1. Introduction
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) is the etiological agent of the coronavirus disease 2019 (COVID-19). The course and outcome of COVID-19 depend on multiple processes underlying the response of the host to the viral infection [
1,
2,
3]. The resulting complexity calls for the application of mathematical modelling tools to describe, analyse, and predict the disease trajectories in relation to virus–host interaction parameters. This extension of the analytical tools needed to understand the pathogenesis of COVID-19 is highlighted by recent efforts to build up a computational resource linking available knowledge on the mechanisms of COVID-19 [
4].
In patients infected with SARS-CoV-2, the race between the viral replication and the immune response determines the course of COVID-19 [
3,
5]. The immune determinants are key to explaining different disease progressions and outcomes [
6] that are extensively analysed [
2]. Heterogeneity in the spectrum of the infection dynamics could be potentially derived from viral variation [
7]. Since the beginning of the SARS-CoV-2 pandemic, a number of new SARS-CoV-2 variants have emerged, such as the Alpha (B.1.1.7), Beta (B.1.351), Gamma (P.1), Delta (B.1.617.2), and more recently Omicron (B.1.1.529) [
8,
9,
10,
11]. However, it is not clear how the observed specific mutations increase the transmissibility and virulence of the virus [
12].
To gain a mechanistic understanding of the relationship between a higher pathogenicity of SARS-CoV-2 variants and specific functions of the mutants, it is required to examine various sources of variability in viral infection/production bearing in mind that minor variations in replication rates could have a profound effect on viral loads [
13]. The variations could be split into two categories. The first one is for those resulting from natural heterogeneity in virus production due to random effects and fluctuations in life cycle reactions. The second group is related to mutation-induced deterministic shifts in the kinetic parameters of SARS-CoV-2 replication, e.g., the receptor binding affinity, the susceptibility to type I interferon (IFN), and others.
The binding affinities between the Receptor Binding Domain (RBD) of the spike protein of SARS-CoV-2 variants and the ACE2 receptor have been recently characterised using a multidisciplinary approach combining all-atom steered molecular dynamics simulations and microscale thermophoresis [
14]. It has been established that the Delta variant, upon the T478K mutation, requires the highest force for the RBD-ACE2 complex to be completely dissociated. Overall, the affinities of SARS-CoV-2 variants to ACE2 are higher than that of the wild-type (WT) with an increase factor ranging from 20–30% to 2.3-times. This links to the ability of the viral variants to infect a broader spectrum of target cells and results in a much higher infectivity, as shown in [
15].
Upon infection with SARS-CoV-2, the type I IFN system is activated in the host cell [
16]. IFN controls SARS-CoV-2 infection by inducing the expression of IFN-stimulated genes (ISGs) that restrict distinct steps of viral replication [
17]. The detection of viral dsRNA is mediated by cytosolic innate sensors (RIG-I, MDA-5) and endosomal toll-like receptors TLRs (3,7,8) [
18]. The type I IFN-mediated inhibition of SARS-CoV-2 growth in infected cells targets the translation initiation complex (PKR activation) and mRNA degradation (OAS activation) and induces an RNA editing enzyme (adenosine deaminase) [
17].
We previously developed a deterministic mathematical model that describes the life cycle of SARS-CoV-2 in the form of ordinary differential equations (ODE) [
19]. The model considers major replication stages including the binding of the virus to the ACE2 receptor, the translation of nonstructural proteins associated with the formation of a translation initiation complex, and RNA degradation. Hence, the model provides an appropriate tool that can be transformed into a stochastic form for examining the variability in the SARS-CoV-2 life cycle for the wild-type virus and its mutants. The latter are characterised by different affinities of their RBD affinity to the ACE receptor and their susceptibility to IFN. In this study, we develop a stochastic model of intracellular SARS-CoV-2 replication.
The stochasticity of the virus replication cycle can be accounted for by including Brownian motions into the deterministic model and by describing it via stochastic differential equations (SDE) [
20,
21,
22]. However, the applicability of this approach is restricted by a daunting task of consistent estimation of the diffusion coefficients and the mode of noise-driven perturbations (additive or multiplicative) for all reaction stages in the model.
Another framework to model a stochastic infection dynamics is to employ a discrete or continuous Markov Chain (MC), which is implemented as a Dynamic Monte-Carlo method. Initially, it has been developed for chemical kinetics [
23,
24]. In this approach, the Markov chain and its parameters can be derived directly from the deterministic model. This provides an essential advantage over SDE-based modelling as the evaluation of parameters of the model is the most challenging problem. In our recent work [
25], the MC-based stochastic modelling approach was successfully implemented to convert the mechanistic ODE model of HIV-1 life cycle into a stochastic Markov Chain Monte Carlo (MCMC) model [
26]. The stochastic model enables us to quantify and explain the emergence of heterogeneities in the virus life cycle including the multiplicity of infection (MOI) and the variability in net viral progeny.
In this paper, we transform the deterministic model of the SARS-CoV-2 life cycle [
19] into a stochastic model of the MCMC-type. We apply the stochastic model to examine the following statistical characteristics of a single-cell SARS-CoV-2 infection:
The cell-to-cell variability in SARS-CoV-2 progeny production;
The multiplicity of single cell infection;
The probability of infection;
The local sensitivity of the virus production to specific life-cycle steps;
The impact of type I IFN; and
The effect of the RBD-ACE2 binding affinity.
In
Section 2, we formulate the stochastic model of the SARS-CoV-2 life cycle and describe its algorithmic implementation.
Section 3 focuses on computational examination of the model behaviour for addressing various biologically relevant questions as listed above. The discussion of the results is presented in
Section 4.
2. Methods
In this section, we introduce the deterministic ODE model of the SARS-CoV-2 life cycle developed in our previous work [
19]. A formal notation is used for the time-dependent variables that are more suitable for the description and implementation of the stochastic MCMC model. The parameters and functional forms of the calibrated reaction kinetics are transformed into the propensity functions of the respective elementary reactions following the Gillespie approach [
23]. The numerical implementation of the MCMC model is based on a hybrid stochastic-deterministic algorithm [
25]. Finally, we introduce the approach to local sensitivity analysis of the stochastic model based on the computation of histogram differences for the ensembles of individually perturbed parameters.
2.1. Deterministic Equations of SARS-CoV-2 Single Cell Infection
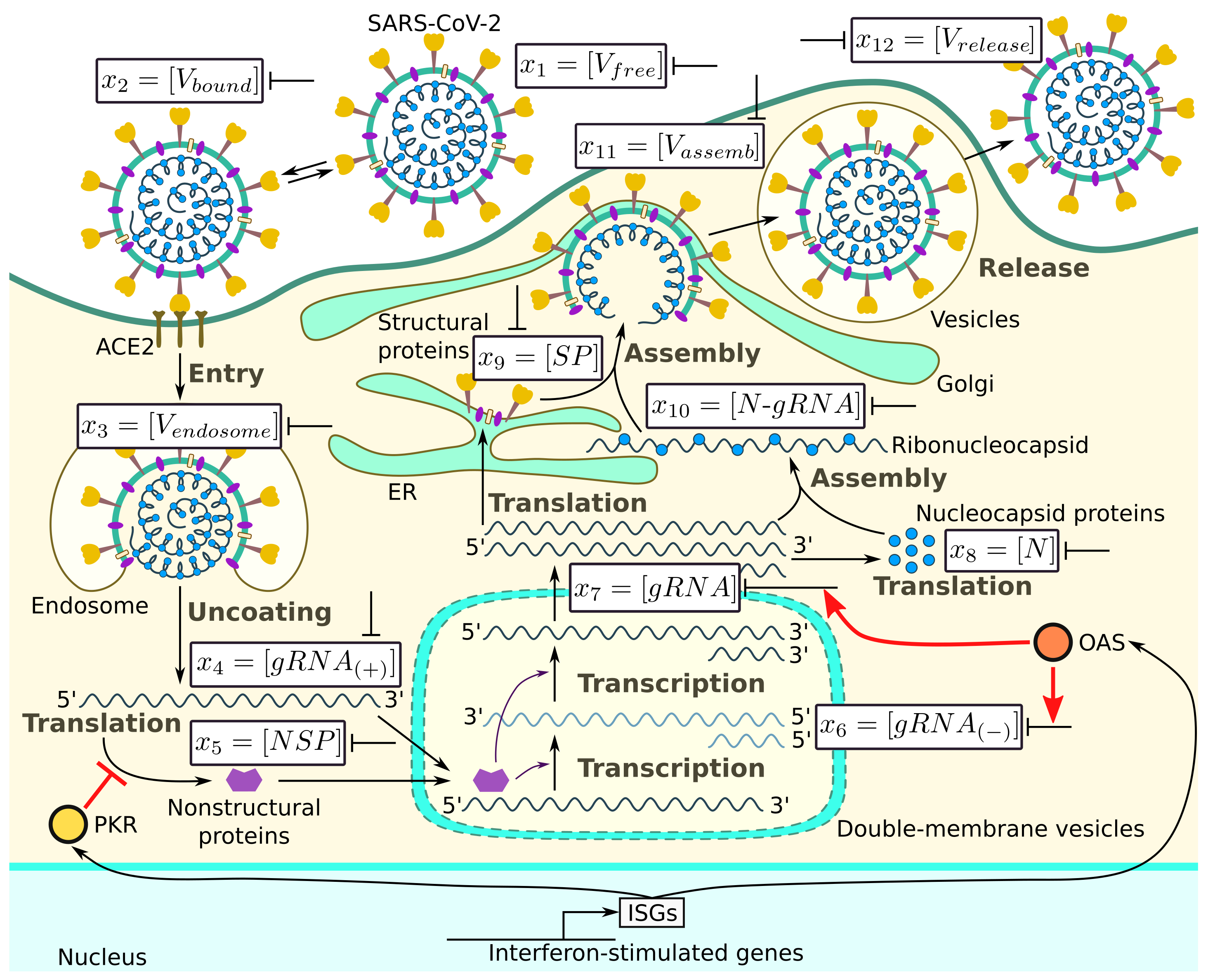
The major steps of the intracellular life cycle of SARS-CoV-2 are schematically presented in
Figure 1. In addition, we indicate the targets for type I IFN-mediated inhibition of virus replication.
