
A Context-Aware Neural Embedding for Function-Level Vulnerability Detection



Abstract
:1. Introduction
- We compare the performance of five mainstream word embedding models, including Word2Vec, GloVe, FastText, ELMo, and bidirectional encoder representations from transformers (BERT) [32]) in the scenario of vulnerable function detection. We demonstrate that among the selected NLP embedding solutions, ELMo is the most suitable one for generating code embedding for vulnerability detection when there are not many code samples available for pre-training.
- Based on the evaluation of embedding solutions, we design a deep neural network built on top of the ELMo module to capture code semantic that is context aware and is capable of learning the long-term dependencies, reflecting potentially vulnerable source-sink patterns in the source code.
- On top of the ELMo-based neural model, we develop a framework for transforming source code functions to meaningful embeddings optimized for vulnerable function detection, without the need for other code analysis tools. A performance evaluation is carried out to examine the effectiveness of the proposed framework with four baseline systems. The results confirm that the proposed framework achieved state-of-the-art performance.
2. Framework Design
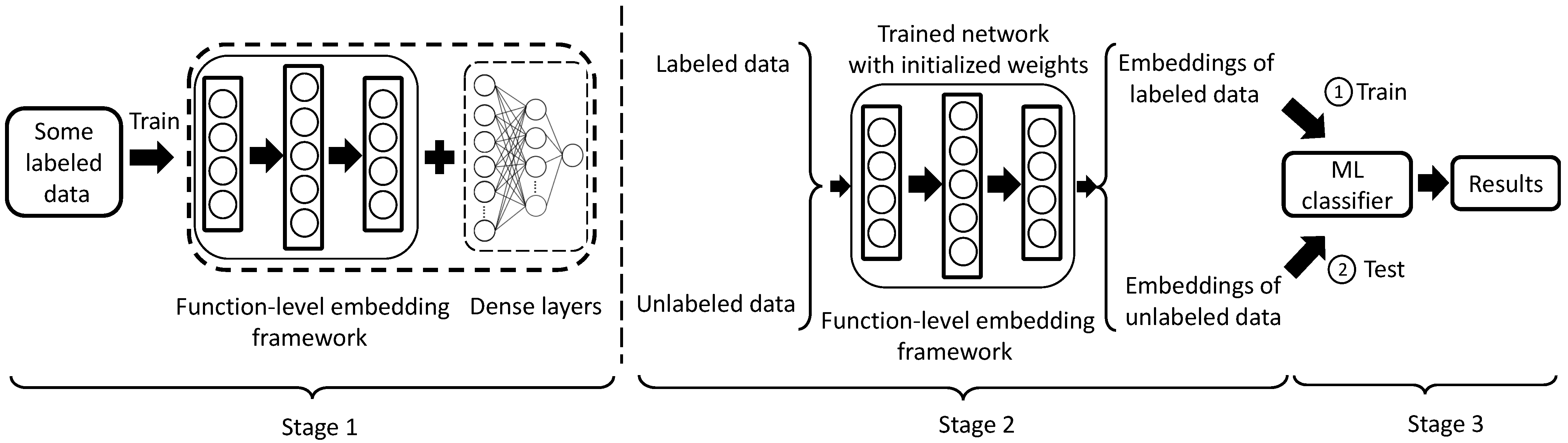
2.1. Workflow
2.2. Code Context Analysis
2.3. Contextual Semantic Learning
2.4. Handling Out-of-Vocabulary Words
2.5. Long-Term Dependency Learning
2.6. Framework Implementation
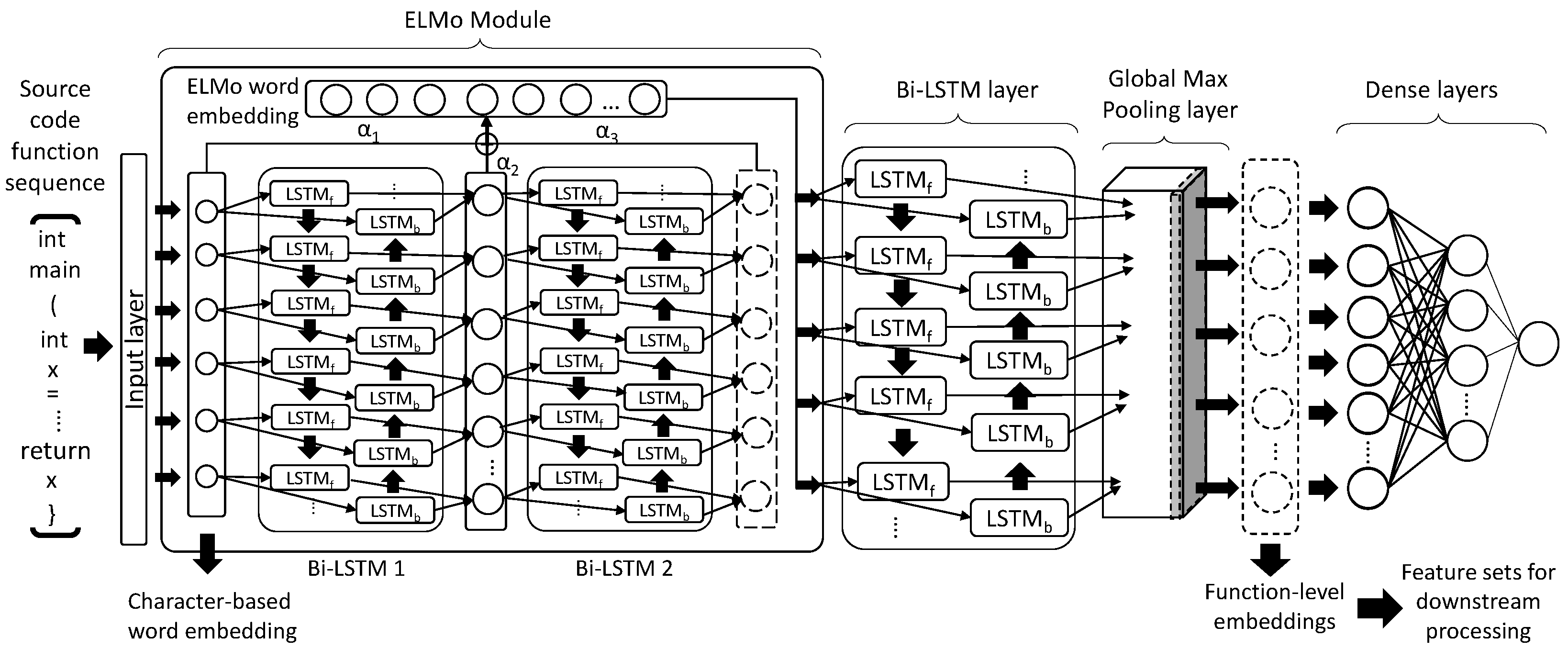
2.6.1. Input Preparation
2.6.2. Network Architecture
2.6.3. Function-Level Embedding Generation
3. Experiments and Evaluation
3.1. Experiment Data Sets
3.2. Experiment Settings
3.2.1. Settings for Evaluating the Effectiveness of Embedding Models
3.2.2. Settings for Determining the Structure of Bi-LSTM
3.2.3. Settings for Evaluating on Real-World Open Source Projects
3.2.4. Settings for the Detection of Context-Related Vulnerabilities
3.2.5. Experiment Environment
3.3. Evaluation Criteria
3.4. Result Analysis
3.4.1. The Effectiveness of Embedding Models
3.4.2. The Structure of Bi-LSTM
3.4.3. Performance Evaluation and Comparison on Real-World Open Source Projects
