



Resilience and Resilient Systems of Artificial Intelligence: Taxonomy, Models and Methods



Abstract
:1. Introduction
1.1. Motivation
1.2. Research Gap
1.3. Objectives and Contributions
- -
- analysis of existing threats and vulnerabilities of the AIS;
- -
- construction of a taxonomic scheme of AIS resilience;
- -
- building the AIS resilience ontology;
- -
- analysis of the existing models and methods of ensuring and assessing the resilience of the AIS;
- -
- determination of future research directions for the development of the theory and practice of resilient AIS.
2. Research Methodology
- -
- Research Question (RQ1): What are the known and prospective threats to AIS?
- -
- Research Question (RQ2): Can all components of AIS resilience for each type of threat be achieved by configuring the AIS architecture and training scenario?
- -
- Research Question (RQ3): Is it possible to evaluate and optimize the resilience of AIS?
- -
- forming a set of resilience factors;
- -
- organizing and defining taxonomic and ontological relationships of AIS resilience factors;
- -
- analyzing AIS resilience solutions and challages.
- -
- threats (their types, sources, and consequences);
- -
- tolerance and adaptation mechanisms (general and specific to AIS);
- -
- resilience indicators (types and optimization issues).
3. Background, Taxonomy and Ontology
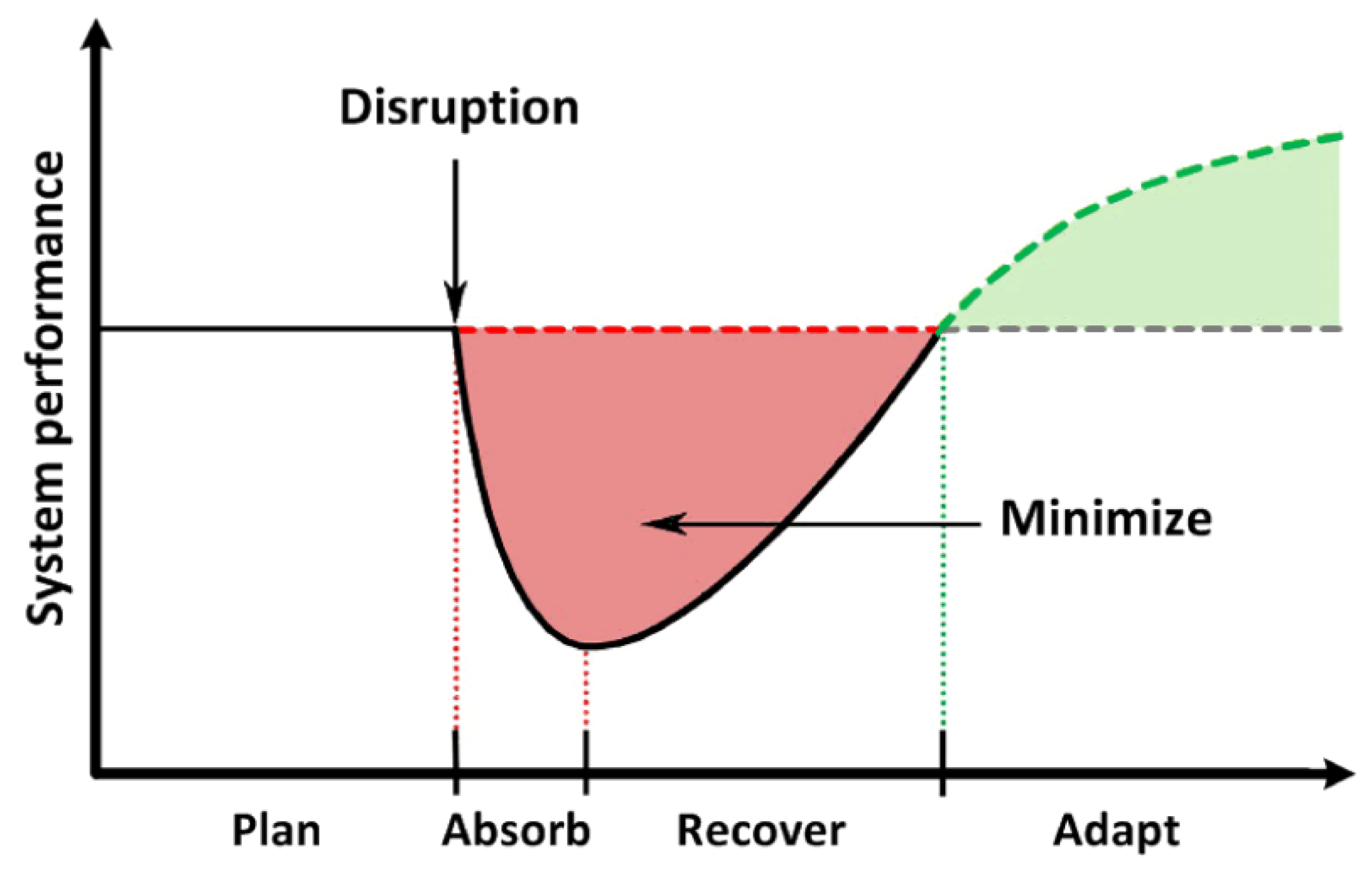
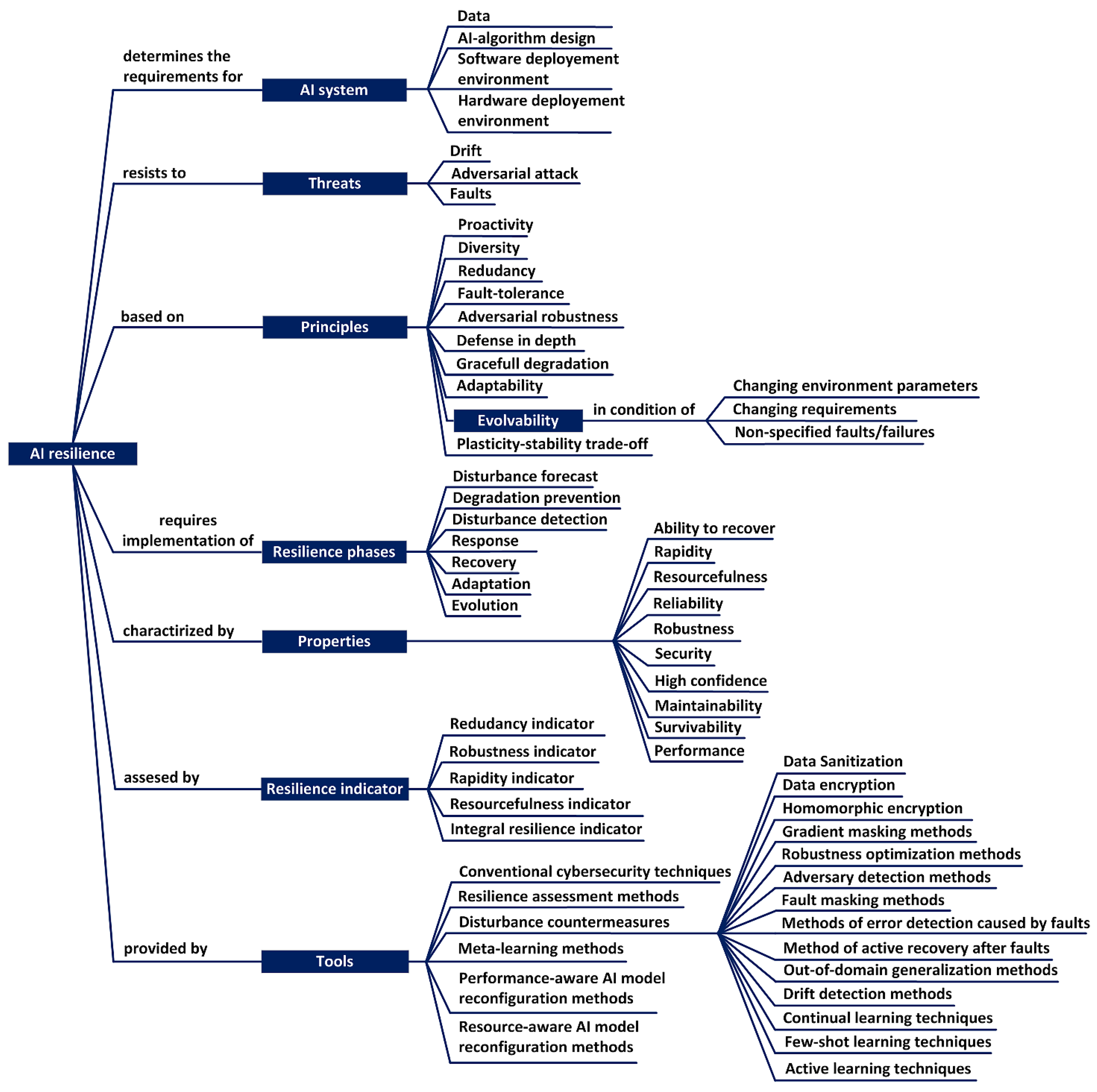
3.1. The Concept of System Resilience
- -
- planning and preparation of the system;
- -
- absorption of disturbance;
- -
- system recovery;
- -
- system adaptation.
- -
- risk assessment through system analysis and simulation of destructive disturbances;
- -
- implementation of methods for detecting destructive disturbances;
- -
- elimination of known vulnerabilities and implementation of a set of defense methods against destructive disturbances;
- -
- ensuring appropriate backup and recovery strategies.
- functional redundancy or diversity, which consists in the existence of alternative ways to perform a certain function;
- hardware redundancy, which is the reservation of the hardware to protect against hardware failures;
- the possibility of self-restructuring in response to external changes;
- predictability of the automated system behavior to guarantee trust and avoid frequent human intervention;
- avoiding excessive complexity caused by poor design practices;
- the ability of the system to function in the most probable and worst-case scenarios of natural and man-made nature;
- controlled (graceful) degradation, which is the ability of the system to continue to operate under the influence of an unpredictable destructive factor by transitioning to a state of lower functionality or performance;
- implementation of a mechanism to control and correct the drift of the system to a non-functional state by making appropriate compromises and timely preventive actions;
- ensuring the transition to a “neutral” state to prevent further damage under the influence of an unknown destructive disturbance until the problem is thoroughly diagnosed;
- learning and adaptation, i.e., reconfiguration, optimization and development of the system on the basis of new knowledge constantly obtained from the environment;
- inspectability of the system, which provides for the possibility of necessary human intervention without requiring unreasonable assumptions from it;
- a human being should be aware of the situation when there is a need for “quick comprehension” of the situation and the formation of creative solutions;
- implementation of the possibility of replacing or backing up automation by people when there is a change in the context for which automation is not prepared, but there is enough time for human intervention;
- implementation of the principle of awareness of intentions, when the system and humans should maintain a common model of intentions to support each other when necessary.
