1. Introduction
The field of Artificial Intelligence (AI) has experienced remarkable growth over the past decade, particularly in Natural Language Processing (NLP). Current state-of-the-art NLP applications, such as translation or text-based recommendations, rely heavily on Deep Neural Networks (DNNs), which use transformer architectures [
1]. Transformer architectures are composed of several blocks that each contain an attention sublayer and a feed-forward sublayer. The two most-widely used transformer neural network architectures for these tasks are Bidirectional Encoder Representations from Transformers (BERT) [
2] and Generative Pre-trained Transformer (GPT) [
3]. There are numerous variants of these models. Compared with their predecessors such as LSTM models [
4], they exhibit significantly higher performance in NLP applications. However, due to the large number of parameters and non-linearities involved, they are even less interpretable than more classic models and are typically just treated as black box decision systems. We developed the methodology in this paper with the aim of controlling undesirable algorithmic biases in recommendation systems that exploit textual information from personal profiles on social networks, such as job or housing offers. Throughout this paper, we emphasise the importance of ethical considerations in the development and deployment of these applications, as they can significantly impact users’ lives.
For a long time, many believed that machine learning algorithms could not be discriminatory since they lack human emotions. This view is, however, outdated now, as different studies have shown that an algorithm can learn and even amplify biases from a biased dataset [
5]. In this paper, we use the term
algorithmic biases to refer to automatic decisions made by a machine learning algorithm that are not neutral, fair, or equitable for a particular subgroup of people (or statistical observations in general). This group is distinguished by a
sensitive variable, such as gender, age, or ethnic origin. The field of study and prevention of these specific algorithmic biases is called
fair learning. Ensuring fairness is essential to ensure an ethical application of algorithms in society. Ethical concerns have become increasingly important in recent years, and the deployment of a discriminatory algorithm is no longer acceptable. Many regulations already address ethical issues related to AI. In the area of privacy, the General Data Protection Regulation (GDPR), adopted by the European Parliament in 2016, allows, for instance, the French Commission on Informatics and Liberty (NCIL) and other independent administrative authorities in France to impose severe penalties on companies that do not manage customer data transparently [
6]. The GDPR is an example of how public authorities are progressively developing legal frameworks and taking actions to mitigate threats. More recently, the so-called
AI act (
https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:52021PC0206, accessed on 14 March 2023) of the European Commission defined a list of
High Risk applications of AI, most of them being related to a strong impact on human life. For instance, job candidate recommendation systems are ranked as
High Risk. Importantly, when sold in or from the European Union, such AI systems will need to have appropriate statistical properties with respect to any potential discrimination they may cause (see Articles 9.7, 10.2, 10.3, and 71.3).
Motivated by the future certification of AI systems based on black box neural networks against discrimination, our article expands on the work of [
7] to address algorithmic biases observed in NLP-based multi-class classification. The main methodological novelties of this paper are: the extension of [
7] to multi-class classification and a demonstration of how to apply it to NLP data in an application ranked as
High Risk by the
AI act. The bias mitigation model proposed in this paper involves incorporating a regularisation term, in addition to a standard loss, when optimising the parameters of a neural network. This regularisation term mitigates algorithmic bias by enforcing the similarity of prediction or error distributions for two groups distinguished by a predefined binary sensitive variable (e.g., males and females), measured using the 2-Wasserstein distance between the distributions. Note that [
7] is the first paper that demonstrated how to calculate pseudo-gradients of this distance in a mini-batch context, enabling the use of this method to train deep neural networks with reduced algorithmic bias.
To extend [
7] to multi-class classification with deep neural networks, we need to address a key problem: estimating the 2-Wasserstein distance between multidimensional distributions (where the dimension equals the number of output classes) requires numerous neural network predictions, leading to slow training. In order to solve this problem, we redefine the regularisation term to apply it to predicted classes of interest, making the bias mitigation problem numerically feasible. Our secondary main contribution from an end-user perspective is to demonstrate how to mitigate algorithmic bias in a text classification problem using modern transformer-based neural network architectures such as RoBERTa small [
8]. It is important to note that our regularisation strategy is model-agnostic and could be applied to other text classification models, such as those based on LSTM architectures. We evaluated our method using the
Bios dataset [
9], which includes over 400,000 LinkedIn biographies, each with an occupation and gender label. This dataset is commonly used to train automatic recommendation models for employers to select suitable candidates for a job and quantify algorithmic biases in the trained models. The
Bios dataset is a key resource for the scientific community studying algorithmic bias in NLP.
2. Definitions and Related Work
Measuring algorithmic biases in machine learning: Different popular metrics exist to measure algorithmic biases in the machine learning literature. In this paper, we used the True Positive Rate gap (TPRg) [
9], which is one of the classic fairness metrics for NLP. Other metrics such as the Statistical Parity [
10] or Equalised Odds [
11] are also very popular. Over 20 different fairness metrics were compared in [
12]. Very important for us, each metric shows specific algorithmic bias properties, and not all of them are compatible with each other [
13,
14,
15]. For instance, the True Positive Rate gap quantifies the difference between the portion of positive predictions (
using common ML notation) in two groups, by only considering the observations that should be classified as positive (
using common ML notation). Another popular metric such as the disparate impact will also quantify this difference, but for all observations. This makes their practical interpretation different.
Impact of AI biases in society: The use of Artificial Intelligence (AI) in decision-making systems has become increasingly widespread in recent years and, with it, concerns about the potential for discriminating biases to affect the outcomes of these decisions. We review below different key studies that have explored the impacts of such biases in AI on society. One such study [
16] focused on the criminal justice system and found that AI algorithms can produce biased outcomes, particularly when trained on non-representative datasets. This can result in higher incarceration rates for certain groups, such as racial minorities, and perpetuate systemic racism in the criminal justice system. Another study by [
17] explored how gender differences and biases can affect the development and use of artificial intelligence in the field of bio-medicine and healthcare. The paper discussed the potential consequences of these differences and biases, including unequal access to healthcare and inaccurate medical diagnoses. Another important area in which algorithmic biases can impact society is the case of online advertisements. Ad targeting based on demographic factors such as race, gender, and age rather than interests or behaviours can perpetuate negative stereotypes and result in discrimination by limiting access to job or housing announcements for certain groups. For example, Facebook’s ad delivery algorithms, by optimising for maximum engagement, can lead to biased outcomes, which result in the amplification of certain groups or messages over others. This can lead to discrimination against certain groups, as advertisers may target their ads to specific demographics or exclude certain groups from seeing their housing and employment advertising, as highlighted by studies such as [
18,
19].
