
Classification of Complicated Urban Forest Acoustic Scenes with Deep Learning Models



Abstract
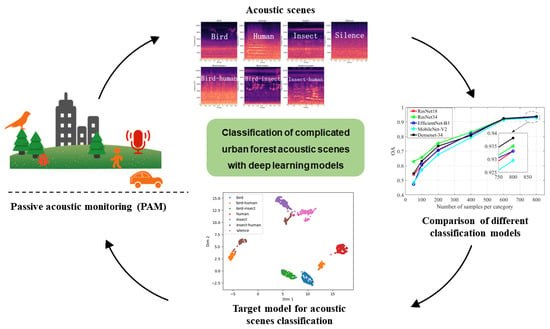
:
1. Introduction
2. Methods
2.1. Study Area
2.2. Data Acquisition and Dataset Construction
2.3. Feature Extraction
2.4. Data Augmentation
2.5. Deep Learning Methods
2.6. Performance Evaluation
2.7. Experimental Environmant
3. Results
3.1. Comparison of the Results of Different Models with Different Amounts of Training Data
3.2. Effect of Training Epochs on Model Classification Results
3.3. Comparison of Different Models’ Ability to Predict New Data
3.4. Analysis Results of Acoustic Scene Classification Using the DenseNet_BC_34 Mode
4. Discussion
4.1. Effect of Training Data Amount and Epochs on Model Classification Performance
4.2. DenseNet_BC_34 Model for Classification of the Acoustic Scenes
4.3. Comparison of Related Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acoustic Scene | Criteria |
|---|---|
| Human (H) | Sound clips contain only human activity sounds. |
| Insect (I) | The sound clip contains only insect calls, such as cicadas. |
| Bird (B) | The sound clip contains only bird sounds. |
| Bird–Human (BH) | A mixture of human sounds and bird sounds in the sound clip. |
| Insect–Human (IH) | A mixture of insect sounds and human sounds in the sound clip. |
| Bird–Insect (BI) | A mixture of bird sounds and insect sounds in the sound clip. |
| Silence (S) | There are no valid sound events in the sound clip. |
| Model | FLOPs (G) | Params (M) |
|---|---|---|
| ResNet18 | 15.01 | 11.17 |
| ResNet34 | 31.14 | 21.28 |
| EfficientNet_b3 | 0.01 | 10.72 |
| MobileNet_v2 | 0.18 | 2.23 |
| DenseNet_BC_34 | 0.40 | 0.12 |
References
- Masood, E. Battle over biodiversity. Nature 2018, 560, 423–425. [Google Scholar] [CrossRef] [Green Version]
- Wu, J. Urban ecology and sustainability: The state-of-the-science and future directions. Landsc. Urban Plan. 2014, 125, 209–221. [Google Scholar] [CrossRef]
- Rivkin, L.R.; Santangelo, J.S.; Alberti, M.; Aronson, M.F.J.; De Keyzer, C.W.; Diamond, S.E.; Fortin, M.; Frazee, L.J.; Gorton, A.J.; Hendry, A.P.; et al. A roadmap for urban evolutionary ecology. Evol. Appl. 2019, 12, 384–398. [Google Scholar] [CrossRef] [Green Version]
- Yang, J. Big data and the future of urban ecology: From the concept to results. Sci. China Earth Sci. 2020, 63, 1443–1456. [Google Scholar] [CrossRef]
- Farina, A.; Pieretti, N.; Malavasi, R. Patterns and dynamics of (bird) soundscapes: A biosemiotic interpretation. Semiotica 2014, 2014, 109. [Google Scholar] [CrossRef]
- Hampton, S.E.; Strasser, C.A.; Tewksbury, J.J.; Gram, W.K.; Budden, A.E.; Batcheller, A.L.; Duke, C.S.; Porter, J.H. Big data and the future of ecology. Front. Ecol. Environ. 2013, 11, 156–162. [Google Scholar] [CrossRef] [Green Version]
- Dumyahn, S.L.; Pijanowski, B.C. Soundscape conservation. Landsc. Ecol. 2011, 26, 1327–1344. [Google Scholar] [CrossRef]
- Hou, Y.; Yu, X.; Yang, J.; Ouyang, X.; Fan, D. Acoustic Sensor-Based Soundscape Analysis and Acoustic Assessment of Bird Species Richness in Shennongjia National Park, China. Sensors 2022, 22, 4117. [Google Scholar] [CrossRef]
- Sugai, L.S.M.; Silva, T.S.F.; Ribeiro, J.W.; Llusia, D. Terrestrial Passive Acoustic Monitoring: Review and Perspectives. Bioscience 2019, 69, 15–25. [Google Scholar] [CrossRef]
