
Assessment of Forest Ecological Function Levels Based on Multi-Source Data and Machine Learning

Abstract
:1. Introduction
2. Materials and Methods
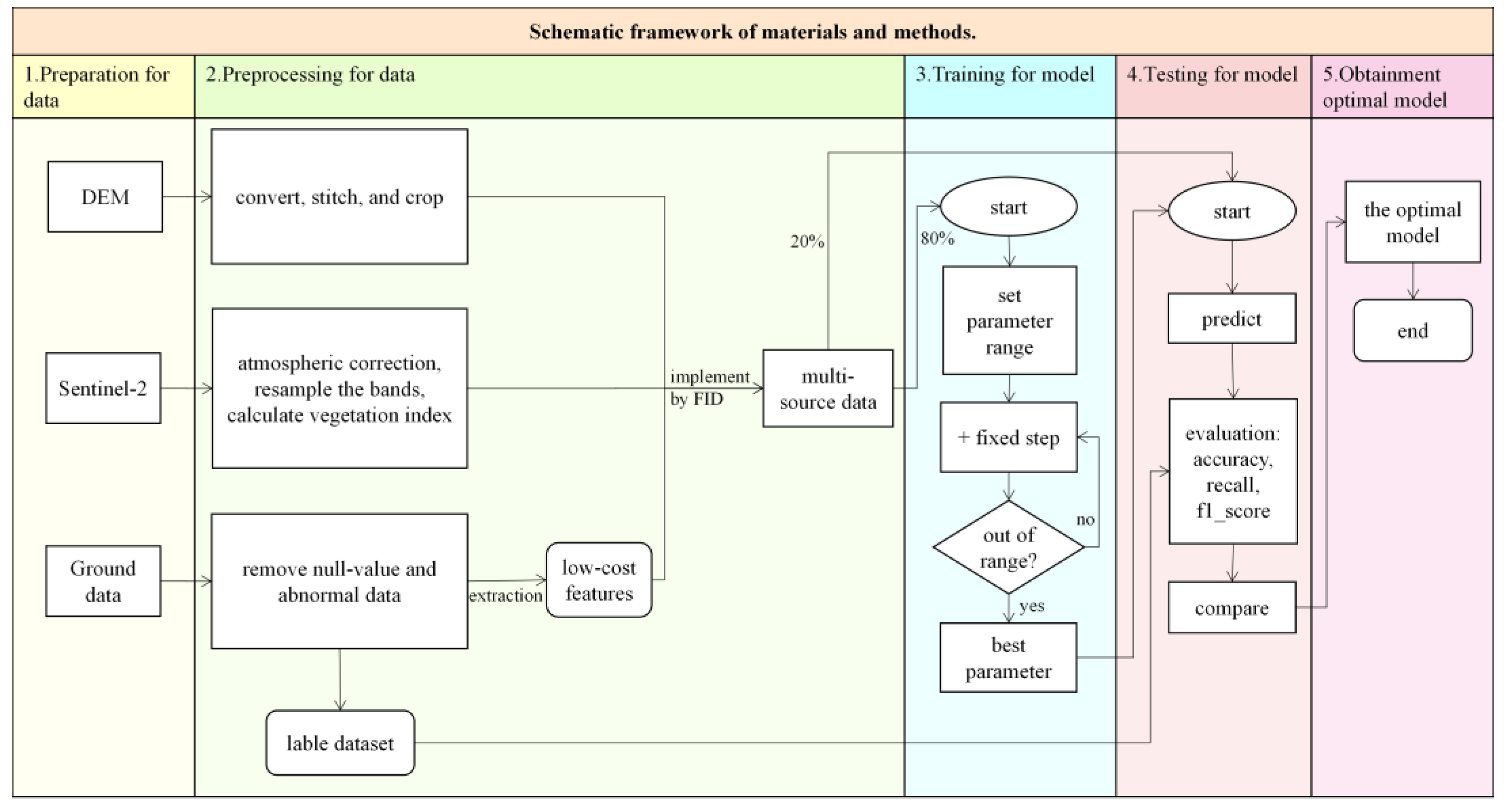
2.1. Schematic Framework of Materials and Methods
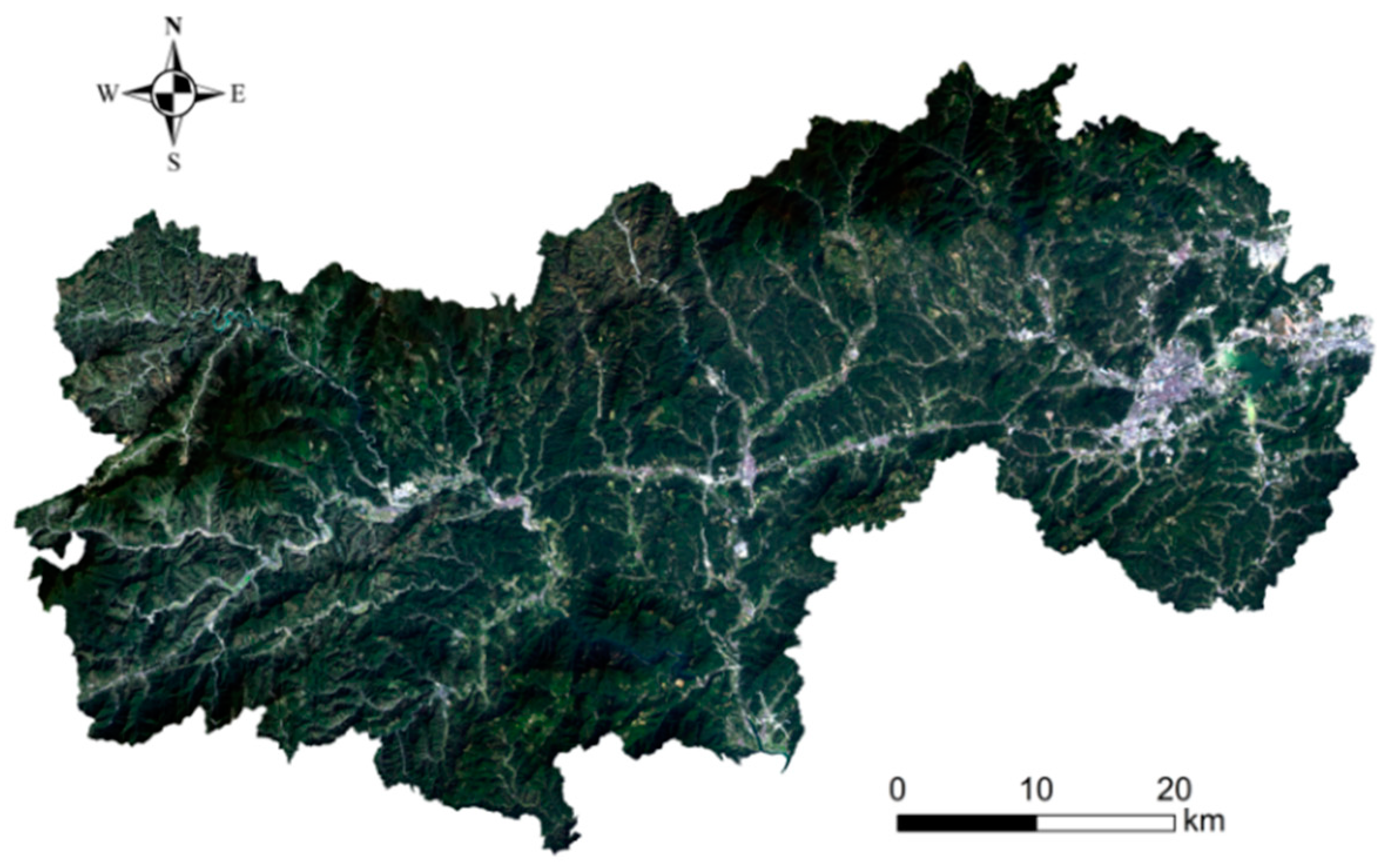
2.2. Overview of the Study Area
2.3. Processing of Label Dataset
2.4. Data Sources and Pre-Processing
2.4.1. Data Sources
2.4.2. Data Pre-Processing
- (1)
- Forest Resources Planning and Design Survey Data
- (2)
- Extraction and processing of characteristic factors based on images from remote sensing and DEM
2.5. Extraction of Feature Factors from Ground Survey Data
2.6. Multi-Source Data Integration
2.7. Methods
2.7.1. Grid SearchCV
2.7.2. Random Forest (RF)
2.7.3. Light Gradient Boosting Machine (LightGBM)
2.7.4. CatBoost
2.7.5. Performance Metrics
3. Results
3.1. Labeling of the Data
3.2. Design of the Data Scheme
3.3. Testing Results
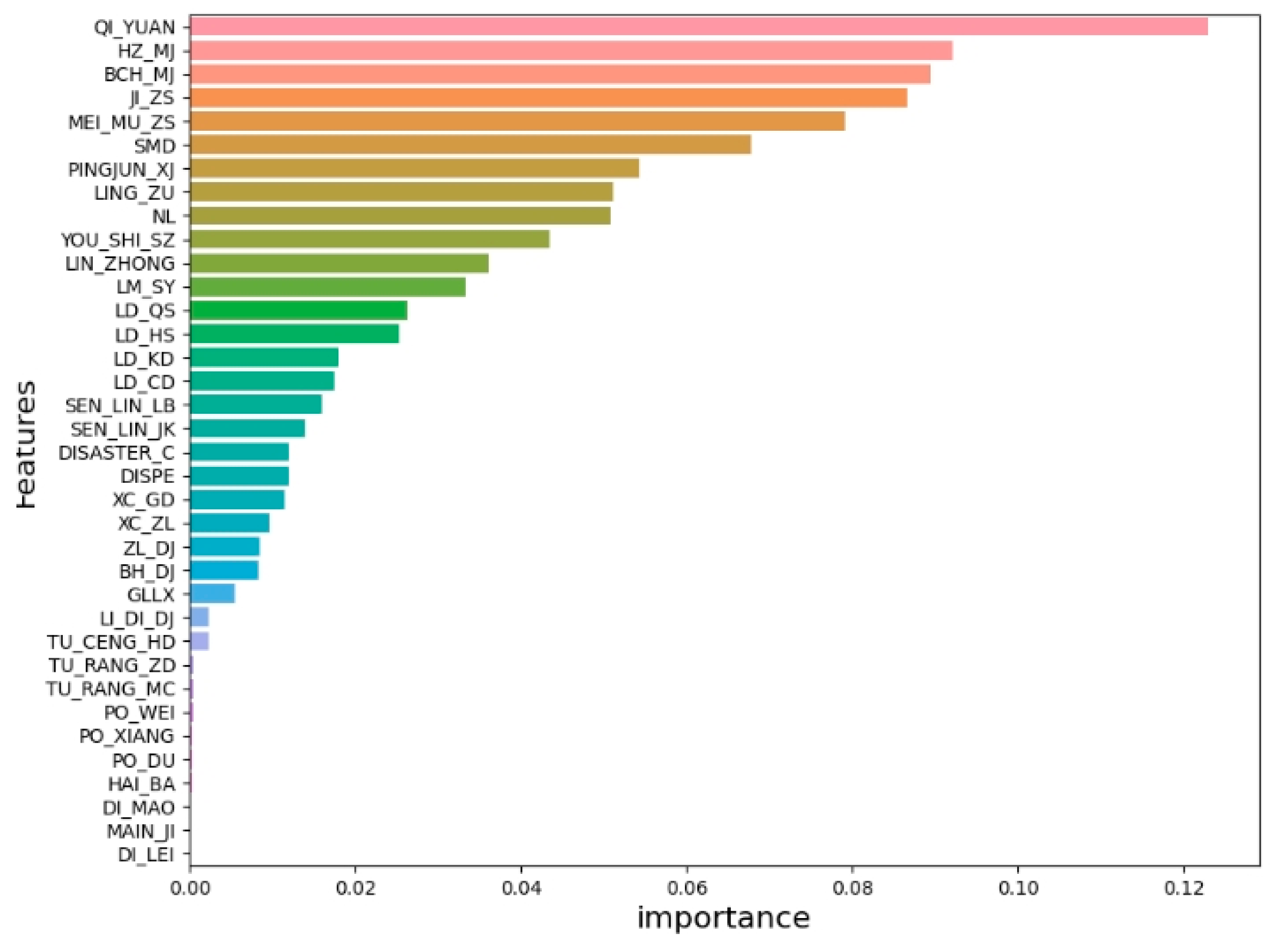
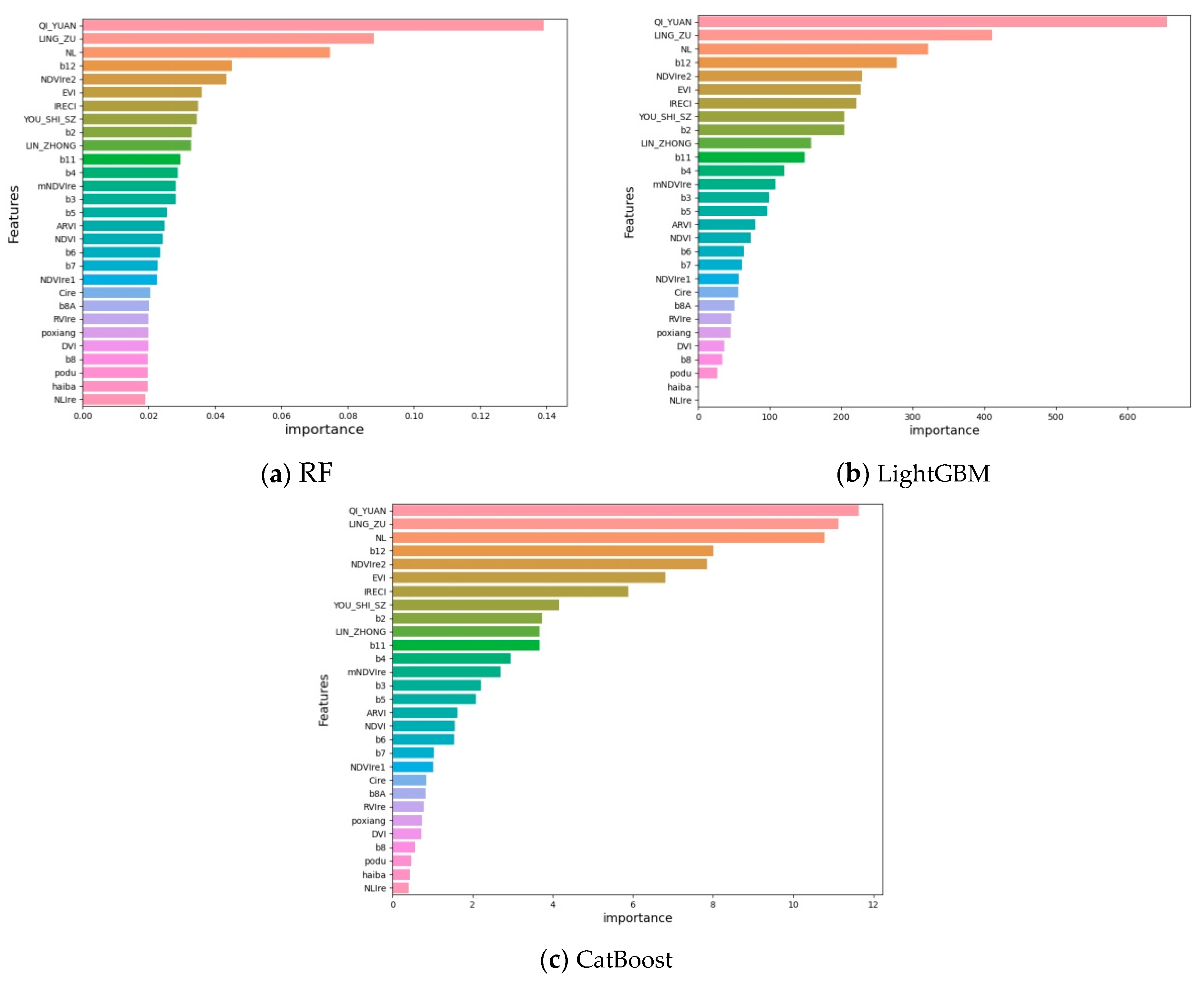
3.4. Ranking of Features’ Importance
4. Discussion
4.1. Performance Metrics
- (1)
- The evaluation indicators are heavily influenced by foresters’ experience
- (2)
- High cost of data acquisition for evaluation indicators
4.2. Complementarity of Multi-Source Data
4.3. The Feasibility of Machine Learning
4.4. Limitations of this Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Wang, S.; Chen, Z.; Tu, S. Research on the Response of Ecosystem Service Function to Landscape Pattern Changes Caused by Land Use Transition: A Case Study of the Guangxi Zhuang Autonomous Region, China. Land 2022, 11, 752. [Google Scholar] [CrossRef]
- Tang, Y.; Shao, Q.; Liu, J.; Zhang, H.; Yang, F.; Cao, W.; Wu, D.; Gong, G. Did Ecological Restoration Hit Its Mark? Monitoring and Assessing Ecological Changes in the Grain for Green Program Region Using Multi-source Satellite Images. Remote Sens. 2019, 11, 358. [Google Scholar] [CrossRef] [Green Version]
- Holling, C.S. Simplifying the complex: The paradigms of ecological function and structure. Eur. J. Oper. Res. 1987, 30, 139–146. [Google Scholar] [CrossRef]
- Aerts, R.; Honnay, O. Forest restoration, biodiversity and ecosystem functioning. BMC Ecol. 2011, 11, 29. [Google Scholar] [CrossRef] [Green Version]
- Brodie, J.F.; Redford, K.H.; Doak, D.F. Ecological Function Analysis: Incorporating Species Roles into Conservation. Trends Ecol. Evol. 2018, 33, 840–850. [Google Scholar] [CrossRef]
