1. Introduction
Clustering in computer vision has had impacts in a broad range of areas such as face processing, motion analysis, domain transfer, and learning representation [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11]. Such computer vision applications utilize clustering as a non-interactive module in larger vision systems. Unfortunately, all existing clustering algorithms require users to specify parameters, e.g., the desired number of clusters or a distance threshold [
12], which requires some kind of interaction with the system.
The holy grail for clustering is an accurate, fully-automatic, and parameter-free algorithm, which has been elusive since researchers started looking for it in the 1930s [
13]. In recent work [
4], the First Integer Neighbor Clustering Hierarchy (FINCH) clustering algorithm FINCH was developed. FINCH uses rounds of a simple nearest-neighbor process that at least reduces the problem to selecting an appropriate partition from a set of computed ones, and the authors declared this algorithm to be “parameter-free”.
We switched to FINCH in various projects. The results of FINCH made us ask: Is there a theoretical reason to believe that one or more thresholds exist to determine when clusters should merge? In general, this seems to be an ill-posed question since thresholds depend on the actual clustering task at hand and sometimes need to be optimized to achieve that task. However, as we show in this paper, under some general conditions, the answer is: Yes, such a threshold exists. The first important novelty of this paper is a proof that the distribution of proper cluster linkages follows a Weibull extreme value distribution. Using that theory, we present an initial process for a data-driven automatic selection of maximum inter-cluster spacing in agglomerative clustering. Given that a threshold exists, we expect future research to provide even better approximations.
We contend that clustering is inherently ill-defined without meaningful features and similarity or distance measures between them. When dealing with a problem that utilizes clustering, the number of potential clusters is exponential, and the clusters may only have meaning when a measure of similarity of the features is given. For example, given many face images, it needs to be defined if clustering should be based on subject identities, personal attributes (gender, hair color), style of the photos, or location. For the same images, what kinds of clusters we expect depends on the features and not the input images.
We conjecture that prior work has not produced successful fully-automatic clustering algorithms because similarity, or distance, measures for hand-made features are rarely uniform or consistent. Over the past decade, representation and transfer learning, metric learning, and deep features have shown powerful aspects that address vision problems with a significantly better recognition ability and an almost unreasonable ability to define similarity measures that are perceptually meaningful [
14]. In our Unreasonable Clusterability of Deep Features Conjecture in
Section 3, we hypothesize that consistent clustering of deep features is unreasonably easy because they are obtained from training, which defines semantics and produces relatively uniform spaces where location and distance have semantic meaning. In this paper, we show that deep features serendipitously have the behavior of producing a representation that supports fully-automatic cluster threshold selection as the approximate uniformity of the space turns out to be one of the general conditions critical to our extreme-linkage theorem.
To show the effectiveness of the Extreme Value Theory-based threshold selection, we evaluate multiple real clustering problems, using both classical Agglomerative Hierarchical Clustering (AHC), and we use our method to select among FINCH partitions. When our Provable Extreme-value Agglomerative Clustering-threshold Estimation (PEACE) is applied to a classical Agglomerative Clustering of Hierarchies, we call the resulting algorithm PEACH. When it is applied to FINCH, we call the result Partition Estimation Technique for FINCH (PET-FINCH).
Evaluation of clustering requires carefully designed experiments to ensure we measure what matters. Many classic clustering papers test on toy datasets with hand-defined features, which generally fail to have the necessary properties to apply our extreme-linkage and unreasonable clusterability theorems. Such toy datasets also fail to match real problems. Since clustering is widely used in vision applications, we prefer to evaluate actual vision problems. This paper is not focused on new clustering techniques, rather, we are focused on obtaining better results when a deep-feature system needs clustering, i.e., we make state-of-the-art systems that use clustering even better. To show this, we cover a wide range of problems where, originally, clustering techniques with hand-tuned parameters were applied, showing that our methods improve results.
One vision problem that formally defines seven different practical clustering protocols of varying sizes is the IARPA (Intelligence Advanced Research Projects Activity) Janus benchmark [
15]. We use these as part of our evaluation. Another common use for clustering of unknown classes occurs in life-long, continual, and open-world learning. To address that application, we define a new clustering evaluation protocol that seeks to model a more realistic classification and clustering scenario where the data to be clustered include a mixture of in-distribution and out-of-distribution samples. This better aligns with many real problems since users do not know which, or how many, clusters will occur. We analyze and report on each of in-, out-, and mixed-distributions to showcase the difference. Another related common vision problem using clustering is transfer clustering [
5], and we use the provided default evaluation protocols here as well. Finally, to show that the PEACH approach does not depend on pre-defined deep features, we evaluate PEACH in deep clustering for unsupervised feature learning and deep features classification where such problems do not have a predetermined number of clusters. While prior work [
10,
11] used hand-tuned clustering parameters, we show that, using our Extreme Value Theory-based threshold selections, we can drop PEACH into these systems and significantly improve performance.
Our contributions include:
- 1.
We prove that, with modest assumptions, ideal and actual nearest-neighbor linkages follow Extreme Value Theory (EVT) and are governed by a Weibull distribution for most datasets.
- 2.
We show that the modest assumptions are generally satisfied by features extracted from deep learning systems.
- 3.
We provide algorithms to efficiently approximate linkage thresholds that are robust to moderate levels of outliers and combine them with agglomerative clustering to introduce a Provable Extreme-value Agglomerative Clustering-threshold Estimation (PEACE).
- 4.
We combine EVT-based threshold selection with the state-of-the-art algorithm FINCH to build PET-FINCH. Over multiple experiments, we show that PET-FINCH generally selects the best partition.
- 5.
Using pre-computed deep features, we show that PEACH provides a statistically significant improvement over the original clustering approach on large face datasets: IARAPA Janus Benchmark B (IJB-B) and Labeled Faces in the Wild (LFW).
- 6.
We introduce a real-world clustering protocol on the ImageNet dataset that is useful for applications of data labeling and incremental learning, and we provide a baseline clustering.
- 7.
We demonstrate how to incorporate PEACH on transfer clustering to provide the new state of the art on those problems.
- 8.
We show that PEACH outperforms the state of the art for Top-1 accuracy of deep clustering on handwritten digits (MNIST).
2. Related Work
This paper is not about a new clustering algorithm but rather about an automated parameter selection for existing algorithms. Thus, most papers are only weakly related and not discussed in detail, and we only review those used in the experiments. Tables in the experiments also include a comparison with a wider range of algorithms that do not perform as well.