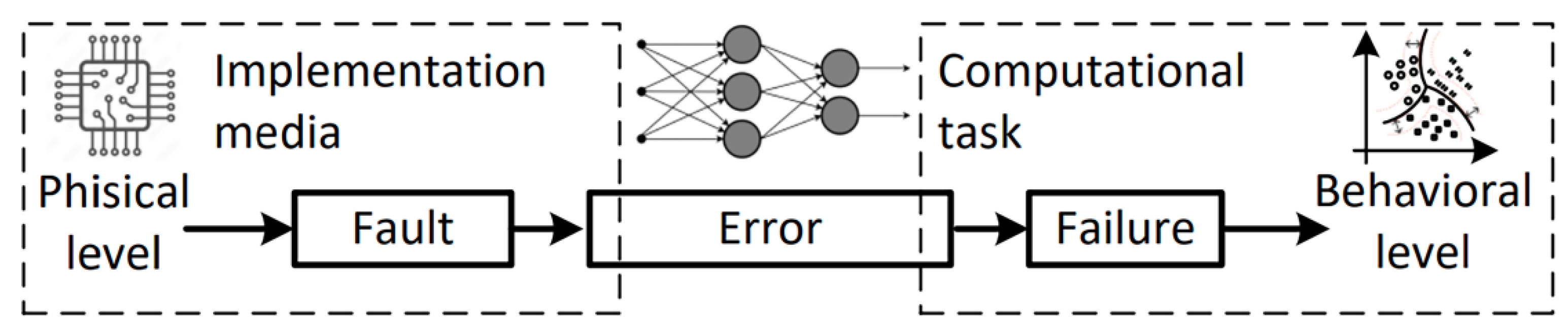
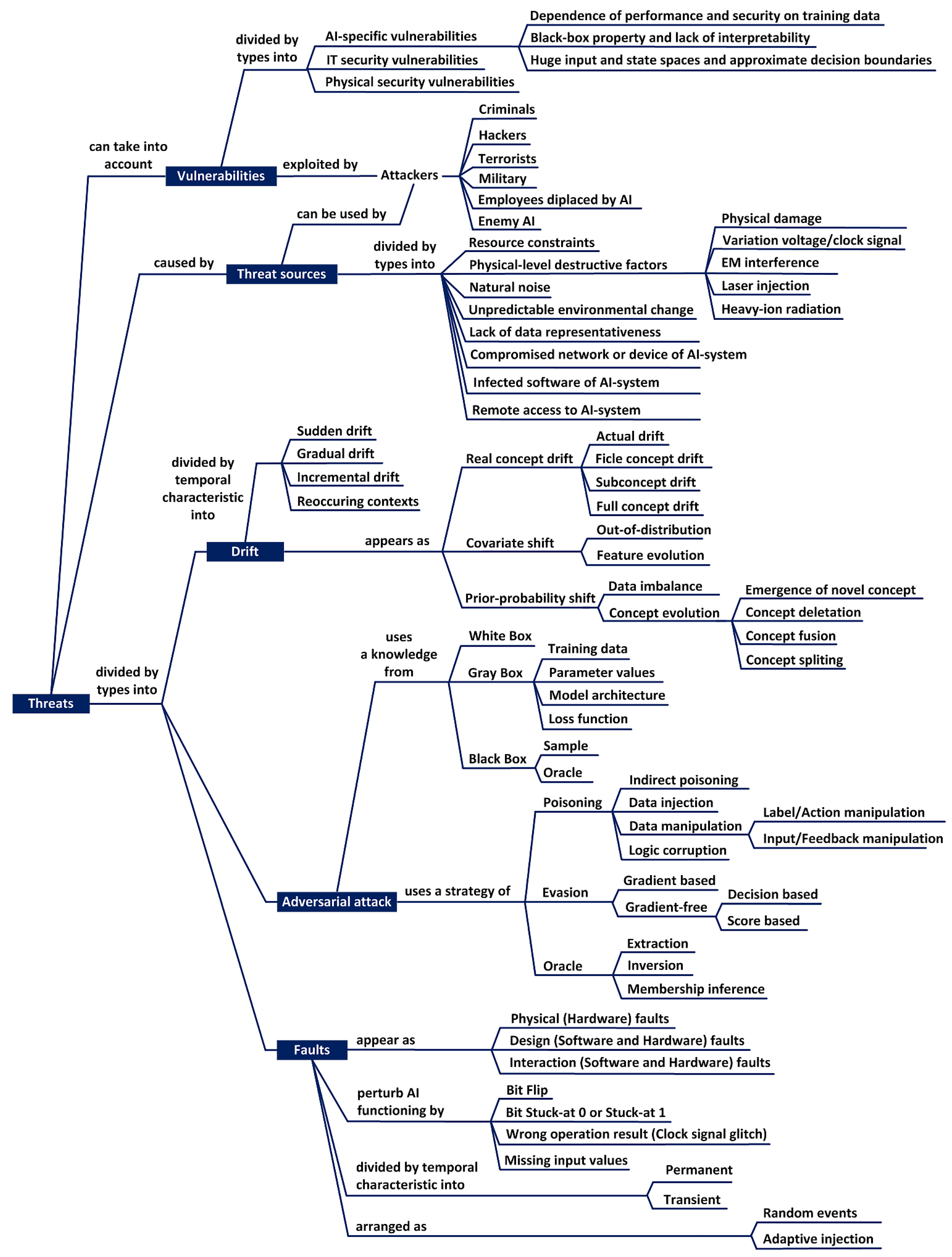
3.2. Vulnerabilities and Threats of AISs
- physical faults that lead to persistent failures or short-term failures of AIS hardware;
- design faults, which are the result of erroneous actions made during the creation of AIS and lead to the appearance of defects in both hardware and software;
- interaction faults that result from the impact of external factors on AIS hardware and software;
- software faults caused by the effect of software aging, which lead to persistent failures or short-term failure of AIS software.
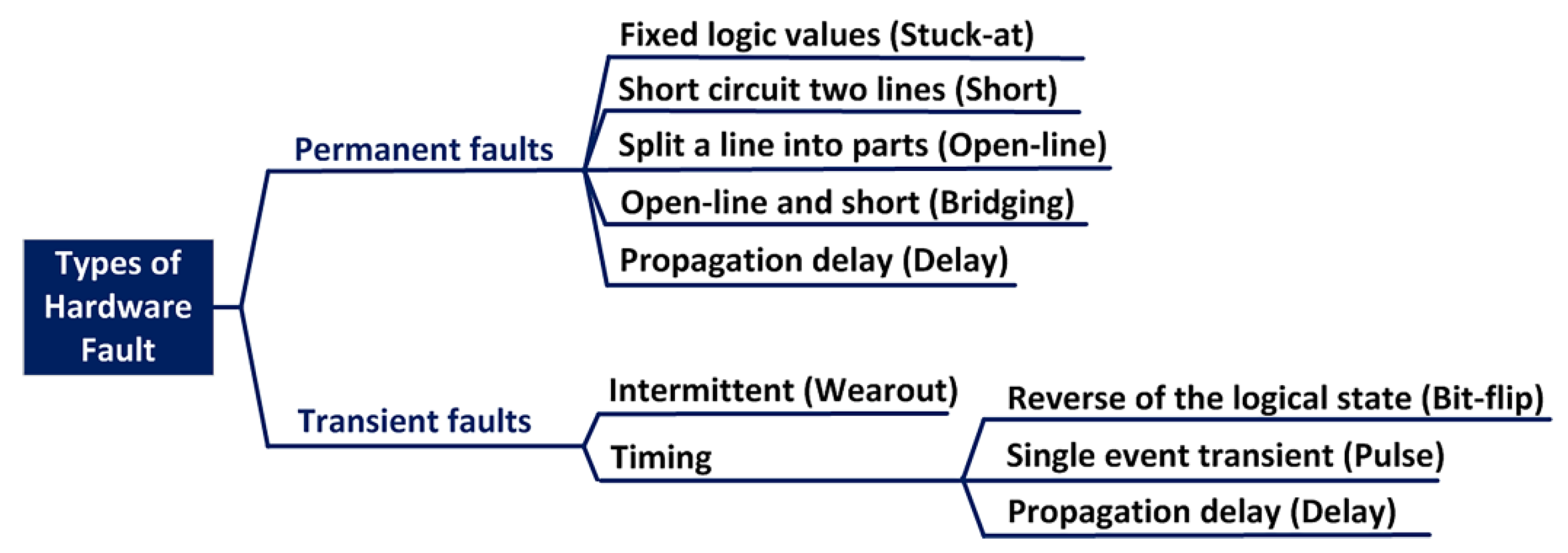
- permanent fault which is continuous and stable over time as result of physical damage;
- transient fault which can only persist for a short period of time as result of external disturbances.
- imperceptibility, which consists in the existence of ways of such minimal (not visible to humans) modification of data that leads to inadequate functioning of AI;
- the possibility of Targeted Manipulation on the output of the neural network to manipulate the system for your own benefit and gain;
- transferability of adversarial examples obtained for one model in order to apply them to another model if the models perform a common task, which allows attackers to use a surrogate model (oracle) to generate attacks for the target model;
- the lack of generally accepted theoretical models to explain the effectiveness of adversarial attacks, making any of the developed defense mechanisms not universal.
- availability attacks, which leads to the inability of the end user to use the AIS;
- integrity attacks, which leads to incorrect AIS decisions;
- confidentiality attacks, where the attacker’s goal is to intercept communication between two parties and obtain private information.
- white-box attacks, which are formed on the basis of full knowledge of the data, model and training algorithm, used by AIS developers to augment data or evaluate model robustness;
- gray-box attacks based on the use of partial information (Model Architecture, Parameter Values, Loss Function or Training Data), but sufficient to attack on the AIS;
- black-box attacks that are formed by accessing the interface of a real AI-model or oracle to send data and receive a response.