- Shen, W.; Li, M.; Huang, C.; Wei, A. Quantifying Live Aboveground Biomass and Forest Disturbance of Mountainous Natural and Plantation Forests in Northern Guangdong, China, Based on Multi-Temporal Landsat, PALSAR and Field Plot Data. Remote Sens. 2016, 8, 595. [Google Scholar] [CrossRef] [Green Version]
- Rizky, P.M.; Safe’i, R.; Kaskoyo, H.; Febryano, I.G. Forestry Value for Health Status: An Ecological Review. IOP Conf. Ser. Earth Environ. Sci. 2022, 995, 012002. [Google Scholar] [CrossRef]
- Ma, L.; Han, H.R. Evaluation of the forest ecosystem health in Beijing area. For. Stud. China 2007, 2, 157–163. [Google Scholar] [CrossRef]
- Fang, X.M. Evaluation of ecological functions of forests in the Aojiang River Basin. For. Surv. Des. 2022, 1, 36–39+61. [Google Scholar]
- Du, Q.; Ji, B.Y.; Xu, J. Research on forest ecological function evaluation based on forest quantity, quality and spatial distribution. Zhejiang For. Sci. Technol. 2013, 33, 46–50. [Google Scholar]
- Lausch, A.; Borg, E.; Bumberger, J.; Dietrich, P.; Heurich, M.; Huth, A.; Jung, A.; Klenke, R.; Knapp, S.; Mollenhauer, H.; et al. Understanding Forest Health with Remote Sensing, Part III: Requirements for a Scalable Multi-Source Forest Health Monitoring Network Based on Data Science Approaches. Remote Sens. 2018, 10, 1120. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.L.; Zhang, X.; Yang, Q.; Zhang, X.Y.; Gong, J.Q.; Dong, H. Evaluation of forest ecological functions in Sanjiuzi Forestry Bureau. Jilin For. Sci. Technol. 2022, 51, 34–37. [Google Scholar]
- Yang, J.; Dai, G.; Wang, S. China’s National Monitoring Program on Ecological Functions of Forests: An Analysis of the Protocol and Initial Results. Forests 2015, 6, 809–826. [Google Scholar] [CrossRef]
- Liu, L.X.; Zhu, S.W. Evaluation of forest ecological functions in Beijing Jingxi Forestry Management Office. Green Technol. 2022, 24, 152–155. [Google Scholar]
- Zhang, X.W.; Zheng, C.M.; Tang, X.J.; Zhang, W.D. Comprehensive index assessment of forest ecological functions in Shanghai. Subtrop. Soil Water Conserv. 2015, 27, 34–37. [Google Scholar]
- Wang, X.Z.; Tan, L.L.; Fan, J.C. Performance Evaluation of Mangrove Species Classification Based on Multi-Source Remote Sensing Data Using Extremely Randomized Trees in Fucheng Town, Leizhou City, Guangdong Province. Remote Sens. 2023, 15, 1386. [Google Scholar] [CrossRef]
