1. Introduction
Most densely populated cities endure road traffic congestion. Traffic congestion causes major problems, such as time delays, air pollution, fuel consumption and accident risks, which are usually caused by the fact that road capacity cannot meet the increasing traffic demand. Traffic congestion is caused by unplanned roads, the dense volume of vehicles and the presence of critical congestion areas. In unplanned roads, transportation departments do not handle traffic closures due to extreme weather conditions and other unforeseen events.
Recently, congestion problems have increased due to the growth in population and the different changes in population density. At present, the traffic system has become a very complex problem because traffic changes are uncertain [
1]. Therefore, it is difficult to obtain high-precision characterization using a standard knowledge model.
Many conventional methods have been developed to solve the problem of traffic congestion, such as urban decentralization, which can be difficult to enforce in practice [
2], and urban planning, which takes into consideration the increasing number of cars in cities before building their infrastructure [
3]. However, these methods can be costly considering the limited land resources.
One can use applications that consider only the present congestion situations on suggested roads to navigate within cities. However, few of these applications reroute users according to real-time traffic congestion as the trip progresses [
4,
5]. Hence, systems and algorithms must be designed in such a way that people can avoid traffic congestion in real time. In addition, other recent studies have attempted to predict traffic congestion in cities. A more specific approach for tackling the problem of linking traffic jams is the partitioning of the links according to traffic congestion in order to devise control strategies for solving this problem. Partitioning a network of roads into homogeneous groups can be extremely useful for traffic control considering that the congestion is spatially correlated in adjacent roads and that it propagates with different speeds [
6].
In [
7], the authors designed a network partition method by using the normalized cut. This method was further adapted and improved, where the authors developed a method based on the definition of the snake similarity matrix and application of the normalized cut algorithm in order to detect directional congestion within clusters and improve the performance of low connectivity networks [
8].
Previous work on trajectory data clustering has mainly focused on the case where objects move freely in Euclidean space [
9,
10]. However, these approaches failed to account for an underlying network that constrains movement. However, network constraints play a crucial role in determining the similarity measure between the trajectories to be clustered.
Another method was proposed in which the authors elaborated an approach based on discovering the clusters of trajectories by grouping similar trajectories that visited the same links of the network [
11]. Then, they extended their work to the case of links, where they grouped the common links that were visited by a large number of trajectories [
12]. Therefore, the community-detection algorithm used in the clustering step of their proposed framework can be sensitive to the presence of noise, which can degrade the quality of clusters.
However, these methods cannot be directly applied to dynamic frameworks. In order to study the feasibility of the control strategy to improve the transportation networks’ performance, in this paper, we focus on the clustering of transportation networks into homogeneous traffic partitions that evolve over time [
13]. Data are essential to the planning and management of issues related to transportation networks. Instead of relying on conventional models, transportation research is increasingly data-driven. With the growing quantity and quality of data being collected from intelligent transportation systems, data-driven transportation research relies on new generation techniques to analyze these data.
Recently, data-driven innovation in transportation science follows two main approaches: the technology-oriented approach to enhance the data resources available to the platform [
14] and the methodology-oriented approach to improve the software part of the platform [
15]. Exploratory data analysis is a heuristic search technique for finding significant relationships between variables in large data sets. Its efficiency is key to deriving insights from big data. It is the first technique when approaching the data. Exploratory data analysis has the objective of identifying attributes in a data set, using univariate data analysis to characterize the data, detecting and minimizing the impact of missing and aberrant values, detecting errors and, finally, combining features to generate new features [
16].
In our case, to perform network partitioning, both the network topology and the link speeds for all time periods are needed. Therefore, data preparation is needed to create a validated data set for evolutionary spectral clustering. Data preparation aims to remove travel time outliers and coarsen the large-scale network in order to improve the computation time and to estimate link speeds. The data are gathered from the Amsterdam transportation network. The network topology is derived from both cameras and geographic information systems. An algorithm was developed to compute missing data [
17].
Spectral clustering has been successfully applied to the clustering of transportation networks based on the spatial features of congestion at specific times [
7,
8,
17]. Previous works have proposed a simple approach to this type of problem that consists of performing static clustering at each time step using only the most recent data. The main drawback of this approach is that it does not explicitly take into account the temporal aspects of traffic states.
Evolutionary spectral clustering represents algorithms for grouping objects evolving over time. It outperforms traditional static clustering by producing clustering results that can adapt to data drifts while being robust to short-term noise. According to [
18], in the context of evolutionary spectral clustering, a good clustering result should fit the current data well while simultaneously not deviating too dramatically from the recent history.
In our previous work, we applied the evolutionary spectral clustering algorithm in order to partition a road network between congested and fluid zones [
19]. However, the major drawback of this algorithm is the cubic time complexity and the high memory demand for computing the Laplacian matrix that makes it insufficient to handle data sets characterized by a large number of patterns.
This paper proposes an efficient evolutionary spectral clustering algorithm that provides a solution to this problem. The proposed algorithm introduces the notion of a smoothed Laplacian matrix with a weighted sum of current and past similarity matrices to efficiently solve the eigenvalue problem by means of the incomplete Cholesky decomposition. It is also equipped with a stopping criterion based on the convergence of the cluster assignments after the selection of each pivot in place of the classical stopping condition based on the low-rank assumption. In order to improve the network’s performance, the similarity matrix is computed in a way to put more weights on neighboring links and to facilitate the connectivity of the clusters.
The similarity, in this case, will be a sparse matrix, as some links have zero similarity, which can simplify the complexity of the clustering algorithm [
8]. Determining the number of clusters in a data set is a frequent problem in data clustering. Choosing the appropriate number of clusters is often ambiguous, with interpretations depending on the shape and scale of the distribution of points in a data set. Many measurements have been developed for finding the optimal number of clusters. In early research, the authors proposed an algorithm to estimate the optimal number of clusters in categorical data clustering by a silhouette coefficient, which is a useful technique for assessing the number of clusters [
20,
21].
The silhouette of data is a measure of how closely it is matched to data within its cluster and how loosely it is matched to data of the neighboring cluster. A silhouette close to 1 implies the datum is in an appropriate cluster, whereas a silhouette close to -1 implies the datum is in the wrong cluster. However, a silhouette only reveals the quality of data in some specific set, and it does not work well in ring-shaped data sets. The gap statistic method is another method used for detecting the number of clusters. The key idea of the gap method is to compare within-cluster dispersion in the observed data to the expected within-cluster dispersion. The gap method performs well assuming that the data come from an appropriate distribution [
22].
In order to identify the correct number of clusters to return from a hierarchical clustering, an efficient algorithm was developed. This algorithm makes use of the same evaluation function that is used by a hierarchical algorithm during clustering to construct an evaluation graph where the x-axis is the number of clusters, and the y-axis is the value of the evaluation function at x clusters. The point of the maximum curvature of this graph is used as the number of clusters to return. This point is determined by finding the area between the two lines that most closely fit the curve [
23]. However, this method works poorly with mixed data types, and it does not work well on very large data sets.
