An Algorithm for Efficient Generation of Customized Priority Rules for Production Control in Project Manufacturing with Stochastic Job Processing Times


Abstract
:1. Introduction
- Is it possible to improve mean value and standard deviation of project individual objectives by applying the generated CPRs?
- Is it possible to save computation time with the 2-phase algorithm?
2. State-of-the-Art
2.1. Problem Definition: RCMPSP
2.2. Approaches for Decentralized Control of RCMPSP
2.3. Reducing Computation Time for Generating CPRs
2.4. Contribution and Motivation
- We consider the use of CPRs for short-term production control in an SRCMPSP environment. The CPRs are assigned to each project.
- We perform a Pareto optimization [40] (pp. 197–199) with the NSGA-III on project level, where the mean and standard deviation of delay and makespan of a single project are considered to evaluate the generated CPRs.
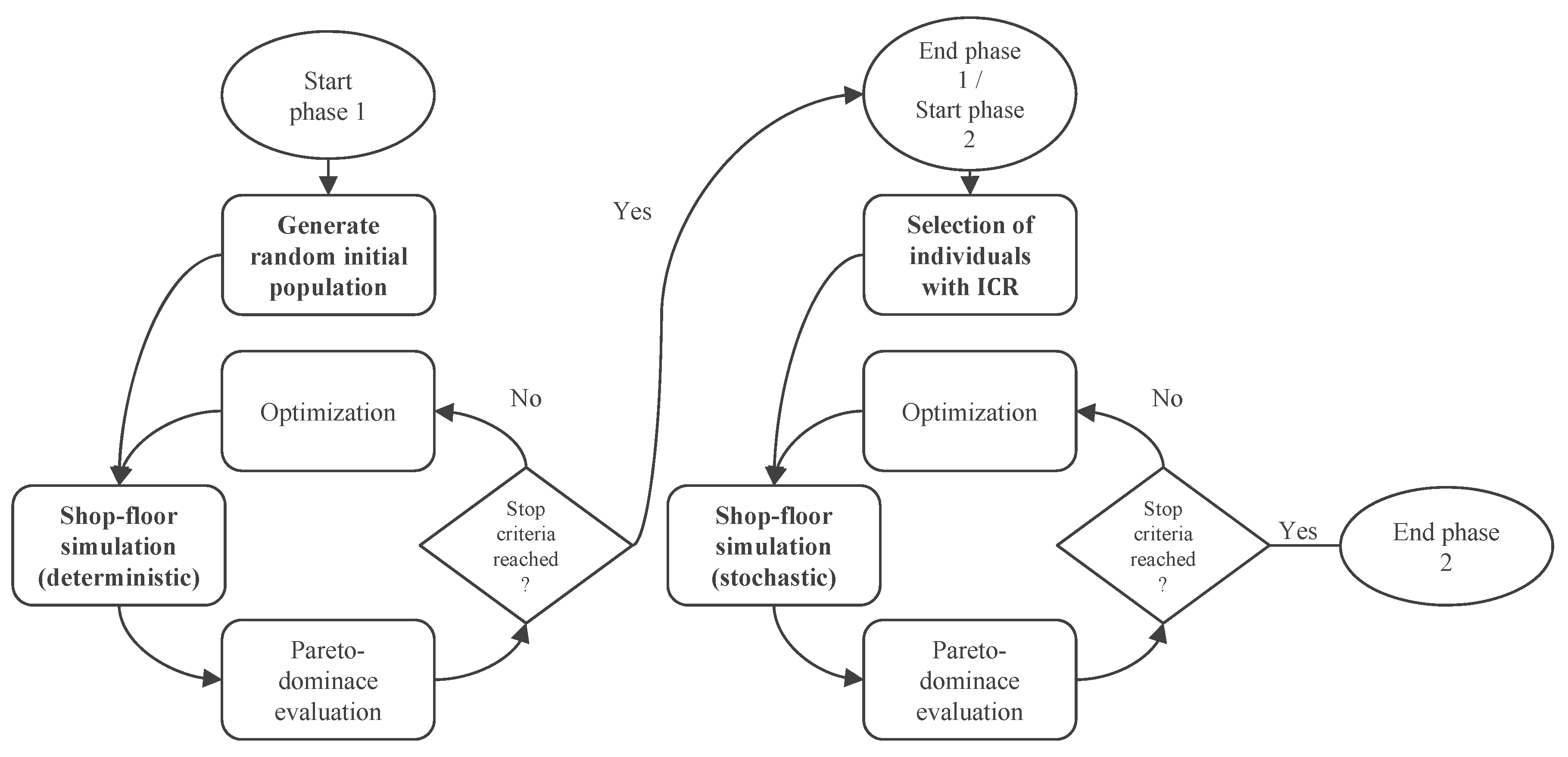
- A deterministic and stochastic optimization phase takes place for reducing computational effort. For the selection of deterministic solutions, we introduce the parameter Initial Copy Rate (ICR), which indicates how many solutions are copied and how many are randomized.
- We developed a software framework for generating CPRs and compared results with several different PRs.
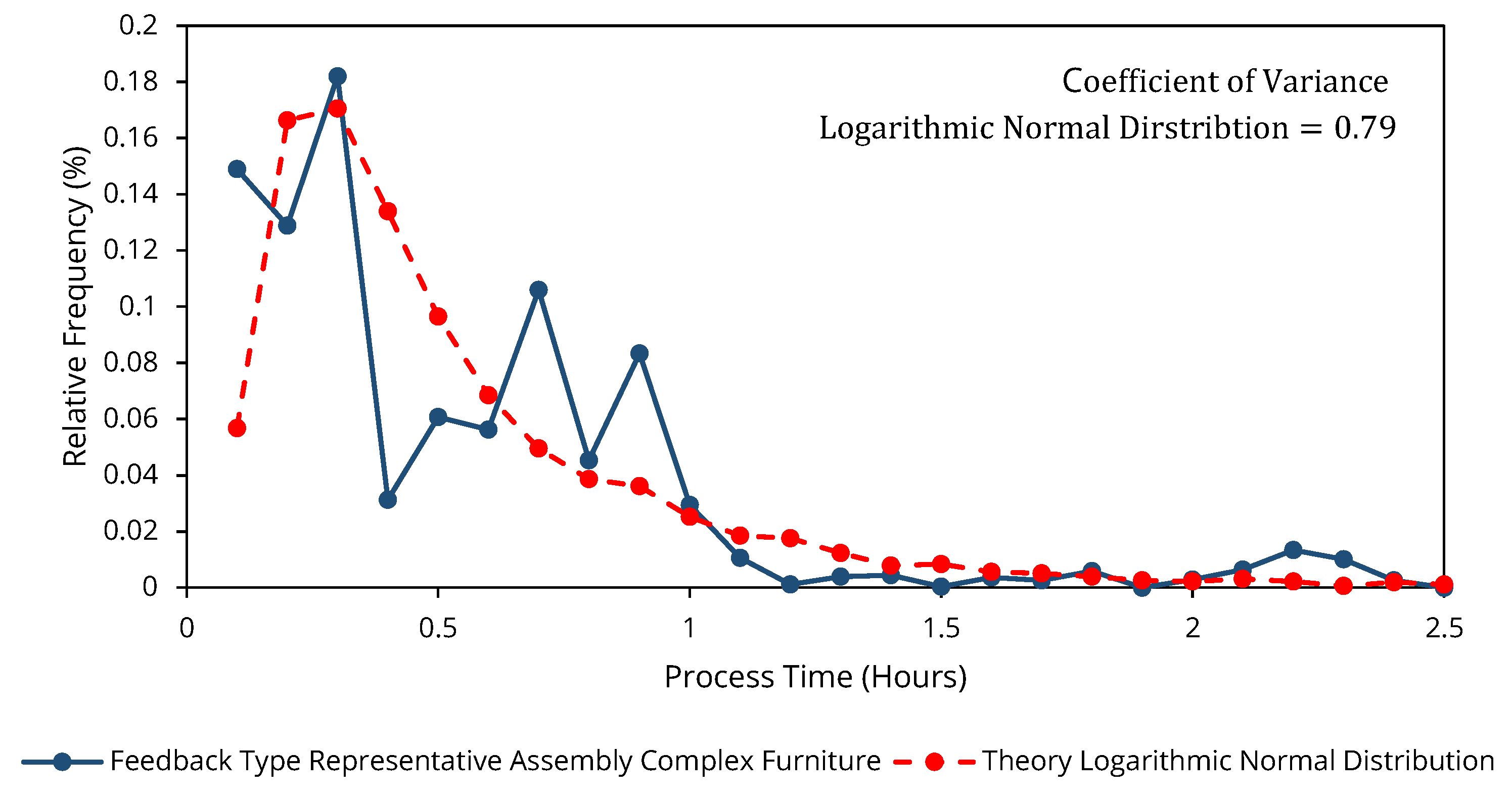
3. Model Extensions of the Stochastic RCMPSP
4. Proposed Algorithm for Generating CPR
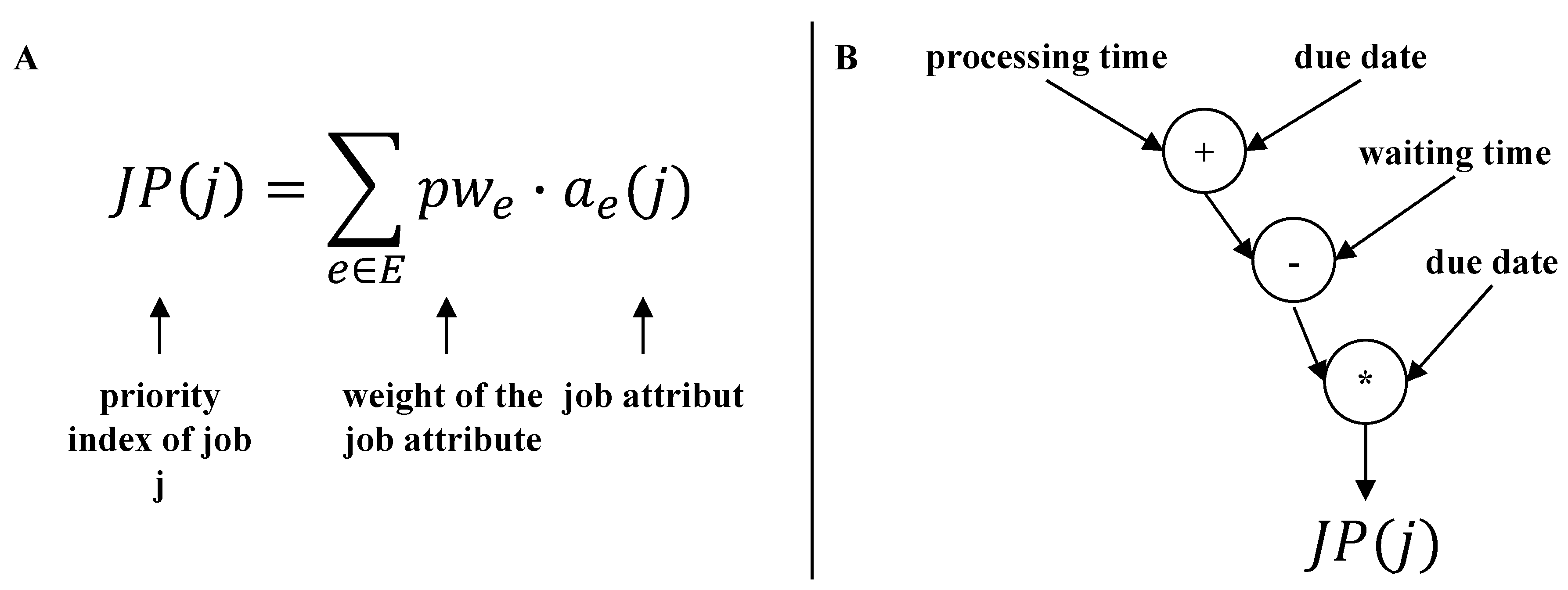
4.1. Representation of CPR
4.2. Two-Phase Genetic Algorithm for Generating CPRs
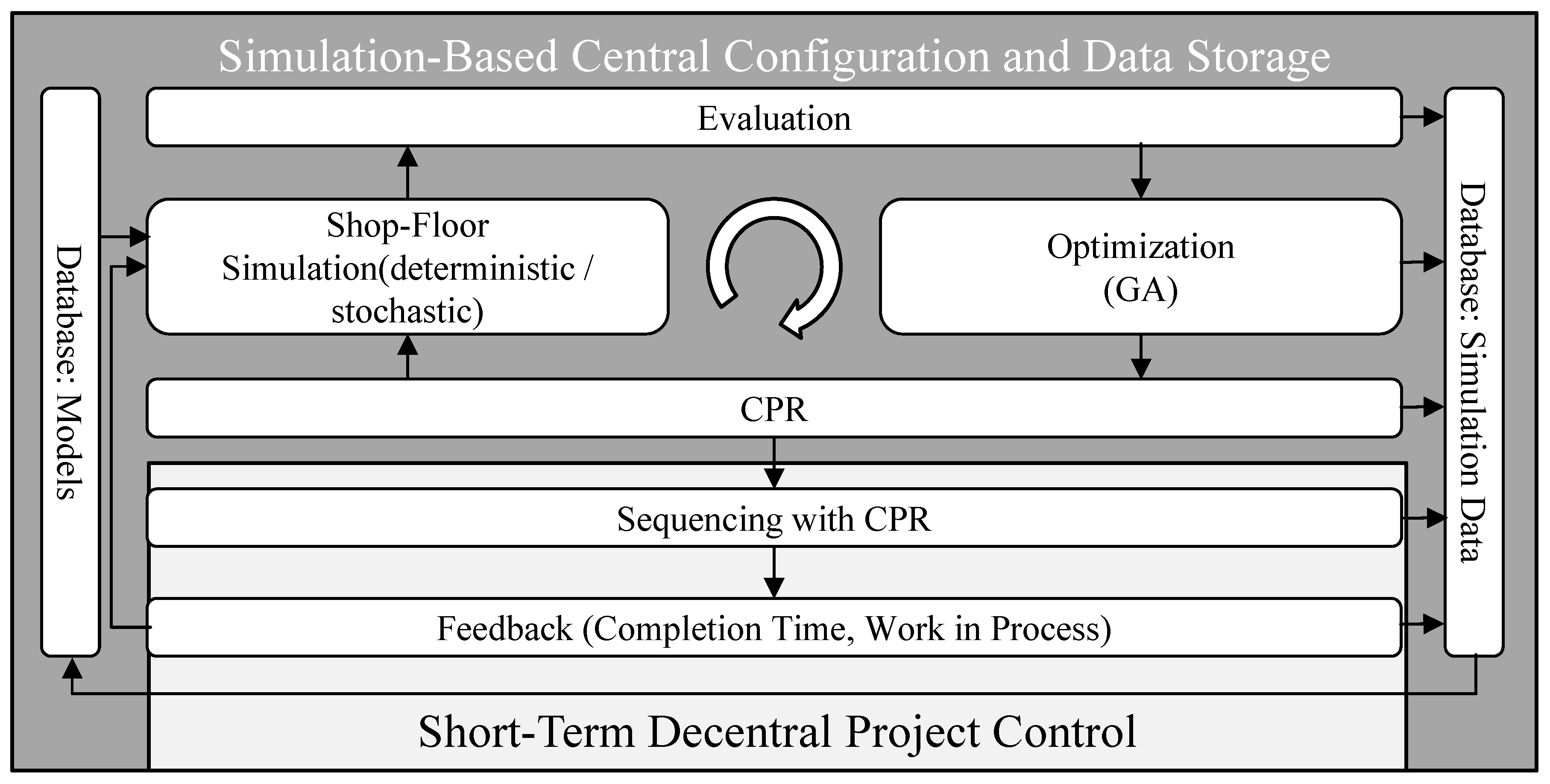
4.3. Overall Concept for Using CPRs and Proposed Software-Framework
5. Results
5.1. Experiment Design for Concept Evaluation
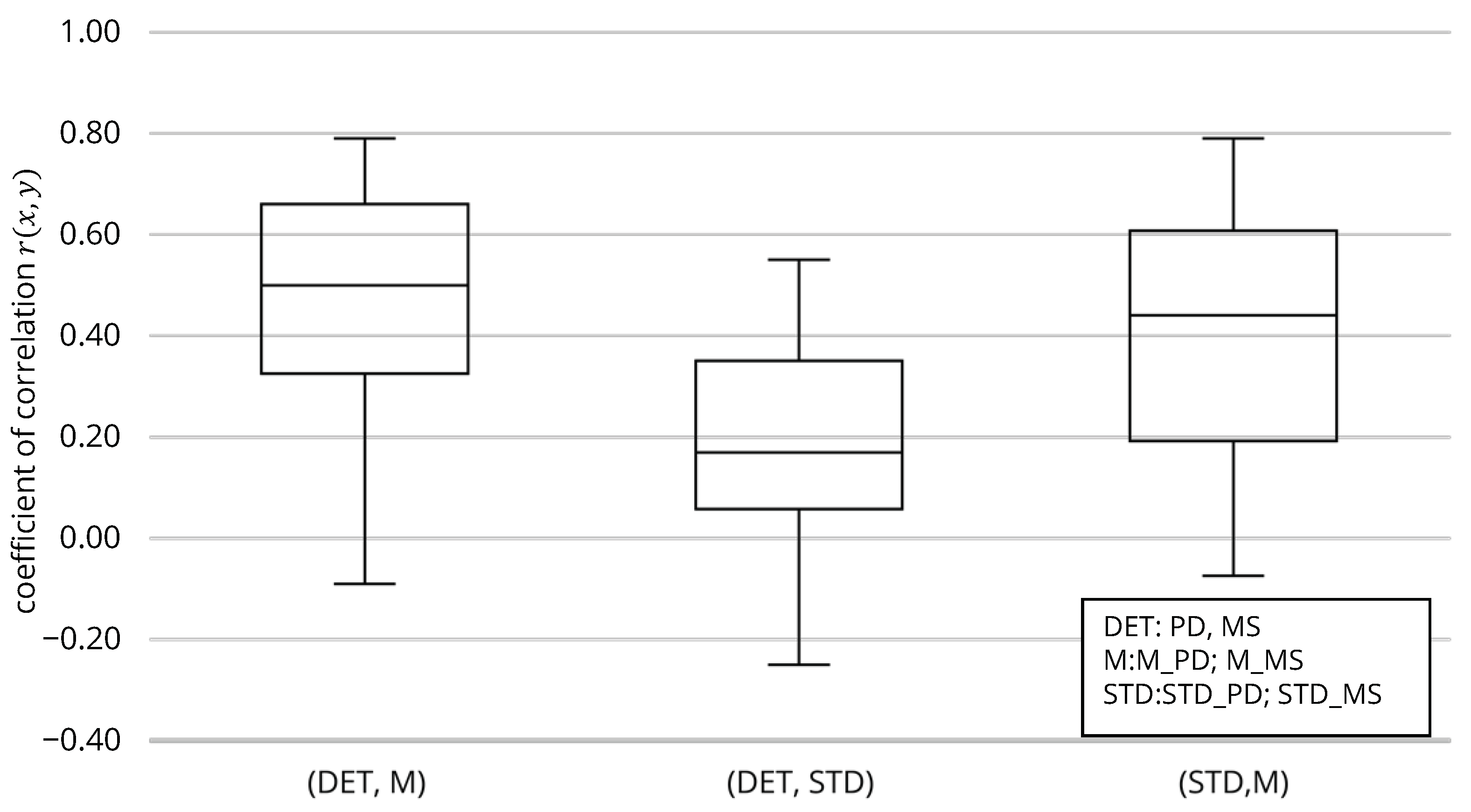
5.2. Comparing Deterministic and Stochastic Solutions
5.3. Comparing Computation Effort
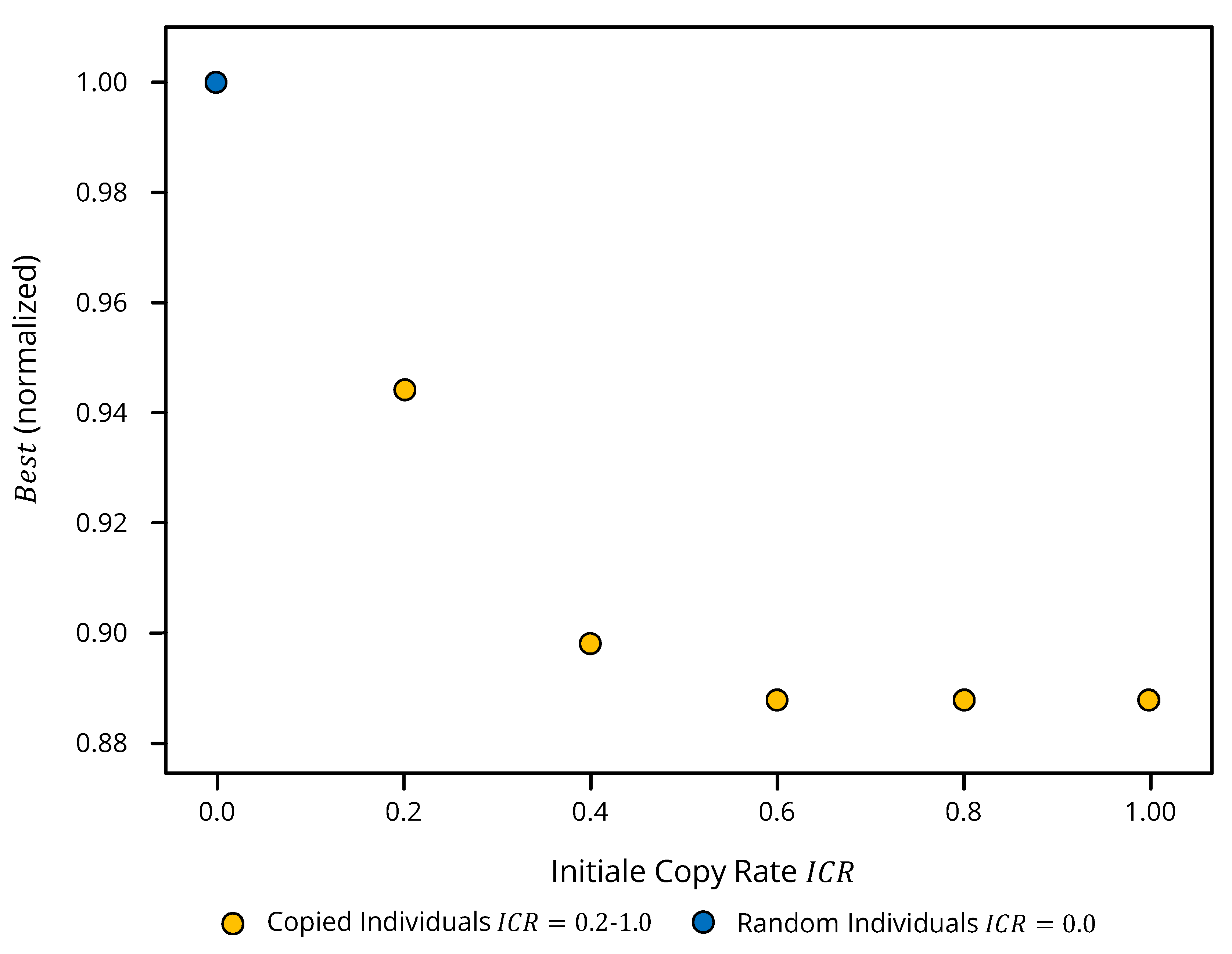
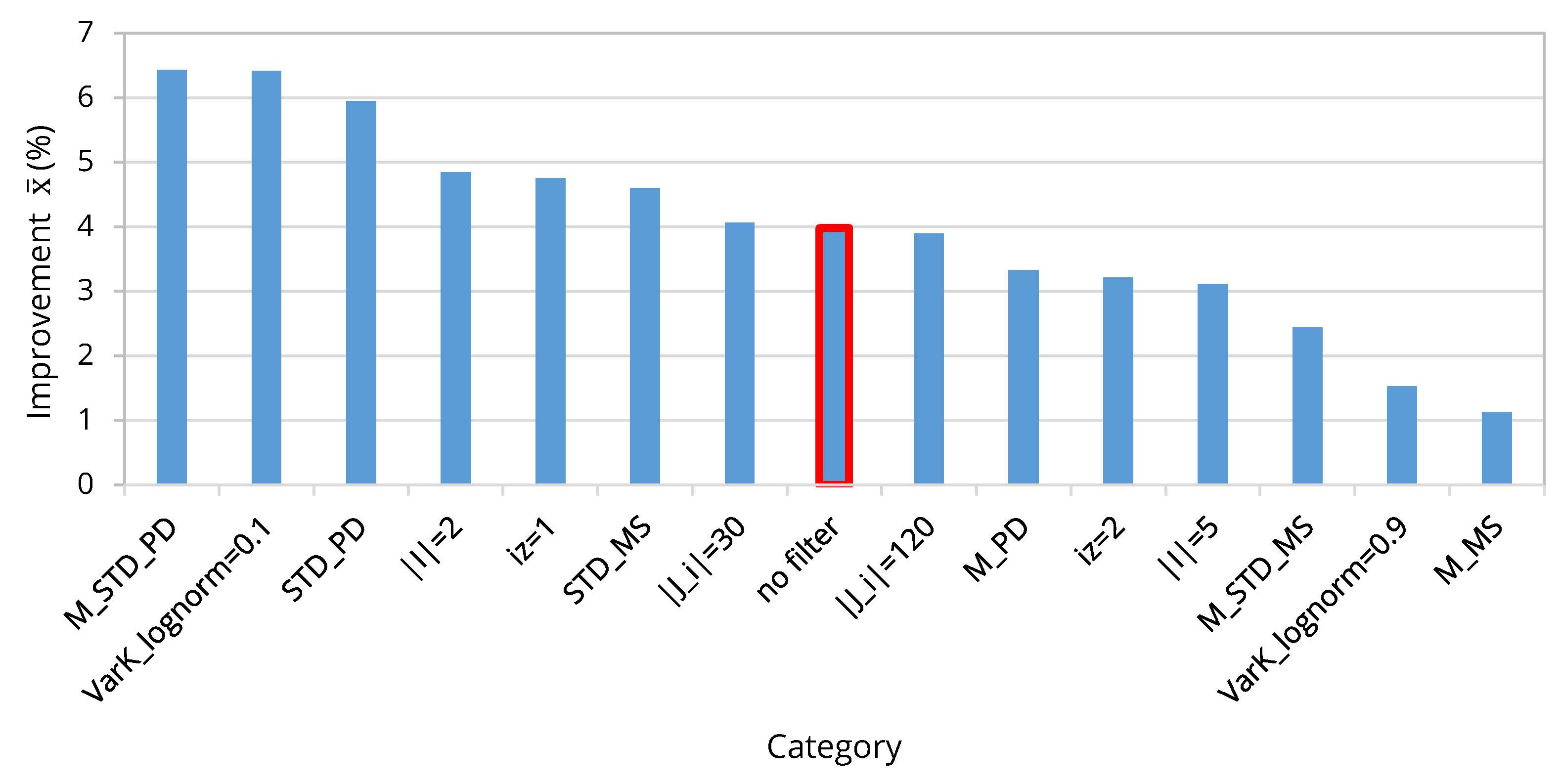
- An optimization of the initial population does not necessarily lead to the best result with respect to the objective value .
