Improving Scalable K-Means++


Abstract
:1. Introduction
2. Existing Algorithms
2.1. K-Means Clustering Problem and the Basic Algorithms
| Algorithm 1: K-means‖ |
Input: Dataset , #clusters K, and over-sampling factor l. Output: Set of prototypes .
|
2.2. Random Projection
3. New Algorithms
3.1. SK-Means‖
| Algorithm 2: SK-means‖ |
Input: Subsets , #clusters K, and #Lloyd’s iterations . Output: Set of prototypes .
|
3.2. SRPK-Means‖
| Algorithm 3: SRPK-means‖ |
Input: Subsets , #clusters K, #Lloyd’s iterations , and random projection dimension P. Output: Set of prototypes .
|
3.3. Parallel Implementation of the Proposed K-Means Initialization Algorithms
3.4. M-Spheres Dataset Generator
| Algorithm 4:M-spheres dataset generator. |
Input: #clusters K, #dimensions M, #points per cluster , nearest center distance , radius of M-sphere . Output: Dataset .
|
| Algorithm 5: randsurfpoint(,d). |
Input: Sphere center , sphere radius d. Output: New point .
|
4. Empirical Evaluation of Proposed Algorithms
4.1. Experiments with Reference Datasets
4.1.1. Experimental Setup
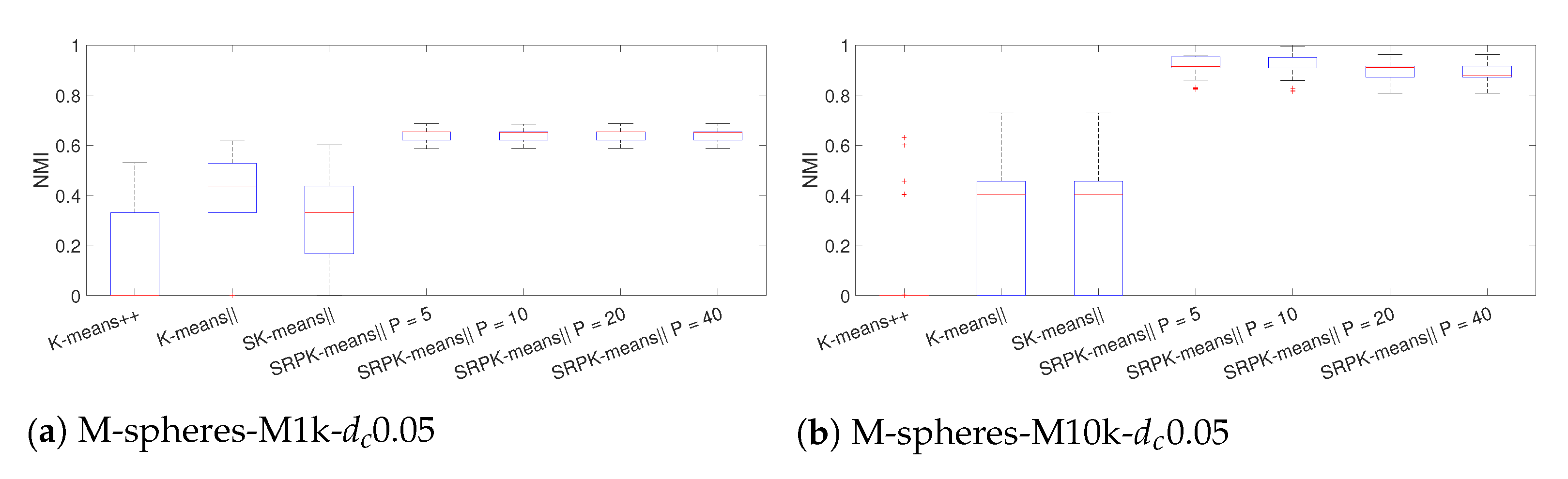
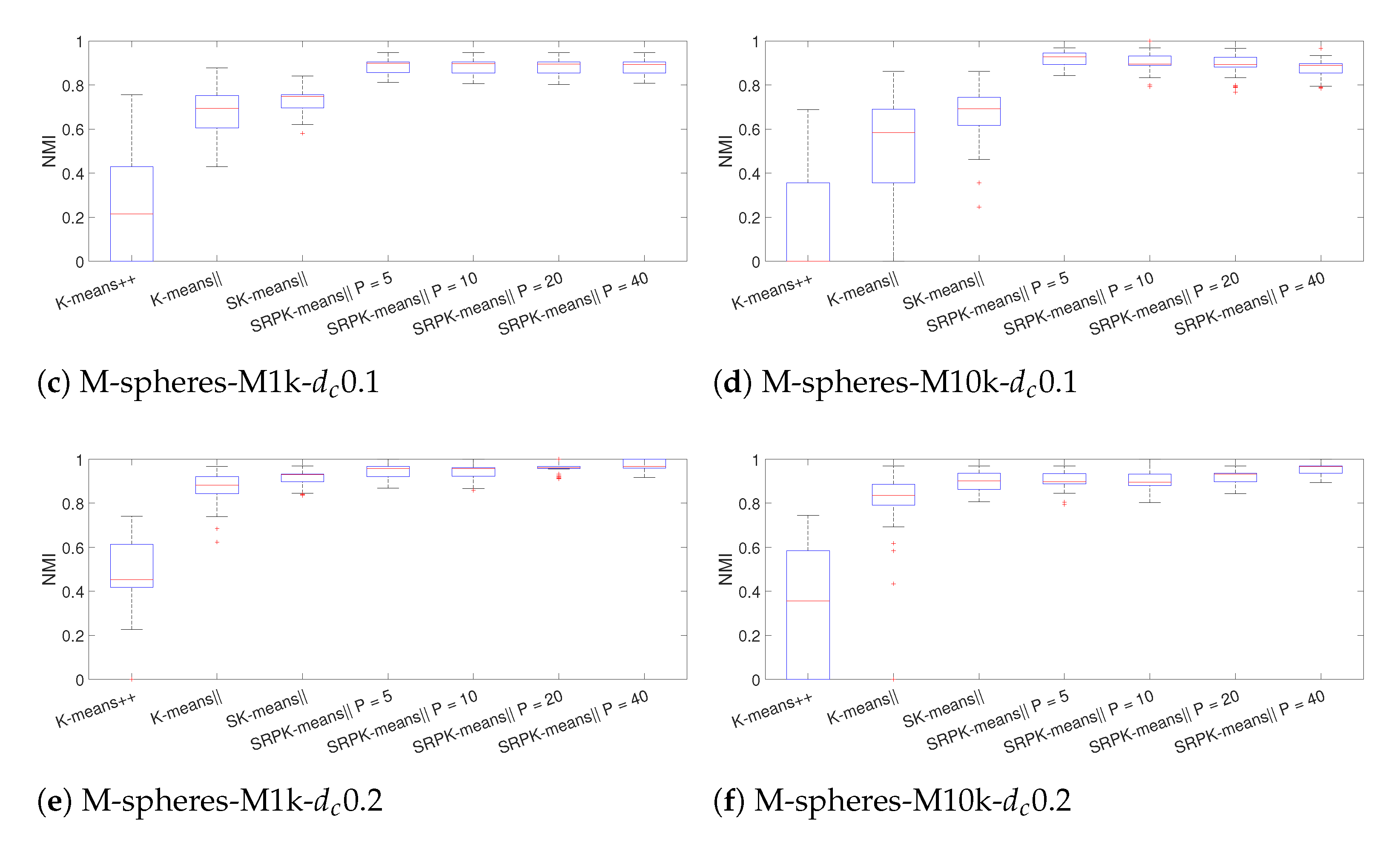
4.1.2. Results for Clustering Accuracy
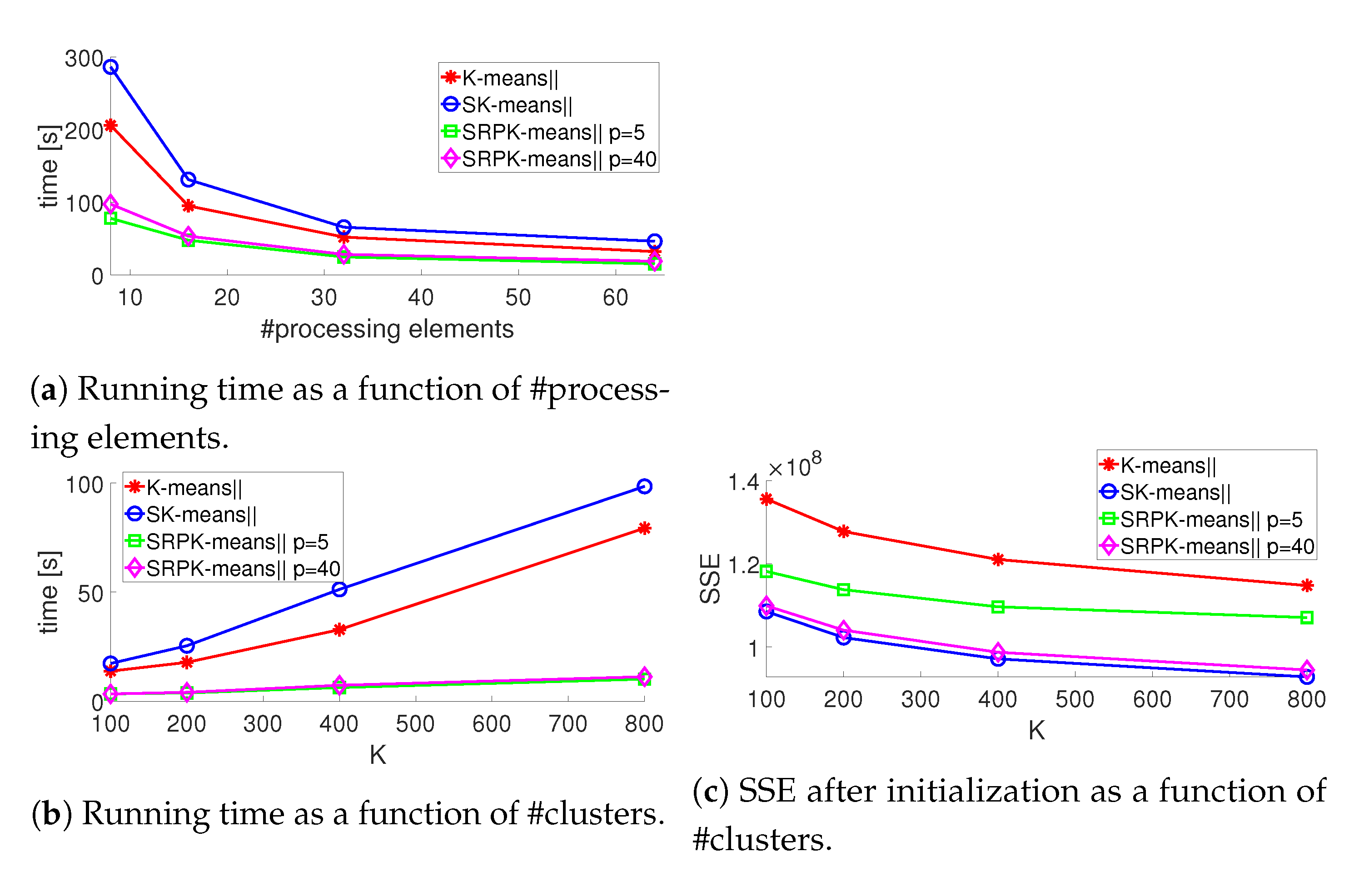
4.1.3. Results for Running Time and Convergence
4.1.4. Results for Scalability
4.2. Experiments with High-Dimensional Synthetic Datasets
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Emre Celebi, M.; Kingravi, H.A.; Vela, P.A. A comparative study of efficient initialization methods for the k-means clustering algorithm. Expert Syst. Appl. 2012, 40, 200–210. [Google Scholar] [CrossRef] [Green Version]
- Fränti, P.; Sieranoja, S. How much can k-means be improved by using better initialization and repeats? Pattern Recognit. 2019, 93, 95–112. [Google Scholar] [CrossRef]
- Hämäläinen, J.; Jauhiainen, S.; Kärkkäinen, T. Comparison of Internal Clustering Validation Indices for Prototype-Based Clustering. Algorithms 2017, 10, 105. [Google Scholar] [CrossRef] [Green Version]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Bahmani, B.; Moseley, B.; Vattani, A.; Kumar, R.; Vassilvitskii, S. Scalable K-means++. Proc. VLDB Endow. 2012, 5, 622–633. [Google Scholar] [CrossRef]
- Xu, Y.; Qu, W.; Li, Z.; Min, G.; Li, K.; Liu, Z. Efficient k -Means++ Approximation with MapReduce. IEEE Trans. Paral. Distrib. Syst. 2014, 25, 3135–3144. [Google Scholar] [CrossRef] [Green Version]