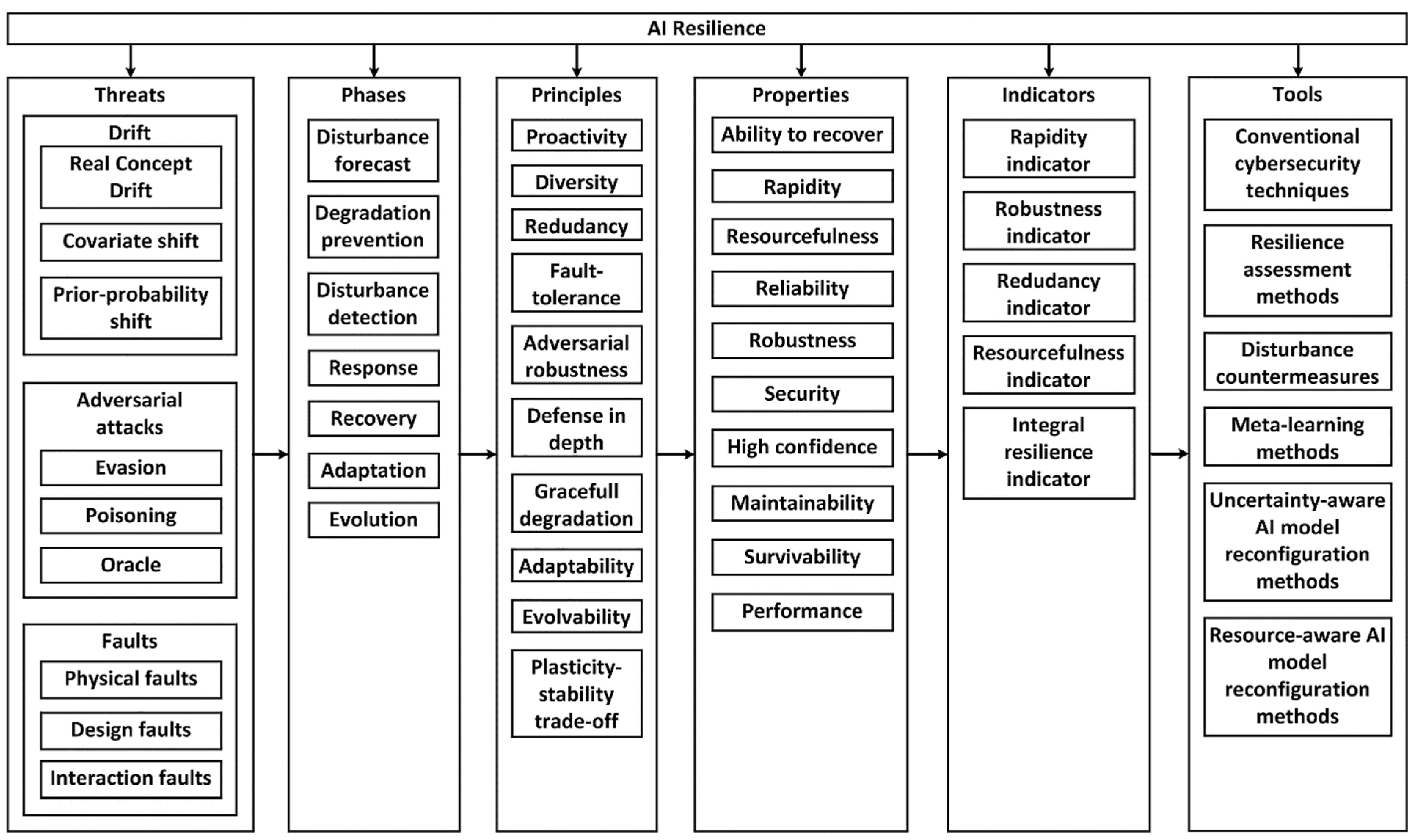
3.3. Taxonomy and Ontology of AIS Resilience
4. Applications of AIS That Require Resiliency
5. Models and Methods to Ensure and Assess AIS Resilience
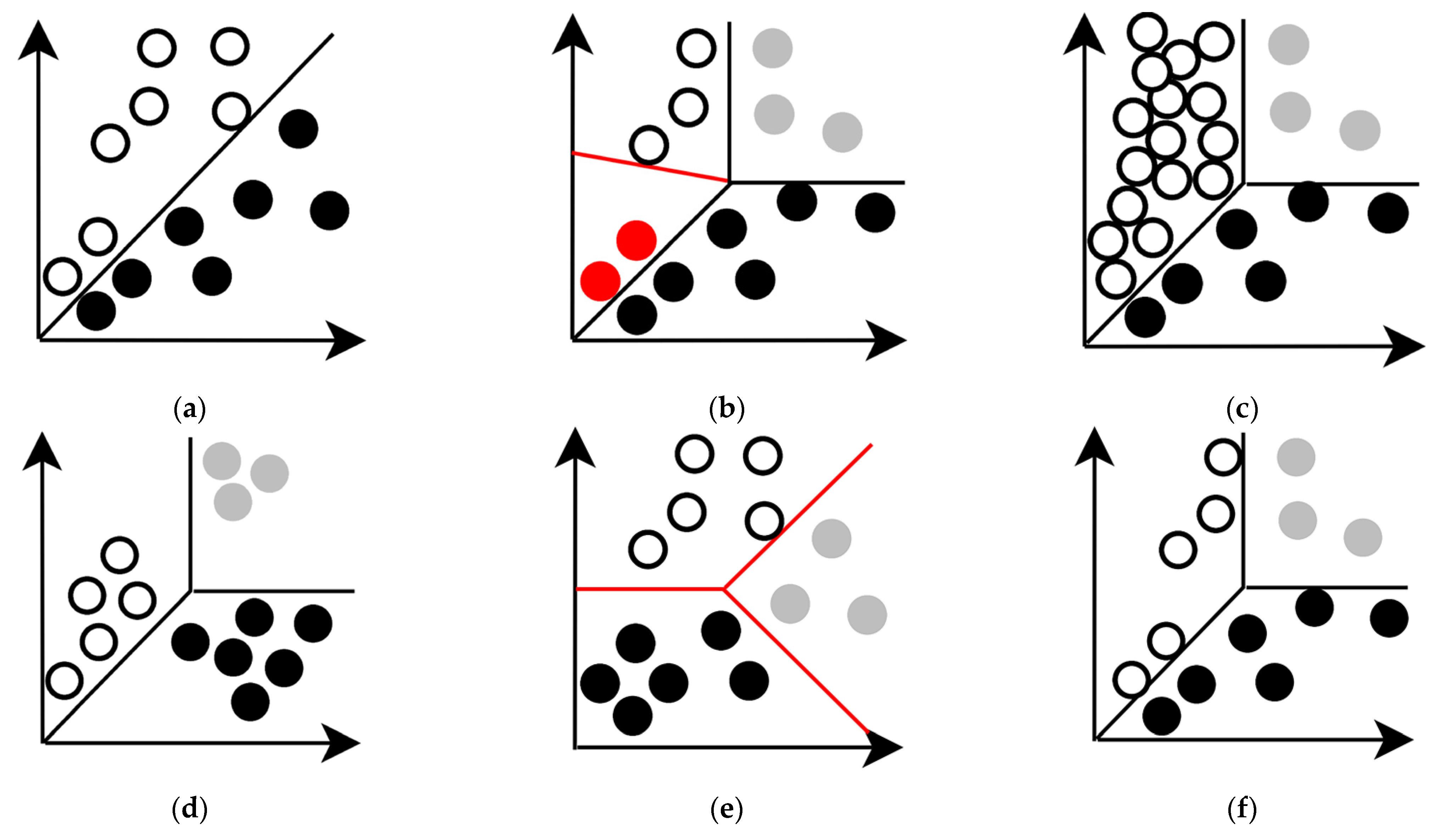
5.1. Proactivity and Robustness
5.2. Graceful Degradation
5.3. Adaptation and Evolution
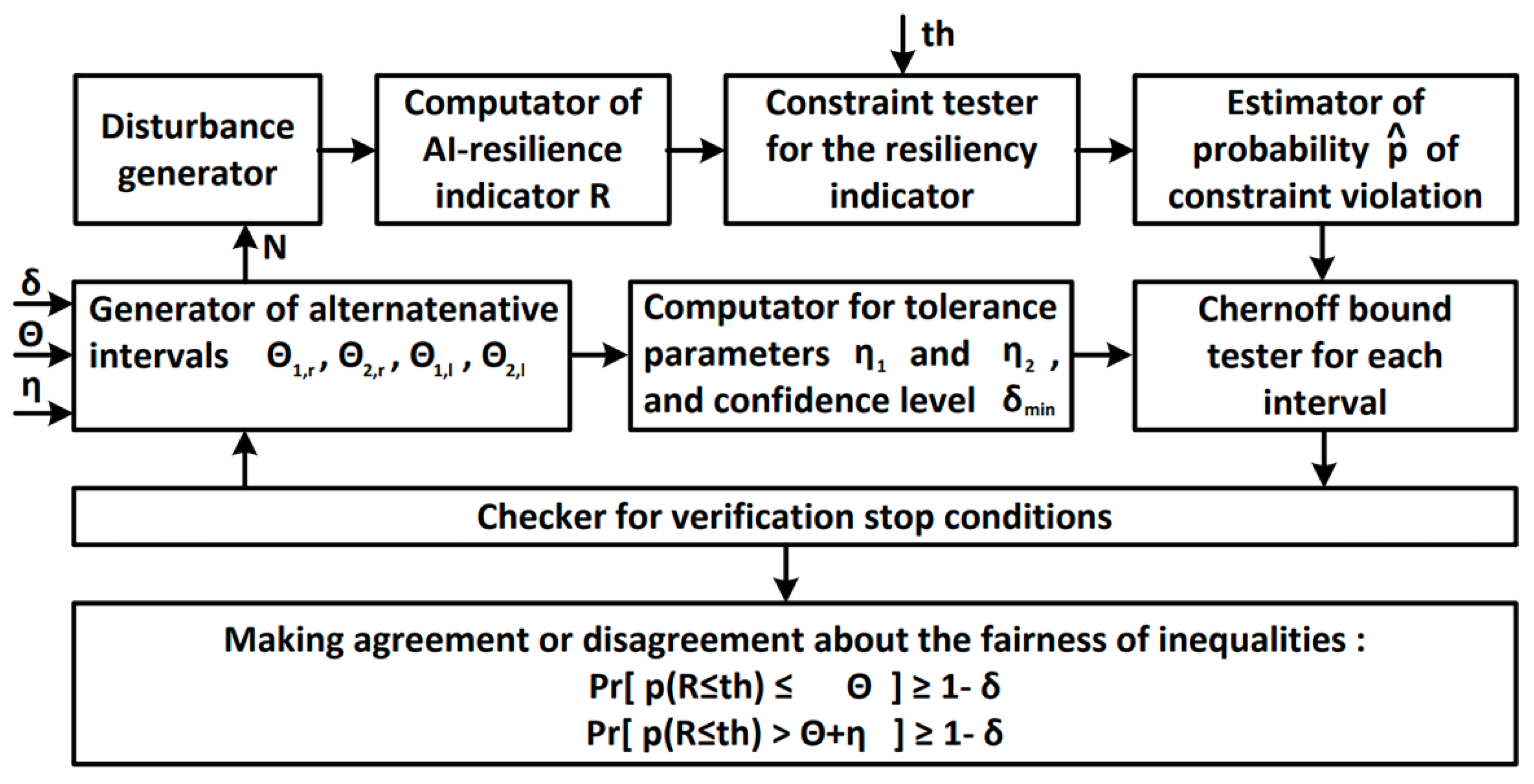
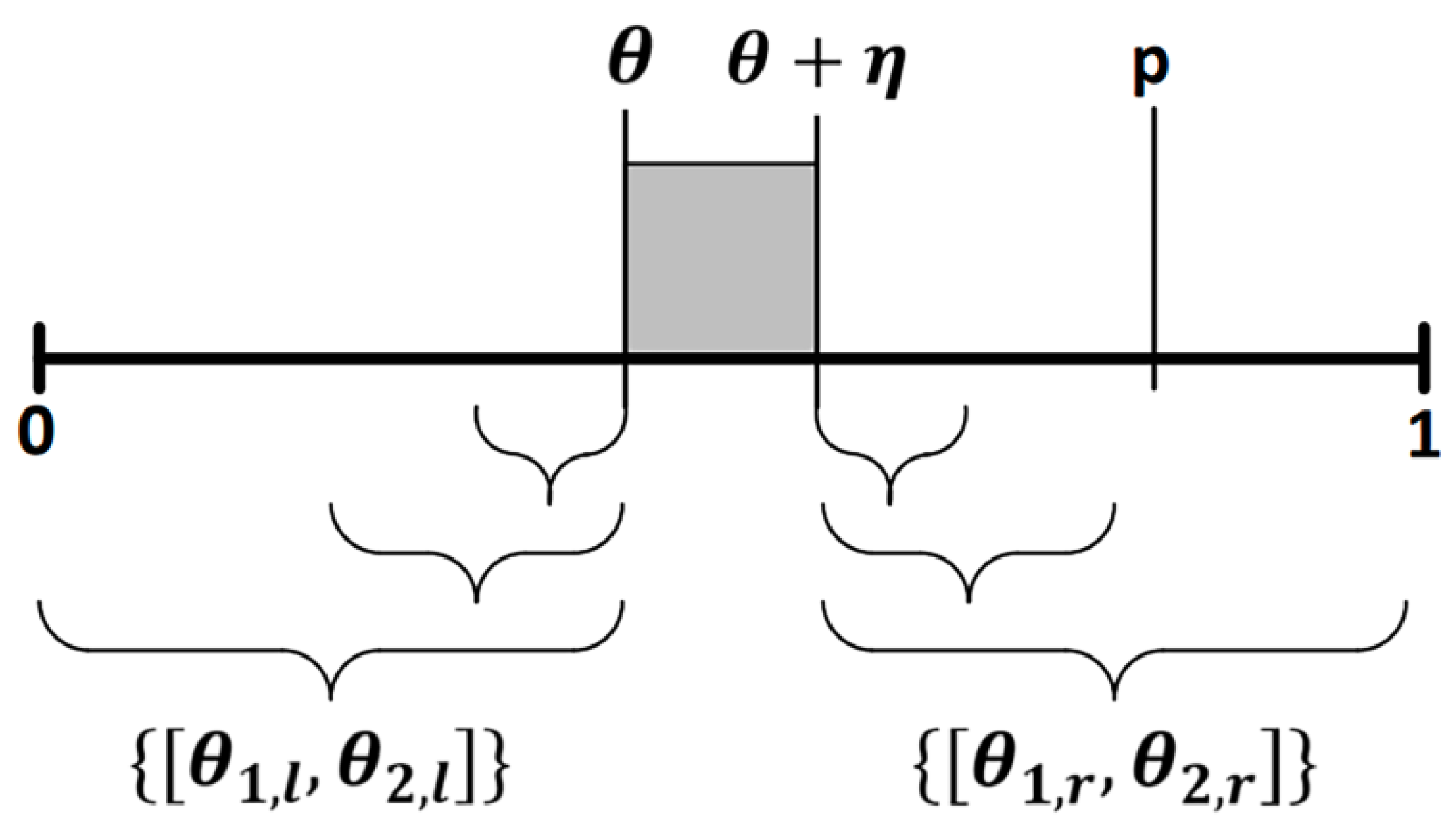
5.4. Methods to Assess AIS Resilience
- -
- Response Time, ;
- -
- Recovery Time, ;
- -
- Performance Attenuation, A;
- -
- Performance Loss, L;
- -
- Robustness, ;
- -
- Rapidity, ;
- -
- Redundancy;
- -
- Resourcefulness;
- -
- Integrated measure of resilience, .
