1. Introduction
Transformer architecture has gained significant attention recently and has emerged as the state-of-the-art approach in various sequence-to-sequence tasks. These tasks encompass a wide range of applications, such as natural language processing [
1], image retrieval [
2], emotion detection [
3], and speech recognition [
4]. In the domain of speech recognition, transformer architecture has enabled the development of end-to-end automatic speech recognition (ASR) systems. Indeed, the advantage of an end-to-end ASR system is that it eliminates the requirement for multiple modules, such as the lexicon, acoustic models, and linguistic models, found in conventional hidden Markov models [
5] or hybrid models that combine neural networks with hidden Markov models [
6]. Instead, in end-to-end systems, all the necessary acoustic and linguistic knowledge is seamlessly integrated within a single neural network. This integration simplifies the ASR process by consolidating all relevant information into a unified framework. However, the transformer models used in various applications, including automatic speech recognition, tend to be excessively large and over-parameterized, as highlighted in [
7,
8,
9].
The complexity of these models has consequences on the memory requirements and the computational cost. These issues can be addressed by studying compression methods that could have the following outcomes [
10]:
- -
Memory Usage Reduction: Compressing transformer models helps mitigate excessive memory requirements, allowing for more efficient utilization of resources.
- -
Prediction Latency and Energy Consumption: By compressing the models, prediction latency is reduced, resulting in faster and more energy-efficient computations.
- -
Inference on Resource-Constrained Devices: Compressed transformer models enable their deployment on devices with limited hardware resources, such as mobile devices, making ASR systems more accessible and efficient.
- -
Ease of Learning, Fine-Tuning, and Distributed Training: Compressed models are easier to train, fine-tune, and distribute, facilitating their adoption in various settings and scenarios.
- -
Ease of Deployment and Updating: Compressed transformer models offer advantages in terms of deployment and updating processes, enabling seamless integration into production systems.
The literature on model compression encompasses a wide range of techniques aimed at addressing the challenges posed by large and over-parameterized models. For instance, Qi et al. [
