1. Introduction
Several types of neural network models have been proposed, such as pattern classification and regression problems. The feedforward neural networks (FNNs) class is common because of their structural stability, strong representation, and large number of available training algorithms. The growth in available data requires greater complexity in the structure of the neural networks to define large data sizes. Such special (FNN) architectures are called deep neural networks (DNNs) and are now very popular in many applications such as cancer diagnosis and medical imaging. Deep learning involves several layers of the nonlinear processing of information. In order to learn abstraction layers with a stronger capacity for generalization and representation, learning architectures are performed as repeated sequences of smaller functions [
1].
Although the training process is more complex because of a lot of hidden layers and several links between them, the random connections initialization is also difficult because it creates the non-convergence of the training algorithm. If the number of neural parameters increases, the possibilities of the state space of all parameters’ values will be unlimited. The probability of beginning the network from an optimal initial step is very little and this is the first problem.
The second problem is the difficulty of discovering the best neural network that can learn training data accurately and with great success in generalization. When the two parameters, namely the number of layers and the number of neurons at each layer, are joined together, there is an infinite number of possibilities. If the chosen network architecture is not suitable for the fixed size network, this will cause under-fitting or over-fitting. A network architecture that is neither too large nor too small is required for a better performance in generalization and less training time.
It might be reasonable to choose a NN architecture through manual design if there are qualified human experts with sufficiently advanced knowledge of the problem to be solved. However, this is clearly not the case for some real-world situations where several advanced data are not available. NNs make a fixed architecture in the back-propagation algorithm, while a constructive algorithm performs dynamic NN architectures.
The constructive algorithm is a supervised learning algorithm, and its dynamic models are commonly used to solve real-world problems. Even so, its mechanism for achieving dynamic NN architectures is totally the opposite. As such, the use of an acceptable NN architecture is still an issue for dealing with real-world problems. A constructive algorithm starts a NN with a limited design, i.e., with a limited number of hidden layers, neurons and links. Firstly, it starts with a simple NN approach, then gradually attaches hidden nodes and weights until an optimal methodology is identified.
Among these constructive algorithms are the cascade-correlation neural networks (CCNNs), which are a well-known class of discriminatory (as opposed to generative) models that have been effective in simulating several processes in development research. The CCNN algorithm is a rapid algorithm, as the new candidate neuron is learned just before connecting to the network, and the weights of the hidden input nodes are frozen in the corresponding process. Consequently, the weights are frequently trained at the output nodes after each new hidden neuron has been added.
In this paper, we proposed a method called “cascade-correlation growing deep learning neural network algorithm (CCG-DLNN)” which uses the growing phase at “growing pruning deep learning neural network algorithm (GP-DLNN)” [
2], however, by training the latest hidden unit (a candidate unit) when connecting to an existing model, and after that, the weights of the hidden inputs are frozen. Consequently, the weights of the output neurons are constantly trained after adding each new hidden neuron as in the CCNN algorithm.
The proposed CCG-DLNN algorithm has two benefits: firstly, the cascade architecture adds the hidden node to the neural network each time and it is not changed after inserting it; secondly, it is a learning algorithm that creates and adds a new hidden neuron. Trials are made to optimize the amount of correlation among the output of the node and the residual error signal.
We aim to increase the accuracy of the deep neural network when we perform it in the context of different real classification problems by combining some cascade-correlation algorithm features and (GP-DLNN) algorithm [
2].
The paper is set out as following:
Section 2 presents a state of the art with respect to the adaptive algorithms.
Section 3 includes a comprehensive overview of the CCG-DLNN algorithm, and proof of convergence is given of the algorithm.
Section 4 is about results and experimental analysis and a conclusion is made in
Section 5.
2. State of the Art
With expanded computational power, artificial neural networks have demonstrated great strength in solving data classification and regression problems in big data fields. Traditional neural network training uses the error-back propagation strategy for the iterative alignment of all parameters. There are many challenges when the number of hidden layers increases, like local minima, slow convergence, and its time-consuming nature [
3].
Unlike traditional neural network (NNs) algorithms that demand the NN architecture description before the start of the training, the dynamic neural network structure allows the network architecture to be designed and trained. A number of algorithms have been suggested to evaluate the optimal network model, including different algorithms for pruning, constructive, and hybrid constructive-pruning algorithm. A constructive algorithm combines neurons, hidden layers, and links into a small neural network architecture within the training. However, a pruning algorithm discards unnecessary hidden layers, nodes, and connections. it begins with large NNs during preparation [
4].
In this paper, two methods were combined which are the cascade-correlation neural network algorithm and a constructive algorithm. At the following two subsections, the advantages of the two methods will be shown in detail to argue why we used them.
