2.1. Simulation Methods
In general, any well-designed areal sampling simulation program can be used for simple comparison of variances and for some of the methods discussed in the following sections. However, as will be made clear shortly, some of the other techniques described here for comparing sampling methods require structured results in the form of raster images. sampSurf [
1,
22] is an R [
23] package that can be used for the simulation of areal sampling methods commonly used in forestry. The package is somewhat unique in that it creates ‘sampling surfaces’ [
24,
25], which are raster images, as a result of the simulation. Briefly, an
N row by
M column raster tract,
, which holds a synthetic population (either from actual field measurements or simulated) of standing trees or downed logs is created. Inclusion zones are added about the individual members of the population for the desired sampling methods to be simulated and those cells that are internal to each inclusion zone are appropriately filled with the estimate of the attribute desired for each individual. The final surface is then created by simple raster addition of estimates within overlapping inclusion zones. The center of each pixel is a sample point, which is used to determine whether the estimate registered for that pixel is within the inclusion zone boundary for a given tree or log. In practice, a resolution of
m is often more than adequate, regardless of tract size, though finer resolutions have been used.
For the simulation examples used here, an internal tract size of 1.5 hectares is created with a
m resolution, and an external 14 m buffer, such that
m, yielding
22,500 sample points, with an overall area
ha. The buffer contains inclusion zones that extend beyond the 1.5-ha internal tract where the trees reside as a simple unbiased method for handling boundary overlap [
26]. A synthetic population of
trees (approximately 261 trees ha
with a basal area of approximately 18.4 m
ha
) common to all simulations was generated using the built-in taper function with randomly assigned shape parameter
, where
is neiloid,
is a cone and
is paraboloid stem form; the taper function for diameter at height
is [
27]:
where
is the butt diameter, with top diameter
at height
H. Corresponding tree volumes are generated from the integral of this equation ([
28] p. 8). The simulated diameter distribution followed a three-parameter Weibull distribution [
29] with location, shape and scale parameters
cm,
,
cm, respectively; heights were generated using a metric version of the all species equation for northern hardwoods in New Hampshire given by Fast and Ducey [
30]. The trees were dispersed throughout the tract area using a spatial inhibition process with an inhibition distance of 3 m ([
31] p. 434). The resulting simulated stand would be representative of a small, well-stocked northern hardwoods stand based on the northern hardwoods stocking guide [
21].
2.2. Areal Sampling Methods
In this paper, we will be using four different areal sampling methods for standing trees to illustrate the different procedures for method comparisons. Each of the sampling methods is design-unbiased and possesses an enlarged circular inclusion zone,
, centered on the
k-th tree with area
m
2. It follows from this that the inclusion probability for the
k-th tree is:
The inclusion probabilities are different for each tree in three of the four methods used, which select trees with probability proportional to size (PPS). Let
be a measurable attribute of interest on the
k-th tree. Estimation follows that for variable probability sampling using the Horvitz–Thompson (HT) estimator ([
18] p. 215, [
32] p. 49) such that:
is the estimator for quantity
. Similarly, given
individuals sampled on the
s-th point, the estimator for that point is:
Using the sampling surface approach, each grid cell receives the estimate
corresponding to the sample point at its center. The surface total,
, is given as the mean over the
m grid cells and is an estimate of the population total,
, which can be deduced from the known synthetic population of trees. The surface variance measures the roughness around the mean plane as:
In the simulations that follow,
represents total tree volume (m
3) unless specifically noted otherwise.
The first sampling method, horizontal point sampling (HPS) ([
12,
18] p. 247, [
13]), selects individuals with probability proportional to basal area, yielding inclusion probability
, where
m
ha
is the basal area factor (BAF) and
m
2 is the basal area for the
k-th tree. The true volume is known for each tree and is calculated by the integration of (1) as noted above. The second sampling method is a simple variant of the previous method where HPS is used to select the individual trees at a given point, which are then subsampled for volume estimation using crude Monte Carlo sampling (CMC) ([
18] p. 94). This method shares the exact same inclusion probability with HPS and differs only in the calculation of individual tree volumes at each sample point. Calculation of volume for the
k-th tree at the
s-th sample point is determined using one subsample point along the stem as:
where
is the cross-sectional area calculated from (1) at a random height along the bole
drawn from the uniform attribute density
. This method is design-unbiased, but approaches unbiasedness asymptotically such that it is quite possible to accumulate a slight bias in the simulations, purely from not drawing a full range of heights in
in the finite sample size of the simulations. Drawing more than one sampled height per tree will alleviate this as will other more complex Monte Carlo methods such as importance sampling ([
33] p. 39).
The third sampling method is critical height sampling (CHS) [
14,
34,
35]. Like the previous two areal methods, CHS shares its tree selection mechanism with HPS. In its most general form, however, CHS uses the diameter at the base (or merchantable stump) of the tree, rather than DBH, to determine the size of
. In this case, CHS is design-unbiased for volume estimation. However, one can also implement CHS using a (normally) smaller inclusion zone for selection that derives from DBH just as the previous two methods. In this case, the volume below DBH is treated as a cylinder, so that the volume of the butt swell is lost. This introduces a small bias into the estimation of volume, but allows the exact same ‘footprint’ in terms of
and associated area,
, to be used for each method. Both alternatives are supported in the sampSurf package, but the latter will be used here.
