
Feature and Language Selection in Temporal Symbolic Regression for Interpretable Air Quality Modelling



Abstract
:1. Introduction
2. Background
2.1. Functional Temporal Regression
2.2. Symbolic Temporal Regression
2.3. Feature Selection for Regression
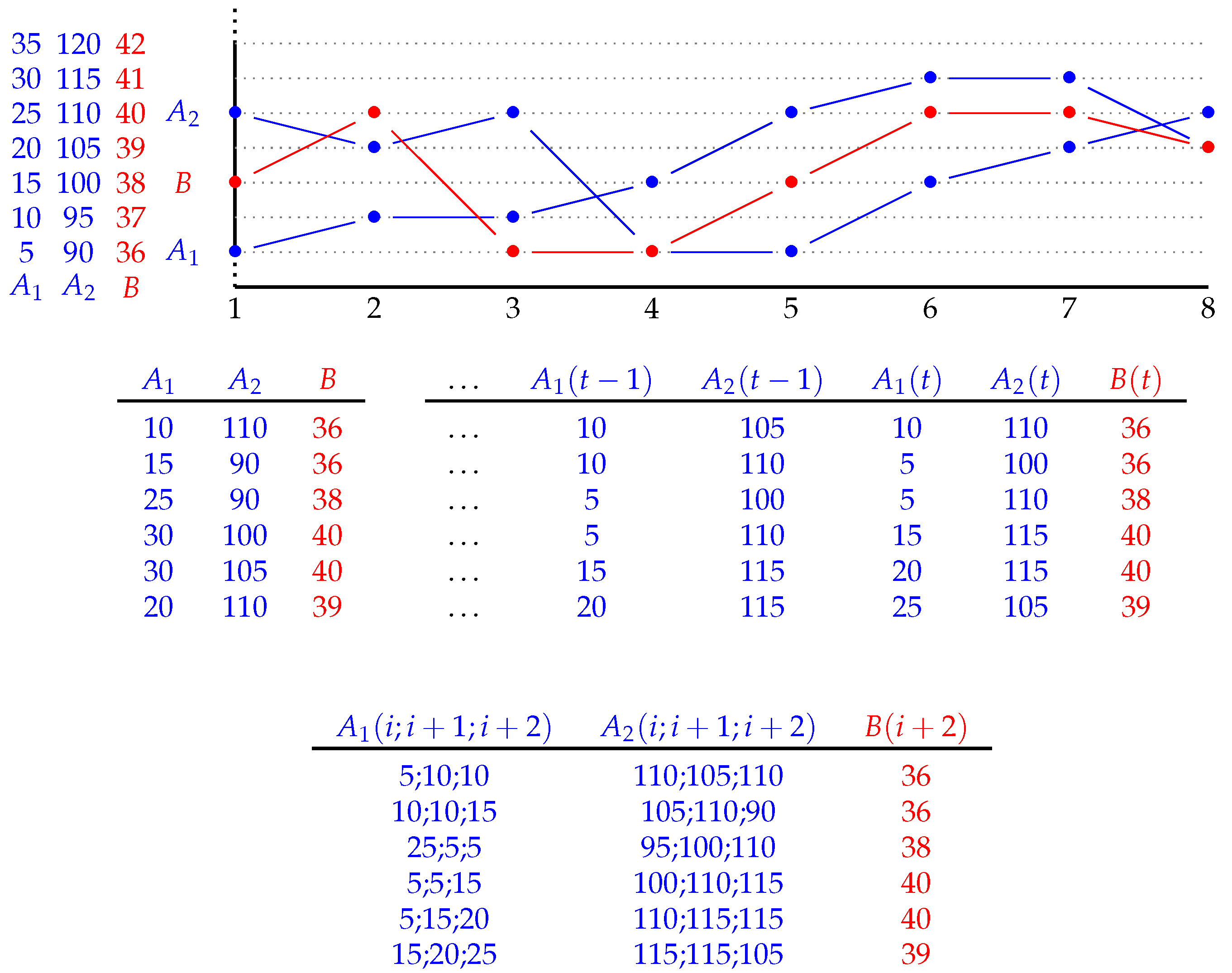
3. Symbolic Temporal Regression
4. Multi-Objective Evolutionary Optimization
5. Data and Experiments
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Holnicki, P.; Tainio, M.; Kałuszko, A.; Nahorski, Z. Burden of mortality and disease attributable to multiple air pollutants in Warsaw, Poland. Int. J. Environ. Res. Public Health 2017, 14, 1359. [Google Scholar] [CrossRef] [Green Version]
- Schwartz, J. Lung function and chronic exposure to air pollution: A cross-sectional analysis of NHANES II. Environ. Res. 1989, 50, 309–321. [Google Scholar] [CrossRef]
- Peng, R.D.; Dominici, F.; Louis, T.A. Model choice in time series studies of air pollution and mortality. J. R. Stat. Soc. Ser. A Stat. Soc. 2006, 169, 179–203. [Google Scholar] [CrossRef] [Green Version]
- Mar, T.; Norris, G.; Koenig, J.; Larson, T. Associations between air pollution and mortality in Phoenix, 1995–1997. Environ. Health Perspect. 2000, 108, 347–353. [Google Scholar] [CrossRef] [PubMed]
- Knibbs, L.; Cortés, A.; Toelle, B.; Guo, Y.; Denison, L.; Jalaludin, B.; Marks, G.; Williams, G. The Australian Child Health and Air Pollution Study (ACHAPS): A national population-based cross-sectional study of long-term exposure to outdoor air pollution, asthma, and lung function. Environ. Int. 2018, 120, 394–403. [Google Scholar] [CrossRef]
- Cifuentes, L.; Vega, J.; Köpfer, K.; Lave, L. Effect of the fine fraction of particulate matter versus the coarse mass and other pollutants on daily mortality in Santiago, Chile. J. Air Waste Manag. Assoc. 2000, 50, 1287–1298. [Google Scholar] [CrossRef]
- Chianese, E.; Camastra, F.; Ciaramella, A.; Landi, T.C.; Staiano, A.; Riccio, A. Spatio-temporal learning in predicting ambient particulate matter concentration by multi-layer perceptron. Ecol. Inform. 2019, 49, 54–61. [Google Scholar] [CrossRef]
- Nieto, P.G.; Lasheras, F.S.; García-Gonzalo, E.; de Cos Juez, F. PM10 concentration forecasting in the metropolitan area of Oviedo (Northern Spain) using models based on SVM, MLP, VARMA and ARIMA: A case study. Sci. Total Environ. 2018, 621, 753–761. [Google Scholar] [CrossRef] [PubMed]
- Gilbert, N.; Goldberg, M.; Beckerman, B.; Brook, J.; Jerrett, M. Assessing spatial variability of ambient nitrogen dioxide in Montreal, Canada, with a land-use regression model. J. Air Waste Manag. Assoc. 2005, 55, 1059–1063. [Google Scholar] [CrossRef] [Green Version]