3.4.4. Detection of Context-Related Vulnerabilities
3.5. Limitations and Future Work
4. Related Work
4.1. Embedding Methods for Source Code
4.2. Software Vulnerability Detection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, N.; Zhang, J.; Rimba, P.; Gao, S.; Zhang, L.Y.; Xiang, Y. Data-driven cybersecurity incident prediction: A survey. IEEE Commun. Surv. Tutorials 2019, 21, 1744–1772. [Google Scholar] [CrossRef]
- Liu, L.; De Vel, O.; Han, Q.L.; Zhang, J.; Xiang, Y. Detecting and Preventing Cyber Insider Threats: A Survey. IEEE Commun. Surv. Tutorials 2018, 20, 1397–1417. [Google Scholar] [CrossRef]
- Chen, X.; Li, C.; Wang, D.; Wen, S.; Zhang, J.; Nepal, S.; Xiang, Y.; Ren, K. Android HIV: A study of repackaging malware for evading machine-learning detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 987–1001. [Google Scholar] [CrossRef] [Green Version]
- Coulter, R.; Han, Q.L.; Pan, L.; Zhang, J.; Xiang, Y. Data-driven cyber security in perspective–intelligent traffic analysis. IEEE Trans. Cybern. 2020, 50, 3081–3093. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. VulDeePecker: A Deep Learning-Based System for Vulnerability Detection. arXiv 2018, arXiv:1801.01681. [Google Scholar]
- Perl, H.; Dechand, S.; Smith, M.; Arp, D.; Yamaguchi, F.; Rieck, K.; Fahl, S.; Acar, Y. Vccfinder: Finding potential vulnerabilities in open-source projects to assist code audits. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, CCS ’15, Denver, CO, USA, 12–16 October 2015; pp. 426–437. [Google Scholar]
- Qiu, J.; Zhang, J.; Luo, W.; Pan, L.; Nepal, S.; Xiang, Y. A survey of Android malware detection with deep neural models. ACM Comput. Surv. 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Wang, M.; Zhu, T.; Zhang, T.; Zhang, J.; Yu, S.; Zhou, W. Security and Privacy in 6G Networks: New Areas and New Challenges. Digit. Commun. Netw. 2020, 6, 281–291. [Google Scholar] [CrossRef]
- Ghaffarian, S.M.; Shahriari, H.R. Software vulnerability analysis and discovery using machine-learning and data-mining techniques: A survey. ACM Comput. Surv. 2017, 50, 1–36. [Google Scholar] [CrossRef]
