Graphs from Features: Tree-Based Graph Layout for Feature Analysis

 , , and
, , and 
Abstract
:
1. Introduction
- The proposal of a graph layout strategy for feature analysis based on circular node placement guided by similarity trees, followed by on-demand edge drawing.
- The proposal of a framework that combines that tree layout with other visual elements anda data representations to support graph based feature analysis.
- An open source tool to implement the ideas of this paper, immediately applicable to data sets in the order of a few thousand points and a few hundred attributes.
2. Related Work
2.1. Automatic Graph-Based Feature Selection Methods
2.2. Visual Feature Selection
3. The Graphs from Features Approach
- When one builds a similarity graph having all the attributes in a dataset as vertices and the similarity between vertices represented by weights on the edges, both the minimum spanning tree and the neighbor joining tree built from that graph have the property of placing the most similar items in neighboring branches.
- When one uses the structure of either tree to layout nodes on the screen radially, it is likely to have, as a consequence of the dissimilarity measure and layout algorithms, similar nodes in the same screen space, and bridging nodes in the middle, which in turn supports visually finding groups of similar features when graph edges are added to the layout.
- When one represents features that way, he or she is capable of finding attributes with similar relevance as well as with different relevance by, respectively, locating them in the same or in opposite neighborhoods (by adding edges with low and high values respectively). Both types of observations are necessary in feature set studies.
4. Methodology
4.1. Feature Relevance