Clustering analysis research dates back to the 1930s [
13]. In addition, hundreds of survey papers exist on general clustering. However, to date, no general algorithm has been fully automated [
4], while FINCH is at least able to provide good default parameters. Another automatically liked clustering approach named Swarm intelligence [
16] still requires parameters and the abundance values of a dataset. Some researchers developed autonomous parameter selection for image segmentation techniques, and argue that they can be viewed as a type of clustering [
17,
18,
19,
20,
21]. Image segmentation is a very special problem with added constraints, and the approaches have failed to generalize to general clustering problems even in other vision applications.
Clustering algorithms are generally divided into centroid-based, density-based, spectral-based, and connectivity-based algorithms. The widely used K-Means [
22] is an iterative centroid-based algorithm. DBSCAN [
23] is a common clustering algorithm using point densities. MeanShift [
24] is another example of density-based algorithms. Spectral Clustering [
25] is a clustering algorithm that uses the eigenvalues (spectrum) of the similarity matrix for the given samples. Various algorithms have explored combinations of these approaches, such as BI-Clustering [
26], Affinity Propagation [
27], Ball Cluster Learning (BCL) [
3], BIRCH [
28] OPTICS [
29], and Power Iteration Clustering (PIC) [
30]. Most of these are not included in our experiments, as on our data, they are significantly worse than those presented.
Another widely applied clustering technique is agglomerative clustering [
31], a connectivity-based hierarchical clustering approach that forms the basis of various other approaches. Agglomerative Hierarchical Clustering (AHC) [
31] builds a hierarchical tree using a bottom-up strategy, successively merging nearest clusters, updating distance, and continuing until all clusters have been merged. The AHC tree can even be cut to obtain any number of clusters. Several different definitions of nearest clusters may be employed; for example, SciPy [
32] implements single linkage, complete linkage, average linkage, and centroid linkage. Recent work defines new objectives and near-optimal complexity algorithms [
33,
34].
Currently, no effective, general-purpose, parameter-free, and fully autonomous clustering algorithm exists, although some techniques do take important steps in that direction. The density-based OPTICS [
29] and the related HDBSCAN [
35], variants of DBSCAN [
23], find the core samples of high density and expand clusters from them to build a cluster hierarchy for variable neighborhood radii. They still require critical parameters, but various implementations provide non-data-driven defaults for such parameters used in our experimental comparisons.
Swarm [
36] is a single-linkage clustering method with semi-automatic parameter selection that has some some superficial similarities with other clustering methods. Swarm’s novelty is its iterative growth process and the use of sequence abundance amplicons to delineate clusters. Swarm presents an internal structure where the most abundant amplicon usually occupies a central position and is surrounded by less abundant amplicons. The way Swarm explores the amplicon-space naturally produces a graph representation of the clusters, in the form of a star-shaped minimum spanning tree. Swarm properly delineates large clusters (representing a high recall), and can distinguish clusters with as little as two differences between their centers (high precision). Swarm-inspired clustering can be used in many clustering techniques such as K-Means and AHC [
16], and the authors observe that the use of the K-Means and the Fuzzy C-Means [
37] in clustering problems are of great importance in the application of the swarm intelligence algorithms. They are largely used for comparing the performance of Swarm-based approaches and creating hybrid proposals. However, Swarm cannot work without abundance values of the dataset, where the user needs to provide both a local parameter and abundance values before using the algorithm—it is not fully-automated.
FINCH [
4] is an agglomerative clustering method that only uses the first neighbor of each sample to discover large chains and groups of data. While FINCH may be a parameter-free clustering algorithm, it is not autonomous as it outputs several possible partitions of the data. The user must still select the appropriate partition. The experiments in [
4] show the best partition using ground-truth information, which yields an over-optimistic view on the performance of the algorithm in fully-automated systems and the idea of automatic parameter selection.
Evaluation Metrics
While generally, clustering has no explicit way to be evaluated, some evaluation protocols provide the ground truth for the clusters, e.g., when clusters should be formed for separate classes in a classification task. Here, we report the metrics that are often applied in these cases:
Normalized Mutual Information (NMI) Ref. [
38] makes it possible to compare the performance of two algorithms that produce different numbers of clusters. Particularly, we compare the obtained clusters
C with ground-truth classes
G. The NMI provides values between 0 (no overlap between clusters) and 1 (perfect clustering).
Let
C be the clustering result for samples
X, with
representing a specific cluster and
G be the ground-truth set, with
representing all samples belonging to class
j. Then, the NMI is computed as [
39]:
Adjusted Rand Index (ARI) Refs. [
40,
41,
42] is a variant of the Rand Index (RI) that is corrected for chance. Such a correction establishes a baseline by using the expected similarity of all pairwise comparisons between clustering results specified by a random model [
43]. To understand ARI, assume
G is the ground-truth and
C the clustering result. Then,
a,
b, and
c are defined as:
- (a)
the number of pairs of samples that are in the same set in G and in the same set in C.
- (b)
the number of pairs of samples that are in different sets in G and in different sets in C.
- (c)
the total number of possible pairs in the dataset (without ordering).
The unadjusted RI can be described as:
To guarantee that random label assignments obtain a value close to zero, the expected
of random clustering results is discounted by defining the ARI:
One severe drawback of ARI is that it is strongly impacted by outliers; thus, it may not have a good reflection on the quality of the clusters. In some cases, ARI scores are increased with a decreasing number of detected clusters. Nevertheless, we provide ARI measures so other researchers can compare with our results in the future.
B-Cubed () F-measure Ref. [
44] is the harmonic mean of
precision
and
recall
, and it can be used to evaluate clustering algorithms that yield a different number of clusters.
precision
calculates the fraction of points in the same cluster that belongs to the same class.
recall
calculates the fraction of points in the same class that is assigned to the same cluster. To compute
,
, and
, a correctness indicator
is defined as 1 when a pair of samples of the same class are in the same cluster, or when a pair of samples of different classes are in different clusters and 0 otherwise. Using this indicator, precision, recall, and F-measure are evaluated as:
where
is the cluster that contains sample
and
is the set of all samples that belong to the same class as
.
3. Threshold Estimation Using Extreme Value Theory
The idea that a single threshold can be determined for agglomerative clustering may be rather unexpected and unreasonable. However, there are many properties of deep networks that were initially unexpected and unreasonable to expect [
14,
45,
46,
47]. There is much we do not understand about deep networks and deep features; in this paper, we will add their unreasonable ability to support good clustering threshold determinations to that list.