- Lin, G.; Wen, S.; Han, Q.; Zhang, J.; Xiang, Y. Software Vulnerability Detection Using Deep Neural Networks: A Survey. Proc. IEEE 2020, 108, 1825–1848. [Google Scholar] [CrossRef]
- Zeng, P.; Lin, G.; Pan, L.; Tai, Y.; Zhang, J. Software Vulnerability Analysis and Discovery using Deep Learning Techniques: A Survey. IEEE Access 2020. [Google Scholar] [CrossRef]
- Chen, Z.; Monperrus, M. A literature study of embeddings on source code. arXiv 2019, arXiv:1904.03061. [Google Scholar]
- Wang, S.; Liu, T.; Tan, L. Automatically learning semantic features for defect prediction. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering (ICSE), Austin, TX, USA, 14–22 May 2016; pp. 297–308. [Google Scholar]
- Lin, G.; Zhang, J.; Luo, W.; Pan, L.; Xiang, Y.; De Vel, O.; Montague, P. Cross-Project Transfer Representation Learning for Vulnerable Function Discovery. IEEE Trans. Ind. Inform. 2018, 14, 3289–3297. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. code2vec: Learning Distributed Representations of Code. arXiv 2018, arXiv:1803.09473. [Google Scholar] [CrossRef] [Green Version]
- Allamanis, M.; Barr, E.T.; Devanbu, P.; Sutton, C. A survey of machine learning for big code and naturalness. ACM Comput. Surv. 2018, 51, 81. [Google Scholar] [CrossRef] [Green Version]
- Scandariato, R.; Walden, J.; Hovsepyan, A.; Joosen, W. Predicting vulnerable software components via text mining. TSE 2014, 40, 993–1006. [Google Scholar] [CrossRef]
- White, M.; Vendome, C.; Linares-Vásquez, M.; Poshyvanyk, D. Toward deep learning software repositories. In Proceedings of the 2015 IEEE/ACM 12th Working Conference on Mining Software Repositories, Florence, Italy, 16–17 May 2015. [Google Scholar]
- Karpathy, A.; Johnson, J.; Fei-Fei, L. Visualizing and understanding recurrent networks. arXiv 2015, arXiv:1506.02078. [Google Scholar]
- Cummins, C.; Petoumenos, P.; Wang, Z.; Leather, H. Synthesizing benchmarks for predictive modeling. In Proceedings of the 2017 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Austin, TX, USA, 4–8 February 2017. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. Available online: https://proceedings.neurips.cc/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf (accessed on 10 November 2021).
