
Dealing with Gender Bias Issues in Data-Algorithmic Processes: A Social-Statistical Perspective

 , , , ,
, , , ,  and
and
Abstract
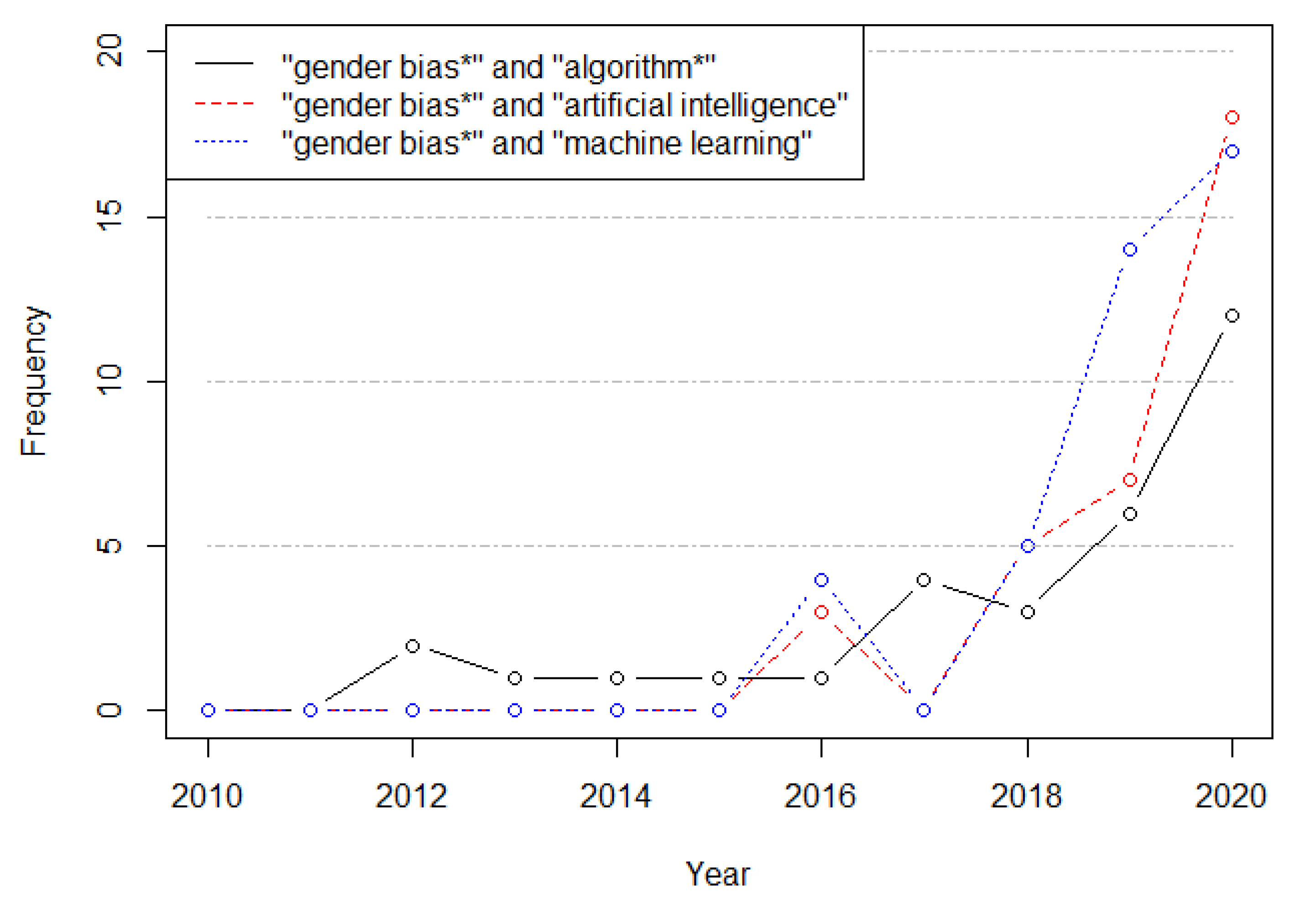
:1. Introduction
2. The Algorithm Concept
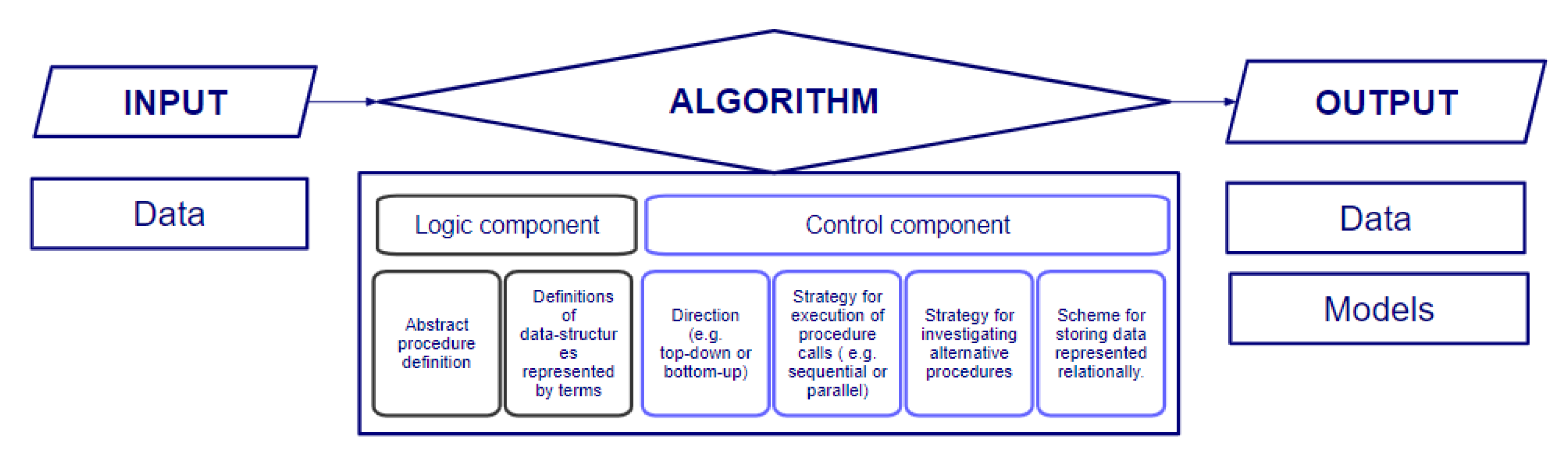
2.1. Algorithm Concept in Science and Engineering
