Fuzzy-Based Multivariate Analysis for Input Modeling of Risk Assessment in Wind Farm Projects



Abstract
:1. Introduction
2. Literature Review
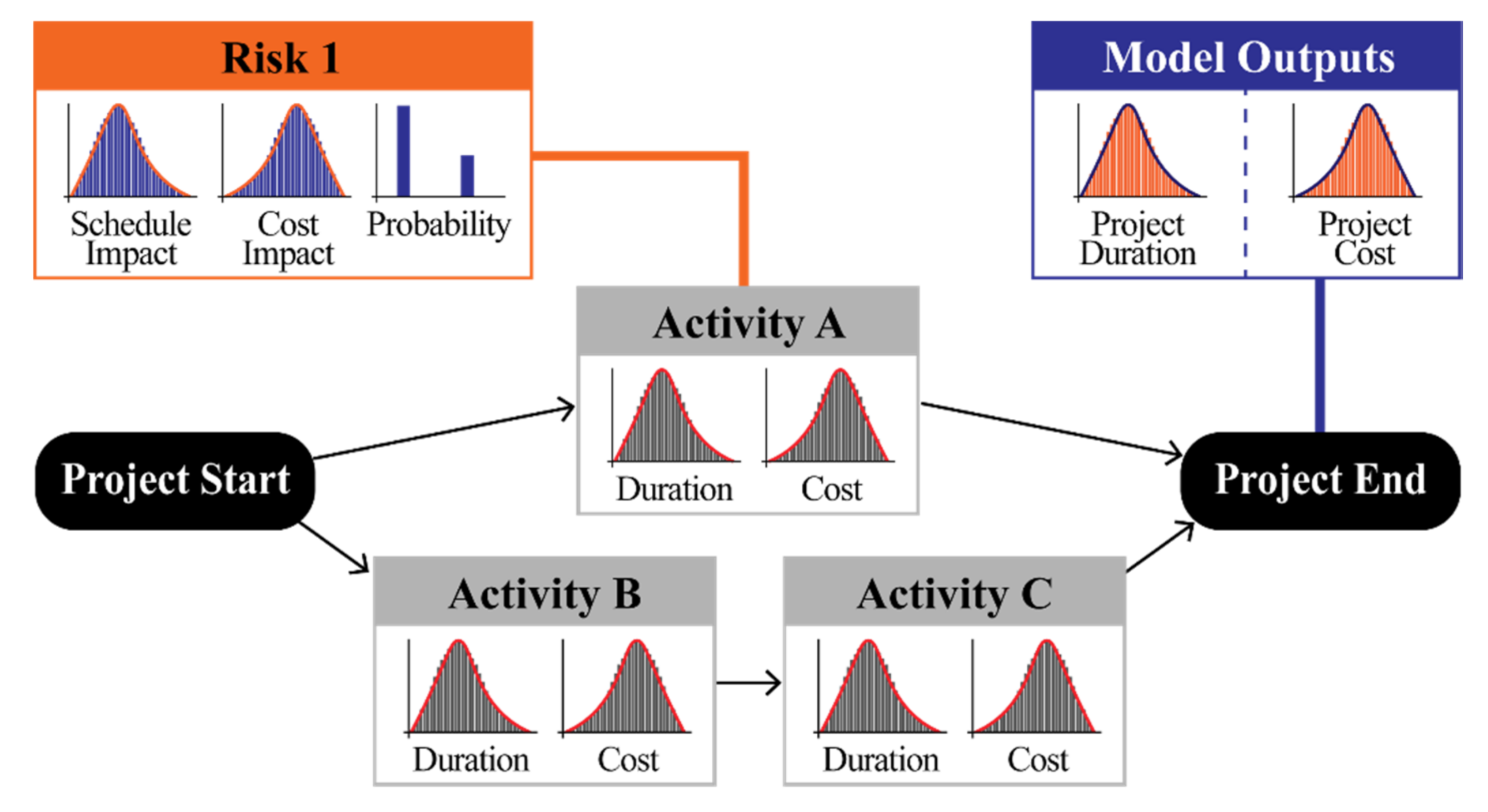
2.1. MCS for Risk Assessment and Input Modeling
2.2. Correlation and Dependence in Risk Assessment
2.3. Construction Risk Assessment in Onshore Wind Project and Its Challenges
2.4. Fuzzy Logic
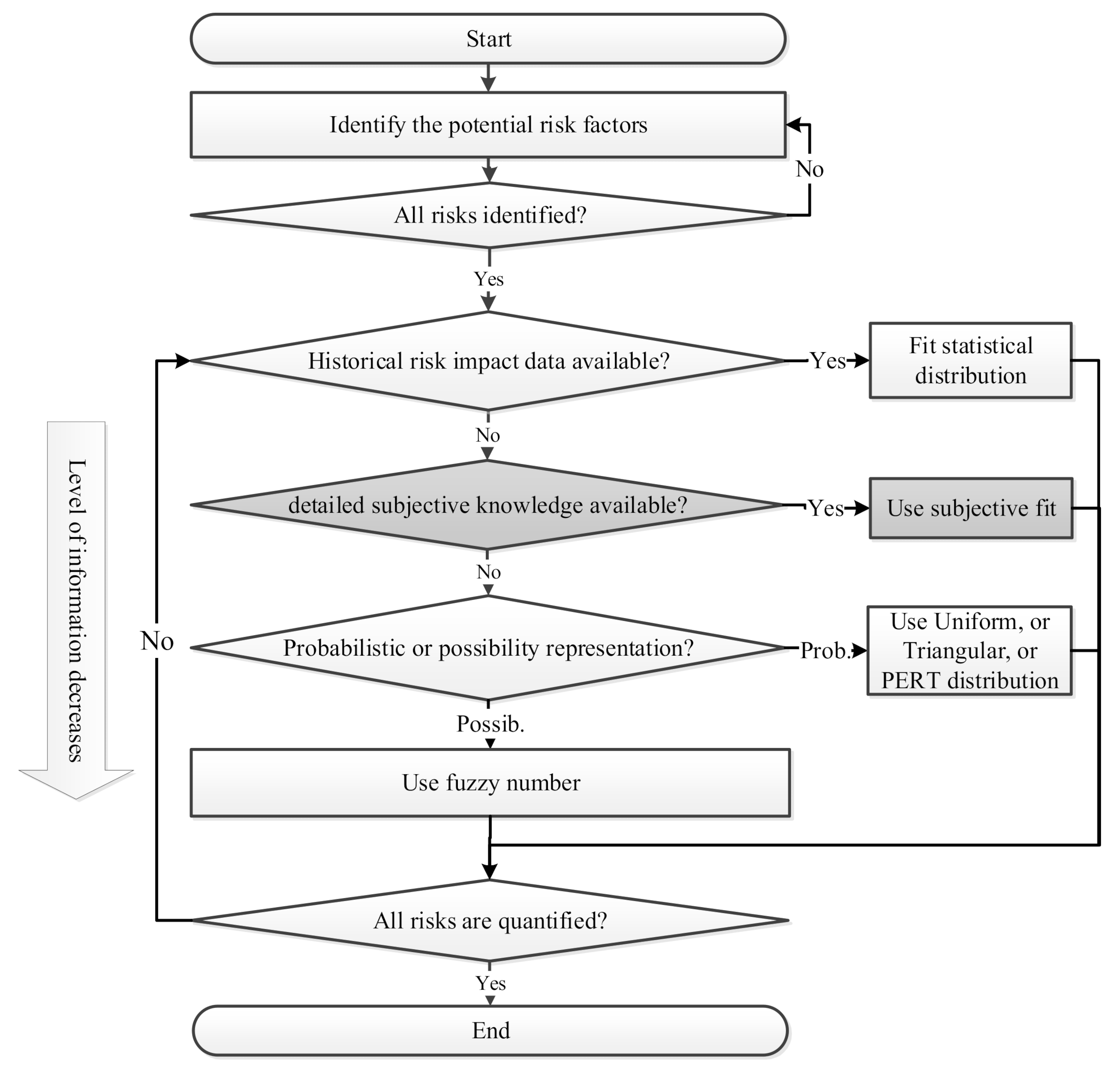
3. Materials and Methods
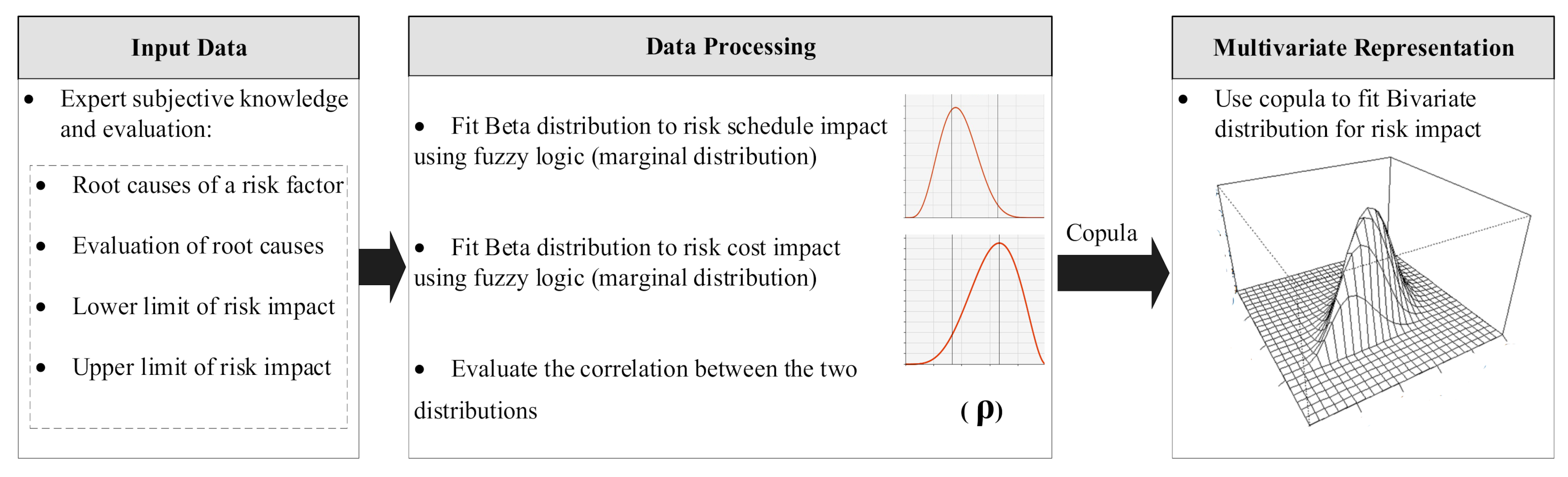
3.1. Input Data
3.2. Data Processing