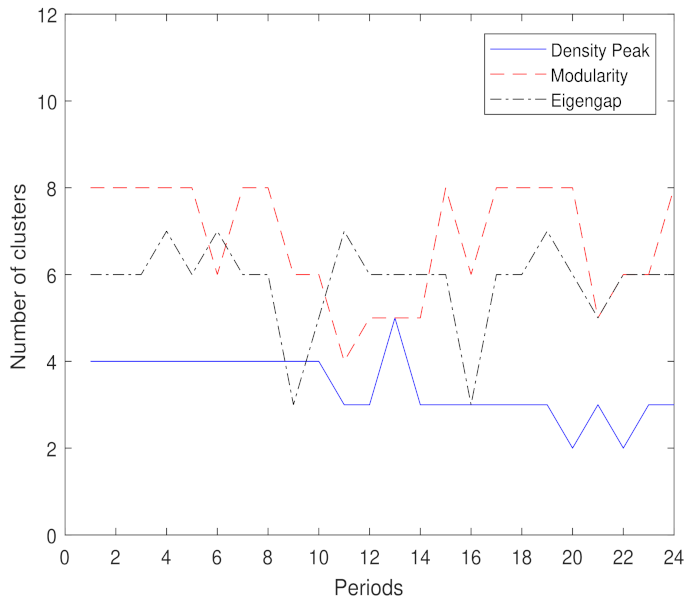
In this paper, we introduce the density peaks algorithm, which has the ability to recognize clusters regardless of their shape. The clustering is performed using the efficient evolutionary spectral clustering algorithm, and we adapted the density peaks clustering algorithm to automatically find the number of clusters, which dynamically changes over time.
This algorithm is based on the assumptions that the cluster centers are surrounded by neighbors with a lower local density and that they also have relatively large distances from other data points with a higher local density. It also has the advantage of visualizing the structure of the data in the decision graph. The proposed algorithm is compared with the modularity and the eigengap methods to show its effectiveness.
The new contributions of this paper are summarized as follows:
We optimize the efficient evolutionary spectral clustering algorithm in order to cluster real world traffic data sets collected from the transportation network of Amsterdam city [
17]. This algorithm was built in order to handle traffic evolving over time.
We extend this algorithm for the preserving cluster membership framework by computing a new sparse similarity matrix that considers traffic at previous times. We show that this algorithm minimizes time and space complexities. We prove that the proposed efficient evolutionary spectral clustering algorithm provides more robustness and effectiveness compared with other static clustering methods in the case of a transportation network.
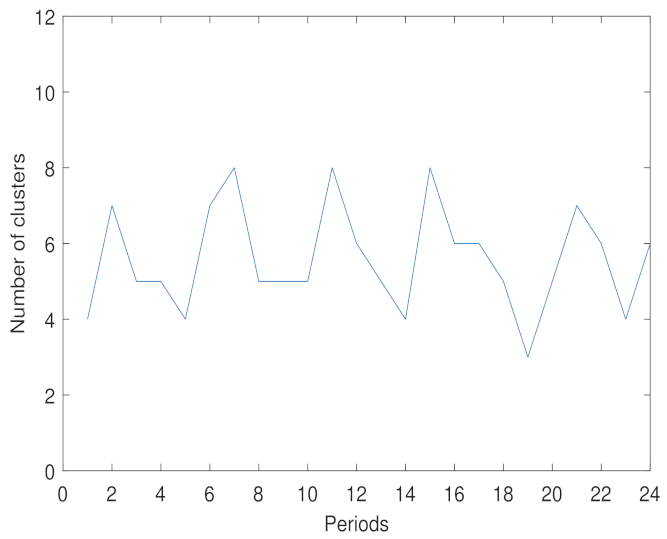
We compute the number of clusters for each time period using the density peak algorithm. We modify this algorithm in order to compute the distance between snakes based on the sparse snake similarity matrix. This algorithm is proven to be more effective than the modularity and the eigengap methods in the case of efficient evolutionary spectral clustering.
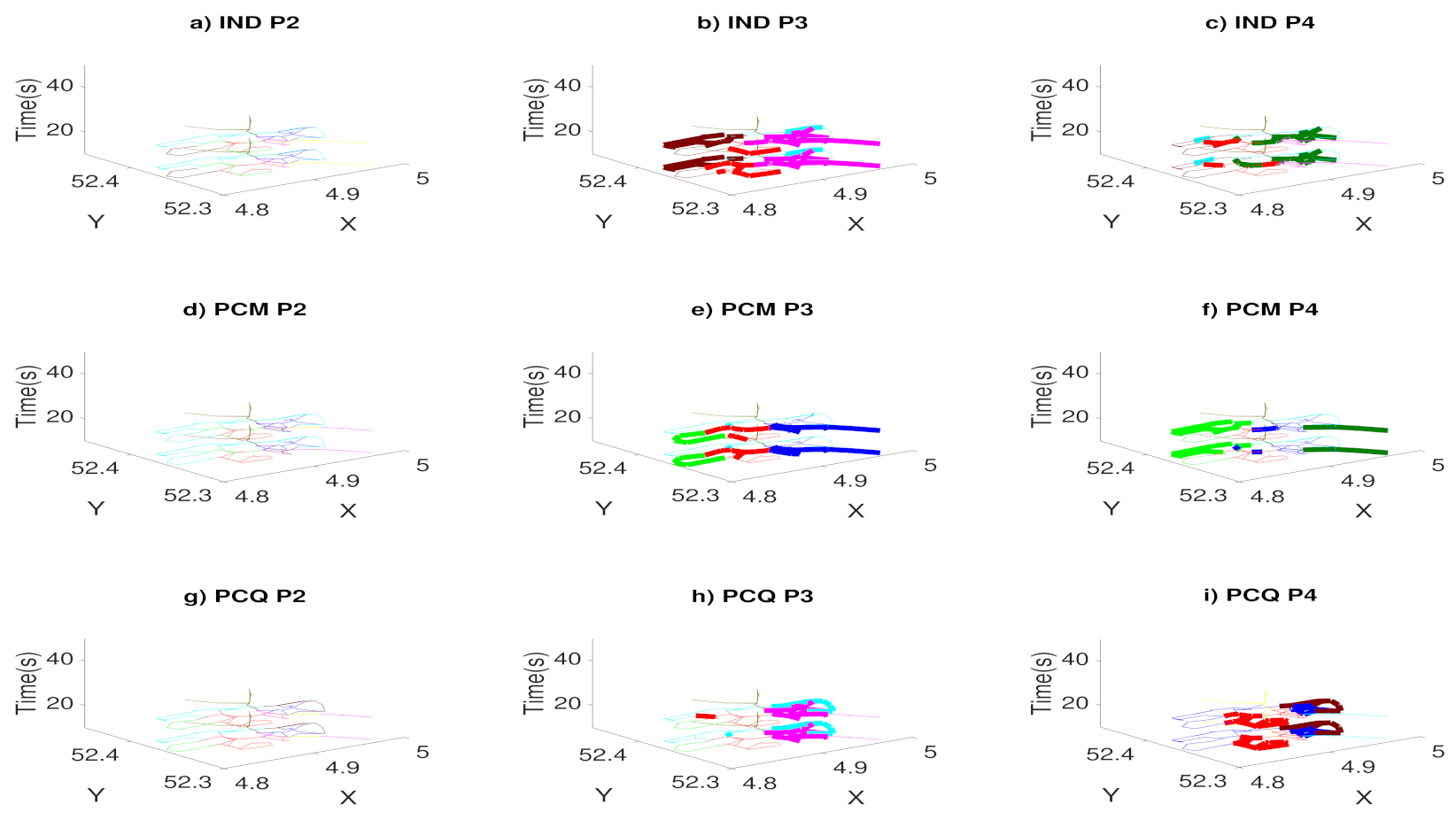
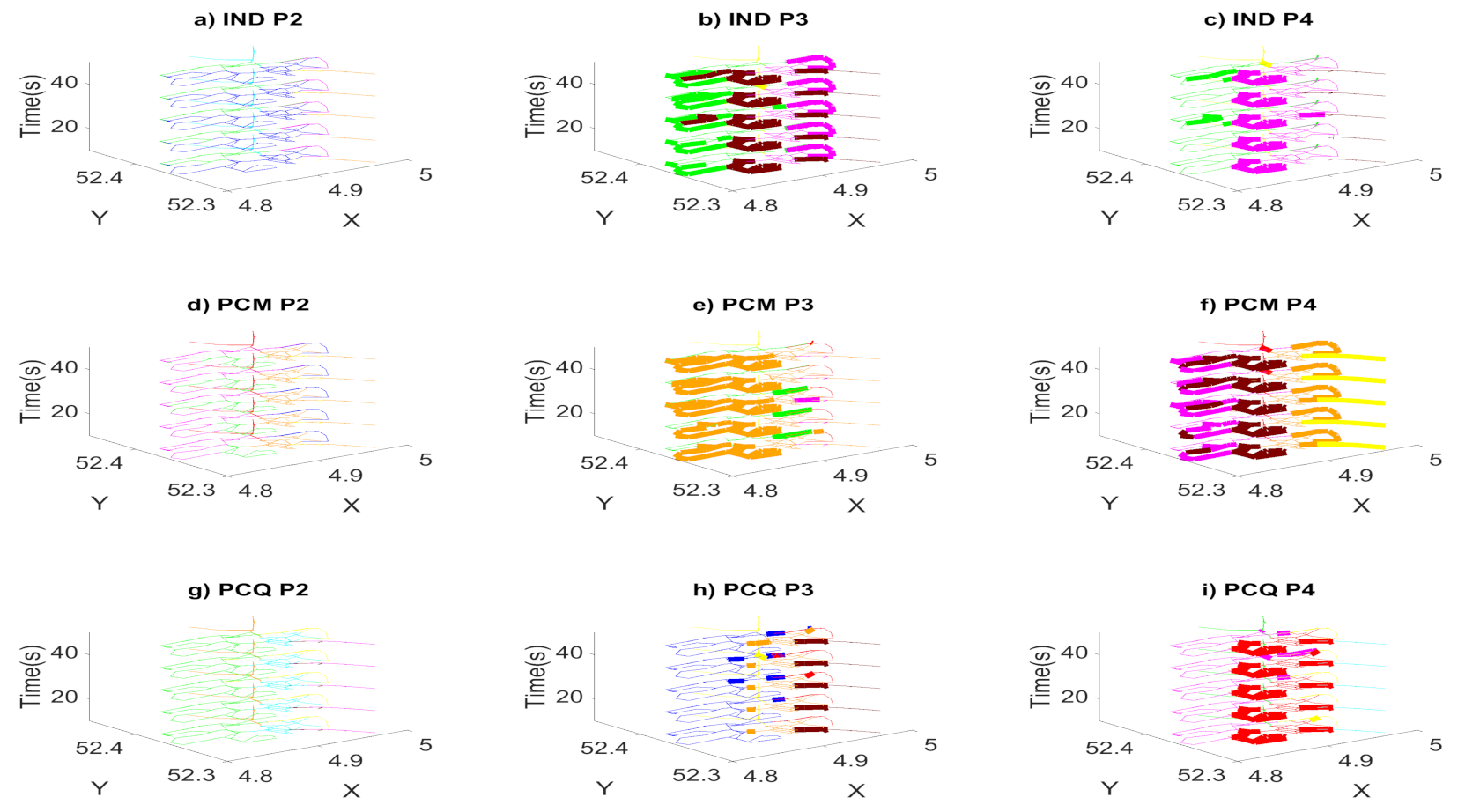
We convert the transportation network into different graph models in order to find directional congestion. We study the evolution of the graph over different time periods of the day. We prove which clustering method is the most efficient for clustering all time-dependent road speed observations into 3D speed maps, and we study the computational times to partition the road network.
