

Solar Irradiance Forecasting with Natural Language Processing of Cloud Observations and Interpretation of Results with Modified Shapley Additive Explanations

 ,
, 
 and
and
Abstract
:1. Introduction
- (1)
- Numerical weather prediction (NWP);
- (2)
- Statistical methods;
- (3)
- Artificial intelligence methods.
- An algorithm of processing cloud observations in natural language for machine learning applications in forecasting SPP generation is proposed;
- It is experimentally substantiated that the use of different features describing the cloudiness increases the accuracy of SPP generation forecasting;
- A comparative analysis of various algorithms for constructing decision tree ensembles in SPP generation forecasting with many categorical features is carried out;
- The possibility of increasing the interpretability of SPP generation forecasts with a modified SHAP algorithm is investigated. The modification consists of combining a number of features that have close meaning for a user during visual interpretation.
2. Materials and Methods
2.1. The SPP under Consideration
- Average annual value of total solar radiation of 1495 kWh/m2;
- Average annual value of total cloudiness of 5.9 points with a maximum of 10 points;
- Average annual cloudiness of the lower level of 2.6 points;
- Average number of hours of sunshine per year of 2823 h, though it has reached 3000 h or more in some years;
- Solar resources for the total calendar year of 1482 kWh/m2.
2.2. Initial Dataset
- Data on generation, solar irradiance, consumption, and weather features have different time ranges of coverage;
- Weather data have a lot of missing values;
- Some of the names of the attribute columns are absolutely non-informative in the context of the real electrical circuit of the station (for example, feeders are represented by telemetering points, not by the names or numbers of outgoing power lines);
- The time resolutions of the data obtained for generation, solar irradiance, consumption, and weather data are different and range from thirty minutes to three hours;
- The volume of data for various components represents time series with several thousand, and sometimes tens of thousands, of values.
2.3. Data Aggregation and Filtering
