Fast Rescheduling of Multiple Workflows to Constrained Heterogeneous Resources Using Multi-Criteria Memetic Computing


Abstract
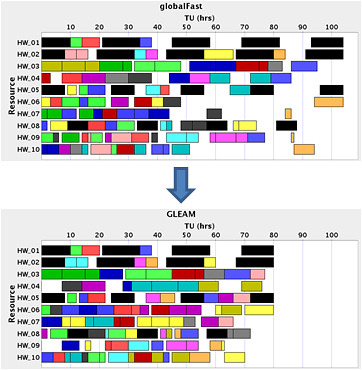
:
1. Introduction
- Scheduling of workflows of parallel branches instead of just a linear sequence of operations (grid jobs);
- Co-allocation of resources for each grid job instead of only one machine (resource) per operation;
- Restricted availability of resources;
- Heterogeneous resource alternatives due to different cost performance ratios as well as different performances or capacities instead of alternatives of uniform resources;
- Multi-objective target function with conflicting criteria like costs, execution times, and rate of utilization. This is necessary to fulfill the different needs of resource providers and users.
- Arrival of new application jobs;
- Cancellation of waiting or already begun application jobs;
- Crash of grid jobs resulting in the termination of the remaining workflow;
- New resources;
- Breakdown of resources;
- Changes of the availability or the cost model of resources.
2. Related Work
3. Formal Problem Definition
- A precedence function p:O × O → {TRUE, FALSE} for the grid jobs;
- An assignment function μ:O → P(P(M)) from grid jobs to resource sets. P(M) is the power set of M, i.e., the set of all possible combinations of resources. Thus, Oij can be performed by a feasible element from P(M). Then μij ∈ P(P(M)) is the set of all possible combinations of resources from M, which together are able to perform the grid job Oij;
- A function t:O × P(M) → , which gives for every grid job Oij the time needed for the processing on a resource set Rij ∈ μij;
- A cost function, c: × P(M) → , which gives for every time z ∈ the costs per time unit of the given resource set.
- All grid jobs are planned and resources are allocated exclusively:
- Precedence relations are adhered to:
- All application jobs Ji have a cost limit ci, which must be observed:
- All application jobs Ji have due dates di, which must be adhered to:
- costs of the application jobs (35%)are measured with respect to the budget of each application job given by the user and averaged.
- completion time of the application jobs (25%)is also measured with respect to a user-given time frame of each application job and averaged.
- total makespan of all application jobs (15%)
- the rate of resource utilization (5%)is gathered for the first 75% of the total makespan only, as in the end phase of a schedule not all resources can be utilized.
- delay of inner grid jobs (20%)inner grid jobs are all non-terminal grid jobs of an application job. If they start late, there is no or only little room to start the final grid job(s) earlier so that the complete application job is finished earlier, resulting in a better value of the main objective completion time. An earlier start of inner grid jobs is in fact a prerequisite for a faster processing of the application job, but it is not honored by the criteria discussed so far. Thus, the delays of inner grid jobs with respect to the earliest starting time of their application job are measured and averaged over all application jobs. For the costs, no corresponding action is required, as a change in costs caused by the substitution of a resource is registered immediately. This illustrates an important difference for an objective function used in an evolutionary search: It is not sufficient to assess quality differences well. The fitness function must also support the search process in finding the way to better solutions in order to achieve improvements.
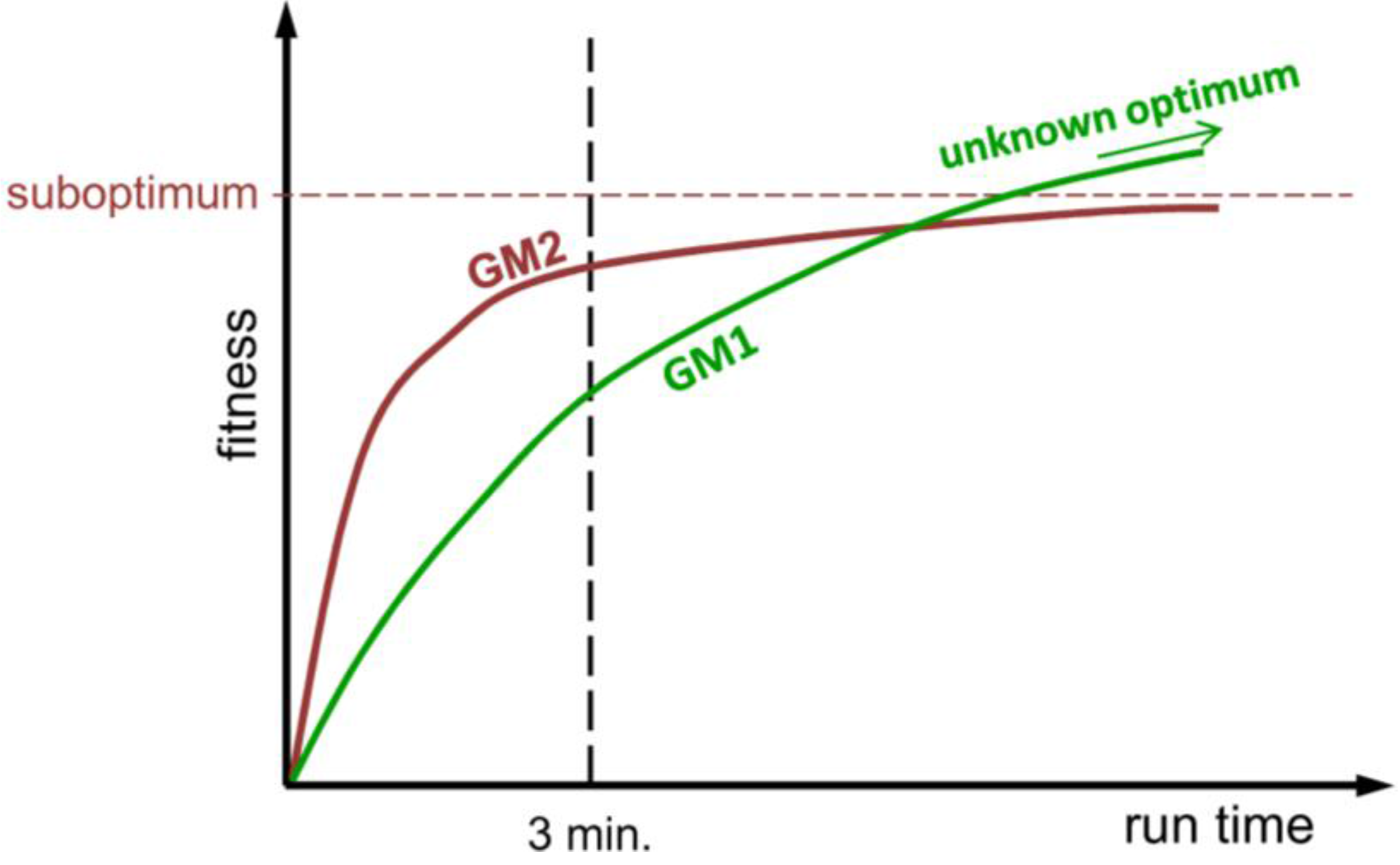
4. The Concept of GORBA for Fast Rescheduling
4.1. Heuristics for Scheduling and Rescheduling
- earliest due time: grid jobs of the application job with the earliest due time first,
- shortest working time of grid job: grid jobs with the shortest working time first,
- shortest working time of application job: grid jobs of the application job with the shortest working time first.
- RAS-1:
- Use the fastest of the earliest available resources for all grid jobs.
- RAS-2:
- Use the cheapest of the earliest available resources for all grid jobs.
