τ × Δ |
| 6. if the value of Ip.gen[r1] out of the given ranges |
| 7. then assign a required random value to Ip.gen[r1] |
| end |
3.6. Players Set Updating Strategy
4. Performance Comparison and Experimental Results
4.1. Test Problems and Compared Algorithms
4.2. Experimental Setup
4.3. Results and Comparision Analysis
5. Conclusions
Acknowledgments
Conflicts of Interest
References
- Dorigo, M.; Gambardella, L.M. Ant colony system: A cooperative learning approach to the traveling salesman problem. IEEE Trans. Evol. Comput. 1997, 1, 53–66. [Google Scholar] [CrossRef]
- Yang, X. Firefly algorithm, stochastic test functions and design optimisation. Int. J. BioInspir. Comput. 2010, 2, 78–84. [Google Scholar] [CrossRef]
- Li, X.; Shao, Z.; Qian, J. An optimizing method based on autonomous animats: Fish-swarm algorithm. Syst. Eng. Theory Pract. 2002, 22, 32–38. [Google Scholar]
- Neshat, M.; Sepidnam, G.; Sargolzaei, M.; Toosi, A.N. Artificial fish swarm algorithm: A survey of the state-of-the-art, hybridization, combinatorial and indicative applications. Artif. Intell. Rev. 2014, 42, 965–997. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Mernik, M.; Liu, S.; Karaboga, D.; Črepinšek, M. On clarifying misconceptions when comparing variants of the Artificial Bee Colony Algorithm by offering a new implementation. Inf. Sci. 2015, 291, 115–127. [Google Scholar] [CrossRef]
- Yang, X.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009. [Google Scholar]
- Woldemariam, K.M.; Yen, G.G. Vaccine-Enhanced Artificial Immune System for Multimodal Function Optimization. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40, 218–228. [Google Scholar] [CrossRef] [PubMed]
- Maass, W.; Natschläger, T.; Markram, H. Real-time computing without stable states: A new framework for neural computation based on perturbations. Neural Comput. 2002, 14, 2531–2560. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y. Brain storm optimization algorithm. In Advances in Swarm Intelligence; Springer: Berlin, Germany, 2011; pp. 303–309. [Google Scholar]
- Wikipedia. Game Theory. Available online: https://en.wikipedia.org/wiki/Game_theory (accessed on 3 March 2016).
- Madani, K.; Hooshyar, M. A game theory-reinforcement learning (GT-RL) method to develop optimal operation policies for multi-operator reservoir systems. J. Hydrol. 2014, 519, 732–742. [Google Scholar] [CrossRef]
- Spiliopoulos, L. Pattern recognition and subjective belief learning in a repeated constant-sum game. Games Econ. Behav. 2012, 75, 921–935. [Google Scholar] [CrossRef] [Green Version]
- Friedman, D.; Huck, S.; Oprea, R.; Weidenholzer, S. From imitation to collusion: Long-run learning in a low-information environment. J. Econ. Theory 2015, 155, 185–205. [Google Scholar] [CrossRef]
- Nax, H.H.; Perc, M. Directional learning and the provisioning of public goods. Sci. Rep. 2015, 5, 8010. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Anderson, S.P.; Goeree, J.K.; Holt, C.A. Stochastic Game Theory: Adjustment to Equilibrium under Noisy Directional Learning; University of Virginia: Charlottesville, VA, USA, 1999. [Google Scholar]
- Stahl, D.O. Rule learning in symmetric normal-form games: Theory and evidence. Games Econ. Behav. 2000, 32, 105–138. [Google Scholar] [CrossRef]
- Nowak, M.A.; Sigmund, K. Evolutionary Dynamics of Biological Games. Science 2004, 303, 793–799. [Google Scholar] [CrossRef] [PubMed]