In a deep feature space, the feature mapping was trained to reduce a loss that results in points with similar semantics, as implicitly defined by the loss function, and which will be mapped closer together. It also produces a continuous space with a data-dependent but normalized dimensional value. If we consider non-degenerate points, i.e., a point that should be clustered with at least one other point, then its nearest neighbors are, with high probability, points with which it should cluster. This observation explains part of the power of FINCH [
4], which clusters the first nearest neighbors.
In our analysis, we use approximate (first) nearest neighbors a subset of points that should cluster. The set of approximate nearest neighbors form a distribution from which we will estimate our threshold for the clustering algorithm such as AHC. We note that, since the approach can use Approximate Nearest-Neighbors (ANN), our complexity can be sub-quadratic since first ANN pairs can be found in
time [
48], while true nearest neighbors take
.
Let us formalize our model and then state our core theorems. Let be a set of points drawn from M classes, which represent the ideal cluster label for each input. Let mapping function be a continuous well-behaved feature extraction function. Let be a mapped sample (Since we do not use the label m during clustering, we here remove class information from the sample index.). Let be the set of all mapped points . Allowing for but not assuming clustering in rounds (as in FINCH), we let let be a cluster formed from at least one point in round r, with being the set of all clusters after round r. Let be the dissimilarity or distance between points and . Let be the dissimilarity or distance gap between clusters and at round r, e.g., distance between their centroids or other cluster distances (linkages) as nearest distances, maximum distances, and average distances. Let the set be the set of link distances of points added in round r. Let be the set of ground-truth correct link distances of connections that ideally should have been added between ANNs in round r; note this is known only to an oracle.
In agglomerative clustering, we initially consider each point a cluster of size one, and then we merge and into a cluster if their gap distance is sufficiently small. In later rounds, these clusters get further merged if their link distance .
Theorem 1 (Extreme-Linkage Theorem). The distribution of the sets of both the ideal link distances and the observed link distance are governed by the Fisher–Tippet (Extreme Value) theory, and because they are sets of minima and are bounded from below, the limiting distribution is a Weibull.
Proof. We consider
, and the proof for
is similar. We start by noting that, at each level, we choose the (approximate) smallest link distances out of the much larger set of pairwise distances. Thus, each
can be viewed as a minimum over a set of distances that are associated with some sampling of the distance between the initial set of points if
and from clusters from the prior level if
. If we view the merging of the clusters in level
r in decreasing order of pair distance
, then each new linkage distance can be seen as a new minimum over an increasing set of items. We can view the set over which we consider the actual minimum as excluding a few items as ignored by the ANN algorithm. Since the Fisher–Tippet Theorem [
49] applies to maxima, we perform a change of variables to use the negative of each distance and then consider the distribution of a maximum set of values
. Let
be the associated distribution of the maximum of
in the Fisher–Tippet Theorem (see
Supplemental Material based on [
50,
51,
52]) and, combined with the knowledge that distances are bounded (
), yields that
converges to a reversed Weibull, as it is the only one of the EVT distributions that are bounded. Changing the variable back yields that the distribution of link distances follows a Weibull distribution. □
Given the Extreme-Linkage Theorem to estimate a threshold, we use a three-parameter Weibull distribution:
where
,
, and
are locations, scale, and shape parameters [
53].
This theorem applies to any clustering algorithm using approximate nearest-neighbor merging, e.g., it applies to both FINCH [