4.2. Graph Construction
4.3. Tree Construction
4.4. Visualization and Interaction
4.5. Projection
4.6. Implementation
5. Results
5.1. Graphs from Features
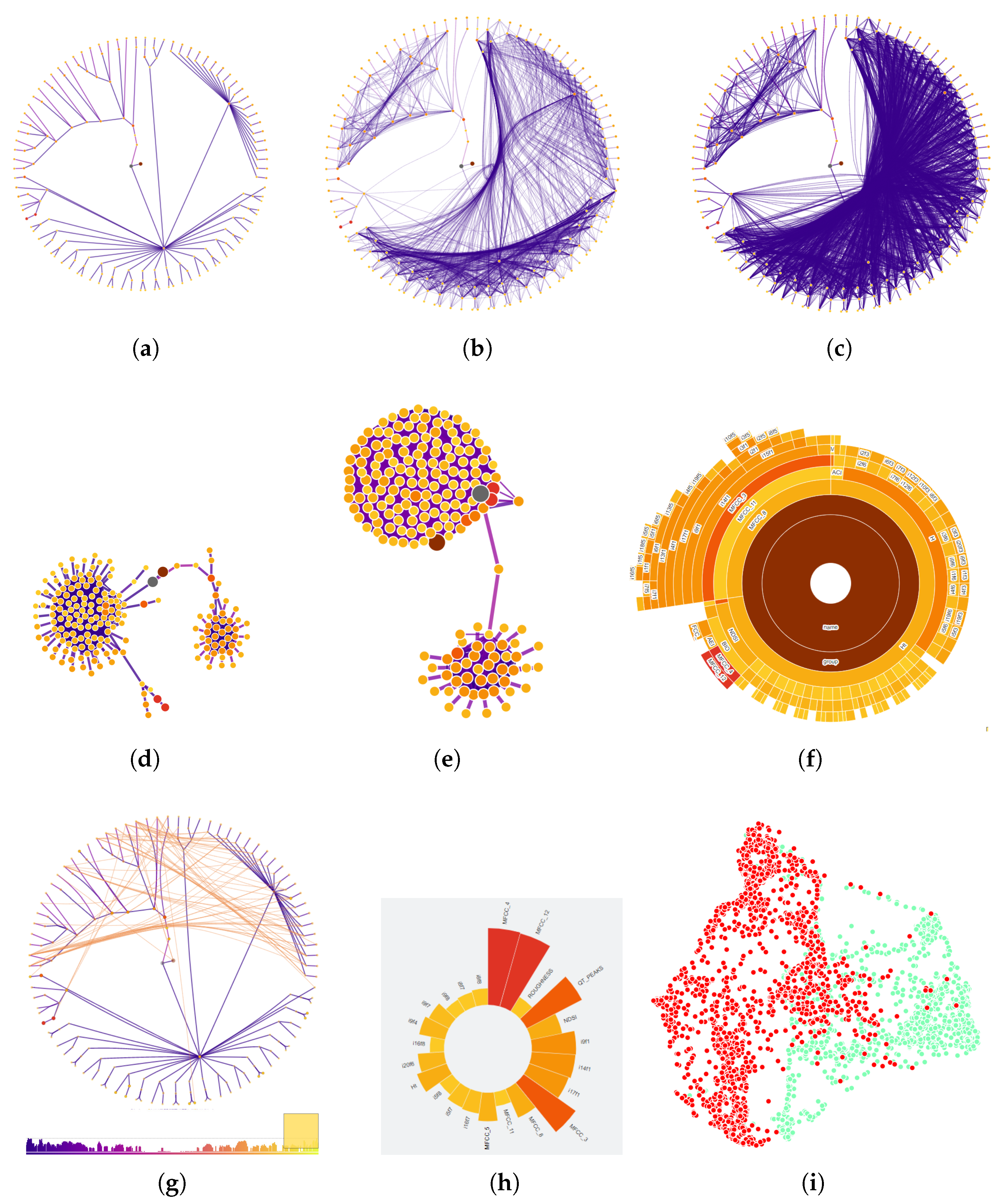
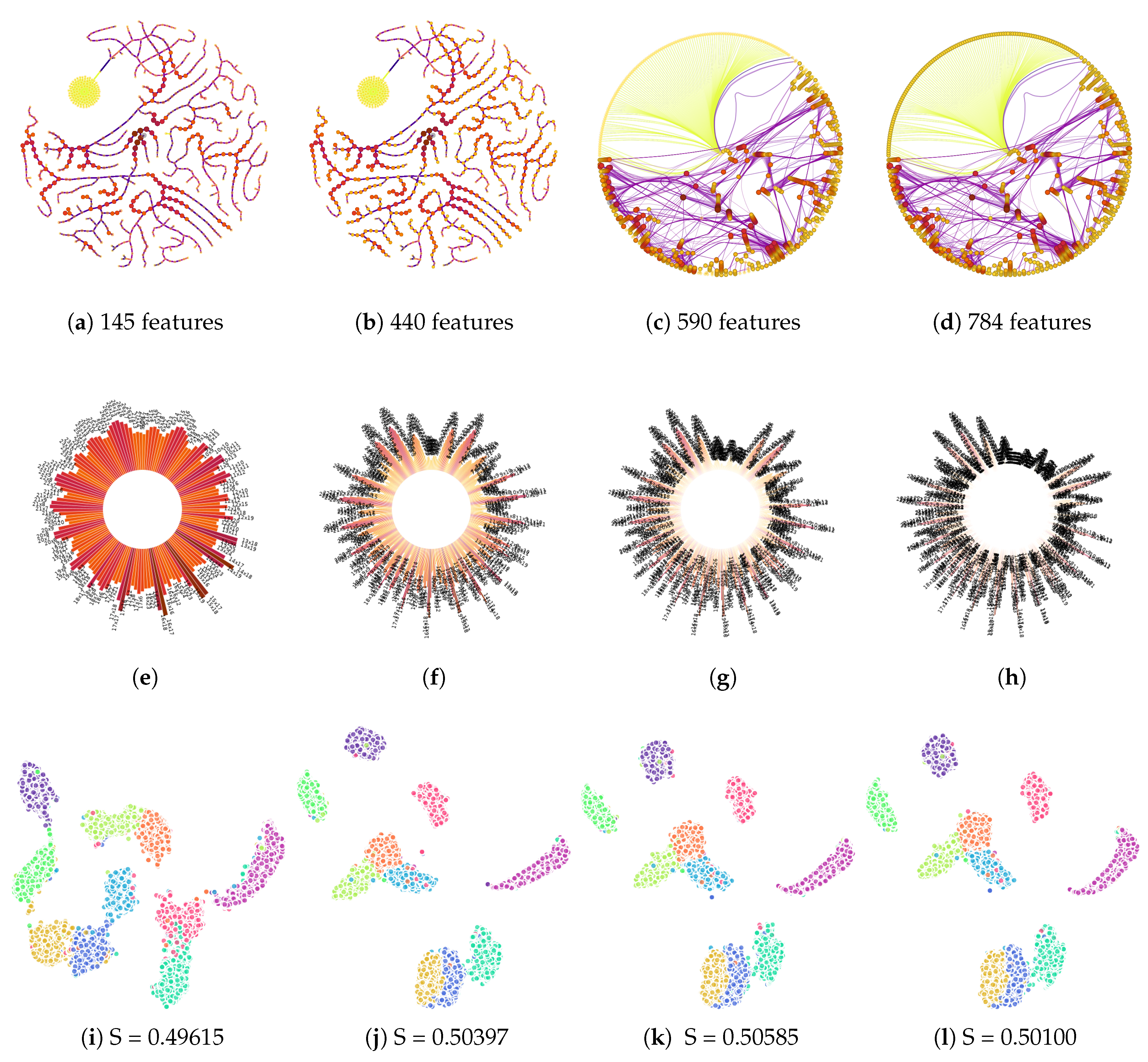
5.1.1. Exploring Features
5.1.2. Identifying Groups of features
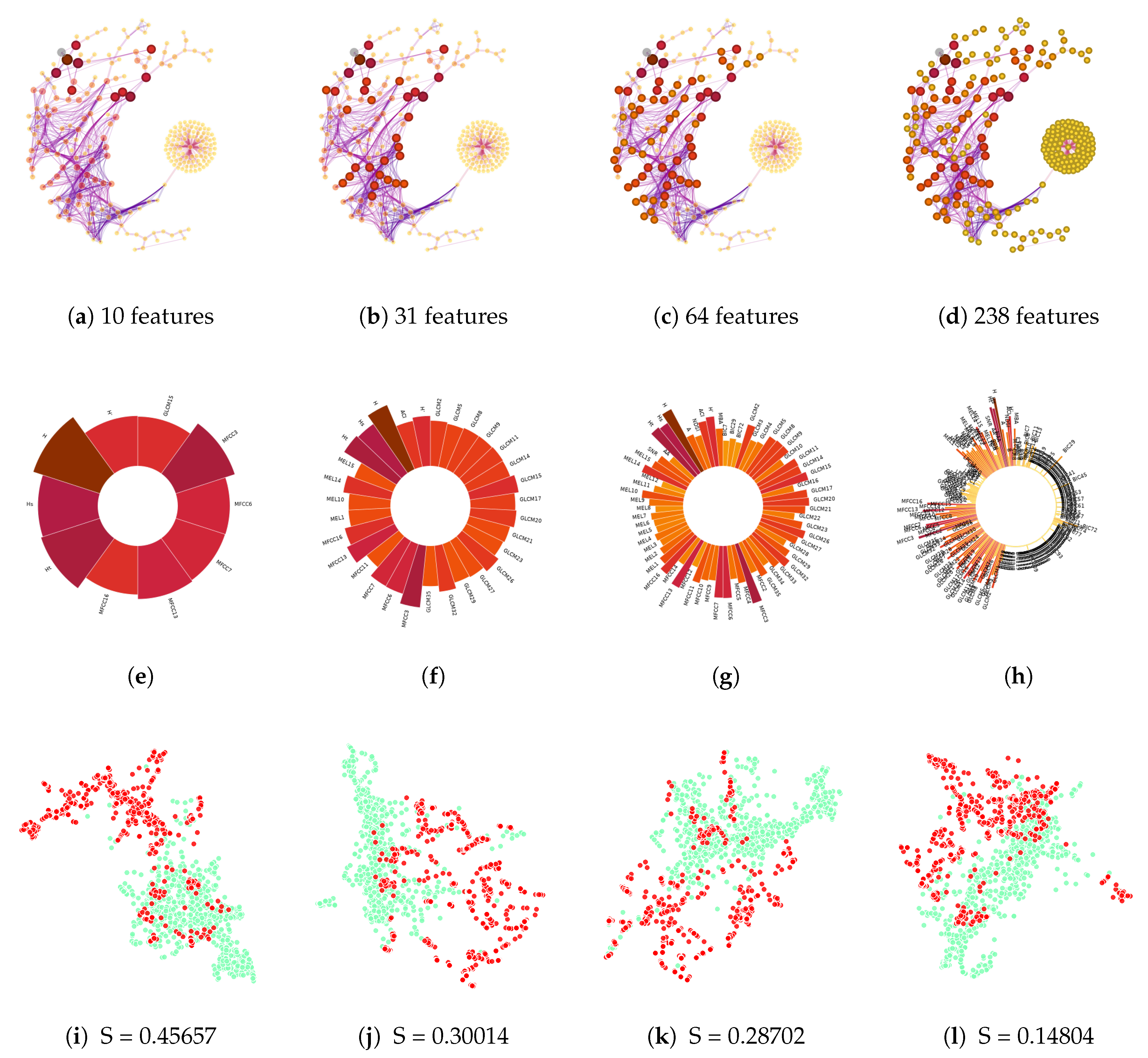
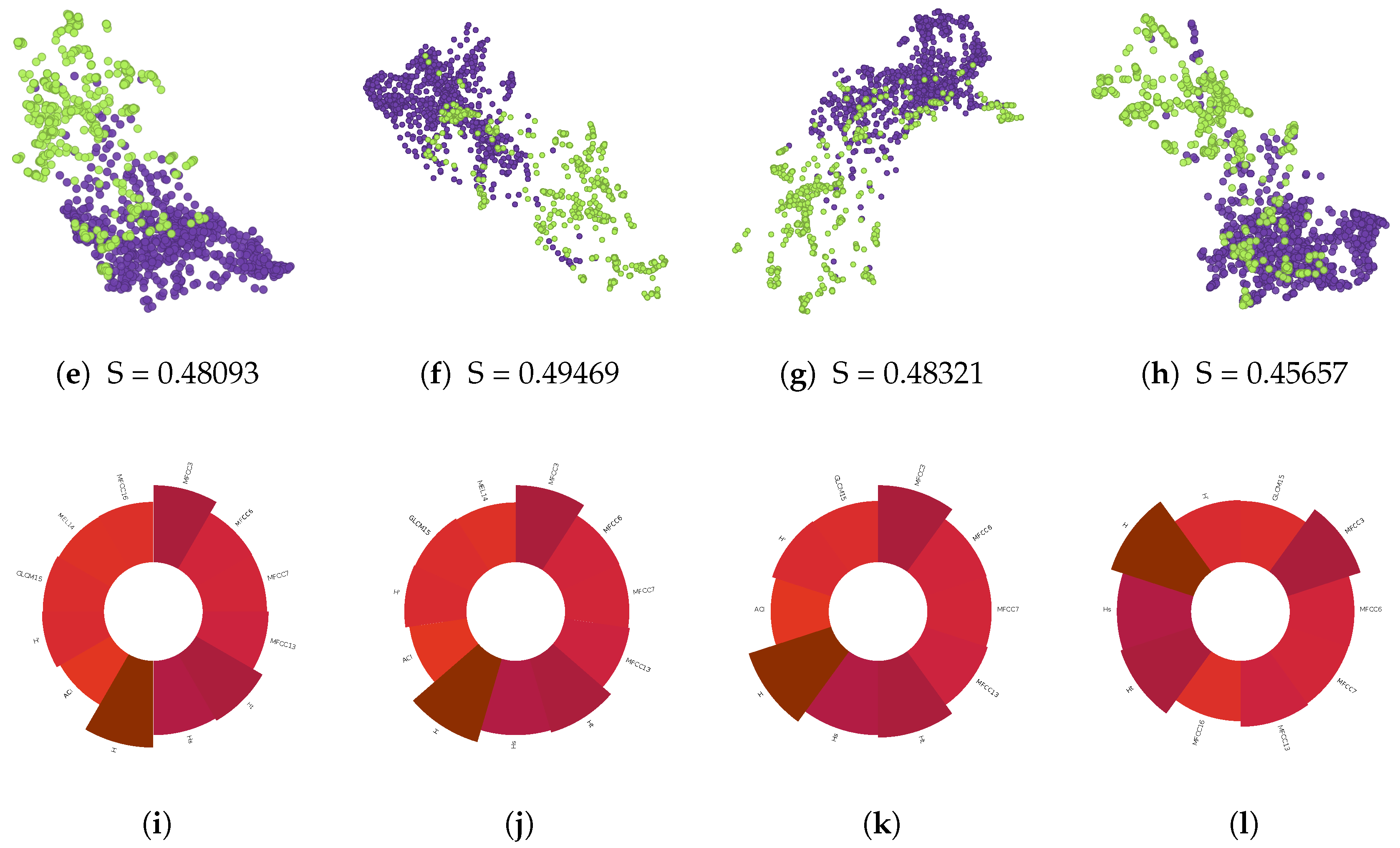
5.2. Selecting Features of Interest by Relevance
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, J.; Chen, Y.; Du, X.; Li, C.; Lu, J.; Zhao, S.; Zhou, X. Big Data Challenge: A Data Management Perspective. Front. Comput. Sci. 2013, 7, 157–164. [Google Scholar] [CrossRef]
- Liu, H.; Motoda, H. Computational Methods of Feature Selection (Chapman & Hall/Crc Data Mining and Knowledge Discovery Series); Chapman & Hall/CRC: London, UK, 2007. [Google Scholar]
- Guyon, I.; Gunn, S.; Nikravesh, M.; Zadeh, L.A. Feature Extraction: Foundations and Applications; Springer: New York, NY, USA, 2008; Volume 207. [Google Scholar]
- Narendra, P.M.; Fukunaga, K. A Branch and Bound Algorithm for Feature Subset Selection. IEEE Trans. Comput. 1977, C-26, 917–922. [Google Scholar] [CrossRef]
- Pudil, P.; Novovičová, J.; Kittler, J. Floating search methods in feature selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Bermejo, P.; Gámez, J.A.; Puerta, J.M. A GRASP algorithm for fast hybrid (filter-wrapper) feature subset selection in high-dimensional datasets. Pattern Recognit. Lett. 2011, 32, 701–711. [Google Scholar] [CrossRef]
- Siedlecki, W.; Sklansky, J. A note on genetic algorithms for large-scale feature selection. Pattern Recognit. Lett. 1989, 10, 335–347. [Google Scholar] [CrossRef]
