
Visual Assessment of Cluster Tendency with Variations of Distance Measures


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- 1)
- RDI may not be representative if the cluster structure in the data points is complex.
- 2)
- The quality of the RDI in VAT is significantly degraded due to the presence of outliers.
2. Materials and Methods
- Symmetry about the diagonal. The dissimilarity matrix is a square symmetrical n × n matrix with dij element equal to the value of a chosen measure of distinction between the ith and jth objects dij = dji.
- The distance values in the matrix are always non-negative dij ≥ 0.
- Identity of indiscernibles. In the matrix, the distinction between an object and itself is set to zero (dii is diagonal element, where dii = 0).
- The triangle inequality takes the form dij + djk ≥ dik ∀ i,j,k.
| Algorithm 1. Visual assessment of the clustering tendency (VAT). |
|
| Algorithm 2. Improved visual assessment of the clustering tendency (iVAT). |
|
| Algorithm 3. DVAT (DiVAT) algorithm. |
|
3. Results of Computational Experiment
- a)
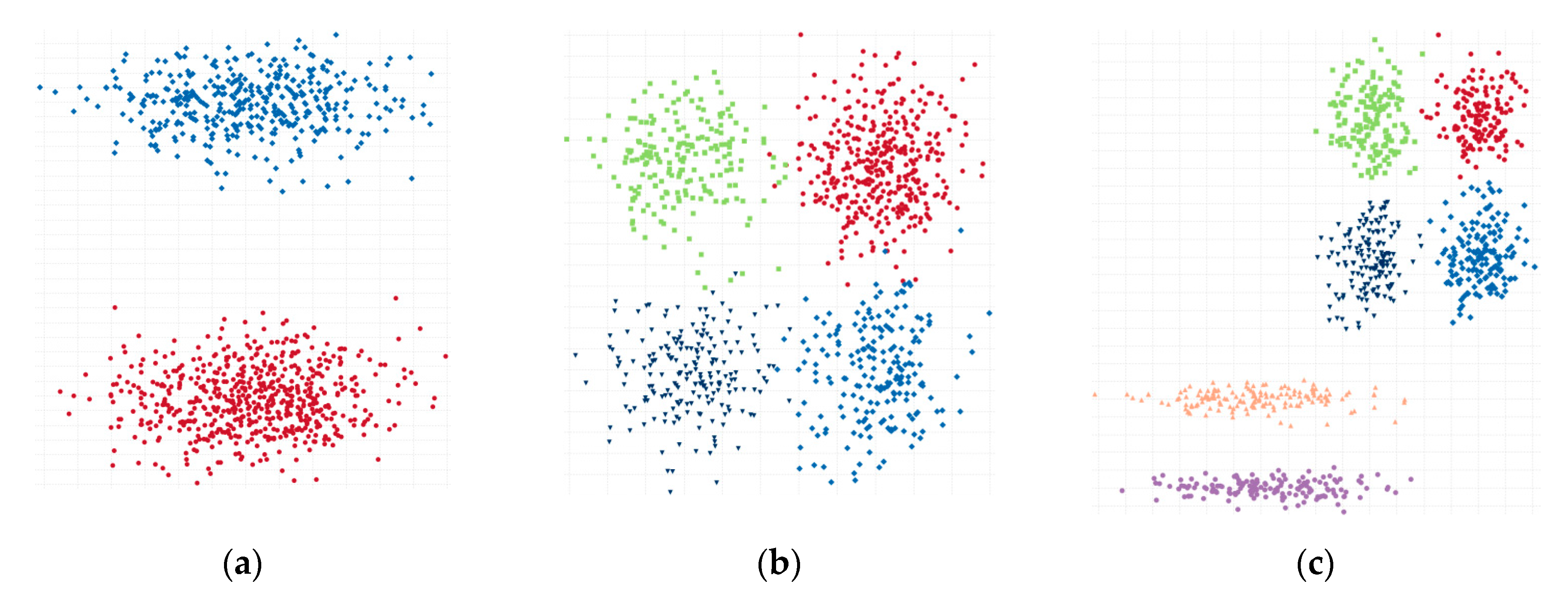
- Long2 is an artificial dataset that contains the collection of two clusters (1000 data points, 2 dimensions) (Figure 1a).