- RAS-3:
- Use RAS-1 or RAS-2 for all grid jobs of an application job according to its time/cost preference given by the user.
4.2. Evolutionary Optimization
4.2.1. GLEAM
- inversion: reversion of the internal order of the genes of a segment.
- segment shifting: a segment is shifted as a whole.
- segment merging: if non-adjacent segments are merged, the operation includes segment shifting.
- segment mutation: all genes of a segment undergo parameter mutation with a given probability.


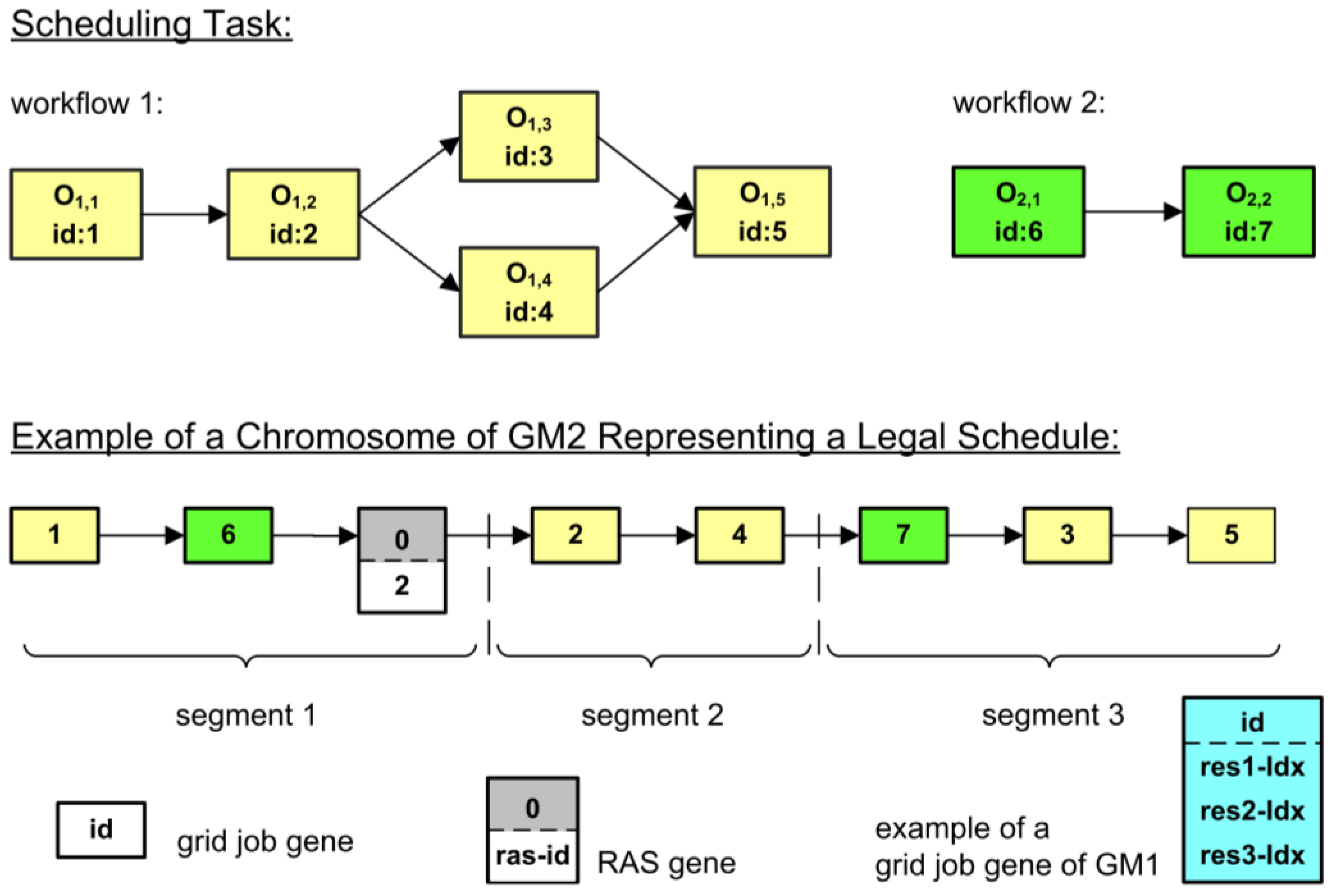
4.2.2. Two Gene Models
- If the grid job has no predecessors, its earliest start time equals the earliest start time of its application job. Otherwise, the latest end time of its predecessors is used as earliest start time.
- Calculate the duration of the grid job on the given resources.
- Search for a free time interval of the calculated duration beginning at the earliest start time from step 1 on all selected resources and allocate them.
- If the grid job has no predecessors, its earliest start time equals the earliest start time of its application job. Otherwise, the latest end time of its predecessors is used as earliest start time.