According to this scheme, the infection process can be divided into several phases: (a) entry, (b) genome transcription and replication, (c) translation of structural and accessory proteins, and (d) assembly and release of virions. We consider all of these phases and present the corresponding equations following [
19].
Entry. This phase is split into four stages:
- (i)
Binding of the receptor-binding domain (RBD) of the viral spike (S) protein to ACE2 receptor (Equation (
1));
- (ii)
Priming of the virus S protein at the host cell surface by the transmembrane protease serine 2 (TMPRSS2), which leads to cleavage of the S proteins at the S1/S2 and S2 sites (Equation (
2));
- (iii)
Fusion at the cellular or endosomal membrane (Equation (
3)); and
- (iv)
Release and uncoating of viral genomic RNA (Equation (
4)).
The population dynamics of the abundance of the respective molecular species is described by the following ordinary differential equations:
where the dot over
denotes the time derivative of
;
is the number of free virions outside the cell membrane;
is the number of virions bound to ACE2 and activated by TMPRSS2;
is the number of virions in endosomes; and
is the number of ss-positive sense genomic RNA.
Genome transcription and replication. This phase is split into three stages:
- (v)
The translation of the released genomic RNA into viral polyproteins (pp1a, pp1ab) which generate a number of non-structural proteins (nsp1-16), including nsp-12, which encodes the RNA-dependent RNA polymerase (RdRp) (Equation (
5));
- (vi)
The RdRp-dependent transcription of a negative sense subgenomic and genomic RNAs (Equation (
6)); and
- (vii)
The RdRp-dependent transcription of a positive sense subgenomic and genomic RNAs (Equation (
7)).
The population dynamics of the abundance of the respective molecular species is described by the following ordinary differential equations:
where
is the number of non-structural proteins;
is the number of negative sense genomic and subgenomic RNAs; and
is the number of positive sense genomic and subgenomic RNAs.
Translation of structural and accessory proteins. This phase is split into two major stages:
- (viii)
The translation of the structural nucleocapsid protein N from subgenomic RNAs by cytosolic ribosomes (Equation (
8));
- (ix)
The translation of the structural proteins S, envelope E, and membrane M proteins characterised in the model by their total abundance
, which takes place in the endoplasmic reticulum (ER) (Equation (
9)).
The population dynamics of the abundance of the respective molecular species is described by the following ordinary differential equations:
where
is the number of N proteins per virion and
is the total abundance of the structural proteins S, envelope E, and membrane M proteins.
Assembly and release of virions. This final phase is split into three major stages:
- (x)
The binding of N proteins and gRNA, resulting in nucleocapsid formation (viral RNA genome coated with N protein) (Equation (
10));
- (xi)
The assembly of virions via encapsulating N-RNA complexes at the ER–Golgi compartment (Equation (
11)); and
- (xii)
The release of the assembled new virions by the infected cell via exocytosis, budding, or cell death (Equation (
12)).
The population dynamics of the abundance of the respective molecular species is described by the following ordinary differential equations:
where
is the number of ribonucleoprotein molecules;
is the number of assembled virions; and
is the number of released virions.
The following functions are present in Equations (
6)–(
11), which parameterise the saturation effects in the process kinetics of RNA transcription, nucleocapsid formation, and virion assembly, respectively:
Thus, the SARS-CoV-2 replication dynamics is described by 12 ODEs (
1)–(
12), which we denote for convenience formally by variables
. The system of equations is nonlinear because of nonlinear Michaelis–Menten-type functions (
13).
2.2. Quantification of SARS-CoV-2 Replication Parameters
The calibration of the model, i.e., the estimation of parameters in the equations to reproduce the scale and kinetics of the SARS-CoV-2 life cycle was performed in our previous study [
19].
The model parameters were calibrated using various data sources characterising (i) the biochemical properties of transcription and translation inherent to coronaviruses (CoV), (ii) the genomic organisation of SARS-CoV-2, (iii) the intracellular protein and RNA turnover, (iv) the in vitro growth data for recombinant (icSARS-CoV-Urbani, icSARS-CoV-GFP, and icSARS-CoVnLuc) and clinical strains of SARS-CoV2 (SARS-CoV-2 isolate WA1 and SARS-CoV-2 Australia/VIC01/2020).
The key sources of quantitative information on the respective processes include [
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40]). Note that all parameters of the model are characterised by some uncertainty (biologically plausible) ranges.
The basal set of the parameter estimates is presented in
Table 1.
2.3. The Stochastic Model
A deterministic system described by ODEs can be translated into a stochastic description in the form of a Markov chain (MC): stochastic Dynamic Monte Carlo (DMC) approach. The stochastic framework considers the exact number of molecular species rather than a continuous approximation of their abundance. For low numbers of species with the interactions modeled following the chemical kinetics framework, an efficient algorithm for moving from a deterministic to probabilistic description of the trajectories has been proposed by Gillespie [
23,
24,
41]. It has been shown that the solution of the MC describing the stochastic dynamics converges in probability to the solution of a related ODE system with proper scaling [
42,
43,
44,
45]. This limiting transition is called the fluid dynamics limit [
42] or the mean field limit [
46]. The theorem on a weak convergence of the MC process to the deterministic solution for specific models of viral infection dynamics has been proven in our earlier studies [
45,
47]. The list of elementary reactions, the corresponding transitions, and the propensities of the respective processes constituting the Markov chain stochastic model corresponding to the underlying ODEs (
1)–(
12) are presented in
Table 2. The propensity function
is defined so that, for given current state
, the product
defines the probability that the
mth reaction occurs in the infinitesimal time interval
[
24].
2.4. Stochastic Modelling Algorithm
To implement a MC numerically, a number of methods have been proposed, with the most popular being the Gillespie’s direct method [
23,
48,
49]. In this method, the model state space vector
is specified by initial values for every component. Here,
is the number of reaction components taking part in the replication process. In our case, the vector is initialised by setting all its components to zero except the first component, which is set to the initial number of free virions:
.
Then, the following steps are performed.
At every interval between the reactions, two uniformly distributed random numbers
on
are generated. The first number gives the next timestep
, where
;
M is the number of reactions in the Markov chain; and
is the propensity of the
mth reaction:
is the probability that the
mth reaction occurs in time-interval
. The second random number determines the next reaction index
p: the smallest integer satisfying
, where
. As we have to search among
reactions, a binary search is employed to accelerate finding the reaction index
p (see [
49]). At the end of the step, the
pth transition is performed, i.e., the state vector
is updated in accordance with
Table 2.