The paper is structured as follows: in
Section 2, we present the graph models and how to compute the similarity matrix. We also introduce the spectral clustering algorithm ans the evolutionary spectral clustering algorithm, and we propose an efficient evolutionary spectral clustering algorithm for the partitioning of a transportation network. In
Section 3, we explain how to automatically find the number of clusters using the density peak algorithm.
Section 4 shows the experimental results, and finally the paper is summarized with our conclusions in
Section 5.
2. Methodology
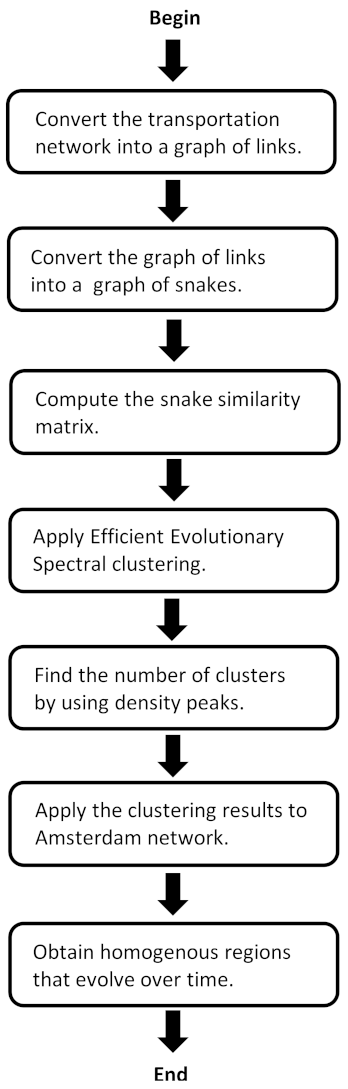
Traffic data change quickly; hence, static spectral clustering algorithms are unable to deal with data where the characteristics of link speeds to be clustered change over time. We are interested in developing a methodology based on evolutionary spectral clustering to dynamically partition a graph-based traffic network into connected and homogeneous clusters. First, we define the network of links and how to convert it into a graph of links. Next, we convert the graph of links into a graph of snakes, and then we compute the similarity matrix between snakes in order to apply clustering algorithms.
Next, we briefly explain the spectral clustering algorithm. We also introduce the evolutionary spectral clustering framework through normalized cuts and finally we give the efficient evolutionary spectral clustering algorithm in order to minimize the time and space complexities.
Figure 1 shows the data flow chart (DFC) that describes our methodological steps, and Glossary shows a summary of notation symbols used in the paper.
2.1. Graph Models
This section defines the structure of the network of links and explains how to convert it into a graph of links and a graph of snakes in order to apply the spectral clustering algorithm.
2.1.1. Network of Links
A network of links is defined as comprising a set of intersection points that are connected by a set of links , where for each link , a speed value is assigned to it. Given the network of roads, we are now able to convert it into a graph of links.
