A Progressive Hedging Approach to Solve Harvest Scheduling Problem under Climate Change

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
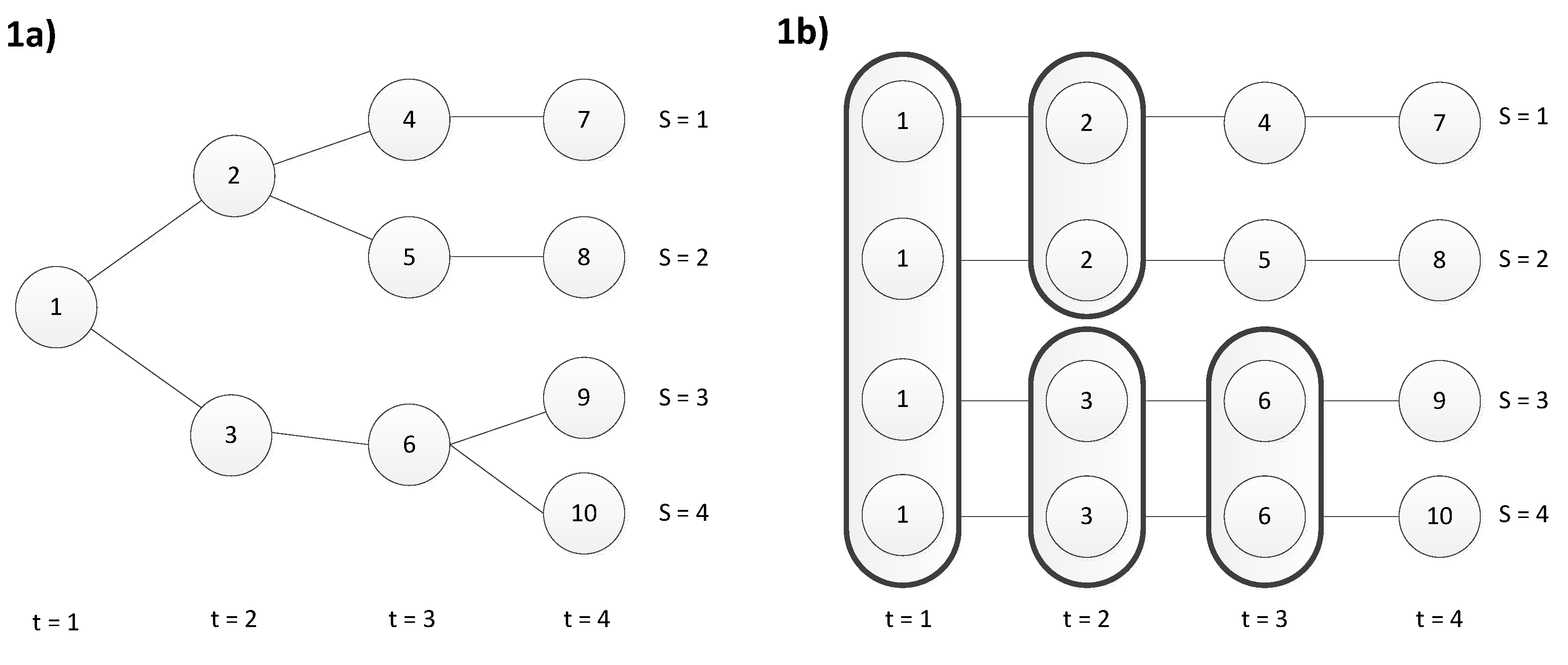
2.1. Problem Description
2.2. Scenario Generation
2.3. The Model
- Stand harvest 0–1
- Volume harvested in period t
- Even-flow of harvest
- Demand constraints
- Adjacency constraints
- Non-anticipativity rule
- Binary requirements
2.4. Progressive Hedging Approach
2.4.1. Methodology
| Algorithm 1. Progressive Hedging |
| begin |
| STEP 0 |
| STEP 1 |
| Solve each scenario by max: |
| STEP 2 |
| Compute the average solution in each node: |
| STEP 3 |
| If the solutions are equal according to the criterion: |
| then terminate. |
| STEP 4 |
| Update |
| Update the penalty factor: |
| STEP 5 |
| Solve each scenario with the penalty term: |
| STEP 6 |
| Update iteration number |
| k = k+1 |
| Return to STEP 2 |
| End |
2.4.2. PH Heuristic
2.5. Instances of the Original Problem
2.6. Hardware and Software
3. Results
3.1. Configurations
3.2. Performance Comparison
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alonso-Ayuso, A.; Escudero, L.F.; Guignard, M.; Quinteros, M.; Weintraub, A. Forestry management under uncertainty. Ann. Oper. Res. 2011, 190, 17–39. [Google Scholar] [CrossRef]
- Watson, R.T.; Zinyowera, M.C.; Moss, R.H. (Eds.) Climate Change 1995: Impacts on Forests. In Contribution of Working Group II to the Second Assessment Report of the Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK, 1995; 878p. [Google Scholar]
- Christensen, J.H.; Hewitson, B.; Busuioc, A.; Chen, A.; Gao, X.; Held, R.; Jones, R.; Kolli, R.K.; Kwon, W.K.; Laprise, R.; et al. Regional Climate Projections: Climate Change. In The Physical Science Basis Contribution of Working group I to the Fourth Assessment Report of the Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK, 2007; Chapter 11; pp. 847–940. [Google Scholar]
- Davis, L.S.; Johnson, K.N.; Howard, T.; Bettinger, P. Forest Management; McGraw Hill Publishing Company: New York, NY, USA, 2001. [Google Scholar]
- Pasalodos-Tato, M.; Makinen, A.; Garcia-Gonzalo, J.; Borges, J.G.; Lämas, T.; Eriksson, O. Assessing uncertainty and risk in forest planning and decision support systems: Review of classical methods and introduction of new approaches. For. Syst. 2013, 22, 282–303. [Google Scholar] [CrossRef] [Green Version]