2.1. Constructive Neural Networks
Constructive neural networks (CoNNs) are a set of algorithms that change the design of the network, automatically generating a network with an acceptable dimension. The algorithms used for the CoNN learning method are called constructive algorithms. A constructive algorithm begins with a small network design and adding layers, nodes, and connections as appropriate during training. The architecture adaptation process resumes until the training algorithm obtains an almost best model that provides a sufficient problem solution [
4].
Constructive algorithms have many huge benefits over pruning algorithms, such as, for constructive algorithms, it is fairly simple to define the initial network architecture, whereas in pruning algorithms, the initial network does not have an accurate number of layers [
5]. In constructive algorithms, at the initial step of the training phase a smaller number of parameters (weights) are to be modified, thus requiring less training data for good generalization; however, we need large amounts of training data in pruning algorithms [
4]. One popular feature of constructive algorithms is to suggest that the hidden nodes that are already installed in the network are useful for modeling part of the underlying task. In such situations, the weights fed to such implemented nodes may be frozen in order to prevent the problem of moving the target. The number of optimized weights is reduced over time to reduce the time and requirements of the memory [
4].
For all these previous reasons, we used a constructive algorithm rather than the pruning algorithm for the proposed algorithm.
CoNN algorithms are different from each other, in terms of [
6]:
- 1
Number of nodes that have been added per layer at each iteration;
- 2
The network grows forward or backward;
- 3
Whether all neurons make the same function;
- 4
Stopping criteria;
- 5
Newly added neuron connectivity pattern;
- 6
Kind of input patterns that deal with binary valued or categorical attributes;
- 7
Type of problems including classification and regression problems or clustering.
We preferred to make our proposed constructive algorithm according to the following characteristics:
- 1
The network grows forward;
- 2
Stopping criteria are based on when the desired accuracy of the network is achieved;
- 3
Kind of input patterns is binary valued;
