1. Introduction
In the supply chain field, simultaneously planning production, inventories and distribution while minimizing the overall cost of these operations is a complex exercise known as the production routing problem (PRP) [
1]. The PRP is a combination of two well-known problems in the literature. On the one hand, we have the lot sizing problem (LSP) and the vehicle routing problem (VRP) on the other hand. LSP determines the best trade-off between production and storage operations. The aim is to simultaneously determine the production schedule, quantities to be produced and quantities to be stored to minimize the overall cost of production and inventory. See [
2] for more detailed literature review on the LSP.
VRP is a difficult NP-Hard problem as a particular case of the traveling salesman problem (TSP) which is itself a NP-Hard problem [
3,
4]. It consists of arranging routes between customers who must be visited at the same time based on the number of vehicles available and finding the best scheduling of visits to minimize the overall cost of transport over the planning horizon. Readers are also invited to see [
5,
6,
7] for a review of the mathematical formulations of the problem and the methods or algorithms used to resolve it.
In the practice of industries, these two problems are disjointedly and sequentially analyzed. However, the work of Chandra et al. [
8,
9] have shown that it is possible to make gains of 3% to 20% on the overall cost of production and distribution by integrating and coordinating the decisions of LSP and VRP. This integrated and coordinated PRP is a NP-hard problem since it contains the VRP. In an integrated concept of supply chain planning, the customer no longer has exclusive control over decisions on his visit dates and quantities to be received. The implementation of new practices such as vendor managed inventory (VMI) and replenishment policies such as order-up-to-level (OU) and maximum level (ML) are necessary to achieve the goal of satisfying customer demand. VMI is a practice in which the supplier decides when and how much to deliver to the customer in a joint manner. He must also ensure that there is no shortage of stock at the customer. In the OU replenishment policy, all customers have maximum storage capacity and the amount delivered is such that the maximum level of storage is reached at each delivery. Whereas in the ML policy, all customers have maximum storage capacity and the quantity delivered is such that the maximum storage level is not exceeded at each delivery (
). See [
10,
11,
12,
13] for more details on the practice of VMI and the use of OU and ML replenishment policies. A detailed literature review of PRP was provided by [
1].
Although PRP is an NP-hard problem, exact methods for its resolution have been proposed. Among these exact approaches, the Lagrangian relaxation was one of the first methods proposed for the resolution of the PRP [
14]. A branch-and-price algorithm was proposed to solve a PRP with the use of a homogeneous fleet of vehicles [
15]. In a study using a single vehicle [
16], the authors used a branch-and-cut (B&C) algorithm to solve the PRP problem. The B&C algorithm has also been proposed to solve the multivehicle version of the PRP [
17].
Given the complexity of the PRP, several heuristics and metaheuristics have been developed for its resolution. In the first works on the PRP introduced by Chandra et al. [
9], an H1 type decomposition method was proposed. The authors decomposed the problem into a capacitated LSP and VRP followed by some local search heuristics to solve the problem. Test results have shown that the integrated approach allows gains on the overall cost of operations ranging from 3% to 20%. Another two-phase decomposition method was presented for solving a PRP with a heterogeneous fleet of vehicles [
18]. The authors used a mixed integer programming (MIP) to solve the first phase of the problem. This first phase of the problem concerns a problem of LSP with direct shipment (DS). In the second phase, an efficient algorithm was used to solve the VRP. It is a H2 type algorithm because the DS decisions are incorporated into the LSP, which is not the case for the H1 type algorithm. The H2 type of two-phase decomposition heuristic (TPDH) has also been used to solve a PRP with external depot (EDPRP) [
19]. The authors used a MIP for solving the LSP problem with DS in the first phase and then used a genetic algorithm to solve the VRP in the second phase.
Metaheuristics are algorithms used to solve difficult combinatorial optimization problems. They are therefore master strategies that use other heuristics to find a better approximation of the best overall solution to an optimization problem. They are mostly used when a more efficient classical method to solve a given combinatorial optimization problem is not known. The high level of abstraction of metaheuristics makes them suitable for a wide range of problems. Thus, they find their application in various fields of scientific research.
Swarm intelligence (SI) is a family of metaheuristics that relies on nature through the interactions of agents (ants, bees, etc.) to solve complex optimization problems. SI has been used in wind energy potential analysis and wind speed forecasting to reduce the operating cost of wind farms [
20]. The authors used a hybrid algorithm that combines the advantages of the genetic and adaptive particle swarm optimization (PSO) algorithm to optimize the weights and biases of the nonlinear network of extreme learning machines (ELMs) to efficiently improve the accuracy of the ELMs.
Another SI based on particle swarm optimization has been proposed for the analysis of handover in the field of spectrum sharing in mobile social networks [
21]. With an increase in the globally adaptive inertia to 75.66% and an increase in data transfer rate of 47.29% compared to the IEEE802.16 protocol, the authors obtained a maximum mean signal-to-noise ratio of 14.8 dB. This value is the overall optimum that is required during handover for any mobile social network. Thus, the authors claim that their algorithm outperforms those in the mobile network literature by 75% by optimizing various aspects of handover.
In the age of big data, analyzing data and extracting relevant information from it is a challenge. A very important issue in this area is the selection of the most informative features in a dataset. Given the success of SI in solving difficult NP problems, it is increasingly used for selecting relevant characteristics in data analysis or in machine learning algorithms. A detailed literature review on the use of SI in feature selection is provided by [
22]. The authors presented a unified SI Framework to explain the methods, techniques, and parameter choice in a SI algorithm for feature selection. They also presented the different datasets used to implement SI algorithms as well as the different SI algorithms.