2.4. Feature Transformation
- (1)
- Convert all characters to lower case;
- (2)
- Replace punctuation marks and the symbols ‘_’, ‘+’, and ‘-’ with spaces;
- (3)
- Apply tokenisation;
- (4)
- Apply stemming.
- LowCb: Cb, CbInc, and CbCalv;
- LowCu: Cu, CuHum, CuFrac, and CuCong;
- LowSt: St, Sc, StNed, StFrac, ScNonCu, and ScFromCu;
- Mid: CuMed, As, and AcFromCu/Cb;
- HiS: CiSpissFromCb, and CiSpissInt;
- HiFrnb: Frnb;
- HiCi: Ci, Cc, Cs, CiUnc, CiCast, CiFl, and CiFibr.
| Algorithm 1. Pseudo Code for the Clouds description transform | |
| Input: X, M, B, n | |
| Output:Y | |
| Initialisation:Yi = 0, i = 1, …, n; X’ = lower(X) | |
| Begin | |
| 1 | Xi = ‘_’ if Xi is not letter, i = 1, …, |X| |
| 2 | T = split(X, ‘_’) |
| 3 | Sj = stemming(Tj), j = 1, …, |T| |
| 4 | for each b in B |
| 5 | if b in S |
| 6 | return Y |
| 7 | end if |
| 8 | end for |
| 9 | Z = join(S, ‘_’) |
| 10 | for each m_key, m_value in M |
| 11 | if m_key in Z |
| 12 | Ym_value = 1 |
| 13 | end if |
| 14 | end for |
| 15 | return Y |
| End | |
2.5. Machine Learning Models
- Adaptive boosting (AB);
- Random forest (RF);
- Extreme gradient boosting (XGB);
- Light gradient boosting (LGBM)
- Categorial boosting (CB).
2.6. Interpretation of Model Output
3. Results and Discussion
3.1. Model Training Results
- The desired dependencies between the solar irradiance and other features were not even approximately linear, since the Ridge linear regression model showed an accuracy much lower than other models and R2 was only 0.5.
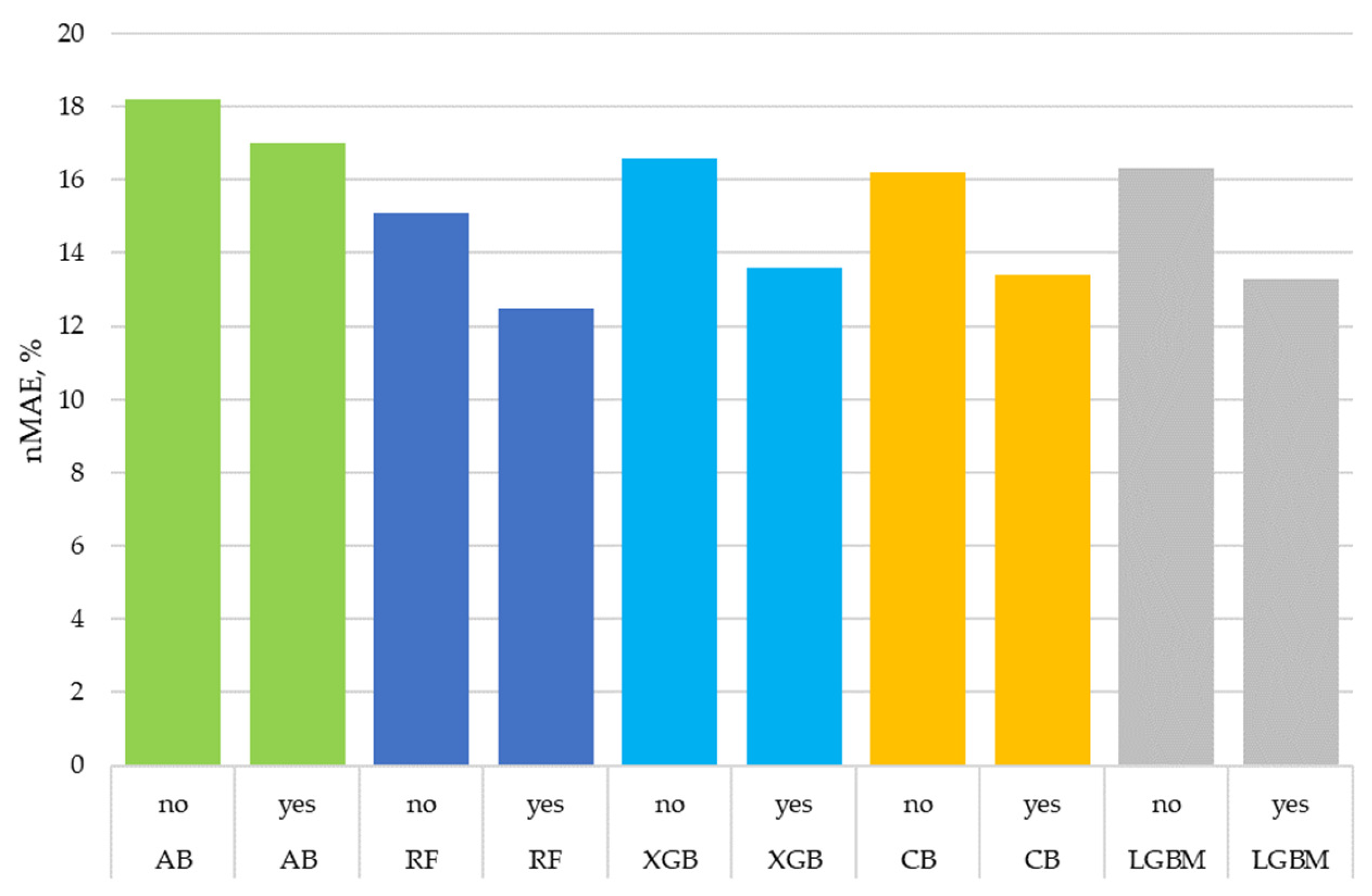
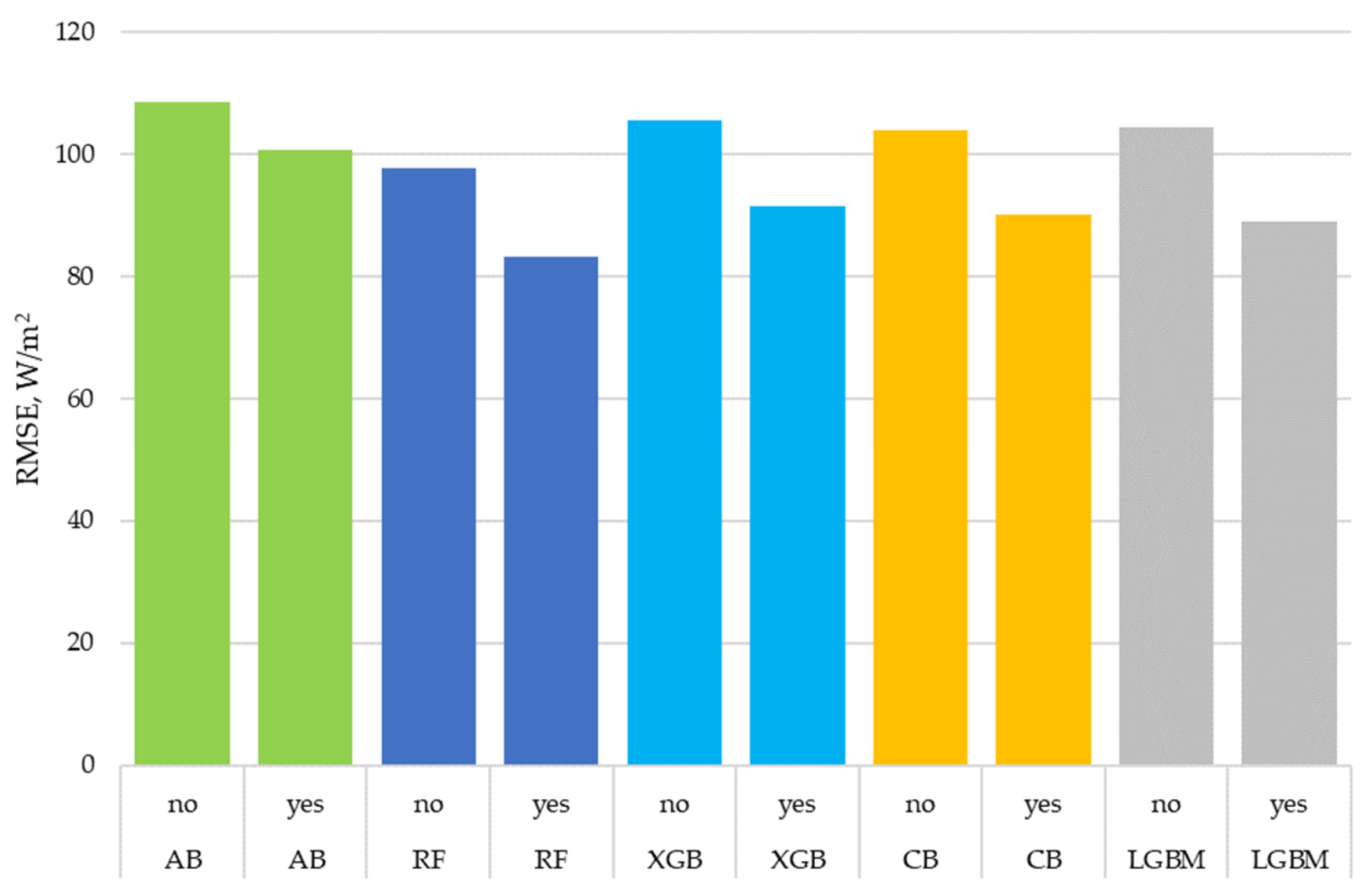
- The use of detailed cloud descriptions performed by the proposed algorithm significantly increased the accuracy of all ensemble models; the achieved averaged improvements were:
- MAE by 15%;
- nMAE by 15%;
- RMSE by 12.7%;
- R2 by 5%.
- It should be noted that the overall cloud level as a percentage of the sky covered by clouds was used in all experiments. Thus, the difference in accuracy was ensured by the proposed algorithm for processing text descriptions of cloudiness in natural language.
- The decrease in accuracy for the kNN when using cloud descriptions may have been due to the fact that the kNN is less suitable for working with binary features.