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. Available online: https://aclanthology.org/D14-1162.pdf (accessed on 10 November 2021).
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Zhu, Y.; Chen, Z.; Wang, S.; Wang, J. SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities. arXiv 2018, arXiv:1807.06756. [Google Scholar] [CrossRef]
- Harer, J.A.; Kim, L.Y.; Russell, R.L.; Ozdemir, O.; Kosta, L.R.; Rangamani, A.; Hamilton, L.H.; Centeno, G.I.; Key, J.R.; Ellingwood, P.M.; et al. Automated software vulnerability detection with machine learning. arXiv 2018, arXiv:1803.04497. [Google Scholar]
- Lin, G.; Zhang, J.; Luo, W.; Pan, L.; De Vel, O.; Montague, P.; Xiang, Y. Software Vulnerability Discovery via Learning Multi-domain Knowledge Bases. IEEE Trans. Dependable Secur. Comput. 2019. [Google Scholar] [CrossRef]
- Lin, G.; Xiao, W.; Zhang, L.Y.; Gao, S.; Tai, Y.; Zhang, J. Deep neural-based vulnerability discovery demystified: Data, model and performance. Neural Comput. Appl. 2021, 33, 1–14. [Google Scholar] [CrossRef]
- Melamud, O.; Goldberger, J.; Dagan, I. context2vec: Learning Generic Context Embedding with Bidirectional Lstm. Available online: https://aclanthology.org/K16-1006.pdf (accessed on 10 November 2021).
- Gardner, M.; Grus, J.; Neumann, M.; Tafjord, O.; Dasigi, P.; Liu, N.H.; Peters, M.; Schmitz, M.; Zettlemoyer, L.S. A Deep Semantic Natural Language Processing Platform. arXiv 2017, arXiv:1803.07640. [Google Scholar]
- Chelba, C.; Mikolov, T.; Schuster, M.; Ge, Q.; Brants, T.; Koehn, P.; Robinson, T. One billion word benchmark for measuring progress in statistical language modeling. arXiv 2013, arXiv:1312.3005. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yamaguchi, F.; Maier, A.; Gascon, H.; Rieck, K. Automatic inference of search patterns for taint-style vulnerabilities. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 17–21 May 2015. [Google Scholar]
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P.T.P. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv 2016, arXiv:1609.04836. [Google Scholar]
- National Vulnerability Database. Available online: https://nvd.nist.gov/ (accessed on 28 September 2021).
- Common Vulnerabilities and Exposures. Available online: https://cve.mitre.org/index.html (accessed on 26 September 2021).
- Wheeler, D.A. Flawfinder. 2021. Available online: https://www.dwheeler.com/flawfinder/ (accessed on 20 September 2021).
- Liu, S.; Lin, G.; Han, Q.L.; Wen, S.; Zhang, J.; Xiang, Y. DeepBalance: Deep-learning and fuzzy oversampling for vulnerability detection. IEEE Trans. Fuzzy Syst. 2019, 28, 1329–1343. [Google Scholar] [CrossRef]
- Keras-Team. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 10 November 2021).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’16), Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. JMLR 2011, 12, 2825–2830. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Framework, Valletta, Malta, 22 May 2010; pp. 45–50. Available online: http://is.muni.cz/publication/884893/en (accessed on 10 November 2021).