- Kasten, E.P.; Gage, S.H.; Fox, J.; Joo, W. The remote environmental assessment laboratory’s acoustic library: An archive for studying soundscape ecology. Ecol. Inform. 2012, 12, 50–67. [Google Scholar] [CrossRef]
- Pijanowski, B.C.; Villanueva-Rivera, L.J.; Dumyahn, S.L.; Farina, A.; Krause, B.L.; Napoletano, B.M.; Gage, S.H.; Pieretti, N. Soundscape Ecology: The Science of Sound in the Landscape. Bioscience 2011, 61, 203–216. [Google Scholar] [CrossRef] [Green Version]
- Krause, B. Bioacoustics: Habitat Ambience & Ecological Balance. Whole Earth Rev. 1987, 57. [Google Scholar]
- Sueur, J.; Krause, B.; Farina, A. Acoustic biodiversity. Curr. Biol. 2021, 31, R1172–R1173. [Google Scholar] [CrossRef]
- Fairbrass, A.J.; Firman, M.; Williams, C.; Brostow, G.; Titheridgem, H.; Jones, K.E. CityNet-Deep learning tools for urban ecoacoustic assessment. Methods Ecol. Evol. 2019, 10, 186–197. [Google Scholar] [CrossRef] [Green Version]
- Lewis, J.W.; Wightman, F.L.; Brefczynski, J.A.; Phinney, R.E.; Binder, J.R.; DeYoe, E.A. Human Brain Regions Involved in Recognizing Environmental Sounds. Cereb. Cortex 2004, 14, 1008–1021. [Google Scholar] [CrossRef] [Green Version]
- Alluri, V.; Kadiri, S.R. Neural Correlates of Timbre Processing, in Timbre: Acoustics, Perception, and Cognition; Springer: Berlin/Heidelberg, Germany, 2019; pp. 151–172. [Google Scholar]
- Eronen, A.; Tuomi, J.; Klapuri, A.; Fagerlund, S.; Sorsa, T.; Lorho, G.; Huopaniemi, J. Audio-based context awareness acoustic modeling and perceptual evaluation. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, New Platz, NY, USA, 6–10 April 2003. [Google Scholar]
- Eronen, A.J.; Peltonen, V.T.; Tuomi, J.; Klapuri, A.; Fagerlund, S.; Sorsa, T.; Lorho, G.; Huopaniemi, J. Audio-based context recognition. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 321–329. [Google Scholar] [CrossRef]
- Lei, B.Y.; Mak, M.W. Sound-Event Partitioning and Feature Normalization for Robust Sound-Event Detection. In Proceedings of the 19th International Conference on Digital Signal Processing (DSP), Hong Kong, China, 20–23 August 2014. [Google Scholar]
- Chu, S.; Narayanan, S.; Kuo, C.C.J. Environmental Sound Recognition with Time-Frequency Audio Features. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1142–1158. [Google Scholar] [CrossRef]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing, Boston, MA, USA, 17–20 September 2015. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Boddapati, V.; Petef, A.; Rasmusson, J.; Lundberg, L. Classifying environmental sounds using image recognition networks. In Proceedings of the 21st International Conference on Knowledge—Based and Intelligent Information and Engineering Systems (KES), Aix Marseille University, St. Charles Campus, Marseille, France, 6–8 September 2017. [Google Scholar]
- Chi, Z.; Li, Y.; Chen, C. Deep Convolutional Neural Network Combined with Concatenated Spectrogram for Environmental Sound Classification. In Proceedings of the 2019 IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 19–20 October 2019. [Google Scholar]
- Mushtaq, Z.; Su, S.-F.; Tran, Q.-V. Spectral images based environmental sound classification using CNN with meaningful data augmentation. Appl. Acoust. 2021, 172, 107581. [Google Scholar] [CrossRef]