Critical height sampling is also a form of CMC sampling. However, with CHS, the selection of a height—the critical height,
, for the
k-th tree on sample point
s—is spatially structured. It is found by determining the point along the tree stem where the angle gauge shows the tree to be exactly borderline. This produces a radially-symmetric parabolic-shaped sampling surface where volume estimates are low near the edge of the inclusion zone and increase as distance from the sample point to the stem decreases radially. Tree volume estimation [
36] follows in a somewhat analogous manner to (6) where:
Here, volume is calculated from the product of tree basal area and the spatially-structured sample height, determined randomly from the distance of the sample point to the tree. The spatial structure of this method also assures that the full range of heights
is always sampled in a full enumeration of the sampling surface within
(within the resolution of the sampling raster). In contrast, CMC sampling is spatially unstructured: regardless of the juxtaposition of sample point relative to the tree, CMC simply draws a random height, which can be anywhere on the tree stem at any point within
. This produces a spatially unstructured sampling surface that appears completely random with the potential for a small amount of bias as noted above. In both CHS and CMC, the volume estimate
is substituted for
in
using the inclusion probability for HPS to arrive at the sample estimate for the
k-th tree on the
s-th sample point.
Alternatively, note that one can also formulate the volume estimator (6) for CMC in terms of drawing a random cross-section,
, and sampling the height at that cross-section,
, yielding
, which makes it exactly analogous to (7). The estimate of volume using this method, when combined with HPS, excludes the volume outside a cylinder from the ground (or stump) to breast height as in CHS with reference height at DBH [
36,
37]; drawing
alleviates this problem. However, the approach in (6) is used in sampSurf [
33] and has been adopted here.
Finally, fixed-area circular plot (CPS) sampling ([
19] p. 276) is the last areal sampling method used in the comparisons. The inclusion probability for all trees is
, where
is constant and is equal to the plot size (where
R is the plot radius in m), as this method samples with probability proportional to the tree frequency. Tree volume is known in the simulations from the integration of (1) as in HPS.
Table 1 presents the parameters used in the simulations and summarizes the sampling surface results for each. Note that the small amount of ‘bias’ that accrues for HPS, CMC and CPS is due solely to the resolution of the raster. As the resolution gets small (
), this bias goes to zero. The exception is CHS, where the small (approximately 1%) bias is due to treating the stem below DBH as a cylinder as noted previously. The variance is given in
Table 1 in terms of the standard deviation, and the surface maximum is noted to be different for each method and sampling effort. The sampling effort can be categorized by the BAF or plot radius for the respective methods. However, it is also reported as the effective sample size,
, which is a measure of the percentage of total points (raster cell centers) in the scene (including the buffer area) that are overlapped by at least one inclusion zone, thus providing a non-zero estimate for volume at the respective point (e.g., [
36,
38]). It is a measure of the total sampled ‘effort’ in each simulation and decreases with plot size or as the BAF increases.
Figure 1 presents the sampling surfaces for the four areal sampling methods corresponding to the first rows for each method in
Table 1 (note that all perspective images have been scaled relative to surface height to facilitate viewing). Recall that the variance for each method is the variability of the individual point estimates about the plane of the mean for each surface [
24,
25]. The surfaces themselves, when regarded devoid of the summary computations, can be deceiving even with some degree of study. The only clear interpretation is that CMC is certainly the most variable surface. However, it is difficult to distinguish between HPS and CPS with regard to variability, because of the number of trees and respective inclusion zones that are heaped within the tract. Furthermore, CHS appears to be the most gently variable surface and could justify the interpretation of the smallest variance from a purely visual perspective. One must keep in mind when viewing these surfaces that though they appear to be all scaled the same, the maxima are different in each case (
Table 1). Because these surfaces are so complex, a simple set of two-tree intersecting sampling surfaces is presented in the
Supplementary Material as a more intuitive guide to their interpretation (
Figures S1 and S2). In addition, a raster version of
Figure 1 is also presented in
Supplementary Material Figure S3. Other surfaces from
Table 1 with different BAFs and plot radii appear similar, but with a smaller overall footprint (e.g.,
).
2.3. Smith Plots
As previously noted, perhaps the simplest and most employed method for discriminating between different unbiased sampling methods is the comparison of variances, such that the method with the smallest variance is often deemed the best:
viz., most efficient. However, as mentioned earlier, one must take into consideration other factors such as cost (or its surrogate, sampling time) in order to attempt to compensate for methods that may provide lower variance, but at the expense of higher sampling effort. One way to avoid this issue is to attempt to equalize the average inclusion zone area over the methods under comparison by choosing design parameters (the BAF, plot size, etc.) for each sampling method that yield inclusion zones that are, on average, approximately the same size. While this method is useful and has been applied in several studies (e.g., [
36,
38]), it can be difficult to find design parameters that yield approximate conformity, especially under PPS designs that often have quite different inclusion zone shapes such as perpendicular distance sampling (PDS) [
39], point relascope sampling (PRS) [
40] and sausage sampling [
41] for downed coarse woody debris. Indeed, when discussing this issue in the comparison of different PDS protocols, Gove et al. [
38] noted that “the goal of equality is elusive, however, and it is only possible to approximate as the inclusion zones scale differently” under the differing protocols; this caveat also applies to the many other sampling methods used on standing trees and downed coarse woody debris, and a more general example might be the comparison of line-based methods to those already mentioned.