2.1.2. Graph of Links
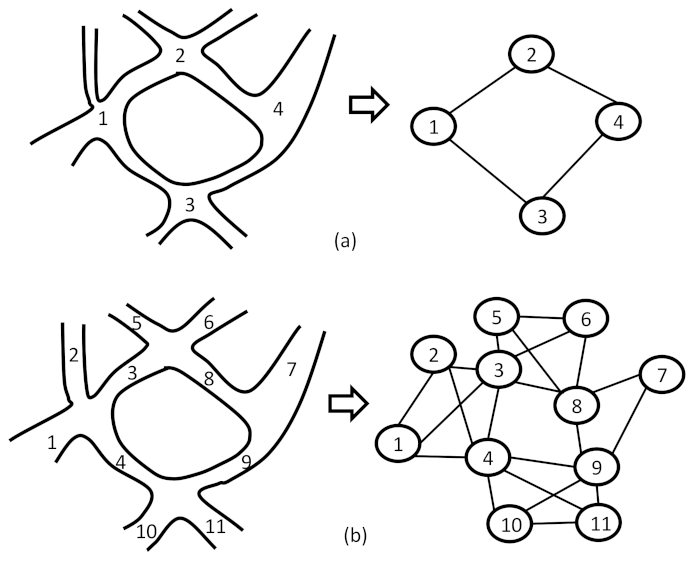
We distinguish two possible representations in order to convert the network of links into a graph of links, which are the primal graph and the dual graph (
Figure 2). In the first representation, the primal graph is constructed by considering each intersection in the network as a node and adding an edge or link between each pair of nodes if there is at least one link connecting them.
In this representation, we maintain the same shape of the network of links; the edges in the graph follow the paths of the real network of links. In the second representation, the dual graph is constructed by considering each link in the network as a node and by establishing an edge between each pair of possible nodes if there is at least one common intersection between them.
In this paper, we use the primal graph, and we model the data of a network of links as a graph in which V and E are the sets of nodes and links, respectively. Two links are spatially connected if either the end or the beginning of them are connected to the same intersection. Based on this definition, all the links entering or exiting the same intersection are assumed to be connected. Moreover, links connecting to the same intersection are considered adjacent. In order to partition the graph edges into connected homogeneous traffic states, we begin to build a graph of snakes.
2.1.3. Graph of Snakes
The graph of snakes is represented as a undirected graph
. The set of vertices
, where
represents the number of network snakes, and the set of edges
represents the similarity between snakes. Although there is a one-to-one association between links and snakes, the same name
is used for both the links and snakes. The value of
N is computed after coarsening the large-scale transportation network of Amsterdam and removing travel time outliers [
17]. A snake is formed as a concatenation of a number
L of adjacent links with similar speeds. Each snake is defined in an iterative process starting from an individual link in the graph.
A snake is defined by
, where
,
is the size of the snake,
is the link composed from an identifier
and a link speed
, and
and
are connected links. The connected clusters’ dissimilarity is used to evaluate the performance of the clustering algorithm for different values of
L [
17].
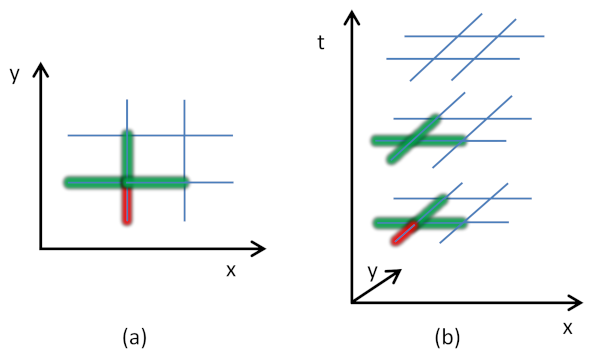
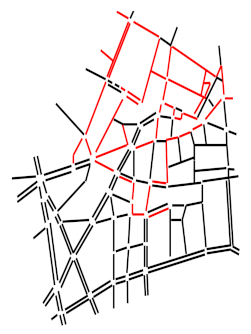
For each of the links, we iteratively build a snake, which is a sequence of links, with the objective of having a minimum variance of all the chosen link speeds at each step. One can consider this as a snake that starts from a link and grows by attracting the most similar adjacent link iteratively (
Figure 3).
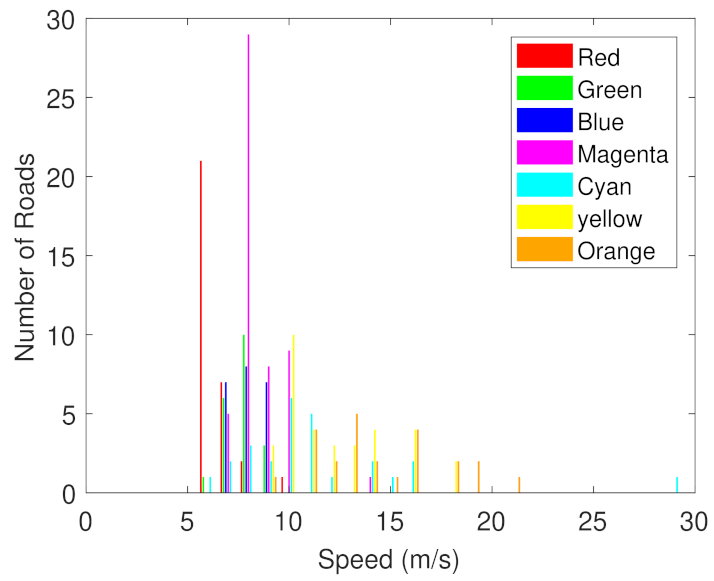
Figure 3 shows an example of a snake, initialized by a link in red. The green links represent the neighborhood, according to two- and three-dimensional approaches.
Note that, at each step, the most similar link to the snake is the adjacent link with the closest speed value to the average speed values of the links in the snake. This procedure identifies interesting patterns as the variance grows with the size of the links. This observation is related to the fact that some parts of the graph are more similar than others, and if a large number of dissimilar links are added, high variance is unavoidable.
Thus, in each step, each snake identifies all the adjacent links and adds the one that has the smallest variance value to the average value of previously added links in that snake. This procedure continues until the snake encompasses all the links in the network. The variance value of the snake at each step
l can be computed by:
where
where
denotes the mean speed of the snake at each step
l, and
is the speed of the link added in the
l-th step.
Clustering the snakes of links requires the construction of a weighted graph that encodes the similarity between data snakes. In the next section, we will explain how to build the snake similarity matrix.
2.2. Similarity
There are many proposed methods in the literature to construct a similarity matrix for a graph, such as the inner product of feature vectors, the Gaussian similarity and the cosine similarity [
25]. In our study, the goal is to define a similarity between each pair of links in the network that takes into account both homogeneity and spatial connectivity. Using this similarity measure, a fully connected graph is built in which one edge exists between every two nodes, meaning that every two snakes in the network are similar.
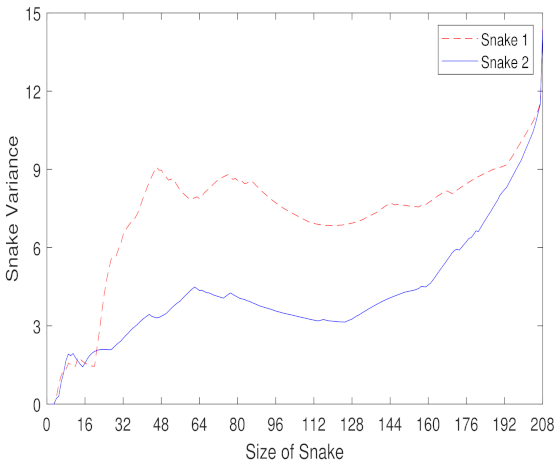
The sequence of the links in a snake not only represents the links with the close speed values but also has some information about the spatial connectivity of the links. As the size of the snake grows, this measure of similarity gives less forget weight on the links that are collected. After some iterations, the snake does not have any good options to add and starts adding links with variant speeds leading to a higher variance.