- Abd Rahman Kassim, M.A.M.; Faidi, M.A.; Omar, H. A tool for assessing ecological status of forest ecosystem. IOP Conf. Ser. Earth Environ. Sci. 2016, 37, 012026. [Google Scholar]
- Relevant Attachments to the Technical Regulations for Category 2 Investigation in Zhejiang Province in 2014. Available online: https://wenku.baidu.com/view/441978e3b80d6c85ec3a87c24028915f804d848a.html (accessed on 28 September 2021).
- GB/T 38590-2020; Technical Regulations for Continuous Inventory of Forest Resources. China National Standard Publishing House: Beijing, China, 2020; pp. 1–48.
- Fang, J.Y.; Wang, G.G.; Liu, G.H.; Xu, S.L. Forest biomass of China: An estimate based on the biomass-volume relationship. Ecol. Appl. 1998, 8, 1084–1091. [Google Scholar]
- Liu, Y.; Fan, Z.P.; You, T.H.; Zhang, W.Y. Large group decision-making (LGDM) with the participators from multiple subgroups of stakeholders: A method considering both the collective evaluation and the fairness of the alternative. Comput. Ind. Eng. 2018, 122, 262–272. [Google Scholar] [CrossRef]
- Keshta, A.E.; Riter, J.C.A.; Shaltout, K.H.; Baldwin, A.H.; Kearney, M.; Sharaf El-Din, A.; Eid, E.M. Loss of Coastal Wetlands in Lake Burullus, Egypt: A GIS and Remote-Sensing Study. Sustainability 2022, 14, 4980. [Google Scholar] [CrossRef]
- Ebodé, V.B. Land Surface Temperature Variation in Response to Land Use Modes Changes: The Case of Mefou River Sub-Basin (Southern Cameroon). Sustainability 2023, 15, 864. [Google Scholar] [CrossRef]
- Fernandez-Beltran, R.; Baidar, T.; Kang, J.; Pla, F. Rice-Yield Prediction with Multi-Temporal Sentinel-2 Data and 3D CNN: A Case Study in Nepal. Remote Sens. 2021, 13, 1391. [Google Scholar] [CrossRef]
- Sumathi, B. Grid search tuning of hyperparameters in random forest classifier for customer feedback sentiment prediction. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 173–178. [Google Scholar]
- Yoshida, Y.; Yuda, E. Workout Detection by Wearable Device Data Using Machine Learning. Appl. Sci. 2023, 13, 4280. [Google Scholar] [CrossRef]
- Xiao, S.; Laurie, A.C. Classification of Australian Native Forest Species Using Hyperspectral Remote Sensing and Machine-Learning Classification Algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2481–2489. [Google Scholar]