- Vafaie, H.; Jong, K.D. Genetic algorithms as a tool for feature selection in machine learning. In Proceedings of the Fourth International Conference on Tools with Artificial Intelligence, Arlington, VA, USA, 10–13 November 1992; pp. 200–203. [Google Scholar]
- Yang, C.; Chuang, L.; Chen, Y.; Yang, C. Feature Selection Using Memetic Algorithms. In Proceedings of the Third Int. Conf. on Convergence and Hybrid Information Technology, Busan, Korea, 11–13 November 2008; Volume 1, pp. 416–423. [Google Scholar]
- Keim, D.A.; Mansmann, F.; Thomas, J. Visual Analytics: How Much Visualization and How Much Analytics? SIGKDD Explor. Newsl. 2010, 11, 5–8. [Google Scholar] [CrossRef]
- Korzhik, V.P.; Mohar, B. Minimal Obstructions for 1-Immersions and Hardness of 1-Planarity Testing. J. Graph Theory 2013, 72, 30–71. [Google Scholar] [CrossRef] [Green Version]
- Paiva, J.G.; Florian, L.; Pedrini, H.; Telles, G.; Minghim, R. Improved Similarity Trees and their Application to Visual Data Classification. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2459–2468. [Google Scholar] [CrossRef]
- Sebban, M.; Nock, R. A hybrid filter/wrapper approach of feature selection using information theory. Pattern Recognit. 2002, 35, 835–846. [Google Scholar] [CrossRef]
- Wilson, D.R.; Martinez, T.R. Improved Heterogeneous Distance Functions. J. Artif. Intell. Res. 1997, 6, 1–34. [Google Scholar] [CrossRef]
- Hero, A.O.; Ma, B.; Michel, O.J.J.; Gorman, J. Applications of entropic spanning graphs. IEEE Signal Process. Mag. 2002, 19, 85–95. [Google Scholar] [CrossRef]
- Bonev, B.; Escolano, F.; Cazorla, M. Feature selection, mutual information, and the classification of high-dimensional patterns. Pattern Anal. Appl. Vol. 2008, 11, 309–319. [Google Scholar] [CrossRef]
- Zhong, E.; Xie, S.; Fan, W.; Ren, J.; Peng, J.; Zhang, K. Graph-Based Iterative Hybrid Feature Selection. In Proceedings of the IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE Computer Society: Piscataway, NJ, USA, 2008; pp. 1133–1138. [Google Scholar]