- 4
This algorithm can deal with classification problems.
Within neural network literature, several CoNN algorithms that are only suitable for classification problems have been proposed. The well-known two-class CoNN algorithms are the tower and pyramid [
7], the tiling [
8], the upstart [
9] and the cascade of perceptron [
10]. The MTower, MPyramid, Mtiling, MUpstart and MPerceptron cascade are the multi-class versions of these algorithms. One can see these algorithms in [
11,
12]. The major constructive algorithms for regression problems, as mentioned in [
13], are dynamic node creation (DNC) [
14,
15,
16,
17,
18,
19,
20,
21,
22], cascade-correlation algorithm (CCA) [
23], projection pursuit regression based on the statistical technique [
24], resource-allocating network [
25], group method of data handling [
26] and miscellaneous [
27].
Among these algorithms, the CCA was chosen as the proposed algorithm and the next subsection will show how CCA works and its advantages over the other algorithms.
2.2. Cascade-Correlation Algorithm
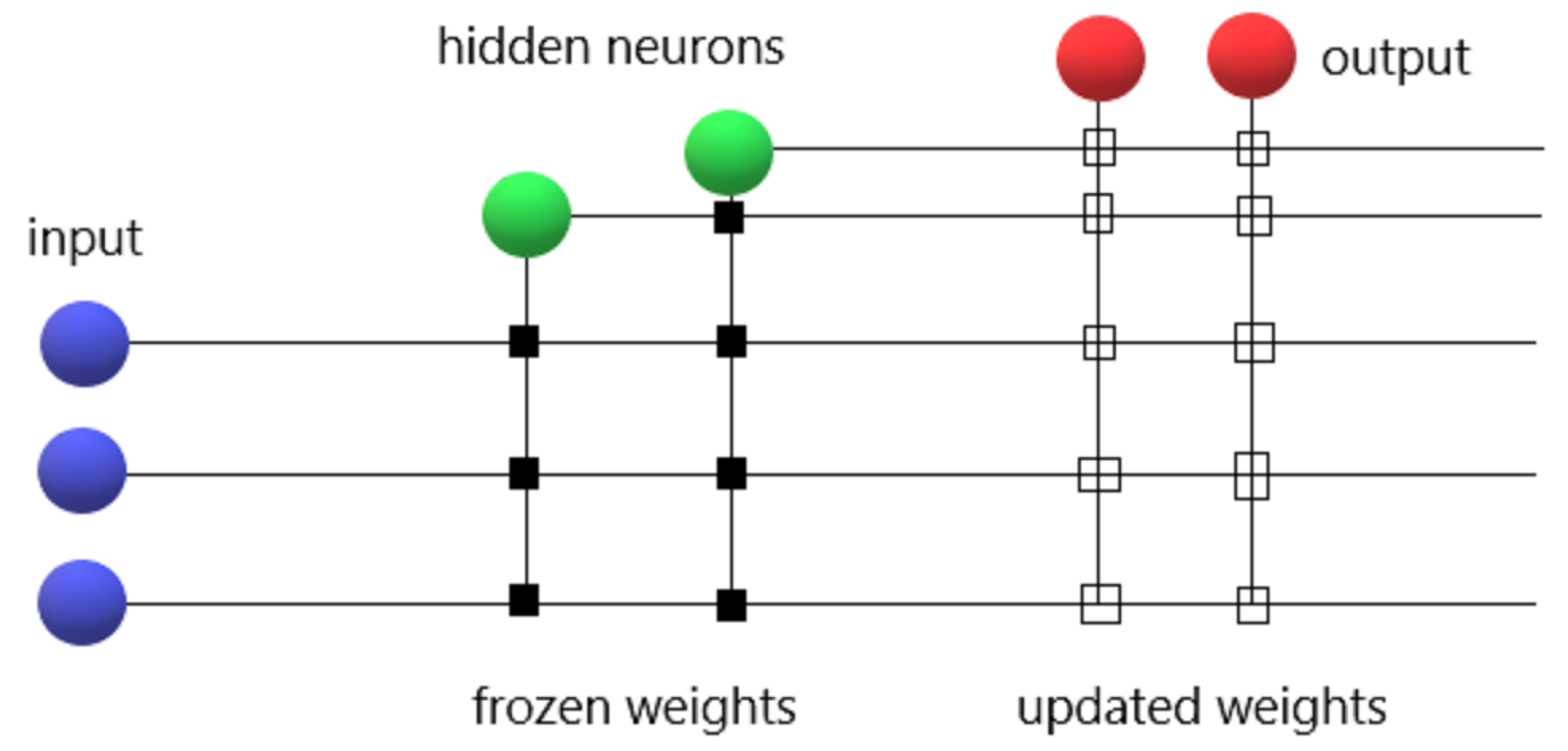
One of the supervised learning models for neural networks is a cascade correlation. Cascade correlation starts with a small number of layers, and then gradually trains and installs new hidden nodes, one at each step, and thus generating many layer models rather than only changing the weights in a fixed topology network. After adding a new hidden node to the network, the weights of this node are fixed at the input side. This node is a fixed feature detector inside the network, ready for output production or many other complex feature detectors to be produced, as seen in
Figure 1. There are two ideas within the CCNN algorithm: firstly, the cascade model, where hidden nodes are connected to the network only once and do not alter after they have been added; secondly, the learning algorithm, which produces and installs new hidden units. The algorithm aims to maximize the magnitude of the correlation between the new unit’s output and the residual error signal for each new hidden unit [
23].
In our proposed algorithm, the CCNN algorithm was chosen due to its following advantages:
- 1
It learns faster than other back-propagation algorithms (CCNN does not use the back-propagation of error signals);
- 2
The network chooses the suitable size and topology at learning step;