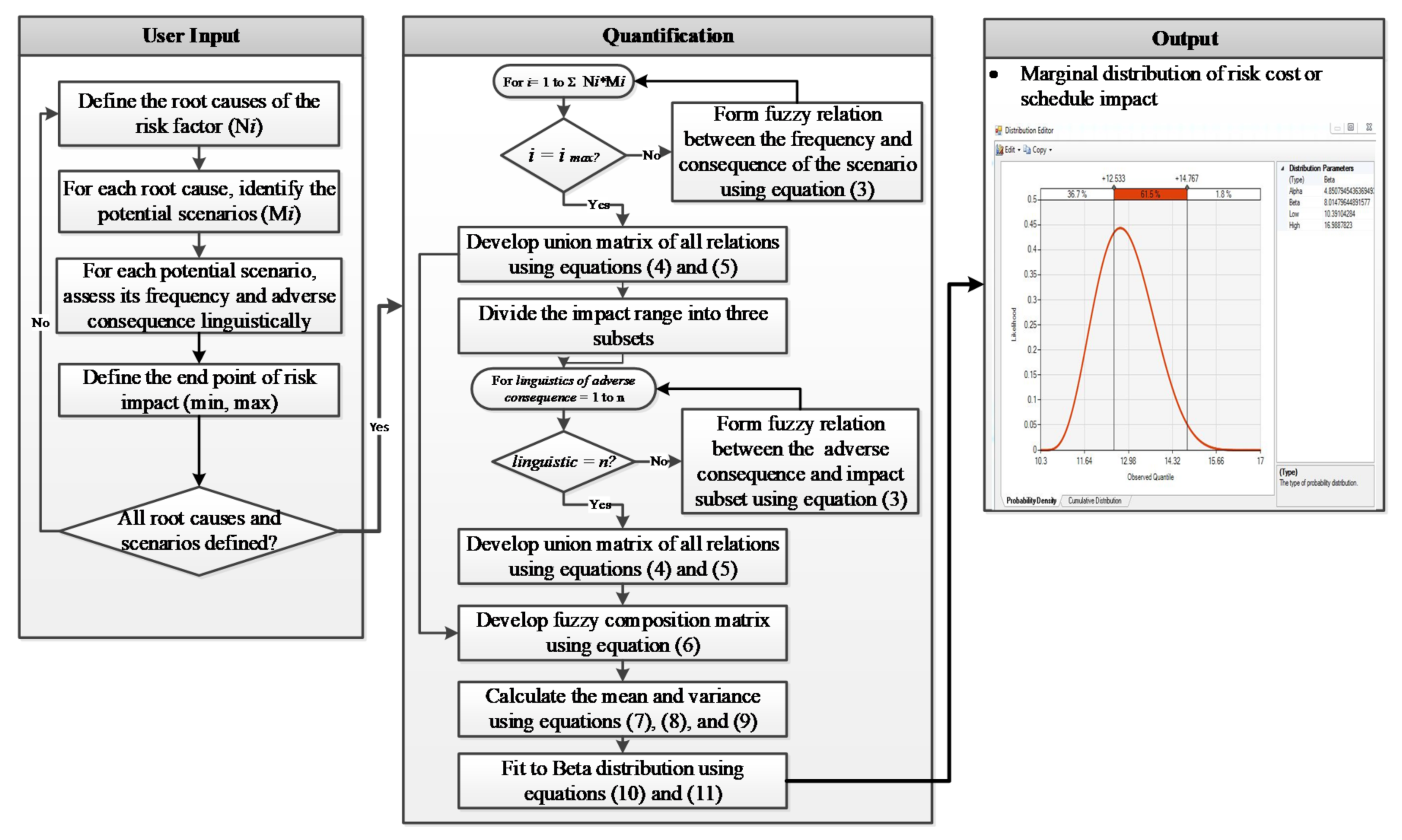
3.2.1. Marginal Distributions
3.2.2. Correlation of Dependent Variables
3.3. Multivariate Representation
4. Application and Results
4.1. Input Data
4.2. Data Processing
4.2.1. Marginal Distributions
4.2.2. Validation of the Marginal Distribution
- Sensitivity Analysis
- Expert Validation
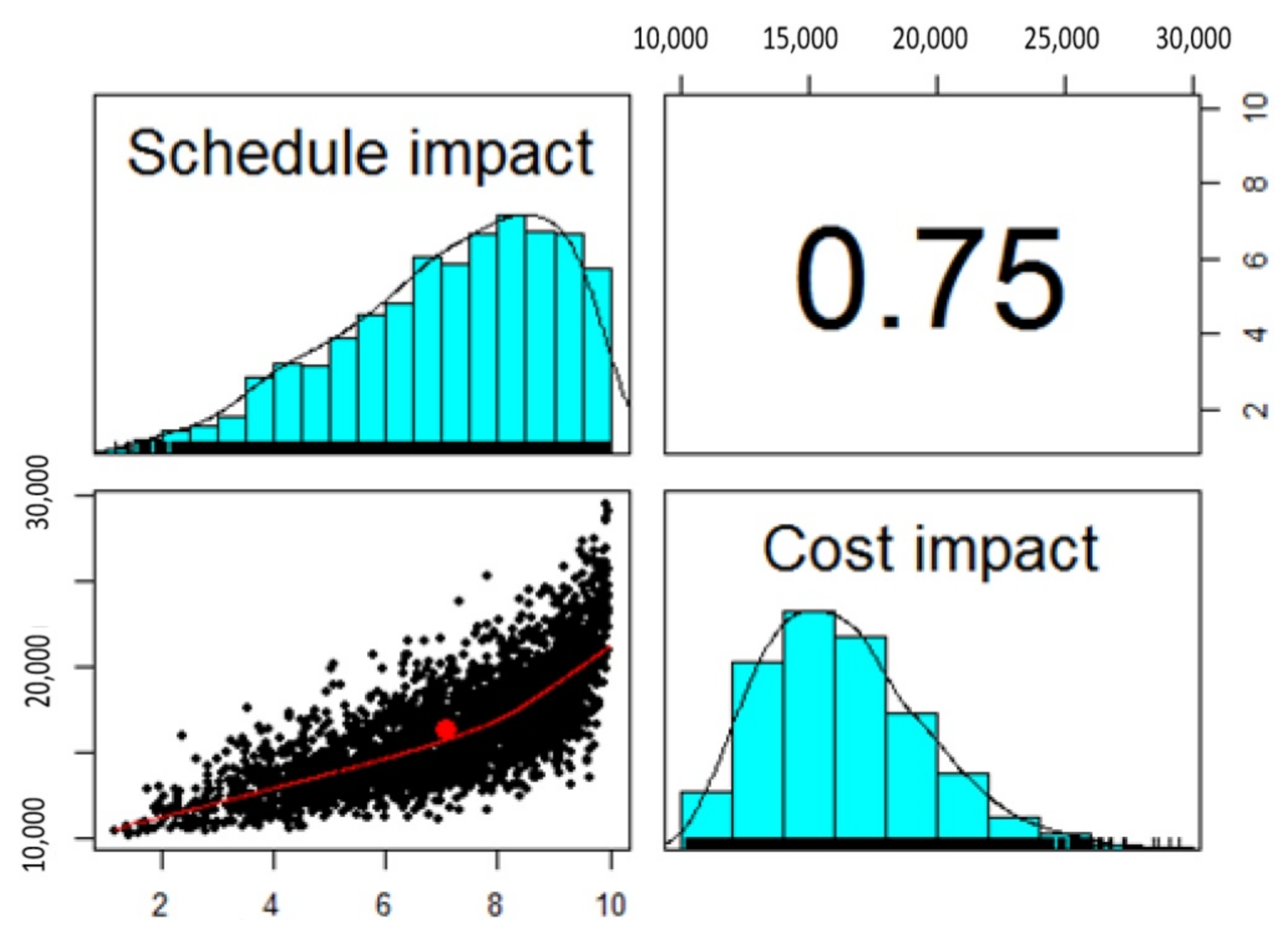
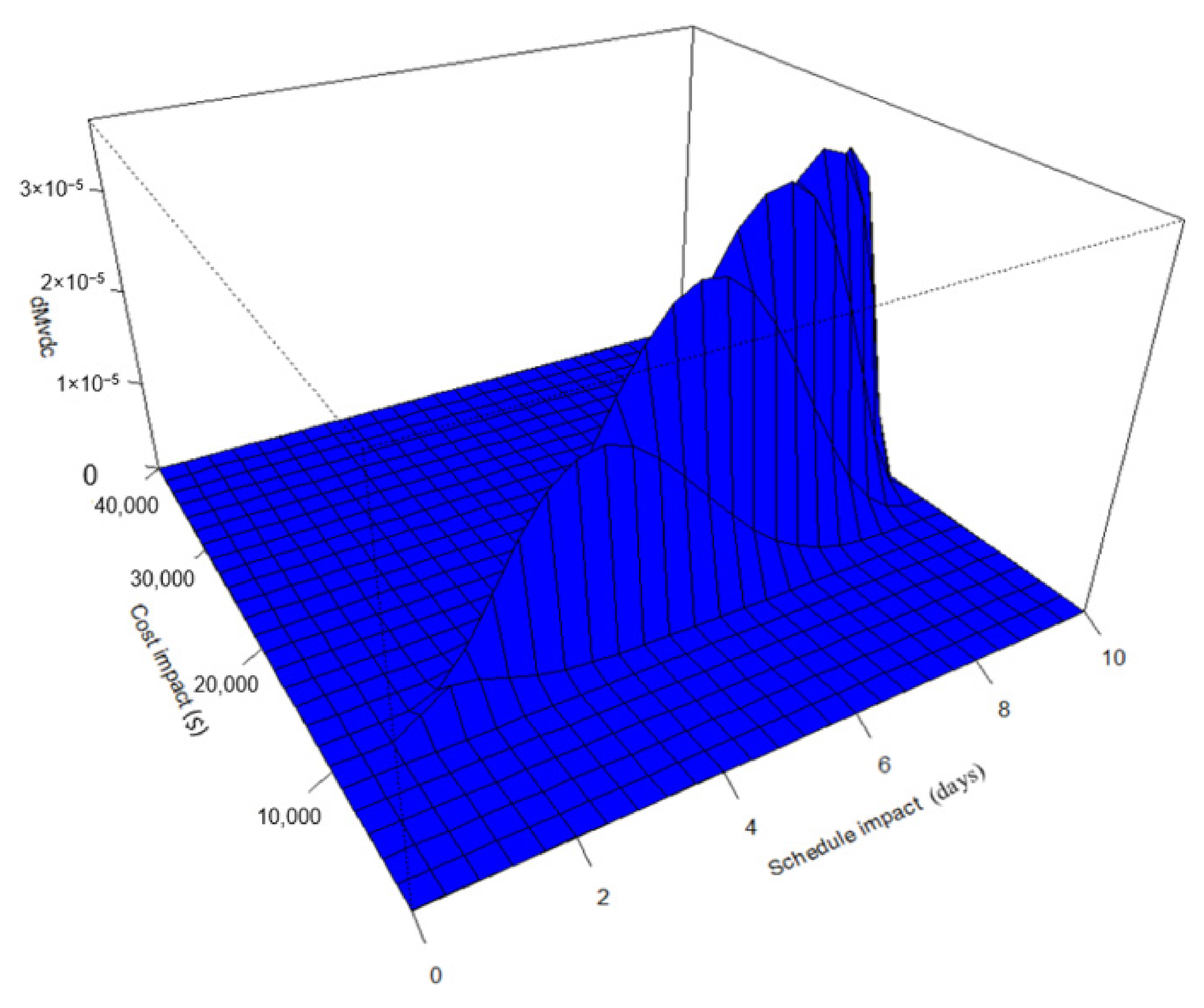
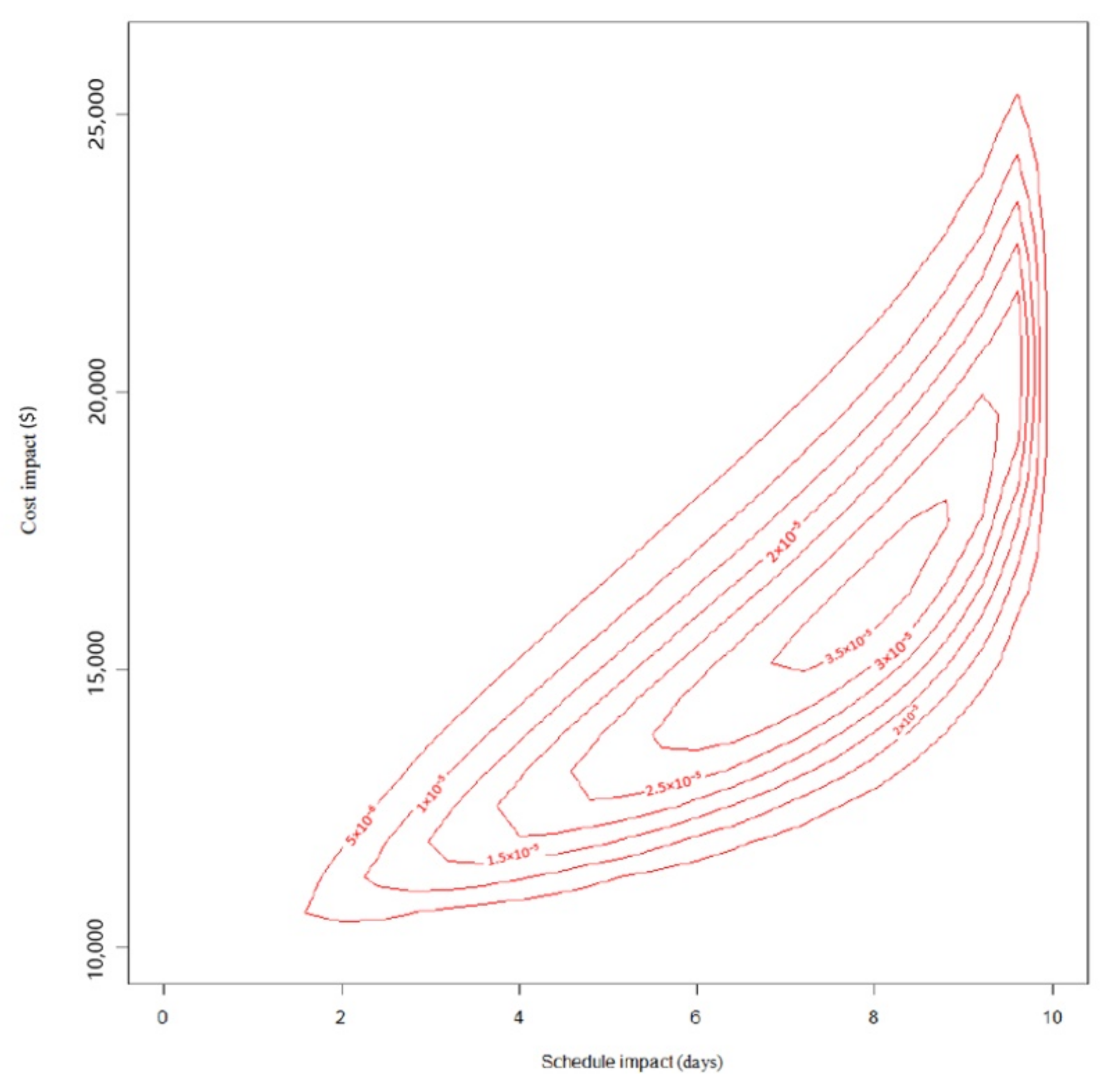
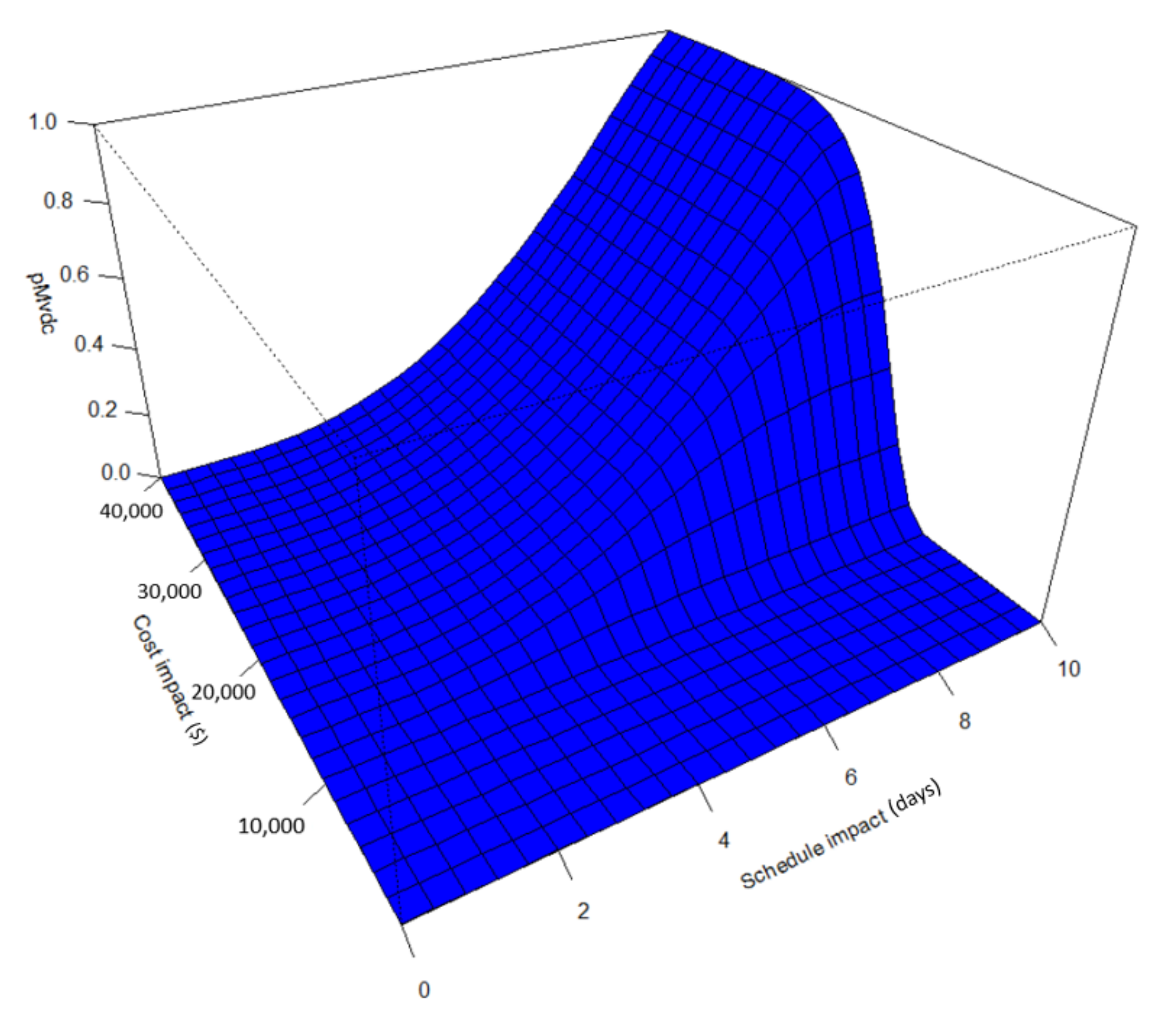