11] established a theoretical understanding of the architecture of deep neural networks, exploring their representation and generalization capabilities for speech processing, which, in turn, affect the empirical performance of the pruned ASR model. Furthermore, in their work, Qi et al. [
12] proposed an alternative model compression technique based on the tensor-train network to reduce the complexity of the ASR model.
In general, model compression techniques involve quantization [
13], pruning [
14], knowledge distillation [
15], matrix decomposition [
16], and parameter sharing [
17]. In the field of automatic speech recognition (ASR), pruning has been successfully employed in various model architectures, such as the multilayer perceptron (MLP), as studied in [
18]; long short-term memory (LSTM) networks, as explored in [
19]; convolutional neural networks (CNN), as described in [
20]; and their combinations, as investigated in [
21]. Regarding transformer-based ASR systems, research has focused on quantization [
22], parameter sharing [
7], weight magnitude pruning [
23], and, recently, on knowledge distillation [
24].
In particular, in [
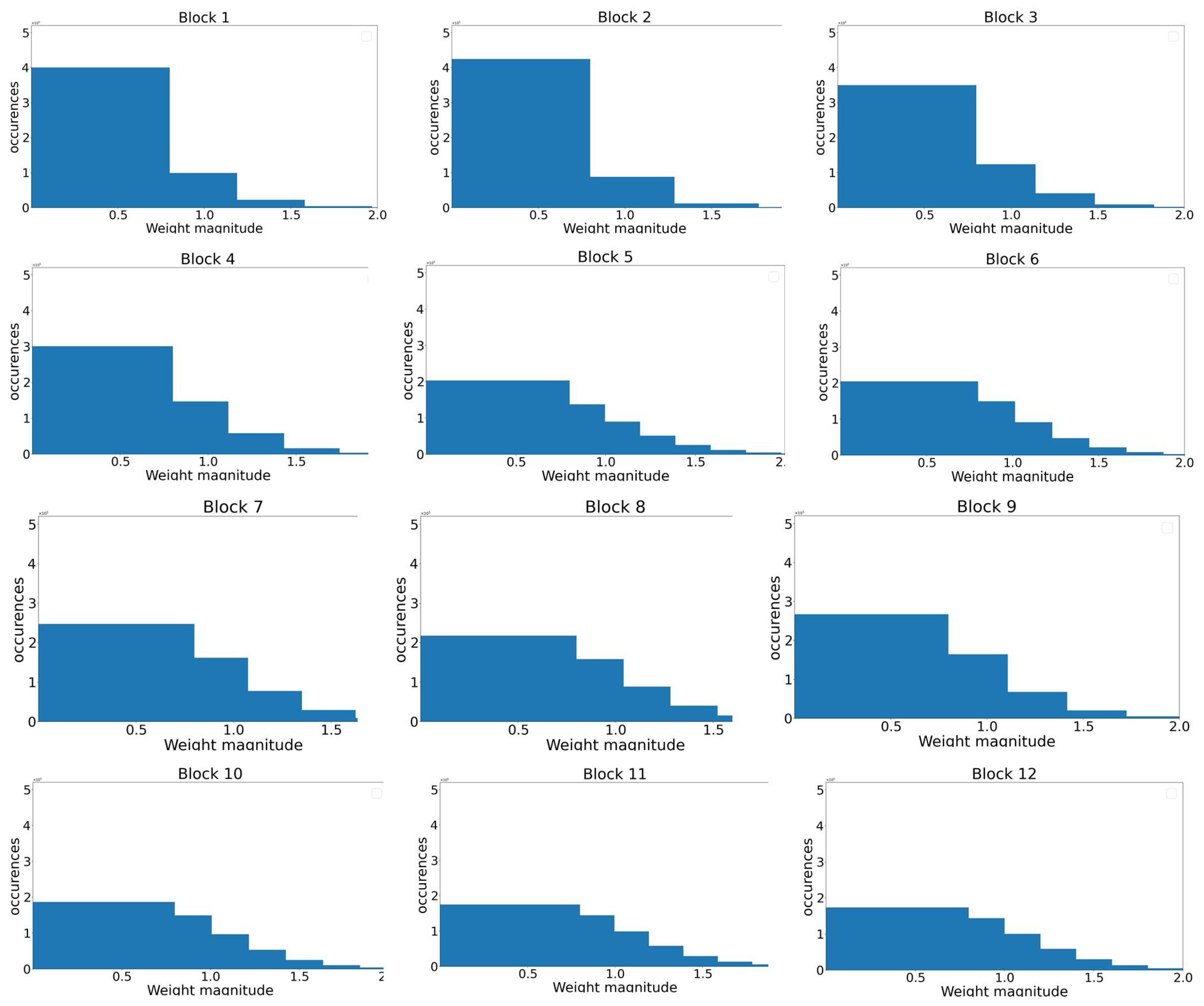
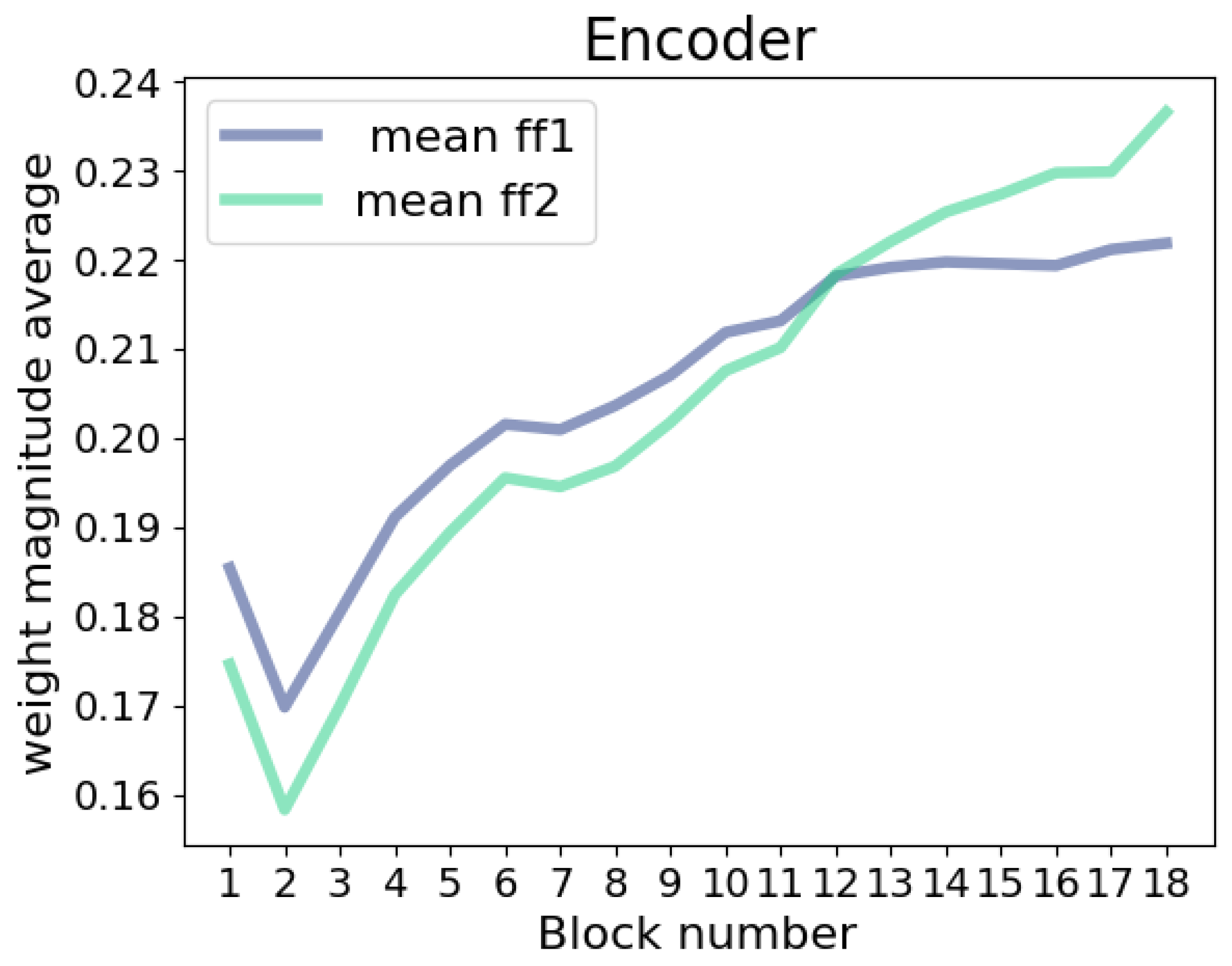
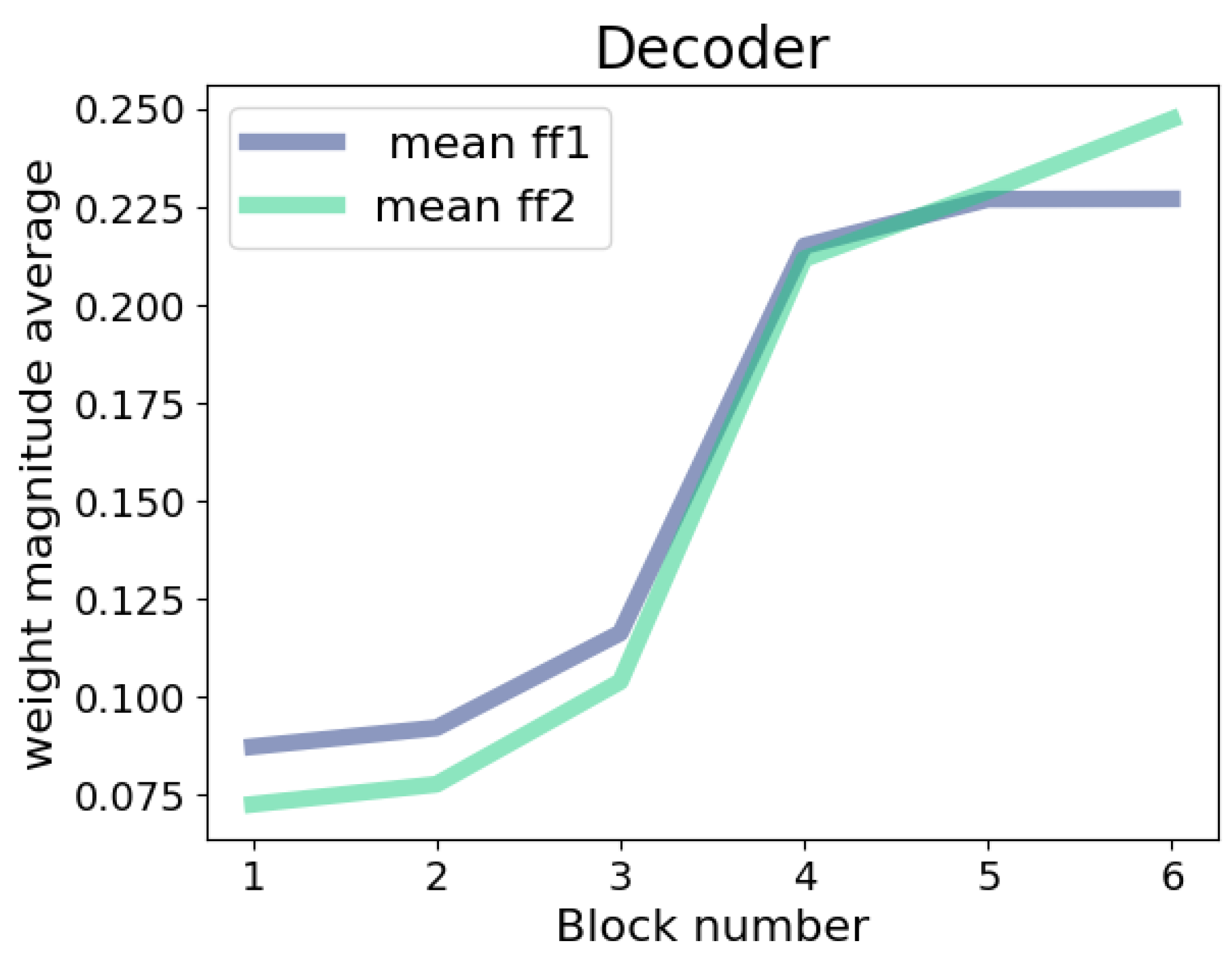
23], we conducted a comprehensive analysis of ASR transformer models across multiple languages. Our findings revealed that the feedforward layers, in comparison to other layers in the model, have the highest parameter count, occupying a substantial portion of the model’s overall size. Furthermore, as these layers undergo global pruning, their Sparsity progressively decreases. The current paper is an extension of this work. Consequently, the focus of the research was directed towards pruning the feedforward layers. To achieve this, the weights of the feedforward layers were examined within each block and between encoder blocks and decoder blocks. This analysis uncovered a progressive distribution of weights in the feedforward layers, with deeper layers having higher weight values. Based on these insights, the primary contribution of the research was the proposal of a pruning technique that takes into account the layer positioning and gradually reduces the weights of the feedforward layers.
The structure of this paper is as follows:
Section 2 provides a comprehensive review of the relevant literature and prior work in the field.