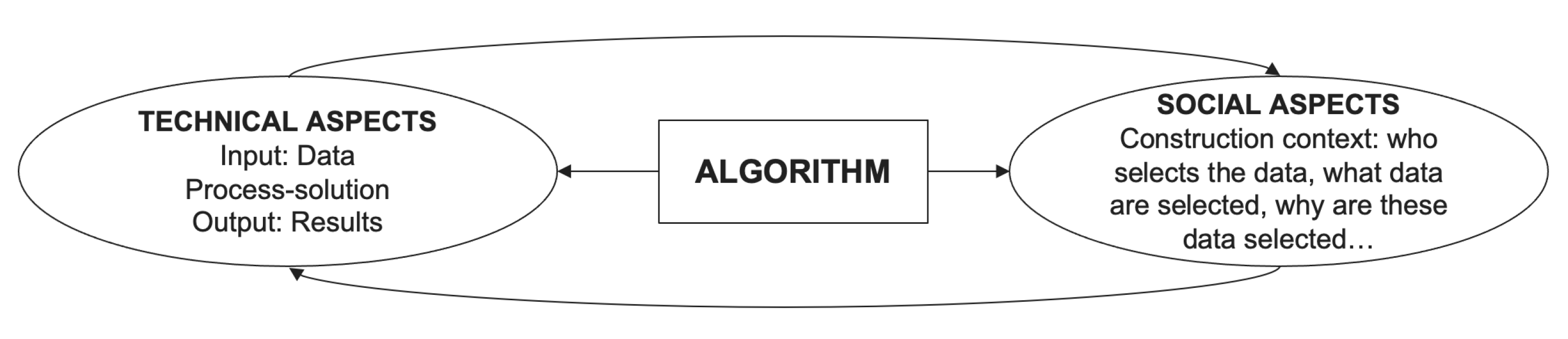
2.2. Algorithm Concept in Social Sciences
3. Data-Algorithmic Bias: Definitions and Classifications
4. Examples of Gender Bias
4.1. Natural Language Processing and Generation
4.2. Speech Recognition
4.3. Decision Management
4.4. Face Recognition
5. Datasets with Gender Bias
