
Detection of Representative Variables in Complex Systems with Interpretable Rules Using Core-Clusters

 , and
, and 
Abstract
:1. Introduction
2. Statistical Methodology
2.1. Graph-Based Representation of the Observations
2.2. Coherence of a Variable Set
2.3. CORE-Clusters
2.4. CORE-Clustering
- All are connected variable sets having a size higher than τ and a coherence . They therefore correspond to CORE-clusters and can be denoted .
- There is no overlap between the clusters, i.e., for all .
2.5. Representative Variables Selection
2.6. General Guidelines for the Choice of and
3. Computational Methodology
3.1. Main Interactions Estimation
3.2. CORE-Clustering Algorithms
3.2.1. Maximum Spanning Tree
| Algorithm 1 Maximum spanning tree algorithm |
| Require: Graph with nodes , and edges , . Require: Weight of edge is .
|
3.2.2. CORE-Clustering Algorithm
| Algorithm 2 CORE-clustering algorithm |
| Require: Graph with nodes , ; and edges , . Require: Weight of edge is . Require: Granularity coefficient and threshold .
|
3.2.3. A Greedy Alternative for CORE-Clusters Detection
| Algorithm 3 Greedy CORE-clustering algorithm |
| Require: Graph with nodes , and edges , . Require: Weight of edge is . Require: Granularity coefficient and threshold .
|
3.3. Central Variables Selection in CORE-Clusters
4. Results
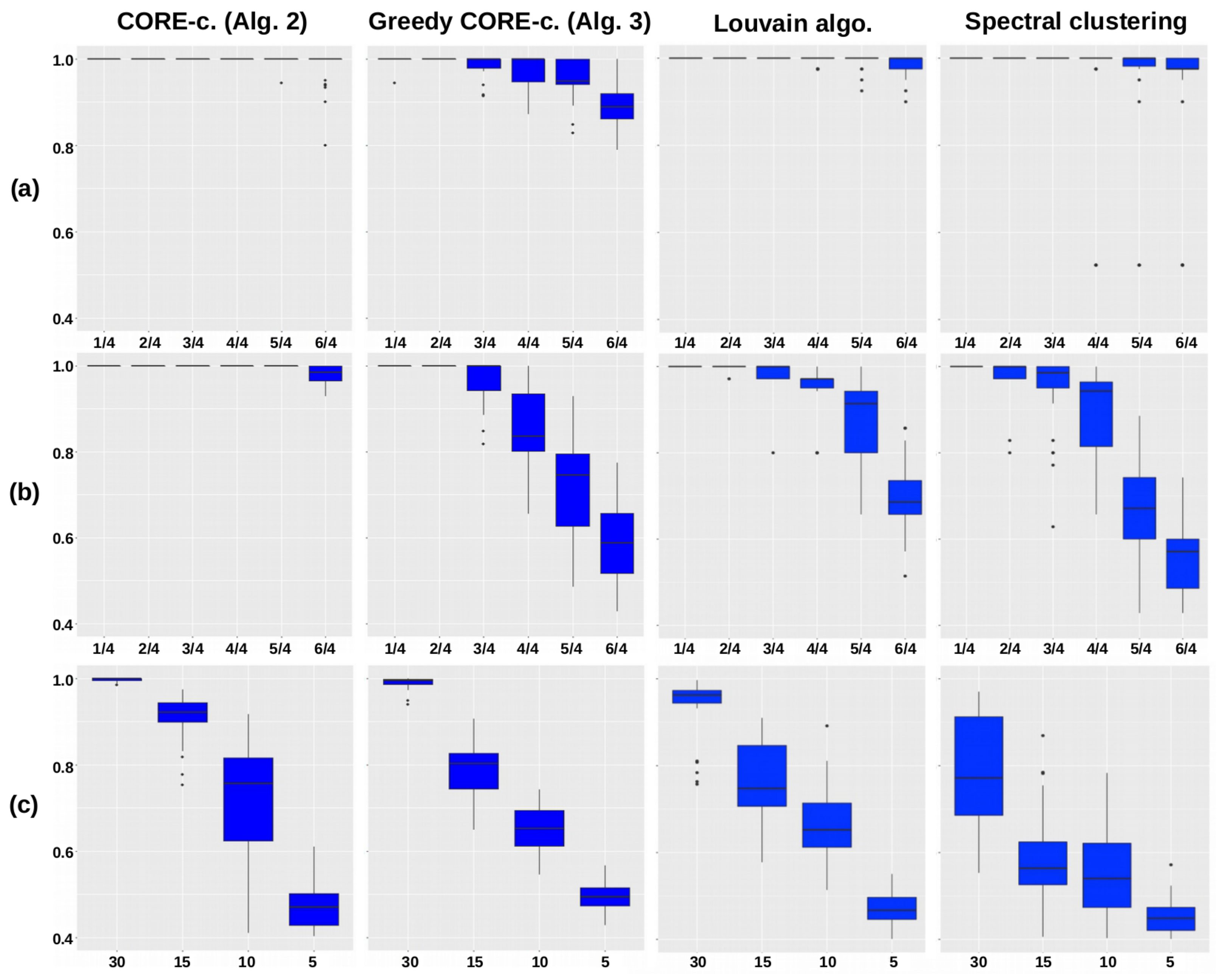
4.1. Core Clustering of Simulated Networks
4.1.1. Experimental Protocol
4.1.2. Measure of Clustering Quality
4.1.3. Results
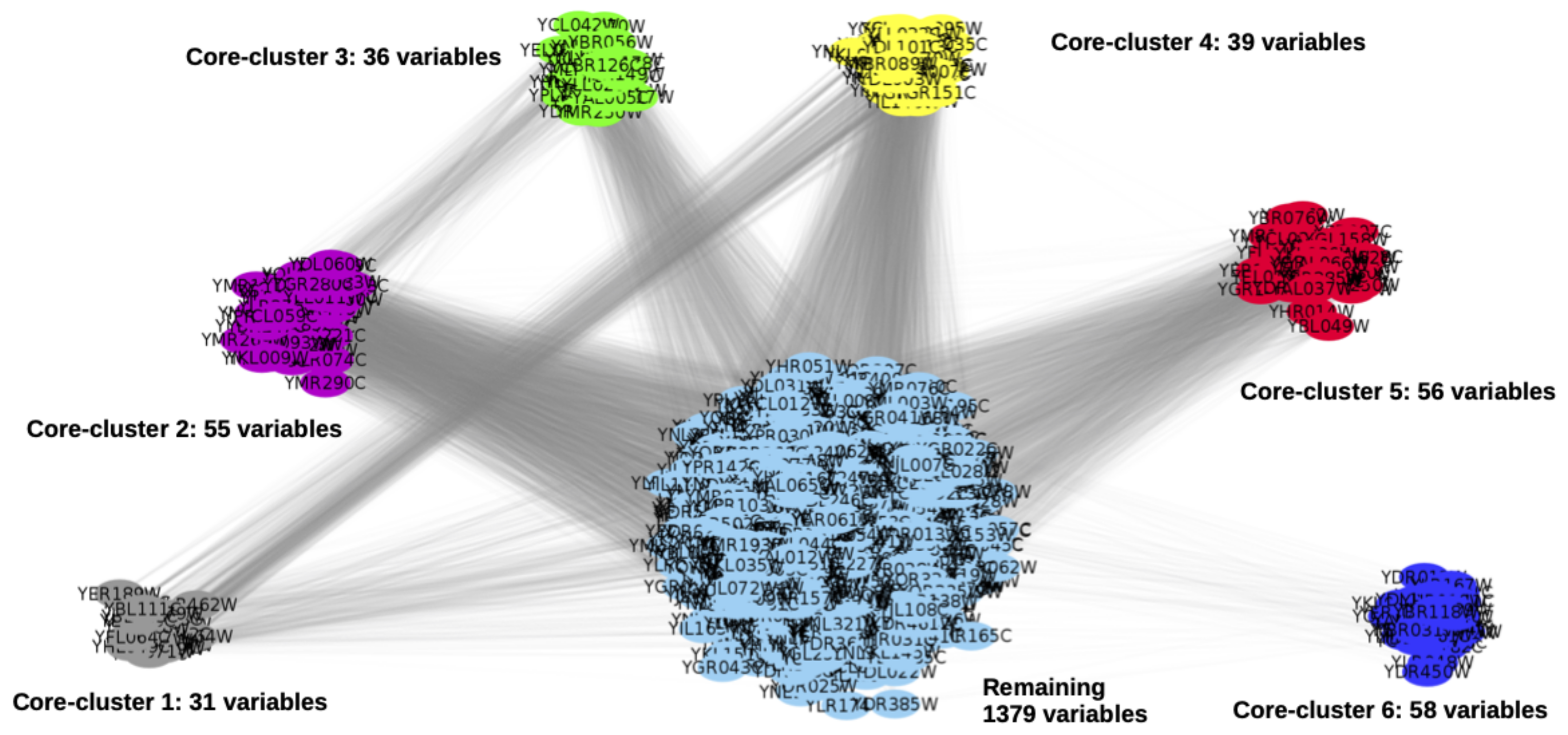
4.2. Application to Real Biological Data
4.2.1. Yeast Dataset
4.2.2. Comparison of the Two CORE-Clustering Algorithms
4.2.3. Impact of the Number of Observations
4.2.4. Comparison with Spectral-Clustering
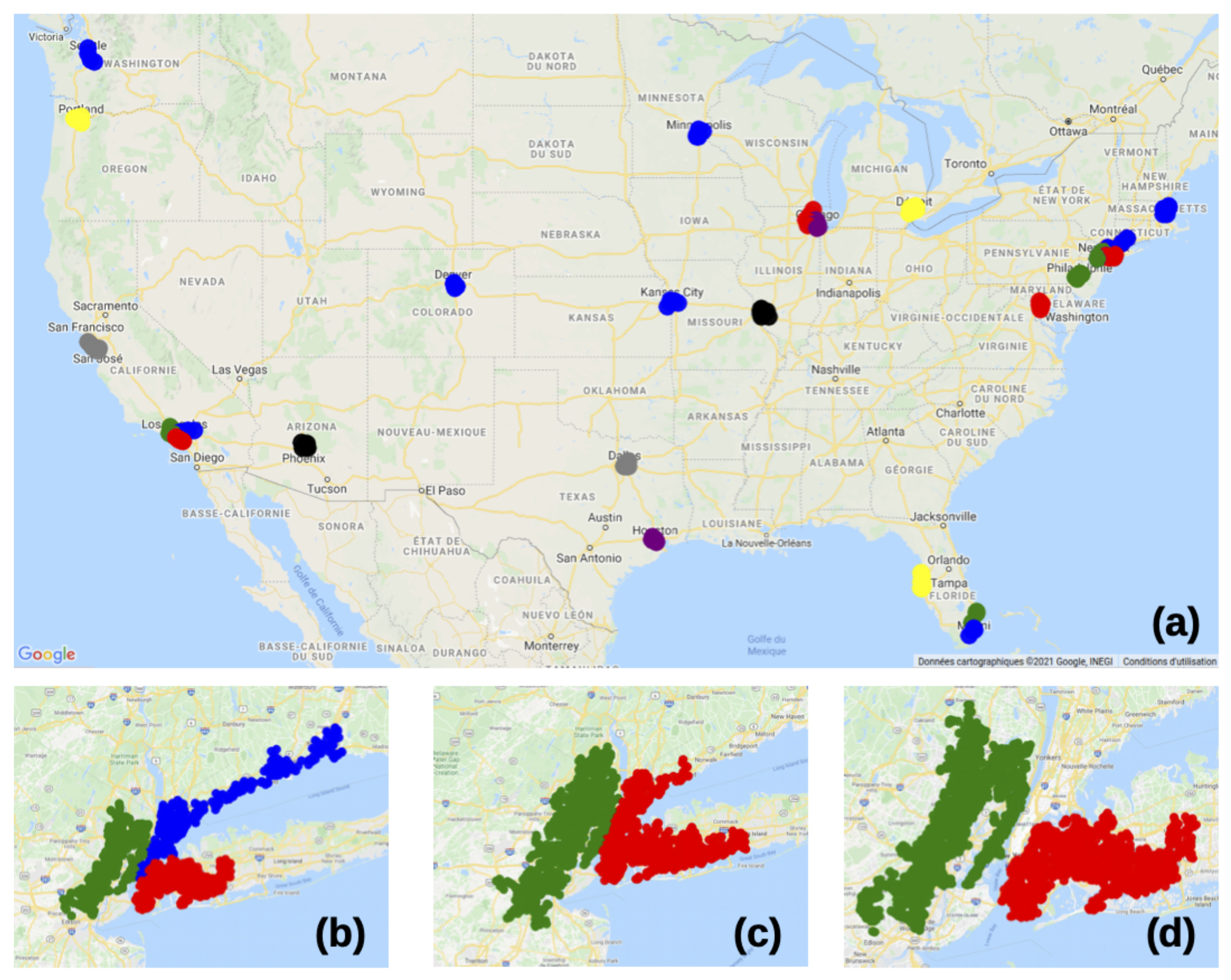
4.3. Application to the U.S. Road Network
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
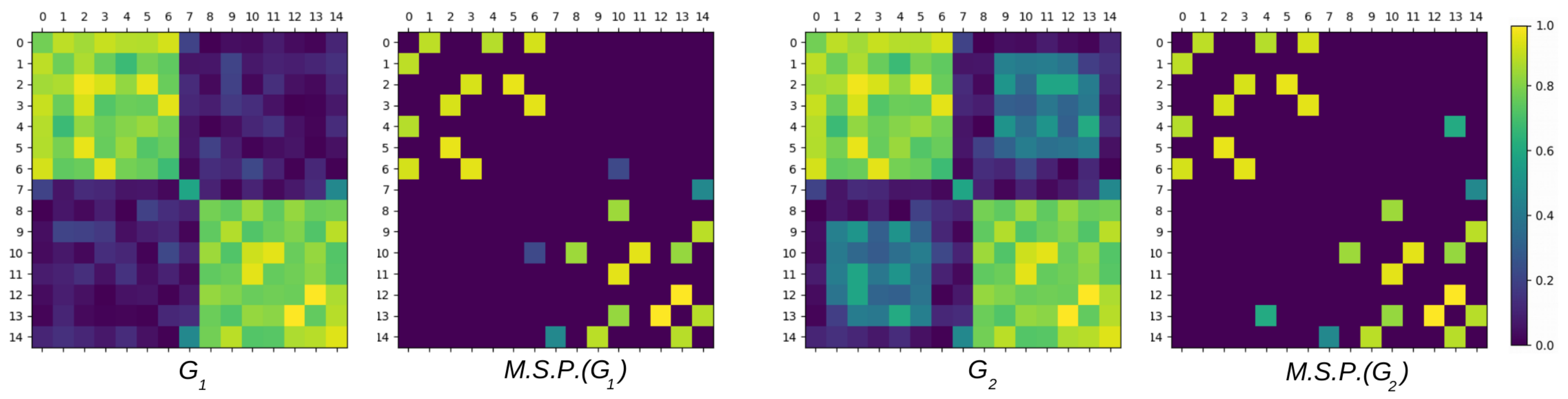
Appendix A. Pertinence of the Representative Variable Detection Model

Appendix A.1. Illustration of the Coherence

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.77 | 0.85 | 0.77 | 0.77 | 0.18 | 0.25 | 0.15 | 0.19 | |