4.3. Multivariate Representation
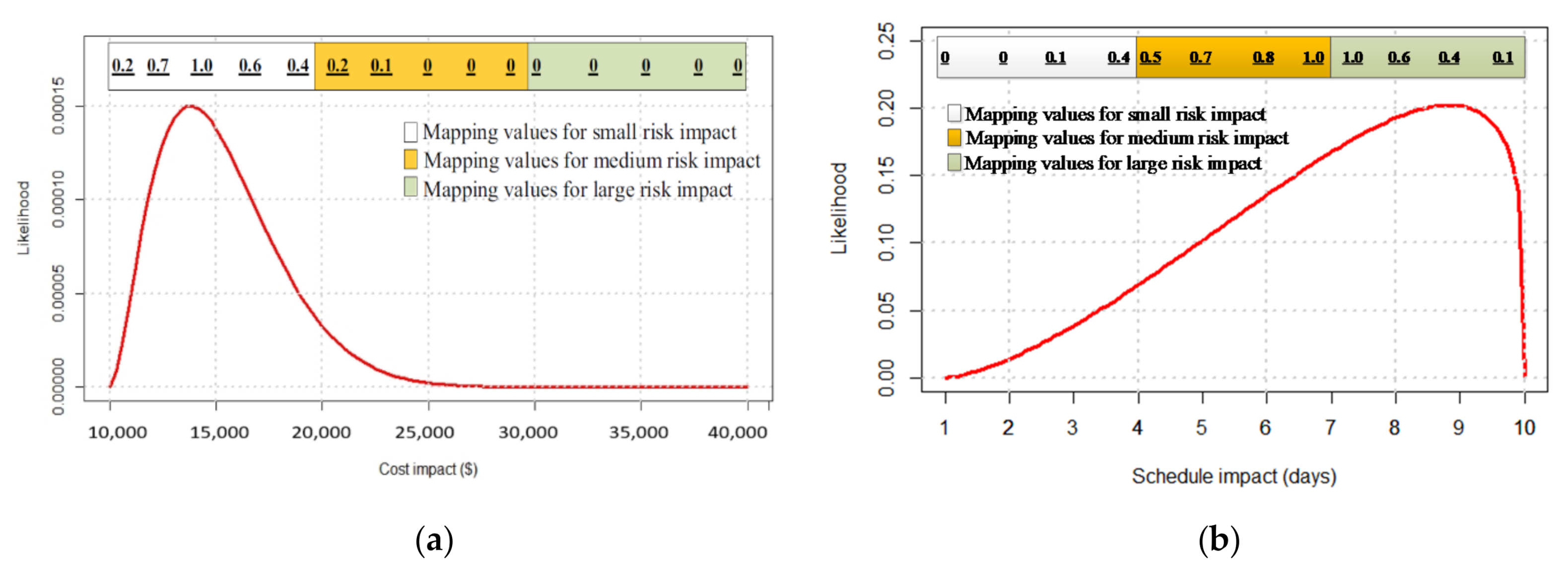
5. Application and Practical Benefits
6. Discussion
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- IRENA. Future of Wind: Deployment, Investment, Technology, Grid Integration and Socio-Economic Aspects; International Renewable Energy Agency: Abu Dhabi, UAE, 2019; ISBN 978-92-9260-155-3. [Google Scholar]
- Renewable Electricity Program. Available online: https://www.alberta.ca/renewable-electricity-program.aspx (accessed on 19 June 2020).