- Han, P.; Zhai, Y.; Liu, W.; Lin, H.; An, Q.; Zhang, Q.; Ding, S.; Zhang, D.; Pan, Z.; Nie, X. Dissection of Hyperspectral Reflectance to Estimate Photosynthetic Characteristics in Upland Cotton (Gossypium hirsutum L.) under Different Nitrogen Fertilizer Application Based on Machine Learning Algorithms. Plants 2023, 12, 455. [Google Scholar] [CrossRef]
- Chang, W.; Wang, X.; Yang, J.; Qin, T. An Improved CatBoost-Based Classification Model for Ecological Suitability of Blueberries. Sensors 2023, 23, 1811. [Google Scholar] [CrossRef]
- Li, H.; Zhang, G.; Zhong, Q.; Xing, L.; Du, H. Prediction of Urban Forest Aboveground Carbon Using Machine Learning Based on Landsat 8 and Sentinel-2: A Case Study of Shanghai, China. Remote Sens. 2023, 15, 284. [Google Scholar] [CrossRef]
- Foody, G.M. Global and Local Assessment of Image Classification Quality on an Overall and Per-Class Basis without Ground Reference Data. Remote Sens. 2022, 14, 5380. [Google Scholar] [CrossRef]
- Yuan, Y.; Liu, Z.G.; Dong, L.B. GIS-based evaluation and analysis of forest ecological function level of Pangu forestry field in Daxinganling. J. Cent. South Univ. For. Sci. Technol. 2016, 36, 108–114. [Google Scholar]
- Stewart, D.H. Data capture in forestry research. J. R. Stat. Soc. 1968, 18, 377–411. [Google Scholar] [CrossRef]
- Olga, M.; Maria, T. The effect of expertise on the quality of forest standards implementation: The case of FSC forest certification in Russia. For. Policy Econ. 2009, 11, 422–428. [Google Scholar]
- Dube, T.; Onisimo, M.; Cletah, S.; Sam, A.A.; Tsitsi, B. Remote sensing of aboveground forest biomass: A review. Trop. Ecol. 2016, 57, 125–132. [Google Scholar]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote sensing technologies for enhancing forest inventories: A review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef] [Green Version]
- Hou, Z.S.; Wang, Z. From model-based control to data-driven control: Survey, classification and perspective. Inf. Sci. 2013, 235, 3–35. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Qiu, Y.; Hao, J.; Yang, J.; Li, L. Mapping snow avalanche debris by object-based classification in mountainous regions from Sentinel-1 images and causative indices. Catena 2021, 206, 105559. [Google Scholar] [CrossRef]