6. Initiatives to Address Gender Bias
6.1. Private Initiatives
6.2. International Organizations
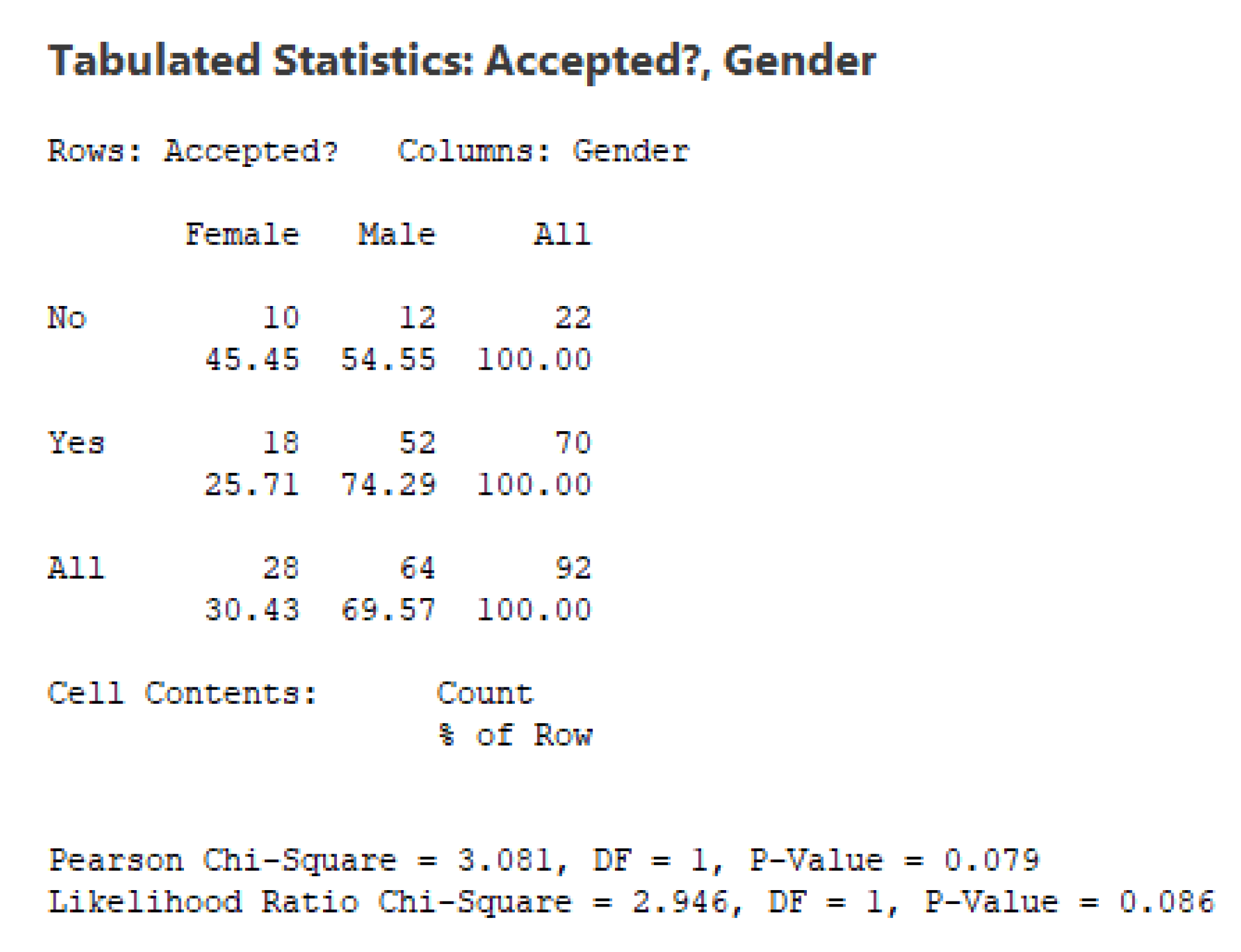
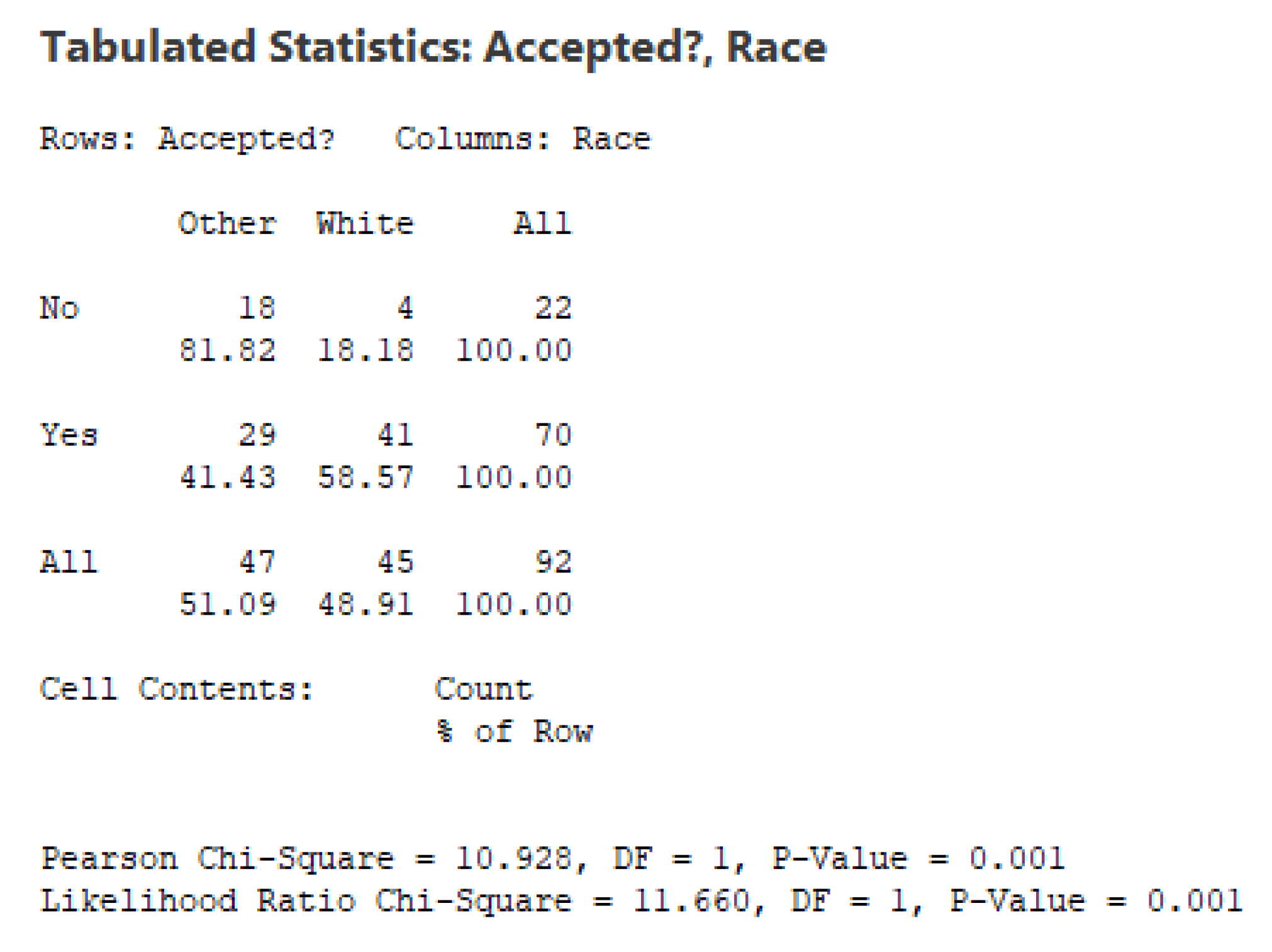
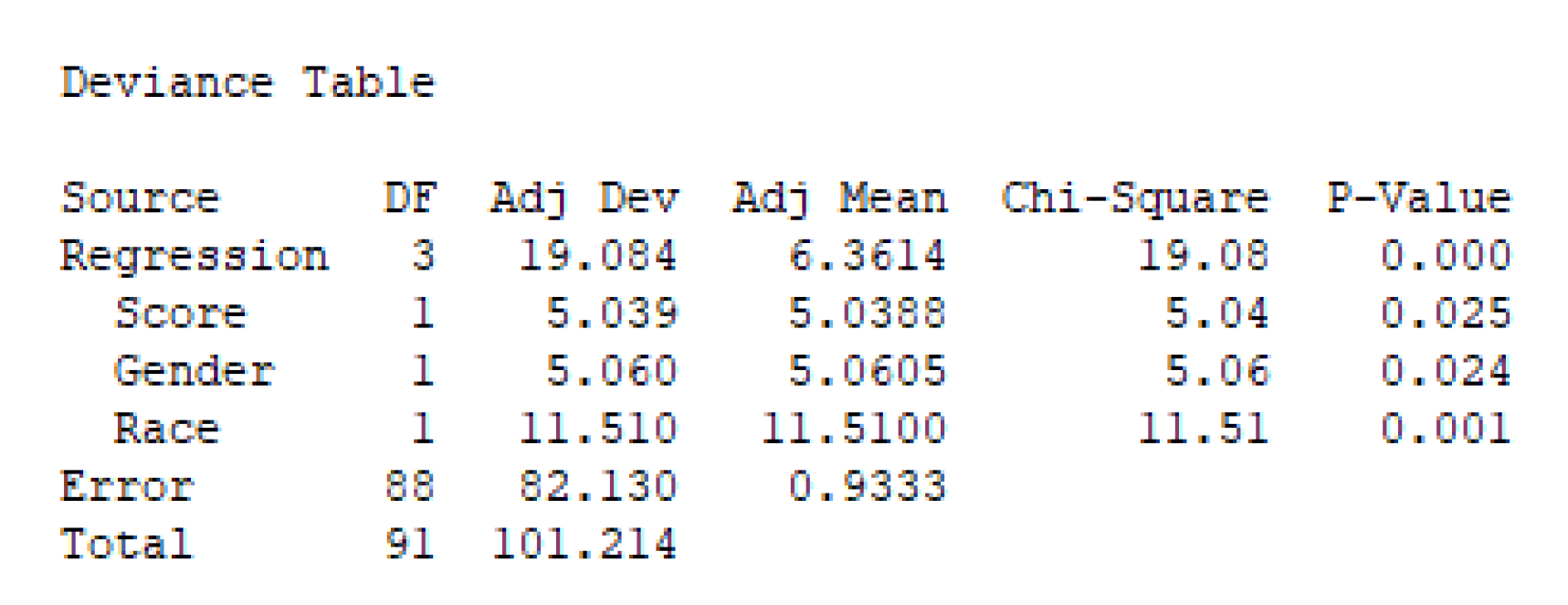
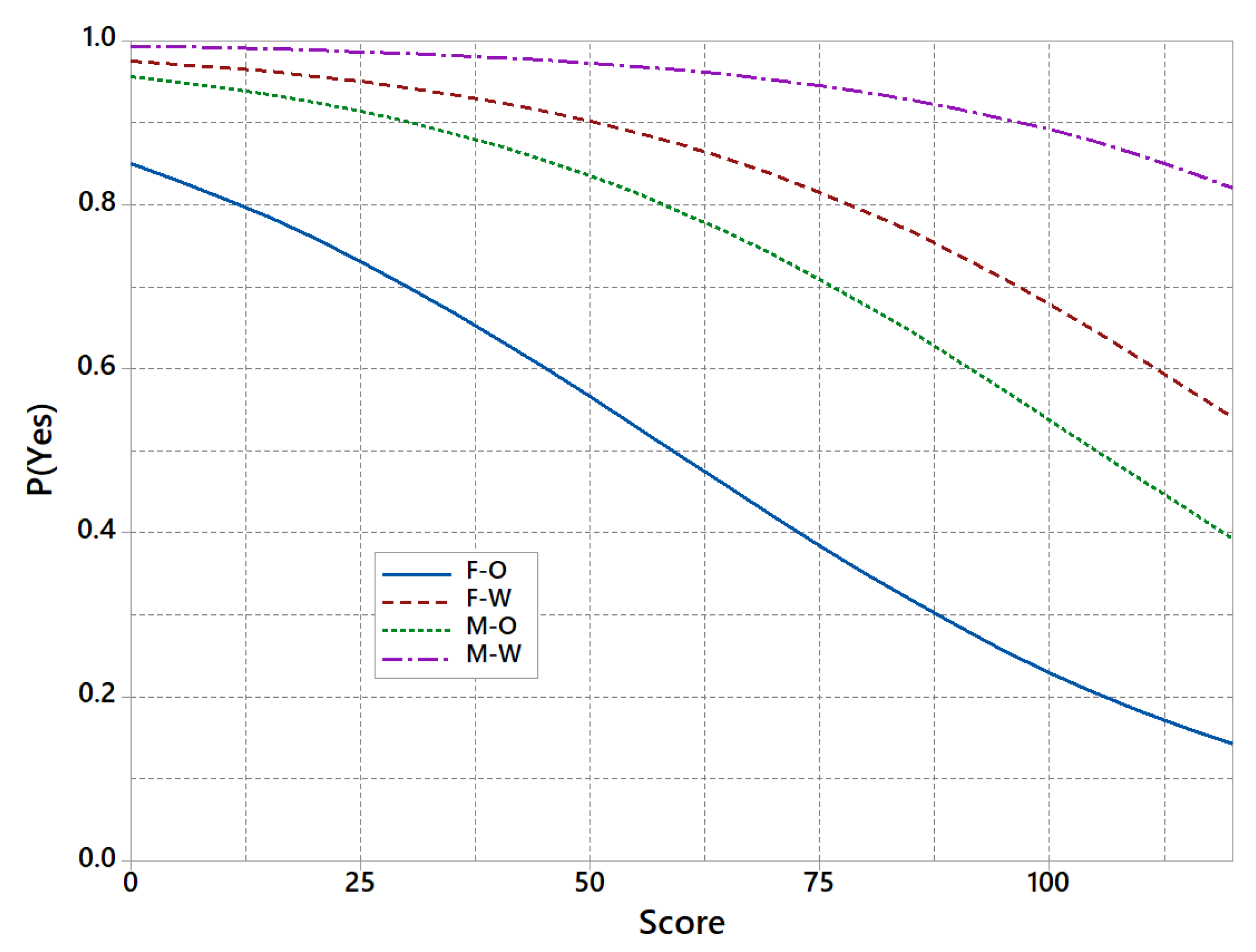
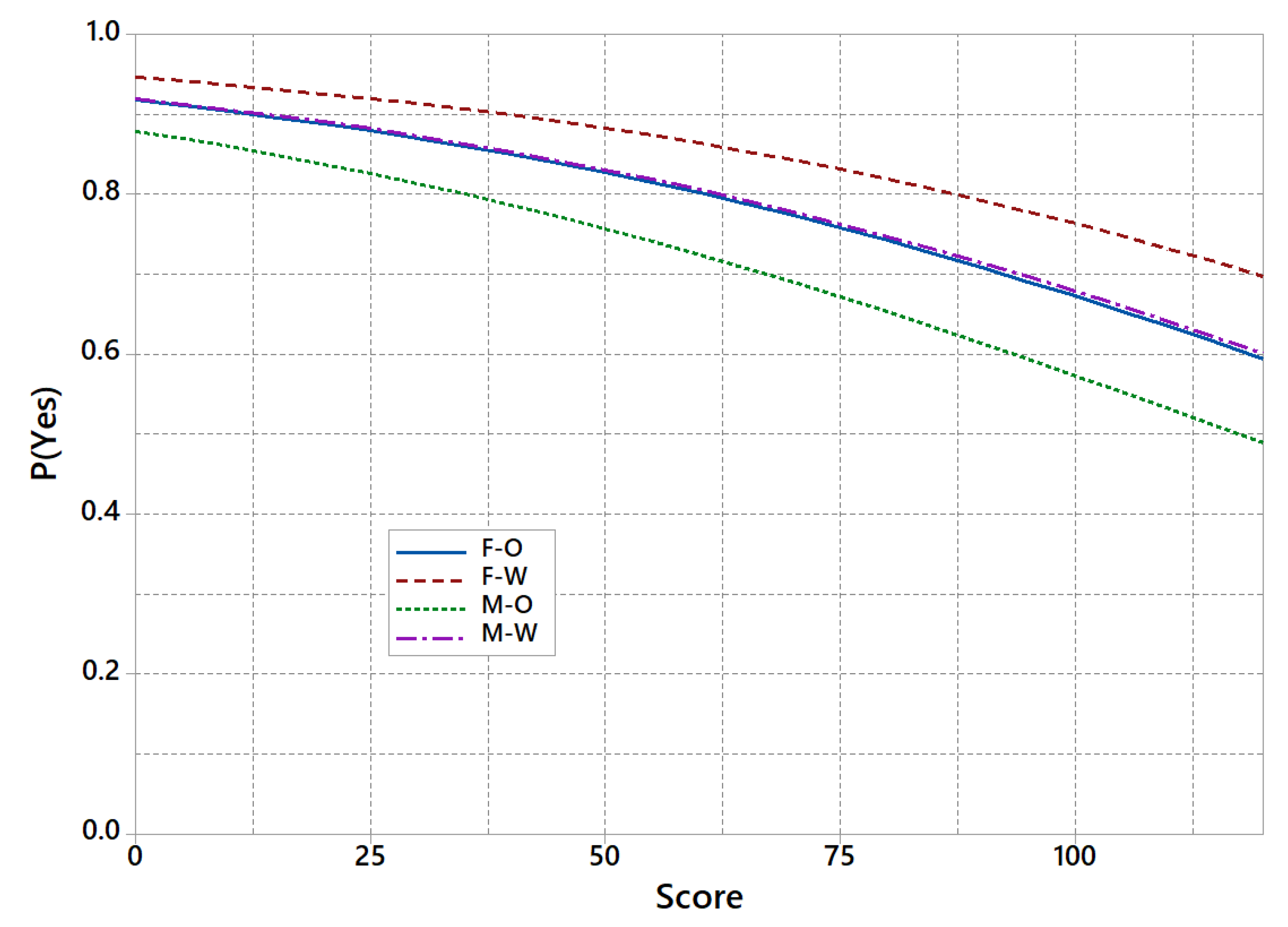
7. An Illustrative Numerical Example
8. Recommendations to Prevent, Identify, and Mitigate Gender Bias
- Preventing gender bias: (i) configure a reasonable representation of both genders among each category of experts working in the design, implementation, validation, and documentation of algorithms; (ii) set a reasonable gender distribution among each category of experts working in the extraction/collection, pre-processing, and analysis of data; (iii) incorporate at least one expert in data-algorithmic bias to the group; and (iv) train all staff (male/female/non-bi) in gender bias (and approaches to prevent, avoid, detect, and correct it).