- Christopher, D.; Manning, P.R.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2009; Chapter 8; pp. 151–175. [Google Scholar]
- Ben-Nun, T.; Jakobovits, A.S.; Hoefler, T. Neural code comprehension: A learnable representation of code semantics. arXiv 2018, arXiv:1806.07336. [Google Scholar]
- Bhoopchand, A.; Rocktäschel, T.; Barr, E.; Riedel, S. Learning Python code suggestion with a sparse pointer network. arXiv 2016, arXiv:1611.08307. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. Codebert: A pre-trained model for programming and natural languages. arXiv 2020, arXiv:2002.08155. [Google Scholar]
- Kanade, A.; Maniatis, P.; Balakrishnan, G.; Shi, K. Learning and evaluating contextual embedding of source code. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 13–18 July 2020. [Google Scholar]
- Hindle, A.; Barr, E.T.; Su, Z.; Gabel, M.; Devanbu, P. On the naturalness of software. In Proceedings of the 34th International Conference on Software Engineering (ICSE), New Delhi, India, 21–23 February 2013. [Google Scholar]
- Lin, G.; Zhang, J.; Luo, W.; Pan, L.; Xiang, Y. POSTER: Vulnerability Discovery with Function Representation Learning from Unlabeled Projects. In Proceedings of the CCS ’17: 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Lin, G.; Xiao, W.; Zhang, J.; Xiang, Y. Deep learning-based vulnerable function detection: A benchmark. In Proceedings of the International Conference on Information and Communications Security, Beijing, China, 15–17 December 2019. [Google Scholar]
- Jia, H.; Peng, X.; Lang, C. Remora optimization algorithm. Expert Syst. Appl. 2021, 185, 115665. [Google Scholar] [CrossRef]
- Peng, H.; Mou, L.; Li, G.; Liu, Y.; Zhang, L.; Jin, Z. Building program vector representations for deep learning. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Chongqing, China, 28–30 October 2015. [Google Scholar]
- Mou, L.; Li, G.; Zhang, L.; Wang, T.; Jin, Z. Convolutional Neural Networks over Tree Structures for Programming Language Processing. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Alon, U.; Brody, S.; Levy, O.; Yahav, E. code2seq: Generating sequences from structured representations of code. arXiv 2018, arXiv:1808.01400. [Google Scholar]
- Ding, S.H.; Fung, B.C.; Charland, P. Asm2vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019. [Google Scholar]
- Zuo, F.; Li, X.; Young, P.; Luo, L.; Zeng, Q.; Zhang, Z. Neural machine translation inspired binary code similarity comparison beyond function pairs. arXiv 2018, arXiv:1808.04706. [Google Scholar]
- Rough-Auditing-Tool-for-Security. Available online: https://code.google.com/archive/p/rough-auditing-tool-for-security/ (accessed on 26 September 2021).
- Engler, D.; Chen, D.Y.; Hallem, S.; Chou, A.; Chelf, B. Bugs as deviant behavior: A general approach to inferring errors in systems code. In SIGOPS Operating Systems Review; ACM: New York, NY, USA, 2001; Volume 35, pp. 57–72. [Google Scholar]
- Neuhaus, S.; Zimmermann, T.; Holler, C.; Zeller, A. Predicting vulnerable software components. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 29 October–2 November 2007. [Google Scholar]