- A low and a too high initial copy rate lead less frequently to the best objective value . Therefore, it can be concluded that either too many randomized solutions or too many copied solutions do not sufficiently represent the correlation between deterministic and stochastic solution and that, therefore, for a diverse initial population, an equal ratio of copied and randomized solutions is most promising.
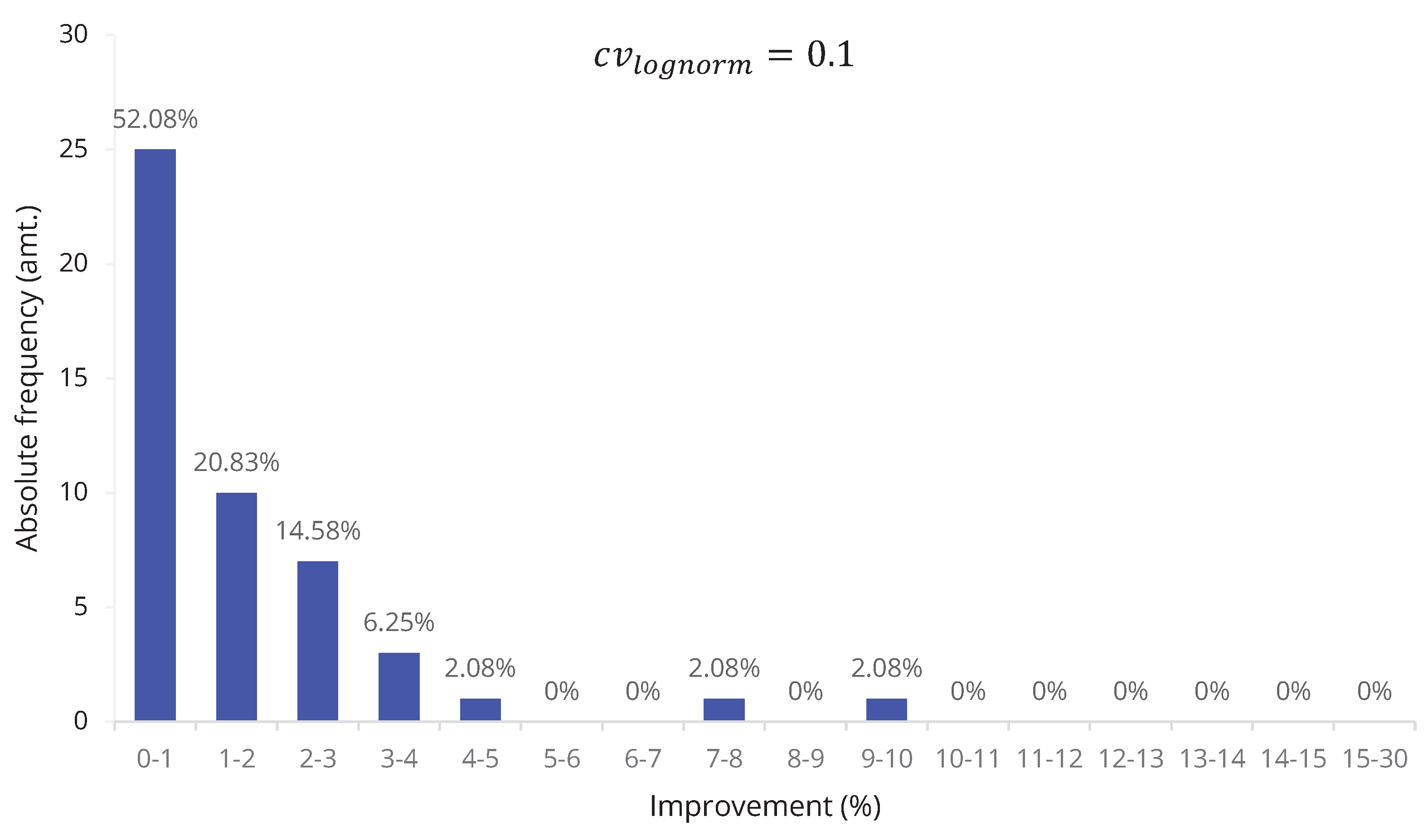
5.4. Evaluation of the Overall Quality of The Algorithm
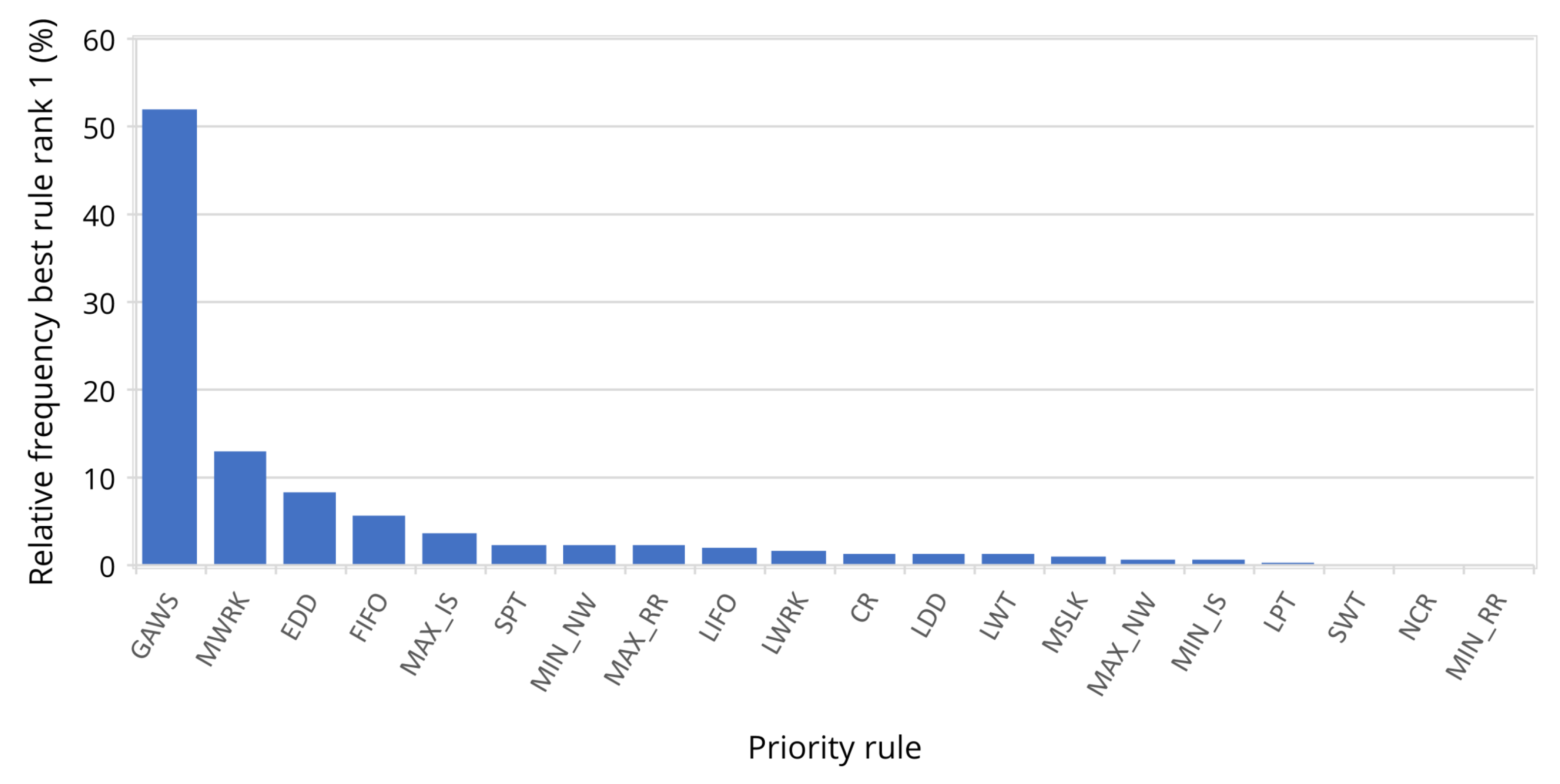
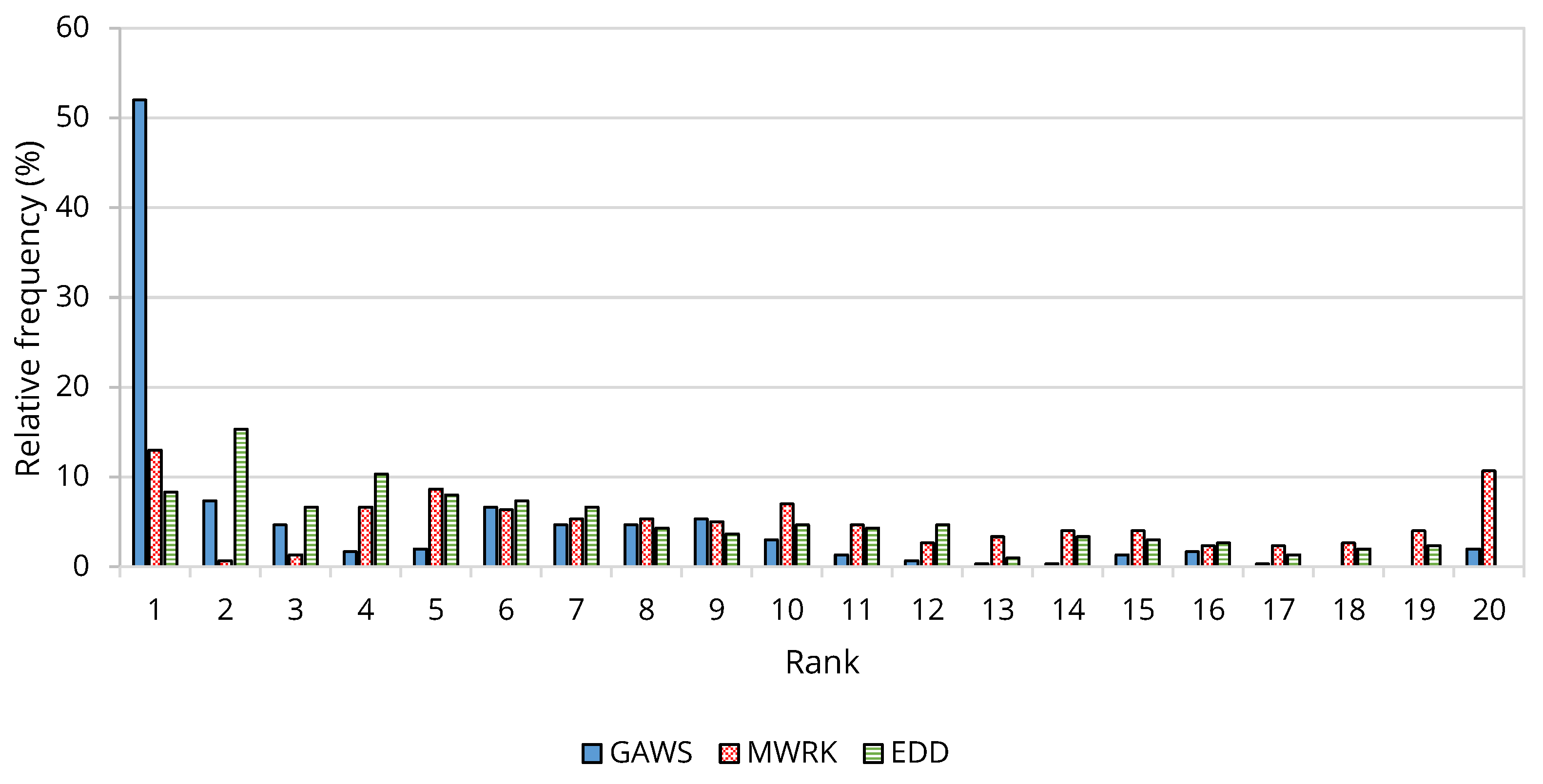
5.5. Comparison with Standard Priority Rules
6. Conclusions and Outlook
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| APS | Advanced Panning and Scheduling |
| CDR | Composite Dispatching Rule |
| CPR | Composite Priority Rule |
| CPPS | Cyber Physical Production System |
| GA | Genetic Algorithm |
| GAWS | Genetic Algorithm Weighted Sum |
| ICR | Initial Copy Rate |
| MES | Manufacturing Execution System |
| MPSPLIB | Multi-Project Scheduling Library |
| PPC | Project Planning and Control |
| PSPLIB | Project Scheduling Linrary |
| RCPSP | Resource Constrained Project Scheduling Problem |
| SH | Sequencing Heuristic |
| SPR | Simple Priority Rules |
| SRCMPSP | Stochastic Resource Constrained Multi-Project Scheduling Problem |
References
- Bischoff, J.; Taphorn, C.; Wolter, D.; Braun, N.; Fellbaum, M.; Goloverov, A.; Ludwig, S.; Hegmanns, T.; Prasse, C.; Henke, M.; et al. Erschließen der Potenziale der Anwendung von Industrie 4.0 im Mittelstand; BMWi: Berlin, Germany, 2015. [Google Scholar]
- Huber, W. Industrie 4.0 Kompakt—Wie Technologien Unsere Wirtschaft und Unsere Unternehmen Verändern; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2018. [Google Scholar] [CrossRef]
- Lödding, H. Verfahren der Fertigungssteuerung: Grundlagen, Beschreibung, Konfiguration; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Glonegger, M. Berücksichtigung Menschlicher Leistungsschwankungen bei der Planung von Variantenfließ-Montagesystemen; Forschungsberichte IWB; Utz, Herbert: München, Germany, 2014; Volume 292. [Google Scholar]