Bias mitigation in NLP: Bias in NLP systems has received significant attention in recent years, with researchers and practitioners exploring various methods for mitigating bias in NLP models. In this subsection, we review some of the existing work on bias mitigation in NLP. The first approach to mitigate bias is to apply
pre-processing techniques to the data used to train the model. Some researchers have proposed methods for removing or neutralising sensitive attributes from the training data, such as gender or race, in order to reduce the likelihood that the model will learn to make decisions based on these attributes. We can reduce the bias directly in the text of the training dataset. For example, in the case of gender bias, like the study in this paper, the most-classic technique is to remove explicit gender indicators [
9]. This technique is the one we used to compare our proposed strategy to another one commonly used in industry. This technique is indeed simple to implement and makes it possible to reduce the bias, but in a partial and not very localised manner. Other classical techniques can be used, such as identifying biased data in word embeddings, which represent words in a vector space. Reference [
20] demonstrated that these embeddings reflect societal biases. There are also methods to show how these embeddings can be unbiased by aligning them with a set of neutral reference vectors [
21,
22]. These de-biasing methods have, however, strong limitations, as explained in [
23], where the authors showed that, although the de-biasing embedding methods can reduce the visibility of gender bias, they do not completely eliminate it.
A second approach is to use
post-processing de-biasing methods. These methods are model-agnostic and, therefore, not specific to NLP since they modify the results of previously trained classifiers in order to achieve fairer results. References [
11,
24] investigated this for binary classification, and Reference [
25] proposed a method for multiclass classification.
The last approach to mitigate biases in AI is to use fairness-aware algorithms, which are specifically designed to take into account the potential for bias and to learn from the data in a way that reduces the risk of making biased decisions. These are the
in-processing methods, which generally do not depend on the type of data input either. The method we propose in this paper is one of them. To achieve this, we can use adversarial learning by adjusting the discriminator. Adversarial learning involves training a model to make predictions while also training a second model to identify and correct any biases in the first model’s predictions. By incorporating this technique into the training process, References [
26,
27] demonstrated that it is possible to reduce the amount of bias present in machine learning models. Another technique is to constrain the predictions with a regularisation technique, such as [
28], but this technique was only used on a logistic regression classifier. On the other hand, Reference [
29] mitigated fairness specifically in neural networks. Finally, References [
30,
31] used fairness metrics constraints and solved the training problem subject to those constraints. All these
in-processing methods apply in the case of binary classification. There is indeed an
in-processing paper that proposes a method for multiclass classification for a computer vision task [
32], but this paper focused on the regularisation of the mean bias amplification and, therefore, did not deal with the classic fairness metrics.
Research implications: We want to emphasise that the
pre-processing and
post-processing methods are complementary to
in-processing methods. Especially when using neural network models, which simultaneously project the input data into an optimal representation (the so-called
latent space or
feature space) and use this optimal data representation for their predictions, we believe that
in-processing methods are those that should be the most-efficient ones. They can indeed both constrain the neural networks to learn fair data representations and fair decision rules based on these data representations. Our paper hence focused on an
in-processing method. In this context, our methodology tackles an issue that was still not addressed in the fair learning literature, as far as the authors know: we tackled algorithmic biases on multi-class neural network classifiers and not on binary classifiers or on non-neural network classifiers. We believe that the potential of such a strategy is high for the future certification of commercial AI systems. The key methodological contribution of our work is to show how to extend [
7] to multi-class classification for regularised mini-batch training of neural networks. As described in
Section 3.3, extending this optimal transport regularisation strategy to multi-class classification requires tackling an important technical lock related to the algorithmic cost of the procedure, which is the heart of this methodological contribution. Note that this regularisation strategy applies to any type of multi-class classification neural network model. Thus, the method is particularly flexible and can be applied in various industrial classification problems. From a practical perspective, our secondary contribution is to showcase using the proposed technique for the future certification of neural network application ranked as High Risk by the European Commission. We used in this paper an NLP application and thoroughly describe the procedure to correct strong biases.
3. Methodology
The bias mitigation technique proposed in this paper extends the regularisation strategy of [
7] to multi-class classification. In this section, we first introduce our notation, then describe the regularisation strategy of [
7] for binary classifiers, and then, extend it to multi-class classifiers. This extension is the methodological contribution of our manuscript.
3.1. General Notations
Input and output observations: Let be the training observations, where and are the input and output observations, respectively. The value p represents the inputs dimension or, equivalently, the number of input variables. It can for instance represent a number of pixels if is an image or a number of words in a text if is a word embedding. The value K represents the output dimensions. In a binary classification context, i.e., if , the fact that or specifies the class of the observation i. In a multi-class classification context, i.e., if , a common strategy consists of using one-hot vectors to encode the class c of observation i: all values , are equal to 0, except the value , which is equal to 1. We use this convention all along this manuscript.
Prediction model: A classifier with parameters is trained so that the predictions it indirectly makes based on the outputs are on average as close as possible to the true output observations in the training set. The link between the model outputs and the prediction depends on the classification context: In binary classification, is the predicted probability that , so it is common to use . Now, by using one-hot-encoded output vectors in multi-class classification, an output represents the predicted probabilities that the observation i is in the different classes . As a consequence, . More interesting for us, the predicted class is the one having the highest probability, so is a vector of size K with null values everywhere, except at the index , where its value is 1.
Loss and empirical risk: In order to train the classification model, the empirical risk
is minimised with respect to the model parameters
:
or, empirically,
, where the loss function
ℓ represents the price paid for the inaccuracy of the predictions. This optimisation problem is almost systematically solved by using variants of stochastic (or mini-batch) gradient descent [
33] in the machine learning literature.
Sensitive variable: An important variable in the field of
fair learning is the so-called
sensitive variable, which we denote
S. This variable is often binary and distinguishes two groups of observations
. For instance,
or
can indicate that the person represented in observation
i is either a male or a female. A widely used strategy to quantify that a prediction model is fair with respect to the variable
S is to compare the predictions it makes on observations in the groups
and
, using a pertinent
fairness metric (see the references of
Section 2). From a mathematical point of view, this means that the difference between the distributions
and
, quantified by the fairness metric, should be below a given threshold. Consider for instance a binary prediction case where
means that the individual
i has access to a bank loan,
means that the bank loan is refused, and that
equal to 0 or 1 refers to the fact that the individual
i is a male or a female. In this case, one can use the difference between the empirical probabilities of obtaining the bank loan for males and females, as a fairness metric, i.e.,
. More advanced metrics may also take into account the input observation
X, the true outputs
Y, or the prediction model outputs
instead of their binarised version
.
3.2. W2reg Approach for Binary Classification
3.2.1. Regularisation Strategy
We now give an overview of the
W2reg approach, described in [
7], to temper algorithmic biases of binary neural network classifiers. The goal of
W2reg is to ensure that the treated binary classifier
generates predictions
for which the distributions in groups
and
do not deviate too much from pure equality. To achieve this, the similarity metric used in [
7] is the 2-Wasserstein distance between the distribution of the predictions in the two groups:
where
is the probability distribution of the predictions made by
in group
and
is the inverse of the corresponding cumulative distribution function. Note that
is mathematically equivalent to the histogram of the model outputs
for an infinity of observations in the group
, after normalisation, so that the histogram integral is 1. We remark that this metric is also based on the model outputs
and not the discrete predictions
(see
Section 3.1—
the prediction model for the formal relation), so the probability distributions
are continuous. Ensuring that this metric remains low makes it possible to control the level of fairness of the neural network model
with respect to
S. As specifically modelled by Equation (
2), this is performed by penalising the average squared difference between the quantiles of the predictions in the two groups. In order to train a neural network that simultaneously makes accurate and fair decisions, the strategy of [
7] then consists of optimising the parameters
of the model
such that
where
is the space of the neural network parameters (e.g., the values of the weights, the bias terms, and the convolution filters in a CNN). As usual, when training a neural network, the parameters
are optimised using a gradient descent approach, where the gradient is approximated at each gradient descent step by using a mini-batch of observations.