- Yi, Z.; Jia, L.; Chen, Q. Crop Classification Using Multi-Temporal Sentinel-2 Data in the Shiyang River Basin of China. Remote Sens. 2020, 12, 4052. [Google Scholar] [CrossRef]
- Wu, F.; Ren, Y.F.; Wang, X.K. Application of Multi-Source Data for Mapping Plantation Based on Random Forest Algorithm in North China. Remote Sens. 2022, 14, 4946. [Google Scholar] [CrossRef]
- Masayasu, M.; Toshiharu, K.; Tsuyoshi, A. Potential of ASTER DEM for Forest Ecological Research. J. Remote Sens. Soc. Jpn. 2007, 27, 39–45. [Google Scholar]
- Liu, H.F.; Qin, O.C.; Meng, H.L.; Lan, H.B. Evaluation of forest ecological functions in Maolan Reserve. Inn. Mong. For. Surv. Des. 2021, 44, 59–63. [Google Scholar]
- Yin, H.L.; Zhang, Z.W.; Song, W.; Zhang, Z.W.; Wu, L.Q.; Deng, T.; Zhang, Q. Evaluation of forest ecological function level in Sehanba North Mandian Forest. J. Beijing For. Univ. 2023, 45, 89–98. [Google Scholar]
- Pes, B. Learning from High-Dimensional and Class-Imbalanced Datasets Using Random Forests. Information 2021, 12, 286. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Mack, B.; Conrad, C. Crop Type Classification Using Fusion of Sentinel-1 and Sentinel-2 Data: Assessing the Impact of Feature Selection, Optical Data Availability, and Parcel Sizes on the Accuracies. Remote Sens. 2020, 12, 2779. [Google Scholar] [CrossRef]
- Shaeela, A.; Muhammad, K.H.; Ramzan, T. Overview and comparative study of dimensionality reduction techniques for high dimensional data. Inf. Fusion 2020, 59, 44–58. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Factors | Classification Standards | Weight | References | ||
|---|---|---|---|---|---|---|
| Ⅰ | Ⅱ | Ⅲ | ||||
| 1 | Forest biomass (t/hm2) | ≥150 | 50~149 | <50 | 0.20 | [19] |
| 2 | Forest naturalness | 1, 2 | 3, 4 | 5 | 0.15 | |
| 3 | Forest community structure | 1 | 2 | 3 | 0.15 | |
| 4 | Tree species structure | 6, 7 | 3, 4, 5 | 1, 2 | 0.15 | |
| 5 | Vegetation coverage (%) | ≥70 | 50~69 | <50 | 0.10 | |
| 6 | Canopy density | ≥0.70 | 0.40~0.69 | 0.20~0.39 | 0.10 | |
| 7 | Mean tree height/m | ≥15.0 | 5.0~14.9 | <5.0 | 0.10 | |
| 8 | Thickness of dead leaves | 1 | 2 | 3 | 0.05 | |
| Naturalness | Division Standard | Code | References |
|---|---|---|---|
| Ⅰ | Forest types are pristine or in a largely untouched state, with little human influence. | 1 | [19] |