- b)
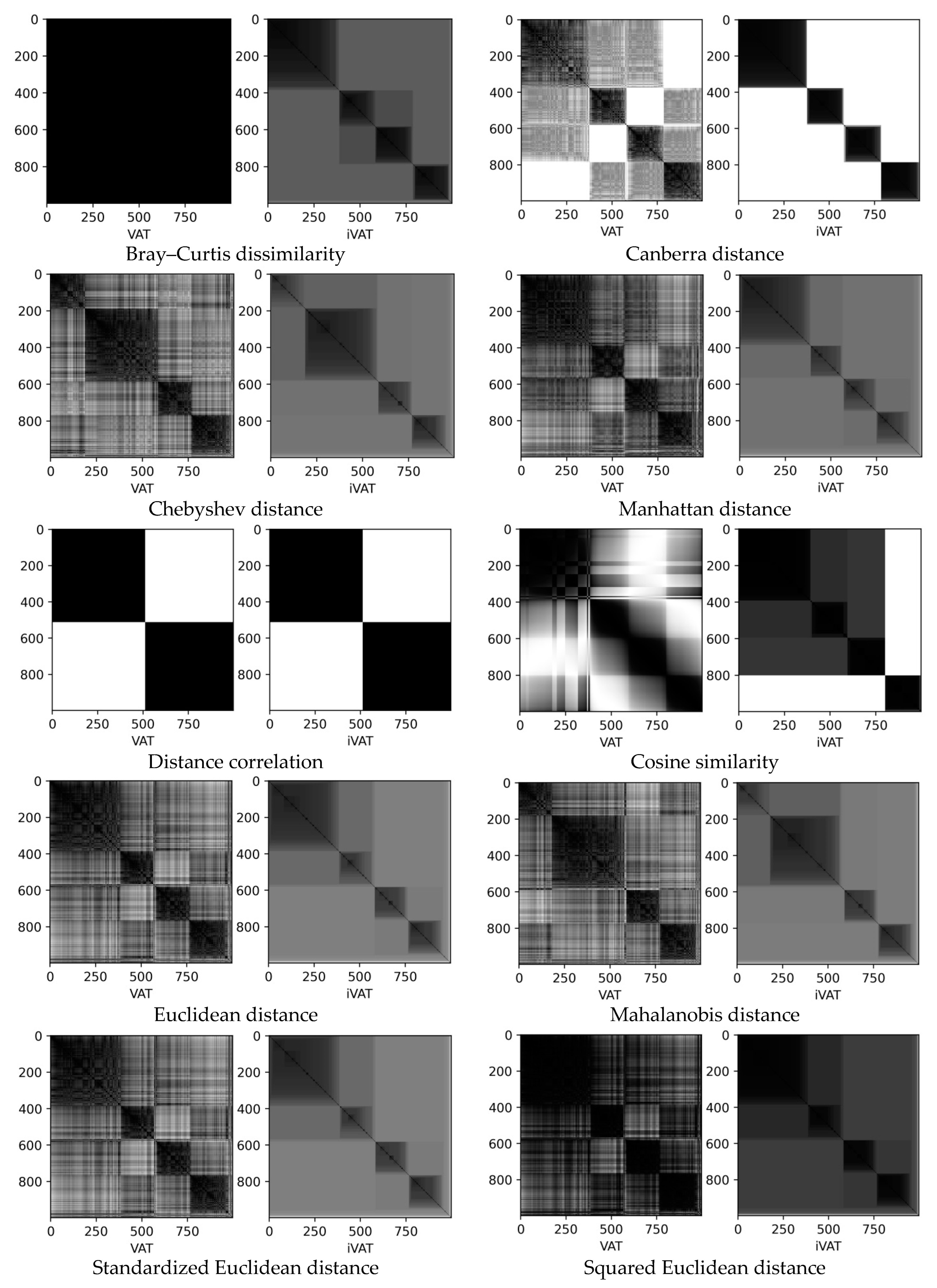
- Sizes1 is an artificial dataset contains the collection of four clusters (1000 data points, 2 dimensions) (Figure 1b).
- c)
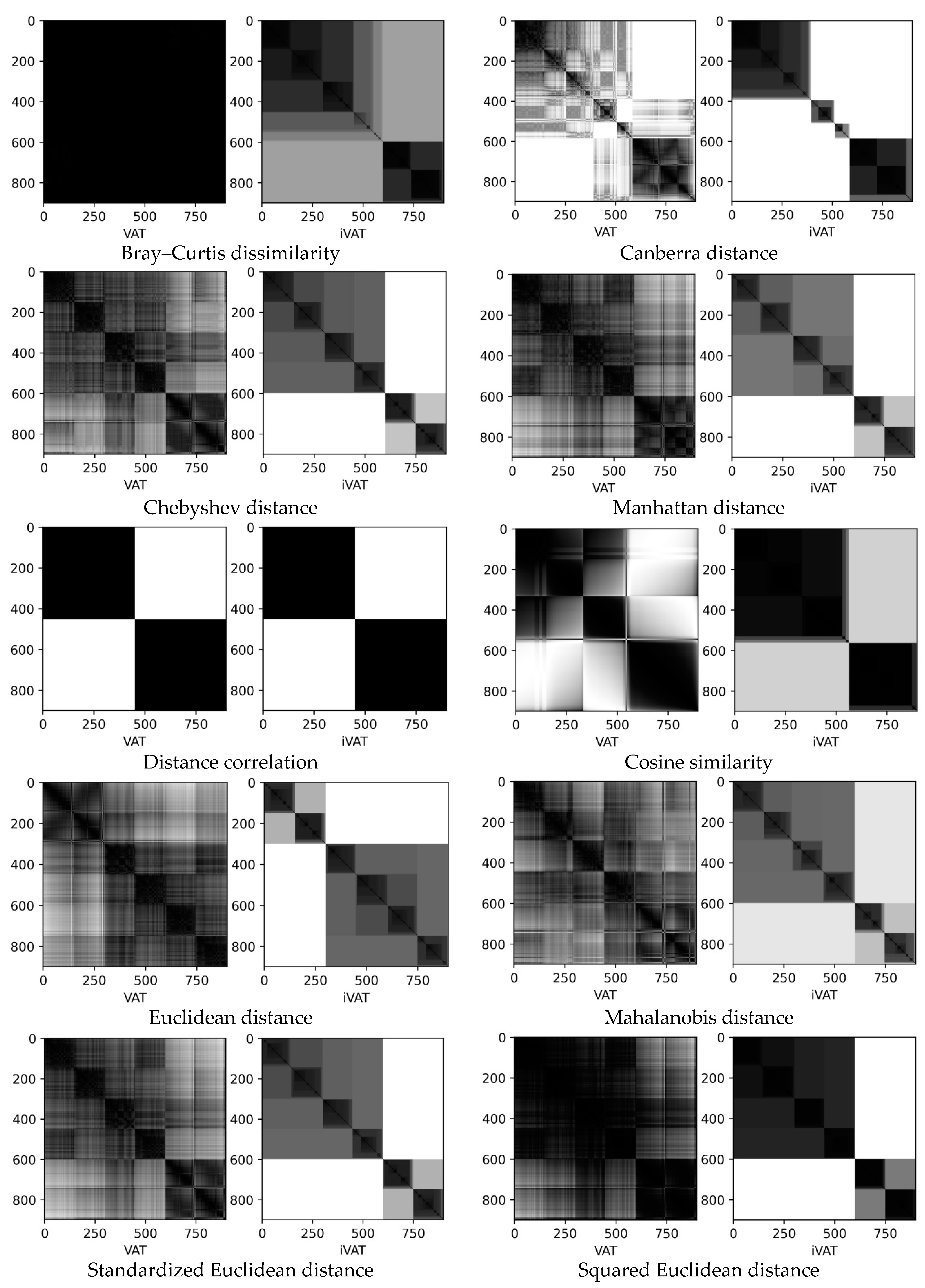