Another literature review focusing on PSO algorithms and ACO algorithms as representative of SI was presented by [
23]. The authors presented a description of the PSO and ACO algorithms as well as a state of the art on other SI algorithms. They also presented a status report on the use of SI in solving real life problems.
Regarding the use of SI in solving PRPs, a PSO algorithm has recently been proposed to solve the planning problem in an intelligent food logistics system model [
24]. The authors have formulated the problem in a mixed integer multi-objective linear programming. Four objectives are addressed in this study. They are the minimization of total system expense, the maximization of average food quality, the minimization of the amount of CO
2 emissions in transportation, and the production and minimization of total weighted delivery time. Tests conducted on small, medium, and large data sets resulted in cost reductions of 15.51% compared to a three-step decomposition method.
A self-adaptive evolutionary algorithm was proposed for berth planning in the operation of maritime container terminals [
25]. The authors proposed a chromosome in which the probabilities of crossover and mutation are encoded in the chromosome. They focused their study on the comparison of several methods of parameter selection in evolutionary algorithms. On the one hand, there are the parameter tuning strategy approaches in which the values of the selected parameters remain unchanged throughout the execution of the algorithm. On the other hand, we have the parameter control approaches in which the parameters of the algorithm are adjusted throughout the execution of the algorithm according to certain strategies. Parameter control can be deterministic, adaptive, or self-adaptive. Test results show that the evolutionary algorithm of self-adaptive parameter control outperforms evolutionary algorithms using deterministic parameter control, adaptive parameter control and parameter tuning strategy by 4.01%, 6.83%, and 11.84% respectively based on the value of the objective function.
Another evolutionary algorithm was used to address a VRP in a “factory in box” [
26]. This “factory in a box” concept involves assembling production modules into containers and transporting the containers to different customer sites. The authors modeled the problem as mixed integer programming to solve the problem and used CPLEX to solve the mathematical model of the problem. In addition to the evolutionary algorithm, they also proposed three metaheuristics including variable neighborhood search (VNS), taboo search (TS), and simulated annealing (SA) to solve the problem. The results of the tests carried out on large-sized instances show that the evolutionary algorithm provides better results than the other metaheuristics (VNS, TS, SA) developed to solve the problem.
Genetic algorithm (GA) is a stochastic strategy for solving complex optimization problems that takes better advantage of concepts from natural genetics and the theory of evolution. It is used to solve a production, inventory and distribution planning problem that takes into account several products. [
27], the authors have solved the integrated problem of LSP and VRP. They also proposed integer programming to minimize the total cost of the system. Tests performed on small instances found an optimality deviation of 1.739% compared to the branch-and-bound (B&B) method. A multi-plant supply chain model with multiple customers was proposed by [
28]. In this supply chain, products are delivered directly from the factory to the customers. The authors developed a hybrid AG to address the minimization of the overall cost of production and distribution. They used a multi-point crossover operator. This number of cut-off points is equal to the length of the chromosome divided by 4 with a 15% probability of crossover.
A greedy randomized adaptive search procedure (GRASP) has been proposed for solving a PRP involving a single type of product over a multi-period planning horizon with the use of a homogeneous fleet of vehicles [
29]. The authors proposed three versions of GRASP for the integrated resolution of the PRP These are a classical GRASP, an improved version of GRASP with the incorporation of reactive mechanisms and a version of GRASP with a path reconnection process. Test results on 90 randomly generated instances with 50, 100 and 200 clients over 20 periods established the effectiveness of GRASP on the traditional method of breaking down the problem into sub-problems. These results also showed that GRASP with path re-connection and GRASP with reactive mechanisms give better results than traditional GRASP (without improvement). A GRASP has also been developed to solve a bi-objectives production and distribution problem [
30]. These objectives concern the minimization of total production and distribution costs and the balancing of the total workload in the supply chain. They used a homogeneous fleet of vehicles to transport products. The results of tests on literature instances show that the GRASP developed allows a relatively small number of non-dominated solutions to be obtained in a very short computing time. Although the approximation of the Pareto front for each instance is discontinuous and not convex, it highlights the trade-off between the two objective functions.
A reactive tabu search was presented for solving a PRP to satisfy a time varying demand with a homogeneous fleet of vehicles over a finite planning horizon [
31]. The authors compared the test results with the results obtained with GRASP on instances of up to 200 clients and 20 periods. This comparison revealed an improvement in results ranging from 10% to 20% on the overall cost of operations with an increase in computing time. A Tabu search (TS) with path relinking (TSPR) was used for PRP resolution with a homogeneous fleet of vehicles [
32]. Tests performed on datasets from the literature have shown that TSPR gives better results than memetic algorithm with population management (MA|PM) and an improvement in results ranging from 2.20% to 8.78% compared to RTS.
An adaptive large neighborhood search (ALNS) procedure was used for computing the lower bound in the formulation of the multivehicle production and inventory routing problem (MVPRP) [
33]. The results of tests carried out on small, medium, and large size instances established the effectiveness of ALNS on GRASP, MA|PM, RTS, and TSPR. The same authors also used ALNS for the computing of upper bounds in a B&C procedure for solving the MVPRP [
17].