4] and any AHC algorithm. This theorem allows us to “reject” any potential linkage that is unlikely. Given the distributional parameters
, to compute the merge distance threshold
that yields a given probability
such that probability
, we use the inverse CDF to derive:
Since the Extreme-Linkage Theorem shows that both the true linkages and the computed linkages follow Weibull distributions, we contend that selecting
to reject improper linkages comes down to fitting the distribution to the set of minima, i.e., the ANN distances. Given the desired level of confidence, such as 99%, a pair merges when consistent with that distribution, we select
as in (
6), i.e.,
is considered the maximum ANN distance which should merge. Considering correct links, the associated, linked points would still be ANN for some set of points within that cluster. Thus, all valid links should be ANNs and a single
computed from an initial set of ANNs is sufficient since ANN of points within a cluster is still subject to that distribution. In
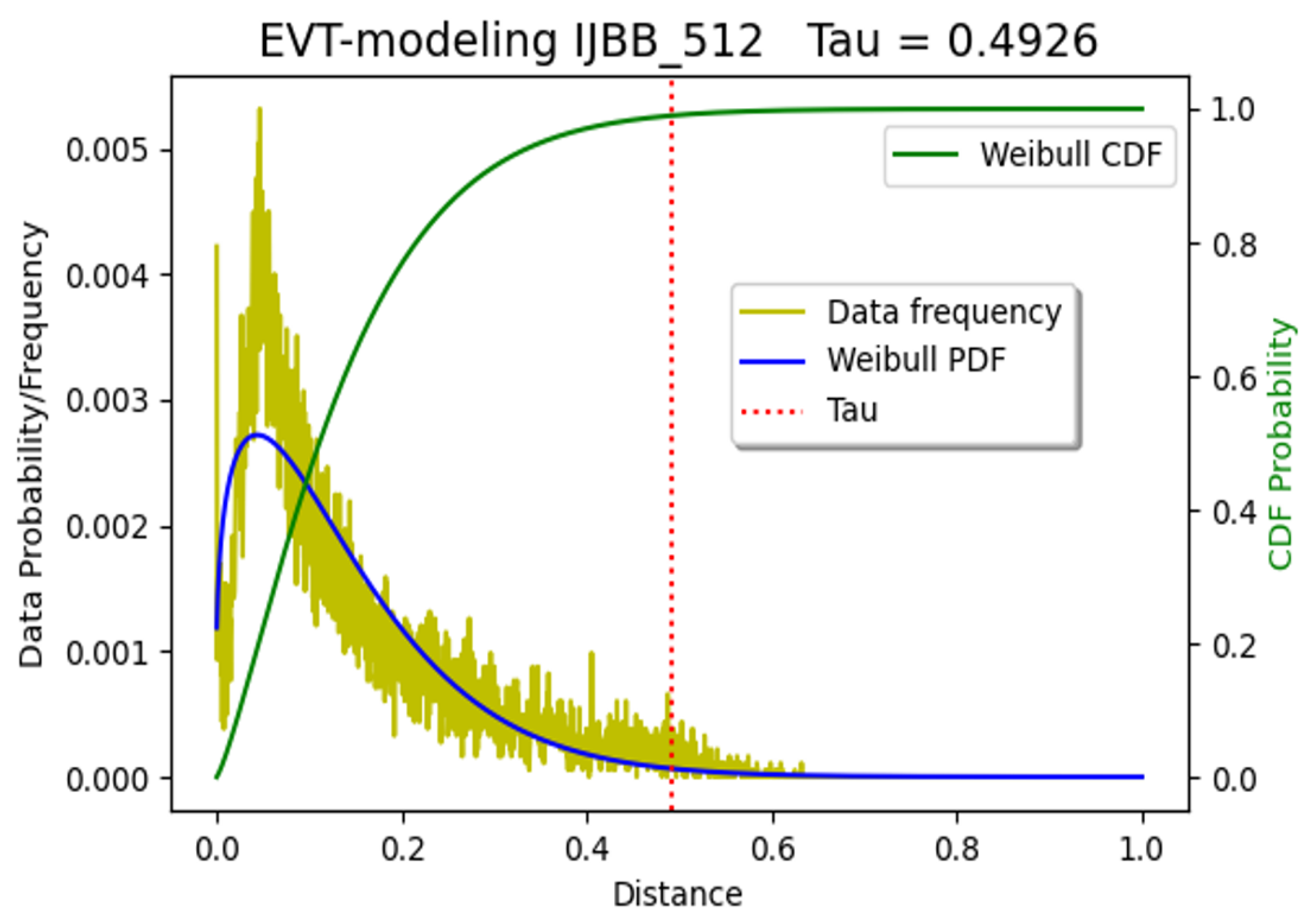
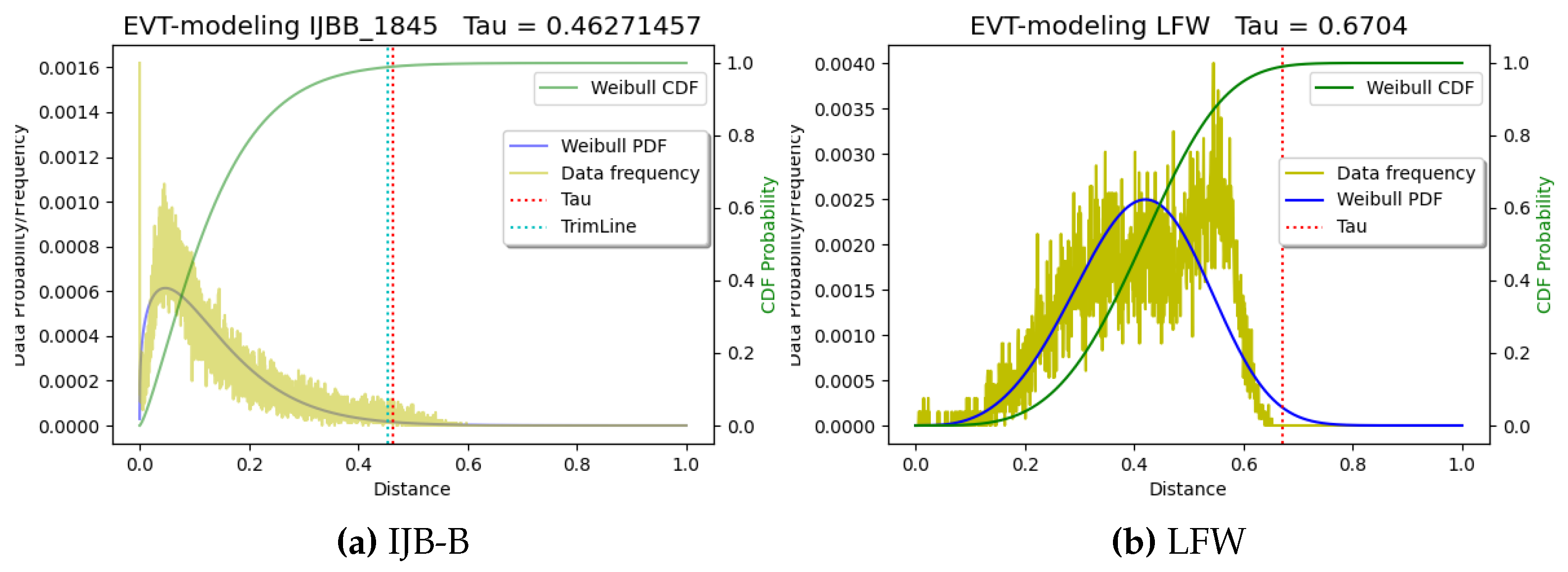
Figure 1 and
Figure 2, and
figures in the Supplemental Material, we fit and compute
to show that the performance is stable for moderate variations in
.
With being defined, we can now state our main conjecture:
Conjecture 1 (Unreasonable Clusterability of Deep Features). Let mapping function be a function from a deep learning classifier trained to separate its training data that yields a -dimensional representation of an input sample. This sample then goes through either a linear or a nearest-neighbor-like classifier.
Let be a transformation, e.g., PCA, of the features into D-dimensional deep features associated with the input sample with the set of all such points being . Let be set by (6) from the Weibull fit to the . If each ideal cluster has sufficiently many points, then using this as the threshold will, with high probability, produce good automatic clustering with semantics given by the function that underlies the deep feature space. The probability of good clustering improves with increased similarity of the training and clustering domains. For clusters that match the network training classes, this conjecture follows from the assumption for a good classifier. However, clustering only data from training classes is pointless since we already have a classifier for that. For generalization to sufficiently close domains, the intuition of the conjecture follows from our Extreme-Linkage Theorem combined with the many known results on how well deep features support domain adaption and transfer learning, including unsupervised and universal adaption [
54,
55,
56,
57,
58,
59]. Proving the conjecture in these cases would require detailed formalization of the exact problem and what it means to be a sufficiently close domain, which is beyond this paper’s scope.
Theory Limitations
We note the proof of the Extreme-Linkage Theorem depends on the Fisher–Tippet Theorem, which is an asymptotic theorem that requires some general smoothness assumptions for convergence—it does not apply in spaces where values occur only on a set of measure zero. The assumptions of the conjecture are sufficient to provide that smoothness, but if a high-dimensional feature space is highly non-uniform, the semantics will be dominated by the dominate directions—hence we often add PCA to normalize. We also note there is a second EVT theorem, with slightly different assumptions that leads to Generalized-Pareto-Distributions, e.g., see [
60]; which EVT model is better for cluster threshold selection is left for future work.
Deep learning methods effectively develop feature spaces where distances have semantic meaning that reflect the distribution of labels used in training. Generic nearest neighbors in high dimensions are often problematic [
61], but deep networks use a fully connected layer to reduce dimensionality with their linear or NN classification stage and create meaning in their feature space. Since clustering does not have supervised data to learn to reduce dimensions, in our work, we often use a PCA projection of features to reduce dimensionality as in [
10].
