
Nero: A Deterministic Leaderless Consensus Algorithm for DAG-Based Cryptocurrencies


Abstract
:1. Introduction
2. Preliminares
2.1. Multi-Valued Consensus
- Agreement: No two correct processes decide on different values.
- Termination: All correct processes eventually decide on a value.
- Validity: A decided value is valid, i.e., it satisfies the predefined predicate denoted valid().
2.2. System Model
3. The Nero Algorithm
3.1. Overview and Intuition
3.2. Data Structures
- Type: VOTE or COMMIT,
- Value: a block hash or a nil value,
- Round.
3.3. The Algorithm
- Valid if there is a set of at least messages of round that are compatible with the value and type of m.
- Pending if there is not a set of at least messages of round that are compatible with the value and type of m but it is still possible to receive new messages of round to produce that set.
- Invalid if there is not a set of at least messages of round that are compatible with the value and type of m, and it is not possible to receive new messages of round to produce that set.
- If process p has received at least valid messages of type COMMIT with the same value, decide that value. There is no need to send a new message because all the other correct processes will eventually receive the same messages and decide the same value as well.
- Else if process p has received at least one valid message of type COMMIT with some value v, send a message of type COMMIT with value v. (There cannot be two commits of different values in the same round).
- Else if process p has received at least valid messages of type VOTE with the same value, send a message of type COMMIT with that value.
- Else if process p has received at least one valid message of type COMMIT with some value v, send a message of type COMMIT with that value.
- Else if process p has received at least one valid message of type COMMIT with some value v in round r and has already committed to another value in round , send a message of type COMMIT with value v only if round . If , send a message of type with the previous committed value .
- Else if process p has received at least valid messages of type VOTE with value nil, send a message of type VOTE with value nil.
- If no block hash value has at least votes, send a message of type VOTE with value nil.