- Marczinski, G. Einsatzgebiete von ERP-, APS- und MES-Lösungen. ERP Manag. 2008, 2008, 62–64. [Google Scholar]
- Niehus, M.R. Adaptive Produktionssteuerung für Werkstattfertigungssysteme durch Fertigungsbegleitende Reihenfolgebildung. Ph.D. Thesis, Technische Universität München, München, Germany, 2016. [Google Scholar]
- Hansmann, K.W. Industrielles Management; 8., völlig überarb. und erw. aufl. ed.; Oldenbourg: München, Germany, 2006. [Google Scholar]
- Nyhuis, P.; Mayer, J.; Kuprat, T. Die Bedeutung von Industrie 4.0 als Enabler für logistische Modelle. In Industrie 4.0; Kersten, W., Ed.; Schriftenreihe der Hochschulgruppe für Arbeits- und Betriebsorganisation e.V. (HAB); Gito: Berlin, Germany, 2014; pp. 79–100. [Google Scholar]
- Peßl, E. Digitale Produktion: Studie über Status, Hemmnisse und Anforderungen österreichischer Produzierender Klein- und Mittelunternehmen und Analyse der Software-Hersteller von MES-Systemen; Inst. Industrial Management/Industriewirtschaft FH JOANNEUM Kapfenberg: Kapfenberg, Austria, 2013. [Google Scholar]
- Branke, J.; Nguyen, S.; Pickardt, C.W.; Zhang, M. Automated Design of Production Scheduling Heuristics: A Review. IEEE Trans. Evol. Comput. 2016, 20, 110–124. [Google Scholar] [CrossRef] [Green Version]
- Hildebrandt, T.; Heger, J.; Scholz-Reiter, B. Towards improved dispatching rules for complex shop floor scenarios. In Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computation; Pelikan, M., Branke, J., Eds.; ACM: New York, NY, USA, 2010; pp. 257–264. [Google Scholar] [CrossRef]
- Pritsker, A.A.B.; Waiters, L.J.; Wolfe, P.M. Multiproject Scheduling with Limited Resources: A Zero-One Programming Approach. Manag. Sci. 1969, 16, 93–108. [Google Scholar] [CrossRef] [Green Version]
- Lova, A.; Tormos, P. Analysis of Scheduling Schemes and Heuristic Rules Performance in Resource-Constrained Multiproject Scheduling. Ann. Oper. Res. 2001, 102, 263–286. [Google Scholar] [CrossRef]