After updating the state vector, the propensities should be updated as well. Here, to accelerate the computation, the propensities are updated only for those reactions in which depends on the updated components in the given step. For this purpose, a special array is prepared in which propensities to be updated are indicated for given component and another similar array for every reaction m.
The process is terminated as soon as the current time exceeds the maximal time set in advance. To decrease the amount of stored information, the values of the state vector are stored at a uniform time-grid with the preset timestep .
The algorithm is implemented in C++. To accelerate the computations, the arrays of pointers to functions are actively used to directly call functions of propensities that should be calculated for a given reaction without spending time on other reactions. The computations were run on Intel Xeon E3-1220 v5 CPU 3 GHz × 4. One realisation of the model with requires about 10 seconds of CPU time for h. For every value of the initial number of free virions , realisations are computed to obtain the statistically significant characteristics described in the next section. For and 10, as much as realisations are computed to obtain smoother histograms.
2.5. Local Stochastic Sensitivity Analysis
To perform a sensitivity analysis on the stochastic model, we followed the previously described approach for a local sensitivity analysis [
25,
50]. We obtained ensembles of the model outputs of interest (e.g., the model variable at a certain time, or some other functional of the model solution) with the baseline and perturbed model parameters. For each parameter
perturbed by a small fixed percentage
s of its baseline value, the sensitivity index can be defined by the histogram difference (sum of the absolute differences between the corresponding histogram bins):
where
is the histogram difference between the ensemble of model outputs
obtained with baseline model parameters and the ensemble
obtained with parameter
increased by a small value
. Employing this definition, the parameters can be ranked by their impact on the model output. The sensitivity indices can be compared to the so-called self-distance
, i.e., the histogram difference between the ensembles obtained twice with the same baseline values of model parameters. The self-distance describes how well the histogram approximates the corresponding probability distribution function for a given number of stochastic model realisations in the ensemble. The sensitivity indices less than or close to the self-distance can be regarded as not having a strong effect [
50]. Alternatively, the sensitivity indices can be defined as the histogram differences divided by the parameter variations
and scaled on their baseline variables to make possible their ranking [
25]. In this paper, we use definition (
14) with one million realisations in each ensemble and
.
3. Results
3.1. Deterministic Versus Stochastic Dynamics of SARS-CoV-2 Replication
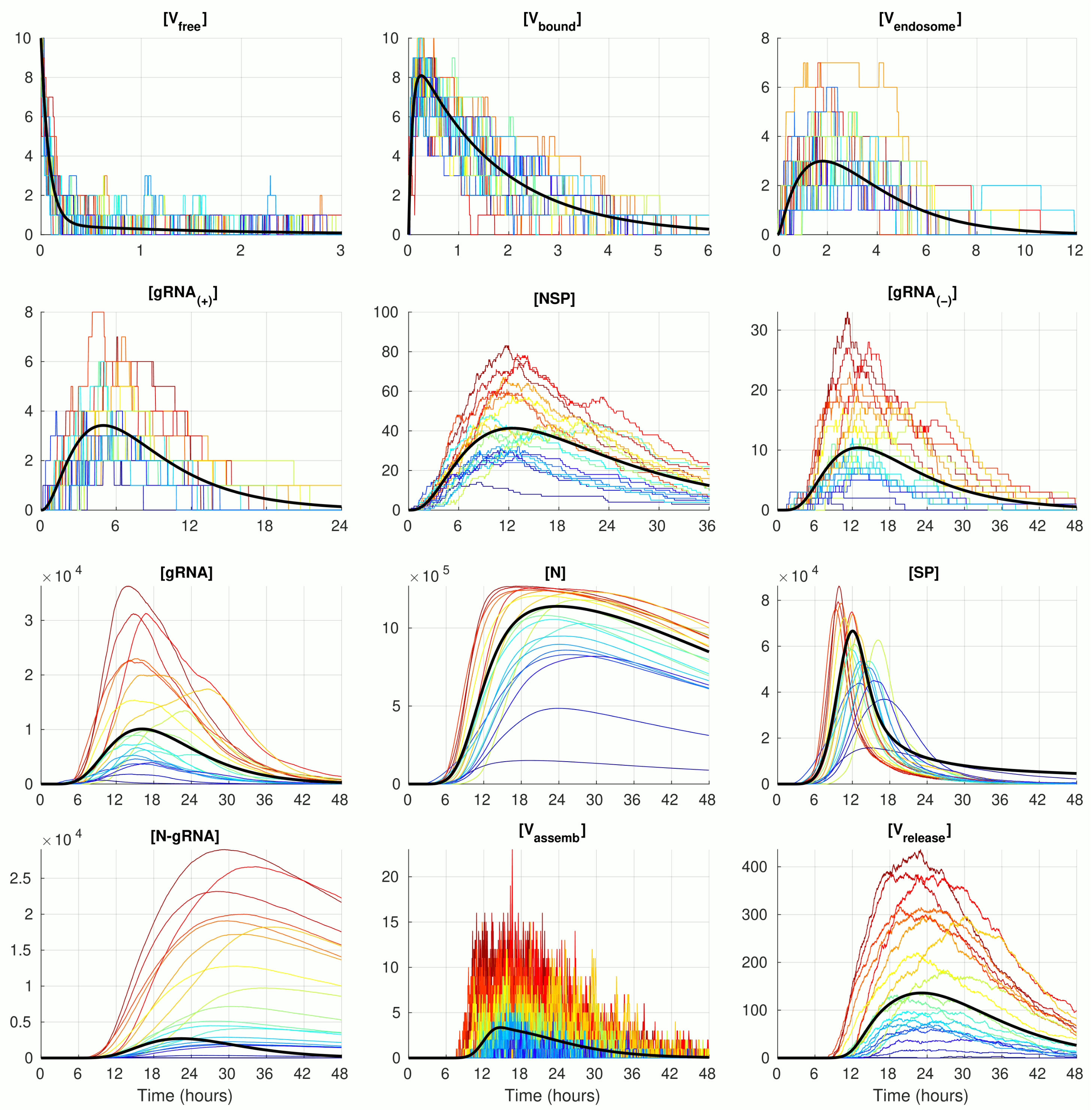
The numerical solution of the deterministic ODE model of SARS-CoV-2 replication for the given number of virions infecting a single cell
, with the model parameter listed in
Table 1 is shown in
Figure 2 (black curve). The stochastic realisations of the MCMC model for
are plotted by coloured lines (twenty arbitrarily taken realisations). The stochastic trajectories significantly deviate from the deterministic solution in both (i.e., up and down) directions. The lines with a more intensive red correspond to stochastic realisations with the highest peak of released virions
. This enables tracing back the trajectories with higher (red and orange) and lower (green and blue) amplitudes of released SARS-CoV-2 through all components. By doing so, one can see that, beginning with the component
, the red lines are strictly above the orange lines, which are in turn above the green and blue lines. Thus, fluctuations resulting in the number of released virions are determined at earlier stages of the virus life cycle process, i.e., in reactions involving
and even
and
.
The trajectories for the components with high abundances such as
,
,
, and
look smoother because the stochastic effects of the reactions on their fluctuations are relatively small compared with the sizes of the respective molecular populations. In contrast, the trajectories for the number of
display rather large and frequent fluctuations. This can be explained by the relatively large value of the parameter
(see
Table 1), which results in a high probability of the assembled virions to be released from the infected cell, i.e., the newly formed virions stay in the intermediate assembled form for a short time.