6. Discussion
7. Conclusions
7.1. Summary
- -
- technical specifications of forthcoming AIS for safety, security, human rights and trust critical domains, should be include resilience capabilities to mitigate all relevant disturbing influences;
- -
- customers, owners, developers, and maintainers of AIS should be taken into account that the system may degrade when faced with a disturbance, and the system needs certain resources and time to recover, adapt and evolve.
7.1.1. RQ1: What Are the Known and Prospective Threats to AIS?
7.1.2. RQ2: Can All Components of AIS Resilience for Each Type of Threat Be Achieved by Configuring the AIS Architecture and Training Scenario?
7.1.3. RQ3: Is It Possible to Evaluate and Optimize the Resilience of AIS?
7.2. Limitations
7.3. Future Research Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, J.; Kovatsch, M.; Mattern, D.; Mazza, F.; Harasic, M.; Paschke, A.; Lucia, S. A Review on AI for Smart Manufacturing: Deep Learning Challenges and Solutions. Appl. Sci. 2022, 12, 8239. [Google Scholar] [CrossRef]
- Khalid, F.; Hanif, M.A.; Shafique, M. Exploiting Vulnerabilities in Deep Neural Networks: Adversarial and Fault-Injection Attacks. arXiv 2021, arXiv:2105.03251. [Google Scholar] [CrossRef]
- Gongye, C.; Li, H.; Zhang, X.; Sabbagh, M.; Yuan, G.; Lin, X.; Wahl, T.; Fei, Y. New passive and active attacks on deep neural networks in medical applications. In Proceedings of the ICCAD ‘20: IEEE/ACM International Conference on Computer-Aided Design, Virtual Event USA, 2–5 November 2020; ACM: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Caccia, M.; Rodríguez, P.; Ostapenko, O.; Normandin, F.; Lin, M.; Caccia, L.; Laradji, I.; Rish, I.; Lacoste, A.; Vazquez, D.; et al. Online fast adaptation and knowledge accumulation (OSAKA): A new approach to continual learning. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 16532–16545. [Google Scholar]
- Margatina, K.; Vernikos, G.; Barrault, L.; Aletras, N. Active Learning by Acquiring Contrastive Examples. arXiv 2021, arXiv:2109.03764. [Google Scholar]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual Lifelong Learning with Neural Networks: A Review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef] [PubMed]
- Ruf, P.; Madan, M.; Reich, C.; Ould-Abdeslam, D. Demystifying Mlops and Presenting a Recipe for the Selection of Open-Source Tools. Appl. Sci. 2021, 11, 8861. [Google Scholar] [CrossRef]
- Ghavami, B.; Sadati, M.; Fang, Z.; Shannon, L. FitAct: Error Resilient Deep Neural Networks via Fine-Grained Post-Trainable Activation Functions. In Proceedings of the 2022 Design, Automation & Test in Europe Conference & Exhibition (DATE), Virtual, 14–23 March 2022. [Google Scholar] [CrossRef]
- Yin, Y.; Zheng, X.; Du, P.; Liu, L.; Ma, H. Scaling Resilient Adversarial Patch. In Proceedings of the 2021 IEEE 18th International Conference on Mobile Ad Hoc and Smart Systems (MASS), Denver, CO, USA, 4–7 October 2021; pp. 189–197. [Google Scholar] [CrossRef]
- Guo, H.; Zhang, S.; Wang, W. Selective Ensemble-Based Online Adaptive Deep Neural Networks for Streaming Data with Concept Drift. Neural Netw. 2021, 142, 437–456. [Google Scholar] [CrossRef] [PubMed]
- Fraccascia, L.; Giannoccaro, I.; Albino, V. Resilience of Complex Systems: State of the Art and Directions for Future Research. Complexity 2018, 2018, 3421529. [Google Scholar] [CrossRef]
- Ruospo, A.; Sanchez, E.; Luza, L.M.; Dilillo, L.; Traiola, M.; Bosio, A. A Survey on Deep Learning Resilience Assessment Methodologies. Computer 2022, 56, 57–66. [Google Scholar] [CrossRef]
- He, Y.; Balaprakash, P.; Li, Y. FIdelity: Efficient Resilience Analysis Framework for Deep Learning Accelerators. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; IEEE: Piscataway Township, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Santos, S.G.T.d.C.; Gonçalves Júnior, P.M.; Silva, G.D.d.S.; de Barros, R.S.M. Speeding Up Recovery from Concept Drifts. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2014; pp. 179–194. [Google Scholar] [CrossRef]
- Lusenko, S.; Kharchenko, V.; Bobrovnikova, K.; Shchuka, R. Computer systems resilience in the presence of cyber threats: Taxonomy and ontology. Radioelectron. Comput. Syst. 2020, 1, 17–28. [Google Scholar] [CrossRef]
- Drozd, O.; Kharchenko, V.; Rucinski, A.; Kochanski, T.; Garbos, R.; Maevsky, D. Development of Models in Resilient Computing. In Proceedings of the 2019 10th International Conference on Dependable Systems, Services and Technologies (DESSERT), Leeds, UK, 5–7 June 2019; IEEE: Piscataway Township, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Allenby, B.; Fink, J. Toward Inherently Secure and Resilient Societies. Science 2005, 309, 1034–1036. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haimes, Y.Y. On the Definition of Resilience in Systems. Risk Anal. 2009, 29, 498–501. [Google Scholar] [CrossRef]
- Vugrin, E.D.; Warren, D.E.; Ehlen, M.A.; Camphouse, R.C. A Framework for Assessing the Resilience of Infrastructure and Economic Systems. In Sustainable and Resilient Critical Infrastructure Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 77–116. [Google Scholar] [CrossRef]
- Cimellaro, G.P.; Reinhorn, A.M.; Bruneau, M. Framework for Analytical Quantification of Disaster Resilience. Eng. Struct. 2010, 32, 3639–3649. [Google Scholar] [CrossRef]
- Fairbanks, R.J.; Wears, R.L.; Woods, D.D.; Hollnagel, E.; Plsek, P.; Cook, R.I. Resilience and Resilience Engineering in Health Care. Jt. Comm. J. Qual. Patient Saf. 2014, 40, 376–383. [Google Scholar] [CrossRef] [PubMed]
- Yodo, N.; Wang, P. Engineering Resilience Quantification and System Design Implications: A Literature Survey. J. Mech. Des. 2016, 138, 111408. [Google Scholar] [CrossRef] [Green Version]
- Brtis, J.S.; McEvilley, M.A.; Pennock, M.J. Resilience Requirements Patterns. INCOSE Int. Symp. 2021, 31, 570–584. [Google Scholar] [CrossRef]
- Barker, K.; Lambert, J.H.; Zobel, C.W.; Tapia, A.H.; Ramirez-Marquez, J.E.; Albert, L.; Nicholson, C.D.; Caragea, C. Defining resilience analytics for interdependent cyber-physical-social networks. Sustain. Resilient Infrastruct. 2017, 2, 59–67. [Google Scholar] [CrossRef]
- Cutter, S.L.; Ahearn, J.A.; Amadei, B.; Crawford, P.; Eide, E.A.; Galloway, G.E.; Goodchild, M.F.; Kunreuther, H.C.; Li-Vollmer, M.; Schoch-Spana, M. Disaster Resilience: A National Imperative. Environ. Sci. Policy Sustain. Dev. 2013, 55, 25–29. [Google Scholar] [CrossRef]
- Wheaton, M.; Madni, A.M. Resiliency and Affordability Attributes in a System Tradespace. In Proceedings of the AIAA SPACE 2015 Conference and Exposition, Pasadena, CA, USA, 31 August–2 September 2015; American Institute of Aeronautics and Astronautics: Reston, Virginia, 2015. [Google Scholar] [CrossRef]
- Crespi, B.J. Cognitive trade-offs and the costs of resilience. Behav. Brain Sci. 2015, 38, e99. [Google Scholar] [CrossRef]
- Dyer, J.S. Multiattribute Utility Theory (MAUT). In Multiple Criteria Decision Analysis; Springer: New York, NY, USA, 2016; pp. 285–314. [Google Scholar] [CrossRef]
- Kulakowski, K. Understanding Analytic Hierarchy Process; Taylor & Francis Group: Singapore, 2020. [Google Scholar] [CrossRef]
- Moskalenko, V.V.; Moskalenko, A.S.; Korobov, A.G.; Zaretsky, M.O. Image Classifier Resilient to Adversarial Attacks, Fault Injections and Concept Drift—Model Architecture and Training Algorithm. Radio Electron. Comput. Sci. Control. 2022, 3, 86. [Google Scholar] [CrossRef]
- Moskalenko, V.; Moskalenko, A. Neural network based image classifier resilient to destructive perturbation influences—Architecture and training method. Radioelectron. Comput. Syst. 2022, 3, 95–109. [Google Scholar] [CrossRef]
- Eggers, S.; Sample, C. Vulnerabilities in Artificial Intelligence and Machine Learning Applications and Data; Office of Scientific and Technical Information (OSTI): Oak Ridge, TN, USA, 2020. [Google Scholar] [CrossRef]
- Tabassi, E. A Taxonomy and Terminology of Adversarial Machine Learning; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2023. [Google Scholar] [CrossRef]
- Torres-Huitzil, C.; Girau, B. Fault and Error Tolerance in Neural Networks: A Review. IEEE Access 2017, 5, 17322–17341. [Google Scholar] [CrossRef]
- Agrahari, S.; Singh, A.K. Concept Drift Detection in Data Stream Mining: A literature review. J. King Saud Univ.–Comput. Inf. Sci. 2021, 34, 9523–9540. [Google Scholar] [CrossRef]
- Museba, T.; Nelwamondo, F.; Ouahada, K. ADES: A New Ensemble Diversity-Based Approach for Handling Concept Drift. Mob. Inf. Syst. 2021, 2021, 5549300. [Google Scholar] [CrossRef]
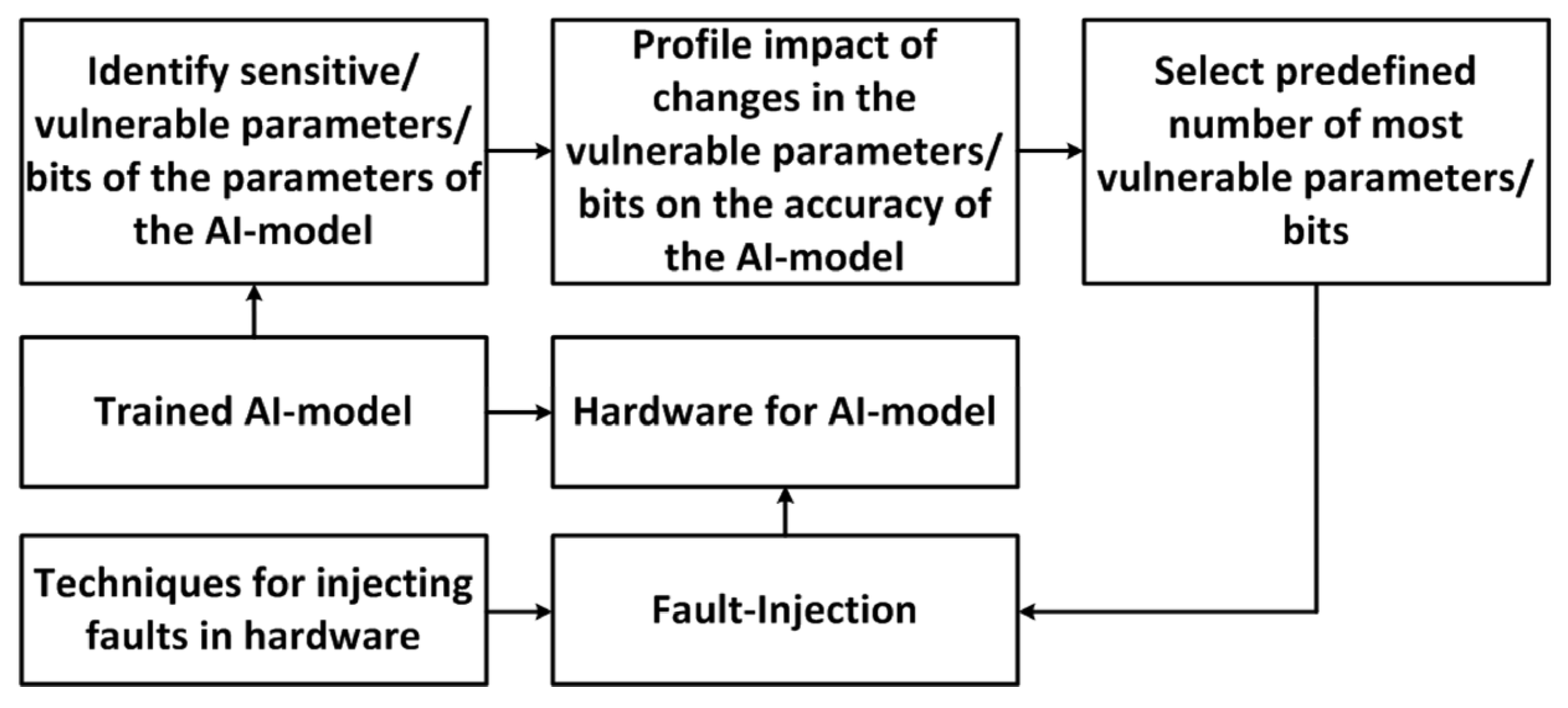
- Malekzadeh, E.; Rohbani, N.; Lu, Z.; Ebrahimi, M. The Impact of Faults on DNNs: A Case Study. In Proceedings of the 2021 IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Athens, Greece, 6–8 October 2021; IEEE: Piscataway Township, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Benevenuti, F.; Libano, F.; Pouget, V.; Kastensmidt, F.L.; Rech, P. Comparative Analysis of Inference Errors in a Neural Network Implemented in SRAM-Based FPGA Induced by Neutron Irradiation and Fault Injection Methods. In Proceedings of the 2018 31st Symposium on Integrated Circuits and Systems Design (SBCCI), Bento Goncalves, Brazil, 27–31 August 2018; IEEE: Piscataway Township, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Li, J.; Rakin, A.S.; Xiong, Y.; Chang, L.; He, Z.; Fan, D.; Chakrabarti, C. Defending Bit-Flip Attack through DNN Weight Reconstruction. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; IEEE: Piscataway Township, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Akhtar, N.; Mian, A. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Zhou, S.; Liu, C.; Ye, D.; Zhu, T.; Zhou, W.; Yu, P.S. Adversarial Attacks and Defenses in Deep Learning: From a Perspective of Cybersecurity. ACM Comput. Surv. 2022, 6, 346–360. [Google Scholar] [CrossRef]
- Khalid, F.; Ali, H.; Abdullah Hanif, M.; Rehman, S.; Ahmed, R.; Shafique, M. FaDec: A Fast Decision-based Attack for Adversarial Machine Learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway Township, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Altoub, M.; AlQurashi, F.; Yigitcanlar, T.; Corchado, J.M.; Mehmood, R. An Ontological Knowledge Base of Poisoning Attacks on Deep Neural Networks. Appl. Sci. 2022, 12, 11053. [Google Scholar] [CrossRef]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. A survey on adversarial attacks and defences. CAAI Trans. Intell. Technol. 2021, 6, 25–45. [Google Scholar] [CrossRef]