- Yousefpour, R.; Jacobsen, J.B.; Thorsen, B.J.; Meilby, H.; Hanewinkel, M.; Oehler, K. A review of decision-making approaches to handle uncertainty and risk in adaptive forest management under climate change. Ann. For. Sci. 2012, 69, 1–15. [Google Scholar] [CrossRef]
- Badilla Veliz, F.; Watson, J.P.; Weintraub, A.; Wets, R.J.B.; Woodruff, D. Stochastic optimization models in forest planning: A progressive hedging solution approach. Ann. Oper. Res. 2015, 232, 259–274. [Google Scholar]
- Hof, J.; Pickens, J. Chance-constrained and chance-maximizing mathematical programs in renewable resource management. For. Sci. 1991, 38, 308–325. [Google Scholar]
- Palma, C.D.; Nelson, J.D. A robust optimization approach protected harvest scheduling decisions against uncertainty. Can. J. For. Res. 2009, 39, 342–355. [Google Scholar] [CrossRef]
- Eyvindson, K.; Kangas, A. Stochastic goal programming in forest planning. Can. J. For. Res. 2014, 44, 1274–1280. [Google Scholar] [CrossRef]
- Kangas, A.; Hartikainen, M.; Miettinen, K. Simultaneous optimization of harvest schedule and measurement strategy. Scand. J. For. Res. 2014, 29, 224–233. [Google Scholar] [CrossRef]
- Birge, J.R.; Louveaux, F. Introduction to Stochastic Programming, 2nd ed.; Springer Series in Operations Research and Financial Engineering; Springer: New York, NY, USA, 2011; Volume 31. [Google Scholar] [CrossRef]
- Rockafellar, R.T.; Uryasev, S. Optimization of conditional value-at-risk. J. Risk 2000, 2, 21–42. [Google Scholar] [CrossRef] [Green Version]
- Rockafeller, R.T.; Wets, R.J.B. Scenarios and policy aggregation in optimization under uncertainty. Math. Oper. Res. 1991, 16, 119–147. [Google Scholar] [CrossRef]
- Lasch, P.; Badeck, F.; Suckow, F.; Lindner, M.; Mohr, P. Model-based analysis of management alternatives at stand and regional level in Brandenburg (Germany). For. Ecol. Manag. 2005, 207, 59–74. [Google Scholar] [CrossRef]
- Lindner, M.; Garcia-Gonzalo, J.; Kolstrom, M.; Green, T.; Reguera, R.; Maroschek, M.; Seidl, R.; Lexer, M.J.; Netherer, S.; Schopf, A.; et al. Impacts of Climate Change on European Forests and Options for Adaptation; Report to the European Commission Directorate-General for Agriculture and Rural Development; 2008; Available online: https://ec.europa.eu/agriculture/sites/agriculture/files/external-studies/2008/euro-forests/annex.pdf (accessed on 19 October 2019).