3.2. Variability in Net Virus Production
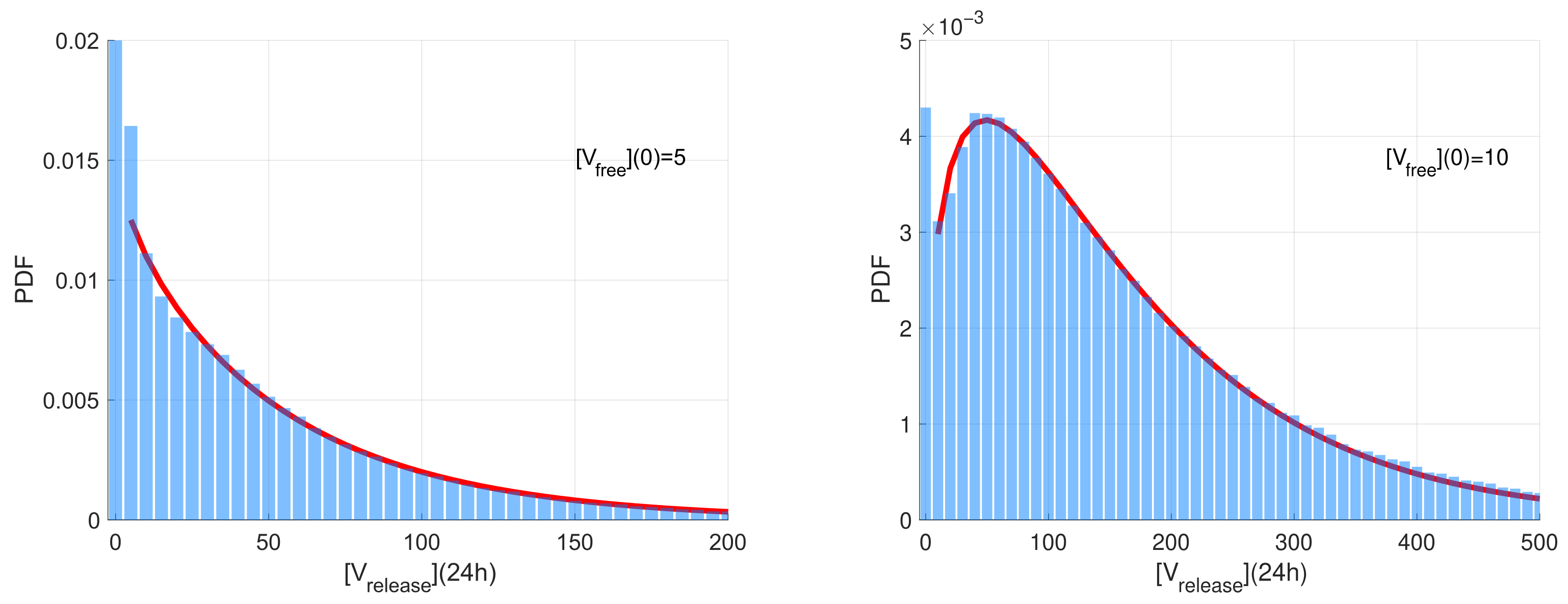
The computed stochastic realisations of the SARS-CoV-2 model were analysed to compute the statistical characteristics of the ensemble: the mean values, the medians, and quantiles. Two representative examples of the histograms of released virions at
h post-infection generated for two different initial doses on infection
(left) and
are shown in
Figure 3. The time
h is selected because it is close to the peak time of production of SARS-CoV-2 virions. The histogram values are normalised with respect to the number of realisations and the range of the released number of virions considered in the histograms. Such normalisation enables the histogram to approximate the probability density function (PDF) describing the distribution.
The histograms have a noticeable peak at zero values for the number of released virions. This peak corresponds to extinct (degenerate) realisations in which no free virions are released. The complementary part of the histograms correspond to realisations characterised by a fully developed replication process resulting in the production of a significant number of free virions. This part of the histogram is rather smooth with an exponential tail. For
, this part is monotonically decaying and can be approximated by the exponential distribution. However, for
, it is non-monotone and shows a clear maximum. The corresponding part of the histogram can be approximated by the Gamma distribution
(note that the exponential distribution is its particular case) [
51]. The results of the least-squares fitting of the Gamma distribution to the histograms (excluding the near-zero peak) are shown in
Figure 3 as red curves.
3.3. Variability of the Individual Reaction Products
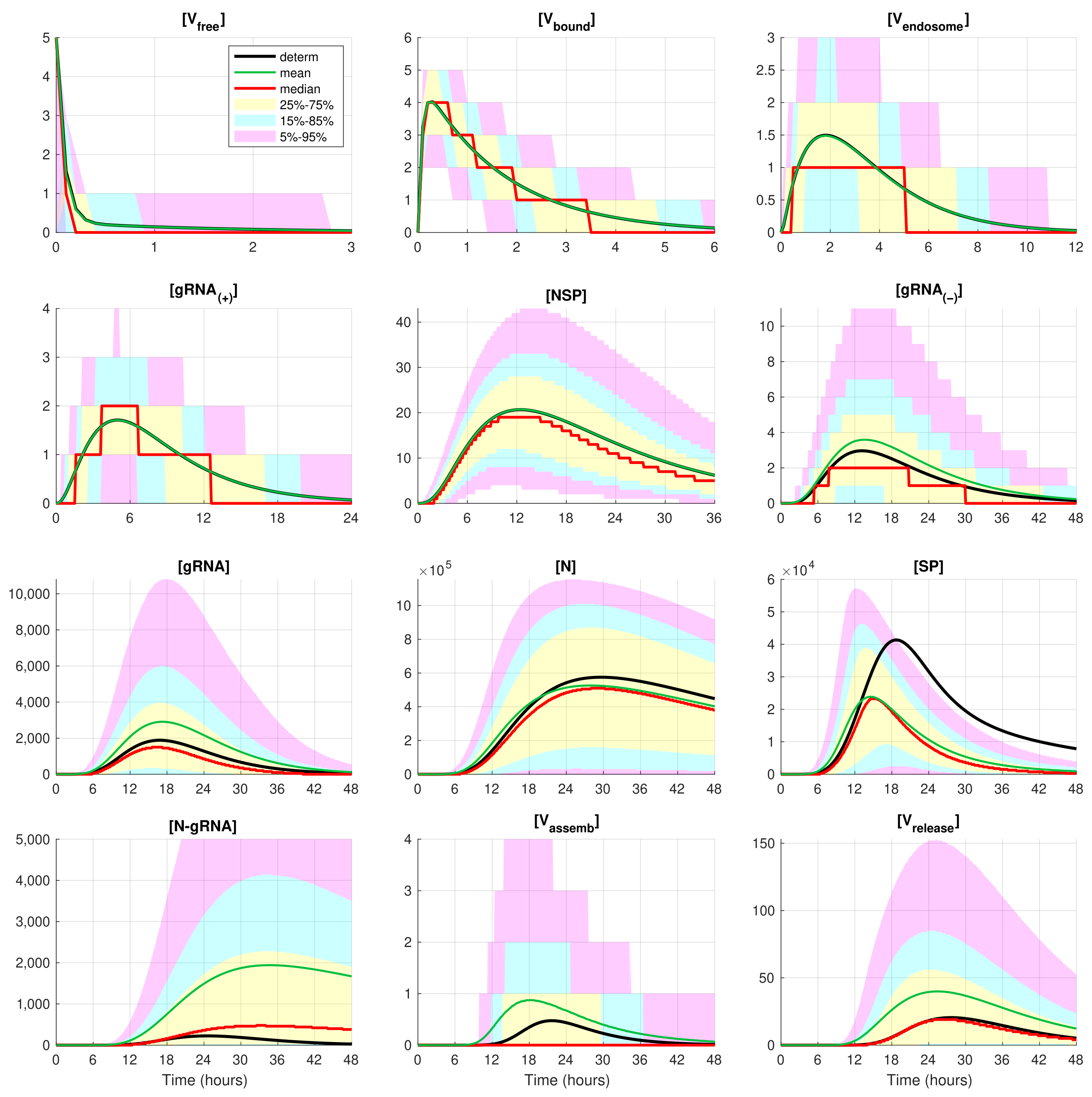
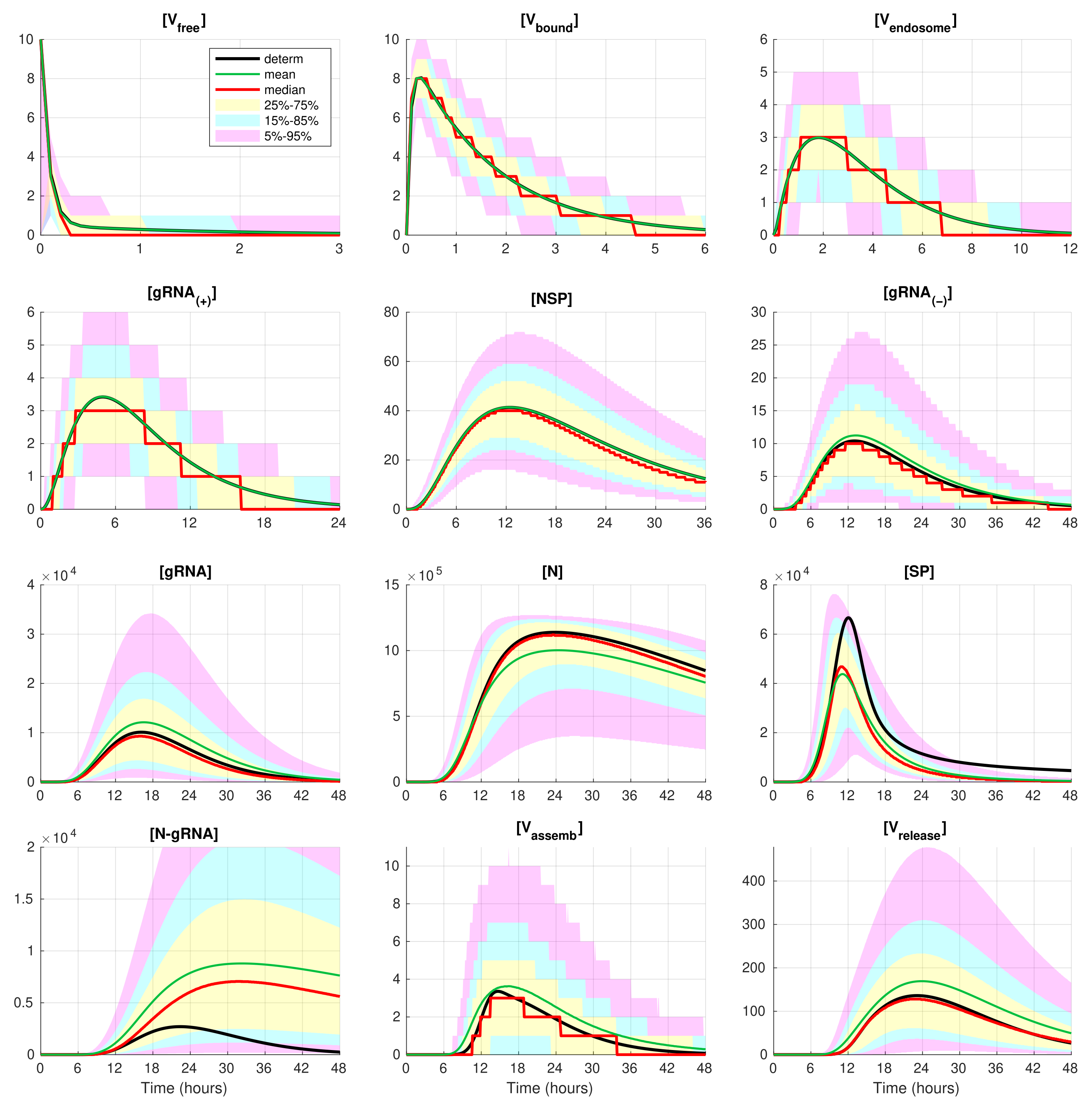
The developed stochastic MCMC model allows us to systematically characterise the statistical properties of variability in the replication kinetics of SARS-CoV-2 emerging from the fluctuations in the underlying biochemical reactions and low numbers of reactants. To this end, an ensemble of
realisations of the stochastic MCMC model is generated and analysed for the mean values, the medians, and uncertainty intervals in terms of various quantiles. The results are summarised in
Figure 4 and
Figure 5, corresponding to infection with 5 and 10 initial virions, respectively.
In these figures, the median values (50% quantile) are shown by the red lines, the green dashed lines indicate the mean values of the realisations, and the black lines indicate the solution to the deterministic model. The median curve can be treated as a trajectory of a so-called typical realisation [
52]. As the histograms for components are mainly unimodal (opposite to the multimodal histograms of the stochastic HIV replication dynamics [
