
A Learnheuristic Algorithm for the Capacitated Dispersion Problem under Dynamic Conditions




Abstract
:1. Introduction
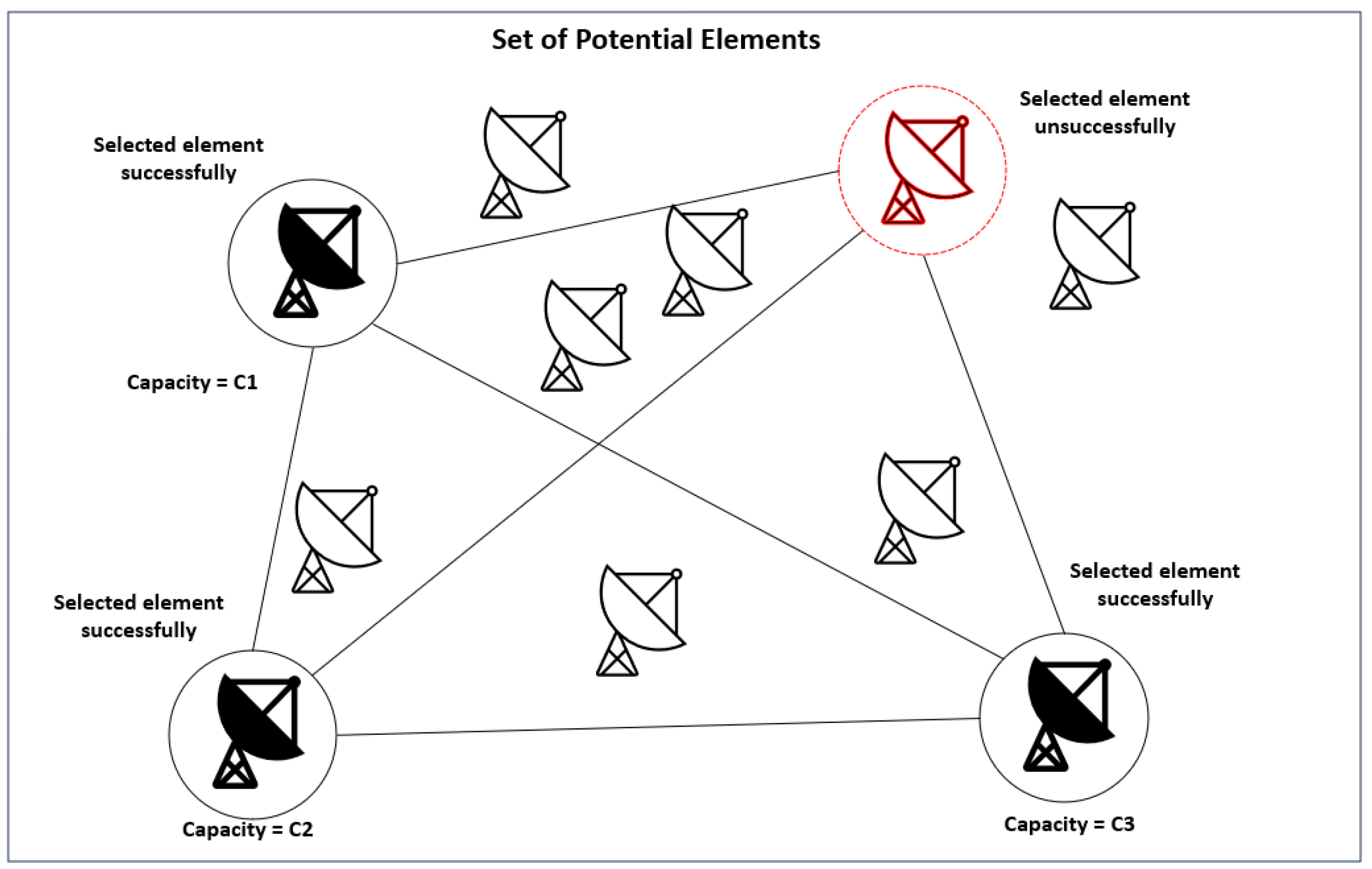
- V represents the element set.
- defines the distance between elements i and j within V.
- E signifies the number of elements chosen.
- is a binary variable that assumes a value of one when element i in V is selected, and it selects zero otherwise.
2. Related Work on Diversity Problems
3. Problem Definition
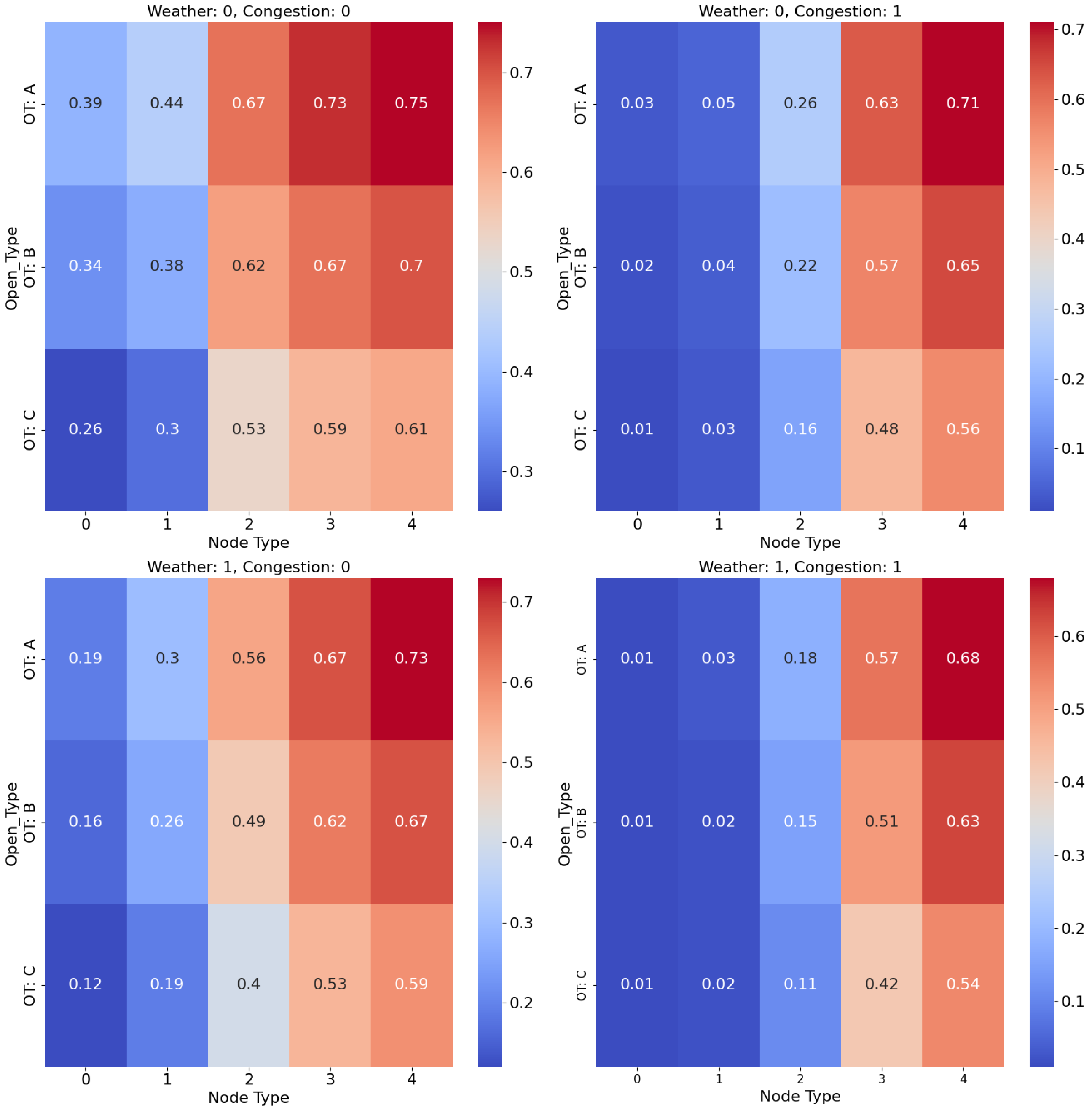
Black Box Definition
- w represents the meteorological conditions directly affecting the networks.