- Nitschke, C.; Innes, J. A tree and climate assessment tool for modelling ecosystem response to climate change. Ecol. Model. 2008, 210, 263–277. [Google Scholar] [CrossRef]
- Seidl, R.; Rammer, W.; Jager, D.; Lexer, M. Impact of bark beetle (Ips typographus L.) disturbance on timber production and carbon sequestration in different management strategies under climate change. For. Ecol. Manag. 2008, 256, 209–220. [Google Scholar] [CrossRef]
- Garcia-Gonzalo, J.; Borges, J.G.; Palma, J.H.N.; Zubizarreta-Gerendiain, A. A decision support system for management planning of Eucalyptus plantations facing climate change. Ann. For. Sci. 2014, 71, 187–199. [Google Scholar] [CrossRef]
- Rammer, W.; Schauflinger, C.; Vacik, H.; Palma, J.H.N.; Garcia-Gonzalo, J.; Borges, J.; Lexer, M.J. A web-based toolbox approach to support adaptive forest management under climate change. Scand. J. For. Res. 2014, 29, 96–107. [Google Scholar] [CrossRef]
- Eriksson, L.O. Planning under uncertainty at the forest level: A systems approach. Scand. J. For. Res. 2006, 21, 111–117. [Google Scholar] [CrossRef]
- Garcia-Gonzalo, J.; Pais, C.; Bachmatiuk, J.; Weintraub, A. Accounting for climate change in a forest planning stochastic optimization model. Can. J. For. Res. 2016, 46, 1111–1121. [Google Scholar] [CrossRef]
- Álvarez-Miranda, E.; Garcia-Gonzalo, J.; Ulloa-Fierro, F.; Weintraub, A.; Barreiro, S. A Multicriteria Optimization Model for Forestry Management under Climate Change Uncertainty: An application in Portugal. Eur. J. Oper. Res. 2018, 269, 79–98. [Google Scholar] [CrossRef]
- Weintraub, A.; Church, R.L.; Murray, A.T.; Guignard, M. Forest management models and combinatorial algorithms: Analysis of state of the art. Ann. Oper. Res. 2000, 96, 271–285. [Google Scholar] [CrossRef]
- Wets, R.J.B. On the relation between stochastic and deterministic optimization. In Control Theory, Numerical Methods and Computer Systems Modelling; Bensoussan, A., Lions, J.L., Eds.; Lecture Notes in Economics and Mathematical Systems; Springer: Berlin/Heidelberg, Germany, 1975; Volume 107, pp. 350–361. [Google Scholar] [CrossRef]
- Alonso-Ayuso, A.; Escudero, L.F.; Ortuno, M.T. BFC, a branch-and-fix coordination algorithmic framework for solving some types of stochastic pure and mixed 0–1 programs. Eur. J. Oper. Res. 2003, 151, 503–519. [Google Scholar] [CrossRef]
- Andalaft, N.; Andalaft, P.; Guignard, M.; Magendzo, A.; Wainer, A.; Weintraub, A. A problem of forest harvesting and road building solved through model strengthening and Lagrangean relaxation. Oper. Res. 2003, 51, 613–628. [Google Scholar] [CrossRef]
- Mulvey, J.M.; Vladimirou, H. Applying the progressive hedging algorithm to stochastic generalized networks. Ann. Oper. Res. 1991, 31, 399–424. [Google Scholar] [CrossRef]
- Crainic, T.G.; Fu, X.; Gendreau, M.; Rei, W.; Wallace, S.W. Progressive hedging-based metaheuristics for stochastic network design. Networks 2011, 58, 114–124. [Google Scholar] [CrossRef]
- Fan, Y.; Liu, C. Solving stochastic transportation network protection problems using the progressive hedging-based method. Netw. Spat. Econ. 2010, 10, 193–208. [Google Scholar] [CrossRef]
- Hvattum, L.M.; Løkketangen, A. Using scenario trees and progressive hedging for stochastic inventory routing problems. J. Heuristics 2009, 15, 527–557. [Google Scholar] [CrossRef]
