1. Introduction
Viruses are entities widely spread all around the biosphere. It is estimated that viral particles are 10 times more abundant than other types of microorganisms and, although their inclusion in a new life domain remains controversial, it is clear that they are not merely parasites [
1,
2,
3]. Viruses actively participate in ecosystem remodeling, population dynamics, and a wide variety of ecological, biogeochemical, genetic, and physiological processes [
4].
Despite their importance and abundance, the viral diversity has not been well characterized. Difficulties in the isolation of pure cultures and the description of viral cycles are common limitations in virus research, since less than 1% of environmental microorganisms can be grown in the laboratory [
5]. Next generation sequencing techniques enabled us to partially overcome these difficulties, revolutionizing this field of virology. Deep sequencing surveys of viral communities (viromes) have revealed a diversity beyond all expectations, and they have evidenced the lack of knowledge we currently have on global viral diversity. Only about 25% of sequences in viromes from marine environments have a match (e-value ≤ 0.001) to a known sequence [
6,
7,
8]. The large diversity and the lack of universal molecular markers make it difficult to organize and characterize known and new viral genomes.
Currently, computational tools such MetaVir2 [
9], and MG-RAST [
10] use available molecular databases to analyze genomes and metagenomes. Nevertheless, they are limited by considering only the fraction of the data generated that has significant similarity to previously annotated data. New approaches based not only on annotated sequence comparisons, but also on all the available information promise to be useful for analyzing individual viral genomes and viromes. For instance, Skewe-Cox et al., used protein sequence clustering to generate viral profile Hidden Markov Models (“vFams”) that were subsequently used for classifying highly divergent sequences [
11]. Furthermore, the identification of highly conserved genes in specific taxonomic groups has been another approach for the taxonomic classification of viral sequences. For instance, diversity analyses of cyanophages, algae viruses, T4 and T7 phages have been conducted following this method, and they enabled the characterization of the viral diversity in the studied environments [
12,
13,
14]. However, the mentioned studies were restricted to specific families and ecosystems.
Using another approach, Kristensen et al. constructed a collection of phage orthologous groups (“POGs”) from bacterial and archeal viruses [
15,
16]. Orthologous gene sets are widely used as a powerful technique in comparative genomics and for viruses it has been suggested that marker genes could be obtained using this technique [
15,
16]. Based on the same concept, eggNOG has been implemented in its latest version a database of orthologous groups focused on viruses (Viral OGs) [
17]. However, they do not include the whole breadth of viral diversity represented in the public databases, since genomes of eukaryotic viruses were not included by either of the mentioned studies. Given the large amount of currently available genetic information, it is imperative to develop and implement new tools to reliably and efficiently analyze these data to better describe viral diversity.
Computational techniques have been used previously for similar issues in biology. Machine learning methods, for example, are algorithms which learn through the experience, attempting to classify information according to shared features. These techniques allow us to extract patterns, trends, and, finally, analyze the information using a non-deterministic way. Supervised learning algorithms such as random forest, support vector machine, and neural networks have been successfully introduced to solve complex biological problems, such as image analysis, microarray expression analysis, QTLs analysis, detection of transcription start sites, epitopes detection, protein identification and function, among others [
18,
19].
In this work we used the methodology proposed by Kristensen et al. for the identification of gene and domain orthologous groups from related viral sequences. We expanded the reach of this approach by incorporating genomes of eukaryotic viruses and applying random forest as a machine learning strategy to identify taxonomically informative orthologous groups. We denominated the set of orthologous groups as Eukaryotic Viruses and Phages Orthologous Groups (ViPhOGs).
3. Results
3.1. The Viral Diversity Represented in Public (NCBI) Databases
We searched for all viral genomes stored in either RefSeq or Genbank databases (April 2015) and obtained 50,728 entries by using the selected set of queries (see methods). Depuration of the search results led to the exclusion of 6617 entries, as some of the keywords in their descriptions indicated that they did not correspond to complete genomes. Entries kept following the depuration step were clustered based on sequence identity in order to collapse near identical viral sequences, which resulted in an overall 57% reduction that reflects a very high redundancy in the searched databases. Bacteriophage sequences decreased from 3573 to 2071 (57.9%), while sequences of eukaryotic viruses went from 40,538 to 13,011 (32.1%). Finally, a second dereplication at the protein level was conducted following the prediction of genes for those genome accessions without protein annotations (see methods).This process led to a final reduced set of 14,057 entries, comprising 1974 bacteriophages and 12,083 eukaryotic viruses. Those accessions are considered as the non-redundant viral diversity stored in NCBI public databases (
Table S1).