- Yamaguchi, F.; Lindner, F.; Rieck, K. Vulnerability extrapolation: Assisted discovery of vulnerabilities using machine learning. In Proceedings of the 5th USENIX Workshop on Offensive Technologies, San Francisco, CA, USA, 8 August 2011. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Qi, H.; Hu, J. VulPecker: An automated vulnerability detection system based on code similarity analysis. In Proceedings of the 32nd Annual Conference on Computer Security Applications, Los Angeles, CA, USA, 5–8 December 2016. [Google Scholar]
- Yamaguchi, F.; Golde, N.; Arp, D.; Rieck, K. Modeling and discovering vulnerabilities with code property graphs. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 18–21 May 2014. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Source | Dataset | # of Functions Used/Collected | |
|---|---|---|---|
| Vulnerable | Non-Vulnerable | ||
| Open-source projects | FFmpeg | 213 | 5701 |
| LibTIFF | 96 | 731 | |
| OpenSSL | 143 | 7068 | |
| Data Set | Training Set | Test Set | ||
|---|---|---|---|---|
| # of Vulnerable Functions | # of Non-Vulnerable Functions | # of Vulnerable Functions | # of Non-Vulnerable Functions | |
| FFmpeg | 70 | 1881 | 143 | 3820 |
| LibTIFF | 32 | 241 | 64 | 490 |
| OpenSSL | 47 | 2332 | 96 | 4736 |
| Software Project | Embedding Model | # of Vulnerable Functions Found in Top-k (Top-k Precision) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Top 10 | Top 20 | Top 30 | Top 40 | Top 50 | Top 100 | Top 150 | Top 200 | ||
| FFmpeg | ELMo + RF | 9 (90%) | 18 (90%) | 22 (73%) | 26 (65%) | 31 (62%) | 48 (48%) | 56 (37%) | 63 (32%) |
| Word2Vec + RF | 8 (80%) | 14 (70%) | 16 (53%) | 20 (50%) | 21 (42%) | 32 (32%) | 39 (26%) | 49 (25%) | |
| FastText + RF | 8 (80%) | 13 (65%) | 17 (57%) | 19 (48%) | 21 (42%) | 32 (32%) | 43 (29%) | 51 (26%) | |
| GloVe + RF | 7 (70%) | 9 (45%) | 12 (40%) | 15 (38%) | 17 (34%) | 27 (27%) | 37 (25%) | 45 (23%) | |
| BERT + RF | 7 (70%) | 9 (45%) | 11 (37%) | 12 (30%) | 18 (36%) | 27 (27%) | 38 (25%) | 44 (22%) | |
| LibTIFF | ELMo + RF | 8 (80%) | 13 (65%) | 16 (53%) | 20 (50%) | 26 (52%) | 42 (42%) | 48 (32%) | 52 (26%) |
| Word2Vec + RF | 5 (50%) | 9 (45%) | 11 (37%) | 13 (33%) | 16 (32%) | 26 (26%) | 38 (25%) | 48 (24%) | |
| FastText + RF | 8 (80%) | 13 (65%) | 15 (50%) | 18 (45%) | 20 (40%) | 32 (32%) | 41 (27%) | 48 (24%) | |
| GloVe + RF | 7 (70%) | 12 (60%) | 13 (43%) | 17 (43%) | 17 (34%) | 30 (30%) | 42 (28%) | 52 (26%) | |
| BERT + RF | 4 (40%) | 9 (45%) | 12 (40%) | 13 (33%) | 16 (32%) | 30 (30%) | 40 (27%) | 51 (26%) | |
| OpenSSL | ELMo + RF | 9 (90%) | 19 (95%) | 27 (90%) | 33 (83%) | 38 (76%) | 53 (53%) | 60 (40%) | 66 (33%) |
| Word2Vec + RF | 5 (50%) | 9 (45%) | 11 (37%) | 13 (33%) | 16 (32%) | 26 (26%) | 38 (25%) | 48 (24%) | |
| FastText + RF | 8 (80%) | 15 (75%) | 24 (80%) | 27 (68%) | 32 (64%) | 38 (38%) | 50 (33%) | 53 (27%) | |
| GloVe + RF | 8 (80%) | 14 (70%) | 19 (63%) | 25 (63%) | 26 (52%) | 35 (35%) | 39 (26%) | 43 (22%) | |
| BERT + RF | 8 (80%) | 13 (65%) | 17 (57%) | 18 (45%) | 22 (44%) | 35 (35%) | 40 (27%) | 45 (23%) | |
| Software Project | Detection System | # of Vulnerable Functions Found in Top-k (Top-k Precision) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Top 10 | Top 20 | Top 30 | Top 40 | Top 50 | Top 100 | Top 150 | Top 200 | ||
| FFmpeg | Our framework + RF | 9 (90%) | 18 (90%) | 24 (80%) | 31 (78%) | 39 (78%) | 61 (61%) | 65 (43%) | 72 (36%) |
| Our framework + SVM | 9 (90%) | 16 (80%) | 19 (63%) | 23 (58%) | 29 (58%) | 51 (51%) | 61 (41%) | 65 (33%) | |