- c denotes the congestion level between nodes.
- o indicates the ratio of operational facilities for each category—each facility belongs to a particular type.
- serves as the intercept term, which represents the baseline log-odds when all other influencing factors are zero.
- modulates the influence of the meteorological conditions (w) on the outcome.
- influences the outcome based on the congestion (c) between nodes.
- influences the outcome based on the ratio of the operation facilities (o) that are currently open.
4. Solution Approaches for the Dynamic Capacitated Dispersion Problem
A Constructive Heuristic
| Algorithm 1 Constructive heuristic (, , ) |
|
| Algorithm 2 Algorithm performance evaluation |
|
5. Numerical Experiments and Results
5.1. Computational Environment
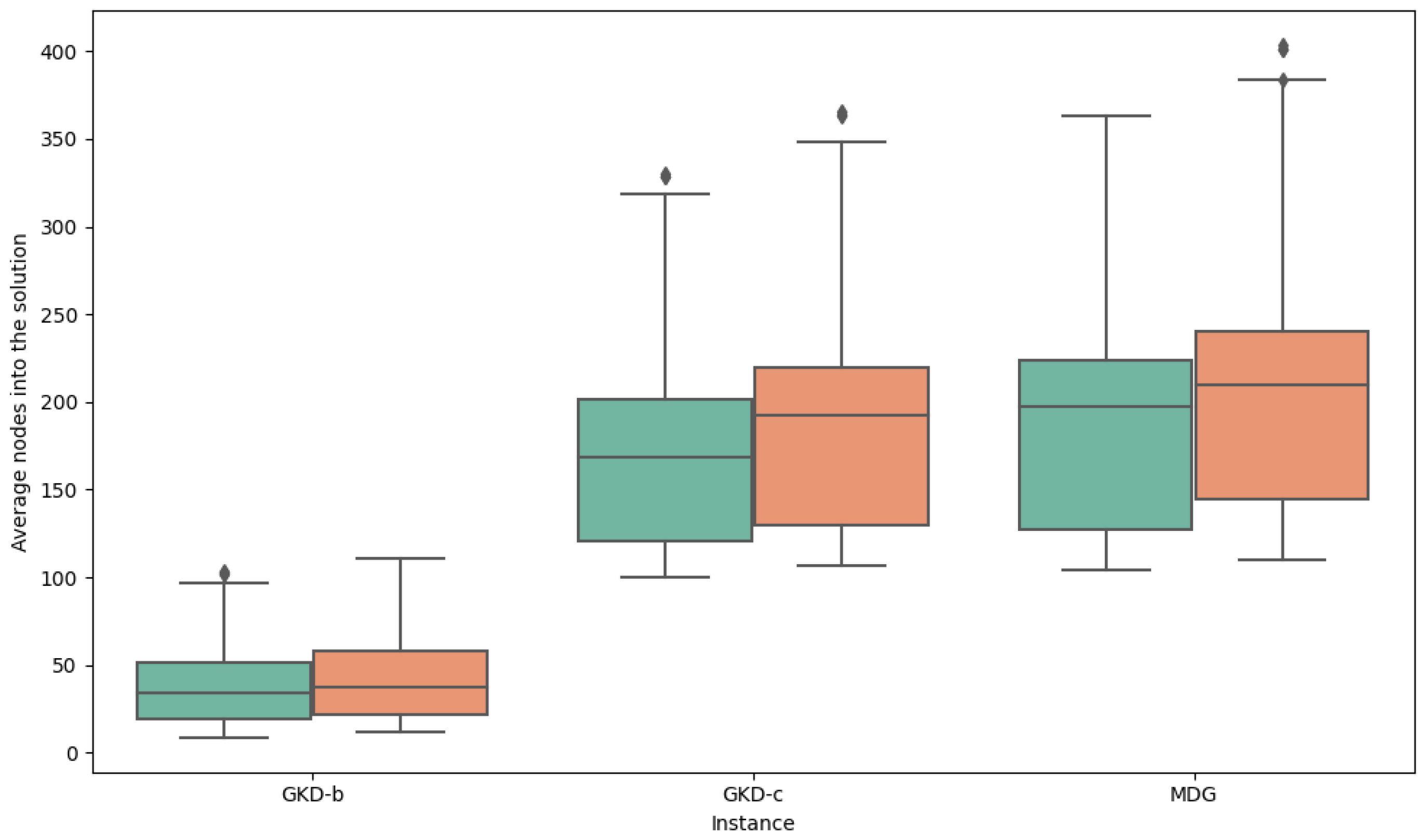
- GKD instances: This is a dataset formed using Euclidean distances with node coordinates generated within a uniform distribution ranging from 0 to 10. Initially proposed in Martí et al. [26], it is divided into two subsets: the GKD-b, which includes instances with 50 and 150 nodes, and the GKD-c subset, which includes instances harboring 500 nodes.
- MDG instances: This dataset encompasses real numbers arbitrarily chosen between 0 and 1000 that originate from a uniform distribution. It was introduced by Duarte and Martí [27] and comprises instances with a sizable 500 nodes.