- Watson, J.P.; Woodruff, D.L. Progressive hedging innovations for a class of stochastic mixed-integer resource allocation problems. Comput. Manag. Sci. 2011, 8, 355–370. [Google Scholar] [CrossRef]
- Marques, A.F.; Borges, J.G.; Garcia-Gonzalo, J.; Lucas, B.; Melo, I. A participatory approach to design a toolbox to support forest management planning at regional level. For. Syst. 2013, 22, 340–358. [Google Scholar] [CrossRef] [Green Version]
- Goycoolea, M.; Murray, A.; Vielma, J.P.; Weintraub, A. Evaluating approaches for solving the area restriction model in harvest scheduling. For. Sci. 2009, 55, 149–165. [Google Scholar]
- Fontes, L.; Landsberg, J.; Tomé, J.; Tomé, M.; Pacheco, C.A.; Soares, P.; Araujo, C. Calibration and testing of a generalized process-based model for use in Portuguese eucalyptus plantations. Can. J. For. Res. 2006, 36, 3209–3221. [Google Scholar] [CrossRef]
- Tomé, M.; Faias, S.P.; Tomé, J.; Cortiçada, A.; Soares, P.; Araújo, C. Hybridizing a stand level process-based model with growth and yield models for Eucalyptus globulus plantations in Portugal. In Proceedings of the IUFRO Conference—Eucalyptus in a Changing World, Aveiro, Portugal, 11–15 October 2004. [Google Scholar]
- Korzukhin, M.D.; Ter-Mikaelian, M.T.; Wagner, R.G. Process versus empirical models: Which approach for forest ecosystem management? Can. J. For. Res. 1996, 26, 879–887. [Google Scholar] [CrossRef]
- Lexer, M.J.; Lexer, W.; Hasenauer, H. The use of forest models for biodiversity assessments at the stand level. For. Syst. 2000, 9, 297–316. [Google Scholar]
- Goulding, C.J. Development of growth models for Pinus radiata in New Zealand: Experience with management and process models. For. Ecol. Manag. 1994, 69, 331–343. [Google Scholar] [CrossRef]
- Pukkala, T.; Kellomäki, S. Anticipatory vs. adaptive optimization of stand management when tree growth and timber prices are stochastic. Forestry 2012, 85, 463–472. [Google Scholar] [CrossRef] [Green Version]
- Albert, M.; Schmidt, M. Climate-sensitive modelling of site-productivity relationships for Norway spruce (Picea abies (L.) Karst.) and common beech (Fagus sylvatica L.). For. Ecol. Manag. 2010, 259, 739–749. [Google Scholar] [CrossRef]
- Trasobares, A.; Zingg, A.; Walthert, L.; Bigler, C. A climate-sensitive empirical growth and yield model for forest management planning of evenaged beech stands. Eur. J. For. Res. 2016, 135, 263–282. [Google Scholar] [CrossRef]
- Soares, P.M.; Cardoso, R.M.; Miranda, P.; Viterbo, P.; Belo-Pereira, M. Assessment of the ENSEMBLES regional climate models in the representation of precipitation variability and extremes over Portugal. J. Geophys. Res. Atmos. 2012, 117. [Google Scholar] [CrossRef] [Green Version]
- Quinteros, M.; Alonso, A.; Escudero, L.; Guignard, M.; Weintraub, A. Una Aplicación de Programación Estocástica a un Problema de Gestión Forestal. Rev. Ing. Sist. 2006, 20, 67–95. [Google Scholar]
- Murray, A.T. Spatial Restrictions in Harvest Scheduling. For. Sci. 1999, 45, 45–52. [Google Scholar]
- McDill, M.E.; Rebain, S.; Braze, J. Har-vest scheduling with area-based adjacency constraints. For. Sci. 2002, 48, 631–642. [Google Scholar]
- Goycoolea, M.; Murray, A.T.; Barahona, F.; Epstein, R.; Weintraub, A. Harvest Scheduling Subject to Maximum Area Restrictions: Exploring Exact Approaches. Oper. Res. 2005, 53, 490–500. [Google Scholar] [CrossRef] [Green Version]