25]), a comprehensive characterisation of the time uncertainty in the evolution of the SARS-CoV-2 components can be restricted to the quantiles of the sample distributions, which specify the related confidence intervals. In
Figure 4 and
Figure 5, the 25–75% confidence intervals (which include 50% of all realisations) are marked by yellow patches. The 15–85% confidence intervals are shown by the light-blue patches. They partly overlap with the 25–75% confidence intervals. The widest 5–95% confidence intervals (which include 90% of all realisations) are shown by the light-pink patches. The coloured patches in
Figure 4 and
Figure 5 provide quantitative details of the evolution of the histograms for all components during the development of the infection process.
Figure 4 and
Figure 5 clearly show that the curves for the mean value trajectories exactly coincide with the deterministic curves for first five species of the SARS-CoV-2 replication steps considered in the model. This is because the first five ODEs (
1)–(
5) describing the kinetics of the respective species are linear. The first nonlinear equation is Equation (
6) containing the nonlinear function
. Starting with
, there is a clear discrepancy between the sample mean values of the stochastic realisations and the deterministic curves. The most noticeable discrepancy is seen for
and
. Analysing the plots for components
,
, and
in
Figure 2,
Figure 4 and
Figure 5, one can conclude that some stochastic realisations have large deviations, significantly exceeding the deterministic and averaged trajectories. Their distributions are far from the Gaussian one.
The figures show that the deterministic solution is rather close to the sample median for . It is known that the median curves are useful for characterising stochastic processes as they represent the most probable trajectory. Note that, for , the sample median curve is identical to zero for the component . This confirms our previous observation about a short availability time of the assembled virions inside an infected cell. The sample mean values for the number of released virions are higher than the median values and the output deterministic solution, and the difference is larger for a smaller number of infection virions.
3.4. Probability of Productive Infection
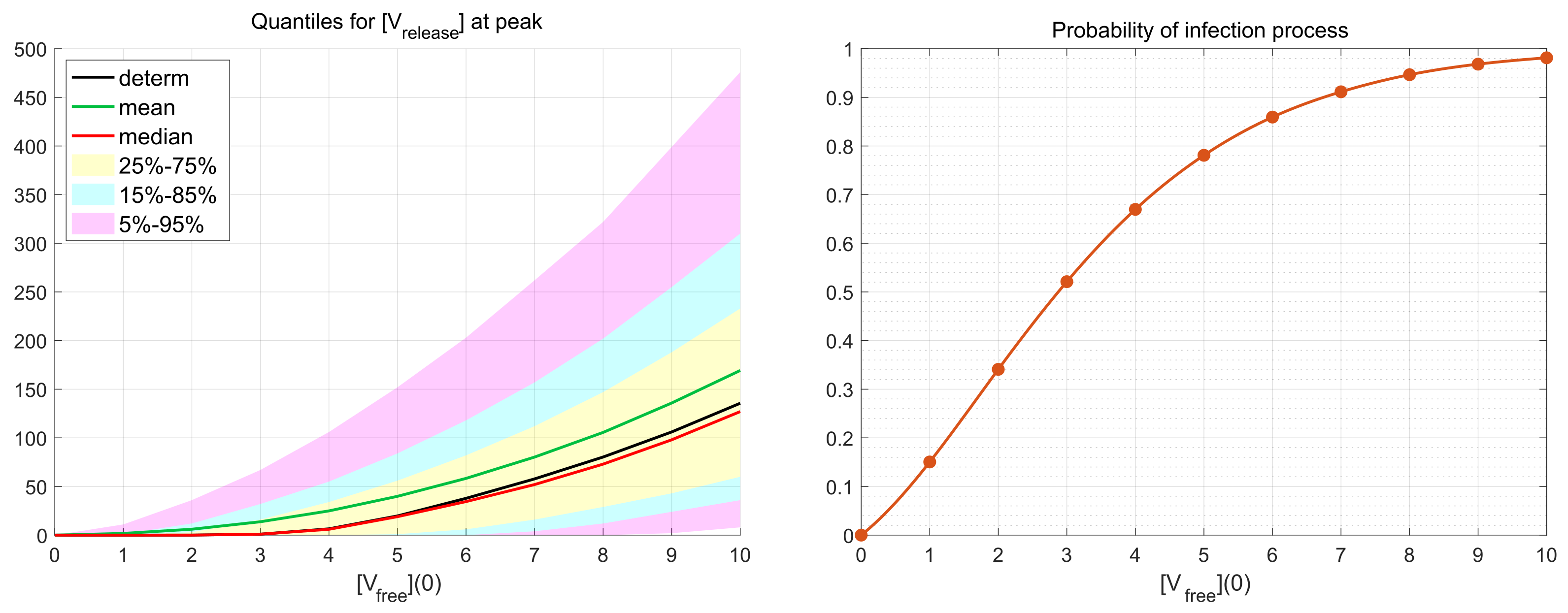
Depending on the viral load and availability of permissive cells, the number of infecting viruses per cell (known as multiplicity of infection, MOI), denoted in our work as
, can vary substantially (see the discussion in [
19]). We examine the effect of various MOI on the scale of virus replication and the probability of a non-degenerate infection. To this end, the numerical simulations have been performed for the initial number of virions
over a representative time interval with
h (hours). This value of
exceeds the peak time
h at which the number of released virions attains its maximal value. Hence, the decreasing phase of the release process after the peak time is reproduced during the simulations as well.