- Zona, A.; Kammouh, O.; Cimellaro, G.P. Resourcefulness quantification approach for resilient communities and countries. Int. J. Disaster Risk Reduct. 2020, 46, 101509. [Google Scholar] [CrossRef]
- Eigner, O.; Eresheim, S.; Kieseberg, P.; Klausner, L.D.; Pirker, M.; Priebe, T.; Tjoa, S.; Marulli, F.; Mercaldo, F. Towards Resilient Artificial Intelligence: Survey and Research Issues. In Proceedings of the 2021 IEEE International Conference on Cyber Security and Resilience (CSR), Rhodes, Greece, 26–28 July 2021; IEEE: Piscataway Township, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Olowononi, F.O.; Rawat, D.B.; Liu, C. Resilient Machine Learning for Networked Cyber Physical Systems: A Survey for Machine Learning Security to Securing Machine Learning for CPS. IEEE Commun. Surv. Tutor. 2020, 23, 524–552. [Google Scholar] [CrossRef]
- Graceful Degradation and Related Fields-ePrints Soton. Welcome to ePrints Soton-ePrints Soton. Available online: https://eprints.soton.ac.uk/455349/ (accessed on 11 February 2023).
- Cavagnero, N.; Santos, F.D.; Ciccone, M.; Averta, G.; Tommasi, T.; Rech, P. Transient-Fault-Aware Design and Training to Enhance DNNs Reliability with Zero-Overhead. In Proceedings of the 2022 IEEE 28th International Symposium on On-Line Testing and Robust System Design (IOLTS), Torino, Italy, 12–14 September 2022; IEEE: Piscataway Township, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Enériz, D.; Medrano, N.; Calvo, B. An FPGA-Based Machine Learning Tool for In-Situ Food Quality Tracking Using Sensor Fusion. Biosensors 2021, 11, 366. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Li, M.; Jiang, W.; Huang, Y.; Lin, R. A Design of FPGA-Based Neural Network PID Controller for Motion Control System. Sensors 2022, 22, 889. [Google Scholar] [CrossRef]
- Barbero, F.; Pendlebury, F.; Pierazzi, F.; Cavallaro, L. Transcending TRANSCEND: Revisiting Malware Classification in the Presence of Concept Drift. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–26 May 2022; IEEE: Piscataway Township, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Pisani, P.H.; Mhenni, A.; Giot, R.; Cherrier, E.; Poh, N.; Ferreira de Carvalho, A.C.P.d.L.; Rosenberger, C.; Amara, N.E.B. Adaptive Biometric Systems. ACM Comput. Surv. 2019, 52, 102. [Google Scholar] [CrossRef]
- Massoli, F.V.; Carrara, F.; Amato, G.; Falchi, F. Detection of Face Recognition Adversarial Attacks. Comput. Vis. Image Underst. 2021, 202, 103103. [Google Scholar] [CrossRef]
- Izuddeen, M.; Naja’atu, M.K.; Ali, M.U.; Abdullahi, M.B.; Baballe, A.M.; Tofa, A.U.; Gambo, M. FPGA Based Facial Recognition System. J. Eng. Res. Rep. 2022, 22, 89–96. [Google Scholar] [CrossRef]
- Hickling, T.; Aouf, N.; Spencer, P. Robust Adversarial Attacks Detection based on Explainable Deep Reinforcement Learning for UAV Guidance and Planning. arXiv 2022, arXiv:2206.02670. [Google Scholar] [CrossRef]
- Bistron, M.; Piotrowski, Z. Artificial Intelligence Applications in Military Systems and Their Influence on Sense of Security of Citizens. Electronics 2021, 10, 871. [Google Scholar] [CrossRef]
- Jurn, Y.N.; Mahmood, S.A.; Aldhaibani, J.A. Anti-Drone System Based Different Technologies: Architecture, Threats and Challenges. In Proceedings of the 2021 11th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 27–28 August 2021; IEEE: Piscataway Township, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Travaini, G.V.; Pacchioni, F.; Bellumore, S.; Bosia, M.; De Micco, F. Machine Learning and Criminal Justice: A Systematic Review of Advanced Methodology for Recidivism Risk Prediction. Int. J. Environ. Res. Public Health 2022, 19, 10594. [Google Scholar] [CrossRef]
- Shen, M.W. Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient. arXiv 2021, arXiv:2202.05302. [Google Scholar] [CrossRef]
- Gallagher, M.; Pitropakis, N.; Chrysoulas, C.; Papadopoulos, P.; Mylonas, A.; Katsikas, S. Investigating Machine Learning Attacks on Financial Time Series Models. Comput. Secur. 2022, 123, 102933. [Google Scholar] [CrossRef]
- Kumar, N.; Vimal, S.; Kayathwal, K.; Dhama, G. Evolutionary Adversarial Attacks on Payment Systems. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, CA, USA, 13–16 December 2021; IEEE: Piscataway Township, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Vo, N.H.; Phan, K.D.; Tran, A.-D.; Dang-Nguyen, D.-T. Adversarial Attacks on Deepfake Detectors: A Practical Analysis. In MultiMedia Modeling; Springer International Publishing: Cham, Switzerland, 2022; pp. 318–330. [Google Scholar] [CrossRef]
- Gaglio, S.; Giammanco, A.; Lo Re, G.; Morana, M. Adversarial Machine Learning in e-Health: Attacking a Smart Prescription System. In AIxIA 2021–Advances in Artificial Intelligence; Springer International Publishing: Cham, Switzerland, 2022; pp. 490–502. [Google Scholar] [CrossRef]
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A. Mitigating Adversarial Effects through Randomization. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–16. [Google Scholar] [CrossRef]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; IEEE: Piscataway Township, NJ, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Srisakaokul, S.; Zhong, Z.; Zhang, Y.; Ti, B.; Xie, T.; Yang, W. Multi-Model-Based Defense Against Adversarial Examples for Neural Networks. arXiv 2018, arXiv:1809.00065. [Google Scholar] [CrossRef]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. PixelDefend: Leveraging Generative Models to Understand and Defend against Advers arial Examples. In Proceedings of the International Conference on Learning Representations, Vancouver, QC, Canada, 30 April–3 May 2018; pp. 1–20. [Google Scholar] [CrossRef]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Protecting Classifiers Against Adversarial Attacks Using Generative Models. arXiv 2018, arXiv:1805.06605. [Google Scholar]
- Makarichev, V.; Lukin, V.; Illiashenko, O.; Kharchenko, V. Digital Image Representation by Atomic Functions: The Compression and Protection of Data for Edge Computing in IoT Systems. Sensors 2022, 22, 3751. [Google Scholar] [CrossRef]
- Laermann, J.; Samek, W.; Strodthoff, N. Achieving Generalizable Robustness of Deep Neural Networks by Stability Training. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; pp. 360–373. [Google Scholar] [CrossRef] [Green Version]
- Jakubovitz, D.; Giryes, R. Improving DNN Robustness to Adversarial Attacks using Jacobian Regularization. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 1–16. [Google Scholar] [CrossRef]
- Leslie, N.S. A useful taxonomy for adversarial robustness of Neural Networks. Trends Comput. Sci. Inf. Technol. 2020, 5, 37–41. [Google Scholar] [CrossRef]
- Shu, X.; Tang, J.; Qi, G.-J.; Li, Z.; Jiang, Y.-G.; Yan, S. Image Classification with Tailored Fine-Grained Dictionaries. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 454–467. [Google Scholar] [CrossRef]
- Deng, Z.; Yang, X.; Xu, S.; Su, H.; Zhu, J. LiBRe: A Practical Bayesian Approach to Adversarial Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 972–982. [Google Scholar] [CrossRef]
- Abusnaina, A.; Wu, Y.; Arora, S.; Wang, Y.; Wang, F.; Yang, H.; Mohaisen, D. Adversarial Example Detection Using Latent Neighborhood Graph. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Venkatesan, S.; Sikka, H.; Izmailov, R.; Chadha, R.; Oprea, A.; de Lucia, M.J. Poisoning Attacks and Data Sanitization Mitigations for Machine Learning Models in Network Intrusion Detection Systems. In Proceedings of the MILCOM 2021–2021 IEEE Military Communications Conference (MILCOM), San Diego, CA, USA, 29 November–2 December 2021; IEEE: Piscataway Township, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Adversarial Examples Are Not Easily Detected. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar] [CrossRef]
- Zhao, W.; Alwidian, S.; Mahmoud, Q.H. Adversarial Training Methods for Deep Learning: A Systematic Review. Algorithms 2022, 15, 283. [Google Scholar] [CrossRef]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Carrara, F.; Becarelli, R.; Caldelli, R.; Falchi, F.; Amato, G. Adversarial Examples Detection in Features Distance Spaces. In Physics of Solid Surfaces; Springer: Berlin/Heidelberg, Germany, 2019; pp. 313–327. [Google Scholar] [CrossRef]
- Jang, M.; Hong, J. MATE: Memory- and Retraining- Free Error Correction for Convolutional Neural Network Weights. J. Lnf. Commun. Converg. Eng. 2021, 19, 22–28. [Google Scholar] [CrossRef]
- Li, W.; Ning, X.; Ge, G.; Chen, X.; Wang, Y.; Yang, H. FTT-NAS: Discovering Fault-Tolerant Neural Architecture. In Proceedings of the 25th Asia and South Pacific Design Automation Conference (ASP-DAC), Beijing, China, 13–16 January 2020; pp. 211–216. [Google Scholar] [CrossRef] [Green Version]
- Hoang, L.-H.; Hanif, M.A.; Shafique, M. TRe-Map: Towards Reducing the Overheads of Fault-Aware Retraining of Deep Neural Networks by Merging Fault Maps. In Proceedings of the 24th Euromicro Conference on Digital System Design (DSD), Palermo, Italy, 1–3 September 2021; pp. 434–441. [Google Scholar] [CrossRef]
- Baek, I.; Chen, W.; Zhu, Z.; Samii, S.; Rajkumar, R.R. FT-DeepNets: Fault-Tolerant Convolutional Neural Networks with Kernel-based Duplication. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; IEEE: Piscataway Township, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Xu, H.; Chen, Z.; Wu, W.; Jin, Z.; Kuo, S.-y.; Lyu, M. NV-DNN: Towards Fault-Tolerant DNN Systems with N-Version Programming. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), Portland, OR, USA, 24–27 June 2019; IEEE: Piscataway Township, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Liu, T.; Wen, W.; Jiang, L.; Wang, Y.; Yang, C.; Quan, G. A Fault-Tolerant Neural Network Architecture. In Proceedings of the DAC ‘19: The 56th Annual Design Automation Conference 2019, Las Vegas, NV, USA, 2–6 June 2019; ACM: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Huang, K.; Siegel, P.H.; Jiang, A. Functional Error Correction for Robust Neural Networks. IEEE J. Sel. Areas Inf. Theory 2020, 1, 267–276. [Google Scholar] [CrossRef]
- Li, J.; Rakin, A.S.; He, Z.; Fan, D.; Chakrabarti, C. RADAR: Run-time Adversarial Weight Attack Detection and Accuracy Recovery. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 790–795. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, P.; Wang, S.; Lin, X. Detection and recovery against deep neural network fault injection attacks based on contrastive learning. In Proceedings of the 3rd Workshop on Adversarial Learning Methods for Machine Learning and Data Mining at KDD, Singapore, 14 August 2021; pp. 1–5. [Google Scholar]