The set of simulations in
Table 1 presents an example where it is rather simple to approximately equalize the sampling effort in terms of average inclusion zone area so that direct comparisons are possible. However, even this is unnecessary, because a simple graphical method based on a power law is available to compare any set of different sampling methods or protocols for a given population of standing trees or downed logs without the effort of adjusting design parameters beforehand. The method was characterized as an ‘empirical law’ for the variance when first described by Smith [
4], who noted the log-log relationship between variance and plot size within experimental block designs. The general variance function is:
where
is the variance in volume among plots of size
, while
V, a scaled variance whose definition depends on that of plot size, and
the slope parameter, are both constants that can be estimated if desired. It is interesting to note that Deming [
42] (p. 206), while mentioning [
4], cites a set of unpublished studies by Mahalanobis evidently culminating in Mahalanobis [
43] and extended in Mahalanobis [
44] as the principle contribution to the variance function (8).
In the current application, interest lies simply in the general form of this relationship for graphical discernment in the comparison of different methods, rather than in parameter estimation per se. Clearly, estimation of (8) is unnecessary for comparison of the simulation results, which can be presented either in raw units or on a log-log scale, whichever is the most convenient. Using this relationship, each of the different sample methods under consideration are simulated several times on the same population using varying design parameters to give a range of average inclusion zone areas as in
Table 1. A simple plot of either the raw variances by average inclusion zone area or their log-log counterpart suffices for the comparison, obviating the requirement for seeking the rather ‘elusive’ goal of equalized sampling effort. The results of applying this method to the simulations in
Table 1 are presented in
Figure 2.
The ‘Smith plot’ clearly shows the ranking of the different methods and would work equally as well were the inclusion zone areas not approximately commensurate as they are in this example. Clearly, and in accordance with theory, HPS is the most efficient method for estimating volume, followed by CHS, with CPS and CMC being the least efficient in this particular population.
This ‘law’ has found uses both in forestry and other areas of agriculture such as agronomy since its inception. A number of early studies has looked at the estimation of the slope parameter,
, in connection with the optimal plot size question. For example, Koch and Rigney [
45] and Hatheway and Williams [
46] studied the estimation of the slope parameter from designed experiments for determining soil heterogeneity with regard to optimal plot size. These authors have suggested a weighted approach to the variance in estimating (8) due to the correlation between neighboring plot measurements in the dependent variable. Similarly, Swallow and Wehner [
47] extended these results by proposing a generalized least squares approach to the estimation of
and its connection to optimal plot size in yields of cucumber. In a related study, Whittle [
48] rigorously explored the relationships between the variance function (8) and the associated spatial covariance function. In a simulation study, Pearce [
49] found that Smith’s law holds over a range of plot areas that would be found in practice, though correlation did affect the relationship over larger plot areas.
Smith’s [
4] relationship (8) has been recognized as a useful tool in forestry where it is sometimes alternatively represented in terms of the coefficient of variation (CV) [
50], rather than the variance. O’Regan and Palley [
51] used Freese’s [
50] relationship to graphically compare HPS and CPS using the average number of trees sampled at a location rather than
, much as in
Figure 2. A more extensive simulation study in Arvanitis and O’Regan [
52] found that adding a quadratic term to the logarithmic version of equation (8) sometimes provided a better fit than equation (8) alone, where plot size or
were used for CPS and HPS, respectively. Graphically, these authors used the variance versus plot size for CPS comparisons, while CV versus average number of trees sampled at a location was used to compare HPS and CPS as in O’Regan and Palley [
51] for both static and growth components. Wensel and John [
53] fitted (8) using
for HPS, which changes the direction of the slope, but presented a simple relationship to convert the results back in terms of
for subsequent graphical comparison with CPS using the logarithm of the variance.
Freese [
50] also noted that spatial pattern and plot shape can play a role in the shape of the relationship between plot size and variability. Reich and Arvanitis [
54], using Freese’s [
50] relationship with stem density, demonstrated that the curve shape (
) can change depending on the spatial pattern. It will also change for different stand attributes of interest in simulations.
More recently, Smith’s [
4] variance function has been employed by Lynch [
9] to determine optimal plot size (or BAF) using Lagrange multipliers in the objective function to minimize the variance subject to total fixed costs. In a companion study, Lynch [
10] provided optimal cost-plus-loss solutions under an expected absolute value loss function and the variance function of Smith [
4], using the cost functions developed by Zeide [
7] and Gambill et al. [
8] for CPS and HPS, respectively. Yang et al. [
55], using the same optimization approach of Lynch [
9], developed a cost function that was specific to the ‘Big BAF’ [
56] sampling scheme. These authors used a CV versus
representation for the variance relationship. These recent papers also present a more thorough coverage of the forestry literature on the Smith [
4] and related Freese [
50] approaches and should be consulted for more information.
