Simple Iterative Method for Generating Targeted Universal Adversarial Perturbations


Abstract
:1. Introduction
2. Materials and Methods
2.1. Targeted Universal Adversarial Perturbations
| Algorithm 1 Computation of a targeted UAP. |
| Input: Set of input images, target class y, classifier , cap on the norm of the perturbation, norm type p (1, 2, or ∞), maximum number of iterations. Output: Targeted UAP vector . 1: , , 2: while and do 3: for in random order do 4: if then 5: 6: if then 7: 8: end if 9: end if 10: end for 11: 12: 13: end while |
2.2. Deep Neural Network Models and Image Datasets
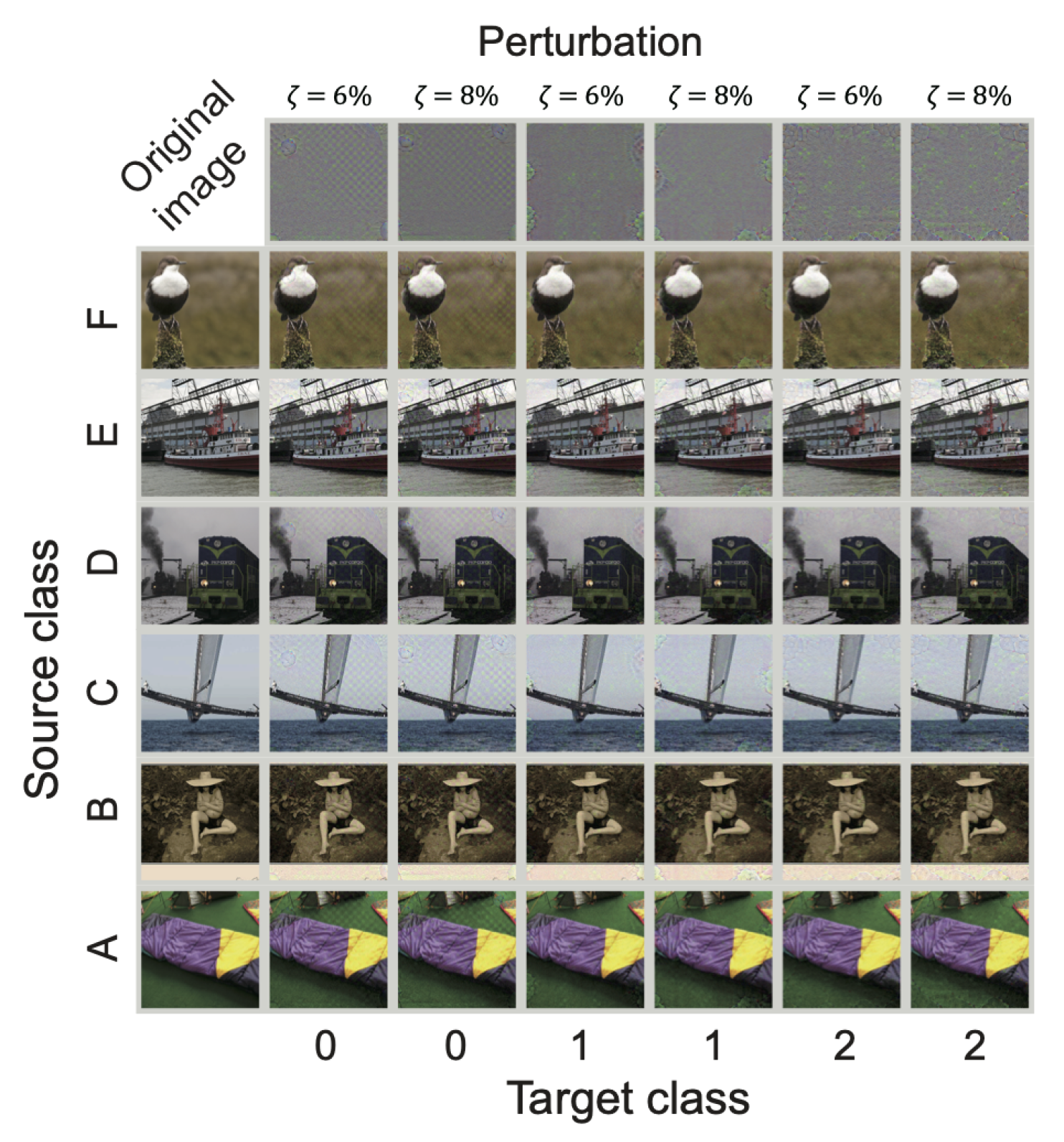
2.3. Generating Targeted Adversarial Perturbations and Evaluating Their Performance
3. Results and Discussion
3.1. Case of the CIFAR-10 Models
3.2. Case of ImageNet Models
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DNN | Deep neural network |
| FGSM | Fast gradient signed method |
| GAN | Generative adversarial network |
| ILSVRC2012 | Large Scale Visual Recognition Challenge 2012 |
| ResNet | Residual network |
| UAP | Universal adversarial perturbation |
| VGG | Visual geometry group |
References
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition. Neural Netw. 2015, 32, 323–332. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial examples: Attacks and defenses for deep learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Machado, G.R.; Silva, E.; Goldschmidt, R.R. Adversarial machine learning in image classification: A survey towards the defender’s perspective. arXiv 2020, arXiv:2009.03728. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Mohsen, S.; Fawzi, A.; Frossard, P. DeepFool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Matyasko, A.; Chau, L.-P. Improved network robustness with adversary critic. arXiv 2018, arXiv:1810.12576. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chaubey, A.; Agrawal, N.; Barnwal, K.; Guliani, K.K.; Mehta, P. Universal adversarial perturbations: A survey. arXiv 2020, arXiv:2005.08087. [Google Scholar]
- Finlayson, S.G.; Bowers, J.D.; Ito, J.; Zittrain, J.L.; Beam, A.L.; Kohane, I.S. Adversarial attacks on medical machine learning. Science 2019, 363, 1287–1289. [Google Scholar] [CrossRef] [PubMed]
- Khrulkov, V.; Oseledets, I. Art of singular vectors and universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Mopuri, K.R.; Ojha, U.; Garg, U.; Babu, R.V. NAG: Network for adversary generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S.; Dong, Y.; Liao, F.; Liang, M.; Pang, T.; Zhu, J.; Hu, X.; Xie, C.; et al. Adversarial attacks and defences competition. In The NIPS ’17 Competition: Building Intelligent Systems; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 195–231. [Google Scholar]