- Javaheripi, M.; Koushanfar, F. HASHTAG: Hash Signatures for Online Detection of Fault-Injection Attacks on Deep Neural Networks. In Proceedings of the IEEE/ACM International Conference on Computer Aided Design (ICCAD), Munich, Germany, 1–4 November 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Valtchev, S.Z.; Wu, J. Domain randomization for neural network classification. J. Big Data 2021, 8, 94. [Google Scholar] [CrossRef]
- Volpi, R.; Namkoong, H.; Sener, O.; Duchi, J.; Murino, V.; Savarese, S. Generalizing to unseen domains via adversarial data augmentation. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 2–8 December 2018; pp. 1–11. [Google Scholar] [CrossRef]
- Xu, Q.; Yao, L.; Jiang, Z.; Jiang, G.; Chu, W.; Han, W.; Zhang, W.; Wang, C.; Tai, Y. DIRL: Domain-Invariant Representation Learning for Generalizable Semantic Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 22 February–3 March 2022; pp. 2884–2892. [Google Scholar] [CrossRef]
- Tang, J.; Shu, X.; Li, Z.; Qi, G.-J.; Wang, J. Generalized Deep Transfer Networks for Knowledge Propagation in Heterogeneous Domains. ACM Trans. Multimedia Comput. Commun. Appl. 2016, 12, 68. [Google Scholar] [CrossRef]
- Jiao, B.; Guo, Y.; Gong, D.; Chen, Q. Dynamic Ensemble Selection for Imbalanced Data Streams with Concept Drift. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Barddal, J.P.; Gomes, H.M.; Enembreck, F.; Pfahringer, B. A survey on feature drift adaptation: Definition, benchmark, challenges and future directions. J. Syst. Softw. 2017, 127, 278–294. [Google Scholar] [CrossRef] [Green Version]
- Goldenberg, I.; Webb, G.I. Survey of distance measures for quantifying concept drift and shift in numeric data. Knowl. Inf. Syst. 2018, 60, 591–615. [Google Scholar] [CrossRef]
- Wang, P.; Woo, W.; Jin, N.; Davies, D. Concept Drift Detection by Tracking Weighted Prediction Confidence of Incremental Learning. In Proceedings of the IVSP 2022: 2022 4th International Conference on Image, Video and Signal Processing, Singapore, 18–20 March 2022; ACM: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under Concept Drift: A Review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef] [Green Version]
- Demšar, J.; Bosnić, Z. Detecting concept drift in data streams using model explanation. Expert Syst. Appl. 2018, 92, 546–559. [Google Scholar] [CrossRef]
- Huang, D.T.J.; Koh, Y.S.; Dobbie, G.; Bifet, A. Drift Detection Using Stream Volatility. In Machine Learning and Knowledge Discovery in Databases; Springer International Publishing: Cham, Switzerland, 2015; pp. 417–432. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, T.; Zha, Z.-J.; Luo, J.; Zhang, Y.; Wu, F. Self-Supervised Domain-Aware Generative Network for Generalized Zero-Shot Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway Township, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Karimi, D.; Gholipour, A. Improving Calibration and out-of-Distribution Detection in Deep Models for Medical Image Segmentation. arXiv 2022, arXiv:2004.06569. [Google Scholar] [CrossRef]
- Shao, Z.; Yang, J.; Ren, S. Calibrating Deep Neural Network Classifiers on out-of-Distribution Datasets. arXiv 2020, arXiv:2006.08914. [Google Scholar]
- Achddou, R.; Di Martino, J.M.; Sapiro, G. Nested Learning for Multi-Level Classification. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway Township, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Huo, Y.; Lu, Y.; Niu, Y.; Lu, Z.; Wen, J.-R. Coarse-to-Fine Grained Classification. In Proceedings of the SIGIR ‘19: The 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; ACM: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Pourpanah, F.; Abdar, M.; Luo, Y.; Zhou, X.; Wang, R.; Lim, C.P.; Wang, X.-Z.; Wu, Q.M.J. A Review of Generalized Zero-Shot Learning Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4051–4070. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.-Y.; Yeh, M.-C. Generative and Adaptive Multi-Label Generalized Zero-Shot Learning. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; IEEE: Piscataway Township, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Baier, L.; Kühl, N.; Satzger, G.; Hofmann, M.; Mohr, M. Handling Concept Drifts in Regression Problems—The Error Intersection Approach. In WI2020 Zentrale Tracks; GITO Verlag: Berlin, Germany, 2020; pp. 210–224. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Bao, C.; Ma, K. Self-Distillation: Towards Efficient and Compact Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4388–4403. [Google Scholar] [CrossRef]
- Laskaridis, S.; Kouris, A.; Lane, N.D. Adaptive Inference through Early-Exit Networks. In Proceedings of the MobiSys ‘21: The 19th Annual International Conference on Mobile Systems, Applications, and Services, Virtual, 24 June–2 July 2021; ACM: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Kirk, R.; Zhang, A.; Grefenstette, E.; Rocktäschel, T. A Survey of Zero-shot Generalisation in Deep Reinforcement Learning. J. Artif. Intell. Res. 2023, 76, 201–264. [Google Scholar] [CrossRef]
- Fdez-Díaz, M.; Quevedo, J.R.; Montañés, E. Target inductive methods for zero-shot regression. Inf. Sci. 2022, 599, 44–63. [Google Scholar] [CrossRef]
- Liu, S.; Chen, J.; Pan, L.; Ngo, C.-W.; Chua, T.-S.; Jiang, Y.-G. Hyperbolic Visual Embedding Learning for Zero-Shot Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway Township, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Shah, K.; Manwani, N. Online Active Learning of Reject Option Classifiers. Proc. AAAI Conf. Artif. Intell. 2020, 34, 5652–5659. [Google Scholar] [CrossRef]
- Yang, Y.; Loog, M. A variance maximization criterion for active learning. Pattern Recognit. 2018, 78, 358–370. [Google Scholar] [CrossRef] [Green Version]
- Maschler, B.; Huong Pham, T.T.; Weyrich, M. Regularization-based Continual Learning for Anomaly Detection in Discrete Manufacturing. Procedia CIRP 2021, 104, 452–457. [Google Scholar] [CrossRef]
- Cossu, A.; Carta, A.; Bacciu, D. Continual Learning with Gated Incremental Memories for sequential data processing. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway Township, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Sokar, G.; Mocanu, D.C.; Pechenizkiy, M. SpaceNet: Make Free Space for Continual Learning. Neurocomputing 2021, 439, 1–11. [Google Scholar] [CrossRef]
- Li, X.; Hu, Y.; Zheng, J.; Li, M.; Ma, W. Central moment discrepancy based domain adaptation for intelligent bearing fault diagnosis. Neurocomputing 2021, 429, 12–24. [Google Scholar] [CrossRef]
- Li, S.; Liu, C.H.; Xie, B.; Su, L.; Ding, Z.; Huang, G. Joint Adversarial Domain Adaptation. In Proceedings of the MM ‘19: The 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; ACM: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Yang, J.; An, W.; Wang, S.; Zhu, X.; Yan, C.; Huang, J. Label-Driven Reconstruction for Domain Adaptation in Semantic Segmentation. In Computer Vision–ECCV 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 480–498. [Google Scholar] [CrossRef]
- Xu, J.; Xiao, L.; Lopez, A.M. Self-Supervised Domain Adaptation for Computer Vision Tasks. IEEE Access 2019, 7, 156694–156706. [Google Scholar] [CrossRef]
- Li, T.; Su, X.; Liu, W.; Liang, W.; Hsieh, M.-Y.; Chen, Z.; Liu, X.; Zhang, H. Memory-augmented meta-learning on meta-path for fast adaptation cold-start recommendation. Connect. Sci. 2021, 34, 301–318. [Google Scholar] [CrossRef]
- Xu, Z.; Cao, L.; Chen, X. Meta-Learning via Weighted Gradient Update. IEEE Access 2019, 7, 110846–110855. [Google Scholar] [CrossRef]
- TPAMI Publication Information. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, C2. [CrossRef]
- Reagen, B.; Gupta, U.; Pentecost, L.; Whatmough, P.; Lee, S.K.; Mulholland, N.; Brooks, D.; Wei, G.-Y. Ares. In Proceedings of the DAC ′18: The 55th Annual Design Automation Conference 2018, San Francisco, CA, USA, 24–29 June 2018; ACM: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Li, G.; Pattabiraman, K.; DeBardeleben, N. TensorFI: A Configurable Fault Injector for TensorFlow Applications. In Proceedings of the IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Charlotte, NC, USA, 15–18 October 2018; pp. 1–8. [Google Scholar]
- Kotyan, S.; Vargas, D. Adversarial robustness assessment: Why in evaluation both L0 and L∞ attacks are necessary. PLoS ONE 2022, 17, e0265723. [Google Scholar] [CrossRef]
- Moskalenko, V.; Kharchenko, V.; Moskalenko, A.; Petrov, S. Model and Training Method of the Resilient Image Classifier Considering Faults, Concept Drift, and Adversarial Attacks. Algorithms 2022, 15, 384. [Google Scholar] [CrossRef]
- Xie, X.; Ma, L.; Juefei-Xu, F.; Xue, M.; Chen, H.; Liu, Y.; Zhao, J.; Li, B.; Yin, J.; See, S. DeepHunter: A coverage-guided fuzz testing framework for deep neural networks. In Proceedings of the ISSTA ′19: 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, Beijing, China, 15–19 July 2019; ACM: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Ehlers, R. Formal Verification of Piece-Wise Linear Feed-Forward Neural Networks. In Automated Technology for Verification and Analysis; Springer International Publishing: Cham, Switzerland, 2017; pp. 269–286. [Google Scholar] [CrossRef] [Green Version]
- Katz, G.; Barrett, C.; Dill, D.L.; Julian, K.; Kochenderfer, M.J. Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks. In Computer Aided Verification; Springer International Publishing: Cham, Switzerland, 2017; pp. 97–117. [Google Scholar] [CrossRef] [Green Version]
- Narodytska, N. Formal Verification of Deep Neural Networks. In Proceedings of the 2018 Formal Methods in Computer Aided Design (FMCAD), Austin, TX, USA, 30 October–2 November 2018; IEEE: Piscataway Township, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Narodytska, N. Formal Analysis of Deep Binarized Neural Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence {IJCAI-18}, Stockholm, Sweden, 13–19 July 2018; International Joint Conferences on Artificial Intelligence Organization: California, CA, USA, 2018. [Google Scholar] [CrossRef] [Green Version]