As it is mentioned above, realisations with zero number of newly produced virions, i.e.,
, are called degenerate or extinct. The developed stochastic model enables the computation of the probability of such extinct cases depending on the MOI. The corresponding results are shown in
Figure 6. New virions are produced in more than 50% of realisations beginning with
. This indicates the high infectious potential of SARS-CoV-2.
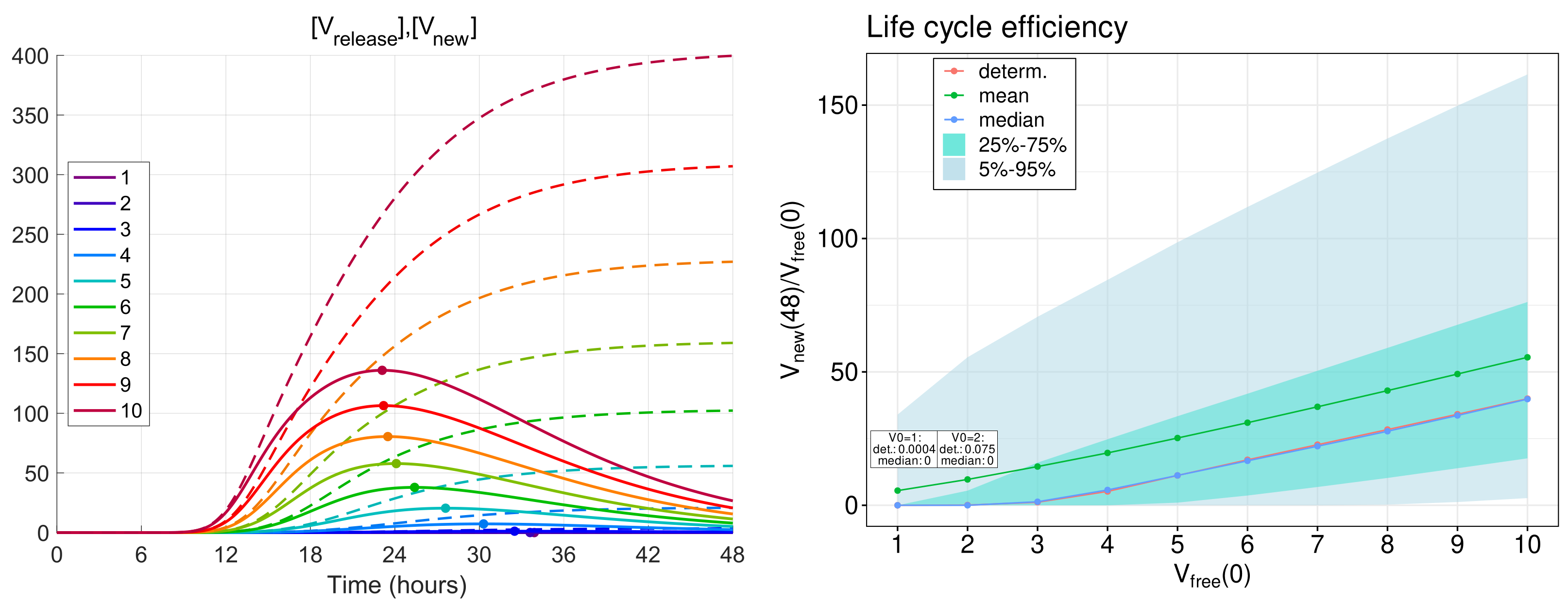
3.5. Efficiency of Life Cycle
The total number of new virions secreted by an infected cell during time
T from the beginning of infection (thus, disregarding their degradation) is given by the formula
obtained by integration of ODE (
12) in which
is set.
To examine the efficiency of a single life cycle of SARS-CoV-2, the kinetics of released virions were computed for the MOI,
, ranging from 1 to 10. The respective functions are shown in
Figure 7 (left) by dashed lines. As one can see, all of the functions tend toward a finite limit, which gives the total viral progeny produced by the infected cell:
The analysis shows that for h approximately equals 99% of the total viral progeny . This means that computation within the time interval of 48 hours gives an appropriately accurate estimate for the total viral progeny: .
The life cycle efficiency can be characterised by the ratio of the total viral progeny to the MOI:
The dependence of the life cycle efficiency on MOI predicted by the deterministic model is presented in
Figure 7 (right) by the blue line with circles. In the stochastic model, the life cycle efficiency varies from realisation to realisation; therefore, several statistical characteristics of this value are plotted in
Figure 7 (right): the mean value—by the green line, the median—by the blue line, the 25–75%, and 5–95% confidence intervals—by the coloured patches.
One can see that the median values are close to the life cycle efficiency computed by the deterministic model, whereas the mean values are higher for all numbers of initial free virions. Note that the total viral progeny secreted by an ensemble of infected cells in tissue should be calculated by summing new virions produced by every cell. Then, just the mean value of the total viral progeny will fall on one cell. Therefore, the mean value of the life cycle efficiency looks to be a proper characteristic of the virion multiplication property of an infected cell.
The calculations show that the mean life cycle efficiency predicted by the stochastic model is noticeably higher than that obtained by the deterministic model, especially for lower MOI. For example, for five initial virions, the stochastic model gives a two times higher value for the life cycle efficiency than the same value obtained in the framework of the deterministic model. This difference indicates that the deterministic model can underestimate the contagiousness of SARS-CoV-2 and confirms the relevance of stochastic modelling of the virus life cycle.