- Qiao, T.; Zhang, S.; Cao, S.; Xu, S. High Accurate Environmental Sound Classification: Sub-Spectrogram Segmentation versus Temporal-Frequency Attention Mechanism. Sensors 2021, 21, 5500. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Yin, B.; Cui, Y.; Li, K.; Du, Z. Research on Environmental Sound Classification Algorithm Based on Multi-feature Fusion. In Proceedings of the IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–20 December 2020. [Google Scholar]
- Wu, B.; Zhang, X.-P. Environmental Sound Classification via Time–Frequency Attention and Framewise Self-Attention-Based Deep Neural Networks. IEEE Internet Things J. 2022, 9, 3416–3428. [Google Scholar] [CrossRef]
- Song, H.; Deng, S.; Han, J. Exploring Inter-Node Relations in CNNs for Environmental Sound Classification. IEEE Signal Process. Lett. 2022, 29, 154–158. [Google Scholar] [CrossRef]
- Tripathi, A.M.; Mishra, A. Environment sound classification using an attention-based residual neural network. Neurocomputing 2021, 460, 409–423. [Google Scholar] [CrossRef]
- Lin, T.; Tsao, Y. Source separation in ecoacoustics: A roadmap towards versatile soundscape information retrieval. Remote. Sens. Ecol. Conserv. 2020, 6, 236–247. [Google Scholar] [CrossRef] [Green Version]
- Sethi, S.S.; Jones, N.S.; Fulcher, B.D.; Picinali, L.; Clink, D.J.; Klinck, H.; Orme, C.D.L.; Wrege, P.H.; Ewers, R.M. Characterizing soundscapes across diverse ecosystems using a universal acoustic feature set. Proc. Natl. Acad. Sci. USA 2020, 117, 17049–17055. [Google Scholar] [CrossRef]
- Goëau, H.; Glotin, H.; Joly, A.; Vellinga, W.; Planqué, R. LifeCLEF Bird Identification Task 2016: The arrival of Deep learning. Comput. Sci. 2016, 2016, 6569338. [Google Scholar]
- LeBien, J.; Zhong, M.; Campos-Cerqueira, M.; Velev, J.P.; Dodhia, R.; Ferres, J.L.; Aide, T.M. A pipeline for identification of bird and frog species in tropical soundscape recordings using a convolutional neural network. Ecol. Inform. 2020, 59, 101113. [Google Scholar] [CrossRef]
- Tabak, M.A.; Murray, K.L.; Reed, A.M.; Lombardi, J.A.; Bay, K.J. Automated classification of bat echolocation call recordings with artificial intelligence. Ecol. Inform. 2022, 68, 101526. [Google Scholar] [CrossRef]
- Quinn, C.A.; Burns, P.; Gill, G.; Baligar, S.; Snyder, R.L.; Salas, L.; Goetz, S.J.; Clark, M.L. Soundscape classification with convolutional neural networks reveals temporal and geographic patterns in ecoacoustic data. Ecol. Indic. 2022, 138, 108831. [Google Scholar] [CrossRef]
- Hong, X.-C.; Wang, G.-Y.; Liu, J.; Song, L.; Wu, E.T. Modeling the impact of soundscape drivers on perceived birdsongs in urban forests. J. Clean. Prod. 2020, 292, 125315. [Google Scholar] [CrossRef]
- Schmidt, A.K.D.; Balakrishnan, R. Ecology of acoustic signaling and the problem of masking interference in insects. J. Comp. Physiol. A Neuroethol. Sens. Neural Behav. Physiol. 2015, 201, 133–142. [Google Scholar] [CrossRef] [PubMed]
- Hao, Z.; Zhan, H.; Zhang, C.; Pei, N.; Sun, B.; He, J.; Wu, R.; Xu, X.; Wang, C. Assessing the effect of human activities on biophony in urban forests using an automated acoustic scene classification model. Ecol. Indic. 2022, 144, 109437. [Google Scholar] [CrossRef]
- Ul Haq, H.F.D.; Ismail, R.; Ismail, S.; Purnama, S.R.; Warsito, B.; Setiawan, J.D.; Wibowo, A. EfficientNet Optimization on Heartbeats Sound Classification. In Proceedings of the 5th International Conference on Informatics and Computational Sciences (ICICoS), Aachen, Germany, 24–25 November 2021. [Google Scholar]