The variable neighborhood search (VNS) was developed for PRP resolution with a homogeneous fleet of vehicles [
34]. The test results for this algorithm show that it is as competitive as the ALNS algorithm.
Introduced by Moscato [
35], memetic algorithm (MA) is a powerful version of GA based on the use of local search to intensify the search in order to increase its efficiency. The preservation of diversity is crucial in evolutionary algorithms in general [
36] and in GA in particular. Crossover and mutation operators are the best means of guaranteeing the diversity of the population from one generation to the next. A good strategy of combining diversification and intensification is the key to success which gives the MA a definite advantage over the GA.
In the area of chain supply planning, MA was used to resolve the LSP. In this problem family, MA has been proposed for a problem of stochastic multi-product sequencing and LSP [
37]. It has also been used for LSP in soft drink plants [
38] and for a multi-stage capacitated LSP [
39]. For the VRP family, MA has been proposed for a VRP with time windows (VRPTW) [
40,
41]. See also [
42,
43] for the capacitated VRP as well as [
44,
45] for the use of heterogeneous fleets of vehicles. The use of MA is also very present in the optimization of integrated problems such as PRP. A MA with population management (MA|PM) has been developed by Boudia and Prins [
46] to solve the integrated production, inventory, and distribution problem. The authors tackled a problem of simultaneous minimization of three costs consisting of the setup cost, the inventories cost and distribution cost. Tests on 90 randomly generated instances showed the efficiency of MA|MP compared to TPDH and GRAPS. The MA was also used in a study aimed at minimizing the overall cost of setup, inventory, and distribution in a multi-plant supply chain. In this supply chain, the information flow management system called “KANBAN” was implemented to manage information [