The applications cited above speak to the versatility of Smith’s [
4] empirical law having been applied in both field (including experimental agronomy) and simulation studies, over a reasonably wide range of plant population forms; not to mention ecology and population biology where it is known as ‘Taylor’s law’ (e.g., [
57]). In the case of simulation, where not only the same population is used, but the same sampling grid, correlation will also be present in the dependent variable as a consequence of sample points being aligned with the grid centers. While it is perfectly acceptable to fit the relationship (8) (or similar) for quantitative comparison of, e.g., the slope parameter for different sampling methods or protocols, the graphical comparison of simulation results, not estimation, is emphasized here; therefore, such considerations based on estimation are unnecessary for this straightforward application, though correlation of a different sort is discussed in the following section.
2.4. Taylor Diagrams
The Smith plots are useful for judging the overall relationship between sampling methods based on their variances (standard deviations or CVs). However useful this may be, it says nothing about the structural or spatial correspondence between the techniques over the spatial field or tract. A measure of this correspondence is the simple pattern covariance or correlation between two simulations. In this sense, ‘pattern’ is used to emphasize that the statistics are computed between the two simulated raster representations over each grid cell, just as the variance, resulting in an evaluation of the strength of spatial correspondence between two sampling methods. Both the covariance and correlation are useful in this sense as they can be related to the variances by defining one particular sampling method as the standard, or reference, to which the others are compared. The simple relationships that allow for this comparison are given through the variance of the difference:
for two random variables
x and
y with corresponding variances
and
. In this application,
x and
y correspond to two matrix simulation results, where
x will be taken as the reference method. Since HPS with
m
ha
(HPSbaf3) has the smallest variance in
Figure 2, this sampling method will be taken as the standard to be compared against.
Taylor [
58] developed a diagram that incorporates all of the information in either (9) or (10) into a type of polar plot by recognizing the similarity of these relationships to the law of cosines:
where the triangular sides are
a,
b and
c with opposite angle
. Equating (10) to (11) gives:
,
,
and, notably,
, the correlation coefficient. Taylor’s [
58] insight makes it possible to compare all four of these statistics simultaneously in a simple visual diagram. This lessens the necessity for lengthy tabular summaries and facilitates the visual grouping of similar sampling methods as compared to the reference based on all four metrics. It should be noted that Taylor’s [
58] original application of this procedure was the analysis of different simulation model runs against observations (our reference method), and others have applied the method similarly [
59,
60]. As such, his presentation is in terms of centered mean squared error, which corresponds to our variance of the difference.
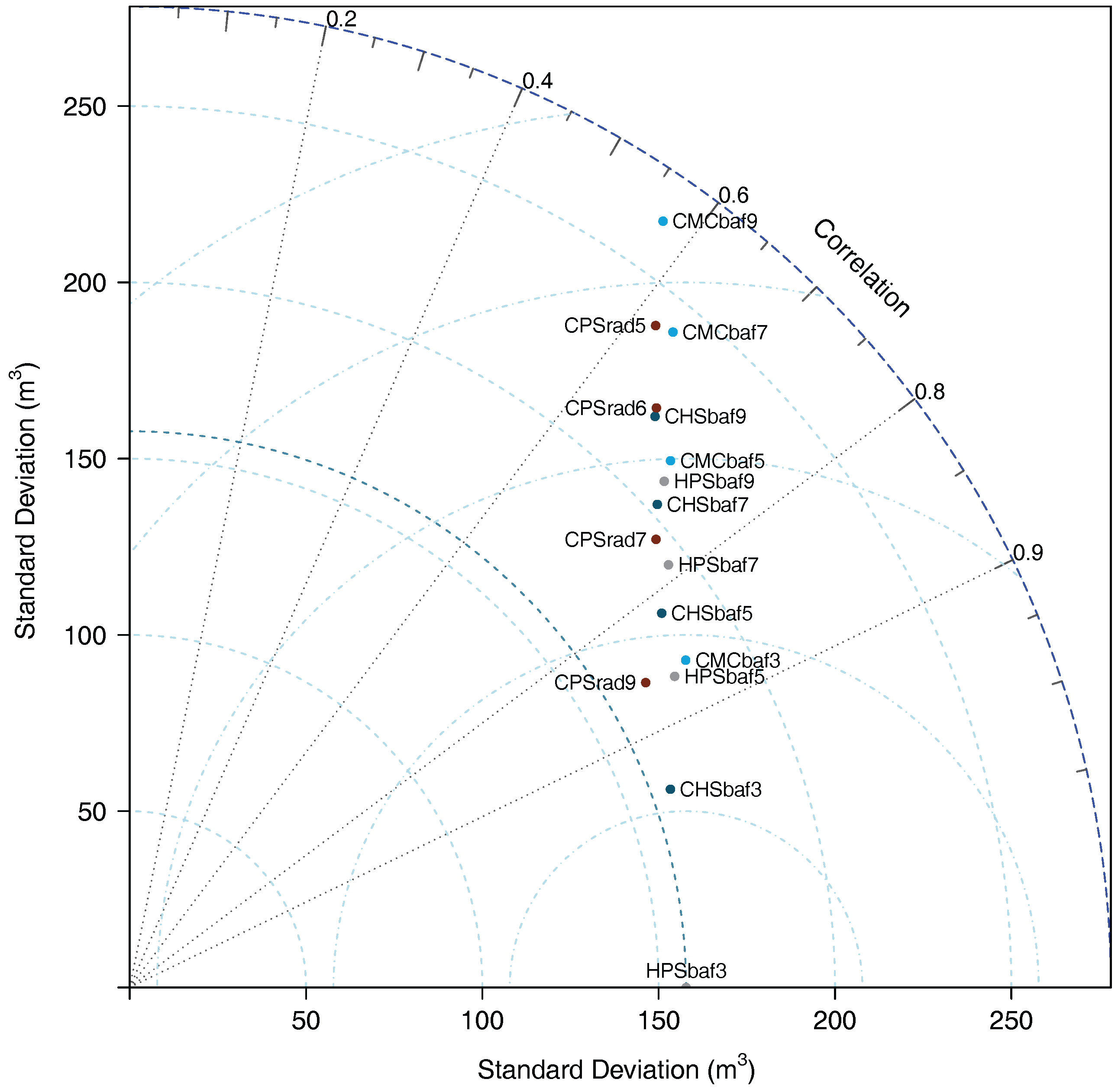
A Taylor diagram for the simulations in
Table 1 is presented in
Figure 3 (see
Table S1 for the requisite statistics). The first point to note is that, due to the polar nature of the diagram, the standard deviations are displayed with respect to the circular arcs joining the two axes. To facilitate comparison, an extra arc is displayed aligning with the reference method, HPSbaf3. Thus, for example, critical height sampling with
(CHSbaf3) is found to be radially closest to the arc of the reference method. In addition, the radial rays emanating from the origin demarcate the correlation,
, which increases clockwise from the