- The best accuracy was obtained with the random forest algorithm; the CatBoost and LightGBM algorithms gave accuracies close to it.
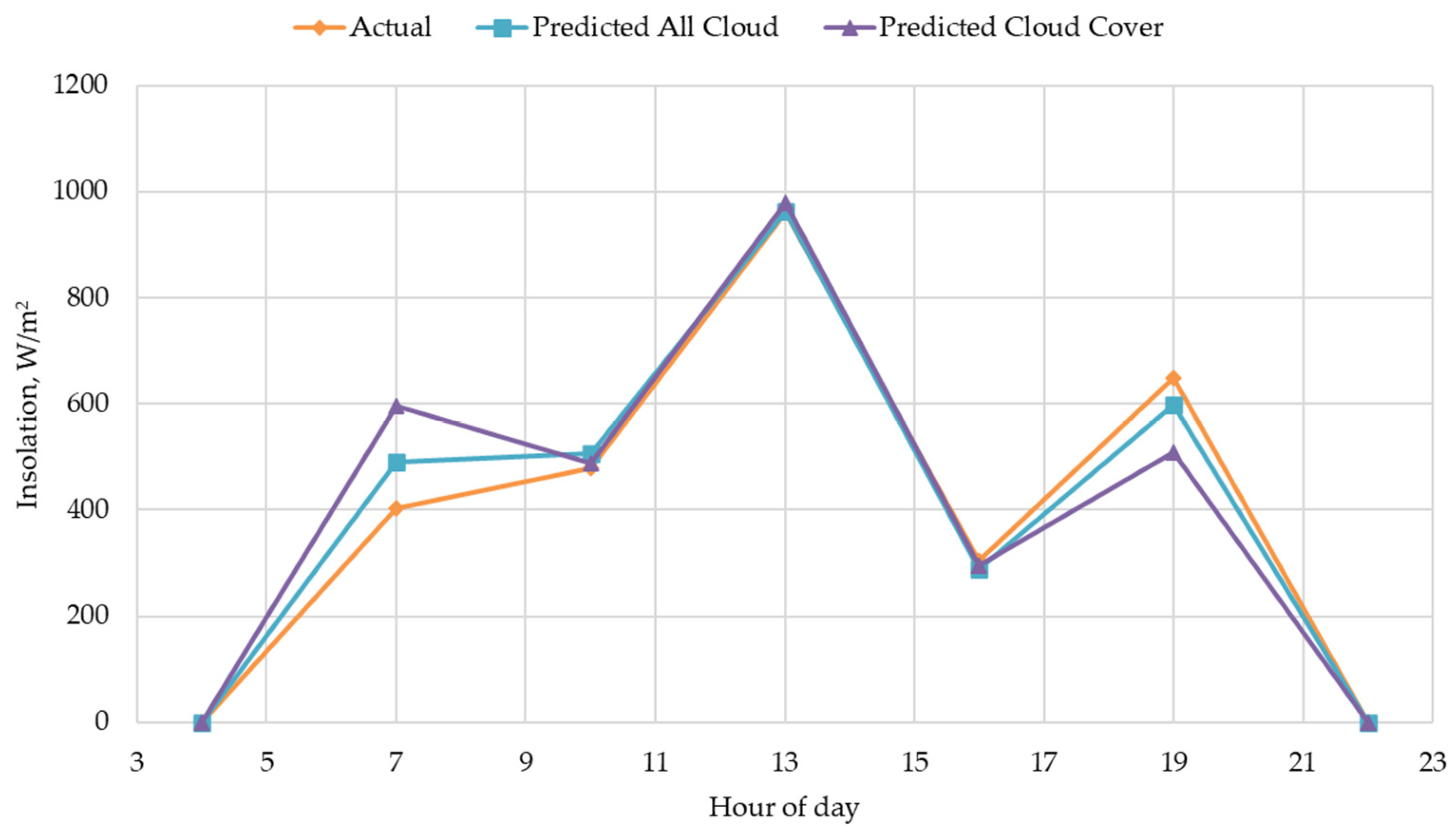
- The resulting accuracy of random forest—R2 = 0.91, nMAE = 12.5%—for the 3-h-ahead forecast of solar irradiance at tilted plane at the Earth’s surface corresponds to the state-of-the-art accuracy when taking into account differences in meteorological conditions between different territories.