| Ⅱ | Natural forest types with obvious human interference or secondary forest types in the later stage of succession, mainly consisting of tree species with high adaptability at the top level of zonality. | 2 | |
| Ⅲ | A secondary forest type with great human disturbance, in the late stage of secondary succession. In addition to pioneer species, top-level species can also be seen. | 3 | |
| Ⅳ | Highly disturbed by humans, succession retrograde, is in an extremely fragile secondary forest stage. | 4 | |
| Ⅴ | Highly and continuously disturbed by humans, with the destruction of almost all zonal forest types, in the late stage of difficult-to-recover retrograde succession. | 5 |
| Tree Species Structure Type | Division Standard | Code | References |
|---|---|---|---|
| Ⅰ | Pure coniferous forests, where the volume of individual coniferous species is greater than or equal to 90% of the total volume. | 1 | [19] |
| Ⅱ | Pure broadleaved forests, where the volume of individual broadleaved species is greater than or equal to 90% of the total volume. | 2 | |
| Ⅲ | Relatively pure coniferous forest, where the volume of individual coniferous species is greater than or equal to 65% and less than 90% of the total volume. | 3 | |
| Ⅳ | Relatively pure broad-leaved forests, where the volume of individual broad-leaved species is greater than or equal to 65% and less than 90% of the total volume. | 4 | |
| Ⅴ | Mixed coniferous forests, where the volume of total coniferous species is greater than or equal to 65% of the total volume. | 5 | |
| Ⅵ | Mixed coniferous and broad-leaved forests, where the volume of total coniferous species or total broad-leaved species is greater than or equal to 35% and less than 65% of the total volume. | 6 | |
| Ⅶ | Broad-leaved mixed forests, where the volume of total broad-leaved species is greater than or equal to 65% of the total volume. | 7 |
| Code | Tree Species/Vegetation Type | Biomass Model | References |
|---|---|---|---|
| 1 | Cunninghamia lanceolata | W = 0.3999 V + 22.5410 | [20] |
| 2 | P. massoniana | W = 0.5101 V + 1.0451 | |
| 3 | Other pine and conifer tree species (besides P. massoniana, Tsuga, Cryptomeria, and Keteleeria), coniferous mixed forest | W = 0.5168 V + 33.2378 | |
| 4 | Cypress | W = 0.6129 V + 46.1451 | |
| 5 | Mixed conifer and deciduous forests | W = 0.8019 V + 12.2799 | |
| 6 | Betula | W = 0.9644 V + 0.8485 | |
| 7 | Deciduous oaks | W = 1.3288 V – 3.8999 | |