- Henderson, S.; Beckerman, B.; Jerrett, M.; Brauer, M. Application of land use regression to estimate long-term concentrations of traffic-related nitrogen oxides and fine particulate matter. Environ. Sci. Technol. 2007, 41, 2422–2428. [Google Scholar] [CrossRef]
- Hoek, G.; Beelen, R.; Hoogh, K.D.; Vienneau, D.; Gulliver, J.; Fischer, P.; Briggs, D. A review of land-use regression models to assess spatial variation of outdoor air pollution. Atmos. Environ. 2008, 42, 7561–7578. [Google Scholar] [CrossRef]
- Lucena-Sánchez, E.; Jiménez, F.; Sciavicco, G.; Kaminska, J. Simple Versus Composed Temporal Lag Regression with Feature Selection, with an Application to Air Quality Modeling. In Proceedings of the Conference on Evolving and Adaptive Intelligent Systems, Bari, Italy, 27–29 May 2020; pp. 1–8. [Google Scholar]
- Kaminska, J. A random forest partition model for predicting NO2 concentrations from traffic flow and meteorological conditions. Sci. Total Environ. 2015, 651, 475–483. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Chapman and Hall/CRC: Wadsworth, OH, USA, 1984. [Google Scholar]
- Clark, P.; Niblett, T. The CN2 Induction Algorithm. Mach. Learn. 1989, 3, 261–283. [Google Scholar] [CrossRef]
- Sciavicco, G.; Stan, I. Knowledge Extraction with Interval Temporal Logic Decision Trees. In Proceedings of the 27th International Symposium on Temporal Representation and Reasoning, Bozen-Bolzano, Italy, 23–25 September 2020; Volume 178, pp. 9:1–9:16. [Google Scholar]
- Lucena-Sánchez, E.; Sciavicco, G.; Stan, I. Symbolic Learning with Interval Temporal Logic: The Case of Regression. In Proceedings of the 2nd Workshop on Artificial Intelligence and Formal Verification, Logic, Automata, and Synthesis , Bozen-Bolzano, Italy, 25 September 2020; Volume 2785, pp. 5–9. [Google Scholar]
- Halpern, J.Y.; Shoham, Y. A Propositional Modal Logic of Time Intervals. J. ACM 1991, 38, 935–962. [Google Scholar] [CrossRef]
- Allen, J.F. Maintaining Knowledge about Temporal Intervals. Commun. ACM 1983, 26, 832–843. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann: Burlington, MA, USA, 2017. [Google Scholar]
- John, G. Robust Decision Trees: Removing Outliers from Databases. In Proceedings of the 1st International Conference on Knowledge Discovery and Data Mining, Montreal, QC, Canada, 20–21 August 1995; pp. 174–179. [Google Scholar]
- Maronna, R.; Martin, D.; Yohai, V. Robust Statistics: Theory and Methods; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Box, G.; Jenkins, G.; Reinsel, G.; Ljung, G. Time Series Analysis: Forecasting and Control; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Siedlecki, W.; Sklansky, J. A note on genetic algorithms for large-scale feature selection. In Handbook of Pattern Recognition and Computer Vision; World Scientific: Singapore, 1993; pp. 88–107. [Google Scholar]