- Xiang, W.; Tran, H.-D.; Johnson, T.T. Output Reachable Set Estimation and Verification for Multilayer Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5777–5783. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gehr, T.; Mirman, M.; Drachsler-Cohen, D.; Tsankov, P.; Chaudhuri, S.; Vechev, M. AI2: Safety and Robustness Certification of Neural Networks with Abstract Interpretation. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; IEEE: Piscataway Township, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Wu, M.; Wicker, M.; Ruan, W.; Huang, X.; Kwiatkowska, M. A Game-Based Approximate Verification of Deep Neural Networks With Provable Guarantees. Theor. Comput. Sci. 2020, 807, 298–329. [Google Scholar] [CrossRef]
- Wicker, M.; Huang, X.; Kwiatkowska, M. Feature-Guided Black-Box Safety Testing of Deep Neural Networks. In Tools and Algorithms for the Construction and Analysis of Systems; Springer International Publishing: Cham, Switzerland, 2018; pp. 408–426. [Google Scholar] [CrossRef] [Green Version]
- Weng, T.-W.; Zhang, H.; Chen, P.-Y.; Yi, J.; Daniel, L.; Hsieh, C.-J.; Gao, Y.; Su, D. Evaluating the Robustness of Neural Networks: An Extreme Value Theory Approach. arXiv 2018, arXiv:1801.10578. [Google Scholar] [CrossRef]
- Huang, X.; Kroening, D.; Ruan, W.; Sharp, J.; Sun, Y.; Thamo, E.; Wu, M.; Yi, X. A survey of safety and trustworthiness of deep neural networks: Verification, testing, adversarial attack and defence, and interpretability. Comput. Sci. Rev. 2020, 37, 100270. [Google Scholar] [CrossRef]
- Baluta, T.; Chua, Z.L.; Meel, K.S.; Saxena, P. Scalable Quantitative Verification For Deep Neural Networks. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), Madrid, Spain, 22–30 May 2021; IEEE: Piscataway Township, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Pautov, M.; Tursynbek, N.; Munkhoeva, M.; Muravev, N.; Petiushko, A.; Oseledets, I. CC-CERT: A Probabilistic Approach to Certify General Robustness of Neural Networks. Proc. AAAI Conf. Artif. Intell. 2022, 36, 7975–7983. [Google Scholar] [CrossRef]
- Feurer, M.; Hutter, F. Hyperparameter Optimization. In Automated Machine Learning; Springer International Publishing: Cham, Switzerland, 2019; pp. 3–33. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Tang, Z.; Chen, D.; Su, K.; Chen, C. Batching Soft IoU for Training Semantic Segmentation Networks. IEEE Signal Process. Lett. 2020, 27, 66–70. [Google Scholar] [CrossRef]
- Steck, H. Hinge Rank Loss and the Area Under the ROC Curve. In Machine Learning: ECML 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 347–358. [Google Scholar] [CrossRef] [Green Version]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The Lovasz-Softmax Loss: A Tractable Surrogate for the Optimization of the Intersection-Over-Union Measure in Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway Township, NJ, USA, 2018. [Google Scholar] [CrossRef] [Green Version]
- Kotłowski, W.; Dembczyński, K. Surrogate Regret Bounds for Generalized Classification Performance Metrics. Mach. Learn. 2016, 106, 549–572. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Lai, J. Stochastic Loss Function. Proc. AAAI Conf. Artif. Intell. 2020, 34, 4884–4891. [Google Scholar] [CrossRef]
- Li, Z.; Ji, J.; Ge, Y.; Zhang, Y. AutoLossGen: Automatic Loss Function Generation for Recommender Systems. In Proceedings of the SIGIR ′22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; ACM: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Sanyal, A.; Kumar, P.; Kar, P.; Chawla, S.; Sebastiani, F. Optimizing non-decomposable measures with deep networks. Mach. Learn. 2018, 107, 1597–1620. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Li, L.; Yan, B.; Koyejo, O.M. Consistent Classification with Generalized Metrics. arXiv 2019, arXiv:1908.09057. [Google Scholar] [CrossRef]
- Jiang, Q.; Adigun, O.; Narasimhan, H.; Fard, M.M.; Gupta, M. Optimizing Black-Box Metrics with Adaptive Surrogates. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar] [CrossRef]
- Liu, L.; Wang, M.; Deng, J. A Unified Framework of Surrogate Loss by Refactoring and Interpolation. In Computer Vision–ECCV 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 278–293. [Google Scholar] [CrossRef]
- Huang, C.; Zhai, S.; Guo, P.; Susskind, J. MetricOpt: Learning to Optimize Black-Box Evaluation Metrics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Duddu, V.; Rajesh Pillai, N.; Rao, D.V.; Balas, V.E. Fault tolerance of neural networks in adversarial settings. J. Intell. Fuzzy Syst. 2020, 38, 5897–5907. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhou, Y.; Zhang, L. On the Robustness of Domain Adaption to Adversarial Attacks. arXiv 2021, arXiv:2108.01807. [Google Scholar] [CrossRef]
- Olpadkar, K.; Gavas, E. Center Loss Regularization for Continual Learning. arxiv 2021, arXiv:2110.11314. [Google Scholar] [CrossRef]
- Kharchenko, V.; Fesenko, H.; Illiashenko, O. Quality Models for Artificial Intelligence Systems: Characteristic-Based Approach, Development and Application. Sensors 2022, 22, 4865. [Google Scholar] [CrossRef] [PubMed]
- Inouye, B.D.; Brosi, B.J.; Le Sage, E.H.; Lerdau, M.T. Trade-offs Among Resilience, Robustness, Stability, and Performance and How We Might Study Them. Integr. Comp. Biol. 2021, 61, 2180–2189. [Google Scholar] [CrossRef]
- Perepelitsyn, A.; Kulanov, V.; Zarizenko, I. Method of QoS evaluation of FPGA as a service. Radioelectron. Comput. Syst. 2022, 4, 153–160. [Google Scholar] [CrossRef]
- Imanbayev, A.; Tynymbayev, S.; Odarchenko, R.; Gnatyuk, S.; Berdibayev, R.; Baikenov, A.; Kaniyeva, N. Research of Machine Learning Algorithms for the Development of Intrusion Detection Systems in 5G Mobile Networks and Beyond. Sensors 2022, 22, 9957. [Google Scholar] [CrossRef]
- Dotsenko, S.; Kharchenko, V.; Morozova, O.; Rucinski, A.; Dotsenko, S. Heuristic Self-Organization of Knowledge Representation and Development: Analysis in the Context of Explainable Artificial Intelligence. Radioelectron. Comput. Syst. 2022, 1, 50–66. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AIS Application Area | AIS Threat Examples | Consequences of the Lack of AIS Resilience |
|---|---|---|
| Industry | Cyber attacks on edge devices of cyber-physical systems that deploy AI for quality inspection in manufacturing may pose a threat. The resources available to edge devices may not be enough to implement reliable built-in cybersecurity [39,50]. | Abnormal system behavior. Emergency situations. Production defects. |
| Fault injection attacks may affect FPGA chips, on which a neural network is deployed for implementing motion controllers, quality control systems in manufacturing processes, emission monitoring systems, or energy management systems [39,51]. | ||
| Adversarial poisoning attacks can be used to target to the training data of digital twins in complex industrial environments by gaining unauthorised access to the sensors or to the data repository [46]. | ||
| Adversarial evasion attacks on intelligent transportation systems, including self-driving vehicles, can take the form of visual patterns painted by attackers on road signs or other objects [47]. These attacks, along with legitimate, naturally occurring out-of-distribution observations, can lead to incorrect decision-making by the intelligent transportation system. | ||
| Security and Cybersecurity | The performance of an AI-based malware detector can degrade due to concept drift [52]. Concept drift can be caused by evolving malware, changes in user behavior, or changes in system configurations. | Security breaches. |
| The performance of an AI-based Biometric Authentication System can degrade due to concept drift [53]. Concept drift can be caused by various factors such as aging, injury or illness of a person, as well as environmental or technological changes. | ||
| Adversarial evasion attacks can be performed against AI-based malware detection or Biometric Authentication systems. For instance, attackers can design unique sunglasses that trick a facial recognition network into granting access to a secure system [2,54]. | ||
| Fault injection attacks can be performed against AI-based Biometric Authentication Systems [2,55]. | ||
| Military and Disaster Response | The disaster response drone is subject to aleatoric and epistemic uncertainties when processing images beyond its competence [48]. If the drone cannot notify the operator about out-of-distribution data in real time, the operator should review all collected data post-hoc. | Unexpected behavior of the automated system. Destruction of property and loss of life. Inefficient resource allocation. |
| An adversarial attack on a reinforcement learning model controlling an autonomous military drone can result in the drone attacking a series of unintended targets [56,57]. | ||
| Anti-UAV system can significantly increase the number of false positives or false negatives in case of domain drift [58]. Drift can be caused by a significant change in the surveillance environment or a change in the appearance of enemy drones. For example, enemy drones may more closely resemble birds, or may be harder to recognize in smoke or lighting effects. | ||
| Policing and Justice | Prior-probability shift lead to discriminatory outcomes in AI-based Recidivism prediction [59]. In this case, if an AI model gives a biased or incorrect prediction, holding the model or its creators accountable can be challenging. | Civil and human rights violations. Violations of the rule of law. |
| AI-based predictive policing lacks transparency, making it challenging to identify and correct biases in the AI model. AIS without interpretability or a behavioral certificate cannot be considered trustworthy [60]. However, the vast majority of researchers do not aggregate behavioral evidence from diverse sources, including empirical out-of-distribution and out-of-task evaluations and theoretical proofs linking model architecture to behavior, to produce behavioral certificates. | ||
| Finance | Adversarial attacks on AI models for financial trading can introduce special small changes to the stock prices that can affect the profitability of other AI trading models [61]. With insider information about the architecture and parameters of the model, an efficient white-box evasion attack can be implemented. Moreover, with insider access to the data, poisoning a small amount of the training data can drastically affect the AI model’s performance. Malicious actors can perform adversarial data perturbation by automatically buying and selling fnancial assets or spoofing (posting and cancelling he bid and offer prices). Additionally, adversarial tweets can also be used to manipulate stock prices because many AI trading models analyze news. | Loss of business profitability. Money laundering. |