- Else if process p has not received at least valid messages of type VOTE with value nil, send a message of type VOTE with the value with most votes.
- Inserts it in the respective election state.
- Updates the tally of the election.
- Tries to validate previous pending messages based on the validation rules.
- Broadcasts m to the network.
- Computes a new message of round based on the received messages and the decision rules.
- Broadcasts the message to the other processes.
3.4. Correctness
3.5. Eventual State Machine Replication
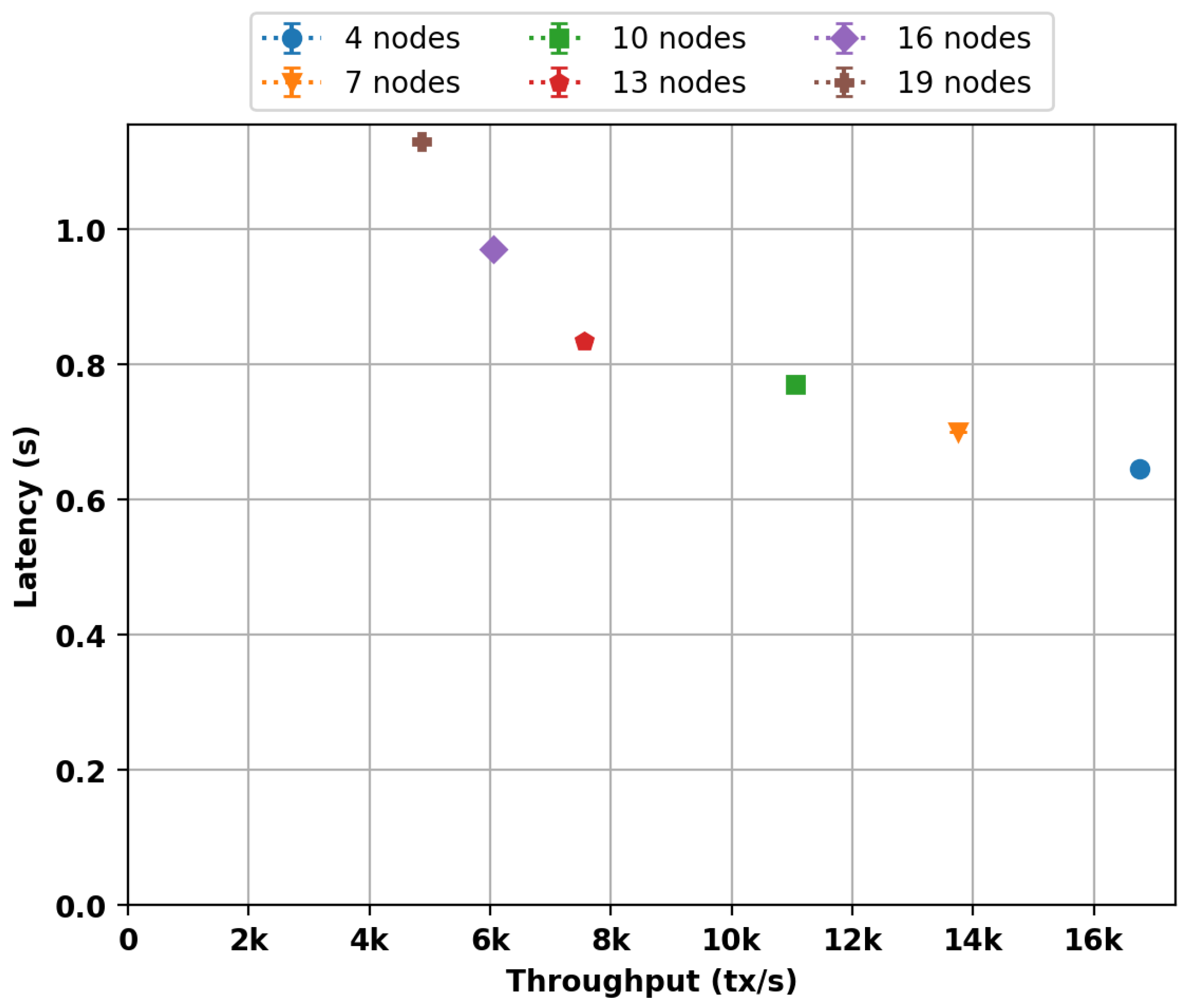
4. Results
4.1. Comparison with Related Work
4.2. Implementation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pease, M.; Shostak, R.; Lamport, L. Reaching Agreement in the Presence of Faults. J. Assoc. Comput. Mach. 1980, 27, 228–234. [Google Scholar] [CrossRef] [Green Version]
- Lamport, L.; Shostak, R.; Pease, M. The Byzantine Generals Problem. ACM Trans. Program. Lang. Syst. 1982, 4, 382–401. [Google Scholar] [CrossRef] [Green Version]
- Dolev, D.; Strong, H. Authenticated Algorithms for Byzantine Agreement. SIAM J. Comput. 1983, 12, 656–666. [Google Scholar] [CrossRef]
- Fischer, M.J.; Lynch, N.A.; Paterson, M.S. Impossibility of Distributed Consensus with One Faulty Process. J. ACM 1985, 32, 374–382. [Google Scholar] [CrossRef]
- Miller, A.; Xia, Y.; Croman, K.; Shi, E.; Song, D. The Honey Badger of BFT Protocols. In Proceedings of the CCS ’16: 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 31–42. [Google Scholar] [CrossRef] [Green Version]
- Dwork, C.; Lynch, N.; Stockmeyer, L. Consensus in the Presence of Partial Synchrony. J. ACM 1988, 35, 288–323. [Google Scholar] [CrossRef]
- Correia, M.; Neves, N.; Veríssimo, P. From Consensus to Atomic Broadcast: Time-Free Byzantine-Resistant Protocols without Signatures. Comput. J. 2006, 49, 82–96. [Google Scholar] [CrossRef] [Green Version]
- Kihlstrom, K.P.; Moser, L.E.; Melliar-Smith, P.M. Byzantine Fault Detectors for Solving Consensus. Comput. J. 2003, 46, 16–35. [Google Scholar] [CrossRef] [Green Version]
- Haeberlen, A.; Kuznetsov, P.; Druschel, P. The case for Byzantine fault detection. In Proceedings of the Second Conference on Hot Topics in System Dependability, Seattle, WA, USA, 8 November 2006; p. 5. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 15 October 2022).