- Berretta, R.; Costa, W.; Moscato, P. Combinatorial Optimization Models for Finding Genetic Signatures from Gene Expression Datasets. In Bioinformatics: Structure, Function and Applications; Humana Press: Totowa, NJ, USA, 2008; pp. 363–377. [Google Scholar]
- Lastra, G.; Luaces, O.; Quevedo, J.R.; Bahamonde, A. Graphical Feature Selection for Multilabel Classification Tasks. In Proceedings International Symposium of Advances in Intelligent Data Analysis; Springer: New York, NY, USA, 2011; Volume 7014, pp. 246–257. [Google Scholar]
- Zhang, Z.; Hancock, E.R. A Graph-Based Approach to Feature Selection. In Proceedings of the International Workshop on Graph-Based Representations in Pattern Recognition; Jiang, X., Ferrer, M., Torsello, A., Eds.; Springer: New York, NY, USA, 2011; Volume 6658, pp. 205–214. [Google Scholar]
- Pavan, M.; Pelillo, M. Dominant Sets and Pairwise Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 167–172. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Hancock, E.R. Hypergraph based information-theoretic feature selection. Pattern Recognit. Lett. 2012, 33, 1991–1999. [Google Scholar] [CrossRef]
- Mandal, M.; Mukhopadhyay, A. Unsupervised Non-redundant Feature Selection: A Graph-Theoretic Approach. In Proceedings of the International Conference on Frontiers of Intelligent Computing: Theory and Applications; Springer: New York, NY, USA, 2013; pp. 373–380. [Google Scholar]
- Zhao, Z.; He, X.; Cai, D.; Zhang, L.; Ng, W.; Zhuang, Y. Graph Regularized Feature Selection with Data Reconstruction. IEEE Trans. Knowl. Data Eng. 2016, 28, 689–700. [Google Scholar] [CrossRef]