5.2. Black Box Parameters
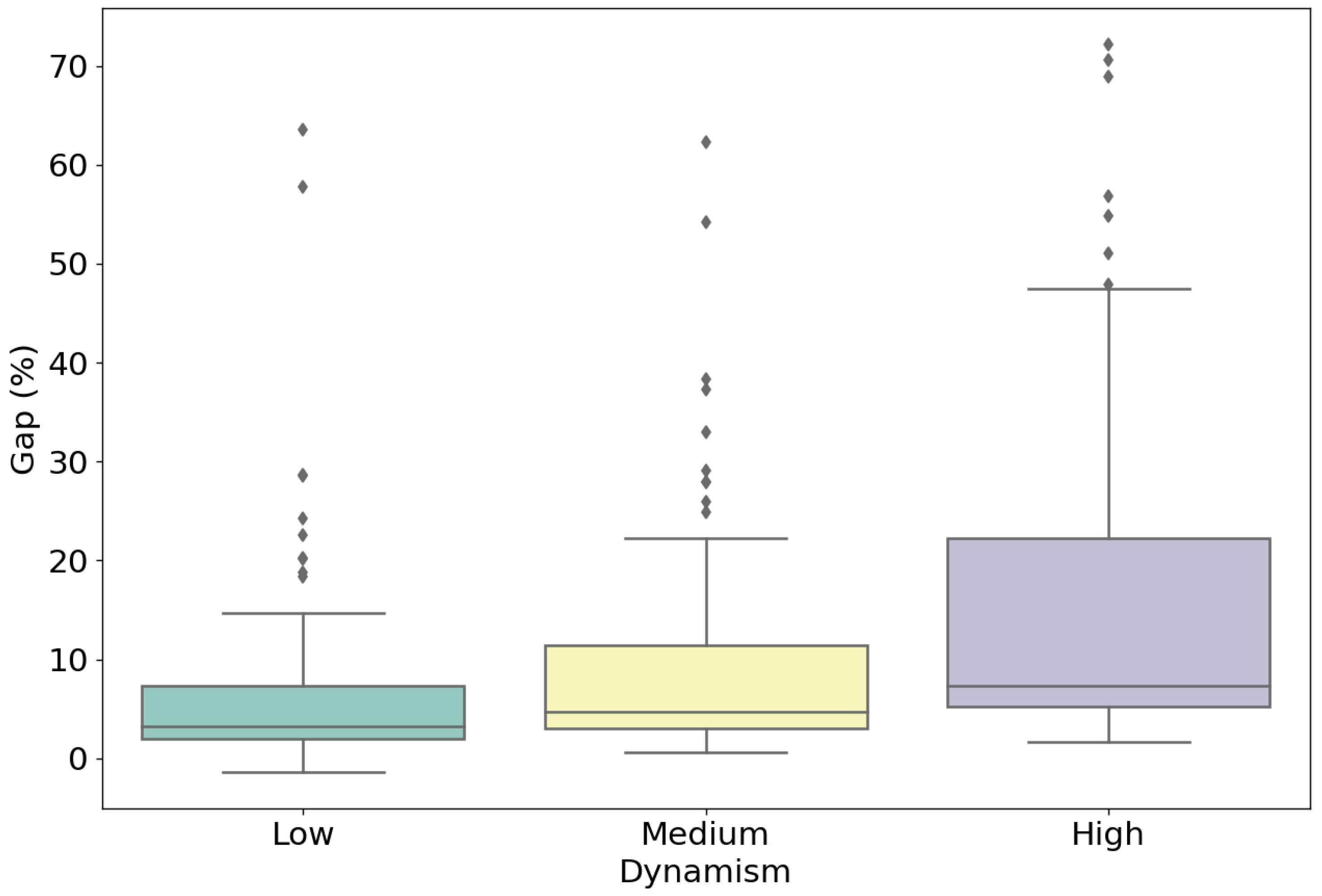
5.3. Analysis of Results
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Govindan, K.; Fattahi, M.; Keyvanshokooh, E. Supply chain network design under uncertainty: A comprehensive review and future research directions. Eur. J. Oper. Res. 2017, 263, 108–141. [Google Scholar] [CrossRef]
- Eskandarpour, M.; Dejax, P.; Miemczyk, J.; Péton, O. Sustainable supply chain network design: An optimization-oriented review. Omega 2015, 54, 11–32. [Google Scholar] [CrossRef]
- Nataraj, S.; Ferone, D.; Quintero-Araujo, C.; Juan, A.; Festa, P. Consolidation centers in city logistics: A cooperative approach based on the location routing problem. Int. J. Ind. Eng. Comput. 2019, 10, 393–404. [Google Scholar] [CrossRef]
- Martí, R.; Martínez-Gavara, A.; Pérez-Peló, S.; Sánchez-Oro, J. A review on discrete diversity and dispersion maximization from an OR perspective. Eur. J. Oper. Res. 2022, 299, 795–813. [Google Scholar] [CrossRef]
- Correia, I.; Melo, T.; Saldanha-da Gama, F. Comparing classical performance measures for a multi-period, two-echelon supply chain network design problem with sizing decisions. Comput. Ind. Eng. 2013, 64, 366–380. [Google Scholar] [CrossRef]
- Tordecilla, R.D.; Copado-Méndez, P.J.; Panadero, J.; Quintero-Araujo, C.L.; Montoya-Torres, J.R.; Juan, A.A. Combining heuristics with simulation and fuzzy logic to solve a flexible-size location routing problem under uncertainty. Algorithms 2021, 14, 45. [Google Scholar] [CrossRef]
- Osaba, E.; Villar-Rodriguez, E.; Del Ser, J.; Nebro, A.J.; Molina, D.; LaTorre, A.; Suganthan, P.N.; Coello, C.A.C.; Herrera, F. A tutorial on the design, experimentation and application of metaheuristic algorithms to real-world optimization problems. Swarm Evol. Comput. 2021, 64, 100888. [Google Scholar] [CrossRef]
- Szepesvári, C. Algorithms for Reinforcement Learning; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Juan, A.A.; Marugan, C.A.; Ahsini, Y.; Fornes, R.; Panadero, J.; Martin, X.A. Using Reinforcement Learning to Solve a Dynamic Orienteering Problem with Random Rewards Affected by the Battery Status. Batteries 2023, 9, 416. [Google Scholar] [CrossRef]
- Rosenkrantz, D.J.; Tayi, G.K.; Ravi, S.S. Facility Dispersion Problems under Capacity and Cost Constraints. J. Comb. Optim. 2000, 4, 7–33. [Google Scholar] [CrossRef]
- Bayliss, C. Machine learning based simulation optimisation for urban routing problems. Appl. Soft Comput. 2021, 105, 107269. [Google Scholar] [CrossRef]
- Mele, U.J.; Gambardella, L.M.; Montemanni, R. A new constructive heuristic driven by machine learning for the traveling salesman problem. Algorithms 2021, 14, 267. [Google Scholar] [CrossRef]
- Kuo, C.C.; Glover, F.; Dhir, K.S. Analyzing and modeling the maximum diversity problem by zero-one programming. Decis. Sci. 1993, 24, 1171–1185. [Google Scholar] [CrossRef]
- Sandoya, F.; Martínez-Gavara, A.; Aceves, R.; Duarte, A.; Martí, R. Diversity and equity models. In Handbook of Heuristics; Springer: Berlin/Heidelberg, Germany, 2018; Volume 2-2, pp. 979–998. [Google Scholar]
- Peiró, J.; Jiménez, I.; Laguardia, J.; Martí, R. Heuristics for the capacitated dispersion problem. Int. Trans. Oper. Res. 2021, 28, 119–141. [Google Scholar] [CrossRef]
- Resende, M.G.; Ribeiro, C.C. Optimization by GRASP; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Duarte, A.; Mladenovic, N.; Sánchez-Oro, J.; Todosijević, R. Variable neighborhood descent. In Handbook of Heuristics; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Glover, F.; Hao, J.K. The case for strategic oscillation. Ann. Oper. Res. 2011, 183, 163–173. [Google Scholar] [CrossRef]
- Martí, R.; Martínez-Gavara, A.; Sánchez-Oro, J. The capacitated dispersion problem: An optimization model and a memetic algorithm. Memetic Comput. 2021, 13, 131–146. [Google Scholar] [CrossRef]