- Dhillon, I.S.; Modha, D.S. A data-clustering algorithm on distributed memory multiprocessors. In Large-Scale Parallel Data Mining; Springer: New York, NY, USA, 2002; pp. 245–260. [Google Scholar]
- Zhao, W.; Ma, H.; He, Q. Parallel K-Means Clustering Based on MapReduce. In Proceedings of the 1st International Conference on Cloud Computing, CloudCom ’09, Munich, Germany, 19–21 October 2009; pp. 674–679. [Google Scholar]
- Elkan, C. Using the triangle inequality to accelerate k-means. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 147–153. [Google Scholar]
- Hamerly, G. Making k-means even faster. In Proceedings of the 2010 SIAM International Conference on Data Mining, Columbus, OH, USA, 29 April–1 May 2010; pp. 130–140. [Google Scholar]
- Drake, J.; Hamerly, G. Accelerated k-means with adaptive distance bounds. In Proceedings of the 5th NIPS Workshop On Optimization for Machine Learning, Lake Tahoe, NV, USA, 7–8 December 2012; pp. 42–53. [Google Scholar]
- Ding, Y.; Zhao, Y.; Shen, X.; Musuvathi, M.; Mytkowicz, T. Yinyang k-means: A drop-in replacement of the classic k-means with consistent speedup. Int. Conf. Mach. Learn. 2015, 37, 579–587. [Google Scholar]
- Bottesch, T.; Bühler, T.; Kächele, M. Speeding up k-means by approximating Euclidean distances via block vectors. Int. Conf. Mach. Learn. 2016, 2578–2586. Available online: http://proceedings.mlr.press/v48/bottesch16.pdf (accessed on 24 December 2020).
- Bachem, O.; Lucic, M.; Lattanzi, S. One-shot coresets: The case of k-clustering. In International Conference On Artificial Intelligence And Statistics; PMLR: Canary Islands, Spain, 2018; pp. 784–792. [Google Scholar]
- Capó, M.; Pérez, A.; Lozano, J.A. An efficient K-means clustering algorithm for massive data. arXiv 2018, arXiv:1801.02949. [Google Scholar]
- Boutsidis, C.; Zouzias, A.; Drineas, P. Random projections for k-means clustering. Adv. Neural Inf. Process. Syst. 2010, 23, 298–306. [Google Scholar]
- Fern, X.; Brodley, C. Random projection for high dimensional data clustering: A cluster ensemble approach. In Proceedings of the 20th International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; pp. 186–193. [Google Scholar]
- Alzate, C.; Suykens, J.A. Multiway spectral clustering with out-of-sample extensions through weighted kernel PCA. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 335–347. [Google Scholar] [CrossRef]
- Napoleon, D.; Pavalakodi, S. A new method for dimensionality reduction using K-means clustering algorithm for high dimensional data set. Int. J. Comput. Appl. 2011, 13, 41–46. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Kluwer Academic Publishers: Norwell, MA, USA, 1998. [Google Scholar]