| 8 | Eucalyptus | W = 1.0357 V + 8.0591 | |
| 9 | Mixed deciduous and Sassafras | W = 0.6255 V + 91.0013 | |
| 10 | Tsuga, Cryptomeria, Keteleeria | W = 0.4158 V + 41.3318 |
| Number of Original Samples | Number of Valid Samples | Number of Tree Species |
|---|---|---|
| 119,792 | 47,596 | 26 |
| Code | Vegetation Index | Formula |
|---|---|---|
| 1 | Atmospherically resistant vegetation index (ARVI) | ARVI = (NIR – (2 * R) + B)/(NIR + (2 * R) + B) |
| 2 | Enhanced vegetation index (EVI) | EVI = 2.5 × (NIR − R)/(NIR + 6 × R − 7.5 × B + 1) |
| 3 | Differential environmental vegetation index (DVI) | DVI = NIR − R |
| 4 | Normalized vegetation index (NDVI) | NDVI = (NIR − R)/(NIR + R) |
| 5 | Ratio red-edge vegetation index (RVIre) | RVIre = NIR/Re |
| 6 | Inverted red-edge chlorophyll index (IRECI) | IRECI = (Re3 − R)/(Re1 − Re2) |
| 7 | Normalized red-edge vegetation index1 (NDVIre1) | NDVIre1 = (NIR − Re1)/(NIR + Re1) |
| 8 | Normalized red-edge vegetation index2 (NDVIre2) | NDVIre2 = (NIR − Re2)/(NIR + Re2) |
| 9 | Non-linear red-edge index (NLIre) | NLIre = ((NIR * NIR) − Re1)/((NIR * NIR) + Re1) |
| 10 | Improved normalized red-edge vegetation index (mNDVIre) | mNDVIre = (NIR − Re1)/(NIR + Re1 − 2 * B) |
| 11 | Red-edge chlorophyll index (CIre) | CIre = (NIR/Re1) − 1 |
| No. | Factor Name | Explanation | Source of Data |
|---|---|---|---|
| 1 | Band 2 | Bule | Sentinel-2 |
| 2 | Band 3 | Green | |
| 3 | Band 4 | Red | |
| 4 | Band 5 | VNIR1 | |
| 5 | Band 6 | VNIR2 | |
| 6 | Band 7 | VNIR3 | |
| 7 | Band 8 | NIR | |
| 8 | Band 8A | Narrow NIR | |
| 9 | Band 11 | SWIR 1 | |
| 10 | Band 12 | SWIR 2 | |
| 11 | HAI_BA | Elevation | DEM |
| 12 | PO_DU | Slope | |
| 13 | PO_XIANG | Aspect | |
| 14 | LIN_ZHONG | Forest category | Forest Resources Planning and Design Survey Data |
| 15 | QI_YUAN | Forest origin | |
| 16 | YOU_SHI_SZ | Dominant species | |
| 17 | NL | Tree age | |
| 18 | LING_ZU | Tree age group | |
| 19–29 | Refer to Table 6 | Vegetation indices generated from optical remote sensing images | |
| Confusion Matrix | Predicted Value | ||||
|---|---|---|---|---|---|
| Category 1 | Category 2 | Category k | Total | ||
| Measured value | Category 1 | ||||
| Category 2 | |||||
| Category k | |||||
| Total | N | ||||
| Ecological Function Level | Comprehensive Score Value (Y) | Forest Ecological Function Index (K) | Code | References |