- Longsquare is an artificial dataset contains the collection of six clusters (1000 data points, 2 dimensions) (Figure 1c).
- d)
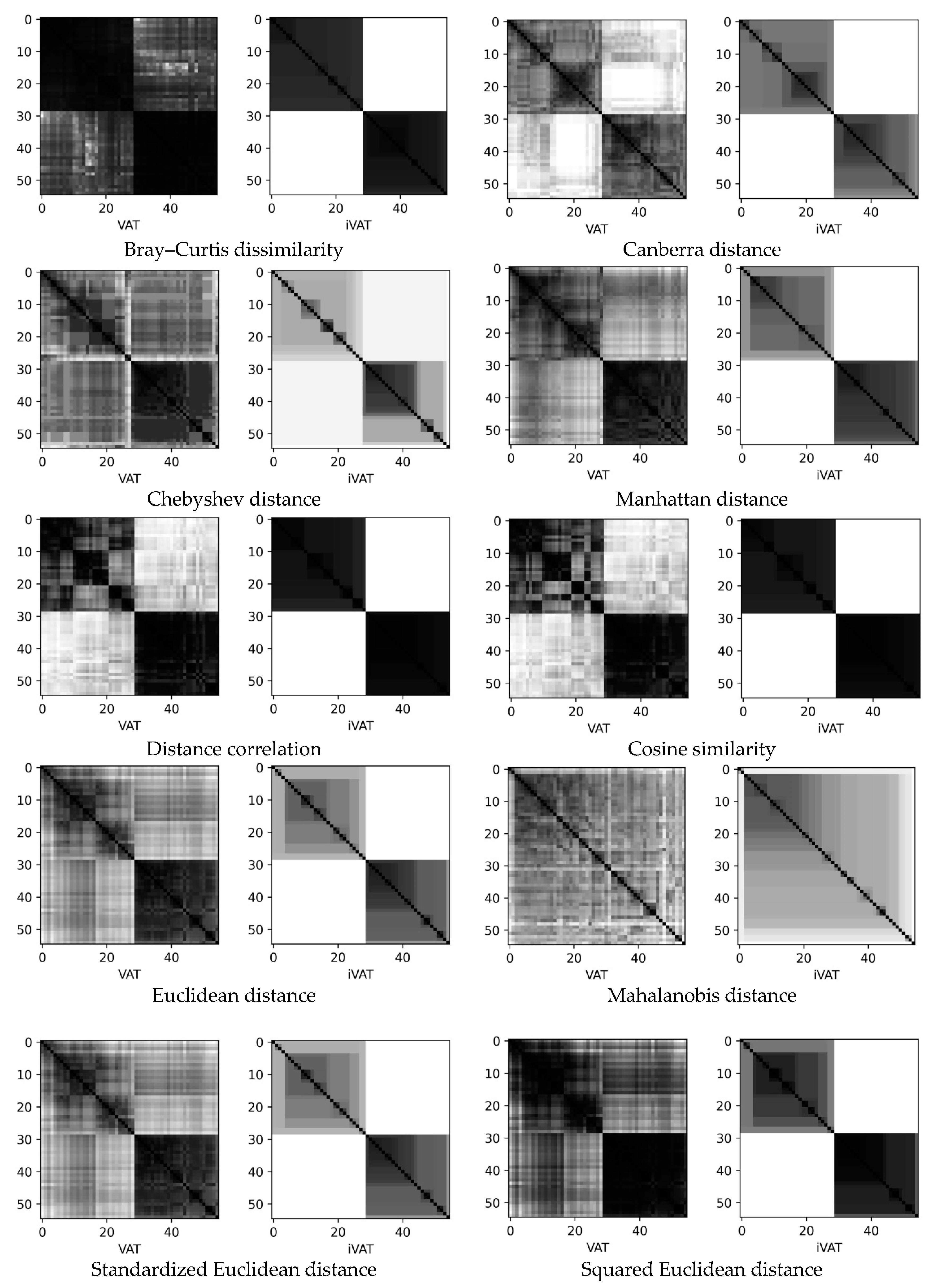
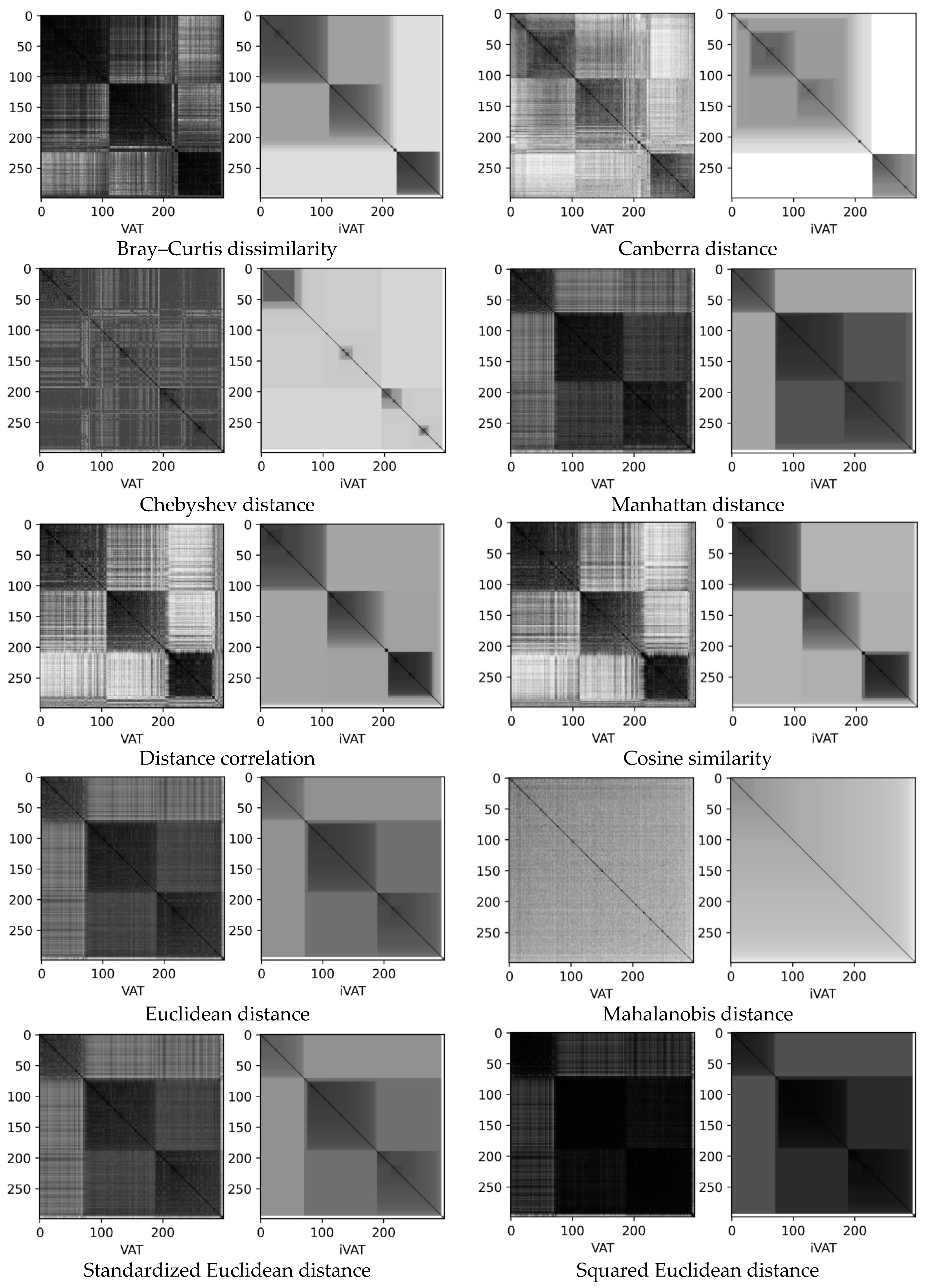
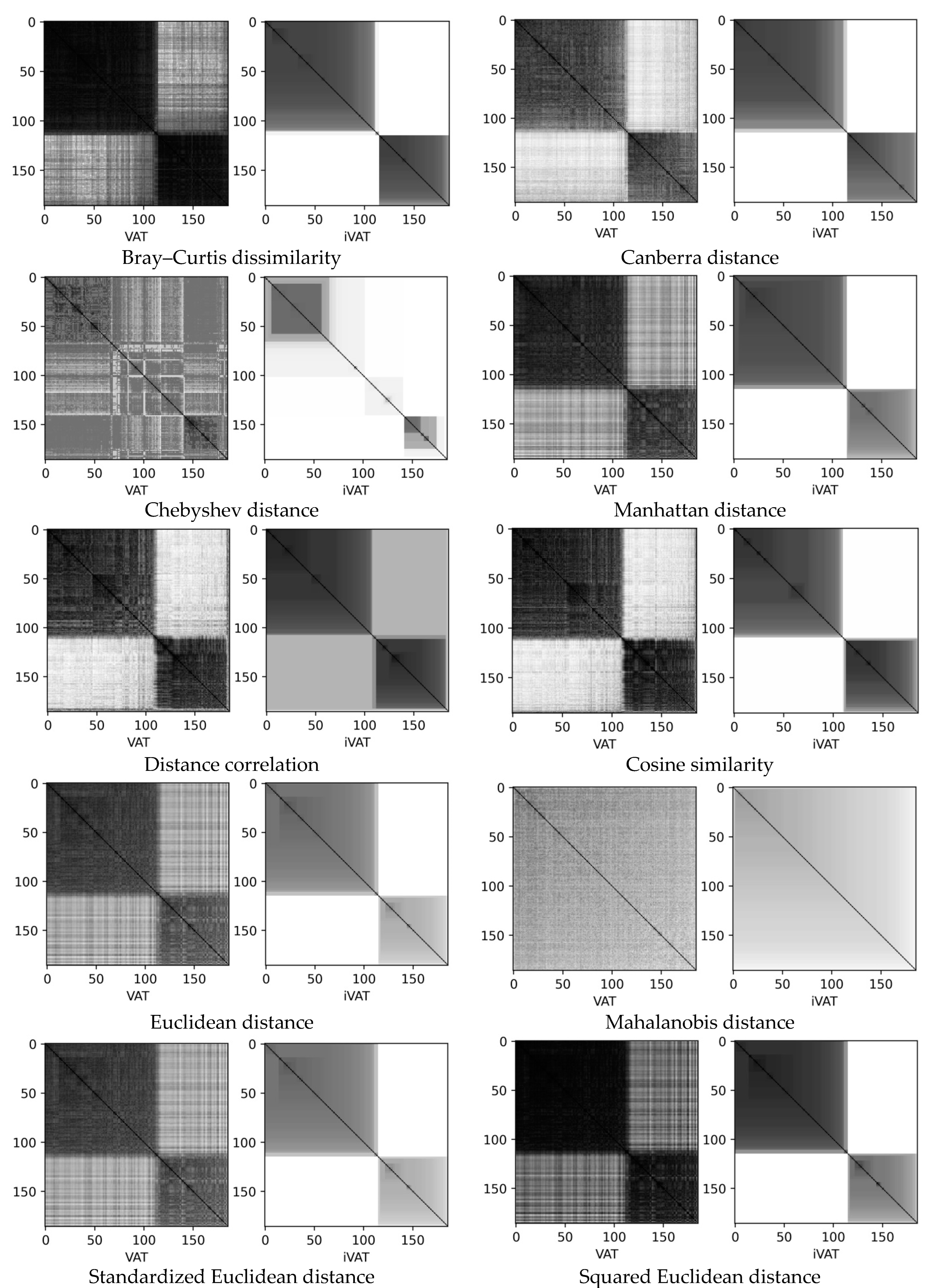
- Microchips are two sets of results of test effects on electrical and radio products for monitoring the current–voltage characteristics of input and output circuits of microcircuits: Microchips 140UD25AS1VK (46 data points, 9 dimensions, 2 clusters) and 1526IE10_002 (3987 data points, 67 dimensions, 4 clusters) [50,51]. For microchip 1526IE10_002, we used the following batch combinations: mixed lots from four (62 parameters), three (41 parameters), and two batches (41 parameters).