- 3
At incremental learning, CCNNs algorithm is useful as it can add new information to the trained network.
The following section will illustrate in detail our proposed algorithm with all its steps.
3. New Proposed Cascade-Correlation Growing Deep Learning Neural Network Algorithm (CCG-DLNN)
The conclusion of the previous section is that the constructive algorithms have many benefits over pruning algorithms in terms of building the NN structure. Usually, constructive neural networks are used to solve the problems of classification. Using this type of network has been shown to result in fewer computation requirements, smaller topologies, faster learning and better classification. Furthermore, this reveals that such constructive neural networks will still develop to a point where 100% of the training data can be correctly identified [
28].
In this section, we present a growing algorithm based on the deep neural architectures (CCG-DLNN).
3.1. Notations and Assumptions
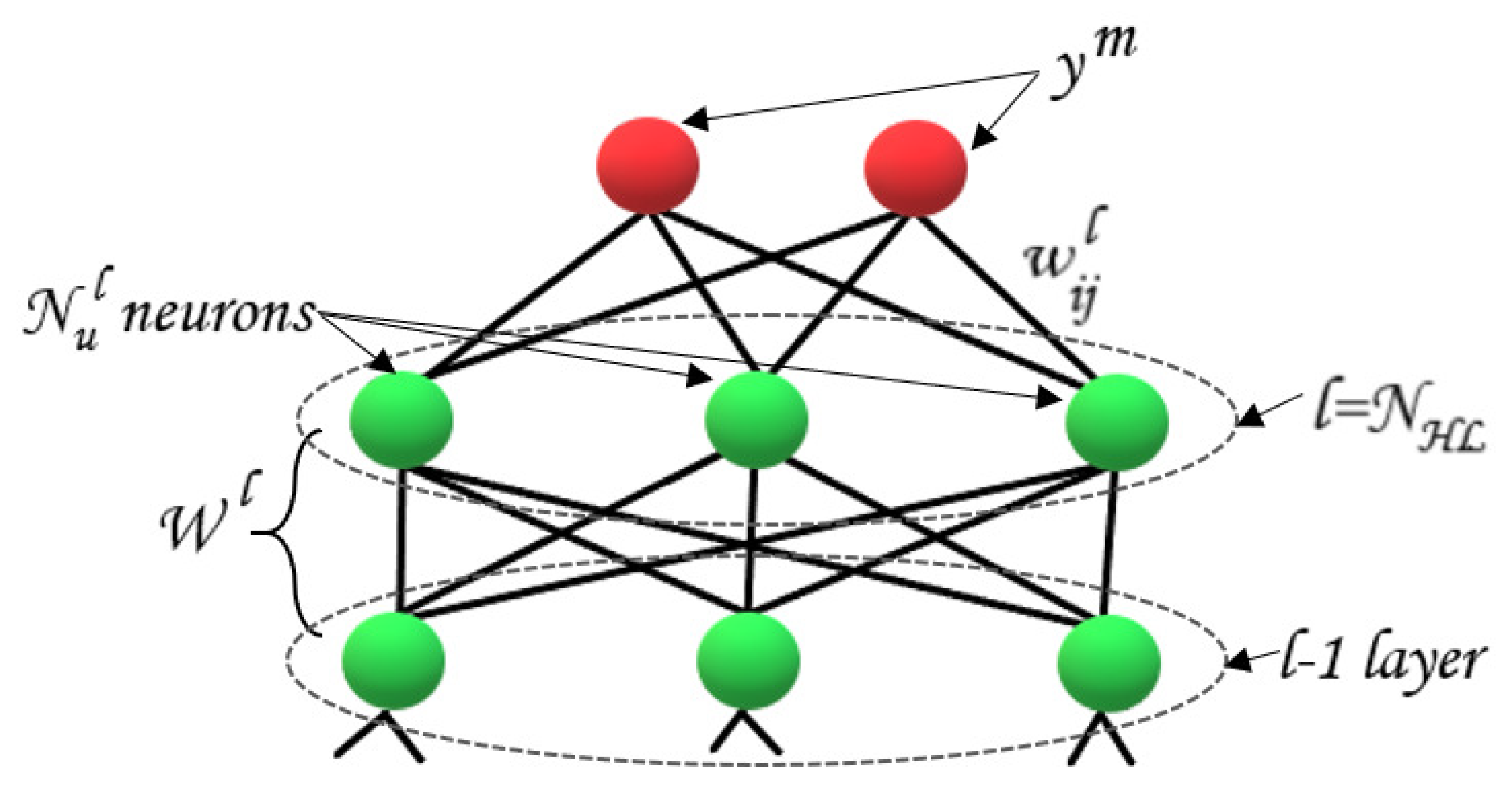
: number of hidden layers as in
Figure 2;
: number of units within the lth layer as in
Figure 2;
S: is the attributes number at the training data set;
l: Layer number, is the input layer, is the output layer and numbers of hidden layers is defined as ;
: is the weight between the ith node at lth layer to the jth node at the (lth − 1) layer
as in
Figure 2;
: is the matrix of weights which links the lth layer to the (lth − 1) layer as in
Figure 2;
: is all the neural network weight connections ;
: is the new weights when the network is increased;
: loss function;
: is the output error resulting from the mth input ;
: the gradient of
based on the parameter
and given by Equation (
1):
To train the deep neural network, we use an online backpropagation algorithm and update the weights using Equation (
2):
where the learning rate is
:
: is the mth input sample of the training input data set , ;
: is the mth desired output of the training output data set , ;
: is the output of the NN obtained for the input
,
as in
Figure 2;
: the output of the ith hidden unit related to the lth hidden layer related to the mth input
and given by Equations (3) and (4):
where
is the summation of the product of previous layers’ neurons outputs and weights and
is the nonlinear activation function that could be sigmoid, tanh or ReLU; and
when
.