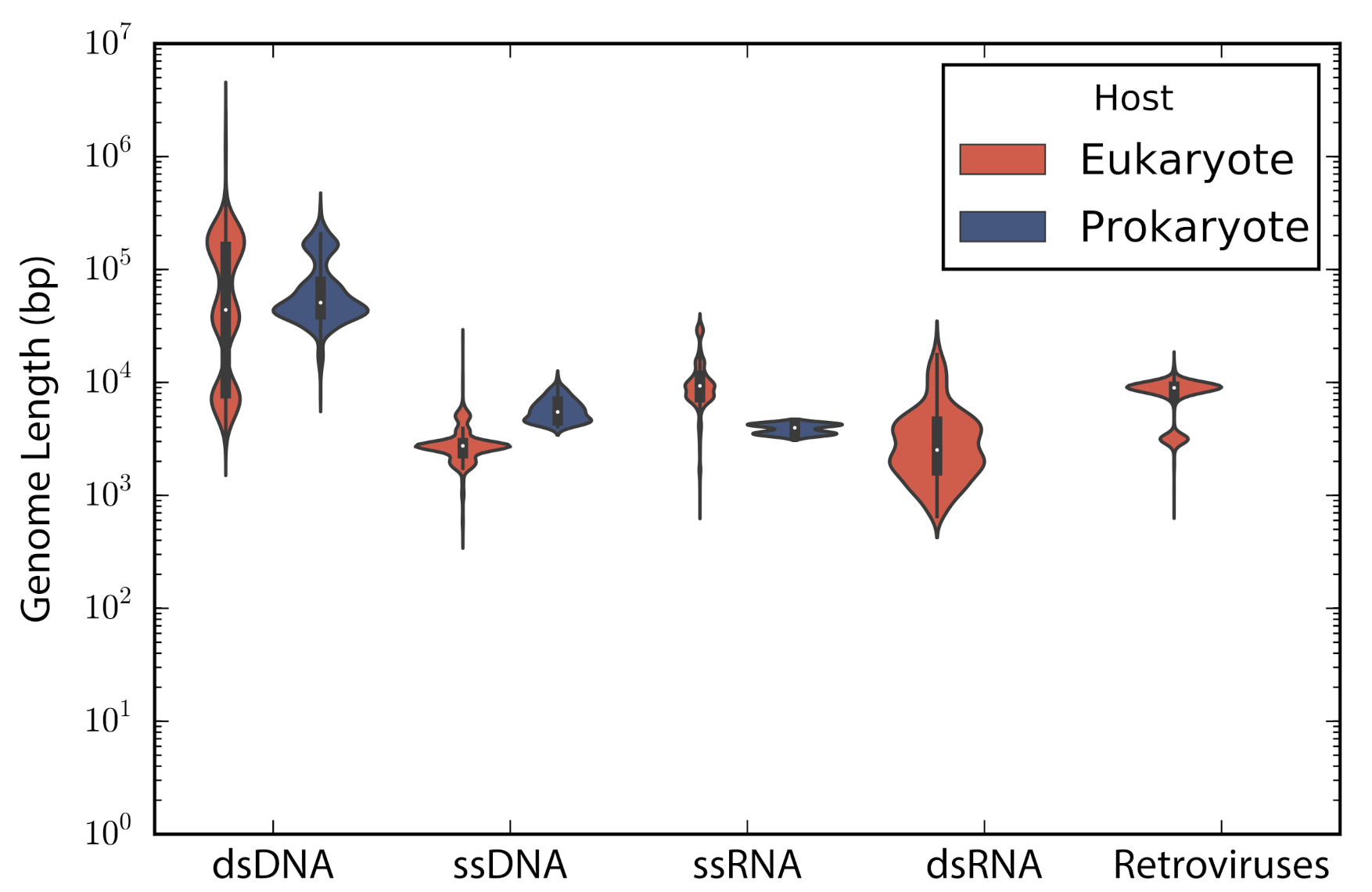
According to the type of genetic material stated in the description of the accessions, these were categorized into: double stranded DNA (dsDNA), single stranded DNA (ssDNA), double stranded RNA (dsRNA), single stranded RNA —despite the sense— (ssRNA), and retro-transcribing viruses (rt-viruses). A total of 1122 accessions did not have a complete taxonomic annotation at the moment of the study; those accessions were found to be either unclassified phages (66), unclassified viruses (80), satellites (203), or assemblies from marine metagenomes (773). The longest genome belonged to the dsDNA virus
Pandoravirus salinus (NC_022098) with a genome length of 2,473,870 bp, whereas the smallest genome belongs to the ssRNA
Lucerne transient streak satellite virus with 324 bp. In general, DNA viruses are larger than RNA viruses (Mann-Whitney test:
p-value = 1.12 × 10
). A comparison of the genome length distribution of phages and eukaryotic viruses shows that dsDNA and ssDNA phages tend to have larger genomes than dsDNA and ssDNA eukaryotic viruses (Mann-Whitney test when comparing dsDNA viruses:
p-value = 7.19 × 10
; Mann-Whitney test when comparing ssDNA viruses:
p-value = 3.08 × 10
). In the case of ssRNA viruses, eukaryotic viruses tend to have larger genomes than phages (Mann-Whitney test when comparing ssRNA viruses:
p-value = 7.89 × 10
) (
Figure 1).