- Vafaie, H.; Jong, K.D. Genetic algorithms as a tool for feature selection in machine learning. In Proceedings of the 4th Conference on Tools with Artificial Intelligence, Arlington, VA, USA, 10–13 November 1992; pp. 200–203. [Google Scholar]
- ElAlamil, M. A filter model for feature subset selection based on genetic algorithm. Knowl. Based Syst. 2009, 22, 356–362. [Google Scholar] [CrossRef]
- Anirudha, R.; Kannan, R.; Patil, N. Genetic algorithm based wrapper feature selection on hybrid prediction model for analysis of high dimensional data. In Proceedings of the 9th International Conference on Industrial and Information Systems, Gwalior, India, 15–17 December 2014; pp. 1–6. [Google Scholar]
- Huang, J.; Cai, Y.; Xu, X. A hybrid genetic algorithm for feature selection wrapper based on mutual information. Pattern Recognit. Lett. 2007, 28, 1825–1844. [Google Scholar] [CrossRef]
- Yang, J.; Honavar, V. Feature subset selection using a genetic algorithm. IEEE Intell. Syst. Their Appl. 1998, 13, 44–49. [Google Scholar] [CrossRef] [Green Version]
- Jiménez, F.; Sánchez, G.; García, J.; Sciavicco, G.; Miralles, L. Multi-objective evolutionary feature selection for online sales forecasting. Neurocomputing 2017, 234, 75–92. [Google Scholar] [CrossRef]
- Mukhopadhyay, A.; Maulik, U.; Bandyopadhyay, S.; Coello, C.C. A survey of multiobjective evolutionary algorithms for data mining: Part I. IEEE Trans. Evol. Comput. 2014, 18, 4–19. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H. Feature Selection for Classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Nakashima, T. Multi-objective pattern and feature selection by a genetic algorithm. In Proceedings of the Genetic and Evolutionary Computation Conference, Las Vegas, NV, USA, 8–12 July 2000; pp. 1069–1076. [Google Scholar]
- Emmanouilidis, C.; Hunter, A.; Macintyre, J.; Cox, C. A multi-objective genetic algorithm approach to feature selection in neural and fuzzy modeling. Evol. Optim. 2001, 3, 1–26. [Google Scholar]
- Liu, J.; Iba, H. Selecting informative genes using a multiobjective evolutionary algorithm. In Proceedings of the Congress on Evolutionary Computation, Honolulu, HI, USA, 12–17 May 2002; pp. 297–302. [Google Scholar]
- Pappa, G.L.; Freitas, A.A.; Kaestner, C. Attribute selection with a multi-objective genetic algorithm. In Proceedings of the 16th Brazilian Symposium on Artificial Intelligence, Porto de Galinhas/Recife, Brazil, 11–14 November 2002; pp. 280–290. [Google Scholar]
- Shi, S.; Suganthan, P.; Deb, K. Multiclass protein fold recognition using multiobjective evolutionary algorithms. In Proceedings of the Symposium on Computational Intelligence in Bioinformatics and Computational Biology, La Jolla, CA, USA, 7–8 October 2004; pp. 61–66. [Google Scholar]