3.2. The Interpretation Examples
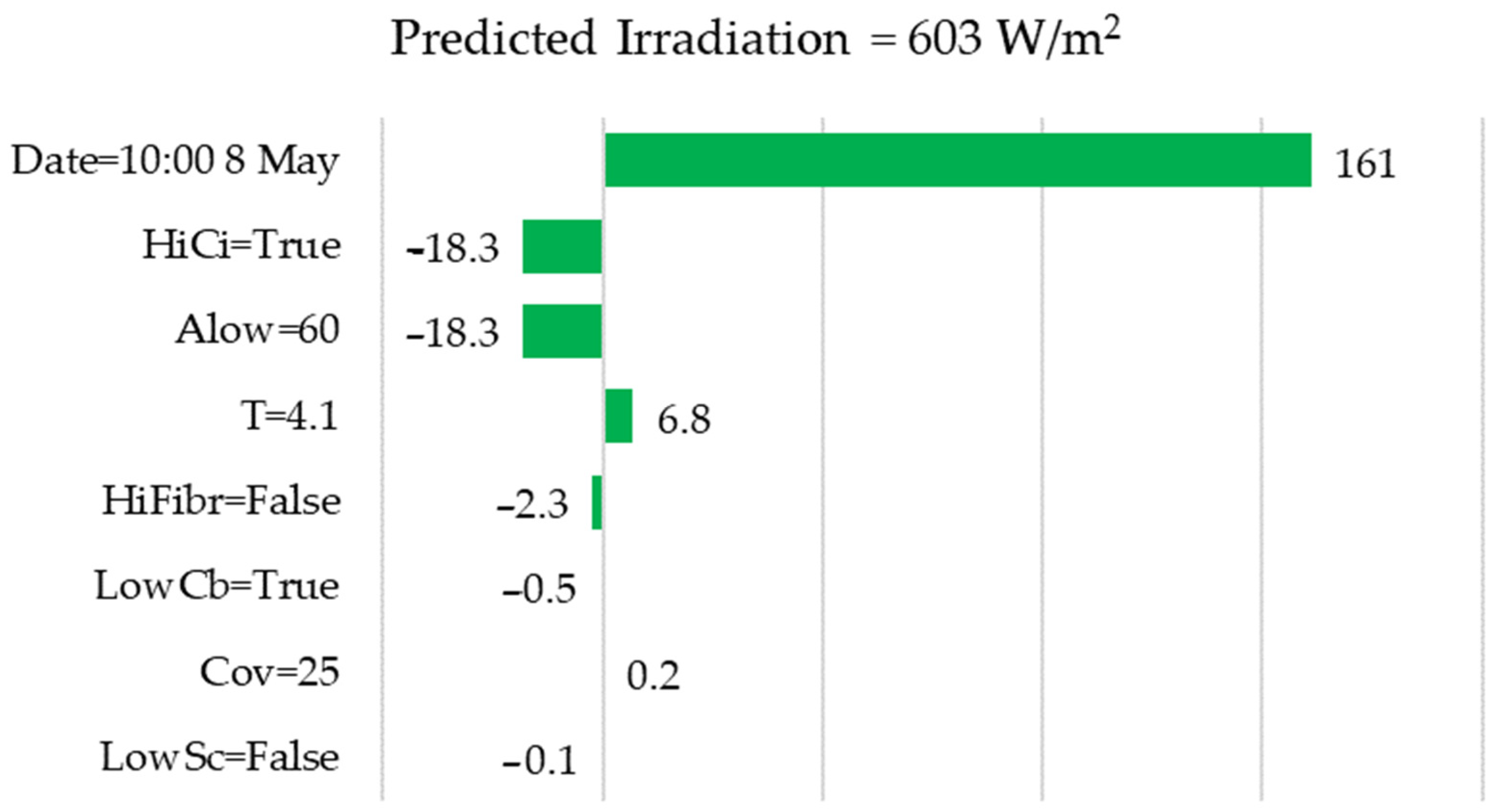
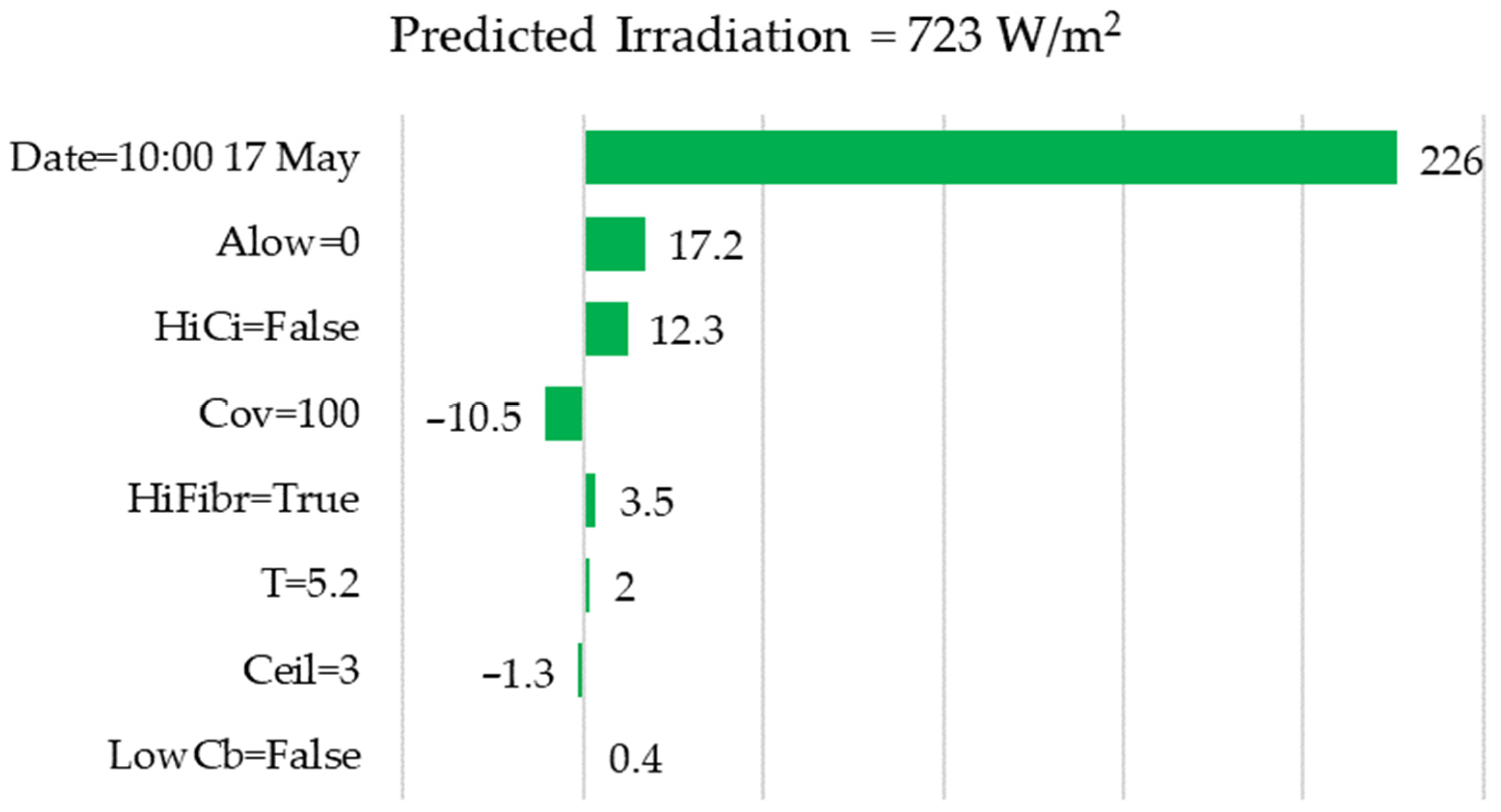
- Figure 9 shows that the model took into account the average percentage of low-level clouds (ALow = 60%) to reduce the forecast value, which is logical, since low-level clouds have a greater impact on the scattering of solar radiation. Also, the model took into account the absence of high cirrus clouds (HiCi = False) to improve the forecast, which is also logical.