- Hayes, J.; Danezis, G. Learning universal adversarial perturbations with generative models. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 24 May 2018; pp. 43–49. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial patch. arXiv 2017, arXiv:1712.09665. [Google Scholar]
- Nicolae, M.-I.; Sinn, M.; Tran, M.N.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; et al. Adversarial Robustness Toolbox v1.0.1. arXiv 2018, arXiv:1807.01069. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Taghanaki, S.A.; Das, A.; Hamarneh, G. Vulnerability analysis of chest X-ray image classification against adversarial attacks. In Understanding and Interpreting Machine Learning in Medical Image Computing Applications; Springer: Cham, Switzerland, 2018; pp. 87–94. [Google Scholar]
- Morgulis, N.; Kreines, A.; Mendelowitz, S.; Weisglass, Y. Fooling a real car with adversarial traffic signs. arXiv 2019, arXiv:1907.00374. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Target Class | Model | ||||
|---|---|---|---|---|---|
| Input | Test | Input | Test | ||
| Golf ball | VGG-16 | 58.0% | 57.6% | 81.6% | 80.6% |
| VGG-19 | 55.3% | 55.2% | 81.3% | 80.1% | |
| ResNet-50 | 66.8% | 66.5% | 90.3% | 89.8% | |
| Broccoli | VGG-16 | 29.3% | 29.0% | 59.7% | 59.5% |
| VGG-19 | 31.2% | 30.5% | 59.7% | 59.4% | |
| ResNet-50 | 46.4% | 46.6% | 74.6% | 73.9% | |
| Stone wall | VGG-16 | 47.1% | 46.7% | 75.0% | 74.5% |
| VGG-19 | 48.4% | 48.1% | 73.9% | 72.9% | |
| ResNet-50 | 74.7% | 74.4% | 92.0% | 91.3% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hirano, H.; Takemoto, K. Simple Iterative Method for Generating Targeted Universal Adversarial Perturbations. Algorithms 2020, 13, 268. https://doi.org/10.3390/a13110268
Hirano H, Takemoto K. Simple Iterative Method for Generating Targeted Universal Adversarial Perturbations. Algorithms. 2020; 13(11):268. https://doi.org/10.3390/a13110268
Chicago/Turabian StyleHirano, Hokuto, and Kazuhiro Takemoto. 2020. "Simple Iterative Method for Generating Targeted Universal Adversarial Perturbations" Algorithms 13, no. 11: 268. https://doi.org/10.3390/a13110268
APA StyleHirano, H., & Takemoto, K. (2020). Simple Iterative Method for Generating Targeted Universal Adversarial Perturbations. Algorithms, 13(11), 268. https://doi.org/10.3390/a13110268