1. Introduction
With the rapid development of information technology, speech transmission technology brings more and more convenience to people’s life. As the main form of human communication, speech information is widely used for its real-time and easy identification [
1,
2,
3]. Whether it is indoor communication or outdoor transmission, the process of sending and receiving speech information will inevitably be affected by the effect of multipath transmission [
4]. After the speech is sent out, it needs to reach the receiving end through multiple transmission paths, and the length and attenuation of each path are different, so the received signal presents the superposition of various speech signals affected by phase, delay and multipath [
5]. In addition, an increasing number of fields and departments need safe and efficient speech transmission technology, and information security [
6] is facing unprecedented development opportunities. Therefore, in the multipath channel, studying the safe transmission and effective extraction of speech information in indoor and outdoor environments is one of the scientific issues that many scholars are interested in.
In recent years, the chaotic phenomena of nonlinear systems have been studied more and more intensively [
7,
8,
9]. Chaos is a nonperiodic bounded dynamic behavior caused by a deterministic nonlinear dynamic system. It has initial sensitivity, internal randomness and unpredictability [
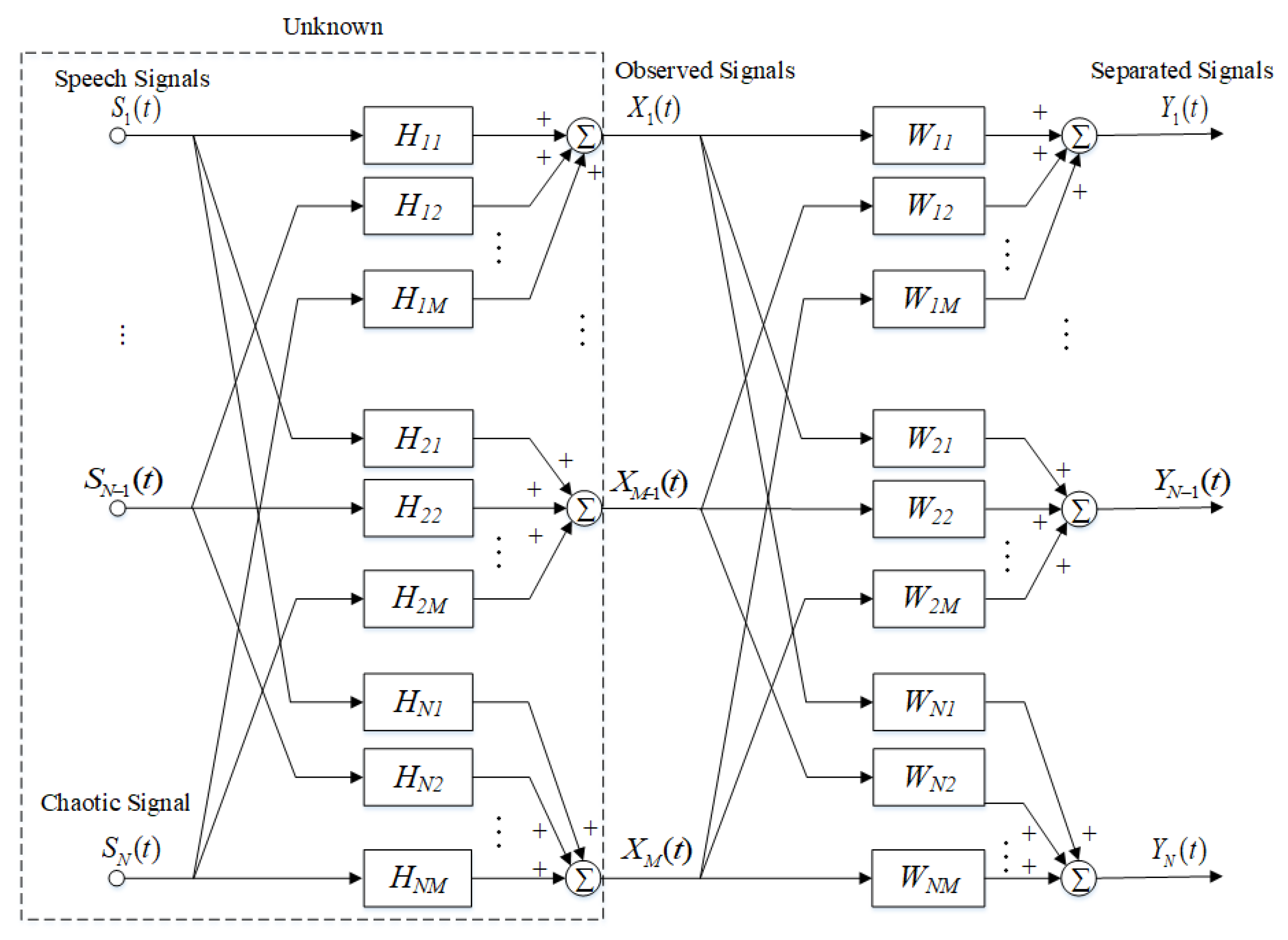
10], which make it play an important role in secure communication. Considering the secure transmission of speech information in wireless transmission environment, the speech signal can be chaotic encrypted or masked at the originating end. For indoor environments, a classic problem of speech communication is the “cocktail party”. In a noisy indoor environment, the sound received by the information-collecting microphone is diverse. The sound received includes the speech, music and other sound sources of multiple people talking at the same time, and there is also the reflected sound generated by the reflection of these sounds by the walls and indoor objects. In fact, whether in indoor or outdoor environments, speech transmission under multipath channels can be abstracted as a convolutional mixed model of signals. At the same time, there is bound to be a lack of source information and channel information during the transmission process. Therefore, separating the desired speech signal from the unknown information is known as classic multichannel convolutional blind source separation (CBSS) [
11,
12,
13].
There are two main types of methods to solve the CBSS problem in multipath channels: time domain and frequency domain. The idea behind time-domain approach [
14,
15] is the need to compute a separation filter in the time domain of equal or greater order than the impulse response filter. The method is often computationally complex, making the complexity of the algorithm high and convergence slow. The frequency-domain approach [
16,
17] is to transform the observed signal into the frequency domain using the short-time Fourier transform (STFT) [
18]. The instantaneous BSS is performed separately for each frequency point in the frequency domain using the standard independent component analysis (ICA) method [
19,
20], which is the key to blind source separation in the frequency domain. Although this method avoids tedious convolution operations and reduces computational effort, the ICA algorithm causes amplitude and permutation ambiguity to be blurred at each frequency point, which reduces the accuracy of the separated signals. The amplitude ambiguity can be handled by normalizing the separation matrix, while the permutation ambiguity is relatively difficult to solve. For this reason, numerous scholars have proposed different methods to solve the permutation ambiguity problem in frequency-domain convolutional blind source separation (FD-CBSS) [
13,
21,
22,
23].