- According to the RAS selected by the RAS gene, a list of alternatives is produced for every primary resource.
- Beginning with the first resources of the lists, the duration of the job is calculated and it is searched for a free time slot for the primary resource and its depending ones, beginning at the earliest start time of step 1. If no suitable slot is found, the resources at the next position of the lists are tried.
- The resources found are allocated to the grid job with the calculated time frame.

4.2.3. Genotypic and Phenotypic Repair
4.2.4. Crossover Operators Designed for Combinatorial Optimization
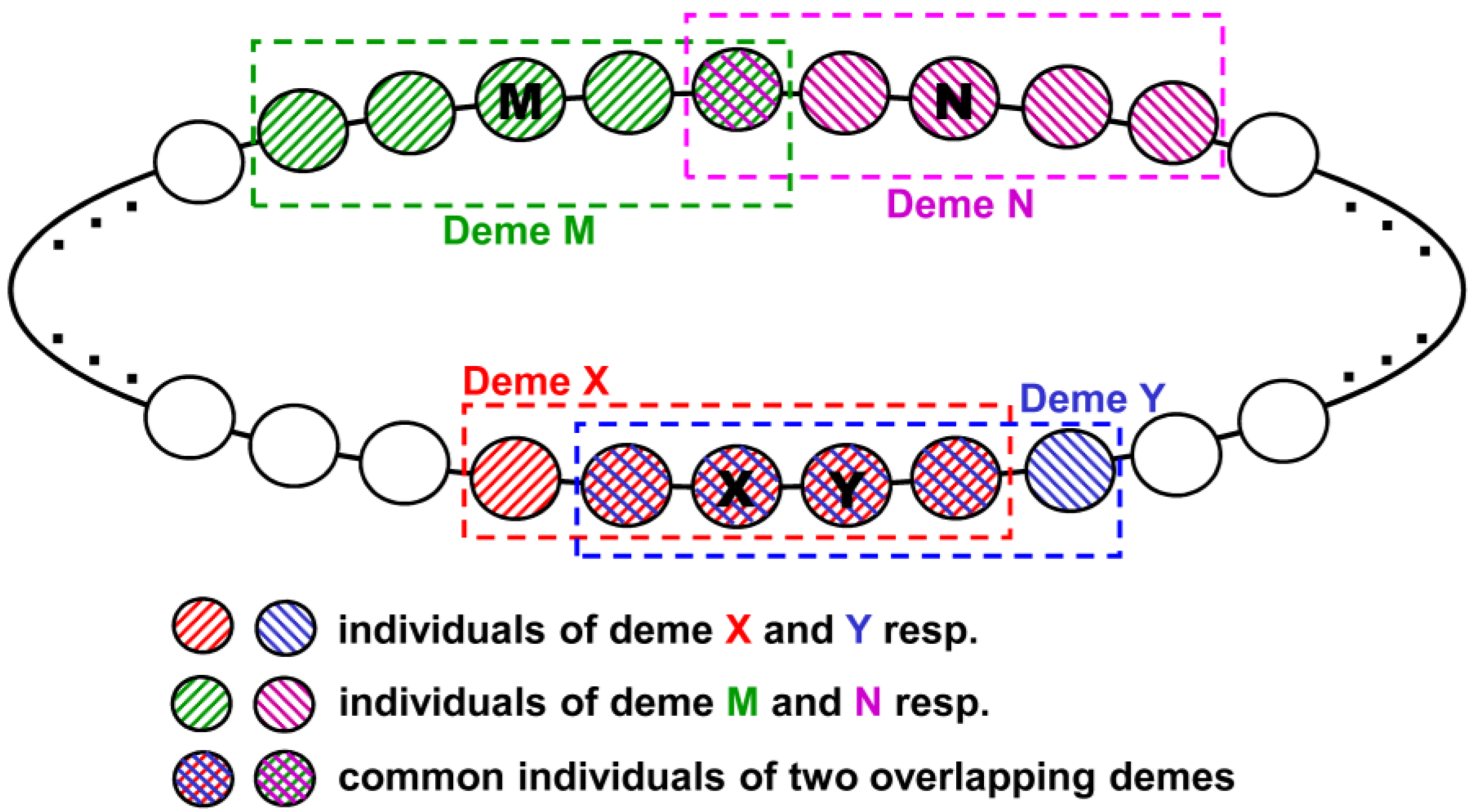
4.3. Memetic Optimization

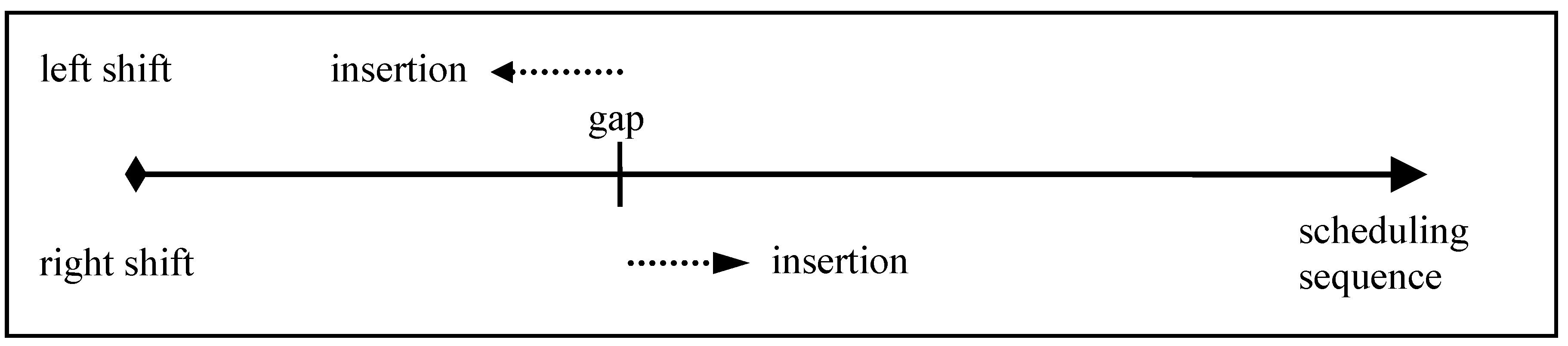
4.3.1. Local Searchers for Left Shift of Grid Jobs of Late Application Jobs (LS-LSLD and LS-LSSD)
4.3.2. Local Searcher Right Shift of Grid Jobs of Preterm Application Jobs (LS-RS)
4.3.3. Local Searcher RAS Selection (LS-RAS)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Overrun | Actual RAS | ||
|---|---|---|---|
| Cheapest | Fastest | Preference | |
| cost | preference | cheapest, preference | cheapest |