47]. A real case study concerning the minimization of the overall cost of production and distribution was conducted in a large automotive company [
48]. In this study, the authors modeled the problem as a non-linear mixed integer programming and used a custom MA for its resolution.
The MA used in this work is an adaptation of the one proposed by Boudia and Prins [
46] to solve an integrated production, inventory, and distribution problem.
The remainder of this work is organized as follows:
Section 2 is a description of the EDPRP.
Section 3 shows the details of the MA used for EDPRP resolution.
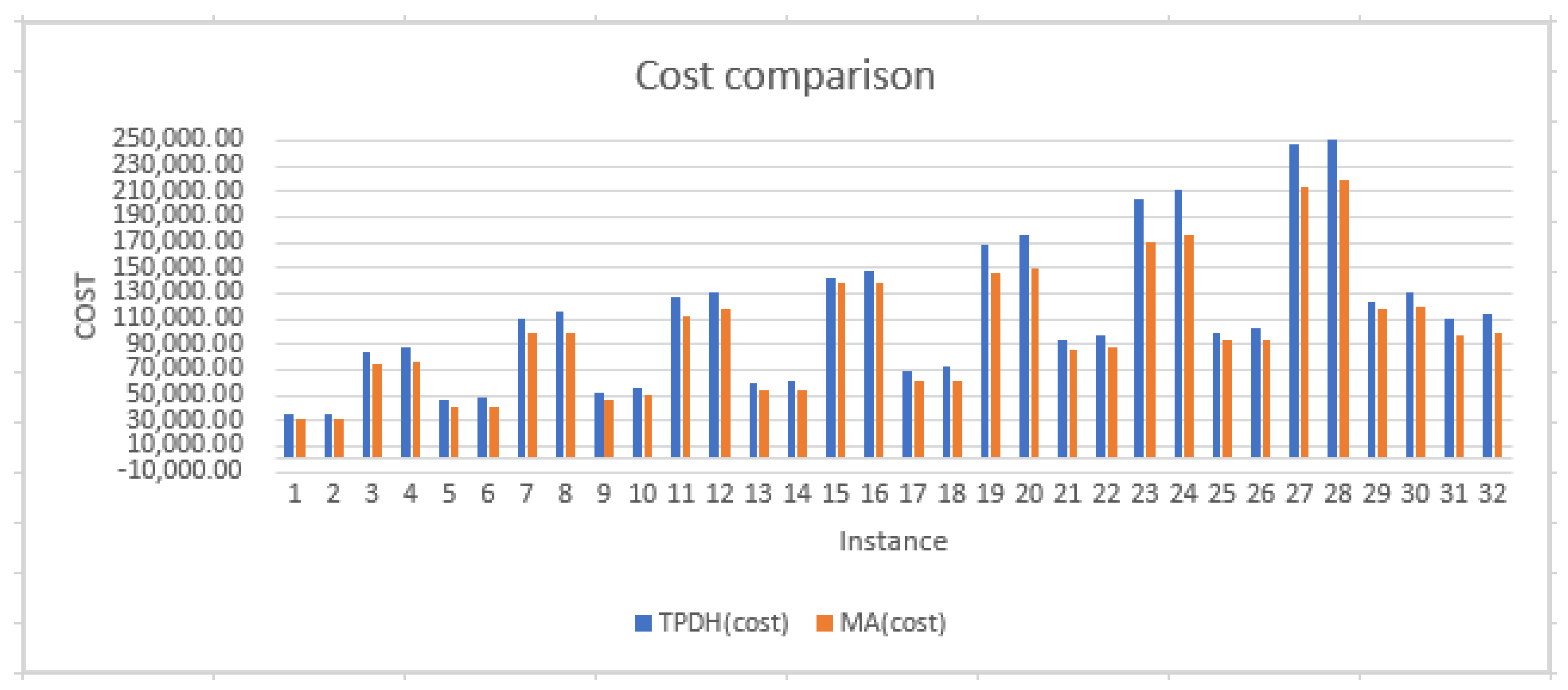
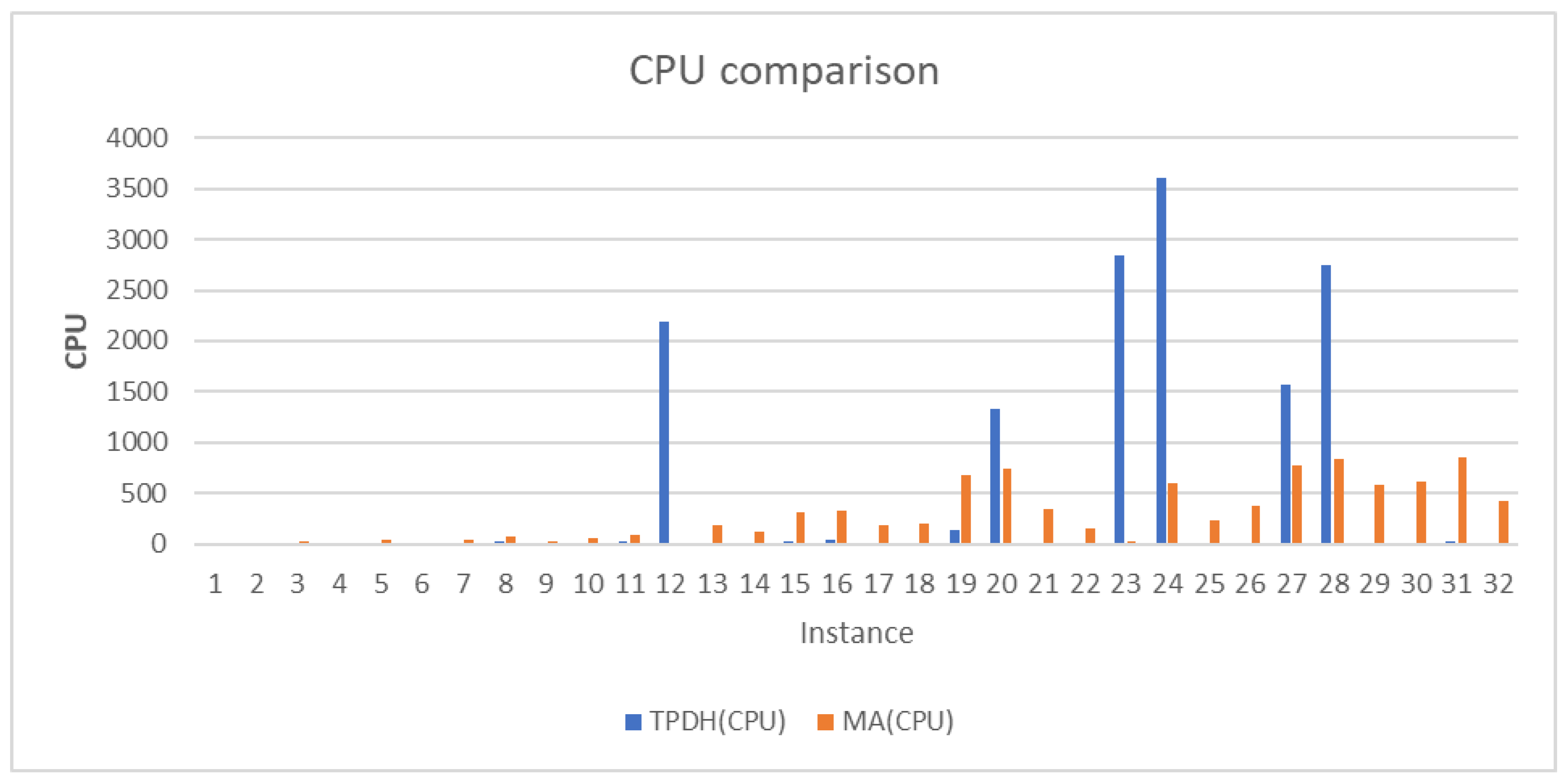
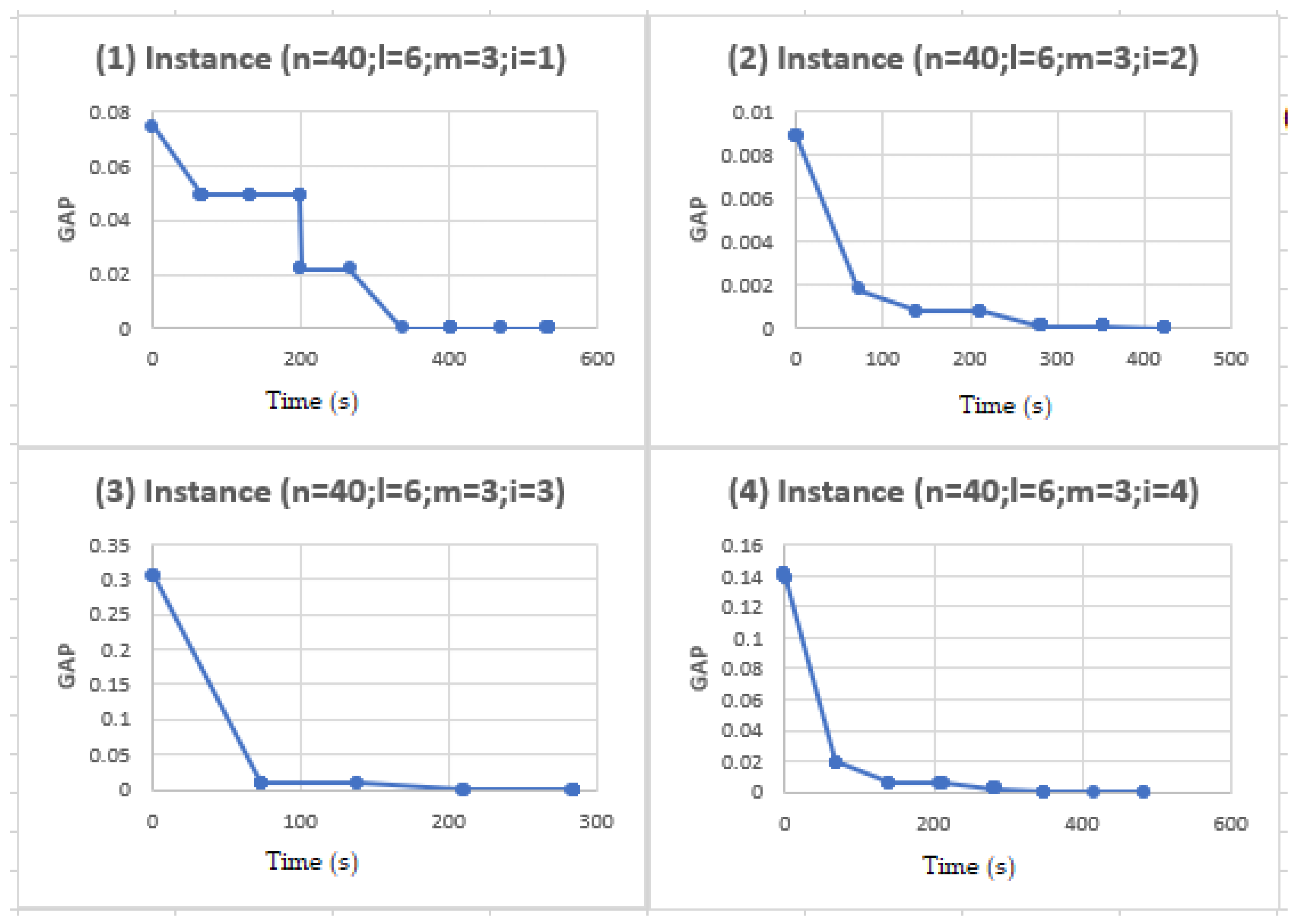
Section 4 highlights the conditions for experimentation and the comparison of the results obtained by the MA and the TPDH of H2 type. Finally,
Section 5 provides a conclusion on the comparative study of MA and TPDH concerning EDPRP.
3. Memetic Algorithm
3.1. Encoding and Evaluating the Solution
3.1.1. Encoding
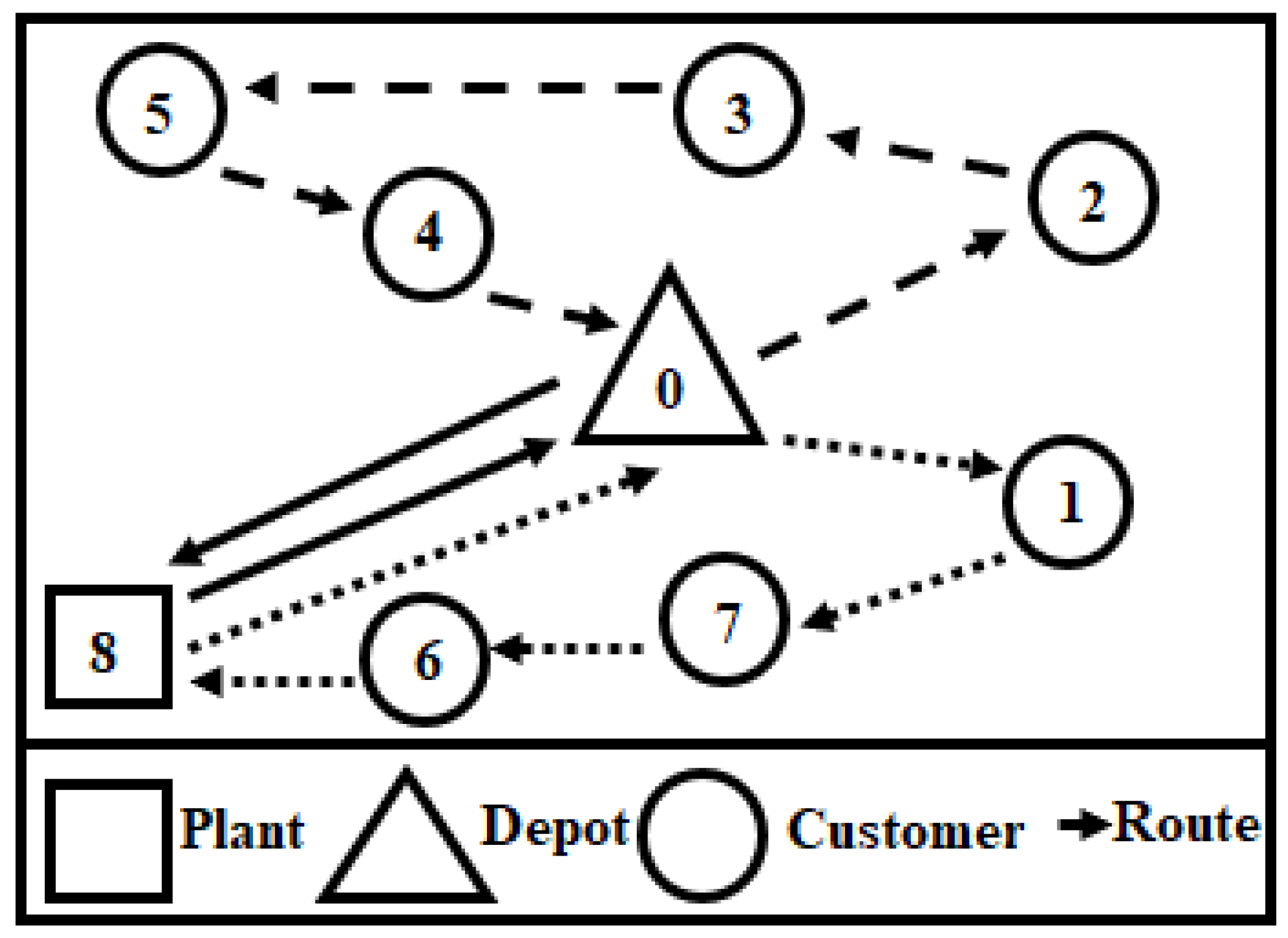
We use the tuple (P, Y, X, R) to describe a complete solution to the problem. In this tuple, P is a list of the quantity produced in each period t of the planning horizon. Each quantity produced or [t] is an integer between 0 and the maximum production capacity of the plant (C). Y is a list of binary numbers over each period t of the planning horizon. = 1 means that there is production at the plant on date t and 0 otherwise. X is a (n + 1) × matrix in which represents the amount of product sent to the depot (i = 0) or to a customer (. is an integer between 0 and the maximum storage capacity of the node and can be made up of several demands for the customer i. R is a list of integers with . It is a successive list of trips delimited by the symbol (0) when the trips belong to the same day or the symbol (−1) when the trips belong to different days. Thus 0 and −1 also refer to the depot in the modeling of the solution. As the symbol (−1) is also the day delimiter, a succession of this symbol indicates a period without a vehicle tour.