Section 3 offers a detailed description of the ASR transformer model under investigation. Subsequently,
Section 4 introduces the proposed variable scale pruning method. The experimental setup and results are presented in
Section 5. Finally,
Section 6 discusses the obtained results and provides the key conclusions derived from this study.
3. ASR Transformer
The transformer model [
1] is a sequence-to-sequence architecture designed to map an input sequence
to an output sequence
. Its structure consists of two main components: the encoder and the decoder. The encoder takes the input sequence and transforms it into an intermediate sequence of encoded features
. On the other hand, the decoder generates predictions for each character
based on the encoded features
and the previously decoded characters
. Both the encoder and the decoder comprise a stack of attention and feedforward network blocks, allowing the model to capture contextual dependencies and make accurate predictions.
3.1. Model Architecture
Our ASR transformer model adopts the architecture described in [
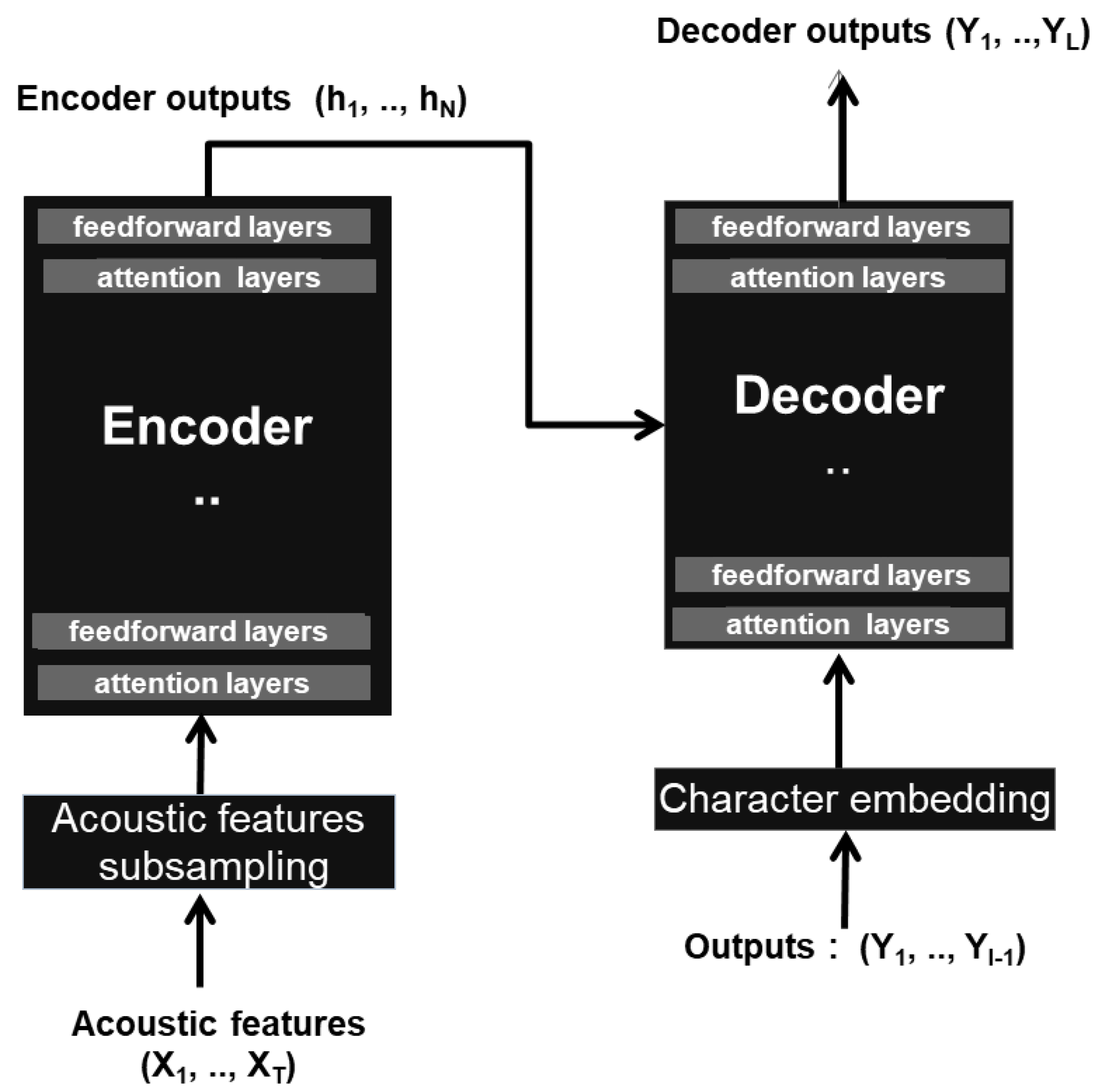
37]. Prior to entering the encoder, the input acoustic features undergo subsampling via two convolution layers. The encoder and decoder modules consist of multi-head attention (MHA) and feedforward (FF) layers. Each layer is accompanied by a residual connection and normalization.
Figure 3 provides a simplified illustration of the ASR transformer model’s structure.
The layers of the encoder refine the representation of the input sequence with a suite of multi-head, self-attention, and linear transformations. The self-attention operation allows frames to gather context from all timesteps and build an informative sequence at a high level [
37]. Specifically, the inputs of each layer are projected into queries
Q, keys
K, and values
V with
,
, and
.
are the elements numbers in different inputs and
are the corresponding element dimensions. Usually, these are
and
.
Scaled Dot-Product Attention [
1] is then computed as:
The MHA is applied to take advantage of the different representations that are simultaneously present. The multi-head attention is obtained by performing this calculation
h times.
h is the number of heads.
where
The projection matrices are , , , and . In this work, .
The outputs of multi-head attention go through a two-layer position-wise feedforward network (FFN) with hidden size
[
1].
and are the biases. The weight matrices are and .
3.2. Model Development
For the development of end-to-end transformer models, we used the Libri-trans [
38] and VoxforgeIT [
39] datasets in conjunction with the Espnet toolkit [
4].
Libri-trans is a subset of the LibriSpeech database, which was created as part of the Librivox project (
librivox.org) [
40]. It contains 236 h of annotated English utterances from audiobooks. VoxforgeIT, on the other hand, is an Italian dataset developed within the Voxforge project (
voxforge.org) and provides 20 h of audiobooks. Both datasets are divided into three sets: a training set, a development set, and a test set. For the Libri-trans dataset, 231 h are used for model training, while 2 h and 3.45 h are allocated for the development and evaluation sets, respectively. In the case of VoxforgeIT, 80% of the data are used for training, and the remaining data are evenly split between the development and test sets. To augment the data, we applied speed perturbation [
41] with ratios of 0.9, 1.0, and 1.1. This technique effectively multiplies the quantity of data by three, providing additional variations for training.
Espnet is an open source toolkit that integrates Kaldi [
42] tools for data processing and parameter extraction, along with PyTorch (
pytorch.org) modules for model estimation. For the input features, we computed 80 filter bank coefficients, which were then normalized based on the mean and variance. Filter bank (F-bank) parameters enable the extraction of relevant information from speech signals in the frequency domain. By capturing the spectral content of speech, they provide a representation that is more suitable for various speech processing tasks including speech recognition.
As for the representation of transcripts, we used subword units. Specifically, the VoxforgeIT system utilizes character-level representation, while the Libri-trans system employs byte-pair coding subwords. For the training stage, we ran stochastic gradient descent (SGD) over the training set with the Adam update rule [
43] using square root learning rate scheduling [
1] (25,000 warmup steps and 64 minibatch sizes). The architecture of the developed models is illustrated in
Table 1. The Libri-trans model consists of 27.92 million parameters, while the VoxforgeIT model has 35.07 million parameters. This corresponds to approximately 107 and 134 megabytes of memory, respectively.