- Das, A.; Kumar, S.; Jain, S. An information-theoretic graph-based approach for feature selection. Sadhana 2020, 45, 11. [Google Scholar] [CrossRef]
- Roffo, G.; Melzi, S.; Castellani, U.; Vinciarelli, A.; Cristani, M. Infinite Feature Selection: A Graph-based Feature Filtering Approach. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef]
- Krause, J.; Perer, A.; Bertini, E. INFUSE: Interactive Feature Selection for Predictive Modeling of High Dimensional Data. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1614–1623. [Google Scholar] [CrossRef]
- Bernard, J.; Steiger, M.; Widmer, S.; Lücke-Tieke, H.; May, T.; Kohlhammer, J. Visual-interactive Exploration of Interesting Multivariate Relations in Mixed Research Data Sets. Comput. Graph. Forum 2014, 33, 291–300. [Google Scholar] [CrossRef]
- May, T.; Bannach, A.; Davey, J.; Ruppert, T.; Kohlhammer, J. Guiding feature subset selection with an interactive visualization. In Proceedings of the 2011 IEEE Conference on Visual Analytics Science and Technology (VAST), Providence, RI, USA, 23–28 October 2011; pp. 111–120. [Google Scholar]
- Wang, Y.; Li, J.; Nie, F.; Theisel, H.; Gong, M.; Lehmann, D.J. Linear Discriminative Star Coordinates for Exploring Class and Cluster Separation of High Dimensional Data. Comput. Graph. Forum 2017, 36, 401–410. [Google Scholar] [CrossRef]
- Sanchez, A.; Soguero-Ruiz, C.; Mora-Jiménez, I.; Rivas-Flores, F.; Lehmann, D.; Rubio-Sánchez, M. Scaled radial axes for interactive visual feature selection: A case study for analyzing chronic conditions. Expert Syst. Appl. 2018, 100, 182–196. [Google Scholar] [CrossRef]
- Artur, E.; Minghim, R. A novel visual approach for enhanced attribute analysis and selection. Comput. Graph. 2019, 84, 160–172. [Google Scholar] [CrossRef]