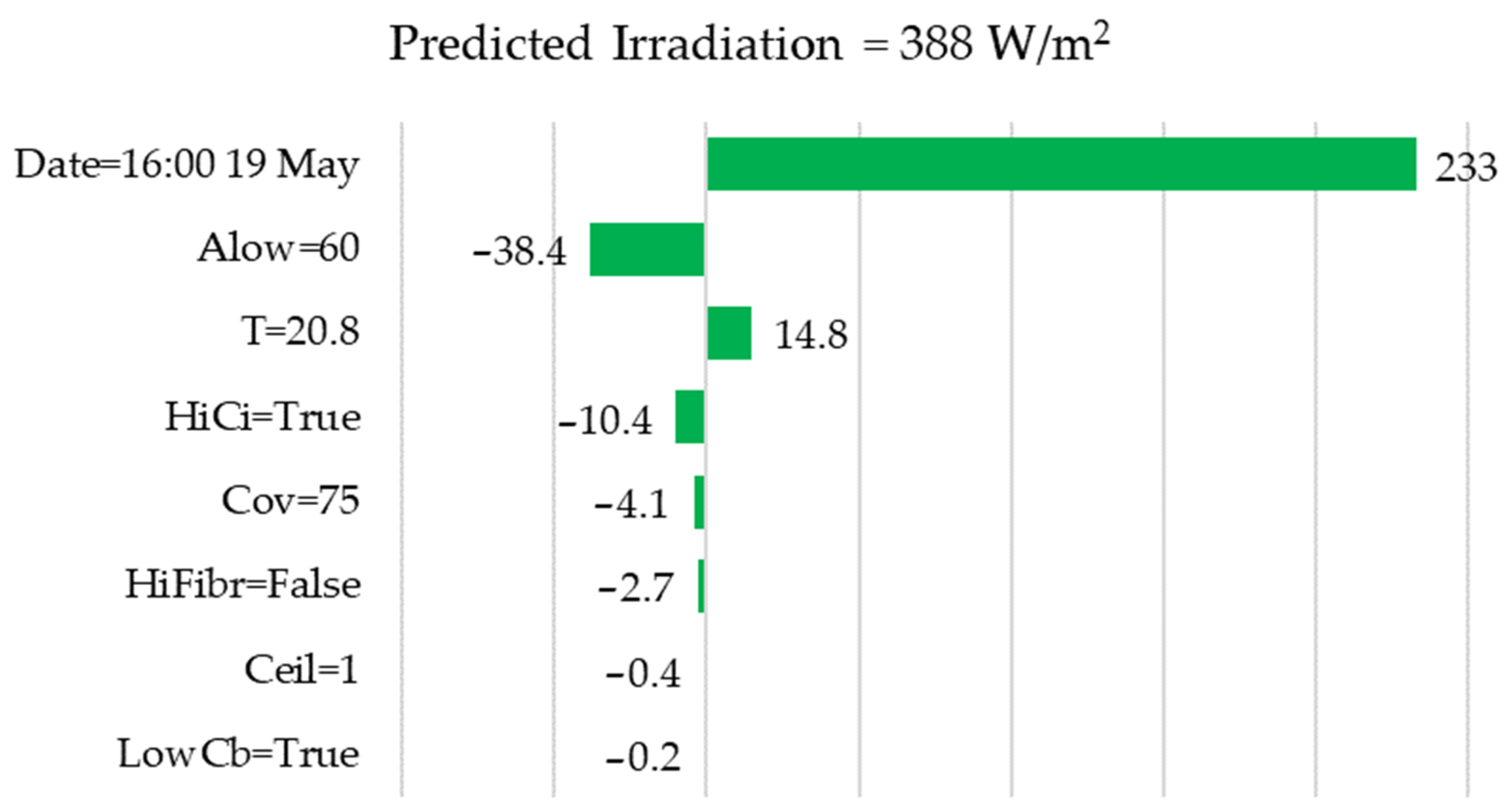
- For the following day and the same hour of the day, the forecast was slightly lower; from Figure 10, it is immediately clear that the reason was the presence of high cirrus clouds (HiCi = True).
4. Conclusions
- Previous studies devoted to solar irradiation or SPP generation forecasting have used only total cloud cover or cloud data extracted from satellite images. This paper proposes to use types of clouds and other features that can be identified from cloud observations in natural language. It was experimentally proven that the use of various features describing cloudiness increases SPP generation forecasting.