In any fitting, there is a question of the impact of outliers. If outliers dominate the tail of the distance distribution, the resulting fit of will result in merging many points that should be outliers. With few outliers, the Weibull fit may end up with a that rejects the outliers. While the theorem and conjecture have assumptions that exclude singletons, in practice, it is hard to know when that assumption will hold. Therefore, in the next section, we develop some approaches to manage outliers and discuss parameter selection.
4. Approach
4.1. PEACE Parameter Selection
Our Provable Extreme-value Agglomerative Clustering-threshold Estimation (PEACE) uses threshold
computed by fitting a Weibull. We note, however, that the fitting and threshold selection still requires a choice of parameters: amount of data to trim, tail-size, and confidence threshold. Thus, unlike FINCH, our approach is not parameter-free. However, we believe our parameters, which are about generic data quality, are more intuitive and better subject to defaults than choosing the actual number of clusters (K in K-Means), choosing between a partition of clusters (FINCH), or estimating maximum point separation within a cluster (
in DBSCAN). Our free parameters for Weibull fitting are about the quality of the data. For example, in most of the experiments herein, we use (
6) with a tail-size of 1% of the data, which reduces the impact of stray outliers even without trimming the tail. For confidence to select that actual threshold given the fit, we use
. If one has a rough estimate of the frequency of outliers, i.e., points that should not cluster, of say
, then one can trim
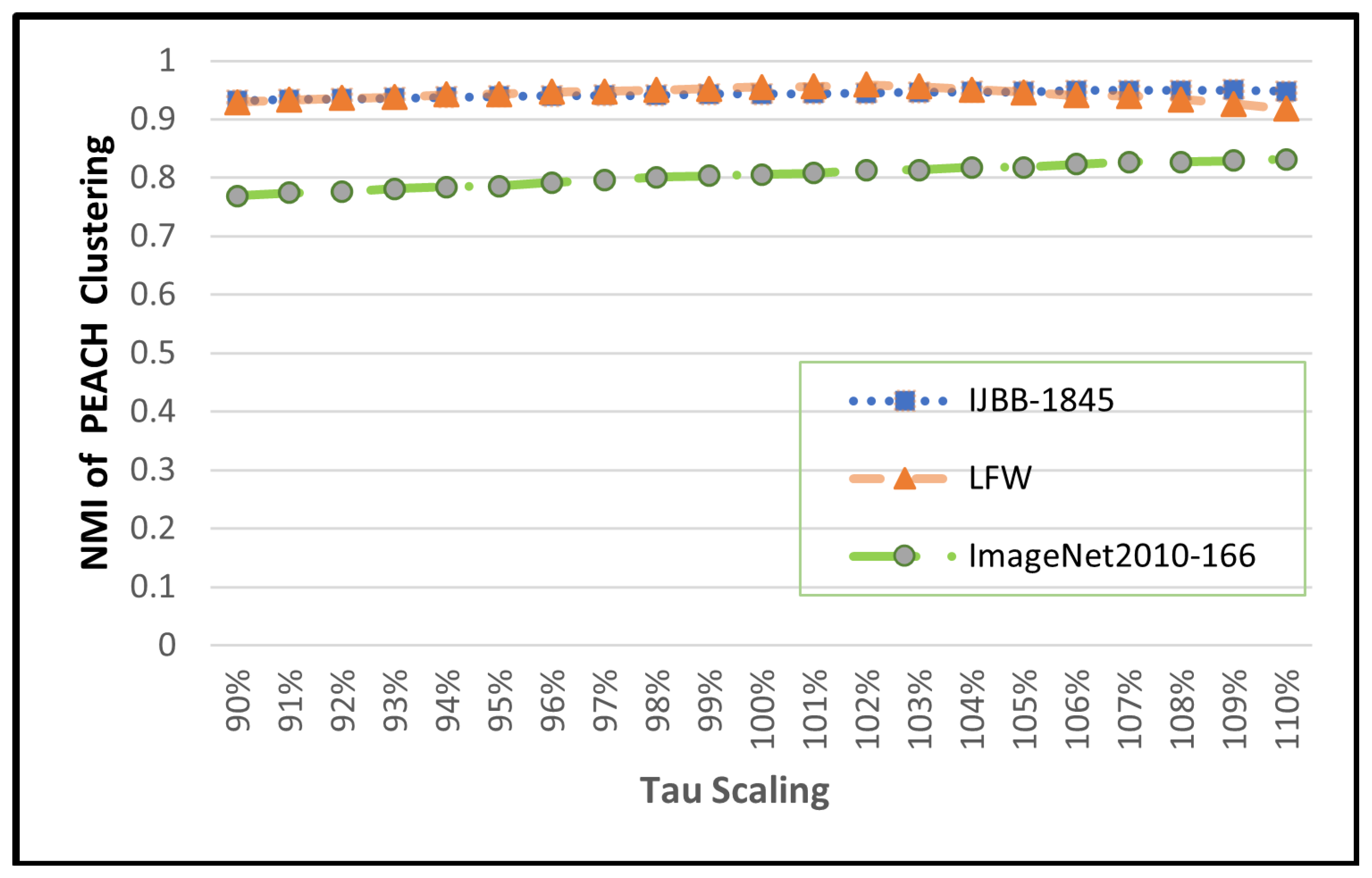
of the data and use the remaining default parameters for the Weibull fitting. This type of approach is sufficient for many applications, and for most problems where one expects to cluster nearly all the data, our defaults (drop 1%, tail 1%, confidence 99%) will work. In general, slight overestimation of outliers is not a problem as results are stable for variations in
; see plots in
Supplemental Material.
However, we observed that some datasets have way more than 1% outliers, and searching for the amount to trim would require some feedback on outliers or fit quality. We tried basic goodness-of-fit measures, such as sample-based Kolmogorov–Smirnov (KS). Unfortunately, those measures were still too weak—with 1000 generated samples from the Weibull fit, none of the distributions in experiments failed a KS test even with the many outliers in Labeled Faces in the Wild (LFW), where we have >50% outliers. Thus, for problems where one is uncertain about the potential for outliers, we developed a heuristic approach to normalize for outliers without a prior guess on the fraction of outliers.