- Confessore, G.; Giordani, S.; Rismondo, S. A market-based multi-agent system model for decentralized multi-project scheduling. Ann. Oper. Res. 2007, 150, 115–135. [Google Scholar] [CrossRef]
- Homberger, J. A multi-agent system for the decentralized resource-constrained multi-project scheduling problem. Int. Trans. Oper. Res. 2007, 14, 565–589. [Google Scholar] [CrossRef]
- Homberger, J. MPSPLIB: Multi Project Scheduling Problem Library. Hochschule für Technik Stuttgart. 2008. Available online: www.mpsplib.com (accessed on 17 October 2020).
- Kolisch, R.; Sprecher, A. PSPLIB—A project scheduling problem library. Eur. J. Oper. Res. 1996, 96, 205–216. [Google Scholar] [CrossRef] [Green Version]
- Blazewicz, J.; Lenstra, J.; Rinnooy Kan, A. Scheduling subject to resource constraints: Classification and complexity. Discret. Appl. Math. 1983, 5, 11–24. [Google Scholar] [CrossRef] [Green Version]
- Ballestín, F. When it is worthwhile to work with the stochastic RCPSP? J. Sched. 2007, 10, 153–166. [Google Scholar] [CrossRef]
- Kolisch, R.; Hartmann, S. Heuristic Algorithms for the Resource-Constrained Project Scheduling Problem: Classification and Computational Analysis. In Project Scheduling: Recent Models, Algorithms and Applications; Węglarz, J., Ed.; Springer US: Boston, MA, USA, 1999; pp. 147–178. [Google Scholar] [CrossRef]
- März, L.; Krug, W.; Rose, O.; Weigert, G. Simulation und Optimierung in Produktion und Logistik; Springer: Berlin, Germany, 2011; Volume 1. [Google Scholar] [CrossRef]
- Herroelen, W. Project Scheduling—Theory and Practice. Prod. Oper. Manag. 2005, 14, 413–432. [Google Scholar] [CrossRef] [Green Version]
- Schade, K. Stochastische Optimierung. In Stochastische Optimierung; Schade, K., Ed.; Stochastic Programming, Vieweg+Teubner: Wiesbaden, Germany, 2012; pp. 45–72. [Google Scholar] [CrossRef]