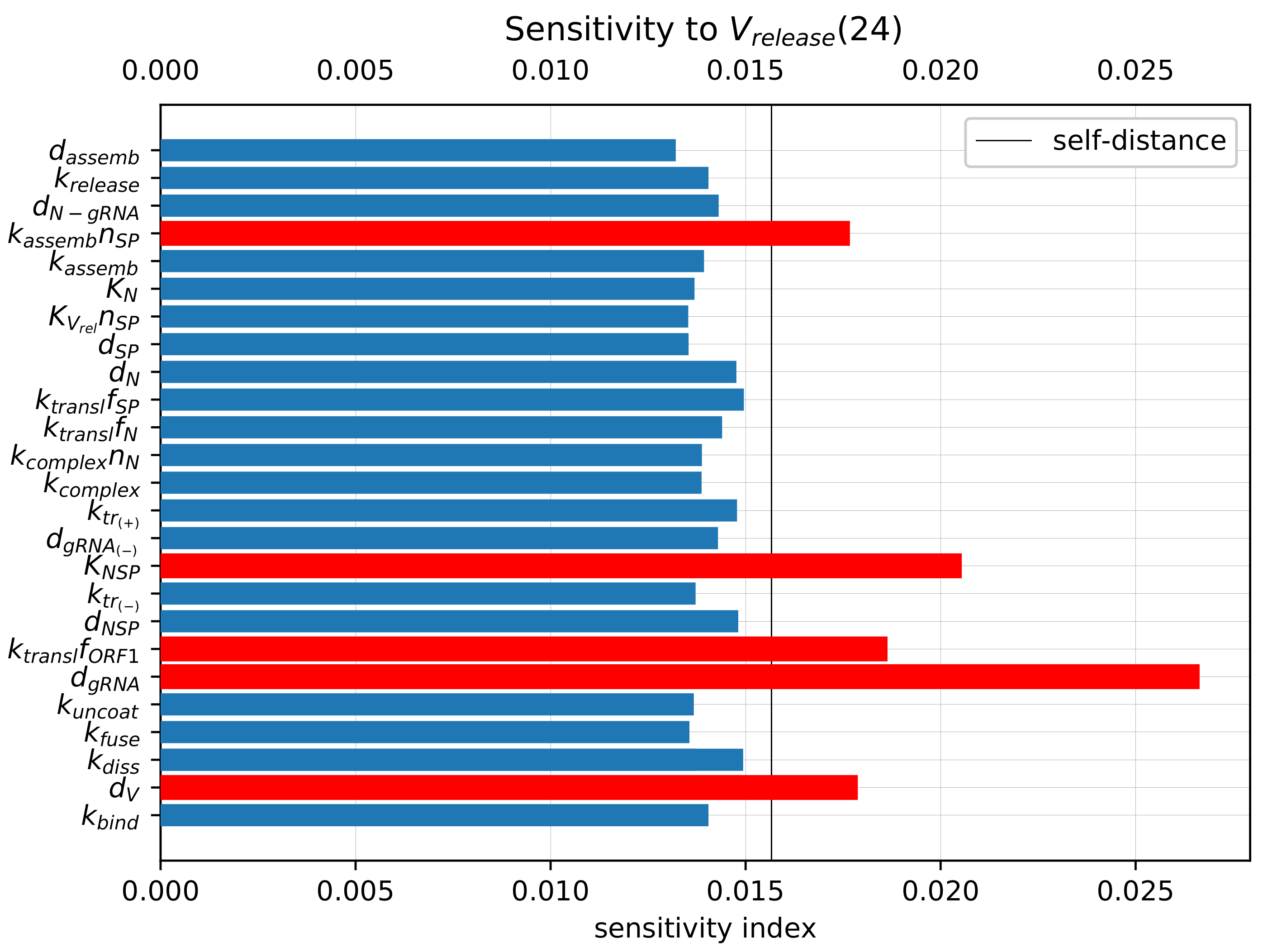
3.6. Sensitivity Analysis of the Model Parameters
To rank the parameters by their influence on the number of released virions, we apply the local sensitivity analysis (see
Section 2.5). The sensitivity indices are based on the ensembles of variable
at time
h for baseline values of model parameters and for parameters perturbed individually by 1%. The computed sensitivity indices as well as the self-distance for baseline set of parameters (
realisations, 500 bins) are shown in
Figure 8. The sensitivity indices for the model output
reveal a similar pattern (data not shown).
The parameters with the largest influence on the model output (marked with the red colour bars in
Figure 8) are similar to those obtained using the sensitivity analysis of the deterministic model [
19]. They include the following (ranked by their impact):
Degradation of the positive-sense vRNA in cytoplasm ();
Threshold number of non-structural proteins enhancing vRNA transcription ();
Translation rate of non-structural proteins ();
Degradation rate of extracellular virions (); and
Assembly rate of structural proteins ().
Importantly, the parameters selected by sensitivity analysis correspond to the processes targeted by the type I interferon response. The effects of varying these parameters are studied in the next section.
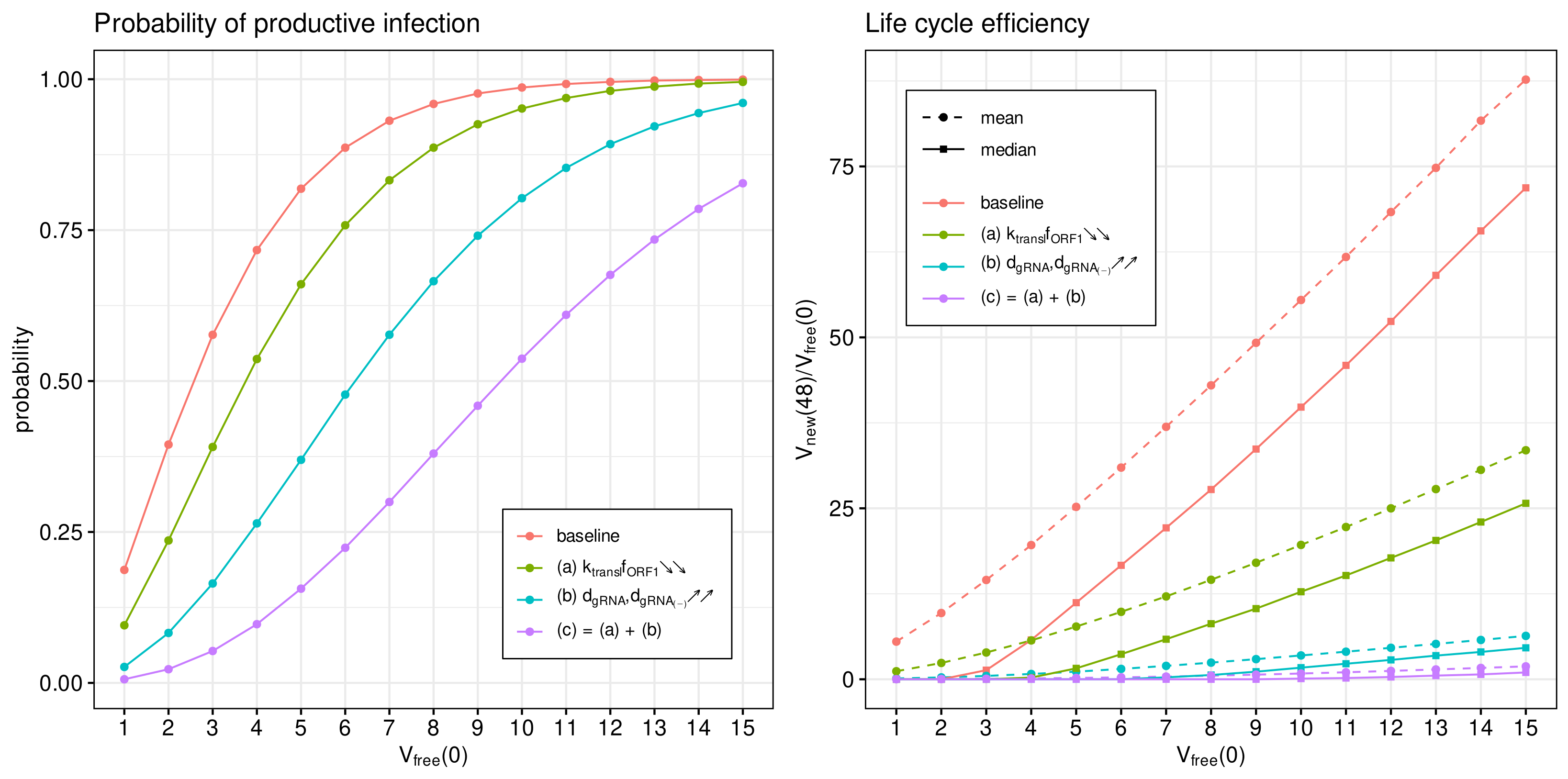
3.7. Inhibitory Effect of Type I IFN
Type I Interferon responses are known to potently impair SARS-CoV-2 replication [
13]. However, it has been reported that the induction of the type I IFN response and interferon-stimulated genes is moderate [
16]. To characterise the sensitivity of the viral life cycle to the type I IFN response, we employed the stochastic model.
The IFN-mediated inhibition of SARS-CoV-2 growth in an infected cell targets the translation initiation complex (by protein kinase R (PKR) activation), and mRNA degradation (via 2
-5
-oligoadenylate synthetase (OAS) activation) and induces an RNA editing enzyme (adenosine deaminase) [
17]. The corresponding effects in the parameterised mathematical model can be associated with variations in the following parameters:
- (a)
The rate constant of translation of released genomic RNA into viral polyproteins pp1a and pp1ab ();
- (b)
The degradation rate constant of RNA (); and
- (c)
= (a) + (b): simultaneous variation in both parameters.
The parameters were increased by a factor of four with respect to the references values (see
Table 1) to quantify the effect on the probability of a non-degenerate infection and the efficient reproduction number for a broad range of MOI, i.e.,
. The results are summarised in
Figure 9.
The probability of non-degenerate infection is shown in
Figure 9 (left). Observe that the enhance IFN response significantly reduces the probability of the infection process developing. The effect is more pronounced for lower MOIs.
In
Figure 9 (right), both the mean and median of the life cycle efficiency are plotted for the baseline and cases (a), (b) and (c) to characterise their partial and combined effects on viral progeny. One can see that the enhanced IFN response reduces new virus production by a factor exceeding 100.