To further investigate, we plot the variance of the first and the second snake of the network of links (
Figure 4). Based on these properties of the snake, we propose to put more weights on the links that are spatially closer to each other, and their corresponding snakes will converge to the same point [
17].
In this case, we obtain a sparse similarity matrix. The snake similarity is defined as follows:
Note that:
where
and
are
l-size snakes corresponding to starting links
i and
j, and
is the number of common link identifiers between the two snakes of size
l. The weight coefficient
is assigned by the user with
. The snake similarity matrix algorithm for the transportation network is given by Algorithm 1.
| Algorithm 1 Snake Similarity Matrix Algorithm for the Transportation Network |
- Require :
set with N links (The same set Γ is used for both the links and the snakes). - 1:
while Link is in the set of links do - 2:
Add the link to the snake - 3:
while length() < L do - 4:
find the adjacent link A of the snake , which has the closest variance to the average value of previously added links in that snake using Equation (1). - 5:
Add this link A to the snake . - 6:
end while - 7:
end while - 8:
while Snake is in do - 9:
while Snake is in do - 10:
Compute the similarity matrix based on Equation (3). - 11:
end while - 12:
end while
|
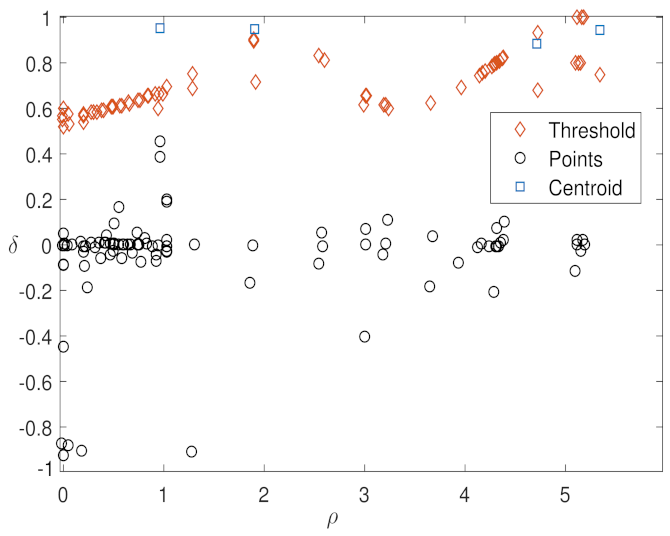
In order to prove the correctness of the algorithm, we consider a graph of links with a certain number of homogeneous regions with different levels of congestion in the graph. The links of one region have the same density or speed value. Each snake adds the adjacent link with the closest speed value to the average speed values of the links in the snake. Snakes start from different links in each of these regions. They first integrate all the links in that region and then start adding from other regions with different levels of congestion.
We can conclude, that after reaching this state, all the snakes within one component will show the same behavior. Moreover, they have many common links during their evolution before reaching the whole component. We use these features to define a similarity matrix constituted by the number of common link identifiers between the pairs of snakes. Snakes with different initial links have a robust trend inside each cluster and converge to the same state before adding links from other clusters.
By running the snake algorithm through the graph from different links, the homogeneous regions are identified. The homogeneous regions in the graph refer to the set of links in which all snakes—starting from any initial link in that component—will end having the same links in that sequence [
8].
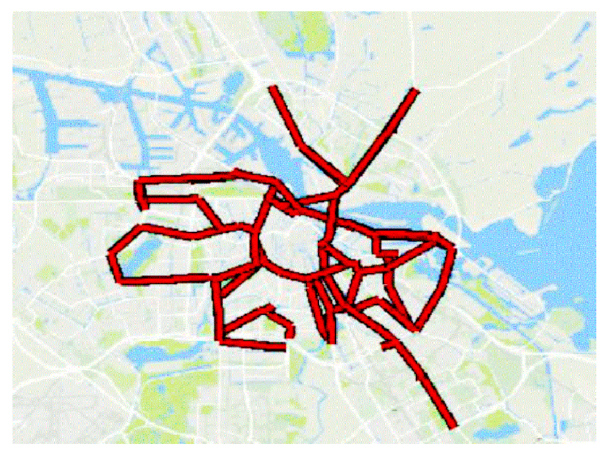
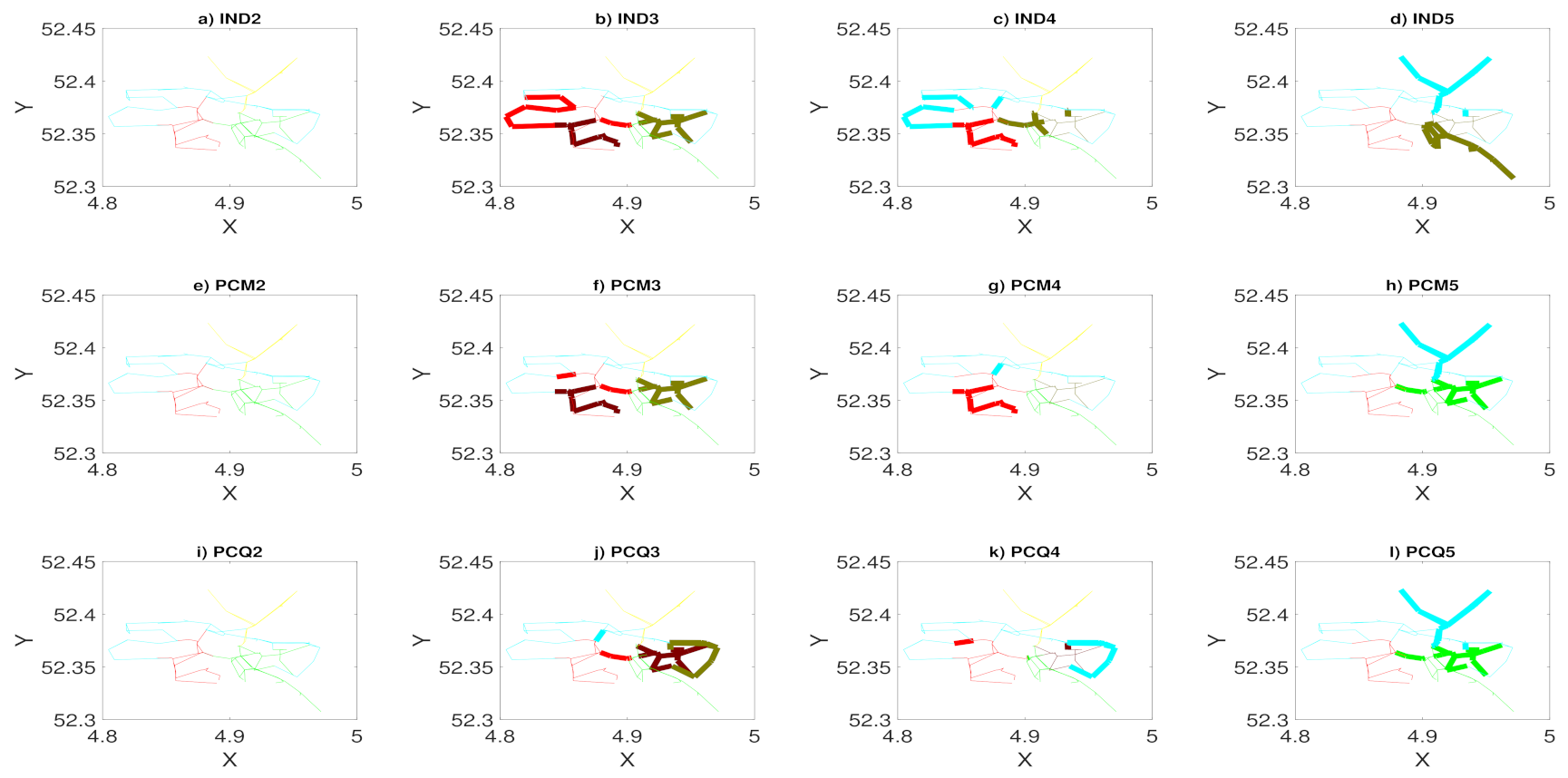
Figure 5 shows a snake computed on the network of the sixth district of Paris.