- A new modification of the SHAP interpretation algorithm was proposed. For the first time, it was shown in detail how the SHAP algorithm can be used to explain obtained SPP generation forecasts.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Leon, L.F.; Martinez, M.; Ontiveros, L.J.; Mercado, P.E. Devices and control strategies for voltage regulation under influence of photovoltaic distributed generation. A review. IEEE Lat. Am. Trans. 2022, 20, 731–745. [Google Scholar] [CrossRef]
- Ghulomzoda, A.; Safaraliev, M.; Matrenin, P.; Beryozkina, S.; Zicmane, I.; Gubin, P.; Gulyamov, K.; Saidov, N. A Novel Approach of Synchronization of Microgrid with a Power System of Limited Capacity. Sustainability 2021, 13, 13975. [Google Scholar] [CrossRef]
- Bramm, A.M.; Eroshenko, S.A.; Khalyasmaa, A.I.; Matrenin, P.V. Grey Wolf Optimizer for RES Capacity Factor Maximization at the Placement Planning Stage. Mathematics 2023, 11, 2545. [Google Scholar] [CrossRef]
- Prema, V.; Bhaskar, M.S.; Almakhles, D.; Gowtham, N.; Rao, K.U. Critical Review of Data, Models and Performance Metrics for Wind and Solar Power Forecast. IEEE Access 2022, 10, 667–688. [Google Scholar] [CrossRef]
- Matrenin, P.; Manusov, V.; Nazarov, M.; Safaraliev, M.; Kokin, S.; Zicmane, I.; Beryozkina, S. Short-Term Solar Insolation Forecasting in Isolated Hybrid Power Systems Using Neural Networks. Inventions 2023, 8, 106. [Google Scholar] [CrossRef]
- Raza, M.Q.; Nadarajah, M.; Ekanayake, C. On recent advances in PV output power forecast. Sol. Energy 2016, 136, 125–144. [Google Scholar] [CrossRef]
- Gandoman, F.H.; Abdel, A.; Shady, H.E.; Omar, N.; Ahmadi, A.; Alenezi, F.Q. Short-term solar power forecasting considering cloud coverage and ambient temperature variation effects. Renew. Energy 2018, 123, 793–805. [Google Scholar] [CrossRef]
- Hoyos-Gómez, L.S.; Ruiz-Muñoz, J.F.; Ruiz-Mendoza, B.J. Short-term forecasting of global solar irradiance in tropical environments with incomplete data. Appl. Energy 2022, 307, 118192. [Google Scholar] [CrossRef]
- Shadab, A.; Ahmad, S.; Said, S. Spatial forecasting of solar radiation using ARIMA model. Remote Sens. Appl. Soc. Environ. 2022, 20, 100427. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 17, 569–582. [Google Scholar] [CrossRef]
- Solano, E.S.; Dehghanian, P.; Affonso, C.M. Solar Radiation Forecasting Using Machine Learning and Ensemble Feature Selection. Energies 2022, 15, 7049. [Google Scholar] [CrossRef]
- Alam, M.S.; Al-Ismail, F.S.; Hossain, M.S.; Rahman, S.M. Ensemble Machine-Learning Models for Accurate Prediction of Solar Irradiation in Bangladesh. Processes 2023, 11, 908. [Google Scholar] [CrossRef]
- Li, P.; Zhou, K.; Lu, X.; Yang, S. A hybrid deep learning model for short-term PV power forecasting. Appl. Energy 2020, 259, 114216. [Google Scholar] [CrossRef]
- Kumari, P.; Toshniwal, D. Deep learning models for solar irradiance forecasting: A comprehensive review. J. Clean. Prod. 2021, 318, 128566. [Google Scholar] [CrossRef]
- Kumari, P.; Toshniwal, D. Long short-term memory–convolutional neural network based deep hybrid approach for solar irradiance forecasting. Appl. Energy 2021, 295, 117061. [Google Scholar] [CrossRef]
- Basaran, K.; Özçift, A.; Kılınç, D. A New Approach for Prediction of Solar Radiation with Using Ensemble Learning Algorithm. Arab. J. Sci. Eng. 2019, 44, 7159–7171. [Google Scholar] [CrossRef]
- Banik, R.; Das, P.; Ray, S.; Biswas, A. An Improved ANN Model for Prediction of Solar Radiation Using Machine Learning Approach. In Applications of Internet of Things; Springer: Singapore, 2021; pp. 233–242. [Google Scholar]
- De, V.; Teo, T.T.; Woo, W.L.; Logenthiran, T. Photovoltaic Power Forecasting using LSTM on Limited Dataset. In Proceedings of the 2018 IEEE Innovative Smart Grid Technologies—Asia (ISGT Asia), Singapore, 22–25 May 2018; pp. 710–715. [Google Scholar]
- Alaraj, M.; Kumar, A.; Alsaidan, I.; Rizwan, M.; Jamil, M. Energy Production Forecasting from Solar Photovoltaic Plants Based on Meteorological Parameters for Qassim Region, Saudi Arabia. IEEE Access 2021, 9, 83241–83251. [Google Scholar] [CrossRef]
- Mutavhatsindi, T.; Sigauk, C.; Mbuvha, R. Forecasting Hourly Global Horizontal Solar Irradiance in South Africa Using Machine Learning Models. IEEE Access 2020, 8, 198872–198885. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, B. An Ensemble Neural Network Based on Variational Mode Decomposition and an Improved Sparrow Search Algorithm for Wind and Solar Power Forecasting. IEEE Access 2021, 9, 166709–166719. [Google Scholar] [CrossRef]
- Karabiber, A.; Alçin, O.F. Short Term PV Power Estimation by means of Extreme Learning Machine and Support Vector Machine. In Proceedings of the 2019 7th International Istanbul Smart Grids and Cities Congress and Fair (ICSG), Istanbul, Turkey, 25–26 April 2019. [Google Scholar]
- Matrenin, P.V.; Khalyasmaa, A.I.; Gamaley, V.V.; Eroshenko, S.A.; Papkova, N.A.; Sekatski, D.A.; Potachits, Y.V. Improving of the Generation Accuracy Forecasting of Photovoltaic Plants Based on k-Means and k-Nearest Neighbors Algorithms. ENERGETIKA Proc. CIS High. Educ. Inst. Power Eng. Assoc. 2023, 66, 305–321. (In Russian) [Google Scholar] [CrossRef]
- WMO. Guide to Instruments and Methods of Observation, 2018th ed.; WMO 8; World Meteorological Organization: Geneva, Switzerland, 2018; pp. 490–492. [Google Scholar]
- Utrillas, M.P.; Marín, M.J.; Estellés, V.; Marcos, C.; Freile, M.D.; Gómez-Amo, J.L.; Martínez-Lozano, J.A. Comparison of Cloud Amounts Retrieved with Three Automatic Methods and Visual Observations. Atmosphere 2022, 13, 937. [Google Scholar] [CrossRef]
- Ahmed, I.; Jeon, G.; Piccialli, F. From Artificial Intelligence to Explainable Artificial Intelligence in Industry 4.0: A Survey on What, How, and Where. IEEE Trans. Ind. Inform. 2022, 18, 5031–5042. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why Should I Trust You? Explaining the Predictions of Any Classifier. 2016. Available online: https://arxiv.org/abs/1602 (accessed on 15 February 2024).
- Lundberg, S.M.; Erion, G.G.; Lee, S.-I. Consistent Individualized Feature Attribution for Tree Ensembles. 2018. Available online: http://arxiv.org/abs/1802.03888(accessed on 15 February 2024).