- Achlioptas, D. Database-friendly random projections: Johnson-Lindenstrauss with binary coins. J. Comput. Syst. Sci. 2003, 66, 671–687, Special Issue on {PODS} 2001. [Google Scholar] [CrossRef] [Green Version]
- Jolliffe, I.T. Principal Component Analysis; Springer: New York, NY, USA, 2002. [Google Scholar]
- Bingham, E.; Mannila, H. Random Projection in Dimensionality Reduction: Applications to Image and Text Data. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 245–250. [Google Scholar]
- Cohen, M.B.; Elder, S.; Musco, C.; Musco, C.; Persu, M. Dimensionality reduction for k-means clustering and low rank approximation. In Proceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing, Portland, OR, USA, 15–17 June 2015; pp. 163–172. [Google Scholar]
- Boutsidis, C.; Zouzias, A.; Mahoney, M.W.; Drineas, P. Randomized dimensionality reduction for k-means clustering. IEEE Trans. Inf. Theory 2014, 61, 1045–1062. [Google Scholar] [CrossRef] [Green Version]
- Cardoso, Â.; Wichert, A. Iterative random projections for high-dimensional data clustering. Pattern Recognit. Lett. 2012, 33, 1749–1755. [Google Scholar] [CrossRef]
- Chan, J.Y.; Leung, A.P. Efficient k-means++ with random projection. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), IEEE, Anchorage, AK, USA, 14–19 May 2017; pp. 94–100. [Google Scholar]
- Sarkar, S.; Ghosh, A.K. On perfect clustering of high dimension, low sample size data. IEEE Trans. Pattern Anal. Mach. Intell. 2019. Available online: https://www.isical.ac.in/~statmath/report/74969-cluster.pdf (accessed on 24 December 2020).
- Hämäläinen, J.; Kärkkäinen, T. Initialization of Big Data Clustering using Distributionally Balanced Folding. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning-ESANN 2016, Bruges, Belgium, 27–29 April 2016; pp. 587–592. [Google Scholar]
- Moreno-Torres, J.G.; Sáez, J.A.; Herrera, F. Study on the Impact of Partition-Induced Dataset Shift on k-fold Cross-Validation. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1304–1312. [Google Scholar] [CrossRef] [PubMed]
- Vattani, A. K-means requires exponentially many iterations even in the plane. Discr. Comput. Geom. 2011, 45, 596–616. [Google Scholar] [CrossRef] [Green Version]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. Available online: https://stacks.stanford.edu/file/druid:xb208zr6261/xb208zr6261.pdf (accessed on 24 December 2020).