- Wind Energy in Alberta. Available online: https://canwea.ca/wind-energy/alberta/ (accessed on 22 October 2020).
- Somi, S.; Gerami Seresht, N.; Fayek, A.R. Framework for risk identification of renewable energy projects using fuzzy case-based reasoning. Sustainability 2020, 12, 5231. [Google Scholar] [CrossRef]
- Leimeister, M.; Kolios, A. A review of reliability-based methods for risk analysis and their application in the offshore wind industry. Renew. Sustain. Energy Rev. 2018, 91, 1065–1076. [Google Scholar] [CrossRef]
- Kwak, Y.H.; Ingall, L. Exploring Monte Carlo simulation applications for project management. Risk Manag. 2007, 9, 44–57. [Google Scholar] [CrossRef]
- Kwak, Y.; Ingall, L. Exploring Monte Carlo simulation applications for project management. IEEE Eng. Manag. Rev. 2009, 37, 83. [Google Scholar] [CrossRef]
- Biller, B.; Gunes, C. Introduction to simulation input modeling. In Proceedings of the 2010 Winter Simulation Conference, Baltimore, MD, USA, 5–8 December 2010; pp. 49–58. [Google Scholar]
- AbouRizk, H. Understanding and Improving Input for Quantitative Risk Analysis in the Construction Industry. Master’s Thesis, University of Alberta, Edmonton, AL, Canada, 2013. [Google Scholar]
- Smith, N.J.; Merna, T.; Jobling, P. Managing Risk in Construction Projects, 2nd ed.; Wiley-Blackwell: Hoboken, NJ, USA, 2009; ISBN 978-1-405-17274-5. [Google Scholar]
- Sadeghi, N.; Fayek, A.R.; Pedrycz, W. Fuzzy Monte Carlo simulation and risk assessment in construction. Comput. Aided Civ. Infrastruct. Eng. 2010, 25, 238–252. [Google Scholar] [CrossRef]
- Hulett, D.; Whitehead, W.; Arrow, J.; Banks, W.; Brady, D. 57R-09: Integrated Cost and Schedule Risk Analysis using Risk Drivers and Monte Carlo Simulation of a CPM Model; AACE International: Fairmont, WV, USA, 2019. [Google Scholar]
- Yan, J. Enjoy the joy of copulas: With a package copula. J. Stat. Softw. 2007, 21, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Zavadska, E.K.; Turskis, Z.; Tamošaitiene, J. Risk assessment of construction projects. J. Civ. Eng. Manag. 2010, 16, 33–46. [Google Scholar] [CrossRef] [Green Version]
- Banaitiene, N.; Banaitis, A. Risk Management in Construction Projects. In Risk Management—Current Issues and Challenges; Banaitiene, N., Ed.; InTechOpen: London, UK, 2012; ISBN 978-953-51-0747-7. [Google Scholar]
- Senesi, C.; Javernick-Will, A.; Molenaar, K. RR280-11: Applying Probabilistic Risk Management in Design and Construction Projects; Construction Industry Institute: Austin, TX, USA, 2013. [Google Scholar]
- Duracz, A. Derivation of Probability Distributions for Risk Assessment. Master’s Thesis, Stockholm University, Stockholm, Sweden, 2006. [Google Scholar]
- Yoe, C. Principles of Risk Analysis: Decision Making Under Uncertainty; CRC Press: Boca Raton, FL, USA, 2016; ISBN 978-1-4398-5750-2. [Google Scholar]
- Law, A.M. Simulation Modeling and Analysis, 5th ed.; McGraw-Hill Education: New York, NY, USA, 2014; ISBN 978-0-07-340132-4. [Google Scholar]
- O’Hagan, A. Expert knowledge elicitation: Subjective but scientific. Am. Stat. 2019, 73, 69–81. [Google Scholar] [CrossRef] [Green Version]
- Morris, D.E.; Oakley, J.E.; Crowe, J.A. A web-based tool for eliciting probability distributions from experts. Environ. Model. Softw. 2014, 52, 1–4. [Google Scholar] [CrossRef]
- Cooke, R.M.; Goossens, L.H.J. Expert judgement elicitation for risk assessments of critical infrastructures. J. Risk Res. 2004, 7, 643–656. [Google Scholar] [CrossRef]
- Galway, L. WR-112-RC: Quantitative Risk Analysis for Project Management: A Critical Review; Rand Corporation: Santa Monica, CA, USA, 2004. [Google Scholar]
- Nasir, D.; McCabe, B.; Hartono, L. Evaluating Risk in Construction–Schedule Model (ERIC–S): Construction schedule risk model. J. Constr. Eng. Manag. 2003, 129, 518–527. [Google Scholar] [CrossRef]
- van Dorp, J.R.; Duffey, M.R. Statistical dependence in risk analysis for project networks using Monte Carlo methods. Int. J. Prod. Econ. 1999, 58, 17–29. [Google Scholar] [CrossRef]
- Galway, L.A. Subjective Probability Distribution Elicitation in Cost Risk Analysis: A Review; Rand Corporation: Santa Monica, CA, USA, 2007. [Google Scholar]
- Meyer, M.; Grisar, C.; Kuhnert, F. The impact of biases on simulation-based risk aggregation: Modeling cognitive influences on risk assessment. J. Manag. Control 2011, 22, 79. [Google Scholar] [CrossRef]
- Dikmen, I.; Budayan, C.; Talat Birgonul, M.; Hayat, E. Effects of risk attitude and controllability assumption on risk ratings: Observational study on international construction project risk assessment. J. Manag. Eng. 2018, 34, 04018037. [Google Scholar] [CrossRef]
- Tversky, A.; Kahneman, D. Judgment under uncertainty: Heuristics and biases. Util. Probab. Hum. Decis. Mak. 1975, 11, 141–162. [Google Scholar] [CrossRef]
- Montibeller, G.; Winterfeldt, D. von Cognitive and motivational biases in decision and risk analysis. Risk Anal. 2015, 35, 1230–1251. [Google Scholar] [CrossRef]
- Li, N.; Fang, D.; Sun, Y. Cognitive psychological approach for risk assessment in construction projects. J. Manag. Eng. 2016, 32, 04015037. [Google Scholar] [CrossRef]
- Touran, A.; Wiser, E.P. Monte Carlo technique with correlated random variables. J. Constr. Eng. Manag. 1992, 118, 258–272. [Google Scholar] [CrossRef]
- Clemen, R.T.; Reilly, T. Correlations and copulas for decision and risk analysis. Manag. Sci. 1999, 45, 208–224. [Google Scholar] [CrossRef] [Green Version]
- Touran, A. Probabilistic cost estimating with subjective correlations. J. Constr. Eng. Manag. 1993, 119, 58–71. [Google Scholar] [CrossRef]
- Ökmen, Ö.; Öztaş, A. Construction project network evaluation with correlated schedule risk analysis model. J. Constr. Eng. Manag. 2008, 134, 49–63. [Google Scholar] [CrossRef]
- Moret, Y.; Einstein, H.H. Modeling correlations in rail line construction. J. Constr. Eng. Manag. 2012, 138, 1075–1084. [Google Scholar] [CrossRef]
- Moret, Y.; Einstein, H.H. Construction cost and duration uncertainty model: Application to high-speed rail line project. J. Constr. Eng. Manag. 2016, 142, 05016010. [Google Scholar] [CrossRef]
- Mawlana, M.; Hammad, A. Joint probability for evaluating the schedule and cost of stochastic simulation models. Adv. Eng. Inform. 2015, 29, 380–395. [Google Scholar] [CrossRef]
- Analytic Method for Probabilistic Cost and Schedule Risk Analysis. Available online: https://www.nasa.gov/pdf/741989main_Analytic%20Method%20for%20Risk%20Analysis%20-649%20Final%20Report.pdf (accessed on 27 October 2020).
- Palisade @RISK: Risk Analysis using Monte Carlo Simulation in Excel and Project. Available online: http://www.palisade.com/risk/default.asp (accessed on 22 October 2020).