- Turkay, C.; Filzmoser, P.; Hauser, H. Brushing Dimensions—A Dual Visual Analysis Model for High-Dimensional Data. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2591–2599. [Google Scholar] [CrossRef] [PubMed]
- Yuan, X.; Ren, D.; Wang, Z.; Guo, C. Dimension Projection Matrix/Tree: Interactive Subspace Visual Exploration and Analysis of High Dimensional Data. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2625–2633. [Google Scholar] [CrossRef] [PubMed]
- Rauber, P.E.; Falcao, A.X.; Telea, A.C. Projections as Visual Aids for Classification System Design. Inf. Vis. 2017, 17, 282–305. [Google Scholar] [CrossRef]
- Mühlbacher, T.; Piringer, H. A Partition-Based Framework for Building and Validating Regression Models. IEEE Trans. Vis. Comput. Graph. 2013, 19, 1962–1971. [Google Scholar] [CrossRef]
- Klemm, P.; Lawonn, K.; Glaßer, S.; Niemann, U.; Hegenscheid, K.; Völzke, H.; Preim, B. 3D Regression Heat Map Analysis of Population Study Data. IEEE Trans. Vis. Comput. Graph. 2016, 22, 81–90. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, J.; Zhan, F.B.; Gong, X.; Brender, J.D.; Langlois, P.H.; Barlowe, S.; Zhao, Y. A visual analytics approach to high-dimensional logistic regression modeling and its application to an environmental health study. In Proceedings of the 2016 IEEE Pacific Visualization Symposium (PacificVis), Taipei, Taiwan, 19–22 April 2016; pp. 136–143. [Google Scholar]
- Dingen, D.; van’t Veer, M.; Houthuizen, P.; Mestrom, E.H.J.; Korsten, E.H.H.M.; Bouwman, A.R.A.; van Wijk, J. RegressionExplorer: Interactive Exploration of Logistic Regression Models with Subgroup Analysis. IEEE Trans. Vis. Comput. Graph. 2019, 25, 246–255. [Google Scholar] [CrossRef]
- Nobre, C.; Streit, M.; Meyer, M.; Lex, A. The State of the Art in Visualizing Multivariate Networks. Comput. Graph. Forum (EuroVis) 2019, 38, 807–832. [Google Scholar] [CrossRef]