| time | fastest, preference | preference | fastest |
4.4. Adaptive Memetic Algorithms
- The simple Memetic Algorithm, where one meme is used without any adaptivity, see also Figure 4,
- The Adaptive Single-memetic Algorithm (ASMA) consisting of one meme, the application of which is adjusted adaptively, and
- The Adaptive Multimeme Algorithm (AMMA), where both, meme selection and their application are controlled adaptively.

5. Experiments
5.1. Benchmarks
| Benchmark class | Time benchmark reserve (%) | Cost benchmark reserve (%) | ||||
|---|---|---|---|---|---|---|
| lRlD | 47.2 | 48.9 | 50.1 | 27.3 | 27.7 | 28.1 |
| sRlD | 53.7 | 55.9 | 58.3 | 25.2 | 25.9 | 26.7 |
| lRsD | 57.2 | 59.2 | 62.1 | 22.3 | 23.3 | 24.1 |
| sRsD | 63.4 | 64.4 | 65.5 | 20.8 | 21.5 | 22.0 |
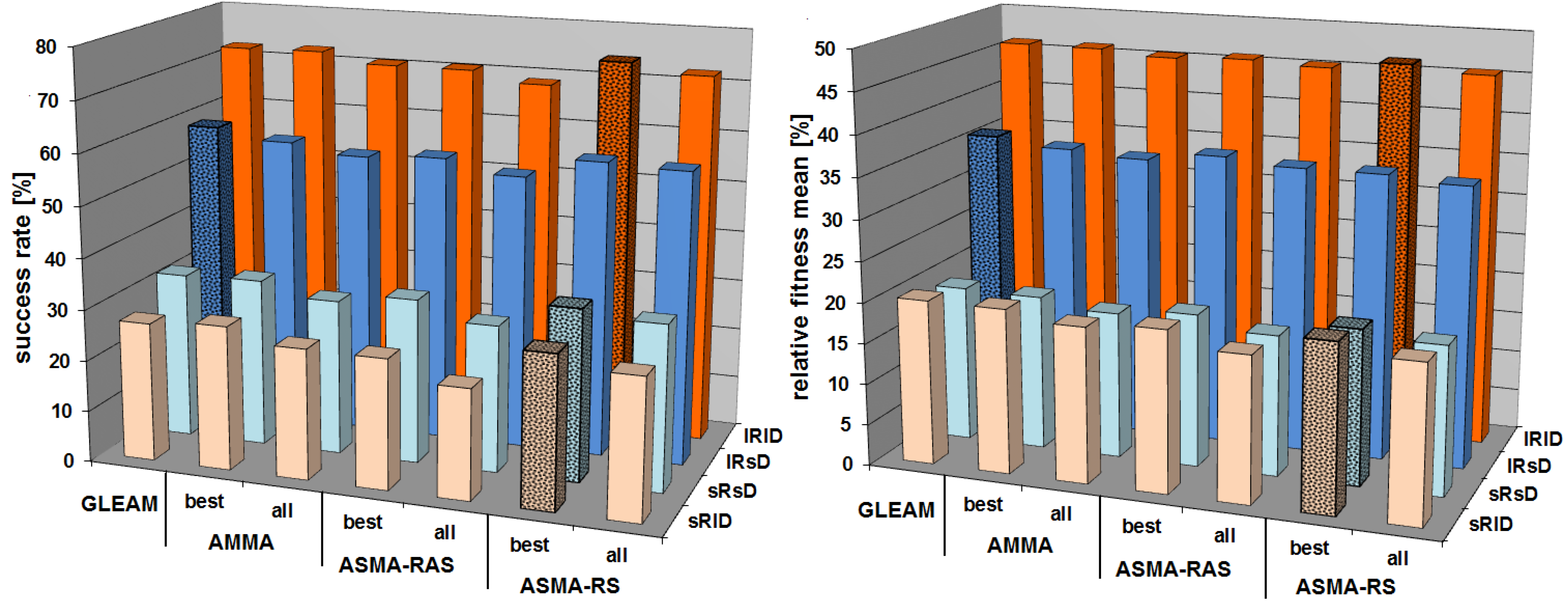
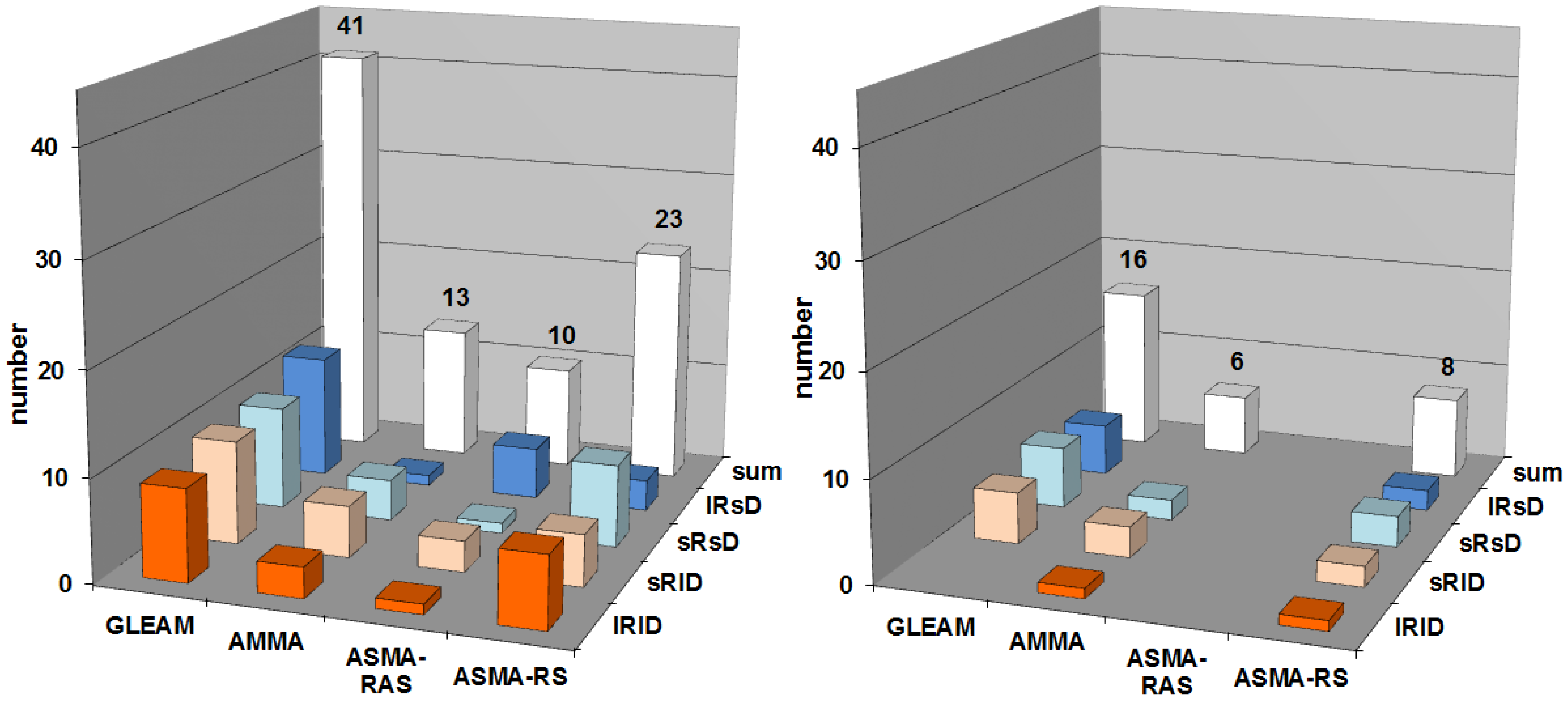
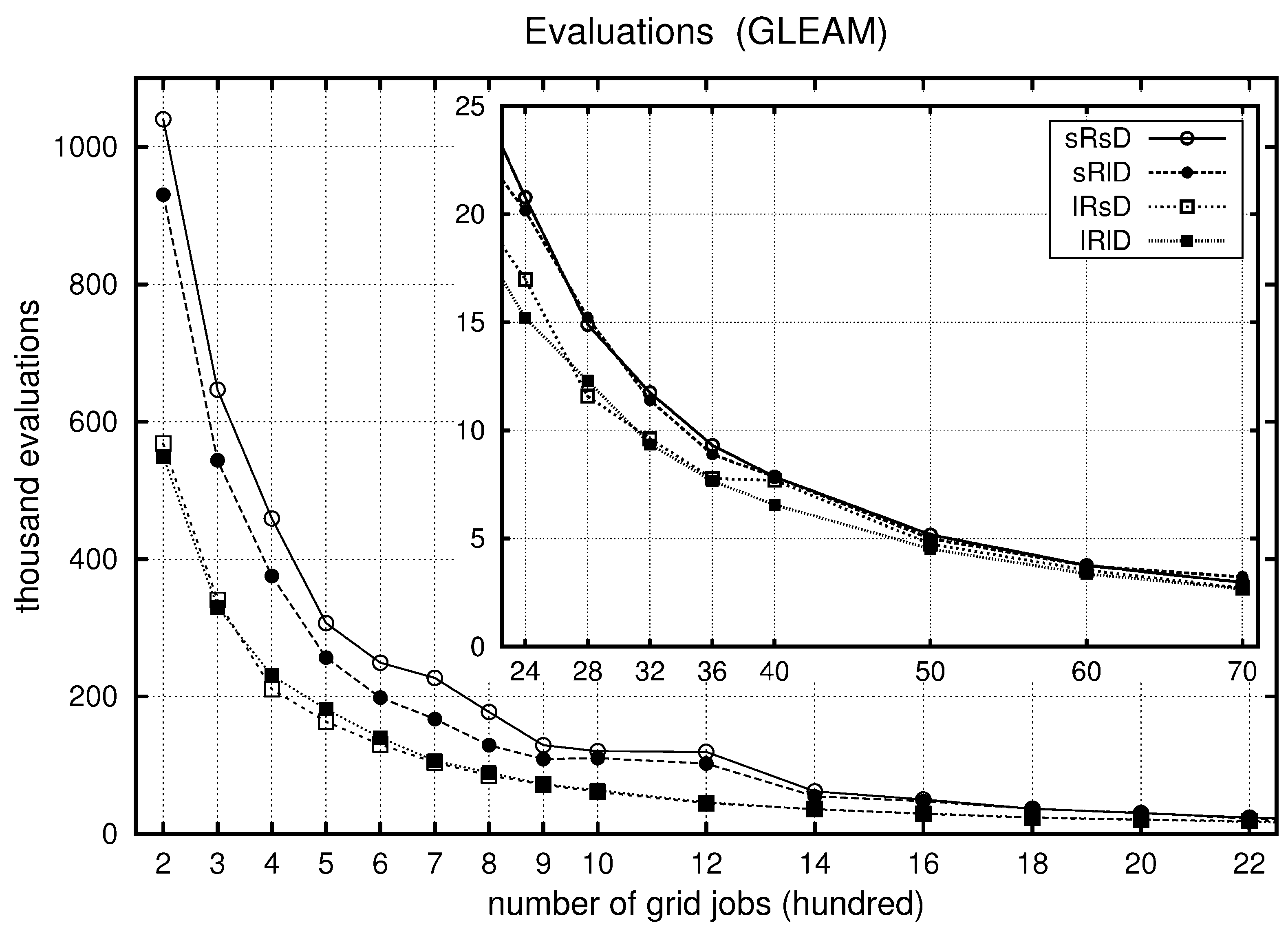
5.2. Experimental Results
5.2.1. Summary of the Results of Earlier Experiments
- The usage of the old plan as described in Section 4.1 is beneficial especially for small amounts of 10 or 20% finished and new grid jobs.