Recognizing that outliers also impact the raw distribution of all pair distances, we set up an equivalent relation to estimating a robust version of our threshold. If we let
be a set of pairwise distances, our equivalent relation for robust threshold estimate
divided by our raw Weibull estimate
should equal the ratio of the median (a robust operator on all points) divided by the outlier-sensitive maximum distance on all points:
Solving that relation for
gives our normalization factor. We can apply this with EVT estimates of the ANN. We normalize by
as follows:
where
employs (
6) with 99% of the data and
then is scaled yield robust
. While approximate nearest neighbors can be computed quickly, if
includes all points, the normalizations would require all pairs, which would require complexity
. The normalization, however, does not really need all pairs, and
as a random sample of a few thousand points produces a good normalization, keeping total complexity to
. While this is just a heuristic, our experiments find it works well, often even better than our theoretically justified approach with default parameters.
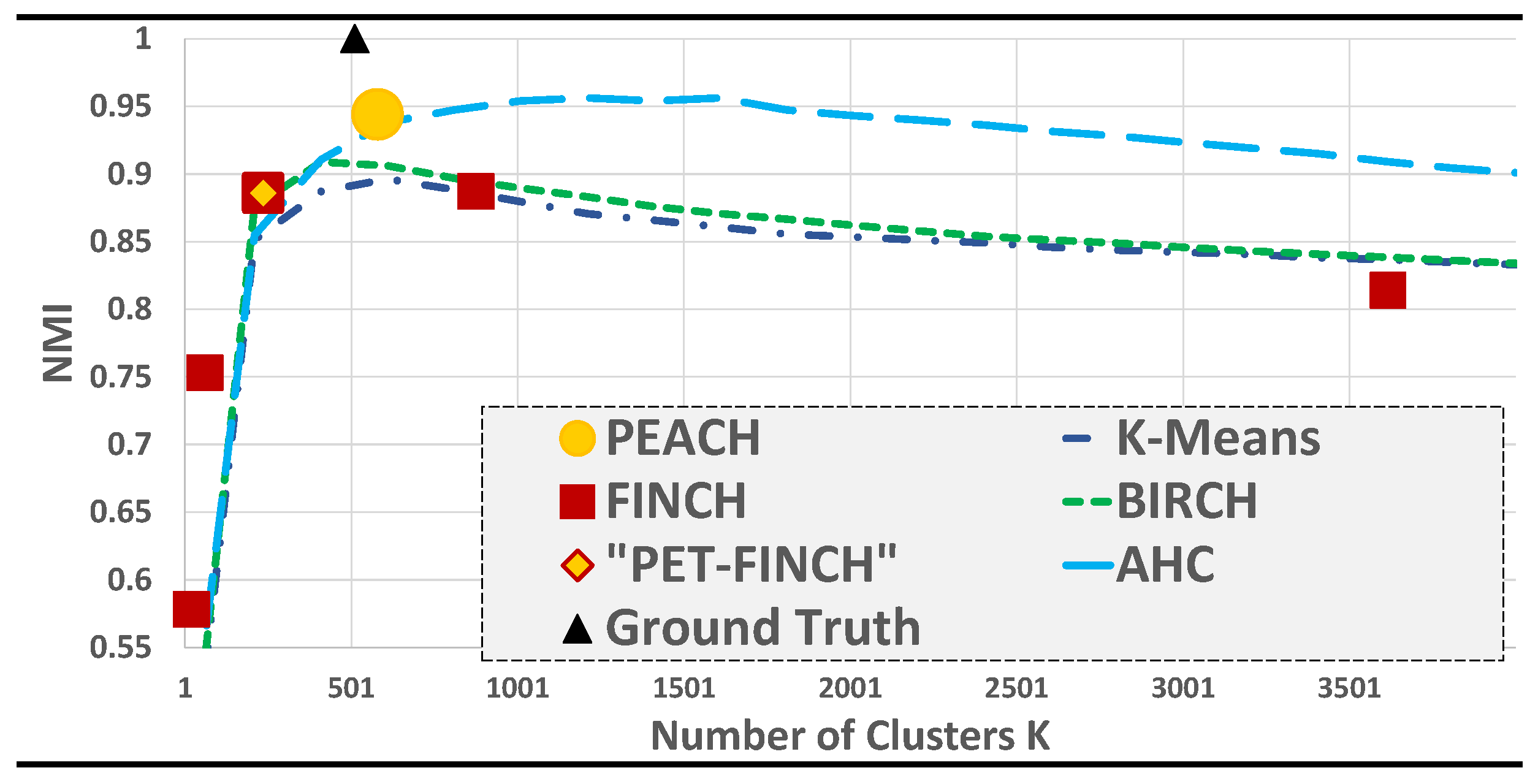
Figure 3 shows PEACH with its automatically selected
is better than K-Means & Balanced Iterative Reducing and Clustering using Hierarchies (BIRCH) [
28] even when those algorithms optimize over the test set; and is close to the optimal value produced when searching for AHC parameters over the test set. We also show the state-of-the-art FINCH algorithm, which produces eight clusters (not all visible), and with EVT theory, PET-FINCH automatically chooses a good partition.