The performance of these models in Automatic Speech Recognition (ASR) is as follows: In the case of Libri-trans, the Word Error Rate (WER) achieved was 6.6% on the test set and 6.3% on the development set. These results surpass the current state-of-the-art performance of 15.1% reported in [
44] on the test set. As for VoxforgeIT, the Character Error Rate (CER) obtained was 9.3% on the test set and 10.3% on the development set. These results also outperform the state-of-the-art performance of 9.6% documented in [
45] on the test set.
5. Experiments and Results
The evaluation of various pruning techniques, including global, local, and variable scale (i.e., adaptive), was performed using the transformer models described in
Section 3.2. Unstructured pruning with the L1 norm were employed to prune connections. Individual weights were set to zero according to their magnitude. The adaptive pruning parameters for the Libri-trans and VoxforgeIT datasets were determined by utilizing the development data. Subsequently, the evaluation was conducted using the test data.
5.1. Baseline Systems
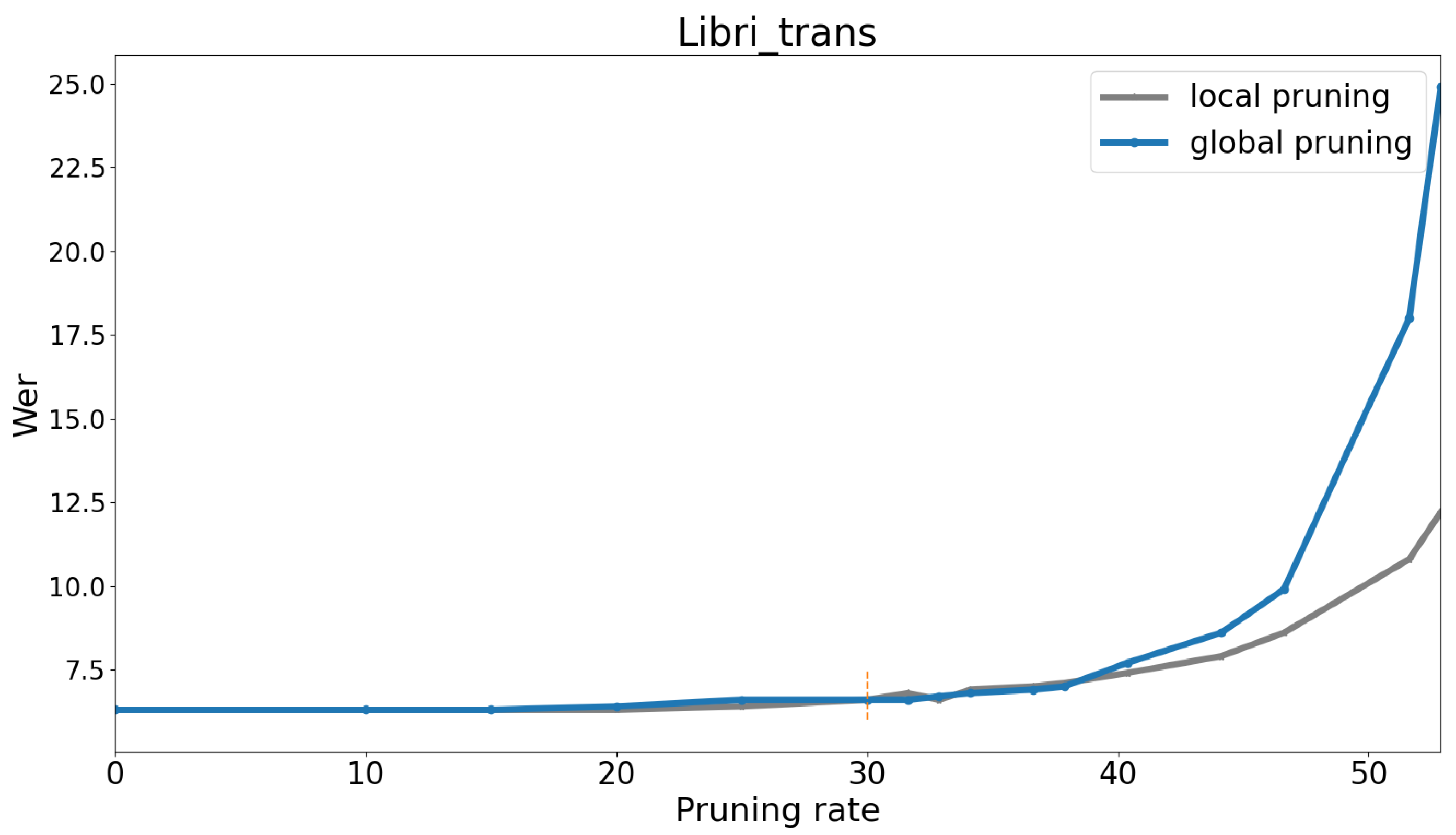
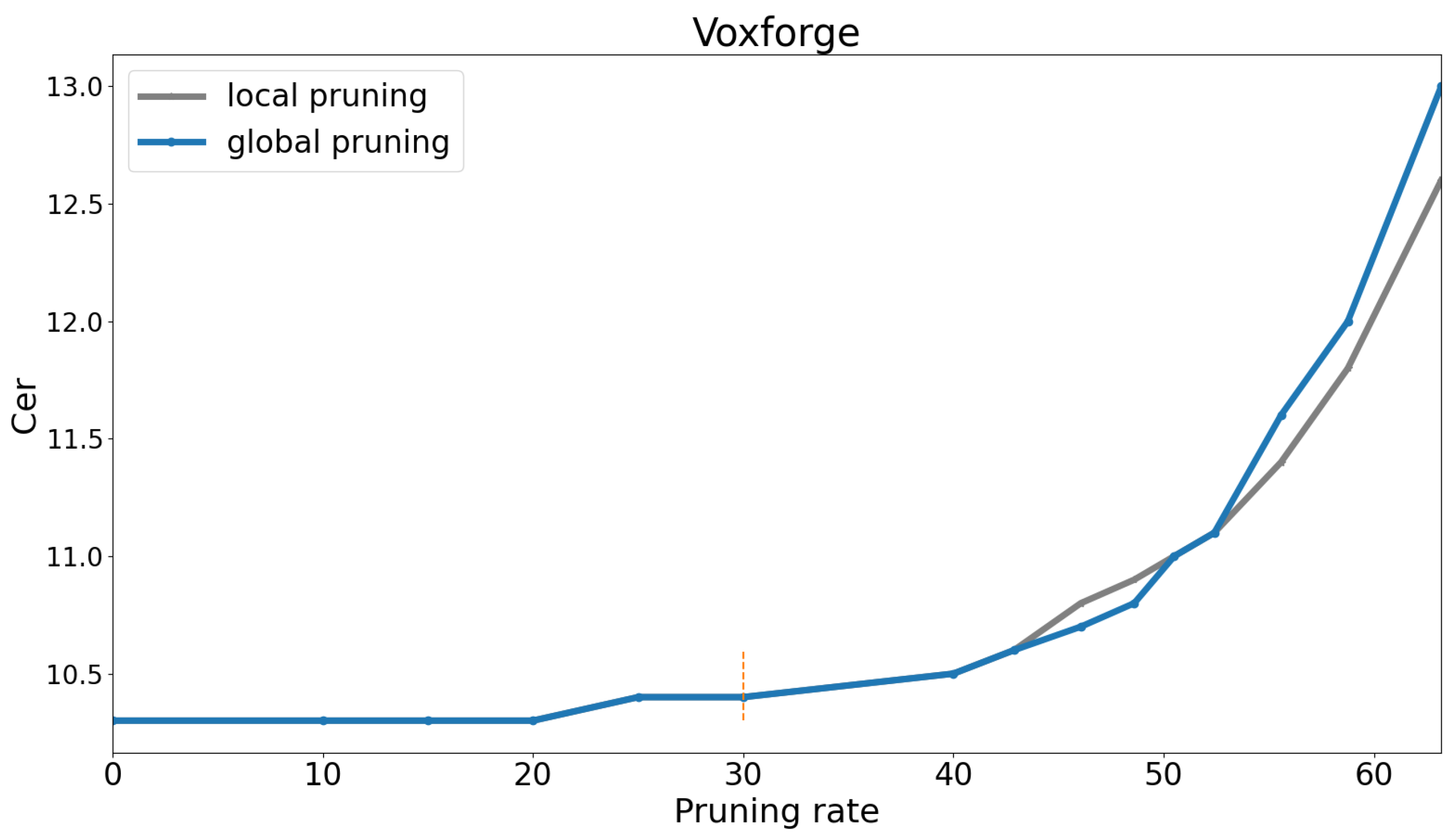
For the purpose of conducting a comparative analysis, we conducted preliminary experiments on both global and local pruning techniques utilizing the test sets from the Libri-trans and VoxforgeIT datasets. The outcomes of these experiments are illustrated on
Figure 9 and
Figure 10.