The knowledge of
R,
X and
allows to compute
for all
and to verify the constraints related to the storage capacity of customers
, the vehicle limit load (
Q) as well as the limitation of the number of vehicles in the fleet (m). With the knowledge of
Y,
X, and
, it is also possible to compute
,
and check the constraints on the storage capacity of the depot
. The dataset of
Table 1 allows to build an example of a complete solution for
n = 10,
l = 3,
m = 2,
C = 304 and
Q = 198. This solution can be described by
Table 2. In
Table 2,
R is a succession of trips that begin at the depot (0 or −1) and end at the depot over a planning horizon of 3 days (or three periods) delimited by the symbol −1.
is the amount sent to each customer or depot
i at the period
t. The amount distributed to customers in the first period is 25 + 18 + 33 = 76. This quantity means that the demand of the first period is met based on the initial stocks of the depot (
= 76). No quantity is sent to the plant since it has no storage capacity.
= 1 means that there is production in the first period of
T. This automatically leads to a replenishment of the depot (0 or −1) with a quantity
= 137 units of products.
P and
Y can therefore be represented by Y [0,0,1] and P [137,0,0]. Finally, with the knowledge of R, X, Y, and P it is possible to evaluate a solution.
3.1.2. Evaluation of the Solution
The cost (or fitness) of a solution
Z can be determined by the following formula