3.2.2. Gradient Estimation
We computed the gradient of Equation (
3) using the standard backpropagation strategy [
34]. For the empirical risk part of Equation (
3), this requires computing the derivatives of the losses
with respect to the neural network outputs
, something routinely performed by packages such as PyTorch, TensorFlow, or Keras, for all mainstream losses. For the 2-Wasserstein part of Equation (
3), the authors of [
7] proposed to use a mathematical strategy to compute the pseudo-derivatives of
with respect to the neural network outputs
. Specifically, to compute the pseudo-derivative of a discrete and empirical approximation of
with respect to a mini-batch output
, the following equation was used:
where
is the number of observations in class
and
are discrete versions of the cumulative distribution functions
defined on a discrete grid of possible output values:
where
and
is the number of discretisation steps. We denote
, and
is defined such that
. Finally,
.
3.2.3. Distinction between Mini-Batch Observations and the Observations for and
As shown in Equation (
4), computing the pseudo-derivatives of the 2-Wasserstein distance
with respect to the model predictions
requires computing the discrete cumulative distribution functions
, with
. Computing
would ideally require computing
for all
n observations
of the training set, which would be a computational bottleneck. To solve this issue, Reference [
7] proposed approximating
at each mini-batch iteration, where Equation (
4) is computed, using a subset of all training observations. This observation subset is composed of
m randomly drawn observations in group
,
m other randomly drawn observations in group
, and the mini-batch observations. This guaranties that there are at least
m observations to compute either
or
and that the impact of each mini-batch observation is represented in
and
. Note that these additional
predictions do not require backpropagating any gradient information, so their computational burden is limited in terms of memory resources. Although it is also reasonable in terms of computational resources, the amount of
additional predictions should remain relatively small to avoid significantly slowing down the gradient descent. In previous experiences on images,
or
often appeared as reasonable, as this allowed mitigating undesirable algorithmic biases and slowed down the whole training procedure by a factor of less than 2. Finally, preserving the amount of such additional predictions to something reasonable at each gradient descent step is at the heart of our methodological contribution when extending
W2reg to multi-class classification.
3.3. Extended W2reg for Multi-Class Classification
As discussed in
Section 1, our work was motivated by the need for bias mitigation strategies in NLP applications where the neural network predicts that an input text belongs to a class among more
K output classes, where
. We show in this section how to take advantage of the properties of [
7] to address this practical problem. We recall that the regularisation strategy of [
7] is model-agnostic, so the fact that we treated NLP data will only be discussed in the Results Section. In terms of methodology, the main issue to tackle is that the model outputs
are in dimension
and not one-dimensional, which would require comparing multivariate point clouds following the optimal transport principles, which were modelled by Equation (
2) for 1D outputs. As we will see below, this generates algorithmic problems to keep the computational burden reasonable and to preserve the representativity of the pertinent information. Solving them requires extending [
7] with strong algorithmic constraints.
3.3.1. Reformulating the Bias Mitigation Procedure for Multi-Class Classification
The strategy proposed by [
7] to mitigate undesired biases is to train optimal decision rules
by optimising Equation (
3), where the 2-Wasserstein distance between the prediction distributions
and
(i.e., the distribution of the predictions
for observations in groups
and
) is given by Equation (
2). As described in
Section 3.1, the predictions
are now a vector of dimension
in a multi-class classification context (specifically,
). Their distributions
and
are then multivariate. In this context, Equation (
2) does not hold, and another optimal transport metric such as the multivariate 2-Wasserstein distance or the Sinkhorn Divergence should be used [
35]. Note that different implementations of these metrics exist and are compatible with our problem, e.g. those of [
36,
37]. This, however, opens a critical issue related to the number of observations needed to reasonably penalise the differences between two multivariate point clouds, representing the observations in groups
and
. If the dimension
K of the compared data becomes large, the number of observations required to reasonably compare the point clouds at each gradient descent step explodes. This problem is very similar to the well-known
curse of dimensionality phenomenon in machine learning, where the amount of data needed to accurately generalise the predictions grows exponentially as the number of dimensions grows.
This issue, therefore, lead us to think about which problem we truly need to solve when tackling undesired algorithmic bias in multi-class classification. From our application perspective, discrimination appears when there the prediction model
is significantly more accurate at predicting a specific output in one of the two groups represented by
. For instance, suppose that someone looks for
Software Engineer jobs and that an automatic prediction model
is used to recommend job candidates to an employer. For a given job candidate
, the prediction model will return a set of
K probabilities, each of them indicating whether
is recommended for the job class
k. Now,
k will denote the class of jobs
is looking for, i.e.,
Software Engineer. The prediction model will be considered as unfair if male profiles are on average clearly more often recommended by
than female profiles, when an unbiased oracle would lead to equal opportunities, i.e.,
where the left-hand term denotes the
True Positive Rate gap (TPRg) and
is a threshold above which the TPRg is considered as unfairly discriminating. As shown in
Section 5, such situations can occur in automatic job profile recommendation systems using modern neural networks. Now that we have clarified the problem we need to tackle, we can reformulate the regularised multi-class model training procedure as follows:
By using this procedure, the number of observations required at each mini-batch step will be first limited to observations in the groups only, which is a first step towards an algorithmically reasonable regularised training procedure. We also believe that this also avoids over-constraining the training procedure, which often penalises its convergence.
3.3.2. Regularisation Strategy
We now push further the algorithmic simplification of the regularisation procedure by focusing on the properties of the mini-batch observations. In this subsection, we suppose that is an input mini-batch observation, and recall that we want to penalise large TPRg for specific classes only. In this mini-batch step, the observations related to true output predictions for which are not concerned by the regularisation, when computing the multivariate cumulative distribution function or . At each mini-batch step, it, therefore, appears as appealing to only consider the dimensions out of , for which at least one true output observation respects , with . This would indeed allow further reducing the amount of additional predictions made in the mini-batch. The dimension of or would, however, vary at each mini-batch step, potentially making the distance estimation unstable if fully considering C-dimensional distributions.