- Embrechts, P.; Lindskog, F.; Mcneil, A. Modelling dependence with copulas and applications to risk management. In Handbook of Heavy Tailed Distributions in Finance; Svetlozar, T.R., Ed.; Elsevier: Amsterdam, The Netherlands, 2003; pp. 329–384. ISBN 978-0-444-50896-6. [Google Scholar]
- Rajgor, G. Building wind farms: Part five: The precarious construction phase needs careful preparation. Renew. Energy Focus 2011, 12, 28–32. [Google Scholar] [CrossRef]
- Turner, G.; Roots, S.; Wiltshire, M.; Trueb, J.; Brown, S.; Benz, G.; Hegelbach, M. Profiling the Risks in Solar and Wind: A Case for New Risk Management Approaches in the Renewable Energy Sector; Swiss Reinsurance: Zurich, Switzerland, 2013. [Google Scholar]
- Finlay-Jones, R. Putting the spin on wind energy: Risk management issues in the development of wind energy projects in Australia. Aust. J. Multi-Discip. Eng. 2007, 5, 61–68. [Google Scholar] [CrossRef]
- Kucukali, S. Risk scorecard concept in wind energy projects: An integrated approach. Renew. Sustain. Energy Rev. 2016, 56, 975–987. [Google Scholar] [CrossRef]
- Rolik, Y. Risk Management in implementing wind energy project. Procedia Eng. 2017, 178, 278–288. [Google Scholar] [CrossRef]
- Mohamed, E.; Gerami Seresht, N.; Hague, S.; AbouRizk, S. Simulation-based approach for risk assessment in onshore wind farm construction projects. In Proceedings of the 9th Asia-Pacific International Symposium on Advanced Reliability and Maintenance Modelling, Vancouver, BC, Canada, 20–23 August 2020. [Google Scholar]
- Fayek, A.R. Fuzzy logic and fuzzy hybrid techniques for construction engineering and management. J. Constr. Eng. Manag. 2020, 146, 04020064. [Google Scholar] [CrossRef]
- Smith, G.R.; Hancher, D.E. Estimating precipitation impacts for scheduling. J. Constr. Eng. Manag. 1989, 115, 552–566. [Google Scholar] [CrossRef]
- Budayan, C.; Dikmen, I.; Talat Birgonul, M.; Ghaziani, A. A computerized method for delay risk assessment based on fuzzy set theory using MS ProjectTM. KSCE J. Civ. Eng. 2018, 22, 2714–2725. [Google Scholar] [CrossRef]
- Andersen, B.; Fagerhaug, T. Root Cause Analysis: Simplified Tools and Techniques; ASQ Quality Press: Milwaukee, WI, USA, 2006; ISBN 978-0-87389-692-4. [Google Scholar]
- Ayyub, B.M. Risk Analysis in Engineering and Economics, 2nd ed.; Chapman and Hall/CRC Press: Boca Raton, FL, USA, 2014; ISBN 9781466518254. [Google Scholar]
- Abdelgawad, M.; Fayek, A.R. Risk management in the construction industry using combined Fuzzy FMEA and Fuzzy AHP. J. Constr. Eng. Manag. 2010, 136, 1028–1036. [Google Scholar] [CrossRef]
- Johnson, D. Triangular approximations for continuous random variables in risk analysis. J. Oper. Res. Soc. 2002, 53, 457–467. [Google Scholar] [CrossRef]
- AbouRizk, S.M.; Halpin, D.W.; Wilson, J.R. Fitting beta distributions based on sample data. J. Constr. Eng. Manag. 1994, 120, 288–305. [Google Scholar] [CrossRef] [Green Version]
- AbouRizk, S.M.; Halpin, D.W.; Wilson, J.R. Visual interactive fitting of beta distributions. J. Constr. Eng. Manag. 1991, 117, 589–605. [Google Scholar] [CrossRef]
- Fayek, A.R.; Lourenzutti, R. Introduction to fuzzy logic in construction engineering and management. In Fuzzy Hybrid Computing in Construction Engineering and Management; Emerald Publishing Limited: Melbourne, Australia, 2018; pp. 3–35. ISBN 978-1-78743-869-9. [Google Scholar]
- AbouRizk, S.M.; Sawhney, A. Subjective and interactive duration estimation. Can. J. Civ. Eng. 1993, 20, 457–470. [Google Scholar] [CrossRef]