The independent vector analysis (IVA) [
24] algorithm has been proposed as an extension of the ICA algorithm, which is mainly used to solve the permutation ambiguity problem in FD-CBSS. Considering the algorithm itself, the traditional independent univariate source prior is replaced by the source prior knowledge of multivariate correlations, using higher-order correlations across frequencies [
25] to prioritize the associated multivariate super-Gaussian distribution over each vector source. This modeling imposes the independence of sources between vectors while preserving the correlation of sources within higher-order vectors, i.e., the structural correlation between the frequency components of each source. The dependent multi-source prior preserves the dependence between the different frequency units of each source and maximizes the independence between the frequency units of the different sources [
26]. Thus, the IVA algorithm alleviates the permutation ambiguity problem in the learning process and does not require subsequent permutation processing. To improve the separation performance and faster convergence of this algorithm, the fast fixed-point IVA (Fast IVA) method [
27] of the Newtonian learning algorithm is applied to better solve the case of CBSS. This has been studied in more depth by subsequent scholars. J. Hao proposed an online IVA algorithm for real-time audio separation and developed a two-channel hardware demonstration system [
28]. M. Anderson applied the IVA model to solve the joint blind source separation problem for fMRI data and in the process derived gradient and Newton-based update rules [
29]. Y. Liang used video information to provide an intelligent initialization for the optimization problem and proposed a fast video-based fixed-point analysis method that still has good separation performance in noisy environments [
30].
To this end, this paper designed a speech information security transmission under chaotic masking and a FD-CBSS algorithm based on Fast IVA. The scheme is designed for the security of speech signals in wireless transmission environments. First, the speech signals to be transmitted were processed by chaotic masking and then sent to the channel for multipath transmission. Then, the encrypted convolutional speech signal in the time domain was transformed into the frequency domain using the short-time Fourier transform (STFT), followed by blind signal extraction using the Fast IVA algorithm. The blind deconvolution process of the signal was completed when the separation matrix converged or when the number of iterations was reached. The algorithm is able to perform permutation simultaneously during the iterative update of the separation matrix and converges quickly.
This paper is organized as follows: in the second part, Chen chaotic systems for confidential transmission are firstly briefly introduced; and then the FD-CBSS under multipath transmission model is highlighted. In the third part, the theoretical basis of the Fast IVA algorithm is first introduced, and the specific implementation steps of the algorithm are listed. Furthermore, a safe and fast overall process of blind deconvolution based on Fast IVA algorithm is illustrated. Finally, the evaluation criteria used to judge the separation performance of the algorithm are presented. The fourth part is to simulate the algorithm experiment and analyze the algorithm performance. In the fifth part, the conclusions and future research prospects are given based on the analysis results.
3. An Efficient Speech CBSS Algorithm in Multipath Channels
In the traditional frequency-domain convolutional blind source separation (FD-CBSS) algorithm, there will inevitably be problems of permutation ambiguity. There are usually two methods to solve such problems: one is a geometric method based on the direction of arrival (DOA) that has strict requirements on the spatial position of the sensor, and another method is based on the correlation of adjacent frequency bands with mutual parameters. These two methods have their own advantages and disadvantages in solving the ambiguity problem of separating sub-signal permutation. However, both methods require an additional permutation step after the CBSS algorithm, which inevitably increases the time complexity and computational complexity of the FD-CBSS process.
For this reason, this paper considers the existing CBSS itself and proposes the Fast IVA algorithm using Newtonian learning method to solve the multipath speech CBSS problem. The algorithm is essentially an extension of the one-dimensional random variables in the ICA algorithm to multi-dimensional random variables. It looks at the sampled data of the same source signal at different frequency points as a vector and performs CBSS of the signals in order, thus solving the permutation ambiguity case without designing additional permutation algorithms. The innovation of this paper is that the optimization algorithm process introduces Taylor series polynomials to quickly approximate the contrast function of Fast IVA algorithm. This step efficiently accomplished the CBSS without the need to design additional sequencing algorithms.
3.1. Fast IVA Algorithm
The Fast IVA algorithm uses the negative entropy criterion to measure the strength of the non-Gaussian and minimizes the contrast function over each frequency band to complete the estimation of the source signals. The advantage of this algorithm is that it performs CBSS in order at the ordered frequency points, thus solving the permutation ambiguity problem. On this basis, this paper uses Taylor series in the algorithm optimization process to approximate the contrast function of Fast IVA and then performs fast and ordered CBSS of speech signals at each frequency point.
Here, the Kullback–Leibler divergence [
34] between the two functions is defined as a measure of high-order dependence, which is the cost function of multivariate random variables. The relative entropy [
24] is expressed as follows:
where
represents the exact joint probability density function of a single source vector;
represents the product of approximate marginal probability distribution functions;
k is the number of frequency points;
represents the matrix determinant operator;
denotes the expectation, and
denotes the Kullback–Leibler scatter calculation.
For simplicity, suppose that
is zero-mean and the separated signal
is pre-whitened so that the rows of the mixing matrix
or the separation matrix
are orthogonal in each dimension, i.e.,
or
. Therefore, Equation (
7) can be simplified as:
In this paper, the fast fixed-points method is chosen to optimize the contrast function. Compared with the natural gradient method, the Fast IVA algorithm avoids the selection of learning rate and has the advantage of fast convergence. During the optimization of the algorithm, we introduce a Taylor series approximation to the contrast function of Lagrangian residue type in the notation of the complex variables in order to be able to quickly obtain the optimal approximate solution. Therefore, the contrast function of the Fast IVA algorithm with Lagrange multipliers
is obtained as follows:
Since the Hessian matrix of the contrast function [
35] is a diagonal matrix under the whiteness constraint, the following simple learning rule can be obtained by applying Newton’s method:
It can be known that the equilibrium point of Equation (
10) above is the local minima of the contrast function, since the demixing matrix is no longer updated. When the equation holds, the equilibrium point is found. The Lagrange multiplier is eliminated to obtain the following fixed point iteration algorithm:
In addition to normalization, the rows of demixing matrix
need to be decorrelated. The symmetric decorrelation is calculated as:
In the algorithm, in order to avoid local optimal solutions, we use the unit matrix as the initial demixing matrix in all frequency points. It can be seen from the derivation process of the algorithm that demixing matrix has no orthogonality constraints and does not produce separation error accumulation, which ingeniously solves the permutation ambiguity in the frequency-domain algorithm. We introduce a Taylor series to optimize the contrast function in the optimization algorithm, which makes it possible to obtain the optimal solution quickly in the iterative update of the separation matrix, simplify the iterative update process and reduce the computational complexity of the algorithm. The specific implementation steps of the core algorithm in this paper are as follows in Algorithm 1.