- Forgy, E.W. Cluster analysis of multivariate data: Efficiency vs. interpretability of classifications. Biometrics 1965, 21, 768–769. [Google Scholar]
- Bradley, P.S.; Fayyad, U.M. Refining Initial Points for K-Means Clustering. ICML 1998, 98, 91–99. [Google Scholar]
- Bachem, O.; Lucic, M.; Krause, A. Distributed and provably good seedings for k-means in constant rounds. Int. Conf. Mach. Learn. 2017, 70, 292–300. [Google Scholar]
- Hämäläinen, J.; Kärkkäinen, T.; Rossi, T. Scalable robust clustering method for large and sparse data. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning-ESANN 2018, Bruges, Belgium, 25–27 April 2018; pp. 449–454. [Google Scholar]
- Johnson, W.B.; Lindenstrauss, J. Extensions of Lipschitz mappings into a Hilbert space. Contemp. Math. 1984, 26, 1. [Google Scholar]
- Rezaei, M.; Fränti, P. Can the Number of Clusters Be Determined by External Indices? IEEE Access 2020, 8, 89239–89257. [Google Scholar] [CrossRef]
- Bottou, L.; Bengio, Y. Convergence properties of the k-means algorithms. Adv. Neural Inf. Process. Syst. 1995, 585–592. Available online: https://papers.nips.cc/paper/1994/file/a1140a3d0df1c81e24ae954d935e8926-Paper.pdf (accessed on 24 December 2020).
- Broder, A.; Garcia-Pueyo, L.; Josifovski, V.; Vassilvitskii, S.; Venkatesan, S. Scalable k-means by ranked retrieval. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 233–242. [Google Scholar]
- Sharma, G.; Martin, J. MATLAB®: A Language for Parallel Computing. Int. J. Parallel Progr. 2009, 37, 3–36. [Google Scholar] [CrossRef] [Green Version]
- Muller, M.E. Some continuous Monte Carlo methods for the Dirichlet problem. Ann. Math. Stat. 1956, 27, 569–589. [Google Scholar] [CrossRef]
- Fränti, P.; Sieranoja, S. K-means properties on six clustering benchmark datasets. Appl. Intell. 2018, 48, 1–17. [Google Scholar] [CrossRef]
- De Vries, C.M.; Geva, S. K-tree: Large scale document clustering. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 718–719. [Google Scholar]
- Kriegel, H.P.; Schubert, E.; Zimek, A. The (black) art of runtime evaluation: Are we comparing algorithms or implementations? Knowl. Inf. Syst. 2017, 52, 341–378. [Google Scholar] [CrossRef]
- Gallego, A.J.; Calvo-Zaragoza, J.; Valero-Mas, J.J.; Rico-Juan, J.R. Clustering-based k-nearest neighbor classification for large-scale data with neural codes representation. Pattern Recognit. 2018, 74, 531–543. [Google Scholar] [CrossRef] [Green Version]
- Kruskal, W.H.; Wallis, W.A. Use of ranks in one-criterion variance analysis. J. Am. Stat. Assoc. 1952, 47, 583–621. [Google Scholar] [CrossRef]
- Saarela, M.; Hämäläinen, J.; Kärkkäinen, T. Feature Ranking of Large, Robust, and Weighted Clustering Result. In Proceedings of the 21st Pacific Asia Conference on Knowledge Discovery and Data Mining-PAKDD 2017, Jeju, Korea, 23–26 May 2017; pp. 96–109. [Google Scholar]
- Äyrämö, S. Knowledge Mining Using Robust Clustering; Vol. 63 of Jyväskylä Studies in Computing; University of Jyväskylä: Jyväskylä, Finland, 2006. [Google Scholar]
- Amdahl, G.M. Validity of the single processor approach to achieving large scale computing capabilities. AFIPS Conf. Proc. 1967, 30, 483–485. [Google Scholar]