|---|---|---|---|---|
| Good | <1.5 | >0.6667 | 1 | [19] |
| Medium | 1.5~2.4 | 0.6667~0.4167 | 2 | |
| Poor | ≥2.5 | ≤0.4 | 3 |
| Data Combination Scheme | Data Source |
|---|---|
| A | Sentinel-2 |
| B | Sentinel-2, DEM |
| C | Sentinel-2, forest resource planning and design survey data |
| D | Sentinel-2, DEM, forest resource planning and design survey data |
| Model | Optimal Values of Hyperparameters |
|---|---|
| RF | n_estimators = 200, max_features = 195 |
| LightGBM | n_estimators = 200, max_depth = 3, learning_rate = 0.1 |
| CatBoost | n_estimators = 500, depth = 11, learning_rate = 0.05 |
| Program | Overall Accuracy Rate | Category Accuracy Rate | Recall | F1 Score | ||
|---|---|---|---|---|---|---|
| Good | Medium | Poor | ||||
| RF-A | 0.46 | 0.57 | 0.80 | 0.35 | 0.39 | 0.39 |
| RF-B | 0.47 | 0.62 | 0.80 | 0.40 | 0.40 | 0.41 |
| RF-C | 0.82 | 0.73 | 0.89 | 0.80 | 0.54 | 0.57 |
| RF-D | 0.82 | 0.76 | 0.89 | 0.83 | 0.66 | 0.62 |
| LightGBM-A | 0.47 | 0.61 | 0.80 | 0.32 | 0.41 | 0.40 |
| LightGBM-B | 0.47 | 0.62 | 0.80 | 0.33 | 0.40 | 0.41 |
| LightGBM-C | 0.73 | 0.71 | 0.90 | 0.58 | 0.52 | 0.55 |
| LightGBM-D | 0.76 | 0.73 | 0.90 | 0.64 | 0.61 | 0.58 |
| CatBoost-A | 0.46 | 0.59 | 0.80 | 0.35 | 0.42 | 0.41 |
| CatBoost-B | 0.48 | 0.62 | 0.81 | 0.42 | 0.42 | 0.43 |
| CatBoost-C | 0.73 | 0.73 | 0.90 | 0.57 | 0.55 | 0.56 |
| CatBoost-D | 0.82 | 0.75 | 0.90 | 0.80 | 0.63 | 0.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, N.; Yao, L.; Wu, D.; Zheng, X.; Luo, S. Assessment of Forest Ecological Function Levels Based on Multi-Source Data and Machine Learning. Forests 2023, 14, 1630. https://doi.org/10.3390/f14081630
Fang N, Yao L, Wu D, Zheng X, Luo S. Assessment of Forest Ecological Function Levels Based on Multi-Source Data and Machine Learning. Forests. 2023; 14(8):1630. https://doi.org/10.3390/f14081630
Chicago/Turabian StyleFang, Ning, Linyan Yao, Dasheng Wu, Xinyu Zheng, and Shimei Luo. 2023. "Assessment of Forest Ecological Function Levels Based on Multi-Source Data and Machine Learning" Forests 14, no. 8: 1630. https://doi.org/10.3390/f14081630
APA StyleFang, N., Yao, L., Wu, D., Zheng, X., & Luo, S. (2023). Assessment of Forest Ecological Function Levels Based on Multi-Source Data and Machine Learning. Forests, 14(8), 1630. https://doi.org/10.3390/f14081630