| Algorithm 1: CBSS based on Fast IVA algorithm |
Step 1: Transform the time-domain convolutional mixed signal by STFT into a
complex-valued signal at each frequency point in the complex frequency domain;
Step 2: Centralize and pre-process the mixed signal at each frequency point;
Step 3: Initialize the demixing matrix for each frequency point;
Step 4: Estimate the separated signal according to Equation (6);
Step 5: Calculate and optimize the contrast function and nonlinear function based
on the estimated source signal;
Step 6: Update the demixing matrix according to Equation (11);
Step 7: Decorrelation of the demixing matrix according to Equation (12);
Step 8: Normalize the separation matrix to resolve the amplitude uncertainty
of the separated sub-signals;
Step 9: Determine whether the separation matrix converges, and if it converges,
execute step 11;
Step 10: If the maximum number of iterations is reached, output the final
separated signal at each frequency point, otherwise return to step 4;
Step 11: Restore the separated signal of each frequency point into a time-
domain separated signal by ISTFT; that is, extract the source speech signal. |
3.2. BSS of Speech Signals with Chaotic Masking in Multipath Channels Based on Fast IVA Algorithm
Considering the information security transmission of speech signals under multipath channels in the wireless transmission environment, this paper processes the confidentiality of speech signal before sending. Due to the characteristics of initial sensitivity and internal randomness of the chaotic system itself, the chaotic sequence of its output is unpredictable, which provides a new design idea for secure communication. In this paper, the message signal and the chaotic signal are superimposed on each other, and the useful signal is covered by the pseudo-random and noise-like characteristics of the chaotic system to realize the confidential transmission of the message signal. Since the speech signal is a small signal, the magnitude of its energy and amplitude is far from that of a chaotic signal. Even though they are both multi-frequency signals, the broadband power spectrum characteristics of the chaotic signal still ensure a good masking effect on the speech signal.
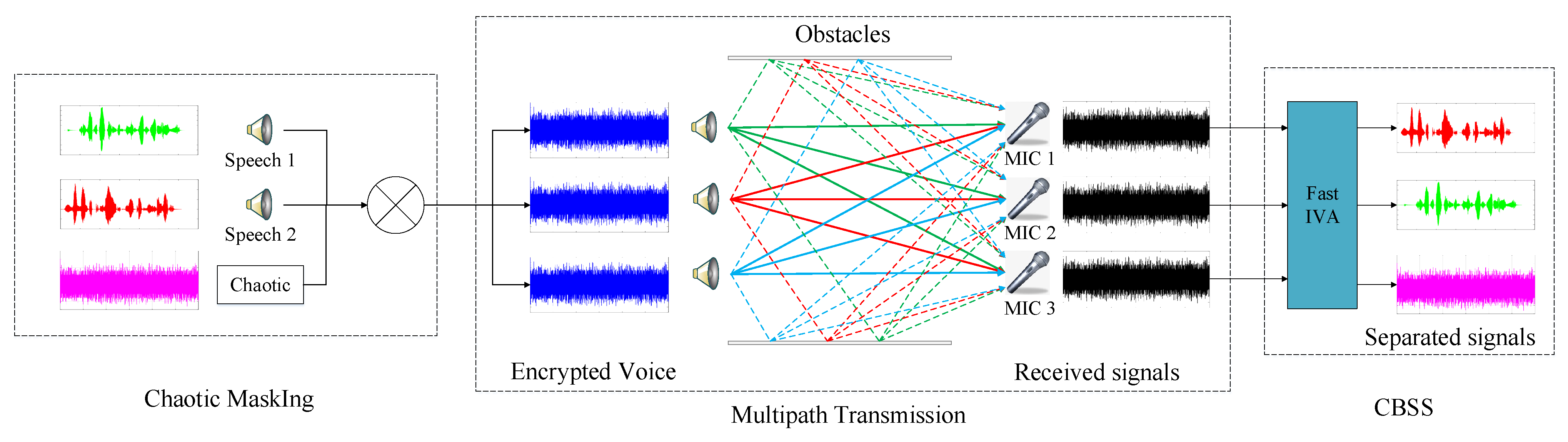
In this paper, chaotic signals are introduced into the source signal for chaotic masking to achieve the secure transmission of speech signals. In addition, this paper also proposes using a Fast IVA algorithm to solve the CBSS in the case of multipath speech secure transmission. Taking three signals (two speeches and one chaotic signal) as an example, we simulate the multipath transmission situation of speech signals and the whole process of blind observation signal separation to extract the source speech signal in the actual environment, as shown in
Figure 3.
From the above model, it can be seen that this paper introduces chaotic masking technology to hide the multiplexed speech signals into the random signals generated by the Chen chaotic dynamical system to ensure the transmission security of speech information. Secondly, the masked speech signals are transmitted via multipath channels to reach the receiving end. The multipath effect made the observed signals inevitably affected by phase and time delay and became a superposition of multiple source signals. The Fast IVA algorithm is applied to solve the FD-CBSS of the unknown observed signals, which efficiently achieved blind separation or extraction of speech signals without an additional sorting process. This greatly reduced the computational complexity of the algorithm and improved the efficiency of the FD-CBSS.
3.3. Evaluation Criteria
During the simulation experiment of CBSS, the signal estimation still differs somewhat from the source signal even in the absence of noise. In this paper, evaluation criteria such as signal distortion ratio (SDR) [
36,
37], signal interference ratio (SIR) [
36,
37] and correlation coefficient [
23] were used to quantitatively analyze the separation performance of the algorithm.