- Wang, C.; Yu, H.; Grout, R.W.; Ma, K.; Chen, J.H. Analyzing information transfer in time-varying multivariate data. In Proceedings of the 2011 IEEE Pacific Visualization Symposium, Hong Kong, China, 1–4 March 2011; pp. 99–106. [Google Scholar]
- Zhang, Z.; McDonnell, K.T.; Mueller, K. A network-based interface for the exploration of high-dimensional data spaces. In Proceedings of the 2012 IEEE Pacific Visualization Symposium, Songdo, Korea, 28 February–2 March 2012; pp. 17–24. [Google Scholar]
- Biswas, A.; Dutta, S.; Shen, H.; Woodring, J. An Information-Aware Framework for Exploring Multivariate Data Sets. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2683–2692. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 36, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Cuadros, A.M.; Paulovich, F.V.; Minghim, R.; Telles, G.P. Point placement by phylogenetic trees and its application to visual analysis of document collections. In Proceedings of the IEEE Symposium on Visual Analytics Science and Technology, Sacramento, CA, USA, 30 October–1 November 2007; pp. 99–106. [Google Scholar]
- Saitou, N.; Nei, M. The neighbor-joining method: A new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 1987, 4, 406–425. [Google Scholar] [PubMed]
- Van der Maaten, L.; Hinton, G. Visualizing High-Dimensional Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Paulovich, F.V.; Nonato, L.G.; Minghim, R.; Levkowitz, H. Least Square Projection: A Fast High-Precision Multidimensional Projection Technique and Its Application to Document Mapping. IEEE Trans. Vis. Comput. Graph. 2008, 14, 564–575. [Google Scholar] [CrossRef] [PubMed]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. Available online: https://arxiv.org/abs/1802.03426 (accessed on 16 November 2020).