To take into account the fact that not all output dimensions
should be considered at each gradient descent step, we then made a simplification hypothesis: we neglected the relations between the different dimensions when comparing the output predictions in groups
and
. This hypothesis is the same as the one made when using Naive Bayes classifiers [
38,
39]. We believe that this hypothesis is particularly suited for one-hot-encoded outputs, as they are constructed to ideally have a single value close to 1 and all other values close to 0. We then split the multivariate regularisation strategy into a multiple one-dimensional strategy and optimised
where
is the metric of Equation (
2),
is the weight given to regularise the TPR gaps in class
, and
are the distributions of the output predictions on dimension
, i.e., the distribution of
, when the true prediction is
, i.e., when
. For a mini-batch observation
related to an output prediction in a regularised class
, the impact of a mini-batch output
on the empirical approximation of
can then be estimated by following the same principles as in [
7]. We can then extend Equation (
4) with
where
are discrete and empirical versions of the cumulative distribution functions of the prediction outputs on dimension
k, i.e., the
, when class
k should be predicted and the observations are in the group
s. Note also that Equation (
4) contains
, which is the number of observations in class
. In order to manage unbalanced output classes in the multi-class classification context, we also use a normalising term
in Equation (
8). It quantifies the number of training observations in group
and class
. Other notations are the same as in Equation (
4).
In a mini-batch step, suppose, finally, that we only need to take into account the classes
among
. These selected classes are those for which at least a
, with
, and
i is an observation of the mini-batch
. We then have to only sample two-times
m predictions, for each of the selected
D classes, to compute the
and
required in Equation (
8). This makes the computational burden to regularise the neural network training procedure reasonable, as the number of additional predictions to make only increases linearly with the number of treated classes at each mini-batch iteration. Note that no additional prediction will also be needed when a mini-batch contains no observation related to a regularised output class. This will naturally be often the case, when the number of classes
K becomes large and/or the mini-batch size
is small.
3.3.3. Proposed Training Procedure
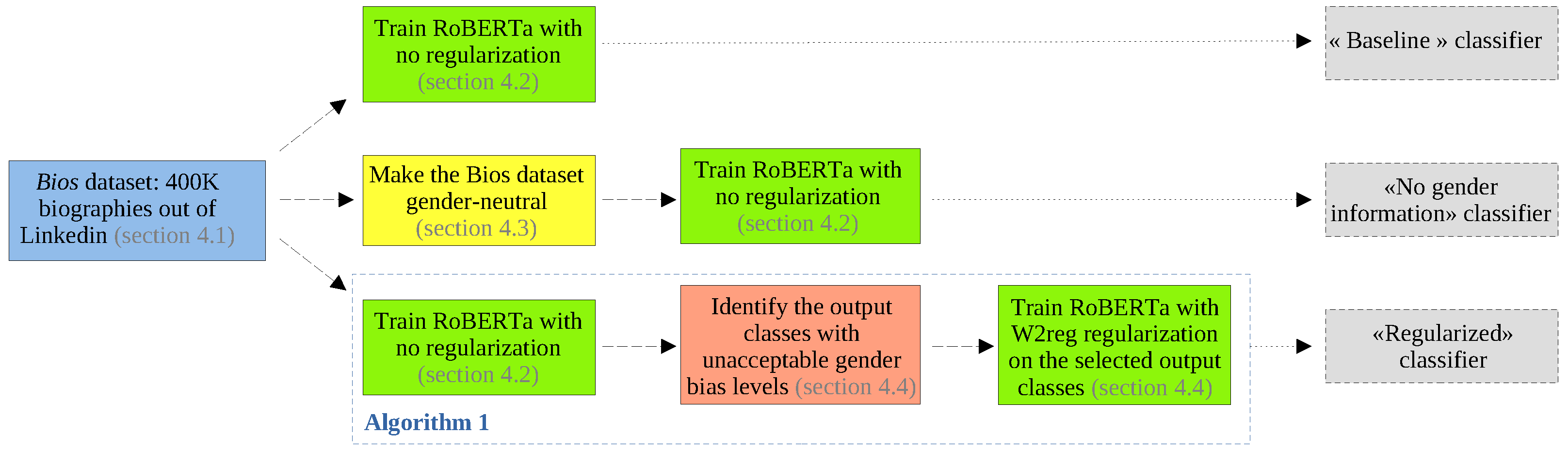
The proposed strategy to train multi-class classifiers with mitigated algorithmic biases on specific classes’ prediction was motivated by the future need of certifying that automatic decision models are not discriminatory. In order to make absolutely clear our strategy, we detail it in Algorithm 1.
| Algorithm 1 Procedure to train bias mitigation multi-class neural network classifiers. |
- Require:
Training observations , where , and , plus a multi-class neural network model . - 1:
[Detection of the output classes with discriminatory predictions] - 2:
Train the baseline parameters of f on with no specific regularisation. - 3:
Find the output classes on which the model has unacceptable True Positive Rate gaps (TPRg) using Equation ( 6). - 4:
[Multi-class W2reg training] - 5:
Re-initialise the training parameters . - 6:
for e in epochs do - 7:
for b in batches do - 8:
Draw the batch observations , where B is a subset of . - 9:
Compute the mini-batch predictions , . - 10:
Detect the output classes among for which at least a , with and . - 11:
For each , pre-compute and using m output predictions , where and . - 12:
Compute the empirical risk and its derivatives with respect to , . - 13:
Compute the pseudo-derivatives of the discretised with respect to the pertinent mini-batch outputs using Equation ( 8). - 14:
Backpropagate the risk derivatives and the pseudo-derivatives of the terms. - 15:
Update the parameters . - 16:
end for - 17:
end for - 18:
return Trained neural network with mitigated biases.