- Gwak, J.; Sim, K.M. A novel method for coevolving PS-optimizing negotiation strategies using improved diversity controlling EDAs. Appl. Intell. 2013, 38, 384–417. [Google Scholar] [CrossRef]
- Gwak, J.; Sim, K.M.; Jeon, M. Novel dynamic diversity controlling EAs for coevolving optimal negotiation strategies. Inf. Sci. 2014, 273, 1–32. [Google Scholar] [CrossRef]
- Rosenstrom, T.; Jylha, P.; Pulkki-Raback, L.; Holma, M.; Raitakari, I.T.; Isometsa, E.; Keltikangas-Jarvinen, L. Long-term personality changes and predictive adaptive responses after depressive episodes. Evol. Hum. Behav. 2015, 36, 337–344. [Google Scholar] [CrossRef]
- Szubert, M.; Jaskowski, W.; Krawiec, K. On Scalability, Generalization, and Hybridization of Coevolutionary Learning: A Case Study for Othello. IEEE Trans. Comput. Intell. AI Games 2013, 5, 214–226. [Google Scholar] [CrossRef]
- Yang, G.C.; Wang, Y.; Li, S.B.; Xie, Q. Game evolutionary algorithm based on behavioral game theory. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2016, 7, 68–73. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Alba, E.; Tomassini, M. Parallelism and evolutionary algorithms. IEEE Trans. Evol. Comput. 2002, 6, 443–462. [Google Scholar] [CrossRef]
- Harik, G.R. Finding Multimodal Solutions Using Restricted Tournament Selection. In Proceedings of the 6th International Conference on Genetic Algorithms, San Francisco, CA, USA, 15–19 July 1995. [Google Scholar]
- Park, T.; Ryu, K.R. A Dual-Population Genetic Algorithm for Adaptive Diversity Control. IEEE Trans. Evol. Comput. 2010, 14, 865–884. [Google Scholar] [CrossRef]
- Kontogiannis, S.; Spirakis, P. Evolutionary games: An algorithmic view. In Lecture Notes in Computer Science; Babaoglu, O., Jelasity, M., Montresor, A., Eds.; Springer: Berlin, Germany, 2005; pp. 97–111. [Google Scholar]
- Ganesan, T.; Elamvazuthi, I.; Vasant, P. Multiobjective design optimization of a nano-CMOS voltage-controlled oscillator using game theoretic-differential evolution. Appl. Soft Comput. 2015, 32, 293–299. [Google Scholar] [CrossRef]
- Liu, W.; Wang, X. An evolutionary game based particle swarm optimization algorithm. J. Comput. Appl. Math. 2008, 214, 30–35. [Google Scholar] [CrossRef]
- Koh, A. An evolutionary algorithm based on Nash Dominance for Equilibrium Problems with Equilibrium Constraints. Appl. Soft Comput. 2012, 12, 161–173. [Google Scholar] [CrossRef]
- He, J.; Yao, X. A game-theoretic approach for designing mixed mutation strategies. In Lecture Notes in Computer Science; Wang, L., Chen, K., Ong, Y.S., Eds.; Springer: Berlin, Germany, 2005; pp. 279–288. [Google Scholar]
- Periaux, J.; Chen, H.Q.; Mantel, B.; Sefrioui, M.; Sui, H.T. Combining game theory and genetic algorithms with application to DDM-nozzle optimization problems. Finite Elem. Anal. Des. 2001, 37, 417–429. [Google Scholar] [CrossRef]
- Lee, D.; Gonzalez, L.F.; Periaux, J.; Srinivas, K.; Onate, E. Hybrid-Game Strategies for multi-objective design optimization in engineering. Comput. Fluids 2011, 47, 189–204. [Google Scholar] [CrossRef] [Green Version]
- Dorronsoro, B.; Burguillo, J.C.; Peleteiro, A.; Bouvry, P. Evolutionary Algorithms Based on Game Theory and Cellular Automata with Coalitions. In Handbook of Optimization: From Classical to Modern Approach; Zelinka, I., Snášel, V., Abraham, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 481–503. [Google Scholar]