- Both sets of heuristics introduced in Section 4.1 contribute well, complement each other and GLEAM.
- It is clearly situation-dependent which heuristic or GLEAM performs best.
5.2.2. Assessment of the Processable Workload

5.2.3. Assessment of the Time and Cost Benchmark Reserves
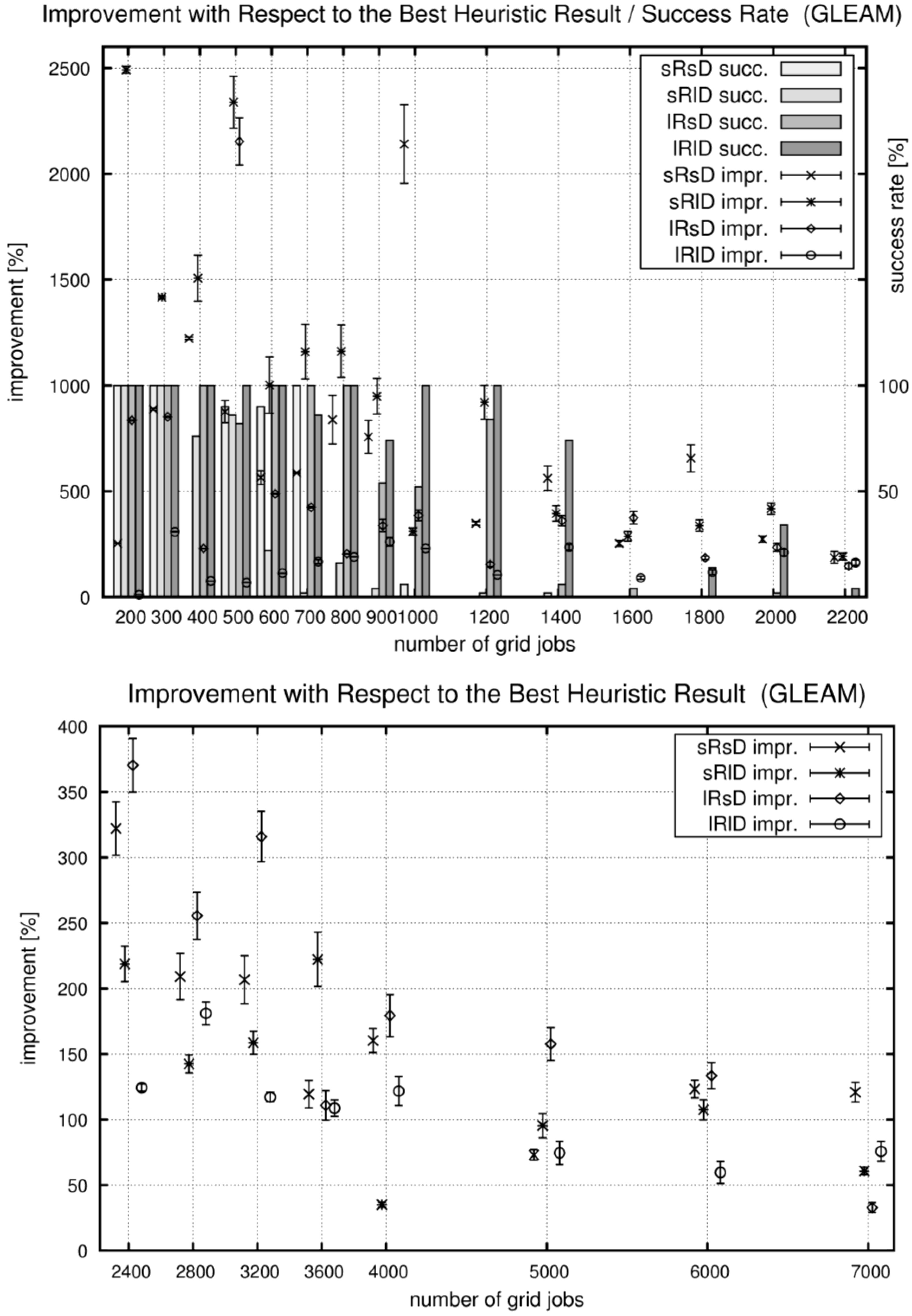
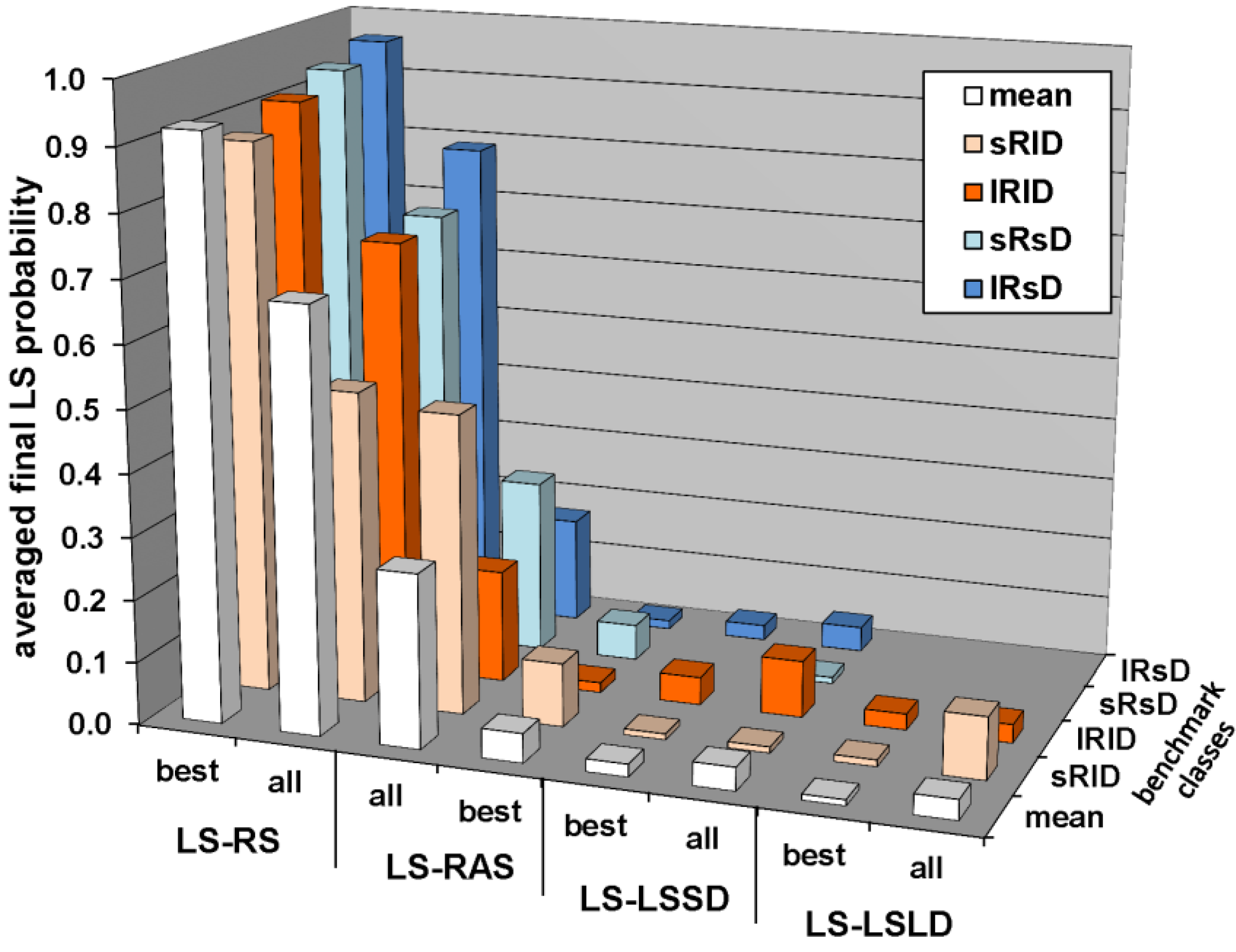
5.2.4. Comparison of the Four Local Searchers


5.2.5. Comparison of Pure GLEAM, AMMA, and the ASMAs Using the Two Best Performing Memes


5.2.6. Processible Workload Revisited

6. Failed Approaches
6.1. Failed Heuristics for the First Planning Phase
6.2. Failed Memetic Approaches
7. Conclusion and Outlook
Acknowledgements
References
- Foster, I.; Kesselman, C. The anatomy of the grid: Enabling scalable virtual organisations. Int. J. High Perform. C 2001, 15, 200–222. [Google Scholar] [CrossRef]
- Jakob, W.; Quinte, A.; Stucky, K.-U.; Süß, W. Optimised Scheduling of Grid Resources Using Hybrid Evolutionary Algorithms. In Proceeding of Parallel Processing and Applied Mathematics (PPAM 2005), LNCS 3911, Poznań, Poland, 11–14 September 2005; Wyrzykowski, R., Dongarra, J., Meyer, N., Waśniewski, J., Eds.; Springer: Berlin, Germany, 2006; pp. 406–413. [Google Scholar]
- Stucky, K.-U.; Jakob, W.; Quinte, A.; Süß, W. Solving Scheduling Problems in Grid Resource Management Using an Evolutionary Algorithm. In Proceeding of on the Move to Meaningful Internet Systems 2006: CoopIS, DOA, GADA, and ODBASE, Part II, LNCS 4276, Montpellier, France, 29 October–3 November 2006; Meersman, R., Tari, Z., Eds.; Springer: Heidelberg, Germany, 2006; pp. 1252–1262. [Google Scholar]
- Giffler, B.; Thompson, G.L. Algorithms for solving production scheduling problems. Oper. Res. 1960, 8, 487–503. [Google Scholar] [CrossRef]
- Glover, F.; Laguna, M. Tabu Search; Kluwer Academic Publisher: Boston, MA, USA, 1997. [Google Scholar]
- Brucker, P. Scheduling Algorithms; Springer: Berlin, Germany, 2004. [Google Scholar]
- Brucker, P.; Knust, S. Complex Scheduling; Springer: Berlin, Germany, 2006. [Google Scholar]
- Setamaa-Karkkainen, A.; Miettinen, K.; Vuori, J. Best compromise solution for a new multiobjective scheduling problem. Comput. Oper. Res. 2006, 33, 2353–2368. [Google Scholar] [CrossRef]
- Wieczorek, M.; Hoheisel, A.; Prodan, R. Taxonomy of the Multi-Criteria Grid Workflow Scheduling Problem. In Grid Middleware and Services—Challenges and Solutions; Talia, D., Yahyapour, R., Ziegler, W., Eds.; Springer: New York, NY, USA, 2008; pp. 237–264. [Google Scholar]
- Dutot, P.F.; Eyraud, L.; Mounié, G.; Trystram, D. Bi-Criteria Algorithm for Scheduling Jobs on Cluster Platforms. In Proceedings of the 16th Annual ACM Symposium on Parallelism in Algorithms and Architectures (SPAA’04), Barcelona, Spain, 27–30 June 2004; pp. 125–132.
- Sakellariou, S.; Zhao, H.; Tsiakkouri, E.; Dikaiakos, M.D. Scheduling Workflows with Budget Constraints. In Integrated Research in GRID Computing (CoreGRID Integration Workshop 2005, Selected Papers), CoreGRID Series; Gorlatch, S., Danelutto, M., Eds.; Springer: Berlin, Germany, 2007; pp. 189–202. [Google Scholar]