- Aggarwal, C.C.; Hinneburg, A.; Keim, D.A. On the surprising behavior of distance metrics in high dimensional space. In International Conference On Database Theory; Springer: New York, NY, USA, 2001; pp. 420–434. [Google Scholar]
- Strehl, A. Relationship-Based Clustering and Cluster Ensembles for High-Dimensional Data Mining. Ph.D. Thesis, The University of Texas at Austin, Austin, TX, USA, 2002. [Google Scholar]
- Li, P.; Hastie, T.J.; Church, K.W. Very sparse random projections. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge diScovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 287–296. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
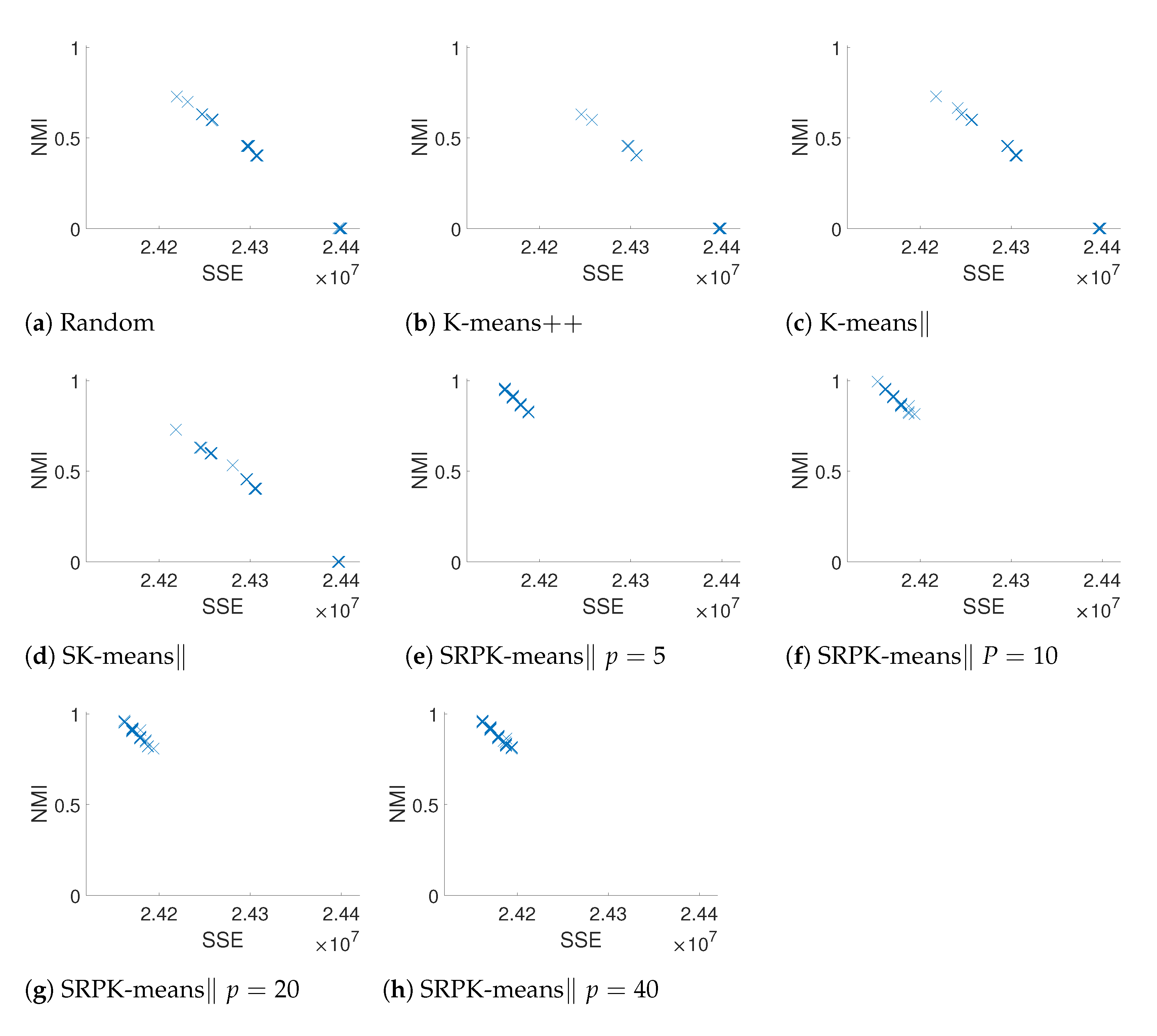{kind=link}
| Dataset | #Observations (N) | #Features (M) | #Clusters (K) |
|---|---|---|---|
| HAR | 7352 | 561 | 6 |
| ISO | 7797 | 617 | 26 |
| LET | 20,000 | 16 | 26 |
| GFE | 27,936 | 300 | 36 |
| MNI | 70,000 | 784 | 10 |
| BIR | 100,000 | 2 | 100 |
| BSM | 583,250 | 77 | 50 * |
| FCT | 581,012 | 54 | 7 |
| SVH | 630,420 | 3072 | 100 * |
| RCV | 781,265 | 1000 | 350 |
| USC | 2,458,285 | 68 | 100 * |
| KDD | 4,898,431 | 41 | 100 * |
| M8M | 8,100,000 | 784 | 265 |
| TIN | 15,860,403 | 384 | 100 * |
| OXB | 16,334,970 | 128 | 100 * |
| Initialization | Final | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| K | K‖ | SK‖ | SRPK‖ | K | K‖ | SK‖ | SRPK‖ | ||||||||
| Data | Stats | ||||||||||||||
| HAR | median | 2.5881 | 1.5577 | 1.3958 | 1.4474 | 1.4192 | 1.4074 | 1.4003 | 1.3803 | 1.3803 | 1.3707 | 1.3707 | 1.3707 | 1.3707 | 1.3707 |
| mad | 0.1498 | 0.0436 | 0.0066 | 0.0250 | 0.0175 | 0.0132 | 0.0116 | 0.0203 | 0.0242 | 0.0057 | 0.0117 | 0.0087 | 0.0082 | 0.0064 | |
| max | 3.2295 | 1.7367 | 1.4316 | 1.5269 | 1.4613 | 1.4504 | 1.4621 | 1.5461 | 1.5461 | 1.4126 | 1.4136 | 1.4110 | 1.4126 | 1.4094 | |
| min | 2.2533 | 1.4782 | 1.3785 | 1.3971 | 1.3907 | 1.3859 | 1.3825 | 1.3707 | 1.3707 | 1.3707 | 1.3707 | 1.3707 | 1.3707 | 1.3707 | |
| ISO | median | 8.9267 | 5.5274 | 4.9617 | 5.7887 | 5.4478 | 5.198 | 5.0575 | 4.7811 | 4.7795 | 4.7617 | 4.7578 | 4.7558 | 4.7538 | 4.7575 |
| mad | 0.1797 | 0.0575 | 0.0271 | 0.0927 | 0.0723 | 0.0486 | 0.0411 | 0.0287 | 0.0246 | 0.0202 | 0.0277 | 0.0306 | 0.0265 | 0.0267 | |
| max | 9.4413 | 5.7650 | 5.0490 | 6.0687 | 5.6078 | 5.2900 | 5.1494 | 4.9228 | 4.8663 | 4.8529 | 4.8469 | 4.8824 | 4.8407 | 4.8787 | |
| min | 8.4326 | 5.3859 | 4.8820 | 5.6207 | 5.2543 | 5.0629 | 4.9383 | 4.7142 | 4.7085 | 4.7087 | 4.7145 | 4.7099 | 4.7084 | 4.7180 | |
| LET | median | 1.7868 | 1.2356 | 1.1415 | 1.3543 | 1.2339 | - | - | 1.1012 | 1.1014 | 1.0985 | 1.0994 | 1.0989 | - | - |
| mad | 0.0517 | 0.0176 | 0.0070 | 0.0372 | 0.0217 | - | - | 0.0062 | 0.0060 | 0.0051 | 0.0064 | 0.0065 | - | - | |
| max | 2.1162 | 1.3133 | 1.1616 | 1.4327 | 1.2991 | - | - | 1.1261 | 1.1192 | 1.1218 | 1.1175 | 1.1219 | - | - | |
| min | 1.6656 | 1.1771 | 1.1175 | 1.2617 | 1.1844 | - | - | 1.0872 | 1.0873 | 1.0883 | 1.0876 | 1.0875 | - | - | |
| GFE | median | 3.0103 | 2.0860 | 1.9218 | 2.1637 | 2.0463 | 1.9813 | 1.9506 | 1.8605 | 1.8550 | 1.8491 | 1.8398 | 1.8397 | 1.8407 | 1.8420 |