2.3. Spectral Clustering
In graph theory, there are many clustering algorithms that assign objects into clusters with respect to their pairwise similarity measure. The success of spectral clustering is based on the fact that it does not make any assumptions about the data structure. Spectral clustering can handle complex and unknown cluster shapes; in these cases, the commonly used methods, such as K-means or mixture models, may fail.
The idea of spectral clustering is to cluster based on the eigenvectors of a similarity matrix W defined on the set of nodes of a graph in which is the set of nodes, N is the number of nodes in the network, and E is the set of edges. The goal is to bring similar nodes to the same cluster, thus, identifying the set of nodes that share similar characteristics. Thus, to partition the graph appropriately, one can minimize the objective function, which can be of the normalized cut type.
For a set of clustering results
such that
, and
for
; the normalized cut is formulated as follows [
26]:
where
K is the number of clusters,
is defined as the complementary set of
. The cut-weight between two subsets
and
is defined as:
A partition can be expressed as an
N-by-
K cluster indicator matrix
Z whose elements are in
, with
if and only if node
i belongs to cluster
j. Let
W denote the graph similarity matrix and
D the diagonal degree matrix with
. The normalized cut can be equivalently written as:
where
is the relaxed continuous-value of
Z with
. This problem can be converted to a trace maximization, where a solution is the matrix
whose columns are the K-eigenvectors associated with the top K-eigenvalues of the Laplacian matrix defined by:
In our work, we compute X for each time period t and we project the data points into , which is the subspace spanned by the columns of X, and then we apply the K-means algorithm to the projected data in order to obtain the clustering results.
2.4. Evolutionary Spectral Clustering
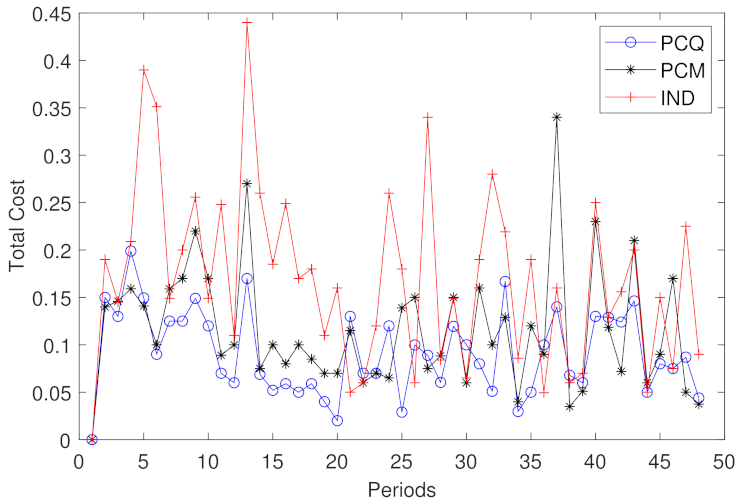
Spectral clustering approaches are usually static algorithms and, hence, need to be adapted to be applied to dynamic evolving traffic. Indeed, the current clusters should depend on the current data traffic features without deviating too dramatically from previous histories [
18]. For this reason, we propose two frameworks of the evolutionary spectral clustering for the partitioning of dynamic transportation networks, which are the preserving cluster quality (PCQ) and the preserving cluster membership (PCM). In both frameworks, the total cost function is defined as a linear combination of the snapshot cost (SC) and the temporal cost (TC):
where
is a parameter assigned by the user, which reflects the user’s emphasis on the snapshot cost and the temporal cost. In the upcoming experiments, we choose
in order to place more emphasis on the snapshot cost while considering, at the same time, the temporal cost. The snapshot cost (SC), which is expressed in the same way for the two frameworks, measures the snapshot quality of the current clustering result with respect to the current data features, whereas the temporal cost (TC) is expressed differently.
In the preserving cluster quality (PCQ) framework, the temporal cost (TC) measures the goodness of fit of the current clustering result with respect to historic data, while in the the preserving cluster membership (PCM) framework, the temporal cost (TC) is expressed as the difference between the current partition and the historic one.
2.4.1. Preserving Cluster Quality (PCQ)
In the context of spectral clustering, we consider two partitions,
and
, which are the results of clustering the transport network at a time period
t. We assume that the two partitions give similar performance at time period
t, but in the case of clustering historic data, the clustering performance using partition
is preferred because it is more consistent with historic data. In this case, the evolutionary normalized cut’s total cost can be expressed as follows [
18]:
where
means evaluated by the partition
. For a given partition, the normalized cut can be written following Equation (7). After some manipulation, we obtain the following total cost:
The PCQ framework consists of finding the optimal solution that minimizes the total cost. This problem can be converted to a trace maximization problem, where a solution is the matrix
whose columns are the K-eigenvectors associated with the top K-eigenvalues of the evolutionary Laplacian matrix defined by the combination of both normalized similarity matrices at time period
t and
[
18]:
This equation is used in two consecutive times t and . After obtaining at time period t, we can project data points into and then apply the K-means clustering algorithm to obtain the final clusters.
2.4.2. Preserving Cluster Membership (PCM)
Consider that two partitions,
and
, cluster the data at time period
t equally well. However, when compared with the historic partition
,
is preferred because it is more consistent with the historic partition. This idea is formalized by [
18]:
where
is the snapshot cost. The temporal cost TC is expressed as the difference between the clustering result at time period
t and the clustering result at time period
. One solution is the norm of the difference between the two projection matrices, which is expressed as:
where
and
are the sets of top K-eigenvectors at time period
t and
, respectively. In this case, the evolutionary total cost can be expressed by:
The PCM framework consists of finding the optimal solution that minimizes the total cost. This problem can be converted to a trace maximization, where the solution is the matrix
whose columns are the top K-eigenvectors associated with the top K-eigenvalues of the evolutionary Laplacian matrix [
18]:
The final clusters can be attained by projecting data into and then applying the K-means algorithm to obtain the final clusters. The two proposed frameworks can handle any variations in the number of clusters.
In the PCQ framework, the temporal cost is only expressed by historic data, not by historic clusters, and therefore the computation at the current time is independent of the number of clusters at the previous time. Moreover, the PCM framework can be used without change when the partitions have a different number of clusters.