- Laguna, M.; Martí, R.C. Scatter Search: Methodology and Implementations in C; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Lu, Z.; Martínez-Gavara, A.; Hao, J.K.; Lai, X. Solution-based tabu search for the capacitated dispersion problem. Expert Syst. Appl. 2023, 223, 119856. [Google Scholar] [CrossRef]
- Gendreau, M. An introduction to tabu search. In Handbook of Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2003; pp. 37–54. [Google Scholar]
- Lu, X.; Van Roy, B.; Dwaracherla, V.; Ibrahimi, M.; Osband, I.; Wen, Z. Reinforcement learning, bit by bit. Found. Trends Mach. Learn. 2023, 16, 733–865. [Google Scholar] [CrossRef]
- Mazyavkina, N.; Sviridov, S.; Ivanov, S.; Burnaev, E. Reinforcement learning for combinatorial optimization: A survey. Comput. Oper. Res. 2021, 134, 105400. [Google Scholar] [CrossRef]
- Calvet, L.; de Armas, J.; Masip, D.; Juan, A.A. Learnheuristics: Hybridizing metaheuristics with machine learning for optimization with dynamic inputs. Open Math. 2017, 15, 261–280. [Google Scholar] [CrossRef]
- Martí, R.; Gallego, M.; Duarte, A. A branch and bound algorithm for the maximum diversity problem. Eur. J. Oper. Res. 2010, 200, 36–44. [Google Scholar] [CrossRef]
- Duarte, A.; Martí, R. Tabu search and GRASP for the maximum diversity problem. Eur. J. Oper. Res. 2007, 178, 71–84. [Google Scholar] [CrossRef]
- Gomez, J.F.; Panadero, J.; Tordecilla, R.D.; Castaneda, J.; Juan, A.A. A multi-start biased-randomized algorithm for the capacitated dispersion problem. Mathematics 2022, 10, 2405. [Google Scholar] [CrossRef]
- Lozano-Osorio, I.; Martínez-Gavara, A.; Martí, R.; Duarte, A. Max–min dispersion with capacity and cost for a practical location problem. Expert Syst. Appl. 2022, 200, 116899. [Google Scholar] [CrossRef]
- Hatami, S.; Calvet, L.; Fernández-Viagas, V.; Framinan, J.M.; Juan, A.A. A simheuristic algorithm to set up starting times in the stochastic parallel flowshop problem. Simul. Model. Pract. Theory 2018, 86, 55–71. [Google Scholar] [CrossRef]
- Rabe, M.; Gonzalez-Feliu, J.; Chicaiza-Vaca, J.; Tordecilla, R.D. Simulation-optimization approach for multi-period facility location problems with forecasted and random demands in a last-mile logistics application. Algorithms 2021, 14, 41. [Google Scholar] [CrossRef]
- Essaid, M.; Idoumghar, L.; Lepagnot, J.; Brévilliers, M. GPU parallelization strategies for metaheuristics: A survey. Int. J. Parallel Emergent Distrib. Syst. 2019, 34, 497–522. [Google Scholar] [CrossRef]
- Dominguez, O.; Juan, A.A.; Faulin, J. A biased-randomized algorithm for the two-dimensional vehicle routing problem with and without item rotations. Int. Trans. Oper. Res. 2014, 21, 375–398. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node Type | Low | Medium | High | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N1 | 0.7 | −0.3 | −2.5 | −0.8 | 0.5 | −0.6 | −3 | −1.85 | −0.4 | −1 | −3.2 | −2 |
| N2 | 0.8 | −0.2 | −2 | −0.55 | 0.6 | −0.4 | −2.5 | −0.8 | −0.2 | −0.6 | −2.7 | −1.2 |
| N3 | 0.9 | −0.15 | −0.5 | 0 | 1 | −0.25 | −0.75 | 0 | 0.75 | −0.5 | −1.75 | −1 |
| N4 | 1 | −0.1 | −0.25 | 0.4 | 1.2 | −0.15 | −0.45 | 0.6 | 1 | −0.25 | −0.45 | 0.3 |
| N5 | 1.1 | −0.05 | −0.1 | 0.6 | 1.3 | −0.1 | −0.2 | 0.8 | 1.1 | −0.1 | −0.2 | 0.5 |
| Instance | Learnheuristic | Static | Gap (%) | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Low (1) | Medium (2) | High (3) | Low (4) | Medium (5) | High (6) | ||||||||||||||||
| Time | Nodes | OF | Time | Nodes | OF | Time | Nodes | OF | Time | Nodes | OF | Time | Nodes | OF | Time | Nodes | OF | (1)–(4) | (2)–(5) | (3)–(6) | |
| GKD-b_11_n50_b02_m5 | 38.4 | 13.6 | 117.9 | 34.1 | 14.4 | 116.7 | 38.7 | 19.9 | 110.4 | 1.9 | 13.0 | 115.5 | 1.7 | 14.2 | 113.6 | 2.0 | 19.7 | 105.7 | 2.10% | 2.75% | 4.39% |
| GKD-b_11_n50_b03_m5 | 31.7 | 20.6 | 107.7 | 34.8 | 21.6 | 106.7 | 46.5 | 31.4 | 94.4 | 1.5 | 21.7 | 107.5 | 1.6 | 23.5 | 105.1 | 2.0 | 33.7 | 91.0 | 0.21% | 1.51% | 3.72% |