| 0.77 | 0.85 | 0.77 | 0.77 | 0.18 | 0.25 | 0.40 | 0.47 |
| 4 | 11 | 3 | 11 | 5 | 11 | 6 | 11 | |
| 4 | 11 | 3 | 11 | 5 | 11 | 3 | 11 |
Appendix A.2. Influence of the Undesirable Relations
| Test 1 | Test 2 | Test 3 | Test 4 | |||||
|---|---|---|---|---|---|---|---|---|
| 1. (0.88) | 1. (0.82) | 1. (0.79) | 1. (0.80) | 1. (0.40) | 1. (0.75) | 1. (0.59) | 1. (0.79) | |
| 1. (0.87) | 1. (0.79) | 1. (0.78) | 1. (0.83) | 1. (0.46) | 1. (0.80) | 1. (0.75) | 1. (0.84) | |
| 1. (0.88) | 1. (0.79) | 1. (0.78) | 1. (0.84) | 1. (0.44) | 1. (0.74) | 1. (0.88) | 1. (0.78) | |
| 1. (0.92) | 1. (0.72) | 1. (0.75) | 1. (0.69) | 1. (0.47) | 1. (0.62) | 1. (0.93) | 0.96 (0.71) | |
| 1. (0.92) | 1. (0.59) | 1. (0.70) | 1. (0.48) | 1. (0.49) | 1. (0.44) | 1. (0.93) | 0.89 (0.59) | |
References
- Liu, Z.; Barahona, M. Graph-based data clustering via multiscale community detection. Appl. Netw. Sci. 2020, 5, 3. [Google Scholar] [CrossRef] [Green Version]