y-axis. Again, CHSbaf3 is quickly located as the method with the highest pattern correlation to HPSbaf3. Finally, semicircular arcs centered on the reference standard deviation denote the distance in terms of
. Thus, once more, CHSbaf3 is the closest in regard to minimizing the variance of the difference with the standard.
While the analysis with respect to CHSbaf3 may be trivial, the diagram in
Figure 3 facilitates comparison of other methods that would be more difficult to glean quickly from
Table S1. For example, the clusters of CPSrad9, HPSbaf5 and CMCbaf3 are all close in relation to each other. Each has approximately the same pattern correlation with HPSbaf3 of approximately
, with CPSrad9 having the smallest standard deviation of the three, as well as the smallest variance difference with the reference method. The result may be somewhat surprising given the difference in the average inclusion zone areas between HPSbaf5 and CPSrad9 compared to the reference method (
Table 1); e.g., the HPSbaf5 surface, even with smaller
for this method, correlates well with HPSbaf3. On the other hand, CPS evidently requires a larger plot size (
) to match the efficiency of HPS in terms of variance, which is also discernible from the Smith plot. Visually connecting a line through all of the CPS methods on the graph shows that they get increasingly further from the standard deviation of the reference method (denoted by the arc through that point on the
x-axis) as the plot radius or inclusion zone area decreases. This relationship is also discernible on the Smith plot (
Figure 2) by regarding the vertical distance from the reference method to the CPS curve as plot size decreases; however, this relationship appears to be more nuanced in that figure, and it does not show the corresponding decrease in correlations as does the Taylor diagram. Visually adding a line connecting each of the individual method sets shows the same tendency to be further from the reference method as
decreases. Not surprisingly, CMCbaf9 has the lowest correlation and largest variance difference with HPSbaf3, coupled with the highest overall variance, which agrees with
Figure 2. Other clusters of sampling methods can also be discerned from the diagram, which may not be as easily detectable from
Table S1; further exploration of the relationships in
Figure 3 is left to the interested reader.
2.5. Wavelet Variance Decomposition
The diagnostics presented thus far for comparing sampling methods are all applied over the full simulation raster without regard to scale. However, it is possible to decompose the resultant statistics—the variance, covariance, correlation—by scale in terms of distance. In what follows, a two-dimensional maximal overlap discrete wavelet transform (MODWT) ([
61] p. 159) is applied to the simulation raster results to perform this scale-based decomposition. The wavelet filter, when applied to the raster simulations, decomposes the image into wavelet coefficients at each different scale corresponding to each different level of the decomposition. The wavelet decomposition produces a new set of anisotropic images at each scale, the sum of which is an overall isotropic raster. A scaling filter is also applied resulting in a raster of scaling or smooth coefficients, whose mean is the sample mean for the simulation at the highest level (coarsest scale). Often, wavelet analysis concerns only these different sets of raw wavelet and scaling coefficients from the MODWT decomposition. However, this same set of wavelet images at the different levels can be easily transformed into wavelet variances, whose sum is the total sample variance in the overall simulation result for each sampling protocol. Likewise, the raw wavelet coefficients from image (simulation) pairs can be used to calculate covariance or correlation results at each scale. In what follows, a short review of the wavelet and scaling filters is presented, with their relation to the wavelet variance decomposition. Subsequently, these results are applied to the simulations and interpreted using the diagnostic plots from the previous sections.