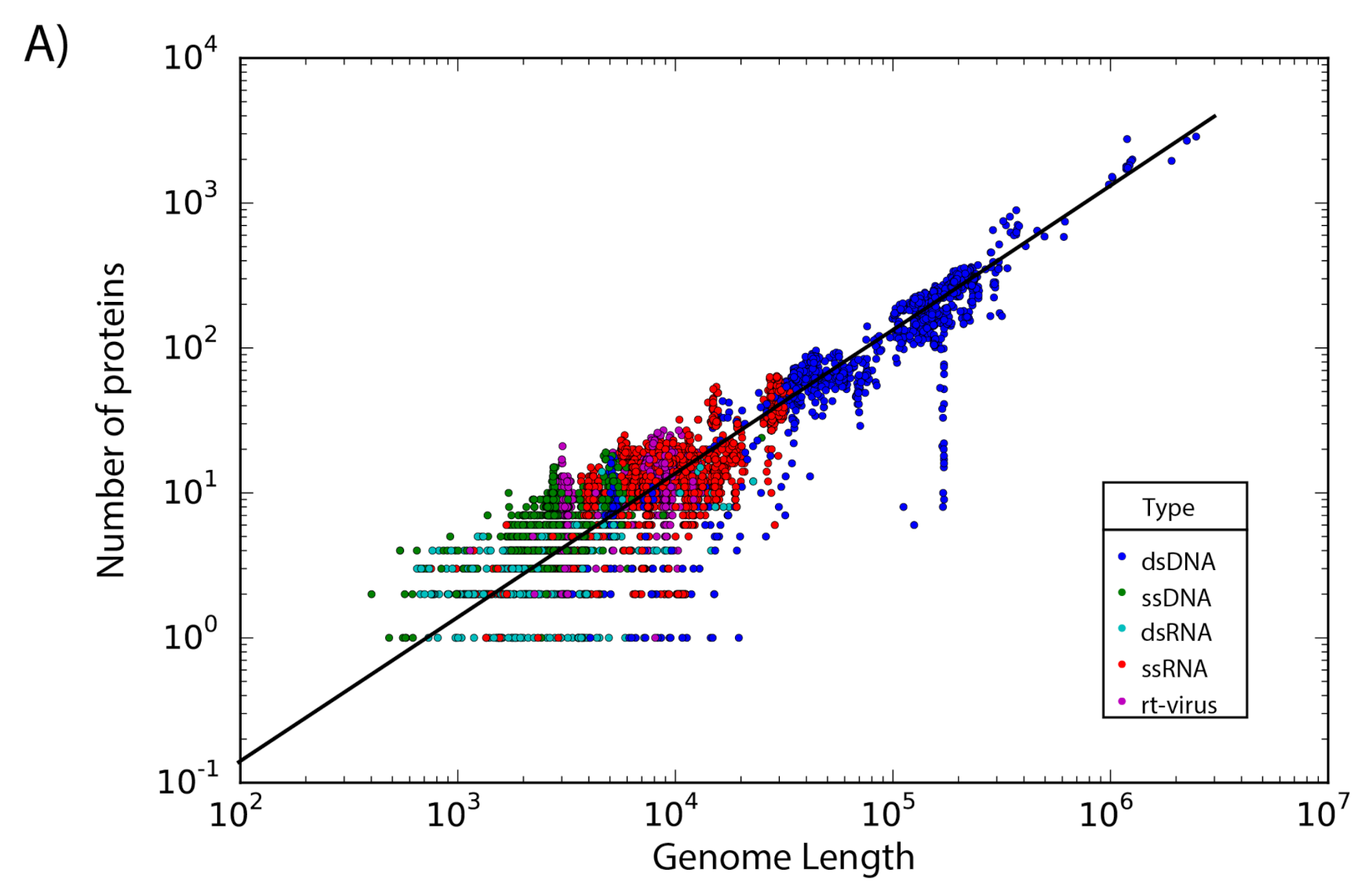
The set of 14,057 non-redundant genomes code for a total of 442,007 proteins, where we observe that the number of genes is directly proportional to the length of the genome. Interestingly, a linear regression suggests a gene density of 12 proteins per kilobase in the case of phages, while in the case of eukaryotic viruses the gene density is only about 2.5 proteins per kilobase; indicating a lower gene density for eukaryotic viruses in comparison with phages (
Figure 2).