- Kuzlu, M.; Cali, U.; Sharma, V.; Güler, O. Gaining Insight into Solar Photovoltaic Power Generation Forecasting Utilizing Explainable Artificial Intelligence Tools. IEEE Access 2020, 8, 187814–187823. [Google Scholar] [CrossRef]
- Gabderakhmanova, T.S.; Kiseleva, S.V.; Frid, S.E.; Tarasenko, A.B. Energy production estimation for Kosh-Agach grid-tie photovoltaic power plant for different photovoltaic module types. J. Phys. Conf. Ser. 2016, 774, 012140. [Google Scholar] [CrossRef]
- Murel, J. Stemming Text Using the Porter Stemming Algorithm in Python. 2023. Available online: https://developer.ibm.com/tutorials/awb-stemming-text-porter-stemmer-algorithm-python/ (accessed on 10 January 2024).
- Khalyasmaa, A.I.; Eroshenko, S.A.; Tashchilin, V.A.; Ramachandran, H.; Piepur Chakravarthi, T.; Butusov, D.N. Industry Experience of Developing Day-Ahead Photovoltaic Plant Forecasting System Based on Machine Learning. Remote Sens. 2020, 12, 3420. [Google Scholar] [CrossRef]
- Solano, E.S.; Affonso, C.M. Solar Irradiation Forecasting Using Ensemble Voting Based on Machine Learning Algorithms. Sustainability 2023, 15, 7943. [Google Scholar] [CrossRef]
- Sarp, S.; Kuzlu, M.; Cali, U.; Elma, O.; Guler, O. An Interpretable Solar Photovoltaic Power Generation Forecasting Approach Using an Explainable Artificial Intelligence Tool. In Proceedings of the 2021 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 16–18 February 2021. [Google Scholar]
- Sansine, V.; Ortega, P.; Hissel, D.; Hopuare, M. Solar Irradiance Probabilistic Forecasting Using Machine Learning, Metaheuristic Models and Numerical Weather Predictions. Sustainability 2022, 14, 15260. [Google Scholar] [CrossRef]
- Elsaraiti, M.; Merabet, A. Solar Power Forecasting Using Deep Learning Techniques. IEEE Access 2022, 10, 31692–31698. [Google Scholar] [CrossRef]
- Lee, W.; Kim, K.; Park, J.; Kim, J.; Kim, Y. Forecasting Solar Power Using Long-Short Term Memory and Convolutional Neural Networks. IEEE Access 2018, 6, 73068–73080. [Google Scholar] [CrossRef]
- Wang, H.; Cai, R.; Zhou, B.; Aziz, S.; Qin, B.; Voropai, N.; Gan, L.; Barakhtenko, E. Solar irradiance forecasting based on direct explainable neural network. Energy Convers. Manag. 2020, 225, 113487. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| File Id | Period, dd.mm.yyyy | Time Resolution, min | Data Type |
|---|---|---|---|
| 1 | 28 October 2019–31 December 2020 | 60 | Solar irradiance |
| 2 | 01 January 2019–31 December 2020 | 60 | SPP generation |
| 3 | 28 October 2019–31 December 2020 | 30 | Power consumption |
| 4 | 06 May 2021–30 September 2021 | 30 | Power consumption |
| 5 | 01 January 2021–30 September 2021 | 60 | SPP generation |
| 6 | 01 October 2022–23 February 2022 | 30 | Power consumption |
| 7 | 01 October 2022–23 February 2022 | 60 | SPP generation |
| Parameter | Parameter Description | Unit/Format |
|---|---|---|
| Time | Local time | dd.MM.yy hh:mm |
| T | Air temperature at a height of 2 m above the Earth’s surface (in this table, all heights are measured from the surface of the Earth) | °C |
| Po | Atmospheric pressure at station level | mm Hg |
| P | Atmospheric pressure normalised to mean sea level | mm Hg |
| Pa | Pressure trend: atmospheric pressure fluctuations over the last three hours | mm Hg |
| U | Relative humidity at a height of 2 m | % |
| DD | Wind direction at a height of 10–12 m | text description (text) |
| Ff | Wind speed at a height of 10–12 m | m/s |
| ff10 | Maximum wind gust at a height of 10–12 m | m/s |
| ClCover | Total cloudiness | % + text |
| LowLevelCl | Stratocumulus clouds, stratus clouds, cumulus clouds and cumulonimbus clouds (lower clouds—up to 2 km in mid-latitudes) | text |
| AmountLowLevCl | Number of observed low-level clouds; the level of medium clouds in their absence | % + text |
| ClCeil | Height of the base of the lowest clouds | m + text |
| MidLevCl | Altocumulus clouds, altostratus clouds, nimbostratus clouds (mid-level clouds—from 2 km to 6 km in mid-latitudes) | text |
| HighLevCl | Cirrus clouds, cirrocumulus clouds and cirrostratus clouds (cloud tops—from 6 km to 13 km in mid-latitudes) | text |
| VV | Horizontal visibility range | km |
| Td | Dew point temperature at a height of 2 m | °C |
| RRR | Amount of precipitation | mm |
| tR | Period of time during which the specified amount of precipitation was accumulated | h |
| E | Condition of the soil surface without snow or measurable ice cover | text |
| Tg | Minimum soil surface temperature overnight | °C |
| E’ | Condition of the soil surface with snow or measurable ice cover | text |
| sss | Snow depth | cm |
| Dataset | Initial Number of Records | Due to Mismatched time Ranges (Records/% of Total) | Due to the Reduction of Data to One Hour Discreteness (Records/% of Total) | Due to the Discarding of Hours with Zero Generation of SPP (Records/% of Total) | Due to the Reduction of Data to a Weather Discreteness of Three Hours (Records/% of Total) |
|---|---|---|---|---|---|
| Generation | 27,600 | 11,784/42.7% | – | 9490/34.3% | 3793/13.7% |
| Insolation | 20,401 | 4584/22.5% | – | 9490/46.5% | 3793/18.6% |
| Consumption | 31,633 | – | 15,817/50% | 9490/30.0% | 3793/12.0% |