- Identifying gender bias: (i) be transparent regarding the composition of the working group (gender distribution and expertise in ethics and data-algorithmic bias), the strategies implemented to mitigate bias, and the results of the tests implemented to detect potential bias; (ii) assess and publish the limitations regarding gender bias; (iii) improve interpretability of ‘black-box’ models; and (iv) analyze periodically the use and results of the algorithms employed.
- Mitigating gender bias: (i) avoid to reuse data and pre-trained models with gender bias that cannot be corrected; (ii) apply methods to get a balanced dataset if needed [49], as well as to measure accuracy levels separately for each gender; (iii) assess different fairness-based measures to choose which ones are more suitable in a particular case; (iv) test different algorithms (and configurations of parameters) to find which one outperforms the others (benchmark instances or datasets with biases are available in the literature to assess new algorithms); (v) modify the dataset to mitigate gender bias relying on specific-domain experts; (vi) document and store previous experiences where bias has been detected in a dataset and how it has been mitigated (as commented before, gender bias tend to be recurrent in some specific fields); and (vii) implement approaches to remove unwanted features related to gender from intermediate representations in deep learning models.
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pearl, J. Probabilistic Reasoning in Intelligent Systems; Kaufmann: San Mateo, CA, USA, 1988. [Google Scholar]
- Draude, C.; Klumbyte, G.; Lücking, P.; Treusch, P. Situated algorithms: A sociotechnical systemic approach to bias. Online Inf. Rev. 2019, 44, 325–342. [Google Scholar] [CrossRef]
- Seaver, N. What should an anthropology of algorithms do? Cult. Anthropol. 2018, 33, 375–385. [Google Scholar] [CrossRef]
- Photopoulos, J. Fighting algorithmic bias. Phys. World 2021, 34, 42. [Google Scholar] [CrossRef]
- Ahmed, M.A.; Chatterjee, M.; Dadure, P.; Pakray, P. The Role of Biased Data in Computerized Gender Discrimination. In Proceedings of the 2022 IEEE/ACM 3rd International Workshop on Gender Equality, Diversity and Inclusion in Software Engineering (GEICSE), Pittsburgh, PA, USA, 20 May 2022; pp. 6–11. [Google Scholar]
- Kuppler, M. Predicting the future impact of Computer Science researchers: Is there a gender bias? Scientometrics 2022, 1–38. [Google Scholar] [CrossRef]
- Brunet, M.E.; Alkalay-Houlihan, C.; Anderson, A.; Zemel, R. Understanding the origins of bias in word embeddings. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 803–811. [Google Scholar]
- Caliskan, A.; Bryson, J.J.; Narayanan, A. Semantics derived automatically from language corpora contain human-like biases. Science 2017, 356, 183–186. [Google Scholar] [CrossRef]
- Mittelstadt, B.D.; Allo, P.; Taddeo, M.; Wachter, S.; Floridi, L. The ethics of algorithms: Mapping the debate. Big Data Soc. 2016, 3, 1–21. [Google Scholar] [CrossRef]
- Tsamados, A.; Aggarwal, N.; Cowls, J.; Morley, J.; Roberts, H.; Taddeo, M.; Floridi, L. The ethics of algorithms: Key problems and solutions. AI Soc. 2022, 37, 215–230. [Google Scholar] [CrossRef]
- Taddeo, M.; Floridi, L. The debate on the moral responsibilities of online service providers. Sci. Eng. Ethics 2016, 22, 1575–1603. [Google Scholar] [CrossRef]
- Gillespie, T. Algorithm. In Digital Keywords; Princeton University Press: Princeton, NJ, USA, 2016; Chapter 2; pp. 18–30. [Google Scholar]
- Kowalski, R. Algorithm = logic + control. Commun. ACM 1979, 22, 424–436. [Google Scholar] [CrossRef]
- Moschovakis, Y.N. What is an Algorithm? In Mathematics Unlimited—2001 and beyond; Springer: Berlin/Heidelberg, Germany, 2001; pp. 919–936. [Google Scholar]
- Sedgewick, R.; Wayne, K. Algorithms; Addison-Wesley Professional: Boston, MA, USA, 2011. [Google Scholar]
- Brassard, G.; Bratley, P. Fundamentals of Algorithmics; Prentice-Hall, Inc.: Englewood Cliffs, NJ, USA, 1996. [Google Scholar]