- Xu, J.X.; Lin, T.-C.; Yu, T.-C.; Tai, T.-C.; Chang, P.-C. Acoustic Scene Classification Using Reduced MobileNet Architecture. In Proceedings of the 20th IEEE International Symposium on Multimedia (ISM), Taichung, Taiwan, 10–12 December 2018. [Google Scholar]
- Mushtaq, Z.; Su, S.-F. Efficient Classification of Environmental Sounds through Multiple Features Aggregation and Data Enhancement Techniques for Spectrogram Images. Symmetry 2020, 12, 1822. [Google Scholar] [CrossRef]
- Briggs, F.; Lakshminarayanan, B.; Neal, L.; Fern, X.Z.; Raich, R.; Hadley, S.J.K.; Hadley, A.S.; Betts, M.G. Acoustic classification of multiple simultaneous bird species: A multi-instance multi-label approach. J. Acoust. Soc. Am. 2012, 131, 4640–4650. [Google Scholar] [CrossRef] [Green Version]
- Strout, J.; Rogan, B.; Seyednezhad, S.M.; Smart, K.; Bush, M.; Ribeiro, E. Anuran call classification with deep learning. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, USA, 5–7 March 2017. [Google Scholar]
- Rabiner, L.; Schafer, R. Theory and Applications of Digital Speech Processing; Universidad Autónoma de Madrid: Madrid, Spain, 2011. [Google Scholar]
- Christin, S.; Hervet, É.; LeComte, N. Applications for deep learning in ecology. Methods Ecol. Evol. 2019, 10, 1632–1644. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- He, K.M.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Deer Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Tan, M.X.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Tan, M.X.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Quoc, V.L. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, 16–20 June 2019. [Google Scholar]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Elsevier: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Stowell, D. Computational bioacoustics with deep learning: A review and roadmap. Peerj 2022, 10, 13152. [Google Scholar] [CrossRef]
- Thian, Y.L.; Ng, D.W.; Hallinan, J.T.P.D.; Jagmohan, P.; Sia, S.Y.; Mohamed, J.S.A.; Quek, S.T.; Feng, M. Effect of Training Data Volume on Performance of Convolutional Neural Network Pneumothorax Classifiers. J. Digit. Imaging 2021, 35, 881–892. [Google Scholar] [CrossRef]
- Mcinnes, L.; Healy, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]
- Mullet, T.C.; Gage, S.H.; Morton, J.M.; Huettmann, F. Temporal and spatial variation of a winter soundscape in south-central Alaska. Landsc. Ecol. 2016, 31, 1117–1137. [Google Scholar] [CrossRef]
- Font, F.; Roma, G.; Serra, X. Freesound technical demo. ACM 2013, 2013, 411–412. [Google Scholar]
- Dufourq, E.; Durbach, I.; Hansford, J.P.; Hoepfner, A.; Ma, H.; Bryant, J.V.; Stender, C.S.; Li, W.; Liu, Z.; Chen, Q.; et al. Automated detection of Hainan gibbon calls for passive acoustic monitoring. Remote. Sens. Ecol. Conserv. 2021, 7, 475–487. [Google Scholar] [CrossRef]







| Model | OA (%) | |||||
|---|---|---|---|---|---|---|
| 50 1 | 100 1 | 200 1 | 400 1 | 600 1 | 800 1 | |
| ResNet18 | 53.86 | 60.33 | 70.95 | 81.71 | 91.79 | 93.31 |
| ResNet34 | 62.90 | 65.79 | 75.31 | 83.02 | 92.12 | 93.50 |
| EfficientNet_b3 | 47.40 | 61.00 | 70.57 | 81.76 | 92.28 | 93.31 |
| MobileNet_v2 | 48.33 | 57.19 | 67.64 | 79.31 | 91.48 | 92.95 |
| DenseNet_BC_34 | 54.69 | 63.21 | 73.50 | 80.71 | 92.40 | 93.81 |
| Model | Epoch | OA (%) | |||||
|---|---|---|---|---|---|---|---|
| 50 1 | 100 1 | 200 1 | 400 1 | 600 1 | 800 1 | ||
| ResNet18 | 50 2 | 51.88 | 59.35 | 69.52 | 81.07 | 91.50 | 92.83 |