4.2. Overall System Operation
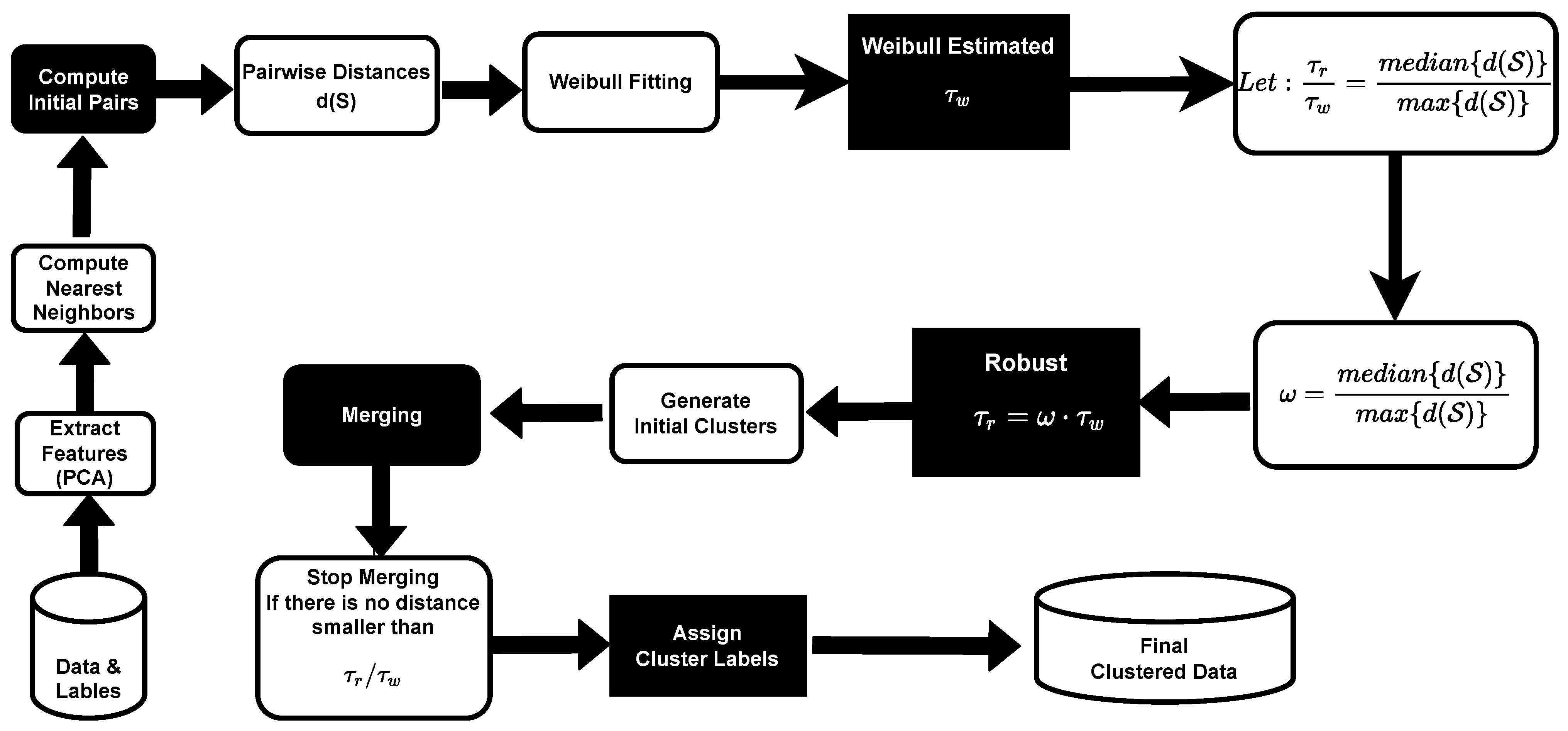
The overall system operation shown in
Figure 4. The processing starts with training data with labels (that we will only use for evaluation), then we extract deep features from a deep learning system. We compute the nearest neighbors of extracted deep features. The nearest neighbors are used to generate initial pairs for PEACH, and we compute the pairwise distance
. Now, we can use Weibull fitting to compute our Weibull estimated threshold
as given in (
6). In order to obtain out robust threshold
, we estimate the median and maximum distance
of all pairs of data points.
By using , we decide if any set of clusters should merge. At the beginning of merging, as typical Agglomerative clustering, PEACH treats every sample as a single cluster, then we generate initial clusters from these single clusters. All paired clusters with link distance below the threshold merge. Next, we find the nearest cluster to each cluster and generate a merging list for this level. Unpaired clusters just pass upward unmerged until they are the closest neighbor of some cluster. We repeat finding all nearest neighbors, building a merge list, and merging until the list of clusters does not change. After merging, we assign cluster labels to the grouped data.
4.3. PET-FINCH
FINCH is an agglomerative clustering method that does not require an input parameter. Instead, FINCH leaves some potential results as output in order to remove an input parameter. The cost is that the user has to find a way to choose one of these partitions as their final result, which is sometimes difficult if there is no ground-truth. This could be called an extra “parameter” that users need to insert into the algorithm. Hence, while the authors of FINCH claim that the algorithm is parameter-free, it is actually not. For some types of experimental datasets, e.g., MNIST, CIFAR, and ImageNet, we already know how many classes the dataset has; however, for some real world problems, there is no way to know the number of clusters contained in the problem. Therefore, knowing how to choose the appropriate partition/result for the FINCH approach presents an issue.
In this section, we introduce the datasets and evaluation protocols of our experiments. Clustering of deep features from pre-trained classification networks has become a common practice. While there are various clustering protocols for a variety of datasets, existing clustering protocols for deep features have used only data from the same domain as training, e.g., face clustering. In many practical applications, the training domain is different from the clustering domain. Therefore, we provide a novel data-distribution view of clustering protocols and then detail our evaluation protocols.
4.4. ImageNet-Based Evaluation Protocols
In-, Out-, Mixed- Distribution Protocol: We base our new in/mixed/out-of-domain protocols on the ILSVRC partitions of 2010 and 2012 [
62] from the ImageNet dataset, using the data splits of [
63]. While previously these splits were used for classification, we adapt them to a novel clustering protocol. Since many available pre-trained deep networks were trained on the 1000 classes of the 2012 dataset, we use the validation set of the 2012 dataset as our in-distribution data. We consider out-of-distribution data to be the 166 classes from the 2010 dataset that have not been re-used in the 2012 dataset. Finally, the mixed-distribution data are a mix of the in- and out-of-distribution data containing images from a total of 1166 classes.
Out-of-Domain Protocol: We use a network that is pre-trained on ILSVRC 2012 training set and apply it to face identity clustering, showing that the clustering properties of deep features transfer across domains. In particular, we use the Labeled Faces in the Wild (LFW) dataset for testing and call this protocol Out-of-domain LFW (OLFW). Labeled Faces in the Wild (LFW) [
64] contains mostly frontal facial images from 5749 people, while only 1680 of them have multiple images. The remaining subjects are singletons and should not be clustered with other subjects—they produce many outliers for our theory. Since performance on OLFW is not comparable to prior work that used in-domain face features for clustering on LFW, we report those in-domain experiments in the
Supplemental Material.
Unsupervised Network Training Protocol: The furthest out-of-domain, with the greatest uncertainty of the feature space and similarity, occurs for unsupervised network training or deep clustering. Initially, the features are random and all data are out-of-distribution. As the networks learn from the samples, they start moving toward in-distribution. However, there is no independent concept of correct classes/clusters and, thus, no practical way to estimate clustering parameters. We follow the protocol of [
10,
11], which requires a fully autonomous clustering subsystem, but where that past work guessed an overestimate of the number of clusters.
4.5. Face Identity Clustering Experiments
The IARPA Janus Benchmark B (IJB-B) [
15] data contain images of up to 1845 subjects in different qualities and face poses, each with at least three images. IJB-B provides seven clustering protocols with an increasing number of subjects. This is one of the largest available datasets for clustering. Since deep networks used for face recognition are usually trained on large corpora of facial images disjoint from the evaluation datasets, these protocols can be regarded as an in-domain and out-of-distribution.