3.2. The CCG-DLNN Algorithm
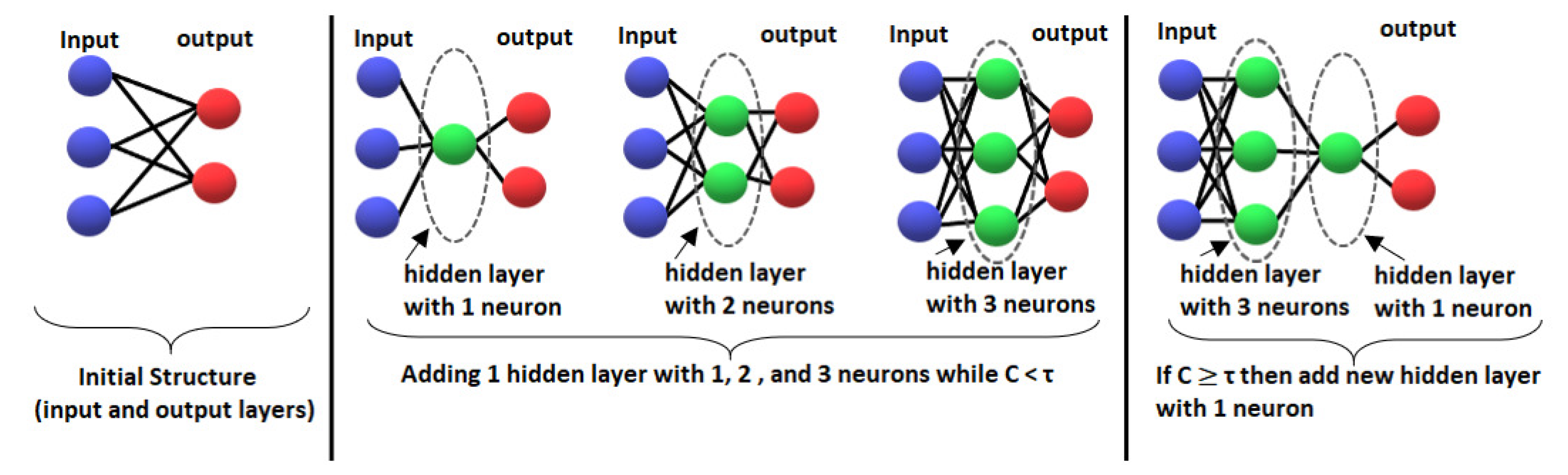
The CCG-DLNN algorithm uses the same strategy like CCNN but by adding more than one hidden layer—that has more than one neuron—between the input and output layers. Therefore, at each iteration, we add a new hidden layer with one neuron or add a new neuron at the last added hidden layer .
At the beginning, the learning algorithm begins with a simple network that has only the input and output layers and does not have any hidden layers. Due to the lack of hidden neurons, this network can be learned by a simple gradient descent algorithm individually applied to each output neuron.
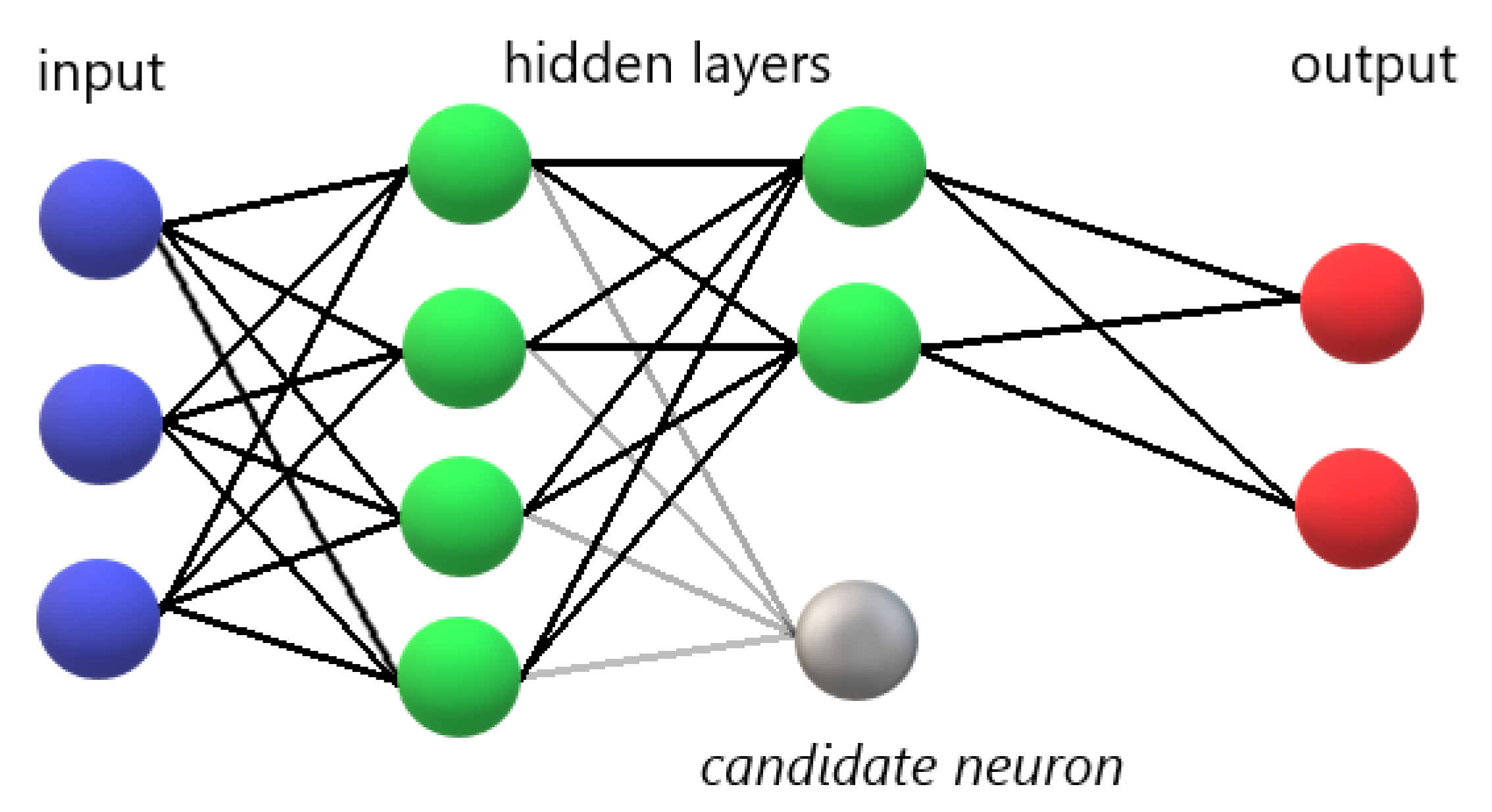
New neurons are connected to the network one by one during the learning process. Each of them is put in a new hidden layer and linked to all the previous hidden neurons at the previous hidden layer. When the neurons are eventually connected to the network (activated), their input connections will freeze and no longer change.