2.5.1. MODWT Basics
In general, to apply the two-dimensional wavelet decomposition, let
denote an
N row by
M column raster image indexed by
as
[
62,
63], corresponding to our individual raster simulation results from
Table 1. The MODWT is applied to
at levels
, with corresponding standardized scale
for the
j-th-level wavelet filter and
for the scaling filter. The
are unitless (in terms of distance in pixels), but can be represented on a physical basis as
, where
m is the resolution of the square grid cells; as noted above,
m in the simulations.
A simple Haar wavelet of length is used in the analysis presented here. The wavelet filter coefficient vector, , for level of the decomposition has coefficients . The corresponding scaling filter coefficient vector is . The Haar filters have coefficients for the j-th level. For example, if , then the Haar filter has coefficients. Therefore, the physical scale for the corresponding wavelet filter is m. This scale gives the width of the wavelet filter corresponding to the change in distance because of the sign change in the coefficients (two negative and two positive). The scaling filter has the same number of coefficients, , but the scale is m, because all coefficients are positive in this filter; it is a smoothing filter.
The two-dimensional Haar filters obtained from the wavelet and scaling vectors at level
are given by the outer (or tensor) product of the vectors as [
64]:
Conceptually, these two-dimensional filters are convolved with
as a moving window through the scene, row-by-row, across columns. Alternatively, these matrices may be padded with zeros to be conformable with
[
65,
66]. In the moving-window approach,
contrasts the diagonal elements in
. The matrix
contrasts rows of
, producing vertical differences. Likewise,
contrasts columns of the image and yielding the horizontal components of variation. Lastly,
produces a matrix of scaling coefficients that corresponds to a mean smooth decomposition. Note that the wavelet matrices now correspond to changes in area rather than distance. The change in area associated with the wavelet filters is at the physical scale of
for given level
j [
63]. For example, in the case of
in (12) above, there are
coefficients, corresponding to a physical area of 4 m
2, with change in area corresponding to 2 m
2 (two negative and two positive coefficients) in the wavelet matrices. Similarly, if
, then
(yielding
filter matrices), with
m corresponding to a change in area of 8 m
2. In the examples that follow, the physical scale is denoted in terms of distance rather than area difference as the former is simpler and conversion can be made directly using the above formula (see also
Table S2).
The matrix approach is both conceptually simple to understand and to implement; however, in application, the matrix
is filtered using the pyramid algorithm. The pyramid algorithm treats rows and columns as univariate time series and filters these individually in a specific manner using the wavelet filter coefficients
and scaling filter coefficients
(for details, see [
63,
64]). In practice, the pyramid algorithm is more complex to implement, but is computationally more efficient than the matrix approach.
In the current application, each individual simulation image
in
Table 1 is decomposed at each level
j by the wavelet filter into matrices conformable with
corresponding to horizontal (
), vertical (
) and diagonal (
) wavelet coefficients; likewise, applying the scaling filter results in a scaling (smooth) matrix (
) that is retained only at level
J. These correspond to the application of the two-dimensional wavelet filter matrices given above, though, again, in practice, they are computed using the pyramid algorithm. The anisotropic matrices can be summed to produce an overall isotropic decomposition as will be discussed in more detail in the variances section. This is all accomplished using the R ssWavelets package [
67], which applies the pyramid algorithm through the methods in the R waveslim package [
68].
Just as in forest sampling, wavelet applications require a boundary correction method in application. Several boundary correction approaches are discussed in detail by Addison [
69] (Section 2.15). The waveslim package uses periodization, which is sometimes referred to as toroidal correction [
70] (p. 152 and 166). Toroidal correction can be conceptualized as a translation of the image about all sides so that when the wavelet filter reaches the end of a row or column, it wraps back around to the beginning of the image. Another method, reflection (folding about each side to create a mirror image), has been advocated by both Lark and Webster [
64] and Ma and Zhang [
65], who cited potential problems with periodization in their applications. However, their applications were quite different, and the concerns they raise with periodization do not appear to be relevant in the current areal sampling application; indeed, it can be argued that periodization is superior in the current application (e.g., see the discussion in [
71]) and is therefore used in this study.
2.5.2. The Two-Dimensional Wavelet Variance and Covariance
Two-dimensional wavelet variance decomposition theory and applications include Mondal and Percival [
62], Geilhufe et al. [
63] and Lark and Webster [
64], the latter of which also includes some information on wavelet covariances when comparing two images (or, in our case, two sampling methods). A recent study using these methods is found in Ma and Zhang [
65]. In these applications in wavelet analysis, one encounters two main classes of variance. The first is called the wavelet variance and only involves the wavelet components of the decomposition (no scaling components are involved). The wavelet variance is calculated at all scales for its contribution to the decomposition of the total surface variance in the simulations. The second is called the sample variance, which does indeed involve both wavelet and scaling components and therefore exists only at level
J. The sample variance is essentially equivalent to the surface variance,
, given in the simulations. The small difference is that the divisor in the latter is
, while the wavelet sample variance is in terms of
. The wavelet sample variance is sometimes referred to as the population variance in sampling (e.g., [
72] p. 23), and the surface variance can be multiplied by
to make the two equivalent. Finally, the concept of the energy in a time series ([
61] p. 42, [
73]) or image [
62] is equivalent to what is more commonly known as the sum of squares.