- Boccaletti, S.; Latora, V.; Moreno, Y.; Chavez, M.; Hwang, D.U. Complex networks: Structure and dynamics. Phys. Rep. 2006, 424, 175–308. [Google Scholar] [CrossRef]
- Newman, M. Networks: An Introduction; Oxford University Press: Oxford, UK, 2009. [Google Scholar]
- MacQueen, J.B. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Seidman, S.B. Network structure and minimum degree. Soc. Netw. 1983, 5, 269–287. [Google Scholar] [CrossRef]
- Giatsidis, C.; Malliaros, F.D.; Thilikos, D.M.; Vazirgiannis, M. CORECLUSTER: A degeneracy based graph clustering framework. In Proceeding of the Twenty-Eight AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Batagelj, V.; Zaversnik, M. Fast algorithms for determining (generalized) core groups in social networks. Adv. Data Anal. Classif. 2011, 5, 129–145. [Google Scholar] [CrossRef]
- Agarwal, P.K.; Har-Peled, S.; Varadarajan, K.R. Geometric approximation via coresets. In Combinatorial and Computational Geometry; MSRI University Press: Berkeley, CA, USA, 2005; pp. 1–30. [Google Scholar]
- Claici, S.; Genevay, A.; Solomon, J. Wasserstein Measure Coresets. arXiv 2020, arXiv:1805.07412. [Google Scholar]
- Baharan, M.; Kaidi, C.; Jure, L. Coresets for robust training of deep neural networks against noisy labels. In In Proceedings of the Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Baykal, C.; Liebenwein, L.; Gilitschenski, I.; Feldman, D.; Rus, D. Data-dependent coresets for compressing neural networks with applications to generalization bounds. arXiv 2018, arXiv:1804.05345. [Google Scholar]
- Bachem, O.; Lucic, M.; Lattanzi, S. One-shot coresets:The case of k-clustering. In Proceeding of the International Conference on Artificial Intelligence and Statistics (AISTATS), Playa Blanca, Spain, 9–11 April 2018; pp. 784–792. [Google Scholar]
- Saeys, Y.; Inza, I.; Larranaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Z.; Morstatter, F.; Sharma, S.; Alelyani, S.; Anand, A.; Liu, H. Advancing Feature Selection Research. in ASU Feature Selection Repository. 2010, pp. 1–28. Available online: http://www.public.asu.edu/huanliu/papers/tr-10-007.pdf (accessed on 14 January 2021).