- Ren, L. Analysis of Nakamoto Consensus. IACR Cryptol. ePrint Arch. 2019, 2019, 943. [Google Scholar]
- Saleh, F. Blockchain without Waste: Proof-of-Stake. Rev. Financ. Stud. 2020, 34, 1156–1190. [Google Scholar] [CrossRef]
- Kiayias, A.; Russell, A.; David, B.; Oliynykov, R. Ouroboros: A Provably Secure Proof-of-Stake Blockchain Protocol. In Proceedings of the Advances in Cryptology—CRYPTO 2017, Santa Barbara, CA, USA, 20–24 August 2017; Katz, J., Shacham, H., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 357–388. [Google Scholar]
- Li, W.; Andreina, S.; Bohli, J.M.; Karame, G. Securing Proof-of-Stake Blockchain Protocols. In Proceedings of the Data Privacy Management, Cryptocurrencies and Blockchain Technology, Oslo, Norway, 14–15 September 2017; Garcia-Alfaro, J., Navarro-Arribas, G., Hartenstein, H., Herrera-Joancomartí, J., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 297–315. [Google Scholar]
- Schneider, F.B. Implementing Fault-Tolerant Services Using the State Machine Approach: A Tutorial. ACM Comput. Surv. 1990, 22, 299–319. [Google Scholar] [CrossRef]
- Cao, B.; Zhang, Z.; Feng, D.; Zhang, S.; Zhang, L.; Peng, M.; Li, Y. Performance analysis and comparison of PoW, PoS and DAG based blockchains. Digit. Commun. Netw. 2020, 6, 480–485. [Google Scholar] [CrossRef]
- Baird, L.; Luykx, A. The Hashgraph Protocol: Efficient Asynchronous BFT for High-Throughput Distributed Ledgers. In Proceedings of the 2020 International Conference on Omni-layer Intelligent Systems (COINS), Barcelona, Spain, 31 August–2 September 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Danezis, G.; Kokoris-Kogias, L.; Sonnino, A.; Spiegelman, A. Narwhal and Tusk: A DAG-Based Mempool and Efficient BFT Consensus. In Proceedings of the EuroSys ’22: Seventeenth European Conference on Computer Systems, Rennes, France, 5–8 April 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 34–50. [Google Scholar] [CrossRef]
- Keidar, I.; Kokoris-Kogias, E.; Naor, O.; Spiegelman, A. All You Need is DAG. In Proceedings of the PODC’21: 2021 ACM Symposium on Principles of Distributed Computing, Virtual Event, 26–30 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 165–175. [Google Scholar] [CrossRef]
- Chen, T.Y.; Huang, W.N.; Kuo, P.C.; Chung, H.; Chao, T.W. DEXON: A Highly Scalable, Decentralized DAG-Based Consensus Algorithm. arXiv 2018, arXiv:1811.07525. [Google Scholar]
- Müller, S.; Penzkofer, A.; Polyanskii, N.; Theis, J.; Sanders, W.; Moog, H. Tangle 2.0 Leaderless Nakamoto Consensus on the Heaviest DAG. arXiv 2022, arXiv:2205.02177. [Google Scholar] [CrossRef]
- Snowflake to Avalanche: A Novel Metastable Consensus Protocol Family for Cryptocurrencies Team Rocket. arXiv 2018, arXiv:1906.08936v2.