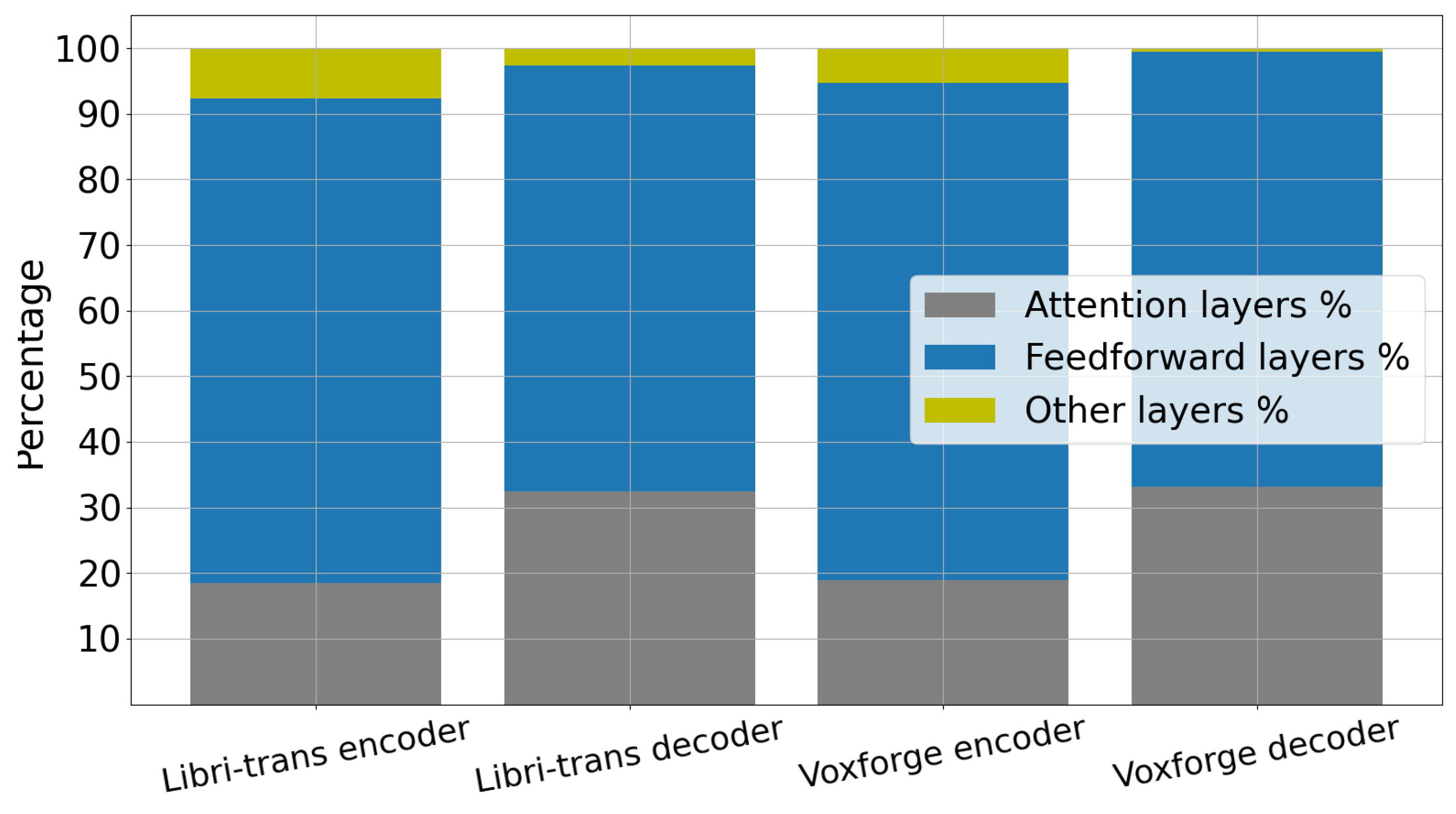
An observation we made is that when the pruning rate is 30%, there is a slight increase in the error rate of approximately 4.7% relative for Libri-trans and 2.1% for VoxforgeIT. Additionally, it is worth noting that the attention layers contribute significantly to the model size, as indicated on
Figure 4. As a result, we will at least fix the attention layer pruning rate at 30% and focus on varying the pruning rate of the feedforward layers fin the subsequent analysis.