Adding a new neuron can be divided into two sections. First, we start with a candidate neuron and receive the input connections from all pre-existing hidden units at the last hidden layer
as in
Figure 3. The candidate unit’s output is not yet added to the current network. We do a sequence of passes over the examples set for training, updating the weights of the candidate unit for each pass at the input side. Second, the candidate is linked to the output neurons (activated) and then all output connections are trained. The entire process is repeated multiple times until the desired accuracy of the network is achieved.
3.3. Steps of CCG-DLNN Algorithm
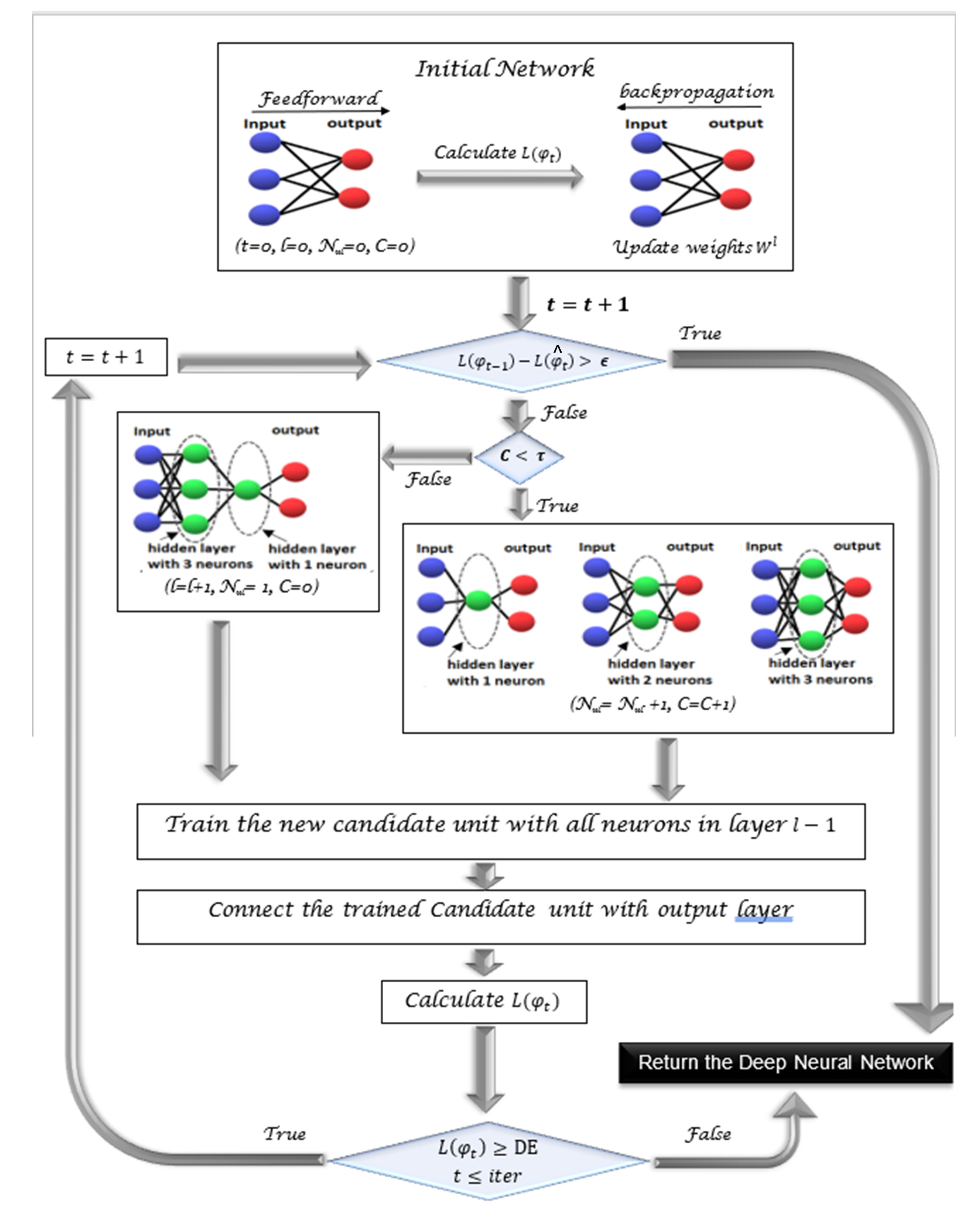
As shown by Algorithm 1 and
Figure 4, the CCG-DLNN algorithm begins with minimal architecture (input and output layers) without any hidden layers, and this simple network is trained and the loss function
is calculated. Let us consider that DE is the desired error [
2],
DE denotes that more neural hidden layers and more nodes are required to fit the training data set correctly. To do so, we add a new completely linked neuron to the last hidden layer or add a new hidden layer. We let
C be introduced to measure changes in the loss function when a new neuron is added to the current hidden layer and
is the threshold to add a new hidden layer. As shown in Equations (5) and (6), if
is degraded compared to
before adding the new neuron, then increases
C by one. Otherwise,
C will be zero. While
C is less than the threshold
, we add one new neuron to the last hidden layer. If
C reaches the threshold value
, then we add a new hidden layer that has one neuron as in
Figure 5:
where
is a growing process threshold.