3.3.1. SDR and SIR
The estimated signal can be represented by four parts, namely, the real source part
, the filtering distortion part
, the interference part of other sources
and the false value
, where
indicates the part of estimated signal that belongs to the source signal (indicating that the sensor acquires information about the target source containing transmission effects);
indicates that the estimated signal does not satisfy the source signal and belongs to the mixed signal, which is the residual after the separation of other sources;
indicates the external noise generated by the algorithm. The specific definition equations for SDR and SIR are
The SDR reveals the ratio of the true source to the other components. The larger the indicator value, the less the separated signal is affected by distortion, interference and artifacts. Furthermore, the larger the SIR value, the less the components of the separated signal are separated from other sources, and the better the performance of the separated signal.
3.3.2. Correlation Coefficient
The correlation coefficient is usually the degree of similarity between the separated signal and the source signal if
and
are used to represent the source signal and the estimated signal, respectively. The mathematical expression is as follows:
The similarity coefficient between the source signal and the estimated signal is between 0 and 1. When two signals are perfectly correlated, the similarity between the source and estimated signals is high. The closer the similarity coefficient is to 1, the better the separation performance of the algorithm. Conversely, the smaller the similarity coefficient, the worse the separation performance of the algorithm.
4. Simulation Experiment and Result Analysis
One male and one female speech signal from the TIMIT database randomly selected as the speech message to be sent, and the signal length is 3 s. The x-component of Chen chaotic system is chosen as the input chaotic signal, and the signal length of the intercepted x-component is the same as the length of speech signals, and the sampling frequency is KHz. First, the speech signals are hidden into the chaotic signal to ensure the security of information transmission. Next, the impulse response filter is used to simulate the multipath effect generated by the speech transmission.
It is important to note here that the filter length directly affects the degree of convolutional mixing of the source signal. The longer the filter, the longer the process of mixing response of the speech signal in the channel, and consequently the more complex the received observation signal and the more difficult the separation or extraction of the source speech signal. In order to simulate the actual transmission environment and for the signals safety, the filter length should be increased. Furthermore, taking into account the difficulty of the separation process, the filter length should be reduced to ensure that the Fast IVA algorithm can obtain better separation results. Considering the above, the filter length set in the experiment of this paper is .
Then, the Fast IVA algorithm is used to separate and extract the speech signals from the observed signal, and the number of algorithm iterations is set to 1000 times. To ensure that the signal has good spectral characteristics in the frequency domain, the Hamming window function is chosen for the STFT transform, as in
Section 2.2. Furthermore, the appropriate number of frequency points is
, and the data frame is
.
Based on the above data and parameter selection, the simulation experiment is carried out and the selection of frequency points is considered in the experiment. The following is a quantitative analysis of the security of the speech signal, the separation results and separation performance of the Fast IVA algorithm, the evaluation of the speech quality, and the complexity of the algorithm from multiple perspectives.
4.1. Security Analysis
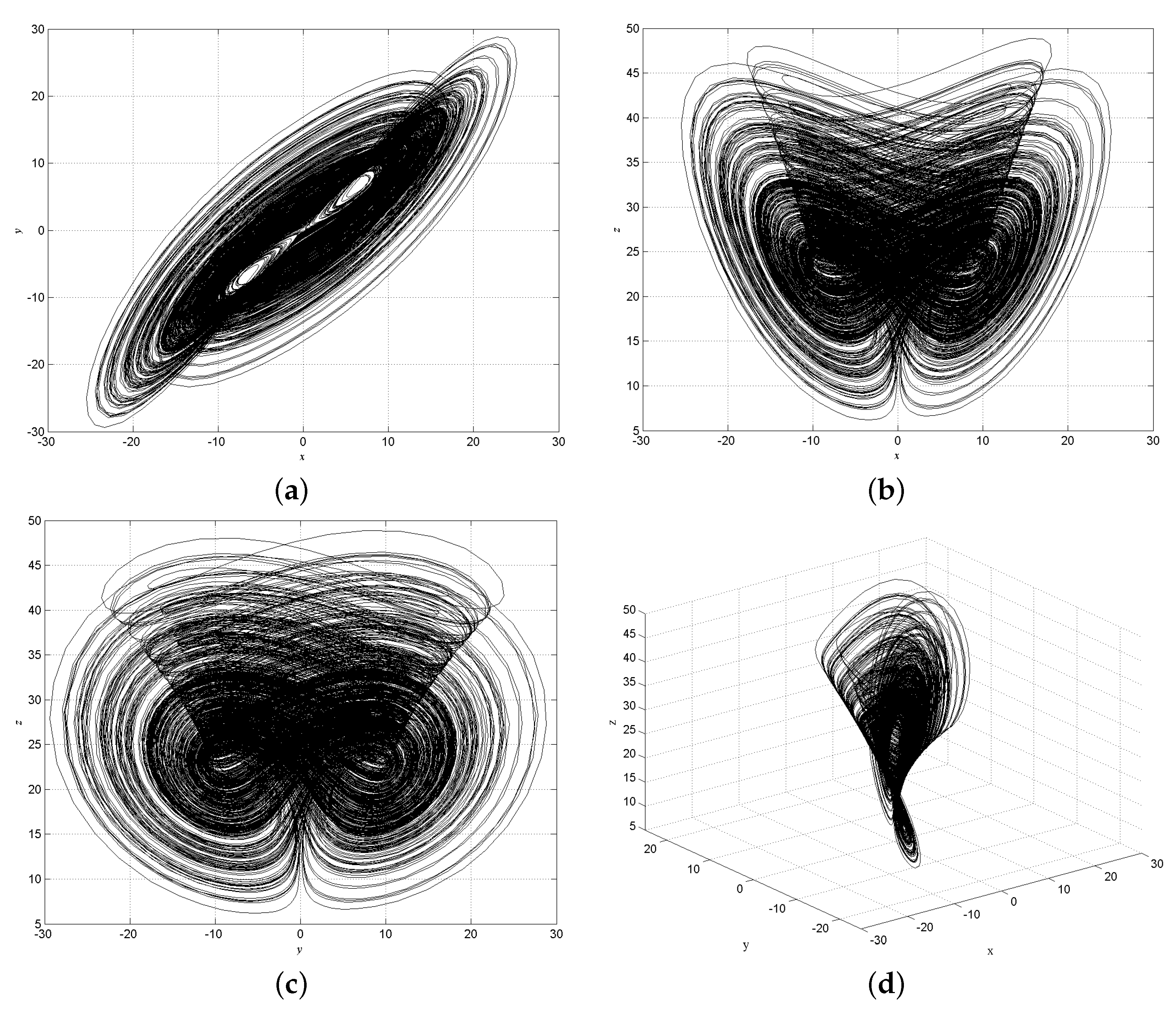
Chen chaotic system has good obfuscation and diffusion properties, and it is better able to resist statistical attacks.