- Ashtiani, B.; Leus, R.; Aryanezhad, M.B. A Novel Class of Scheduling Policies for the Stochastic Resource-Constrained Project Scheduling Problem. SSRN Electron. J. 2008. [Google Scholar] [CrossRef] [Green Version]
- Stork, F. Stochastic Resource-Constrained Project Scheduling. Ph.D. Thesis, Technische Universitat Berlin, Berlin, Germany, 2001. [Google Scholar] [CrossRef]
- Ashtiani, B.; Leus, R.; Aryanezhad, M.B. New competitive results for the stochastic resource-constrained project scheduling problem: Exploring the benefits of pre-processing. J. Sched. 2011, 14, 157–171. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An Evolutionary Many-Objective Optimization Algorithm Using Reference-Point-Based Nondominated Sorting Approach, Part I: Solving Problems With Box Constraints. IEEE Trans. Evol. Comput. 2014, 18, 577–601. [Google Scholar] [CrossRef]
- Kück, M.; Broda, E.; Freitag, M.; Hildebrandt, T.; Frazzon, E.M. Towards adaptive simulation-based optimization to select individual dispatching rules for production control. In Proceedings of the 2017 Winter Simulation Conference (WSC), Las Vegas, NV, USA, 3–6 December 2017; pp. 3852–3863. [Google Scholar] [CrossRef]
- Grundstein, S.; Freitag, M.; Scholz-Reiter, B. A new method for autonomous control of complex job shops—Integrating order release, sequencing and capacity control to meet due dates. J. Manuf. Syst. 2017, 42, 11–28. [Google Scholar] [CrossRef]
- Fink, A.; Homberger, J. Decentralized Multi-Project Scheduling. In Handbook on Project Management and Scheduling; Schwindt, C., Zimmermann, J., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Volume 1, pp. 685–706. [Google Scholar]
- Chand, S.; Singh, H.; Ray, T. Evolving heuristics for the resource constrained project scheduling problem with dynamic resource disruptions. Swarm Evol. Comput. 2019, 44, 897–912. [Google Scholar] [CrossRef]
- Hildebrandt, T.; Freitag, M. Bessere Prioritätsregeln für komplexe Produktionssysteme mittels multi-kriterieller simulationsbasierter Optimierung. In Simulation in Production and Logistics 2015; Rabe, M., Clausen, U., Eds.; Fraunhofer Verlag: Stuttgart, Germany, 2015; pp. 309–318. [Google Scholar]