In comparing the Laplacian graphs of both frameworks, we can see that they differ in terms of how they measure the historic partition.
and
have in common the first term, which refers to the current data expressed by the symmetric Laplacian at time
t. The difference between these two is found in the second term. For the PCQ framework, it is equal to the symmetric Laplacian at time
, whereas for the PCM framework, it is expressed by the set of eigenvectors
at time
. The evolutionary spectral clustering algorithm for the transportation network is given by Algorithm 2.
| Algorithm 2 Evolutionary Spectral Clustering Algorithm |
- Require :
Similarity matrix , Number of to construct. - 1:
Compute the degree matrix . - 2:
Compute the Laplacian L matrix for PCQ or PCM using Equations (16) or (12). - 3:
Solve the the eigen equation . - 4:
Find the K top eigenvalues and their corresponding eigenvectors of L. - 5:
Compute as a matrix containing the vectors as columns. - 6:
Create the Matrix in from U by normalizing the rows by the norm 1. - 7:
for i=1,...,N do - 8:
let be the normalizing vector corresponding to the ith row of . - 9:
end for - 10:
Cluster the data points in with the K-means algorithm to obtain clusters .
|
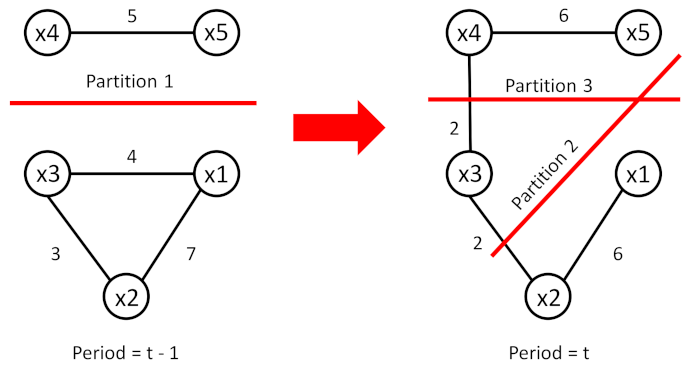
We explain the steps of the evolutionary spectral clustering algorithm by considering the following example.
Figure 6 shows two graphs at time periods
and
t. In this example, we choose a number of classes equal to two for the two periods.
The similarity matrices of the two graphs are defined as follows:
It is clear that the graph at time period t-1 should be clustered by partition 1 when we apply the evolutionary spectral clustering algorithm. In order to partition the graph at time period t, we run the evolutionary spectral clustering algorithm by applying the
framework. We obtain the following Laplacian matrix:
Next, we solve the the eigen problem. We obtain the eigenvector matrix as follows:
Since the values of U are in the interval , then we choose equal to U. Next, we compute as the ith row of . Finally, we apply the K-means algorithm to the data points and we obtain the two clusters of partition 3: and . It is shown that both partition 2 and partition 3 are good for time period t; however, partition 3 should be preferred because it is more consistent with partition 1 at time period .
2.5. Efficient Evolutionary Spectral Clustering Algorithm
A major issue of the evolutionary spectral clustering algorithm is its computational and memory cost. If we denote by
N the number of the data snakes at a given time, solving the eigenvalue problem has a complexity
and the
evolutionary Laplacian does not fit into the main memory when
N is large. To solve this problem, we define the following eigenvalue problem involving the smoothed Laplacian as follows [
27]:
where
This similarity matrix for PCQ is defined as:
Notice that, in contrast to evolutionary spectral clustering, we consider all the previous time steps before the actual time point using an iterative process because of the low computation of the efficient evolutionary spectral clustering algorithm. However, the computation of the similarity matrix for PCM is not adopted for the efficient evolutionary spectral clustering algorithm. Thus, in the objective to make a comparative study with the PCM framework, we propose a similarity matrix for PCM defined as follows:
The second term of the equation is multiplied by
in order to reduce the term
to the identity matrix when the smoothed Laplacian is computed. To achieve the reduction of the eigenvalue problem, the similarity matrix
is replaced with its incomplete Cholesky decomposition (ICD) [
28].
An ICD of a matrix
allows us to compute a low-rank approximation of accuracy
of
matrix
, where
with
, such that
. The value of
m is computed by the incomplete Cholesky decomposition algorithm [
28]. The ICD selects the rows and columns of
, which are called pivots considering that the ranks of approximation are close to the rank of the original matrix. The first step in solving the problem with efficient evolutionary spectral clustering is to reduce the eigenvalue problem of both PCQ and PCM. Thus, we obtain
. After that, we replace
with its
factorization and substitute
R with its singular value decomposition. As a result, we will obtain the following equation:
where
and
such that
and
,
,
. We have to solve an eigenvalue problem of size
, involving the matrix
that is smaller than the size
of the original problem.
In addition, the eigenvectors problem can be estimated as
, where the related eigenvalues are
. At last, the cluster assignment for the
ith data points are obtained from the pivoted LQ factorization of matrix
:
such that
is a permutation matrix as defined in [
27],
is a lower triangular matrix, and
is the unitary matrix.
The classic ICD algorithm is based on the supposition that the Laplacian matrix has a small rank. A new stopping criterion assumes that the cluster assignments tend to converge after selecting each pivot. Therefore, for the cluster assignments
at step
s and
atstep
, the normalized mutual information (NMI) is calculated. The time step
s is used for an iterative process of the algorithm. The NMI is defined by [
29]:
where the mutual information between the partitions
and
is defined as:
The term
represents the number of shared patterns between the clusters
and
, and
is the number of clusters in partition
. The entropy of the partition
is defined as:
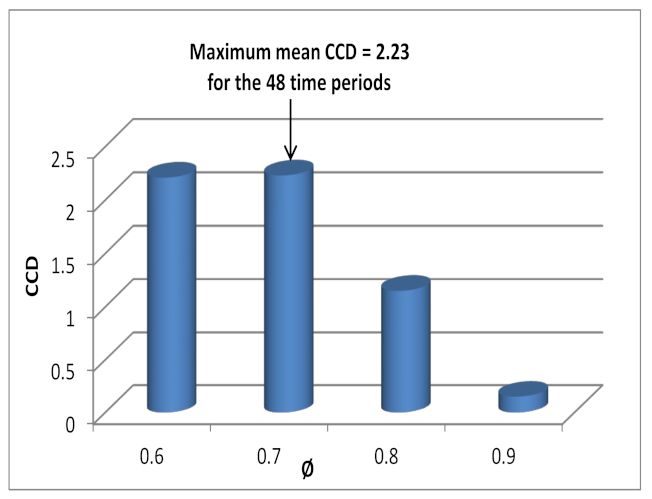
A higher NMI value means that the clustering algorithms generate identical partitions. The NMI value is bounded in (0,1), equaling 1 when the two partitions are identical and 0 when they are independent. Consequently, the ICD algorithm terminates when , where is a user-defined threshold value.