- Skiena, S.S. The Algorithm Design Manual; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Nilsson, N.J. The Quest for Artificial Intelligence; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Pedreschi, D.; Giannotti, F.; Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F. Meaningful explanations of black box AI decision systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9780–9784. [Google Scholar]
- Oneto, L.; Chiappa, S. Fairness in machine learning. In Recent Trends Learn from Data; Springer: Cham, Switzerland, 2020; pp. 155–196. [Google Scholar]
- Danaher, J.; Hogan, M.J.; Noone, C.; Kennedy, R.; Behan, A.; De Paor, A.; Felzmann, H.; Haklay, M.; Khoo, S.M.; Morison, J.; et al. Algorithmic governance: Developing a research agenda through the power of collective intelligence. Big Data Soc. 2017, 4, 2053951717726554. [Google Scholar] [CrossRef] [Green Version]
- Beer, D. Power through the algorithm? Participatory web cultures and the technological unconscious. New Media Soc. 2009, 11, 985–1002. [Google Scholar]
- Seaver, N. Algorithms as culture: Some tactics for the ethnography of algorithmic systems. Big Data Soc. 2017, 4, 2053951717738104. [Google Scholar]
- Kitchin, R. Thinking critically about and researching algorithms. Inf. Commun. Soc. 2017, 20, 14–29. [Google Scholar]
- Wellner, G.; Rothman, T. Feminist AI: Can we expect our AI systems to become feminist? Philos. Technol. 2020, 33, 191–205. [Google Scholar]
- Ihde, D. Technosystem: The Social Life of Reason by Andrew Feenberg. Technol. Cult. 2018, 59, 506–508. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Friedman, B.; Nissenbaum, H. Bias in computer systems. ACM Trans. Inf. Syst. (TOIS) 1996, 14, 330–347. [Google Scholar]
- Ntoutsi, E.; Fafalios, P.; Gadiraju, U.; Iosifidis, V.; Nejdl, W.; Vidal, M.E.; Ruggieri, S.; Turini, F.; Papadopoulos, S.; Krasanakis, E.; et al. Bias in data-driven artificial intelligence systems—An introductory survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1356. [Google Scholar]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar]
- Olteanu, A.; Castillo, C.; Diaz, F.; Kıcıman, E. Social data: Biases, methodological pitfalls, and ethical boundaries. Front. Big Data 2019, 2, 13. [Google Scholar]
- Baeza-Yates, R. Bias on the web. Commun. ACM 2018, 61, 54–61. [Google Scholar]
- Introna, L.; Nissenbaum, H. Defining the web: The politics of search engines. Computer 2000, 33, 54–62. [Google Scholar]
- Prates, M.O.; Avelar, P.H.; Lamb, L.C. Assessing gender bias in machine translation: A case study with Google translate. Neural. Comput. Appl. 2020, 32, 6363–6381. [Google Scholar]
- Bolukbasi, T.; Chang, K.W.; Zou, J.Y.; Saligrama, V.; Kalai, A.T. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. Adv. Neural Inf. Process. Syst. 2016, 29, 4349–4357. [Google Scholar]
- Tatman, R. Gender and dialect bias in YouTube’s automatic captions. In Proceedings of the First ACL Workshop on Ethics in Natural Language Processing, Valencia, Spain, 4 April 2017; pp. 53–59. [Google Scholar]
- Tatman, R.; Kasten, C. Effects of Talker Dialect, Gender & Race on Accuracy of Bing Speech and YouTube Automatic Captions. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 934–938. [Google Scholar]
- Dastin, J. Amazon scraps secret AI recruiting tool that showed bias against women. In Ethics of Data and Analytics; Auerbach Publications: Boca Raton, FL, USA, 2018; pp. 296–299. [Google Scholar]
- Ensmenger, N. Beards, sandals, and other signs of rugged individualism: Masculine culture within the computing professions. Osiris 2015, 30, 38–65. [Google Scholar]
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; pp. 77–91. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Therneau, T.; Atkinson, B. Rpart: Recursive Partitioning and Regression Trees; R package Version 4.1-15; 2019. Available online: https://cran.r-project.org/web/packages/rpart/index.html (accessed on 19 July 2022).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Tang, R.; Du, M.; Li, Y.; Liu, Z.; Zou, N.; Hu, X. Mitigating gender bias in captioning systems. In Proceedings of the Web Conference, Ljubljana, Slovenia, 19–23 April 2021; pp. 633–645. [Google Scholar]
- Yatskar, M.; Zettlemoyer, L.; Farhadi, A. Situation recognition: Visual semantic role labeling for image understanding. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5534–5542. [Google Scholar]