| Adversarial attacks can be launched on fraud detection algorithms [62], which can lead to an improvement in the formation of synthetic identities, fraudulent transactions, fraudulent claims to insurance companies, and more. | ||
| Adversarial attacks on Deep fakes detector can cause it to malfunction [63]. Deep fakes are used to impersonate another person for money laundering. | ||
| Healthcare | Adversarial modification of medical data can be used to manipulate patient billing [64]. | Deterioration of health. Increased healthcare costs. |
| An automatic e-health system for prescriptions can be deceived by adversarial inputs that are forged to subvert the model’s prediction [64]. | ||
| Changes in treatment protocols, new diagnostic methods, and changes in demand for services may cause the trained diagnostic model to become outdated [64]. In addition, adversarial attacks on AI-based diagnostic system can also lead to concept drift. The concept drift, in turn, can lead to inaccuracies in prediction and incorrect diagnoses. |
| Approach | Capability | Weakness | Methods and Algorithms |
|---|---|---|---|
| Gradient masking | Perturbation absorption | Vulnerability to attacks based on gradient approximation or black-box optimization with evolution strategies | Non-differentiable input transformation [65,66] |
| Defensive distillation [67] | |||
| Models selection from a family of models [68] | |||
| Generative model PixelDefend or Defense-GAN [69,70] | |||
| Robustness optimization | Perturbation absorption and performance recovery | Significant computational resource consumption to obtain a good result | Adversarial retraining [80] |
| Stability training [72] | |||
| Jacobian regularization [73] | |||
| Sparse coding-based representation [75] | |||
| Intra-concentration and inter-separability regularization [30,31,74] | |||
| Provable defenses with the Reluplex algorithm [81] | |||
| Detecting adversarial examples | Rejection Option in the presence of adversarial inputs with the subsequent AI-decision explanation and passing the control to a human | Not reliable enough | Light-weight Bayesian refinement [76] |
| Adversarial example detection using latent neighborhood graph [77] | |||
| Feature distance space analysis [82] | |||
| Training Data Sanitization algorithms based on Reject on Negative Impact approach [78] |
| Approach | Capability | Weakness | Methods and Algorithms |
|---|---|---|---|
| Fault masking | Perturbation absorption | Computational intensive model synthesis | Weights representation with error-correcting codes [83] |
| Neural architecture search [84] | |||
| Fault-tolerant training based on fault injection to weight or adding noise to gradients during training [85] | |||
| Explicit redundancy | Perturbation detection and absorption | Computationally intensive model synthesis and inference redundancy overhead | Duplication of critical neurons and synapses [86] |
| Multi-versioning framework for constructing ensembles [87] | |||
| Error correcting output coding framework for constructing ensembles [88] | |||
| Error detection | Rejection Option in the presence of neural weight errors with the subsequent recovery by downloading a clean copy of weights | The model does not improve itself and information from vulnerable weights is not spread among other neurons | Encoding the most vulnerable model weights using a low-collision hash-function [89] |
| Checksum-based algorithm that computes low-dimensional binary signature for each weight group [90] | |||
| Comparision contrastive loss function value for diagnostic data with the reference value [91] |
| Approach | Capability | Weakness | Methods and Algorithms |
|---|---|---|---|
| Out-of-domain generalization | Absorption of disturbance | Less useful for real concept drift | Domain randomization [93] |
| Adversarial data augmentation [94] | |||
| Domain-invariant representation [95] | |||
| Heterogeneous-domain knowledge propagation [96] | |||
| Ensemble selection | Absorption of disturbance | Not suitable for large deep neural networks and high-dimensional data | Dynamically weighted Ensemble [97] |
| Feature dropping [98] | |||
| Concept Drift detection | Rejection Option in the presence of Concept drift with the subsequent adaptation | Not reliable when exposed to noise, adversarial attacks or faults | Data distribution-based detection [99] |
| Performance-based detection [100] | |||
| Multiple hypothesis-based detection [101] | |||
| Contextual-based detection [102,103] | |||
| Out-of-distribution detection | Rejection Option in the presence of out-of-distribution data with the subsequent passing the control to a human and active learning | Expensive calibration process to obtain a good result | Data and training based epistemic uncertainties estimation [104] |
| Model-based epistemic uncertainties estimation [105] | |||
| Post-hoc epistemic uncertainties estimation [106] |
| Approach | Capability | Weakness | Methods and Algorithms |
|---|---|---|---|
| Prediction granularity (hierarchical prediction) | Using confident coarse-grained prediction instead of low-confident fine-grained prediction | Approach efficiency depends on architectural solution, data balanciness for each hierarchical level and response design for coarse-grained prediction. | Nested Learning for Multi-Level Classification [108]. |
| Coarse-to-Fine Grained Classification [109]. | |||
| Generalized Zero-Shot Learning | Ability to recognize samples whose categories may not have been seen at training | Not reliable enough due to hubness in semantic space and projection domain shift problem. | Embedding-based methods [110]. |
| Generative-based methods [111]. | |||
| Switching between models or branches | Cost or performance aware adaptive inference | Complicated training and inference protocols. | Switching between simpler and complex model [112]. |
| Adaptive inference with Self-Knowledge Distillation [113]. | |||
| Adaptive inference with Early-Exit Networks [114]. |
| Approach | Capability | Weakness | Methods and Algorithms |
|---|---|---|---|
| Active learning, continual learning and lifelong learning | Might update the AIS knowledge about data distribution (active learning case), or begin to give the AIS knowledge about new task (continual/lifelong learning case). | Low-confidence samples should be continuously labelled by the oracle (operator) manual intervention typically is expensive. It is necessary to adjust settings to combat catastrophic forgetting problems. | Active learning with Stream-based sampling [118] |
| Active learning with Pool-based sampling [119] | |||
| Regularization-based continual learning [120] | |||
| Memory-based continual learning [121] | |||
| Model-based continual learning [122] | |||
| Domain Adaptation | Effective in overcoming the difficulty of passing between domains when the target domain lacks labelled data. Can be used in heterogenous setting, where the task is changing as opposed to the domain. | Such methods can be intensive during the training phase and will require large amounts of computational resources. Quick adaptation might not be achievable in this paradigm. | Discrepancy-based Domain Adaptation [123] |
| Adversarial Domain Adaptation [124] | |||
| Reconstruction-based Domain Adaptation [125] | |||
| Self-supervised Domain Adaptation [126] | |||
| Meta-learning | These methods are effective in creating effective and adaptive models. Stand out applications include fast, continual, active, and few-shot learning, domain generalisation, and adversarial defence. | Meta-learning models can be very resource-intensive to instantiate, due to the necessity to train on large amounts of data. | Memory-based methods [127] |
| Gradient-based methods [128] | |||
| Unified (combined) methods [129] |
| Approach | Capability | Weakness | Examples of Method or Algorithm |
|---|---|---|---|
| Surrogate losses | Obtained loss function is better aligned to metric | These hand-designed losses not only require tedious manual effort and white-box metric formulation, but also tend to be specific to a given metric. | Batching Soft IoU for Semantic Segmentation [148] |
| Hinge-rank-loss as approximation of Area under the ROC Curve [149] | |||
| Convex Lovasz extension of sub-modular losses [150] | |||
| Strongly proper composite losses [151] | |||
| Trainable surrogate losses | Removed the manual effort to design metric-approximating losses. | Loss learning based on metric relaxation schemes instead of a direct metric optimization. | Stochastic Loss Function [152] |
| Loss combination techniques [153] | |||
| Direct metric optimization with true metric embedding | Providing of correction term for metric optimization. | Their common limitation is that they require the evaluation metric to be available in closed-form. | Plug-in classifiers for non-decomposable performance measures [154] |
| Consistent binary classification with generalized performance metrics [155] | |||
| Optimizing black-box metrics with adaptive surrogates [156] | |||
| A unified framework of surrogate loss by refactoring and interpolation [157] | |||
| Black-box evaluation metrics optimization using a differentiable value function | Directly modeling of black-box metrics which can in turn adapt the optimization process. | There is a need to change the AI-model by introducing conditional parameters. The learning algorithm is complicated by metric meta-learning and meta-testing | Learning to Optimize Black-Box Evaluation Metrics [158] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moskalenko, V.; Kharchenko, V.; Moskalenko, A.; Kuzikov, B. Resilience and Resilient Systems of Artificial Intelligence: Taxonomy, Models and Methods. Algorithms 2023, 16, 165. https://doi.org/10.3390/a16030165
Moskalenko V, Kharchenko V, Moskalenko A, Kuzikov B. Resilience and Resilient Systems of Artificial Intelligence: Taxonomy, Models and Methods. Algorithms. 2023; 16(3):165. https://doi.org/10.3390/a16030165
Chicago/Turabian StyleMoskalenko, Viacheslav, Vyacheslav Kharchenko, Alona Moskalenko, and Borys Kuzikov. 2023. "Resilience and Resilient Systems of Artificial Intelligence: Taxonomy, Models and Methods" Algorithms 16, no. 3: 165. https://doi.org/10.3390/a16030165
APA StyleMoskalenko, V., Kharchenko, V., Moskalenko, A., & Kuzikov, B. (2023). Resilience and Resilient Systems of Artificial Intelligence: Taxonomy, Models and Methods. Algorithms, 16(3), 165. https://doi.org/10.3390/a16030165