- Corona-Suárez, G.A.; AbouRizk, S.M.; Karapetrovic, S. Simulation-based fuzzy logic approach to assessing the effect of project quality management on construction performance. J. Qual. Reliab. Eng. 2014, 2014, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Ayyub, B.M.; Haldar, A. Project scheduling using fuzzy set concepts. J. Constr. Eng. Manag. 1984, 110, 189–204. [Google Scholar] [CrossRef]
- Oliveros, A.V.O.; Fayek, A.R. Fuzzy logic approach for activity delay analysis and schedule updating. J. Constr. Eng. Manag. 2005, 131, 42–51. [Google Scholar] [CrossRef]
- Diógenes, J.R.F.; Claro, J.; Rodrigues, J.C. Barriers to onshore wind farm implementation in Brazil. Energy Policy 2019, 128, 253–266. [Google Scholar] [CrossRef]
- Lucko, G.; Rojas, E.M. Research validation: Challenges and opportunities in the construction domain. J. Constr. Eng. Manag. 2010, 136, 127–135. [Google Scholar] [CrossRef]
- Saltelli, A.; Tarantola, S.; Campolongo, F.; Ratto, M. Sensitivity Analysis in Practice: A Guide to Assessing Scientific Models; John Wiley & Sons: Hoboken, NJ, USA, 2004; ISBN 978-0-470-87093-8. [Google Scholar]
- Ashraf, W.; Glinicki, M.A.; Olek, J. Statistical analysis and probabilistic design approach for freeze–thaw performance of ordinary Portland Cement concrete. J. Mater. Civ. Eng. 2018, 30, 04018294. [Google Scholar] [CrossRef]
- Wolodzko, T. Additional Univariate and Multivariate Distributions, R Package. Available online: https://cran.r-project.org/web/packages/extraDistr/index.html (accessed on 27 October 2020).
- Ospina, L.G.G.; Rueda, A.J.B.; Bessolo, A.F.M.; Tienda, J.L.P. A Methodological proposal for risk analysis in the construction of tunnels. In Advances in Informatics and Computing in Civil and Construction Engineering; Mutis, I., Hartmann, T., Eds.; Springer International Publishing: Basel, Switzerland, 2019; pp. 815–822. ISBN 978-3-030-00219-0. [Google Scholar]
- Salah, A.; Moselhi, O. Contingency modelling for construction projects using fuzzy-set theory. Eng. Constr. Archit. Manag. 2015, 22, 214–241. [Google Scholar] [CrossRef]
- Fayek, A.R.; Oduba, A. Predicting industrial construction labor productivity using fuzzy expert systems. J. Constr. Eng. Manag. 2005, 131, 938–941. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Root Cause/Scenario | Frequency of Occurrence (F) | Adverse Consequence (C) |
|---|---|---|---|
| 1 | Construction noise is low | Likely | Very small |
| 2 | Construction noise is medium | Likely | Large |
| 3 | Construction noise is high | Unlikely | Large |
| 4 | Harm to activities is low | Unlikely | Small |
| 5 | Harm to activities is medium | Somewhat likely | Large |
| 6 | Harm to activities is high | Unlikely | Very large |
| 7 | Traffic disturbance is low | Very likely | Very small |
| 8 | Traffic disturbance is medium | Somewhat likely | Large |
| 9 | Traffic disturbance is high | Unlikely | Very large |
| 10 | Poor communication | Unlikely | Medium |
| Element of Linguistic Variable | Frequency of Occurrence (F) | ||||
|---|---|---|---|---|---|
| Very Unlikely | Unlikely | Somewhat Likely | Likely | Very Likely | |
| 0 | 1 | 0 | 0 | 0 | 0 |
| 0.1 | 0.8 | 0.8 | 0 | 0 | 0 |
| 0.2 | 0.2 | 1.0 | 0 | 0 | 0 |
| 0.3 | 0 | 0.8 | 0.5 | 0 | 0 |
| 0.4 | 0 | 0 | 0.8 | 0 | 0 |
| 0.5 | 0 | 0 | 1 | 0.5 | 0 |
| 0.6 | 0 | 0 | 0.8 | 0.8 | 0 |
| 0.7 | 0 | 0 | 0.5 | 1.0 | 0.5 |
| 0.8 | 0 | 0 | 0 | 0.8 | 0.8 |
| 0.9 | 0 | 0 | 0 | 0.6 | 0.9 |
| 1.0 | 0 | 0 | 0 | 0 | 1 |
| Element of Linguistic Variable | Adverse Consequence (C) | ||||
|---|---|---|---|---|---|
| Very Small | Small | Medium | Large | Very Large | |
| 0 | 1 | 1 | 0 | 0 | 0 |
| 0.1 | 0.81 | 0.9 | 0 | 0 | 0 |
| 0.2 | 0.25 | 0.5 | 0 | 0 | 0 |
| 0.3 | 0 | 0 | 0.2 | 0 | 0 |
| 0.4 | 0 | 0 | 0.8 | 0 | 0 |
| 0.5 | 0 | 0 | 1 | 0 | 0 |
| 0.6 | 0 | 0 | 0.8 | 0 | 0 |
| 0.7 | 0 | 0 | 0.2 | 0 | 0 |
| 0.8 | 0 | 0 | 0 | 0.5 | 0.25 |
| 0.9 | 0 | 0 | 0 | 0.9 | 0.81 |