5.2. Pruning Settings
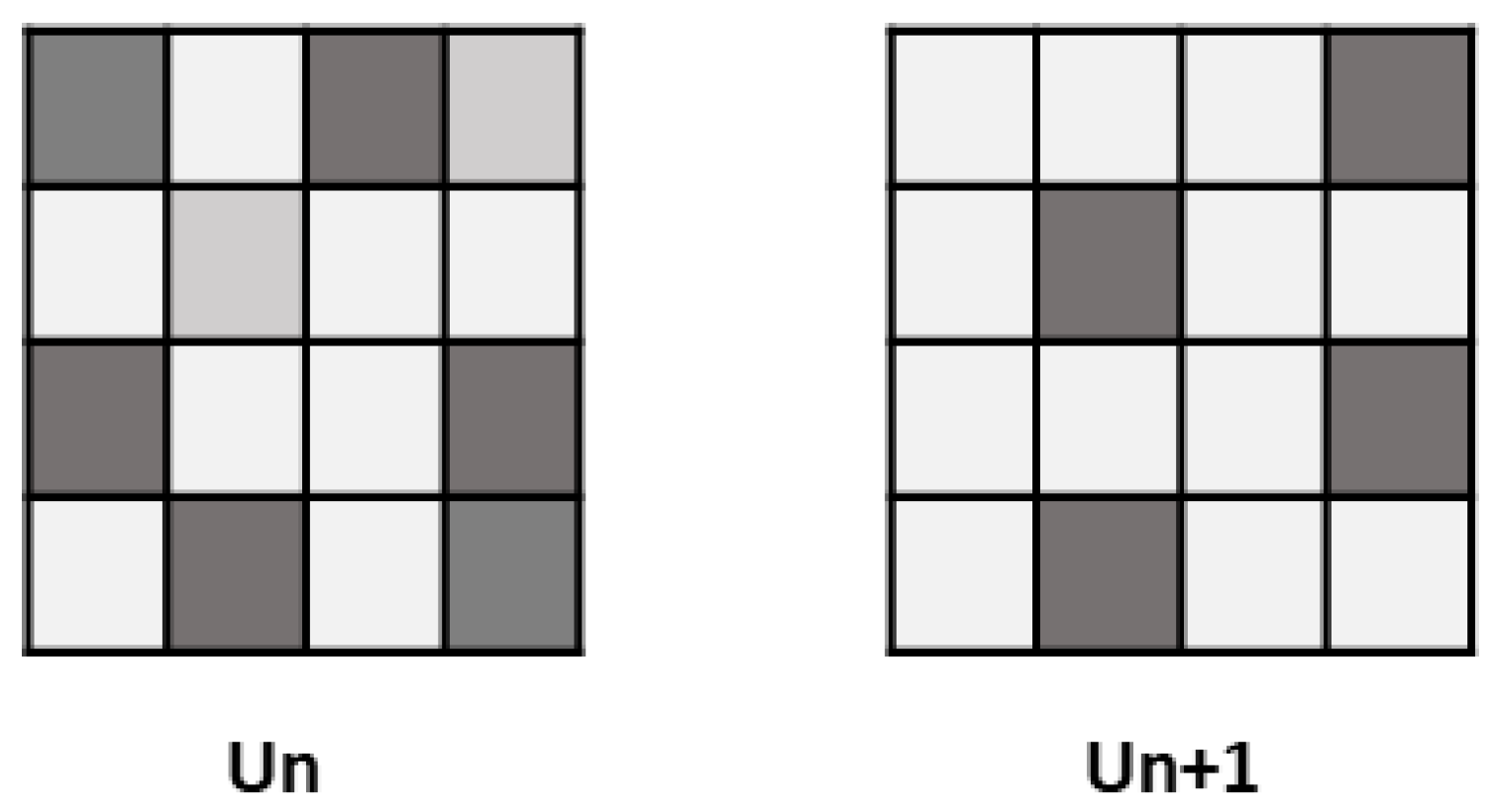
The adaptive pruning technique was applied in a single step to the feedforward and to the attention layers after the model was trained. The encoder and decoder pruning rates are represented by the arithmetic sequences U and V. To fix the initial pruning amounts and and the differences and , adaptive pruning was applied to the development data as follows:
The algorithm was executed three times on each dataset, with different pruning rates applied to the attention layers. Specifically, for the Libri-trans dataset, the pruning rates used were 30%, 35%, and 40%. For the VoxforgeIT dataset, the pruning rates employed were 35%, 40%, and 45%. and were chosen empirically. For example, for a pruning rate of 30% and = 0.01, the first encoder layer is pruned with the coefficient = 0.3; the second is pruned with = = 0.3 − 0.01 = 0.29. Thus, for a 12th encoder block, the pruning rate of the last layer is = 0.19 (i.e., a pruning rate of 19%).
The results of the adaptive pruning technique applied to development data are reported in
Appendix A. They are illustrated by
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6. Among these results, the best tradeoffs between WER and Sparsity are identified and highlighted in bold. To determine the optimal tradeoff, one must select a specific WER value from the table and then choose the lowest associated sparsity level. Based on the obtained tradeoffs, we deduced the encoder parameters
and
, which correspond to the optimal initial pruning amounts. For both the Libri-trans and VoxforgeIT settings, we extracted the optimal values of the (WER, Sparsity) pairs from
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6. Subsequently, we organize and present these optimal values comparatively in
Table 2 and
Table 3. This arrangement allows us to effectively demonstrate the relative trade-offs achieved for each set of parameters.
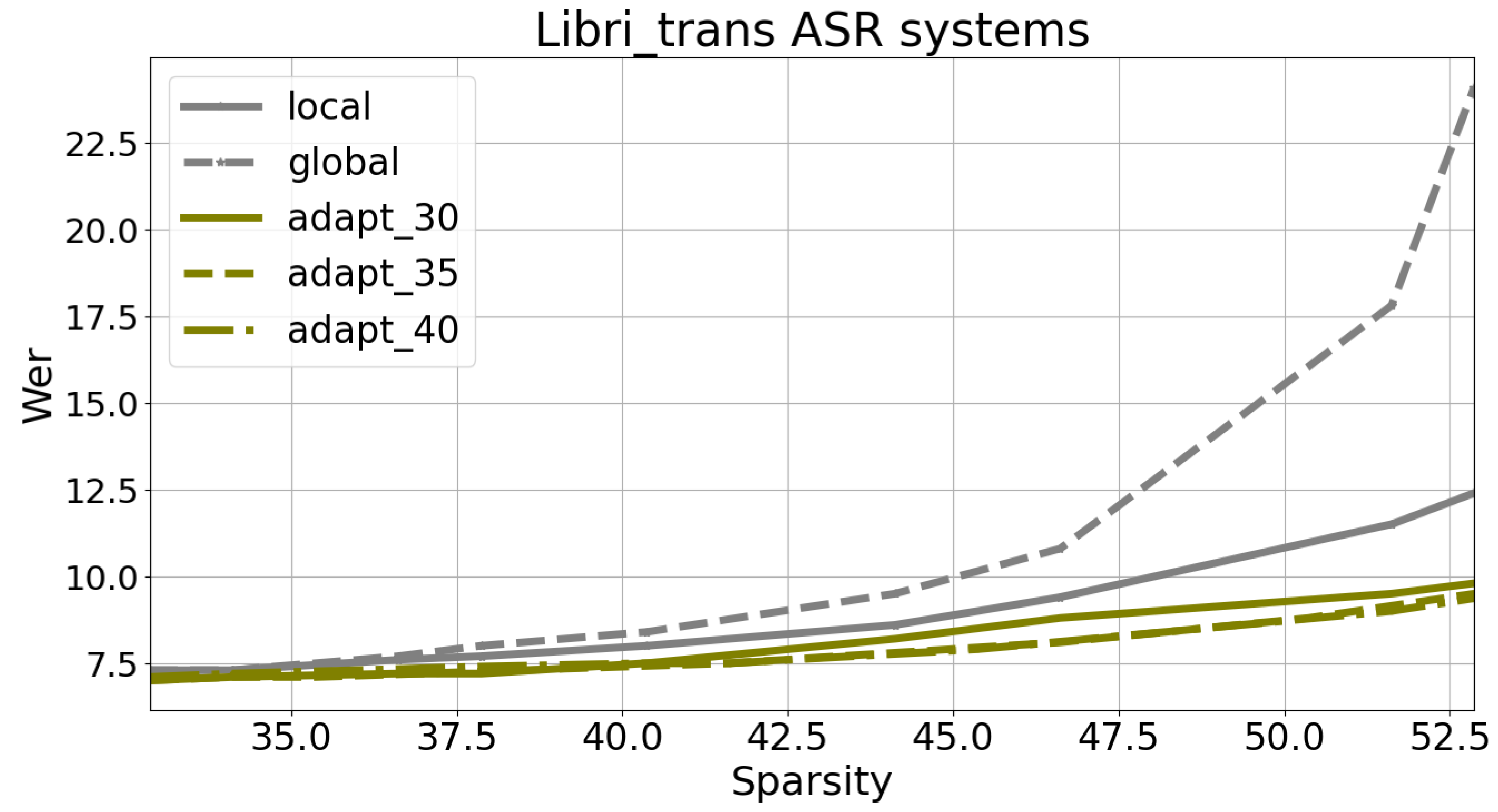
Figure 11 and
Figure 12 present the optimal pairs (WER, Sparsity) for different pruning rates, along with the results for global and local pruning for the purpose of comparison.
In both the Libri-trans and VoxforgeIT datasets, adaptive pruning demonstrates superior performance compared with local and global pruning methods. This outcome was expected due to the estimation of variable scale pruning parameters using the development data.