|
5. Results and Discussion
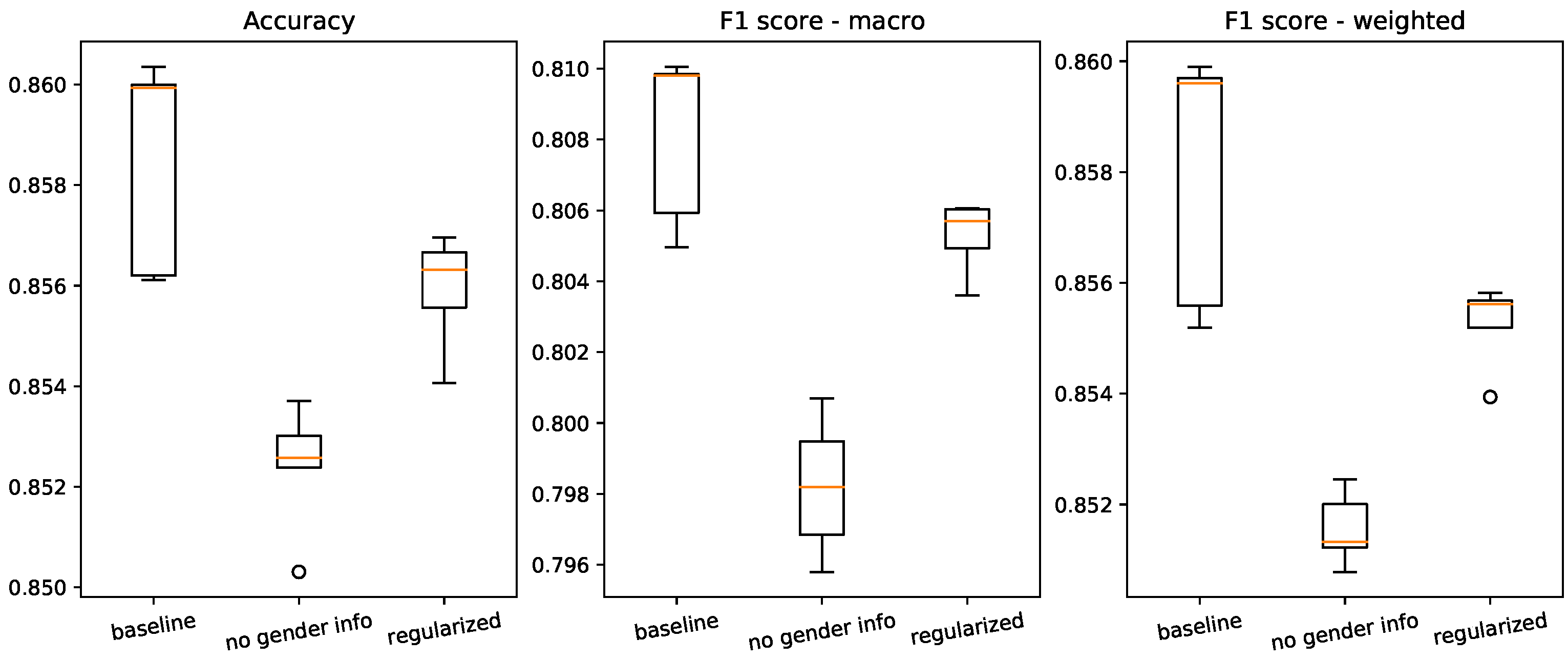
In commercial applications, fair prediction algorithms will be obviously more popular and useful if they remain accurate. Thus, we made sure that our regularisation technique did not have a strongly negative impact on the prediction accuracy. We then quantified different accuracy metrics: first, the average accuracy and, then, two variants of the F1-score, as it is very appropriate for a multiclass classification problem like ours. These two variants are the so-called “macro” F1-score, where we calculate the metric for each class, then we average it without taking into account the number of individuals per class; and the “weighted” F1-score, where the means are weighted using the classes’ representativeness. We can draw similar conclusions for these three metrics, as shown in
Figure 4: our regularisation method was certainly a little below the baseline in terms of accuracy, but it was more stable. In addition, it was clearly more accurate than the gender-neutralising technique of
Section 4.3.
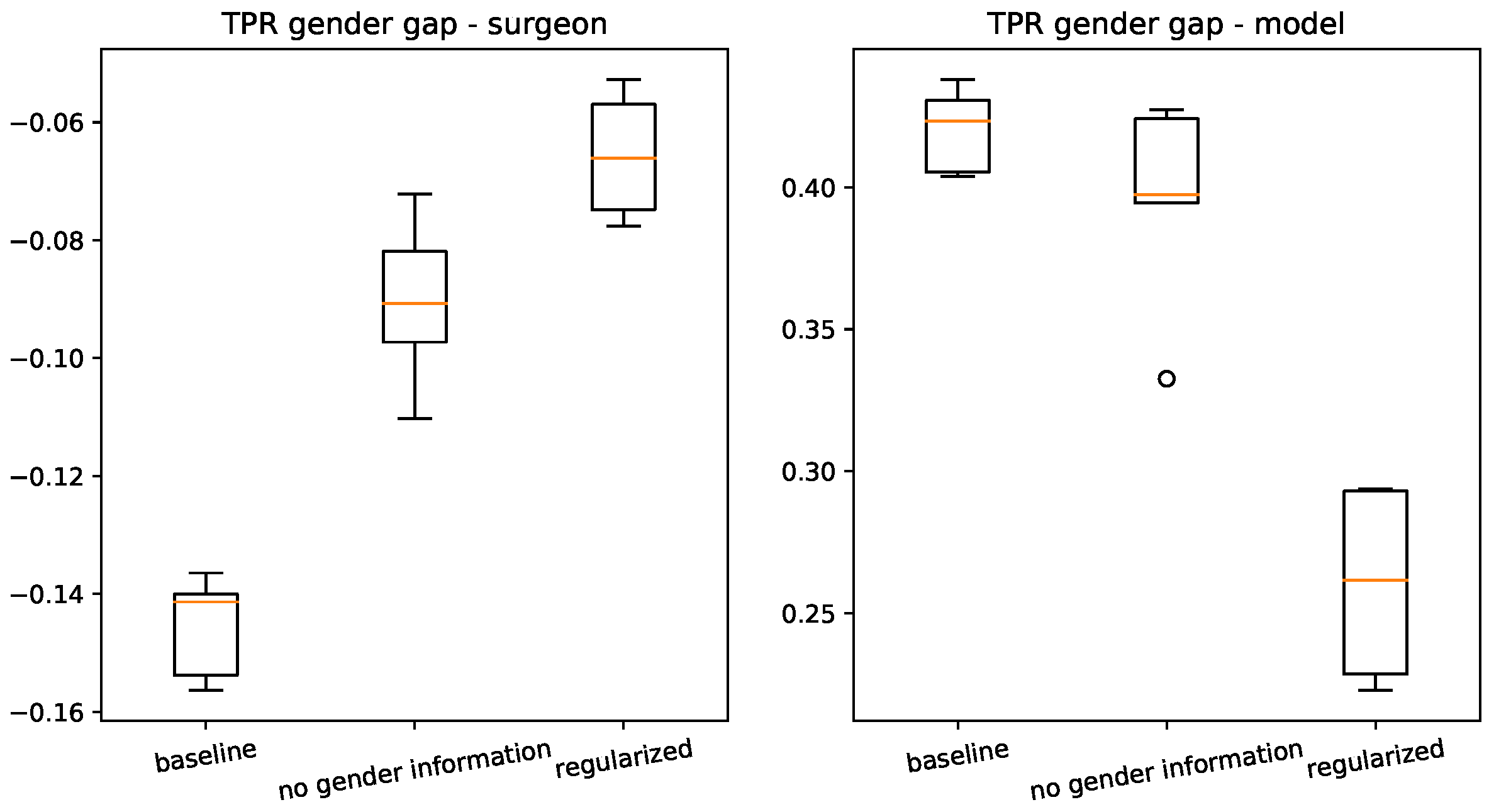
We then specifically observed the impact of our regularisation strategy in terms of the TPR gap on the two regularised classes:
Surgeon and
Model. Boxplots of the TPR gap for these output classes are shown in
Figure 5. They confirmed that the algorithmic bias was reduced for these two classes. For the class
Surgeon, removing gender indicators had a strong effect, but the regularisation strategy further reduced the biases. For the class
Model, removing gender indicators had little effect, and the regularisation strategy reduced the biases by almost a factor of two.