| mad | 0.0994 | 0.0231 | 0.0155 | 0.0415 | 0.0258 | 0.0727 | 0.0704 | 0.0151 | 0.0146 | 0.0117 | 0.0129 | 0.0123 | 0.0119 | 0.0113 | |
| max | 3.3933 | 2.1737 | 1.9793 | 2.2439 | 2.1042 | 2.0302 | 1.9990 | 1.9440 | 1.9105 | 1.8999 | 1.8783 | 1.8700 | 1.8757 | 1.8771 | |
| min | 2.7908 | 2.0247 | 1.8819 | 2.0618 | 1.9802 | 1.9424 | 1.9039 | 1.8252 | 1.8197 | 1.8236 | 1.8172 | 1.8211 | 1.8227 | 1.8195 | |
| MNI | median | 1.9539 | 1.2495 | 1.1074 | 1.2156 | 1.1752 | 1.1458 | 1.1279 | 1.1013 | 1.1013 | 1.0979 | 1.0980 | 1.0979 | 1.0979 | 1.0980 |
| mad | 0.0624 | 0.0152 | 0.0032 | 0.0117 | 0.0093 | 0.0068 | 0.0048 | 0.0027 | 0.0024 | 0.0017 | 0.0023 | 0.0018 | 0.0026 | 0.0027 | |
| max | 2.2474 | 1.3056 | 1.1171 | 1.2428 | 1.1968 | 1.1606 | 1.1390 | 1.1146 | 1.1075 | 1.1052 | 1.1046 | 1.1069 | 1.1105 | 1.1095 | |
| min | 1.8138 | 1.2131 | 1.1006 | 1.1885 | 1.1472 | 1.1296 | 1.1136 | 1.0977 | 1.0977 | 1.0977 | 1.0977 | 1.0977 | 1.0977 | 1.0977 | |
| BIR | median | 3.0658 | 1.9912 | 1.8677 | - | - | - | - | 1.8440 | 1.8187 | 1.7781 | - | - | - | - |
| mad | 0.1375 | 0.0544 | 0.0269 | - | - | - | - | 0.0469 | 0.0451 | 0.0261 | - | - | - | - | |
| max | 3.4694 | 2.3346 | 1.9533 | - | - | - | - | 2.0238 | 2.0943 | 1.8973 | - | - | - | - | |
| min | 2.6292 | 1.8770 | 1.8074 | - | - | - | - | 1.7438 | 1.7409 | 1.7248 | - | - | - | - | |
| BSM | median | 1.9621 | 1.1802 | 1.0780 | 1.4680 | 1.1957 | 1.1038 | 1.1012 | 1.1914 | 1.1631 | 1.0698 | 1.2124 | 1.1324 | 1.0800 | 1.0903 |
| mad | 0.1943 | 0.0741 | 0.0376 | 0.1593 | 0.0779 | 0.0511 | 0.0564 | 0.0818 | 0.0684 | 0.0374 | 0.1006 | 0.0741 | 0.0504 | 0.0577 | |
| max | 2.5054 | 1.4593 | 1.1776 | 1.8995 | 1.4179 | 1.2237 | 1.2130 | 1.4205 | 1.4553 | 1.1684 | 1.5541 | 1.2875 | 1.1813 | 1.2063 | |
| min | 1.5003 | 0.9999 | 0.9908 | 1.1971 | 0.9996 | 0.9779 | 0.9780 | 0.9929 | 0.9616 | 0.9739 | 1.0283 | 0.9668 | 0.9706 | 0.9664 | |
| FCT | median | 3.8766 | 2.2187 | 1.9273 | 2.2076 | 2.1004 | 2.0086 | 1.9773 | 1.9801 | 2.0000 | 1.9132 | 1.9781 | 1.9670 | 1.9461 | 1.9385 |
| mad | 0.3322 | 0.1013 | 0.0343 | 0.0654 | 0.0581 | 0.0508 | 0.0380 | 0.0634 | 0.0784 | 0.0354 | 0.0542 | 0.0506 | 0.0466 | 0.0435 | |
| max | 5.5290 | 2.5274 | 2.0294 | 2.4008 | 2.2494 | 2.1397 | 2.0698 | 2.2457 | 2.3487 | 2.0293 | 2.1752 | 2.1434 | 2.0852 | 2.0601 | |
| min | 3.1329 | 1.9329 | 1.8645 | 2.0808 | 2.0013 | 1.8657 | 1.8652 | 1.8644 | 1.8644 | 1.8644 | 1.8644 | 1.8644 | 1.8644 | 1.8644 | |
| SVH | median | - | 1.3559 | 1.0855 | 1.1820 | 1.1464 | 1.1155 | 1.0992 | - | 1.0703 | 1.0704 | 1.0704 | 1.0705 | 1.0706 | 1.0708 |
| mad | - | 0.0636 | 0.0014 | 0.0185 | 0.0149 | 0.0075 | 0.0042 | - | 0.0003 | 0.0004 | 0.0005 | 0.0005 | 0.0003 | 0.0003 | |
| max | - | 1.5968 | 1.0889 | 1.2279 | 1.1765 | 1.1290 | 1.1083 | - | 1.0711 | 1.0720 | 1.0711 | 1.0717 | 1.0714 | 1.0712 | |
| min | - | 1.3027 | 1.0836 | 1.1639 | 1.1246 | 1.1082 | 1.0922 | - | 1.0696 | 1.0698 | 1.0698 | 1.0700 | 1.0703 | 1.0703 | |
| RCV | median | - | 2.5506 | 2.1405 | 2.5897 | 2.4864 | 2.3575 | 2.2313 | - | 2.0876 | 2.0913 | 2.0780 | 2.0757 | 2.0702 | 2.0715 |