- e)
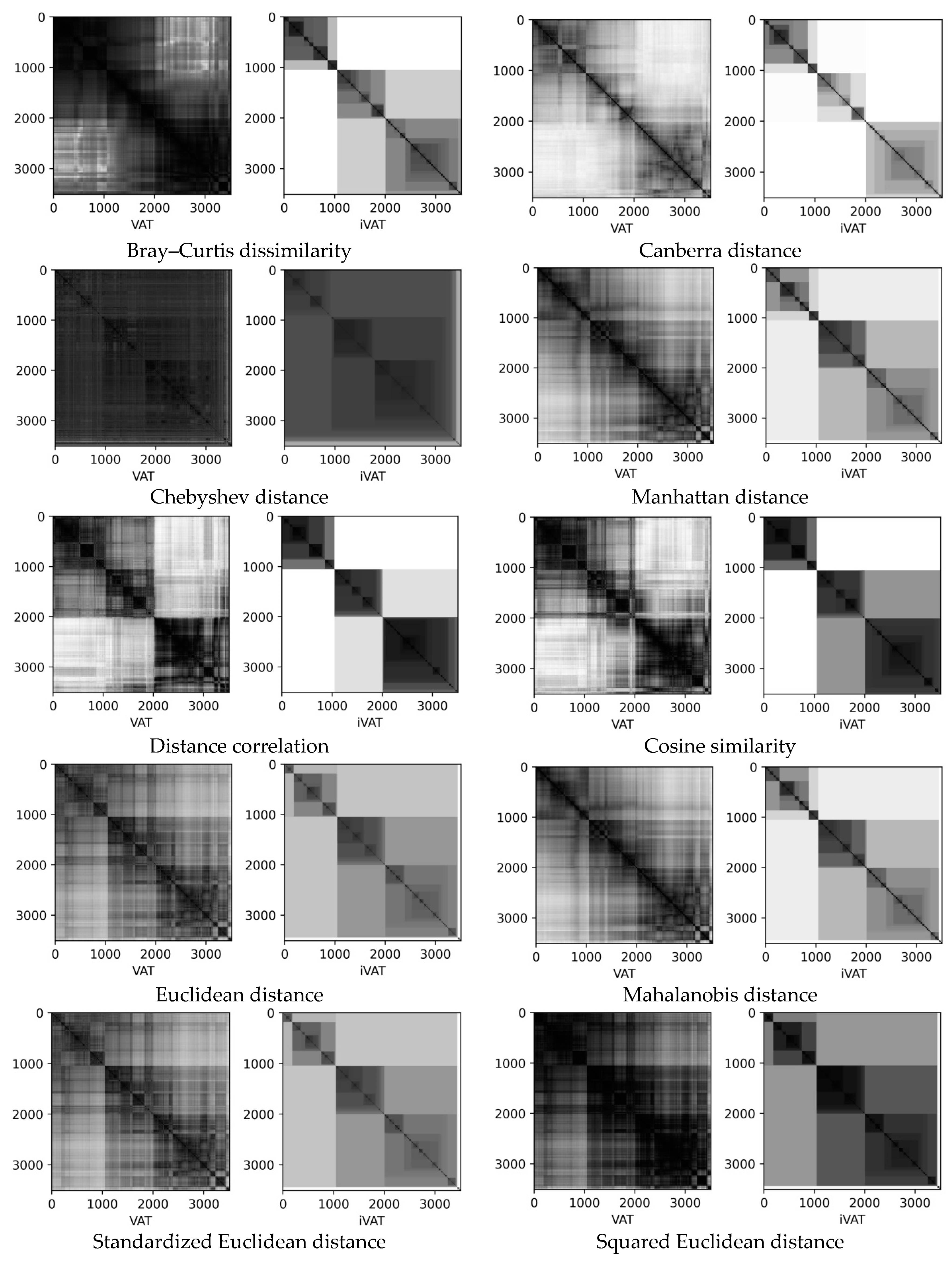
- Siberian Forest Compartments Dataset [52] is a set of some taxation characteristics of forest stands, on which outbreaks of mass reproduction of the Siberian silkworms were recorded at a certain time (15,523 data points, 150 dimensions). The Siberian Forest Compartments Dataset contains three forestry strands: Irbey forestry (2330 data points), Chunsky forestry (3271 data points), and Lower Yenisei forestry (3619 data points).
3.1. Synthetic Datasets
3.2. Microchips Datasets
3.3. Siberian Forest Compartments Datasets
4. Discussion
Author Contributions
Funding
Conflicts of Interest
Appendix A










References
- Amigó, E.; Gonzalo, J.; Artiles, J.; Verdejo, M.F. A comparison of extrinsic clustering evaluation metrics based on formal constraints. Inf. Retr. 2009, 12, 613. [Google Scholar] [CrossRef] [Green Version]
- Calinski, R.B.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; Wiley: New York, NY, USA, 1990; p. 368. [Google Scholar]
- Rousseeuw, P. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Bezdek, C.; Hathaway, R.J. Vat: A tool for visual assessment of (cluster) tendency. In Proceedings of the IJCNN, Honolulu, HI, USA, 12–17 May 2002; pp. 2225–2230. [Google Scholar]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice Hall College Div: Hoboken, NJ, USA, 1988. [Google Scholar]
- Everitt, B. Graphical Techniques for Multivariate Data; North-Holland Press: New York, NY, USA, 1978. [Google Scholar]
- Forina, M.; Lanteri, S.; Díez, I. New index for clustering tendency. Anal. Chim. Acta 2001, 446, 59–70. [Google Scholar] [CrossRef]
- Hopkins, B.; Skellam, J.G. A New Method for determining the Type of Distribution of Plant Individuals. Ann. Bot. 1954, 18, 213–227. [Google Scholar] [CrossRef]
- Lawson, R.G.; Jurs, P.J. Cluster analysis of acrylates to guide sampling for toxicity testing. J. Chem. Inf. Comput. Sci. 1990, 30, 137–144. [Google Scholar] [CrossRef]
- Fernández Pierna, J.A.; Massart, D.L. Improved algorithm for clustering tendency. Anal. Chim. Acta 2000, 408, 13–20. [Google Scholar] [CrossRef]
- Prim, R.C. Shortest Connection Networks and some Generalizations. Bell Syst. Tech. J. 1957, 36, 1389–1401. [Google Scholar] [CrossRef]
- Kruskal, J.B. On the Shortest Spanning Subtree of a Graph and the Traveling Salesman Problem. Proc. Am. Math. Soc. 1956, 7, 48–50. [Google Scholar] [CrossRef]
- Xie, X.L.; Beni, G. A Validity Measure for Fuzzy Clustering. IEEE Trans. Pattern Anal. Mach. Intel. 1991, 13, 841–847. [Google Scholar] [CrossRef]
- Kumar, D.; Bezdek, J.C. Visual approaches for exploratory data analysis: A survey of the visual assessment of clustering tendency (VAT) family of algorithms. IEEE Trans. Syst. Man Cybern. 2020, 6, 10–48. [Google Scholar] [CrossRef]
- Wang, L.; Nguyen, U.T.; Bezdek, J.C.; Leckie, C.A.; Ramamohanarao, K. iVAT and aVAT: Enhanced visual analysis for cluster tendency assessment. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Hyderabad, India, 21–24 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 16–27. [Google Scholar]
- Havens, T.C.; Bezdek, J.C.; Leckie, C.; Palaniswami, M. Extension of iVAT to asymmetric matrices. In Proceedings of the Fuzzy Systems (FUZZ), 2013 IEEE International Conference, Hyderabad, India, 7–10 July 2013; pp. 1–6. [Google Scholar]
- Zhong, C.; Yue, X.; Lei, J. Visual hierarchical cluster structure: A refined coassociation matrix based visual assessment of cluster tendency. Pattern Recognit. Lett. 2015, 59, 48–55. [Google Scholar] [CrossRef]
- Huband, J.M.; Bezdek, J.C.; Hathaway, R.J. Revised visual assessment of (cluster) tendency (reVAT). In Proceedings of the North American Fuzzy Information Processing Society (NAFIPS), Banff, AB, Canada, 27–30 June 2004; pp. 101–104. [Google Scholar]