- Greiner, D.; Periaux, J.; Emperador, J.M.; Galván, B.; Winter, G. Game Theory Based Evolutionary Algorithms: A Review with Nash Applications in Structural Engineering Optimization Problems. Arch Comput. Method E 2016. [Google Scholar] [CrossRef]
- Niyato, D.; Hossain, E.; Zhu, H. Dynamics of Multiple-Seller and Multiple-Buyer Spectrum Trading in Cognitive Radio Networks: A Game-Theoretic Modeling Approach. IEEE Trans. Mob. Comput. 2009, 8, 1009–1022. [Google Scholar] [CrossRef]
- Wei, G.; Vasilakos, A.V.; Zheng, Y.; Xiong, N. A game-theoretic method of fair resource allocation for cloud computing services. J. Supercomput. 2010, 54, 252–269. [Google Scholar] [CrossRef]
- Jiang, G.; Shen, S.; Hu, K.; Huang, L.; Li, H.; Han, R. Evolutionary game-based secrecy rate adaptation in wireless sensor networks. Int. J. Distrib. Sens. N 2015, 2015, 25. [Google Scholar] [CrossRef]
- Tembine, H.; Altman, E.; El-Azouzi, R.; Hayel, Y. Evolutionary Games in Wireless Networks. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40, 634–646. [Google Scholar] [CrossRef] [PubMed]
- Fontanari, J.F.; Perlovsky, L.I. A game theoretical approach to the evolution of structured communication codes. Theory Biosci. 2008, 127, 205–214. [Google Scholar] [CrossRef] [PubMed]
- Mejia, M.; Pena, N.; Munoz, J.L.; Esparza, O.; Alzate, M.A. A game theoretic trust model for on-line distributed evolution of cooperation in MANETs. J. Netw. Comput. Appl. 2011, 34, 39–51. [Google Scholar] [CrossRef]
- Bulo, S.R.; Torsello, A.; Pelillo, M. A game-theoretic approach to partial clique enumeration. Image Vis. Comput. 2009, 27, 911–922. [Google Scholar] [CrossRef] [Green Version]
- Misra, S.; Sarkar, S. Priority-based time-slot allocation in wireless body area networks during medical emergency situations: An evolutionary game-theoretic perspective. IEEE J. Biomed. Health 2015, 19, 541–548. [Google Scholar] [CrossRef] [PubMed]
- Qin, Z.; Wan, T.; Dong, Y.; Du, Y. Evolutionary collective behavior decomposition model for time series data mining. Appl. Soft Comput. 2015, 26, 368–377. [Google Scholar] [CrossRef]
- Hausknecht, M.; Lehman, J.; Miikkulainen, R.; Stone, P. A neuroevolution approach to general atari game playing. IEEE Trans. Comput. Intell. AI Games 2014, 6, 355–366. [Google Scholar] [CrossRef]
- Hu, H.; Stuart, H.W. An epistemic analysis of the Harsanyi transformation. Int. J. Game Theory 2002, 30, 517–525. [Google Scholar] [CrossRef]
- Colman, A.M. Cooperation, psychological game theory, and limitations of rationality in social interaction. Behav. Brain Sci. 2003, 26, 139. [Google Scholar] [CrossRef] [PubMed]
- Borgers, T.; Sarin, R. Learning through reinforcement and replicator dynamics. J. Econ. Theory 1997, 77, 1–14. [Google Scholar] [CrossRef]
- Reynolds, R.G. Cultural algorithms: Theory and applications. In New Ideas in Optimization; Corne, D., Dorigo, M., Glover, F., Eds.; McGraw-Hill Ltd.: Maidenhead, UK, 1999; pp. 367–378. [Google Scholar]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Draa, A. On the performances of the flower pollination algorithm—Qualitative and quantitative analyses. Appl. Soft Comput. 2015, 34, 349–371. [Google Scholar] [CrossRef]
- Veček, N.; Mernik, M.; Črepinšek, M. A chess rating system for evolutionary algorithms: A new method for the comparison and ranking of evolutionary algorithms. Inf. Sci. 2014, 277, 656–679. [Google Scholar] [CrossRef]
- GitHub, Inc. (US). Available online: https://github.com/simonygc/GameEA.git (accessed on 14 July 2017).