| 1.0 | 0 | 0 | 0 | 1 | 1 |
| Frequency of Occurrence (F) | Adverse Consequence (C) | ||
| 0 | 0.1 | 0.2 | |
| 0.5 | 0.5 | 0.5 | 0.25 |
| 0.6 | 0.8 | 0.8 | 0.25 |
| 0.7 | 1.0 | 0.81 | 0.25 |
| 0.8 | 0.8 | 0.8 | 0.25 |
| 0.9 | 0.6 | 0.6 | 0.25 |
| Frequency of Occurrence (F) | Adverse Consequence (C) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.1 | 0.8 | 0.8 | 0.5 | 0.2 | 0.8 | 0.8 | 0.8 | 0.2 | 0.5 | 0.8 | 0.8 |
| 0.2 | 1.0 | 0.9 | 0.5 | 0.2 | 0.8 | 1.0 | 0.8 | 0.2 | 0.5 | 0.9 | 1 |
| 0.3 | 0.8 | 0.8 | 0.5 | 0.2 | 0.8 | 0.8 | 0.8 | 0.2 | 0.5 | 0.8 | 0.8 |
| 0.4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.8 | 0.8 |
| 0.5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.9 | 1 |
| 0.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.8 | 0.8 |
| 0.7 | 1.0 | 0.81 | 0.25 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.9 | 1 |
| 0.8 | 0.8 | 0.8 | 0.25 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.8 | 0.8 |
| 0.9 | 0.9 | 0.81 | 0.25 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.5 | 0.5 |
| 1.0 | 1 | 0.81 | 0.25 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| No. | Adverse Consequence (C) | Impact (I) |
|---|---|---|
| 1 | Very small | Small |
| 2 | Small | Small |
| 3 | Medium | Medium |
| 4 | Large | Large |
| 5 | Very large | Large |
| Adverse Consequence (C) | Impact (I) | ||||
|---|---|---|---|---|---|
| 20.0 | 22.5 | 25.0 | 27.5 | 30.0 | |
| 0.3 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 |
| 0.4 | 0.7 | 0.8 | 0.8 | 0.8 | 0.7 |
| 0.5 | 0.7 | 0.85 | 1 | 0.85 | 0.7 |
| 0.6 | 0.7 | 0.8 | 0.8 | 0.8 | 0.7 |
| 0.7 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 |
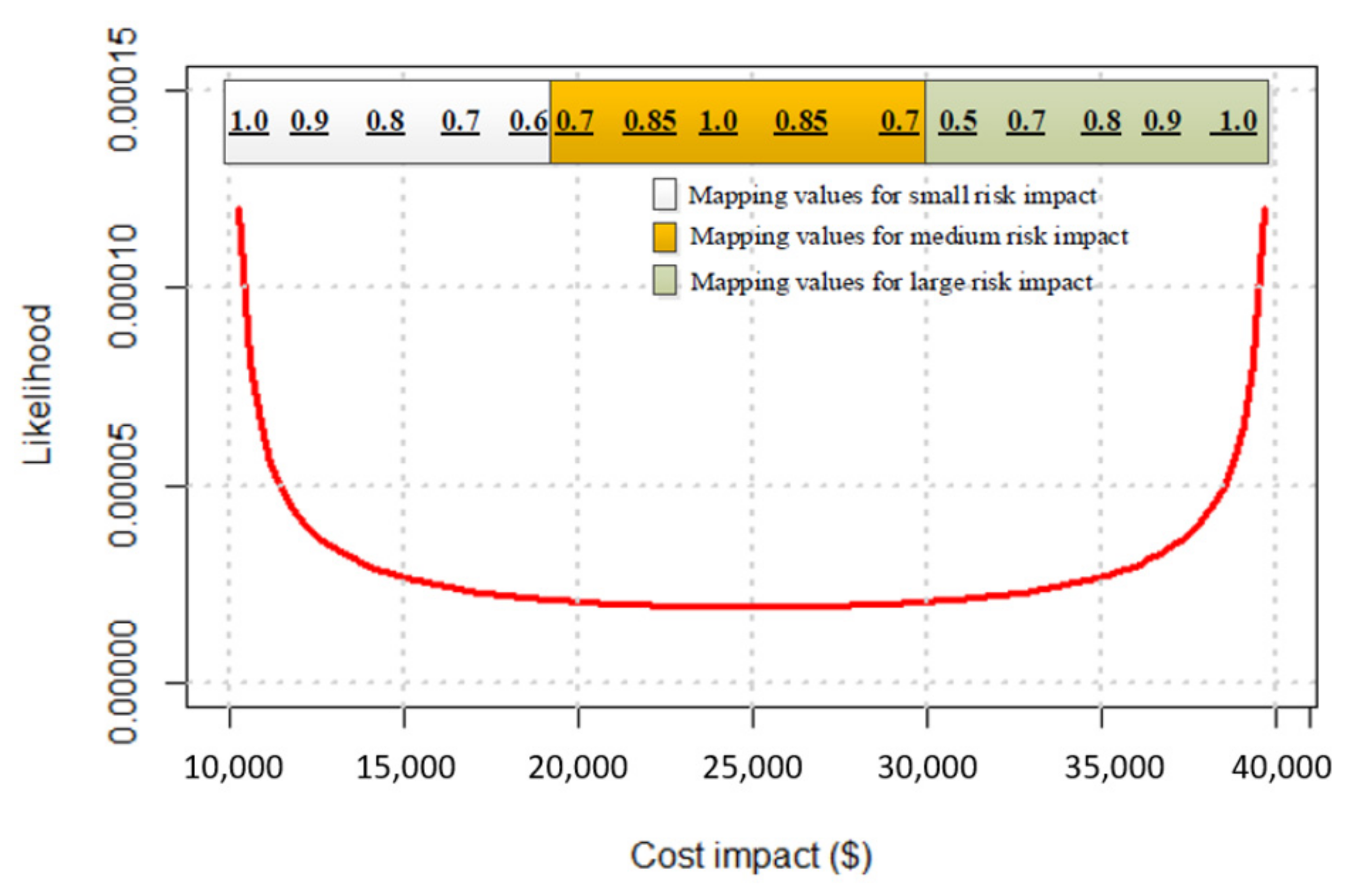
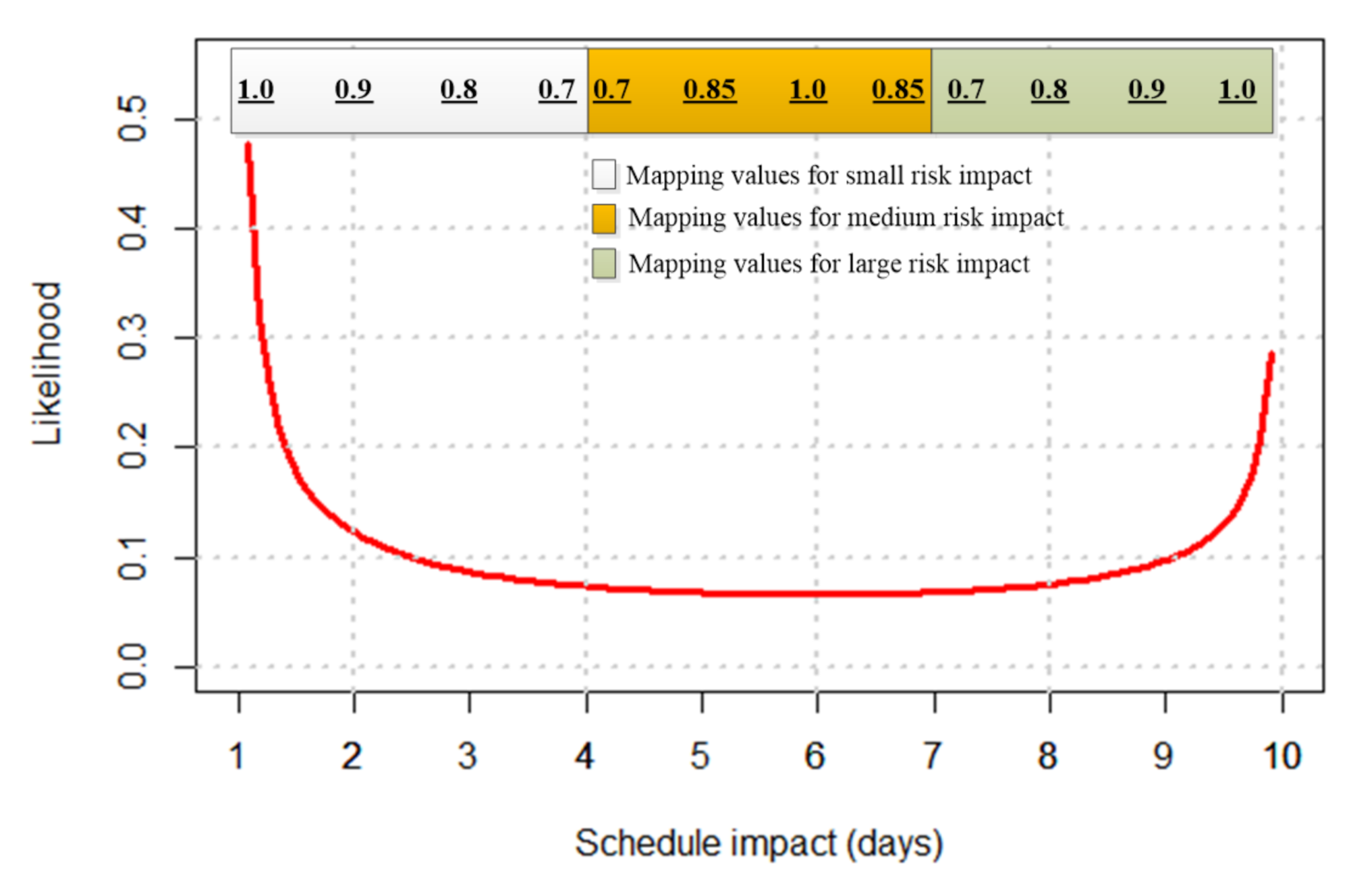
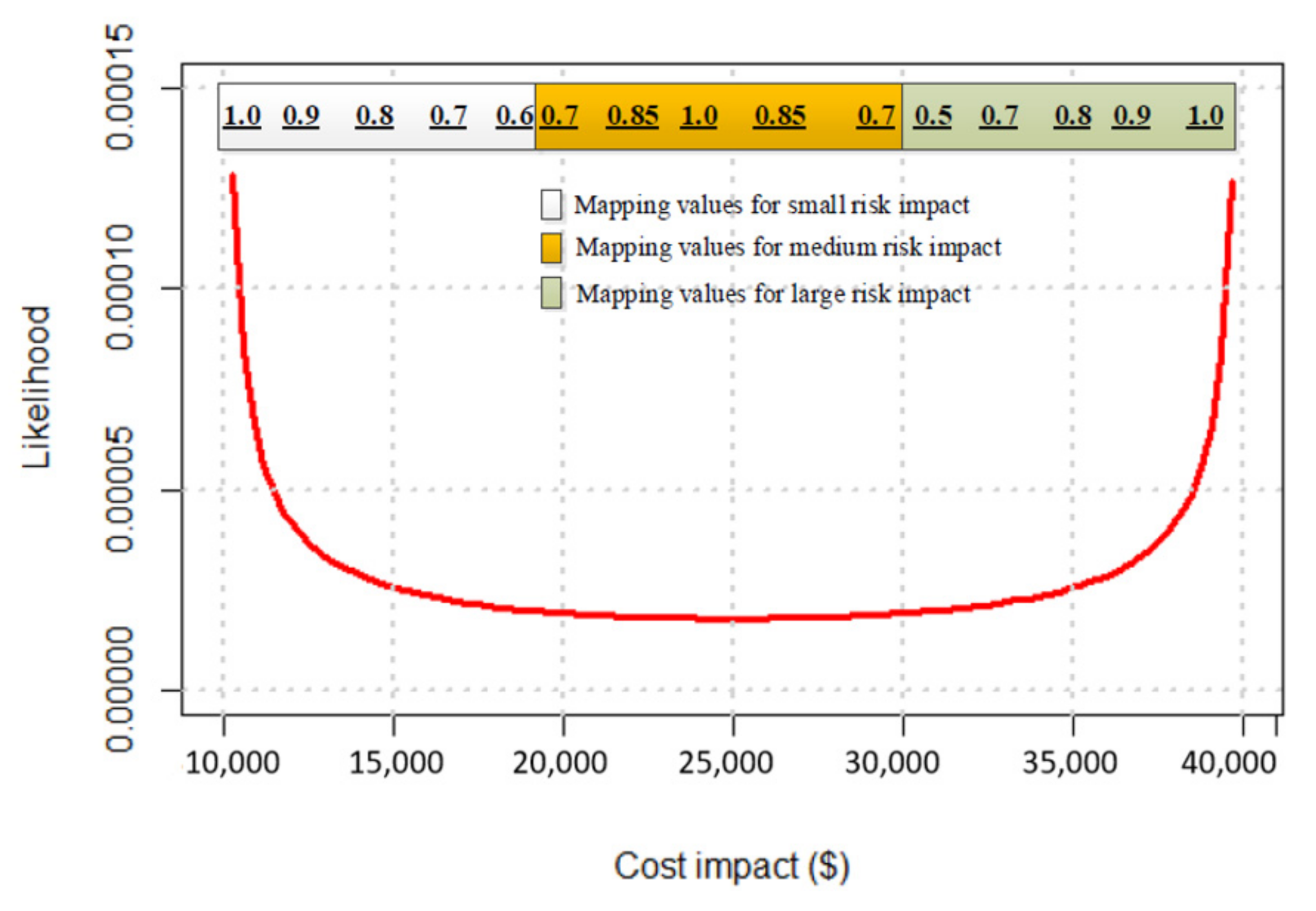
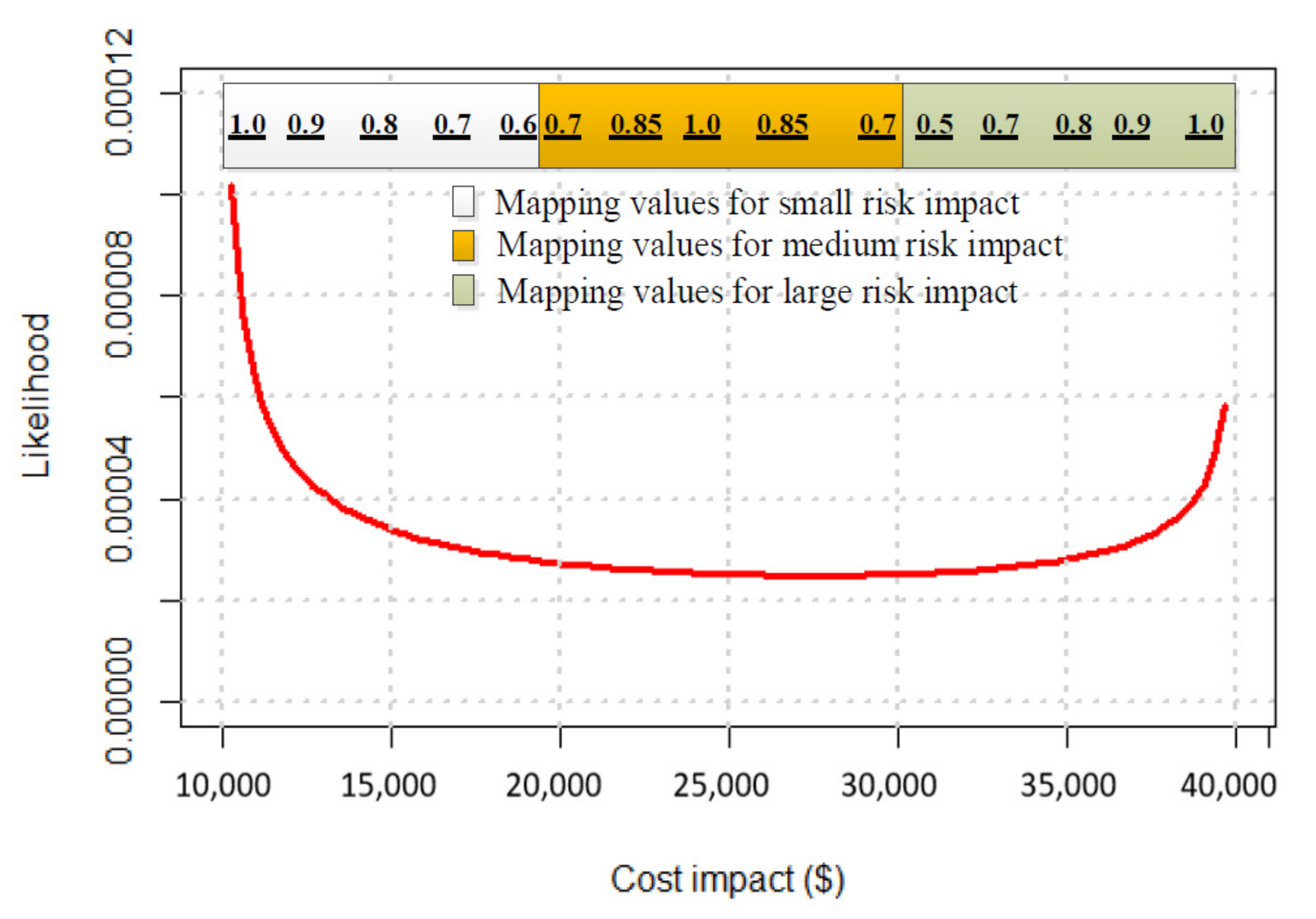
| Adverse Conseq. | Impact | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 12.5 | 15 | 17.5 | 20 | 22.5 | 25 | 27.5 | 30 | 32.5 | 35 | 37.5 | 40 | |
| 0 | 1.0 | 0.9 | 0.8 | 0.7 | 0.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.1 | 0.9 | 0.9 | 0.8 | 0.7 | 0.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.2 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.3 | 0 | 0 | 0 | 0 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0 | 0 | 0 | 0 |
| 0.4 | 0 | 0 | 0 | 0 | 0.7 | 0.8 | 0.8 | 0.8 | 0.7 | 0 | 0 | 0 | 0 |
| 0.5 | 0 | 0 | 0 | 0 | 0.7 | 0.85 | 1.0 | 0.85 | 0.7 | 0 | 0 | 0 | 0 |
| 0.6 | 0 | 0 | 0 | 0 | 0.7 | 0.8 | 0.8 | 0.8 | 0.7 | 0 | 0 | 0 | 0 |
| 0.7 | 0 | 0 | 0 | 0 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0 | 0 | 0 | 0 |
| 0.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 |
| 0.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.7 | 0.8 | 0.9 | 0.9 |
| 1.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.7 | 0.8 | 0.9 | 1.0 |
| Frequency of Occurrence | Impact | Row Sum | Multiplication | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.0 | 12.5 | 15.0 | 17.5 | 20.0 | 22.5 | 25.0 | 27.5 | 30.0 | 32.5 | 35.0 | 37.5 | 40.0 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.1 | 0.8 | 0.8 | 0.8 | 0.7 | 0.7 | 0.8 | 0.8 | 0.8 | 0.7 | 0.7 | 0.8 | 0.8 | 0.8 | 10.0 | 1.00 |
| 0.2 | 1.0 | 0.9 | 0.8 | 0.7 | 0.7 | 0.85 | 1 | 0.85 | 0.7 | 0.7 | 0.8 | 0.9 | 1.0 | 10.9 | 2.18 |
| 0.3 | 0.8 | 0.8 | 0.8 | 0.7 | 0.7 | 0.8 | 0.8 | 0.8 | 0.7 | 0.7 | 0.8 | 0.8 | 0.8 | 10.0 | 3.00 |
| 0.4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.7 | 0.8 | 0.8 | 0.8 | 3.6 | 1.44 |
| 0.5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.7 | 0.8 | 0.9 | 1.0 | 3.9 | 1.95 |
| 0.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.7 | 0.8 | 0.8 | 0.8 | 3.6 | 2.16 |
| 0.7 | 1.0 | 0.9 | 0.8 | 0.7 | 0.6 | 0 | 0 | 0 | 0.5 | 0.7 | 0.8 | 0.9 | 1.0 | 7.9 | 5.53 |