| mad | - | 0.0233 | 0.0022 | 0.0138 | 0.0041 | 0.0045 | 0.0040 | - | 0.0027 | 0.0018 | 0.0019 | 0.0014 | 0.0026 | 0.0022 | |
| max | - | 2.5886 | 2.1427 | 2.5979 | 2.4945 | 2.3652 | 2.2363 | - | 2.0922 | 2.0951 | 2.0823 | 2.0778 | 2.0767 | 2.0755 | |
| min | - | 2.4849 | 2.1345 | 2.5647 | 2.4830 | 2.3523 | 2.2228 | - | 2.0812 | 2.0863 | 2.0764 | 2.0737 | 2.0688 | 2.0674 | |
| Initialization | Final | ||||||||||||||
| K | K‖ | SK‖ | SRPK‖ | K++ | K‖ | SK‖ | SRPK‖ | ||||||||
| Data | Stats | ||||||||||||||
| USC | median | - | 1.7014 | 1.1936 | 1.5530 | 1.3218 | 1.2284 | 1.1989 | - | 1.1903 | 1.1779 | 1.1736 | 1.1688 | 1.1718 | 1.1709 |
| mad | - | 0.0394 | 0.0036 | 0.0338 | 0.0217 | 0.0079 | 0.0037 | - | 0.0070 | 0.0057 | 0.0072 | 0.0091 | 0.0091 | 0.0049 | |
| max | - | 1.7671 | 1.2016 | 1.6178 | 1.3542 | 1.2415 | 1.2038 | - | 1.2020 | 1.1908 | 1.1803 | 1.1841 | 1.1869 | 1.1829 | |
| min | - | 1.6110 | 1.1877 | 1.4957 | 1.2799 | 1.2191 | 1.1934 | - | 1.1781 | 1.1712 | 1.1595 | 1.1566 | 1.1602 | 1.1667 | |
| KDD | median | - | 30.5335 | 2.5466 | 3.1781 | 2.6651 | 2.5817 | 2.5162 | - | 2.5218 | 2.4726 | 2.4853 | 2.4582 | 2.4755 | 2.4529 |
| mad | - | 7.3666 | 0.0337 | 0.1019 | 0.0483 | 0.0562 | 0.0440 | - | 0.0372 | 0.0419 | 0.0698 | 0.0413 | 0.0464 | 0.0316 | |
| max | - | 58.0452 | 2.5962 | 3.3024 | 2.7083 | 2.6275 | 2.6367 | - | 2.6288 | 2.5432 | 2.6241 | 2.5223 | 2.5640 | 2.5406 | |
| min | - | 22.2667 | 2.4803 | 2.9935 | 2.5447 | 2.4483 | 2.4878 | - | 2.4614 | 2.4084 | 2.3961 | 2.3927 | 2.4032 | 2.4330 | |
| M8M | median | - | 2.6631 | 2.2390 | 2.9313 | 2.6415 | 2.4185 | 2.3153 | - | 2.2159 | 2.2154 | 2.2139 | 2.2139 | 2.2141 | 2.2139 |
| mad | - | 0.0164 | 0.0009 | 0.0286 | 0.0150 | 0.0071 | 0.0041 | - | 0.0012 | 0.0008 | 0.0010 | 0.0009 | 0.0005 | 0.0009 | |
| max | - | 2.6959 | 2.2412 | 2.9835 | 2.6690 | 2.4299 | 2.3176 | - | 2.2203 | 2.2165 | 2.2162 | 2.2155 | 2.2145 | 2.2157 | |
| min | - | 2.6391 | 2.2376 | 2.8782 | 2.6192 | 2.4091 | 2.3043 | - | 2.2143 | 2.2131 | 2.2128 | 2.2126 | 2.2131 | 2.2132 | |
| TIN | median | - | 10.7568 | 8.8782 | 9.7335 | 9.4194 | 9.2042 | 9.0595 | - | 8.8060 | 8.8065 | 8.8058 | 8.8075 | 8.8073 | 8.8073 |
| mad | - | 0.1498 | 0.0057 | 0.1054 | 0.0879 | 0.0338 | 0.0139 | - | 0.0012 | 0.0014 | 0.0016 | 0.0018 | 0.0016 | 0.0030 | |
| max | - | 11.1649 | 8.8812 | 9.9343 | 9.5627 | 9.2543 | 9.0841 | - | 8.8091 | 8.8077 | 8.8091 | 8.8106 | 8.8093 | 8.8108 | |
| min | - | 10.4721 | 8.8623 | 9.5824 | 9.3339 | 9.1431 | 9.0474 | - | 8.8031 | 8.8029 | 8.8042 | 8.8047 | 8.8044 | 8.8024 | |
| OXB | median | - | 1.7678 | 1.5375 | 1.6432 | 1.6249 | 1.6014 | 1.5829 | - | 1.5267 | 1.5268 | 1.5254 | 1.5256 | 1.5255 | 1.5255 |
| mad | - | 0.0181 | 0.0004 | 0.0055 | 0.0058 | 0.0028 | 0.0017 | - | 0.0006 | 0.0002 | 0.0003 | 0.0005 | 0.0005 | 0.0004 | |
| max | - | 1.8224 | 1.5384 | 1.6575 | 1.6315 | 1.6082 | 1.5850 | - | 1.5286 | 1.5271 | 1.5258 | 1.5266 | 1.5262 | 1.5261 | |
| min | - | 1.7506 | 1.5367 | 1.6393 | 1.6162 | 1.5995 | 1.5797 | - | 1.5258 | 1.5259 | 1.5251 | 1.5250 | 1.5250 | 1.5250 | |
| KDD | USC | OXB | TIN | M8M | RCV | SVH | |
|---|---|---|---|---|---|---|---|