- Huband, J.; Bezdek, J.; Hathaway, R. BigVAT: Visual assessment of cluster tendency for large data sets. Pattern Recognit. 2005, 38, 1875–1886. [Google Scholar] [CrossRef]
- Hathaway, R.; Bezdek, J.C.; Huband, J. Scalable visual assessment of cluster tendency for large data sets. Pattern Recognit. 2006, 39, 1315–1324. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Hathaway, R.; Huband, J. Visual assessment of clustering tendency for rectangular dissimilarity matrices. IEEE Trans. Fuzzy Syst. 2007, 15, 890–903. [Google Scholar] [CrossRef]
- Sledge, I.; Huband, J.; Bezdek, J.C. (Automatic) cluster count extraction from unlabeled datasets. In Proceedings of the Joint International Conference on Natural Computation and International Conference on Fuzzy Systems and Knowledge Discovery, Jinan, China, 1820 October 2008; Volume 1, pp. 3–13. [Google Scholar]
- Wang, L.; Leckie, C.; Kotagiri, R.; Bezdek, J. Automatically determining the number of clusters in unlabeled data sets. IEEE Trans. Knowl. Data Eng. 2009, 21, 335–350. [Google Scholar] [CrossRef]
- Havens, T.C.; Bezdek, J.C.; Keller, J.M.; Popescu, M. Clustering in ordered dissimilarity data. Int. J. Intell. Syst. 2009, 24, 504–528. [Google Scholar] [CrossRef]
- Clerc, M.; Kennedy, J. The particle swarm—Explosion, stability, and convergence in a multi-dimensional complex space. IEEE Trans. Evolut. Comput. 2002, 6, 58–73. [Google Scholar] [CrossRef] [Green Version]
- Pham, N.V.; Pham, L.T.; Nguyen, T.D.; Ngo, L.T. A new cluster tendency assessment method for fuzzy co-clustering in hyperspectral image analysis. Neurocomputing 2018, 307, 213–226. [Google Scholar] [CrossRef]
- Kumar, D.; Bezdek, J.C. Clustering tendency assessment for datasets having inter-cluster density variations. In Proceedings of the 2020 International Conference on Signal Processing and Communications (SPCOM), Bangalore, India, 19–24 July 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Zelnik-manor, L.; Perona, P. Self-tuning spectral clustering. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2004; Volume 17, pp. 1601–1608. [Google Scholar]
- Perona, P.; Freeman, W. A factorization approach to grouping. In Proceedings of the Computer Vision—ECCV’98, Freiburg, Germany, 2–6 June 1998; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1406, pp. 655–670. [Google Scholar]
- Campello, R.J.G.B.; Moulavi, D.; Sander, J. Density-based clustering based on hierarchical density estimates. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2013; pp. 160–172. [Google Scholar]
- Rathore, P.; Bezdek, J.C.; Santi, P.; Ratti, C. ConiVAT: Cluster Tendency Assessment and Clustering with Partial Background Knowledge. arXiv 2020, arXiv:2008.09570. [Google Scholar]
- Rathore, P.; Bezdek, J.C.; Palaniswami, M. Fast Cluster Tendency Assessment for Big, High-Dimensional Data. In Fuzzy Approaches for Soft Computing and Approximate Reasoning: Theories and Applications; Lesot, M.J., Marsala, C., Eds.; Studies in Fuzziness and Soft Computing; Springer: Cham, Switzerland, 2021; Volume 394. [Google Scholar]
- Basha, M.S.; Mouleeswaran, S.K.; Prasad, K.R. Sampling-based visual assessment computing techniques for an efficient social data clustering. J. Supercomput. 2021, 8, 8013–8037. [Google Scholar] [CrossRef]
- Prasad, K.R.; Kamatam, G.R.; Myneni, M.B.; Reddy, N.R. A novel data visualization method for the effective assessment of cluster tendency through the dark blocks image pattern analysis. Microprocess. Microsyst. 2022, 93, 104625. [Google Scholar] [CrossRef]
- Datta, S.; Karmakar, C.; Rathore, P.; Palaniswami, M. Scalable Cluster Tendency Assessment for Streaming Activity Data using Recurring Shapelets. In Proceedings of the 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022; pp. 1036–1040. [Google Scholar] [CrossRef]