- Branke, J.; Hildebrandt, T.; Scholz-Reiter, B. Hyper-heuristic Evolution of Dispatching Rules: A Comparison of Rule Representations. Evol. Comput. 2015, 23, 249–277. [Google Scholar] [CrossRef]
- Nguyen, S.; Zhang, M.; Tan, K.C. Surrogate-Assisted Genetic Programming With Simplified Models for Automated Design of Dispatching Rules. IEEE Trans. Cybern. 2017, 47, 2951–2965. [Google Scholar] [CrossRef]
- Jorapur, V.S.; Puranik, V.S.; Deshpande, A.S.; Sharma, M. A Promising Initial Population Based Genetic Algorithm for Job Shop Scheduling Problem. J. Softw. Eng. Appl. 2016, 9, 208–214. [Google Scholar] [CrossRef] [Green Version]
- Werner, F. A Survey of Genetic Algorithms for Shop Scheduling Problems. In Heuristics: Theory and Application; Siar, P., Ed.; Nova Science Publishers: Hauppauge, NY, USA, 2013; pp. 161–222. [Google Scholar]
- Nguyen, S.; Zhang, M.; Johnston, M.; Tan, K.C. Automatic Design of Scheduling Policies for Dynamic Multi-objective Job Shop Scheduling via Cooperative Coevolution Genetic Programming. IEEE Trans. Evol. Comput. 2014, 18, 193–208. [Google Scholar] [CrossRef]
- Nguyen, S.; Zhang, M.; Johnston, M.; Tan, K.C. A Computational Study of Representations in Genetic Programming to Evolve Dispatching Rules for the Job Shop Scheduling Problem. IEEE Trans. Evol. Comput. 2013, 17, 621–639. [Google Scholar] [CrossRef]
- Omar, M.; Baharum, A.; Hasan, Y. A job-shop scheduling problem (JSSP) using genetic algorithm (GA). In Proceedings of the 2nd im TG T Regional Conference, Penang, Malaysia, 13–15 June 2006. [Google Scholar]
- Goldberg, D.E. Genetic Algorithm in Search, Optimization, and Machine Learning; Addison-Wesley: Reading, MA, USA, 1989; Volume XIII. [Google Scholar]
- Python Software Foundation. Python. 2019. Available online: www.python.org (accessed on 17 October 2020).
- Kühn, M. PyScOp. 2019. Available online: https://tlscm.mw.tu-dresden.de/scm/git/PyScOp_2.0 (accessed on 17 October 2020).