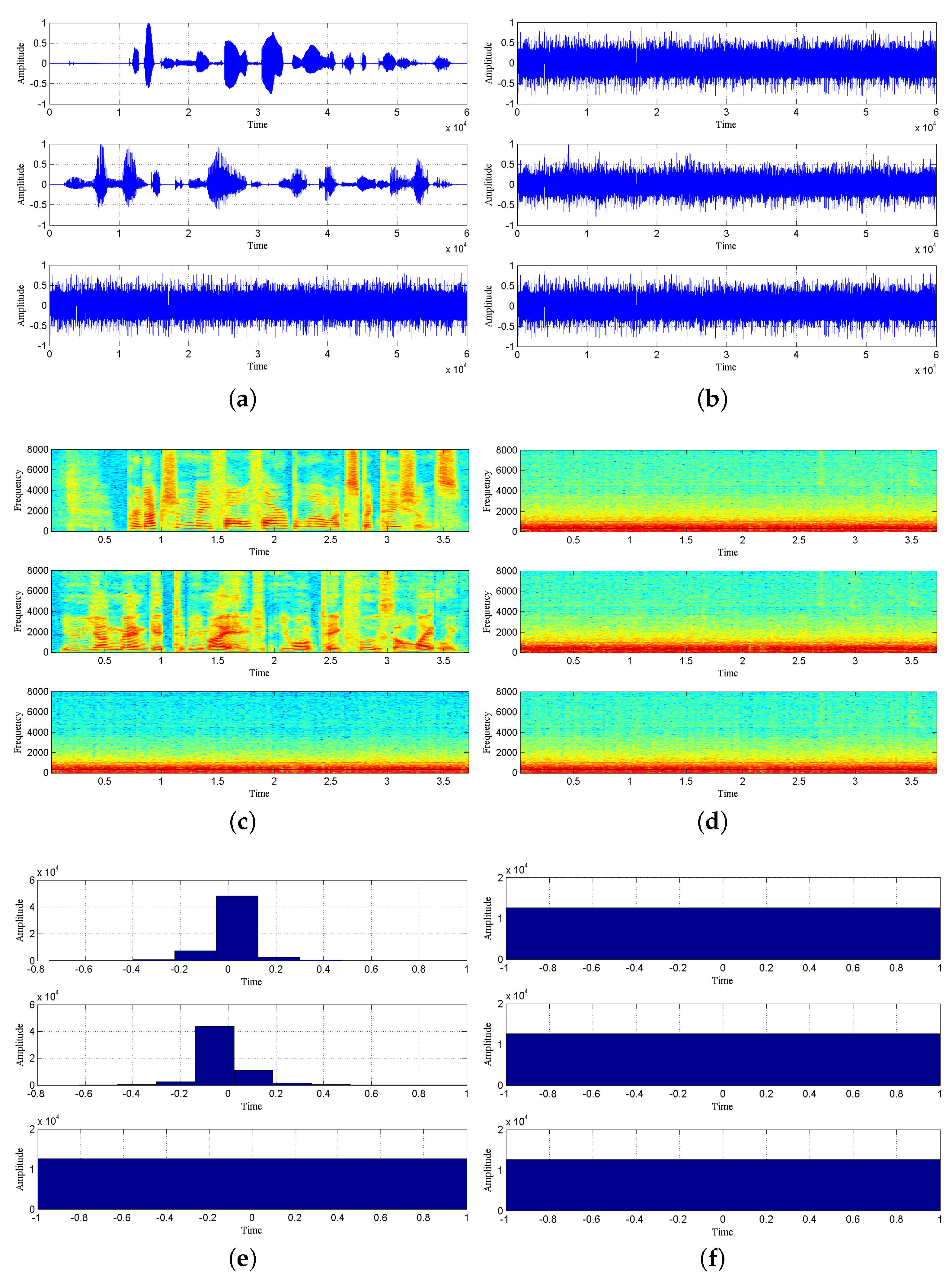
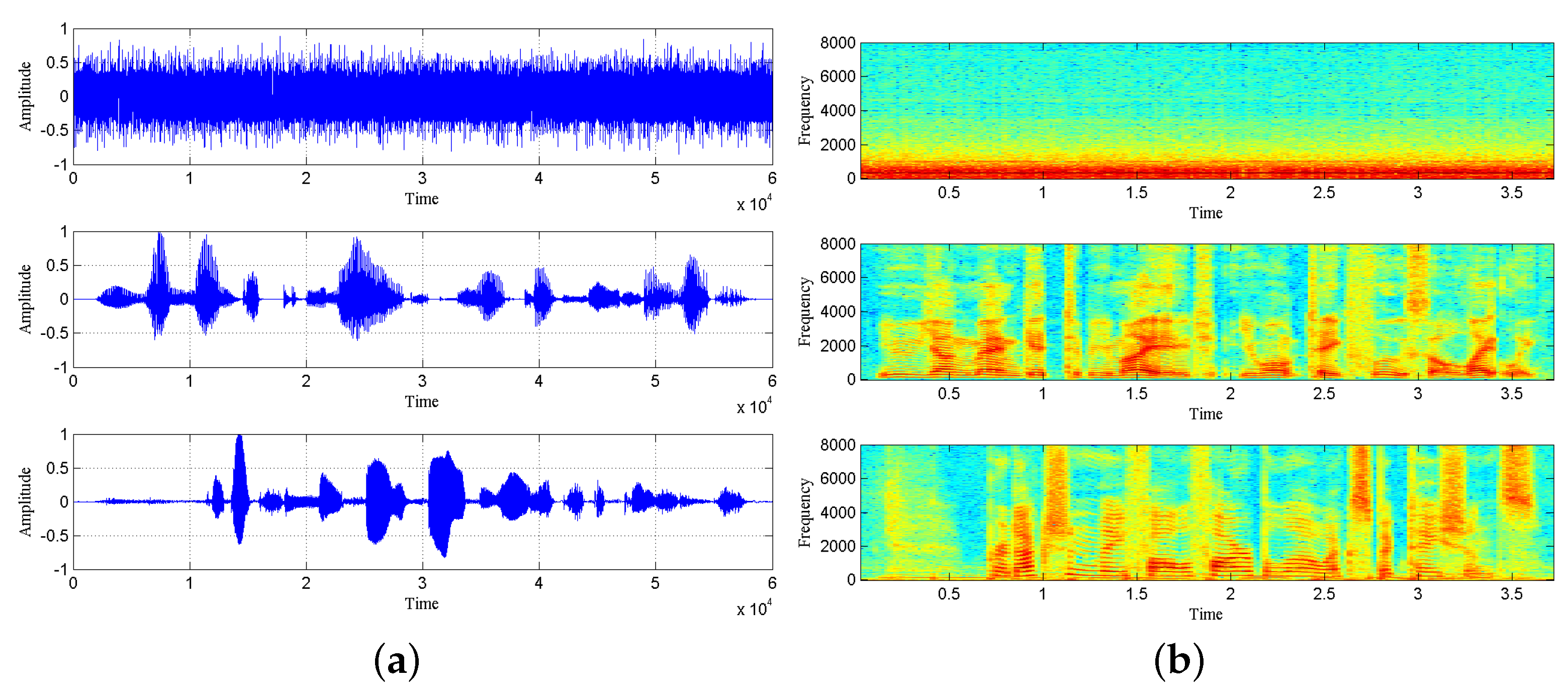
Figure 4 shows the waveforms, spectrograms and histograms of the source and observation signals obtained by simulation, and the security of transmission system can be seen intuitively.