3.2. Eukaryotic Viruses and Phages Orthologous Groups (ViPhOG)
We searched for domains in all identified and predicted proteins using InterProScan [
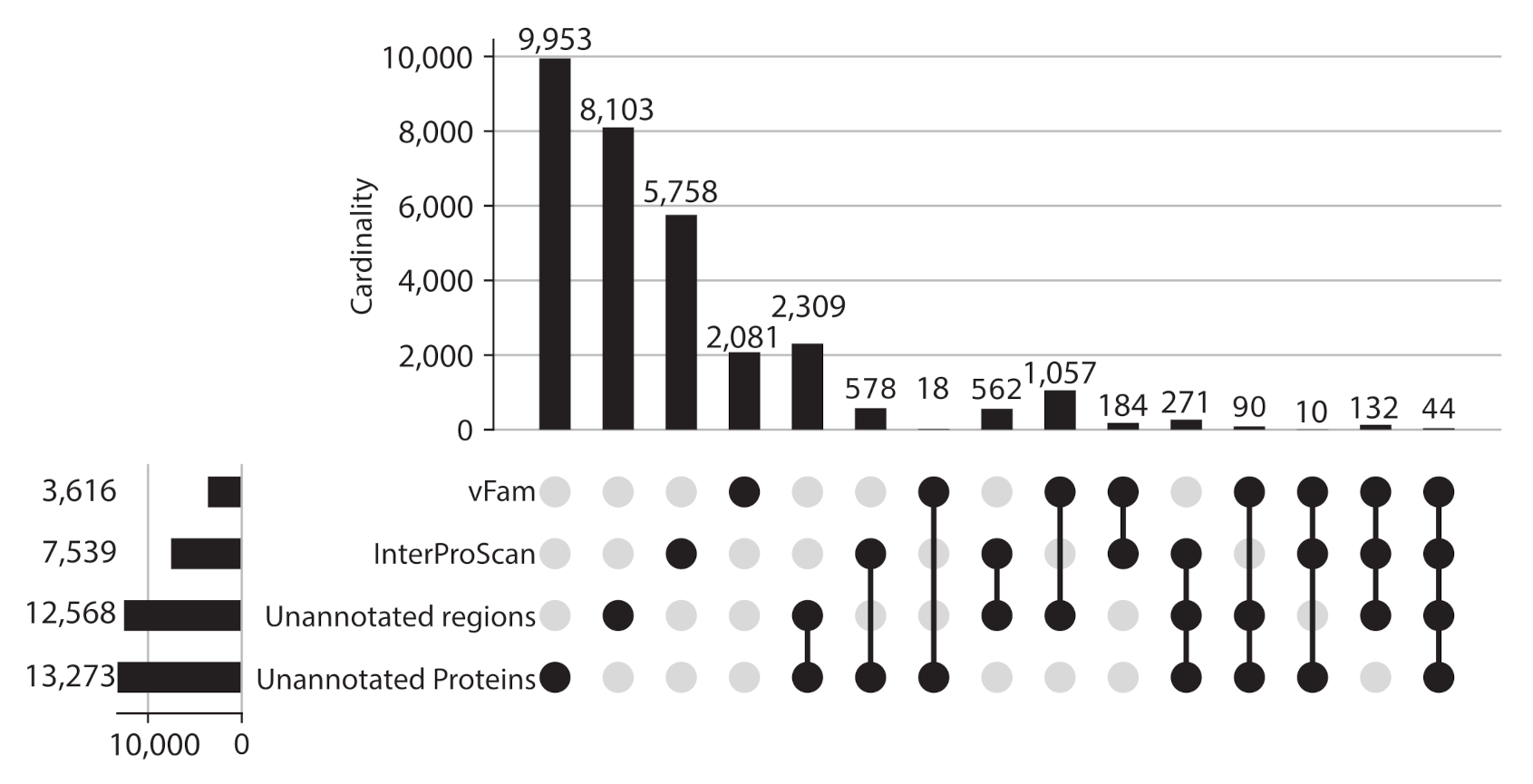
25]. Domains were found only in 52.59% of the proteins (232,033 proteins), which means that even for the sequences stored in public databases half of the information belongs to the viral dark matter. In an attempt to gain further information, unannotated proteins were used as a query against vFams, but only 39,344 (8.9%) proteins had a significant match to entries in this database.