- Schmidt, T.; Kühn, M.; Genßler, P.R. Design of Project-oriented Calculation Models for Job Priorities by Using a Customized Genetic Algorithm. In Simulation in Produktion und Logistik 2017; Wenzel, S., Peter, T., Eds.; Kassel University Press: Kassel, Germany, 2017; pp. 99–108. [Google Scholar]
- Law, A.M.; Kelton, W.D. Simulation Modeling and Analysis, 3rd ed.; internat. ed., [nachdr.] ed.; McGraw-Hill Series in Industrial Engineering und Management Science; McGraw-Hill: Boston, MA, USA, 2000. [Google Scholar]
- Sexton, R.S.; Dorsey, R.E.; Johnson, J.D. Optimization of neural networks: A comparative analysis of the genetic algorithm and simulated annealing. Eur. J. Oper. Res. 1999, 114, 589–601. [Google Scholar] [CrossRef]
- Das, I.; Dennis, J.E. Normal-Boundary Intersection: A New Method for Generating the Pareto Surface in Nonlinear Multicriteria Optimization Problems. SIAM J. Optim. 1998, 8, 631–657. [Google Scholar] [CrossRef] [Green Version]
- Freitag, M.; Hildebrandt, T. Automatic design of scheduling rules for complex manufacturing systems by multi-objective simulation-based optimization. CIRP Ann. 2016, 65, 433–436. [Google Scholar] [CrossRef]
- Hildebrandt, T.; Branke, J. On Using Surrogates with Genetic Programming. Evol. Comput. 2015, 23, 343–367. [Google Scholar] [CrossRef]
- Haupt, R. A survey of priority rule-based scheduling. Spektrum 1989, 11, 3–16. [Google Scholar] [CrossRef]
- Vanhoucke, M. Integrated Project Management Sourcebook; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
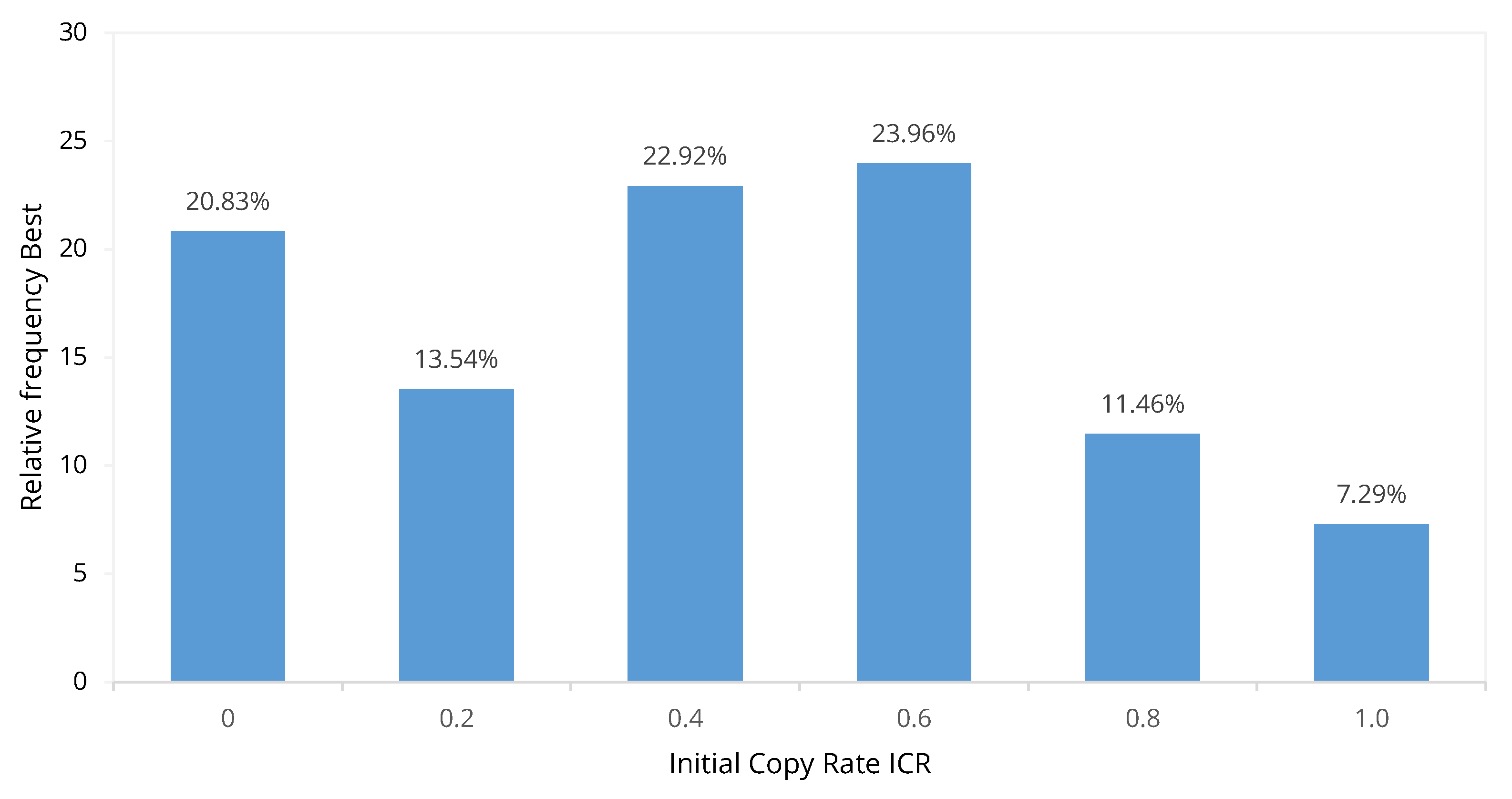{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.47 | ±0.08 | |
| 0.18 | ±0.07 | |
| 0.34 | ±0.08 |
| Statistic | 0.2–1.0 | Best | Worst | |||||
|---|---|---|---|---|---|---|---|---|
| 66.6 | 69.7 | 64.6 | 62.5 | 58.3 | 66.4 | 79.17 | 55.2 | |
| 0.28 | 0.39 | 0.42 | 0.26 | 0.05 | 0.26 | 0.66 | −0.37 | |
| 0.37 | 0.46 | 0.44 | 0.41 | 0.32 | 0.40 | 0.58 | 0.22 | |
| 2.20 | 2.42 | 2.40 | 2.59 | 3.15 | 2.55 | 2.30 | 3.06 | |
| ±0.45 | ±049 | ±0.49 | ±0.53 | ±0.64 | ±0.52 | ±0.47 | ±0.62 |