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. ACM Comput. Surv. 2018, 50, 94:1–94:45. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.; Ioannidis, S.; Szaier, M.; Li, X.; Kaeli, D.; Dy, J. Iterative Spectral Method for Alternative Clustering. Proc. Mach. Learn. Res. 2018, 84, 115–123. [Google Scholar]
- Chen, J.; Chang, Y.; Castaldi, P.; Cho, M.; Hobbs, B.; Dy, J. Crowdclustering with Partitions Labels. Proc. Mach. Learn. Res. 2018, 84, 1127–1136. [Google Scholar]
- Yu, L.; Liu, H. Feature Selection for High-Dimensional Data: A Fast Correlation-Based Filter Solution. In Proceedings of the International Conference on Machine Learning (ICML-2003), Washington, DC, USA, 21–24 August 2003; pp. 856–863. [Google Scholar]
- Brunet, A.C.; Loubes, J.M.; Azais, J.M.; Courtney, M. Method of Identification of a Relationship between Biological Elements. WO Patent App. PCT/EP2015/060,779, 3 December 2015. [Google Scholar]
- Brunet, A.C.; Azais, J.M.; Loubes, J.M.; Amar, J.; Burcelin, R. A new gene co-expression network analysis based on Core Structure Detection (CSD). arXiv 2016, arXiv:1607.01516. [Google Scholar]
- Pollack, M. The Maximum Capacity through a Network. Oper. Res. 1960, 8, 733–736. [Google Scholar] [CrossRef]
- Hu, T.C. The Maximum Capacity Route Problem. Oper. Res. 1961, 9, 898–900. [Google Scholar] [CrossRef] [Green Version]
- Randall, K.H. Cilk: Efficient Multithreaded Computing. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1998. [Google Scholar]
- Cysouw, M. R Function Cor.Sparse. 2018. Available online: https://www.rdocumentation.org/packages/qlcMatrix/versions/0.9.2/topics/cor.sparse (accessed on 2 February 2018).
- Kruskal, J.B. On the Shortest Spanning Subtree of a Graph and the Traveling Salesman Problem. Proc. Am. Math. Soc. 1956, 7, 48–50. [Google Scholar] [CrossRef]
- Tarjan, R. Depth first search and linear graph algorithms. SIAM J. Comput. 1972, 1, 146–160. [Google Scholar] [CrossRef]
- Steele, J.M. Minimal spanning trees for graphs with random edge lengths. In Mathematics and Computer Science II; Springer: Berlin/Heidelberg, Germany, 2002; pp. 223–245. [Google Scholar]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Zan, B.F.; Noon, C.E. Shortest Path Algorithms: An Evaluation Using Real Road Networks. Transp. Sci. 1998, 32, 65–73. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2002), Vancouver, BC, Canada, 9–14 December 2002; pp. 849–856. [Google Scholar]
- Blondel, V.; Guillaume, J.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 10008. [Google Scholar] [CrossRef] [Green Version]
- Spellman, P.T.; Sherlock, G.; Zhang, M.Q.; Vishwanath, I.R.; Anders, K.; Eisen, M.B.; Brown, P.O.; Botstein, D.; Futcher, B. Comprehensive Identification of Cell-Cycle-regulated Genes of Yeast Saccharomyces cerevisiae by Microarray Hybridization. Mol. Biol. Cell 1998, 9, 3273–3297. [Google Scholar] [CrossRef] [PubMed]
- Gadat, S.; Gavra, I.; Risser, L. How to calculate the barycenter of a weighted graph. Informs 2018, 43. [Google Scholar] [CrossRef] [Green Version]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Champion, C.; Brunet, A.-C.; Burcelin, R.; Loubes, J.-M.; Risser, L. Detection of Representative Variables in Complex Systems with Interpretable Rules Using Core-Clusters. Algorithms 2021, 14, 66. https://doi.org/10.3390/a14020066
Champion C, Brunet A-C, Burcelin R, Loubes J-M, Risser L. Detection of Representative Variables in Complex Systems with Interpretable Rules Using Core-Clusters. Algorithms. 2021; 14(2):66. https://doi.org/10.3390/a14020066
Chicago/Turabian StyleChampion, Camille, Anne-Claire Brunet, Rémy Burcelin, Jean-Michel Loubes, and Laurent Risser. 2021. "Detection of Representative Variables in Complex Systems with Interpretable Rules Using Core-Clusters" Algorithms 14, no. 2: 66. https://doi.org/10.3390/a14020066
APA StyleChampion, C., Brunet, A. -C., Burcelin, R., Loubes, J. -M., & Risser, L. (2021). Detection of Representative Variables in Complex Systems with Interpretable Rules Using Core-Clusters. Algorithms, 14(2), 66. https://doi.org/10.3390/a14020066