Given the proportion of unannotated sequences, protein regions without domain or vFam annotation were also considered for further analysis, meaning that the final set of viral regions consisted of: 365,368 annotated regions (309,251 InterPro domains + 56,137 vFam matches), 157,591 unannotated regions of at least 40 residues (69,333 regions in between annotated domains + 88,258 regions in between vFam matches) and 170,637 unannotated proteins (proteins with no hit to vFam or InterProScan). The set of orthologous groups was built from the symmetric best matches between viral regions using the software COGsoft [
4] (see methods). A total of 31,150 ViPhOGs with at least three members were obtained. Interestingly, most of the ViPhOGs were built from a single type of viral regions: unannotated proteins (9953), unannotated regions (8103) or annotated regions (8023). Among all possible combinations of viral region types, the highest number of clusters was obtained for the combination of unannotated proteins and unannotated regions (2309) (
Figure 3). This suggests that although the vast majority of regions and proteins in viral genomes are uncharacterized, they are conserved among the different chosen viruses.
The median amount of regions clustered in a ViPhOG was 5 (IQR:3,11) with the largest ViPhOG having 3440 regions from 1180 different genomes of both phages and eukaryotic viruses. This large ViPhOG contained regions mainly annotated as Helicases. However, it was not the only ViPhOG that comprised a rather large number of regions, as a total of 1081 ViPhOGs contained more than 100 regions (
Table S2). In terms of the host type, we found 14,746 ViPhOGs represented exclusively by eukaryotic viral genomes, 10,100 ViPhOGs represented only by phage genomes and the remaining 6304 ViPhOGs were represented by both phages and eukaryotic viral genomes. As a ViPhOG may include paralogs, any given genome can contribute with several regions to a single ViPhOG. However, the number of regions per genome for each ViPhOG was on average 1.008 (max: 9.162), which indicates that the vast majority of ViPhOGs are composed of orthologs instead of paralogs. This is also evidenced in
Table S2, where most of the ViPhOGs have the same number of genomes as regions, indicating that each genome contributed only one region to each orthologous group.
3.3. A Random Forest Classifier Correctly Classifies Viral Genomes According to the Presence of ViPhOGs
We used the Scikit-learn random forest implementation to test if ViPhOGs can be used as features to predict taxonomy (see methods). From the model testing, it was determined that in general a model with 60 estimators had a reasonably good balance between classification-score and computation time, as models with 60 estimators result in a high classification score and less variance (
Figure S1). Therefore, a random forest classifier with 60 estimators was run separately for each of the evaluated taxonomic levels. For each taxonomic level, all genomes classified into a taxon at the analyzed level were used. For the order level, the algorithm received a matrix of 1031 ViPhOGs and 4698 genomes to classify into 7 Orders. In the case of family, the matrix contained 11,328 ViPhOGs and 11,978 genomes from 84 different families, and for the genus level, the size of the matrix was 20,310 ViPhOGs and 10,151 genomes from 335 different genera. For each case, matrices were split in 100 train and test (70:30 distribution) sets. The mean accuracy score achieved was 99.06%, 95.60%, and 89.58% for order, family, and genus, respectively (
Figure 4,
Figures S2 and S3).
As the classification score suggests, the chosen algorithm excelled at accurately classifying the genomes into their respective taxonomic groups; where most of the misclassification cases were a small proportion of the genomes represented by each of the assessed taxons (
Figure S4). The 10 most common classification mistakes per taxonomic level are shown in the
Table S3. Although we observed that the classification error does not perfectly correlate with the total number of available genomes for the classification, it is evident that the lower the number of genomes available for a given taxon, the higher the classification error (
Figure S5).
3.4. Informative ViPhOGs: Signatures of the Taxonomy of Viral Genomes
As the good performance of the models suggests, there is a set of ViPhOGs that allows to identify with high accuracy the taxonomic group of each genome. Therefore, we aimed at minimizing the number of ViPhOGs capable of reaching high accuracy of classification for each given taxonomic level (see methods). That approach allowed us to determine that a reduced set of 20 ViPhOGs was enough to achieve a high accuracy score for the order level. For the family and genus levels, the number of ViPhOGs needed was 388 and 1392, respectively (
Figure S6). We designated those ViPhOGs as “Informative ViPhOGs”. Their taxonomic assignment and their functional annotation (if available) is presented in the
Table S4.