| GKD-b_12_n50_b02_m5 | 22.0 | 11.5 | 146.3 | 22.2 | 11.6 | 145.4 | 28.7 | 14.6 | 140.4 | 1.0 | 13.4 | 138.0 | 1.2 | 14.6 | 135.3 | 1.4 | 20.2 | 128.3 | 6.05% | 7.45% | 9.42% |
| GKD-b_12_n50_b03_m5 | 35.3 | 22.2 | 134.6 | 37.2 | 23.1 | 132.8 | 42.9 | 32.0 | 122.9 | 1.4 | 21.6 | 130.5 | 1.5 | 23.1 | 128.4 | 1.9 | 32.7 | 119.4 | 3.13% | 3.40% | 2.95% |
| GKD-b_13_n50_b02_m5 | 26.6 | 14.0 | 69.0 | 27.2 | 14.4 | 68.5 | 34.4 | 19.3 | 62.6 | 1.2 | 15.2 | 63.2 | 1.2 | 16.1 | 61.9 | 1.5 | 23.6 | 53.3 | 9.09% | 10.73% | 17.44% |
| GKD-b_13_n50_b03_m5 | 32.7 | 19.1 | 58.0 | 30.9 | 19.2 | 57.9 | 43.0 | 27.9 | 49.0 | 1.5 | 22.0 | 54.0 | 1.6 | 23.4 | 52.6 | 2.0 | 33.4 | 43.0 | 7.36% | 10.13% | 13.99% |
| GKD-b_14_n50_b02_m5 | 27.3 | 14.2 | 60.5 | 28.1 | 15.2 | 59.0 | 34.3 | 21.6 | 50.7 | 1.2 | 15.6 | 56.7 | 1.3 | 17.6 | 53.5 | 1.6 | 25.5 | 42.7 | 6.61% | 10.30% | 18.63% |
| GKD-b_14_n50_b03_m5 | 38.1 | 24.2 | 47.0 | 41.3 | 25.4 | 45.6 | 49.3 | 34.9 | 34.9 | 1.6 | 25.4 | 45.4 | 1.7 | 27.3 | 43.4 | 2.0 | 37.4 | 31.7 | 3.39% | 4.94% | 10.19% |
| GKD-b_15_n50_b02_m5 | 21.7 | 8.9 | 115.4 | 21.0 | 8.9 | 113.0 | 24.4 | 9.8 | 104.3 | 0.9 | 11.6 | 114.0 | 1.0 | 12.3 | 110.1 | 1.1 | 15.3 | 99.3 | 1.16% | 2.61% | 4.99% |
| GKD-b_15_n50_b03_m5 | 39.3 | 21.2 | 113.0 | 42.4 | 23.3 | 109.8 | 55.6 | 35.2 | 93.7 | 1.7 | 23.6 | 109.5 | 1.9 | 27.4 | 104.9 | 2.2 | 39.5 | 88.6 | 3.15% | 4.68% | 5.75% |
| GKD-b_16_n50_b02_m15 | 26.9 | 13.3 | 51.3 | 27.6 | 13.9 | 49.9 | 34.5 | 21.1 | 40.2 | 1.1 | 13.8 | 48.9 | 1.1 | 14.4 | 47.5 | 1.5 | 21.7 | 38.4 | 4.89% | 5.05% | 4.53% |
| GKD-b_16_n50_b03_m15 | 30.3 | 14.8 | 28.9 | 29.6 | 14.6 | 29.5 | 35.3 | 19.2 | 26.6 | 1.3 | 17.9 | 26.2 | 1.4 | 19.0 | 25.2 | 1.7 | 26.8 | 20.9 | 10.31% | 17.30% | 27.34% |
| GKD-b_17_n50_b02_m15 | 24.8 | 12.3 | 23.2 | 25.3 | 12.3 | 23.1 | 30.5 | 15.8 | 19.3 | 1.0 | 13.9 | 20.3 | 1.1 | 15.5 | 18.5 | 1.5 | 22.8 | 13.5 | 14.02% | 24.86% | 43.48% |
| GKD-b_17_n50_b03_m15 | 35.5 | 21.6 | 13.5 | 36.4 | 22.9 | 12.7 | 42.7 | 31.3 | 8.8 | 1.5 | 22.5 | 13.0 | 1.7 | 24.4 | 11.9 | 1.9 | 33.2 | 8.1 | 4.27% | 6.36% | 8.96% |
| GKD-b_18_n50_b02_m15 | 25.6 | 11.5 | 91.2 | 24.7 | 11.0 | 92.2 | 26.7 | 12.5 | 89.1 | 1.1 | 14.8 | 81.0 | 1.2 | 15.8 | 79.6 | 1.4 | 21.9 | 71.8 | 12.64% | 15.78% | 23.98% |
| GKD-b_18_n50_b03_m15 | 31.3 | 17.4 | 74.3 | 33.2 | 17.4 | 73.9 | 34.4 | 22.9 | 66.8 | 1.3 | 18.9 | 71.2 | 1.4 | 19.9 | 69.4 | 1.7 | 27.1 | 60.5 | 4.34% | 6.55% | 10.38% |
| GKD-b_19_n50_b02_m15 | 24.1 | 13.5 | 89.9 | 26.8 | 14.3 | 88.2 | 35.2 | 21.7 | 79.4 | 1.0 | 13.1 | 88.4 | 1.1 | 14.3 | 86.4 | 1.4 | 22.0 | 76.2 | 1.71% | 2.09% | 4.24% |
| GKD-b_19_n50_b03_m15 | 36.3 | 22.6 | 77.9 | 37.3 | 23.6 | 76.6 | 44.9 | 33.3 | 65.5 | 1.6 | 24.0 | 76.0 | 1.6 | 26.4 | 73.2 | 2.0 | 36.9 | 60.3 | 2.52% | 4.62% | 8.64% |
| GKD-b_20_n50_b02_m15 | 25.0 | 13.6 | 90.7 | 24.5 | 13.6 | 90.1 | 29.1 | 17.0 | 84.7 | 1.0 | 13.9 | 87.8 | 1.1 | 15.0 | 86.0 | 1.4 | 21.0 | 77.8 | 3.29% | 4.78% | 8.91% |
| GKD-b_20_n50_b03_m15 | 30.5 | 19.7 | 79.7 | 33.1 | 20.9 | 78.3 | 44.5 | 30.6 | 64.4 | 1.3 | 20.2 | 77.9 | 1.5 | 21.9 | 75.6 | 1.9 | 32.7 | 60.3 | 2.30% | 3.58% | 6.82% |
| GKD-b_41_n150_b02_m15 | 162.2 | 35.7 | 141.2 | 165.6 | 37.5 | 139.9 | 197.5 | 55.5 | 132.7 | 7.8 | 39.4 | 139.9 | 8.5 | 43.9 | 137.7 | 11.7 | 67.6 | 127.5 | 0.87% | 1.64% | 3.41% |
| GKD-b_41_n150_b03_m15 | 198.6 | 56.9 | 132.4 | 205.8 | 60.1 | 130.7 | 254.3 | 95.7 | 117.6 | 10.6 | 58.0 | 130.0 | 11.4 | 64.0 | 127.0 | 15.2 | 105.6 | 111.5 | 1.82% | 2.88% | 5.51% |
| GKD-b_42_n150_b02_m15 | 166.9 | 38.4 | 62.5 | 165.3 | 39.4 | 61.6 | 194.9 | 53.9 | 55.5 | 8.2 | 41.9 | 61.1 | 8.8 | 45.8 | 59.4 | 11.1 | 62.1 | 53.7 | 2.40% | 3.71% | 3.34% |
| GKD-b_42_n150_b03_m15 | 196.9 | 57.5 | 51.5 | 195.4 | 58.7 | 50.7 | 234.6 | 84.0 | 45.1 | 11.0 | 60.4 | 51.5 | 11.4 | 63.8 | 50.4 | 14.2 | 92.9 | 42.7 | 0.02% | 0.60% | 5.57% |