- Fernandes, F.E.; Guanci, Y.; Do, H.M. Detection of privacy-sensitive situations for social robots in smart homes. In Proceedings of the 2016 IEEE International Conference on Automation Science and Engineering (CASE), Fort Worth, TX, USA, 21–25 August 2016. [Google Scholar]


{kind=link}
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| Tmax | Maximum of game iteration number | N | Size of players/population |
| W1 | Payoffs weight | W2 | Losses weight |
| P1 | Imitation probability | P2 | Learning probability |
| P3 | speculative probability | n | Dimension of problem |
| T | tth game generation | Ha | Total number of speculation |
| Hs | Total number of successful speculation | Ii | ith player/individual |
| Iia | Active payoff of game of Ii | Iip | Passive payoff of game of Ii |
| Iiobj | objectives of Ii | Iiv | Total payoffs of Ii |
| No. | Name | n | Function | Range |
|---|---|---|---|---|
| f1 | Sphere | 30 | xi ∈ [−100, 100] | |
| f2 | Schwefel 2.22 | 30 | xi ∈ [−10, 10] | |
| f3 | Schwefel 2.21 | 30 | xi ∈ [−100, 100] | |
| f4 | Rosenbrock | 30 | xi ∈ [−30, 30] | |
| f5 | Step | 30 | xi ∈ [−100, 100] | |
| f6 | Noisy Quartic | 30 | xi ∈ [−1.28, 1.28] | |
| f7 | Goldstein-price | 2 | xi ∈ [−2, 2] | |
| f8 | Branin | 2 | x1 ∈ [−5, 10]x2 ∈ [0, 15] | |
| f9 | Six-hump camelback | 2 | xi ∈ [−5, 5]n | |
| f10 | Rastrigin | 30 | xi ∈ [−5.12, 5.12] | |
| f11 | Griewank | 30 | xi ∈ [−600, 600] | |
| f12 | Schwefel 2.26 | 30 | xi ∈ [−500, 500] | |
| f13 | Ackley | 30 | xi ∈ [−32, 32] |
| Iteration | Optimum Solution | StGA | IMGA | RTS | DPGA | GameEA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Average | Standard Deviation | Average | Standard Deviation | Average | Standard Deviation | Average | Standard Deviation | Average | Standard Deviation | |||
| f1 | 1.5 × 105 | 0 | 6.12 × 10−34 | 1.27 × 10−38 | 2.04 × 10−34 | 5.23 × 10−34 | 7.90 × 10−43 | 1.74 × 10−42 | 1.47 × 10−52 | 4.17 × 10−52 | 4.33 × 10−96 | 2.79 × 10−95 |