The image information of the source signal and the observed signal after chaotic masking is shown in
Figure 4. The time-domain waveform, spectrograms and histogram of the observed signal are given in
Figure 4b–f, respectively, to compare the graphical information of the observed signal with that of the source signal. It is obvious that the source speech information is no longer found in the observed signal, which is enough to show that the chaotic signal plays a good masking effect on the speech signal and achieves the confidential transmission of speech information.
4.2. Correlation Coefficient Analysis
The selection of the source signal, experimental conditions and parameter settings are the same as described previously. Then, the blind observation signal after chaotic masking are processed at the receiver to achieve the extraction of source signal. In this paper, the Fast IVA algorithm is proposed to use it to perform FD-CBSS for the blind observation signal, and the waveforms of the separation result are shown in
Figure 5.
In
Figure 5, it can be seen that the waveform shapes of the separated signals obtained using the Fast IVA algorithm are almost identical when compared with the source signal graphical information, both in time domain waveform and spectrogram. Therefore, from a subjective point of view, it can be considered that the algorithm realizes the blind extraction of the source speech signal. However, it is not enough to rely on visual judgment only. Here we use the correlation coefficient as the objective evaluation criterion of the separated signal, and the data in
Table 1 are the average of 20 experiments.
In
Table 1, s1 and s2 represent the source speech signals, while
,
and
represent the separated signals obtained by the Fast IVA algorithm. As you can see, the correlation coefficient between the separated signal
and the chaotic signal is as high as 0.9991, which is close to 1. In addition, the correlation coefficients between the separated signals
and
and the corresponding source speech signals s2 and s1 are 0.9932 and 0.9278, respectively, which proves that the algorithm achieves the recovery of speech signals. The algorithm not only achieved the estimation of source speech signal, but also enabled a better recovery of the wide-spectrum chaotic signal. Thus, a high degree of reduction in the separated signal is illustrated from an objective point of view, and the blind extraction effect of the noise-like signal is guaranteed.
This paper proposes using the Fast IVA algorithm, which exploits both the statistical independence between multi-source signals and the internal dependence of each signal. The algorithm is not only fast and effective but also solves the permutation ambiguity problem in the FD-CBSS process and eliminates the permutation design in the standard ICA frequency-domain algorithm. To verify the superiority of this algorithm for convolutional blind signal separation and extraction, it is compared with two algorithms from the literature [
38,
39]. To this end, we conducted a large number of repeated experiments to reduce the randomness and improve the reliability of the results. To assess the stability of these algorithms, this experiment controlled for the consistency of the input signals and parameters, and 20 Monte Carlo experiments were conducted with each separation algorithm as a single variable only. The three blind separation algorithms are compared in terms of separation accuracy (average correlation coefficient).
Table 2 shows the average values of the above indicators obtained after 20 trials.
From the comparative analysis of the experimental results, it can be seen that the Fast IVA algorithm has the highest correlation coefficient and has better separation accuracy. By comparing with EFICA algorithm and IF algorithm, it is proved that the algorithm has better convergence speed and separation performance. The Fast IVA algorithm used in this paper not only eliminates the tedious permutation process among the separated sub-signals and reduces the computational complexity of the algorithm but also has better separation performance.