The sample variance derives from the familiar relation (see, e.g.,
https://en.wikipedia.org/wiki/Algebraic_formula_for_the_variance):
therefore, the total energy in the image is given by the sums of squares of all elements [
62]:
and substituting in the image decomposition matrices over all
j gives:
Note from the last relation that the wavelet transformation is energy preserving [
62]. In two dimensions, the sample (population) variance is given by:
which, in terms of (13) is
and substituting (15) gives [
62]
where
is the total average energy. The penultimate relationship states that the surface variance can be decomposed as the mean sum of squares of the anisotropic wavelet decomposition matrices over all levels plus the squared smooth at level
J, less the squared mean. Again, it should be noted that since the energy in the wavelet decomposition matrices is preserved through
, the sample variance can be decomposed by scale without loss of information.
The sample covariance can be decomposed in a similar manner to the variance. In this case, the idea is to compare two images,
and
, with the same raster extents
and resolution
, generated from different sampling methods on the same population of trees. Relation (13) generalizes to:
with total covariance energy—sums of cross products of all elements—given (loosely) as:
For both the variance and covariance, it is perfectly reasonable to look at anisotropic and isotropic components of the variance as images at any decomposition level, analogous to the raw wavelet coefficient results. For example, letting
denote the matrix of the squares of the individual components
, then
yields the average energy images for the horizontal decomposition over all levels. For covariances, this would be written in terms of the horizontal decompositions from the two sampling methods via the Hadamard matrix product (
https://en.wikipedia.org/wiki/Hadamard_product_(matrices)). That is, if
and
represent the horizontal decompositions for two sampling methods, then
are the corresponding average energy contribution matrices to the overall covariance matrix between the two sampling methods. Marginal sums and totals can be calculated for each level in the decomposition as explained in Gove [
71], and the correlation can be calculated from these quantities for use in comparing methods by, e.g., the Taylor diagram.
2.5.3. Distance-Based Smith Plots
A MODWT wavelet decomposition to level
was applied to each of the simulation results in
Table 1. The isotropic wavelet variances were calculated for each level of the decomposition using the methods described above. The Smith plot discussed earlier can be used to provide a summary of the wavelet analysis for each simulation.
Figure 4 presents a set of Smith plots where each panel corresponds to a level of the MODWT decomposition in terms of distance,
. These individual Smith plots, having decomposed the overall sampling surface variance by distance class, illustrate the variance relationships among sampling methods at different scales, where the same interpretation applies to these as to
Figure 2.
Recall that for these simulations, HPS is the best sampling method for volume in
Figure 2, which accords with theory. However, when we decompose the sampling surface at different levels, this is no longer consistently the case (
Figure 4). For example, HPS has the lowest variance only at the middle (
m) scales. At the other scales (
m), CHS has uniformly the lowest variance. As noted earlier, for
m, the wavelet (
) and scaling filters (
), as well as their associated two-dimensional anisotropic matrix versions in (12) show that that the decomposition is comparing pairs of sample points. Thus, the associated wavelet variances for each simulation are for this scale of differences in the overall sampling surfaces. Regarding the simple two-tree examples in
Figure S2, note that differences in adjoining cells are either zero or large (at the boundary of inclusion zones) under HPS because of the ‘stair-step’ manner in which the individual surfaces accumulate for each tree. Within an inclusion zone, moving from one point to another causes no change in the estimate because of the flat surface, and thus, no change in the variance at this scale. However, large jumps in variance accrue as the filter straddles adjoining points inside and outside (or vice versa) the inclusion zone, reflecting the well-known importance of checking borderline trees in practice. In contrast, under CHS, the differences are small between adjoining sample points and vary little throughout the inclusion zones depending on the taper of the associated tree stems. The gradual change within individual tree inclusion zones accumulates to associated gradual changes in the overlap zones. This results in lower variance at smaller scales for CHS compared to HPS and the other methods. While one can reason this out from the way we know that sampling works both theoretically and in practice under these two methods for one or two trees, it would be difficult to extend this thinking to a forest with many trees and overlapping inclusion zones. For example, regarding the full simulation surfaces in
Figure 1, it would be difficult to justify extending such interpretations to the entire tract without the benefit of the analytic wavelet analysis. In summary, in accordance with theory, moving a point
under HPS can cause a large change in variance near the inclusion zone boundaries, which is reflected in the higher variance for HPS than CHS at this lowest scale, where the same movement under CHS causes a smaller change to the variance. It should be noted that the variance at this finest scale is on the order of a tenth of the overall sampling surface variance for HPS, CHS and CPS (
Figure 2), while it comprises a more substantial amount of the overall variance for the spatially random CMC method as would be expected.
CPS consistently has the highest variance of the methods, except at the two smallest scales. Again, this would be expected from theory. The high variance for CMC follows by application of the arguments given above for HPS and CHS. Since CMC is a random, spatially unstructured method, adjacent points can have large differences, especially at the one- and two-meter scales.