- Wang, L.; Geng, X.; Bezdek, J.; Leckie, C.; Kotagiri, R. Enhanced visual analysis for cluster tendency assessment and data partitioning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1401–1414. [Google Scholar] [CrossRef]
- Shirkhorshidi, S.; Aghabozorgi, S.; Wah, T. A Comparison Study on Similarity and Dissimilarity Measures in Clustering Continuous Data. PLoS ONE 2015, 10, e0144059. [Google Scholar] [CrossRef] [Green Version]
- Alfeilat, H.; Hassanat, A.; Lasassmeh, O.; Tarawneh, A.; Alhasanat, M.; Salman, H.; Prasath, V. Effects of Distance Measure Choice on K-Nearest Neighbor Classifier Performance: A Review. Big Data 2019, 7, 221–248. [Google Scholar] [CrossRef] [Green Version]
- Weller-Fahy, D.J.; Borghetti, B.J.; Sodemann, A.A. A Survey of Distance and Similarity Measures Used Within Network Intrusion Anomaly Detection. IEEE Commun. Surv. Tutor. 2015, 17, 70–91. [Google Scholar] [CrossRef]
- Canberra Distance. Available online: https://academic.oup.com/comjnl/article/9/1/60/348137?login=false (accessed on 14 October 2022).
- McLachlan, G. Mahalanobis Distance. Resonance 1999, 4, 20–26. [Google Scholar] [CrossRef]
- Distance Correlation. Available online: https://arxiv.org/abs/0803.4101 (accessed on 14 October 2022).
- Han, J.; Kamber, M.; Pei, J. Data mining: Concepts and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2012. [Google Scholar]
- Bray–Curtis Dissimilarity. Available online: https://esajournals.onlinelibrary.wiley.com/doi/10.2307/1942268 (accessed on 14 October 2022).
- Havens, C.; Bezdek, J.C. An efficient formulation of the improved visual assessment of cluster tendency (iVAT) algorithm. IEEE Trans. Knowl. Data Eng. 2012, 24, 813–822. [Google Scholar] [CrossRef]
- Havens, T.C.; Bezdek, J.C.; Keller, J.M.; Popescu, M.; Huband, J.M. Is VAT really single linkage in disguise? Ann. Math. Artif. Intell. 2009, 55, 237. [Google Scholar] [CrossRef]
- Artificial Clustering Datasets. Available online: https://github.com/milaan9/Clustering-Datasets (accessed on 14 October 2022).
- Shkaberina, G.S.; Orlov, V.I.; Tovbis, E.M.; Kazakovtsev, L.A. On the Optimization Models for Automatic Grouping of Industrial Products by Homogeneous Production Batches. Commun. Comput. Inf. Sci. 2020, 1275, 421–436. [Google Scholar]
- Kazakovtsev, L.A.; Antamoshkin, A.N.; Masich, I.S. Fast deterministic algorithm for EEE components classification. IOP Conf. Ser. Mater. Sci. Eng. 2015, 94, 012015. [Google Scholar] [CrossRef]
- Rezova, N.; Kazakovtsev, L.; Shkaberina, G.; Demidko, D.; Goroshko, A. Data pre-processing for ecosystem behaviour analysis. In Proceedings of the 2022 IEEE International Conference on Information Technologies, Varna, Bulgaria, 15–16 September 2022. in press. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shkaberina, G.; Rezova, N.; Tovbis, E.; Kazakovtsev, L. Visual Assessment of Cluster Tendency with Variations of Distance Measures. Algorithms 2023, 16, 5. https://doi.org/10.3390/a16010005
Shkaberina G, Rezova N, Tovbis E, Kazakovtsev L. Visual Assessment of Cluster Tendency with Variations of Distance Measures. Algorithms. 2023; 16(1):5. https://doi.org/10.3390/a16010005
Chicago/Turabian StyleShkaberina, Guzel, Natalia Rezova, Elena Tovbis, and Lev Kazakovtsev. 2023. "Visual Assessment of Cluster Tendency with Variations of Distance Measures" Algorithms 16, no. 1: 5. https://doi.org/10.3390/a16010005
APA StyleShkaberina, G., Rezova, N., Tovbis, E., & Kazakovtsev, L. (2023). Visual Assessment of Cluster Tendency with Variations of Distance Measures. Algorithms, 16(1), 5. https://doi.org/10.3390/a16010005