| 0.8 | 0.8 | 0.8 | 0.8 | 0.7 | 0.6 | 0 | 0 | 0 | 0.5 | 0.7 | 0.8 | 0.8 | 0.8 | 7.3 | 5.84 |
| 0.9 | 0.9 | 0.9 | 0.8 | 0.7 | 0.6 | 0 | 0 | 0 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 6.4 | 5.76 |
| 1.0 | 1.0 | 0.9 | 0.8 | 0.7 | 0.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4.0 | 4.00 |
| Element of Linguistic Variable | Frequency of Occurrence (F) | ||||
|---|---|---|---|---|---|
| Very Unlikely | Unlikely | Somewhat Likely | Likely | Very Likely | |
| 0 | 1 | 0 | 0 | 0 | 0 |
| 0.1 | 1 | 0 | 0 | 0 | 0 |
| 0.2 | 0.5 | 0.5 | 0 | 0 | 0 |
| 0.3 | 0 | 1 | 0 | 0 | 0 |
| 0.4 | 0 | 0.5 | 0.5 | 0 | 0 |
| 0.5 | 0 | 0 | 1 | 0 | 0 |
| 0.6 | 0 | 0 | 0.5 | 0.5 | 0 |
| 0.7 | 0 | 0 | 0 | 1.0 | 0 |
| 0.8 | 0 | 0 | 0 | 0.5 | 0.5 |
| 0.9 | 0 | 0 | 0 | 0 | 1 |
| 1.0 | 0 | 0 | 0 | 0 | 1 |
| Element of Linguistic Variable | Adverse Consequence (C) | ||||
|---|---|---|---|---|---|
| Very Small | Small | Medium | Large | Very Large | |
| 0 | 1 | 0 | 0 | 0 | 0 |
| 0.05 | 1 | 0 | 0 | 0 | 0 |
| 0.1 | 0.5 | 0 | 0 | 0 | 0 |
| 0.15 | 0 | 0.5 | 0 | 0 | 0 |
| 0.2 | 0 | 1.0 | 0 | 0 | 0 |
| 0.25 | 0 | 1.0 | 0 | 0 | 0 |
| 0.3 | 0 | 0.5 | 0 | 0 | 0 |
| 0.35 | 0 | 0 | 0.5 | 0 | 0 |
| 0.4 | 0 | 0 | 1 | 0 | 0 |
| 0.45 | 0 | 0 | 1 | 0 | 0 |
| 0.5 | 0 | 0 | 1 | 0 | 0 |
| 0.55 | 0 | 0 | 1 | 0 | 0 |
| 0.6 | 0 | 0 | 0.5 | 0 | 0 |
| 0.65 | 0 | 0 | 0 | 0.5 | 0 |
| 0.7 | 0 | 0 | 0 | 1.0 | 0 |
| 0.75 | 0 | 0 | 0 | 1.0 | 0 |
| 0.8 | 0 | 0 | 0 | 0.5 | 0 |
| 0.85 | 0 | 0 | 0 | 0 | 0.5 |
| 0.9 | 0 | 0 | 0 | 0 | 1 |
| 0.95 | 0 | 0 | 0 | 0 | 1 |
| 1.0 | 0 | 0 | 0 | 0 | 1 |
| Trial | Impact Mapping Values 1 | PDF 2 | Distribution | ||
|---|---|---|---|---|---|
| Small | Medium | Large | |||
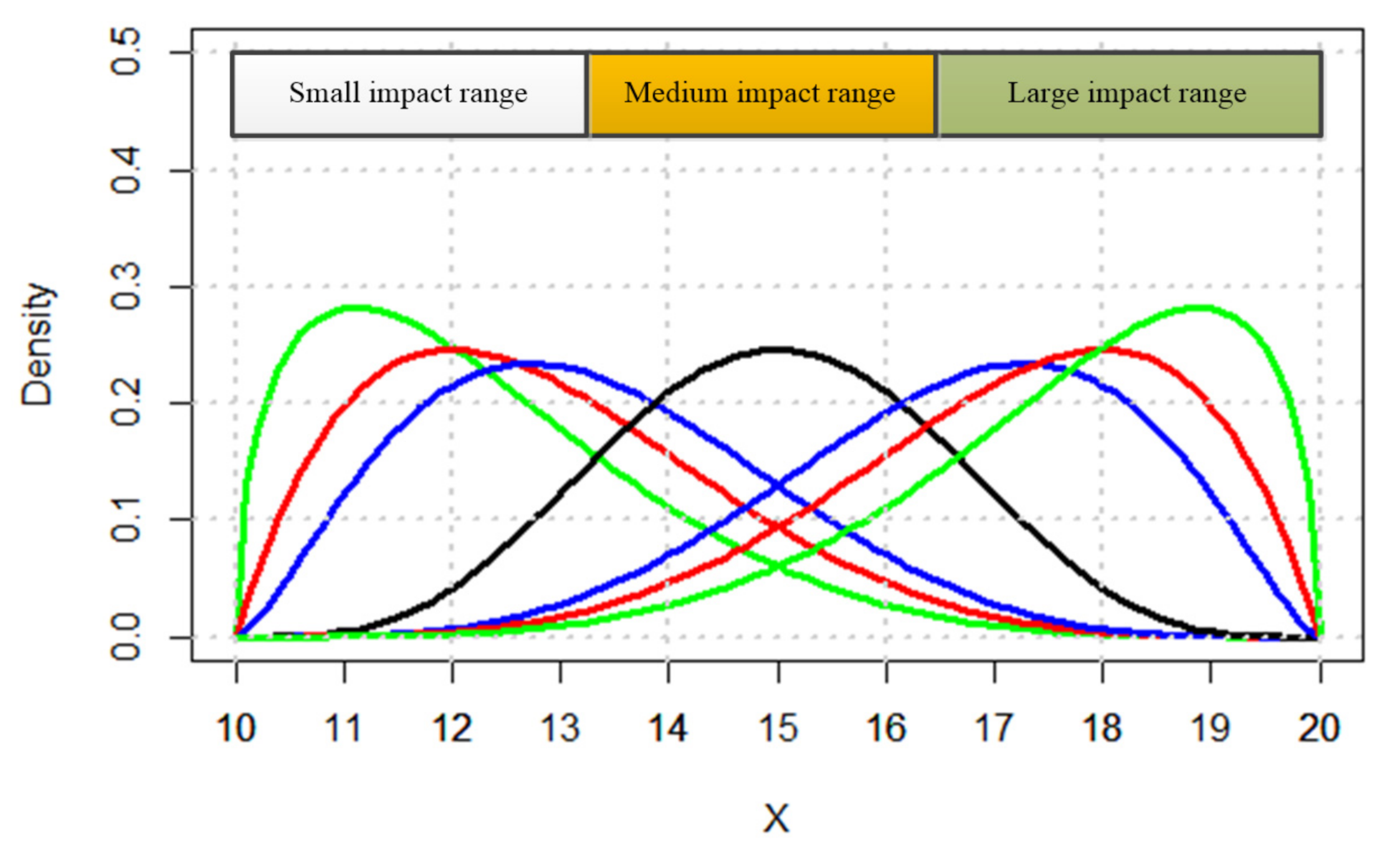
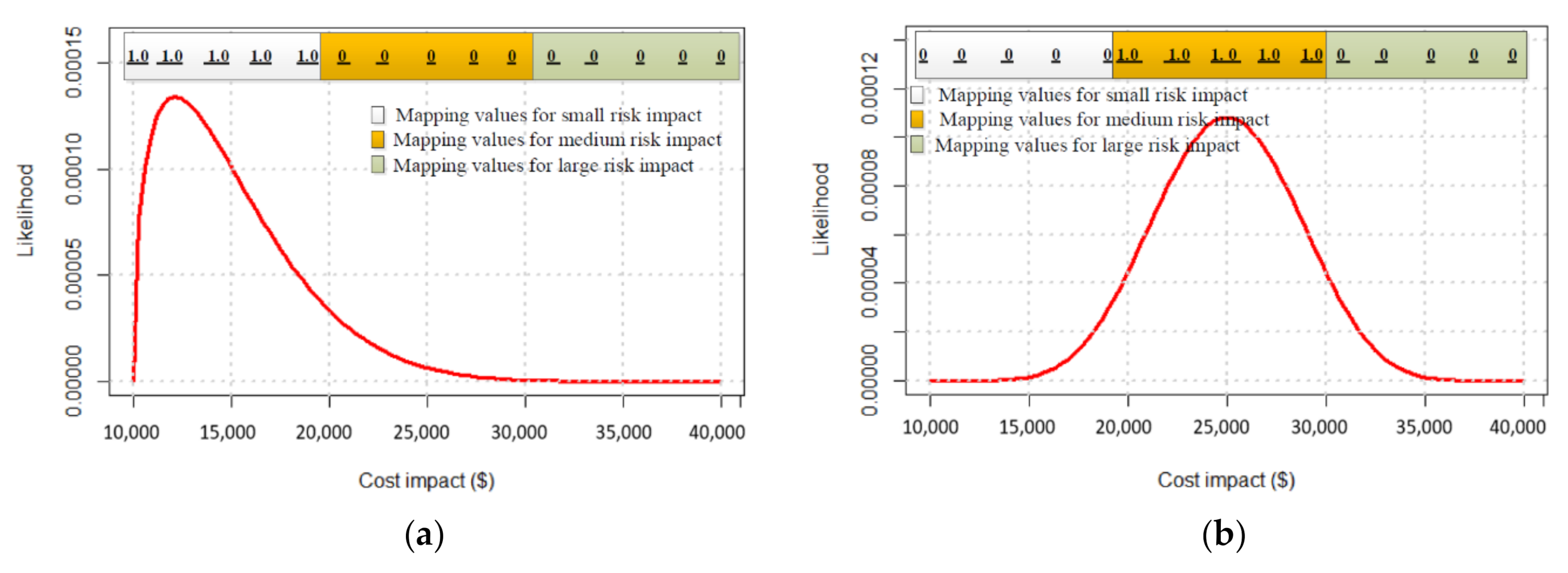
| A | 1 | 0 | 0 | Figure 11a | Skews right, as values for small impact subset are equal to 1. |
| B | 0 | 1 | 0 | Figure 11b | Symmetric, with peak at middle where mapping values equal 1. |
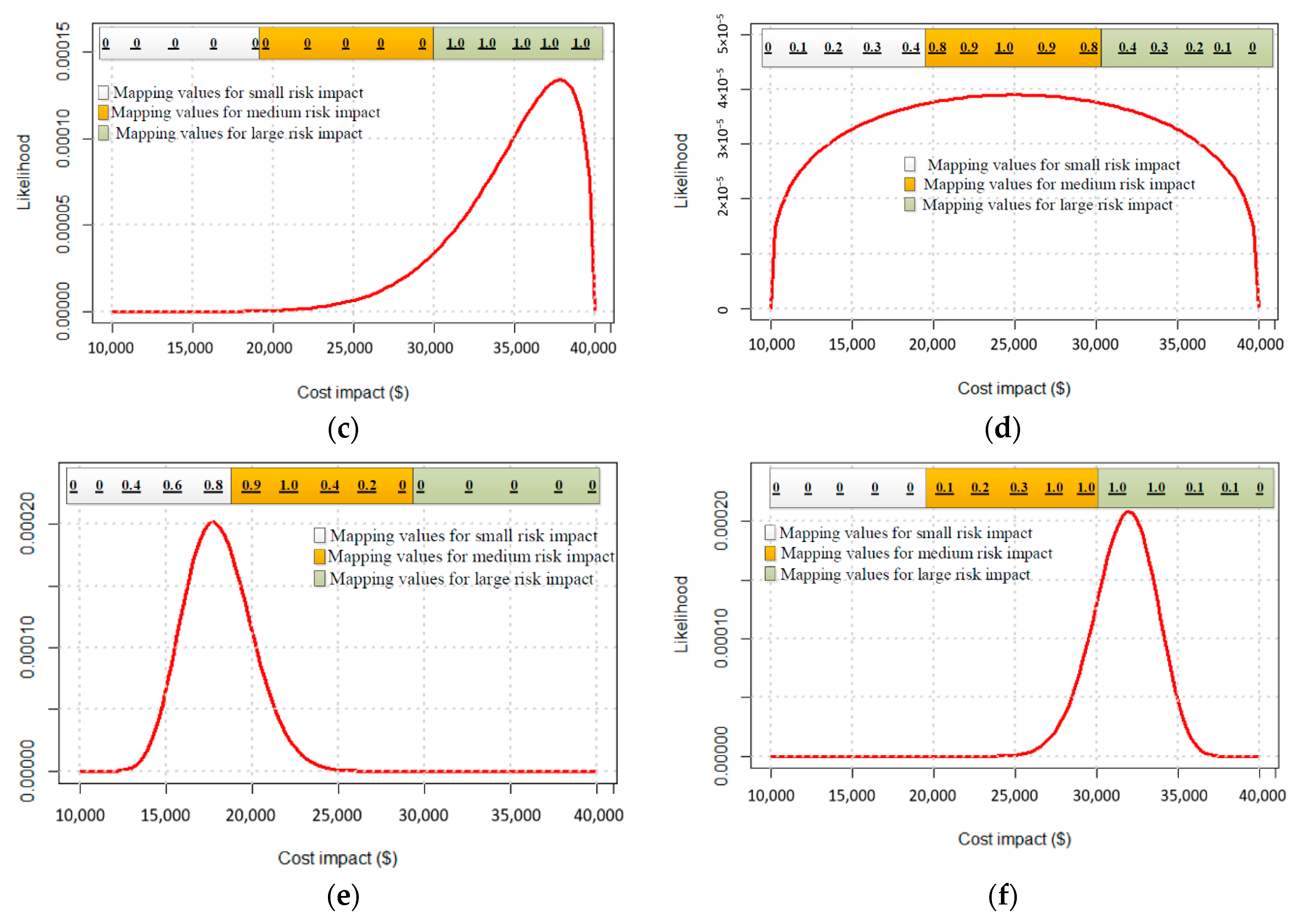
| C | 0 | 0 | 1 | Figure 11c | Skews left, as values for large impact subset are equal to 1. |
| D | ↓ | peak = 1, other = ↓ | ↓ | Figure 11d | Symmetric as in trial (b), but with greater variance. |
| E | ↑ until joint point | ↓ until joint point | 0 | Figure 11e | Skews towards small and medium joint point, where values are greatest. |
| F | 0 | ↑ until joint point | ↓ until joint point | Figure 11f | Skews towards medium and large joint point, where values are greatest |
| Trial | Statistical Parameters of Beta Distribution | |||
|---|---|---|---|---|
| Minimum ($) | Maximum ($) | α | ß | |
| A | 10,000 | 40,000 | 1.5 | 7.5 |
| B | 10,000 | 40,000 | 8.5 | 8.5 |
| C | 10,000 | 40,000 | 7.5 | 1.5 |
| D | 10,000 | 40,000 | 1.3 | 1.3 |
| E | 10,000 | 40,000 | 12.035 | 32.785 |
| F | 10,000 | 40,000 | 35.175 | 13.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohamed, E.; Jafari, P.; AbouRizk, S. Fuzzy-Based Multivariate Analysis for Input Modeling of Risk Assessment in Wind Farm Projects. Algorithms 2020, 13, 325. https://doi.org/10.3390/a13120325
Mohamed E, Jafari P, AbouRizk S. Fuzzy-Based Multivariate Analysis for Input Modeling of Risk Assessment in Wind Farm Projects. Algorithms. 2020; 13(12):325. https://doi.org/10.3390/a13120325
Chicago/Turabian StyleMohamed, Emad, Parinaz Jafari, and Simaan AbouRizk. 2020. "Fuzzy-Based Multivariate Analysis for Input Modeling of Risk Assessment in Wind Farm Projects" Algorithms 13, no. 12: 325. https://doi.org/10.3390/a13120325
APA StyleMohamed, E., Jafari, P., & AbouRizk, S. (2020). Fuzzy-Based Multivariate Analysis for Input Modeling of Risk Assessment in Wind Farm Projects. Algorithms, 13(12), 325. https://doi.org/10.3390/a13120325