- Yu, J.; Buyya, R. A Budget Constrained Scheduling of Workflow Applications on Utility Grids using Genetic Algorithms. In Proceedings of the 15th IEEE International Symposium on High Performance Distributed Computing (HPDC 2006), Workshop on Workflows in Support of Large-Scale Science, Paris, France, 19–23 June 2006; pp. 1–10.
- Kurowski, K.; Nabrzyski, J.; Oleksiak, A.; Węglarz, J. Scheduling jobs on the grid—Multicriteria approach. Comput. Methods Sci. Technol. 2006, 12, 123–138. [Google Scholar] [CrossRef]
- Kurowski, K.; Nabrzyski, J.; Oleksiak, A.; Węglarz, J. A multicriteria approach to tow-level hierarchy scheduling in grids. J. Sched. 2008, 11, 371–379. [Google Scholar] [CrossRef]
- Tchernykh, A.; Schwiegelshohn, U.; Yahyapour, R.; Kuzjurin, N. On-Line hierarchical job scheduling on grids with admissible allocation. J. Sched. 2010, 13, 545–552. [Google Scholar] [CrossRef]
- Kurowski, K.; Oleksiak, A.; Węglarz, J. Multicriteria, multi-user scheduling in grids with advanced reservation. J. Sched. 2010, 13, 493–508. [Google Scholar] [CrossRef]
- Deb, K.; Pratab, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evolut. Comput. 2002, 6, 181–197. [Google Scholar] [CrossRef]
- Mika, M.; Waligóra, G.; Węglarz, J. Modelling and solving grid allocation problem with network resources for workflow applications. J. Sched. 2011, 14, 291–306. [Google Scholar] [CrossRef]
- Xhafa, F.; Alba, E.; Dorronsoro, B.; Duran, B.; Abraham, A. Efficient Batch Job Scheduling in Grids Using Cellular Memetic Algorithms. In Metaheuristics for Scheduling in Distributed Computing Environments; Xhafa, F., Abraham, A., Eds.; Springer: Berlin, Germany, 2008; pp. 273–299. [Google Scholar]
- Jakob, W.; Quinte, A.; Stucky, K.-U.; Süß, W. Fast Multi-Objective Scheduling of Jobs to Constrained Resources Using a Hybrid Evolutionary Algorithm. In Proceeding of Parallel Problem Solving from Nature (PPSN X), LNCS 5199, Dortmund, Germany, 13–17 September 2008; Rudolph, G., Jansen, T., Lucas, S., Poloni, C., Beume, N., Eds.; Springer: Berlin, Germany, 2008; pp. 1031–1040. [Google Scholar]
- Alba, E.; Dorronsoro, B.; Alfonso, H. Cellular memetic algorithms. J. Comput. Sci. Technol. 2005, 5, 257–263. [Google Scholar]
- Gorges-Schleuter, M. Genetic Algorithms and Population Structures—A Massively Parallel Algorithm. Ph.D. Thesis, Department of Computer Science, University of Dortmund, Germany, 1990. [Google Scholar]
- Jakob, W.; Gorges-Schleuter, M.; Blume, C. Application of Genetic Algorithms to Task Planning and Learning. In Proceeding of Parallel Problem Solving from Nature (PPSN II), Brussels, Belgium, 28–30 September 1992; Männer, R., Manderick, B., Eds.; Elsevier: Amsterdam, The Netherlands, 1992; pp. 291–300. [Google Scholar]
- Jakob, W. A general cost-benefit-based adaptation framework for multimeme algorithms. Memet. Comput. 2010, 3, 201–218. [Google Scholar] [CrossRef]
- Jakob, W. HyGLEAM: Hybrid GeneraL-Purpose Evolutionary Algorithm and Method. In Proceedings of World Multiconf on Systematics, Cybernetics and Informatics (SCI’ 2001), Volume III, Orlando, FL, USA, 22–25 July 2001; Callaos, N., Esquivel, S., Burge, J., Eds.; pp. 187–192.