- Antoniadis, K.; Desjardins, A.; Gramoli, V.; Guerraoui, R.; Zablotchi, I. Leaderless Consensus. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS), Washington, DC, USA, 7–10 July 2021. [Google Scholar] [CrossRef]
- Crain, T.; Gramoli, V.; Larrea, M.; Raynal, M. (Leader/Randomization/Signature)-free Byzantine Consensus for Consortium Blockchains. arXiv 2017, arXiv:1702.03068v2. [Google Scholar]
- Antoniadis, K.; Guerraoui, R.; Malkhi, D.; Seredinschi, D.A. State Machine Replication Is More Expensive Than Consensus. In Proceedings of the DISC, New Orleans, LA, USA, 15–19 October 2018. [Google Scholar]
- Mills, D.L. Computer Network Time Synchronization: The Network Time Protocol on Earth and in Space, 2nd ed.; CRC Press, Inc.: Boca Raton, FL, USA, 2010. [Google Scholar]
- Lamshöft, K.; Dittmann, J. Covert Channels in Network Time Security. In Proceedings of the IH&MMSec ’22: 2022 ACM Workshop on Information Hiding and Multimedia Security, Santa Barbara, CA, USA, 27–28 June 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 69–79. [Google Scholar] [CrossRef]
- Menezes, A.J.; Vanstone, S.A.; Oorschot, P.C.V. Handbook of Applied Cryptography, 1st ed.; CRC Press, Inc.: Boca Raton, FL, USA, 1996. [Google Scholar]
- Antwi, R.; Gadze, J.D.; Tchao, E.T.; Sikora, A.; Nunoo-Mensah, H.; Agbemenu, A.S.; Obour Agyekum, K.O.B.; Agyemang, J.O.; Welte, D.; Keelson, E. A Survey on Network Optimization Techniques for Blockchain Systems. Algorithms 2022, 15, 193. [Google Scholar] [CrossRef]
- Castro, M.; Liskov, B. Practical Byzantine Fault Tolerance. In Proceedings of the OSDI ’99: Third Symposium on Operating Systems Design and Implementation, New Orleans, LA, USA, 22–25 February 1999; USENIX Association: Berkeley, CA, USA, 1999; pp. 173–186. [Google Scholar]
- Yin, M.; Malkhi, D.; Reiter, M.K.; Gueta, G.G.; Abraham, I. HotStuff: BFT Consensus with Linearity and Responsiveness. In Proceedings of the PODC ’19: 2019 ACM Symposium on Principles of Distributed Computing, Toronto, ON, Canada, 29 July–2 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 347–356. [Google Scholar] [CrossRef] [Green Version]
- Moniz, H. The Istanbul BFT Consensus Algorithm. arXiv 2020, arXiv:2002.03613. [Google Scholar]
- Buchman, E.; Kwon, J.; Milosevic, Z. The latest gossip on BFT consensus. arXiv 2018, arXiv:1807.04938. [Google Scholar]
- Crain, T.; Gramoli, V.; Larrea, M.; Raynal, M. DBFT: Efficient Leaderless Byzantine Consensus and its Application to Blockchains. In Proceedings of the 2018 IEEE 17th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 1–3 November 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Voron, G.; Gramoli, V. Dispel: Byzantine SMR with Distributed Pipelining. arXiv 2019, arXiv:1912.10367. [Google Scholar]
- Konnov, I.V.; Widder, J. ByMC: Byzantine Model Checker. In Proceedings of the ISoLA, Limassol, Cyprus, 5–9 November 2018. [Google Scholar]


{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morais, R.; Crocker, P.; Leithardt, V. Nero: A Deterministic Leaderless Consensus Algorithm for DAG-Based Cryptocurrencies. Algorithms 2023, 16, 38. https://doi.org/10.3390/a16010038
Morais R, Crocker P, Leithardt V. Nero: A Deterministic Leaderless Consensus Algorithm for DAG-Based Cryptocurrencies. Algorithms. 2023; 16(1):38. https://doi.org/10.3390/a16010038
Chicago/Turabian StyleMorais, Rui, Paul Crocker, and Valderi Leithardt. 2023. "Nero: A Deterministic Leaderless Consensus Algorithm for DAG-Based Cryptocurrencies" Algorithms 16, no. 1: 38. https://doi.org/10.3390/a16010038
APA StyleMorais, R., Crocker, P., & Leithardt, V. (2023). Nero: A Deterministic Leaderless Consensus Algorithm for DAG-Based Cryptocurrencies. Algorithms, 16(1), 38. https://doi.org/10.3390/a16010038