- Collette, Y.; Siarry, P. Multiobjective Optimization: Principles and Case Studies; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Deb, K. Multi-Objective Optimization Using Evolutionary Algorithms; Wiley: London, UK, 2001. [Google Scholar]
- Durillo, J.; Nebro, A. JMetal: A Java Framework for Multi-Objective Optimization. Av. Eng. Softw. 2011, 42, 760–771. [Google Scholar] [CrossRef]
- Johnson, R.A.; Bhattacharyya, G.K. Statistics: Principles and Methods, 8th ed.; Wiley: Hoboken, NJ, USA, 2019. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the IEEE 5th International Conference on Data Science and Advanced Analytics, Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]



{kind=link}
{kind=link}
| HS Modality | Definition w.r.t. the Interval Structure | Example | ||
|---|---|---|---|---|
| (after) | ⇔ |  | ||
| (later) | ⇔ | |||
| (begins) | ⇔ | |||
| (ends) | ⇔ | |||
| (during) | ⇔ | |||
| (overlaps) | ⇔ | |||
| Variable | Unit | Mean | St.Dev. | Min | Median | Max |
|---|---|---|---|---|---|---|
| Air temperature | °C | 10.9 | 8.4 | −15.7 | 10.1 | 37.7 |
| Solar duration | h | 0.23 | 0.38 | 0 | 0 | 1 |
| Wind speed | ms | 3.13 | 1.95 | 0 | 3.00 | 19 |
| % relative humidity | − | 74.9 | 17.3 | 20 | 79.0 | 100 |
| Air pressure | hPa | 1003 | 8.5 | 906 | 1003 | 1028 |
| Traffic | − | 2771 | 1795.0 | 30 | 3178 | 6713 |
| NO | μgm | 50.4 | 23.2 | 1.7 | 49.4 | 231.6 |
| Month | cc | mae | rmse | rae (%) |
| Jan | 0.75 | 10.47 | 13.38 | 63.61 |
| Feb | 0.73 | 10.67 | 12.86 | 67.86 |
| Mar | 0.65 | 12.66 | 16.04 | 73.62 |
| Apr | 0.68 | 12.05 | 14.62 | 75.87 |
| May | 0.71 | 10.00 | 13.63 | 61.86 |
| Jun | 0.61 | 12.57 | 15.34 | 79.93 |
| Jul | 0.59 | 11.90 | 15.09 | 79.35 |
| Aug | 0.69 | 13.62 | 17.07 | 70.74 |
| Sep | 0.72 | 11.47 | 15.21 | 64.24 |
| Oct | 0.83 | 8.84 | 11.11 | 52.95 |
| Nov | 0.76 | 8.58 | 11.25 | 61.18 |
| Dec | 0.77 | 9.32 | 12.05 | 57.15 |
| average | 0.71 | 11.01 | 12.84 | 67.36 |
| Month | cc | mae | rmse | rae (%) |
| Jan | 0.77 | 9.35 | 13.21 | 56.84 |
| Feb | 0.75 | 9.89 | 12.92 | 62.91 |
| Mar | 0.67 | 12.71 | 16.59 | 73.90 |
| Apr | 0.76 | 9.86 | 13.41 | 62.09 |
| May | 0.71 | 10.34 | 13.99 | 63.97 |
| Jun | 0.70 | 11.24 | 14.58 | 71.45 |
| Jul | 0.67 | 11.21 | 14.87 | 74.74 |
| Aug | 0.76 | 11.87 | 15.96 | 61.63 |
| Sep | 0.60 | 12.88 | 18.82 | 72.13 |
| Oct | 0.76 | 9.74 | 13.35 | 58.37 |
| Nov | 0.74 | 8.91 | 11.93 | 63.58 |
| Dec | 0.75 | 9.55 | 12.93 | 58.55 |
| average | 0.72 | 9.85 | 13.28 | 60.28 |
| Month | cc | mae | rmse | rae (%) |
| Jan | 0.80 | 9.79 | 12.21 | 59.51 |
| Feb | 0.83 | 8.35 | 10.58 | 53.16 |
| Mar | 0.81 | 9.45 | 12.66 | 54.94 |
| Apr | 0.71 | 11.43 | 14.30 | 71.95 |
| May | 0.73 | 10.67 | 13.86 | 66.02 |
| Jun | 0.72 | 10.61 | 13.63 | 67.41 |
| Jul | 0.75 | 9.94 | 12.57 | 66.29 |
| Aug | 0.77 | 12.80 | 15.45 | 66.44 |
| Sep | 0.78 | 11.31 | 14.56 | 63.34 |
| Oct | 0.82 | 9.00 | 11.58 | 53.96 |