- Sarma, K.; de Jong, K. An Analysis of the Effects of Neighborhood Size and Shape on Local Selection Algorithms. In Proceeding of Parallel Problem Solving from Nature (PPSN IV), LNCS 1141, Berlin, Germany, 22–26 September 1996; Voigt, H.-M., Ebeling, W., Rechenberg, I., Schwefel, H.-P., Eds.; Springer: Berlin, Germany, 1996; pp. 236–244. [Google Scholar]
- Nguyen, Q.H.; Ong, Y.-S.; Lim, M.H.; Krasnogor, N. Adaptive cellular memetic algorithms. Evol. Comput. 2009, 17, 231–256. [Google Scholar]
- Xhafa, F.; Abraham, A. Meta-Heuristics in Grid Scheduling Problems. In Metaheuristics for Scheduling in Distributed Computing Environments; Xhafa, F., Abraham, A., Eds.; Springer: Berlin, Germany, 2008; pp. 1–37. [Google Scholar]
- Eiben, A.E.; Smith, J.E. Introduction to Evolutionary Computation; Natural Computing Series; Springer: Berlin, Germany, 2003. [Google Scholar]
- De Jong, K.A. Evolutionary Computation—A Unified Approach; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Blume, C.; Jakob, W. GLEAM—General Learning Evolutionary Algorithm and Method: Ein Evolutionärer Algorithmus und Seine Anwendungen; Series of the Institute for Applied Computer Science/Automation Technology; KIT Scientific Publishing: Karlsruhe, Germany, 2009; Volume 32. [Google Scholar]
- Blume, C. Automatic Generation of Collision Free Moves for the ABB Industrial Robot Control. In Proceedings of Knowledge-Based Intelligent Electronic Systems (KES’97), Part II, Adelaide, Australia, 21–23 May 1997; Jain, L.C., Ed.; IEEE: Piscataway, NJ, USA; pp. 672–683.
- Blume, C. Optimization in Concrete Precasting Plants by Evolutionary Computation. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO 2000), Volume LBP, Las Vegas, NV, USA, 10–12 July 2000; Morgan Kaufmann: San Francisco, CA, USA; pp. 43–50.
- Gorges-Schleuter, M. A Comparative Study of Global and Local Selection in Evolution Strategies. In Proceeding of Parallel Problem Solving from Nature (PPSN V), LNCS 1498, Amsterdam, The Netherlands, 27–30 September 1998; Eiben, A.E., Bäck, T., Schoenauer, M., Schwefel, H.-P., Eds.; Springer: Berlin, Germany, 1998; pp. 367–377. [Google Scholar]
- Gorges-Schleuter, M. Explicit Parallelism of Genetic Algorithms through Population Structures. In Proceeding of Parallel Problem Solving from Nature (PPSN I), LNCS 496, Dortmund, Germany, 1–3 October 1990; Schwefel, H.-P., Männer, R., Eds.; Springer: Berlin, Germany, 1991; pp. 150–159. [Google Scholar]
- Stucky, K.-U.; Jakob, W.; Quinte, A.; Süß, W. Tackling the Grid Job Planning and Resource Allocation Problem Using a Hybrid Evolutionary Algorithm. In Proceeding of Parallel Processing and Applied Mathematics (PPAM 2007), LNCS 4967, Gdansk, Poland, 9–12 September 2007; Wyrzykowski, R., Dongarra, J., Karczewski, K., Waśniewski, J., Eds.; Springer: Berlin, Germany, 2008; pp. 589–599. [Google Scholar]
- Davis, L. Handbook of Genetic Algorithms; V. Nostrand Reinhold: New York, NY, USA, 1991. [Google Scholar]
- Bierwirth, C.; Mattfeld, D.C.; Kopfer, H. On Permutation Representations for Scheduling Problems. In Proceeding of Parallel Problem Solving from Nature (PPSN IV), LNCS 1141, Berlin, Germany, 22–26 September 1996; Voigt, H.-M., Ebeling, W., Rechenberg, I., Schwefel, H.-P., Eds.; Springer: Berlin, Germany, 1996; pp. 310–318. [Google Scholar]
- Moscato, P. On Evolution, Search, Optimization, Genetic Algorithms and Martial Arts—Towards Memetic Algorithms; California Institute of Technology: Pasadena, CA, USA, 1989. [Google Scholar]
- Jakob, W.; Blume, C.; Bretthauer, G. Towards a Generally Applicable Self-Adapting Hybridization of Evolutionary Algorithms. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO 2004), LNCS 3102, Part 1 and Volume LBP, Seattle, WA, USA, 26–30 June 2004; Deb, K., Ed.; Springer: Berlin, Germany, 2004; pp. 790–791. [Google Scholar]
- Ong, Y.-S.; Keane, A.J. Meta-Lamarckian learning in memetic algorithms. IEEE Trans. Evol. Comput. 2004, 8, 99–110. [Google Scholar] [CrossRef]
- Hart, W.E.; Krasnogor, N.; Smith, J.E. Recent Advances in Memetic Algorithms; Series of Studies in Fuzziness and Soft Computing; Springer: Berlin, Germany, 2005; Volume 166. [Google Scholar]
- Chen, X.; Ong, Y.-S.; Lim, M.-H.; Tan, K.C. A Multi-Facet Survey on Memetic Computation. IEEE Trans. Evol. Comput. 2011, 5, 591–607. [Google Scholar] [CrossRef]
- Krasnogor, N.; Smith, J. A tutorial for competent Memetic Algorithms: Model, taxonomy, and design issues. IEEE Trans. Evol. Comput. 2005, 5, 474–488. [Google Scholar] [CrossRef]
- Nguyen, Q.H.; Ong, Y.-S.; Krasnogor, N. A Study on Design Issues of Memetic Algorithm. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC 2007), Singapore, 25–28 September 2007; pp. 2390–2397.
- Orvosh, D.; Davis, L. Shall We Repair? Genetic Algorithms, Combinatorial Optimization, and Feasibility Constraints. In Proceedings of the Fifth International Conference on Genetic Algorithms (ICGA), Urbana-Champaign, IL, USA, 17–21 July 1993; Forrest, S., Ed.; Morgan Kaufmann: San Mateo, CA, USA, 1993; p. 650. [Google Scholar]
- Whitley, D.; Gordon, V.; Mathias, K. Lamarckian Evolution, the Baldwin Effect and Function Optimization. In Proceedings of Parallel Problem Solving from Nature (PPSN III), LNCS 866, Jerusalem, Israel, 9–14 October 1994; Davidor, Y., Schwefel, H.-P., Männer, R., Eds.; Springer: Berlin, Germany, 1994; pp. 6–14. [Google Scholar]
- Jakob, W. HyGLEAM—An Approach to Generally Applicable Hybridization of Evolutionary Algorithms. In Proceedings of Parallel Problem Solving from Nature (PPSN VII), LNCS 2439, Granada, Spain, 7–22 September 2002; Merelo Guervós, J.J., Adamidis, P., Beyer, H.-G., Fernández-Villacañas, J.-L., Schwefel, H.-P., Eds.; Springer: Berlin, Germany, 2002; pp. 527–536. [Google Scholar]
- Hasan, K.S.H.; Sarker, R.; Essam, D.; Cornforth, D. Memetic algorithms for solving job-shop scheduling problems. Memet. Comput. 2009, 1, 69–83. [Google Scholar] [CrossRef]
- Zhang, G. Investigating Memetic Algorithm for Solving the Job Shop Scheduling Problems. In Proceedings of the International Conference on Artificial Intelligence and Computational Intelligence (AICI ’10), Sanya, China, 23–24 October 2010; IEEE: Piscataway, NJ, USA; pp. 429–432.