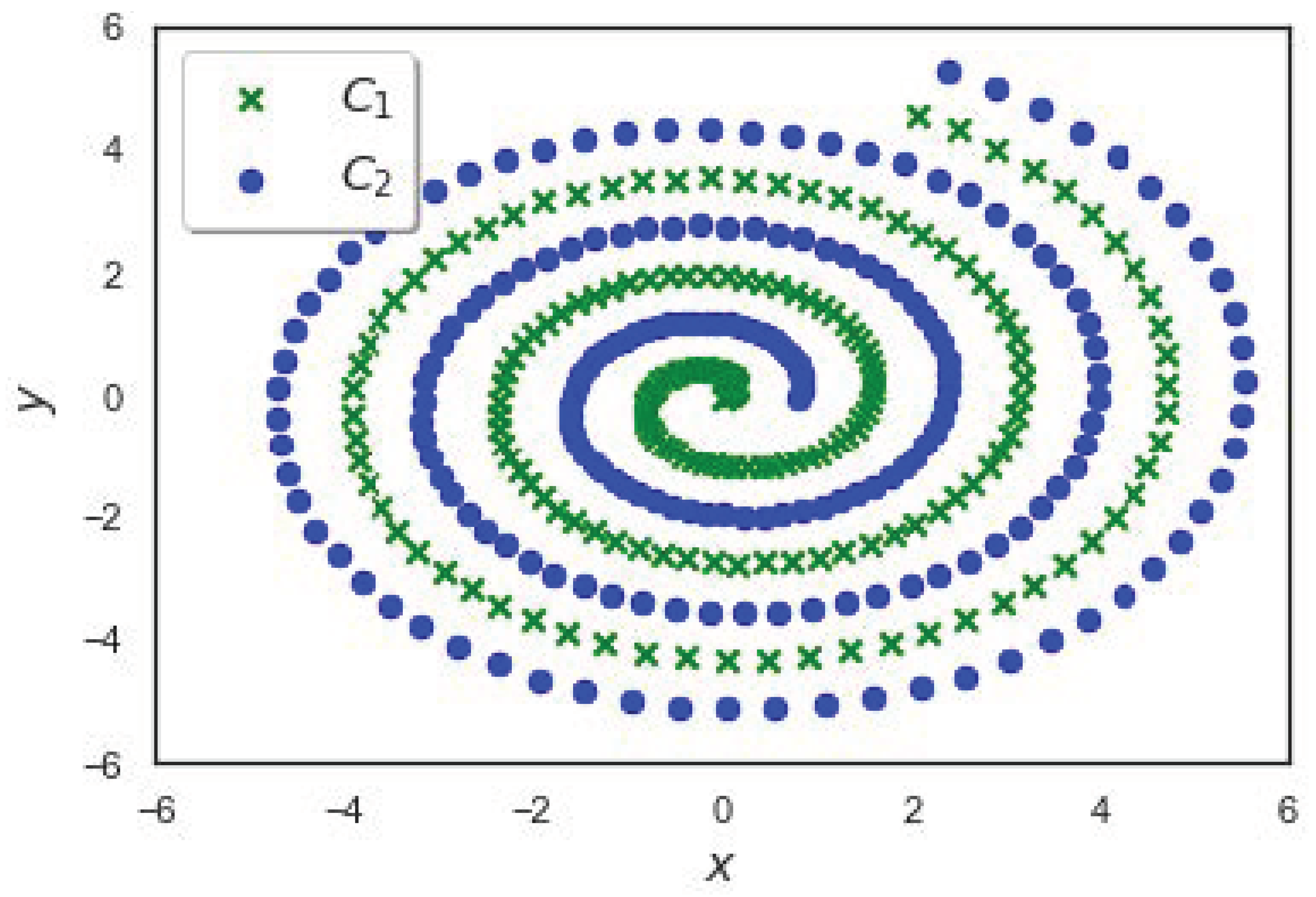
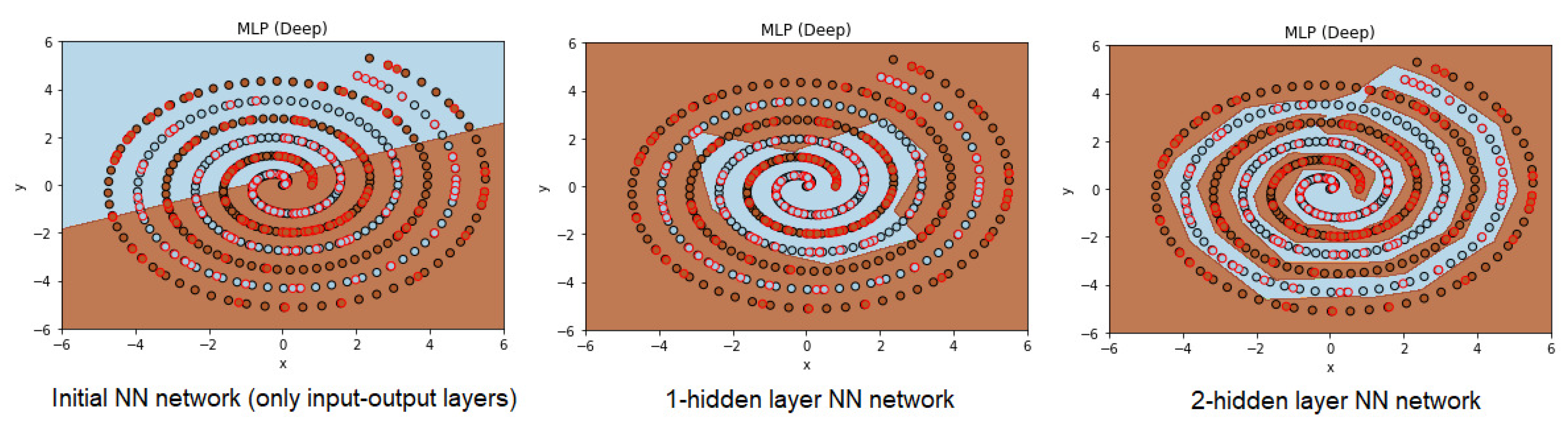
The stage of the neuron can be divided into two parts. First, we start with a candidate neuron that accepts input links at the last hidden layer from all pre-existing hidden units. The candidate unit’s output is not yet connected to the active network. We run several passes over the training set examples, adjusting the candidate unit’s input weights for each pass. Second, the candidate is connected to the (activated) output neurons, and then all output connections are learned. The entire cycle is repeated until the network’s required accuracy is achieved. Increasing the number of hidden layers may or may not increase the accuracy, as it really depends on the difficulty of the solved problem.
Increasing the number of hidden layers much more than a sufficient number of layers would reduce the accuracy of the test set. It will make the network over-fit the training set, that is, it will know the training data, but it will not be able to generalize to new unknown data [
29].
The large weights in the neural network are a sign of over-fitting. The research in [
30] defined weights in a qualified network in a more coherent manner, by preventing them from taking broad values using Equation (
7):
where
is all the neural network weight connections,
is the output error, and
l is a lower bound and
u is an upper bound.
| Algorithm 1: Cascade-Correlation Growing Deep Learning Neural Network |
![Algorithms 14 00158 i001]() |
3.4. The Convergence Proof
Theorem 1. There exists a weight setting for neurons within the newly added layer l and the output neurons in the CCG-DLNN algorithm such that the number of patterns misclassified by the network after the addition of the N neurons to the l layer and the retraining of the output weights is less than the number of patterns misclassified before that (i.e., ).
Proof. At iteration t, the loss function
will be:
where:
For hidden layer
l:
if
, then:
from [
31], we have:
Let us dispose of the summing symbol for simplicity. The summation symbol is important, particularly for the definition of the stochastic gradient descent (SGD) versus batch gradient descent. In the batch gradient descent, we focus only on the error of all the training examples at once when we look at each error at a time in the SGD. However, just to keep things easy, we are going to assume that we are referring to each error one at a time:
from Equation (
9):
from Equation (
11):
If we add new one neuron to the last hidden layer, then
will be:
where
is the weight from the newly added neuron to the output neuron and
is the output of the newly added neuron.
So Equation (
19) will be:
After adding a new neuron and from Equation (
9):
from Equation (
21):
from Equation (
23):
□
So the number of unclassified patterns by the network after adding the N neurons in layer l and the extra training of the output weights is less than the amount of patterns unclassified before that.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}