| Comparing GAWS Rank = 1 to | |||
|---|---|---|---|
| Statistic | Rank 2 | MW Rank | Rank 20 |
| 3.31 | 10.82 | 24.86 | |
| 2.66 | 8.49 | 17.64 | |
| 2.88 | 7.56 | 20.65 | |
| (%) | ±0.46 | ±1.20 | ±3.27 |
| Comparing GAWS Rank ≠ 1 to | |||
|---|---|---|---|
| Statistic | Rank 2 | MW Rank | Rank 20 |
| −10.60 | 3.63 | 18.90 | |
| −3.22 | 2.91 | 14.68 | |
| 19.15 | 5.43 | 15.66 | |
| (%) | ±3.03 | ±0.86 | ±2.48 |
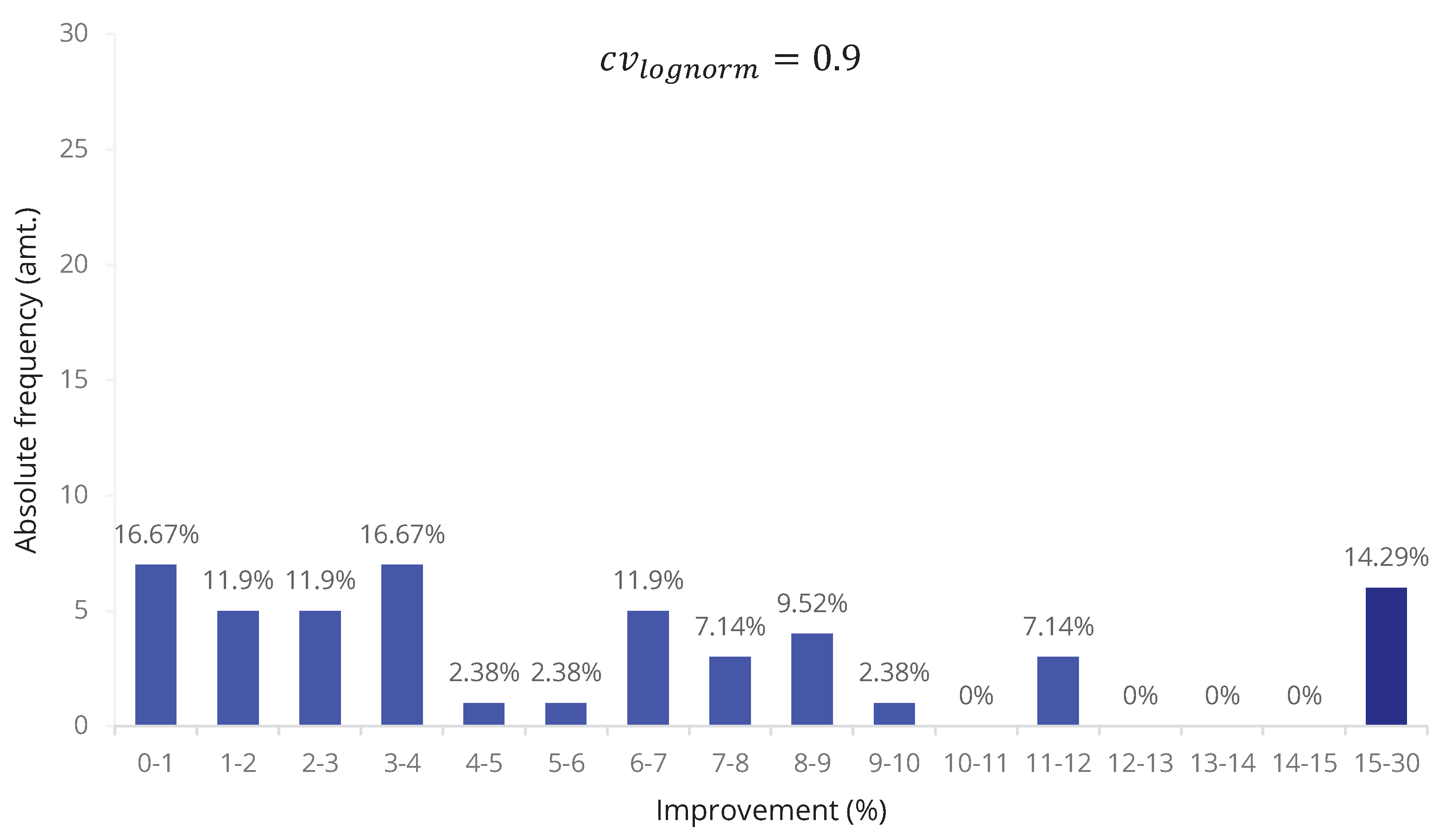
| Filter | GAWS = 1st Front (%) | 2nd Best PR = 1st Front | 2nd Best PR = 1st Front (%) |
|---|---|---|---|
| 91 | FIFO | 65 | |
| = 0.1 | 95 | FIFO | 61 |
| = 0.9 | 88 | FIFO | 69 |
| 94 | FIFO | 74 | |
| 90 | MSLK | 42 | |
| 92 | FIFO | 86 | |
| 92 | FIFO | 72 | |
| 82 | LWRK | 42 | |
| 98 | FIFO | 88 | |
| 89 | FIFO | 55 | |
| 95 | MAX_NW | 88 | |
| 95 | MAX_NW | 64 | |
| 89 | FIFO | 71 | |
| 77 | FIFO | 72 | |
| 100 | MWRK | 58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kühn, M.; Völker, M.; Schmidt, T. An Algorithm for Efficient Generation of Customized Priority Rules for Production Control in Project Manufacturing with Stochastic Job Processing Times. Algorithms 2020, 13, 337. https://doi.org/10.3390/a13120337
Kühn M, Völker M, Schmidt T. An Algorithm for Efficient Generation of Customized Priority Rules for Production Control in Project Manufacturing with Stochastic Job Processing Times. Algorithms. 2020; 13(12):337. https://doi.org/10.3390/a13120337
Chicago/Turabian StyleKühn, Mathias, Michael Völker, and Thorsten Schmidt. 2020. "An Algorithm for Efficient Generation of Customized Priority Rules for Production Control in Project Manufacturing with Stochastic Job Processing Times" Algorithms 13, no. 12: 337. https://doi.org/10.3390/a13120337
APA StyleKühn, M., Völker, M., & Schmidt, T. (2020). An Algorithm for Efficient Generation of Customized Priority Rules for Production Control in Project Manufacturing with Stochastic Job Processing Times. Algorithms, 13(12), 337. https://doi.org/10.3390/a13120337