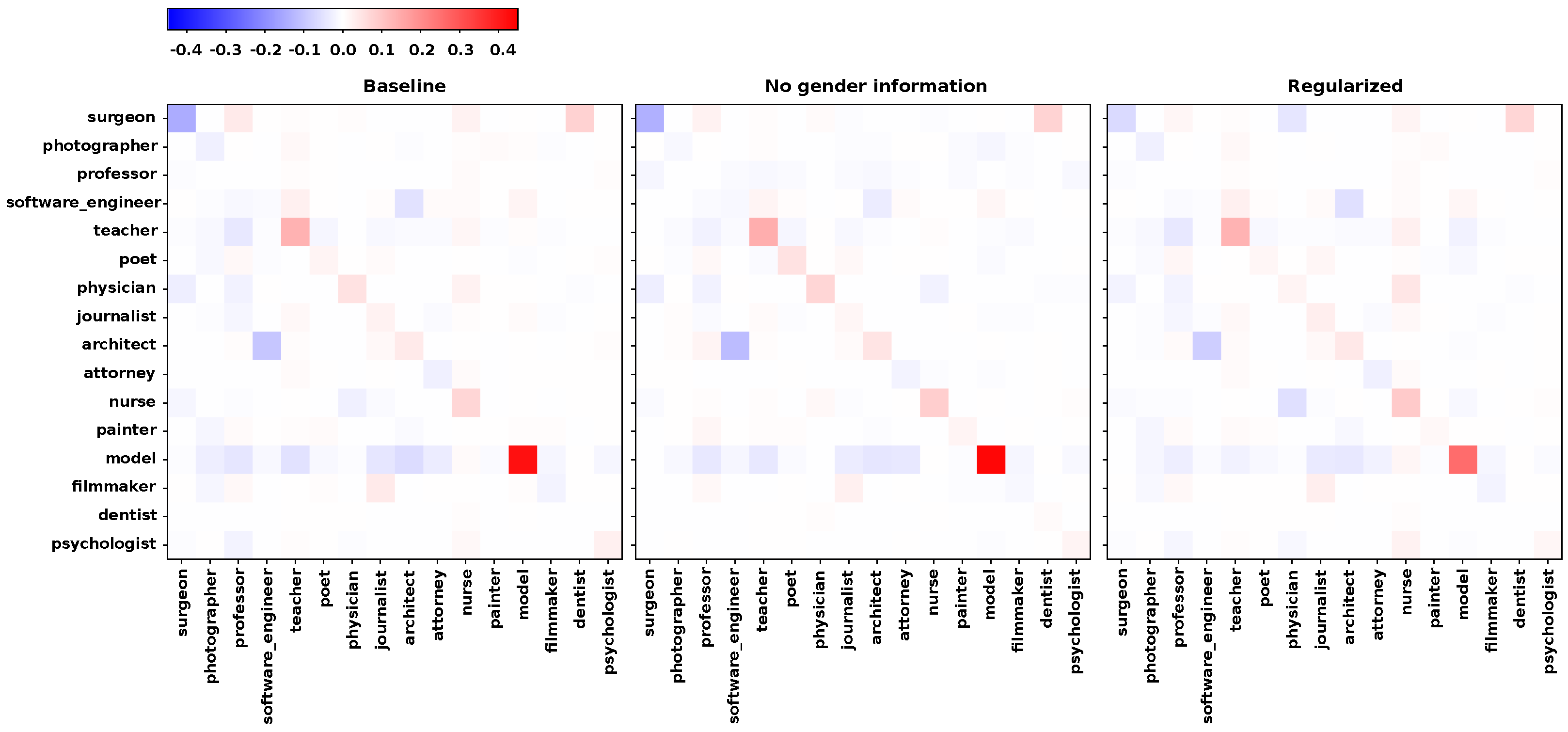
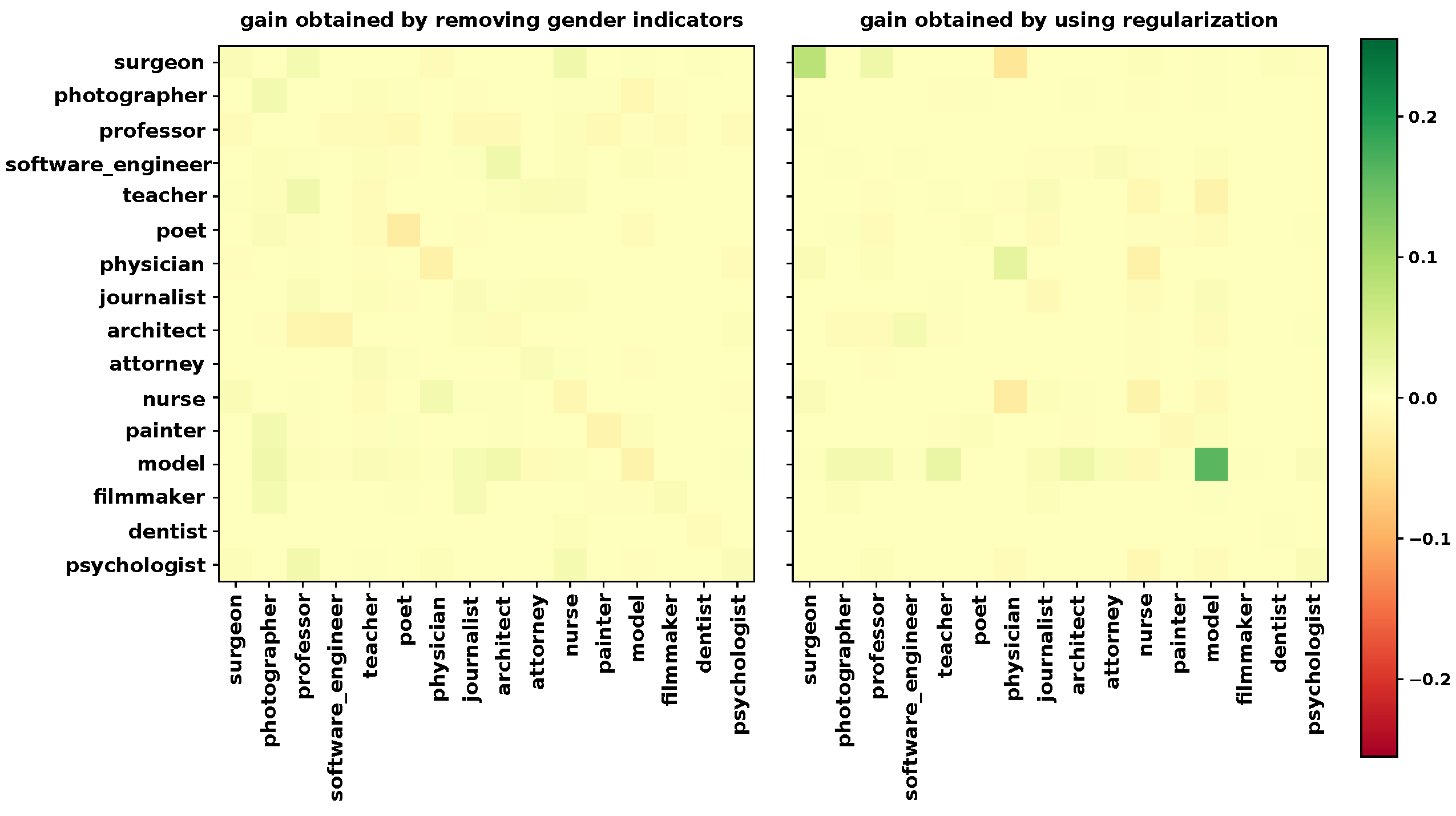
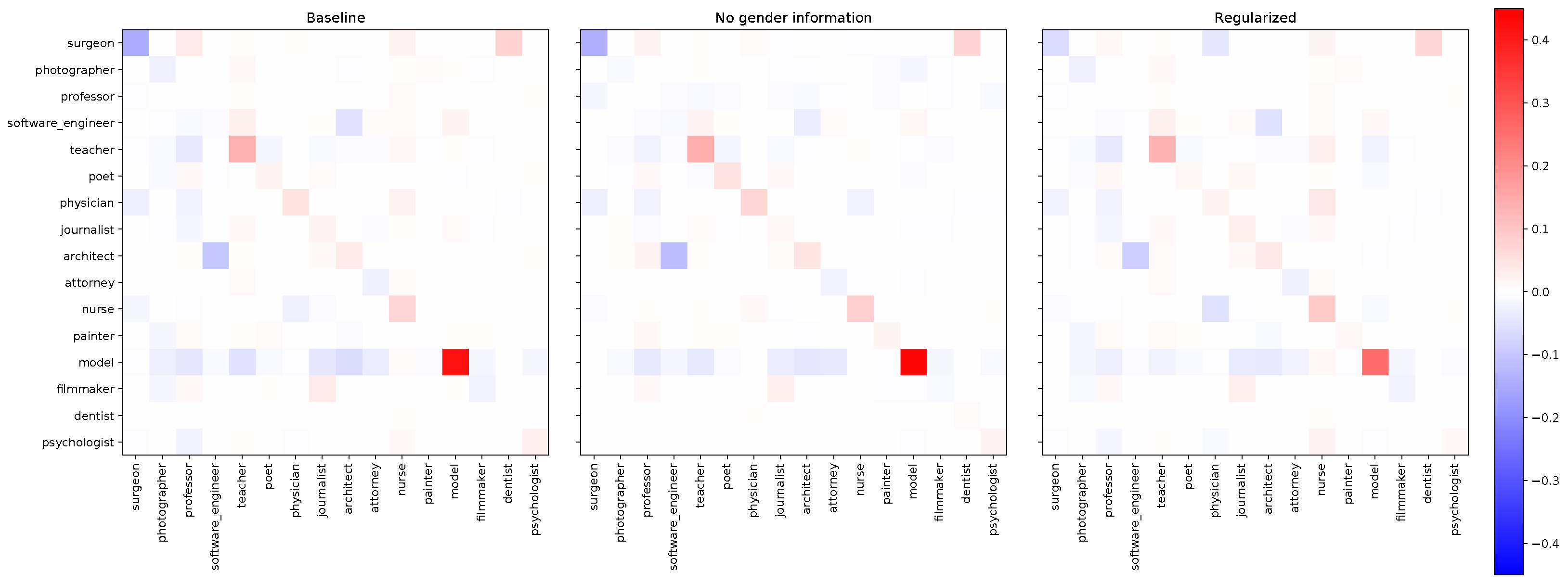
We finally wanted to make sure that reducing the unacceptable biases on these two classes would not be at the expense of newly generated biases. We then measured the difference between the average (on the five models) confusion matrix for females and males only. In
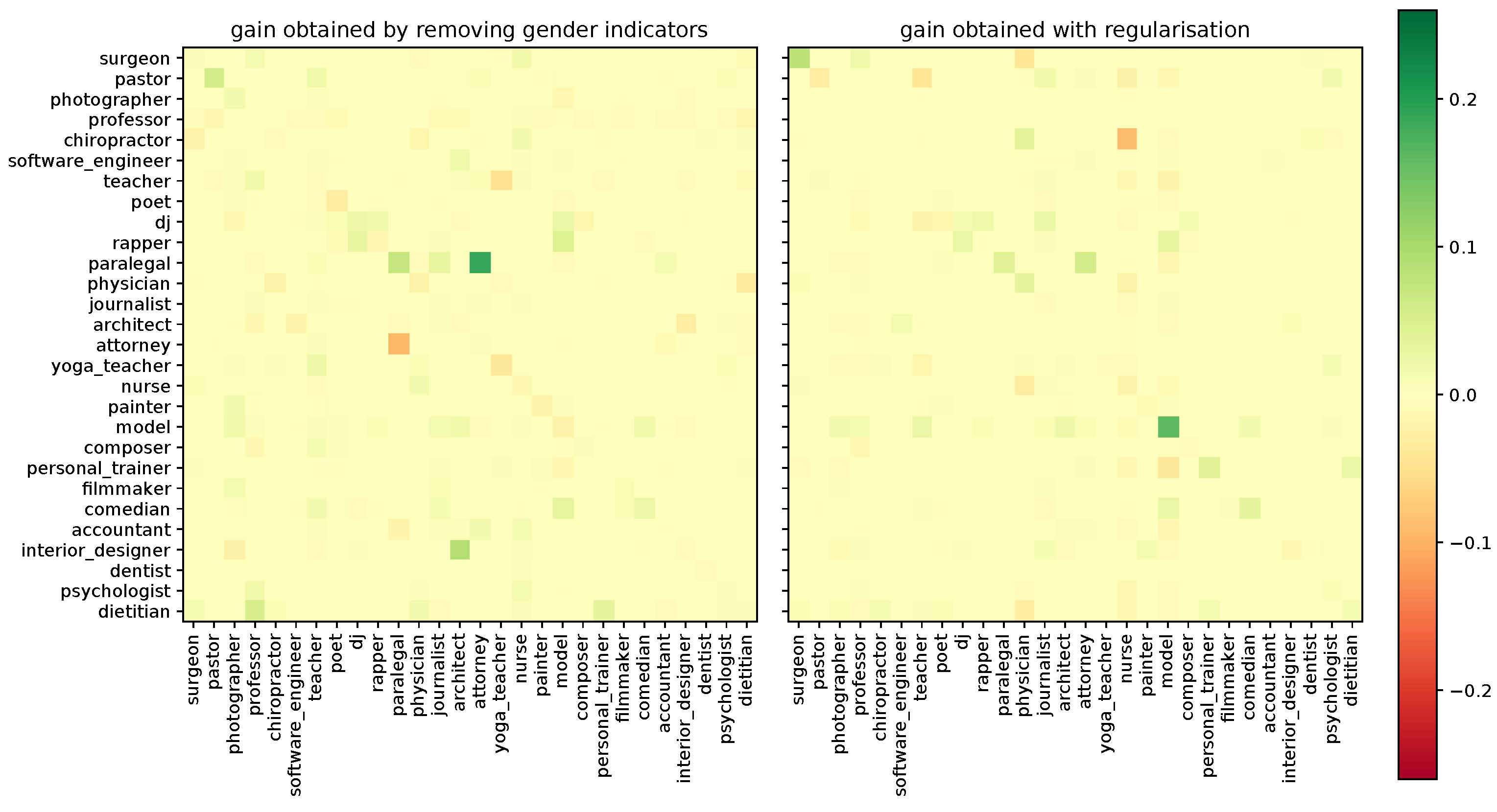
Figure 2, we see the evolution of our biases according to the selected method. Note first that the diagonal of these matrix differences corresponds to the TPR gaps. We also remark that we only represent the results obtained on the 16 most-frequent occupations for visibility concerns, but the complete matrices are show in the
Appendix A. On our two regularised classes, we came closer to white (i.e., non-bias), and for the other classes, we also observed a decrease in bias in general and no outlier point. For a finer analysis and more clarity, we represent in
Figure 6 the difference between the absolute values of the baseline matrix of
Figure 2 and each of the compared matrices (i.e., with neutralised genders and regularisation). This clearly represents to us the “gains” of these two bias-reduction methods to compare them.