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Dias, F.F.; Pedrini, H.; Minghim, R. Soundscape segregation based on visual analysis and discriminating features. Ecol. Inform. 2020, 101184. [Google Scholar]
- Hilasaca, L.M.H. Visual Active Learning para Rotulagem por Características Discriminantes em Paisagens Acústicas. Master’s Thesis, Instituto de Ciências Matemáticas e de Computação, Universidade de São Paulo, São Carlos, Brazil, 9 July 2020. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Description | Data Items | Features | Data Labels |
|---|---|---|---|---|
| News | snipets of news | 381 | 612 | 7 |
| Corel 1k | images descriptors | 1000 | 150 | 10 |
| Cantareira | soundscape descriptors | 1662 | 238 | 2 |
| CostaRica | soundscape descriptors | 3061 | 187 | 2 |
| Mnist | digits pixels intensity descriptors | 10,000 | 784 | 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Minghim, R.; Huancapaza, L.; Artur, E.; Telles, G.P.; Belizario, I.V. Graphs from Features: Tree-Based Graph Layout for Feature Analysis. Algorithms 2020, 13, 302. https://doi.org/10.3390/a13110302
Minghim R, Huancapaza L, Artur E, Telles GP, Belizario IV. Graphs from Features: Tree-Based Graph Layout for Feature Analysis. Algorithms. 2020; 13(11):302. https://doi.org/10.3390/a13110302
Chicago/Turabian StyleMinghim, Rosane, Liz Huancapaza, Erasmo Artur, Guilherme P. Telles, and Ivar V. Belizario. 2020. "Graphs from Features: Tree-Based Graph Layout for Feature Analysis" Algorithms 13, no. 11: 302. https://doi.org/10.3390/a13110302
APA StyleMinghim, R., Huancapaza, L., Artur, E., Telles, G. P., & Belizario, I. V. (2020). Graphs from Features: Tree-Based Graph Layout for Feature Analysis. Algorithms, 13(11), 302. https://doi.org/10.3390/a13110302