5. Experimental Results
We report the results of PEACH, which is fully automatic and does not use the test set to optimize parameters. Ideally, we would not need to compare against results optimized on the test set or by using ground-truth parameters. Still, to be consistent with past work, we report results of other algorithms from their papers for classic algorithms optimized over ground-truth. In particular, if they require specifying the number of clusters, e.g. K-Means, we report their performance on either the ground-truth number or the PEACH detected number of classes, whichever provides the best score. For FINCH, we report on their best partition results, despite there not being a way to choose that in practice, and note that PET-FINCH automatically selects that partition in all cases with one exception. Note that these are optimistic results for the algorithms as the performance would be worse, often much worse, if we would guess their parameters or obtain them via validation.
PEACH can be applied using many different distance metrics and dissimilarity measures, such as Euclidean distance, Mahalanobis distance, or cosine dissimilarity. Since most previous publications indicate a higher performance with cosine for deep features, we employ the cosine dissimilarity for all approaches when supported and fall back to Euclidean distance when required. In addition, we reduce dimensionality and apply whitening using PCA as in [
10].
5.1. Face Clustering on IJB-B
We evaluate several clustering algorithm on all seven of IJB-B protocols. We advance the state of the art on all seven standard protocols but show only four in
Table 1 in the main paper, the remainder in later tables. To facilitate comparison, we use the 128-dimensional features that have been used for identity clustering in PAHC [
1,
65], provided by the authors of those papers. We also compare with the current state-of-the-art [
2], which utilizes more advanced features with hard negative mining, so they are not directly comparable on clustering alone as PEACH may even do better with their features. Nevertheless, we still outperform DCC-NEG without tuning clustering parameters on the test set as was done in [
2]. Classic algorithms other than PEACH and PET-FINCH use
hyperparameters optimized for best performance on the test set, yet it is observed that PEACH
provides the best NMI and
performance for all of the existing algorithms on the IJB-B protocols. Moreover, both PEACH versions significantly advance over the best baselines with those features. We also evaluated a smaller clustering problem, randomly choosing three subjects—over ten runs, we always got perfect clustering (NMI = 1) for PEACH, which shows that it works fine with a small number of clusters.
5.2. ImageNet-Based Experiments
For all our ImageNet experiments, we use the ResNet-101 network pre-trained on ILSVRC 2012 [
62] data, which achieves a top-1 error rate of 20.69% on the ILSVRC 2012 validation set. While these features are no longer state-of-the-art on ImageNet, our focus is on clustering not classification performance. We extract features for samples from ILSVRC 2010 and 2012 as detailed in
Section 4.3. We chose to use the 1000 dimensional logits, i.e., the features before Softmax activation, and reduce their dimensionality to 128 by PCA.
The performance of our clustering algorithm compared to other approaches can be observed for different distributions in
Table 2. While the parameter-dependent clustering algorithms need to know the actual number of clusters present in the data, they still cannot match the performance of some of the claimed parameter-independent approaches (FINCH) and our completely automatic approach (PEACH). The results depict that PEACH provides the best performance even when compared to parameter-dependent approaches that use ground-truth information to provide the same number of clusters as the number of classes. In addition, PEACH outperforms the best performing partition of FINCH, the current state of the art, and claimed parameter-free algorithm. The experiments on ImageNet also demonstrate the feasibility of our clustering approach to work with large-scale datasets.
We use OLFW to test out-of-domain clustering, where we employ the same ILSVRC-2012 pre-trained deep feature extraction, but use these features to cluster faces. Results can be found in the last column in
Table 1. PEACH outperforms PAHC even when PAHC uses ground-truth number of clusters. The heuristically-scaled version PEACH is the most robust to outliers and has the best performance. Additionally, PEACH is able to identify 1221 clusters, which is close to the 1680 subjects with more than one image,
even though the features were not trained on face data. Note that FINCH uses PyFlann to find nearest neighbor, which results in slightly different NMIs each time, and we report what we actually obtain.
In a final ImageNet comparison, we compare a transfer clustering task. Results are provided in
Table 3. The prior state of the art, Deep Transfer Clustering (DTC) [
5], uses a ResNet-18 backbone and a heuristic for estimating the number of clusters. It works well with only 30 classes to cluster, but we find that its performance drops significantly with 118 classes. Using a ResNet-18 architecture trained on the 800 classes and 128 PCA dimensions, PEACH outperforms DTC, even by a large margin for the 118 classes problem. PEACH also outrivals the other algorithms, even when they use the ground-truth number of clusters.
In
Table 3, we do not compare against approaches that develop self-supervised features on the target dataset [
66], as such work focuses on better features not just on clustering. With their improved features, they report an NMI of 0.82, slightly better than our 0.818. However, also using better features, e.g., using a ResNet-50 PEACH, significantly improves to an NMI of 0.90.
5.3. Deep Clustering
Recent work [
10,
11] proposes an unsupervised feature learning approach, combining self-supervision and clustering to capture complementary statistics from large-scale data. During network training, the traditional clustering algorithms with hand-tuned parameters K-Means [
22] and PIC [
30] are used to cluster features at every epoch. We replace these clustering algorithms with the specified approach (AHC, FINCH, PEACH) and train for 100 epochs.
We report the deep clustering results for training the ILSVRC 2012 validation set in
Table 4. When used alongside network training to cluster features at each epoch for an unsupervised deep learning approach, PEACH provides the best results. The improvement over FINCH would be even great if we would not have manually selected the best partition. More sensitive parameter-dependent algorithms are worse with bad guesses when used inside of deep- and deeper-clusters. This highlights that clustering approaches like PEACH are indispensable since it is impossible to know beforehand how many classes are present in unsupervised learning. We also report the top-1 accuracy of deep clustering on MNIST in
Table 5, which shows PEACH outperforms K-Means and FINCH at mature epochs.
5.4. Timing
As shown in
Table 6, PEACH(
) is faster than all tested algorithms for large face clustering problems of IJB-B, with the exception of FINCH which is the fastest by far. While both PEACH and FINCH have overall time complexity of
, PEACH has a larger constant because of a greater number of rounds of merging and its need to estimate the scaling
and threshold.
For example, consider IJB-B 1024, the rough timing is FINCH∼8 s, PEACH∼79 s, AHC∼100 s, BIRCH∼102 s, K-Means∼877 s, OPTICS∼1255 s, and Spectral clustering was stopped after running for more than a day. While FINCH is faster, PEACH is more accurate and does not require user selection among the final partitions. For large problems, PEACH is faster than standard Agglomerative clustering since it stops merging sooner.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}