Figure 6 confirms our intuition given in
Figure 2: in the case where the gender indicators were removed, the gain was rather slight and depended on the class. In the case of our regularisation, the two regularised classes obtained a very clear positive gain, and there was no marked negative gain on the rest of the matrix.
6. Conclusions
In this paper, we defined a strategy to address the critical need for certifying that commercial prediction models present moderate discrimination biases. We specifically defined a new algorithm to mitigate undesirable algorithmic biases in multi-class neural network classifiers and applied it to an NLP application that is ranked as High Risk by EU regulations. Our method was shown to successfully temper algorithmic biases in this application and outperformed a classic strategy both in terms of prediction accuracy and mitigated bias. In addition, the computational times were only reasonably increased compared with a baseline training method. The state-of-the-art of in-processing unbiasing methods mainly focuses on binary models, and our approach addresses the multiclass problem. The possibility of choosing which classes to regularise and of applying a different for each class gives a wide range of application of the method.
We want to make clear two potential difficulties that we anticipate for future users of our method: (1) The W2reg method allows the user to choose a specific
value for each regularised class. As mentioned in the previous paragraph, this makes the method very flexible and gives control on the level of regularisation required to obtain reasonable biases for each output class. Finding optimal regularisation weights can, however, be time consuming for the user. Note that this compromise between accuracy and regularisation is, however, extremely common in engineering science. (2) As thoroughly discussed in
Appendix A, the regularisation strategy is also effective when the training set has a reasonable amount of observations in a treated class. Using our method in order to later certify that a multi-class classification neural network is not biased for a specific output class will then require having enough training data in this class. This phenomenon is related to the generalisation properties of any decision model trained on reference data. More observations will have to be acquired in these classes otherwise.
Now that [
7] has been extended to multi-class classification, a natural perspective would be to also use it for the regression case. We expect this extension to be methodologically straightforward, as the binary and multi-class W2reg strategies for classification already regularise continuous outputs (specifically, the probabilities of belonging to a class). A more challenging perspective would be to adapt and eventually reformulate W2reg to other popular decision models, as all applications of AI are not based on neural networks. Adapting W2reg to other fairness criteria would finally make it more versatile.
We finally want to emphasise that, although our method was applied to NLP data, it can be easily applied to any multi-class neural network classifier. We also believe that it could be simply adapted to other fairness metrics. Our regularisation method was implemented to work as a loss in PyTorch and is compatible with PyTorch-GPU. It is freely available on GitHub (
https://github.com/lrisser/W2reg accessed on 14 March 2023).


 ,
, 

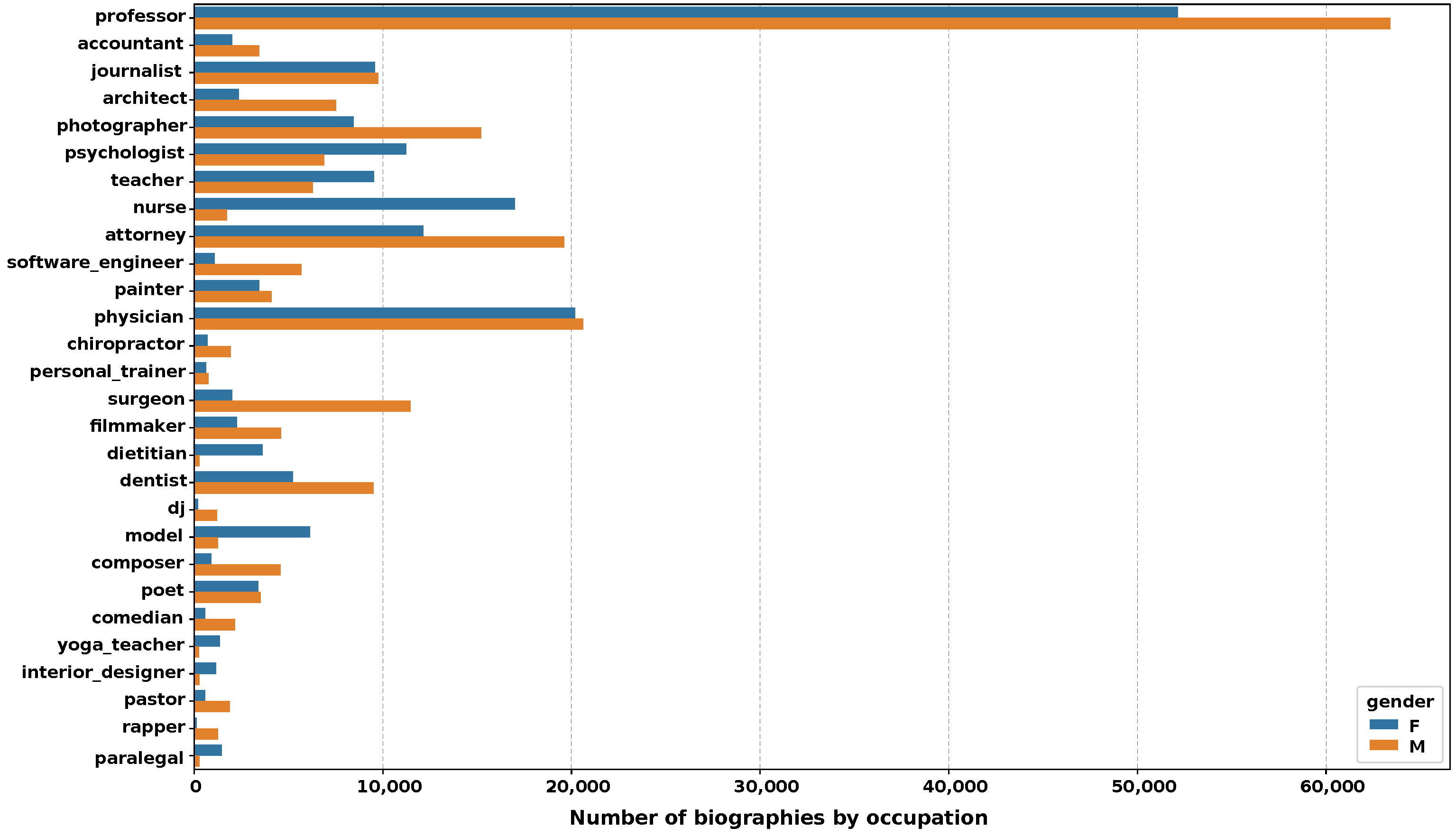{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