In this three-part formula, denotes the total cost of production. This cost can be subdivided into two costs. Namely the variable cost of production defined by the sum of the costs of productions per period and the sum of setup costs when there is production on the day t (). Then we have the cost of the inventory expressed by and finally the cost of distribution (transport) represented by . In this last part, The |R| represents the size or number of symbols in R and alt( ) is a function such as alt(i) = i if and alt(i) = 0 if i = −1 (day delimiter). The parameter refers to the Euclidian distance between the i node and the node j.
3.2. Construction of the Initial Population
Let Pop_size be the size or number of individuals (solutions) in the initial population . This population consists of a Pop_size number of randomly generated solutions. Everyone in the initial population is generated in three steps described as follows:
The construction of Y consists in determining the days of production. Here, it is a question of determining the days t for which . To achieve this goal, we will first determine the total quantity produced over the planning horizon. Let NP be this quantity of products. It can be obtained by the following relationship: NP = . It is equal to the difference between the sum of the demands of all customers and the sum of the initial inventory at the depot and at the customers. Once the total quantity to be produced is calculated, we determine the number of days required to produce that quantity. To avoid a problem of hard bin packing with the limited fleet, we will limit the capacity of the fleet to 90%. Let be the capacity of the fleet and NY (NY = ) the number of days needed to produce NP. Then and NY are calculated as follows: and NY = . Once NY is determined, a NY number of days are randomly drawn in T/{}. It is not possible to produce on the last day of the planning horizon () because this production cannot be distributed to customers. Here, P can already be initialized by assigning NP to for which t is the smallest value of T having without considering the violation of maximum production capacity (C).