| K-means‖ | 5.0 ± 0.1 | 3.0 ± 0.3 | 26.0 ± 1.8 | 52.1 ± 1.3 | 98.5±2.9 | 14.1 ± 1.8 | 13.7 ± 0.8 |
| SK-means‖ | 8.7 ± 0.2 | 5.0 ± 0.2 | 39.1 ± 0.5 | 65.8 ± 0.9 | 145.5 ± 0.6 | 20.6 ± 0.7 | 17.3 ± 0.2 |
| SRPK-means‖ | 7.9 ± 0.1 | 3.9 ± 0.1 | 23.7 ± 0.3 | 24.9 ± 0.4 | 32.2 ± 0.3 | 4.8 ± 0.1 | 3.4 ± 0.2 |
| SRPK-means‖ | 10.2 ± 0.2 | 5.6 ± 0.3 | 27.4 ± 0.6 | 28.5 ± 1.3 | 37.9 ± 0.6 | 5.6 ± 0.5 | 3.3 ± 0.2 |
| HAR | ISO | LET | GFE | MNI | BIR | BSM | FCT | SVH | RCV | USC | KDD | M8M | TIN | OXB | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| K-means | 25.5 | 31.5 | 79 | 62 | 86 | 94 | 36 | 14 | - | - | - | - | - | - | - |
| ±11.1 | ±8.7 | ±22.1 | ±15.8 | ±30.3 | ±22.7 | ±11.9 | ±11.1 | - | - | - | - | - | - | - | |
| K-means‖ | 28.5 | 33.5 | 68.5 | 59 | 86 | 97 | 35 | 9.5 | 32.5 | 20 | 81 | 82 | 31 | 37.5 | 27.5 |
| ±10.5 | ±11.0 | ±22.8 | ±15.6 | ±30.5 | ±22.2 | ±12.4 | ±10.3 | ±2.5 | ±2.3 | ±8.5 | ±24.5 | ±1.1 | ±3.8 | ±2.3 | |
| SK-means‖ | 23.5 | 25.5 * | 63 * | 52 | 73 | 86.5 | 25.5 * | 1 * | 28.5 | 19 | 86 | 72 | 24 * | 33 * | 22 * |
| ±9.4 | ±9.2 | ±20.2 | ±14.6 | ±30.7 | ±24.8 | ±13.5 | ±5.6 | ±3.7 | ±1.4 | ±19.2 | ±22.2 | ±1.3 | ±1.7 | ±1.7 | |
| SRPK-means‖ | 27 | 35 | 77 | 60 | 87 | - | 35 | 6 * | 35 | 20.5 | 93.5 | 96.5 | 33 | 40 | 28.5 |
| ±9.5 | ±9.5 | ±22.8 | ±16.1 | ±37.2 | - | ±12.1 | ±4.2 | ±2.1 | ±1.3 | ±31.4 | ±25.2 | ±1.5 | ±2.5 | ±1.6 | |
| SRPK-means‖ | 19 * | 30 | 76.5 | 55.5 | 72.5 | - | 30.5 | 5 * | 32 | 20 | 83.5 | 78 | 31.5 | 38.5 | 28 |
| ±10.5 | ±10.0 | ±21.1 | ±13.2 | ±30.3 | - | ±11.4 | ±5 | ±2.2 | ±1.3 | ±19.8 | ±24.2 | ±1.7 | ±3 | ±1.8 | |
| SRPK-means‖ | 20 * | 30 | - | 53.5 | 83 | - | 26.5 * | 4 * | 30 | 17 * | 77 | 69 | 30 | 39 | 27.5 |
| ±9.0 | ±8.7 | - | ±13.8 | ±32.9 | - | ±10.6 | ±4.8 | ±2.1 | ±1.2 | ±17.2 | ±18.9 | ±1.2 | ±2.6 | ±2.1 | |
| SRPK-means‖ | 19 * | 28 | - | 50 | 66 | - | 24 * | 4 * | 27 | 17 * | 98.5 | 70 | 28.5 | 35.5 | 28.5 |
| ±9.4 | ±9.1 | - | ±17.3 | ±27.7 | - | ±11.8 | ±5.3 | ±2.9 | ±0.9 | ±27.4 | ±25.4 | ±2.0 | ±4.5 | ±2.6 |
| Dataset | #Observations (N) | #Features (M) | #Clusters (K) | Center Distance () | Radius () |
|---|---|---|---|---|---|
| M-spheres-M1k-0.05 | 100,000 | 1000 | 10 | 0.05 | 1.0 |
| M-spheres-M1k-0.1 | 100,000 | 1000 | 10 | 0.1 | 1.0 |
| M-spheres-M1k-0.2 | 100,000 | 1000 | 10 | 0.2 | 1.0 |
| M-spheres-M10k-0.05 | 100,000 | 10,000 | 10 | 0.05 | 1.0 |
| M-spheres-M10k-0.1 | 100,000 | 10,000 | 10 | 0.1 | 1.0 |
| M-spheres-M10k-0.2 | 100,000 | 10,000 | 10 | 0.2 | 1.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hämäläinen, J.; Kärkkäinen, T.; Rossi, T. Improving Scalable K-Means++. Algorithms 2021, 14, 6. https://doi.org/10.3390/a14010006
Hämäläinen J, Kärkkäinen T, Rossi T. Improving Scalable K-Means++. Algorithms. 2021; 14(1):6. https://doi.org/10.3390/a14010006
Chicago/Turabian StyleHämäläinen, Joonas, Tommi Kärkkäinen, and Tuomo Rossi. 2021. "Improving Scalable K-Means++" Algorithms 14, no. 1: 6. https://doi.org/10.3390/a14010006
APA StyleHämäläinen, J., Kärkkäinen, T., & Rossi, T. (2021). Improving Scalable K-Means++. Algorithms, 14(1), 6. https://doi.org/10.3390/a14010006