Figure 4 seems to indicate that CMC can be close to CHS and HPS, especially at the middle scales. Note in the CMC results at the coarsest (32 m) scale that the variance actually increases for
m
ha
. This anomaly suggests that the CMC process at this scale violates Smith’s empirical law, though only by a small amount (note the scale for variance on this panel), which is not to be unexpected from a spatially unstructured random process.
The variances presented in
Figure 4 are in terms of the average energy,
. This includes the empirical wavelet variance (
Supplementary Material, Section S.4.2) over all levels, but at the coarsest level,
J, also includes the smooth component of the variance. Thus, these add to the sample variance less the squared mean over all levels for each method. A complementary plot that uses only the wavelet variances is presented in
Figure S4, which illustrates the relationship between wavelet variance and distance. Note that these figures show clear maxima for HPS, CHS and CPS, and minima for CMC. Geilhufe et al. [
63] provides more interpretation for these plots, including the link between the maxima and a characteristic scale [
74] to the images.
2.5.4. Distance-Based Taylor Plots
Just as the Smith plots can be applied to the MODWT wavelet analysis to facilitate the interpretation of the sampling variance relationships by scale, the Taylor diagrams can be adapted in a similar manner for a different summary perspective of the results.
Figure S5 presents the complete set of Taylor diagrams for the MODWT analysis corresponding to
Figure 4. These diagrams have the same interpretation as that for the overall sampling surface variance in
Figure 3, but for the distance-based components of the variance relationships. The following discussion will concentrate on distances
m as presented in
Figure 5 as an illustration of the interpretation and potential use of these diagrams for wavelet decomposition of sampling surfaces.
The analysis of the MODWT Smith plot determined that CHS was the most efficient method on a 1-m scale; it is also possible to determine from that plot that CHSbaf3 has the lowest variance at this scale. This simulation result therefore becomes the standard method to compare against at 1 m. Perhaps the most striking result at this distance is the lack of correlation between the standard and the other sampling methods. The closest in terms of pattern correlation (and difference standard deviation) is CHSbaf5 with . Correlations decrease and difference variances increase in a somewhat predictable manner for the other methods. Note that those methods with similar inclusion zone coverage area and those most closely related appear to be the closest to the standard in terms of and , with preference to other CHS variants first, followed by HPS and CPS. Furthermore, similar to the Smith plots, the CMC sampling methods cannot be considered to share attributes similar to CHS for reasons already mentioned. Even with the same overall inclusion zone area, CMCbaf3 is a poor substitute compared to the best method at the 1-m scale. Again, the difference lies in the spatially unstructured surface of CMC methods versus the predictably spatially structured surface under CHS.
Note particularly in
Figure S5 that each distance decomposition scale for the Taylor diagrams has a different reference (standard) sampling method, which can be discerned from the Smith plots as in the 1-m case. At the 8-m scale, HPSbaf3 becomes the reference method (
Figure 5). Perhaps the most salient relationship at this scale is that HPSbaf3 and CMCbaf3 are highly correlated, with pattern correlation
and similar standard deviations. Recall that at a scale of
m, the wavelet filters are contrasting the changes in area corresponding to 128 m
2 (
Table S2) out of a block twice that size. Therefore, the average difference between the blocks tends to be similar for the two sampling methods as the filters traverse the image. This point will be revisited in the Discussion. The groups of CHSbaf3, HPSbaf5, and CMCbaf5 are also quite highly correlated with HPSbaf3 with
. The standard deviation for CPSrad9 is close to that for the reference method, but the correlation is less than the aforementioned group, yielding a larger overall difference standard deviation, due at least partially perhaps to the difference in selection probability mechanism between it and HPSbaf3 and the mismatch between inclusion zone coverage.
In general, the Taylor diagrams in
Figure S5 allow us to see the progression from small- through large-scale variability while accounting for pattern correlation and difference standard deviation. The smallest scales, 1 and 2 m, show similar patterns that are interpretable with regard to our understanding of the sampling methods themselves and their associated sampling surfaces. For example, CHSbaf3 has the lowest variance for both 1-m and 2-m scales. This makes sense because, as noted on the Smith plot, if we were to move a sample point one meter in any direction, the estimate would change little. However, this same mechanism works against the other sampling methods with different sampling effort, since there can be large jumps between estimates at overlap boundaries within a given method and, thus, low pattern correlation in comparison to CHSbaf3; CMC is the outlier, with essentially no spatial structure. The correlations increase and the difference standard deviations decrease at the 2-m scale. This could be due to the fact that though the scale has increased by only one meter, the area difference comparison is 8 m
2 out of a total block of 16 m
2; this evidently results in estimates encompassed by this larger area of sample points being less correlated for CHSbaf3 (note the increase (almost double) in the standard deviation for CHSbaf3 between the 1- and 2-m diagrams). At the same time, the other sampling methods are becoming more correlated with the reference method at this scale. At 4 m, the results are very similar to those of 8 m discussed above, though the pattern correlations with the reference, HPSbaf3, are less and the difference standard deviations larger. The two largest scales point towards a trend of all methods converging as distance increases between sample points.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}