| GKD-b_43_n150_b02_m15 | 165.6 | 39.0 | 46.0 | 166.7 | 38.6 | 45.9 | 182.4 | 50.5 | 41.5 | 8.8 | 45.7 | 42.8 | 9.5 | 49.2 | 41.6 | 11.6 | 65.4 | 37.6 | 7.33% | 10.44% | 10.30% |
| GKD-b_43_n150_b03_m15 | 197.1 | 58.1 | 39.3 | 197.4 | 61.7 | 38.2 | 243.9 | 94.5 | 29.9 | 10.9 | 60.5 | 38.2 | 11.6 | 67.1 | 36.4 | 15.2 | 105.3 | 26.4 | 2.86% | 4.75% | 13.00% |
| GKD-b_44_n150_b02_m15 | 166.8 | 38.2 | 80.7 | 166.4 | 39.3 | 80.0 | 193.8 | 53.1 | 73.8 | 7.7 | 38.4 | 78.9 | 8.2 | 41.6 | 77.2 | 10.7 | 59.6 | 69.4 | 2.19% | 3.66% | 6.38% |
| GKD-b_44_n150_b03_m15 | 191.4 | 56.5 | 69.8 | 201.3 | 58.8 | 69.2 | 249.1 | 91.3 | 60.6 | 11.2 | 62.6 | 68.2 | 12.3 | 71.3 | 65.5 | 15.4 | 108.2 | 54.5 | 2.33% | 5.65% | 11.18% |
| GKD-b_45_n150_b02_m15 | 159.6 | 37.1 | 88.6 | 163.7 | 37.9 | 87.9 | 184.3 | 49.7 | 82.0 | 7.5 | 37.5 | 86.1 | 7.8 | 39.8 | 84.7 | 9.9 | 53.6 | 78.0 | 2.89% | 3.67% | 5.13% |
| GKD-b_45_n150_b03_m15 | 207.2 | 60.6 | 77.4 | 209.4 | 64.1 | 75.9 | 254.4 | 94.0 | 66.4 | 11.3 | 63.1 | 73.8 | 12.0 | 69.3 | 71.5 | 15.0 | 102.1 | 62.3 | 4.92% | 6.22% | 6.57% |
| GKD-b_46_n150_b02_m45 | 162.9 | 37.1 | 101.3 | 161.2 | 36.9 | 101.2 | 177.9 | 47.5 | 95.9 | 7.4 | 37.1 | 99.3 | 7.8 | 39.6 | 98.1 | 10.0 | 55.3 | 90.5 | 1.95% | 3.07% | 5.98% |
| GKD-b_46_n150_b03_m45 | 199.4 | 59.0 | 90.5 | 204.6 | 62.3 | 88.9 | 248.3 | 93.4 | 78.3 | 10.7 | 58.6 | 89.4 | 11.4 | 64.0 | 87.4 | 14.8 | 101.2 | 74.0 | 1.22% | 1.72% | 5.81% |
| GKD-b_47_n150_b02_m45 | 163.7 | 37.4 | 142.0 | 154.5 | 38.3 | 141.2 | 174.9 | 49.1 | 135.9 | 7.7 | 38.6 | 139.7 | 8.1 | 41.6 | 137.9 | 10.2 | 55.4 | 130.7 | 1.68% | 2.42% | 4.01% |
| GKD-b_47_n150_b03_m45 | 178.9 | 51.9 | 133.0 | 180.0 | 53.7 | 132.3 | 223.1 | 81.9 | 122.2 | 10.0 | 53.8 | 130.4 | 10.7 | 58.2 | 129.1 | 14.0 | 91.5 | 117.1 | 1.99% | 2.43% | 4.32% |
| GKD-b_48_n150_b02_m45 | 151.8 | 37.0 | 79.3 | 157.9 | 38.6 | 78.2 | 182.6 | 55.6 | 71.3 | 7.6 | 38.0 | 78.5 | 8.3 | 42.2 | 76.4 | 11.8 | 65.8 | 67.7 | 0.93% | 2.33% | 5.19% |
| GKD-b_48_n150_b03_m45 | 194.0 | 61.0 | 69.1 | 194.1 | 66.2 | 67.7 | 238.9 | 102.7 | 57.1 | 11.0 | 60.7 | 68.0 | 11.8 | 67.8 | 65.9 | 15.4 | 110.7 | 53.4 | 1.61% | 2.71% | 6.78% |
| GKD-b_49_n150_b02_m45 | 140.0 | 30.3 | 148.7 | 137.0 | 30.2 | 148.0 | 146.3 | 36.1 | 143.4 | 6.5 | 31.1 | 146.1 | 6.6 | 32.5 | 145.2 | 8.4 | 43.5 | 139.5 | 1.78% | 1.93% | 2.78% |
| GKD-b_49_n150_b03_m45 | 170.6 | 49.9 | 134.2 | 170.1 | 51.2 | 133.9 | 210.5 | 79.7 | 123.2 | 9.9 | 52.9 | 128.5 | 10.7 | 58.1 | 126.2 | 14.0 | 91.2 | 115.7 | 4.44% | 6.15% | 6.48% |
| GKD-b_50_n150_b02_m45 | 140.3 | 35.3 | 88.8 | 148.4 | 36.5 | 87.8 | 172.8 | 50.0 | 82.1 | 7.6 | 37.7 | 86.4 | 8.0 | 40.9 | 85.0 | 11.0 | 60.8 | 78.0 | 2.74% | 3.27% | 5.26% |
| GKD-b_50_n150_b03_m45 | 187.8 | 50.6 | 77.1 | 190.9 | 51.0 | 76.5 | 212.2 | 69.9 | 72.1 | 9.6 | 50.7 | 72.7 | 9.9 | 53.4 | 71.8 | 12.6 | 75.9 | 66.0 | 6.04% | 6.63% | 9.15% |
| Instance | Learnheuristic | Static | Gap (%) | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Low (1) | Medium (2) | High (3) | Low (4) | Medium (5) | High (6) | ||||||||||||||||
| Time | Nodes | OF | Time | Nodes | OF | Time | Nodes | OF | Time | Nodes | OF | Time | Nodes | OF | Time | Nodes | OF | (1)–(4) | (2)–(5) | (3)–(6) | |
| GKD-c_01_n500_b02_m50 | 1579.2 | 119.9 | 7.6 | 1584.2 | 122.9 | 7.5 | 1776.5 | 160.8 | 7.0 | 76.8 | 124.1 | 7.4 | 81.4 | 133.0 | 7.3 | 104.3 | 183.5 | 6.8 | 2.11% | 3.13% | 3.25% |
| GKD-c_01_n500_b03_m50 | 1895.2 | 170.0 | 6.7 | 1844.2 | 173.7 | 6.7 | 2120.7 | 258.5 | 6.0 | 105.2 | 179.1 | 6.6 | 109.7 | 191.9 | 6.5 | 144.3 | 296.3 | 5.7 | 2.12% | 2.95% | 5.44% |
| GKD-c_02_n500_b02_m50 | 1630.6 | 114.2 | 7.7 | 1665.4 | 116.4 | 7.6 | 1780.5 | 150.6 | 7.1 | 73.2 | 115.7 | 7.5 | 75.5 | 121.5 | 7.4 | 98.2 | 168.9 | 6.9 | 2.48% | 3.04% | 4.04% |