| f2 | 2.0 × 105 | 0 | 3.32 × 10−29 | 1.78 × 10−28 | 6.40 × 10−32 | 1.36 × 10−31 | 7.18 × 10−37 | 6.19 × 10−37 | 5.19 × 10−45 | 7.90 × 10−45 | 1.52 × 10−66 | 4.61 × 10−66 |
| f3 | 5.0 × 105 | 0 | 7.00 × 10−15 | 1.37 × 10−14 | 4.28 × 10–6 | 3.64 × 10−6 | 1.54 × 10−5 | 1.91 × 10−5 | 3.12 × 10−9 | 1.18 × 10−8 | 7.85 × 10−4 | 2.26 × 10−3 |
| f4 | 2.0 × 106 | 0 | 5.454 | 3.662 | 5.554 | 4.522 | 1.391 | 1.211 | 3.047 | 3.558 | 0.0374 | 0.264 |
| f5 | 1.5 × 105 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| f6 | 3.0 × 105 | 0 | 1.37 × 10−2 | 3.24 × 10−3 | 7.52 × 10−3 | 2.24 × 10−3 | 1.82 × 10−3 | 4.56 × 10−4 | 1.46 × 10−2 | 3.93 × 10−3 | 7.66 × 10−3 | 1.82 × 10−3 |
| f7 | 1.0 × 104 | 3 | 3 | 0 | 3 | 0 | 3 | 0 | 3 | 0 | 3 | 0 |
| f8 | 1.0 × 104 | 0.398 | 0.398 | 0 | 0.398 | 0 | 0.398 | 0 | 0.398 | 0 | 0.398 | 0 |
| f9 | 1.0 × 104 | −1.032 | −1.032 | 0 | −1.032 | 0 | −1.032 | 0 | −1.032 | 0 | −1.032 | 0 |
| f10 | 5.0 × 105 | 0 | 11.809 | 2.369 | 0.358 | 0.746 | 0 | 0 | 0 | 0 | 0 | 0 |
| f11 | 2.0 × 105 | 0 | 1.63 × 10−3 | 3.91 × 10−3 | 3.54 × 10−3 | 7.73 × 10−3 | 2.07 × 10−3 | 5.31 × 10−3 | 1.28 × 10−3 | 3.31 × 10−3 | 0 | 0 |
| f12 | 9.0 × 105 | −12,569.4866 | −11,195.1 | 284.5 | −12,008.1 | 284.9 | −12,443.9 | 142.4 | −12,550.5 | 43.9 | −12,569.4866 | 0 |
| f13 | 1.5 × 105 | 0 | 3.55 × 10−15 | 0 | 4.69 × 10−15 | 1.67 × 10−15 | 5.26 × 10−15 | 1.79 × 10−15 | 3.55 × 10−15 | 0 | 6.84 × 10−16 | 1.30 × 10−15 |
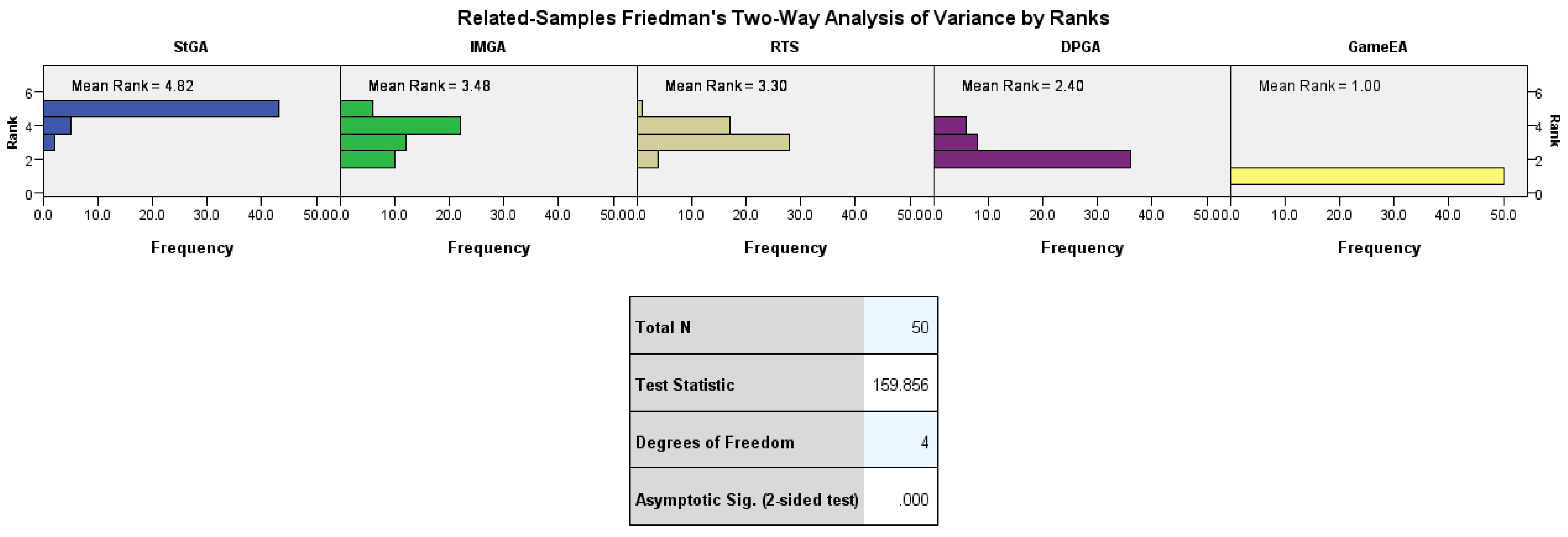
| Function | Null Hypothesis | Test | Decision | Results of Pairwise Comparisons (GameEA Versus) | |||
|---|---|---|---|---|---|---|---|
| StGA | IMGA | RTS | DPGA | ||||
| f1 | The distributions of StGA, IMGA, RTS, DPGA and GameEA are the same. | Related-Samples Friedman’s Two-Way Analysis of Variance by Ranks | Reject the null hypothesis | Reject | Reject | Reject | Reject |