| Weather | 9087 | 3928/43.2% | – | 2626/28.9% | – |
| Designation | Category | Description |
|---|---|---|
| NoCloud | Low, Middle, High | No clouds recorded |
| Sc | Low | Stratocumulus clouds |
| St | Low | Stratus clouds |
| Cb | Low | Cumulonimbus clouds |
| CuHum | Low | Cumulus flat clouds |
| CuFrac | Low | Cumulus fractus clouds |
| CiUnc | High | Cirrus claw clouds |
| CiSpissFromCb | High | Dense cirrus clouds emerging from cumulonimbus ones |
| CuMed | Middle | Cumulus mediocris |
| CuCong | Low | Cumulus congestus clouds |
| CbInc | Low | Cumulonimbus filament clouds (anvil cloud) |
| CbCalv | Low | Cumulonimbus calvus |
| Frnb | High | Fractonimbus clouds |
| StNeb | Low | Stratus nebulosus |
| StFra | Low | Layered fractus clouds |
| As | Mid | Alto-stratus clouds |
| ScNonCu | Low | Stratocumulus clouds that did not originate from cumulus clouds |
| Ci | High | Spindrift clouds |
| Cc | High | Cirrocumulus clouds |
| Cs | High | Cirrostratus clouds |
| AcFromCu/Cb | Mid | Altocumulus clouds originating from cumulus clouds (or cumulonimbus clouds) |
| ScFromCu | Low | Stratocumulus clouds originating from cumulus clouds |
| CiSpissInt | High | Cirrus dense curled clouds |
| CiCast | High | Spindrift castellanus clouds |
| CiFl | High | Cirrus floccus |
| Cu | Low | Cumulus clouds |
| CiFibr | High | Cirrus fibratus |
| Height Value from ClCeil Column | Replacement in the Training Set |
|---|---|
| 800 | 1 |
| 1250 | 2 |
| 2500 | 3 |
| NoCloud | 4 |
| Attribute | Description | Source | Format |
|---|---|---|---|
| Day | Day number of the year | Pre-processed SPP data | Integer |
| Hour | Hour number in a day | Pre-processed SPP data | Integer |
| T | Air temperature, °C | RP5 open database | Real |
| ClearSI | Estimated solar irradiance at the atmospheric boundary, W/m2 | NASA open database | Real |
| ClCover | Total cloudiness, % | RP5 open database | Integer |
| ClCeil | Cloud height | Pre-processed RP5 open database | Category: 1, 2, 3, 4 |
| ALow | Amount of observed low-level clouds, in their absence—mid-level, % | Pre-processed RP5 open database | Integer |
| LowCb | Availability of clouds of this category | Boolean | |
| LowCu | |||
| LowSc | |||
| Mid | Pre-processed RP5 open database | ||
| HiCl | |||
| HiFibr | |||
| HiCi | |||
| I | Measured solar irradiance, W/m2 | SPP data | Real |
| Model | Using Cloud Descriptions | MAE, W/m2 | nMAE, % | RMSE, W/m2 | R2 |
|---|---|---|---|---|---|
| Ridge | no | 154.1 | 32.8 | 190.2 | 0.49 |
| Ridge | yes | 151.6 | 32.3 | 187.8 | 0.5 |
| kNN | no | 84.0 | 17.9 | 116.5 | 0.81 |
| kNN | yes | 95.9 | 20.4 | 134.0 | 0.75 |
| AB | no | 85.3 | 18.2 | 108.5 | 0.83 |
| AB | yes | 80.0 | 17.0 | 100.6 | 0.86 |
| RF | no | 70.7 | 15.1 | 97.6 | 0.87 |
| RF | yes | 58.6 | 12.5 | 83.1 | 0.91 |
| XGB | no | 77.8 | 16.6 | 105.4 | 0.84 |
| XGB | yes | 63.7 | 13.6 | 91.4 | 0.88 |
| CB | no | 75.9 | 16.2 | 103.8 | 0.85 |
| CB | yes | 63.1 | 13.4 | 90.1 | 0.89 |
| LGBM | no | 76.7 | 16.3 | 104.4 | 0.85 |
| LGBM | yes | 62.6 | 13.3 | 88.9 | 0.89 |
| Paper | The Best Models | Cloud Data Usage | Forecast Explanation |
|---|---|---|---|
| [5,16,20] | MLP | No | No |
| [8] | LSTM | Clear sky index | No |
| [11,16,19,34,35] | DT ensemble | No | No |
| [12,33] | DT ensemble | Total cloud cover | No |
| [13,18,36,37,38] | LSTM | No | No |
| [15] | LSTM | Cloud type (as a single feature) and total cloud cover | No |
| [17,23] | MLP | Total cloud cover | No |
| [21] | ENN | No | No |
| [22] | SVR, ELM | No | No |
| [30] | LSTM | Total cloud cover | SHAP algorithm |
| [39] | MLP | No | Direct explainable neural network provides general dependencies, but not explanation for each individual forecast |
| This research | DT ensembles | The new algorithm to process cloud observations in natural language is proposed | The new modified SHAP algorithm was proposed for explanation of SPP generation forecasts |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matrenin, P.V.; Gamaley, V.V.; Khalyasmaa, A.I.; Stepanova, A.I. Solar Irradiance Forecasting with Natural Language Processing of Cloud Observations and Interpretation of Results with Modified Shapley Additive Explanations. Algorithms 2024, 17, 150. https://doi.org/10.3390/a17040150
Matrenin PV, Gamaley VV, Khalyasmaa AI, Stepanova AI. Solar Irradiance Forecasting with Natural Language Processing of Cloud Observations and Interpretation of Results with Modified Shapley Additive Explanations. Algorithms. 2024; 17(4):150. https://doi.org/10.3390/a17040150
Chicago/Turabian StyleMatrenin, Pavel V., Valeriy V. Gamaley, Alexandra I. Khalyasmaa, and Alina I. Stepanova. 2024. "Solar Irradiance Forecasting with Natural Language Processing of Cloud Observations and Interpretation of Results with Modified Shapley Additive Explanations" Algorithms 17, no. 4: 150. https://doi.org/10.3390/a17040150
APA StyleMatrenin, P. V., Gamaley, V. V., Khalyasmaa, A. I., & Stepanova, A. I. (2024). Solar Irradiance Forecasting with Natural Language Processing of Cloud Observations and Interpretation of Results with Modified Shapley Additive Explanations. Algorithms, 17(4), 150. https://doi.org/10.3390/a17040150