- Watson, J.P.; Woodruff, D.L.; Strip, D.R. Progressive hedging innovations for a stochastic spare parts support enterprise problem. Nav. Res. Logist. 2007. [Google Scholar]
- Williams, B.K. Adaptive management of natural resources—Framework and issues. J. Environ. Manag. 2011, 92, 1346–1353. [Google Scholar] [CrossRef] [PubMed]
- Eyvindson, K.; Kangas, A. Evaluating the required scenario set size for stochastic programming in forest management planning: Incorporating inventory and growth model uncertainty. Can. J. For. Res. 2016, 46, 340–347. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
| EF | PH | Statistics | |||
|---|---|---|---|---|---|
| Instance | Gap [%] | Time [s] | Gap [%] | Time [s] | Saved Time [%] |
| 100SD0% | NO SOL | NO SOL | 1.2 | 354.5 | - |
| 100SD25% | 23.2 | 36,000 | 7.5 | 2458.1 | 91.7 |
| 100SD50% | 5.2 | 36,000 | 4.8 | 920.2 | 98.3 |
| 100SD75% | 4.3 | 36,000 | 3.9 | 469.3 | 98.6 |
| 100SD90% | 3.6 | 36,000 | 3.5 | 765.2 | 98.7 |
| 100SD95% | NO SOL | NO SOL | 0.9 | 226.00 | - |
| 100SD100% | NO SOL | NO SOL | 1.9 | 5974 | - |
| 200SD0% | NO SOL | NO SOL | 3.8 | 608.4 * | - |
| 200SD25% | 49.4 | 36,000 | 5.4 | 3963.5 | 88.9 |
| 200SD50% | 27.9 | 36,000 | 6.2 | 827.1 | 97.7 |
| 200SD75% | 6.4 | 36,000 | 6.1 | 261.7 | 98.5 |
| 200SD90% | 2.9 | 36,000 | 2.7 | 224.6 | 98.7 |
| 200SD95% | NO SOL | NO SOL | 1.6 | 5410.6 | - |
| 200SD100% | NO SOL | NO SOL | 1.3 | 5853.8 | - |
| 400SD0% | NO SOL | NO SOL | 3.4 | 3006.7 | - |
| 400SD25% | 6.1 | 36,000 | 5.8 | 3996.8 | 69.6 |
| 400SD50% | 5.2 | 36,000 | 4.9 | 1082.2 | 95 |
| 400SD75% | 7.2 | 36,000 | 6.8 | 514.4 | 97.1 |
| 400SD90% | 5.0 | 36,000 | 4.7 | 429.0 | 97.5 |
| 400SD95% | NO SOL | NO SOL | 2.6 | 6887.6 * | - |
| 400SD100% | NO SOL | NO SOL | 1.7 | 6068.4 | - |
| 800SD0% | NO SOL | NO SOL | 2.3 | 3109.4 | - |
| 800SD25% | 1.0 | 11,092 | 1.1 | 3268.6 | 66.6 |
| 800SD50% | 1.5 | 9029 | 1.7 | 2275.1 | 76.3 |
| 800SD75% | 7.8 | 36,000 | 7.5 | 1406.8 | 92.2 |
| 800SD90% | 8.8 | 36,000 | 8.1 | 1390.9 | 93.8 |
| 800SD95% | NO SOL | NO SOL | 4.7 | 9519.8 * | - |
| 800SD100% | NO SOL | NO SOL | 2.7 | 11,603.2 * | - |
| 1000SD0% | NO SOL | NO SOL | 1.8 | 4844 | - |
| 1000SD25% | 0.9 | 6061 | 1.0 | 1574 | 91.4 |
| 1000SD50% | 1.0 | 8279 | 1.3 | 5283 | 91.6 |
| 1000SD75% | 7.9 | 36,000 | 7.5 | 2404 | 92.9 |
| 1000SD90% | 8.8 | 36,000 | 8.6 | 1787 | 93.8 |
| 1000SD95% | NO SOL | NO SOL | 13.7 | 36,000 | - |
| 1000SD100% | NO SOL | NO SOL | 13.1 | 36,000 | - |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garcia-Gonzalo, J.; Pais, C.; Bachmatiuk, J.; Barreiro, S.; Weintraub, A. A Progressive Hedging Approach to Solve Harvest Scheduling Problem under Climate Change. Forests 2020, 11, 224. https://doi.org/10.3390/f11020224
Garcia-Gonzalo J, Pais C, Bachmatiuk J, Barreiro S, Weintraub A. A Progressive Hedging Approach to Solve Harvest Scheduling Problem under Climate Change. Forests. 2020; 11(2):224. https://doi.org/10.3390/f11020224
Chicago/Turabian StyleGarcia-Gonzalo, Jordi, Cristóbal Pais, Joanna Bachmatiuk, Susana Barreiro, and Andres Weintraub. 2020. "A Progressive Hedging Approach to Solve Harvest Scheduling Problem under Climate Change" Forests 11, no. 2: 224. https://doi.org/10.3390/f11020224
APA StyleGarcia-Gonzalo, J., Pais, C., Bachmatiuk, J., Barreiro, S., & Weintraub, A. (2020). A Progressive Hedging Approach to Solve Harvest Scheduling Problem under Climate Change. Forests, 11(2), 224. https://doi.org/10.3390/f11020224