To make this procedure faster, we need to check the convergence of the cluster assignments only when the approximation of the similarity matrix is good enough. Thus, we stop the computation when the quality of the approximation of the similarity matrix is greater than a predefined threshold as follows:
where
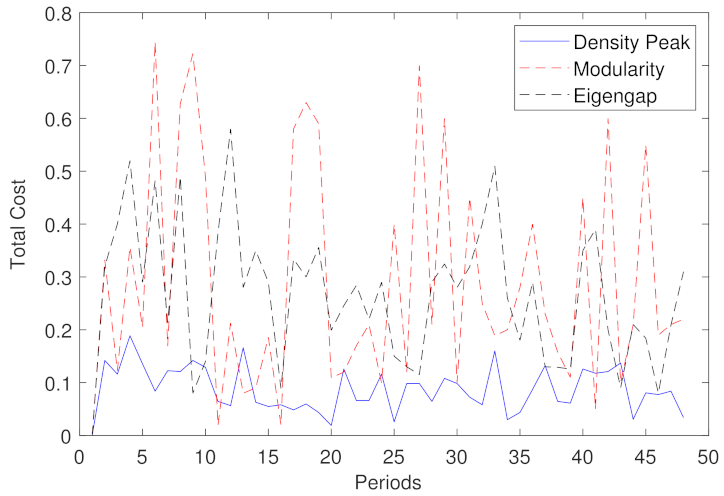
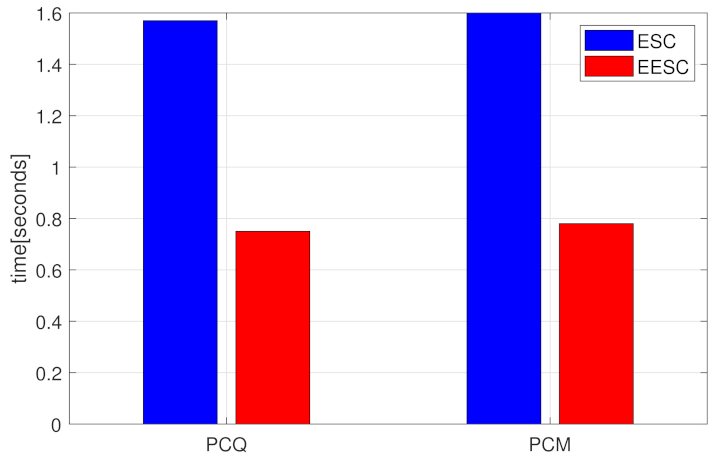
Finally, to prevent the termination of the ICD algorithm too early with the poor and insufficient performance of clusters, we choose , which is a suitable choice through experiences. As a result, this criterion decreases the number of selected pivots and improves the computational complexity. This methodology outperforms the evolutionary spectral clustering and the normalized spectral clustering algorithm that is denoted by IND, which independently applies the spectral clustering algorithm on the speed of road segments in only the time step t and ignores all the historic data before t.
It is shown that the computational complexity of the efficient evolutionary spectral clustering algorithm is
[
27]. On the other hand, the methods of the evolutionary spectral clustering have a complexity of
as a result of the fully eigen decomposition of the
similarity matrices that are included at each time
t. Consequently, this method is an effective tool for dealing with large-scale clustering problems with a time complexity of
. The efficient evolutionary spectral clustering algorithm for the transportation network is given by Algorithm 3.
| Algorithm 3 Efficient Evolutionary Spectral Clustering Algorithm for Transportation Networks |
- Require :
Similarity matrices thresholds and . - 1:
for t=2,...,T do - 2:
Compute the matrix (Equations (23) and (24))
, initialize the matrix P to zero and the matrices and Y to one. - 3:
Compute the number of clusters using density peaks. - 4:
while do - 5:
Start incomplete Cholesky decomposition and update the matrices Y, P and [ 27, 28]. - 6:
Compute using Equation (31). - 7:
Compute . - 8:
if then - 9:
Calculate the decomposition of . - 10:
Evaluate the singular value decomposition of . - 11:
Obtain the approximated eigenvectors through . - 12:
Evaluate factorization with row pivoting as . - 13:
Compute cluster assignment for a data snake (Equation (26)). - 14:
Save the current assignments for the N data snakes in a vector . - 15:
Calculate according to the Equation (27). - 16:
end if - 17:
end while - 18:
end for
|
5. Conclusions
The goal of our study was to partition a transportation network by incorporating temporal smoothness in evolutionary spectral clustering. We presented two frameworks for partitioning the network. In the first framework, the temporal cost is expressed as how well the current partition clusters the historic variation of link speeds. The second framework is different from the first regarding how the temporal smoothness is measured. In this framework, the temporal cost is expressed as the difference between the current partition and the historic one. In both frameworks, a cost function is defined in order to regularize the temporal smoothness.
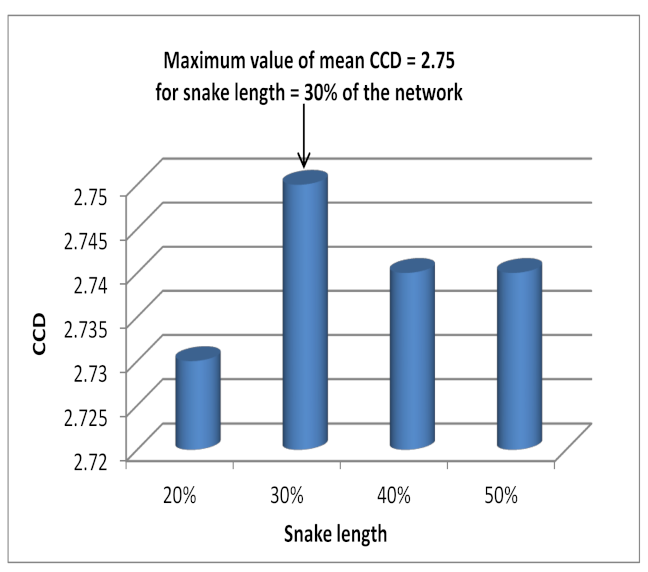
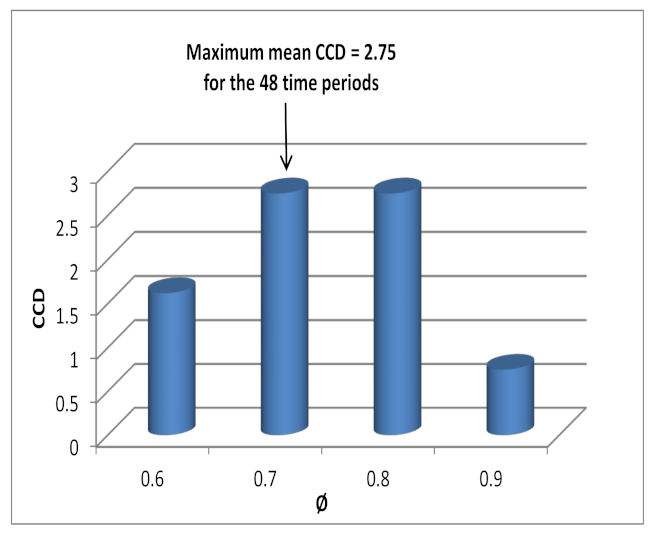
In order to determine the appropriate number of clusters, we used the density peak algorithm, which we proved to be efficient when compared with the modularity and the maximum eigengap methods. Experimental studies on the Amsterdam city network demonstrated that the two efficient evolutionary spectral clustering frameworks provided results that are stable and consistent in an environment where traffic can change over time.
In future work, we will address the following constraints and limitations. We will consider the case where some sensors do not provide valid measurements for specific time intervals. We will extend our efficient evolutionary spectral algorithm to be applied in the case of missing speed data. We will also consider the case of the insertion and removal of links in the network.
In a transportation network, a road can either be closed or opened. In this case, the size of the similarity matrix can change between time periods. Moreover, we will work on another promising application for the partitions computed by efficient evolutionary spectral clustering, which is to predict future travel times using deep-learning algorithms.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}