| 100 2 | 53.64 (+1.76) | 59.95 (+0.60) | 70.95 (+1.43) | 81.71 (+0.64) | 91.64 (+0.14) | 93.31 (+0.48) | |
| 150 2 | 53.86 (+0.21) | 59.95 (+0.00) | 70.95 (+0.00) | 81.71 (+0.00) | 91.64 (+0.00) | 93.31 (+0.00) | |
| 200 2 | 53.86 (+0.00) | 60.33 (+0.38) | 70.95 (+0.00) | 81.71 (+0.00) | 91.79 (+0.15) | 93.31 (+0.00) | |
| ResNet34 | 50 2 | 58.50 | 64.29 | 75.17 | 82.72 | 91.55 | 92.76 |
| 100 2 | 62.90 (+4.40) | 64.29 (+0.00) | 75.31 (+0.14) | 83.02 (+0.31) | 92.12 (+0.57) | 93.50 (+0.74) | |
| 150 2 | 62.90 (+0.00) | 65.79 (+1.50) | 75.31 (+0.00) | 83.02 (+0.00) | 92.12 (+0.00) | 93.50 (+0.00) | |
| 200 2 | 62.90 (+0.00) | 65.79 (+0.00) | 75.31 (+0.00) | 83.02 (+0.00) | 92.12 (+0.00) | 93.50 (+0.00) | |
| EfficientNet_b3 | 50 2 | 36.31 | 52.83 | 67.69 | 80.26 | 91.50 | 92.97 |
| 100 2 | 44.55 (+8.24) | 56.93 (+4.10) | 69.05 (+1.36) | 81.31 (+1.05) | 92.28 (+0.78) | 93.21 (+0.24) | |
| 150 2 | 47.40 (+2.85) | 58.62 (+1.69) | 69.47 (+0.43) | 81.47 (+0.16) | 92.28 (+0.00) | 93.21 (+0.00) | |
| 200 2 | 47.40 (+0.00) | 61.00 (+2.38) | 70.57 (+1.10) | 81.76 (+0.29) | 92.28 (+0.00) | 93.31 (+0.10) | |
| MobileNet_v2 | 50 2 | 41.62 | 50.59 | 63.17 | 76.12 | 90.45 | 92.36 |
| 100 2 | 44.86 (+3.24) | 53.15 (+2.55) | 64.81 (+1.64) | 78.90 (+2.78) | 91.36 (+0.91) | 92.79 (+0.43) | |
| 150 2 | 47.67 (+2.81) | 55.24 (+2.09) | 66.93 (+2.12) | 79.19 (+0.29) | 91.48 (+0.12) | 92.95 (+0.17) | |
| 200 2 | 48.33 (+0.67) | 57.19 (+1.95) | 67.64 (+0.72) | 79.31 (+0.12) | 91.48 (+0.00) | 92.95 (+0.00) | |
| DensNet_BC_34 | 50 2 | 49.24 | 56.59 | 69.69 | 78.41 | 90.62 | 91.79 |
| 100 2 | 52.05 (+2.81) | 60.57 (+3.98) | 72.88 (+3.19) | 80.67 (+2.26) | 91.78 (+1.17) | 92.86 (+1.07) | |
| 150 2 | 53.12 (+1.07) | 63.21 (+2.64) | 73.41 (+0.52) | 80.71 (+0.05) | 92.19 (+0.41) | 93.64 (+0.79) | |
| 200 2 | 54.69 (+1.57) | 63.21 (+0.00) | 73.50 (+0.09) | 80.71 (+0.00) | 92.40 (+0.21) | 93.81 (+0.16) | |
| Model | OA (%) |
|---|---|
| ResNet18 | 70.69 |
| ResNet34 | 69.47 |
| EfficientNet_B3 | 65.65 |
| MobileNet_V2 | 61.18 |
| DenseNet_BC_34 | 73.50 |
| Class | TP | TN | FP | FN | ACC (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|---|---|---|
| B | 191 | 1182 | 18 | 9 | 98.07 | 91.39 | 95.50 | 93.40 |
| BH | 172 | 1189 | 11 | 28 | 97.21 | 93.99 | 86.00 | 89.82 |
| BI | 189 | 1190 | 10 | 11 | 98.50 | 94.97 | 94.50 | 94.74 |
| H | 189 | 1179 | 21 | 11 | 97.71 | 90.00 | 94.50 | 92.20 |
| I | 190 | 1190 | 10 | 10 | 98.57 | 95.00 | 95.00 | 95.00 |
| IH | 188 | 1190 | 10 | 12 | 98.43 | 94.95 | 94.00 | 94.47 |
| S | 195 | 1192 | 8 | 5 | 99.07 | 96.06 | 97.50 | 96.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Zhan, H.; Hao, Z.; Gao, X. Classification of Complicated Urban Forest Acoustic Scenes with Deep Learning Models. Forests 2023, 14, 206. https://doi.org/10.3390/f14020206
Zhang C, Zhan H, Hao Z, Gao X. Classification of Complicated Urban Forest Acoustic Scenes with Deep Learning Models. Forests. 2023; 14(2):206. https://doi.org/10.3390/f14020206
Chicago/Turabian StyleZhang, Chengyun, Haisong Zhan, Zezhou Hao, and Xinghui Gao. 2023. "Classification of Complicated Urban Forest Acoustic Scenes with Deep Learning Models" Forests 14, no. 2: 206. https://doi.org/10.3390/f14020206
APA StyleZhang, C., Zhan, H., Hao, Z., & Gao, X. (2023). Classification of Complicated Urban Forest Acoustic Scenes with Deep Learning Models. Forests, 14(2), 206. https://doi.org/10.3390/f14020206