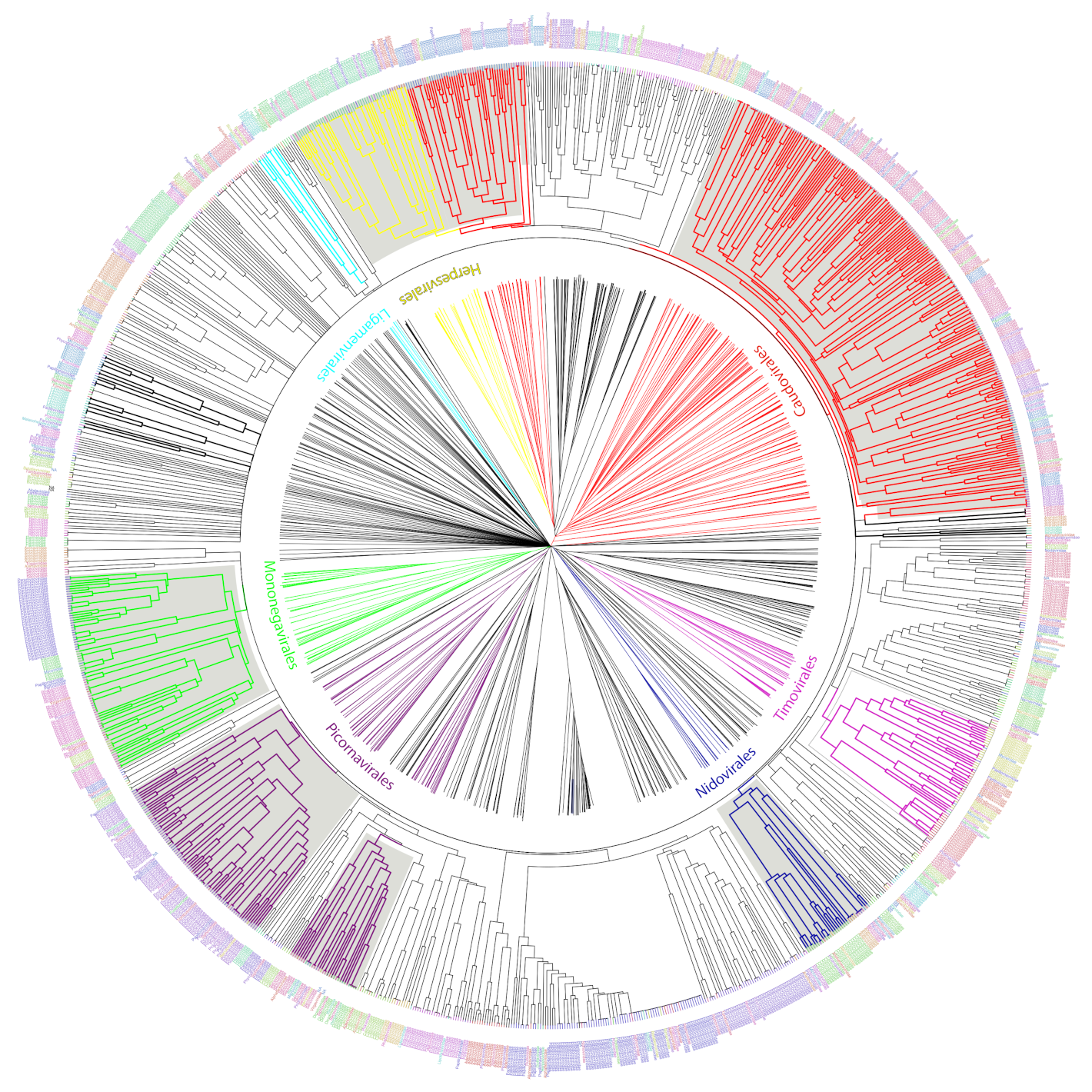
We used the set of informative ViPhOGs to build an UPGMA tree that delineates the viral diversity clustering, based on the presence or absence of these genomic characteristics (see methods). Genomes that belong to a defined order constitute a defined clade in the tree. Furthermore, in all cases except for
Caudovirales, there was a consistent branching of the orders containing the corresponding families and genera designated by the International Committee on Taxonomy of Viruses (ICTV) (
Figure 5). A closer look at the tree revealed some interesting viral features.