- Hart, W.E. Adaptive Global Optimization with Local Search. Ph.D. Thesis, University of California, USA, 1994. [Google Scholar]
- Krasnogor, N.; Blackburne, B.P.; Burke, E.K.; Hirst, J.D. Multimeme Algorithms for Protein Structure Prediction. In Proceedings of Parallel Problem Solving from Nature (PPSN VII), LNCS 2439, Granada, Spain, 7–22 September 2002; Merelo Guervós, J.J., Adamidis, P., Beyer, H.-G., Fernández-Villacañas, J.-L., Schwefel, H.-P., Eds.; Springer: Berlin, Germany, 2002; pp. 769–778. [Google Scholar]
- Chen, X.; Ong, Y.-S. A conceptual modeling of meme complexes in stochastic search. IEEE Trans. Syst. Man Cybern. Part C 2012, 5, 612–625. [Google Scholar] [CrossRef]
- Wieczorek, M.; Prodan, R.; Fahringer, T. Comparison of Workflow Scheduling Strategies on the Grid. In Proceeding of Parallel Processing and Applied Mathematics (PPAM 2005), LNCS 3911, Poznań, Poland, 11–14 September 2005; Wyrzykowski, R., Dongarra, J., Meyer, N., Waśniewski, J., Eds.; Springer: Berlin, Germany, 2006; pp. 792–800. [Google Scholar]
- Tobita, T.; Kasahara, H. A standard task graph set for fair evaluation of multiprocessor scheduling algorithms. J. Sched. 2002, 5, 379–394. [Google Scholar] [CrossRef]
- Hönig, U.; Schiffmann, W. A comprehensive Test Bench for the Evaluation of Scheduling Heuristics. In Proceedings of the 16th IASTED International Conference on Parallel and Distributed Computing and Systems (PDCS’04), MIT Cambridge, MIT Cambridge, MA, USA, 9–11 November 2004; Gonzales, T., Ed.; pp. 439–803.
- Süß, W.; Quinte, A.; Jakob, W.; Stucky, K.-U. Construction of Benchmarks for Comparison of Grid Resource Planning Algorithms. In Proceedings of the Second International Conference on Software and Data Technologies (ICSOFT 2007), Volume PL, Barcelona, Spain, 22–25 July 2007; INSTICC Press: Setubal, Portugal, 2007; pp. 80–87. [Google Scholar]
- Strack, S.; Jakob, W.; Bengel, G.; Quinte, A.; Stucky, K.-U.; Süß, W. New Parameters for the Evaluation of Benchmarks for Fast Evolutionary Scheduling of Workflows with Tight Time and Cost Restrictions. In Proceedings of the International Conference on Genetic and Evolutionary Methods (GEM’12), Las Vegas, NV, USA, 16–19 July 2012; Arabnia, H.R., Hashemi, T.R., Solo, A.M.G., Eds.; CSREA Press: Las Vegas, NV, USA, 2012. [Google Scholar]
- Jakob, W.; Quinte, A.; Stucky, K.-U.; Süß, W. Fast Multi-Objective Rescheduling of Grid Jobs by Heuristics and Evolution. In Proceedings of Parallel Processing and Applied Mathematics (PPAM 2009), LNCS 6068, Wroclaw, Poland, 13–16 September 2009; Wyrzykowski, R., Dongarra, J., Karczewski, K., Waśniewski, J., Eds.; Springer: Berlin, Germany, 2010; pp. 21–30. [Google Scholar]
- Jakob, W.; Möser, F.; Quinte, A.; Stucky, K.-U.; Süß, W. Fast multi-objective rescheduling of workflows using heuristics and memetic evolution. Scalable Comput. Pract. Exp. 2010, 2, 173–188. [Google Scholar]
- Neumann, K.; Morlock, M. Operations Research; Carl Hanser: München, Germany, 2002. [Google Scholar]
- Schuster, C. No-Wait Job-Shop Scheduling: Komplexität und Local Search. Ph.D. Thesis, University Duisburg-Essen, Germany, 2003. [Google Scholar]
- Adams, J.; Balas, E.; Zawak, D. The shifting bottleneck procedure for job shop scheduling. Manage Sci. 1988, 34, 391–401. [Google Scholar] [CrossRef]
- Chen, L.-P.; Lee, M.S.; Pulat, P.S.; Moses, S.A. The shifting bottleneck procedure for job-shops with parallel machines. Int. J. Ind. Syst. Eng. 2006, 1, 244–262. [Google Scholar] [CrossRef]
- Pitsoulis, L.S.; Resende, M.G.C. Greedy Randomized Adaptive Search Procedures. In Handbook of Applied Optimization; Pardalos, P.M., Resende, M.G.C., Eds.; Oxford University Press: New York, NY, USA, 2001; pp. 168–181. [Google Scholar]
- Maykasoğlu, A.; Özbakir, L.; Dereli, T. Multiple Dispatching Rule Based Heuristic for Multi-Objective Scheduling of Job Shops using Tabu Search. In Proceedings of the 5th International Conference on Managing Innovations in Manufacturing (MIM 2002), Milwaukee, WI, USA, 9–11 September 2002; pp. 396–402.
- Möser, F.; Jakob, W.; Quinte, A.; Stucky, K.-U.; Süß, W. An Assessment of Heuristics for Fast Scheduling of Grid Jobs. In Proceedings of the Fifth International Conference on Software and Data Technologies (ICSOFT 2010), Volume 1, Athens, Greece, 22–24 July 2010; Cordeiro, J., Virvou, M., Shishkov, B., Eds.; INSTICC Press: Setubal, Portugal, 2010; pp. 184–191. [Google Scholar]
- Hahnenkamp, B. Integration Anwendungsneutraler Lokaler Suchverfahren in den Adaptiven Memetischen Algorithmus HyGLEAM für Komplexe Reihenfolgeoptimierung. Ph.D. Thesis, AIFB, University of Karlsruhe, Germany, 2007. [Google Scholar]
- Feng, L.; Ong, Y.-S.; Tsang, I.W.-H.; Tan, A.-H. An Evolutionary Search Paradigm that Learns with Past Experiences. In Proceeding of the 2012 IEEE Congress on Evolutionary Computation (CEC), Brisbane, Australia, 10–15 June 2012; pp. 1–8.
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Jakob, W.; Strack, S.; Quinte, A.; Bengel, G.; Stucky, K.-U.; Süß, W. Fast Rescheduling of Multiple Workflows to Constrained Heterogeneous Resources Using Multi-Criteria Memetic Computing. Algorithms 2013, 6, 245-277. https://doi.org/10.3390/a6020245
Jakob W, Strack S, Quinte A, Bengel G, Stucky K-U, Süß W. Fast Rescheduling of Multiple Workflows to Constrained Heterogeneous Resources Using Multi-Criteria Memetic Computing. Algorithms. 2013; 6(2):245-277. https://doi.org/10.3390/a6020245
Chicago/Turabian StyleJakob, Wilfried, Sylvia Strack, Alexander Quinte, Günther Bengel, Karl-Uwe Stucky, and Wolfgang Süß. 2013. "Fast Rescheduling of Multiple Workflows to Constrained Heterogeneous Resources Using Multi-Criteria Memetic Computing" Algorithms 6, no. 2: 245-277. https://doi.org/10.3390/a6020245
APA StyleJakob, W., Strack, S., Quinte, A., Bengel, G., Stucky, K. -U., & Süß, W. (2013). Fast Rescheduling of Multiple Workflows to Constrained Heterogeneous Resources Using Multi-Criteria Memetic Computing. Algorithms, 6(2), 245-277. https://doi.org/10.3390/a6020245