5.3. Pruning Evaluation
The three types of pruning, namely local, global, and variable scale, were applied to the test data without any parameter modifications. The values of , , , and remained the same as those set on the development data.
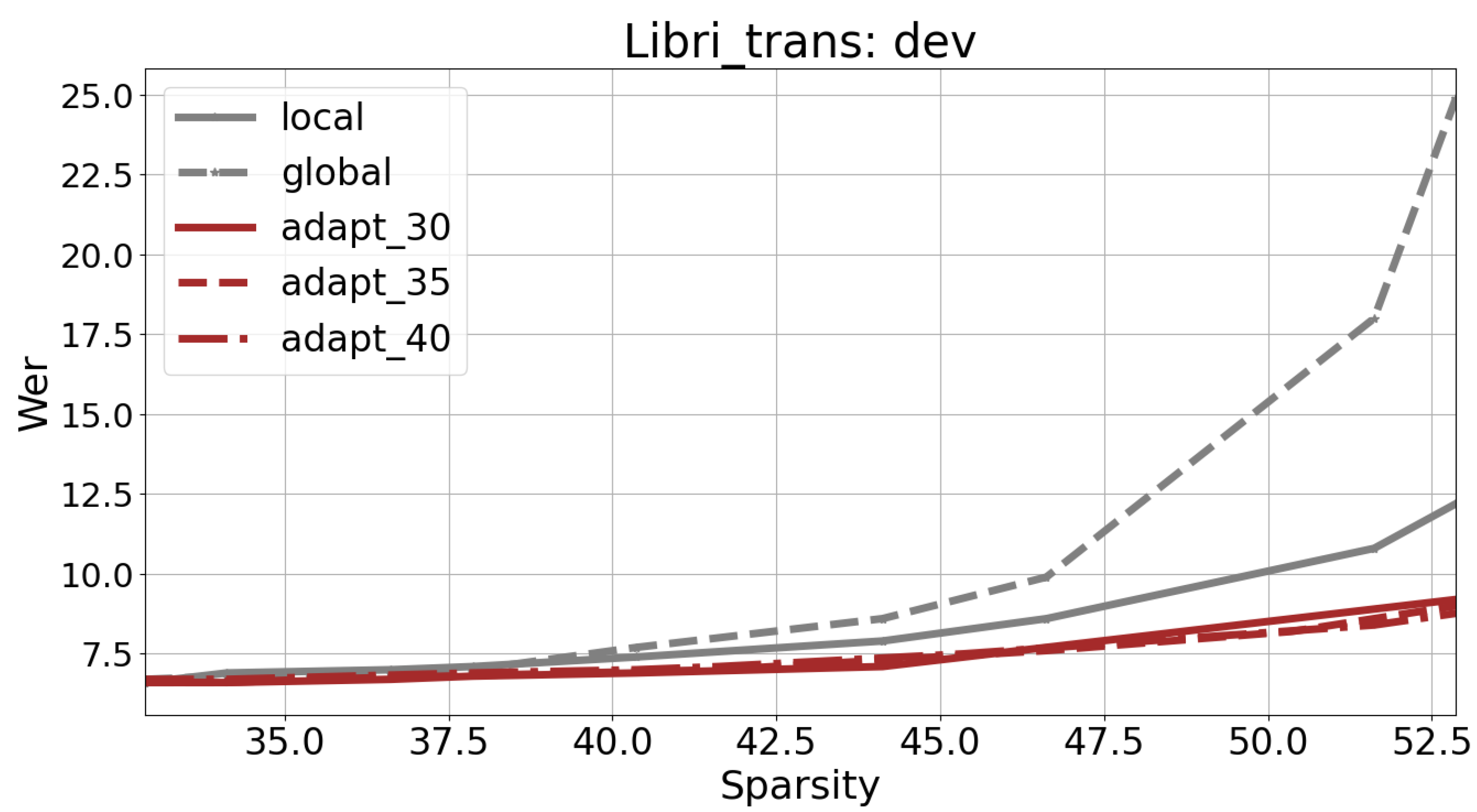
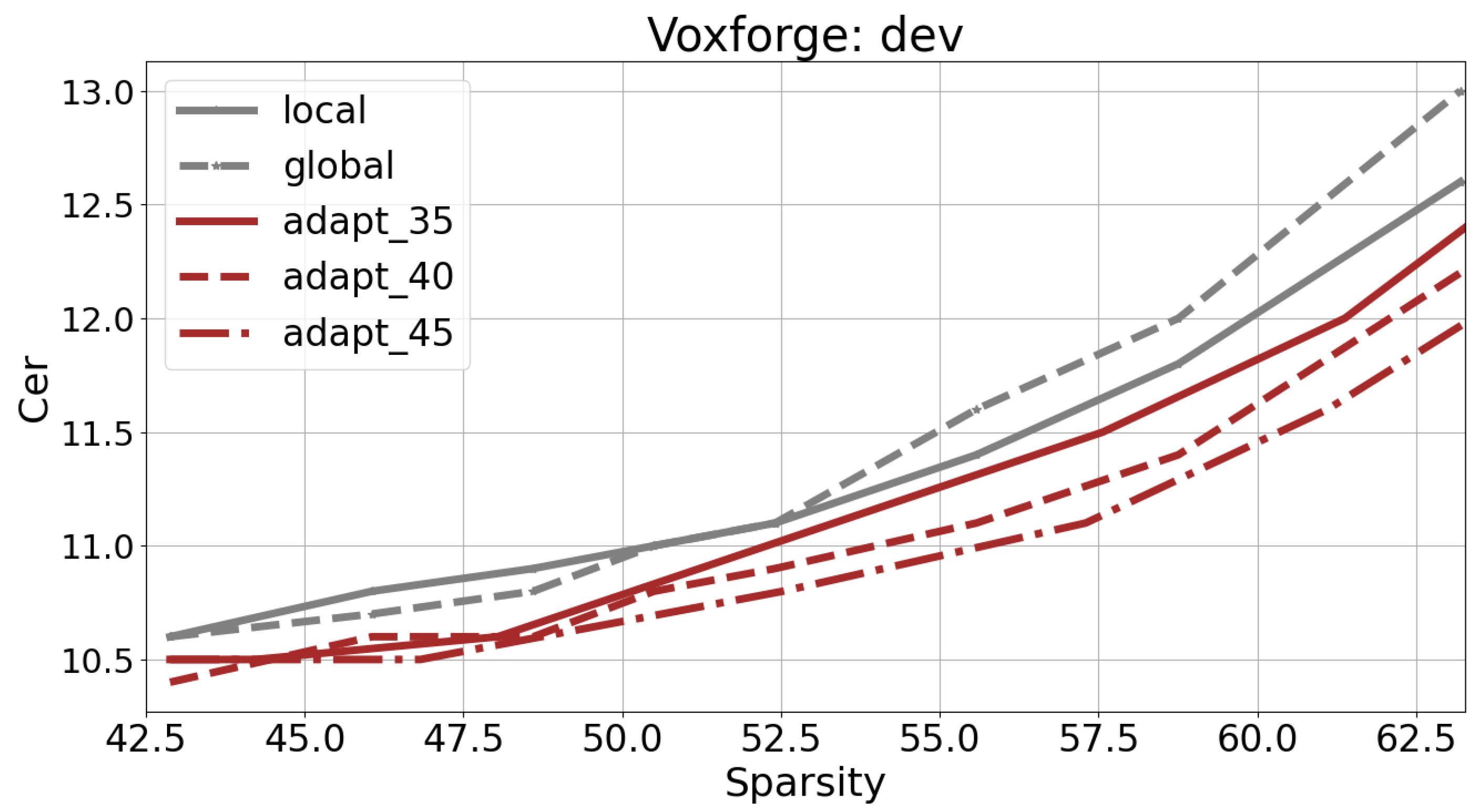
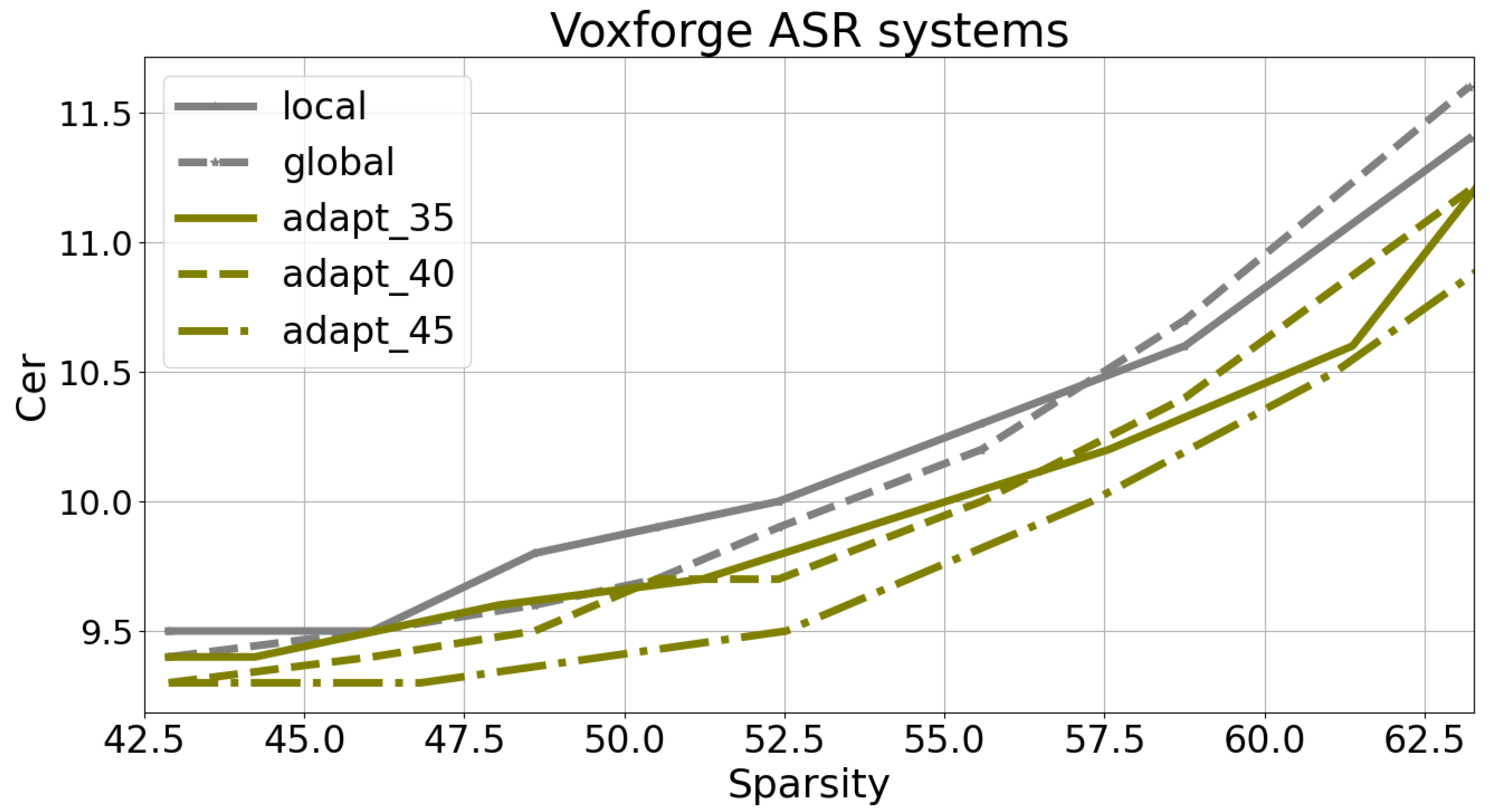
Figure 13 and
Figure 14 present the error rates for varying Sparsity levels, reaching up to 52.5% for Libri-trans and 62.5% for VoxforgeIT. It is noteworthy that, beyond these thresholds, the application of global pruning results in a significant increase in the error rate. Specifically, the error rate exceeds 24% for Libri-trans and 13.9% for VoxforgeIT.
In all cases, variable scale pruning demonstrates superior performance compared with global and local pruning techniques.
The Word Error Rate (WER) of the non-pruned Libri-trans system is reported to be 6.6% in
Section 3.2. According to
Figure 13, when the WER is 7.3%, variable scale pruning achieves a Sparsity gain of 7%. This allows the model to be compressed to 52.5% while maintaining a WER of 8.9%. This corresponds to a relative increase in the error rate of approximately 13.5%.
>In
Section 3.2, it is stated that the non-pruned VoxforgeIT system achieved a Character Error Rate (CER) of 9.3%. The information presented in
Figure 14 clearly shows that, for a CER of 9.5%, the variable scale pruning models exhibit 6% higher Sparsity values compared with the locally or globally pruned models. Furthermore, when the pruned system achieves a Sparsity level of 57%, the CER remains at approximately 10%. As a result, we can deduce an absolute increase in the error rate of 0.7% when the model is compressed to 57%.
It is worth noting that VoxforgeIT’s transformer model demonstrates a higher level of over-parameterization compared with that of Libri-trans, as evidenced by its larger Sparsity at the same increase in error rate.
Overall, these results highlight the effectiveness of variable scale pruning in achieving a favorable trade-off between Sparsity and error rate for both datasets. Setting a maximum allowable relative increase of 10% in the error rate (i.e., WER = 7.3% for Libri-trans and CER = 10.3% for VoxforgeIT), the most optimal pairs of (error rate, pruning rate) were found to be (7.6%, 43%) for the Libri-trans system and (10.3%, 59.5%) for the VoxforgeIT system.
6. Conclusions and Future Work