(i) Bacteriophages. The family Tectiviridae (dsDNA viruses) shares a clade with the genus Rosemblanvirus and Salasvirus, both members of the family Podoviridae (also dsDNA viruses from the order Caudovirales), while the other bacteriophage families Inoviridae, Microviridae (both ssDNA), and Leviviridae (ssRNA) appear as independent clades without shared characteristics among them or members of the order Caudovirales. Regarding archaeal viruses, the family Fuselloviridae and the order Ligamenvirales, which includes the families Rudiviridae and Lipothrixviridae, form a single clade. Furthermore, most of the families of archaeal viruses had very few representatives, revealing a bias in the explored diversity;
(ii) Characteristics shared between eukaryotic viruses and phages. The order Herpesvirales appears as a sister clade of a subset of the Caudovirales, in particular, members of the Myoviridae family. Moreover, the Nucleo-Cytoplastmatic Large DNA Viruses (NCLDV) group is enclosed by the Caudovirales clade. We looked for ViPhOGs present in members of all NCLDV families and found ViPhOGs number 937 and 1598, which are associated with helicase domains and, as mentioned before, prevalent among dsDNA viruses in general; ViPhOG 821, which codes for a ribonucleotide reductase and is shared mainly among members of the families Myoviridae, Herpesviridae, and Poxviridae; ViPhOG 865, a serine/threonine kinase domain, and ViPhOG 72, an EF binding domain, both also very common in members of Herpesviridae;
(iii) RNA viruses. Those from the family Chrysoviridae (dsRNA) grouped with Totiviridae (dsRNA), in particular with the genus Totivirus that also infects fungi. Interestingly, there was a clade formed by different positive sense ssRNA viruses, which had no other common taxonomic assignment. This clade included the families Tombusviridae, Nodaviridae, Bromoviridae, Virgaviridae, Togaviridae, Hepeviridae, Closteroviridae, and the families of the order Tymovirales.
4. Discussion
In recent years, as metagenomics has revealed a great diversity of phages from different biomes, and evidenced the huge unexplored diversity that the viral world holds. The use of genetic signatures to describe and characterize the diversity of specific groups of viruses have been successfully applied in diverse contexts [
29,
30]. Different strategies have been described including POGs [
15,
16], vFams [
11], viralOGs from EggNOG [
31], and pVOGs [
32]. Here, we followed the methodology by Kristensen et al., and took it a step further by extending the search of orthologous groups beyond bacterial and archeal viruses to also include eukaryotic viruses, which consolidated a final set of 14,057 non-redundant genomes.
We took a non-waste-information approach in order to get orthologous groups among (i) annotated domains, (ii) unannotated regions of annotated proteins, and (iii) unannotated proteins, all derived from the non-redundant diversity of viruses stored in public databases. This strategy proved to be useful given that a large majority of the ViPhOGs were constituted solely or in combination of unannotated regions or unannotated proteins. Finally, we established a comprehensive set of 31,150 orthologous groups that we denominated ViPhOGs.
As the ICTV provides a single classification scheme that reflects the evolutionary relationship among viruses, we evaluated the possibility that the presence or absence of ViPhOGs in viral genomes reflected the ICTV taxonomy using a machine learning approach. The low misclassification scores reached by the random forest algorithm suggested that the use of ViPhOGs as features for performing taxonomic classification of viruses had great potential. Therefore, we determined the subset of informative ViPhOGs that could be considered as markers or signatures for the different taxonomic groups defined by the ICTV at the order, family, and genus levels.
We found a high degree of agreement between clustering identified using informative ViPhOGs and the monophyletic orders described by ICTV. Example of those were the
Nidovirales [
33],
Ligamenvirales [
34],
Mononegavirales [
35], and
Tymovirales [
36] whose branches shows a clear separation in accordance to the proposed families and genera.
Importantly, the current approach has been consistent with recent changes in the ICTV taxonomy. For example, the family
Pneumoviridae, whose members were considered as a subfamily of the family
Paramyxoviridae up till 2016 [
35,
37]. Our classification mechanism used the ICTV classification from 2014, but was capable of showing the separation of the family
Paramyxoviridae. The tree clearly showed how eukaryotic viruses from the genera
Metapneumovirus and
Pneumovirus (now known as
Metapneumovirus and
Orthopneumovirus, respectively) form a separate clade (now Family Pneumoviridae), whose sister clade is the family
Paramyxoviridae.