For any customer
i,
is initialized with the necessary quantity so that
and
at least constitute a demand (for each costumer
i,
). For example, if the demand
= 10, for
= 5, we have on a
= 5. For
= 10, we have
= 0 and for
= 15 we have
= 0. For each period
t, giving priority to customers who are out of stock, we aggregate demands for each customer
i without violating its storage limit capacity
, and that of the fleet
in respect of the quantity of products available at the depot the day before
. The quantities produced are then adapted to the production capacity
C and then to the capacity of the fleet
and those of the depot
. This makes it possible to resolve the production capacity overrun authorized in step 1. This approach is an adaptation of the dynamic programming (DP) proposed by Wagner and Whitin [
49] for the resolution of the classic LSP.
After determining
P and
X, the quantities sent to customers per period are successively aggregated to reach the capacity of a vehicle This operation is repeated until the number of vehicles necessary to deliver the products of each period is determined. This procedure is an adaptation of Clarke and Wright’s economic algorithm [
50] through the imposition of a limited fleet. At this stage,
R does not yet contain the plant represented by the node
i =
n + 1. The plant is added to
R only in the periods
t for which
= 1. The number of symbol
n + 1 added is equal to the number of vehicles necessary to send all the production of the period
t to the depot (for
= 1 with
t , the number of vehicles needed to transport
from the plant to the depot is
). Once the initial population has been constituted, a selection and crossover procedure are carried out for the formation of the child population
. In this study, the population size of children is set at
POP_size/2. The following section describes the procedure of selection and crossover of parents of the initial population for the constitution of
.
3.3. Selection and Crossover Procedure
Each child from the initial generation
is the result of the crossover of two parents selected by a binary tournament procedure. A selection by binary tournament consists of selecting the best solution from two randomly drawn solutions in the population
. Let
A be the parent selected at the first selection procedure and
B the parent selected at the second selection procedure. Then a two-point crossover procedure of parents
A and
B is implemented for the determination of a single child
E. The crossover procedure can be described as follows: Let us note by (
) the membership operator. By this operator writing
AR means that
R belongs to
A. Let us note
or
R(
p) the element of rank
p in
R and
or
R(
p→q) the sub-list of
R going from
p to
q. In this work, the cutting points must correspond only to the day delimiter (−1). For the determination of cutting points, a random draw of two dates
,
with
is made. Then
and
are determined so that
and
. Let
pos(
t) be the function that at each date associates its position in
(
p = pos(
t)).
will be segmented into three parts. The left part will be identified by
. The middle of
is represented by
and the right part by
. Similarly, parent
B will also be segmented according to the values of
and
determined for the
segmentation. The construction of child
E from the crossover of
A and
B is done as follows: let
,
, and
be the three parts of
. These three parts will be initialized as follows:
=
,
=
and
=
. After the initialization of
, a check is made to correct any anomalies in its construction. Contrary to Boudia et Prins’ correction strategy of browsing the symbols in
[
28] we adopt a simplified correction strategy of browsing the symbols in
. This strategy allows to quickly identify the missing customers in
and make the appropriate corrections. The correction is as follows: Let
i be the browsing index of
,
the total quantity delivered to the customer
i over
T in
and
the total quantity of product that was to be delivered to
i over
T. We have
=
and
. Through a comparison between
and
, We group customers into three subsets. The first subset is that of customers representing Case 1 such as
=
. The second subset representing Case 2 concerns the customers
i for whom
and Case 3 brings together the customers for whom
. In the process of repairing the chromosome, all customers affected by Case 2 are treated first. Then come the customers concerned by Case 3 and finally those concerned by Case 1. Each case is treated as follows:
Case 1. If , then there is nothing to do for the costumer i. All demands are already met by the initial stock () and the quantities delivered over T ().
Case 2. If , then a reverse browsing of T is made (from i to 1). is successively reduced by a demand . For a given period t, if falls to 0 then i is removed from its trip at the date t in . This correction stops at the period t at which .
Case 3. If , let be the out-of-stock date at i if it is not supplied from the last date on which its initial stock covers its demands and the quantity needed to complete to . Browsing T from τ to , is corrected as follows:
- (1)
If ≠ 0, then add to
- (2)
If Q (vehicle limit capacity) is violated, then i is removed from its current tour.
- (3)
Try the best insertion of i in one of the existing trips of the date t. Making the best insertion of a customer i in a trip is to compare the cost of all the trips obtained by iteratively moving the costumer i from the beginning of the tour to its end. The best insertion will designate the position of i offering the minimum transportation cost for the trip.
- (4)
If the attempt at a better insertion fails and the number of vehicles used on the date t is less than m (m is the number of vehicles in the fleet) then a new trip is created.
- (5)
If all the vehicles in the fleet are already in use, then we are fragmenting the quantity Fragmentation consists of determining the trip with the maximum residual capacity and inserting the maximum demand contained in . The rest of the quantities to be delivered ( after updating) are distributed at the following days. The correction stops when = 0.
NB: If τ = 1, then the quantity inserted is equal to the sum of the complement of the initial stock to a demand and a maximum number of demands .
However, if = 0, is corrected by implementing steps (3), (4), and (5).