| Cross-VD [14] | 7 (70%) | 9 (45%) | 14 (47%) | 17 (43%) | 18 (36%) | 30 (30%) | 39 (26%) | 46 (23%) | |
| Multi-VD [27] | 9 (90%) | 14 (70%) | 20 (67%) | 24 (60%) | 28 (56%) | 47 (47%) | 60 (40%) | 70 (35%) | |
| DeepBalance [38] | 9 (90%) | 15 (75%) | 20 (67%) | 26 (65%) | 33 (66%) | 61 (61%) | 63 (42%) | 71 (36%) | |
| Flawfinder | Found 44 vulnerable functions, but not in the Top 200 list | ||||||||
| LibTIFF | Our framework + RF | 7 (70%) | 15 (75%) | 22 (73%) | 25 (63%) | 28 (56%) | 41 (41%) | 50 (33%) | 56 (28%) |
| Our framework + SVM | 8 (80%) | 14 (70%) | 18 (60%) | 21 (53%) | 27 (54%) | 40 (40%) | 50 (33%) | 59 (30%) | |
| Cross-VD [14] | 9 (90%) | 14 (70%) | 18 (60%) | 19 (48%) | 24 (48%) | 34 (34%) | 39 (26%) | 49 (25%) | |
| Multi-VD [27] | 8 (80%) | 12 (60%) | 20 (67%) | 22 (55%) | 26 (52%) | 41 (41%) | 46 (31%) | 53 (27%) | |
| DeepBalance [38] | 8 (80%) | 15 (75%) | 20 (67%) | 21 (53%) | 25 (50%) | 41 (41%) | 45 (30%) | 56 (28%) | |
| Flawfinder | 0 | 0 | 1 (3%) | 2 (5%) | 2 (4%) | 7 (7%) | 12 (8%) | 12 (6%) | |
| OpenSSL | Our framework + RF | 9 (90%) | 19 (95%) | 28 (93%) | 33 (83%) | 40 (80%) | 58 (58%) | 64 (43%) | 68 (34%) |
| Our framework + SVM | 9 (90%) | 19 (95%) | 28 (93%) | 34 (85%) | 41 (82%) | 57 (57%) | 63 (42%) | 66 (33%) | |
| Cross-VD [14] | 9 (90%) | 19 (95%) | 28 (93%) | 31 (78%) | 32 (64%) | 43 (43%) | 56 (37%) | 61 (31%) | |
| Multi-VD [27] | 8 (80%) | 19 (95%) | 28 (93%) | 30 (75%) | 39 (78%) | 56 (56%) | 63 (42%) | 65 (33%) | |
| DeepBalance [38] | 8 (80%) | 19 (95%) | 29 (97%) | 33 (83%) | 41 (82%) | 57 (57%) | 63 (42%) | 67 (34%) | |
| Flawfinder | 0 | 0 | 0 | 0 | 5 (10%) | 55 (55%) | 56 (37%) | 56 (28%) | |
| Software Project | Our Framework | The Number and the Proportion of Buffer Errors Vulnerabilities in the Total Found Vulnerabilities in Top-k | The Number and the Proportion of Buffer Errors Vulnerabilities Accounted for All Vulnerabilities in the Test Set | ||||
|---|---|---|---|---|---|---|---|
| Top 10 | Top 20 | Top 30 | Top 40 | Top 50 | |||
| FFmpeg | with RF | 4 (44%) | 10 (56%) | 12 (50%) | 15 (48%) | 17 (44%) | 47 (33%) |
| with SVM | 4 (44%) | 9 (56%) | 10 (53%) | 12 (52%) | 13 (45%) | ||
| LibTIFF | with RF | 6 (86%) | 10 (67%) | 16 (73%) | 18 (72%) | 19 (68%) | 43 (67%) |
| with SVM | 6 (75%) | 10 (71%) | 14 (78%) | 17 (21%) | 19 (70%) | ||
| OpenSSL | with RF | 2 (22%) | 5 (26%) | 6 (21%) | 8 (24%) | 9 (23%) | 17 (18%) |
| with SVM | 2 (22%) | 5 (26%) | 6 (21%) | 8 (24%) | 9 (22%) | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, H.; Lin, G.; Li, L.; Jia, H. A Context-Aware Neural Embedding for Function-Level Vulnerability Detection. Algorithms 2021, 14, 335. https://doi.org/10.3390/a14110335
Wei H, Lin G, Li L, Jia H. A Context-Aware Neural Embedding for Function-Level Vulnerability Detection. Algorithms. 2021; 14(11):335. https://doi.org/10.3390/a14110335
Chicago/Turabian StyleWei, Hongwei, Guanjun Lin, Lin Li, and Heming Jia. 2021. "A Context-Aware Neural Embedding for Function-Level Vulnerability Detection" Algorithms 14, no. 11: 335. https://doi.org/10.3390/a14110335
APA StyleWei, H., Lin, G., Li, L., & Jia, H. (2021). A Context-Aware Neural Embedding for Function-Level Vulnerability Detection. Algorithms, 14(11), 335. https://doi.org/10.3390/a14110335