| GKD-c_02_n500_b03_m50 | 1956.9 | 195.5 | 6.7 | 1964.5 | 200.2 | 6.6 | 2183.0 | 284.9 | 5.9 | 114.9 | 206.5 | 6.4 | 123.4 | 219.3 | 6.3 | 151.9 | 329.7 | 5.5 | 3.93% | 4.33% | 6.60% |
| GKD-c_03_n500_b02_m50 | 1621.8 | 115.8 | 7.5 | 1596.2 | 116.8 | 7.5 | 1745.8 | 151.5 | 7.0 | 74.6 | 120.6 | 7.3 | 78.7 | 127.4 | 7.3 | 98.8 | 171.1 | 6.8 | 3.04% | 3.39% | 2.68% |
| GKD-c_03_n500_b03_m50 | 1972.0 | 199.9 | 6.6 | 2065.7 | 210.3 | 6.4 | 2334.2 | 329.0 | 5.5 | 115.8 | 210.3 | 6.4 | 126.0 | 230.8 | 6.2 | 160.5 | 364.4 | 5.2 | 1.56% | 3.33% | 6.71% |
| GKD-c_04_n500_b02_m50 | 1582.6 | 100.6 | 7.3 | 1608.4 | 101.6 | 7.2 | 1698.1 | 132.0 | 6.7 | 68.5 | 106.8 | 6.9 | 72.3 | 115.5 | 6.9 | 102.2 | 171.4 | 6.1 | 5.35% | 5.10% | 9.34% |
| GKD-c_04_n500_b03_m50 | 1933.4 | 193.1 | 6.4 | 1991.6 | 202.5 | 6.3 | 2248.1 | 288.1 | 5.6 | 116.1 | 207.9 | 6.2 | 124.2 | 227.7 | 6.0 | 162.6 | 341.7 | 5.0 | 2.89% | 5.45% | 11.33% |
| GKD-c_05_n500_b02_m50 | 1508.3 | 110.3 | 7.4 | 1605.7 | 111.6 | 7.3 | 1774.8 | 146.2 | 6.9 | 73.3 | 117.1 | 7.4 | 79.6 | 128.6 | 7.2 | 106.2 | 183.7 | 6.5 | 0.76% | 2.14% | 6.31% |
| GKD-c_05_n500_b03_m50 | 1915.9 | 200.1 | 6.6 | 1907.1 | 208.6 | 6.5 | 2156.4 | 307.8 | 5.7 | 113.7 | 201.8 | 6.4 | 118.2 | 217.5 | 6.3 | 153.7 | 343.7 | 5.3 | 2.88% | 3.21% | 8.22% |
| GKD-c_06_n500_b02_m50 | 1511.0 | 117.0 | 7.5 | 1518.4 | 120.2 | 7.5 | 1680.1 | 161.7 | 6.9 | 77.4 | 125.8 | 7.3 | 81.6 | 134.9 | 7.2 | 107.1 | 192.1 | 6.6 | 3.36% | 4.53% | 5.05% |
| GKD-c_06_n500_b03_m50 | 1827.0 | 184.6 | 6.5 | 1925.6 | 190.6 | 6.4 | 2124.9 | 275.3 | 5.7 | 114.2 | 201.1 | 6.3 | 122.8 | 222.1 | 6.1 | 157.5 | 342.1 | 5.2 | 3.38% | 4.59% | 10.45% |
| GKD-c_07_n500_b02_m50 | 1551.2 | 120.1 | 7.4 | 1523.6 | 122.1 | 7.4 | 1720.3 | 156.4 | 7.0 | 80.8 | 130.5 | 7.1 | 86.9 | 140.5 | 7.1 | 110.1 | 191.4 | 6.7 | 4.34% | 4.19% | 4.78% |
| GKD-c_07_n500_b03_m50 | 1968.1 | 200.5 | 6.6 | 1905.1 | 210.3 | 6.5 | 2171.7 | 317.9 | 5.7 | 113.3 | 204.1 | 6.5 | 121.2 | 222.0 | 6.4 | 156.3 | 347.7 | 5.3 | 0.44% | 1.05% | 5.75% |
| GKD-c_08_n500_b02_m50 | 1486.1 | 116.1 | 7.6 | 1510.8 | 119.4 | 7.6 | 1619.2 | 163.6 | 6.9 | 72.7 | 118.2 | 7.5 | 77.2 | 127.3 | 7.4 | 103.1 | 182.9 | 6.8 | 1.65% | 2.03% | 1.61% |
| GKD-c_08_n500_b03_m50 | 1771.6 | 197.2 | 6.6 | 1867.0 | 204.2 | 6.5 | 2116.3 | 296.4 | 5.8 | 111.9 | 204.1 | 6.5 | 119.0 | 220.6 | 6.4 | 149.0 | 324.1 | 5.6 | 1.47% | 1.48% | 3.94% |
| GKD-c_09_n500_b02_m50 | 1651.9 | 121.9 | 7.4 | 1634.3 | 125.5 | 7.4 | 1793.8 | 167.1 | 6.8 | 78.2 | 128.2 | 7.3 | 84.0 | 138.7 | 7.2 | 110.2 | 197.4 | 6.5 | 1.23% | 2.45% | 5.39% |
| GKD-c_09_n500_b03_m50 | 1803.9 | 178.6 | 6.4 | 1786.6 | 185.4 | 6.3 | 2060.3 | 272.6 | 5.7 | 111.1 | 196.7 | 6.3 | 119.4 | 218.7 | 6.1 | 153.1 | 333.2 | 5.4 | 1.08% | 3.65% | 6.37% |
| GKD-c_10_n500_b02_m50 | 1465.0 | 113.4 | 7.7 | 1483.2 | 115.9 | 7.7 | 1621.5 | 152.8 | 7.1 | 72.4 | 117.4 | 7.6 | 76.3 | 124.7 | 7.4 | 99.5 | 173.5 | 6.8 | 1.77% | 2.98% | 3.82% |
| GKD-c_10_n500_b03_m50 | 1730.9 | 191.9 | 6.7 | 1738.6 | 197.1 | 6.6 | 1969.5 | 285.1 | 5.9 | 108.5 | 195.6 | 6.5 | 114.9 | 212.1 | 6.4 | 147.4 | 318.3 | 5.5 | 2.26% | 3.45% | 7.34% |
| MDG-b_01_n500_b02_m50 | 1386.4 | 105.8 | 14.6 | 1390.5 | 107.7 | 14.2 | 1565.6 | 147.2 | 9.2 | 69.9 | 110.4 | 12.2 | 73.8 | 118.2 | 10.7 | 99.1 | 170.5 | 5.9 | 20.24% | 33.02% | 56.78% |
| MDG-b_01_n500_b03_m50 | 1798.3 | 214.4 | 4.4 | 1846.4 | 223.2 | 4.0 | 2184.6 | 322.9 | 1.9 | 119.4 | 221.5 | 3.8 | 126.8 | 241.1 | 3.3 | 160.8 | 368.5 | 1.1 | 14.63% | 21.87% | 70.62% |
| MDG-b_02_n500_b02_m50 | 1563.4 | 142.6 | 13.2 | 1555.6 | 148.8 | 12.2 | 1698.6 | 199.4 | 7.4 | 91.6 | 151.4 | 12.6 | 93.6 | 160.8 | 11.4 | 116.0 | 216.2 | 6.9 | 5.21% | 7.45% | 7.28% |
| MDG-b_02_n500_b03_m50 | 1772.0 | 211.7 | 5.4 | 1797.4 | 221.7 | 4.8 | 2070.1 | 325.2 | 2.0 | 115.1 | 212.1 | 4.8 | 122.1 | 230.7 | 4.0 | 153.7 | 344.9 | 1.4 | 12.08% | 20.98% | 44.87% |