- Zhao, J.; Wang, T.; Yatskar, M.; Ordonez, V.; Chang, K.W. Men also like shopping: Reducing gender bias amplification using corpus-level constraints. arXiv 2017, arXiv:1707.09457. [Google Scholar]
- D’Amour, A.; Srinivasan, H.; Atwood, J.; Baljekar, P.; Sculley, D.; Halpern, Y. Fairness is Not Static: Deeper Understanding of Long Term Fairness via Simulation Studies. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 525–534. [Google Scholar]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A systematic review on imbalanced data challenges in machine learning: Applications and solutions. ACM Comput. Surv. (CSUR) 2019, 52, 1–36. [Google Scholar]
- Panteli, N.; Urquhart, C. Job crafting for female contractors in a male-dominated profession. New Technol. Work. Employ. 2022, 37, 102–123. [Google Scholar] [CrossRef]
- Tiainen, T.; Berki, E. The re-production process of gender bias: A case of ICT professors through recruitment in a gender-neutral country. Stud. High. Educ. 2019, 44, 170–184. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | G | R | S | A? | # | G | R | S | A? |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M | O | 75 | Y | 47 | M | W | 65 | Y |
| 2 | M | O | 70 | Y | 48 | F | O | 35 | N |
| 3 | F | O | 55 | Y | 49 | M | O | 55 | Y |
| 4 | F | O | 25 | Y | 50 | M | O | 80 | Y |
| 5 | M | O | 60 | Y | 51 | M | O | 55 | Y |
| 6 | M | O | 50 | Y | 52 | F | W | 85 | Y |
| 7 | M | O | 65 | N | 53 | F | W | 60 | Y |
| 8 | M | W | 25 | Y | 54 | F | O | 65 | Y |
| 9 | M | W | 20 | Y | 55 | M | W | 67 | Y |
| 10 | M | W | 77 | Y | 56 | M | O | 60 | N |
| 11 | F | W | 55 | N | 57 | M | W | 65 | Y |
| 12 | M | W | 60 | Y | 58 | F | O | 75 | N |
| 13 | F | O | 62 | N | 59 | M | W | 35 | Y |
| 14 | M | W | 70 | Y | 60 | F | O | 25 | Y |
| 15 | M | W | 45 | Y | 61 | M | O | 70 | N |
| 16 | M | W | 40 | Y | 62 | F | O | 65 | N |
| 17 | F | O | 40 | Y | 63 | F | O | 51 | Y |
| 18 | F | O | 45 | Y | 64 | M | W | 75 | Y |
| 19 | F | W | 35 | Y | 65 | M | W | 73 | Y |
| 20 | M | W | 80 | Y | 66 | M | O | 79 | N |
| 21 | M | O | 45 | Y | 67 | M | O | 92 | Y |
| 22 | M | O | 58 | Y | 68 | M | O | 60 | Y |
| 23 | M | O | 85 | Y | 69 | M | W | 85 | N |
| 24 | F | W | 30 | Y | 70 | M | O | 95 | Y |
| 25 | M | O | 75 | N | 71 | M | W | 85 | Y |
| 26 | M | W | 95 | Y | 72 | F | W | 84 | N |
| 27 | F | O | 85 | Y | 73 | M | W | 95 | Y |
| 28 | M | O | 77 | N | 74 | M | O | 97 | Y |
| 29 | F | O | 94 | N | 75 | M | O | 90 | Y |
| 30 | M | O | 90 | Y | 76 | F | O | 80 | N |
| 31 | M | O | 99 | N | 77 | M | W | 90 | Y |
| 32 | M | W | 70 | Y | 78 | M | O | 97 | N |
| 33 | F | O | 65 | N | 79 | M | W | 93 | Y |
| 34 | F | W | 103 | Y | 80 | M | O | 100 | Y |
| 35 | M | O | 90 | Y | 81 | M | W | 113 | Y |
| 36 | M | W | 25 | Y | 82 | M | W | 100 | Y |
| 37 | M | W | 60 | Y | 83 | M | W | 65 | Y |
| 38 | F | O | 45 | Y | 84 | M | O | 105 | Y |
| 39 | M | W | 60 | Y | 85 | M | O | 99 | N |
| 40 | M | W | 0 | Y | 86 | F | W | 107 | Y |
| 41 | F | W | 65 | Y | 87 | M | O | 120 | N |
| 42 | F | W | 70 | Y | 88 | F | W | 90 | N |
| 43 | M | W | 60 | Y | 89 | M | W | 82 | Y |
| 44 | M | W | 60 | Y | 90 | M | O | 105 | Y |
| 45 | M | W | 65 | Y | 91 | M | O | 65 | N |
| 46 | F | W | 60 | Y | 92 | M | W | 107 | Y |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castaneda, J.; Jover, A.; Calvet, L.; Yanes, S.; Juan, A.A.; Sainz, M. Dealing with Gender Bias Issues in Data-Algorithmic Processes: A Social-Statistical Perspective. Algorithms 2022, 15, 303. https://doi.org/10.3390/a15090303
Castaneda J, Jover A, Calvet L, Yanes S, Juan AA, Sainz M. Dealing with Gender Bias Issues in Data-Algorithmic Processes: A Social-Statistical Perspective. Algorithms. 2022; 15(9):303. https://doi.org/10.3390/a15090303
Chicago/Turabian StyleCastaneda, Juliana, Assumpta Jover, Laura Calvet, Sergi Yanes, Angel A. Juan, and Milagros Sainz. 2022. "Dealing with Gender Bias Issues in Data-Algorithmic Processes: A Social-Statistical Perspective" Algorithms 15, no. 9: 303. https://doi.org/10.3390/a15090303
APA StyleCastaneda, J., Jover, A., Calvet, L., Yanes, S., Juan, A. A., & Sainz, M. (2022). Dealing with Gender Bias Issues in Data-Algorithmic Processes: A Social-Statistical Perspective. Algorithms, 15(9), 303. https://doi.org/10.3390/a15090303