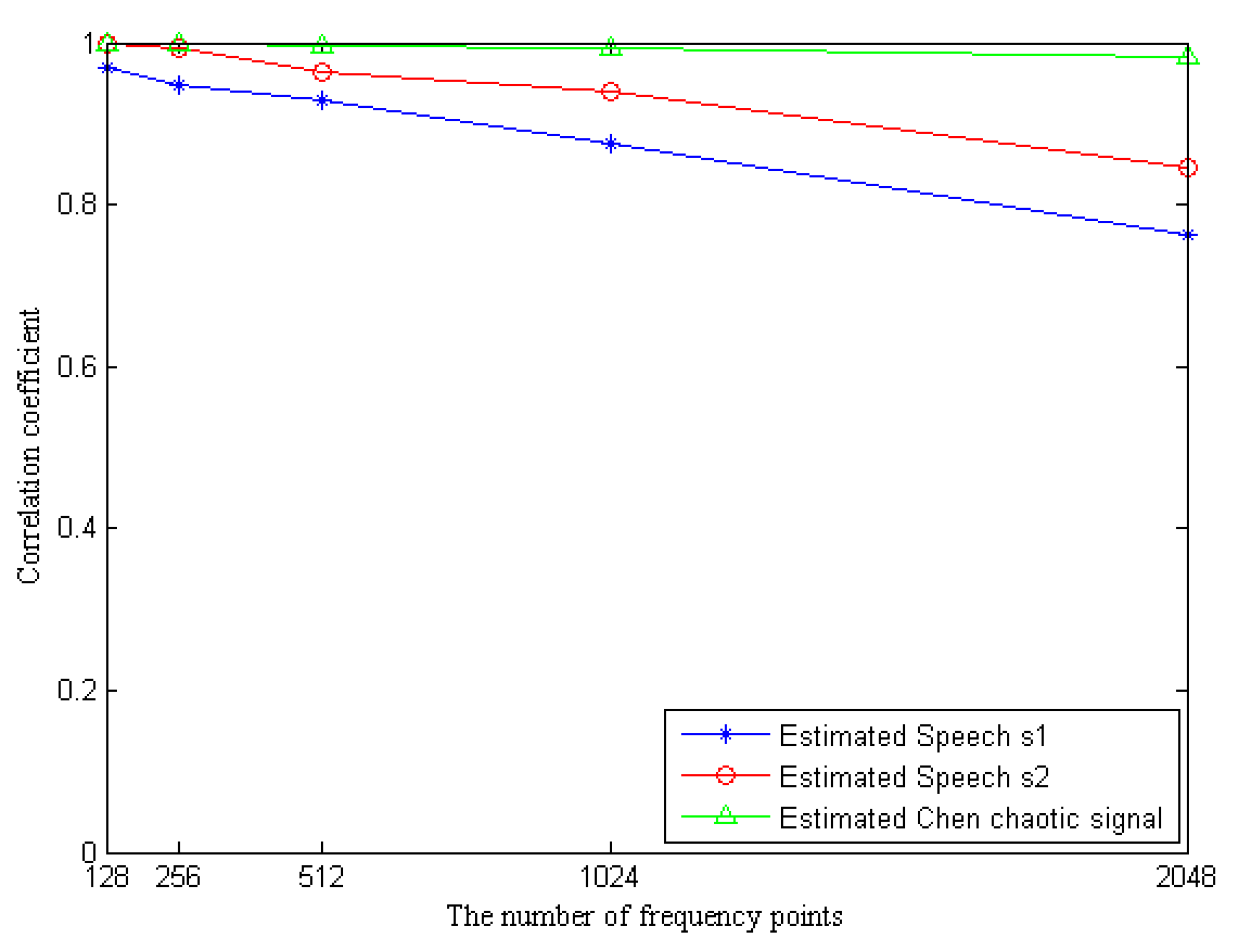
4.3. The Influence of Frequency Points in STFT
When setting the experimental parameters of the STFT, we mention one of the more important parameters, namely the number of frequency points. This is also the number of samples in the short-time window, and this parameter has an important impact on the STFT. The number of frequency points is too small, making the process of STFT too tedious and complicated, increasing the computational complexity of the algorithm. If the number of frequency points is too large, many features of the speech signal will be lost, which will affect the separation or extraction results of the blind extraction algorithm. Therefore, it is especially important to choose a suitable number of frequency points. We will discuss this parameter next, setting the number of frequency points to
. The other experimental conditions are guaranteed to be constant, and the simulation experiments were performed sequentially using the Fast IVA algorithm, with the correlation coefficient as the evaluation criterion. The experimental results are the average data of 20 trials, as shown in
Figure 6.
The effect of the parameter selection of frequency points on the separation result is intuitively reflected in
Figure 6. The larger the number of frequency points, the larger the number of samples in the short time window. For a speech signal with a certain length, the fewer frames are obtained by adding windows, which makes more speech features lost and results in a poorer recovered speech signal. With a smaller the number of frequency points, the opposite result is obtained. The experimental results in
Figure 6 also confirm this relationship. When the number of frequency points
, the average correlation coefficients of the speech estimation signals extracted by this algorithm are all above 0.96, and the separation effect is very good. When the number of frequency points
, the correlation coefficients of the estimated signals of speech s1 and s2 can reach about 0.92 and 0.96, respectively. Although the correlation coefficients have decreased, the separation results are still better. When the number of frequency points
or even larger, the correlation coefficient of the speech estimation signal decreases more obviously, which makes the separation result worse. To ensure that the separation results obtained by this algorithm are better and to avoid too much computation in the STFT process, we compromise by choosing a frequency point
. In addition, it can be seen from
Figure 6 that the change of frequency points has little effect on the separation results of Chen’s chaotic signal. Therefore, the superiority of the algorithm used in this paper is that it can guarantee the quality of the separated speech signal of good quality while still extracting the chaotic signal of noise class well.
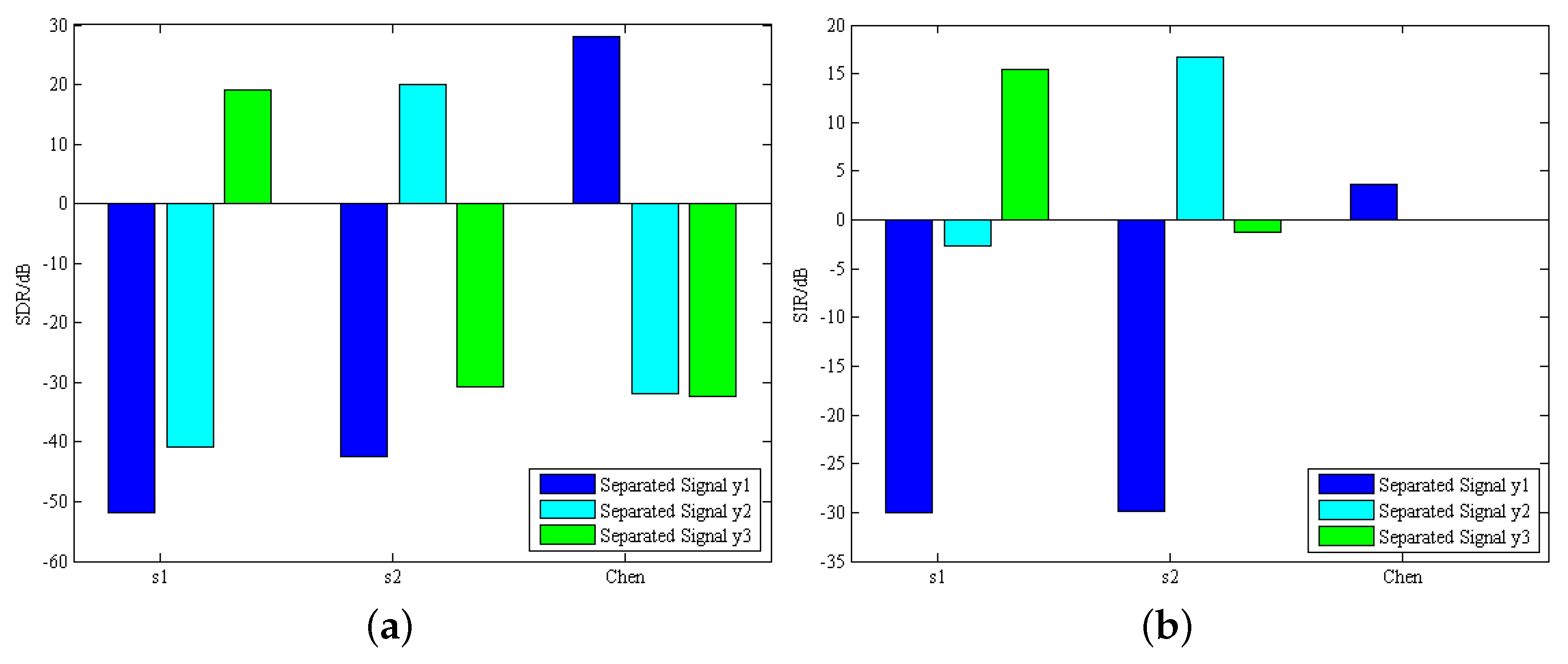
4.4. SDR/SIR Analysis
This section analyzes the degree of distortion and interference of the estimated speech signal. Here, the quantitative evaluation is based on SDR and SIR, which verifies the goodness of the separation results of the Fast IVA algorithm. The performance index is shown in
Figure 7, where the SDR and SIR data values are the average values obtained from 10 tests.