| Nov | 0.80 | 8.22 | 10.60 | 58.61 |
| Dec | 0.84 | 8.08 | 10.42 | 49.51 |
| average | 0.78 | 9.09 | 12.70 | 60.93 |
| Month | cc | mae | rmse | rae (%) |
| Jan | 0.75 | 9.59 | 13.75 | 58.31 |
| Feb | 0.84 | 7.93 | 10.41 | 50.43 |
| Mar | 0.78 | 10.26 | 13.42 | 59.65 |
| Apr | 0.71 | 10.29 | 14.45 | 64.75 |
| May | 0.77 | 9.36 | 12.65 | 57.91 |
| Jun | 0.70 | 11.08 | 14.59 | 70.45 |
| Jul | 0.65 | 10.96 | 15.21 | 73.09 |
| Aug | 0.75 | 12.10 | 16.19 | 62.84 |
| Sep | 0.78 | 10.09 | 14.01 | 56.49 |
| Oct | 0.75 | 10.12 | 13.98 | 60.67 |
| Nov | 0.79 | 7.83 | 10.74 | 55.85 |
| Dec | 0.87 | 7.11 | 9.54 | 43.61 |
| average | 0.76 | 8.87 | 13.24 | 54.11 |
| Variable | Lag | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Air temperature | −0.77 | −0.50 | 0.00 | −1.14 | 0.00 | 0.00 | 0.00 | 0.93 | 0.00 | 0.00 |
| Sol.duration | 0.00 | 0.00 | 0.00 | 7.36 | 0.00 | 7.26 | 0.00 | 0.00 | 0.00 | 0.00 |
| Wind speed | −2.006 | −2.50 | −1.85 | 7.36 | 0.00 | −1.14 | 0.00 | 0.00 | 0.00 | −1.08 |
| Rel.humidity | −0.29 | −0.19 | −0.23 | −0.22 | 0.00 | 0.00 | 0.29 | 0.00 | 0.21 | 0.00 |
| Air pressure | 0.00 | 1.97 | −2.25 | 0.00 | 0.00 | −2.47 | 0.71 | 0.48 | −1.21 | 1.59 |
| Traffic | −0.82 | −0.22 | 0.43 | −0.32 | 0.45 | −0.28 | 0.00 | 0.00 | 0.00 | 0.00 |
| Month | cc | mae | rmse | rae (%) | Language |
|---|---|---|---|---|---|
| Jan | 0.87 | 7.73 | 10.54 | 46.91 | |
| Feb | 0.86 | 7.39 | 9.70 | 47.65 | |
| Mar | 0.79 | 10.73 | 13.93 | 63.41 | |
| Apr | 0.85 | 7.77 | 10.86 | 48.57 | |
| May | 0.84 | 7.87 | 10.53 | 50.52 | |
| Jun | 0.82 | 9.07 | 11.60 | 58.00 | |
| Jul | 0.78 | 10.00 | 12.87 | 65.62 | |
| Aug | 0.83 | 10.82 | 13.90 | 55.97 | |
| Sep | 0.81 | 9.50 | 13.17 | 53.77 | |
| Oct | 0.81 | 9.31 | 12.42 | 55.58 | |
| Nov | 0.80 | 8.34 | 11.04 | 61.27 | |
| Dec | 0.85 | 7.31 | 10.47 | 45.10 | |
| average | 0.83 | 8.82 | 11.75 | 54.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lucena-Sánchez, E.; Sciavicco, G.; Stan, I.E. Feature and Language Selection in Temporal Symbolic Regression for Interpretable Air Quality Modelling. Algorithms 2021, 14, 76. https://doi.org/10.3390/a14030076
Lucena-Sánchez E, Sciavicco G, Stan IE. Feature and Language Selection in Temporal Symbolic Regression for Interpretable Air Quality Modelling. Algorithms. 2021; 14(3):76. https://doi.org/10.3390/a14030076
Chicago/Turabian StyleLucena-Sánchez, Estrella, Guido Sciavicco, and Ionel Eduard Stan. 2021. "Feature and Language Selection in Temporal Symbolic Regression for Interpretable Air Quality Modelling" Algorithms 14, no. 3: 76. https://doi.org/10.3390/a14030076
APA StyleLucena-Sánchez, E., Sciavicco, G., & Stan, I. E. (2021). Feature and Language Selection in Temporal Symbolic Regression for Interpretable Air Quality Modelling. Algorithms, 14(3), 76. https://doi.org/10.3390/a14030076