3.4. Example of Application of the Crossover and Repair Procedure
Consider the dataset (
n = 10,
l = 6,
k = 2) described in
Table 3. Let
A and
B be two solutions got from the initial population. Chromosome
A is represented by
Table 4 and Solution
B is represented by
Table 5. Let
= 3 and
= 5 be the cut points of chromosomes
A and
B (
and
correspond to dates or periods on the planning horizon). Child C represented in
Table 6 will consist of three parties.
The left side of C is noted = ). The middle of C is and the right part of C is .
After the C chromosome is formed, abnormalities can be found. To repair the C chromosome, we go through the customers list and make the following corrections:
is the total amount of products that should have been received by customer i and the amount received by the customer i.
Customers for whom : i ∊ {3;4;8}
For the customer
i = 3, we have
= 60 + 15 = 75 and
= 15 × 6 −
= 90 − 30 = 60. By browsing
T from
t = 6 to
t = 1, we subtract a demand to
on the date
t = 4 and we get
= 75 − 15 = 60. Thus, the amount sent to
i at period 4 becomes
= 15 − 15 = 0 and
i = 3 is removed from the tour of period 4. The result of this correction is shown in
Table 7.
For the customer
i = 4, we have
= 49 and
= 7 × 6 − 7 = 35. By browsing
T from
t = 6 to
t = 1, we remove 2 demands in
to the period
t = 4 to get
= 35 and
= 21 − 7 − 7 = 7. See
Table 8 for
C chromosome after correction for
i = 4.
For the customer
i = 8, we have
= 104 and
= 13 × 6 − 13 = 65. The successive subtraction of a demand in
to equalize
allows to obtain the following results. Subtracting a demand from the period 6 allows to have
= 104 − 13 = 91 and
= 0. So, the customer 8 is removed from the tour of period 6. Subtracting two demands in
in the period
t = 4 allows to have
= 91 − 13 − 13 = 65 and
= 39 − 13 − 13 = 13. The result of this correction is presented in
Table 9.
Customers for whom: : i ∊ {1;2;7}
For the customer i = 1, = 20 + 20 = 40 and = 6 × 10 − 10 = 50.
We have
= 50 − 40 = 10. So,
must be completed (management of a supplement) with a quantity of 10 products to reach
. We have
τ =
and
=
+
− 75 = 76 + 0 − 75 = 1;
=
+
− 0 = 1 + 151 − 0 = 152;
=
+
− 152 = 152 + 152 − 152 = 152. The quantity delivered to all customers in the period
t = 4 is 20 + 7 + 13 + 44 = 84. So
=
+
– 84 = 152 + 0 − 84 = 68 and
>
= 10. The tour of period 4 contains
i = 1, so we apply (1) by adding
to
. We have
= 10 + 20 = 30. This changes the vehicle’s load from 84 to 94 in period 4 for a maximum load of 198. The load of the vehicle is not violated, and the process stops for the customer
i = 1.
Table 10 illustrates the correction for customer
i = 1.
For the customer i = 2, = 15 and = 60, hence = 60 − 15 = 45.
We have
τ =
and
=
+
− 94 = 152 + 0 − 94 = 58 >
. The tour of the period
t = 4 does not contain
i = 2, hence we apply the step (3) by making a better insertion of
i = 2 in the tour of period
t = 4. As a result of this insertion, the new load of the vehicle will be 139 < 198. The procedure stops for
i = 2. The resulting chromosome is shown in
Table 11.
For the customer i = 7, = 0 and = 22, hence = 22 − 0 = 22.
We have
τ =
and
=
+
− 94 = 152 + 0 − 139 = 13; and
=
+
− 0 = 13 + 44 = 57;
=
+
− (16 + 19)= 57 + 0 − 35 = 22 ≥
. The tour of the period
t = 6 does not contain
i = 7, hence we apply the stage (3) by also making a better insertion of
i = 7 in the tour of the period 6. As a result of this insertion, the new load of the vehicle will be 16 + 19 + 22 = 57 < 198. The procedure stops for
i = 2. It is noticeable here that
= 0 after the delivery of the customer 7 (see
Table 12).
Customers for whom = : i ∊ {5;6;8;9;10}.
For customers 5, 6, 8, 9, and 10 there is nothing to do because the theoretical amount to be received is equal to the amount received. The result of this repair procedure is presented in
Table 13.
3.5. Local Search Procedures
Three local search algorithms have been developed for the intensification phases of MA. , these algorithms can be described as follows:
SWAP1 (S1): It is a local search algorithm which allows to exchange the position of two customers i and j during the same period t (∀t ∈ T) in accordance with the capabilities of the vehicles assigned to transport the products. This exchange is only possible if customer i and j are visited on the same date t regardless they belong to the same trip.
BEST INSERTION (BI): The BI consists in removing customer i from its current trip on the date t and searching in all existing trips on the date t the position that offers the minimum cost of transport in accordance with the capacity of the vehicles .
SWAP2 (S2): This algorithm consists of exchanging two customers i and j visited respectively at consecutive periods t and t + 1. If that does not cause a stock outage and meets the conditions of maximum capacity of production C, storage (), and vehicles Q, the resulting solution is compared to the best current solution .
3.6. Global Description of the MA
Let
be the population of the generation
g with
(
is the initial population).
the maximum number of generations,
the population of children and
the end criterion. The MA used in this work can be described by the algorithm in Algorithm 1.
| Algorithm 1. Memetic Algorithm |
![Algorithms 14 00027 i001]() |









{kind=link}
{kind=link}
{kind=link}
{kind=link}