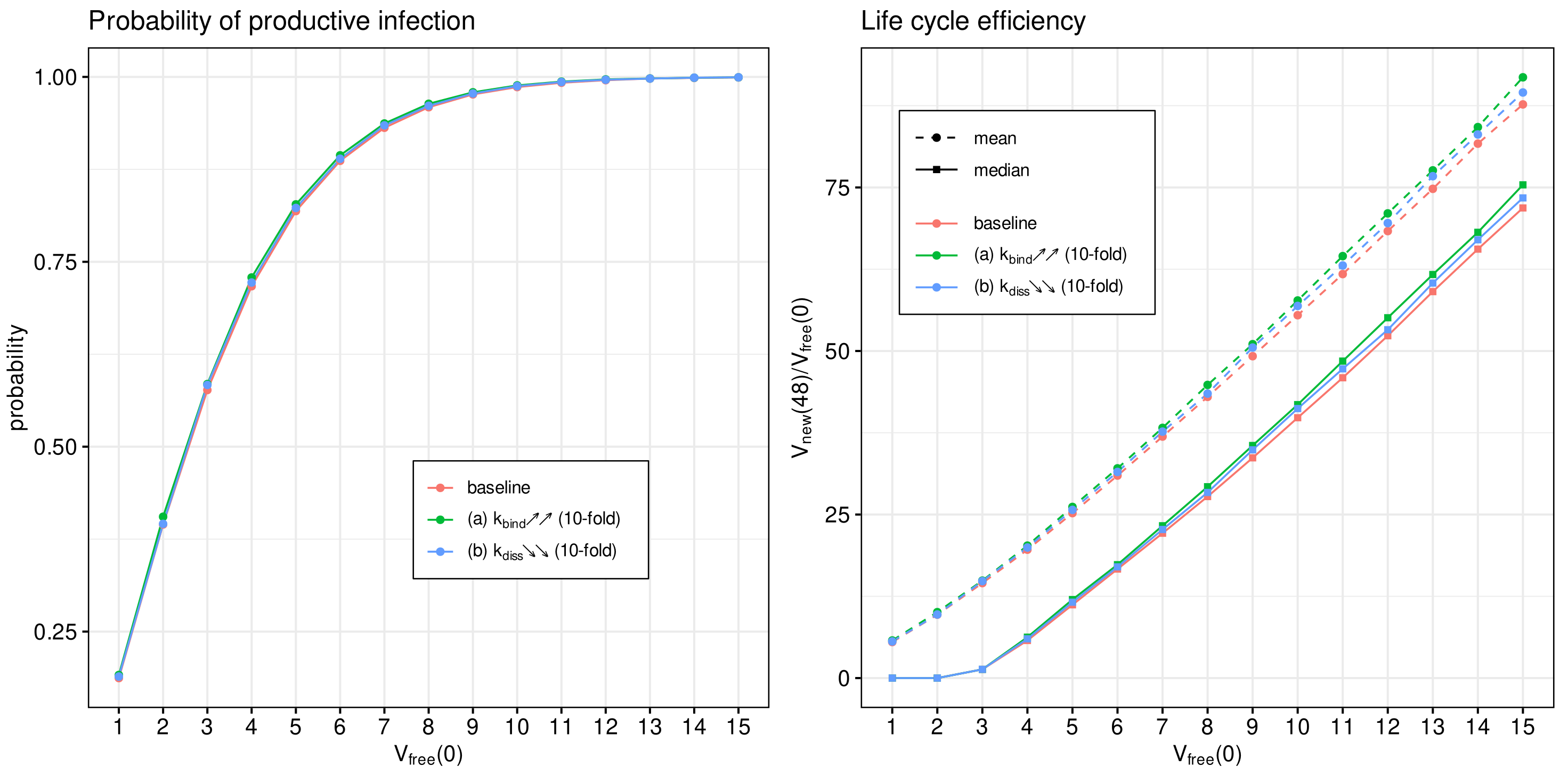
3.8. Effect of Binding Affinity
The attachment of the spike protein of SARS-CoV-2 to the angiotensin-converting enzyme 2 receptor located on human cells is the first step of virus entry into host cells. It initiates the cascade of life cycle biochemical reactions [
9,
16]. It has been shown recently that the evolution of SARS-CoV-2 results in an emergence of viral variants of concern with the enhanced transmissibility and virulence [
8]. Some mutations directly affect the affinity of the virus spike protein to the ACE2 receptor [
12,
15].
We use the developed model to examine the effect of binding affinity variation on the efficiency of the SARS-CoV-2 life cycle. To this end, the model parameter representing the rate constant of virion binding to the ACE2 receptor
is varied from its basal value by 10 times to cover the range of observed increase or decrease in the binding affinities [
14,
53]. To quantify the binding rate effects on the probability of non-degenerate infections of host cells and the efficient reproduction number for a broad range of MOI (
), the parameter
is increased (respectively, reduced) by a factor of 10 with respect to the reference value (see
Table 1). The obtained results are summarised in
Figure 10. Both the mean and median sample estimates are plotted to characterise their partial and combined effects on viral progeny.
One can see that the variation in the probability of infection and the net progeny of the life cycle is rather subtle. This feature might reflect the fact that an enhanced transmissibility of a certain SARS-CoV-2 mutants should be rather attributed to the ability of the variants to infect cells with the lower level of ACE2 receptors, which is consistent with the viewpoint in [
15].
4. Discussion
We developed a stochastic model of SARS-CoV-2 replication in human cells. The model is formulated following the Dynamic Monte Carlo Markov Chain approach and utilises the calibrated parameters of our previously developed deterministic model [
19]. Some predictions of the deterministic model might vary substantially for small numbers of molecular species participating in the virus life cycle, which is typical for a single cell infection. Numerical implementation of this model based on the Gillespie-type algorithm [
23] enabled the calculation of all necessary statistical characteristics of the infection process variability. The probability for a non-degenerate infection process and the life cycle efficiency have been calculated for various MOI (i.e., the initial number of infecting viruses) and model parameters.
The simulation results suggest that the type I IFN response has a very strong effect on inhibition of the total viral progeny. This feature is consistent with the role of the type I IFN response to SARS-CoV-2 infection susceptibility [
13]. Hence, our study supports the application of type I IFN as an early therapy [
54]. Surprisingly, the effect of a 10-fold variation of the binding rate of SARS-CoV-2 to ACE2 turned out to be negligible for the probability of infection and viral production. This indicates that, in the analysis of the infectivity of the virus, it is necessary to go beyond a single cell infection and to consider the infection spreading in a population of host cells starting from low MOIs. It has been proposed recently that the greater infection efficiency of the SARS-CoV-2 Delta variant with its higher affinity for ACE-2 might be mainly due to the ability to infect cells with low numbers of ACE2 [
14,
15].
Recent data suggest that the Omicron variant is less effective at reducing the host cell interferon response [
55]. Therefore, the intracellular IFN should have a stronger inhibitory effect on the virus replication for the Omicron mutant compared with the Delta variant, through targeting the translation initiation complex and mRNA degradation. Indeed, the sensitivity analysis of the stochastic model predicts a very strong suppressive impact of the type I IFN response on the probability of productive infection and the net viral progeny. These features should be relevant for understanding less severe disease courses observed in patients infected with the Omicron variant.
Our study provides a detailed model (overall, 12 life cycle intermediates) of the stochastic dynamics of SARS-CoV-2 replication in productively infected cells. This model can be regarded as a module for computational knowledge repository for studying the virus–host interaction mechanisms [
4]. The virus replication stages considered in the study are inhibited by a type I IFN response of cells. However, we do not describe the induction and kinetics of the intracellular IFN response [
18] and the factors used by SARS-CoV-2 (e.g., ORF3b, ORF6, and N proteins) to counteract the cellular innate immune response [
16,
56]. These will be the subject of future extensions of the model.
Understanding the variability in viral dynamics in infected host cells and its response to endogenous or exogenous perturbations of various nature is helpful for the development of effective antiviral treatments. Mathematical modelling of SARS-CoV-2 viral dynamics enables understanding the kinetic mechanisms and identifying potential therapeutic targets that can be useful for the development of efficient materials to suppress SARS-CoV-2 infection.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}