This paper presents a novel approach for pruning transformer models in end-to-end speech recognition, addressing the significant complexity and size of these models that hinder their efficient deployment in Automatic Speech Recognition tasks. While transformer systems exhibit excellent performance, their large size poses challenges for practical implementation. In order to overcome this limitation, our work focused on studying and optimizing pruning techniques specifically tailored to the transformer architecture.
In this study, we devised a method that centers around analyzing the evolution of weights within the feedforward layers present in both the encoder and decoder blocks of the transformer. Through careful observation, we found that deeper layers tend to possess higher weights compared with earlier layers. Leveraging this insight, our proposed approach, named variable scale pruning, applies a pruning rate that decreases progressively as the layer depth increases.
To validate the effectiveness of our method, we conducted experimental evaluations on diverse databases. The results showcased the superiority of our approach over traditional local and global pruning methods. Remarkably, our technique achieved an impressive model compression rate of up to 59.5%, all while maintaining a less than 10% relative reduction in accuracy.
Looking ahead, there are exciting research directions to explore. One such avenue involves investigating the application of variable scale pruning on attention head layers, which play a vital role in the transformer’s performance. Additionally, we intend to delve into fine-tuning techniques for the pruned models, aiming to further optimize their performance without sacrificing compression gains. In the present era, there is a growing trend in the adoption of large and pre-trained models, known as foundation models. Through fine-tuning, these models continually improve their efficiency and hold a crucial advantage in being able to work with minimal labeled data. The pruning of such models offers a compelling and promising avenue for further research.
By advancing the field of transformer model pruning for end-to-end speech recognition, our work contributes to the broader goal of enabling the widespread adoption of efficient and high-performing transformer systems in real-world applications.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