| f2 | Reject the null hypothesis | Reject | Retain | Retain | Retain | ||
| f3 | Reject the null hypothesis | Reject | Retain | Retain | Retain | ||
| f4 | Reject the null hypothesis | Reject | Reject | Reject | Reject | ||
| f6 | Retain the null hypothesis | Retain | Retain | Retain | Retain | ||
| f10 | Reject the null hypothesis | Reject | Reject | Retain | Retain | ||
| f11 | Reject the null hypothesis | Reject | Reject | Reject | Reject | ||
| f12 | Reject the null hypothesis | Reject | Reject | Reject | Reject | ||
| f13 | Retain the null hypothesis | Retain | Retain | Retain | Retain | ||
| Sample 1-Sample 2 | Test Statistic | Standard Error | Standard Test Statistic | Significance | Adjust Significance |
|---|---|---|---|---|---|
| GameEA-DPGA | 1.400 | 0.316 | 4.427 | 0.000 | 0.000 |
| GameEA-RTS | 2.300 | 0.316 | 7.273 | 0.000 | 0.000 |
| GameEA-IMGA | 2.480 | 0.316 | 7.842 | 0.000 | 0.000 |
| GameEA-StGA | 3.820 | 0.316 | 12.080 | 0.000 | 0.000 |
| DPGA-RTS | 0.900 | 0.316 | 2.846 | 0.004 | 0.044 |
| DPGA-IMGA | 1.080 | 0.316 | 3.415 | 0.001 | 0.006 |
| DPGA-StGA | 2.420 | 0.316 | 7.653 | 0.000 | 0.000 |
| RTS-IMGA | 0.180 | 0.316 | 0.569 | 0.569 | 1.000 |
| RTS-StGA | 1.520 | 0.316 | 4.807 | 0.000 | 0.000 |
| IMGA-StGA | 1.340 | 0.316 | 4.237 | 0.000 | 0.000 |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, G. Game Theory-Inspired Evolutionary Algorithm for Global Optimization. Algorithms 2017, 10, 111. https://doi.org/10.3390/a10040111
Yang G. Game Theory-Inspired Evolutionary Algorithm for Global Optimization. Algorithms. 2017; 10(4):111. https://doi.org/10.3390/a10040111
Chicago/Turabian StyleYang, Guanci. 2017. "Game Theory-Inspired Evolutionary Algorithm for Global Optimization" Algorithms 10, no. 4: 111. https://doi.org/10.3390/a10040111
APA StyleYang, G. (2017). Game Theory-Inspired Evolutionary Algorithm for Global Optimization. Algorithms, 10(4), 111. https://doi.org/10.3390/a10040111