| MDG-b_03_n500_b02_m50 | 1475.1 | 134.2 | 12.0 | 1499.1 | 140.2 | 11.1 | 1678.7 | 190.2 | 6.6 | 88.6 | 150.0 | 9.4 | 93.8 | 159.9 | 8.6 | 116.7 | 217.6 | 5.3 | 28.66% | 29.06% | 25.48% |
| MDG-b_03_n500_b03_m50 | 1841.9 | 239.5 | 4.7 | 1878.1 | 255.6 | 4.1 | 2095.0 | 362.8 | 1.5 | 126.1 | 241.5 | 4.5 | 133.5 | 264.4 | 3.7 | 161.1 | 383.3 | 1.2 | 4.66% | 9.04% | 21.97% |
| MDG-b_04_n500_b02_m50 | 1462.3 | 122.4 | 12.9 | 1470.3 | 127.6 | 11.9 | 1648.5 | 173.8 | 7.0 | 81.9 | 134.4 | 7.9 | 86.8 | 144.5 | 7.3 | 113.6 | 206.9 | 5.5 | 63.56% | 62.27% | 26.19% |
| MDG-b_04_n500_b03_m50 | 1811.2 | 210.5 | 4.9 | 1812.0 | 225.2 | 4.3 | 2094.0 | 331.8 | 1.6 | 122.6 | 227.8 | 4.3 | 130.2 | 252.6 | 3.4 | 164.4 | 365.5 | 1.0 | 12.89% | 25.96% | 51.06% |
| MDG-b_05_n500_b02_m50 | 1419.5 | 118.5 | 13.6 | 1427.3 | 123.1 | 12.7 | 1600.5 | 167.9 | 7.6 | 77.3 | 125.5 | 11.5 | 82.0 | 134.5 | 10.4 | 108.1 | 192.6 | 5.7 | 18.35% | 22.27% | 33.91% |
| MDG-b_05_n500_b03_m50 | 1735.6 | 197.0 | 5.0 | 1767.8 | 207.5 | 4.4 | 2015.4 | 306.8 | 1.8 | 111.2 | 198.2 | 4.0 | 118.3 | 217.1 | 3.6 | 153.7 | 337.5 | 1.4 | 24.19% | 20.74% | 32.24% |
| MDG-b_06_n500_b02_m50 | 1444.1 | 116.5 | 13.7 | 1461.7 | 120.0 | 13.1 | 1609.5 | 163.8 | 8.2 | 75.6 | 121.8 | 13.0 | 80.2 | 132.2 | 11.5 | 108.2 | 194.7 | 6.0 | 5.57% | 13.57% | 36.91% |
| MDG-b_06_n500_b03_m50 | 1796.1 | 222.5 | 4.9 | 1844.9 | 237.9 | 4.2 | 2175.7 | 347.6 | 1.5 | 126.6 | 239.6 | 3.8 | 137.5 | 271.8 | 3.1 | 166.1 | 401.9 | 0.9 | 28.53% | 37.25% | 72.18% |
| MDG-b_07_n500_b02_m50 | 1580.0 | 122.0 | 13.7 | 1653.7 | 126.4 | 12.8 | 1767.7 | 169.8 | 7.8 | 82.4 | 134.0 | 11.2 | 87.7 | 144.6 | 9.3 | 113.3 | 203.4 | 5.6 | 22.55% | 38.32% | 39.54% |
| MDG-b_07_n500_b03_m50 | 1874.5 | 210.0 | 5.5 | 1928.2 | 221.5 | 5.0 | 2249.5 | 336.1 | 2.0 | 116.5 | 213.2 | 5.0 | 123.6 | 230.4 | 4.3 | 156.3 | 347.6 | 1.7 | 11.24% | 16.10% | 17.93% |
| MDG-b_08_n500_b02_m50 | 1639.8 | 115.2 | 13.9 | 1658.6 | 117.4 | 13.0 | 1834.8 | 162.4 | 8.0 | 73.8 | 117.9 | 8.8 | 80.1 | 130.0 | 8.4 | 108.6 | 193.0 | 4.8 | 57.79% | 54.24% | 68.93% |
| MDG-b_08_n500_b03_m50 | 1975.8 | 220.3 | 5.7 | 2119.5 | 232.1 | 5.1 | 2359.8 | 338.2 | 2.1 | 120.0 | 219.0 | 5.3 | 126.3 | 237.0 | 4.5 | 155.7 | 344.3 | 1.7 | 7.72% | 13.94% | 23.52% |
| MDG-b_09_n500_b02_m50 | 1570.9 | 104.9 | 15.7 | 1577.4 | 108.2 | 15.1 | 1739.8 | 150.8 | 9.3 | 72.1 | 112.1 | 13.3 | 76.5 | 121.0 | 11.8 | 105.1 | 181.9 | 6.3 | 18.81% | 27.92% | 47.93% |
| MDG-b_09_n500_b03_m50 | 1918.4 | 198.1 | 5.5 | 1929.3 | 207.2 | 5.0 | 2182.6 | 305.4 | 2.1 | 115.8 | 203.0 | 5.6 | 123.7 | 223.4 | 4.7 | 158.4 | 341.0 | 1.4 | –1.41% | 5.68% | 47.44% |
| MDG-b_10_n500_b02_m50 | 1505.8 | 117.0 | 14.8 | 1517.1 | 119.7 | 13.9 | 1653.5 | 159.4 | 8.7 | 78.4 | 125.5 | 13.9 | 84.0 | 133.9 | 11.7 | 106.9 | 185.4 | 7.1 | 5.93% | 18.97% | 23.02% |
| MDG-b_10_n500_b03_m50 | 1842.2 | 203.7 | 5.1 | 1890.6 | 216.8 | 4.5 | 2135.5 | 327.6 | 1.7 | 117.7 | 212.7 | 4.3 | 124.4 | 235.8 | 3.6 | 157.9 | 359.4 | 1.1 | 20.19% | 27.95% | 54.85% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomez, J.F.; Uguina, A.R.; Panadero, J.; Juan, A.A. A Learnheuristic Algorithm for the Capacitated Dispersion Problem under Dynamic Conditions. Algorithms 2023, 16, 532. https://doi.org/10.3390/a16120532
Gomez JF, Uguina AR, Panadero J, Juan AA. A Learnheuristic Algorithm for the Capacitated Dispersion Problem under Dynamic Conditions. Algorithms. 2023; 16(12):532. https://doi.org/10.3390/a16120532
Chicago/Turabian StyleGomez, Juan F., Antonio R. Uguina, Javier Panadero, and Angel A. Juan. 2023. "A Learnheuristic Algorithm for the Capacitated Dispersion Problem under Dynamic Conditions" Algorithms 16, no. 12: 532. https://doi.org/10.3390/a16120532
APA StyleGomez, J. F., Uguina, A. R., Panadero, J., & Juan, A. A. (2023). A Learnheuristic Algorithm for the Capacitated Dispersion Problem under Dynamic Conditions. Algorithms, 16(12), 532. https://doi.org/10.3390/a16120532