Despite the absence of a link between several ssRNA(+) families in the ICTV taxonomy of 2014, in the ViPhOG-based tree built here families
Tombusviridae,
Nodaviridae,
Bromoviridae,
Virgaviridae,
Closteroviridae, and
Hepeviridae were grouped together with the families of the order
Tymovirales. In the most recent ICTV taxonomy the families
Bromoviridae,
Virgaviridae,
Togaviridae, and
Closteroviridae were assigned to the order
Martellivirales; and the family
Hepesviridae to the order
Hepelivirales. These two new orders (
Hepelivirales and
Martellivirales), together with the
Tymovirales, belong now to the Class
Alsuviricetes and the phylum
Kitrinoviricota. Furthermore, in our tree the families
Tombusviridae and
Nodaviridae are a sister clade of what seems now to be the
Alsuviricetes clade.
Tombusviridae and
Nodaviridae belong now to the orders
Tolivirales (Class:
Tolucaviricetes) and Nodamuvirales (class:
Magsaviricetes), respectively. All classes, together with
Alsuviricetes, constitute now the Kingdom
Kitrinoviricota. This suggests that a tree generated with conserved amino acid features could identify basal evolutionary relationships among viruses matching the new scope of the ICTV [
38].
Misclassification cases were very limited and more common in the lowest taxonomic level (Genus) than in the highest taxonomic level (Order). Although we did not observe a perfect negative correlation between the number of genomes available and the number of misclassification cases, we did observe that genera like Mupapillomavirus, Yetapoxvirus, Kappapapillomavirus, and families such as Alphatetraviridae and Amalgaviridae with two or three genomes available per taxa were frequently misclassified. Another kind of misclassification event occurred between related taxa. Such was the case for eukaryotic viruses of the Genus Vesiculovirus that were confounded with members of the Genus Sprivivirus. Both genera belong to the family Rhabdoviridae. Interestingly, this pair of genera share more ViPhOGs between each other than against any other member of the family Rhabdoviridae. This observation could be the basis of a more in-depth study which could potentially lead to the suggestion of both genera being part of a new sub-family which separates them from the rest of the family. Lastly, regarding misclassification events, we want to acknowledge that there is still a place for improvement of the classification models. We identified misclassification cases where a taxon was misclassified and the confusion does not appear to be directed by genomic relatedness. As an example we chose to discuss the case of the Caulimoviridae family. This family had 123 representative genomes in our database and in 10% of the cases it was misclassified as Myoviridae. Only a few representative genomes of each family have (at most) 3 ViPhOGs in common (ViPhOGs number 731, 1158, and 269). Those 3 ViPhOGs are not informative ViPhOGs for Myoviridae, and appear to be present in several different viral families and clades, therefore, there is no clear answer to why the classifier confused these two unrelated families.
One of the major strengths of the presented work is that, in addition to genomes of prokaryotic and archeal viruses, we included genomes of eukaryotic viruses. As expected, not a single ViPhOG was present in all viral genomes. Viruses do not encode for ribosomes or any other universal markers that allow the study of their phylogenetic relationships. Furthermore, it has been accepted that viruses have not evolved from a single common ancestor [
3,
39,
40,
41], which might be reflected in the high number of polytomies observed in the informative ViPhOGs tree. Besides the absence of an universal ViPhOG, a not negligible number of ViPhOGs were formed by regions from phages and eukaryotic viruses. Further analyses would be needed to determine if the fact that a ViPhOG is shared between eukaryotic and prokaryotic/archeal viruses is due to functional convergence, or if it is because those viruses presumably have an evolutionary relationship as is the case for
Herpesviridae and
Siphoviridae [
42,
43,
44] or as ssRNA(+) viruses, which presumably co-evolved with their hosts before they split into eukaryotes [
3,
45].
The fact that a machine learning approach, based solely on genomic features reached a high score when classifying viruses in their assigned taxa, highlights how the viral taxonomy based on ecological (e.g., pathogenicity and host range) and molecular (e.g., composition of the virus genome and sequence similarity) features is a robust system able to depict the evolutionary relationships among viruses. The informative ViPhOGs dataset is, therefore, nothing but a reflection of the efforts done to establish a taxonomic system for viruses and the strength of machine learning algorithms that were able to depict patterns among a comprehensive dataset. We consider that the result, the ViPhOGs and the informative ViPhOGs datasets, may be used as a start point to hypothesize about the genetic relationships among known viral groups and as a useful tool to attempt to characterize and define the viral dark matter that is being exposed via metagenomics. We released the ViPhOGs dataset hoping that: (i) the community can use it as a tool to explore the genetic relationships among viral clades encouraging viral research, (ii) to facilitate the exploration of specific viral groups by the use of its ViPhOGs, and (iii) to obtain viral profiles in specific biomes. We want to encourage the community to exploit the benefits of the use of this comprehensive set of orthologous groups in a world of fast evolving entities that quickly lose their protein sequence conservation.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