Figure 7 represents the performance evaluation of the separation results by different metrics; that is, the SDR and SIR values between each separated signal and the source signal, where s1 and s2 represent the two source speech signals and Chen is the chaotic signal. As shown in
Figure 7a, the dark blue bars indicate the SDR values obtained after comparing the separated signal
with s1, s2 and s3. The SDR values with s1 and s2 are negative, and the SDR value with Chen is 27.9537 dB, which determines that the separated signal
is chaotic. Furthermore, the SDR values of the estimated signals of source speech s1 and s2 are also both close to 20 dB, which shows that the separated signals are less affected by distortion and interference. Similarly, in
Figure 6b, the SIR values with s1 and s2 are negative due to the higher energy and larger bandwidth of the chaotic signal, and the SIR with s3 is calculated to be 3.6834 dB. The SIR values of both s1 and s2 estimated signals are calculated to be around 15 dB, while the SIR value of the chaotic signal is almost 0, indicating that the estimated signal has few components separated from other sources, which in turn proves the superior performance of the separated signal.
4.5. Perceptual Evaluation of Speech Quality
Perceptual evaluation of speech quality (PESQ) [
40] is an objective, full-reference speech quality evaluation method with the International Telecommunication Union labeling code ITU-T P.863. PESQ was specially developed for simulating subjective tests commonly used in telecommunications to evaluate human voice quality. Therefore, PESQ uses real speech samples as test signals, based on comparative measurements between the original reference signal and the extracted signal. PESQ was created to provide a subjective Mean Opinion Score (MOS) [
41] predictive value for objective speech quality evaluation, and it can be mapped to a scaled range of MOS values. The PESQ score ranges from −0.5 to 4.5, with higher scores indicating better speech quality.
The experimental conditions are the same as described above, and here the quality of separated speech is evaluated. The PESQ values of each estimated speech
and
compared with the original reference speech s1 and s2 are given in
Table 3. Among them, the PESQ value calculated between
and s2 is as high as 3.9232, while the PESQ value between
and s1 is also 3.9754. By mapping the PESQ values to MOS, the quality of separated speech can be called “good”. It is again verified that the Fast IVA algorithm has good separation performance for blind deconvolution of chaos-obscured speech signals and ensures the quality of separated speech signals.
To illustrate the high perceptual quality of the speech signal extracted by this algorithm, the results are analyzed here in comparison with other algorithms. The same experimental conditions as set as those in the literature [
42], and 20 repeated experiments are performed to reduce the randomness of the results and obtain more stable and accurate results. The calculation result in
Table 4 is the average value of PESQ obtained after 20 tests.
In
Table 4, the PESQ value obtained by DTW algorithm is 3.17, and the PESQ value obtained by Fast IVA algorithm in this paper is relatively high, which can reach 4.04. Compared with the PESQ value obtained by DTW algorithm, it is 0.87 higher, which is enough to show that the quality of the extracted speech signal is good. This shows that the algorithm has better separation results than other traditional blind separation algorithms. The reason is that the Fast IVA algorithm is a blind extraction process performed sequentially on each vector frequency point without the need for a subsequent permutation process, thus ensuring high-quality estimated speech.
4.6. Complexity Analysis
In this section, the computational complexity of the algorithm is analyzed and the time complexity of the key operational steps is now calculated for the FD-CBSS algorithm based on Fast IVA. Let the number of frequency points of STFT be
K and the total number of frames of data be
B. Assume that the number of source signals
N is the same as the number of observed signals
M. For convenience, only multiplication operations are considered when calculating the complexity, and the complex-valued multiplication is a four-fold relation of the real-valued multiplication [
43]. The real-valued multiplication operations required for the main procedure are shown in
Table 5, where
represents the number of iterations of the Fast IVA algorithm.
Combining the above analysis, the time complexity of the main steps of the Fast IVA algorithm is calculated. Therefore, the time complexity of the overall process of the algorithm is the sum of above processes, which is
In order to compare the computational complexity of various algorithms, the running time of the frequency domain permutation algorithm in the literature [
43] is given. Choose the same equipment and operating operating environment, the number of speech signals is
, the length of the speech signal is 10 s and the sampling frequency is
Hz. In
Table 5, the running time required for the completion of each algorithm is compared to illustrate the time complexity of the Fast IVA algorithm.
As shown in
Table 6, the running times of the algorithm designed in [
43] and in this paper are 13.7 s and 7.9 s, respectively. The significantly smaller running times indicate the low complexity of the algorithms. The biggest advantage of this algorithm is that the signal permutation is done during the signal separation process, eliminating the need for subsignal permutation algorithm design. Based on the computational complexity analysis of the above algorithms and the comparative analysis of the experimental results, the CBSS algorithm designed in this paper cannot only achieve high quality extraction of speech signals, but it can also complete the separation of signals quickly with low time complexity.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}